EKSTRAKSI FITUR PRODUK DENGAN MENGGALI ULASAN PENGGUNA
Faza Nailul Maziya
1, Rully A Hendrawan
2, Renny P Kusumawardani
31,2,3
Jurusan Sistem Informasi, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember
(ITS) Surabaya, 60111, Indonesia
Telp: (031)5939214, Fax : (031) 5964965
Email :
[email protected]
1,
[email protected]
2,
[email protected]
3Abstrak
Seiring dengan berkembangnya e-commerce saat ini, semakin meningkat pula jumlah review pengguna tentang produk yang mereka konsumsi. Bahkan, untuk sebuah produk yang terkenal, angka review bisa mencapai ratusan. Hal ini membuat pelanggan yang berpotensi sulit untuk menentukan produk mana yang harus dibeli karena terlalu banyak komentar yang dibaca.
Pada tugas akhir ini, penulis akan melakukan ekstraksi fitur produk dari review pengguna pada website. Disini, penulis menggunakan teknik Association Rule Mining untuk mencari fitur – fitur yang frequent dan juga Natural Language Processing yakni Parsing untuk memecah kata atau frase dalam kalimat dan mengidentifikasi jenis kata atau frase tersebut. Selain itu, penulis juga akan melakukan penggalian opini untuk mencari fitur- fitur beserta sifatnya. Dan untuk memperbaiki precision dan recall serta teknik pruning yang juga akan dieksplorasi yakni teknik compactness pruning dan Redundancy pruning.
Tugas akhir ini akan menghasilkan sebuah tool pengekstraksi fitur produk dari ulasan pengguna yang mana nantinya dapat membantu pengembang dalam menyimpulkan apakah review tersebut positif atau negative berdasarkan fitur. Dan dapat bermanfaat bagi pelanggan dalam pengambilan keputusan atas sebuah produk dengan melihat fitur dari produk.
Key Words:
penggalian opini, ekstraksi fitur review,association rule mining, NLP
1. Pendahuluan
Perkembangan e-commerce saat ini sangatlah cepat. Banyak sekali produk yang dijual melalui web, dan banyak pula orang yang membeli produk di web. Untuk meningkatkan kepuasan pelanggan dan pengalaman belanja mereka, telah menjadi keharusan bagi pedagang online untuk memberikan kewenengan kepada pelanggan mereka untuk aktif dalam memberikan review atau umpan balik maupun mengekspresikan pendapat pada produk yang mereka beli. Dengan kenyamanan dan akses yang luas terhadap penggunaan
internet saat ini, orang-orang pun semakin gemar menulis review. Konsekuensinya, jumlah review dari produk pun meningkat juga. Beberapa produk yang terkenal bisa mencapai ratusan review pada situs yang terkenal. Hal ini membuat pelanggan yang berpotensi kesulitan untuk membaca review yang dapat membantunya mengambil keputusan untuk membeli produk.
Untuk itu diperlukan sebuah kemudahan akses bagi pelanggan untuk melihat review dengan mudah dan tepat guna [2]. Maka dari itu dalam tugas akhir kali ini, penulis akan melakukan extraksi fitur dengan menggunakan ulasan pengguna. Terdapat dua langkah yang seharusnya dilakukan dalam penelitian ini:
1. Mengidentifikasi fitur- fitur dari produk diulas oleh pelanggan atau bisa disebut opinion features dan sekaligus menentukan fitur- fitur yang memiliki frekuensi tinggi.
2. Untuk setiap fitur, kita identifikasi berapa banyak review pelanggan yang memiliki opini positif maupun opini negatif.
Berikut ilustrasi sederhananya. Asumsikan kita akan meresume review kamera digital. Biasanya pada kamera digital pelanggan akan berkomentar tentang kualitas gambar, ukuran, blitz, dan lainnya. Misalnya, terdapat 300 review pelanggan yang memberikan opini positif mengenai kualitas gambar, dan hanya 7 yang mengekspresikan opini negatif.
Tabel 1 Contoh List Fitur Positif- Negatif
Kualitas Gambar Positif 300 Negatif 7 Size Positif 124 Negatif 14
Dengan mengekstrak setiap fitur pada review, pelanggan yang ingin membeli produk menjadi lebih mudah melihat kesan pelanggan sebelumnya terhadap produk tersebut.
Namun pada TA ini, penulis hanya akan melakukan langkah pertama, yakni mengidentifikasi fitur- fitur yang direview pelanggan yaitu mengekstrak fitur- fitur tersebut dengan menggunakan beberapa metode yakni Association Rule dan NLP (Natural
Language Processing) .
2. Sistem Ekstraksi Fitur
Ekstraksi fitur merupakan sebagian langkah dari sistem penyimpulan ulasan berdasarkan fitur- fitur yang diulas pada ulasan produk oleh pengguna. Sistem ekstraksi dibangun dengan beberapa langkah dan metode. Inputan dari sistem berupa ulasan pengguna berdasarkan produk yang diulas. Dari data tersebut, dicari mana yang merupakan fitur yang sering muncul digunakan metode ARM untuk mendapatkan fitur yang sering muncul dalam ulasan. Setelah mendapatkan fitur yang sering muncul, dilakukan pruning karena fitur yang didapat dari ARM tidak semua benar. Untuk melakukan pruning, digunakan metode redundancy pruning yakni menggunakan support dimana jika fitur memilki nilai kurang dari p-support yang telah ditentukan maka fitur akan dibuang. Setelah mendapatkan fitur yang sudah dipruning, selanjutnya mencari fitur- fitur yang tidak sering muncul, namun diperbincangan di ulasan. Untuk mendapatkannya, dicari kata- kata sifat yang menyertai fitur yang sering muncul. Fitur- fitur yang tidak sering muncul diekstrak melalui pendekatan kata sifat tersebut. Jika terdapat fitur di sekitar kalimat yang tidak mengandung frequent
feature maka fitur tersebut merupakan infrequent feature.
Gambar 1 Alur Sistem
3. Parsing
Untuk mendapatkan kata benda atau frase dari review tersebut maka dilakukan parsing kalimat menggunakan Stanford Parser. library yang digunakan adalah stanford-parser-2010-02-26.jar[9] yang mana menghasilkan sebuah tree dari sebuah kalimat. Dari tree tersebut, akan dilakukan rekursi untuk mendapatkan frase, dan dari frase tersebut diekstrak untuk mendapatkan kata- kata.
3.1
Parsing Kalimat untuk
Mendapatkan Tree
Untuk memparsing kalimat, digunakan Stanford parser. hasil dari parsing kalimat tersebut berupa tree.
Gambar 2 Parsing Tree Kalimat
3.2
Mendapatkan Noun Phrase dari
Tree
Dari hasil parsing berupa tree, selanjutnya adalah mendapatkan noun phrase, atau dari label postag berupa /NP. Jadi semua kata atau kalimat yang berlabel “NP” akan disimpan dalam sebuah databes. Dalam project ini adalah disimpan dalam Arraylist.
Gambar 3 Parsing Tree Frase
3.3
Mendapatkan List Kata- kata
dari Frase
Setelah mendapatkan frase, dilakukan pemecahan frase untuk mendapatkan list kata- kata yang nantinya dari kata- kata tersebut akan dilakukan association rule mining dengan algoritma FP- Growth untuk mendapatkan
frequent feature atau fitur yang sering muncul.
Tabel 2 Hasil Pecah Frase
digital G3 artistic
cameras 5mp photographic
Nikon lot needs
Parsing Frequent Feature Generation Feature Pruning Opinion Word Extraction Infrequent Feature Identification
CP5700 just mind
Olympus Megapixel fiance
C5050 power main
CP5000 camera focus
Canon 15casual Fuji
4. Frequent Feature
Setelah melakukan proses Parsing dan
stemming, akan didapatkan banyak sekali kata- kata.
Untuk mendapatkan hasil yang sesuai dengan tujuan tugas akhir ini maka perlu dilakukan pengidentifikasian fitur yang sering muncul pada review dengan menggunakan Association Rule Mining dan dengan algoritma FP- Growth.
Dari hasil parsing yang menghasilkan list kata, selanjutnya adalah mencari kata- kata yang sering muncul dan juga kandidat frase menggunakan Association Rule
Mining(ARM). Algoritma yang digunakan adalah algoritma FP- Growth. Dengan rincian:
Tabel 3 Parameter generate rule dengan Algoritma FP- Growth DeltaValue 0.05 findAllRulesForSupportLevel True lowerBoundMinSupport 0.005 maxNumberOfItems -1 metricType Confidence minMetric 0.005 numRulesToFind 100 positiveIndex 2 rulesMustContain transactionsMustContain upperBoundMinSupport 1.0 useORForMustContainList True
Dari beberapa kali uji coba nilai support. Nilai dari table diatas yang paling efisien untuk mendapatkan
frequent feature. untuk menjalankan ARM dibutuhkan
library weka yakni weka.lib.
5. Feature Pruning
Setelah mendapatkan fitur yang sering muncul dari hasil Association Rule Mining, dipastikan terdapat fitur yang kurang berguna walaupun fitur tersebut sering muncul. Fitur – fitur tersebut kita anggap sebagai kandidat fitur. Maka dari itu diperlukan teknik pruning untuk mendapatkan fitur yang sebenarnya. Teknik pruning yang digunakan dalam tugas akhir ini adalah teknik redundancy pruning, dimana dihitung p- support
dari masing- masing kandidat. Kandidat yang memiliki P- support yang tidak memenuhi nilai p- support yang ditentukan akan dihilangkan.
Redundancy pruning merupakan teknik pruning
yakni menghilangkan fitur- fitur yang redundan. Dalam hal ini redundan didefinisikan menggunakan perhitungan p- support atau pure support. p- support dari fitur adalah sejumlah kalimat yang memiliki fitur dan pada kalimat tersebut tidak mengandung fitur yang memiliki superset. Maka dari itu dihilangkan fitur- fitur yang memiliki p-
support kurang dari 3. Misalnya, terdapat fitur “manual”,
yang mana memiliki support sebanyak 10 kalimat. Dan fitur “manual” tersebut merupakan subset dari fitur “manual mode” dan “manual setting”. Yang mana masing- masing dari fitur tersebut memilki support 3, dan 4. Maka fitur tersebut tidak dihilangkan karena p-support dari masing- masing fitur lebih dari 3.
6. Opinion Words Extraction
Untuk mendapatkan fitur- fitur yang tidak sering muncul namun dibahas di review dilakukan pencarian fitur dengan pendekatan kata- kata sifat. Maka dilakukan ekstraksi kata- kata sifat yang terdapat pada review. Namun dalam tugas akhir ini tidak menggenerate semua kata sifat yang ada pada review namun diambil kata- kata sifat yang menyertai fitur yang sering muncul. sebagai contoh, lihat dua kalimat di bawah ini:
Kalimat 1: “the butterfly is beautiful and gets honey in that flower.”
Kalimat 2: “I take an incredible pictures.”
Pada kalimat pertama terdapat fitur : butterfly yang mana dekat dengan kata sifat: beautiful. Dan pada kalimat kedua terdapat fitur :pictures yang mana dekat dengan kata sifat incredible. Dari kalimat itu kita dapat mengekstrak atau mendapatkan kata sifat dengan melihat fitur yang sebelumnya sudah kita dapatkan dan mencari kata sifat yang dekat dengan fitur. Hasil dari kata sifat dapat kita simpan di database dan digunakan untuk mencari infrequent feature.
7. Infrequent Feature
Untuk mendapatkan kata- kata sifat digunakan
frequent feature. dan kata- kata sifat tersebut digunakan
untuk mendapatkan infrequent feature atau fitur yang tidak sering muncul namun diperbincangankan dalam ulasan pengguna. Langkah untuk mendapatkan infrequent
feature adalah dengan mencari fitur- fitur yang terdekat
dengan kata sifat yang sudah didapat di dalam kalimat. Jadi untuk setiap kalimat yang sudah disimpan di database ulasan dicari yang tidak mengandung fitur yang sering muncul tetapi mengandung kata sifat. Kemudian dicari
kata benda atau frase dan disimpan sebagai fitur yang tidak sering muncul. sebagai contoh:
Kalimat 1: “the camera is absolutely amazing” Kalimat 2: “the software is amazing.”
Pada kalimat 1 dan 2 sama-sama memiliki kata sifat
amazing. Dari kalimat 1 membicarakan tentang camera,
dan pada kalimat 2 adalah software. Asumsikan bahwa camera merupakan sebuah frequent feature. maka dari itu, fitur software dapat dikatakan berupa infrequent feature, karena memiliki sifat yang dimiliki oleh frequent feature.
8. Uji Coba Ekstraksi
Hasil terakhir sistem ekstraksi berupa list fitur- fitur hasil ekstraksi yang diperoleh dari pendekatan metode- metode yang telah dilakukan. Hasil fitur berupa fitur frekuen ditambah dengan fitur infrekuen. Hasil dari ekstraksi ini akan dibandingkan dengan hasil ekstraksi yang telah dilakukan jurnal[6].
Tabel 4 Uji Coba Ekstraksi
Uji Coba Ekstraksi Produk Jumlah produk yang dihasilkan Jumlah produk yang sama Jumlah produk yang tidak sama %produk sistem terhadap produk jurnal Kamera 1 53 34 19 0.25 DVD 113 31 82 0.323 MP3 198 44 154 0.427 Kamera 2 62 21 41 0.368 Handphone 106 29 77 0.3411 Rata- rata 106 32 74 0..341
Dibandingkan dengan jumlah hasil ekstraksi fitur oleh jurnal (dapat dilihat di table 5.9), selisih dari hasil ekstraksi sekitar 11 fitur. Namun untuk ketepatan fitur masih kurang. Selisih dari fitur yang sama masih tinggi, yakni sekitar 30%.. akan tetapi, setelah dilakukan pengecekan fitur. Fitur yang dihasilkan oleh sistem masih relevan bagi produk yang diekstrak. Sehingga dapat dikatakan sistem masih bisa diterima.
8.1
Uji Performa Sistem
Uji performa sistem untuk tugas akhir adalah menggunakan ukuran precision dan recall[11]. Precision adalah perbandingan jumlah data yang berhasil ditemukembalikan (information retrieval) terhadap jumlah data hasil dari sistem. Sedangkan recall adalah perbandingan jumlah data yang ditemukembalikan terhadap data yang relevan atau data yang benar.
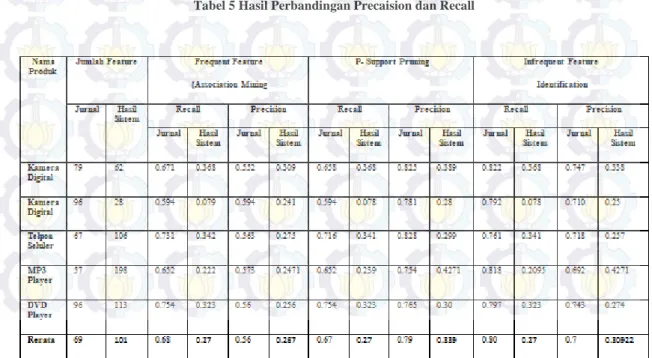
Performa sistem dilakukan dengan membandingkan nilai precision dan recall dari sistem dengan nilai precision recall yang dihasilkan dari jurnal. Performa dilakukan untuk setiap langkah dalam proses pengekstrakan. Hasil dari perrhitungan performa sistem dapat dilihat pada table 5.
Tampak bahwa nilai perhitungan hasil system dibandingkan dengan jurnal tampak memilih selisih besar. Hal tersebut dikarenakan sistem menghasilkan frequent
feature melalui ARM yang kurang maksimal. Minimum
support yang digunakan pada jurnal sebesar 0.01. ketika jurnal melakukan ARM dengan minimum support sebesar 0.01, hasil recall yang dihasilkan sebesar 0.433. sedangkan hasil precision dari sistem hanya sebesar 0.234 . Hal ini kemungkinan disebabkan oleh atribut dan instance sebagai inputan dari ARM sangat berbeda. Sistem mendapatkan data atribut dan instance dari kata- kata yang dihasilkan oleh sistem parser. sedangkan jurnal menggunakan postag NLP 2000[4]. Dari hasil analisa data yang diteliti memang masih terdapat kata- kata yang bukan kata benda namun masuk sebagai kata benda. Hal ini disebabkan pada saat mencari kata benda didapat dengan melakukan parsing kalimat. Selain itu sistem menggunakan bantuan Weka untuk melakukan proses ARM. Sedangkan jurnal menggunakan ARM Miner. Dari uji coba yang dilakukan beberapa kali dengan minimum support berbeda terdapat perbedaan dari hasil ARM. Pada jurnal mendapat nilai 0.68 pada precision karena hasil fitur yang didapat dari sistem jurnal yaitu ARM Miner memilki hasil dengan jumlah kecil, sehingga
mendapatkan precision yang cukup bagus. Sedangkan pada sistem ini hasil ARM Weka dengan minimum support 0.01 mendapatkan fitur yang banyak. Sehingga nilai precision menjadi kecil. Hal tersebut berpengaruh pada nilai precision di setiap metode. Memang terlihat precision semakin meningkat setelah dilakukan pruning. Namun untuk sistem ini nilai precision masih tergolong rendah. Sedangkan untuk recall dari sistem ini juga masih rendah dibandingkan dengan jurnal namun masih terlihat tinggi secara umum. Kenaikan recall dari sebelum dilakukan pruning dan setelah dilakukan pruning sama dengan jurnal, yakni sekitar 0.1 %. Namun, pada tahap infrequent fitur, sistem mengalami penurunan performa. Hal itu disebabkan fitur bertambah,sehingga pembagi pun bertambah. Seperti telah dijelaskan diatas, salah satu hal yang menyebabkan performa adalah nilai minimum support dan confiden yang ditentukan. Pada sistem ini dilakukan beberapa kali ujicoba dengasn minimum support dan confident yang berbeda namun hanya tiga yang didokumentasikan.
Berikut merupakan table hasil perbandingan precision recall berdasarkan minimum support yang ditentukan.
Tabel 6 Perbandingan Precision Recall berdasarkan minimum support produ k Minimum support 0.01 0.003 0.005 prec isio n recall preci sion recall preci sion recall Cano n G3 0.29 5 0.098 0.29 8 0.01 0.25 0.078 DVD 0.21 4 0.302 0.25 8 0.375 0.27 4 0.323 Mp3 0.22 0.405 0.21 0.417 0.22 2 0.427 1 Nikon 0.32 0 0.33 0.33 8 0.368 0.33 8 0.368 Nokia 0.21 0.31 0.26 0.337 0.27 3 0.341 Rata- rata 0.25 18 0.289 0.27 28 0.302 0.27 2 0.320 Tampak bahwa terdapat selisih ketikan minimum support ditentukan sebesar 0.01, 0.03, dan 0.05. rata- rata selisih sebesar 0.023 Terbukti bahwa minimum support dan confiden mempengaruhi nilai precision dan recall. Dan untuk nilai terbaik ada pada saat minimum support sebesar 0.05 dan confiden sebesar 0.05.
Dari nilai precision didapat bahwa ketepatan tebakan sistem untuk mengekstraksi fitur masih sedikit tepat jika dibandingkan dengan hasil jurnal. Begitu juga performa berapa banyak yang berhasil ditebak berdasarkan recall yang masih kurang jika dibandingkan dengan jurnal. Namun dari sistem menghasilkan fitur yang masih relevan terhadap produk yang diekstrak.
8.2
Analisis Hasil Ekstraksi
Dari hasil ekstraksi terlihat bahwa hasil ekstraksi dari sistem dibandingkan dengan hasil jurnal masih kurang. Masih banyak fitur yang diekstrak jurnal tidak terdapat pada hasil sistem. Seperti yang sudah dijelaskan sebelumnya, hal ini dikarenakan hasil dari ARM yang kurang sehingga fitur yang diolah di langkah atau metode selanjutnya-pun kurang. Pemecahan kata dari kalimat dengan menggunakan standford parser juga menjadi salah satu penyebab hasil yang didapat kurang, sehingga berpengaruh pada precision dan recall. Setelah melakukan uji coba sistem, sebenranya terdapat satu lagi yang mempengaruhi ekstraksi. Yaitu pada instance untuk inputan weka. Apabila intansce berdasarkan kata frase seperti “the digital camera”, “the picture quality”, atau “a big hug”. Maka instance yang dihasilkan banyak, sehingga hasil fitur yang diekstrak tidak maksimal. Dan menghasilkan recall dan precision sangat rendah. Namun jika instance berdasarkan pada kalimat, instance yang dihasilkan lebih sedikit. Namun kemungkinan fitur yang diekstrak besar. Hal ini dipengaruhi dengan support dan confidence. Support merupakan kumunculan fitur yang bersama dibagikan dengan jumlah instance atau transaksi. Sebagai contoh fitur: digital camera. Nilai support dapat dihitung dengan jumlah digital camera dibagikan dengan jumlah transaksi yang mengandung fitur digital camera. Sehingga hasil fitur lebih baik karena seperti yang dijelaskan sebelumnya kemungkinan fitur terjadi bersama dalam kalimat dibandingkan dengan frase lebih besar. Dan nilai recall lebih baik daripada recall dari instance berdasarkan frase. Namun nilai precision lebih rendah. Hal ini dikarenakan sistem yang masih kurang optimal dalam pengekstrakan dibandingkan dengan jurnal.
Dari uji coba sistem, hasil ekstraksi dari sistem tidak semua sama dengan hasil ekstraksi dari jurnal. Hal tersebut dikarenakan beberapa tools metode yang berbeda dengan jurnal. Pada jurnal yang diacu, tools yang digunakan untuk mencari kata benda dari kalimat menggunakan pos-tagger NLP 2000[5]. Sedangkan untuk sistem ini menggunakan Standford Parser[6]
9.
Kesimpulan
Setelah dilakukan uji coba dan analisis terhadap sistem yang dibuat, maka dapat diambil kesimpulan sebagai berikut:
1. Language Parser digunakan untuk mencari kata benda atau frase dengan melakukan parsing dalam ekstraksi fitur menggunakan ulasan pengguna. Dalam Tugas Akhir ini yang digunakan adalah Standford Parser.
2. Semua hasil parsing yang didefinisikan sebagai kata benda sudah sesuai, yakni yang memiliki format postag NN/ NNP/ NNS.
3. Metode morphologi yang diambil dari Weka dilakukan untuk mendapatkan kata-kata dasar dari kata-kata yang berimbuhan yang disebut dengan proses stemming
4. Metode stopword removal dengan menggunakan weka melalui fungsi stopword() dilakukan untuk menghapus kata-kata yang merupakan stopword. Seperti or, and, at, dan lainnya.
5. Metode Association Rule Mining dilakukan untuk mendapatkan kata-kata benda dan sifat yang sering muncul bersamaan. Hasil dari ARM dianggap sebagai kandidat fitur. Minimum support dan confidence yang digunakan untuk sistem ini adalah 0.005 – 0.01.
6. Hasil yang didapat dari metode infrequent feature sangat sedikit dan memang tidak signifikan. Hal ini juga diungkapkan pada jurnal [2]
7. Setelah dilakukan metode pruning dari hasil kandidat fitur, hasil precision dan recall menjadi lebih baik.
8. Walaupun hasil dari sistem memiliki recall dan precision lebih rendah dari jurnal, hasil ekstraksi yang dihasilkan cukup baik dan cukup relevan. Sistem ini memiliki kekurangan; proses pengekstrakan cukup lama, yaitu sekitar 4-5 menit. Hal ini disebabkan oleh proses parsing yang komputasinya memakan waktu cukup lama (2-3 menit).
10.
Saran
Berikut adalah beberapa saran yang diajukan untuk perbaikan dan pengembangan lebih lanjut:
1. Disarankan untuk menggunakan tools ARM selain Weka, dapat dicoba menggunakan ARM-Miner atau tool ARM lain. Hal ini dikarenakan memori dari Weka yang terbatas. Sehingga untuk data besar Weka akan mengalami Heap
Space Memory.
2. Dalam sistem ini masih belum menggunakan database. Namun hanya memanfaatkan database pada memori sehingga dapat terjadi over memori sewaktu- waktu jika algoritma yang dijalankan salah atau overloop.
3. Tidak semua hasil dari parsing yang diketahui sebagai kata benda adalah kata benda. Namun ada kata- kata yang terdeteksi sebagai kata benda. Hal ini dikarenakan proses parsing per kalimat. Maka dari itu, perlu ketelitian dan kesabaran dalam pengecekan kata. Saran saya, dilakukan pengecekan dalam kamus atau melakukan postagging ualng.
4. Karena masih terdapat banyak kata- kata yang tidak bersih seperti stopword dan yang lain, disarankan untuk lebih bersih dalam melakukan preprosesing data. Dapat menggunakan stemming, stopword removal, atau fuzzy matching untuk melakukan preprosesing.
11.
Daftar Pustaka
[1] Agrawal, R. and Srikant, R. 1994. “Fast algorithm for mining association rules.” VLDB’94, 1994.
Covington, Michael.Fundamental Algorithm
for Dependency Parsing.2001.Artificial
Intelligence Center, The University of Georgia.
[2] Hu, M., and Liu, B. 2004. Mining
Opinion Features in Customer Reviews. To
appear in AAAI’04.
[3] Jokinen P., and Ukkonen, E. 1991. Two
algorithms for approximate string matching in static texts. In A. Tarlecki, (ed.),
Perbandingan Data arff berdasarkan Frase dan Sentence
produk Berdasarkan Frase Berdasarkan Sentence
Jumlah Atribut
Jumlah Instance
Precision Recall Jumlah
Atribut Jumlah Instance Precision Recall Kamera 1 640 3648 0. 43 0.1 640 597 0.25 0.078 DVD 555 4341 0.307 0.042 555 838 0.274 0.3233 MP3 900 5431 0.21 0.054 900 1359 0.222 0.427 Kamera 2 395 2155 0.473 0.158 395 354 0.338 0.368 Handphone 555 3302 0.375 0.07 555 577 0.07 0.667
Mathematical Foundations of Computer Science.
[4] NLP Enciclopedia – LIS
http://www.cnlp.org/publications/03NLP.LI S.Encyclopedia.pdf
[5] NLProcessor – Text Analysis Toolkit. 2000.
http://www.infogistics.com/textanalysis.htm l
[6] Opinion Mining, Sentiment Analysis, and Opinion Spam Detection – Data Set Hu and Liu.2004.
http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html
[7] Soelaiman, R., and Arini, Ni Made.Analisis.2006. Kinerja Algoritma Fold- Growth dan FP- Growth Pada Penggalian Pola Asosiasi.Seminar Nasional
Aplikasi Teknologi Informasi 2006 ISSN: 1907-5022
[8] Tan, Pang- Ning; Michael, Steinbach; Kumar, Vipin (2005).”Chapter 6. Association Analysis: Basic Concept and Algorithms”. Introduction to Data Mining [9] The Stanford Natural Language Processing Group – Stanford Log- linear Part- Of- Speech Tagger. 2010.
http://nlp,stanford.edu/software/tagger.shml [10] Measuring Search Effectiveness http://newadonis.creighton.edu/hsl/searching /Recall-Precision.html
[11] Manning, Raghavan, Schutze.2008. “Chapter 8 Evaluation and Result Summaries”. Introduction to Information Retrieval.