BAB 2
LANDASAN TEORI
2.1 Nilai Raport
2.1.1 Definisi Nilai Raport
Raport adalah buku yang berisi keterangan mengenai nilai kepandaian dan prestasi belajar murid di sekolah, yang biasanya dipakai sebagai laporan guru kepada orang tua siswa atau wali murid. Raport juga dibagikan setiap akhir semester kepada orang tua yang mendapat surat pengumuman dari sekolah kapan waktu pengambilan raport. Fungsi dari raport itu sendiri adalah:
1. Sebagai pengukuran kepandaian dari siswa selama menempuh pelajaran selama di sekolah dari pertama kali masuk sekolah sampai lulus sekolah.
2. Bagi sekolah raport merupakan tolak ukur kurikulum apakah sudah memenuhi standart atau belum, jika belum maka ada hal yang harus lebih ditingkatkan agar dari tahun ketahun mutu pendidikan terus ditingkatkan.
3. Bagi orang tua siswa berfungsi sebagai sejauh mana prestasi anak di sekolah jika penilaian belum sesuai apa yang diinginkan orang tua maka orang tua harus mengabil tindakan agar anak/siswa lebih giat belajar.
2.2 Faktor- Faktor Yang Mempengaruhi Nilai Raport
Menurut Slameto faktor-faktor yang mempengaruhi nilai raport siswa dapat digolongkan menjadi dua, yaitu:
1. Faktor internal, yaitu faktor yang ada dalam diri individu yang sedang belajar, yang terdiri dari: faktor jasmaniah (kesehatan dan cacat tubuh), faktor psikologis (inteligensi, perhatian, minat, bakat, motif, dan kesiapan), faktor kelelahan.
2. Faktor eksternal, yaitu faktor dari luar individu yang terdiri dari: faktor keluarga, faktor sekolah, faktor masyarakat.
Dalam penelitian ini, penulis akan membagi enam faktor yang
mempengaruhi nilai raport siswa yaitu: motivasi belajar, cara belajar, kompetensi guru, lingkungan keluarga, sarana dan prasarana di sekolah dan lingkungan masyarakat.
2.2.1 Pengertian Motivasi Belajar
Motivasi adalah perubahan energi dalam diri seseorang yang ditandai dengan timbulnya perasaan dan reaksi untuk mencapai tujuan. Motivasi memiliki dua komponen yaitu komponen dalam dan komponen luar, komponen dalam ialah kebutuhan yang ingin dipuaskan sedangkan komponen luar ialah tujuan yang hendak dicapai. Motivasi sangat diperlukan di dalam belajar. Hasil belajar akan menjadi optimal, jika ada motivasi. Makin tepat motivasi yang diberikan, akan makin berhasil pula pelajaran itu. Motivasi mempunyai fungsi yang sangat penting dalam belajar siswa, karena motivasi akan menentukan intensitas usaha belajar yang di lakukan oleh siswa. Motivasi belajar siswa meliputi:
1. Ketekunan dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu:
a) Kehadiran di sekolah b) Mengikuti PBM di kelas c) Belajar di rumah
2. Minat dan ketajaman perhatian dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu:
a) Kebiasaan dalam mengikuti pelajaran b) Semangat dalam mengikuti PBM 3. Berprestasi dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu:
a) Keinginan untuk berprestasi b) Kualifikasi hasil belajar 4. Mandiri dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu:
a) Penyelesaian tugas/PR
b) Menggunakan kesempatan di luar jam pelajaran
2.2.2 Pengertian Cara Belajar
Cara belajar pada dasarnya merupakan satu cara atau strategi belajar yang diterapkan siswa. Cara belajar adalah rangkaian kegiatan yang dilaksanakan dalam usaha belajarnya. Cara belajar merupakan suatu cara bagaimana siswa melaksanakan kegiatan belajar misalnya bagaimana mereka mempersiapkan belajar, mengikuti pelajaran, aktivitas belajar mandiri yang dilakukan, pola belajar mereka, cara mengikuti ujian.
Cara atau kebiasaan belajar yang baik harus dilaksanakan oleh siswa.
Dengan kebiasaan belajar yang baik akan lebih bermakna dan tujuan untuk memperoleh prestasi belajar yang baik dapat sesuai dengan harapan.
2.2.3 Pengertian Kompetensi Guru
Kompetensi guru adalah pengetahuan, keterampilan dan kemampuan yang dikuasai oleh seseorang yang telah menjadi bagian dari dirinya, sehingga ia dapat melaksanakan tugas-tugas dalam bidang pekerjaan tertentu.
2.2.4 Pengertian Lingkungan Keluarga
Keluarga adalah lembaga pendidikan yang pertama dan utama. Anak-anak pertama kali mendapatkan didikan dan bimbingan di dalam keluarga. Pengaruh keluarga dalam pendidikan anak sangat besar dalam berbagai macam sisi. Keluargalah yang menyiapkan potensi pertumbuhan dan pembentukan kepribadian anak. Lebih jelasnya, kepribadian anak tergantung pada pemikiran dan tingkah laku kedua orang tua serta lingkungannya.
Kedua orang tua memiliki peran yang sangat penting dalam mewujudkan kepribadian anak. Orang tua harus berperan aktif dalam mendukung keberhasilan siswa, orang tua disamping menyediakan alat-alat yang dibutuhkan anak untuk belajar, yang lebih penting bagaimana memberikan bimbingan, pengarahan agar anak lebih bersemangat untuk berprestasi dan tidak melanggar
tata-tertib sekolah.
Menurut Slameto (2003:60) lingkungan keluarga akan memberi pengaruh pada siswa. Dari penjelasan di atas dapat disimpulkan bahwa indikator-indikator lingkungan keluarga yang dapat mempengaruhi prestasi anak adalah sebagai berikut:
1. Cara orang tua dalam mendidik anak
Cara orangtua mendidik anaknya besar pengaruhnya terhadap belajar anak.
Keluarga adalah lembaga pendidikan yang pertama dan utama. Orang tua yang tidak atau kurang perhatian misalnya keacuhan orang tua tidak menyediakan peralatan sekolah, akan menyebabkan anak kurang berhasil dalam belajar. Orang tua dapat menolong anak yang mengalami kesulitan dalam belajar dengan bimbingan tersebut.
2. Relasi antara anggota keluarga
Relasi antar anggota keluarga yang terpenting adalah relasi orang tua dengan anaknya. Selain itu relasi anak dengan saudaranya atau dengan anggota keluarga yang lain pun turut mempengaruhi belajar anak. Sebenarnya relasi antar anggota keluarga ini erat hubungannya dengan cara orang tua mendidik. Demi kelancaran keberhasilan belajar siswa, perlu diusahakan relasi yang baik dalam keluarga tersebut.
3. Suasana rumah
Suasana rumah yang dimaksudkan adalah kejadian atau situasi yang sering terjadi di keluarga. Suasana rumah juga merupakan faktor yang penting yang tidak termasuk faktor yang disengaja. Agar anak dapat belajar dengan baik perlulah diciptakan suasana rumah yang tenang dan tentram sehingga anak betah di rumah dan dapat belajar dengan baik.
4. Keadaan ekonomi keluarga
Keadaan ekonomi anak erat kaitannnya dengan belajar anak. Pada kondisi ekonomi keluarga yang relative kurang menyebabkan orang tua tidak dapat
memenuhi kebutuhan anak, tetapi faktor kesulitan ekonomi dapat menjadi pendorong keberhasilan anak. Keadaan ekonomi yang berlebih juga dapat menimbulkan masalah dalam belajar.
2.2.5 Pengertian Sarana dan Prasarana di Sekolah
Prasarana pendidikan adalah fasilitas yang secara tidak langsung menunjang jalannya proses pendidikan atau pengajaran, seperti halaman, kebun, taman sekolah, jalan menuju sekolah, tetapi jika dimanfaatkan secara langsung untuk proses belajar mengajar, seperti taman sekolah untuk pengajaran biologi, halaman sekolah sekaligus lapangan olah raga, komponen tersebut merupakan sarana pendidikan. Prasarana pendidikan misalnya lokasi/tempat, bangunan sekolah, lapangan olah raga dan sebagainya, sedangkan sarana pendidikan adalah semua peralatan serta perlengkapan yang langsung digunakan dalam proses pendidikan di sekolah. Contoh: gedung sekolah, ruangan, meja, kursi, alat peraga dan lain- lain.
Secara umum sarana pendidikan terdiri atas 3 (tiga) kelompok besar, yaitu:
1. Bangunan dan perabot sekolah.
2. Alat pelajaran yang terdiri atas pembukuan dan alat-alat peraga dan laboratorium.
3. Media pendidikan yang dapat dikelompokan menjadi audiovisual yang menggunakan alat terampil.
2.2.6 Pengertian Lingkungan Masyarakat
Lingkungan masyarakat adalah tempat terjadinya sebuah interaksi suatu sistem dalam menghasilkan sebuah kebudayaan yang terikat oleh norma-norma dan adat istiadat yang berlangsung dalam kurun waktu yang lama. Lingkungan masyarakat terdiri dari kegiatan siswa dalam masyarakat, mass media, teman bergaul, bentuk kehidupan masyarakat. Manusia merupakan makluk sosial dan hidup di tengah- tengah masyarakat. Di dalam masyarakat terdapat norma-morma yang harus dipatuhi oleh anggota masyarakat. Norma-norma tersebut berpengaruh dalam pembentukan kepribadian warganya dalam bertindak dan bersikap. Untuk itulah lingkungan masyarakat mempunyai pengaruh terhadap keberhasilan belajar anak.
Secara umum lingkungan diartikan sebagai kesatuan ruang dengan semua benda, daya keadaan dan mahluk hidup, termaksut manusia dan perilakunya yang mempengaruhi kelangsungan perilaku kehidupan dan kesejahteraan manusia serta mahluk hidup lainnya.
2.3 Data
Istilah data berasal dari bahasa Latin yaitu datum yang merupakan bentuk jamak berarti sesuatu yang diberi. Pengertian data merupakan sekumpulan fakta yang diperoleh dan kemudian diperuntukan menjadi sebuah data untuk diproses atau diolah sehingga menjadi sesuatu yang dapat dimengerti oleh orang lain. Data adalah sesuatu yang belum memiliki arti bagi penerimanya dan masih membutuhkan adanya suatu pengolahan. Data dapat berwujud suatu kondisi atau keadaan, suara, huruf, simbol, gambar, angka, ataupun bahasa lainnya yang dapat digunakan sebagai bahan untuk melihat objek, lingkungan, kejadian ataupun suatu konsep. Jenis data berdasarkan cara memperolehnya dapat di bagi atas dua bagian, yaitu:
2.3.1 Data Primer
Data primer merupakan data yang didapat dari sumber pertama, baik dari individu atau perseorangan seperti hasil wawancara atau pengisian kuisioner yang biasa dilakukan oleh peneliti. Biasanya data primer secara langsung diambil dari objek-objek penelitian oleh peneliti, baik per orangan maupun organisasi.
2.3.2 Data Sekunder
Data sekunder merupakan data primer yang diperoleh pihak lain atau data primer yang telah diolah lebih lanjut dan disajikan baik oleh pengumpul data primer atau pihak lain yang pada umumnya disajikan dalam bentuk tabel-tabel atau diagram-diagram (Sugiarto, dkk, 2001).
2.2.3 Data Kualitatif dan Data Kuantitatif
Data kualitatif adalah data yang sifatnya hanya menggolongkan saja, termasuk dalam klasifikasi data kualitatif adalah data yang berskala ukur nominal dan ordinal, sedangkan data kuantitatif adalah data yang
berbentuk angka termasuk dalam klasifikasi data kualitatif adalah data yang berskala ukur interval dan rasio.
2.4 Variabel
Variabel adalah suatu sebutan yang dapat diberi angka (kuantitatif) atau nilai mutu (kualitatif). Variabel merupakan pengelompokkan secara logis dari dua atau lebih atribut dari objek yang diteliti misalnya: tidak sekolah, tidak tamat SD, tidak tamat SMP, dan sebagainya, maka variabelnya adalah tingkat pendidikan dari objek penelitian itu. Variabel tingkat pendidikan merangkum semua atribut tadi.
Variabel merupakan suatu istilah yang berasal dari kata vary dan able yang berarti “berubah” dan “dapat”. Jadi, kata variabel berarti dapat berubah-ubah.
Nilai itu berupa nilai kuantitatif maupun kualitatif. Dilihat dari segi nilainya, variabel dibedakan atas dua, yaitu variabel diskrit dan variabel kontiniu. Variabel diskrit nilai kuantitatifnya selalu berupa bilangan bulat, sedangkan variabel kontiniu nilai kuantitatifnya bisa berupa pecahan (http://rakim-ypk.blogspot.com).
Menurut Supranto.J, variabel merupakan suatu yang nilainya berubah- ubah menurut waktu atau berbeda menurut elemen/tempat, sehingga setiap variabel dapat diberi nilai dan nilai itu berubah-ubah. Nilai itu berupa nilai kuantitatif maupun kualitatif. Nilai variabel dapat dibedakan menjadi 4 tingkatan skala yaitu nominal, ordinal, interval, dan rasio. Nominal ialah angka yang berfungsi hanya untuk membedakan dan merupakan identitas. Ordinal ialah angka yang selain berfungsi sebagai nominal juga menunjukkan urutan, bahwa sesuatu lebih baik, lebih bagus. Interval ialah angka yang selain berfungsi sebagai nominal dan ordinal juga menunjukkan jarak yang sama. Rasio ialah angka yang selain berfungsi sebagai nominal, ordinal dan interval, juga menunjukkan berapa kali, sebab angka nol letaknya tidak sembarang. Dilihat dari segi nilainya, variabel di bedakan menjadi dua, yaitu variabel diskrit dan variabel kontinu.
Variabel diskrit nilai kuantitatifnya selalu berupa bilangan bulat. Variabel kontinu nilai kuantitatifnya bias berupa pecahan. Sugiarto(2001), dalam bukunya mengemukakan kaitan hubungan suatu variabel dengan variabel lainnya, dikenal
adanya bermacam-macam bentuk variabel, sebagai berikut:
1. Variabel independen (independent variable), yaitu variabel yang menjadi sebab terjadinya (terpengaruhnya) variabel dependen (variabel tak bebas).
Variabel independen atau variabel bebas sering juga disebut dengan variabel stimulus atau predictor, atau variabel antecedent.
2. Variabel dependen (dependent variable), yaitu variabel yang nilainya dipengaruhi oleh variabel independen. Variabel ini juga sering disebut sebagai variabel terikat.
3. Variabel moderator yaitu variabel yang memperkuat atau memperlemah hubungan antara suatu variabel dependen dengan independen.
4. Variabel intervening, seperti variabel moderator, tetapi nilainya tidak dapat diukur, seperti kecewa, gembira, sakit hati, dan sebagainya.
5. Variabel kontrol, yaitu variabel yang dapat dikendalikan oleh peneliti.
Dalam penelitian ini yang menjadi variabel independen yaitu:
𝑋1 = Motivasi Belajar 𝑋2 = Cara Belajar 𝑋3 = Kompetensi Guru 𝑋4 = Lingkungan Keluarga 𝑋5 = Sarana Prasarana di Sekolah 𝑋6 = Lingkungan Masyarakat
Dan yang menjadi variabel dependen yaitu:
𝑌 = Nilai Raport
2.5 Matriks
Matriks adalah suatu kumpulan angka-angka yang juga sering disebut elemen- elemen yang disusun secara teratur menurut baris dan kolom sehingga berbentuk persegi panjang, dimana panjang dan lebarnya ditunjukkan oleh banyaknya kolom dan baris serta dibatasi tanda “[ ]” atau “( )” .
Matriks A yang berukuran dari m baris dan k kolom (m×k) adalah:
𝐴𝑚×𝑘 =
𝑎11 𝑎12 𝑎21 𝑎22
⋮ ⋮
… 𝑎1𝑘
… 𝑎2𝑘
⋮ ⋮
𝑎𝑚1 𝑎𝑚2 … 𝑎𝑚𝑘
Entri 𝑎𝑖𝑗 disebut elemen matriks pada baris ke-i dan kolom ke-j.
2.6 Nilai Eigen (Eigen Value)
Misalkan A adalah matriks persegi berukuran 𝑝 × 𝑝 dan I adalah matriks identitas berukuran 𝑝 × 𝑝. Skalar 𝜆1, 𝜆2, … , 𝜆𝑝 yang memenuhi persamaan: |A - 𝜆I| = 0 disebut nilai eigen atau akar karakteristik. Dan suatu matriks A berukuran 𝑝 × 𝑝 dan 𝜆 adalah nilai eigen dari matriks A jika terdapat suatu vektor x tak nol sedemikian sehingga 𝐴𝑥 = 𝜆𝑥, maka x disebut vektor eigen atau vektor karakteristik dari matriks A yang bersesuaian dengan nilai eigen 𝜆. Untuk mencari nilai eigen matriks A yang berukuran 𝑝 × 𝑝, dapat ditulis kembali sebagai suatu persamaan homogen |A - 𝜆I| = 0. Dengan I adalah matriks identitas yang berordo sama dengan matriks A.
Persamaan nilai karakteristik eigen value adalah sebagai berikut:
det 𝐴 − 𝜆𝐼 = 0
Keterangan:
𝐴 = Matriks korelasi dengan orde n x n 𝐼 = Matriks identitas
𝜆 = eigen value
2.7 Menentukan Metode Pengumpulan Data 2.7.1 Populasi
Menurut Supranto (2010), Populasi ialah kumpulan yang lengkap dari seluruh elemen yang sejenis, tetapi dapat dibedakan karena karakteristiknya. Populasi berarti keseluruhan unit atau individu dalam ruang lingkup yang ingin diteliti.
Populasi dibedakan menjadi populasi sasaran (target population) dan populasi
sampel (sampling population). Populasi sasaran adalah keseluruhan individu dalam areal/wilayah/lokasi/kurun waktu yang sesuai dengan tujuan penelitian.
Populasi sampel adalah keseluruhan individu yang akan menjadi satuan analisis dalam populasi yang layak dan sesuai untuk dijadikan sampel penelitian sesuai dengan kerangka sampelnya (sampling frame).
2.7.2 Sampel
Santoso (2010), Sampel bisa diartikan sebagai bagian dari populasi, bisa sebagian dari populasi namun tidak semua elemen populasi. Sampel diadakan karena pertimbangan penghematan waktu, biaya dan tenaga daripada jika semua elemen populasi harus diteliti.
2.7.3 Penentuan Jumlah Sampel
Pengambilan jumlah sampel dalam penelitian ini menggunakan rumus Isaac dan Michael, penggunaan metode ini karena jumlah populasi kurang dari 100, dan rumusnya sebagai berikut:
𝑛 = 𝜒² . 𝑁. 𝑃. 𝑄 𝑑2 𝑁 − 1 + 𝜒² . 𝑃 . 𝑄
Keterangan:
n = Jumlah sampel
𝜒² =Chi Kuadrat yang harganya tergantung derajat kebebasan dan tingkat kesalahan. Untuk derajat kebebasan 1 dan kesalahan 5% harga chi kuadrat = 3,841.
N = Jumlah Populasi P = Peluang benar = 0,5 Q = Peluang salah = 0,5
d = perbedaan antara rata-rata sampel dengan rata-rata populasi. Penetapan bisa 0,01;0,05; dan 0,10
2.8 Uji Validitas dan Reliabilitas 2.8.1 Uji Validitas
Validitas menunjukkan sejauh mana suatu alat pengukur itu mengukur apa yang ingin diukur. Untuk mengetahui valid atau tidaknya suatu item pertanyaan dapat dihitung koefisien korelasinya. Ukuran yang dipakai untuk mengetahui derajat hubungan, terutama untuk data kuantitatif, dinamakan koefisien korelasi.
Koefisien korelasi adalah statistik yang menunjukkan kuat dan arah saling hubungan antara variasi dua distribusi skor. Pengujian validitas tiap item pertanyaan dilakukan dengan menggunakan rumus product moment pearson :
𝑟𝑥𝑖𝑦 = 𝑛 𝑛𝑖=1𝑋𝑖𝑌𝑖 − 𝑛𝑖=1𝑋𝑖 𝑛𝑖=1𝑌𝑖
𝑛 𝑛𝑖=1𝑋𝑖2 − 𝑛𝑖=1𝑋𝑖 2 𝑛 𝑛𝑖=1𝑌𝑖2− 𝑛𝑖=1𝑌𝑖 2
Keterangan:
𝑟𝑥𝑖𝑦 = koefisien korelasi antara variabel x ke-i dan variabel y n = jumlah sampel
𝑋𝑖 = skor variabel bebas ke-i dimana i=1,2,…,n
∑𝑌𝑖 = skor variabel terikat ke-i
2.8.2 Uji Reliabilitas
Reliabilitas adalah indeks yang menunjukkan sejauh mana suatu alat pengukur dapat dipercaya atau diandalkan. Bila suatu alat pengukur dipakai dua kali untuk mengukur gejala yang sama dan hasil pengukuran diperoleh relatif koefisien, maka alat pengukur tersebut reliabel.
Suatu variabel dikatakan reliabel jika memberikan nilai cronbach alpha > 0,60. Rumus Cronbach Alpha (CA) adalah sebagai berikut:
𝛼 = 𝑘
𝑘 − 1 1 − 𝑛𝑖=1𝑆𝑖2 𝑆𝑡 Keterangan :
𝛼 = Koefisien realibilitas
k = Banyaknya pertanyaan dalam setiap variabel
𝑆𝑖2 = Jumlah varians skor variabel ke-i dimana i = 1,2,…,n St = Varians total
2.9 Transformasi Data Ordinal menjadi Interval
Proses transformasi merupakan upaya yang dilakukan untuk merubah data ordinal menjadi data interval misalnya analisis diskriminan dimana variabel bebasnya harus berskala interval. Data ordinal yang ditransformasikan menjadi data interval adalah data penelitian yang diperoleh menggunakan instrumen berupa angket yang memiliki jawaban berupa skala likert. Cara melakukan proses transformasi data ordinal menjadi data interval menggunakan Metode MSI (Method Of successive Interval). Adapun langkah-langkahnya sebagai berikut:
1. Mencari f (frekuensi) jawaban responden.
2. Setiap frekuensi dibagi dengan banyaknya responden dan hasilnya disebut proporsi.
3. Menentukan nilai proporsi kumulatif dengan menjumlahkan nilai proporsi secara berurutan perkolom skor.
4. Menghitung nilai Z untuk setiap proporsi dengan menggunakan tabel distribusi Normal.
5. Menentukan nilai densitas untuk setiap nilai Z yang diperoleh dengan menggunakan tabel densitas.
6. Menentukan SV (Scale Value = nilai skala) dengan rumus sebagai berikut:
𝑆𝑉𝑖 = 𝐷𝑒𝑛𝑠𝑖𝑡𝑎𝑠 𝑎𝑡 𝐿𝑜𝑤𝑒𝑟 𝐿𝑖𝑚𝑖𝑡 − 𝐷𝑒𝑛𝑠𝑖𝑡𝑎𝑠 𝑎𝑡 𝑈𝑝𝑝𝑒𝑟𝐿𝑖𝑚𝑖𝑡 𝐴𝑟𝑒𝑎 𝐵𝑒𝑙𝑜𝑤 𝑈𝑝𝑝𝑒𝑟 𝐿𝑖𝑚𝑖𝑡 − 𝐴𝑟𝑒𝑎 𝐵𝑒𝑙𝑜𝑤 𝐿𝑜𝑤𝑒𝑟 𝐿𝑖𝑚𝑖𝑡
Keterangan:
SV = Interval rata-rata
Densitas at Lower Limit = Kepadatan batas bawah Densitas at Upper Limit = Kepadatan batas atas Area Below Upper Limit = Daerah di bawah batas atas Area Below Lower Limit = Daerah di atas batas bawah
7. Menentukan nilai transformasi dengan rumus 𝑌 = 𝑆𝑉 + 1 + 𝑆𝑉𝑚𝑖𝑛
2.10 Analisis Diskriminan
Analisis diskriminan merupakan suatu analisis multivariat yang digunakan untuk mengelompokkan suatu individu atau objek ke dalam suatu individu atau objek kedalam suatu kelompok yang telah ditentukan sebelumnya berdasarkan variabel-variabel tertentu. Analisis diskriminan dapat digunakan jika variabel dependen terdiri dari dua kelompok atau lebih kelompok. Pengelompokkan pada analisis bersifat apriori, artinya seorang peneliti sudah mengetahui sebelumnya individu atau objek mana saja yang masuk ke dalam kelompok 1, 2, 3, 4 dan 5.
Analisis diskriminan adalah salah satu teknik analisa statistika dependensi yang memiliki kegunaan untuk mengklasifikasikan objek beberapa kelompok. Pengelompokan dengan analisis diskriminan ini terjadi karena ada pengaruh satu atau lebih variabel lain yang merupakan variabel dependen.
Analisis diskriminan mirip dengan analisis regresi linier berganda (multivariable regression). Perbedaannya analisis digunakan apabila variabel independennya menggunakan skala kategoris (digunakan apabila menggunakan skala nominal
dan ordinal) dan variabel independennya menggunakan skala metrik (interval dan rasio), sedangkan dalam regresi berganda variabel dependennya harus metric dan variabelnya independen dapat metrik maupun nonmetrik.
Sama seperti regresi berganda, dalam analisis diskriminan variabel dependen hanya satu, sedangkan variabel independennya banyak (multiple).
Analisis diskriminan merupakan teknik yang akurat untuk memprediksi seseorang termasuk kategori apa, dengan catatan data-data yang terlibat terjamin akurasinya.
2.10.1 Tujuan Analisis Diskriminan
Tujuan analisis diskriminan secara umum adalah:
1. Membuat suatu fungsi diskriminan atau kombinasi linear, dari prediktor atau variabel bebas yang bisa mendiskriminasi atau membedakan katagori variabel tak bebas, artinya mampu membedakan suatu objek (responden) masuk kelompok yang mana.
2. Menguji apakah ada perbedaan signifikan antara kelompok, dikaitkan dengan variabel bebas.
3. Menentukan variabel bebas yang mana yang memberikan sumbangan terbesar terhadap terjadinya perbedaan antar kelompok.
4. Mengklasifikasi atau mengelompokkan responden ke dalam suatu kelompok didasarkan pada nilai variabel bebas.
5. Mengevaluasi keakuratan klasifikasi (the accuracy of classification).
2.10.2 Proses Dasar Analisis Diskriminan Proses dasar Analisis Diskriminan adalah:
1. Memisahkan variabel-variabel menjadi variabel dependen dan variabel independen.
2. Menentukan metode untuk membuat fungsi diskriminan. Pada dasarnya ada dua metode dasar untuk itu, yaitu:
a. Simultaneous Estimation, di mana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses diskriminan.
b. Stepwise Estimation, di mana variabel dimasukkan satu persatu kedalam model diskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model dan ada kemungkinan satu atau lebih variabel independen yang dibuang dari model.
3. Menguji signifikansi dari fungsi diskriminan yang telah terbentuk menggunakan Wilk’s Lambda, Pilai, F test lainnya.
4. Melakukan interpretasi terhadap fungsi diskriminan tersebut.
5. Menguji ketepatan klasifikasi dari fungsi diskriminan, termasuk mengetahui ketepatan klasifikasi secara individual dengan casewise diagnostics.
2.10.3 Asumsi dalam Analisis Diskriminan
Berikut ini asumsi yang harus dipenuhi agar model diskriminan dapat digunakan:
1. Multivariat Normality, atau variabel independen yang seharusnya berdistribusi normal. Jika data tidak berdistribusi normal, hal ini akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan. Regresi logistik bisa dijadikan alternatif metode jika memang data tidak berdistribusi normal. Tujuan uji normal adalah ingin mengetahui, apakah distribusi dengan berbentuk lonceng (bell shapped). Data yang baik adalah data yang mempunyai pola seperti distribusi normal, yaitu distribusi data tersebut tidak menceng ke kiri atau menceng ke kanan. Uji normalitas pada multivariat sebenarnya kompleks, karena harus dilakukan pada seluruh variabel secara bersama-sama. Namun, uji ini bisa juga dilakukan pada setiap variabel dengan logika bahwa jika secara individual masing-masing variabel memenuhi asumsi normalitas, maka secara bersama-sama (multivariat) variabel-variabel tersebut juga dianggap memenuhi asumsi normalitas. Adapun kriteria pengujiannya adalah:
a. Angka signifikansi (Sig.) ≥ 0,05, maka data tersebut berdistribusi normal.
b. Angka signifikansi (Sig.) < 0,05, maka data tersebut tidak berdistribusi normal.
2. Matriks Kovarian dari semua variabel independen seharusnya sama atau
equal.
3. Tidak ada korelasi antara dua variabel independen.
4. Tidak adanya data yang sangat ekstrim pada variabel independen.
2.10.4 Model Analisis Diskriminan
Model analisis diskriminan mirip regresi berganda. Perbedaannya adalah kalau variabel dependen regresi berganda dilambangkan dengan “Y” maka dalam analisis diskriminan dilambangkan dengan “D”. Model analisis diskriminan adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai variabel independen, yaitu:
𝐷𝑖 = 𝑏0+ 𝑏1𝑋𝑖1+ 𝑏2𝑋𝑖2+ 𝑏3𝑋𝑖3… + 𝑏𝑗𝑋𝑖𝑗 + ⋯ + 𝑏𝑘𝑋𝑖𝑘 Keterangan:
𝐷𝑖 = nilai (skor) diskriminan dari responden (objek) ke-i i = 1,2,…,n.
𝑏0 = Intercep atau konstanta
𝑏𝑗 = koefisien atau timbangan diskriminan dari variabel atau atribut ke-j 𝑗 = 1,2,…,k
𝑋𝑖𝑗 = variabel (atribut) ke-j dari responden ke-i.
Yang diestimasi adalah koefisien bj, koefisien fungsi diskriminan bj di perkirakan sedemikian rupa sehingga nilai D kelompok mempunyai nilai fungsi diskriminan yang sangat berbeda. Ini terjadi kalau rasio jumlah kuadrat antar- kelompok (between group sum of squares) dengan jumlah kuadrat dalam kelompok (within group sum of squares) untuk skor fungsi diskriminan menacapai maksimum atau rasio varian antar-kelompok dengan varian dalam kelompok sebesar mungkin (maksimum). Objek dalam kelompok homogen atau relatif homogen, sedangkan antar-kelompok sangat heterogen. Berdasarkan nilai D itulah keanggotaan seseorang diprediksi.
Fungsi diskriminan adalah persamaan regresi dengan sebuah variabel tidak bebas yang mencerminkan keanggotaan kelompok. Apabila kelompoknya hanya
ada dua, maka fungsi diskriminan melibatkan regresi ganda dengan sebuah variabel tak bebas atau responden dengan harga-harga 0 dan 1 (Sudjana, 1996).
Tujuan fungsi diskriminan adalah untuk menggambarkan ciri-ciri suatu pengamatan dari bermacam-macam populasi yang diketahui, baik secara grafis ataupun secara aljabar dengan membentuk fungsi diskriminan. Dengan kata lain, analisis diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih.
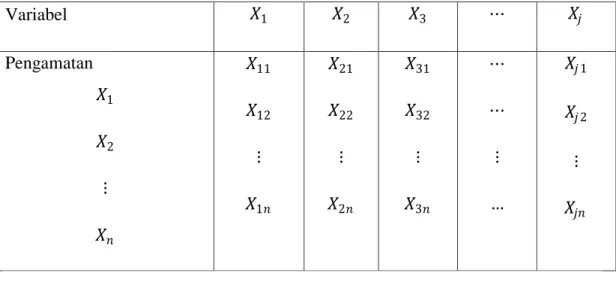
Suatu fungsi diskriminan layak untuk dibentuk bila terdapat perbedaan nilai rataan diantara kelompok-kelompok yang ada. Oleh karena itu sebelum fungsi diskriminan dibentuk perlu dilakukan pengujian terhadap perbedaan vektor nilai rataan dari kelompok-kelompok tersebut. Pada data pengamatan sebuah sampel yang berukuran n yang terdiri atas j buah variabel yaitu 𝑋1, 𝑋2, 𝑋3,…,𝑋𝑗. Data pengamatan tersebut dapat disajikan dalam bentuk matriks-matriks berikut:
Tabel 2.1 Matriks Pengamatan
Variabel 𝑋1 𝑋2 𝑋3 ⋯ 𝑋𝑗
Pengamatan 𝑋1 𝑋2
⋮ 𝑋𝑛
𝑋11 𝑋12
⋮ 𝑋1𝑛
𝑋21 𝑋22
⋮ 𝑋2𝑛
𝑋31 𝑋32
⋮ 𝑋3𝑛
⋯
⋯
⋮
…
𝑋𝑗 1 𝑋𝑗 2
⋮ 𝑋𝑗𝑛
Untuk variabel 𝑋𝑗 (j = 1, 2, 3, ..., k) yang dihitung adalah variansinya, diberi lambang 𝑆𝑗𝑗 dengan rumus:
𝑆𝑗𝑗 = 𝑛 𝑘𝑛=1𝑋𝑗𝑛2 − ( 𝑘𝑛=1𝑋𝑗𝑛)2
𝑛 𝑛 − 1 Apabila semuanya ada j buah varians, yaitu 𝑆11 , 𝑆22 , 𝑆33… S ij yang
masing-masing merupakan varians untuk variabel. 𝑋1, 𝑋2, 𝑋3 . . . 𝑋𝑗 Untuk variabel 𝑋1 dan 𝑋2 dimana i ≠ j terdapat kovarians, diberi lambang 𝑆𝑖𝑗 yang dapat dihitung dengan rumus berikut:
𝑆𝑖𝑗 =𝑛 𝑘𝑛=1𝑋𝑖𝑛𝑋𝑗𝑛 − 𝑘𝑛=1𝑋𝑖𝑛 𝑘𝑛=1𝑋𝑗𝑛 𝑛(𝑛 − 1)
Apabila semuanya ada
j 1
buah kovarians, dimana i = j maka 𝑆𝑖𝑗 menjadi 𝑆𝑗𝑗, varians untuk variabel 𝑋𝑗, dan bahwa 𝑆𝑖𝑗 = 𝑆𝑗𝑖. Varians dan kovarians ini disusun dalam sebuah matriks yang disebut dengan matriks varians-kovarians dengan bentuk sebagai berikut:S =
𝑆11 𝑆12 𝑆13 … 𝑆1𝑗 𝑆21 𝑆22 𝑆23 … 𝑆2𝑗 𝑆31
... 𝑆𝑗 1
𝑆32 ... 𝑆𝑗 2
𝑆33 ... 𝑆𝑗 3
… ...
… 𝑆3𝑗
... 𝑆𝑗𝑗
Misalkan ada dua kelompok yang memiliki variabel masing-masing j buah yaitu 𝑋11, 𝑋12,…,𝑋1𝑗 dalam kelompok 1 dan 𝑋21, 𝑋22, … , 𝑋2𝑗 dalam kelompok 2. Perhatikan bahwa 𝑋𝑖𝑗 menyatakan variabel ke-j dalam kelompok ke-i dengan i = 1 atau 2, sedangkan j = 1, 2, …, k. Variabel dalam setiap kelompok dapat pula dituliskan dalam bentuk vektor kolom sebagai berikut:
𝑋1 = 𝑋11 𝑋12 𝑋13 . . . 𝑋1𝑗
dan 𝑋2 = 𝑋21 𝑋22 𝑋23 . . . 𝑋2𝑗
Keterangan:
𝑋1𝑗 = menyatakan variabel X ke-j dalam kelompok ke-1 𝑋2𝑗 = menyatakan variabel X ke-j dalam kelompok ke-2
Hasil pengamatan ini akan menghasilkan rata-rata untuk tiap variabel yang dalam bentuk vektor dapat ditulis sebagai berikut:
𝑋 1= 𝑋 11 𝑋 12 𝑋 13 . . . 𝑋 1𝑗
dan 𝑋 2 = 𝑋 21 𝑋 22 𝑋 23 . . . 𝑋 2𝑗
Keterangan:
𝑋 1𝑗 =Rata-rata variabel ke-j dalam kelompok ke-1 𝑋 2𝑗 = Rata-rata variabel ke-j dalam kelompok ke-2
Dari masing-masing rata-rata dari kelompok 1 dan rata-rata dari kelompok 2, selanjutnya akan dihitung varian dan kovariannya tersebut dalam matriks 𝑆1 dan 𝑆2 , masing-masing dari kelompok ke-1 dan kelompok ke-2 yaitu:
𝑆1 =
𝑆11 𝑆12 𝑆13 … 𝑆1𝑗 𝑆21 𝑆22 𝑆23 … 𝑆2𝑗 𝑆31
... 𝑆𝑗 1
𝑆32 ... 𝑆𝑗 2
𝑆33 ... 𝑆𝑗 3
… ...
… 𝑆3𝑗
... 𝑆𝑗𝑗
dan 𝑆2 =
𝑆11 𝑆12 𝑆13 … 𝑆1𝑗 𝑆21 𝑆22 𝑆23 … 𝑆2𝑗 𝑆31
... 𝑆𝑗 1
𝑆32 ... 𝑆𝑗 2
𝑆33 ... 𝑆𝑗 3
… ...
… 𝑆3𝑗
... 𝑆𝑗𝑗
Keterangan:
𝑆1 = matriks varians kovarians dari kelompok ke-1 𝑆2 = matriks varians kovarians dari kelompok ke-2
Meskipun dalam 𝑆1 dan 𝑆2 digunakan 𝑆𝑖𝑗 yang sama namun jelas besarnya berlainan antar 𝑆𝑖𝑗 dalam 𝑆1 dan 𝑆𝑖𝑗 dalam 𝑆2 . Kedua datanya juga berlainan yaitu 𝑆𝑖𝑗 dalam 𝑆1 diambil dari kelompok 1 dan 𝑆𝑖𝑗 dalam 𝑆2 diambil dari kelompok 2. Kedua buah matriks varians-kovarians gabungan yang diberi lambang S dengan rumus:
𝑆 = 𝑛1− 1 𝑆1+ 𝑛2− 1 𝑆2 𝑛1+ 𝑛2 − 2 Keterangan:
S = Matriks varian-kovarian gabungan
𝑆1, 𝑆2 = Matriks varians kovarians dari kelompok ke-1 dan kelompok ke-2 𝑛1, 𝑛2 = Jumlah sampel kelompok ke-1 dan ke-2
2.10.5 Algoritma dan Model Matematis
Secara ringkas, langkah-langkah dari analisis diskriminan adalah:
1. Pengecekan adanya kemungkinan hubungan linier antara variabel bebas.
Pengecekan dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada hasil output SPSS, matriks korelasi dapat di lihat pada Pooled Within-Groups Matrices.
2. Uji vektor rata-rata kedua kelompok
Pengujian terhadap vektor nilai rataan antar kelompok dilakukan dengan hipotesis:
H0 : µ1 = µ2 (Tidak ada perbedaan antar kelompok) H1 : µ1 ≠ µ2 (Ada perbedaan antar kelompok)
Angka signifikan:
Jika angka Sig ≥ 0,05, tidak ada perbedaan antar kelompok Jika angka Sig < 0,05, ada perbedaan antar kelompok
Jika dari hasil pengujian diperoleh adanya perbedaan vektor nilai rataan, fungsi diskriminan layak disusun untuk mengkaji hubungan antar kelompok serta berguna untuk mengelompokkan objek ke salah satu kelompok tersebut. Pada SPSS 17, uji ini dilakukan secara univariate (yang diuji bukan berupa vektor), dengan bantuan tabel Tests of Equality of Group Means.
3. Pemeriksaan asumsi homoskedastisitas dengan uji Box’s M
Pengujian terhadap kesamaan matriks kovarians (∑) antar kelompok dilakukan dengan hipotesis:
H0 : Matriks kovarians kelompok adalah sama
H1 : Matriks kovarians kelompok adalah berbeda secara nyata
Keputusan dengan dasar signifikansi bias dilihat dari angka signifikannya Jika Sig ≥ 0,05 berarti H0 diterima
Jika Sig < 0,05 berarti H0 ditolak
Sama tidaknya grup kovarian matriks juga dapat dilihat dari tabel output Log Determinant. Jika dalam pengujian ini H0 ditolak maka proses selanjutnya seharusnya tidak bisa dilakukan.
4. Pembentukan Model Diskriminan a. Pembentukan Fungsi Linier
Pada output SPSS 17, koefisien untuk tiap variabel yang masuk dalam model dapat dilihat pada tabel Canonical Discriminant Function Coefficient.
Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient bagia Unstandardized diaktifkan.
b. Menghitung Discriminant Score
Setelah fungsi liniernya dibentuk, maka dapat dihitung skor diskriminan untuk tiap observasi dengan cara memasukkan nilai-nilai variabel penjelasnya.
c. Menghitung Cutting Score
Untuk memprediksi responden masuk ke dalam kelompok yang mana, maka dapat menggunakan Optimum Cutting Score. Memang dari komputer informasi ini sudah diperoleh. Untuk cara mengerjakan secara manual Cutting Score dapat dihitung dengan rumus sebagai berikut dengan ketentuan:
1. Untuk dua kelompok yang mempunyai ukuran yang sama cutting score dinyatakan dengan rumus (Simamora, 2005):
𝑍𝑐𝑒 =𝑍𝐴+ 𝑍𝐵
2
Keterangan:
𝑍𝑐𝑒 = Cutting score untuk kelompok yang mempunyai ukuran yang sama
𝑍𝐴 = Centroid kelompok A 𝑍𝑩 = Centroid kelompok B
2. Untuk dua kelompok yang mempunyai ukuran yang berbeda, rumus cutting score yang digunakan adalah:
𝑍𝐶𝑈 = 𝑁𝐴𝑍𝐵 + 𝑁𝐵𝑍𝐴
𝑁𝐴+ 𝑁𝐵
Keterangan:
𝑍𝐶𝑈 = Cutting score untuk kelompok yang mempunyai ukuran yang berbeda
𝑁𝐴 = Jumlah sampel kelompok A 𝑁𝐵 = Jumlah sampel kelompok B 𝑍𝐴 = Centroid kelompok A 𝑍𝑩 = Centroid kelompok B
Centroid adalah nilai rata-rata skor diskriminan untuk kelompok tertentu.
Kemudian nilai-nilai discriminant score tiap observasi akan dibandingkan dengan nilai cutting score, sehingga dapat diklasifikasikan suatu obsevasi akan termasuk kedalam kelompok yang mana. Dapat di hitung dengan bantuan tabel Function at Group Centroids dari output SPSS 17.
d. Perhitungan Hit Ratio
Setelah semua observasi diprediksi keanggotaannya, dapat di hitung Hit ratio, yaitu rasio antara observasi yang tepat pengklasifikasiannya dengan total seluruh observasi. Seberapa valid model diskriminan yang telah dihasilkan?. Jawaban pertanyaan ini terkait dengan validasi model. SPSS 17 menggunakan validasi dengan metode Leave One Out. Misalkan ada sebanyak n observasi, akan dibentuk fungsi linier dengan observasi sebanyak n - 1. Observasi yang tidak disertakan dalam pembentukan fungsi linier ini akan diprediksi keanggotaannya dengan fungsi yang sudah dibentuk tadi. Proses ini akan diulang dengan kombinasi observasi yang berbeda-beda, sehingga fungsi linier yang dibentuk ada sebanyak n. Inilah yang disebut dengan metode Leave One Out.
2.11.6 Pengujian Hipotesis
Intepretasi hasil analisis diskriminan tidak berguna jika fungsinya tidak signifikan. Hipotesis yang diuji adalah H0 yang menyatakan bahwa rata-rata semua variabel dalam semua kelompok adalah sama. Dalam SPSS 17, uji dilakukan dengan menggunakan wilks’lambda. Jika dilakukan pengujian sekaligus beberapa fungsi sebagaimana dilakukan pada analisis diskriminan,
statistic wilks’lamda adalah hasil lamda univariat untuk setiap fungsi.
Kemudian, tingkat signifikan diestimasi berdasarkan chi-square yang telah ditransformasi secara statistik. Setelah analisis diketahui, kemudian dilihat apakah wilks’lambda berasosiasi dengan fungsi diskriminan. Selanjutnya angka ini di transformasi menjadi chi-square dengan derajat kebebasan (df) yang akan digunakan dalam pengambilan keputusan dengan uji kriteria hipotesis berikut.
Jika Fhitung ≥ Ftabel maka H0 ditolak dan H1 diterima Jika Fhitung < Ftabel maka H0 diterima dan H1 ditolak
Selanjutnya dengan menggunakan nilai Fhitung, dapat diambil keputusan untuk menerima atau menolak H0. Jika H0 diterima maka akan diberikan kesimpulan bahwa tidak ada perbedaan pada faktor yang mempengaruhi nilai raport. Sebaliknya jika H0 ditolak maka terdapat perbedaan faktor yang mempengaruhi nilai raport, dengan nilai signifikan < α. H0 ditolak, sehingga proses analisis diskriminan dapat digunakan.