BAB II
TINJAUAN PUSTAKA
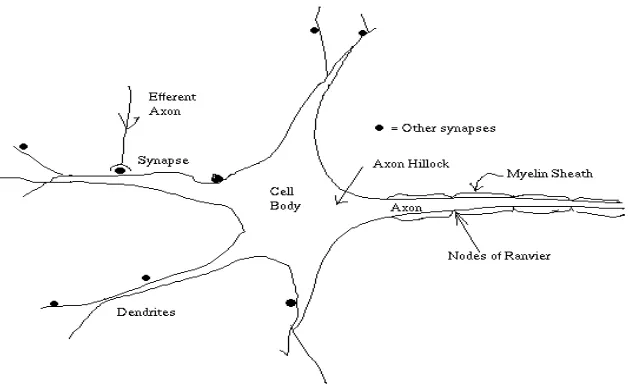
2.1 JARINGAN SARAF SECARA BIOLOGIS
Jaringan saraf adalah salah satu representasi buatan dari otak manusia yang selalu mencoba untuk mensimulasikan proses pembelajaran pada otak manusia. Istilah buatan disini digunakan karena jaringan saraf ini diimplementasikan dengan menggunakan program komputer yang mampu menyelesaikan sejumlah proses perhitungan selama proses pembelajaran (Fausett, 1994).
Setiap sel saraf memiliki satu inti sel. Inti sel ini yang akan bertugas untuk melakukan pemrosesan informasi. Informasi tersebut akan diterima dendrit. Informasi hasil olahan ini akan menjadi masukan bagi neuron lain. Informasi yang dikirimkan antar neuron
adalah berupa rangsangan yang dilewatkan melalui dendrit. Informasi yang datang akan diterima oleh dendrit dan dijumlahkan lalu dikirim melalui axon ke dendrit akhir. Informasi ini akan diterima oleh neuron lain jika memenuhi batasan tertentu. Batasan tertentu dikenal dengan nama nilai ambang (threshold) yang dikatakan teraktivasi (Haykin, 2008).
Menurut Siang (2005) Jaringan Saraf Tiruan dibentuk sebagai generalisasi model matematika dari jaringan saraf biologi, dengan asumsi bahwa :
1. Pengolahan informasi terdiri dari elemen-elemen sederhana yang disebut
neuron.
2. Sinyal dilewatkan dari satu neuron ke neuron yang lain melalui hubungan koneksi.
3. Tiap hubungan koneksi mempunyai nilai bobot sendiri.
Gambar 2.1 Saraf Secara Biologis (Haykin, 2008)
2.2 JARINGAN SARAF TIRUAN (JST)
JST dibuat pertama kali pada tahun 1943 oleh neurophysiologist Waren McCulloch dan
logician Walter Pits. Teknologi yang tersedia pada saat itu belum memungkinkan mereka berbuat lebih jauh. JST merupakan suatu sistem pemrosesan Informasi yang memiliki karaktristik-karakteristik menyerupai jaringan saraf Biologi. Hal yang sama diutarakan oleh Simon Haykin yang menyatakan Bahwa JST adalah sebuah mesin yang dirancang untuk memodelkan cara otak manusia mengerjakan fungsi atau tugas-tugas tertentu. Mesin ini memiliki kemampuan menyimpan pengetahuan berdasarkan pengalaman dan menjadikanya simpanan pengetahuan yang dimiliki menjadi bermanfaat (Haykin, 2008).
2.2.1Karakteristrik JST
Karakteristik JST ditentukan oleh 3 hal yaitu:
1. Pola hubungan antar neuron disebut arsiktektur jaringan.
2. Metode untuk menentukan nilai bobot tiap hubungan disebut pembelajaran/ pelatihan.
2.2.2 Struktur dan Komponen JST
JST terdiri dari sejumlah elemen pemroses sederhana yang disebut dengan neuron. Tiap
neuron terhubung sambungan komunikasi dimana tiap sambungan mempunyai nilai bobot sendiri. Nilai bobot ini menyediakan informasi yang akan digunakan oleh jaringan untuk memecahkan masalah.
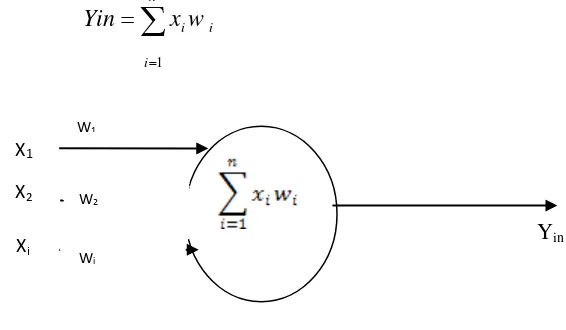
Neuron buatan ini dirancang untuk menirukan karakteristik neuron biologis. Secara prinsip diberikan serangkaian masukan (input) yang masing-masing menggambarkan keluaran (output) yang kemudian akan menjadi masukan bagi neuron lain. Setiap input akan dikalikan dengan suatu faktor penimbang tertentu (wi) yang analog dengan tegangan
synapsis. Semua input tertimbang itu dijumlahkan untuk menentukan tingkat aktivasi suatu
neuron. Gambar 2.2 menunjukkan serangkaian input dengan nama x1, x2, ..., xn
neuron buatan. Untuk mendapat keluaran dari setiap input digunakan:
(2.1)
Yin
Keterangan : X1,X2,... Xi : Data Input, w1, w2, wi : Bobot , Y-in :
Gambar 2.2 Model Neuron Buatan (Fausett, 1994) Sinyal output
2.2.3 Pemrosesan Informasi dalam JST
Aliran informasi yang diproses disesuaikan dengan arsitektur jaringan (Wulandari et al, 2012). Beberapa konsep utama yang berhubungan dengan proses adalah:
1. Masukan (Input), setiap input bersesuaian dengan suatu atribut tunggal. Serangkaian input pada JST diasumsikan sebagai vektor X yang bersesuaian dengan sinyal-sinyal yang masuk ke dalam sinapsis neuron biologis. Input
merupakan sebuah nilai yang akan diproses menjadi nilai output. 2. Keluaran (Output), output dari jaringan adalah penyelesaian masalah.
3. Bobot (Weight), mengekspresikan kekuatan relatif (atau nilai matematis) dari
input data awal. Penyesuaian yang berulang-ulang terhadap nilai bobot menyebabkan JST “belajar”. Bobot-bobot ini diasumsikan sebagai vektor w. setiap bobot bersesuaian dengan tegangan (strength) penghubung sinapsis biologis tunggal.
4. Fungsi Penjumlahan, menggandakan setiap nilai input xi dengan bobot wi
5. Fungsi Alih (Transfer Function), menghitung stimulasi internal atau level aktivasi dari saraf.
dan menjumlahkannya bersama-sama untuk memperoleh suatu output Y. Fungsi penjumlahan ini bersesuaian dengan badan sel biologis (soma).
2.2. 4 Fungsi Aktivasi
Fungsi aktivasi merupakan fungsi yang digunakan untuk meng-update nilai-nilai bobot periterasi dari semua nilai input. Secara sederhana fungsi aktivasi adalah proses untuk mengalikan input dengan bobotnya kemudian menjumlahkannya (penjumlahan sigma). Ada beberapa fungsi aktifasi yang sering digunakan dalam jaringan saraf tiruan antara lain :
1. Fungsi Sigmoid Biner
e x
dimana x : nilai sinyal keluaran dari satu neuron yang akan diaktifkan
e : nilai konstanta dengan nilai = 2.718281828
2. Fungsi Identitas (linear)
Fungsi linear memiliki nilai output yang sama dengan nilai input-nya.
3. Fungsi Saturating Linear
Fungsi ini akan bernilai 0 jika input-nya kurang dari -1/2 dan akan benilai 1 jika input-nya lebih dari ½.
4. Fungsi Symetrik
Fungsi ini akan bernilai -1 jika input-nya kurang dari -1 dan akan bernilai 1 jika
input-nya lebih dari 1. 5. Fungsi Sigmoid Bipolar
Fungsi Sigmoid Bipolar hampir sama dengan fungsi Siqmoid Biner hanya saja
output dari fungsi ini memiliki range antara 1 sampai -1
dimana x : nilai sinyal keluaran dari satu neuron yang akan diaktifkan
e : nilai konstanta dengan nilai = 2.718281828
2. 2.5 Arsitektur Jaringan Saraf Tiruan
Secara umum arsitektur JST terdiri dari atas beberapa lapisan yaitu sebagai berikut (Dhaneswara dan Moertini, 2004):
Lapisan masukan merupakan lapisan yang terdiri dari beberapa neuron yang akan menerima sinyal dari luar dan kemudian meneruskan ke neuron-neuron lain dalam jaringan.
2. Lapisan Tersembunyi (hidden layer)
Lapisan tersembunyi merupakan tiruan dari sel-sel saraf konektor pada jaringan saraf biologis. Lapisan tersembunyi berfungsi meningkatkan kemampuan jaringan dalam memecahkan masalah.
3. Lapisan Keluaran (output layer)
Lapisan keluaran berfungsi menyalurkan sinyal-sinyal keluaran hasil pemrosesan jaringan. Lapisan ini juga terdiri dari sejumlah neuron. Lapisan keluaran merupakan tiruan sel-sel saraf motor pada jaringan saraf biologi.
Arsitektur Jaringan Saraf Tiruan terdiri dari 2 macam jaringan yaitu sebagai berikut:
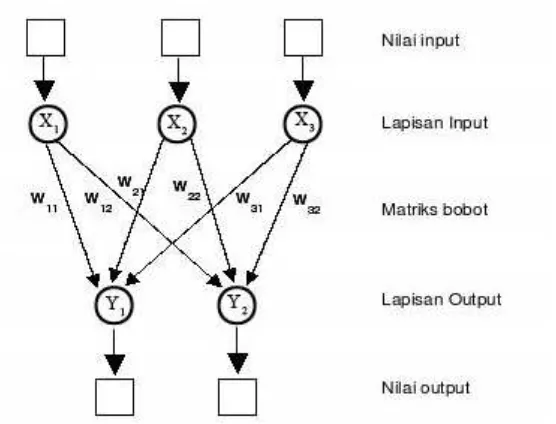
1. Jaringan Lapisan Tunggal (Single Layer )
Jaringan single layer terdiri atas satu lapisan input dan satu lapisan output dengan setiap
Keterangan : X1,X2,X3: node lapisan input, Y1,Y2: node lapisan Output, w11, w12…w31 : bobot
untuk menghubungkan sinyal input masukan dengan keluaran.
Gambar 2.3 JST Lapisan Single Layer (Fausset, 1994)
Untuk mendapatkan nilai keluaran node 1 (Y1) didapat dengan mengalikan sinyal masukan
dengan bobot yang menuju node Y1 = (x1 *w11) + (x2 * w21) + (x3 *w31). Dengan cara
yang sama dapat dihitung untuk nilai keluaran dari Y2
Y
. Sehingga dapat dirumuskan:
i
∑
= ni ij iv
x 1
= (2.4)
Rumus 2.4 dapat digunakan jika tidak terdapat bias. Jika menggunakan bias maka Y1
= v01 + (x1 *w11) + (x2 * w21) + (x3 *w31
dan
)
Yi = v0 j
∑
= ni ij iv
x 1
Nilai input dalam gambar 2.4 merupakan nilai objek yang akan dihitung/ diteliti yang sudah disesuaikan dengan batas nilai fungsi aktifasi yang digunakan. Misalnya jika menggunakan fungsi aktifasi Sigmoid Biner maka nilai xi yang dapat digunakan adalah
dalam interval -1 s/d 1. Jika nilai xi lebih besar atau lebih kecil dari interval tersebut maka
data terlebih dahulu dinormalisasi.
Nilai Input
Neuron-Neuron pada Lapisan
Input V41
V13 V21 V
V
23 V
31
V33 42
V11 V
V
12 22 V32 V43
Neuron-Neuron pada Lapisan tersembunyi
Z21 Z31
Z11 Z12 Z22 Z32
Neuron-Neuron pada Lapisan output
Nilai Output
Keterangan :x1 .. x4 : lapisan input ,z1 .. z3 : Lapisan tersembunyi ,y1, y2 : lapisan output
Gambar 2.5 JST Lapisan Multi Layer (Fausset, 1994)
Untuk mendapatkan nilai keluaran node 1 (Z1) didapat dengan mengalikan sinyal masukan
dengan bobot yang menuju node Z1 = (x1 *V11) + (x2 * V21) + (x3 *V31) + (x4 *v41.
Dengan cara yang sama dapat dihitung untuk nilai keluaran dari z2 dan z3
(2.5)
.
Untuk mendapatkan nilai keluaran node 1 (Y1) didapat dengan mengalikan sinyal masukan
dengan bobot yang menuju node Y1 = (x1 *z11) + (x2 * z21) + (x3 *z31
Dengan cara yang sama dapat dihitung untuk nilai keluaran dari y )
Jika pada gambar 2.4 ditambah bias menuju lapisan tersembunyi (b1) dengan bobotnya v01
dan bias menuju lapisan output (b2) dengan bobotnya w01, maka rumus 2.5 dan 2.6 akan
2.2.6 Proses Pembelajaran Jaringan Saraf Tiruan
sehingga jaringan ini tidak dapat melakukan segalanya seperti kemampuan saraf sesungguhnya. Proses pembelajaran suatu JST melibatkan tiga pekerjaan, sebagai berikut:
1. Menghitung output.
2. Membandingkan output dengan target yang diinginkan. 3. Menyesuaikan bobot dan mengulangi proses
Pada umumnya, jika menggunakan Jaringan Saraf Tiruan, hubungan antara input
dan output harus diketahui secara pasti. Jika hubungan tersebut telah diketahui maka dapat dibuat suatu model. Hal lain yang penting adalah proses belajar hubungan input/output
dilakukan dengan pembelajaran. Pelatihan Jaringan Saraf bertujuan untuk mencari bobot-bobot yang terdapat pada setiap layer.
Ada dua jenis pelatihan dalam sistem jaringan saraf tiruan, yaitu:
1. Pembelajaran Terawasi (Supervised Learning). Dalam proses pelatihan ini, jaringan dilatih dengan cara diberikan data yang disebut pelatihandata.Pelatihan dataterdiri atas pasangan input-output yang diharapkan dan disebut associative memory. Setelah jaringan dilatih, associative memory dapat mengingat suatu pola. Dalam tesis ini akan digunakan pembelajaran terawasi yaitu dengan menggunakan metode
backpropagation.
2. Pembelajaran Tidak Terawasi (Unsupervised Learning). Dalam proses pelatihan ini, jaringan dilatih hanya dengan diberi data input yang memiliki kesamaan sifat tanpa disertai output.
2.3 METODE BACKPROPAGATION
Backpropagation
merupakan salah satu metode pelatihan dari Jaringan Saraf Tiruan.
Backpropagation
menggunakan arsitektur
multilayer
dengan metode pelatihan
supervised
pelatihan
.
Metode
Backpropagation
ini dikembangkan oleh Rumelhart
Hinton dan Williams sekitar tahun 1986. Menurut teori
Backpropagation
, metode ini
secara efektif bisa menentukan pendekatan yang paling baik dari data yang
Backpropagation
merupakan generalisasi aturan delta (
Widrow-Hoff
).
Backpropagation
menerapkan metode
gradient descent
untuk meminimalkan
error
kuadrat total dari keluaran yang dihitung oleh jaringan.
Backpropagation
melatih
jaringan untuk memperoleh keseimbangan antara “kemampuan jaringan” untuk
mengenali pola yang digunakan selama pelatihan dan “kemampuan jaringan”
merespon secara benar terhadap pola masukan yang serupa (tapi tidak sama) dengan
pola pelatihan
.2.3.1 Algoritma Backpropagation:
1. Inisialisasi bobot (ambil bobot awal dengan nilai random yang cukup kecil antara 0 sampai 1).
2. Untuk setiap pasangan vektor pelatihan lakukan langkah 3 sampai langkah 8. 3. Tiap-tiap unit input (Xi dimana i=1,2,3,...,n) menerima sinyal masukan xi
4. Tiap-tiap unit tersembunyi (Z
dan menjalankan sinyal tersebut ke semua unit pada lapisan yang ada diatasnya atau selanjutnya (dalam hal ini adalah lapisan tersembunyi).
j
Z
dimana j=1,2,3,...,p) jumlahkan bobotnya dengan sinyal-sinyal input masing-masing :
inj= v0 j
∑
gunakan fungsi aktivasi untuk menghitung sinyal output-nya:
Zj = f(Zinj
dan kirimkan sinyal tersebut ke semua unit di layer atasnya (unit-unit output layer)
) (2.10)
5.
Tiap-tiap unit
output
(
Y
ky
dimana
k=1,2,3,...,m
) jumlahkan bobotnya dengan
sinyal-sinyal
input
masing-masing:
ink = w0 j
∑
gunakan fungsi aktivasi untuk menghitung sinyal outputnya :
dan kirimkan sinyal tersebut ke semua unit di lapisan atasnya (unit-unit output).
6.
Tiap-tiap unit output (
Y
kδ
dimana
k=1,2,3,...,m
) menerima target pola yang
berhubungan dengan pola input pembelajaran, hitung informasi
error
-nya:
k = (tk-yk) f’(y_ink
kemudian hitung koreksi bobot (yang nantinya akan digunakan untuk memperbaiki nilai
w
hitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai w
(2.14)
0k
∆w
):
0k = α δk
kirimkan ini ke unit-unit yang ada lapisan bawahnya.
(2.15)
7.
Tiap-tiap unit tersembunyi (
Z
jδ_in
dimana
j=1,2,3,...,p
) menjumlahkan delta
input
-nya (dari unit-unit yang berada pada lapisan di atas-nya):
j
∑
kalikan nilai ini dengan turunan dari fungsi aktivasinya untuk menghitung informasi
error :
δj = δ_ in j f’(z_inj
kemudian hitung koreksi bobot (yang nantinya akan digunakan untuk memperbaiki nilai
v
hitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai v
(2.18)
0j
∆v
):
8.
Tiap-tiap unit
output
(Yk
w
dimana k=1,2,3,...,m) memperbaiki bias dan bobotnya (
j
= 0,1,2,...,p
):
jk(baru) = wjk(lama)+ ∆wjk
tiap-tiap unit tersembunyi (Z
(2.20)
j
v
dimana j = 1,2,3,...,p) memperbaiki bias dan bobotnya (i = 0,1,2,...,n):
ij(baru) = vij (lama)+ ∆ vij
9.
Tes kondisi berhenti.
(2.21)
Tahap 3 sampai dengan tahap 5 merupakan bagian dari
feedforward
, tahap 6
sampai 8 merupakan bagian dari
backpropagation (
Fausset,1994).
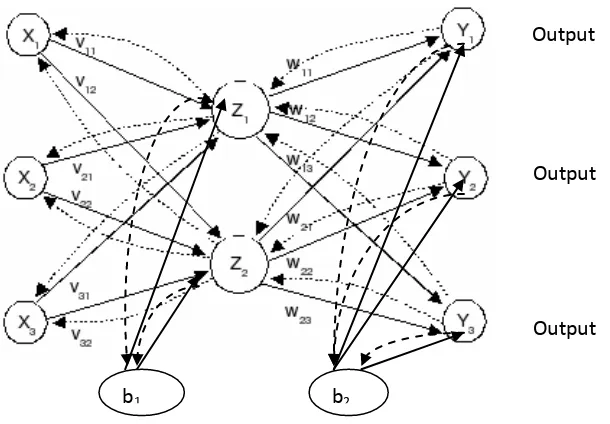
2.3.2 Arsitektur Backpropagation:
Pada gambar 2.5 dapat dilihat gambar arsitektur Backpropagation dengan 3 nodeinput layer
masukan 2 node pada hidden layer, 3 node output layer dan 2 bias 1 menuju hidden layer, 1 menuju output layer. Pada gambar 2.6 arsitektur backpropagation terdapat dua jenis tanda panah yaitu tanda panah maju ( ) dan tanda panah mundur ( ). Tanda panah maju digunakan pada saat proses feedforward untuk mendapatkan sinyal keluaran dari output layer. Jika nilai error yang dihasilkan lebih besar dari batas error yang digunakan dalam sistem, maka akan dilakukan koreksi bobot dan bias. Koreksi bobot dapat dilakukan dengan menambah atau menurunkan nilai bobot.
Keterangan:Y1..Y3 : output, X1…Xn : data input, b1,b2: bias, Z1, Z2
Gambar 2.5 Gambar Arsitektur Backpropagation (Fausett, 1994) : hidden Layer
2.3.3 Meningkatkan Hasil Metode Backpropagation
Masalah utama yang dihadapi dalam Backpropagation adalah lamanya iterasi yang harus dilakukan. Backpropagation tidak dapat memberikan kepastian tentang berapa epoch yang harus dilalui untuk mencapai kondisi yang diinginkan. Untuk meningkatkan hasil yang diperoleh dengan metode backpropagation dapat dilakukan dengan analisis bobot dan bias awal, jumlah unit tersembunyi, waktu iterasi dan penambahan mom
2.3.3.1 Pemilihan Bobot dan Bias Awal
Bobot awal akan mempengaruhi apakah jaringan mencapai titik minimum lokal (local minimum) atau global, dan seberapa cepat konvergensinya dalam pelatihan. Inisialisasi bobot awal dapat dilakukan dengan 2 (dua) Metode yaitu: Inisialisasi Bobot dan Bias awal secara Random dan Inisialisasi Bobot dan Bias awal dengan Metode Nguyen Widrow.
Bobot dalam Backpropagation tidak boleh diberi nilai yang sama. Penyebabnya adalah karena jika bobot sama jaringan tidak akan terlatih dengan benar. Jaringan mungkin saja gagal untuk belajar terhadap serangkaian contoh-contoh pelatihan. Misalnya dengan kondisi
Output
Output
Output
tetap atau bahkan error semakin besar dengan diteruskannya proses pelatihan. Untuk mengatasi hal ini maka inisialisasi bobot dibuat secara acak.
Bobot yang menghasilkan nilai turunan aktivasi yang kecil sedapat mungkin dihindari karena akan menyebabkan perubahan bobotnya menjadi sangat kecil. Demikian pula nilai bobot awal tidak boleh terlalu besar karena nilai turunan fungsi aktivasinya menjadi sangat kecil juga.Dalam Standar Backpropagation, bobot dan bias diisi dengan bilangan acak kecil. Untuk inisialisasi bobot awal secara random maka nilai yang digunakan adalah antara -0.5 sampai 0.5 atau -1 sampai 1.
2.3.3.2 Jumlah Unit Tersembunyi
Berdasarkan hasil teoritis, Backpropagation dengan sebuah hidden layer sudah cukup untuk mampu mengenali sembarang pasangan antara masukan dan target dengan tingkat ketelitian yang ditentukan. Akan tetapi penambahan jumlah hidden layer kadangkala membuat pelatihan lebih mudah. Jika jaringan memiliki lebih dari hidden layer, maka algoritma pelatihan yang dijabarkan sebelumnya perlu direvisi. Dalam propagasi maju, keluaran harus dihitung untuk Setiap layer, dimulai dari hidden layer paling bawah (terdekat dengan unit
masukan). Sebaliknya dalam propagasi mundur, faktor δ perlu dihitung untuk tiap hidden
layer, dimulai dari lapisan keluaran (Hajar, 2005).
2.3.3.3 Waktu Iterasi
Tujuan utama penggunaan Backpropagation adalah mendapatkan keseimbangan antara pengenalan pola pelatihan secara benar dan respon yang baik untuk pola lain yang sejenis. Jaringan dapat dilatih terus menerus hingga semua pola pelatihan dikenali dengan benar. Akan tetapi hal itu tidak menjamin jaringan akan mampu mengenali pola pengujiandengan tepat. Jadi tidaklah bermanfaat untuk meneruskan iterasi hingga semua kesalahan pola pelatihan = 0.
data (pelatihan dan pengujian). Selama kesalahan ini menurun, pelatihan terus dijalankan. Akan tetapi jika kesalahannya sudah meningkat, pelatihan tidak ada gunanya diteruskan. Jaringan sudah mulai mengambil sifat yang hanya dimiliki secara spesifik oleh data pelatihan (tapi tidak dimiliki oleh data pengujian) dan sudah mulai kehilangan kemampuan melakukan generalisasi.
2.3.3.4 Momentum
Pada standar Backpropagation, perubahan bobot didasarkan atas gradien yang terjadi untuk pola yang dimasukkan saat itu. Modifikasi yang dapat dilakukan adalah melakukan perubahan bobot yang didasarkan atas ”ARAH GRADIEN” pola terakhir dan pola sebelumnya (momentum) yang dimasukkan. Jadi tidak hanya pola masukan terakhir saja yang diperhitungkan.
Penambahan momentum dimaksudkan untuk menghindari perubahan bobot yang mencolok akibat adanya data yang sangat berbeda dengan yang lain. Apabila beberapa data terakhir yang diberikan ke jaringan memiliki pola yang serupa (berarti arah gradien sudah benar), maka perubahan bobot dilakukan secara cepat. Namun apabila data terakhir yang dimasukkan memiliki pola yang berbeda dengan pola sebelumnnya, maka perubahan bobot dilakukan secara lambat (Fausset, 1994).
Penambahan momentum, bobot baru pada waktu ke (T + 1) didasarkan atas bobot pada waktu T dan (T-1). Di sini harus ditambahkan 2 variabel baru yang mencatat besarnya momentum untuk 2 iterasi terakhir. Jika μ adalah konstanta yang menyatakan parameter momentum (Dhaneswara dan Moertini, 2004).
Jika menggunakan momentum maka bobot baru dihitung berdasarkan persamaan:
wjk(T+1) = wjk(T) + αδk zj + μ ( wjk(T) – wjk(T-1)) (2.24) dan
vij(T+1) = vij(T) + αδj xi + μ ( vij(T) – vij(T-1)) (2.25)
Dalam proses testing ini diberikan input data yang disimpan dalam disk (file testing). JST yang telah dilatih akan mengambil data tersebut dan memberikan output yang merupakan “Hasil Prediksi JST”. JST memberikan output berdasarkan bobot yang disimpan dalam proses pelatihan.
Pada akhir testing dilakukan perbandingan antara hasil prediksi (output JST) dan hasil asli (kondisi nyata yang terjadi). Hal ini adalah untuk menguji tingkat keberhasilan JST dalam melakukan prediksi.
2.4 METODE NGUYEN WIDROW
Nguyen Widrow mengusulkan cara membuat inisialisasi bobot dan bias ke unit tersembunyi sehingga menghasilkan iterasi lebih cepat. Metode Nguyen Widrow akan menginisialisasi bobot-bobot lapisan dengan dengan nilai antara -0.5 sampai 0.5. Sedangkan bobot dari lapisan input ke lapisan tersembunyi dirancang sedemikian rupa sehingga dapat meningkatkan kemampuan lapisan tersembunyi dalam melakukan proses pembelajaran (Fausset, 1994)
Metode Nguyen Widrow secara sederhana dapat diimplementasikan dengan prosedur sebagai berikut:
Tetapkan:
n = jumlah unit masukan(input)
p = jumlah unit tersembunyi
β = faktor skala =
(
0.7( )
p 1n)
(2.22)Hal inilah yang menyebabkan faktor skala β yang digunakan dalam metode Nguyen Widrow menggunakan nilai 0.7. Nilai 0.7 dalam faktor skala metode Nguyen Widrow diharapkan dapat menghasilkan bias dan bobot yang mampu menyesuaikan dengan pola pelatihan dalam
backpropagation.
Algoritma inisialisasi Nguyen Widrow adalah sebagai berikut:
Kerjakan untuk setiap unit pada lapisan tersembunyi (j=1,2,...,p):
a. Inisialisasi bobot-bobot dari lapisan input ke lapisan tersembunyi
v
ij= bilangan acak dalam interval [-0,5: 0,5]
b. Hitung ||vj
c. Inisialisasi ulang bobot-bobot : ||
vij
|| || j
ij
v v
β
= (2.23)
d. Set bias b1j = bilangan random antara -
β
sampaiβ
2.5 NORMALISASI DATA
Normalisasi adalah penskalaan terhadap nilai-nilai masuk ke dalam suatu range tertentu. Hal ini dilakukan agar nilai input dan target output sesuai dengan range dari fungsi aktivasi yang digunakan dalam jaringan. Normalisasi ini dilakukan untuk mendapatkan data berada dalam interval 0 sampai dengan 1. Hal ini disebabkan karena nilai dalam fungsi aktifasi Sigmoid Biner adalah berada diantara 0 dan 1. Tapi akan lebih baik jika ditransformasikan keinterval yang lebih kecil. Misalnya pada interval [0,1..0,9], karena mengingat fungsi Sigmoid Biner nilainya tidak pernah mencapai 0 ataupun 1 (Santoso at el, 2007).
X = max min min
). (
) )(
(
x a
b
a x
x
+ −
− × −
(2.26)
Dimana:
Xmax : Nilai maximum data aktual
Xmin : Nilai minimum data aktual
a : Data terkecil
b : Data terbesar
x
: Data aktual
2.6
PENELITIAN TERKAIT
Terdapat beberapa riset yang telah dilakukan oleh banyak peneliti berkaitan dengan
penulisan penelitian ini. Adapun penelitian tersebut dapat dilihat pada tabel 2.1 di
Tabel 2.1 Penelitian Terkait
Nama Peneliti Judul Pembahasan
Tahun
Andrijasa M.F,
Mistianingsih,
Penerapan Jaringan Syaraf Tiruan
Untuk Memprediksi Jumlah
learning rate untuk
mendapatkan hasil prediksi
yang akurat dalam penelitian
yang dilakukannya learning
rate terbaik adalah 0.01
dengan 1 hidden layer.
2010
absolute rata-rata (KAR)
dalam metode
Backpropagation.
2005
Hajar I Penggunaan Backpropagation
neural network pada relay jarak
untuk mendeteksi gangguan pada
jaringan transmisi.
Backpropagation neural
network deprogram secara
terpadu menggunakan
algoritma generalized delta
rule (GDR) untuk mengenali
pola-pola bentuk gelombang
tegangan dan arus pada
kondisi saluran transmisi
terganggu, dengan
menggunakan tegangan dan
arus phasa sebagai input,
output backpropagation
adalah keputusan trip/tidak
trip.
2005
Siana Halim, Penerapan Jaringan Saraf Tiruan
untuk Peramalan
Membandingkan MAD
dengan MSE dalam Model
GARCH dan MAD dengan
dengan Momentum untuk
Klasifikasi Data
membandingkan hasil yang
diperoleh dengan 1 lapisan
tersembunyi dengan 2 lapisan
tersembunyi dengan
Eksperimen Data Aplikasi