Fakultas Ilmu Komputer
Universitas Brawijaya
2578
Prediksi Jumlah Kunjungan Wisatawan Mancanegara Ke Bali
Menggunakan Support Vector Regression dengan Algoritma Genetika
Listiya Surtiningsih1, M. Tanzil Furqon2, Sigit Adinugroho3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Sektor pariwisata menjadi salah satu penopang perekonomian yang ada di Indonesia. Selama ini sumbangan wisatawan mancanegara Bali terhadap wisman nasional hampir mencapai 40% sehingga menjadikan Bali banyak menyumbang terhadap jumlah kunjungan wisman nasional. Prediksi kunjungan wisatawan mancanegara sangat penting bagi pemerintah dan industri, karena prediksi menjadi dasar dalam perencanaan kebijakan yang efektif. Metode Support Vector Regression (SVR) merupakan metode prediksi yang memiliki kemampuan dalam mengatasi data skala besar pada fase training dan mampu mengenali pola dari data time series. Hasil prediksi akan bernilai baik jika nilai parameter penting dari SVR dapat ditentukan secara benar dengan cara dilakukan optimasi. Salah satu metode optimasi adalah Algoritma Genetika (GA). GA akan melakukan optimasi terhadap parameter penting dari SVR untuk mendapatkan parameter terbaik sehingga dapat menghasilkan prediksi yang lebih baik. Hasil pengujian menunjukkan nilai MAPE yang diperoleh adalah 2,513% dengan parameter terbaik yaitu range lamda 1 – 10, range kompleksitas 1 – 100, range epsilon 0,00001 – 0,001, range gamma 0,00001 – 0,001, range sigma 0,01 – 3,5, Iterasi SVR 1250, generasi GA 90, populasi 70, crossover rate 0,6, mutation rate 0,4, jumlah fitur 2 dan jumlah periode prediksi 1 bulan. Berdasarkan hasil pengujian, metode GA-SVR pada data kunjungan wisatawan mancanegara ke Bali sesuai untuk prediksi jangka pendek.
Kata kunci: prediksi, wisatawan mancanegara, SVR, algoritma genetika, MAPE Abstract
The tourism sector becomes one of the pillars in the Indonesian economy. As Bali has been contributing for more than 40 percent of international tourist arrivals in Indonesia. Predicting tourism demand are very important for the government and industry, as predicting the basis for effective policy planning. Support Vector Regression (SVR) is prediction method that has the ability to handle large-scale data in the training phase and it can to recognize patterns of time series data. The predicted result will be good if the value of the important parameters of the SVR can be determined correctly by optimization. One of optimization methods is Genetic Algorithm (GA). GA will be optimizing parameter of SVR to get the right value of SVR parameter to getting better predictions. The test shows the value of MAPE obtained is 2,513% with best parameters those are range of lamda 1 – 10, range of complexity 1 – 100, range of epsilon 0,00001 – 0,001, range of gamma 0,00001 – 0,001, range of sigma 0,01 – 3,5, Iteration of SVR 1250, generation of GA 90, population 70, crossover rate 0,6, mutation rate 0,4, features 2 and prediction period 1 month. Based on the test results, GA-SVR method on the data of foreign tourist arrivals to Bali is appropriate for short-term prediction.
Keywords: prediction, foreign tourist, SVR, genetic algorithm, MAPE
1. PENDAHULUAN
Salah satu tujuan wisata di Indonesia yang telah terkenal di luar maupun dalam negeri yaitu Provinsi Bali. Bali merupakan destinasi wisata yang banyak diminati terutama oleh wisatawan
mancanegara (wisman). Bali memiliki daya tarik yang dapat membuat Indonesia dikenal sebagai salah satu Negara dengan destinasi tempat wisata yang populer (Tribunnews, 2016).
Dengan berbagai daya tarik yang dimilikinya, Bali mampu menarik perhatian
wisatawan lokal maupun mancanegara. Sebanyak 40% wisatawan mancanegara melewati gate Bali, sehingga menjadikan Bali banyak menyumbang terhadap jumlah kunjungan wisatawan mancanegara nasional. Menurut Badan Pusat Statistik pada tahun 2016, jumlah kunjungan wisatawan mancanegara ke Bali meningkat 22,55% dibandingkan pada tahun 2015.
Tingginya arus wisata ke Bali harus diimbangi dengan sarana dan prasarana tempat yang memadai hingga keamanan yang baik pula. Peningkatan jumlah kunjungan wisatawan mancanegara ke Bali jika tidak diimbangi dengan sarana dan prasarana tempat yang memadai dapat menurunkan minat untuk kembali berkunjung ke Bali serta berdampak pula terhadap sektor perekonomian masyarakat Bali.
Untuk itu, perlu adanya prediksi terhadap jumlah kunjungan wisatawan manacanegara ke Bali setiap bulannya. Dengan dilakukannya prediksi jumlah kunjungan wisatawan mancanegara diharapkan dapat membantu pemerintah daerah maupun dinas pariwisata provinsi Bali dalam mengoptimalkan fasilitas, sarana, prasarana hingga keamanan wisatawan yang berkunjung dan meningkatkan sektor perekonomian masyarakat Bali maupun negara.
Penelitian mengenai peramalan jumlah kunjungan wisatawan mancanegara ke Lombok periode 2010 – 2015 yang telah dilakukan oleh Misriati, dkk (2016) menggunakan metode Jaringan Syaraf Tiruan (JST). Hasil dari peneilitian tersebut menunjukkan metode JST mampu menghasilkan MAPE sebesar 9,5%.
Salah satu metode yang dapat digunakan untuk memprediksi jumlah kunjungan wisatawan mancanegara yaitu Support Vector Regression (SVR). SVR merupakan metode yang mampu meramalkan data secara non linier. Metode ini dapat mengubah data ke dalam dimensi yang lebih tinggi (Christianni dan Taylor, 2000). Penelitian yang dilakukan oleh Messad dan Rasel, (2013) dengan menggunakan metode SVR dalam melakukan prediksi harga pasar saham pada periode 2009 – 2012. Penelitian tersebut menghasilkan error rate yang rendah dengan rata-rata kesalahan 0,15.
Namun, adapun kelemahan yang dimiliki SVR yaitu nilai parameter SVR cukup sensitif terjebak dalam local optimum. Menurut Messad dan Rasel (2013) metode SVR dapat memberikan hasil prediksi yang baik jika nilai parameter pentingnya dapat ditentukan dengan
baik (Messad & Rasel, 2013).
Maka diperlukan sebuah metode pengoptimalan yang mampu menghasilkan parameter yang optimal sehingga hasil prediksi yang diperoleh menjadi lebih baik. Salah satu metode optimasi yang dapat digunakan yaitu Algoritma Genetika (GA). Metode ini dapat memecahkan masalah optimasi dalam bidang computer science dengan tingkat kesuksesan yang tinggi (Mu'asyaroh & Mahmudy, 2016).
Hal ini dibuktikan pada penelitian yang dilakukan oleh Yuan (2012) dalam memprediksi volume penjualan menggunakan SVR dengan algoritma genetika dan membandingkannya dengan metode lain. Hasil dari penelitian menunjukkan bahwa SVR-GA mampu memberikan hasil error rate yang lebih baik dibandingkan dengan metode lain yaitu SVR,
Artificial Neural Nework (ANN),
Backpropagation (BPN), dan Least Mean Square (LMS).
Dari permasalahan yang telah dipaparkan, akan dilakukan prediksi untuk memprediksi jumlah kunjungan wisatawan mancanegara ke Bali menggunakan SVR dengan optimasi Algoritma Genetika. Diharapkan penelitian ini mampu menghasilkan tingkat error rate yang kecil.
2. TINJAUAN PUSTAKA 2.1. Prediksi
Prediksi adalah sebuah peramalan mengenai apa yang akan terjadi di masa depan dalam jangka waktu pendek (Taylor, Celuch, & Goodwin., 2004). Secara umum, ada dua jenis prediksi yaitu kualitatif dan kuantitatif. Prediksi kualitatif merupakan prediksi yang bersifat subjektif, hal ini karena didasarkan pada pengalaman empiris, intuisi pengambilan keputusan dan emosi manusia. Sedangkan, prediksi kuantitatif merupakan prediksi yang bersifat objektif sebab didasarkan pada data aktual dan diolah menggunakan metode tertentu. 2.2. Normalisasi
Normalisasi atau normalisasi data adalah suatu cara mengubah data ke menjadi nilai yang mudah dipahami (Patel & Mehta, 2011). Normalisasi bertujuan untuk mendapatkan data dengan ukuran yang lebih kecil yang mewakili data yang asli tanpa kehilangan karakteristik sendirinya. Keseluruhan data akan dinormalisasi dengan fungsi linier (Parto & Sahu, 2015):
𝑁𝑜𝑟𝑚𝑎𝑙𝑖𝑠𝑎𝑠𝑖 = 𝑥−𝑚𝑖𝑛
max − 𝑚𝑖𝑛 (1)
dimana :
x = data ke-i
min = data minimum dari data yang digunakan
max = data maksimum dari data yang digunakan
2.3. Algoritma Genetika
Algoritma genetika adalah sebuah metode adaptif yang sering digunakan untuk mengatasi permasalahan optimasi. Algoritma genetika terdiri dari beberapa tahapan yaitu representasi kromosom, crossover, mutasi dan seleksi. Algoritma genetika dimulai dari pembuatan solusi alternative (populasi). Setiap solusi mewakili sebagai individual atau kromosom. Algoritma genetika awalnya diciptakan oleh John Holland pada tahun 1960 dan 1970-an, Algoritma genetika menggunakan analogi alami berdasarkan seleksi alam (Noersasongko, et al., 2016).
2.3.1. Crossover
Crossover adalah teknik pindah silang atau dikenal dengan proses reproduksi/perkawinan antara dua kromosom parent menjadi sebuah kromosom baru (offspring).
Crossover yang digunakan dalam penelitian ini adalah Extended Intermediate Crossover merupakan metode crossover yang menghasilkan offspring dengan mengkombinasikan nilai 2 parent. Kombinasi tersebut dipilih dengan random dari populasi. Contohnya P1 dan P2 merupakan parent yang sebelumnya telah dilakukan seleksi untuk melakukan crossover, sehingga offspring (C1 dan C2) dapat dibangkitkan (Pramesti, Mahmudy, & Indriati., 2015):
𝐶1= 𝑃1+ 𝛼(𝑃2− 𝑃1) (2)
𝐶2= 𝑃2+ 𝛼(𝑃1− 𝑃2) (3)
Variabel α dipilih dibangkitkan secara acak (random) misalkan dengan range [0,1].
2.3.2. Mutasi
Mutasi adalah suatu proses yang membuat individu baru dengan cara melakukan modifikasi terhadap satu atau beberapa gen dalam suatu individu yang sama. Proses mutasi bertujuan untuk mengubah gen yang hilang dari populasi selama proses seleksi dan menggantinya dengan gen yang tidak ada dalam populasi awal
(Mahmudy, 2013).
Mutasi yang digunakan dalam penelitian ini adalah Random Mutation. Teknik mutasi ini dilakukan dengan cara memilih satu induk secara random dari populasi.
𝐶𝑖= 𝑥𝑖+ 𝑟(𝑚𝑎𝑥𝑖− 𝑚𝑖𝑛𝑖) (4)
2.3.3. Seleksi
Pada tahapan seleksi bertujuan untuk menentukan individu yang akan dipilih untuk reproduksi dan berapa banyak keturunan masing-masing individu yang dihasilkan. Tujuan utama dari seleksi yaitu untuk menekankan pada solusi yang baik dan menghilangkan solusi yang buruk dalam suatu populasi, sekaligus mempertahankan ukuran populasi konstan (Shukla, Pandey, & Mehrotra., 2015).
Seleksi yang digunakan dalam penelitian ini adalah Elitism Selection. Proses ini dilakukan dengan mengurutkan seluruh individu (Parent dan Offspring) dari fitness terbesar hingga terkecil dan meloloskan individu dengan fitness terbaik sejumlah populasi ke generasi berikutnya.
2.4 Support Vector Regression
Support Vector Regression (SVR) adalah penerapan dari Support Vector Machine (SVM) yang diperkenalkan oleh Vapink (1995) untuk kasus regresi. Konsep SVR didasarkan pada risk minimization, yaitu untuk mengestimasi suatu fungsi dengan cara meminimalkan batas atas dari generalization error, sehingga SVR mampu mengatasi overfitting.
Abe (2005) menyatakan tujuan dari SVR ini adalah untuk memetakan vector input ke dalam dimensi yang lebih tinggi dengan menggunakan fungsi kernel.
Untuk menangani kasus regresi, Vijayakumar dan Wu (1999) mengenalkan algoritma sekuensial untuk SVR sehingga dapat memberikan solusi yang optimal dan waktu komputasi yang lebih cepat dibandingkan dengan SVR konvensional. Langkah-langkah tersebut adalah sebagai berikut:
Langkah 1:
Inisialisasi parameter SVR yang akan digunakan diantaranya gamma (𝛾), kompleksitas (𝐶), epsilon (𝜀), lamda (𝜆) dan parameter kernel Radial Basis Function (RBF) yaitu sigma (𝜎) serta jumlah iterasi maksimum.
Selain itu, inisialisasi 𝛼𝑖 dan 𝛼𝑖∗ (untuk
inisialisasi awal, diberikan nilai 0). Langkah 2:
Membentuk Matriks Hessian dengan menggunakan Persamaan (5).
𝑅𝑖𝑗 = 𝐾(𝑥, 𝑥𝑖) + 𝜆2 untuk 𝑖, 𝑗 = 1,2, … , 𝑙 (5)
dimana
𝑅𝑖𝑗 = Matriks Hessian baris ke-i
kolom ke-j 𝐾(𝑥, 𝑥𝑖) = fungsi kernel
𝜆 = variabel skalar 𝑙 = jumlah data Langkah 3:
Melakukan proses sequential learning yang terdiri dari:
1. Menghitung nilai error (𝐸) yang ditunjukkan pada Persamaan (6).
𝐸𝑖= 𝑦𝑖− ∑𝑙𝑗=1(𝛼𝑗∗− 𝛼𝑗) 𝑅𝑖𝑗 (6)
dimana
𝐸𝑖 = nilai error ke-i
𝑦𝑖 = nilai aktual
𝛼𝑗∗, 𝛼𝑗 = Lagrange Multipliers
𝑅𝑖𝑗 = Matriks Hessian baris ke-i
kolom ke-j
2. Menghitung 𝛿𝛼𝑖∗ dan 𝛿𝛼𝑖 dengan
menggunakan Persamaan (7).
𝛿𝛼𝑖∗= min {max [𝛾(𝐸𝑖− 𝜀), −𝛼𝑖∗], 𝐶 − 𝛼𝑖∗}
𝛿𝛼𝑖= min {max [𝛾(−𝐸𝑖− 𝜀), −𝛼𝑖], 𝐶 − 𝛼𝑖}
(7) dimana
𝛾 = nilai Learning Rate 𝐸𝑖 = nilai error ke-i
𝜀 = nilai kerugian 𝐶 = nilai kompleksitas 𝛼𝑖∗, 𝛼𝑖 = Lagrange Multipliers
3. Menghitung nilai Lagrange Multipliers dengan menggunakan Persamaan (8). 𝛼𝑖∗= 𝛼𝑖∗+ 𝛿𝛼𝑖∗
𝛼𝑖= 𝛼𝑖+ 𝛿𝛼𝑖 (8)
dimana
𝛼𝑖∗, 𝛼𝑖 = Lagrange Multipliers
Langkah 4:
Mengulang proses sequential learning pada langkah ketiga hingga mencapai jumlah iterasi maksimum atau memiliki kondisi berhenti yaitu max (|𝛿𝛼𝑖∗|) < 𝜀 dan max (|𝛿𝛼𝑖|) < 𝜀
Langkah 5:
Jika data memenuhi persyaratan (𝛼𝑖∗− 𝛼𝑖)
tidak sama dengan 0, maka dapat disebut sebagai support vector.
Langkah 6:
Melakukan pengujian dengan menggunakan Persamaan (9). 𝑓(𝑥) = ∑𝑙𝑖=1(𝛼𝑖∗− 𝛼𝑖)(𝐾(𝑥, 𝑥𝑖) + 𝜆2) (9) dimana 𝛼𝑖∗, 𝛼𝑖 = Lagrange Multipliers 𝐾(𝑥, 𝑥𝑖) = fungsi kernel 𝜆 = variabel skalar 𝑙 = banyak data Langkah 7:
Menghitung nilai error rate menggunakan Mean Absolute Percentage Error (MAPE) dengan rumus: 𝑀𝐴𝑃𝐸 =1 𝑛∑ | 𝑦𝑖− 𝑦′𝑖 𝑦𝑖 | 𝑛 𝑖=1 × 100% (10) dimana n = Jumlah wisman yi = Nilai data latih
y’i = Nilai hasil prediksi
i = Indeks
Hasil evaluasi nilai prediksi dapat dilihat pada Tabel 1 (Anggrainingsih, Aprianto & Sihwi., 2015).
Tabel 1. Hasil Evaluasi MAPE dalam Prediksi
MAPE (%) Evaluasi
MAPE ≤ 10% Akurasi Prediksi Tinggi 10% < MAPE ≤ 20% Akurasi Prediksi Baik 20% < MAPE ≤ 50% Akurasi Prediksi Sedang
MAPE > 50% Akurasi Prediksi Tidak Akurat Langkah 8:
Selesai.
3. METODOLOGI
3.1. Model Algoritma Genetika-SVR
Proses awal dalam optimasi SVR dengan algoritma genetika yaitu melakukan normalisasi data terlebih dahulu. Normalisasi dilakukan diawal untuk mengurangi waktu komputasi. Selanjutnya, membangkitkan kromosom sejumlah populasi untuk di proses dalam algoritma genetika. Algoritma Genetika digunakan untuk memperoleh parameter SVR
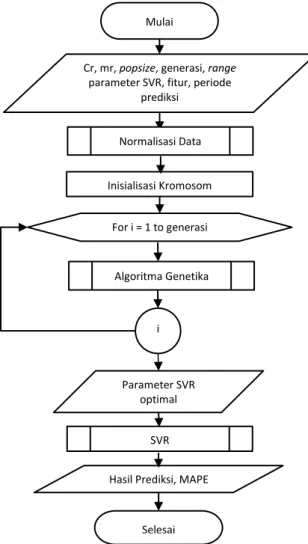
yang optimal. Setelah proses Algoritma Genetika selesai dan mendapatkan parameter SVR yang optimal akan dilanjutkan ke proses SVR. Pada proses SVR akan menghasilkan model regresi yang akan digunakan dalam melakukan prediksi. Model regresi yang telah didapat akan dicoba pada data uji untuk mengetahui seberapa bagus model tersebut. Diagram alir proses Algoritma Genetika-SVR dapat dilihat pada Gambar 1.
Gambar 1. Diagram alir algoritma genetika-SVR 3.2. Data Penelitian
Data yang digunakan dalam penelitian adalah data jumlah kunjungan wisatawan mancanegara ke Bali pada tahun 2001 – 2016 per bulan yang diambil dari Website Badan Pusat Statistik di http://www.bali.bps.go.id.
4. PENGUJIAN DAN ANALISIS
Terdapat 11 pengujian yang dilakukan dalam penelitian. Pengujian yang dilakukan antara lain jumlah generasi, iterasi SVR, jumlah populasi, kombinasi crossover rate dan mutation
rate, range nilai parameter SVR yang dioptimasi, jumlah fitur dan periode prediksi. 4.1. Pengujian dan Analisis Jumlah Generasi
Pada Gambar 2 ditunjukkan bahwa nilai MAPE cenderung menurun ketika jumlah generasi GA yang semakin besar. Hal ini dikarenakan, ketika jumlah generasi meningkat maka semakin besar pula eksplorasi solusi untuk mendapatkan individu terbaik. Tetapi, meningkatnya jumlah generasi juga mempengaruhi lama proses Algoritma Genetika untuk menemukan solusi dan nilai MAPE yang dihasilkan tidak menjamin selalu baik.
Jumlah
generasi yang optimal dari pengujian ini
adalah 90.
Gambar 2. Hasil pengujian jumlah generasi 4.2. Pengujian dan Analisis Jumlah Iterasi
SVR
Dari pengujian jumlah Iterasi SVR, didapatkan hasil optimal yaitu 1250. Hal ini dapat dilihat pada Gambar 3, ketika jumlah iterasi meningkat maka nilai MAPE cenderung menurun. Hal ini dikarenakan, ketika jumlah iterasi semakin banyak maka kemampuan SVR akan semakin baik dalam mengenali pola data dan iterasi yang semakin banyak berpengaruh pula terhadap lama proses pembelajaran yang akan dilakukan. Namun, jumlah iterasi yang terlalu banyak memungkinkan terjadinya kondisi overfit yang artinya SVR baik dalam mengenali pola data latih tetapi buruk dalam mengenali pola data uji.
13,247332 12,351455 12,295524 12,319956 12,296037 12,295531 12,295302 12,295419 12,295243 12,295381 11,500000 12,000000 12,500000 13,000000 13,500000 14,000000 10 20 30 40 50 60 70 80 90 100 R at a-ra ta M A PE Jumlah Generasi Mulai
Cr, mr, popsize, generasi, range parameter SVR, fitur, periode
prediksi Inisialisasi Kromosom For i = 1 to generasi i Parameter SVR optimal
Hasil Prediksi, MAPE
Selesai Algoritma Genetika
Normalisasi Data
Gambar 3. Hasil pengujian jumlah iterasi SVR 4.3. Pengujian dan Analisis Jumlah Populasi
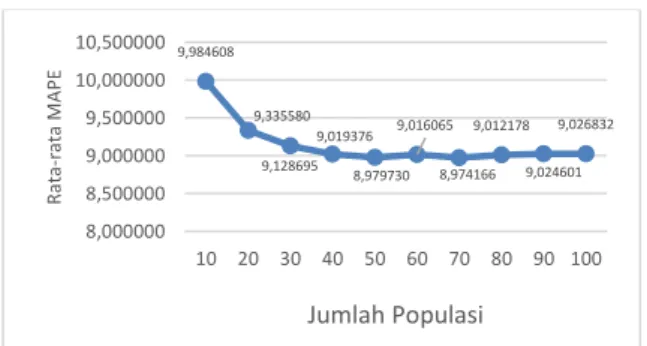
Pada Gambar 4 dapat dilihat bahwa nilai MAPE cenderung menurun ketika jumlah populasi yang semakin banyak. Hal ini dikarenakan, jumlah populasi yang semakin besar dapat berpengaruh terhadap banyaknya individu terbaik yang akan ditemukan dan sebaliknya. Tetapi, jumlah populasi yang terlalu besar tidak menjamin individu yang terbentuk semakin baik. Jumlah populasi yang optimal dari pengujian ini adalah 70.
Gambar 4. Hasil pengujian jumlah populasi 4.4. Pengujian dan Analisis Kombinasi
Crossover Rate (Cr) dan Mutation Rate
(Mr)
Dari Gambar 5 dapat dilihat bahwa nilai MAPE cenderung meningkat ketika nilai crossover rate (Cr) membesar dan nilai mutation rate (Mr) mengecil. Hal ini dikarenakan, nilai Cr yang terlalu besar dapat menurunkan kemampuan GA dalam eksploitasi. Sedangkan, nilai Mr yang terlalu kecil dapat menurunkan kecepatan GA dalam mengeksplorasi area baru sehingga hasil offspring yang dihasilkan kurang beragam. Kombinasi Cr dan Mr yang terbaik dari pengujian ini adalah 0,6 dan 0,4.
Gambar 5. Hasil pengujian kombinasi cr & mr 4.5. Pengujian dan Analisis Range Nilai
Gamma
Pada pengujian range nilai gamma didapatkan range terbaik adalah 0,00001 – 0,001. Dari Gambar 6 dapat dilihat bahwa nilai MAPE cenderung meningkat ketika nilai gamma yang semakin besar. Hal ini dikarenakan, parameter gamma berpengaruh terhadap pengaturan kecepatan pembelajaran. Semakin tinggi nilai gamma pembelajaran akan berjalan cepat namun dapat mengabaikan nilai minimum sehingga cepat mencapai konvergensi. Tetapi, jika nilai gamma terlalu kecil dapat mengakibatkan laju pembelajaran yang berjalan lambat.
Gambar 6. Hasil pengujian range nilai gamma 4.6. Pengujian dan Analisis Range Nilai C
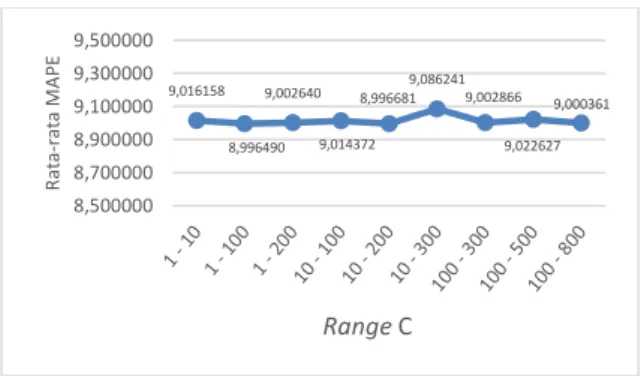
Pada pengujian range nilai C didapatkan range terbaik adalah 1-100. Dari Gambar 7 dapat dilihat bahwa nilai MAPE cenderung stabil. Hal ini dikarenakan, parameter c berpengaruh terhadap nilai pinalti yang diberikan ketika terjadi kesalahan dalam melakukan prediksi. Nilai c yang rendah menunjukkan toleransi kesalahan yang kecil begitu pula sebaliknya. 18,793565 12,295493 10,603570 11,447535 11,112790 9,339129 9,075885 9,172421 0,000000 4,000000 8,000000 12,000000 16,000000 20,000000 50 100 250 500 750 1000 1250 1500 R at a-ra ta M A PE Jumlah Iterasi SVR 9,984608 9,335580 9,128695 9,019376 8,979730 9,016065 8,974166 9,012178 9,024601 9,026832 8,000000 8,500000 9,000000 9,500000 10,000000 10,500000 10 20 30 40 50 60 70 80 90 100 R at a-ra ta M A PE Jumlah Populasi 9,030724 9,021913 9,006813 9,018216 9,021219 8,982818 9,075427 9,069181 9,170136 8,500000 8,650000 8,800000 8,950000 9,100000 9,250000 mr 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 cr 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 R at a-ra ta M A PE Kombinasi Cr & Mr 10,432097 10,324573 9,037121 10,332365 9,007134 44,591535 44,483074 44,403404 44,130496 0,000000 10,000000 20,000000 30,000000 40,000000 50,000000 60,000000 R at a-ra ta M A PE Range Gamma
Gambar 7. Hasil pengujian range nilai C 4.7. Pengujian dan Analisis Range Nilai
Epsilon
Dari Gambar 8 dapat dilihat bahwa nilai MAPE cenderung meningkat ketika nilai epsilon semakin besar. Hal ini dikarenakan, parameter epsilon berpengaruh terhadap pengaturan batas kesalahan dari fungsi f(x). Sehingga, nilai epsilon yang kecil menunjukkan batas kesalahan yang ditoleransi kecil pula dan proses pembelajaran menjadi lebih lama untuk menemukan pola yang cocok. Range nilai epsilon yang terbaik pada pengujian ini adalah 0,00001-0,001.
Gambar 8. Hasil pengujian range nilai epsilon 4.8. Pengujian dan Analisis Range Nilai
Sigma
Pada pengujian range nilai sigma didapatkan range terbail adalah 0,01-3,5. Dari Gambar 9 dapat dilihat bahwa nilai MAPE cenderung menurun ketika nilai rentang sigma yang semakin kecil. Hal ini dikarenakan, parameter sigma merupakan variabel pada kernel RBF yang berpengaruh terhadap pemetaan data yang terbentuk. Nilai sigma yang terlalu kecil dapat menghasilkan model yang overfit.
Gambar 9. Hasil pengujian range nilai sigma 4.9. Pengujian dan Analisis Range Nilai
Lamda
Dari Gambar 10 dapat dilihat bahwa nilai MAPE cenderung menurun ketika rentang nilai lamda yang semakin kecil. Hal ini dikarenakan, nilai lamda yang semakin besar cenderung memberikan hasil regresi yang baik namun jika nilai lamda terlalu tinggi akan membuat proses pembelajaran menjadi tidak stabil dan berjalan lambat. Range nilai lamda yang terbaik dari pengujian ini adalah 1-10.
Gambar 10. Hasil pengujian range nilai lamda 4.10. Pengujian dan Analisis Range Nilai
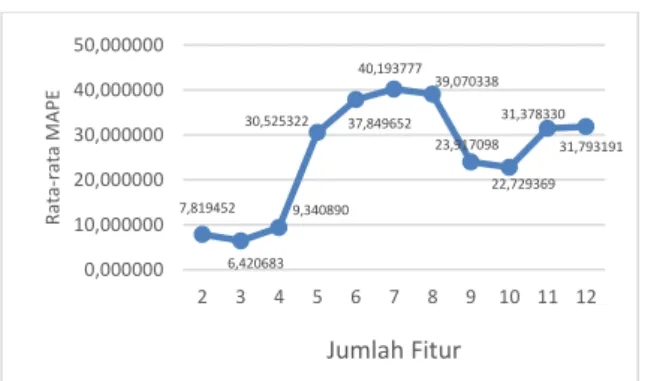
Jumlah Fitur
Dari Gambar 11 dapat dilihat bahwa nilai MAPE cenderung meningkat dan tidak stabil ketika jumlah fitur semakin besar. Hal ini dikarenakan, dalam melakukan prediksi jumlah kunjungan wisatawan dalam jangka pendek akan berpengaruh terhadap jumlah fitur untuk mengenali pola terhadap periode prediksi. Semakin besar fitur yang digunakan maka semakin buruk pola yang dapat dikenali. Jumlah fitur terbaik dari pengujian ini adalah 3.
9,016158 8,996490 9,002640 9,014372 8,996681 9,086241 9,002866 9,022627 9,000361 8,500000 8,700000 8,900000 9,100000 9,300000 9,500000 R at a-ra ta M A PE Range C 9,007513 8,995992 8,989447 9,000000 8,986595 35,559757 61,921128 61,613291 61,917997 0,000000 10,000000 20,000000 30,000000 40,000000 50,000000 60,000000 70,000000 R at a-ra ta M A PE Range Epsilon 9,040767 9,051531 9,117709 9,030093 9,052521 9,039429 9,021305 9,004013 9,063952 8,600000 8,700000 8,800000 8,900000 9,000000 9,100000 9,200000 R at a-ra ta M A PE Range σ 12,286813 11,468484 11,799776 11,859644 12,073311 11,6996439,013102 9,277763 9,155637 0,000000 5,000000 10,000000 15,000000 20,000000 R at a-ra ta M A PE Range Lamda
Gambar 11. Hasil pengujian jumlah fitur 4.11. Pengujian dan Analisis Periode
Prediksi
Pada pengujian periode Prediksi didapatkan jumlah periode prediksi terbaik adalah 1 bulan. Dari Gambar 12 dapat dilihat bahwa nilai MAPE cenderung meningkat ketika jumlah periode prediksi yang semakin besar. Hal ini dikarenakan, pada data jumlah kunjungan wisatawan, metode Support Vector Regression (SVR) tidak cocok untuk melakukan peramalan jangka panjang.
Gambar 12. Hasil pengujian jumlah periode 5. PENUTUP
Berdasarkan hasil yang diperoleh dalam penelitian prediksi jumlah kunjungan wisatawan mancanegara ke Bali menggunakan Support Vector Regression (SVR) yang dioptimasi dengan Algoritma Genetika didapatkan nilai kesalahan (error rate) / MAPE sebesar 2,513%.
Beberapa saran yang dapat dipertimbangkan untuk mengembangkan penelitian ini yaitu penggunaan metode optimasi Algoritma Genetika dapat diganti menggunakan metode optimasi lain seperti metode PSO, ACO atau metode lain untuk membandingkan tingkat error rate dengan metode berbeda serta penggunaan kernel selain Radial Basis Function (RBF).
DAFTAR PUSTAKA
Abe, S. 2005. Support Vector Machine for Pattern Classification. Springer, London. Anggrainingsih, R., Aprianto, G. R. & Sihwi, S.
W. 2015. Time Series Forecasting Using Exponential Smoothing To Predict The Number of Website Visitor of Sebelas Maret University. Proc. of 2015 2nd Int. Conference on Information Technology, Computer and Electrical Engineering (ICITACEE), 1-6.
Christianini, N. & Taylor, J.S. 2000. An Introduction to Support Vector Machines and Other Kernel-based Learning Method. Cambridge University Press.
Mahmudy, W. F. 2013. Algoritma Evolusi. Program Teknologi Informasi dan Ilmu Komputer, Malang.
Meesad, P. & Rasel, R. I. 2013. Predicting Stock Market Price Using Support Vector Regression. 2013 International Conference on Informatics, Electronics and Vision (ICIEV), 1-6.
Misriati, T. 2016. Seminar Nasional Ilmu Pengetahuan dan Teknologi Komputer Nusa Mandiri. Jakarta: AMIK BSI.
Mu'asyaroh, F. L. & Mahmudy, W. 2016. Implementasi Algoritma Genetika dalam Optimasi Model AHP dan TOPSIS untuk Penentuan Kelayakan Pengisian Bibit Ayam Broiler di Kandang Peternak. Jurnal Teknologi Informasi dan Ilmu Komputer (JTIIK), 3(4), 226-237.
Noersasongko, E., Julfia, F. T., Syukur, A; Purwanto., Pramuenendar, R. A. & Supriyanto, C. 2016. A Tourism Arrival Forecasting Using Genetic Alhorithm based Neural Network. Indian Journal of Science and Technology, 9(4).
Parto, S. & Sahu, K. 2015. Normalization: A Preprocessing Stage. Burla, Odisha, India: Department of CSE & IT.
Patel, V. R. & Mehta, R. G. 2011. Impact of Outlier Removal and Normalization Approach in Modified K-Means Clustering Algorithm. IJCSI International Journal of Computer Science, 8(5).
Pramesti, D., Mahmudy, W. F. & Indriati. 2015. Optimasi Komposisi Pakan Kambing Potong menggunakan Algoritma Genetika. 7,819452 6,420683 9,340890 30,525322 37,849652 40,193777 39,070338 23,917098 22,729369 31,378330 31,793191 0,000000 10,000000 20,000000 30,000000 40,000000 50,000000 2 3 4 5 6 7 8 9 10 11 12 R at a-ra ta M A PE Jumlah Fitur 2,512964 5,594041 12,292324 16,788346 19,384097 22,674619 25,938883 25,558573 27,640173 29,283450 30,447859 30,209457 0,000000 5,000000 10,000000 15,000000 20,000000 25,000000 30,000000 35,000000 1 2 3 4 5 6 7 8 9 10 11 12 R at a-ra ta M A PE
DORO: Repository Jurnal Mahasiswa PTIIK University Brawijaya, 5(13).
Shukla, A., Pandey, H. & Mehrotra, D. 2015.
Comparative Review of Selection
Techniques in Genetic Algorithm. Noida: Amity University.
Taylor, S. A., Celuch, K. & Goodwin, S. 2004. The Importance of Brand Equity to Customer Loyalty. Journal of Product and Brand Management, 13(4), 217-227. Tribunnews. 2016. Bali, Destinasi Favorit
Penyumbang Devisa Terbesar. [Online]
Tersedia di:
http://www.tribunnews.com/wonderful- indonesia/2016/12/15/bali-destinasi-favorit-penyumbang-devisa-terbesar [Diakses 24 April 2017].
Vapink, V., Golowich, S. & Smola, A. 1997. Support Vector Method for Function Approximation, Regression Estimation, and Signal Processing. Cambridge: MIT Press. Vijayakumar, S. & Wu, S. 1999. Sequential
Support Vector Classiers and Regression. Proc. International Conference on Soft Computing (SOCO’99). Saitama: RIKEN Brain Science Institute, 610-619.
Yuan, F. C. 2012. Parameters Optimization Using Genetic Algorithms in Support Vector Regression for Sales Volume Forecasting. Applied Mathematics, 3 October, 1480–1486.