TUGAS AKHIR
PENGENALAN UCAPAN MENGGUNAKAN MEL
FREQUENCY CEPSTRAL COEFFICIENT DAN K-NN
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik
Program Studi Teknik Elektro
Fakultas Sains dan Teknologi Universitas Sanata Dharma
Oleh :
EDWIN ADIADHMA NIM: 165114071
PROGRAM STUDI TEKNIK ELEKTRO FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
FINAL PROJECT
SPEECH RECOGNITION USING MEL FREQUENCY
CEPSTRAL COEFFICIENT AND K-NN
Presented as Partial Fullfillment of The Requirements To Obtain Bachelor of Engineering Degree
In Electrical Engineering Study program
Faculty of Science and Technology, Sanata Dharma University
EDWIN ADIADHMA NIM: 165114071
ELECTRICAL ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
iv
HALAMAN PERSEMBAHAN
Motto :
“Bermimpilah setinggi langit asalkan langitnya
kelihatan”
Persembahan
Tugas Akhir ini kupersembahkan kepada
Tuhan Yesus yang selalu membimbing
Kedua Orang Tua dan Keluarga yang selalu mendoakan dan
mendukung
Dan semua orang yang membantu dalam pengerjaan Tugas Akhir
vi
INTISARI
Suara merupakan salah satu bagian dari panca indera. Ucapan manusia dihasilkan oleh pita suara yang memiliki karakteristik unik dan berbeda pada tiap orang. Telinga sebagai panca indera dapat mengenali berbagai macam ucapan manusia dan mendefinisikan huruf, kalimat atau kata yang diucapkan. Secara khusus penulis membuat sistem pengenalan ucapan angka 0 – 9.
Penelitian ini memproses ucapan manusia yang telah terekam. Sistem ini menggunakan mikrofon untuk merekam ucapan. Ucapan yang terekam diproses menggunakan laptop untuk menjalankan proses pengenalan dan mengenali ucapan yang terekam. Ucapan yang menjadi objek dalam penelitian ini ada dua jenis ucapan, yaitu ucapan laki-laki dan ucapan perempuan. Proses pengenalan ucapan meliputi beberapa subproses seperti perekaman, pemotongan sinyal, windowing, ekstraksi ciri, dan penentuan hasil pengenalan ucapan.
Sistem pengenalan ucapan mengguna metode Mel Frequency Cepstral Coefficients dalam melakukan ekstraksi ciri dan klasifikasi menggunakan metode k-NN. Program pengenalan ucapan sudah dapat berhasil dibuat dan dapat bekerja sesuai dengan apa yang diharapkan. Pengujian pengenalan ucapan mampu memperoleh pengenalan hingga 81% pada ucapan laki-laki dan 80% pada ucapan perempuan pada saat koefisien k pada klasifikasi k-NN dengan nilai 1.
Kata kunci : Pengenalan Ucapan, Mel Frequency Cepstral Coefficients (MFCC), k-Nearest
vii
ABSTRACT
Sound is one part of the five senses. Human speech is produced by vocal cords which have unique characteristics and differ from person to person. The ear as the five senses can recognize various kinds of human speech and define the letters, sentences or words that are spoken. In particular, the authors make a speech recognition system for the numbers 0 - 9.
This study processes recorded human speech. This system uses a microphone to record speech. The recorded speech is processed using a laptop to carry out the recognition process and recognize the recorded speech. There are two types of speech as the object of this research, namely male speech and female speech. The speech recognition process includes several sub-processes such as recording, signal truncation, windowing, feature extraction, and determination of speech recognition results.
The speech recognition system uses the Mel Frequency Cepstral Coefficients method in performing feature extraction and classification using the k-NN method. The speech recognition program has been created successfully and is working as expected. The speech recognition test was able to obtain recognition of up to 81% in male speech and 80% for female speech when the k coefficient on the k-NN classification was 1.
Keyword : Speech Recognition, Mel Frequency Cepstral Coefficients (MFCC), k-Nearest Neighbor (k-NN)
viii
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas segala anugerah yang telah Ia berikan sehingga penulis dapat menyelesaikan laporan Tugas Akhir yang berjudul “Pengenalan Ucapan Menggunakan Mel Frequency Cepstral Coefficient dan K-NN”.
Tugas Akhir ini disusun memenuhi salah satu syarat memperoleh gelar Sarjana Teknik pada Program Studi Teknik Elektro, Fakultas Sains dan Teknologi, Universitas Sanata Dharma. Dalam penulisan tugas akhir ini, penulis menyadari bahwa ada banyak pihak yang memberikan dukungan dan bimbingan dari berbagai pihak sehingga tugas akhir ini dapat diselesaikan dengan baik. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada:
1. Tuhan Yesus Kristus yang selalu memberkati.
2. Bapak Sudi Mungkasi, S.Si, M.Math.Sc.,Ph.D., selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
3. Bapak Ir.Tjendro, M.Kom., selaku Ketua Program Studi Teknik Elektro, Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
4. Bapak Dr. Linggo Sumarno, selaku Dosen Pembimbing Tugas Akhir yang selalu sabar membimbing serta memberikan dorongan kepada penulis dalam menyelesaikan penulisan Tugas Akhir ini.
5. Bapak Damar Widjaja, Ph.D dan Bapak Dr. Iswanjono, selaku dosen penguji tugas akhir yang telah memberikan masukan serta saran dalam penyempurnaan penulisan Tugas Akhir ini.
6. Bapak dan Ibu Dosen yang telah memberikan banyak pengetahuan baru selama penulis menempuh pendidikan di Program Studi Teknik Elektro, Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
7. Bapak dan Ibu, serta adik yang selalu mendoakan dan memberikan dukungan sampai pencapaian menyelesaikan studi di jenjang perkuliahan.
8. Teman-teman Rakat Moke tercinta : Elthon Djendi, Agung Purwanto, Kadek Adi Sukma Wijaya, Donatus Toka, Charis Yeter Ebenhaezer Waruwu, A. Surya Yovendra, Albertus Wahyu Pratama, Alberto Martua Siregar
x
DAFTAR ISI
HALAMAN PERSETUJUAN ... i
HALAMAN PENGESAHAN ... ii
LEMBAR PERNYATAAN KEASLIAN KARYA ... iii
HALAMAN PERSEMBAHAN ... iv
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... v
INTISARI ... vi
ABSTRACT ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Tujuan dan Manfaat Penelitian ... 2
1.3 Batasan Masalah ... 2
1.4 Metodologi Penelitian ... 3
BAB II LANDASAN TEORI... 5
2.1 Suara ... 5 2.2 Sampling ... 5 2.3 Pre-processing ... 5 2.3.1 Pre-emphasis ... 5 2.3.2 Frame Blocking ... 6 2.3.3 Blackman Window ... 6
2.3.4 Fast Fourier Transform (FFT) ... 7
2.4 Mel Frequency ... 7
2.5 K-Nearest Neighbor (K-NN) ... 8
BAB III PERANCANGAN ... 9
3.1 Sistem pengenalan Ucapan ... 9
3.1.1 Ucapan manusia ... 10
xi
3.1.3 Sound Card ... 11
3.1.4 Proses Perekaman ... 11
3.1.5 Proses Pengenalan Ucapan ... 12
3.1.5.1 Perekaman ... 13 3.1.5.2 Pre-processing ... 13 3.1.5.3 Ekstraksi Ciri ... 13 3.1.5.4 K-NN ... 13 3.1.5.5 Keluaran ... 13 3.2 Klasifikasi K-NN ... 14 3.3 Suara Uji ... 14
3.4 Perancangan Perangkat Lunak ... 15
3.4.1 Perancangan Diagram Blok Program ... 16
3.4.2 Proses Perekaman ... 17
3.4.3 Pre-emphasis ... 18
3.4.4 Frame Blocking ... 19
3.4.5 Windowing ... 19
3.4.6 FFT (Fast Fourier Transform) ... 20
3.4.7 Ekstraksi Ciri MFCC ... 20
3.4.8 Klasifikasi K-NN ... 21
BAB IV HASIL DAN PEMBAHASAN ... 23
4.1 Interface Program Pengenalan Ucapan Menggunakan Mel Frequency Cepstral Coefficient dan K-NN ... 23
4.1.1 Popup Menu ... 26
4.1.2 Tombol REKAM ... 26
4.1.3 Tombol RESET ... 27
4.1.4 Tombol KELUAR ... 27
4.2 Hasil Pengujian Program Pengenalan Ucapan Angka ... 27
4.2.1 Pengujian Non Real Time... 27
4.2.2 Pengujian Real Time ... 29
BAB V KESIMPULAN DAN SARAN ... 32
5.1 Kesimpulan ... 32
5.2 Saran ... 32 DAFTAR PUSTAKA ... L-1 LAMPIRAN 1 ... L-2
xii
DAFTAR GAMBAR
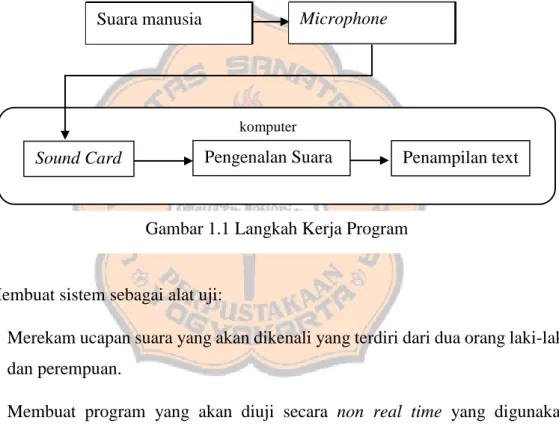
Gambar 1.1 Langkah Kerja Program ... 3
Gambar 2.1 Contoh overlapping ... 6
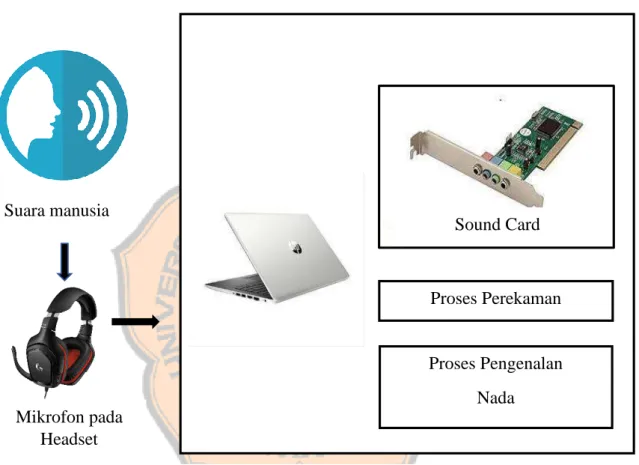
Gambar 3.1 Sistem Pengenalan Ucapan ... 9
Gambar 3.2 Headset Logitech G332 ... 10
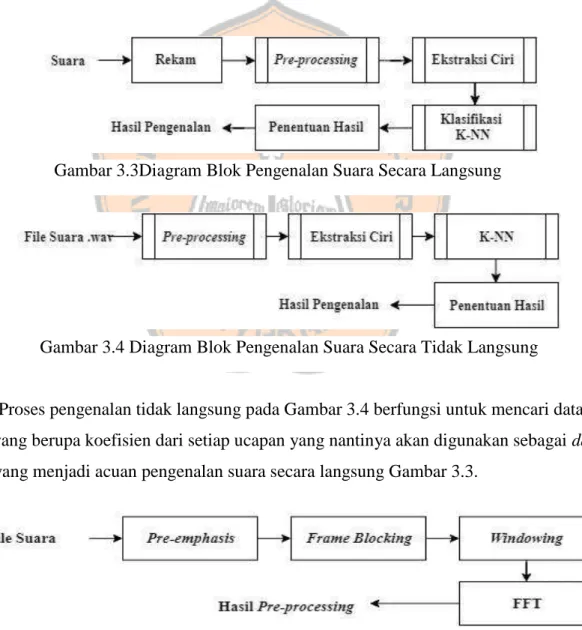
Gambar 3.3Diagram Blok Pengenalan Suara Secara Langsung ... 12
Gambar 3.4 Diagram Blok Pengenalan Suara Secara Tidak Langsung ... 12
Gambar 3.5 Diagram Blok Pre-processing ... 12
Gambar 3.6 Hasil Klasifikasi K-NN... 14
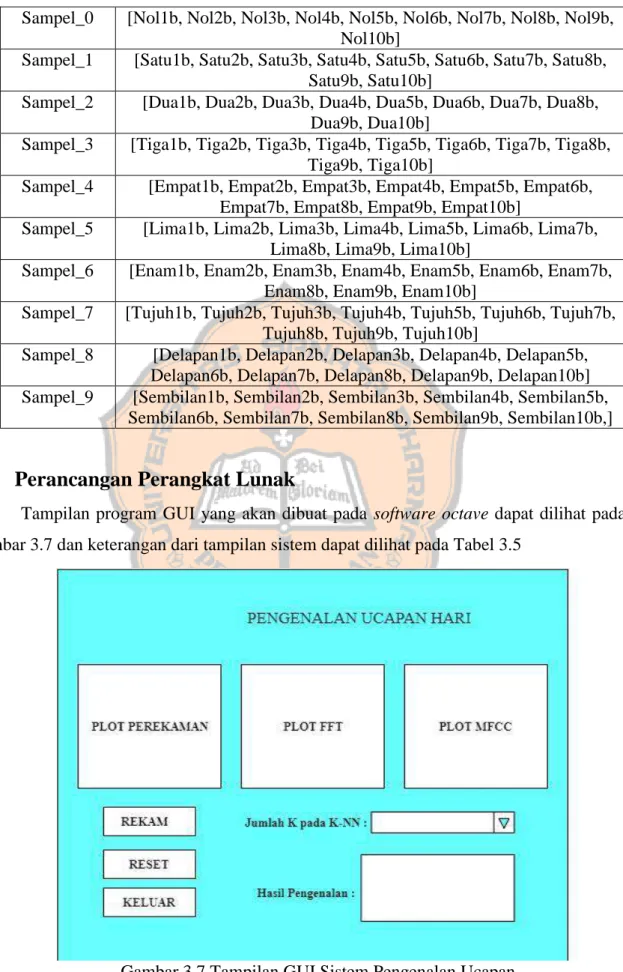
Gambar 3.7 Tampilan GUI Sistem Pengenalan Ucapan ... 15
Gambar 3.8 Diagram Alir Program Pengenalan ... 16
Gambar 3.9 Diagram Alir Keseluruhan Program ... 17
Gambar 3.10 Diagram Alir Perekaman ... 18
Gambar 3.11 Diagram Alir Proses Pre-emphasis ... 18
Gambar 3.12 Diagram Alir Frame Blocking ... 19
Gambar 3.13 Diagram Alir Proses Windowing... 19
Gambar 3.14 Diagram Alir Proses FFT ... 20
Gambar 3.15 Diagram Alir Proses Ekstraksi Ciri MFCC ... 21
Gambar 3.16 Diagram alir Proses Klasifikasi K-NN ... 22
Gambar 4.1 Ikon Octave 5.1.0 ... 24
Gambar 4.2 Tampilan Awal Octave ... 24
Gambar 4.3 Tampilan Program Pengenalan Ucapan... 25
Gambar 4.4 Hasil Pengenalan Ucapan ... 25
Gambar 4.5 Pengaruh Variasi Nilai K Terhadap Pengenalan Ucapan Secara Non Real Time. ... 28
xiii
DAFTAR TABEL
Tabel 3.1 Spesifikasi Headset Logitech G332... 10
Tabel 3.2 Lanjutan spesifikasi Headset Logitech G332 ... 11
Tabel 3.3 Data training ... 14
Tabel 3.4 Data testing ... 15
Tabel 3.5 Keterangan Tampilan GUI Sistem Pengenalan Ucapan ... 16
Tabel 4.1 Tingkat Pengenalan Hasil pengujian Non Real Time ... 28
Tabel 4.2 Confusion Matrix Pengenalan Secara Non Real Time pada k=1. ... 29
Tabel 4.3 Tingkat Pengenalan Hasil Pengujian Real Time ... 30
Tabel 4.4 Confusion Matrix Pengenalan Ucapan Perempuan Secara Real Time Pada k=1. ... 30
Tabel 4.5 Confusion Matrix Pengenalan Ucapan Laki - Laki Secara Real Time Pada k=1. ... 31
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Suara manusia dihasilkan oleh pita suara yang bergetar ketika ada tekanan udara. Suara yang diucapkan olah manusia berbentuk gelombang sinyal [1]. Setiap manusia memiliki suara yang berbeda-beda dan tidak akan ada yang sama persis. Hal itu tejadi karena gelombang suara yang dihasilkan oleh pita suara berbeda-beda. Perbedaan tersebut ditandai dengan tinggi rendahnya gelombang suara. Meskipun suara manusia berbeda-beda pendengar tetap mengetahui arti kata yang diucapkan.
Sistem pendengaran manusia dapat mengenali ucapan manusia meskipun suaranya berbeda. Dari pernyataan tersebut penulis ingin membuat satu sistem yang dapat mengenali ucapan manusia yang dapat diterjemahkan secara otomatis menjadi tulisan seperti yang ada pada sistem speech-to-text yang ada pada handphone masa kini.
Pada tahun 2013 terdapat penelitian dengan judul “Pengenalan Suara Manusia Menggunakan Metode Linear Predictive Coding”[2]. Penelitian tersebut menyatakan bahwa pengenalan suara (speech recognition) tidak membutuhkan biaya yang besar dan tidak membutuhkan peralatan khusus. Pada tahun 2014 juga terdapat penelitian serupa dengan judul “Pengenalan Ucapan Angka Secara Real Time Menggunakan Ekstraksi Ciri Fast Fourier Transform (FFT) dan Fungsi Similaritas Kosinus”[3].
Penelitian tersebut hanya mengenali satu suara dari satu orang sedangkan penulis pada penelitian kali ini dapat mengenali dua jenis suara dari dua orang berbeda. Dalam penelitian ini penulis menggunakan metode Mel Frequency Cepstral Coefficient (MFCC) untuk ekstraksi ciri dan metode K-Nearest Neighbor (K-NN) untuk klasifikasi. Hal ini membedakan penelitian penulis dengan penelitian sebelumnya.
1.2 Tujuan dan Manfaat Penelitian
Tujuan dari penelitian ini adalah untuk membuat program yang dapat mengenali ucapan manusia.
Manfaat dari penelitian ini adalah :
a. Sebagai alat bantu bagi difabel tuna rungu sehingga dapat membaca hasil identifikasi ucapan.
b. Sebagai literatur bagi penelitian selanjutnya.
1.3 Batasan Masalah
Proses pengambilan input pada sistem pengenalan ucapan ini menggunakan mikrofon yang tertanam di headset yang digunakan. Input ucapan kemudian diproses menggunakan software Octave yang bertugas untuk melakukan pengenalan dan klasifikasi. Agar penelitian ini lebih terfokus penulis menetapkan batasan-batasan masalah sebagai berikut:
a. Sinyal masukan berupa ucapan angka dalam bahasa Indonesia.
b. Ucapan yang dikenali berupa ucapan angka Nol, Satu, Dua, Tiga, Empat, Lima, Enam, Tujuh, Delapan, Sembilan, selain itu dikenali sebagai salah satu dari Nol – Sembilan.
c. Ucapan yang dikenali dari dua orang.
d. Menggunakan aplikasi Octave dalam pembuatan program. Pada penelitian ini menggunakan versi 5.1.0.
e. Menggunakan metode Mel Frequency Cepstral Coefficient untuk ekstraksi ciri. f. Menggunakan Blackman Window pada proses windowing.
g. Menggunakan metode K-NN untuk klasifikasi.
h. Menggunakan mikrofon pada headset Logitech G-332. i. Keluaran berupa teks pada monitor.
1.4 Metodologi Penelitian
Langkah-langkah penelitian :
Pengumpulan referensi berupa buku-buku dan jurnal-jurnal ilmiah mengenai pengenalan suara, metode ekstraksi ciri Mel Frequency Cepstral Coefficient (MFCC), dan metode klasifikasi K-NN.
1. Pembuatan langkah kerja.
Berikut merupakan langkah kerja dari program:
.
2. Membuat sistem sebagai alat uji:
a. Merekam ucapan suara yang akan dikenali yang terdiri dari dua orang laki-laki dan perempuan.
b. Membuat program yang akan diuji secara non real time yang digunakan sebagai dasar untuk membuat program secara real time dan untuk menguji apakah program berjalan atau tidak menggunakan basis data dan data uji. c. Membuat tampilan GUI dengan menggunakan perangkat lunak Octave.
Program ini berfungsi sebagai trigger yang berisikan push button untuk menjalankan, merekam, menganalisa, dan mengakhiri program
d. Membuat program yang diuji secara real time untuk mengetahui apakah program berjalan atau tidak secara langsung dengan menggunakan basis data dan data uji.
Suara manusia Microphone
Sound Card
komputer
Pengenalan Suara Penampilan text
e. Melakukan pengujian secara real time dengan menggunakan ucapan laki-laki dan perempuan sehingga mendapatkan hasil keluaran yang sesuai dengan yang diinginkan
3. Pengambilan data
Pengambilan data dilakukan untuk mendapatkan data yang diinginkan sesuai dengan sistem pengenalan. Penelitian ini menggunakan dua jenis ucapan, yaitu ucapan laki-laki dan ucapan perempuan. Data yang diambil dari dua jenis ucapan dibagi menjadi dua jenis, yaitu database dan datatest. Pengambilan data dari setiap ucapan yaitu 10 ucapan Nol, Satu, Dua, Tiga, Empat, Lima, Enam, Tujuh, Delapan, Sembilan. Pengambilan data dilakukan dengan jarak kurang lebih 5 cm dari bibir. Data yang diambil dari setiap ucapan berjumlah 10 buah data. Jumlah data yang diambil dari setiap ucapan, yaitu 10 ucapan × 10 buah data × 2 jenis ucapan (laki-laki dan perempuan) = 200 data.
4. Pembuatan database
Proses pembuatan database adalah sebagai berikut: a. Perekaman ucapan.
b. Rekaman ucapan disimpan sebagai file dengan format ‘.wav’. c. Ekstraksi ciri yang dilakukan pada file ‘.wav’ ucapan.
d. Hasil ekstraksi ciri yang berupa angka dan perhitungan dilakukan di setiap ucapan.
e. Hasil perhitungan disimpan ke dalam array database. f. Array tersebut disimpan dalam format ‘.mat’.
g. Array database digunakan sebagai acuan untuk mengenali ucapan. 5. Analisa dan penyimpulan hasil percobaan
Analisa data dilakukan dengan cara meneliti pengaruh variasi nilai K pada K-NN, dan menganalisa keakuratan data terhadap pemrosesan suara dengan membandingkannya dengan database.
5
BAB II
LANDASAN TEORI
2.1 Suara
Suara merupakan penerimaan beberapa gelombang dan resepsi yang ada di otak [4]. Suara manusia termasuk gelombang atau sinyal. Sama seperti sinyal pada umumnya suara manusia juga memliki amplitudo dan frekuensi tertentu. Sistem pendengaran manusia hanya mampu mendengar suara pada rentang frekuensi 20 Hz sampai dengan 20 kHz. Hz (Hertz) sendiri merupakan satuan frekuensi. Suara percakapan (speech) manusia memiliki frekuensi 300 – 3000 Hz [5].
2.2 Sampling
Sampling merupakan proses pencuplikan gelombang suara yang akan menghasilkan gelombang diskret dari gelombang analog. Dalam proses pencuplikan, ada yang disebut dengan laju pencuplikan (sampling rate). Sampling rate menandakan berapa banyak pencuplikan gelombang analog dalam satu detik. Satuan dari sampling rate ialah Hertz (Hz). Secara teori Nyquist-Shamon yang menyebutkan bahwa untuk mencegah hilangnya informasi dalam sebuah konversi sinyal kontinu ke diskrit, pencuplikan minimal harus dua kali lebih besar dari sinyal asli [6]. Kriteria Nyquist perlu diperhatikan dalam melakukan pencuplikan. Kriteria Nyquist menyatakan sebuah sinyal harus memiliki sampling rate yang lebih besar dari 2 kali frekuensi paling tinggi yang muncul di sebuah sinyal.
2.3 Pre-processing
Pre-processing merupakan serangkaian tahapan dimana sinyal suara diproses untuk mengekstraksi ciri dari suara. Berikut merupakan tahapan pre-processing:
2.3.1 Pre-emphasis
Pre-emphasis merupakan salah satu jenis filter yang sering digunakan sebelum sebuah sinyal diproses lebih lanjut. Filter ini mempertahankan frekuensi-frekuensi tinggi pada sebuah spektrum yang umumnya tereliminasi pada saat proses produksi suara[7]. Tujuan dari pre-emphasis adalah untuk mengompensasi bagian frekuensi tinggi yang ditekan pada saat produksi suara manusia. Selain itu juga dapat memperkuat informasi penting dari frekuensi tinggi[4]. Berikut merupakan perhitungan dari pre-emphasis :
Sinyal suara s(n) dikirim ke filter high-pass:
S2(n) = S(n) – a * S(n-1) (2.1) dengan S2(n) merupakan sinyal output dan nilai a biasanya antara 0.9 dan 1.0. Sedangkan Z-transform dari filter adalah:
H(z) = 1 – a * z-1 (2.2)
2.3.2 Frame Blocking
Frame blocking bertujuan untuk memperkecil terjadinya perubahan sinyal yang diakibatkan oleh perubahan artikulasi dari orang yang mengucapkan suara[7]. Panjang frame yang biasa digunakan adalah 10-30 mili detik. Pada proses Frame blocking umumnya terjadi proses overlapping, hal ini terjadi untuk mempertahankan ciri atau karakteristik suara pada tiap batas perpotongan frame.
Proses overlapping berguna untuk mempertahankan karakteristik dari suara yang mungkin hilang akibat adanya jarak antar frame pada proses frame blocking
2.3.3 Blackman Window
Proses windowing bertujuan untuk mengurangi kemungkinan terjadinya kebocoran spektral (aliasing). Aliasing adalah munculnya sinyal baru yang terjadi karena rendahnya frekuensi sampling atau karena proses frame blocking[11]. Pengenalan suara ini
menggunakan Blackman window. Untuk mendapatkan hasil yang maksimal pada proses FFT, maka sampel suara yang telah dibagi menjadi beberapa frame perlu dijadikan suara continue dengan cara mengalikan tiap frame windowing tertentu. Berikut persamaan Blackman window:
w(n)=0.42 – 0.5 cos 2𝜋𝑛
𝑀−1 + 0.08 cos 4𝜋𝑛
𝑀−1
(2.3)
dengan w(n) adalah variabel windowing, M adalah jumlah data dari sinyal, n = waktu diskrit ke-n
2.3.4 Fast Fourier Transform (FFT)
Fast Fourrier Transform (FFT) merupakan algoritma yang menghitung Discrete
Fourier transform (DFT) dari suatu urutan bilangan, yang merubah sebuah sinyal dari
domain waktu atau jarak ke domain frekuensi atau sebaliknya[7]. FFT menghilangkan proses perhitungan yang kembar dalam DFT. Algoritma FFT hanya membutuhkan N log2 N perkalian kompleks[4]. Persamaan matematis FFT diuraikan pada persamaan (2.4).
𝑋n = ∑
𝑁−1𝑘=0𝑥
(n)𝑊
𝑁𝑛𝑘(2.4) dengan
𝑊
𝑁𝑛𝑘= 𝑒
−𝑗2𝜋/𝑁 , n=0, 1, 2, ..., N-1, dan k= 0, 1, 2, ..., N-1X(n) adalah keluaran dalam domain frekuensi, x adalah masukkan dalam domain waktu dan N adalah runtun masukan disket, e adalah natural number (2.7182818284…), k adalah indeks dalam domain frekuensi (0, 1, 2, …, N-1), n adalah indeks dalam domain waktu (0,1,2, …, N-1), j adalah konstanta fourrier.
2.4 Mel Frequency
MFCC didasarkan atas variasi bandwidth kritis terhadap frekuensi pada telinga menusia yang merupakan filter yang bekerja secara linier pada frekuensi rendah dan bekerja secara logaritmik pada frekuensi tinggi. Filter ini digunakan untuk menangkap karakteristik fonetis penting dari sinyal ucapan. Untuk meniru kondisi telinga, karakteristik ini digambarkan dalam skala mel-frekuensi, yang merupakan frekuensi linier di bawah 1000 Hz dan frekuensi logaritmik di atas 1000 Hz. Biasanya frekuensi pencuplikan yang digunakan diatas 10000 Hz agar dapat meminimalkan efek aliasing pada konversi analog-digital. [8]
2.5 K-Nearest Neighbor (K-NN)
K-Nearest Neighbor atau K-NN adalah salah satu algoritma yang berguna untuk klasifikasi. K-NN bekerja berdasarkan jarak minimum dari data baru ke sampel data latih untuk menentukan K tetangga terdekat. Nantinya akan dapatkan nilai mayoritas sebagai hasil prediksi dari data yang baru tersebut.
Dalam algoritma K-NN terdapat ketentuan jarak yaitu Euclidean Distance . Euclidean distance adalah jarak antara dua titik atau koordinat yang diturunkan dari rumus phytaghoras[10]. Euclidean distance antara titik dan adalah panjang garis yang menghubungkan keduanya ab.ab sendiri adalah sisi miring dari garis yang dibentuk pada sumbu x dan sumbu y antara koordinat a dan b. Sebagai contoh, untuk menghitung jarak antara dua titik xs dan xt dengan metode Euclidean, digunakan rumus:
𝑑
𝑠,𝑡= √∑ (𝑥
𝑛 𝑠− 𝑦
𝑡)
21
(
2.5)dengan
𝑑
𝑠,𝑡 merupakan jarak data latih dan data uji,𝑥
𝑠 adalah data latih,𝑦
𝑡 adalah data uji,𝑛
adalah dimensi data .Langkah-langkah dari algoritma K-NN :
1. Tentukan parameter K = jumlah banyakanya terdekat.
2. Hitung jarak antara data baru dan semua data yang ada di data latih.
3. Urutkan jarak tersebut dan tentukan tetangga mana yang terdekat berdasarkan jarak minimum ke – K.
9 Suara manusia
BAB III
PERANCANGAN
3.1 Sistem pengenalan Ucapan
Blok sistem pengenalan suara ditampilkan pada Gambar 3.1
Sistem pengenalan suara manusia terdiri dari perangkat keras dan perangkat lunak. Perangkat keras yang digunakan adalah mikrofon built-in pada headset dan laptop. Perangkat lunak yang dibuat dengan menggunakan Octave tersebut memiliki peran penting dalam proses pengenalan suara manusia, seperti pada saat perekaman suara manusia dan proses pengenalan suara manusia yang telah terekam. Proses perekaman suara dilakukan oleh laptop melalui media mikrofon lalu masuk ke jalur line in pada sound Card.
Proses Pengenalan Nada Proses Perekaman Mikrofon pada Headset Sound Card
3.1.1 Ucapan manusia
Suara manusia adalah suatu sinyal percakapan yang dihasilkan oleh manusia ketika melakukan percakapan. Sinyal suara terdiri dari serangkaian suara yang masing-masing menyimpan sepotong informasi. Suara manusia dapat dibedakan menjadi dua tipe berdasarkan cara menghasilkannya yaitu voiced dan unvoiced. Voiced sounds merupakan suara yang dihasilkan dari getaran pita suara, sedangkan unvoiced sounds dihasilkan dari gesekan antara udara dengan vocal tract [8].
3.1.2 Mikrofon
Mikrofon yang digunakan adalah mikrofon built-in dari headset Logitech G-332. Mikrofon ini dipilih karena bentuknya yang ringkas, portabel, dan dapat sekaligus mendengarkan hasil rekaman dengan headset.
Dipilihnya headset ini karena jarak microphone dengan mulut sudah sesuai dengan jarak pengucapan yaitu kurang lebih 5 cm
Tabel 3.1 Spesifikasi Headset Logitech G332 Frequency
Response
100 – 20.000 Hz
Sensitivity 107 dB/mW
Impedance output 5k Ohm
Cable length 2 meter
Tabel 3.2 Lanjutan spesifikasi Headset Logitech G332 Audio output
connector
3.5 mm stereo
Weight 280 g
Pickup pattern Cardioid (Unidirectional)
Headset Logitech G332 memiliki pola pengambilan suara ke segala arah (unidirectional) sehingga dapat menangkap suara dari berbagai arah. Headset ini memiliki respons frekuensi dari 100 Hz hingga 20.000 Hz, sensitivitas suara 107dB/Mh, dan impedansi output 5000 Ohm. Headset ini juga memiliki beban yang ringan yaitu 280 gram.
3.1.3 Sound Card
Sound card berfungsi mengubah sinyal analog dari mikrofon menjadi sinyal digital. Sound card yang digunakan adalah sound card yang sudah terpasang pada motherboard dari laptop. Proses konversi sinyal analog menjadi sinyal digital hingga kemudian disimpan, diperlukan pengaturan yang meliputi pengaturan sampling rate (laju pencuplikan). Pengaturan tersebut dilakukan pada proses perekaman oleh program yang akan dibuat.
3.1.4 Proses Perekaman
Proses perekaman merupakan proses masuknya suara melalui mikrofon. Proses perekaman berfungsi untuk mengubah data sinyal analog menjadi data sinyal digital dengan frekuensi pencuplikan yang telah ditentukan dalam durasi yang telah ditentukan. Hasil sinyal digital kemudian disimpan dan digambarkan pada plot, lalu data suara yang telah terekam diberi nama sesuai dengan ucapan yang diinginkan, kemudian dapat diproses untuk dikenali lewat proses sistem pengenalan ucapan manusia.
3.1.5 Proses Pengenalan Ucapan
Proses pengenalan ucapan terdiri dari proses sampling, pre-processing, ekstraksi ciri MFCC, klasifikasi K-NN, dan hasil pengenalan. Proses pengenalan suara dibagi menjadi dua, yaitu secara langsung dan tidak langsung. Blok diagram pengenalan suara secara langsung dapat dilihat pada Gambar 3.3 dan blok pengenalan suara secara tidak langsung dapat dilihat pada Gambar 3.4. Pada proses pre-processing terdapat beberapa subproses seperti pre-emphasis, frame blocking, windowing, dan FFT. Blok diagram pre-processing dapat dilihat pada Gambar 3.5 dan blok diagram ekstraksi ciri MFCC dapat dilihat pada gambar 3.6
Proses pengenalan tidak langsung pada Gambar 3.4 berfungsi untuk mencari data latih yang berupa koefisien dari setiap ucapan yang nantinya akan digunakan sebagai data base yang menjadi acuan pengenalan suara secara langsung Gambar 3.3.
Gambar 3.3Diagram Blok Pengenalan Suara Secara Langsung
Gambar 3.4 Diagram Blok Pengenalan Suara Secara Tidak Langsung
3.1.5.1 Perekaman
Proses ini bertujuan untuk masukkan data berupa suara manusia secara analog yang kemudian akan diubah menjadi digital ketika masuk kedalam laptop. Suara direkam dengan memakai frekuensi pencuplikan sebesar 6000 Hz, frekuensi ini ditentukan berdasarkan frekuensi suara yang dapat didengar manusia dari 300 – 3000 Hz dilanjutkan dengan berdasar kriteria Nyquist yaitu minimal frekuensi pencuplikan harus dua kali dari frekuensi sebenarnya [3].
3.1.5.2 Pre-processing
a. Pre-emphasis
Pre-emphasis bertujuan untuk mengompensasi komponen frekuensi tinggi pada sebuah spektrum[7]. Proses ini juga berfungsi untuk mengurangi efek distorsi, atenuasi, dan saturasi pada media terekam.
b. Frame Blocking
Frame blocking bertujuan untuk membagi sampel sinyal suara pada beberapa frame tertentu yang akan digunakan dari data terekam. Frame blocking pada sistem ini terjadi secara overlap
c. Windowing
Fungsi windowing adalah untuk mengurangi efek diskontinuitas dari sinyal digital hasil perekaman. Pada sistem ini penulis menggunakan Blackman window.
d. Fast Fourier Transform (FFT)
Proses FFT bertujuan untuk memperoleh parameter tertentu yang akan dilanjutkan ke tahap MFCC
3.1.5.3 Ekstraksi Ciri
Proses ekstraksi ciri pada program ini menggunakan metode Mel Frequency Cepstral Coefficient (MFCC). MFCC merupakan metode yang populer digunakan dalam melakukan ekstraksi ciri data suara.
3.1.5.4 K-NN
Proses K-NN merupakan proses klasifikasi penentuan hasil. Hasil klasifikasi ditentukan dari kelas yang paling sering keluar.
3.1.5.5 Keluaran
0.1 0.2 0.25 0.3 0.5
K1 K2 K1 K1 K2
Gambar 3.6 Hasil Klasifikasi K-NN
3.2 Klasifikasi K-NN
Metode K-NN bertugas untuk mengklasifikasi hasil keluaran setelah proses ekstraksi ciri. K-NN mengklasifikasi hasil ekstraksi ciri dengan menggunakan jarak terdekat dengan urutan descending sorting atau pengurutan dari data terkecil. Urutan kerja metode K-NN dapat dilihat pada Gambar 3.7
Keluaran dari klasifikasi K-NN digambarkan seperti gambar 3.7. Setelah diurutkan maka dapat ditentukan kelasnya dari kelas yang sering muncul. Koefisien pada K-NN sering digunakan angka ganjil seperti 1,3,5,7 dst.
3.3 Suara Uji
Suara uji merupakan suara yang direkam untuk melakukan ujivoba pada program secara tidak langsung atau non – real time. Penulis memiliki dua data yaitu data training dan data testing.
Tabel 3.3 Data training
Sampel_0 [Nol1, Nol2, Nol3, Nol4, Nol5, Nol6, Nol7, Nol8, Nol9, Nol10] Sampel_1 [Satu1, Satu2, Satu3, Satu4, Satu5, Satu6, Satu7, Satu8, Satu9,
Satu10]
Sampel_2 [Dua1, Dua2, Dua3, Dua4, Dua5, Dua6, Dua7, Dua8, Dua9, Dua10] Sampel_3 [Tiga1, Tiga2, Tiga3, Tiga4, Tiga5, Tiga6, Tiga7, Tiga8, Tiga9,
Tiga10]
Sampel_4 [Empat1, Empat2, Empat3, Empat4, Empat5, Empat6, Empat7, Empat8, Empat9, Empat10]
Sampel_5 [Lima1, Lima2, Lima3, Lima4, Lima5, Lima6, Lima7, Lima8, Lima9, Lima10]
Sampel_6 [Enam1, Enam2, Enam3, Enam4, Enam5, Enam6, Enam7, Enam8, Enam9, Enam10]
Sampel_7 [Tujuh1, Tujuh2, Tujuh3, Tujuh4, Tujuh5, Tujuh6, Tujuh7, Tujuh8, Tujuh9, Tujuh10]
Sampel_8 [Delapan1, Delapan2, Delapan3, Delapan4, Delapan5, Delapan6, Delapan7, Delapan8, Delapan9, Delapan10,]
Sampel_9 [Sembilan1, Sembilan2, Sembilan3, Sembilan4, Sembilan5, Sembilan6, Sembilan7, Sembilan8, Sembilan9, Sembilan10,]
Tabel 3.4 Data testing
Sampel_0 [Nol1b, Nol2b, Nol3b, Nol4b, Nol5b, Nol6b, Nol7b, Nol8b, Nol9b, Nol10b]
Sampel_1 [Satu1b, Satu2b, Satu3b, Satu4b, Satu5b, Satu6b, Satu7b, Satu8b, Satu9b, Satu10b]
Sampel_2 [Dua1b, Dua2b, Dua3b, Dua4b, Dua5b, Dua6b, Dua7b, Dua8b, Dua9b, Dua10b]
Sampel_3 [Tiga1b, Tiga2b, Tiga3b, Tiga4b, Tiga5b, Tiga6b, Tiga7b, Tiga8b, Tiga9b, Tiga10b]
Sampel_4 [Empat1b, Empat2b, Empat3b, Empat4b, Empat5b, Empat6b, Empat7b, Empat8b, Empat9b, Empat10b]
Sampel_5 [Lima1b, Lima2b, Lima3b, Lima4b, Lima5b, Lima6b, Lima7b, Lima8b, Lima9b, Lima10b]
Sampel_6 [Enam1b, Enam2b, Enam3b, Enam4b, Enam5b, Enam6b, Enam7b, Enam8b, Enam9b, Enam10b]
Sampel_7 [Tujuh1b, Tujuh2b, Tujuh3b, Tujuh4b, Tujuh5b, Tujuh6b, Tujuh7b, Tujuh8b, Tujuh9b, Tujuh10b]
Sampel_8 [Delapan1b, Delapan2b, Delapan3b, Delapan4b, Delapan5b, Delapan6b, Delapan7b, Delapan8b, Delapan9b, Delapan10b] Sampel_9 [Sembilan1b, Sembilan2b, Sembilan3b, Sembilan4b, Sembilan5b,
Sembilan6b, Sembilan7b, Sembilan8b, Sembilan9b, Sembilan10b,]
3.4 Perancangan Perangkat Lunak
Tampilan program GUI yang akan dibuat pada software octave dapat dilihat pada Gambar 3.7 dan keterangan dari tampilan sistem dapat dilihat pada Tabel 3.5
Tabel 3.5 Keterangan Tampilan GUI Sistem Pengenalan Ucapan
No. NAMA BAGIAN KETERANGAN
1 PLOT HASIL REKAMAN Tampilan grafik untuk suara hasil perekaman 2 PLOT HASIL FFT Tampilan grafik untuk hasil FFT
3 PLOT HASIL MFCC Tampilan grafik hasil ekstraksi ciri MFCC
4 REKAM Tombol tekan untuk memulai perekaman
5 RESET Tombol tekan untuk mengulangi proses
6 KELUAR Tombol tekan untuk mengakhiri aplikasi
7 KOEFISIEN K PADA K-NN Tombol pilih untuk memilih koefisien K 8 HASIL PENGENALAN Menunjukkan hasil pengenalan suara
Pada Gambar 3.7 tampilan GUI terdapat tiga buah tombol tekan, tombol REKAM berfungsi untuk merekam suara, tombol RESET untuk mengosongkan plot penampil, dan tombol KELUAR berfungsi untuk keluar dari program Octave. Pada GUI ini terdapat tiga buah plot penampil, PLOT REAKAMAN berfungsi untuk untuk menampilkan grafik hasil perekaman, PLOT FFT berfungsi untuk menampilkan hasil sinyal yang telah diproses FFT, dan PLOT MFCC berfungsi untuk menampilkan hasil sinyal yang telah diproses MFCC.
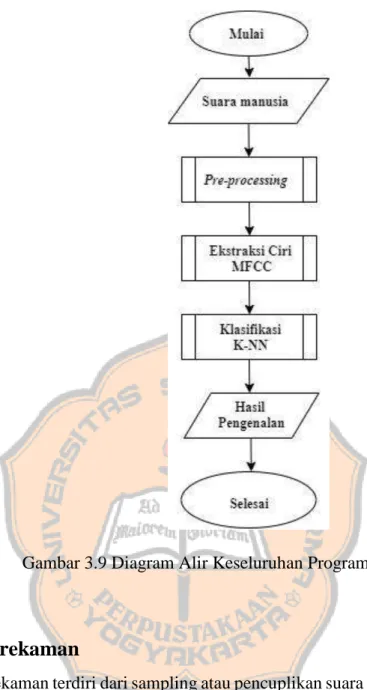
3.4.1 Perancangan Diagram Blok Program
Ketika pengguna akan memulai program pengenalan ucapan hari, pengguna akan mendapati tampilan GUI pada program octave pada gambar 3.7. Terdapat tiga push button yang digunkan. Ada tiga penampil grafik untuk grafik perekaman, grafik hasil FFT, dan grafik hasil MFCC. Diagram alir keseluruhan sistem dapat dilihat pada Gambar 3.9.
Gambar 3.9 Diagram Alir Keseluruhan Program
3.4.2 Proses Perekaman
Proses perekaman terdiri dari sampling atau pencuplikan suara dengan nilai frekuensi sampling yang telah ditentukan yaitu 8000 Hz. Penulis memilih nilai frekuensi sampling berdasarkan teori Nyquist yang menyatakan bahwa sampling rate harus dua kali lipat frekuensi tertinggi dari sinyal yang akan dilakukan sampling tersebut.
Panjang durasi perekaman yang dilakukan adalah dua detik. Pemilihan durasi ini ditentukan berdasarkan perkiraan panjang durasi pengucapan setiap nama hari. Hasil rekaman disimpan dalam file dengan format .wav. Alir perekaman dapat dilihat pada Gambar 3.10.
3.4.3 Pre-emphasis
Pre-emphasis merupakan suatu proses filter yang bertujuan untuk mengompensasi frekuensi tinggi. Masukan pada tahap ini adalah hasil dari perekaman secara langsung dan tidak langsung yang kemudian dilakukan proses konklusi antara masukan dengan keluaran. Koefisien emphasis atau alpa yang digunakan pada proses ini bernilai 0.95 yang di dapat dari referensi [11]. Proses emphasis ditunjukkan oleh diagram alir pada Gambar. 3.11.
Gambar 3.10 Diagram Alir Perekaman
3.4.4 Frame Blocking
Pada tahap ini hasil dari pre-emphasis akan diambil sepanjang nilai frame, dan akan menghasilkan jumlah frame yang banyak karena terjadi overlapping. Diagram alir pada Gambar 3.12 menunjukkan proses frame blocking.
Gambar 3.12 Diagram Alir Frame Blocking
3.4.5 Windowing
Windowing bertujuan untuk nghilangkan diskontinuitas yang disebabkan oleh proses frame blocking. Windowing yang dipakai dalam sistem ini menggunakan blackman window, pemilihan blackman window karena blackman window memiliki mainlobe yang besar dan sidelobe yang kecil.
3.4.6 FFT (Fast Fourier Transform)
FFT (Fast Fourier Transform) bertujuan untuk mengubah setiap frame dari domain waktu ke domain frekuensi, yang berarti menyimpan hasil perekaman suara dalam domain frekuensi. FFT dilakukan setelah sinyal melalui proses windowing. Proses perhitungan FFT ditunjukkan pada diagram alir Gambar 3.14.
Gambar 3.14 Diagram Alir Proses FFT
3.4.7 Ekstraksi Ciri MFCC
Pada proses ekstraksi ciri masukan berasal dari hasil perhitungan FFT. Proses awal perhitungan MFCC adalah menentukan jumlah filterbanks, Filter batas atas dan filter batas bawah kemudian proses perhitungan pada filterbanks. Proses MFCC ditunjukkan pada diagram alir Gambar 3.15
Gambar 3.15 Diagram Alir Proses Ekstraksi Ciri MFCC
3.4.8 Klasifikasi K-NN
K-NN bertugas untuk mengklasifikasikan hasil ekstraksi ciri MFCC. Proses pengklasifikasian diurutkan dari nilai koefisien terkecil hingga koefisien terbesar dan
melihat banyaknya kelas yang sering muncul. Proses klasifikasi K-NN ditunjukkan pada diagram alir Gambar 3.16
23
BAB IV
HASIL DAN PEMBAHASAN
Program yang telah dibuat perlu diuji. Pengujian berguna untuk mengetahui kinerja program tersebut dalam melakukan pengenalan ucapan. Hasil pengujian berupa data yang diperoleh saat proses pengujian. Data – data hasil pengujian menunjukkan program yang telah dirancang dapat berjalan dengan baik atau tidak. Analisa dan pembahasan dilakukan pada data hasil pengujian yang telah diperoleh.
4.1 Interface Program Pengenalan Ucapan Menggunakan Mel
Frequency Cepstral Coefficient dan K-NN
Perancangan program menggunakan software Octave 5.1.0. Pengujian program pengenalan ucapan menggunakan laptop spesifikasi :
Prosesor : Intel(R) Core(TM) i3-6006U CPU @ 2.00GHz RAM : 8 GB
Tipe sistem : Sistem operasi 64 bit
Tampilan GUI dibuat agar dapat mempermudah pengguna saat menggunakan program. Dalam tampilan GUI, program “PENGENALAN UCAPAN” mempunyai tiga push button, tiga axes, satu pop up menu satu edit text dan satu static text. Setiap elemen dalam GUI membentuk satu kesatuan proses yang digunakan untuk program “PENGENALAN UCAPAN”. Pengguna program diwajibkan untuk memilih nilai koefisien ‘k’ terlebih dahulu pada popup menu. Variasi nilai koefisien ‘k’ berpengaruh pada saat klasifikasi.
Proses pengenalan ucapan dapat dilakukan dengan melakukan langkah – langkah berikut :
1. Menekan dua kali ikon Octave pada layar desktop dengan ambar ikon seperti Gambar 4.1.
Gambar 4.1 Ikon Octave 5.1.0
2. Setelah melakukan langkah 1, tampilan utama software Octave akan muncul seperti Gambar 4.2.
Gambar 4.2 Tampilan Awal Octave
3. Sebelum membuka program “PENGENALAN UCAPAN”, memastikan Current Directory (1) sudah sesuai dengan tempat menyimpan program.
4. Mengetikkan perintah ‘pkg load signal’ pada command window untuk mengaktifkan modul pengolah sinyal pada Octave yang belum termuat secara otomatis ketika menjalankan program Octave.
5. Mengetikkan perintah ‘Pengenalan_Ucapan’ untuk memunculkan tampilan program pengenalan ucapan. Setelah itu tampilan program pengenalan ucapan akan muncul seperti pada Gambar 4.3.
Gambar 4.3 Tampilan Program Pengenalan Ucapan
6. Memilih variasi nilai koefisien ‘k’ pada K-NN yang akan digunakan. Variasi nilai koefisien ‘k’ yang tersedia adalah 1, 3, 5, 7.
7. Menekan tombol ‘REKAM’ untuk merekam ucapan yang akan dikenali. Hasil dari suara yang terekam ditampilkan pada PLOT REKAMAN, hasil dari FFT ditampilkan pada PLOT FFT, dan hasil dari ekstraksi ciri ditampilkan pada PLOT EKTRAKSI MFCC. Hasil pengenalan ucapan terlihat seperti pada Gambar 4.4.
8. Mengulang kembali proses pengenalan ucapan dengan menekan tombol ‘RESET’, dan mengulang kembali langkah 6 dan 7.
9. Mengakhiri program pengenalan ucapan dengan menekan tombol ‘KELUAR’.
4.1.1 Popup Menu
Pada tampilan program terdapat sebuah popup menu untuk variasi nilai koefisien ‘k’ pada K-NN. Variasi nilai koefisien ‘k’ yang disediakan adalah 1, 3, 5, dan 7. Koefisien yang digunakan merupakan bilangan ganjil yang berfungsi meningkatkan akurasi dibandingkan dengan bilangan genap dan dibatasi hanya empat koefisien karena semakin besar koefisien semakin turun akurasinya. Program pengenalan ucapan dapat berjalan dengan baik setelah pengguna memilih variasi dari nilai yang diinginkan.
4.1.2 Tombol REKAM
Tombol ‘REKAM’ digunakan ketika pengguna akan menjalankan program pengenalan ucapan. Tombol ‘REKAM’ berisikan beberapa sub proses yang membentuk suatu kesatuan dalam proses pengenalan ucapan angka. Sub proses yang ada pada tombol ‘REKAM’ terdiri dari perekaman ucapan, pre-emphasis, frame blocking, Blackman windowing, Fast Fourier Transform (FFT), dan ekstraksi ciri MFCC untuk penentuan keluaran
Sub proses berikutnya ada sub proses pre-emphasis. Sub proses pre-emphasis berguna untuk mengompensasi bagian frekuensi tinggi dari ucapan manusia [7]. Sub proses berikutnya ada sub proses frame blocking. memperkecil terjadinya perubahan sinyal yang diakibatkan oleh perubahan artikulasi dari orang yang mengucapkan suara [7]. Sub proses berikutnya ada sub proses blackman windowing. Sub proses blackman windowing berguna untuk kemungkinan terjadinya kebocoran spektral (aliasing) [11]. Sub proses berikutnya ada sub proses FFT. Sub proses FFT berguna untuk merubah sebuah sinyal dari domain waktu atau jarak ke domain frekuensi atau sebaliknya[7].
Sub proses berikutnya ada sub proses ekstraksi ciri MFCC. Sub proses MFCC berguna untuk mendapatkan hasil ekstraksi ciri dari sebuah gelombang sinyal ucapan. Sub proses berikutnya ada sub proses klasifikasi. Sub proses klasifikasi berguna untuk
mengklasifikasikan hasil dari ekstraksi ciri dan dibandingkan dengan database dengan menggunakan metode K-NN.
4.1.3 Tombol RESET
Fungsi dari tombol reset adalah mengembalikan tampilan seperti pada saat awal dimulai dengan cara mengosongkan gambar PLOT PEREKAMAN, PLOT FFT, PLOT MFCC, dan tulisan hasil ucapan yang dikenali.
4.1.4 Tombol KELUAR
Fungsi dari tombol KELUAR adalah untuk menutup interface dari program pengenalan ucapan dan mengembalikan pada tampilan sebelumnya.
4.2 Hasil Pengujian Program Pengenalan Ucapan Angka
Pengujian dilakukan dengan dua metode pengujian yaitu secara real time dan non real time. Pengujian secara non real time dilakukan dengan membandingkan hasil ekstraksi ciri dari ucapan yang menjadi database dengan ucapan yang menjadi datatest. Data masukan untuk pengujian non real time menggunakan rekaman ucapan angka sebagai datatest untuk dibandingkan dengan rekaman ucapan angka yang telah disimpan sebagai database sebelumnya.
Pengujian real time dilakukan dengan menggunakan masukan secara langsung dari pengguna, ketika pengguna mereka ucapan angka yang akan dikenali saat itu juga hasil keluaran dari pengenalan ucapan angka akan tertampil. Dalam pengujian real time parameter yang digunakan adalah hasil terbaik dari pengenalan terbaik dari proses non realtime yang telah dijadikan database.
4.2.1 Pengujian Non Real Time
Pengujian secara non real time menggunakan ucapan angka referensi yang disimpan sebagai database dan data uji yang telah direkam sebelumnya yang disimpan sebagai datatest. Dalam sistem pengujian non real time, dua jenis data ucapan angka ini diproses untuk mengetahui parameter terbaik dari variasi nilai koefisien ‘k’ yang digunakan pada saat proses klasifikasi.
Data referensi yang disimpan sebagai database disimpan sebagai sebuah file dengan format ‘.mat’ yang bernama ‘dbase.mat’. Setelah memiliki referensi database kemudian diuji tingkat akurasi pengenalannya dengan data uji yang disebut datatest.
Data uji yang disimpan sebagai datatest disimpan sebagai sebuah file dengan format ‘.mat’ yang bernama ‘dtest.mat’. Setelah memiliki dua buah file yang telah disimpan, kemudian menguji program untuk pengujian non real time.
Berdasarkan proses pengujian yang telah dilakukan dapat diketahui nilai terbaik dari variasi koefisien ‘k’. Data tingkat pengenalan dipresentasikan dalam persentase yang menunjukkan pengenalan ucapan berdasarkan variasi nilai koefisien ‘k’.
Tabel 4.1 Tingkat Pengenalan Hasil pengujian Non Real Time Nilai k Tingkat pengenalan (%)
1 85
3 81
5 76
7 70
Grafik pada Gambar 4.5 menunjukkan pengaruh perubahan nilai ‘k’ terhadap pengenalan ucapan. Dalam grafik tersebut pengenalan terbaik terdapat pada saat nilai ‘k’=1 yang mampu mengenali hingga 85 persen.
Gambar 4.5 Pengaruh Variasi Nilai K Terhadap Pengenalan Ucapan Secara Non Real Time.
60 65 70 75 80 85 90 0 1 2 3 4 5 6 7 8 T in g k at P en g en alan ( %) Variasi Nilai k
Pengaruh Perubahan Nilai 'k' Terhadap
Pengenalan Ucapan Secara Non Real Time
Ketidakmampuan pengenalan ucapan untuk mengenali hingga 100 persen terjadi karena ada pengenalan ucapan yang salah. Pengenalan ucapan secara non real time ditunjukkan pada Tabel 4.2
Tabel 4.2 Confusion Matrix Pengenalan Secara Non Real Time pada k=1.
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 10 0 0 0 0 0 0 0 0 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 2 7 0 0 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 7 0 2 0 1 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 0 0 8 0 Sembilan 0 0 0 0 0 0 0 0 0 10
Hasil pengenalan yang terlihat pada tabel tersebut menunjukkan adanya kesalahan dalam pengenalan ucapan. Kesalahan pengenalan terjadi pada angka 1, 2, 3, 4, 6, dan 8 yang membuat tingkat pengenalan berkurang. Tingkat pengenalan hanya mencapai 85 persen terjadi karena keterbatasan metode yang dipakai dalam membuat sistem program pengenalan ucapan angka. Kesalahan yang terjadi disebabkan oleh hasil ekstraksi ciri dari satu ucapan masuk ke dalam range ekstraksi ciri dari ucapan lain sehingga sistem mengenali ucapan tersebut dengan ucapan yang lain
4.2.2 Pengujian Real Time
Pengujian secara real time dapat mengenali secara langsung ucapan yang telah diucapkan oleh pengguna. Ucapan yang diucapkan pengguna langsung di proses dan hasilnya dibandingkan dengan database yang telah dibuat pada proses non real time.
Berdasarkan proses pengujian secara real time yang telah dilakukan dapat diketahui nilai terbaik dari variasi koefisien ‘k’. Data tingkat pengenalan dipresentasikan dalam persentase yang menunjukkan pengenalan ucapan berdasarkan variasi nilai koefisien ‘k’.
Tabel 4.3 Tingkat Pengenalan Hasil Pengujian Real Time
Grafik pada Gambar 4.6 menunjukkan pengaruh perubahan nilai ‘k’ terhadap pengenalan ucapan. Dalam grafik tersebut pengenalan terbaik terdapat pada saat nilai ‘k’=1 yang mampu mengenali hingga 81 persen untuk ucapan perempuan, dan 80 persen pada ucapan laki – laki. Pengenalan ucapan perempuan secara real time ditunjukkan pada Tabel 4.4 dan pengenalan ucapan laki-laki secara real time ditunjukkan pada Tabel 4.5
Tabel 4.4 Confusion Matrix Pengenalan Ucapan Perempuan Secara Real Time Pada k=1.
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 7 0 3 0 0 0 0 0 0 0 Satu 0 10 1 0 0 0 0 0 0 1 Dua 0 0 8 0 0 0 0 0 1 0 Tiga 0 0 0 7 0 3 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 1 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 1 0 0 0 9 0 Sembilan 0 0 2 0 0 0 0 0 2 6 Nilai K Tingkat Pengenalan Laki – Laki Perempuan 1 80 81 3 77 79 5 72 73 7 69 70
Gambar 4.6 Pengaruh Variasi Nilai K Terhadap Pengenalan Ucapan Secara Real Time
65 70 75 80 85 1 3 5 7 T in g k at P en g en alan ( %) Nilai K
Pengaruh Perubahan Nilai 'k' Terhadap Pengenalan Ucapan Secara Real Time
Laki-Laki Perempuan
Tabel 4.5 Confusion Matrix Pengenalan Ucapan Laki - Laki Secara Real Time Pada k=1.
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 6 0 2 0 2 0 0 0 0 0 Satu 0 10 0 0 0 0 0 0 0 0 Dua 0 2 7 0 0 0 0 0 1 0 Tiga 0 0 0 10 0 0 0 0 0 0 Empat 0 0 0 0 8 0 1 0 1 0 Lima 0 0 0 3 0 7 0 0 0 0 Enam 0 0 0 0 2 0 8 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 0 0 8 0 Sembilan 0 0 0 0 1 0 0 0 2 7
Perbedaan tingkat pengenalan suara pada objek laki-laki dan perempuan tidak terlalu signifikan hanya 1- 2 % saja.
32
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari percobaan dan pengujian sistem pengenalan ucapan dapat disimpulkan sebagai berikut :
1. Implementasi sistem pengenalan ucapan sudah dapat bekerja.
2. Program pengenalan ucapan sudah mampu mengenali ucapan dari dua orang berbeda -laki-laki dan perempuan- yang meliputi ucapan nol, satu, dua, tiga, empat, lima, enam, tujuh, delapan, sembilan.
3. Parameter nilai koefisien ‘k’ mempengaruhi tingkat pengenalan ucapan. Hasil pengenalan terbaik pada k=1 sebesar 81% pada suara perempuan dan 80% pada suara laki-laki.
5.2 Saran
Saran untuk pengembangan lebih lanjut pada sistem pengenalan ucapan adalah sebagai berikut :
1. Pengembangan sistem dengan menggunakan sistem klasifikasi yang lebih lanjut seperti jaringan syaraf tiruan.
2. Pengembangan data latih yang lebih banyak agar dapat mengenali ucapan dari banyak orang.
DAFTAR PUSTAKA
[1] Tandillo, Joseph Masarani., Rasmana, Sujianto Tri., Pusparani, Ira., 2016, Identifikasi Suara Manusia Berdasarkan Jenis Kelamin Menggunakan Ekstraksi Fitur Short Time Fourier Transform, JCONES, vol. 5, no. 1, hal 177-183 [2] Anam, Khoirul, 2013, Pengenalan Suara Manusia Menggunakan Metode Linier
Predictive Coding, Skripsi, Jurusan Teknik Informatika, Fakultas Sains dan Teknologi, Universitas Negeri Maulana Malik Ibrahim, Malang,
[3] Setyawan, Yohanes Robby, 2014, Pengenalan Ucapan Angka Secara Real Time menggunakan Ekstraksi Ciri FFT dan Fungsi Similaritas Kosinus, Tugas Akhir, Jurusan Teknik Elektro, FST, Universitas Sanata Dharma, Yogyakarta
[4] Walters, E. G., 1968, Fundamentals of Telephone Communication Systems. Western Electric Company. 1969. p. 2.1, Broadway, New York.
[5] Wijaya, A ., 2011, Aplikasi Hidden Markov Model Pada Pintu Geser Berbasis Suara, Tugas Akhir, Jurusan Teknik Elektro, FST, Universitas Sanata Dharma, Yogyakarta. [6] Skalar, B. 1998, Digital Communications Fundamental And Application, New
Jersey, PTR Prentice Hall.
[7] Tan L., Jiang J., 2013, Digital Signal Processing: Fundamentals Ana Applications 2nd Edition, Academic Press, Oxford.
[8] Setiawan, A, Hidayanto, A., & Isnanto, R., 2011, Aplikasi Pengenalan Ucapan dengan Ekstraksi Mel-Frquency Cepstrum Coefficients (MFCC) Melalui Jaringan Syaraf Tiruan Learning Vector Quantization (LVQ) untuk Mengoprasikan Kursor Komputer. Transmisi, [82-86]. https://www.researchgate.net/publication/277998882_Aplikasi_Pengenalan_Ucapa n_dengan_Ekstraksi_Mel-frequency_Cepstrum_Coefficients_MFCC_Melalui_Jaringan_Syaraf_Tiruan_JST_ Learning_Vector_Quantization_LVQ_untuk_Mengoperasikan_Kursor_Komputer (diakses 8 februari 2020 )
[9] Suwandi, 2011, Perancangan Program Aplikasi Absensi Pada Binus Learning Community SAC dengan menggunakan Hidden Markov Model, Program Ganda Teknik Informatika dan Matematika, Bina Nusantara Jakarta.
[10] Fediano, J ., 2019, Alih Aksara Sunda Tulisan Tangan Menggunakan Metode Ekstraksi Ciri Freeman Chain Code (FCC) dan Metode Klasifikasi K-Nearest Neighbor (KNN), Skripsi, Jurusan Teknik Informatika, FST, Universitas Sanata Dharma, Yogyakarta.
[11] Oppenheim. A.V., Ana R. W. Schafer., 1999, Discrete-Time. Signal Processing. Upper Saddle River, NJ: Prentice-Hall, Pp. 468-471.
LAMPIRAN 1
IMPLEMENTASI SISTEM PENGENALAN
A. Implementasi Perangkat Keras
Bentuk fisik dari perangkat keras yang digunakan dalam pengenalan ucapan. Alat-alat yang digunakan pada sistem pengenalan ucapan ditunjukkan pada Gambar L-1.
B. Implementasi Perangkat Lunak
Implementasi perangkat lunak telah dijelaskan pada subbab 4.1 tentang tampilan GUI sistem pengenalan ucapan
LAMPIRAN 2
LAMPIRAN 3
DATA HASIL PENGUJIAN
A. Data Pengujian Non Real Time
Tabel L-1 Confusion Matrix Pengujian Non Real Time Pada k=1
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 10 0 0 0 0 0 0 0 0 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 2 7 0 0 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 7 0 2 0 1 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 0 0 8 0 Sembilan 0 0 0 0 0 0 0 0 0 10 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 85 100×
100 % = 85 %Tabel L-2 Confusion Matrix Pengujian Non Real Time Pada k=3
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 8 0 2 0 0 0 0 0 0 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 2 7 0 0 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 7 0 2 0 1 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 2 0 1 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 0 0 8 0 Sembilan 0 0 0 0 0 0 0 0 2 8
Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖
𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 81100
×
100 % = 81 %Tabel L-3 Confusion Matrix Pengujian Non Real Time Pada k=5
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 7 0 2 0 1 0 0 0 0 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 2 5 0 0 0 2 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 6 0 2 0 2 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 2 0 1 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 0 0 8 0 Sembilan 0 0 0 0 0 0 0 2 1 7 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 76 100×
100 % = 76 %Tabel L-4 Confusion Matrix Pengujian Non Real Time Pada k=7
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 5 0 3 0 2 0 0 0 0 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 2 5 0 2 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 6 0 2 0 2 0 Lima 0 0 0 2 0 8 0 0 0 0 Enam 0 0 3 0 0 0 7 0 0 0 Tujuh 0 2 0 0 0 0 0 8 0 0 Delapan 0 0 0 0 2 0 0 0 8 0 Sembilan 0 0 0 0 0 0 0 2 1 7
Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖
𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 70100
×
100 % = 70 %B. Data Pengujian Real Time
Tabel L-5 Tingkat Pengenalan Ucapan perempuan Secara Real Time Pada k=1
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 7 0 3 0 0 0 0 0 0 0 Satu 0 10 0 0 0 0 0 0 0 0 Dua 0 0 8 0 0 0 0 0 2 0 Tiga 0 0 0 7 0 3 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 2 0 6 0 Sembilan 0 0 0 0 0 0 0 0 1 9 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 81 100×
100 % = 81 %Tabel L-6 Tingkat Pengenalan Ucapan perempuan Secara Real Time Pada k=3
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 6 0 3 0 1 0 0 0 0 0 Satu 0 10 0 0 0 0 0 0 0 0 Dua 0 0 8 0 1 0 0 0 1 0 Tiga 0 0 0 7 0 3 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 1 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 1 0 2 0 2 0 5 0 Sembilan 0 0 2 0 0 0 0 0 2 9 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 79 100×
100 % = 79 %Tabel L-7 Tingkat Pengenalan Ucapan perempuan Secara Real Time Pada k=5
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 5 0 3 0 2 0 0 0 0 0 Satu 0 8 0 0 0 0 0 2 0 0 Dua 0 0 8 0 0 0 0 0 2 0 Tiga 0 0 0 7 0 3 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 2 0 8 0 0 0 0 Enam 0 1 3 0 0 0 6 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 1 0 2 0 2 0 5 0 Sembilan 0 0 0 0 0 0 0 0 1 9 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 73 100×
100 % = 73 %Tabel L-8 Tingkat Pengenalan Ucapan perempuan Secara Real Time Pada k=7
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 5 0 3 0 1 0 1 0 0 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 0 8 0 1 0 0 0 1 0 Tiga 0 0 0 7 0 3 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 2 0 8 0 0 0 0 Enam 0 1 3 0 0 0 6 0 0 0 Tujuh 0 2 0 0 0 0 0 8 0 0 Delapan 0 0 1 0 1 0 3 0 5 0 Sembilan 0 0 0 0 0 1 0 0 1 8 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 70 100×
100 % = 70 %Tabel L-9 Tingkat Pengenalan Ucapan laki-laki Secara Real Time Pada k=1
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 7 0 3 0 0 0 0 0 0 0 Satu 0 10 0 0 0 0 0 0 0 0 Dua 0 0 8 0 1 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 0 0 2 0 1 0 7 0 Sembilan 0 0 0 0 0 0 0 0 2 8 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 %= 80
100
×
100 % = 80 %Tabel L-10 Tingkat Pengenalan Ucapan laki-laki Secara Real Time Pada k=3
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 6 0 2 0 2 0 0 0 0 0 Satu 0 10 0 0 0 0 0 0 0 1 Dua 0 0 8 0 1 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 1 0 7 0 1 0 1 0 Lima 0 0 0 0 0 10 0 0 0 0 Enam 0 0 3 0 0 0 7 0 0 0 Tujuh 0 0 0 0 0 0 0 10 0 0 Delapan 0 0 2 0 2 0 0 0 6 0 Sembilan 0 0 1 0 0 0 1 0 3 5 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 77 100×
100 % = 77 %Tabel L- 11 Tingkat Pengenalan Ucapan laki-laki Secara Real Time Pada k=5
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 5 0 3 0 1 0 1 0 0 0 Satu 0 10 0 0 0 0 0 0 0 1 Dua 0 0 8 0 1 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 7 0 3 0 0 0 Lima 0 0 0 1 0 9 0 0 0 0 Enam 0 1 2 0 0 0 7 0 0 0 Tujuh 0 2 0 0 0 0 0 8 0 0 Delapan 0 0 3 0 1 0 0 0 6 0 Sembilan 0 0 2 0 2 0 0 0 2 4
Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖
𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
×
100 % = 72100
×
100 % = 72 %Tabel L- 12 Tingkat Pengenalan Ucapan laki-laki Secara Real Time Pada k=7
Input Output Nol Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan
Nol 5 0 3 0 0 0 0 0 2 0 Satu 0 8 1 0 0 0 0 0 0 1 Dua 0 0 8 0 1 0 0 0 1 0 Tiga 0 0 0 8 0 2 0 0 0 0 Empat 0 0 0 0 7 0 2 0 1 0 Lima 0 0 0 1 0 9 0 0 0 0 Enam 0 0 1 0 2 0 7 0 0 0 Tujuh 0 1 2 0 0 0 0 7 0 0 Delapan 0 0 2 0 1 0 0 0 6 1 Sembilan 0 0 2 0 0 0 2 0 2 4 Tingkat pengenalan = 𝑇𝑖𝑛𝑔𝑘𝑎𝑡 𝑑𝑎𝑡𝑎 𝑑𝑖𝑘𝑒𝑛𝑎𝑙𝑖 𝐽𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎