PENDAHULUAN
Latar BelakangPada saat ini penampilan informasi dalam bentuk citra semakin banyak dibutuhkan. Hal ini tidak lepas dari karakteristik citra yang cenderung mudah dipahami. Surat kabar, televisi, dan situs web di internet adalah sebagian contoh media yang banyak menampilkan informasi dalam bentuk citra.
Dibandingkan dengan citra dalam media konvensional seperti kertas, citra digital lebih mudah untuk diproses sesuai kebutuhan. Selain itu citra digital lebih mudah dalam hal transmisinya ke tempat lain. Namun demikian, jumlah bit yang dibutuhkan oleh data citra cukup besar, dan akibatnya waktu yang dibutuhkan dalam transmisinya ke tempat lain melalui saluran komunikasi juga cukup lama. Oleh karena itu upaya untuk memperkecil kebutuhan ruang penyimpanan dari citra digital menjadi sangat penting, agar dalam transmisinya melalui saluran komunikasi juga menjadi lebih cepat.
Pemampatan citra bertujuan meminimalkan kebutuhan ruang penyimpanan untuk merepresentasikan citra digital. Prinsip umum yang digunakan pada proses pemampatan citra adalah mengurangi redundansi data di dalam citra sehingga ruang penyimpanan yang dibutuhkan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula (Munir, 2004).
Salah satu metode pemampatan citra yang banyak diterapkan adalah Transform Coding. Pada pemampatan citra berbasis Transform Coding, matriks citra didekomposisi dengan tujuan untuk memadatkan sebanyak mungkin informasi citra ke dalam sejumlah kecil koefisien transformasi. Dengan demikian koefisien-koefisien transformasi lain yang kurang penting yaitu koefisien transformasi yang memuat sedikit informasi citra dapat dikuantisasi secara kasar atau bahkan diabaikan, sehingga efisiensi pemampatan bisa lebih baik. Singular Value Decomposition (SVD) merupakan suatu teknik transformasi yang penting dalam pemampatan citra, karena transformasi ini memungkinkan efisiensi pemadatan informasi yang optimal untuk sembarang citra (Jain, 1989). Namun selain koefisien transformasi yang berupa nilai singular, proses transformasi citra dengan SVD juga menghasilkan vektor-vektor singular yang juga perlu disimpan bersama dengan koefisien transformasi. Vector Quantization (VQ) adalah teknik kuantisasi yang bekerja pada vektor. Pada VQ, pemampatan data vektor didapat
dengan hanya menyimpan indeks dari vektor tersebut, dimana dalam pengkodean dan pendekodeannya mengacu pada sejenis tabel yang disebut codebook .
Pemampatan citra SVD yang Hybrid dengan DCT dikembangkan oleh Wongsawat et al (2004), menggunakan Adaptive Multistage Vector Quantization (AMVQ) dalam pengkodean vektor-vektor singular SVD.
Karya ilmiah ini akan membahas dan mendemonstrasikan kerja pemampatan citra SVD berdasarkan skema yang diperkenalkan oleh Wongsawat et al. (2004).
Tujuan
Adapun tujuan dilakukannya penelitian ini adalah :
1. Mempelajari dan mengimplementasikan metode pemampatan citra berbasiskan transformasi Singular Value Decomposition (SVD).
2. Menganalisa kinerja metode pemampatan citra SVD yang diukur dari kualitas citra hasil pemampatan (Peak Signal To Noise Ratio) dan efisiensi pemampatan (Bit Per Pixel), serta membandingkannya dengan kinerja metode pemampatan citra Joint Photographic Experts Group (JPEG).
Ruang Lingkup
Dalam penelitian ini dibuat suatu sistem yang dapat memampatkan citra dan merekonstruksi citra hasil pemampatan dengan metode SVD, dimana citra asli yang akan dimampatkan adalah citra dengan format bitmap (BMP) 8-bit per pixel skala keabuan (grayscale). Pemampatan citra terutama difokuskan pada citra digital fotografi.
Manfaat
Hasil penelitian ini diharapkan dapat memberikan alternatif dalam pemilihan metode pemampatan citra yang terbaik.
TINJAUAN PUSTAKA
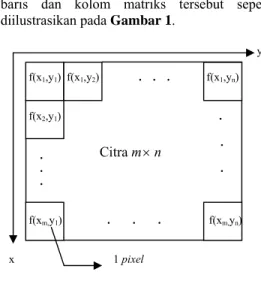
Citra DigitalSebuah citra dapat didefinisikan sebagai sebuah fungsi dua dimensi f(x,y), dimana x dan y menunjukkan koordinat spasial, dan nilai f pada sembarang koordinat (x,y) disebut intensitas atau kecerahan citra pada titik tersebut. Ketika x, y, dan nilai f berbentuk diskret berhingga, maka citra itu disebut sebuah citra digital (Gonzales & Woods, 2002).
Sebuah citra digital dapat ditampilkan dalam
bentuk matriks berdimensi m
×
n, dengan mbaris dan kolom matriks tersebut seperti diilustrasikan pada Gambar 1.
y f(x1,y1) f(x1,y2) . . . f(x1,yn) f(x2,y1) . . . . . . f(xm,y1) . . . f(xm,yn) x 1 pixel
Gambar 1. Representasi citra m× n
Setiap elemen matriks tersebut menunjukkan nilai elemen citra (pixel). Suatu citra dengan format 8 bit memiliki 256 intesitas warna pada setiap elemen citranya, nilai 0 untuk tingkat paling gelap dan 255 untuk tingkat yang paling terang (Gonzales & Woods 2002).
Pemampatan Citra
Pada umumnya representasi citra digital membutuhkan ruang penyimpanan yang cukup besar. Sebagai contoh sebuah citra bitmap 1024
×
768 pixel dengan format 8-bit membutuhkan768 KB ruang penyimpanan. Besarnya jumlah data yang berkaitan dengan informasi citra digital merupakan sebuah masalah yang bisa mengakibatkan mahalnya biaya penyimpanan, misalnya space dalam harddisk, dan biaya transmisi.
Pemampatan citra dapat mengatasi masalah besarnya kebutuhan ruang penyimpanan citra dan lamanya waktu transmisi. Hal utama dalam proses pengurangan jumlah data citra adalah penghilangan redundansi data (Gonzales & Woods, 2002).
Dua buah citra digital dengan jumlah data yang berbeda dapat merepresentasikan satu informasi yang sama. Ini artinya salah satu citra mengandung redundansi data, yaitu memuat data yang tidak memiliki informasi yang relevan atau data yang hanya mengulang sesuatu yang telah diketahui sebelumnya. Pemampatan citra dicapai dengan mengurangi ataupun menghilangkan satu atau lebih diantara ketiga jenis redundansi data sebagai berikut (Gonzales & Woods, 2002) :
1. Coding Redundancy, adalah redundansi yang terjadi karena jumlah bit yang
digunakan untuk merepresentasikan sebuah kode terlalu banyak.
2. Interpixel Redundancy, adalah redundansi yang terjadi karena tingginya korelasi antara satu pixel dengan pixel lainnya, artinya nilai
intensitas warna pixel yang saling
bersebelahan seringkali sama. Sehingga sebenarnya nilai intensitas warna pixel dapat diprediksi dari intensitas warna pixel tetangganya.
3. Psychovisual Redundancy, adalah redundansi yang terjadi karena mata manusia tidak merespon dengan kepekaan yang sama terhadap semua informasi visual. Beberapa informasi memiliki tingkat kepentingan yang lebih rendah dibandingkan dengan informasi lain. Sehingga bisa dihilangkan tanpa berpengaruh signifikan terhadap pemahaman atas citra secara keseluruhan.
Metode pemampatan citra dapat diklasifikasikan ke dalam dua kelompok besar yaitu (Munir, 2004) :
1. Metode lossless, adalah metode
pemampatan citra yang merekonstruksi citra hasil pemampatan identik pixel demi pixel dengan citra semula yang belum dimampatkan. Tidak ada informasi yang hilang akibat pemampatan. Metode ini cocok untuk memampatkan citra yang mengandung informasi penting yang tidak boleh rusak akibat pemampatan. Misalnya memampatkan gambar hasil diagnosa medis. 2. Metode lossy, adalah metode pemampatan citra yang merekonstruksi citra hasil pemampatan hampir sama dengan citra semula. Biasanya ada sedikit informasi yang hilang akibat pemampatan, tetapi dapat ditolerir oleh persepsi mata. Dengan menggunakan metode ini, efisiensi pemampatan bisa lebih baik.
Singular Value Decomposition (SVD)
SVD adalah suatu teknik untuk mentransformasi matriks. Pada pemampatan citra berbasiskan Transform Coding, transformasi matriks citra dilakukan untuk memetakan sinyal citra menjadi representasi lain yang lebih cocok untuk pemampatan. Dalam hal ini matriks citra ditransformasi sehingga sebagian besar dari informasi citra terkonsentrasi ke dalam koefisien-koefisien transformasi yang jumlahnya relatif kecil, untuk kemudian dikuantisasi dan dikodekan (Jain, 1989).
Tujuan dari proses transformasi adalah untuk menemukan korelasi antar pixel, atau untuk memadatkan sebanyak mungkin
2 1 1 1
( , )
'( , )
m n r i i j i kA i j
A i j
λ
= = = +−
=
∑∑
∑
1,
k k i iε
λ
==
∑
informasi kedalam sejumlah kecil koefisien transformasi. Proses kuantisasi kemudian secara selektif mengeliminasi atau mengkuantisasi secara lebih kasar koefisien yang membawa informasi paling sedikit. Koefisien-koefisien ini memiliki pengaruh yang paling kecil terhadap kualitas citra yang akan direkonstruksi (Gonzales & Woods, 2002).
Transformasi SVD memungkinkan sebagian besar informasi citra termuat dalam sedikit koefisien transformasi, sedangkan sebagian besar koefisien lain menjadi tidak penting. Jika
A adalah sebuah matriks dengan dimensi m
×
n, maka SVD dari A adalah (Wongsawat et al, 2004):
T
A U V
= ∑
dimana U dan V adalah matriks orthogonal yang
masing-masing berdimensi m
×
m dan n×
n,dan Σ adalah matriks koefisien transformasi m
×
n yang semua elemen selain diagonalnyabernilai 0. 11 1 1 1
k n m mk mn
a
a
a
A
a
a
a
⎛
⎞
⎜
⎟
= ⎜
⎜
⎟
⎟
⎝
⎠
K
K
M
O
M
L
L
(
1... ...
2 k m)
U
=
u u
u
u
(
1... ...
2)
T T k nV
=
v v
v
v
Σ = diag (σ1, ... ,σmin(m,n))Dimana σi adalah nilai singular ke-i. ui
adalah vektor kolom ke-i dari U dan vi adalah
vektor kolom ke-i dari V. Vektor ui disebut
vektor singular kiri dari σi, sedangkan vektor vi
disebut vektor singular kanan dari σi.
Vektor-vektor singular kiri tidak lain adalah
vektor ciri-vektor ciri dari AAT,, sedangkan
vektor-vektor singular kanan adalah vektor
ciri-vektor ciri dari ATA. Akar ciri-akar ciri dari
AAT atau ATA adalah kuadrat dari nilai-nilai
singular untuk matriks A. Nilai-nilai singular σi
ini tidak lain adalah elemen-elemen diagonal dari matriks Σ dan tersusun dalam urutan dari besar ke kecil. Oleh karena itu kita bisa
mendapatkan aproksimasi A dengan
menggunakan SVD sebagian:
'
Tk k k
A
=
U
∑
V
Dalam hal ini A’ adalah matriks aproksimasi
rank-k untuk matriks A. Uk dan Vk adalah
matriks yang diambil dari k kolom pertama U
dan V dan Σk = diag (σ1, ... ,σk) dengan k<r.
Seringkali aproksimasi matriks yang sangat baik
bisa didapatkan hanya dengan menggunakan sebagian kecil nilai singular, atau dengan k yang jauh lebih kecil dari r. Besarnya energi atau informasi yang dikandung oleh matriks aproksimasi dapat dihitung (Wongsawat et al, 2004) :
dimana
T T
2
akar ciri dari AA atau A A
i i
λ σ
=
=
Sedangkan Square Error antara matriks A dengan matriks aproksimasi A’ adalah hasil penjumlahan dari akar ciri yang diabaikan, yaitu (Dapena & Ahalt,2004) :
dimana
λ σ
i=
i2.
Kuantisasi Skalar Seragam
Nilai singular-nilai singular hasil transformasi SVD yang akan disimpan nilainya bersifat kontinu dan intervalnya cukup besar. Ini mengakibatkan besarnya jumlah bit yang dibutuhkan dalam penyimpanan. Oleh karena itu perlu dilakukan kuantisasi. Kuantisasi skalar merupakan proses pemetaan sebuah nilai skalar terhadap nilai tertentu yang dianggap mewakilinya, dimana nilai yang mungkin mewakili menjadi terbatasi banyaknya. Nilai-nilai ini disebut level rekonstruksi. Selanjutnya nilai ini diperkecil menjadi suatu nilai indeks sehingga bit yang diperlukan untuk menyimpannya menjadi berkurang. Indeks inilah yang dapat digunakan pada proses dekuantisasi untuk mengetahui level rekonstruksi mana yang mewakili skalar awal tadi.
Sebuah pengkuantisasi skalar seragam
l-level memiliki l+1 l-level keputusan d0, d1, ... , dl,
dan l level rekonstruksi r0, r1, ... , rl-1. di
membagi range data ke dalam l interval [d0, d1)
[d1, d2) ... [dl-1, dl), dengan panjang interval
yang sama yaitu (Spielman, 1996):
0 l
d
d
l
−
∆ =
dimana dl dan d0 masing-masing adalah nilai
maksimum dan nilai minimum dari data yang dikuantisasi.
Kuantisasi terhadap sebuah nilai a artinya
menemukan interval [di, di+1) yang memuat a
dan mengganti a dengan indeks i.
0
a d
i
= ⎢
⎢
−
⎥
⎥
∆
Sedangkan proses dekuantisasi menerjemahkan nilai indeks i ke dalam level
rekonstruksi ri yang merupakan rataan dari
interval yang relevan, menggunakan rumus :
1
2
i i id
d
r
=
+
+,
0 id
=
d
+ ∆
i
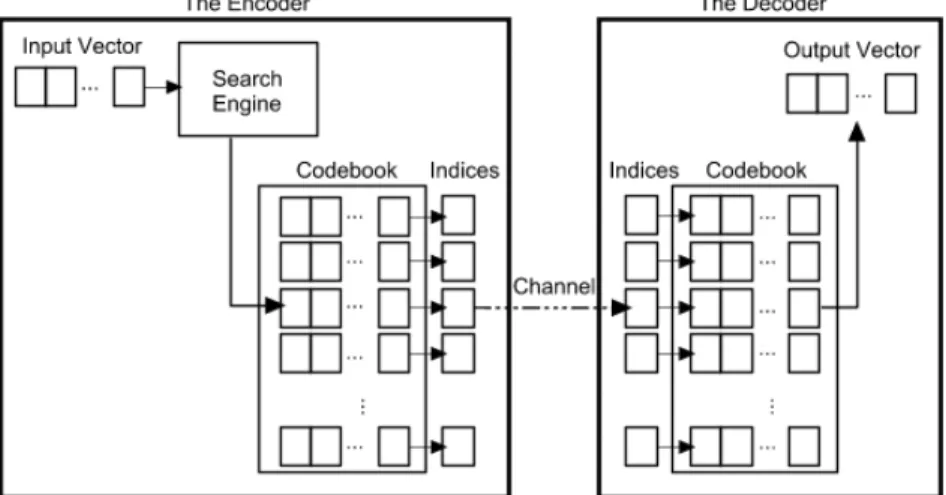
Vector Quantization (VQ)Selain nilai singular, pemampatan citra SVD juga mensyaratkan pengkodean vektor-vektor singular yang bersesuaian. Vektor-vektor ini dikodekan dengan sebuah teknik kuantisasi yang disebut Vector Quantization (VQ). VQ merupakan teknik kuantisasi yang dilakukan pada sebuah blok, atau sebuah vektor, dari nilai-nilai dalam satu waktu. VQ memetakan
vektor-vektor berdimensi u pada ruang vektor-vektor Ru ke
dalam sebuah himpunan terhingga
vektor-vektor Y = {yi : i = 1, 2,...,N} dalam Ru. Setiap
vektor yi disebut codevector atau codeword,
dan himpunan dari semua codeword disebut codebook. VQ terdiri dari dua operasi, yaitu encoder dan decoder. Encoder menerima vektor input dan menghasilkan output berupa indeks dari codeword yang memberikan distorsi paling minimum. Distorsi paling minimum ini ditentukan berdasarkan jarak euclid antara vektor input dengan setiap codeword dalam codebook. Jarak euclid antara vektor input x
dengan codeword yi didefinisikan sebagai :
2 1 ( , )i u ( j ij) j d x y x y = =
∑
−dimana xj adalah elemen ke-j dari vektor input x,
yij adalah elemen ke-j dari codeword yi, dan u
adalah dimensi vektor. Setelah codeword terdekat ditemukan, indeks dari codeword inilah
yang akan disimpan dalam media penyimpanan data digital atau dikirimkan melalui saluran komunikasi (Qasem, 2005). Indeks yang menunjukkan codeword membutuhkan ruang penyimpanan yang lebih kecil, sehingga terjadilah pemampatan data.
Ketika decoder menerima indeks ini, decoder akan mengubahnya kembali menjadi
codeword yang bersesuaian dengan
menggunakan codebook yang identik dengan codebook pada encoder. Sebagai contoh, encoder dan decoder VQ dapat dilihat pada
Gambar 2.
Algoritma Linde-Buzo-Gray (LBG)
Codebook yang akan diacu dalam proses VQ dibentuk berdasarkan algoritma LBG. Algoritma ini diperkenalkan oleh Linde, Buzo, dan Gray pada tahun 1980. LBG merupakan salah satu algoritma iteratif dalam pembentukan codebook dari sebuah himpunan vektor training. Adapun langkah-langkahnya adalah sebagai berikut (Qasem, 2005):
1. Tentukan jumlah codeword N atau ukuran codebook yang akan dibuat.
2. Bentuk codebook awal dengan cara memilih N codeword secara acak dari training vector.
3. Dengan menggunakan jarak euclid, kelompokkan vektor input pada codeword. Vektor input menjadi satu kelompok dengan codeword yang memiliki jarak euclid minimum.
Rata–rata dari jarak euclid setiap vektor terhadap codewordnya disebut dengan distorsi rata–rata dari codebook tersebut. Variabel inilah yang akan digunakan untuk menentukan tingkat kecocokan dari sebuah codebook.
Gambar 2. Encoder dan Decoder dalam VQ
4. Hitung himpunan codeword yang baru berdasarkan kelompok–kelompok yang sudah terbentuk. Codeword baru dibentuk dengan mencari rata–rata dari tiap elemen dari seluruh vektor yang merupakan anggota dari kelompok tersebut.
∑
==
m j ij ix
m
y
11
dimana i merupakan indeks komponen dari tiap–tiap vektor, dan m adalah banyaknya
vektor yang berada pada kelompok tersebut.
5. Ulangi langkah 3 dan 4 sampai codebok tidak berubah atau perubahannya kecil. Perubahan codebook dilihat dari rataan distorsi antara training vector dengan codebook. Jika selisih distorsi ternormalisasi dari sebuah iterasi dengan iterasi selanjutnya lebih kecil dari suatu nilai batas, maka algoritma dihentikan (Khan & Smith, 2000).
Seringkali dalam pengelompokkan vektor input menghasilkan satu atau lebih codeword tidak memiliki anggota. Keadaan ini dapat diatasi dengan beberapa cara, diantaranya dengan memecah codeword yang memiliki anggota paling banyak menjadi dua untuk menggantikan codeword yang tidak memiliki anggota (Khan & Smith, 2000).
Multistage VQ
Ide dasar Multistage VQ adalah untuk membagi tugas pengkodean VQ menjadi beberapa tingkat berurutan. Tingkat pertama melakukan aproksimasi level pertama dari vektor input. Aproksimasi kemudian diperbaiki oleh aproksimasi level kedua yang muncul pada tingkat kedua, untuk kemudian diperbaiki lagi pada tingkat ketiga, dan seterusnya (Khan & Smith, 2000). Pembentukan codebook adalah sebagai berikut: sebuah himpunan vektor training digunakan untuk membentuk codebook pertama. Dengan menggunakan codebook ini, sebuah himpunan vektor error dihitung dari
aproksimasi vektor training oleh codebook. Himpunan vektor error ini kemudian digunakan untuk membentuk codebook untuk tingkat 2, dan seterusnya. Prosedur pengkodeannya dijelaskan dalam gambar 3. Dalam algoritma encoder, pada awalnya vektor
input x akan diaproksimasi dengan
menggunakan codebook pertama C1.
Selanjutnya vektor error r1 dihitung dan
codebook tingkat kedua C2 digunakan untuk
mengaproksimasi vektor error tingkat pertama
r1, dan seterusnya. Algoritma decoder
merekonstruksi vektor aproksimasi ˆxsecara
sederhana dengan penjumlahan vektor.
Penerapan SVD dalam Pemampatan Citra
Sebuah citra digital dapat direpresentasikan
dengan sebuah matriks m
×
n pixel. Oleh karenaitu maka matriks citra dapat pula ditransformasi SVD dan diaproksimasi rank-k oleh sebuah matriks baru yang dibangun dengan memakai hanya sebagian kecil nilai singular (yaitu sebanyak k) dan vektor singular yang bersesuaian.
Aproksimasi ini adalah pemampatan selama jumlah bit yang dibutuhkan untuk menyimpan nilai-nilai singular dan vektor-vektor singular yang relevan lebih kecil dibandingkan dengan jumlah bit yang dibutuhkan oleh citra aslinya. Konsep dasar pemampatan citra dengan SVD adalah penggunaan rank-k sekecil mungkin dalam membangun matriks aproksimasi dan pengkodean vektor singular dengan ukuran codebook yang tidak terlalu besar dalam VQ, sehingga diharapkan efisiensi pemampatan yang baik bisa dicapai. Namun demikian dalam penerapannya harus diperhitungkan secara bijak agar kualitas citra hasil pemampatan masih cukup baik.
Metode Pemampatan Citra JPEG
JPEG adalah metode pemampatan citra standar yang umum digunakan pada citra fotografi. Nama JPEG merupakan singkatan dari Joint Photographic Experts Group, nama dari komite yang melakukan standarisasi terhadap metode ini (Wikipedia, 2007).
Struktur Encoder JPEG adalah sebagai berikut (Bovik, 2000):
1. Unit transformasi sinyal DCT.
Pada bagian ini dilakukan penghitungan
matriks koefisien DCT dari setiap blok 8
×
8pixel, sehingga informasi citra dipadatkan kedalam sejumlah kecil koefisien DCT. 2. Pengkuantisasi.
Pengkuantisasi memetakan setiap koefisien DCT ke dalam sebuah level dari bilangan berhingga. Ini dilakukan dengan membagi
a)
b)
Gambar 3. Multistage VQ. a) encoder, b) decoder