BAB III
METODOLOGI PENELITIAN
3.1 Gambaran Umum Objek PenelitianIflix merupakan sebuah platform teknologi berupa layanan jasa streaming video-on-demand berupa website dan mobile application. Iflix pertama kali di dirikan pada tahun 2014 oleh Mark Britt di Malaysia dan di Indonesia layanan ini masuk pada tanggal 19 April 2016 bekerjasama dengan perusahaan Telekomunikasi Indonesia (Telkom). Iflix menyediakan ratusan ribu video dengan berbagai kategori, mulai dari film action sampai serial televisi dengan dukungan kualitas video yang cukup tinggi.
Sumber : https://www.iflix.com/browse
Gambar 3.1 Tampilan Aplikasi Iflix
Kelebihan dari aplikasi ini adalah konsumen dapat menonton film dengan cara melakukan streaming melalui jaringan internet. Selain itu film pada aplikasi Iflix dapat ditonton dengan cara mengunduh film terlebih dahulu kemudian menontonnya secara offline. Untuk dapat menonton pada Iflix, dapat menggunakan perangkat berbeda seperti tablet, smartphone, dan laptop.
Serial yang ditawarkan untuk dapat ditonton pada Iflix cukup beragam, mulai dari drama, komedi, anime, documenter, lifestyle, reality show dan drama korea. Menonton pada aplikasi Iflix dapat dilakukan dalam bentuk gratis ataupun berbayar. Biaya berlangganan pada aplikasi Iflix setiap bulan memiliki tarif sebesar Rp. 39.000 dan untuk berlangganan satu tahun memiliki tarif sebesar Rp. 375.000. Menonton pada Iflix dengan cara tidak berbayar memiliki beberapa kelemahan yakni terdapat iklan pada saat melakukan streaming film. Untuk fitur berlangganan, benefit yang didapatkan berupa streaming bebas iklan, dapat menyimpan film dan dapat ditonton secara offline, serta akses tanpa batas kepada beberapa serial film.
3.2 Desain Penelitian
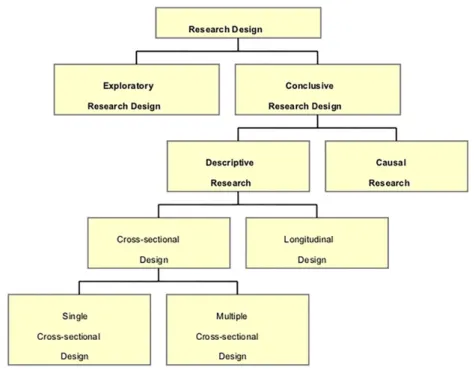
Desain penelitian adalah sebuah kerangka kerja dalam melakukan penelitian yang menggunakan prosedur khusus dalam memperoleh informasi untuk menyelesaikan permasalahan yang ditemukan dalam riset (Malhotra, 2010). Berikut ini merupakan gambar dari jenis model penelitian:
Sumber : Malhotra et al. (2004), p. 65
Menurut Malhotra (2010), desain penelitian terdiri dari dua jenis:
1. Exploratory Research Design adalah penelitian dengan tujuan mencari gagasan dan informasi mengenai masalah yang sedang diteliti.
2. Conclusive Research Design adalah penelitian yang digunakan untuk membantu mengambil keputusan dalam menentukan, mengevaluasi, dan memilih keputusan pada situasi tertentu serta tujuan yang ingin dicapai dalam penelitian.
Pada penelitian ini, peneliti menggunakan jenis Conclusive Research Design untuk menguji hipotesis serta hubungan antara variabel dalam model penelitian. Menurut Malhotra (2010), Conclusive Research Design dibagi menjadi dua, yaitu descriptive research dan causal research:
1. Descriptive Research adalah penelitian yang bertujuan untuk mendeskripsikan permasalahan atau fenomena yang ada. Penelitian ini berguna ketika peneliti bertujuan mendapatkan jawaban terkait suatu fenomena pasar seperti frekuensi pembelian dan prediksi pengguna.
2. Causal Research adalah penelitian yang bertujuan untuk membuktikan hubungan sebab akibat antara variabel yang diteliti.
Pada penelitian ini, peneliti menggunakan jenis penelitian descriptive research untuk mendeskripsikan fenomena yang terjadi pada apilasi Iflix. Jenis penelitian ini cocok untuk menggambarkan karakterisik sejumlah konsumen. Dengan metode ini, peneliti berharap mendapatkan penggambaran persepsi masyarakat terhadap suatu produk menjadi lebih jelas.
Menurut Malhotra (2010), descriptive research sendiri terbagi menjadi dua, yaitu cross-sectional design dan longitudinal design. Penelitian ini menggunakan metode cross-sectional design yang kemudian diklasifikasikan menjadi dua yaitu single sectional design dan multiple sectional design. Single cross-sectional design adalah metode pengumpulan data dalam penelitian dari responden dalam satu waktu sedangkan multiple cross-sectional design dilakukan dalam waktu yang berbeda untuk mengumpulkan sampel. Berdasarkan uraian tersebut,
penelitian ini menggunakan metode single cross-sectional design untuk mendapatkan data serta informasi yang dilakukan dalam waktu tertentu.
Pengumpulan data dilakukan oleh peneliti dengan cara menyebarkan kuesioner yang berisi pertanyaan terstruktur untuk mendapatkan informasi dari responden yang nantinya akan diolah menjadi data. Penelitian ini secara umum meneliti mengenai faktor-faktor yang mempengaruhi stickiness dan intention to make in-app purchase terhadap layanan Iflix. Variabel yang digunakan adalah hedonic value, utilitarian value, attitude, satisfaction, stickiness dan intention to make in-app purchase.
3.3 Metode Pengumpulan Data
Dalam penelitian, data digunakan untuk menganalisis serta menjadi alat pendukung yang kuat dalam penelitian. Data dibagi menjadi dua, yaitu data primer dan data sekunder (Malhotra, 2010). Data primer adalah data yang didapatkan langsung dari sumber seperti wawancara, survei, dan kuesioner. Sedangkan, data sekunder adalah data yang didapatkan dari sumber tidak langsung atau dari luar seperti buku, jurnal ilmiah, dan internet. Dalam penelitian ini, penulis menggabungkan kedua metode pengumpulan data, adapun prosedur yang dilakukan sebagai berikut:
1. Mengumpulan informasi dari artikel, literatur, dan jurnal ilmiah sebagai pendukung penelitian serta dalam penyusunan penelitian.
2. Menyusun kuisioner sebagai media untuk mengumpulkan data primer. Penulis menyusun kuisioner dengan memilih kata-kata yang tepat sehingga responden dapat memahami pertanyaan dengan mudah dengan tujuan mendapatkan hasil yang relevan.
3. Melakukan penyebaran kuesioner kepada responden sebanyak 30 orang dengan tujuan melakukan pre-test.
4. Hasil dari pre-test kemudian dianalisa menggunakan aplikasi IBM SPSS versi 23 dan jika memenuhi syarat uji validitas dan reliabilitas maka kuesioner dapat digunakan untuk mengumpulkan data yang ditentukan yaitu sejumlah n x 5 (Hair et al., 2014)
3.4 Ruang Lingkup Penelitian 3.4.1 Target Populasi
Populasi merupakan gabungan dari beberapa elemen yang memiliki kesamaan kriteria untuk menyelesaikan masalah dalam penelitian (Malhotra, 2010). Target populasi terdiri dari 4 aspek, yaitu sampling unit, extent, element, dan time frame (Malhotra, 2010). Menurut Malhotra (2010), element adalah objek yang memiliki informasi yang dicari dalam penelitian. Sampling unit merupakan dasar unsur populasi yang menjadi dasar untuk dijadikan sampel (Malhotra, 2010). Sampling unit yang digunakan dalam penelitian ini adalah pria dan wanita, mengetahui dan pernah menggunakan aplikasi Iflix namun belum melakukan berlangganan pada aplikasi tersebut. Pembatasan pada penelitian ini dilakukan di wilayan Tangerang dan Jakarta dengan cakupan yang lebih spesifik. Penulis juga mengumpulkan data berupa menyebarkan kuesioner dari bulan Maret 2020 sampai dengan bulan April 2020.
3.4.2 Sampling Techniques
Menurut Malhotra (2010), sampling techniques dibagi menjadi 2 jenis, yaitu:
1. Probability Sampling
Teknik sampling yang memberikan probabilitas yang tetap kepada setiap elemen yang ditentukan.
2. Non-probability Sampling
Teknik sampling yang tidak memberikan peluang yang sama kepada elemen untuk menjadi sampel dalam penelitian.
Dalam Malhotra (2010), non-probability sampling terdari dari 4 jenis, yaitu: 1. Convenience Sampling
Teknik sampling dengan mengambil sampel dengan tidak menentukan kualifikasi responden terlebih dahulu.
2. Judgemental Sampling
Teknik sampling dimana elemen dari populasi dipilih berdasarkan penilaian peneliti untuk mewakili populasi yang tepat dalam penelitian.
3. Quota Sampling
Teknik sampling yang terdiri dari 2 bagian yaitu pengembangan kategori dari elemen populasi dan kemudian memilih melalui pertimbangan peneliti. 4. Snowball Sampling
Teknik sampling dimana responden dipilih secara acak dan kemudian responden selanjutnya berdasarkan referensi atau informasi dari responden terdahulu.
Pada penelitian ini, penulis menggunakan teknik non-probability sampling dengan metode judgemental sampling. Penulis memilih elemen populasi berdasarkan pertimbangan melalui screening yang penulis buat dan diharapkan dapat mewakili populasi lainnya dalam penelitian ini.
3.4.3 Sampling Size
Menurut Malhotra (2010), sampling size adalah jumlah elemen yang termasuk ke dalam sebuah penelitian. Sampel penelitian pertama ini diambil sebanyak 30 responden sebagai uji coba pre-test. Penentuan jumlah sampel nantinya mengacu kepada Hair et al., (2014) sejumlah n x 5 berdasrkan jumlah yang mau di observasi. Jumlah indikator dalam penelitain ini adalah 24 indikator sehingga jumlah sampel minimum yang dibutuhkan adalah sejumlah 24 x 5 yaitu 120 responden.
3.4.5 Periode Penelitian
Penelitian ini dilakukan dalam kurun waktu sekitar 5 bulan, berawal dari bulan Februari 2020 sampai dengan Juni 2020. Peneliti memulai penelitian ini dengan menyusun latar belakang penelitian dan rumusan masalah lalu dihubungkan dengan penelitian terdahulu yang sesuai dengan penelitian ini. Peneliti kemudian melanjutkan dengan merancang kuesioner penelitian dengan maksud mengumpulkan data pendukung penelitian. Penliti kemudian melakukan proses mengolah data dan yang terakhir membuat kesimpulan dan saran bagi penelitian ini dan penelitian selanjutnya yang sejenis.
3.5 Identifikasi Variabel Penelitian 3.5.1 Variabel Eksogen
Variabel eksogen merupakan variabel yang berperan sebagai variabel bebas dalam model dan bersifat laten (Hair et al., 2014). Variabel eksogen menggambarkan sebuah model yang bersifat bebas atau berdiri sendiri dalam sebuah model sebagai tolak ukur variabel tersebut. Dalam penelitian ini, yang merupakan variabel eksogen adalah hedonic value dan utilitarian value.
3.5.2 Variabel Endogen
Variabel endogen adalah variabel yang terikat dan dipengaruhi oleh variabel lain dalam model (Hair et al., 2014). Secara struktur, variabel endogen dipengaruhi oleh variabel lain. Dalam penelitian ini yang termasuk dalam variabel endogen adalah attitude, satisfaction, stickiness, dan intention to make in-app purchase.
Sumber : Hair et al., 2014
3.5.3 Variabel Teramati
Variabel teramati disebut juga sebagai observed variable atau measured variable. Variabel ini dapat diukur secara empiris dan dapat disebut sebagai indikator. Kuesioner pada penelitian ini akan mewakili variabel teramati. Pada penelitian ini terdapat 24 pertanyaan pada kuesioner yang mewakili 24 indikator tersebut.
3.6 Definisi Operasional Variabel
Dalam penelitian ini terdapat indikator yang menjadi indikasi peneliti untuk digunakan dalam membantu mengukur sebuah variabel dalam model penelitian. Indikator tersebut dibuat dengan tujuan menjelaskan variabel yang digunakan guna menghindari kesalahpahaman dalam penafsiran definisi pada setiap variabel yang digunakan oleh peneliti. Definisi operasional pada penelitian ini disusun berdasarkan teori-teori dari berbagai literatur maupun jurnal ilmiah lainnya. Skala pengukuran variabel yang digunakan adalah likert scale 7 points, dimana point 1 menunjukan sangat tidak setuju dan point 7 menggambarkan sangat setuju. Definisi operasional dibuat peneliti dalam bentuk tabel dan dapat dilihat sebagai berikut:
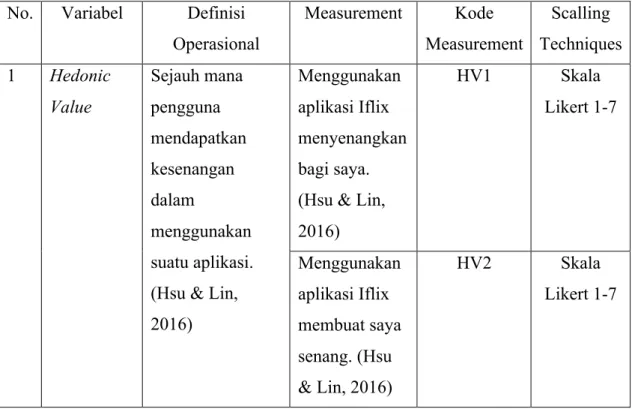
Tabel 3.1 Definisi Operasional Variabel
No. Variabel Definisi Operasional Measurement Kode Measurement Scalling Techniques 1 Hedonic Value Sejauh mana pengguna mendapatkan kesenangan dalam menggunakan suatu aplikasi. (Hsu & Lin, 2016)
Menggunakan aplikasi Iflix menyenangkan bagi saya. (Hsu & Lin, 2016) HV1 Skala Likert 1-7 Menggunakan aplikasi Iflix membuat saya senang. (Hsu & Lin, 2016) HV2 Skala Likert 1-7
Saya menikmati menggunakan aplikasi Iflix (Hsu & Lin, 2016) HV3 Skala Likert 1-7 Proses menonton film di aplikasi Iflix nyaman. (Al-hawari & Mouakket, 2012) HV4 Skala Likert 1-7 2 Utilitarian Value Sejauh mana seseorang mempercayai dengan menggunakan aplikasi tersebut dapat menjalankan aktifitas lebih baik (Hsu & Lin, 2016).
Saya merasa, film di aplikasi Iflix
berkualitas. (Gan & Wang, 2017). UV1 Skala Likert 1-7 Saya merasa aplikasi Iflix menawarkan film yang terbaik. (Gan & Wang, 2017) UV2 Skala Likert 1-7 Aplikasi Iflix membuat saya mudah menemukan UV3 Skala Likert 1-7
film yang saya inginkan. (Gan & Wang, 2017). Aplikasi Iflix membuat saya cepat dalam menemukan film yang saya inginkan. (Gan & Wang, 2017). UV4 Skala Likert 1-7 3 Attitude Attitude didefinisikan sebagai perasaan positif terhadap suatu objek tertentu. (Hsu & Lin, 2016). Saya memiliki kesan yang positif terhadap aplikasi Iflix (Yang, 2010). AT1 Skala Likert 1-7 Saya suka menggunakan aplikasi Iflix. (Hsu & Lin, 2016) AT2 Skala Likert 1-7 Menonton film menggunakan aplikasi Iflix adalah ide AT3 Skala Likert 1-7
yang bijaksana. (Yang, 2010) Menyenangkan bagi saya terhubung ke layanan Iflix. (Curras-Perez, Ruiz-Mafe, & Sanz-Blas, 2013) AT4 Skala Likert 1-7
4 Satisfaction Kepuasan adalah reaksi yang terjadi pada konsumen setelah menyelesaikan pembelian suatu produk atau layanan yang dimanifestasikan melalui persepsi melebihi harapan (Marinkovic et al. 2014). Menggunakan aplikasi Iflix untuk menonton film membuat saya merasa puas. (Hsu & Lin, 2016) ST1 Skala Likert 1-7 Menonton film pada aplikasi Iflix melebihi ekspetasi saya. (Deng, Kuo, & Wu, 2009) ST2 Skala Likert 1-7 Saya merasakan pengalaman ST3 Skala Likert 1-7
yang menyenangkan menonton film pada aplikasi Iflix. (Hsu, Olorunniwo, & Udo, 2006) Menurut saya, menonton film pada aplikasi Iflix merupakan hal yang tepat (Hsu, Olorunniwo, & Udo, 2006). ST4 Skala Likert 1-7
5 Stickiness Sejauh mana pengguna menggunakan kembali aplikasi yang digunakan dan memperpanjang penggunaan aplikasi setiap menggunakannya. (Hsu & Lin, 2016). Saya akan menggunakan aplikasi Iflix lebih lama dibanding aplikasi lain (Hsu & Lin, 2016). SK1 Skala Likert 1-7 Saya akan menghabiskan lebih banyak waktu menonton film menggunakan SK2 Skala Likert 1-7
aplikasi Iflix. (Hsu & Lin, 2016) Saya akan sesering mungkin menonton film menggunakan aplikasi Iflix (Hsu & Lin, 2016). SK3 Skala Likert 1-7 Saya menggunakan aplikasi Iflix untuk menonton film setiap kali saya terhubung dengan internet (Hsu & Lin, 2016). SK4 Skala Likert 1-7 6 Intention to make in-app purchase Intention to make in-app purchases didefinisikan sebagai sejauh mana pengguna ingin membeli produk atau jasa yang ada di dalam
Saya tertarik untuk berlangganan aplikasi Iflix premium dalam waktu dekat. (Hsu & Lin, 2016)
IN1 Skala
3.7 Teknik Pengolahan Analisis Data
3.7.1 Analisis Data Pre-Test Menggunakan Faktor Analisis
Menurut Malhotra (2010) faktor analisis merupakan teknik pengurangan indikator yang digunakan untuk meringkas data agar lebih efisien. Faktor analisis menjadi sebuah indikator untuk melihat ada atau tidaknya hubungan atau kolerasi pada setiap indikator dan melihat apakah indkator yang digunakan dapat mewakili
aplikasi dimasa yang akan datang. (Hsu & Lin, 2016) Saya berencana untuk berlangganan Iflix premium di kemudian hari. (Kang, Park, & Zo, 2016) IN2 Skala Likert 1-7 Kemungkinan saya untuk berlangganan Iflix premium tinggi. (Kang, Park, & Zo, 2016)
IN3 Skala
Likert 1-7
Jika saya ingin berlangganan online film streaming, saya akan memilih Iflix premium (Kang, Park, & Zo, 2016)
IN4 Skala
varibel laten. Pada penelitian ini, faktor analisis digunakan juga untuk melihat apakah data yang digunakan atau di olah valid dan reliabel atau tidak. Selain itu, faktor analisis juga mengidentifikasi masing-masing variabel menjadi satu kesatuan atau mengukur hal yang berbeda (Malhotra, 2010).
3.7.2 Uji Validitas
Uji validitas digunakan untuk mengukur (measurement) dan juga mengetahui apakah variabel yang digunakan terukur secara efisien atau tidak di dalam setiap variabel yang digunakan dalam penelitian (Malhotra, 2010). Sebuah indikator dalam penelitian dikatakan valid jika indikator tersebut mampu menafsirkan sesuatu yang diukur oleh indikator tersebut. Nilai validitas yang semakin tinggi menunjukan semakin baik penelitian tersebut. Metode dalam pengujian uji validitas menggunakan metode factor analysis. Alat ukur (measurement) dikatakan valid berdasarkan ketentuan dari tabel dibawah ini:
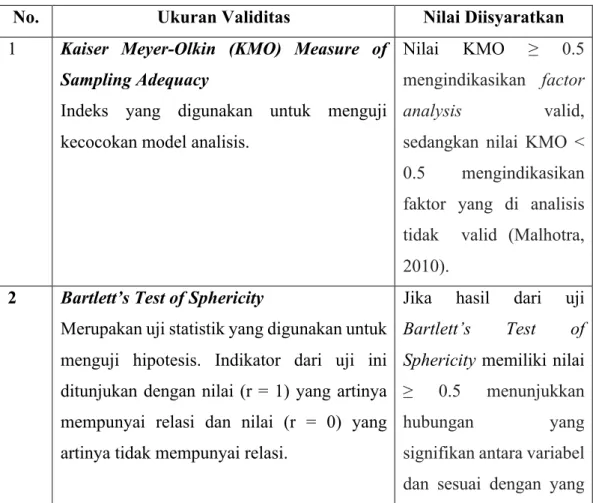
Tabel 3.2 Uji Validitas
No. Ukuran Validitas Nilai Diisyaratkan
1 Kaiser Meyer-Olkin (KMO) Measure of Sampling Adequacy
Indeks yang digunakan untuk menguji kecocokan model analisis.
Nilai KMO ≥ 0.5 mengindikasikan factor
analysis valid,
sedangkan nilai KMO < 0.5 mengindikasikan faktor yang di analisis tidak valid (Malhotra, 2010).
2 Bartlett’s Test of Sphericity
Merupakan uji statistik yang digunakan untuk menguji hipotesis. Indikator dari uji ini ditunjukan dengan nilai (r = 1) yang artinya mempunyai relasi dan nilai (r = 0) yang artinya tidak mempunyai relasi.
Jika hasil dari uji Bartlett’s Test of Sphericity memiliki nilai ≥ 0.5 menunjukkan hubungan yang signifikan antara variabel dan sesuai dengan yang
diharapkan dan valid (Malhotra, 2010).
3 Anti Image Matrices
Digunakan untuk memprediksi hubungan antara variabel apakah memiliki kesalahan atau tidak.
Nilai MSA = 1 menandakan bahwa varibel tidak memiliki kesalahan, Nilai MSA ≥ 0.5 variabel harus dianalisa lebih lanjut, Nilai MSA ≤ tidak dapat dianalisis lebih lanjut (Malhotra, 2010).
4 Factor Loading of Component Matrix Merupakan besarnya korelasi suatu indikator dengan tujuan untuk menentukan validitas setiap indikator dalam penggabungan setiap variabel.
Indikator dinyatakan valid jika memiliki nilai factor loading sebesar 0.50 (Malhotra, 2010).
3.7.3 Uji Reliabilitas
Uji reliabilitas digunakan untuk mengetahui tingkat kehandalan dalam sebuah penelitian (Malhotra, 2010). Tingkat reliabilitas dapat dilihat dari data yang telah di isi oleh responden dengan pernyataan yang stabil dan konsisten. Uji reliabilitas merupakan alat ukur yang menjadi indikator seberapa konsisten hasil measurement ketika berkali-kali digunakan terhadap responden berbeda (Malhotra, 2010). Ketika hasil dari pengukuran data reliabel maka menunjukan bahwa variabel penelitian tersebut dapat digunakan di dalam penelitian dimasa yang akan datang atau penelitian selanjutnya. Penelitian dikatakan lulus uji validitas dan reliabilitas jika nilai Cronbach Alpha tidak kurang dari 0.60.
3.7.4 Metode Analisis Data dengan Structural Equation Model (SEM) Penelitian ini akan menggunakan metode Structural Equation Model (SEM) untuk menganalisis data berdasarkan jurnal utama yang dijadikan acuan oleh peneliti. Structural Equation Model (SEM) merupakan teknik statistik multivariat
yang menggabungkan beberapa aspek regresi berganda dengan tujuan menguji hubungan faktor dependen dan analisis faktor tidak terukur dengan multivariabel yang digunakan untuk memprediksi hubungan dari dependen yang saling berhubungan (Hair et al., 2014).
Structural Equation Model (SEM) memiliki berbagai peran diantaranya sebagai sistem persamaan simultan, analisis kasus linier, analisis lintasan (path analysis), analysis of covariance stucture, dan model persamaan struktural (Hair et al., 2014) jika dilihat dari sudut pandang metodologi. Analisa hasil penelitian menggunakan metode SEM karena model penelitian ini memiliki lebih dari 1 variabel endogen. Software yang harus digunakan adalah Lisrel versi 10 untuk melakukan uji validitas, reliabilitas, dan uji hipotesis penelitian. Struktural model disebut juga sebagai latent variable relationship.
Persamaan umumnya adalah : η = γ ξ + ζ
η = β η + γ ξ + ζ
Dimana menurut Hair et al. (2014) :
η (eta “eight-ta”) = konstruk yang terkait dengan variabel Y yang diukur γ (gamma) = jalur yang mewakili hubungan sebab akibat (regression coefficient) dari ζ ke η
β (beta) = jalur yang mewakili hubungan sebab akibat (regression coefficient) dari satu konstruk η ke konstruk η lainnya
ζ (zeta “zay-ta”) = cara menangkap kovariasi antara kesalahan konstruksi η ξ (xi “KSI atau KZI”) = konstruk yang terkait dengan variabel X yang diukur
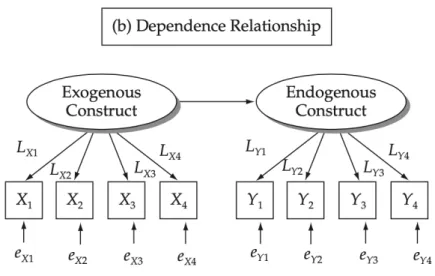
Confirmatory Factor Analysis (CFA) sebagai model pengukuran (measurement model) terdiri dari dua jenis pengukuran :
1. Model pengukuran untuk variabel bebas (variabel eksogen), dengan persamaan :
X = λx ξ + ζ
2. Model pengukuran untuk variabel tak bebas (variabel endogen), dengan persamaan :
Y = λy η + ζ
Persamaan tersebut digunakan dengan asumsi: 1. ζ tidak berkolerasi dengan ξ
2. ε tidak berkolerasi dengan η 3. δ tidak berkolerasi dengan ξ
4. ζ, ε, dan δ tidak saling berkolerasi (mutually correlated) 5. γ – β adalah non singular
Dimana menurut Hair et al. (2014) :
X = vektor variabel eksogen yang diamati Y = vektor variabel endogen yang diamati
λx (lambda X) = matriks koefisiensi regresi y atas ξ λy (lambda Y) = matrik koefisiensi regresi y atas η ε (epsilon) = vektor kekeliruan dalam mengukur y δ (delta) = vektor kekeliruan dalam mengukur x
γ (gamma) = matrik koefisiensi variabel ξ dalam persamaan struktural
3.7.5 Variabel dalam Structural Equation Model
Dalam structural equation model terdapat dua jenis variabel yaitu variabel laten dan variabel terukur (measured variable). Variabel terukur merupakan variabel yang dapat diamati dan diukur secara empiris yang disebut sebagai indikator dalam penelitian. Sedangkan, variabel laten (latent variable) adalah konsep abstrak yang menjadi perhatian khusus pada structural equation model (Hair et al.,2014).
Menurut Hair et al. (2014), variabel laten dibagi menjadi dua jenis yaitu variabel eksogen dan variabel endogen. Variabel eksogen menjadi variabel bebas pada semua persamaan dalam model yang dinotasikan sebagai ξ (xi “KSI atau KZI”). Variabel endogen menjadi variabel terikat paling sedikit pada satu persamaan dalam model dengan notasi η (eta “eight-ta”).
3.7.6 Tahapan Prosedur SEM
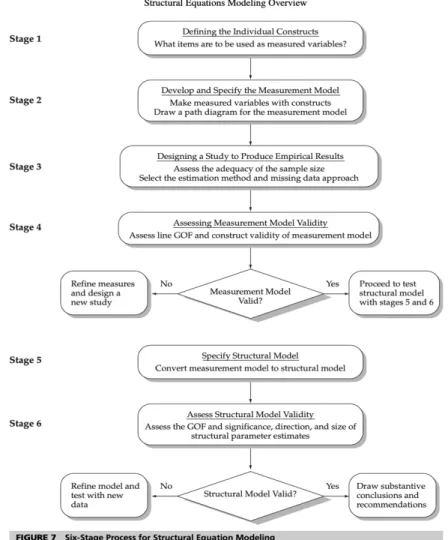
Menurut Hair et al. (2014), terdapat enam tahapan prosedur pembentukan dan analisis SEM, yaitu:
Sumber : Hair et al. (2014)
Gambar 3.4 Prosedur Structural Equation Modeling
1. Menentukan konstruk individual sebagai dasar teori untuk model SEM 2. Mengembangkan model keseluruhan dalam pengukuran
3. Merancang studi untuk menghasilkan hasil empiris
4. Menilai validitas model pengukuran dengan melihat nilai dari: a. Standardized Loading Factor (SLF)
b. Construct Reliability (CR) c. Variance Extracted (VE) 5. Menentukan model stuktural
6. Menilai validitas model struktural sesuai dengan kesesuaian goodness of fit (GOF) dengan melihat evaluasi dari:
a. Degree of Freedom (df) b. Normed Chi-Square
c. Root Mean Square Error of Approximation (RMSEA) d. Comparative Fit Index (CFI)
e. Parsimony Normed Fit Index (PNFI)
Menurut Hair et al. 2014, pengolahan data menggunakan SEM terbagi menjadi dua model, yaitu measurement model dan structural model.
3.7.6.1 Kecocokan Model Pengukuran (Measurement Model of Fit)
Measurement model pada SEM biasa disebut sebagai teknik CFA (Confirmatory Factor Analysis). Kecocokan model pengukuran (measurement model fit) dilakukan dalam setiap model pengukuran (hubungan antara variabel laten dan teramati) secara terpisah melalui uji validitas dan uji reliabilitas (Hair et al. 2014).
1. Uji Validitas
Suatu variabel dikatakan memiliki validitas yang baik ketika nilai t-tabel (t-value) lebih besar dari nilai kritis (≥ 1.96) dan muatan factor loading lebih besar sama dengan dari 0.5.
2. Uji Reliabilitas
Reliabilitas adalah tingkat yang menunjukan bahwa indikator memiliki konsistensi tinggi dalam mengukur konstruk latennya. Menurut Hair et al. (2014) terdapat 2 indikasi untuk mengukur tinggi rendahnya reliabilitas dalam SEM, yaitu:
Sumber : Hair et al. 2014
Gambar 3.6 Rumus Evaluasi Reliabilitas
Suatu variabel dikatakan mempunyai relibialitas yang baik jika: a. Nilai construct reliability (CR) > 0.70
b. Nilai variance extracted (VE) > 0.50
3.7.6.2 Kecocokan Model Struktural (Structural Model Fit)
Hair et al. (2014) mengelompokan goodness of fit menjadi 3 bagian, yaitu absolute fit measurement (ukuran kecocokan absolut), incremental fit measurement (ukuran kecocokan inkremental), dan parcimonious fit measure (ukuran kecocokan parsimoni).
1. Absolute fit measurement biasanya digunakan untuk menentukan derajat prediksi model keseluruhan terhadap matriks korelasi dan kovarian. Nilai goodness of fit yang lebih besar dan nilai badness-of-fit yang lebih kecil mengindikasikan model penelitian memiliki tingkat kecocokan yang lebih baik. Dalam Hair et al. (2014), indeks dalam absolute fit measurement yang digunakan adalah :
a. χ2 statistic
Indeks kecocokan absolut yang paling mendasar adalah indeks χ2 statistik. Disebutkan dalam Hair et al. (2014), beberapa hal pada uji GOF χ2 mengurangi kesesuaian model yang dapat merusak validitas keseluruhannya. Untuk alasan ini, para ahli telah mengembangkan banyak ukuran alternatif yang sesuai untuk mengoreksi bias terhadap sampel besar dan meningkatkan kompleksitas model.
b. Goodness of Fit Index (GFI)
GFI adalah upaya awal untuk menghasilkan kecocokan statistik yang kurang sensitif terhadap ukuran sampel. Kisaran nilai GFI yang
mungkin adalah 0 hingga 1, dengan nilai yang lebih tinggi menunjukan kesesuaian lebih baik. Pada penelitian di masa lalu, nilai GFI lebih besar dari 0.90 biasanya dianggap baik. Namun, ada yang berpendapat bahwa nilai yang harus digunakan adalah 0.95 (Hair et al., 2014).
c. Root Mean Square Error of Approximation (RMSEA)
RMSEA secara eksplisit mencoba untuk mengoreksi kompleksitas model dan ukuran sampel dengan memasukan masing-masing perhitungan. Nilai RMSEA yang lebih rendah menunjukan kesesuaian yang lebih baik. Nilai RMSEA adalah antara 0,03 dan 0,08 dengan tingkat kepercayaan 95% (Hair et al., 2014).
d. Root Mean Square Residual (RMR) dan Standardized Root Mean Residual (SRMR)
Nilai RMR dan SRMR yang lebih rendah mewakili kecocokan yang lebih baik, aturan praktisnya menunjukan bahwa jika nilai SRMR lebih dari 0,1 menunjukan adanya masalah dengan kecocokan (Hair et al., 2014).
e. Normed Chi-Square
Ukuran GOF ini adalah rasio sederhana dari χ2 dengan df yang secara umum memiliki rasio 3 : 1 atau kurang dikaitkan dengan model yang lebih baik, kecuali dalam keadaan sampel yang lebih besar dari 750 atau keadaaan lainnya seperti tingkat kompleksitas model yang tinggi (Hair et al., 2014).
Pada penelitian ini, peneliti memutuskan untuk indikator pengukuran yang digunakan untuk mengukur Absolute fit measurement adalah Root Mean Square Error of Approximation (RMSEA).
2. Incremental fit measurement berbeda dari indeks kecocokan absolut dalam menilai seberapa baik model yang diperkirakan cocok relatif terhadap model baseline alternatif. Incremental fit measurement digunakan untuk membandingkan null model atau dasar dengan model diusulkan yang disebut sebagai independence model yang mengasumsikan semua variabel
yang diamati tidak berkorelasi. Implikasinya, tidak ada reduksi data yang dapat memperbaiki model karena data tidak berisi multi-item factors sehingga kelompok indeks ini mencerminkan perbaikan dalam kesesuaian dengan spesifikasi dari hubungan multi-item construct. Dalam Hair et al. (2014), indeks dalam Incremental fit measurement yang digunakan adalah : a. Normed Fit Index (NFI)
NFI adalah salah satu indeks kecocokan inkremental asli. NFI adalah rasio perbedaan dalam nilai χ2 untuk fitted model dengan null model dibagi dengan nilai χ2 untuk null model. Kisaran rasio antara 0 dan 1, dan model dengan kecocokan sempurna akan menghasilkan NFI 1 (Hair et al., 2014).
b. Tucker Lewis Index (TLI)
TLI secara konseptual mirip dengan NFI , tetapi TLI memiliki berbagai variasi karena merupakan perbandingan dari nilai-nilai chi-square normed untuk null model dan yang ditentukan. Nilai yang direkomendasikan untuk TLI adalah > 0.90 (Hair et al., 2014).
c. Comparative Fit Index (CFI)
CFI merupakan salah satu indeks yang paling banyak digunakan karena memiliki banyak sifat yang diinginkan, termasuk relatif, tidak sensitif terhadap kompleksitas model. CFI memiliki rentan nilai berkisar 0 dan 1, dengan nilai yang lebih tinggi menunjukan kesesuaian yang lebih baik. Nilai CFI > 0.90 biasanya direkomendasikan dalam penelitian (Hair et al., 2014).
d. Relative Noncentrality Index (RNI)
Seperti indeks kecocokan tambahan lainnya, nilai yang lebih tinggi menunjukan kecocokan yang lebih baik, dan nilai RNI yang umumnya berkisar antara 0 dan 1. Nilai RNI yang lebih rendah dari 0.90 biasanya tidak terkait dengan kecocokan yang baik (Hair et al., 2014).
Pada penelitian ini, peneliti memutuskan untuk indikator pengukuran yang digunakan untuk mengukur Incremental fit measurement adalah Comparative Fit Index (CFI).
3. Parcimonious fit measure digunakan untuk mengukur model yang memiliki degree of fit dengan tingkat paling tinggi dari setiap degree of freedom. a. Adjusted Goodness of Fit Index (AGFI)
AGFI dilakukan dengan menyesuaikan GFI dengan rasio degree of freedom yang digunakan dalam model. Nilai AGFI biasanya lebih rendah dari nilai GFI secara proporsional dengan kompleksitas model (Hair et al., 2014).
b. Parsimony Normed Fit Index (PNFI)
PNFI menyesuaikan NFI dengan menggandakannya dengan parsimony ratio. Nilai PNFI yang relatif tinggi menunjukkan kecocokan yang relatif lebih baik (Hair et al., 2014). Nilai PNFI diantara 0 dan 1.
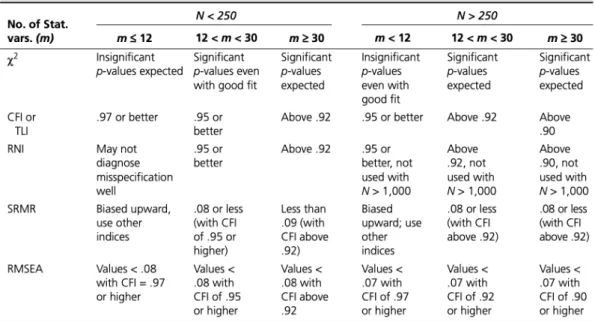
Pada penelitian ini, peneliti memutuskan untuk indikator pengukuran yang digunakan untuk mengukur Parcimonious fit measure adalah Parsimony Normed Fit Index (PNFI).Detail nilai standar untuk setiap kriteria di atas dapat dilihat pada gambar 3.6:
Sumber : Hair et al. 2014
3.7.7 Model Pengukuran
Pada penelitian ini terdapat enam model pengukuran berdasarkan variabel yang diukur yaitu:
1. Hedonic Value
Dalam model ini terdapat empat pertanyaan yang merupakan first order confirmatory factor analysis (1st CFA) yang mewakili satu latent variable yaitu hedonic value ditandai dengan ξ1. Variabel hedonic value memiliki empat indikator seperti pada tabel 3.1 dan model pengukurannya digambarkan sebagai berikut:
2. Utilitarian Value
Dalam model ini terdapat empat pertanyaan yang merupakan first order confirmatory factor analysis (1st CFA) yang mewakili satu latent variable yaitu utilitarian value ditandai dengan ξ2. Variabel utilitarian value memiliki lima indikator seperti pada tabel 3.1 dan model pengukurannya digambarkan sebagai berikut:
3. Attitude X1 X2 X3 X4 δ1 δ2 t δ3 t δ4 1 Hedonic Value ξ1 λX11 λX21 λX31 λX41 X5 X6 X7 δ5 δ6 δ7 t Utilitarian Value ξ2 λX52 λX62 λX72 λX82 X8 δ8 1
Dalam model ini terdapat empat pertanyaan yang merupakan first order confirmatory factor analysis (1st CFA) yang mewakili satu latent variable yaitu attitude ditandai dengan η 1. Variabel attitude memiliki lima indikator seperti pada tabel 3.1 dan model pengukurannya digambarkan sebagai berikut:
4. Satisfaction
Dalam model ini terdapat empat pertanyaan yang merupakan first order confirmatory factor analysis (1st CFA) yang mewakili satu latent variable yaitu satisfaction ditandai dengan η2. Variabel satisfaction memiliki empat indikator seperti pada tabel 3.1 dan model pengukurannya digambarkan sebagai berikut:
Y2 Y1 Attitude η 1 λY13 Y4 ε1 Y3 ε2 ε3 ε4
λY23 λY33 λY43
Satisfaction η 2 λY64 Y6 Y7 Y8 λY74 λY84 λY54 Y5 ε5 ε6 ε7 ε8
5. Stickiness
Dalam model ini terdapat empat pertanyaan yang merupakan first order confirmatory factor analysis (1st CFA) yang mewakili satu latent variable yaitu stickiness ditandai dengan η3. Variabel stickiness memiliki empat indikator seperti pada tabel 3.1 dan model pengukurannya digambarkan sebagai berikut:
6. Intention to make in-app purchase
Dalam model ini terdapat empat pertanyaan yang merupakan first order confirmatory factor analysis (1st CFA) yang mewakili satu latent variable yaitu intention to make in-app purchase ditandai dengan η4. Variabel stickiness memiliki empat indikator seperti pada tabel 3.1 dan model pengukurannya digambarkan sebagai berikut:
Y11 Stickiness η3 ε11 Y12 λY115 ε12 λY125 λY95 Y9 ε9 λY105 ε10 Y10 Y13 ε15 λY156 Y14 ε16 λY166 Intention to Make in-app Purchase η4 ε13 Y15 λY136 λY146 Y16 ε14
3.8 Analisis Hubungan
Untuk melakukan analisa structural model perlu dilakukan uji hipotesis. Hipotesis merupakan pernyataan sementara sebagai parameter dari sesuatu yang perlu diverifikasi kebenarannya (Lind, Marchal, & Wathen, 2012). Uji hipotesis sendiri merupakan sebuah prosedur untuk menentukan apakah pernyataan tersebut masuk akal (Lind, Marchal, & Wathen, 2012). Menurut Lind, Marchal, & Wathen (2012) terdapat lima tahapan dalam uji hipotesis, yaitu:
1. Menyatakan Null Hypothesis (H0) dan Alternate Hypothesis (H1) Langkah pertama adalah tentukan Null Hypothesis (H0) atau hipotesis yang akan di uji. H0 merupakan pernyataan yang menjadi parameter untuk pengujian. Jika sampel memberikan cukup bukti bahwa pernyataan tersebut salah maka H0 tidak ditolak. H1 akan mendeskripsikan apa yang akan disimpulkan jika data menolak H0 (Lind, Marchal, & Wathen, 2012).
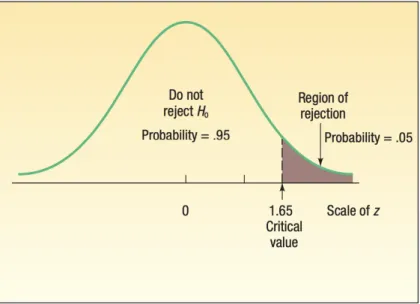
2. Menentukan tingkat signifikansi
Tingkat signifikansi (level of significance) merupakan tingkat probabilitas atau kemungkinan dari penolakan H0 jika benar. Hal ini berhubungan dengan resiko yang diambil ketika data menunjukan untuk menolak H0. Menurut Lind, Marchal, & Wathen (2012), tingkat signifikasi dinotasikan dengan lambang α (alpha). Pada penelitian ini, tingkat signifikansi yang digunakan oleh peneliti adalah 0.05. Pada tingkat signifikansi juga terdapat dua jenis kekeliruan, yaitu:
2. Type 2 error : terjadi jika hasil sampel tidak menolak H0
Sumber : Lind, Marchal, & Wathen (2012)
Gambar 3.8 Summarizes decision researcher could make & possible consequences
3. Memilih Uji Statistik
Nilai ditentukan dari informasi sampel dan digunakan untuk menentukan apakah akan menerima atau menolak null hypothesis (Lind, Marchal, & Wathen, 2012). Dalam penelitian ini, yang digunakan adalah uji distribusi t (t value). Apabila nilai t-value lebih besar sama dengan nilai critical value makan hipotesis nol ditolak (Lind, Marchal, & Wathen, 2012).
4. Formulasi aturan keputusan (formulate a decision rule)
Aturan keputusan adalah pernyataan dari kondisi spesifik dimana hipotesis nol ditolak atau tidak ditolak. Area penolakan mendefinisikan semua lokasi yang nilainya sangat besar atau sangat kecil sehingga probabilitas kemunculannya dibawah hipotesis nol (Lind, Marchal, & Wathen, 2012). Pada penelitian ini, peneliti menggunakan one-tailed test dengan critical value sebesar 1.65.
5. Membuat Keputusan
Tahap terakhir dalam pengujian hipotesis adalah menghitung uji statistik. Tahap ini, peneliti melakukan perbandingan antara nilai t-value hasil output dari pengolahan data dengan critical t-value. Menurut Lind, Marchal, & Wathen (2012) nilai kritis yang digunakan adalah sebesar 1.65. Hasil dari perbandingan ini akan menjadi keputusan apakah peneliti akan menolak atau menerima H0.
Sumber : Lind, Marchal, & Wathen (2012)
3.9 Model Struktural Keseluruhan Penelitian (Path Diagram) H1 (+) H2 (+) H3 (+) H4 (+) H6 (+) H5 (+) H7 (+) H8 (+) H9 (-) H10 (+)