BAB III
METODOLOGI PENELITIAN
3.1.Tempat dan Waktu
Penelitian ini dilakukan di lingkungan Kampus Anggrek dan Kampus Syahdan
Universitas Bina Nusantara Program Strata Satu – Reguler. Dan penelitian dilaksanakan pada semester Ganjil 2004 – 2005 tepatnya pada Bulan Pebruari – Maret 2005.
1.2. Pengumpulan Data
Pengumpulan data dalam penelitian ini menggunakan metode survey dan observasi untuk mengumpulkan data dengan rincian sebagai berikut:
A. Metode Survey dengan instrumen kuesioner ditujukan kepada Mahasiswa untuk memperoleh data – data primer yaitu persepsi mahasiswa .
B. Metode Observasi digunakan untuk mengumpulkan data-data primer dari Manajemen dalam hal ini Biro Layanan Registrasi dan Informasi serta Biro
Operasional dan Pengembangan TI yang berkaitan dengan layanan kepada mahasiswa, serta data-data sekunder dari Buku-buku, jurnal dan literatur
lainnya..
Maka secara keseluruhan penelitian ini termasuk jenis penelitian Kuantitatif karena banyak mengumpulkan data-data yang bersifat numerik.
3.2.1.Sampel dan Jumlah Sampel
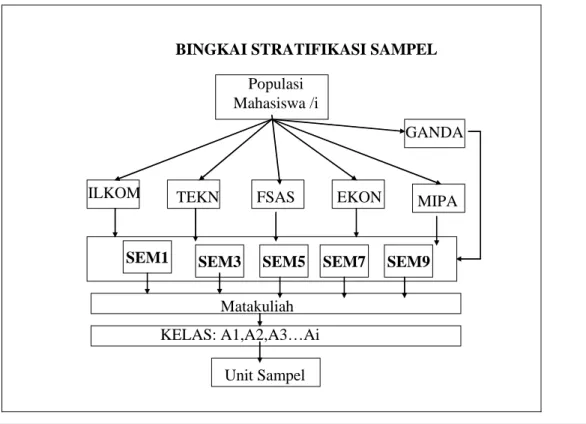
Penelitian ini mengambil sampel populasi Mahasiswa / Mahasiswi aktif Bina Nusantara pada periode semester Ganjil 2004 – 2005 pada semua jurusan yang ada yaitu Fakultas MIPA, Fakultas Ilmu Komputer, Fakultas Sastra , Fakultas Ekonomi dan Fakultas Teknik dan Program Ganda pada program Strata Satu – Reguler.Gambar 06 dibawah menunjukkan sample frame yang ada yaitu pertama Populasi mahasiswa dibagi atas 6 sub populasi ( berdasarkan Fakultas), selanjutnya tiap subpopulasi dibagi stratanya berdasarkan Angkatan ( semester Ganjil), dan tiap angkatan terdiri atas beberapa Kelas dan Matakuliahnya.
Tetapi stratifikasi yang digunakan untuk pengambilan sample sampai pada strata ke satu ( Fakultas).
BINGKAI STRATIFIKASI SAMPEL
Populasi Mahasiswa /i
ILKOM TEKN FSAS EKON
SEM1 SEM3 SEM5
MIPA KELAS: A1,A2,A3…Ai Matakuliah SEM7 SEM9 Unit Sampel GANDA
Gambar 7 : Bingkai Sample Penelitian
Sedangkan teknik sampling yang digunakan adalah Probability sampling
dengan metode Stratifikasi Random, yaitu dilakukan dengan cara membuat lapisan-lapisan ( strata ) yang homoogen, kemudian dari setiap lapisan diambil
sejumlah subjek secara acak. Jumlah subjek dari setiap lapisan adalah sampel penelitian dengan jumlah proporsional dari subpopulasi Mahasiswa.
Untuk jumlah sample ditentukan dengan rumus sebagai berikut:
2
1
Ne
N
n
+
=
n = ukuran Sampel N = ukuran Populasie = persentase toleransi ketidak telitian karena kesalahan pengambilan sampel yang dapat digunakan. ( menurut newman, disarankan e= 0.10).
Maka berdasarkan formula tersebut jumlah sampel dihitung sebagai berikut: Total populasi ( N ) adalah Mahasiswa Binus semester Ganjil 2004-2005 saat ini adalah 22.243 mahasiswa , maka jumlah sampel adalah ( n ) dan presentasi toleransi kesalahan ( e) = 5 % adalah :
)
)
05
.
0
(
)
243
.
22
((
1
243
.
22
2x
n
+
=
392
.
937
393
607
.
55
1
243
.
22
=
≈
+
=
n
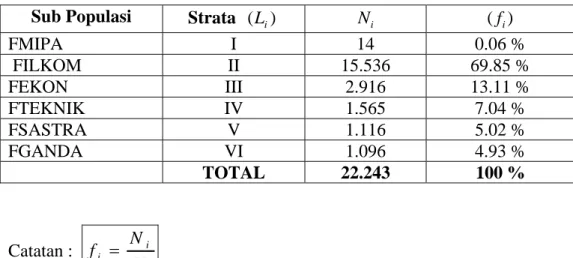
Dan pembagiannya berdasarkan stratifikasi menurut angkatan dapat dilihat pada tabel 01 sebagai berikut;
Tabel 01 : Tabel Strata populasi
Sub Populasi Strata (Li) Ni (fi)
FMIPA I 14 0.06 % FILKOM II 15.536 FEKON III 2.916 13.11 % FTEKNIK IV 1.565 7.04 % FSASTRA V 1.116 5.02 % FGANDA VI 1.096 4.93 % TOTAL 22.243 100 % 69.85 % Catatan : N N f i i =
Maka perhitungan sampel per Strata (L) adalah:
n1 =393 x 0.06% = 1 = 2 n 393 x 69.85% = 274 393 x 13.11% = 51 = 3 n 393x 7.04% = 28
=
4n
=
5n
393x 5.02% = 20 393 x 4.93% = = 6 n 19 Total 393 respondenJadi total sampel dengan teknik stratifikasi random sampling diperlukan minimum berjumlah 393 responden untuk mengestimasi parameter populasi Mahasiwa Binus dengan jumlah 22.243 orang pada semester tersebut.
3.2.2.Instrumen
Penelitian ini menggunakan instrumen kuesioner yang didisain menurut Likert- Type response format untuk menjabarkan indikator – indikator variabel yang telah didefinisikan pada 5 tingkat pilihan, dan hasilnya diukur dengan mengunakan skala
Ordinal. Kelima tingkat pilihan jawaban / skala pada Linkert –Type response format yaitu:
Tabel 02: Tabel Skala Pengukuran Instrumen Skala Nilai Tingkat
Kinerja
(Performace)
Tingkat Kepentingan
( Importance )
1 Sangat Kurang Sangat Tdk Penting
2 Kurang Tidak Penting
3 Cukup Cukup Penting
4 Baik Penting
5 Sangat Baik Sangat Penting
Dan untuk kuesioner yang menanyakan data demografis responden serta pertanyaan untuk pilihan dan tingkat penggunaan tipe layanan menggunakan Skala Nominal.
Sedangkan komposisi dan hubungan instrumen survey dan responde digambarkan pada tabel berikut:
Tabel 03: Tabel Hubungan variabel,instrumen dan responden
Variabel Dimensi Indikator Alat Responden Kepuasan Pelanggan (UIS) Conten Accuracy Format Easy of use Timeliness Speed C1,C2,C3,C4 A1,A2,A3,A4 F1,F2,F3,F4 E1,E2,E3,E4 T2,T2,T3,T4 S1,S2,S3,S4 Kuesioner Mahasiswa dan Manajemen
1.3. Validitas dan Reliabilitas
Hasil penelitian adalah valid jika terdapat kesamaan antara data yang terkumpul melalui instrumen dengan data yang sesungguhnya terjadi pada objek yang diteliti. Hasil penelitian adalah reliabel jika terdapat kesamaan data dalam waktu yang berbeda.
Instrumen yang valid berarti alat ukur yang digunakan untuk mendapatkan data adalah valid. Atau dengan kata lain, instrumen tersebut dapat mengukur apa yang seharusnya diukur. Instrumen yang reliabel adalah instrumen yang bila digunakan beberapa kali untuk mengukur objek yang sama, akan menghasilkan data yang sama (Sugiyono, 2002).
Uji validitas dari sebuah variabel instrumen pada penelitian ini dilakukan dengan
menghitung nilai r (corrected item-total correlation pada SPSS v13) dari masing-masing butir dari variabel tersebut. Sebuah butir dikatakan valid apabila mempunyai nilai r > 0,3.
Jika terdapat butir yang tidak memenuhi kriteria tersebut maka butir tersebut dibuang
atau diperbaiki. Selanjutnya proses diulang sampai semua butir dari sebuah variabel
adalah valid dengan nilai r > 0,3 (Sugiyono, 2002).
Uji reliabilitas dari sebuah variabel instrumen yang memakai skala Likert pada
penelitian ini dilakukan dengan menghitung nilai α Cronbach (alpha pada SPSS v13). Sebuah variabel dikatakan reliabel jika memiliki nilai α Cronbach > 0,8 (Usman, 1995).
1.4. Metode Analisis
1.4.1. Model PenelitianModel penelitian ini digambarkan dengan mengukur Kesenjangan antara Variabel Kepentingan dan Variabel Kinerja yang diberikan responden yang diperoleh dari instrumen yang menayakan persepsi responden berdasarkan 6 dimensi variabel yaitu content,acuracy,format, easy of use,timely dan speed.
CONTENT ACCURACY FORMAT EASY USE TIMELY SPEED X1 X2 X3 X4 X5 X6 Importance Customer Perception Importance Performance Performance Management Perception Management Perception Customer Perception Customer Gap User Satisfaction
Gambarl 08: Diagram Model Hubungan Variabel Penelitian
1.4.2. Variabel Penelitian
Definisi operasional dari variable yang digunakan antara lain:
1. CONTENT adalah jumlah informasi yang diberikan baik kuantitas maupun kualitasnya.
2. FORMAT adalah bentuk dan tata letak dari penampilan informasi di layar .
3. ACCURACY adalah ketepatan data yang diinformasikan dan terhindar dari adanya sifat bias.
4. EASY OF USE merupakan tingkat kemudahan dalam mengoperasikan instruksi-instruksi yang ada dalam tampilan informasi.
5. TIMELY merupakan tingkat ketepatan informasi yang diberikan dengan waktu dibutuhkan sesuai jadwal yang ditetapkan.
6. SPEED merupakan tingkat penyajian informasi dapat diakses per satuan waktu tertentu ( detik).
Semua variabel tersebut terbagi atas dua jenis yaitu berdasarkan Kepentingan ( Importance ) dan berdasarkan Kinerja ( Performance ) dari persepsi Pelanggan yaitu Mahasiswa Binus.
1.4.3. Analisis Statistik dan Selang Kepercayaan ( Confident Interval ).
Ada beberapa tekhnik analisis yang digunakan antara lain;
1. Analisis Kesenjangan( GAP Analysis) : metoda ini dipakai untuk mengukur / melihat besar kesenjangan terhadap kualitas layanan yang diharapkan .
RUMUS:
∆
=
µ
1−
µ
2
2. Uji T- Berpasangan : metoda ini dipakai untuk membandingkan 2 variabel yang sama dengan perlakuan berbeda. Dalam hal ini perbandingan akan dilakukan antara kaulitas layanan YANG DIHARAPKAN ( Expected services) dengan kualitas layanan yang diterima ( Perceived Services).
RUMUS: n Sd
D
T
=
−
µ
− dan1
)
(
2 2−
−
=
− −n
D
D
S
dn
D
Z
/
σ
µ
−
=
− T = t_hitung Sd = Standard deviasiD = selisih rata-rata variable X
Analisis data yang dilakukan dalam penelitian ini menggunakan selang kepercayaan ( confident interval )=95 % atau dengan tingkat kesalahan ( error)