All sources 25 Internet sources 7 Own documents 8 Plagiarism Prevention Pool 10
8.1%
Results of plagiarism analysis from 2017-12-27 23:53 UTC
[doi 10.1109%2Ficeei.2015.7352551] M ahyuddin, K; Nasution, M .; Elveny, M arischa; Syah, Rahmad; Noah.pdf
[0] "CR-INT137-Enhancing to method for ...ot; dated 2017-10-09
3.6% 17 matches
[1] "CR-INT136-Social network extractio...ot; dated 2017-10-09
2.5% 13 matches
[2] "CR-INT135-Information Retrieval on...ot; dated 2017-10-09
2.8% 13 matches
[3] "3028-3639-1-RV.pdf" dated 2017-10-30
2.6% 10 matches
[4] "CR-INT110-Semantic interpretation ...ot; dated 2017-10-09
2.6% 11 matches
[5] "3472-4529-1-SM.pdf" dated 2017-10-30
1.6% 7 matches
[6] www.academia.edu/1248413/Extracted_Social_Network_Mining
1.6% 6 matches
[7] from a PlagScan document dated 2017-06-27 13:50
0.6% 1 matches
[8]
from a PlagScan document dated 2017-08-11 13:54 0.6% 1 matches
4 documents with identical matches
[13] from a PlagScan document dated 2017-05-18 06:57
0.6% 1 matches
[14] from a PlagScan document dated 2017-10-19 10:04
0.5% 1 matches
[15] from a PlagScan document dated 2017-04-24 08:44
0.5% 1 matches
[16] from a PlagScan document dated 2017-04-24 08:44
0.5% 1 matches
[17] from a PlagScan document dated 2017-10-23 08:48
0.4% 1 matches
[18] from a PlagScan document dated 2017-10-17 05:44
0.4% 1 matches
[19] https://pdfs.semanticscholar.org/b27f/cacfecbfde2209ef2bdd1849b9ff24530ebd.pdf
0.2% 2 matches
[20] from a PlagScan document dated 2017-07-07 07:40
0.5% 1 matches
[21] from a PlagScan document dated 2017-10-03 08:48
0.4% 1 matches
[22] www.academia.edu/3144197/Simple_Search_Engine_Model_Adaptive_Properties_for_Doubleton
0.4% 1 matches
[23] "ICTS_2017_paper_18.pdf" dated 2017-09-24
0.3% 1 matches
[24] https://www.researchgate.net/profile/Sop...n=publication_detail
0.3% 1 matches
[25] https://www.researchgate.net/profile/Tom...commender-System.pdf
0.2% 1 matches
[26] https://www.researchgate.net/profile/Amj...n=publication_detail
0.3% 1 matches
[27] "3658-5101-1-RV.pdf" dated 2017-10-30
0.4% 1 matches
[28] www.academia.edu/1248689/A_Methodology_to_Extract_Social_Network_from_the_Web
0.0% 1 matches
PlagLevel: selected / overall
32 matches from 29 sources, of which 7 are online sources.
Settings
Data policy: Compare with web sources, Check against my documents, Check against my documents in the organization repository, Check against organization repository, Check against the Plagiarism Prevention Pool
--Behavior of the Resources in the Growth of Social
Network
Mahyuddin K. M. Nasution
[0] Centre of Information SystemUniversitas Sumatera Utara Padang Bulan 20155 USU Medan Indonesia [email protected], [email protected] [0]
Marischa Elveny and Rahmad Syah
Information Technology Departement, Fasilkom-TIUniversitas Sumatera Utara Padang Bulan 20155 USU Medan Indonesia [email protected], [email protected] [3]
Shahrul Azman Noah
Knowledge Technology Research Group, Faculty of Information Science & Technology
Universiti Kebangsaan Malaysia Bangi 43600 UKM Selangor Malaysia
Abstract—Social network can be extracted from different sources of information, but the resources was growing dynamically require a flexible approach. Each social network has the resources, but the relationship between resources and information sources requires explanation. This paper is aimed to address the behavior of the resource in the growth of social networks by using the association rules and statistical calculations to explain the evolutionary mechanisms. There is a strong effect on the growth of the resources of social networks and totally behavior of resources has positive effect.
Keywords—Superficial method; independence; multiple regression; association rule; timeline; total effect.
I.[6]INTRODUCTION
Automatic extracting the social network is an relatively approach which is formed through modal relations [1], that depends heavily on dynamically the Web as information source [2].[2] In discrete mathematic literature, the social network extraction formally has considered as a Certain product, it could be represented as a n n× matrix M of vertices vi in V as a set of actors, i = 1,…,n, and for generating their relations ej in E as a set of edges, j = 1,…,m, whereby ej = mik in M is 1 for ej in E, if two actors vi and vk are adjacent, 0 otherwise [3]. While the Web contained enormous amount of information of social actors and clues about relations among them: We can always find new actors and add vertices to the [6] resultant network, but also occasionally we cannot find old actors whereby their representation on vertices we cannot eliminate it. In other word, we may create the new connection between actors or disconnect the original relation between them [4,5].
We considered that a social network as resources, i.e.
[6]
actor/vertex, relation/edge, web/document, or connection/path,
[6]
but no information about the relations of them as resources for explaining the dynamism of social network [6,7]. Therefore,
this paper is aimed at addressing the dynamism of social network based on resources. In this case, the evolutionary mechanisms, a guide to express an approach.
II. REVIEW AND APPROACH
The use of Web is steadily gaining ground in extracting of social networks [1], but dealing with everything that can be changed dynamically in Web it needs a flexible approach [8]. There is most flexible method for extracting social network automatically from Web, that is the superficial method, but the method is less trustworthy [9]. Therefore, we use the evolutionary mechanism [10] for extracting social network and based on it we do the designing and choosing the rules [1].
In line with superficial methods, we have developed an approach using association rules to enhance the methods for extracting the social network of specialized web pages [12]. In this case, we were selecting some social actors as the seeds in order to enable declaring their names properly. It is used to reduce bias. For that purpose, we define the association rule as follows:
Definition 1. Let Z = {1, zz2, …, z| |Z} is a set of attributes
literal, and each Mi is a set of transaction, and Mii = 1,…,n are
subsets of attributes, or Mi be subsets of Z. The implication X = Y with two possible values T = TRUE or F = FALSE as an association rule if X Y, are subsets of Z and X ŀY = ø.
For representing some of attributes in search space ȍ, we denote a keyword as tx, an actor name as seed is ta, other actor
names are tb, but in a document there are also attributes like tt
is title, te as event, ty as publication year, etc. Supposing that
the implementation of co-occurrence in a query as q = “ta
AND tx”, [2]Dbis a collection of documents containing actor names tb. Then the transaction be [0] Mi = {q b, j}, i = 1,…,n, j = 1,…,m for n seeds, or Mi+1 = {{q b, j},ty}, thus we have Q = Db The 5th International Conference on Electrical Engineering and Informatics 2015
August 10-11, 2015, Bali, Indonesia
as implication, where q in Q is a subset of ȍ, bj in Db is a
subset of ȍ, ty in Db is a subset of ȍ. This is a proof of the
following theorem.
Theorem 1. If any query represents a co-occurrence, then the association rule is applicable in the search space ȍ.
Corollary 1. If there are an actor in the search space and the actor as a seed, then via association rule there are one or more other actors in the search space.
In real world, each people connected with other people. The Web is representation of the real world [13]. Therefore, in the Web page is possible two or more actors exist (co-occurrence). Is not every Web page created by the author as an actor is to discuss about other actors. Specially, in ȍ, one or more Web pages contain the tables as presentation of the online database. If a seed exits in one of Web pages and the seed is a part of query, then the Web page with a unique URL is possible has other actor names. For example, let ta =
“Mahyuddin K. M. Nasution” and tx = “DBLP”, we have a
query q = “Mahyuddin K. M. Nasution” AND “DBLP”, and q submitted to the search engine likes Google, we obtain a Web page has a table contains other names [12]. Generally, the search engine got one or more snippets about q and by rank, from the top to the bottom consist of snippets sequentially according to their compatibility to ta and tx. A keyword has
been used for retrieving information appropriately as expected, if the mentioned information exists in the search space [14]. Thus a keyword and a seed together to remove impact of ambiguity and bias that comes from search space. In this case, a seed is as bait for fishing all documents related to the seed. While a keyword is to rank all document according to suitability to information needed. A lot of Web pages have connection between any seed and others actors, where co-occurrence exist in the page, because of an event and a record in the document. Therefore, if a title represented a document, there are one or more names as authors of documents or Web pages, then presence of new actor names and their relationships can be sorted by ascending according to the published year of the document. Each seed would be established the relationship for the first time with the other actor, and the next relationship with more other different actors. The growth of social actors (vertices) and the relationships (edges) between a seed and other actors caused by increasing the number of document on Web, and indirectly it has described the dynamics of social networks.
In the social network, the degree of a vertex d v( ) is the number of other vertices to v they are connected. Or d v( ) = k,
vi in V i, = 1,…,n where k = n-1.
Definition 2. Let SN is a social network with n vertices. SN is a star network if d v( ) = n-1 for one vertex only in SN or d v( ) =1 for another.
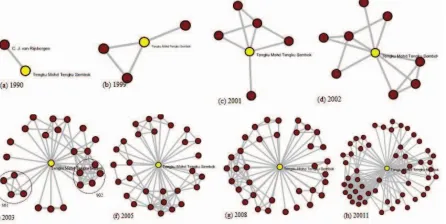
On the one hand, the timeline of network growth based on a seed (as an actor) show the history of his/hers social activities such as the relationship between the authors or the research collaboration in the academic social network. In this
case, an actor is a centre in a star network and the network will grow with the emergence of other actors, where other actors might become a vertex with degree d v(i) greater than one, see
Fig. 1. Therefore, extracting [1] social networks from the Web is not only involve a number of documents/Web pages, but it also involves a dependence between the actors, relationships, and documents, whereby dependence test performed using chi square Ȥ2 to the contingency table with k rows and l columns, and by both k and l the degree of freedom [15] defines as follows
Fig. 1. Timeline of social network based on a seed.
df = (k 1), - 1)(l - 1) (
if the cells of table contain uij, i = 1,…,k and j =1,…,l, then the
expected value E for all uij are
E u( ij) = ((Ȉi=1,…,kuij)(Ȉj=1,…,luij))/(Ȉi=1,…,kȈj=1,…,luij) (2)
and we have
Ȥ2 = (Ȉ(fo – fe)2)/fe, 3) (
where fo = uij is the frequency of observed data and fe = E u( ij)
is the frequency of expected data.
On the other hand, a social network by relying to the seed and year variables will be accompanied with a timeline of growth. A timeline can be used to show a snapshot of evolutionary mechanism in order to predict the extent to which the growth of a social network, a list of events in chronological order, but this is to understand event and trends for a particular subject. We use the multiple-regression as an evolutionary mechanism for predicting a growth of social network, i.e. y to be regressed against two or more factors, and the relationship in multiple-regression [16] is
y = ȕ0 + Ȉi=1,…,k. ȕkxk 4) (
In general, there is effect of y to xi, for instance i = 1,2, we
have the multiple-regression of y against x1 and x2:
Ȉx1y = ȕ1Ȉx1 2
+ ȕ2Ȉx1x2.
By dividing this equation by Ȉx12, we get an effect total tr as
follows
tr = ȕ1 + ȕ1ȕ2. 5) (
In the same way, for y against x1, x2 and x3 we have
tr = ȕ1 + ȕ1ȕ2 + … + ȕ1ȕ2ȕ3, (6)
where ȕ1 means the direct effect, and ȕ1ȕ2 ,…, ȕ1ȕ2ȕ3 mean the
indirect effect.
Finally, we proposed an approach to extract social network as base for revealing the dynamism of social networks. An approach as follows
1) make a query for representing co-occurrence of an
actor name and a keyword,
2) submit a query to any search engine,
3) make sure the actor name and the keyword contained
are exactly same such as in the query,
4) access the listed URL for extracting and then getting information.
Furthermore, we will examine the dependence between all resources of social network and determine the behavior of dynamism based on predictive models.
III.EXPERIMENTS
2) vertices: the seeds and the new actor, and 3) edges: the relationship between actors.
We declare attributes of resources as follows: NoS as Number of Seeds, NoP as Number of Papers, NoNV as Number of New Vertices, and NoE as Number of Edges, see Table 1. Based on publication year documents we obtain an increase in the number of each factor in resources, see Table II.
If the sample contained in the Table I were calculated by
H0: The resources of social network are not independent. [25]
H1: The resources of social network are independent. [0] resources: actor/vertex, relation/edge, and Web/document.
In context of the evolutionary mechanisms, the prediction models with resources take a position as conduit of information about dynamism of social network. The multiple-regressions are one of the methods to determine causal relationships between factors as resources of social network. Based on data in Table II we obtain an increase in the number of each factor in resource and then we conduct calculation.
First model, therefore, involves papers as dependent variable y and seed as independent variable x1 based on (4) is
y = -3.7639 + 5.7799x1. 7) (
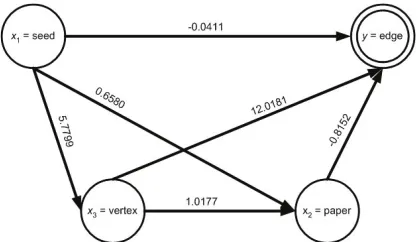
Briefly, three equations (7), (8) and (9) are summarized in Table III.
Fig. 2. An effect network for 4 resources of social network
Table III contains beta values for determining behavior of resources of social network that is to measure effect of each resource to growth of social network. As showed by Fig. 2. From beta values there is direct effect of seeds to increase number f dges, o eut trong b sffect ef eed o s so irowth t g f o papers and vertices, while the papers have strongest effect for growing edges. The last, vertices have strong effect for existing edges. It is detailed as follows,
1) direct effect of the seeds (x1) toward y = -0.0411,
2) indirect effect via the papers (x2) = (5.7799)(12.0181) =
69.4634.
3) indirect effect via the vertices (x3) = (0.6580)(-8.1516)
= -5.3638.
4) indirect effect via x2 and x3 =
(5.7799)(1.0177)(-9.1516) = -47.9494.
And the effect total is tr = 16.1092. So even though the resources have different effects on the growth of social networks, but overall all the resources effect the dynamic of social networks.
IV. CONCLUSION
In this study we have presented an analysis for finding behavior of resources of social network. The resources of social networks – actor/vertex, relation/edge, Web/document, or connection/path – have different behavior toward growth of social networks based on social network extracting by using association rule. In total, the effects of resources positively affect the growth of vertices and edges in a social network based on predictions models. The future work will involve the extraction of a social network to describe the research collaboration.
References
[1] Mahyuddin K. M. Nasution and S. A. M. Noah, "[0]Superficial method for extracting social network for academic using Web snippets", In Yu, J. et al., (eds.).[0]Rough Set and Knowledge Technology, LNAI 6401, Heidelberg, Springer, 483-490, 2010.
[2] Mahyuddin K. M. Nasution (Mahyuddin), "Kaedah dangkal bagi pengekstrakan rangkaian sosial akademik dari Web", Ph.D. Dissertation, Universiti Kebangsaan Malaysia (in Malay), 2013.
[3] Marco Conti, Andrea Passarella, and Fabio Pezzoni, "A model for the generation of social network graphs"[20], IEEE International Symposium on
a World of Wireless, Mobile and Multimedia Networks (WoWMoM):
1-6, 2011.
[4] Marco Brambilla and Alessandro Bozzon, "Web data management through crowdsourcing upon social networks", IEEE/ACM International Conference on Advances in Social Network Analysis and Mining: 1123-1127, 2012.
[5] Steve Hanneke and Eric P. Xing. 2007. "Discrete temporal models of social networks", In E. M. Airoldi et al. (Eds.): ICML 2006 Ws, LNCS 4503, Springer-Verlag Berlin Heidelberg, 115-125, 2007.
[6][19]Dongsheng Duan, Yuhua Li, Ruixuan Li, and Zhengding Lu,
"[19]Incremental K-clique clustering in dynamic social networks", Artif.
Intell. Rev. 38, 129-147, 2012.
[7] Stella Heras, Katie Atkinson, Vicente Botti, Floriana Grasso, Vicente Juli'an, and Peter McBurney, "Research opportunities for argumentation in social networks", Artif. Intell. Rev. 39, 39-62, 2013.
[8] Mahyuddin K. M.[0]Nasution and Shahrul Azman Noah, "Information retrieval model:[0]A social network extraction perspective", [0] IEEE
International Conference on Information Retrieval & Knowledg
Management (CAMP12), Putrajaya, Malaysia, 2012.
[9] Mahyuddin . . asution, K M N. . . S oah, A Mnd N . aad, a SSocial S " network extraction:[0]Superficial method and information retrieval", [22]In
Proceeding of International Conference on Informatics for Developme
(ICID'11), c2-110-c2-115, 2011.
[10] L. Jintao, R. Licheng, Y. Yinpu, Y., and X. Guangdong, "Research on the evolutionary mechanism of social network based on competitive
selection", IEEE International Conference on Computational Aspects of
Social Networks, 624-628, 2010.
[11] S. Phelps, P. McBurney, P., and S. Parsons, "Evolutionary mechanism design: a review", Auton Agent Multi-Agent Syst 21, 237-264, 2010. [12] Mahyuddin K. M. Nasution and Shahrul Azman Noah, "[0]Extraction of
academic social network from online database", In Shahrul Azman Mohd Noah et al. (eds.[0]), Proceeding of 2011 International Conference
on Semantic Technology and Information Retrieval (STAIRS'11)),
Putrajaya, Malaysia, IEEE, 64-69, 2011.
[13] P. Mika, "[0]Social Networks and the Semantic Web", Springer, Heidelberg, Berlin, 2007.
[14] Mahyuddin K. M. Nasution, "[0]New method for extracting keyword for the social actor", Intelligent Information and Database Systems (ACIIDS), LNCS Vol. 8397, Heidelberg, Springer, 83-92, 2014.
[15] Shusaku Tsumoto and Shoji Hirano, "Contingency table and
granularity"[21], Annual Meeting of the North American Fuzzy Information
Processing Society (NAFIPS), 665-669, 2007.
[16] G. Robins, P. Pattison, and S. Wasserman, "[6]Logit models and logistic regressions for social networks", [6]Psychometrika, 64, 371-394, 1999.