Class-indexing-based term weighting for automatic text
classification
Fuji Ren
⇑,1, Mohammad Golam Sohrab
1Faculty of Engineering, University of Tokushima, 2-1 Minami Josanjima, Tokushima 770-8506, Japan
a r t i c l e
i n f o
Article history:
Received 21 February 2012
Received in revised form 27 January 2013 Accepted 17 February 2013
Available online 27 February 2013
Keywords: Text classification Indexing Term weighting Machine learning Feature selection Classifier
a b s t r a c t
Most of the previous studies related on different term weighting emphasize on the docu-ment-indexing-based and four fundamental information elements-based approaches to address automatic text classification (ATC). In this study, we introduce class-indexing-based term-weighting approaches and judge their effects in high-dimensional and comparatively low-dimensional vector space over the TF.IDF and five other different term weighting approaches that are considered as the baseline approaches. First, we implement a class-indexing-based TF.IDF.ICF observational term weighting approach in which the inverse class frequency (ICF) is incorporated. In the experiment, we investigate the effects of TF.IDF.ICF over the Reuters-21578, 20 Newsgroups, and RCV1-v2 datasets as benchmark collections, which provide positive discrimination on rare terms in the vector space and biased against frequent terms in the text classification (TC) task. Therefore, we revised the ICF function and implemented a new inverse class space density frequency (ICSdF), and generated the TF.IDF.ICSdF method that provides a positive discrimination on infrequent and frequent terms. We present detailed evaluation of each category for the three datasets with term weighting approaches. The experimental results show that the proposed class-indexing-based TF.IDF.ICSdF term weighting approach is promising over the compared well-known baseline term weighting approaches.
Ó2013 Elsevier Inc. All rights reserved.
1. Introduction
With large amount of textual information available digitally, effective retrieval is difficult to accomplish without good text to vector representation in order to enhance automatic text classification (ATC)[3,8,23,33]. In the vector space model (VSM)[32], the content of a text is represented as a vector in the term space. The term weight is the degree of importance of termtiin documentdj. The term weighting schemes play a significant role in effective text classification (TC). Therefore, an
effective indexing-based term weighting approach can generate more information-rich terms and assign appropriate weighting values to the terms.
In general, text to vector representation can be classified into two tasks: indexing and term weighting[14,19]. Indexing based on the documents provides a meta-language for describing the document, where the information about a set of doc-uments in a certain classckis missing. In the TC task, the analysis of document contents by traditional term indexing that is
based on documents is not enough to enhance the performance of classification task. Accurate retrieval depends on the exactness of the document retrieval process and class description for a certain termti= {t1,t2,. . .,tn} in the TC task. Most
research does not show the diversity of category information for a certain class in the classification task.
0020-0255/$ - see front matterÓ2013 Elsevier Inc. All rights reserved.
http://dx.doi.org/10.1016/j.ins.2013.02.029
⇑Corresponding author.
E-mail addresses:[email protected](F. Ren),[email protected](M.G. Sohrab). 1
Both authors contributed equally to this work.
Contents lists available atSciVerse ScienceDirect
Information Sciences
The motivation for exploiting the class-indexing-based term weighting method for TC can be attributed to two main properties. First, a more information-rich term weighting method with effective indexing can generate a more effective clas-sifier. Second, there is a demand for dimensionality reduction through inverse class space density frequency (ICSdF). A major characteristic or difficulty of TC is the high dimensionality of the feature space[10]. Since the conventional TF.IDF term weighting scheme favors rare terms and the term space consists of hundreds of thousands of rare terms, sparseness fre-quently occurs in document vectors. Therefore, a novel term weighting method is needed to overcome the problem of high dimensionality and for the effective indexing based on class to enhance the classification task.
Recently, many experiments have been conducted using a document-indexing-based term weighting approach to address the classification task as a statistical method[6,17,24,29–31,37,38]. TF.IDF is considered to be the most popular term weight-ing method in successfully performweight-ing the ATC task and document-indexweight-ing[30]. Salton and Buckley[30]discussed many term weighting approaches in the information retrieval (IR) field, and found that normalized TF.IDF is the best document weighting function. Therefore, this term weighting scheme is used as a standard in this study and as a default term weighting function for TC. However, there are some drawbacks of the classic TF.IDF term weighting scheme for the TC task. In the training vector space, to compute the weight of a certain term, the category information is constantly omitted by the doc-ument-indexing-based TF.IDF term weighting method. In contrast, the inverse document frequency (IDF) function provides the lowest score of those terms that which appear in multiple documents; because of this, the TF.IDF score gives positive discrimination to rare terms and is biased against frequent terms. At present, because TF.IDF uses a default term weighting parameter in the classification task, a variety of feature selection techniques, such as information gain[18], chi-square test, and document frequency[49], have been used to reduce the dimension of the vectors. Flora and Agus[4]performed some experiments to recommend the best term weighting function for both document and sentence-level novelty mining. The results show that the TFIDF weighting function outperforms in TREC2003 and TREC2004 datasets.
In the indexing process[29,38], two properties are of main concern: semantic term weighting[5,13,25,39]and statistical term weighting[12], where term weighting is related to a term’s meaning and to the discriminative supremacy of a term that appears in a document or a group of documents, respectively. Leo et al.[25]proposed a semantic term weighting by exploit-ing the semantics of categories and indexexploit-ing term usexploit-ing WordNet. In this approach, they replaced the IDF function with a semantic weight (SW) and the experiment’s results, which were based on overall system performance, showed that the pro-posed TF.SW scheme that outperformed TF.IDF. However, the amount of training data was small and they were not able to show the improvement in the performance of a certain category in the dataset. Nevertheless, it is possible to address a lim-ited number of terms in a term index by semantic term weighting, but with large number of terms in the term index, it is difficult to provide the appropriate semantic knowledge of a term based on categories. Therefore, statistical term weighting approaches are more promising to compute the score of a term. Lartnatte and Theeramunkong[42]investigated the various combinations of inter-class standard deviation, class standard deviation and standard deviation with TF.IDF, and the average results showed that the TF.IDF was superior in nine out of ten term weighting methods. Only one method performed better than TF.IDF by 0.38% on average.
Recently, Youngjoong and Jungyun[15]proposed a new classification algorithm with feature projection techniques based on unsupervised learning. The TF.IDF is used as a feature weighting criterion. The classification approach is based on voting score incorporated with three different modules: voting ratio, modified weight, and adopted
v
2feature selection method. In this approach, they project the elements using binary approach; if the category for an element is equal to a certain category, the output value is 1 otherwise 0. In the second part, where category frequency is the number of categories between any of the two features which is co-occurred in a certain category is computed. Therefore, they adoptedv
2feature selection method to get the final voting score. The experiment results show that this approach is promising when the numbers of labeled train-ing documents are up to 3000 approximately. The system failed to improve the performances in comparatively large number of labeled training documents in three different datasets.In the last few years, researchers have attempted to improve the performance of TC by exploiting statistical classification approaches[46,47]and machine learning techniques, including probabilistic Bayesian models[20,28,43], support vector ma-chines (SVMs)[7,11,26,44], decision trees[20], Rocchio classifiers[21], and multivariate regression models[35,48]. However, a novel term weighting scheme with a good indexing technique is needed in addition to these statistical methods to truly enhance the classification task. Therefore, in this study, we have developed a novel class-indexing-based term weighting scheme that enhances the indexing process to generate more informative terms. This study makes the following contributions:
1. We propose an automatic indexing method using the combination of document-based and class (category)-based approaches.
2. The proposed class-indexing-based term weighting approach has two aspects:
a. The TF.IDF.ICF term weighting that favors the rare terms and is biased against frequent terms. b. The TF.IDF.ICSdF term weighting that gives a positive discrimination both to rare and frequent terms.
3. The proposed class-indexing-based TF.IDF.ICSdF term weighting approach is outperformed with existing term weight-ing approaches.
The remainder of this study is organized as follows. Section2presents the proposed class-indexing- based term weighting methods. In Section3, we elaborate on the centroid, Naı¨ve Bayes and SVM classifier. Section4presents the performance eval-uation results. Finally, we conclude the study in Section5.
2. Indexing: combining document and class oriented indexing
In information retrieval and automatic text processing, the construction of effective indexing vocabularies has always been considered the single most important step[34]. Therefore, an information-rich term weighting method with effective indexing can generate a more effective classifier.
2.1. Conventional approach: document-indexing-based term weighting scheme
The most widely used traditional document-indexing-based TF.IDF term weighting approach for ATC has two subtasks. First is the term frequency based analysis of the text contents, and second is the determination of terms that are in the doc-ument spacedj. In addition, measuring term specificity was first proposed by Sparck Jones[37]and it later became known as
the IDF. The reasoning is that a term with a high document frequency (DF) count may not be a good discriminator, and it should be given less weight. Therefore, IDF means that a term that occurs in many documents is not a good document dis-criminator. The IDF function assigns the lowest score to those terms that appear in multiple documents in a document space D=d1,d2,. . .,dn. To quantitatively judge the similarity between a pair of documents, a weighting method is needed to
deter-mine the significance of each term in differentiating one document from another. The common term weighting method is TF.IDF[30], as defined in Eq.(1):
WTF:IDFðti;djÞ ¼tfðti;djÞ 1þlog D dðtiÞ
: ð1Þ
Its cosine normalization is denoted as
Wnorm
TF:IDFðti;djÞ ¼
tfðti;djÞ 1þlog D
dðtiÞ
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi X
ti2dj
tfðti;djÞ 1þlog D
dðtiÞ
h i2
s ; ð2Þ
whereDdenotes the total number of documents in the collection,tfðti;djÞis the number of occurrences of termtiin document
dj,d(ti) is the number of documents in the collection in which termtioccurs at least once,dðDtiÞis referred to as the DF, anddðDtiÞis
the IDF of termti.
2.2. Proposed approach: class-indexing-based term weighting scheme
Of greater interest is that term and document frequencies that depend only on the occurrence characteristics of terms in documents are not enough to enhance the classification task. In terms of class-oriented indexing, a subset of documents from document spaceD=d1,d2,. . .,dnis allocated to a certain class in order to create a VSM in the training procedure. In the
tradi-tional TF.IDF method, a list of identical documents is linked with a single term and the IDF function provides the lowest score for that term. However, it is not obvious that in the classification task, the IDF function provides the lowest score for those terms that are identical. These identical documents linked with a certain termtimight be a sub-part of a certain categoryck. Therefore,
it is important to explore the occurrence characteristics of terms in both the document spaceD= {d1,d2,. . .,dn} and the class
space. In class-oriented indexing, a subset of documents from the global document space is allocated to a certain classck
(k= 1, 2,. . .,m) according to their topics in order to create a boundary line vector space in the training procedure. Therefore, the class space is defined asC= {(d11,d12,. . .,d1n)2C1, (d21,d22,. . .,d2n)2C2,. . ., (dm1,dm2,. . .,dmn)2Cm} where a set of
doc-uments with same topics is assigned to a certain classckin the training procedure. In the class space, where the category itself
has its own domain and domain size is dissimilar to other categories, which is based on the number of documents that the do-main contains. For this reason, the knowledge of a set of relevant documents containing a certain termtiin a certain classckis
considered to determine the category mapping in the training procedure.
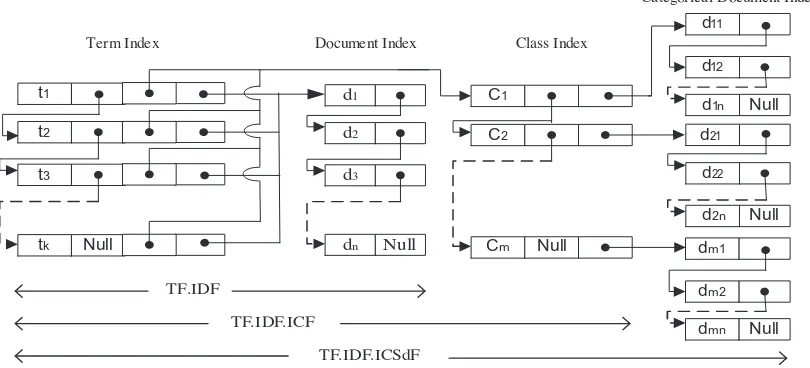
A simple overview of the proposed class-indexing is shown inFig. 1where the proposed class-based indexing is incorpo-rated with term, document and class index. The nodes of term, document and class index contain two fields: data and link. While provide the dataset as an input to assign scores for lexical terms, the data field of term index contains a term and the corresponding three outbound link fields where the first link points to the node containing the next term. The second and third link points to the class and document index to find out the relevant class and the relevant documents respectively that the term falls into. The data field of document index contains a document and the corresponding link field points to the node containing the next document. Therefore the combination of term and document index or the combination of term, docu-ment and class index, we can generate TF.IDF or TF.IDF.ICF term weighting scheme respectively.
identity of a set of documents that a certain term falls into a certain class. Which is later we call the class space density fre-quency. The effectiveness of this indexing is that, the lexical terms obtain the prior knowledge from class index in the train-ing mode to create vector space model. Ustrain-ing class-indextrain-ing based term weighttrain-ing method, more informative term can be generate to examine the existence of a term not only to compute the occurrence of a term in a certain class but also compute the occurrence of a set of relevant documents in a certain class. FromFig. 1and the above discussions it is noticeable that, the proposed class-oriented-indexing requires more space to store additional data as well as computational cost is higher than document-indexing for the training formulation.
In class-indexing-based term weighting method, terms are examined for frequency and to compute their occurrence in a certain class. They are also used to compute the occurrence of a set of relevant documents that are clustered[2]for a certain termtiin a certain classck. Two factors are considered for category mapping using class-indexing-based term weighting
scheme: (1) class-frequency (CF)-based category mapping of each term and (2) class-space-density-based category mapping of each term.
2.2.1. Class-frequency-based category mapping of each term: TF.IDF.ICF term weighting scheme
In the classic document-indexing-based VSM, the criterion of numeric representation of text to document vectors are products of local (term frequency) and global (IDF) parameters, that is, TF.IDF. In the class-frequency-based category map-ping term weighting scheme, the ICF is multiplied by TF.IDF, generating TF.IDF.ICF. In this method, the existence of a category is indicated by assigning a numerical value 1 when a term is relevant for a certain categoryck, and 0 when a term is not
rel-evant. The TF.IDF.ICF term weighting scheme introduces the concept of category mapping using the ICF function. In ICF, a term that occurs in many categories is not a good discriminator. Consequently, the ICF function gives the lowest score to those terms that appear in multiple classes in class spaceC=c1,c2,. . .,cm. Therefore, the numeric representation of a term
is the product of term frequency (local parameter), IDF (global parameter), and ICF (categorical global parameter), repre-sented as
Its cosine normalization is denoted as
Wnorm
whereCdenotes the total number of predefined categories in the collection,c(ti) is the number of categories in the collection
in which termtioccurs at least once,cðCtiÞis referred to as the CF, and C
cðtiÞis the ICF of termti.
The TF.IDF.ICF approach is our primary motivation to revise the document-indexing-based term weighting approach and lead to a new class-indexing-based term weighting approach. For a valid term, the evidence of clustered relevant documents, where documents are grouped into a certain categoryckfor a certain termti, is missing in this method. Such a method gives
positive discrimination to rare terms and is biased against frequent terms. Because, the IDF and ICF functions are incorpo-rated with TF and both assigns the lowest score to those terms that appear in multiple documents in document space and
t1
multiple categories in class space, respectively. Therefore, we redesigned the ICF and implemented a new inverse class space density frequency (ICSdF) method that provides positive discrimination for both rare and frequent terms.
2.2.2. Class-space-density-based category mapping of each term: TF.IDF.ICSdF term weighting scheme
Both TF.IDF and TF.IDF.ICF term weighting schemes emphasize on rare terms, which favor terms appearing in only a few documents multiplied by the IDF function and a few classes multiplied by the ICF function, respectively. In the class-space-density-based category mapping of each term, the inverse class-space-density frequency (ICSdF) is multiplied by the TF.IDF to generate the TF.IDF.ICSdF. Because the ICF function gives the lowest score to those terms that appear in multiple classes without any prior knowledge of the class space, a new class-space-density-frequency-based category mapping is proposed. It should be possible to improve the classification performance by addressing the prior knowledge of a certain term in a certain category in the training procedure, in particular, by determining the number of outbound document links for a certain termti
through a certain categoryck. More specifically, the weight of each term depends not only on its occurrence characteristics in
documents and classes but also on its class density (Cd) where a set of relevant documents are linked with a certain termti.
2.2.2.1. Determining the category mapping by class density of each term. In a VSM, documents are usually represented as vec-tors inn-dimensional space by describing each documentdjby a numerical value of a feature vector. For a certain termti,
first the class weight is assigned a numerical value between 1 and 0 for overlapping and non-overlapping terms in a certain classck, respectively.
If a certain termtifalls into certain classck, in the next computational process, the number of total outbound document
links is calculated through a certain classckthat the termtifalls into. The outbound document links represent a collection of
tightly clustered documents for a certain termtiin a certain class. Thus, the class densityCdis defined as a rate of documents that include the termtiin the categoryck. In mathematical representation,
CdðtiÞ ¼ nckðtiÞ
Nck
; ð6Þ
wherenckðtiÞdenotes the number of documents that include the termtiand are a member of the categoryck, andNckdenotes
the total number of documents in a certain categoryck.
2.2.2.2. Determining the class space density of each term. In the computational process, the class space density (CSd) is the sum of the outbound class links for a certain term ti and each class link is measured by class density. In mathematical
representation,
CSdðtiÞ ¼
X
ck
CdðtiÞ: ð7Þ
Therefore, the inverse class space density frequency is denoted as
ICSdFðtiÞ ¼log C CSdðtiÞ
: ð8Þ
The numeric representation of a term is the product of term frequency (local parameter), IDF (global parameter), and in-verse class space density frequency (ICSdF), which represents the combination of categorical local and global parameters. Therefore, the proposed term weighting scheme TF.IDF.ICSdF for a certain termtiin documentdjwith respect to category
ckis defined as
Its cosine normalization is denoted as
WnormTF:IDF:ICSdFðti;dj;ckÞ ¼
2.3. An example: term representation in class-space-density-frequency indexing
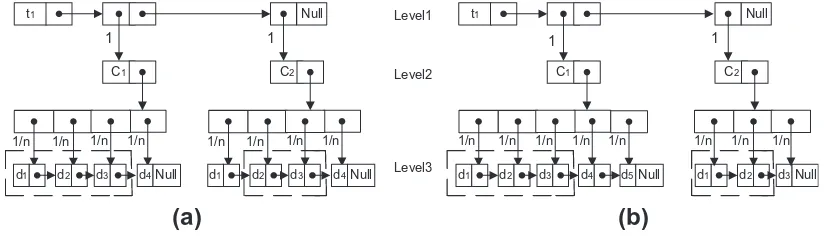
We use an example to judge the effectiveness ofCSdFin the vector space. We assume that a dataset contains of two cat-egoriesC1andC2. A termt1appears in two classesC1andC2.C1andC2, each contain four documents as a balance corpus distribution inFig. 2a and five and three documents as an unbalance corpus distribution inFig. 2b, respectively. If termt1 appears in any category, the weight oft1is assigned by binary value, 0 or 1 from Level1 to Level2.
TagLevel1 to Level2¼
1; if term appears in a certain class thatti2 jckj
0; otherwise
In the next computational step from Level2 to Level3, the weight oft1is 1/nwhen it appears in relevant documents in a certain class domain otherwise zero. Wherenis the total number of documents in a certain class.
TagLevel2 to Level3¼
The dotted rectangular area inFig. 2indicates that the documents are relevant for a termt1. In consider ofFig. 2a, the class density of termt1 in category C1is Cdðt1Þ ¼nc1ðt1Þ=Nc1¼3=4¼0:75;C2is Cdðt1Þ ¼nc2ðt1Þ=Nc2¼2=4¼0:50 andCSdðt1Þ ¼
P
ckCdðt1Þ ¼0:75þ0:50¼1:25. Similarly inFig. 2b for unbalanced corpus distribution, the class density of termt1in
cate-goryC1isCdðt1Þ ¼nc1ðt1Þ=Nc1¼3=5¼0:60;C2isCdðt1Þ ¼nc2ðt1Þ=Nc2¼2=3¼0:67 andCSdðt1Þ ¼PckCdðt1Þ ¼0:60þ0:67¼ 1:2.
From the above computation, it is noticeable that the score of the class density of categoryC1is higher than that ofC2, and C2is higher thanC1in terms of balance and unbalance corpus distribution. Therefore, in the training vector space, while we compute the average score of a certain termtiin a certain categoryck, the class density will cause the greatest possible
sep-aration between the categories because it can make use the categories to explore the outbound document links through a certain category for a certain term.
In contrast, since the termt1appears in two categories inFig. 2, therefore, without explore the categories ofC1andC2, the ICFscore will be log (2/2) = 0; because the ICF only conveys the information whether a term belongs to a category or not. In other words, we assume thatt1appears in almost all documents in category 1 and in only one document in category 2. From the initial information, it is comprehensible that the termt1belongs to category 1, but according to theICFfunction, because the termt1appears in two categories, theICFscore will be zero and fails to provide the greatest possible separation between the categories. Thus, theICFfunction provides positive discrimination for rare terms which may not include in a certain cat-egory domain. It is noticeable that, the ICSdF function provides a judgment score that is not biased against frequent or infre-quent terms.
Fig. 2.Term representation in class-space-density-frequency indexing: (a) balance corpus distribution and (b) unbalance corpus distribution.
Table 1
Contingency table of prediction for a categoryCk.
ck ck
ti A B
ti C D
Recently, many term weighting methods such as, relevance frequency[16,24], probability based approach[24], mutual information[24,33], odds ratio[24,33], correlation coefficient[24]have been reported that these term weighting methods can significantly improve the performance of ATC. Therefore, to compare with other weighting approaches, we implement these term weighting methods based on four fundamental information elements which is mentioned inTable 1.Table 2
shows the mathematical expression of these weighting schemes.
3. Classifier
In the machine learning workbench, some classifiers[46,50]like centroid-based, support vector machine (SVM), and naı¨ve bayes (NB) have achieved great success in TC. In order to evaluate the effects of the proposed term weighting ap-proaches over existing weighting methods, these three classification schemes are used in three datasets.
3.1. Centroid classifier
In this study, for simplicity and linearity, we implement a centroid classifier[9,40,41], a commonly used method, to judge the effectiveness of the proposed class-indexing-based term weighting approaches and to compare it with the conventional TF.IDF term weighting approach. In the VSM, each documentdjis considered to be a vector in the term space. To calculate the
centroid of a certain classck, add the training set of document vectorsdj(j= 1, 2. . .,n) in the classck(k= 1, 2. . .,m):
Sum centroid;Csumk ¼
X
d2ck
dj: ð11Þ
The normalized version ofCsumk is as follows:
Normalized centroid;Cnorm
2is defined as 2-norm vectorC
sum
k . Next, calculate the similarity between a query document and each
normal-ized centroid class vector by inner-product measure, as follows:
simðdj;ckÞ ¼djCnormk : ð13Þ
Consequently, the test vector (or query vector)djis assigned to the class levelckwhose class prototype vector is very
sim-ilar to the query vector in performing the classification task.
LðCkÞ ¼arg max
Naı¨ve Bayes (NB)[50]classifier is one of the oldest formal classification algorithms, and widely used classification algo-rithm in the field of ATC. In Bayesian model, the assumption is based on a prior and posterior probability. Finding the prob-ability of a certain document typedj
Ccan only be based on the observationti. The conditional probabilityP(Cjti) can bewritten according to Bayes’ rule:
PðCjtiÞ ¼
PðtijCÞPðCÞ
PðtiÞ ð
15Þ
Since, the denominator does not depend on the category, we can therefore omit the probabilityP(ti). The probabilityP(tijC)
can be estimated as:
Term weighting functions to be compared.
By assuming that each term follows a probability distribution function for a normal distribution with mean
l
and standard deviationr
in each categoryc, therefore the Eq.(16)can be written as:PðtijCÞ ¼
Given this probability for a single term, the logarithm of the probability for all m terms in the data is
lnPðTijCkÞ ¼ln
The prior probabilityP(C) of a certain class is estimated using a Laplacean prior as:
PðCÞ ¼1þNt;c
DþNc; ð
19Þ
Nt,cis the number of documents in a certain classck,Dis the total number of documents andNcis the total number of classes.
3.3. Support vector machines
In the machine learning approaches, support vector machines (SVMs) are considered one of the most robust and accurate methods among all well-known algorithms[45]. Therefore, as a third learning classifier, SVM based classification toolbox SVM_Light2(Joachims, 1998, 1999, 2002) is used in this experiment. All parameters were left at default values. The parameter cwas set to 1.0, which is considered as a default setting in this toolbox.
4. Evaluations
In this section, we provide empirical evidence for the effectiveness of the proposed term weighting approaches over six different term weighting approaches. The experiment results show the consistency of the proposed term weighting ap-proaches outperforms the conventional apap-proaches in high-dimensional vector space consisting of rare terms and in the comparatively low-dimensional vector space where reduce the rare terms using threshold setting through a certain category from the training data set.
4.1. Experimental datasets
To evaluate the performance of proposed term weighting approaches with existing baseline approaches, we conducted our experiments using Reuters-21578,320 Newsgroups,4and RCV1-v2/LYRL20045which is widely used benchmark collections
in the classification task.
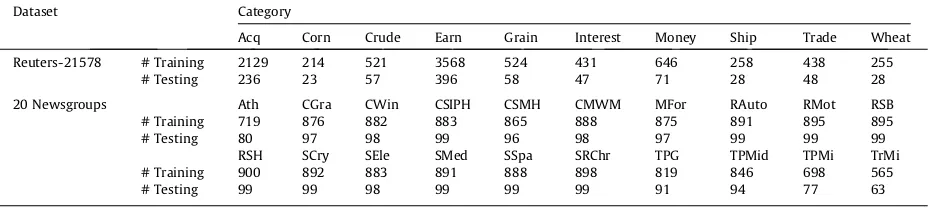
4.1.1. Reuters-21578 dataset
In Reuters-21578, the ten top-sized categories of Apte’ split are adopted, which splits data into a test set and a training set. Because the system is evaluated with 10-fold cross validation, we merged the training and testing documents together. The Reuters-21578 corpus contains 9976 documents.
4.1.2. 20 Newsgroups dataset
The second dataset that we used in this experiment is the 20 Newsgroups, which is a popular dataset to use against ma-chine learning techniques such as TC and text clustering. It contains approximately 18,828 news articles across 20 different newsgroups. For convenience, we call the 20 categories Atheism, CompGraphics, CompOsMsWindowsMisc, CompSysIbmP-cHardware, CompSysMaCompSysIbmP-cHardware, CompWindowsx, MiscForsale, RecAutos, RecMotorcycles, RecSportBaseBall, RecSpor-tHockey, SciCrypt, SciElectronics, SciMed, SciSpace, SocReligionChristian, TalkPoliticsGuns, TalkPoliticsMideast, TalkPoliticsMisc, and TalkReligionMisc as ‘‘Ath,’’ ‘‘CGra,’’ ‘‘CMWM,’’ ‘‘CSIPH,’’ ‘‘CSMH,’’ ‘‘CWin,’’ ‘‘MFor,’’ ‘‘RAuto,’’ ‘‘RMot,’’ ‘‘RSB,’’ ‘‘RSH,’’ ‘‘SCry,’’ ‘‘SEle,’’ ‘‘SMed,’’ ‘‘SSpa,’’ ‘‘SRChr,’’ ‘‘TPG,’’ ‘‘TPMid,’’ ‘‘TPMisc,’’ and ‘‘TRMi,’’ respectively.
We employ the commonly used 10-fold cross validation technique in which the Reuters-21578 and 20 Newsgroups data-sets are randomly divided into 10-fold. Each turn on one data fold is used for testing and the remaining folds are used for
training. Table 3 shows the description of only one of the possible sample datasets for the Reuters-21578 and 20 Newsgroups.
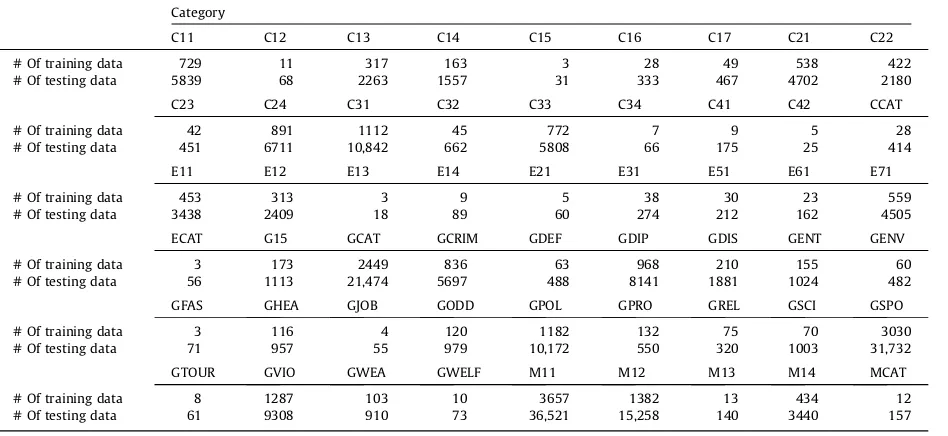
4.1.3. RCV1-v2 dataset/LYRL2004
The RCV1[22]dataset, RCV1-v2/LYRL2004 is adopted, which contains a total of 804,414 documents with 103 categories from four parent topics. As single-label in concern in this study, therefore we extract all the documents which are labeled with at least once. We found that only approximate 23,000 documents out of 804,414 are labeled with at least once. Beside this, we therefore, considered a document which is labeled with two categories a parent with child category. Then we re-moved the parent category and child category is assigned in order to produce single-label classification for each document. From RCV1-v2/LYRL2004, a single topic is assigned a total of 229,221documents which falls into 54 different categories. We keep the same split, the first 23,149 documents as for training and the remainder 206,072 documents is for testing.Table 4
shows the description of training and testing split over RCV1-v2 dataset.
4.2. Feature selection by threshold setting
This study emphasizes on a novel class-indexing-based term weighting scheme to enhance the classification task. There-fore, we do not adopt feature selection techniques such as information gain, mutual information, chi-square test, and doc-ument frequency as feature selection criterion[1,2,26,27,36]. Nevertheless, we first normalize all the documents in the document space using several preprocessing steps, including converting uppercase letters in a token to lowercase, removing punctuation, eliminating word on the smart stop word list that contains 571 words, and reducing inflected words to their root form using stemming. After normalizing the documents, we perform a local feature (term) selection by term frequency in a certain category (TFC). In this approach, we rank and assess all features based on their appearance in a certain category ck, and arrange them in descending order. In this way, we select only some of the features and remove others by setting
com-mon thresholds for each category in the two datasets. The idea behind using a threshold is to create a high-dimensional vec-tor space (including numerous rare terms) and a comparatively low-dimensional vecvec-tor space (removing rare terms) to judge the performance of the proposed TF.IDF.ICF and TF.IDF.ICSdF approaches compared with the traditional TF.IDF ap-proach in both high-dimensional and low-dimensional vector space. Setting the thresholds, we conducted experiments in two different sessions: one in which the high-dimensional vector space is considered and other in which the comparatively low-dimensional vector space is considered.
The high-dimensional and low-dimensional vector spaces are generated by setting the threshold
q
= 3 andq
= 10, respec-tively, in each category of the Reuters-21578 and 20 Newsgroups datasets. In the high-dimensional vector space, the thresh-oldq
= 3 eliminates all the terms that appear for not more than two times in a certain classckof the two datasets. Therefore,we investigate the effects of the proposed and traditional term weighting schemes in this vector space with the centroid classifier. In contrast, the threshold
q
= 10 is assigned to the comparatively low-dimensional vector space and it eliminates all the terms that appear for not more than nine times in a certain category of the datasets. This action judges the effects of the proposed and traditional term weighting schemes in this vector space with the centroid classifier. With the thresholds ofq
= 3 andq
= 10 set in the Reuters-21578 and 20 Newsgroups datasets, the total number of unique terms in term space Ti= {t1,t2,. . .,tn} decreased from 8974 to 8286 and 19,634 to 12,377, respectively. Thus, we manage the vector space toeliminate a certain level of infrequent terms by setting the thresholds, in order to justify the effectiveness of proposed and traditional term weighting approaches in high-dimensional and comparatively low-dimensional vector space.
4.3. Performance measurement
The standard methods used to judge the performance of a classification task are precision, recall, and the F1 measure
[10,47]. These measures are defined based on a contingency table of predictions for a target category ck. The precision
P(Ck), recallR(Ck), and the F1 measureF1(Ck) are defined as follows:
Table 3
One sample dataset fold from 10-fold cross validation.
Dataset Category
Acq Corn Crude Earn Grain Interest Money Ship Trade Wheat
Reuters-21578 # Training 2129 214 521 3568 524 431 646 258 438 255
# Testing 236 23 57 396 58 47 71 28 48 28
20 Newsgroups Ath CGra CWin CSIPH CSMH CMWM MFor RAuto RMot RSB
# Training 719 876 882 883 865 888 875 891 895 895
# Testing 80 97 98 99 96 98 97 99 99 99
RSH SCry SEle SMed SSpa SRChr TPG TPMid TPMi TrMi
# Training 900 892 883 891 888 898 819 846 698 565
PðCkÞ ¼
TP(Ck) is the set of test documents correctly classified to the categoryCk,FP(Ck) is the set of test documents incorrectly
classified to the category,FN(Ck) is the set of test documents wrongly rejected, andTN(Ck) is the set of test documents
cor-rectly rejected. To compute the average performance, we used macro-average, micro-average, and overall accuracy. The macro-average of precision (PM), recall (RM), and theF
1measure FM1
of the class space are computed as
PM¼m1X
Therefore, The micro-average of precision (Pl), recall (Rl), and theF1measure Fl1
of the class space are computed as
Pl¼
In this study, we designed two experiment environments with high-dimensional and comparatively low-dimensional vector spaces to evaluate the performance of the proposed TF.IDF.ICSdF and TF.IDF.ICF approaches and compared them with six different weighting approaches. The reason of chosen two environments is to examine the performance of the proposed term weighting schemes.Tables 5–10present the results achieved, where the number in bold indicates the best result for each category and as well as the macro-F1 over the total categories.
Table 4
RCV1-v2 dataset training and testing split.
Category
C11 C12 C13 C14 C15 C16 C17 C21 C22
# Of training data 729 11 317 163 3 28 49 538 422
# Of testing data 5839 68 2263 1557 31 333 467 4702 2180
C23 C24 C31 C32 C33 C34 C41 C42 CCAT
# Of training data 42 891 1112 45 772 7 9 5 28
# Of testing data 451 6711 10,842 662 5808 66 175 25 414
E11 E12 E13 E14 E21 E31 E51 E61 E71
# Of training data 453 313 3 9 5 38 30 23 559
# Of testing data 3438 2409 18 89 60 274 212 162 4505
ECAT G15 GCAT GCRIM GDEF GDIP GDIS GENT GENV
# Of training data 3 173 2449 836 63 968 210 155 60
# Of testing data 56 1113 21,474 5697 488 8141 1881 1024 482
GFAS GHEA GJOB GODD GPOL GPRO GREL GSCI GSPO
# Of training data 3 116 4 120 1182 132 75 70 3030
# Of testing data 71 957 55 979 10,172 550 320 1003 31,732
GTOUR GVIO GWEA GWELF M11 M12 M13 M14 MCAT
# Of training data 8 1287 103 10 3657 1382 13 434 12
4.4.1. Results with high-dimensional vector space
The high-dimensional vector space is generated by setting the threshold to
q
= 3 in the Reuters-21578 and 20 News-groups datasets.Tables 5–7show F1measure F1(Ck) of a certain category in the Reuters-21578 dataset over centroid, NB,and SVM classifier respectively. In these tables, in comparing with other weighting methods, TF.IDF.ICF and TF.IDF.ICSdF is outperformed over other methods in centroid and SVM classifier respectively. The RF is showing its own superiority in NB classifier.
In contrast,Tables 8–10show F1measure F1(Ck) of a certain category in the 20 Newsgroups dataset over centroid, NB, and
SVM classifier respectively. The result shows that TF.IDF.ICSdF shows its own superiority in Centroid and SVB methods. It achieves higher accuracy 19 of 20 in centroid and 20 of 20 categories in SVM over other methods. The TF.IDF is showing its own superiority in NB classifier.
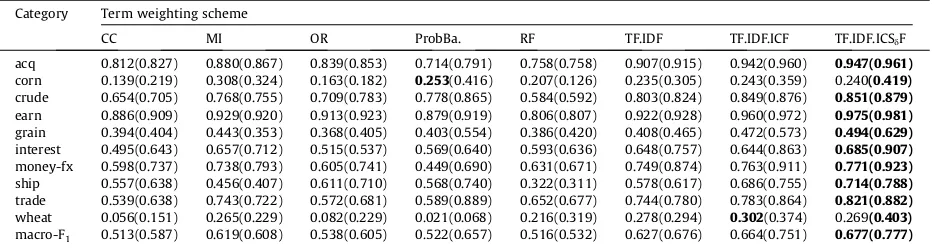
Table 5
Performance onF1measure in the Reuters-21578 dataset with thresholdq= 3 andq= 10 over the Centroid classifier. Category Term weighting scheme
CC MI OR ProbBa. RF TF.IDF TF.IDF.ICF TF.IDF.ICSdF
acq 0.707(0.717) 0.825(0.834) 0.799(0.810) 0.784(0.800) 0.814(0.817) 0.897(0.906) 0.917(0.925) 0.930(0.934)
corn 0.076(0.083) 0.453(0.444) 0.245(0.281) 0.205(0.252) 0.455(0.445) 0.432(0.508) 0.468(0.539) 0.391(0.477) crude 0.389(0.403) 0.793(0.793) 0.670(0.699) 0.639(0.748) 0.763(0.772) 0.820(0.836) 0.829(0.849) 0.826(0.838) earn 0.799(0.853) 0.891(0.898) 0.852(0.861) 0.765(0.871) 0.872(0.873) 0.936(0.938) 0.946(0.950) 0.958(0.960)
grain 0.033(0.017) 0.307(0.360) 0.263(0.283) 0.163(0.479) 0.320(0.318) 0.375(0.372) 0.408(0.424) 0.377(0.435) interest 0.439(0.363) 0.659(0.641) 0.527(0.527) 0.546(0.547) 0.617(0.633) 0.702(0.788) 0.712(0.856) 0.713(0.892)
money-fx 0.445(0.463) 0.701(0.656) 0.509(0.645) 0.428(0.576) 0.633(0.685) 0.695(0.829) 0.704(0.898) 0.682(0.891) ship 0.305(0.276) 0.675(0.639) 0.625(0.624) 0.587(0.751) 0.667(0.668) 0.732(0.763) 0.758(0.783) 0.760(0.785)
trade 0.289(0.273) 0.716(0.747) 0.507(0.589) 0.462(0.865) 0.758(0.758) 0.819(0.833) 0.836(0.887) 0.828(0.853) wheat 0.193(0.189) 0.495(0.447) 0.293(0.336) 0.189(0.187) 0.525(0.522) 0.520(0.544) 0.540(0.559) 0.511(0.529) macro-F1 0.367(0.364) 0.651(0.646) 0.532(0.565) 0.477(0.608) 0.642(0.649) 0.693(0.732) 0.707(0.767) 0.697(0.759)
Note: The number in parenthesis denotes the performance with thresholdq= 10.
Table 6
Performance onF1measure in the Reuters-21578 dataset with thresholdq= 3 andq= 10 over the NB classifier. Category Term weighting scheme
CC MI OR ProbBa. RF TF.IDF TF.IDF.ICF TF.IDF.ICSdF
acq 0.799(0.858) 0.786(0.859) 0.795(0.880) 0.759(0.863) 0.783(0.867) 0.750(0.797) 0.753(0.867) 0.751(0.858) corn 0.237(0.496) 0.249(0.448) 0.243(0.392) 0.104(0.117) 0.254(0.491) 0.242(0.420) 0.206(0.448) 0.215(0.454) crude 0.620(0.736) 0.599(0.730) 0.635(0.781) 0.615(0.712) 0.631(0.739) 0.575(0.578) 0.620(0.738) 0.603(0.748) earn 0.901(0.932) 0.907(0.937) 0.914(0.946) 0.827(0.892) 0.897(0.931) 0.886(0.876) 0.886(0.932) 0.879(0.931) grain 0.546(0.673) 0.520(0.668) 0.547(0.660) 0.465(0.577) 0.535(0.655) 0.517(0.618) 0.537(0.679) 0.515(0.671) interest 0.516(0.664) 0.529(0.729) 0.531(0.679) 0.500(0.605) 0.501(0.714) 0.486(0.630) 0.501(0.668) 0.487(0.708) money-fx 0.572(0.818) 0.580(0.792) 0.591(0.778) 0.482(0.638) 0.573(0.782) 0.572(0.711) 0.583(0.749) 0.574(0.751) ship 0.552(0.794) 0.577(0.790) 0.572(0.794) 0.521(0.637) 0.608(0.783) 0.558(0.720) 0.484(0.727) 0.481(0.735) trade 0.579(0.758) 0.596(0.728) 0.582(0.715) 0.466(0.689) 0.595(0.712) 0.577(0.563) 0.593(0.684) 0.566(0.692) wheat 0.416(0.620) 0.434(0.599) 0.390(0.558) 0.161(0.211) 0.424(0.579) 0.435(0.573) 0.437(0.587) 0.525(0.580) macro-F1 0.574(0.735) 0.578(0.728) 0.580(0.718) 0.490(0.594) 0.580(0.725) 0.560(0.649) 0.560(0.708) 0.560(0.713)
Note: The number in parenthesis denotes the performance with thresholdq= 10.
Table 7
Performance onF1measure in the Reuters-21578 dataset with thresholdq= 3 andq= 10 over the SVM classifier. Category Term weighting scheme
CC MI OR ProbBa. RF TF.IDF TF.IDF.ICF TF.IDF.ICSdF
acq 0.812(0.827) 0.880(0.867) 0.839(0.853) 0.714(0.791) 0.758(0.758) 0.907(0.915) 0.942(0.960) 0.947(0.961)
corn 0.139(0.219) 0.308(0.324) 0.163(0.182) 0.253(0.416) 0.207(0.126) 0.235(0.305) 0.243(0.359) 0.240(0.419)
crude 0.654(0.705) 0.768(0.755) 0.709(0.783) 0.778(0.865) 0.584(0.592) 0.803(0.824) 0.849(0.876) 0.851(0.879)
earn 0.886(0.909) 0.929(0.920) 0.913(0.923) 0.879(0.919) 0.806(0.807) 0.922(0.928) 0.960(0.972) 0.975(0.981)
grain 0.394(0.404) 0.443(0.353) 0.368(0.405) 0.403(0.554) 0.386(0.420) 0.408(0.465) 0.472(0.573) 0.494(0.629)
interest 0.495(0.643) 0.657(0.712) 0.515(0.537) 0.569(0.640) 0.593(0.636) 0.648(0.757) 0.644(0.863) 0.685(0.907)
money-fx 0.598(0.737) 0.738(0.793) 0.605(0.741) 0.449(0.690) 0.631(0.671) 0.749(0.874) 0.763(0.911) 0.771(0.923)
ship 0.557(0.638) 0.456(0.407) 0.611(0.710) 0.568(0.740) 0.322(0.311) 0.578(0.617) 0.686(0.755) 0.714(0.788)
trade 0.539(0.638) 0.743(0.722) 0.572(0.681) 0.589(0.889) 0.652(0.677) 0.744(0.780) 0.783(0.864) 0.821(0.882)
wheat 0.056(0.151) 0.265(0.229) 0.082(0.229) 0.021(0.068) 0.216(0.319) 0.278(0.294) 0.302(0.374) 0.269(0.403)
macro-F1 0.513(0.587) 0.619(0.608) 0.538(0.605) 0.522(0.657) 0.516(0.532) 0.627(0.676) 0.664(0.751) 0.677(0.777)
The above results show that the class-indexing-based TF.IDF.ICSdF and TF.IDF.ICF, both term weighting approaches out-performed the conventional approaches. This is especially the case for the TF.IDF.ICF approach in which both IDF and the ICF functions give positive discrimination on rare terms and the high-dimensional vector space is considered with numerous rare terms in the term space. Therefore, by setting the threshold at
q
= 3, the TF.IDF.ICF and TF.IDF.ICSdF term weighting ap-proaches are showing its own superiority over the centroid and SVM classifier respectively.4.4.2. Results with comparatively low-dimensional vector space
The low-dimensional vector space is generated by setting the threshold to
q
= 10 in the two datasets, Reuters-21578 and 20 Newsgroups. Tables 5–7 where the result with parenthesis shows F1 measure F1(Ck) of a certain category in theReuters-21578 dataset over centroid, NB, and SVM classifier respectively. In these tables, in comparing with other weighting methods, TF.IDF.ICF and TF.IDF.ICSdF is outperformed over other methods in centroid and SVM classifier respectively. CC is showing its superiority in NB classifier.
Table 8
Performance onF1measure in the 20 Newsgroups dataset with thresholdq= 3 andq= 10 over the Centroid classifier. Category Term weighting scheme
CC MI OR RF TF.IDF TF.IDF.ICF TF.IDF.ICSdF
Ath 0.4441(0.6092) 0.4134(0.6499) 0.7270(0.6556) 0.6328(0.6682) 0.7514(0.7612) 0.8216(0.6347) 0.8218(0.8289)
CGra 0.3529(0.4385) 0.5161(0.5950) 0.5317(0.5305) 0.5766(0.6290) 0.7496(0.7445) 0.7988(0.6063) 0.8055(0.8108)
CMWM 0.4085(0.1577) 0.4025(0.1092) 0.1104(0.0967) 0.0902(0.1818) 0.1390(0.1313) 0.1430(0.1280) 0.1747(0.1474) CSIPH 0.3663(0.4322) 0.4928(0.5378) 0.4506(0.5093) 0.5229(0.5593) 0.6799(0.6645) 0.7180(0.5397) 0.7348(0.7180)
CSMH 0.3321(0.3989) 0.6237(0.6634) 0.5904(0.6093) 0.6356(0.6720) 0.7864(0.7781) 0.8297(0.6743) 0.8342(0.8286)
CWin 0.4323(0.5083) 0.5364(0.5489) 0.6211(0.5457) 0.5491(0.5844) 0.6763(0.6617) 0.7253(0.5681) 0.7558(0.7259)
MFor 0.3296(0.6485) 0.6374(0.6329) 0.3679(0.5993) 0.6368(0.6815) 0.7758(0.7794) 0.8251(0.5150) 0.8283(0.8385)
RAuto 0.3717(0.4511) 0.7149(0.7768) 0.7257(0.7730) 0.7493(0.7961) 0.8843(0.8889) 0.9308(0.7315) 0.9312(0.9387)
RMot 0.3148(0.6878) 0.7552(0.6504) 0.5865(0.6503) 0.5288(0.6626) 0.9292(0.9235) 0.9623(0.6344) 0.9627(0.9621)
RSB 0.4468(0.6390) 0.6209(0.6208) 0.7282(0.6293) 0.6402(0.6568) 0.8481(0.8452) 0.9516(0.6327) 0.9518(0.9565)
RSH 0.5310(0.2452) 0.3604(0.2378) 0.4829(0.3458) 0.3036(0.3429) 0.7965(0.7894) 0.9324(0.3706) 0.9338(0.9359)
SCry 0.6687(0.7277) 0.7259(0.8138) 0.8007(0.8125) 0.7860(0.8229) 0.8775(0.8828) 0.9227(0.8125) 0.9254(0.9277)
SEle 0.2545(0.5070) 0.5116(0.4890) 0.5761(0.4646) 0.4140(0.5481) 0.7670(0.7621) 0.8316(0.4551) 0.8346(0.8277)
SMed 0.2643(0.6794) 0.7232(0.7981) 0.7444(0.7859) 0.7421(0.8270) 0.9067(0.9134) 0.9464(0.7991) 0.9468(0.9536)
SSpa 0.5303(0.4198) 0.7279(0.7949) 0.7736(0.7889) 0.7855(0.8252) 0.9047(0.9100) 0.9296(0.7710) 0.9297(0.9346)
SRChr 0.2429(0.7006) 0.6888(0.7118) 0.7284(0.7129) 0.6937(0.7560) 0.8409(0.8465) 0.8718(0.6984) 0.8719(0.8764)
TPG 0.4691(0.6471) 0.6733(0.7558) 0.7284(0.7443) 0.7226(0.7863) 0.8389(0.8366) 0.8691(0.7437) 0.8696(0.8689)
TPMid 0.6186(0.7163) 0.7732(0.8198) 0.6760(0.8070) 0.8055(0.8421) 0.9009(0.9054) 0.9382(0.8389) 0.9382(0.9477)
TPMi 0.2506(0.5234) 0.5314(0.5665) 0.5901(0.5669) 0.5484(0.6257) 0.7251(0.7290) 0.8039(0.5685) 0.8039(0.8133)
TrMi 0.1741(0.3690) 0.3905(0.4712) 0.5022(0.4657) 0.3755(0.4781) 0.5994(0.6199) 0.6450(0.4504) 0.6451(0.6615)
macro-F1 0.3902(0.5253) 0.5910(0.6122) 0.6021(0.6047) 0.5870(0.6473) 0.7689(0.7687) 0.8199(0.6086) 0.8250(0.8251)
Note: The number in parenthesis denotes the performance with thresholdq= 10.
Table 9
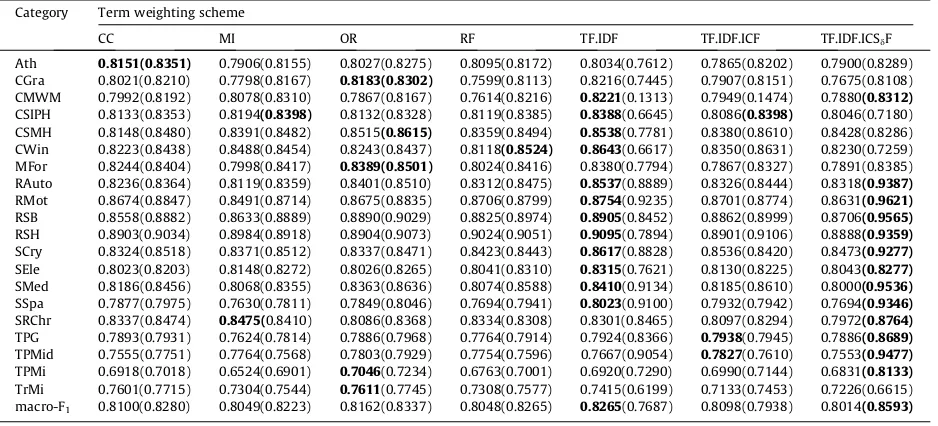
Performance onF1measure in the 20 Newsgroups dataset with thresholdq= 3 andq= 10 over the NB classifier. Category Term weighting scheme
CC MI OR RF TF.IDF TF.IDF.ICF TF.IDF.ICSdF
Ath 0.8151(0.8351) 0.7906(0.8155) 0.8027(0.8275) 0.8095(0.8172) 0.8034(0.7612) 0.7865(0.8202) 0.7900(0.8289) CGra 0.8021(0.8210) 0.7798(0.8167) 0.8183(0.8302) 0.7599(0.8113) 0.8216(0.7445) 0.7907(0.8151) 0.7675(0.8108) CMWM 0.7992(0.8192) 0.8078(0.8310) 0.7867(0.8167) 0.7614(0.8216) 0.8221(0.1313) 0.7949(0.1474) 0.7880(0.8312)
CSIPH 0.8133(0.8353) 0.8194(0.8398) 0.8132(0.8328) 0.8119(0.8385) 0.8388(0.6645) 0.8086(0.8398) 0.8046(0.7180) CSMH 0.8148(0.8480) 0.8391(0.8482) 0.8515(0.8615) 0.8359(0.8494) 0.8538(0.7781) 0.8380(0.8610) 0.8428(0.8286) CWin 0.8223(0.8438) 0.8488(0.8454) 0.8243(0.8437) 0.8118(0.8524) 0.8643(0.6617) 0.8350(0.8631) 0.8230(0.7259) MFor 0.8244(0.8404) 0.7998(0.8417) 0.8389(0.8501) 0.8024(0.8416) 0.8380(0.7794) 0.7867(0.8327) 0.7891(0.8385) RAuto 0.8236(0.8364) 0.8119(0.8359) 0.8401(0.8510) 0.8312(0.8475) 0.8537(0.8889) 0.8326(0.8444) 0.8318(0.9387)
RMot 0.8674(0.8847) 0.8491(0.8714) 0.8675(0.8835) 0.8706(0.8799) 0.8754(0.9235) 0.8701(0.8774) 0.8631(0.9621)
RSB 0.8558(0.8882) 0.8633(0.8889) 0.8890(0.9029) 0.8825(0.8974) 0.8905(0.8452) 0.8862(0.8999) 0.8706(0.9565)
RSH 0.8903(0.9034) 0.8984(0.8918) 0.8904(0.9073) 0.9024(0.9051) 0.9095(0.7894) 0.8901(0.9106) 0.8888(0.9359)
SCry 0.8324(0.8518) 0.8371(0.8512) 0.8337(0.8471) 0.8423(0.8443) 0.8617(0.8828) 0.8536(0.8420) 0.8473(0.9277)
SEle 0.8023(0.8203) 0.8148(0.8272) 0.8026(0.8265) 0.8041(0.8310) 0.8315(0.7621) 0.8130(0.8225) 0.8043(0.8277)
SMed 0.8186(0.8456) 0.8068(0.8355) 0.8363(0.8636) 0.8074(0.8588) 0.8410(0.9134) 0.8185(0.8610) 0.8000(0.9536)
SSpa 0.7877(0.7975) 0.7630(0.7811) 0.7849(0.8046) 0.7694(0.7941) 0.8023(0.9100) 0.7932(0.7942) 0.7694(0.9346)
SRChr 0.8337(0.8474) 0.8475(0.8410) 0.8086(0.8368) 0.8334(0.8308) 0.8301(0.8465) 0.8097(0.8294) 0.7972(0.8764)
TPG 0.7893(0.7931) 0.7624(0.7814) 0.7886(0.7968) 0.7764(0.7914) 0.7924(0.8366) 0.7938(0.7945) 0.7886(0.8689)
TPMid 0.7555(0.7751) 0.7764(0.7568) 0.7803(0.7929) 0.7754(0.7596) 0.7667(0.9054) 0.7827(0.7610) 0.7553(0.9477)
TPMi 0.6918(0.7018) 0.6524(0.6901) 0.7046(0.7234) 0.6763(0.7001) 0.6920(0.7290) 0.6990(0.7144) 0.6831(0.8133)
TrMi 0.7601(0.7715) 0.7304(0.7544) 0.7611(0.7745) 0.7308(0.7577) 0.7415(0.6199) 0.7133(0.7453) 0.7226(0.6615) macro-F1 0.8100(0.8280) 0.8049(0.8223) 0.8162(0.8337) 0.8048(0.8265) 0.8265(0.7687) 0.8098(0.7938) 0.8014(0.8593)
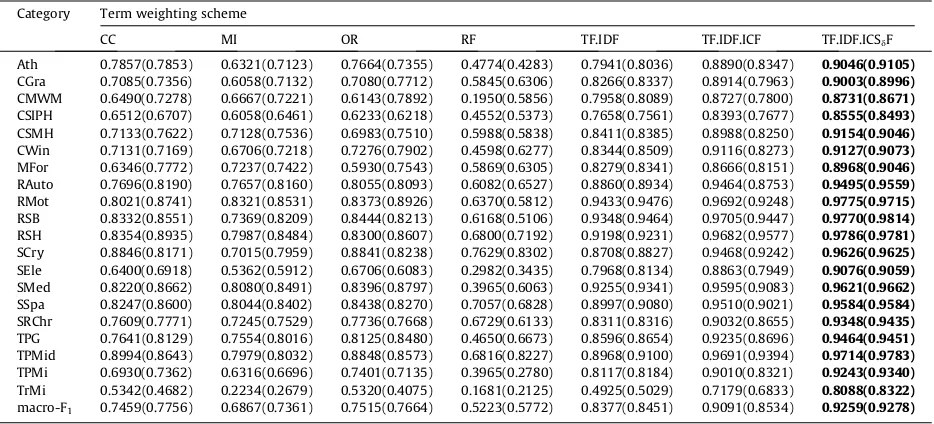
In contrast,Tables 8–10where the result with parenthesis shows F1measure F1(Ck) of a certain category in the 20
News-groups dataset over centroid, NB, and SVM classifier respectively. The result shows that TF.IDF.ICSdF shows its own superi-ority in among three classifiers. It achieves higher accuracy 20 of 20 categories in centroid, 11 of 20 in NB, and 20 of 20 categories in SVM over other term weighting approaches.
The above results show that the class-indexing-based TF.IDF.ICSdF and TF.IDF.ICF approaches outperformed over the dif-ferent term weighting approaches. This is especially the case for the TF.IDF.ICSdF approach, which shows its superiority al-most all the categories in the dataset.
4.4.3. Results with RCV1-v2 dataset
In this dataset, we do not introduce any thresholds because of unbalanced document distribution in the training process.
Table 4shows that majority of the categories have a small domain, some of them are only contains three to thirteen docu-ments in a certain category. Therefore, the total number of unique terms in term spaceTi= {t1,t2,. . .,tn} is 58,885, which
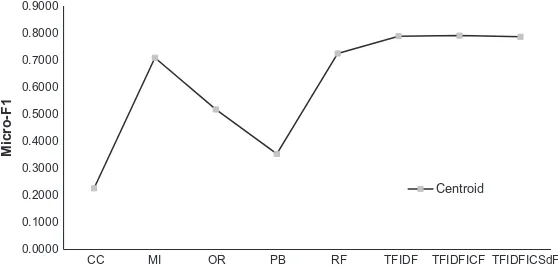
includes many rare terms in the vector space.Fig. 7shows the performance based on micro-F1 over the centroid classifier. In this figure, the TF.IDF.ICF showing its own superiority over other weighing methods, which achieved the highest micro-F1 score (79.06). The TFIDF and TF.IDF.ICSdF are second and third rank with micro-F1 score is 78.87 and 78.63 respectively.
4.5. Overall performances and discussions
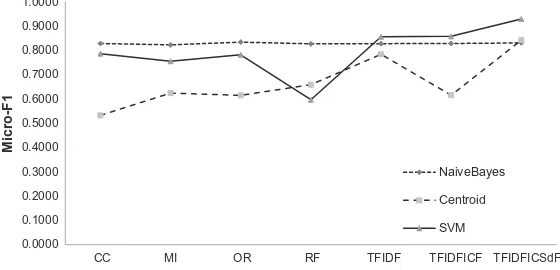
Figs. 3–6show the performance comparison with micro-F1on eight different term weighting methods over the
Reuters-21578 and 20 Newsgroups datasets with setting threshold
q
= 3 andq
= 10 using three different learning classifiers. InFigs. 3,Table 10
Performance onF1measure in the 20 Newsgroups dataset with thresholdq= 3 andq= 10 over the SVM classifier. Category Term weighting scheme
CC MI OR RF TF.IDF TF.IDF.ICF TF.IDF.ICSdF
Ath 0.7857(0.7853) 0.6321(0.7123) 0.7664(0.7355) 0.4774(0.4283) 0.7941(0.8036) 0.8890(0.8347) 0.9046(0.9105)
CGra 0.7085(0.7356) 0.6058(0.7132) 0.7080(0.7712) 0.5845(0.6306) 0.8266(0.8337) 0.8914(0.7963) 0.9003(0.8996)
CMWM 0.6490(0.7278) 0.6667(0.7221) 0.6143(0.7892) 0.1950(0.5856) 0.7958(0.8089) 0.8727(0.7800) 0.8731(0.8671)
CSIPH 0.6512(0.6707) 0.6058(0.6461) 0.6233(0.6218) 0.4552(0.5373) 0.7658(0.7561) 0.8393(0.7677) 0.8555(0.8493)
CSMH 0.7133(0.7622) 0.7128(0.7536) 0.6983(0.7510) 0.5988(0.5838) 0.8411(0.8385) 0.8988(0.8250) 0.9154(0.9046)
CWin 0.7131(0.7169) 0.6706(0.7218) 0.7276(0.7902) 0.4598(0.6277) 0.8344(0.8509) 0.9116(0.8273) 0.9127(0.9073)
MFor 0.6346(0.7772) 0.7237(0.7422) 0.5930(0.7543) 0.5869(0.6305) 0.8279(0.8341) 0.8666(0.8151) 0.8968(0.9046)
RAuto 0.7696(0.8190) 0.7657(0.8160) 0.8055(0.8093) 0.6082(0.6527) 0.8860(0.8934) 0.9464(0.8753) 0.9495(0.9559)
RMot 0.8021(0.8741) 0.8321(0.8531) 0.8373(0.8926) 0.6370(0.5812) 0.9433(0.9476) 0.9692(0.9248) 0.9775(0.9715)
RSB 0.8332(0.8551) 0.7369(0.8209) 0.8444(0.8213) 0.6168(0.5106) 0.9348(0.9464) 0.9705(0.9447) 0.9770(0.9814)
RSH 0.8354(0.8935) 0.7987(0.8484) 0.8300(0.8607) 0.6800(0.7192) 0.9198(0.9231) 0.9682(0.9577) 0.9786(0.9781)
SCry 0.8846(0.8171) 0.7015(0.7959) 0.8841(0.8238) 0.7629(0.8302) 0.8708(0.8827) 0.9468(0.9242) 0.9626(0.9625)
SEle 0.6400(0.6918) 0.5362(0.5912) 0.6706(0.6083) 0.2982(0.3435) 0.7968(0.8134) 0.8863(0.7949) 0.9076(0.9059)
SMed 0.8220(0.8662) 0.8080(0.8491) 0.8396(0.8797) 0.3965(0.6063) 0.9255(0.9341) 0.9595(0.9083) 0.9621(0.9662)
SSpa 0.8247(0.8600) 0.8044(0.8402) 0.8438(0.8270) 0.7057(0.6828) 0.8997(0.9080) 0.9510(0.9021) 0.9584(0.9584)
SRChr 0.7609(0.7771) 0.7245(0.7529) 0.7736(0.7668) 0.6729(0.6133) 0.8311(0.8316) 0.9032(0.8655) 0.9348(0.9435)
TPG 0.7641(0.8129) 0.7554(0.8016) 0.8125(0.8480) 0.4650(0.6673) 0.8596(0.8654) 0.9235(0.8696) 0.9464(0.9451)
TPMid 0.8994(0.8643) 0.7979(0.8032) 0.8848(0.8573) 0.6816(0.8227) 0.8968(0.9100) 0.9691(0.9394) 0.9714(0.9783)
TPMi 0.6930(0.7362) 0.6316(0.6696) 0.7401(0.7135) 0.3965(0.2780) 0.8117(0.8184) 0.9010(0.8321) 0.9243(0.9340)
TrMi 0.5342(0.4682) 0.2234(0.2679) 0.5320(0.4075) 0.1681(0.2125) 0.4925(0.5029) 0.7179(0.6833) 0.8088(0.8322)
macro-F1 0.7459(0.7756) 0.6867(0.7361) 0.7515(0.7664) 0.5223(0.5772) 0.8377(0.8451) 0.9091(0.8534) 0.9259(0.9278)
Note: The number in parenthesis denotes the performance with thresholdq= 10.
0.0000 0.1000 0.2000 0.3000 0.4000 0.5000 0.6000 0.7000 0.8000 0.9000 1.0000
CC MI OR PB RF TFIDF TFIDFICF TFIDFICSdF
Micro-F1
NaiveBayes
Centroid
SVM
4for Reuters-21578 andFigs. 5, 6for 20 Newsgroups, the proposed TF.IDF.ICSdF outperforms in SVM and centroid classifier to compare with other term weighting approaches.
InFig. 7for RCV1-v2, the TF.IDF.ICF outperforms in centroid classifier. The vector space of RCV1-v2 which includes many rare terms and therefore, it gives positive discrimination on this dataset.
The results of the above experiments show that the proposed class-indexing-based TF.IDF.ICSdF term weighting method consistently outperforms in high-dimensional and in comparatively low-dimensional vector spaces over the other methods. Moreover, the TF.IDF.ICSdF approach shows its superiority not only in overall, micro-F1, and macro-F1but also in all the cat-egories of the 20 Newsgroups and a majority of the Reuters-21578 datasets using SVM and centroid classifier. Another pro-posed class-indexing-based TF.IDF.ICF term weighting approach outperformed on RCV1-v2, which is very high-dimensional vector space with numerous rare terms are included in the VSM.
0.0000 0.1000 0.2000 0.3000 0.4000 0.5000 0.6000 0.7000 0.8000 0.9000 1.0000
CC MI OR PB RF TFIDF TFIDFICF TFIDFICSdF
Micro-F1
NaiveBayes
Centroid
SVM
Fig. 4.Performance comparison with micro-F1in the Reuters-21578 dataset with setting threshold usingq= 10 over the Centroid, NB, and SVM classifier.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
CC MI OR RF TFIDF TFIDFICF TFIDFICSdF
Micro-F1
NaiveBayes
Centroid
SVM
Fig. 5.Performance comparison with micro-F1in the 20 Newsgroups dataset with setting threshold usingq= 3 over the Centroid, NB,and SVM classifier.
0.0000 0.1000 0.2000 0.3000 0.4000 0.5000 0.6000 0.7000 0.8000 0.9000 1.0000
CC MI OR RF TFIDF TFIDFICF TFIDFICSdF
Micro-F1
NaiveBayes
Centroid
SVM
However, it is important to note that from the experiments result the combination of TF.IDF.ICSdF and centroid or TF.IDF.ICSdF and SVM, which can significantly improve the system performance. It is also noticeable that, the TF.IDF.ICSdF approach is very effective when we reduce the vector space. Therefore, it is important to generate more informative terms in the class-indexing-based term weighting method in order to enhance the automatic indexing task. Our study shows that the TF.IDF.ICSdF approach is a novel term weighting method that demonstrates a consistently higher performance over other term weighting approaches.
It is worth to mention that, in Reuter-21578, the results of some small categories like wheat and corn are compara-tively poor along with other categories in this dataset. We, therefore, examined the Reuters-21578 dataset to explore the possible reason for providing poor accuracy. In high dimensional vector space, the category wheat and corn contains 1169(13.02%) and 1153(12.8%) terms respectively, to represent their own domain which we found very small in compare with other categories. And in comparatively low dimensional vector space, the category wheat and corn contains 515(6.2%) and 471(5.7%) terms respectively. These categories are semantically much correlated and most of the terms are overlapped with each other.
5. Conclusion
In this study, we investigated the effectiveness of proposed class-indexing-based TF.IDF.ICSdF and TF.IDF.ICF approaches with other different term weighing approaches using a centroid, Naı¨ve Bayes, and SVM classifier to address the ATC task. The proposed term weighting approaches are effective in enhancing the classification task. The experiments were conducted using the Reuters-21578, 20 Newsgroups and RCV1-v2 datasets as benchmark collections. First, we proposed a new class-based indexing method to replace the traditional document indexing task. Then, we implemented a class-indexing-class-based TF.IDF.ICF term weighting approach that led to a new class-indexing-based TF.IDF.ICSdF term weighing approach that emphasizes on addressing class space density rather than class space.
The proposed class-indexing-based term weighting approaches outperformed the six different term weighting ap-proaches. In particular, the TF.IDF.ICSdF approach consistently outperformed in SVM and centroid classifier over other term weighting approaches. Since SVM is considered one of the most robust and achieved great success in TC, therefore, the com-bination of TF.IDF.ICSdF and SVM can significantly improve the performance of TC and in other applications.
From the experiment results, it is clear that the TF.IDF.ICSdF approach is very promising in domain based applications like text classification, information retrieval, information extraction, emotion recognition, topic identification, and many other applications in machine learning workbench. The TF.IDF.ICSdF approach may further use to compute the weight of basic eight emotions6classification for intelligent robot.
From the experiment results, it is noticeable that the TF.IDF.ICSdF approach is very effective when we reduce the vector space. Therefore, the proposed TF.IDF.ICSdF approach can overcome the problem of high dimensionality. It gives positive dis-crimination both in rare or in frequent terms. Although, the proposed TF.IDF.ICSdF consistently performed well in single-label classification task, however, in its current form needs to apply on multi-label classification task; to judge whether the pro-posed method can significantly perform well or not to handle multi-label classification.
Future extension of this proposed methodology aim to improve the performance of text classification to introduce hybrid-indexing by exploiting semantic hybrid-indexing technique. The classification performance can be further improved by combining class-indexing and semantic indexing. In future work, beside single-label classification, we will conduct our experiments with multi-label classification.
0.0000 0.1000 0.2000 0.3000 0.4000 0.5000 0.6000 0.7000 0.8000 0.9000
CC MI OR PB RF TFIDF TFIDFICF TFIDFICSdF
Micro-F1
Centroid
Fig. 7.Performance comparison with micro-F1in the RCV1-v2 dataset over the Centroid classifier.
6
Acknowledgement
This research has been partially supported by the Ministry of Education, Science, Sports and Culture of Japan under Grant-in-Aid for Scientific Research (A) No. 22240021.
References
[1] J. Chen, H. Huang, S. Tian, Y. Qua, Feature selection for text classification with Naı¨ve Bayes, Expert Systems with Applications 36 (2009) 5432–5435. [2] T.F. Covoes, E.R. Hruschka, Towards improving cluster-based feature selection with a simplified silhouette filter, Information Sciences 181 (2011)
3766–3782.
[3] F. Debole, F. Sebastiani, Supervised term weighting for automated text categorization, in: Proceedings of the 2003 ACM Symposium on Applied Computing, Melbourne, FL, USA, 2003, pp. 784–788.
[4] S. Flora, T. Agus, Experiments in term weighting for novelty mining, Expert Systems with Applications 38 (2011) 14094–14101.
[5] F. Figueiredo, L. Rocha, T. Couto, T. Salles, M.A. Goncalves, Word co-occurrence features for text classification, Information Systems 36 (2011) 843–858. [6] N. Fuhr, C. Buckley, A probabilistic learning approach for document indexing, ACM Transactions on Information Systems 9 (1991) 223–248. [7] S. Godbole, S. Sarawagi, S. Chakrabarti, Scaling multi-class support vector machine using inter-class confusion, in: Proceedings of the 8th ACM
International Conference on Knowledge Discovery and Data Mining, ACM Press, New Orleans, 2002, pp. 513–518.
[8] Y. Guo, Z. Shao, N. Hua, Automatic text categorization based on content analysis with cognitive situation models, Information Sciences 180 (2010) 613– 630.
[9] E.H. Han, G. Karypis, Centroid-based document classification: analysis and experimental results, Principles of Data Mining and Knowledge Discovery (2000) 424–431.
[10] T. Joachims, Text categorization with support vector machines: learning with many relevant features, in: Proceedings of 10th European Conference on Machine Learning, Springer Verlag, Heidelberg, Germany, 1998, pp. 137–142.
[11] T. Joachims, A statistical learning model of text classification for support vector machines, in: Proceedings of the 24th ACM International Conference on Research and Development in Information Retrieval, 2001.
[12] M.G.H. Jose, Text representation for automatic text categorization, 2003 <http://www.esi.uem.es/jmgomez/tutorials/eacl03/slides.pdf>.
[13] B. Kang, S. Lee, Document indexing: a concept-based approach to term weight estimation, Information Processing and Management 41 (5) (2005) 1065–1080.
[14] S. Kansheng, H.Jie.L. Hai-tao, Z. Nai-tong, S. Wen-tao, Efficient text classification method based on improved term reduction and term weighting, The Journal of China Universities of Posts and Telecommunications 18 (2011) 131–135.
[15] Y. Ko, J. Seo, Text classification from unlabeled documents with bootstrapping and feature projection techniques, Information Processing and management 45 (2009) 70–83.
[16] M. Lan, C.L. Su, Y. Lu, Supervised and traditional term weighting methods for automatic text categorization, IEEE Transactions on Pattern Analysis and Machine Intelligence 31 (2009) 721–735.
[17] J.H. Lee, Combining multiple evidence from different properties of weighting schemes, in: Proceedings of the 18th International Conference on Research and Development in Information Retrieval 1995, pp. 180–188.
[18] C. Lee, G.G. Lee, Information gain and divergence-based feature selection for machine learning- based text categorization, Information Processing & Management 42 (1) (2006) 155–165.
[19] D.D. Lewis, Text representation for intelligent text retrieval: a classification-oriented view, in: S.J. Paul (Ed.), Text-Based Intelligent Systems: Current Research and Practice in Information Extraction and Retrieval, Lawrence Erlbaum Associates, Inc., Publishers, Hillsdale, New Jersey, USA, 1992, pp. 179–197.
[20] D.D. Lewis, M. Ringuette, A Comparison of two learning algorithms for text categorization, in: Proceedings of the Third Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 1994, pp. 81–93.
[21] D.D. Lewis, R.E. Schapire, J.P. Callan, R. Papka, Training algorithms for linear text classifiers, in: Proceedings of 19th ACM International Conference on Research and Development in Information Retrieval, 1996, pp. 298–30.
[22] D.D. Lewis, Y. Yang, T. Rose, F. Li, RCV1: a new benchmark collection for text categorization research, Journal of Machine Learning research 5 (2004) 361–397.
[23] W. Li, D. Miao, W. Wang, Two-level hierarchical combination method for text classification, Expert Systems with Applications 38 (2011) 2030–2039. [24] Y. Liu, H. Loh, A. Sun, Imbalanced text classification: a term weighting approach, Expert Systems with Applications 36 (2009) 690–701.
[25] Q. Luo, E. Chen, H. Xiong, A semantic term weighting scheme for text classification, Expert Systems with Applications 38 (2011) 12708–12716. [26] S. Maldonado, R. e Weber, J. Basak, Simultaneous feature selection and classification using kernel-penalized support vector machines, Information
Sciences 181 (2011) 115–128.
[27] H. Ogura, H. Amano, M. Kondo, Comparison of metrics for feature selection in imbalanced text classification, Expert Systems with Applications 38 (2011) 4978–4989.
[28] F. Peng, A. McCallum, Information extraction from research papers using conditional random fields, Information Processing and Management 42 (2006) 963–979.
[29] G. Salton, A Theory of Indexing, Bristol, UK, 1975.
[30] G. Salton, A. Wong, C.S. Yang, A vector space model for automatic indexing, Association of Computing Machines 18 (1975) 613–620. [31] G. Salton, C. Buckley, Term-weighting approaches in automatic text retrieval, Information Processing and Management 24 (1988) 513–523. [32] G. Salton, M.J. McGill, Introduction to Modern Information Retrieval, New York, 1983.
[33] F. Sebastiani, Machine learning in automated text categorization, ACM Computing Surveys 34 (2002) 1–47.
[34] G. Salton, C.S. Yang, C.T. Yu, Contribution to the theory of indexing, in: Proceedings of International Federation for Information Processing Congress 74, Stockholm, American Elsevier, New York, 1973.
[35] H. Schutze, D. Hull, J.O. Pedersen, A comparison of classifiers and document representations for the routing problem, in: Proceedings of the 18th ACM International Conference on Research and Development in Information Retrieval, 1995, pp. 229–237.
[36] W. Shang, H. Huang, H. Zhu, Y. Lin, Y. Qu, Z. Wang, A novel feature selection algorithm for text categorization, Expert Systems with Applications 33 (2007) 1–5.
[37] K. Sparck Jones, A statistical interpretation of term specificity and its application in retrieval, Journal of Documentation 28 (1972) 11–21. [38] K. Sparck Jones, Index term weighting, Information Storage and Retrieval 9 (1973) 619–633.
[39] A. Tagarelli, Exploring dictionary-based semantic relatedness in labeled tree data, Information Sciences 220 (2012) 244–268. [40] S. Tan, An improved centroid classifier for text categorization, Expert Systems with Applications 35 (2008) 279–285.
[41] T. Theeramnukkong, V. Lertnattee, Improving centroid-based text classification using term distribution-based weighting system and clustering, in: International Symposium on Communications and Information Technologies, 2001, pp. 33–36.
[42] T. Theeramnukkong, V. Lertnattee, Effect of term distributions on centroid-based text categorization, Information Sciences 158 (2004) 89–115. [43] K. Tzeras, S. Hartmann, Automatic indexing based on Bayesian inference networks, In Proceedings of SIGIR-93, 16th ACM International Conference on
[44] C.H. Wan, L.H. Lee, R. Rajkumar, D. Isa, A hybrid text classification approach with low dependency on parameter by integrating K-nearest neighbor and support vector machine, Expert Systems with Applications 39 (2012) 11880–11888.
[45] X. Wu, V. Kumar, et al, Top 10 algorithms in data mining, Knowledge and Information Systems 14 (2008) 1–37.
[46] R. Xia, C. Zong, S. Li, Ensemble of feature sets and classification algorithms for sentiment classification, Information Sciences 181 (2011) 1138–1152. [47] Y. Yang, An evaluation of statistical approaches to text categorization, Journal of Information Retrieval 1 (1999) 67–88.
[48] Y. Yang, C.G. Chute, An example-based mapping method for text categorization and retrieval, ACM Transactions on Information Systems 12 (3) (1994) 252–277.
[49] Y. Yang, J.O. Pedersen, A Comparative study on feature selection in text categorization, In Proceedings of ICML-97, 14th International Conference on Machine Learning, Nashville, TN, 1997, pp. 412–420.