BAB 2
LANDASAN TEORI
2.1 Disleksia
Disleksia adalah ketidakmampuan bahasa, yang berpengaruh dalam hal membaca, menulis, berbicara dan mendengarkan. Ini adalah disfungsi atau gangguan dalam penggunaan kata-kata. Akibatnya, hubungan dengan orang lain dan kinerja dalam setiap mata pelajaran di sekolah dapat dipengaruhi oleh disleksia (Bolhasan, 2009). Masalah-masalah membaca dalam anak-anak disleksia dinyatakan dalam kesulitan ekstrim dalam memperoleh subskill dasar membaca seperti identifikasi kata dan decode fonologi (surat suara). Kesulitan seperti ini telah diperkirakan terjadi pada sekitar 10% sampai 15% dari usia anak sekolah dan cenderung disertai dengan kekurangan tertentu dalam kemampuan kognitif yang berkaitan dengan membaca dan keterampilan keaksaraan lainnya. Pola Gejala ini sering disebut disleksia, atau sebaliknya, ketidakmampuan membaca tertentu (Vellutino et al, 2004).
Anak-anak disleksia membutuhkan seorang guru yang mengerti bagaimana frustasi dari anak-anak yang pintar, yang tidak mampu melakukan apa yang murid-murid lain lakukan dengan mudah yaitu membaca dan menghafal. Mereka membutuhkan seseorang yang guru yang memahami bahwa kesulitan ini adalah karena perbedaan otak, bukan karena kemalasan, kurangnya kecerdasan, ataupun kurangnya motivasi. Mereka membutuhkan seorang guru yang tidak akan menyerah pada mereka. Guru yang bersedia untuk belajar bagaimana mengajar semua kelemahan mereka. Mereka juga membutuhkan guru yang tahu bahwa mereka menderita dari kecemasan yang ekstrim. Lebih dari apa pun, siswa ini takut bahwa guru mereka akan membuat mereka terlihat bodoh di depan teman-teman mereka (Borton, 2003). Sejarah penelitian tentang perkembangan disleksia telah didominasi oleh teori visual. Secara historis, teori pengembangan dalam membaca juga diasumsikan bahwa pemrosesan visual adalah inti untuk perbedaan individu dalam akuisisi membaca (Goswami, 2008).
2.1.1 Bentuk Kesulitan Membaca Anak-Anak Disleksia
Menurut Badan Penelitian dan Pengembangan Departemen Pendidikan Nasional pada tahun 2007, kesulitan membaca anak-anak disleksia adalah :
a. Penambahan (Addition)
Menambah huruf pada suku kata.
Contoh : suruh -> disuruh, buku -> bukuku b. Penghilangan (Omission)
Menghilangkan huruf pada suku kata. Contoh : kelapa -> lapa, kelas -> kela c. Pembalikan kiri-kanan (Inversion)
Membalikkan bentuk huruf, kata, ataupun angka dengan arah terbalik kirikanan.
Contoh : buku -> duku, palu -> lupa d. Pembalikan atas-bawah (ReversalI)
Membalikkan bentuk huruf, kata, ataupun angka dengan arah terbalik atasbawah.
Contoh : m -> w, u -> n, 6 -> 9 e. Penggantian (Substitusi)
Mengganti huruf atau angka.
Contoh : mega -> meja, nanas -> mamas, 3 -> 8
2.1.2 Ciri-ciri Anak-anak Penderita Disleksia
Masalah disleksia dirujuk kepada beberapa ciri (Ramasami, 2008) yaitu: a. Sukar dalam berbahasa.
b. Ketidakseimbangan dengan kebolehan intelektual. c. Tidak lancar ketika membaca sesuatu.
d. Tidak dapat menulis dengan lancar dan tepat (sukar dalam meniru tulisan). e. Mata mudah menjadi penat setelah beberapa menit jika perhatian
menumpu kepada tulisan
2.2 Metode Multisensori
Pendekatan ini dikenal juga sebagai pendekatan system fonik-visual-auditory-kinestetik. Pendekatan ini dikembangkan oleh Gillingham dan Stillman (Gearheart, 1976:93). Pada dasarnya pendekatan ini sangat baik digunakan dalam belajar membaca, khususnya membaca permulaan. Akan tetapi pendekatan ini dapat juga digunakan dalam meningkatkan pemahaman akan bahasa baik yang didengar maupun yang diucapkan oleh orang lain sebelumnya (Supriyanto, 2007). Pendekatan multisensori mendasarkan pada asumsi bahwa anak akan belajar lebih baik jika materi pelajaran disajikan dalam berbagai modalitas. Modalitas yang sering dilibatkan adalah
visual (penglihatan), auditory (pendengaran), kinesthetic (gerakan), dan tactile
(perabaan). Metode ini merupakan salah satu program remedial membaca untuk anak disleksia, namun dirasakan bahwa beberapa prinsip dalam metode ini dapat diterapkan, dan diharapkan mampu mengatasi beberapa kendala penerapan metode membaca dalam pembelajaran. Penggunaan berbagai alat bantu sebagai media pembelajaran dapat membangkitkan keinginan dan minat yang baru, membangkitkan motivasi, memberikan rangsangan kegiatan belajar, bahkan membawa pengaruh-pengaruh psikologis pada siswa. Media akan dapat menarik minat anak dan akhirnya berkonsentrasi untuk belajar dan memahami pelajaran (Poppyariana, 2011).
Pendekatan multisensori ini dilakukan berdasarkan prinsip pengamatan terhadap berbagai indera-indera secara terpadu yang dimiliki oleh seseorang. Multisensori artinya memfungsikan seluruh indera sensori (indera penangkap) dalam memperoleh kesan-kesan melalui perabaan, visual, perasaan, kinestetis, dan pendengaran. Dengan mengembangkan berbagai kemampuan pengamatan yang dimiliki oleh seseorang, guru memberikan rangsangan melalui berbagai modalitas sensori yang dimilikinya (Supriyanto, 2007). Metode multisensori ini baik digunakan untuk anak-anak disleksia. Sementara jika melihat prinsip dari metode multisensori ini didalam penerapannya memiliki beberapa kelebihan dalam memperbaiki dan mempercepat proses membaca (Poppyariana, 2011).
2.3 Speech Recognition
Speech Recognition yang dikenal sebagai Automatic Speech Recognition (ASR), atau komputer pengenalan suara merupakan proses mengkonversi sinyal suara ke urutan kata-kata, melalui sebuah algoritma diimplementasikan sebagai komputer Program. (Anusuya & Katti, 2009)
Speech Recognition juga merupakan pengenalan pola, dimana ada dua fase dalam pengenalan pola diawasi, yaitu, pelatihan dan pengujian. Proses ekstraksi fitur yang relevan untuk klasifikasi umum di kedua fase. Selama fase traning, parameter dari model klasifikasi yang diperkirakan dengan menggunakan sejumlah besar contoh kelas (data training). Selama fase pengujian atau fase pengenalan, fitur pola uji (data
speech test) dicocokan dengan model yang dilatih dari masing-masing dan setiap kelas. Pola tes itu kemudian dinyatakan ke dalam model yang memiliki pola tes terbaik (Gaikwad et al, 2010).
2.3.1 Teknik-Teknik dalam Speech Recognition
Ada 4 teknik yang dapat dilihat dalam Speech Recognition (Gaikwad, Gawali & Yannawar, 2010) yaitu :
a. Speech Analysis Technique
Speech data mengandung berbagai jenis informasi yang menunjukkan identitas pembicara. Tahapan speech analysis berkaitan dengan ukuran frame yang cocok untuk segmentasi sinyal suara dalam analisa dan ekstraksi yang lebih lanjut.
b. Feature Extraction Technique
Ekstraksi fitur speech dalam kategorisasi masalah adalah tentang mengurangi dimensi dari vektor input ketika mempertahankan membedakan kekuatan sinyal. Seperti kita ketahui dari pembentukan dasar
speaker identification dan sistem verifikasi, bahwa jumlah pelatihan dan vektor uji diperlukan untuk masalah klasifikasi yang tumbuh dengan dimensi masukan yang diberikan sehingga kita membutuhkan fitur ekstraksi dari sinyal suara.
c. Modeling Technique
Tujuan dari modeling technique adalah untuk menghasilkan speaker models yang menggunakan fitur vektor pembicara khusus. Speaker modeling technique dibagi menjadi dua klasifikasi yaiut speaker recognition dan speaker identification. Speaker identification technique
secara otomatis mengidentifikasi siapa yang berbicara berdasarkan informasi individual yang terintegrasi dalam sinyal suara. Speaker recognation juga dibagi menjadi dua bagian yaitu speaker dependant dan
speaker independent. Dalam modus speaker independent dari speech recognation, komputer harus mengabaikan karakteristik khusus pembicara dari sinyal suara dan mengekstrak pesan yang dimaksudkan.
Disisi lain dalam kasus speaker recognation machine harus mengekstrak karakteristik pembicara dalam sinyal akustik. Tujuan utama dari speaker identification adalah membandingkan sinyal pidato dari pembicara tak dikenal ke database pembicara yang sudah dikenal. Sistem ini dapat mengenali pembicara, yang telah dilatih dengan sejumlah pembicara. Speaker recognition juga dapat dibagi menjadi dua metode, text dependent and text independent. Dalam metode text dependent pembicara mengatakan kata kunci atau kalimat yang memiliki teks yang sama untuk menguji pelatihan dan pengenalan. Sedangkan text independent tidak bergantung pada teks tertentu yang diucapkan.
d. Matching Techniques
Mesin speech recognition mencocokkan sebuah kata yang terdeteksi dengan kata yang sudah diketahui salah satu dari teknik-teknik berikut :
1. Whole Word Matching
Mesin membandingkan sinyal digital-audio yang datang terhadap template rekaman kata. Teknik ini membutuhkan waktu lebih sedikit pengolahan dari pencocokan sub-kata, tetapi mensyaratkan bahwa pengguna (atau seseorang) merekam setiap kata yang akan
dikenali, kadang-kadang beberapa ratus ribu kata. Template seluruh kata juga membutuhkan memori penyimpanan yang besar (antara 50 dan 512 byte per kata) dan hanya praktis jika pengenalan kosakata tersebut sudah dikenal ketika aplikasi dikembangkan.
2. Sub Word Matching
Mesin mencari sub-kata, biasanya fonem dan kemudian melakukan pengenalan pola lanjut. Teknik ini membutuhkan lebih banyak pemrosesan dari pencocokan seluruh kata, tetapi membutuhkan penyimpanan lebih sedikit (antara 5 dan 20 byte per kata). Selain itu, pengucapan kata dapat ditebak dari teks bahasa Inggris tanpa mengharuskan pengguna untuk berbicara kata yang sebelumnya.
2.3.2 Jenis-Jenis dari Speech Recognition
Sistem pengenalan suara dapat dipisahkan dalam beberapa kelas yang berbeda dengan mendeskripsikan jenis ucapan-ucapan mereka (Anusuya & Katti, 2009) yaitu :
a. Isolated Words
Isolated word recognizers biasanya memerlukan setiap ucapan harus tenang (karena kurangnya sinyal audio) pada kedua sisi sampel. Ia menerima satu kata atau ucapan tunggal pada satu waktu. Sistem ini memiliki pernyataan "Dengar / Tidak-Dengar", di mana mereka membutuhkan pembicara untuk menunggu dalam mengucapkan kata demi kata (biasanya melakukan pengolahan selama jeda).
b. Connected Words
Sistem connected words (atau lebih tepatnya 'ucapan yang terhubung') hampir serupa dengan isolated words, namun memungkinkan ucapan jeda minimal antara mereka.
c. Continuous Speech
Continuous speech recognizers memungkinkan pengguna untuk berbicara hampir secara alami, sedangkan komputer menentukan kontennya.
Pengenalan dengan kemampuan Continuous speech adalah beberapa dari yang paling sulit karena mereka menggunakan metode khusus untuk menentukan batas ucapan.
d. Spontaneous Speech
Pada tingkat dasar, itu dapat dianggap sebagai pidato yang terdengar secara alami. Sebuah sistem speech recognition dengan kemampuan spontaneous speech harus mampu menangani berbagai variasi dari fitur-fitur speech
alami seperti kata-kata yang dijalankan bersama-sama, "ums" dan "ahs", dan bahkan sedikit gagap.
2.3.3 Tipe-Tipe Speech Recogniton
Ada 2 tipe Speech Recognition, dilihat dari ketergantungan pembicara yaitu (Sukarso dan Syarif, 2007) :
a. Independent Speech Recognition
Independent Speech Recognition yaitu sistem pengenal ucapan tanpa terpengaruh dengan siapa yang berbicara, tetapi mempunyai keterbatasan dalam jumlah kosakata. Model ini akan mencocokan setaip ucapan dengan kata yang dikenali dan memilih yang ”sepertinya” cocok. Untuk mendapatkan kecocokan kata yang diucapkan maka digunakan model statistic yang dikenal dengan nama Hidden Markov Model (HMM)
b. Dependent Speech Recognition
Dependent Speech Recognition yaitu sistem pengenal ucapan yang memerlukan pelatihan khusus dari pembicara, dimana hasil pelatihan dari masing-masing pembicara akan disimpan dalam sebuah profil. Profil inilah yang nantinya digunakan untuk berinteraksi dengan sistem pengenal ucapan dan sistem akan bergantung siapa yang berbicara. Sistem ini biasanya lebih mudah untuk dikembangkan, dimana contoh suara sudah dibuat sebelumnya dan disimpan dalam database (basis data) dan jumlah kosakatanya lebih besar dibandingkan dengan independent speech
recognition. Proses pengenalan ucapan dengan cara membandingkan ucapan pembicara dengan contoh suara yang ada.
Dalam penelitian ini kita menggunakan tipe Independent Speech Recognition karena kita menggunakan metode Hidden Markov Model.
2.4 Hidden Markov Model (HMM)
Fondasi Hidden Markov Model (HMM) modern yang berbasis teknologi continuous speech recognition ditetapkan pada tahun 1970-an oleh kelompok-kelompok di Carnegie-Mellon dan IBM yang memperkenalkan penggunaan HMM dan kemudian di Bell Labs dimana HMM diperkenalkan. Hidden Markov Model (HMM) menyediakan kerangka kerja yang sederhana dan efektif untuk pemodelan variasi waktu dalam urutan spektral vektor. Sebagai konsekuensinya, hampir semua sekarang ini kosakata yang besar dalam sistem continuous speech recognition didasarkan pada HMM. Penerapan praktis dari HMMs dalam sistem modern melibatkan kecanggihan yang cukup dalam menyajikan arsitektur inti sistem continuous speech recognition
berbasis HMM. HMMs terletak hampir di semua sistem pengenalan suara yang modern dan meskipun kerangka dasar tidak berubah secara signifikan dalam dekade terakhir atau lebih, teknik pemodelan rinci dikembangkan dalam kerangka ini telah berevolusi ke keadaan kecanggihan yang cukup. Hasilnya telah stabil dan signifikan (Gales & Young, 2008).
HMM dimungkinkan untuk digunakan setiap model speech. Bahkan jika unit
speech buruk yang dipilih, HMM memiliki kemampuan untuk menyerap karakteristik suboptimal dalam model parameter, hal ini tentu saja membatasi kinerja sistem. Kata-kata tampaknya menjadi unit yang paling alami untuk dijadikan model, karena apa yang ingin dikenali dan model dalam bahasa juga menggunakan kata-kata sebagai unit dasar. Memang, recognizers yang menggunakan model level-kata tampil cukup baik. Bagian dari keberhasilan ini adalah karena fakta bahwa mereka mampu menangkap efek fonem koartikulasi dalam kata-kata. Sebenarnya hal tersebut ditunjukkan dengan
semakin besar unit, akan semakin baik recognizer. Namun, karena ada banyak kata-kata unik, data training yang dibutuhkan untuk setiap kata-kata ini, membuat sistem semacam ini tidak mudah diperluas. Jadi untuk kosakata besar speech recognition
yang alami, unit kata tidak benar-benar pilihan. Tapi untuk kosakata yang kecil yang terdefinisi dengan baik, misalnya seperangkat perintah, mereka sangat cocok. Biasanya model topologi kiri ke kanan digunakan yang dimana jumlah keadaan tergantung pada jumlah fonem dalam kata. Salah satu bagian per fonem adalah aturan praktis yang baik (Wiggers, 2003).
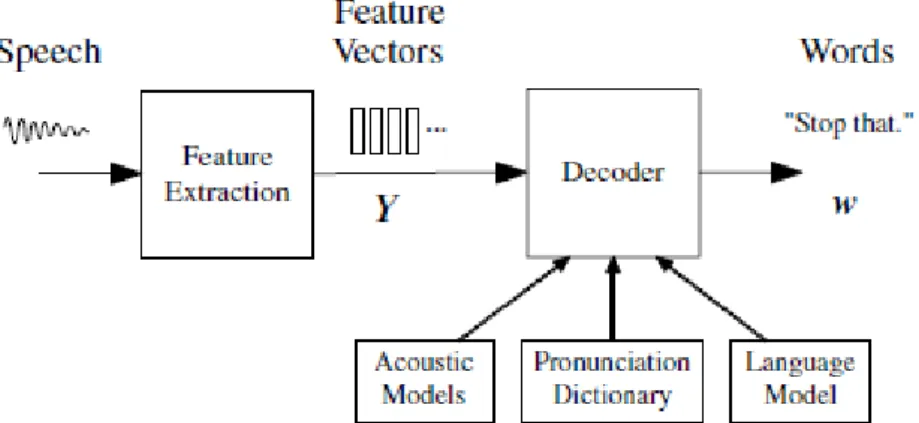
Komponen-komponen utama dari kosakata continuous speech recogniser yang besar diilustrasikan pada gambar 2.1. Input gelombang audio dari mikrofon diubah menjadi urutan ukuran tetap vektor akustik Y 1: T = y1,. . . , yT dalam proses yang disebut feature extraction. Decoder kemudian mencoba untuk menemukan urutan kata-kata w1: L = w1, ..., wL yang kemungkinan besar telah menghasilkan Y.
Namun, karena persamaan ini tidak dapat dihitung secara langsung karena jumlah urutan observasi yang mungkin tak pernah habis, maka aturan 1 Bayes digunakan untuk mengubah (2.1) ke dalam :
Keterangan :
Y adalah Sinyal suara sebagai sumber observasi.
w adalah urutan kata yang memiliki probabilitas tertinggi yang diucapkan.
P(w) adalah probabilitas bahwa string kata w akan diucapkan. Disebut juga model bahasa.
P(Y|w) adalah probabilitas bahwa ketika string kata w diucapkan, akustik Y akan diamati. Disebut juga model akustik.
Kemungkinan p (Y|w) ditentukan oleh model akustik dan P(w) sebelumnya ditentukan oleh model bahasa. Unit dasar dari suara ditunjukkan oleh model akustik telepon Gales & Young, 2008). Akibatnya, sebuah speech recognizer terdiri dari tiga komponen yaitu bagian preprocessing yang menerjemahkan sinyal suara menjadi urutan simbol observasi, model bahasa yang memberitahu kita seberapa besar kemungkinan string kata tertentu terjadi dan model akustik yang memberitahu kita bagaimana kata string kemungkinan akan diucapkan. Pada bagian berikutnya tiga subsistem akan dijelaskan (Wiggers, 2003).
Gambar 2.1 Arsitektur dari Hidden Markov Model
2.5 Microsoft SAPI
Speech Application Programming Interface (SAPI) adalah sebuah API yang dikembangkan oleh Microsoft yang digunakan sebagai pengenal suara didalam lingkungan pemrograman aplikasi Windows. Sampai saat ini SAPI dikemas baik berupa SDK (System Development Kit) maupun disertakan dalam sistem operasi Windows itu sendiri. Aplikasi yang telah menggunakan SAPI antara lain Microsoft Office, dan Windows Vista, 7 dan 8. Secara arsitektur pemrograman SAPI dapat dilihat sebagai sebuah middleware yang terletak antara aplikasi dan speech engine (Sukarso dan Syarif, 2007).
Komponen utama di dalam SAPI adalah sebagai berikut (Sukarso dan Syarif, 2007) : a. Voice Command
Sebuah obyek level tinggi untuk perintah dan kontrol menggunakan pengenalan suara.
b. Voice Dictation
Sebuah obyek level tinggi untuk continous dictation speech recognition. c. Voice Talk
Sebuah obyek level tinggi untuk speech synthesis. d. Voice Telephony
Sebuah obyek untuk menulis aplikasi telepon berbasiskan pengenalan suara.
e. Direct Speech Recognition
Sebuah obyek sebagai mesin untuk mengontrol pengenalan suara (direct control of recognition engine)
f. Direct Text to Speech
Sebuah obyek sebagai mesin yang mengontrol synthesis. g. Audio Object