Load Balancing with Task Division and Addition
Ranjan Kumar Mondal1, Payel Ray2, Debabrata Sarddar3
1, 2
Department of CSE, University of Kalyani, Kalyani, India
3
Assistant Professor, Department of CSE, University of Kalyani, Kalyani, India
ABSTRACT
Cloud Computing is an emerging computing paradigm. It aims to share data, calculations, and service transparently over a scalable network of nodes. Since Cloud computing stores the data and disseminated resources in the open environment.
So, the amount of data storage increases quickly. In the cloud storage, load balancing is a key issue. It would consume a lot of cost to maintain load information, since the system is too huge to timely disperse load.
There are several heterogeneous nodes in a cloud computing system. Namely, each node has different capability to execute task; hence, only consider the CPU remaining of the node is not enough when a node is chosen to execute a task. Therefore, how to select an efficient node to execute a task is very important in a cloud computing.
In this paper, we propose a new scheduling algorithm that choose a suitable node with its average task. It is very easy way to select an appropriate node. This approach can provide efficient utilization of computing resources and maintain the load balancing in cloud computing environment.
Keywords: Cloud Computing, Load Balancing, Distributed System, Threshold.
I. INTRODUCTION
A Cloud computing is emerging as a new paradigm of large scale distributed computing. It
has moved computing and data away from desktop and portable PCs, into large data centers. It provides the scalable IT resources such as applications and services, as well as the infrastructure on which they operate, over the Internet, on pay-per-use basis to adjust the capacity quickly and easily. It helps to accommodate changes in demand and helps any organization in avoiding the capital costs of software and hardware. Thus, Cloud Computing is a framework for enabling a suitable, on-demand network access to a shared pool of computing resources (e.g. networks, servers, storage, applications, and services). These resources can be provisioned and de-provisioned quickly with minimal management effort or service provider interaction.
This further helps in promoting availability. Due to the exponential growth of cloud computing, it has been widely adopted by the industry and there is a rapid expansion in data-centers.
According to the National Institute of Standards and Technology (NIST), cloud computing exhibits several characteristics:
On-demand Self-service- A consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service provider.
Broad Network Access- Capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, tablets, laptops, and workstations).
Resource Pooling- The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand.
There is a sense of location independence in that the customer generally has no control or knowledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or datacenter). Examples of resources include storage, processing, memory, and network bandwidth.
Rapid Elasticity- Capabilities can be elastically provisioned and released, in some cases automatically, to scale rapidly outward and inward commensurate with demand. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be appropriated in any quantity at any time.
transparency for both the provider and consumer of the However, they are usually not flexible and cannot match the dynamic changes to the attributes during the execution time. Dynamic algorithms are more flexible and take into consideration different types of attributes in the system both prior to and during run-time[1]. Load balancing is the process of improving the performance of system through a redistribution of load among processor.
In general, load balancing algorithms follow two major classifications:
Depending on how the charge is distributed and how
processes are allocated to nodes (the system load);
Depending on the information status of the nodes (System Topology).
In the first case it designed as designed as centralized approach, distributed approach or hybrid approach in the second case as static approach, dynamic or adaptive approach.
a) Classification According to the System Load Centralized approach: In this approach, a single node is responsible for managing the distribution within the whole system.
Distributed approach: In this approach, each node
independently builds its own load vector by collecting the load information of other nodes. Decisions are made locally using local load vectors. This approach is more suitable for widely distributed systems such as cloud computing.
Mixed approach: A combination between the two
approaches to take advantage of each approach.
b) Classification According to the System Topology Static approach: This approach is generally defined in
the design or implementation of the system.
Dynamic approach: This approach takes into
account the current state of the system during load balancing decisions. This approach is more suitable for widely distributed systems such as cloud computing.
Adaptive approach: This approach adapts the load
distribution to system status changes, by changing their parameters dynamically and even their algorithms. This approach is able to offer better performance when resources of specific, for instance, when implement organism sequence assembly, it is probable have to big requirement toward memory remaining. And in order to reach the best efficient in the execution each tasks, so we will aimed tasks property to adopt a different condition decision variable in which it is according to resource of task requirement to set decision variable.
IV. METHOD
Step 1: It is to calculate the Min Task of each node for all tasks, respectively.
Step 2: It is to divide with the Min Task to each node for all tasks, respectively.
Step 3:Againit is to calculate the Min Task of each task for all nodes, respectively.
Step 4:Again it is to divide with the Min Task to each task for all nodes, respectively.
Step 5: It is to add the alltasks for all nodes, respectively.
Step 6: It is to find the maximum added Task from all node.
Step 6: It is to find the Min Task from selected node. Step 7: It is to find the next maximum added Task from all node.
Step 8: It is to find the unassigned Min Task from selected node.
Step 9: Repeat Step 7 to Step 8, until all tasks have been completed totally.
3 Case study
NodeTask
C
11C
12C
13C
14t
112
13
10
14
t
216
24
13
25
t
326
31
12
33
t
417
24
18
31
Step 1: It is to calculate the Min Task of each node for all tasks, respectively.
NodeTask
C
11C
12C
13C
14Min
Task
t
112
13
10
14
10
t
216
24
13
25
13
t
326
31
12
33
12
t
417
24
18
31
17
Step 2: It is to divide with the Min Task to each node for all tasks, respectively.
NodeTask C
11C
12C
13C
14t
11.2
1.3
1
1.4
t
21.3
1.8
1
1.9
t
32.2
2.9
1
2.7
t
41
1.4
1.1
1.8
Step 3:Againit is to calculate the Min Task of each task for all nodes, respectively.
NodeTask
C
11C
12C
13C
14t
11.2
1.3
1
1.4
t
21.3
1.8
1
1.9
t
32.2
2.9
1
2.7
t
41
1.4
1.1
1.8
Min Task
1
1.3
1
1.4
Step 4:Again it is to divide with the Min Task to each task for all nodes, respectively.
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Step 5:It is to add the alltasks for all nodes, respectively.
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Total
5.7
5.6
4.1
5.4
Step 6: It is to find the maximum added Task from all node.
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Total
5.7
5.6
4.1
5.4
Step 6: It is to find the Min Task from selected node.
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Total
5.7
5.6
4.1
5.4
Step 7: It is to find the next maximum added Task from all node.
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Total
5.7
5.6
4.1
5.4
Step 8: It is to find the unassigned Min Task from selected node.
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Total
5.7
5.6
4.1
5.4
Again
NodeTask
C
11C
12C
13C
14t
11.2
1
1
1
t
21.3
1.3
1
1.3
t
32.2
2.2
1
1.9
t
41
1.1
1.1
1.2
Final Result
NodeTask
C
11C
12C
13C
14t
112
13
10
14
t
216
24
13
25
t
326
31
12
33
t
417
24
18
31
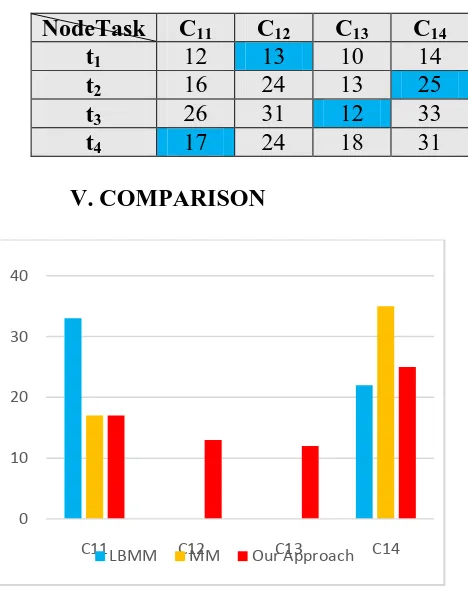
V. COMPARISON
Fig 1.The comparison of completion time of each task at different node for case study.
VI. CONCLUSION
In this paper, we proposed an efficient scheduling algorithm, LBTSSN, for the cloud computing network to assign tasks to computing nodes according to their resource capability. Similarly, our approach can achieve better load balancing and performance than other algorithms, such as, MM and LBMM from the case study.
In this paper, we have presented a new scheduling algorithm for scheduling. The goal of the scheduler in this paper is minimizing makespan and maximizes resources utilization.
ACKNOWLEDGMENT
We would like to express our gratitude to Dr. Kalyani Mali, Head of Department, Computer Science and Engineering of University of Kalyani. Without her assistance and guidance, we would not have been able to
make use of the university’s infrastructure and
laboratory facilities for conducting our research.
REFERENCES
[1] Hung, Che-Lun, Hsiao-hsi Wang, and Yu-Chen Hu. "Efficient Load Balancing Algorithm for Cloud Computing Network." In International Conference on Information Science and Technology (IST 2012), April, pp. 28-30. 2012.
[2] Armstrong, R., Hensgen, D., Kidd, T.: The relative performance of various mapping algorithms is independent of sizable variances in run-time predictions. In: 7th IEEE Heterogeneous Computing Workshop, pp. 79—87, (1998)
[3] Freund, R., Gherrity, M., Ambrosius, S., Campbell, M., Halderman, M., Hensgen, D., Keith, E., Kidd, T., Kussow, M., Lima, J., Mirabile, F., Moore, L., Rust, B., Siegel, H.: Scheduling resources in multi-user, heterogeneous, computing environments with SmartNet. In: 7th IEEE Heterogeneous Computing Workshop, pp. 184—199, (1998)
[4] Freund, R. F., Siegel, H. J. : Heterogeneous processing. IEEE Computer, vol. 26, pp.13—17, (1993) [5] Ritchie, G., Levine, J.: A Fast, Effective Local Search for Scheduling Independent Jobs in Heterogeneous Computing Environments. Journal of Computer Applications, vol. 25, pp. 1190—1192, (2005) [6] Braun, T. D., Siegel, H. J., Beck, N., Bölöni, L. L., Maheswaran, M., Reuther, A. I., Robertson, J. P., Theys, M. D., Yao, B., Hensgen, D., Freund, R. F.: A Comparison of Eleven Static Heuristics for Mapping a Class of Independent Tasks onto Heterogeneous Distributed Computing Systems. Journal of Parallel and Distributed Computing, vol. 61, pp. 810—837, (2001) [7] Wang, S. C., Yan, K. Q., Liao, W. P., Wang, S. S.: Towards a Load Balancing in a threelevel cloud computing network. In: Computer Science and Information Technology, pp. 108—113, (2010).
[8] Ranjan Kumar Mondal, Enakshmi Nandi, and Debabrata Sarddar. "Load Balancing Scheduling with Shortest Load First." International Journal of Grid and Distributed Computing 8.4 (2015): 171-178.
[9] Ranjan Kumar Mondal, Debabrata Sarddar ―Load
Balancing with Task Subtraction of Same Nodes‖.
International Journal of Computer Science and Information Technology Research ISSN 2348-120X (online) Vol. 3, Issue 4, pp: (162-166), Month: October - December 2015.
0 10 20 30 40
AUTHORS PROFILE
Ranjan Kumar Mondal received his M.Tech in Computer Science and Engineering from University of Kalyani, Kalyani, Nadia; and B.Tech in Computer Science and Engineering from Government College of Engineering and Textile Technology, Berhampore, Murshidabad, West Bengal under West Bengal University of Technology, West Bengal, India. At present, he is a Ph.D research scholar in Computer Science and Engineering from University of Kalyani. His research interests include Cloud Computing, Wireless and Mobile Communication Systems.
Payel Ray received her M.Tech in Computer Science and Engineering from Jadavpur University, Jadavpur, India; and B.Tech in Computer Science &Engineeringfrom Murshidabad Collage of Engineering and Tehnology, Berhampore, Murshidabad, West Bengal under West Bengal University of Technology, West Bengal, India. At present, she is a Ph.D research scholar in Computer Science and Engineering from University of Kalyani. Her research interests include Cloud Computing, Wireless Adhoc and Sensor Network and Mobile Communication Systems.