4 BAB II KAJIAN TEORI A. Peringkasan Teks Otomatis
Peringkasan teks merupakan proses untuk mendapatkan ringkasan teks secara otomatis dengan menggunakan bantuan komputer. Ringkasan teks adalah kumpulan kalimat penting dari suatu teks yang menggambarkan inti teks tersebut dan mempunyai informasi teks aslinya. Menurut Niladri (2007:448), peringkasan teks otomatis merupakan penelitian yang penting pada bidang natural language processing.
Alguliev & Aliguliyev (2009:128) mengungkapkan bahwa proses peringkasan teks dapat dibagi menjadi tiga tahap, yakni:
1. Menganalisa teks dan memilih beberapa bagian penting 2. Mengubah hasil analisis menjadi representasi ringkasan
3. Mengubah representasi ringkasan menjadi ringkasan yang sesuai.
Ada dua pendekatan pada peringkasan teks, yakni extract dan abstract. Pada peringkasan extract, ringkasan dihasilkan dengan mengambil beberapa kalimat penting dari teks asli. Banyaknya kalimat yang diambil ditentukan oleh tingkat kompresi ringkasan. Tingkat kompresi adalah perbandingan panjang ringkasan dengan teks asli. Tingkat kompresi merupakan faktor penting dalam menentukan kualitas ringkasan. Semakin kecil tingkat kompresi maka semakin sedikit pula ringkasan yang dihasilkan, namun lebih banyak informasi yang hilang. Sebaliknya, semakin besar tingkat kompresi maka ringkasan menjadi semakin banyak, banyak informasi penting yang dihasilkan. Tingkat kompresi ringkasan dipilih sesuai kebutuhan. Tingkat kompresi yang baik berkisar dari 5% sampai 30% (Mani,
5
2001:14). Pada penelitian ini besar tingkat kompresi yang dipilih adalah 20% agar ringkasan yang dihasilkan tidak terlalu sedikit atau terlalu banyak.
Peringkasan abstract merupakan peringkasan dengan menyertakan kata atau kalimat yang tidak ada pada teks asli. Mani (2001:6) mengungkapkan bahwa abstract mempunyai kemungkinan untuk menghasilkan ringkasan yang lebih sedikit tetapi mempunyai informasi lebih dari ringkasan extract. Akan tetapi, abstract membutuhkan pemahaman yang mendalam mengenai natural language processing seperti semantic representation, inference, dan natural language generation (Ye et al, 2007:1643). Semantic representation berhubungan dengan arti kata dan bagaimana mengombinasikan kata menjadi kalimat yang bermakna. Inference merupakan proses untuk menentukan apakah suatu hipotesis bahasa alami dapat disimpulkan dari suatu premis bahasa alami. Natural language generation merupakan proses menghasilkan kalimat bermakna dalam bentuk bahasa alami dari beberapa representasi.
Berdasarkan banyak sumber teks yang akan diringkas, peringkasan teks dibagi menjadi dua, yakni peringkasan single document dan peringkasan multi document (Dragomir, 2002:400). Pada single document, sumber ringkasan merupakan dokumen tunggal sedangkan multi document meringkas beberapa sumber dokumen. Berdasarkan metodenya, peringkasan teks dapat dibedakan menjadi dua, yakni peringkasan generik dan peringkasan query (Aliguliyev, 2010:423). Peringkasan generik akan menghasilkan ringkasan secara umum sedangkan peringkasan query akan menghasilkan ringkasan sesuai dengan query. Query merupakan kalimat atau topik yang ditentukan oleh pengguna.
6
Banyak penelitian yang sudah dilakukan dalam bidang peringkasan teks. Kebanyakan penelitian menggunakan peringkasan extract karena komputasinya lebih mudah. Beberapa metode yang telah digunakan dalam peringkasan extract pada teks bahasa Inggris, antara lain: Algoritma genetika (Qazvinian et al, 2008), Modified Discrete Differential Evolution (Alguliev & Aliguliyev, 2009), Textrank (Mihalcea & Tarau, 2004). Adapun beberapa metode yang telah diterapkan pada teks bahasa Indonesia, antara lain: Maximum Marginal Relevance (Mustaqhfiri, 2011), Fuzzy (Gerbawani, 2013), dan Non-negative Matrix Factorization (Ridok, 2014).
Pada penelitiannya, Qazvinian et al (2008:442) menyimpulkan bahwa metodenya efisien dalam peringkasan teks. Alguliev & Aliguliyev (2009:136) menyimpulkan bahwa metodenya dapat meningkatkan hasil ringkasan secara signifikan. Mihalcea & Tarau (2004:411) menyimpulkan bahwa penggunaan metode Textrank menghasilkan ringkasan yang lebih baik dibandingkan metode graf lainnya. Penelitian Mustaqhfiri et al (2011:146), menunjukkan hasil tingkat keakuratan sebesar 67.4%. Hasil penelitian Gerbawani (2013:19) menunjukkan bahwa akurasi rata-rata terbaik yang diperoleh adalah sebesar 50.6%. Penelitian Ridok (2014:44) menghasilkan tingkat keakuratan sebesar 64.6%. Penelitian Mustaqhfiri, Gerbawani, dan Ridok menggunakan dokumen teks berita.
B. Jenis Teks Bahasa Indonesia
Menurut Suparno & Yunus (2009:1.11), teks atau karangan dapat disajikan dalam lima jenis, yakni: narasi, deskripsi, eksposisi, argumentasi, dan persuasi. Berikut penjelasan masing-masing jenis teks:
7
1. Narasi: jenis tulisan yang menceritakan proses kejadian atau peristiwa. Sasarannya adalah memberikan gambaran yang jelas kepada pembaca mengenai fase, langkah, urutan, atau rangkaian terjadinya suatu hal.
Contoh teks narasi adalah sebagai berikut:
Ketika aku sedang dalam perjalanan menuju ke sekolah, aku melihat Budi yang sedang berjalan dengan sangat cepat. Dia terlihat seolah – olah dikejar sesuatu, padahal waktu itu jam masih menunjukan pukul 7. Karena merasa penasaran, aku mengikutinya dari belakang. Akan tetapi aku begitu terkejut karena Budi tidak menuju ke sekolah. Aku pun merasa curiga dengan sikapnya. Kemudian aku memanggilnya, dan benar saja wajah Budi terlihat sangat gugup dan ketakutan. Ternyata dia ingin membolos waktu itu, untungnya aku mengetahui rencananya itu sehingga dia membatalkannya.
2. Deskripsi: ragam tulisan yang melukiskan atau menggambarkan sesuatu berdasarkan kesan-kesan dari pengamatan, pengalaman, dan perasaan penulisnya.
Contoh teks deskripsi adalah sebagai berikut:
Tempat tinggalku tidaklah begitu besar. Rumahku hanya memiliki luas sekitar 68 m2. Dengan luas seperti itu, aku hanya memiliki 3 kamar tidur, satu kamar mandi, ruang tamu, keluarga dan dapur. Ruang tidur utamanya terletak di samping ruamg tamu. Sedangkan ruang tidur lainnya berdekatan di dekat ruang keluarga. Sementara itu, dapur rumahku tidak begitu lebar, luasnya hanya sekitar 10 m2. Tepat di tengah – tengah dapurku terdapat meja makan yang terbuat dari kayu. Kamar mandi kami yang hanya satu terletak di samping dapur dekat pintu menuju halaman luar. Meskipun tidak begitu besar, rumahku sangatlah nyaman untuk ditempati.
3. Eksposisi: ragam tulisan yang bertujuan menerangkan, menyampaikan, atau menguraikan sesuatu yang dapat memperluas atau menambah pengetahuan dan pandangan pembacanya.
8
Contoh teks eksposisi adalah sebagai berikut:
Susu adalah minuman yang sangat bermanfaat bagi tubuh. Hal ini dikarenakan susu banyak mengandung vitamin dan mineral yang sangat berguna. Kandungan yang paling banyak di dalam susu adalah kalsium. Zat inilah yang akan membuat tubuh dan tulang kita menjadi kuat. Bahkan susu juga bisa membantu pertumbuhan tulang agar menjadi lebih tinggi. Selain kalsium, susu juga memiliki kandungan protein. Zat ini sangat dibutuhkan untuk membangun sel – sel di dalam tubuh. Terlebih lagi susu juga memiliki lemak, lemak inilah yang akan digunakan sebagai sumber energi di dalam tubuh. Oleh karena itu, meminum susu sangat baik untuk tubuh kita.
4. Argumentasi: ragam wacana yang dimaksudkan untuk meyakinkan pembaca mengenai kebenaran yang disampaikan oleh penulisnya.
Contoh teks argumentasi adalah sebagai berikut:
Setelah Lulus dari SMA, langkah selanjutnya adalah menuju dunia perkuliahan. Di sana Anda akan memilih satu konsentrasi study atau jurusan. Tetapi memilih jurusan perkuliahan tidaklah semudah yang dibayangkan, perlu beberapa pertimbangan agar Anda tidak salah dalam memilihnya. Memilih jurusan haruslah sesuai dengan minat dan bakat karena jika salah dalam mengambil jurusan, maka kehidupan kampus akan terasa sangat sulit. Disamping itu, pilihlah jurusan yang memiliki prospek yang cerah. Jika memilih jurusan yang prospeknya cerah, maka Anda tidak akan kesulitan dalam hal mencari pekerjaan setelah lulus. Oleh karena itu, sebelum memilih jurusan, pertimbangkanlah dengan sangat matang agar tidak salah dalam memilih.
5. Persuasi: karangan yang ditujukan untuk mempengaruhi sikap dan pendapat pembaca mengenai sesuatu hal yang disampaikan penulisannya. Contoh teks persuasi adalah sebagai berikut:
Sampah yang menumpuk adalah sesuatu yang menjijikan. Tumpukan sampah ini bahkan bisa menimbulkan bau yang tidak sedap. Selain itu, tumpukan sampah juga bisa menjadi sarang penyakit. Banyak sekali penyakit yang bisa ditimbulkan dari sampah – sampah yang menumpuk, diantaranya adalah diare, demam berdarah, dan masih banyak lagi. Oleh
9
karena itu, marilah kita bersama – sama membersihkan sampah yang berserakan agar tidak menumpuk sehingga kita semu bisa terbebabas dari bahaya sampah yang bisa ditimbulkan.
C. Preprocessing
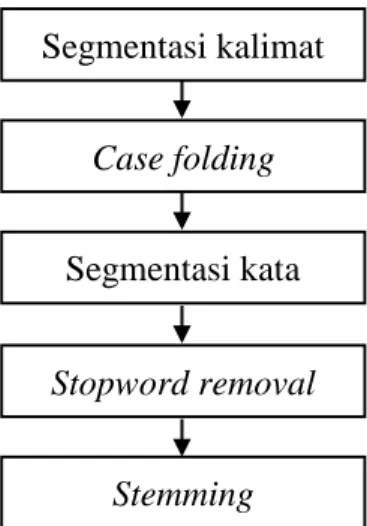
Preprocessing merupakan proses dengan tujuan untuk menyiapkan teks yang akan diringkas sehingga proses peringkasan dapat dilakukan oleh komputer. Ada beberapa tahap pada preprocessing, yakni segmentasi kalimat, case folding, segmentasi kata, stopword removal, dan stemming. Gambar 1 menunjukkan diagram alur dari preprocessing.
Gambar 1. Diagram Alur Preprocessing 1. Segmentasi Kalimat
Segmentasi kalimat merupakan proses untuk memisahkan kalimat dari teks yang akan diringkas. Proses ini memerlukan aturan khusus untuk menentukan batas kalimat. Pada umumnya, batas kalimat adalah titik (.), tanda tanya (?), atau tanda seru (!). Akan tetapi, jika hanya mengandalkan ketiga tanda baca tersebut maka kemungkinan terjadi kesalahan cukup besar. Untuk meminimalkan kesalahan, batas yang digunakan adalah tanda baca diikuti spasi dan huruf kapital. Agar hasil
Segmentasi kalimat Case folding
Segmentasi kata
Stopword removal
10
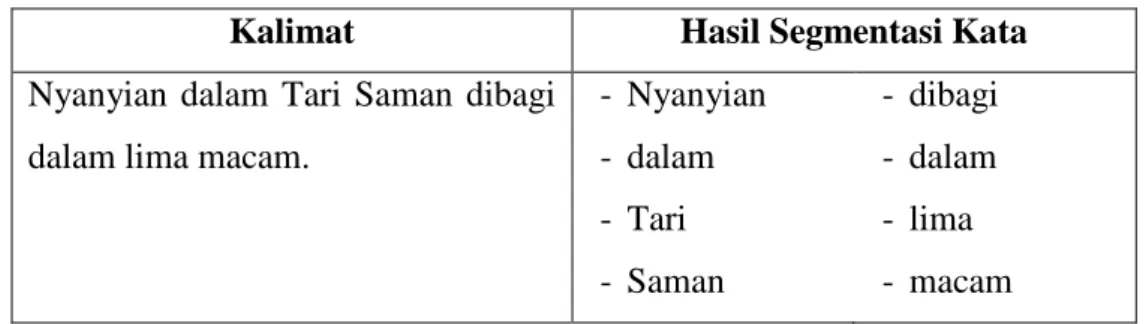
segmentasi lebih akurat maka dipastikan terlebih dahulu kata sebelum tanda baca bukan suatu singkatan. Hal ini bertujuan agar singkatan yang berada di tengah kalimat tidak menjadi akhir kalimat. Tabel 1 menunjukkan contoh segmentasi kalimat.
Tabel 1. Contoh Segmentasi Kalimat
Teks Awal Hasil Segmentasi
Nyanyian dalam Tari Saman dibagi dalam lima macam. Regnum adalah nyanyian berupa suara auman. Dering adalah suara auman yang dilakukan oleh semua penari.
- Nyanyian dalam Tari Saman dibagi dalam lima macam.
- Regnum adalah nyanyian berupa suara auman.
- Dering adalah suara auman yang dilakukan oleh semua penari.
2. Case Folding
Case folding adalah proses mengubah setiap huruf pada kalimat menjadi huruf kecil. Hal ini akan membantu proses pencarian kata yang sama. Tabel 2 menunjukkan contoh case folding.
Tabel 2. Contoh Case Folding
Kalimat Awal Hasil Case Folding
- Nyanyian dalam Tari Saman dibagi dalam lima macam.
- Regnum adalah nyanyian berupa suara auman.
- Dering adalah suara auman yang dilakukan oleh semua penari.
- nyanyian dalam tari saman dibagi dalam lima macam.
- regnum adalah nyanyian berupa suara auman.
- dering adalah suara auman yang dilakukan oleh semua penari.
11 3. Segmentasi Kata
Segmentasi kata adalah proses memisahkan kata pada setiap kalimat. Proses pemisahan kata dapat dilakukan berdasarkan white space (spasi, tab) pada kalimat. Setelah kata berhasil dipisahkan, tanda baca pada awal maupun akhir kata dihapus. Penghapusan tanda baca bertujuan agar proses selanjutnya dapat dilakukan dengan baik. Tabel 3 menunjukkan contoh segmentasi kata.
Tabel 3. Contoh Segmentasi Kata
Kalimat Hasil Segmentasi Kata
Nyanyian dalam Tari Saman dibagi dalam lima macam.
- Nyanyian - dalam - Tari - Saman - dibagi - dalam - lima - macam 4. Stopword Removal
Stopword removal merupakan proses menghilangkan kata-kata tertentu pada kalimat. Kata-kata tersebut kurang mempunyai makna dan banyak muncul pada kalimat. Contoh kata tersebut adalah kata penghubung, kata ganti, dll. Stopword removal dilakukan dengan mencocokkan setiap kata dengan daftar stopword. Jika kata tersebut ada pada daftar stopword maka kata tersebut dihilangkan. Tabel 4 menunjukkan contoh stopword removal.
Tabel 4. Contoh Stopword Removal
Teks awal Hasil Stopword Removal
- Nyanyian dalam Tari Saman dibagi dalam lima macam.
- Nyanyian Tari Saman dibagi lima. - Regnum nyanyian berupa suara
12 - Regnum adalah nyanyian berupa
suara auman.
- Dering adalah suara auman yang dilakukan oleh semua penari.
- Dering suara auman dilakukan penari.
5. Stemming
Stemming merupakan proses mengembalikan kata turunan ke bentuk akar kata (kata dasar) menggunakan aturan tertentu. Pada penelitian ini algoritma stemming yang digunakan adalah algoritma Nazrief & Adriani. Algoritma ini mempunyai tingkat presisi yang tinggi karena berdasarkan morfologi bahasa Indonesia. Algoritma Nazrief & Adriani menggunakan beberapa aturan untuk menghilangkan awalan dan akhiran dari sebuah kata kemudian mencocokkan dengan daftar kata dasar. Semakin lengkap daftar kata maka semakin tinggi akurasi algoritma ini (Ledy, 2009:200). Tabel 5 menunjukkan contoh stemming menggunakan Algoritma Nazrief & Adriani.
Tabel 5. Contoh Stemming
Kata Awal Hasil Stemming
- tari - saman - mengandung - pendidikan - keagamaan - sopan - santun - kepahlawanan - kekompakan - dan - kebersamaan - tari - saman - kandung - didik - agama - sopan - santun - pahlawan - kompak - dan - sama
13
Algoritma Nazrief & Adriani mempunyai tahapan sebagai berikut (Asian, 2007:60):
1. Kata yang ingin dicari kata dasarnya dicek dalam daftar kata dasar. Jika ada dalam daftar, maka kata tersebut adalah adalah kata dasar. Selanjuntnya, untuk setiap akhir langkah di bawah, langkah 1 dilakukan kembali.
2. Penghapusan inflection suffixes (-kah, -lah, -tah, -pun, -ku, -mu, -nya). Jika berupa partikel (-kah, -lah, -tah, -pun), ulangi langkah ini untuk menghapus possesive pronouns (-ku, -mu, -nya).
3. Penghapusan derivative suffixes (-i, -kan, -an).
4. Penghapusan awalan be-, di-, ke-, me-, pe-, se-, dan te-. a. Langkah 4 ini tidak dilakukan bila:
Kata mempunyai gabungan awalan dan imbuhan yang tidak diperbolehkan dalam Tabel 6.
Awalan yang akan dihilangkan, sama dengan awalan yang telah dihilangkan sebelumnya
Awalan telah dihilangkan sebanyak tiga kali
b. Identifikasi tipe awalan dan disambiguitasnya jika diperlukan. Awalan mempunyai dua tipe, yaitu:
plain: awalan di-, ke-, se- dapat dihilangkan secara langsung.
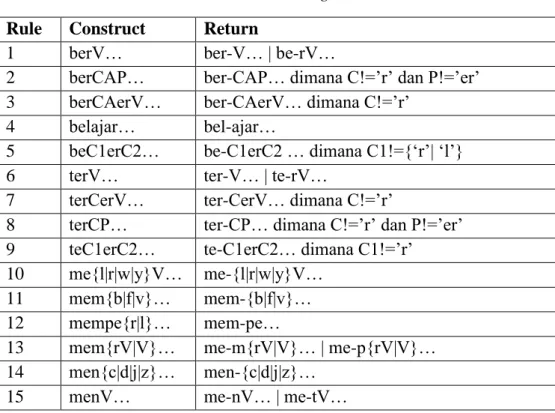
complex: awalan be-, te-, me-, pe- harus dianalisis ambiguitasnya menggunakan Tabel 7. Awalan ini mempunyai bermacam variasi. Awalan me- dapat berubah menjadi mem- atau men- tergantung dari huruf awal akar kata.
14
c. Lakukan langkah 1. Jika bukan merupakan akar kata, maka ulangi langkah 4 ini secara berulang sampai menemukan akar katanya atau sampai kondisi 4a terjadi. Bila kondisi 4a tidak terjadi dan akar kata belum diperoleh, maka lanjutkan ke langkah 5.
5. Apabila sampai langkah 4 akar kata belum ditemukan, lakukan analisis apakah kata tersebut masuk dalam tabel disambiguitas kolom terakhir atau tidak. 6. Apabila semua proses di atas gagal, maka kata awal merupakan kata dasar.
Tabel 6. Kombinasi Awalan dan Akhiran yang Tidak Diperbolehkan Awalan Akhiran yang tidak diperbolehkan
ber- -i di- -an ke- -i -kan me- -an ter- -an per- -an
Tabel 7. Aturan Stemming Prefiks Rule Construct Return
1 berV… ber-V… | be-rV…
2 berCAP… ber-CAP… dimana C!=’r’ dan P!=’er’ 3 berCAerV… ber-CAerV… dimana C!=’r’
4 belajar… bel-ajar…
5 beC1erC2… be-C1erC2 … dimana C1!={‘r’| ‘l’}
6 terV… ter-V… | te-rV…
7 terCerV… ter-CerV… dimana C!=’r’
8 terCP… ter-CP… dimana C!=’r’ dan P!=’er’ 9 teC1erC2… te-C1erC2… dimana C1!=’r’ 10 me{l|r|w|y}V… me-{l|r|w|y}V…
11 mem{b|f|v}… mem-{b|f|v}… 12 mempe{r|l}… mem-pe…
13 mem{rV|V}… me-m{rV|V}… | me-p{rV|V}… 14 men{c|d|j|z}… men-{c|d|j|z}…
15 16 meng{g|h|q}… meng-{g|h|q}…
17 mengV… meng-V… | meng-kV…
18 menyV… meny-sV…
19 mempV… mem-pV… dimana V!=’e’
20 pe{w|y}V… pe-{w|y}V…
21 perV… per-V… | pe-rV…
23 perCAP… per-CAP… dimana C!=’r’ dan P!=’er’ 24 perCAerV… per-CAerV… dimana C!=’r’
25 pem{b|f|v}… pem-{b|f|v}…
26 pem{rV|V}… pe-m{rV|V}… | pe-p{rV|V}… 27 pen{c|d|j|z}… pen-{c|d|j|z}…
28 penV… pe-nV… | pe-tV…
29 peng{g|h|q}… peng-{g|h|q}…
30 pengV… peng-V… | peng-kV…
31 penyV… peny-sV…
32 pelV… pe-lV… pengecualian untuk “pelajar”, kembalikan ajar
33 peCerV… per-erV… dimana C!={r|w|y|l|m|n}
34 peCP… pe-CP… dimana C!={r|w|y|l|m|n} dan P!=’er’ Keterangan:
V = vokal C = konsonan
P = bagian kecil kata misal “er”
Pada penelitiannya, Asian (2007:76) mengusulkan beberapa aturan tambahan untuk meningkatkan keakuratan algoritma Nazief & Adriani. Aturan tambahan tersebut adalah:
1. Aturan kata plural
Jika kata yang dihubungkan sama, maka kata dasar adalah salah satu kata tersebut. Contoh “buku-buku” menjadi “buku”. Jika ditemukan kata seperti “bolak-balik”, “suap-menyuap” dll, maka masing-masing kata di-stem, jika hasil stem sama, maka hasil stem tersebut merupakan kata dasar. Jika hasil stem tidak sama, maka kata awal adalah kata dasar.
16 2. Kondisi tambahan
Aturan tambahan dapat dilihat pada Tabel 8. Penjelasan masing-masing aturan tambahan adalah sebagai berikut:
Pada awalan te-, ditambahkan Rule 35 sehingga kata seperti “terpercaya” dapat di-stem menjadi “percaya”.
Pada awalan pe-, ditambahkan Rule 36 sehingga kata seperti “pekerja” dapat di-stem menjadi “kerja”.
Pada awalan me-, Rule 12 dimodifikasi sehingga kata seperti “mempengaruhi” dapat di-stem menjadi “pengaruh”.
Pada awalan me-, Rule 16 dimodifikasi sehingga kata seperti “mengkritik” dapat di-stem menjadi “kritik”.
Tabel 8. Aturan Tambahan dan Aturan yang Diubah Rule Construct Return
35 terC1erC2… ter-C1erC2… dimana C1 != ‘r’
36 peC1erC2… pe-C1erC2… dimana C!={r|w|y|l|m|n}
12 mempe… mem-pe…
16 meng{g|h|q|k}… meng-{g|h|q|k}… 3. Pengubahan urutan algoritma
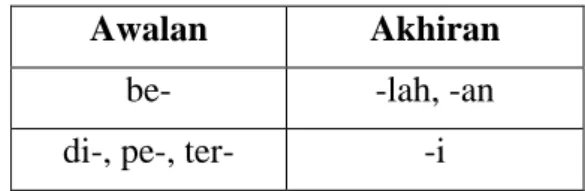
Urutan algoritma dapat mempengaruhi hasil stemming. Sebagai contoh kata “bertingkah” akan di-stem menjadi “ting”, bukan “tingkah”. Pada kata seperti itu, untuk mendapatkan hasil yang benar urutannya adalah hapus prefiks kemudian hapus sufiks. Kata yang menggunakan aturan ini adalah kata yang mempunyai kriteria pada Tabel 9.
17
Tabel 9. Kombinasi Awalan dan Akhiran Syarat Urutan Algoritma Diubah
Awalan Akhiran
be- -lah, -an
di-, pe-, ter- -i
D. Klasterisasi Kalimat (Alguliev & Aliguliyev, 2009)
Klasterisasi adalah proses mengelompokkan data berdasarkan perhitungan kemiripan data (Alguliev & Aliguliyev, 2009:130). Klasterisasi dipelajari secara mendalam pada banyak bidang seperti text mining, pattern recognition, information retrieval (IR), dan sebagainya. Klasterisasi dokumen merupakan masalah utama pada text mining dan dapat didefinisikan sebagai upaya mengelompokkan dokumen ke dalam klaster berdasarkan topik atau konten utamanya. Klasterisasi dokumen juga berguna untuk membuat ringkasan, ekstraksi topik otomatis, deteksi topik, dan manajemen informasi pada perpustakaan digital (Aliguliyev, 2010:425).
Alguliev & Aliguliyev (2009:130) mengungkapkan bahwa ada tiga syarat utama pada klasterisasi kalimat, yaitu:
1. Dua klaster yang berbeda tidak mempunyai kalimat yang sama di dalamnya. 2. Setiap kalimat harus termuat dalam klaster
3. Setiap klaster harus mempunyai minimal satu kalimat
Li (2006:199) mengungkapkan bahwa klasterisasi mempunyai empat komponen dasar, yaitu:
a. Representasi data b. Perbedaan antar data c. Fungsi objektif
18 d. Prosedur optimasi
Pada klasterisasi kalimat, komponen perbedaan antar data diganti dengan kemiripan kalimat selain itu, prosedur optimasi pada penelitian ini menggunakan Modified Discrete Differential Evolution. Penjelasan lebih lanjut mengenai komponen dalam klasterisasi kalimat adalah sebagai berikut:
1. Representasi Data
Teks merupakan himpunan kalimat, sehingga teks 𝐷 dapat direpresentasikan sebagai berikut: 𝐷 = {𝑆1, 𝑆2, 𝑆3, … , 𝑆𝑛}. 𝑆𝑖 = {𝑡1, 𝑡2, 𝑡3, … , 𝑡𝑚𝑖}, dengan 𝑆𝑖 mewakili kalimat dan 𝑡𝑗 mewakili kata yang berbeda.
2. Kemiripan Kalimat
Penghitungan kemiripan kalimat mempunyai peran penting pada NLP dan IR. Kemiripan kalimat digunakan di penelitian tentang teks seperti text mining, information retrieving, peringkasan teks, dan klasterisasi teks. Salah satu metode yang dapat digunakan untuk menghitung kemiripan kalimat adalah metode Normalized Google Distance (NGD). Metode ini menghitung kemiripan kalimat berdasarkan kesamaan kata yang muncul pada dua kalimat. Sebelum menghitung kemiripan kalimat, kemiripan antar kata (term) dihitung terlebih dahulu. Menurut Alguliev & Aliguliyev (2009:131), kesamaan term menggunakan NGD adalah sebagai berikut:
𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) = exp(−𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙))
dimana
𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) =
max{log(𝑓𝑘) , log(𝑓𝑙)} − log(𝑓𝑘𝑙) 𝑛 − min{log(𝑓𝑘) , log(𝑓𝑙)}
(1)
19 Keterangan :
𝑡𝑘, 𝑡𝑙=term
𝑓𝑘=banyak kalimat yang memuat term 𝑘 𝑛=banyak kalimat
Berdasarkan Persamaan (1), persamaan tingkat kemiripan antar kalimat 𝑆𝑖 dan 𝑆𝑗 adalah sebagai berikut:
𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗) =∑𝑡𝑘∈𝑆𝑖∑𝑡𝑙∈𝑆𝑗𝑠𝑖𝑚𝑁𝐺𝐷(𝑡𝑘, 𝑡𝑙) 𝑚𝑖𝑚𝑗
Keterangan:
𝑚𝑖=banyak term pada kalimat 𝑖 3. Fungsi Objektif
Klasterisasi membutuhkan fungsi objektif untuk menentukan klasterisasi sudah optimal atau belum. Berdasarkan penelitian Alguliev & Aliguliyev (2009:131), fungsi objektif klasterisasi kalimat adalah:
𝐹 = (1 + 𝑠𝑖𝑔𝑚(𝐹1)) 𝐹2
𝑠𝑖𝑔𝑚 merupakan fungsi sigmoid yang memetakan bilangan nyata ke [0,1].
𝑠𝑖𝑔𝑚(𝑧) = 1
1 + exp(−𝑧)
Persamaan (4) menyeimbangkan kemiripan intra-klaster dan ketidakmiripan antar klaster berikut:
𝐹1 = ∑|𝐶𝑝| ∑ 𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗) 𝑆𝑖,𝑆𝑗∈𝐶𝑝 𝑘 𝑝=1 𝐹2 = ∑ 1 |𝐶𝑝| ∑ 1 |𝐶𝑞| 𝑘 𝑞=𝑝+1 ∑ ∑ 𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗) 𝑆𝑗∈𝐶𝑞 𝑆𝑖∈𝐶𝑝 𝑘−1 𝑝=1 Keterangan: 𝐶𝑃 = 𝐾𝑙𝑎𝑠𝑡𝑒𝑟 (3) (4) (5) (6) (7)
20
Persamaan (6) menentukan kemiripan intra-klaster dan Persamaan (7) menentukan ketidakmiripan antar klaster.
4. Modified Discrete Differential Evolution
Modified Discrete Differential Evolution (MDDE) adalah modifikasi dari metode Differential Evolution (DE). DE merupakan metode untuk menyelesaikan masalah optimasi yang diperkenalkan oleh Rainer Storn dan Kenneth Price pada tahun 1997. Metode ini merupakan salah satu metode evolutionary selain algoritma genetika dan fuzzy. Tahapan pada DE adalah inisialisasi populasi, evaluasi fitness, mutasi, crossover, dan seleksi (Storn & Prince, 1997).
Ada beberapa perbedaan antara MDDE dan DE, yaitu: setiap elemen pada populasi MDDE menggunakan bilangan asli, mutasi berdasarkan algoritma genetika, dan tidak ada tahap crossover. Penggunaan bilangan asli pada MDDE memudahkan klasterisasi karena setiap elemen dapat mewaliki suatu klaster.
Setiap elemen pada MDDE bernilai diantara 1 sampai k, dimana 𝑘 mewakili banyak klaster. Inisialisasi populasi pada MDDE dilakukan dengan membuat populasi berisi serangkaian nilai acak dari 1 sampai 𝑘. Representasi sebuah populasi adalah sebagai berikut:
𝑋𝑟(𝑡) = [𝑥𝑟,1(𝑡), 𝑥𝑟,2(𝑡), 𝑥𝑟,3(𝑡), … , 𝑥𝑟,𝐷(𝑡)] 𝑥𝑟,𝑠(𝑡) ∈ {1,2, …, 𝑘} 𝑟 = 1,2,3, … , 𝑁&𝑠 = 1,2,3, …, 𝐷 Keterangan: 𝑡=generasi 𝑁=banyak populasi 𝑘=banyak klaster
𝐷=banyak elemen / banyak kalimat
21
Sebagai contoh, misalkan banyak kalimat=6, banyak klaster=2, dan banyak populasi =3, maka contoh populasinya adalah:
𝑋1(𝑡) = [1,2,1,2,2,1], 𝑋2(𝑡) = [2,1,2,1,1,2], 𝑋3(𝑡) = [2,1,1,1,2,2]
Populasi 𝑋1(𝑡) mempunyai makna kalimat 1,3,6 berada pada klaster 1 dan kalimat 2,4,5 berada pada klaster 2.
Setelah populasi awal dibuat, perhitungan fitness dilakukan. Perhitungan fitness dilakukan untuk menentukan kualitas dari masing-masing populasi. Berdasarkan Persamaan (4), (6), dan (7), fitness yang sesuai adalah:
𝐹𝑖𝑡𝑛𝑒𝑠𝑠(𝑋𝑟(𝑡)) = 𝐹(𝑋𝑟(𝑡)) 𝑓𝑖𝑡𝑛𝑒𝑠𝑠1(𝑋𝑟(𝑡)) = 𝐹1(𝑋𝑟(𝑡))
𝑓𝑖𝑡𝑛𝑒𝑠𝑠2(𝑋𝑟(𝑡)) =
1 𝐹2(𝑋𝑟(𝑡))
Tahap selanjutnya pada MDDE adalah mutasi. Untuk setiap populasi 𝑋𝑟(𝑡), dibuat populasi 𝑀𝑟(𝑡 + 1) = [𝑚𝑟,1(𝑡 + 1), 𝑚𝑟,2(𝑡 + 1), , … , 𝑚𝑟,𝐷(𝑡 + 1)], yang didefinisikan sebagai berikut:
𝑚𝑟,𝑠(𝑡 + 1) = {1, 𝑟𝑛𝑑(𝑠) < 𝑠𝑖𝑔𝑚 (𝑦𝑟,𝑠(𝑡 + 1)) 0, 𝑟𝑛𝑑(𝑠) ≥ 𝑠𝑖𝑔𝑚 (𝑦𝑟,𝑠(𝑡 + 1))
𝑀𝑟(𝑡 + 1) merepresentasikan perubahan yang diperlukan untuk mentransformasi 𝑋𝑟(𝑡) menjadi 𝑌𝑟(𝑡 + 1). 𝑌𝑟(𝑡 + 1) merupakan calon populasi generasi selanjutnya. Jika 𝑚𝑟,𝑠(𝑡 + 1) = 1 maka elemen tersebut akan disalin dari 𝑋𝑟(𝑡) ke 𝑌𝑟(𝑡 + 1). Jika 𝑚𝑟,𝑠(𝑡 + 1) = 0 maka elemen tersebut dimutasi. Proses
mutasi adalah dengan melakukan inversi posisi elemen 𝑋𝑟(𝑡) yang mempunyai (9)
(11)
(12) (10)
22
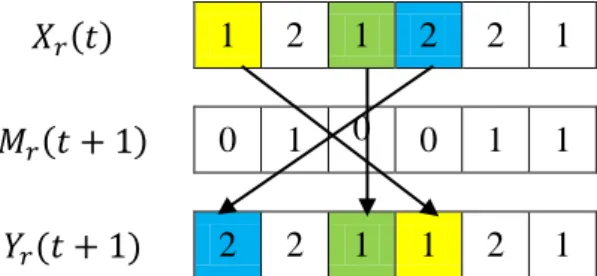
elemen nol pada populasi 𝑀𝑟(𝑡 + 1). Contoh proses inversi ditunjukkan pada Gambar 2 sebagai berikut:
𝑋𝑟(𝑡) 1 2 1 2 2 1 𝑀𝑟(𝑡 + 1) 0 1 0 0 1 1 𝑌𝑟(𝑡 + 1) 2 2 1 1 2 1
Gambar 2. Contoh Proses Inversi
Setelah populasi hasil mutasi terbentuk, selanjutnya dilakukan proses seleksi. Nilai fitness populasi hasil mutasi dibandingkan dengan nilai fitness populasi awal. Populasi dengan nilai fitness lebih besar dipilih menjadi populasi generasi selanjutnya. Proses seleksi didefinisikan sebagai berikut:
𝑋𝑟(𝑡 + 1) = {𝑌𝑟(𝑡 + 1) , 𝑓(𝑌𝑟(𝑡 + 1)) < 𝑓(𝑋𝑟(𝑡)) 𝑋𝑟(𝑡) , 𝑓(𝑌𝑟(𝑡 + 1)) ≥ 𝑓(𝑋𝑟(𝑡))
Kriteria penghentian MDDE dapat menggunakan batas waktu CPU atau batas generasi maksimal (𝑡𝑚𝑎𝑥). Setelah generasi optimal didapatkan, dipilih populasi dengan nilai fitness terbesar. Populasi tersebut merupakan hasil klasterisasi yang akan digunakan pada pemilihan kalimat penting.
E. Pemilihan Kalimat Penting (Aliguliyev, 2010)
Pada peringkasan teks menggunakan klasterisasi kalimat, masing-masing klaster dipilih satu kalimat yang mewakili klaster tersebut. Perhitungan kalimat terpenting pada setiap klaster menggunakan fungsi bobot rata-rata kalimat pada klaster sebagai berikut:
23 𝑑𝑒𝑔𝐶𝑝(𝑆𝑖) = 1
|𝐶𝑝|
∑ 𝑠𝑖𝑚𝑁𝐺𝐷(𝑆𝑖, 𝑆𝑗), 𝑖 ≠ 𝑗
𝑆𝑗∈𝐶𝑃
Kalimat dengan nilai 𝑑𝑒𝑔𝐶𝑝 terbesar setiap klaster merupakan kalimat yang akan ditampilkan pada ringkasan.
F. Evaluasi Ringkasan (Steinberger & Jeˇzek, 2009)
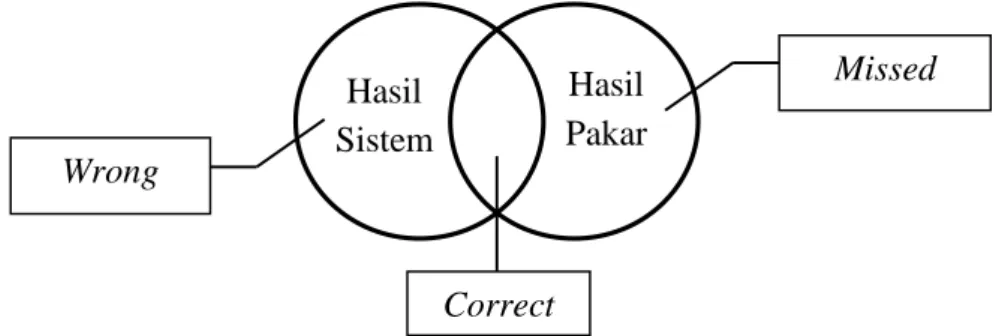
Pada dasarnya, evaluasi ringkasan dilakukan dengan membandingkan hasil ringkasan sistem dengan hasil ringkasan pakar. Kalimat yang ada pada ringkasan pakar dan ringkasan sistem dinamakan correct. Kalimat hasil ringkasan pakar yang tidak ada dalam ringkasan sistem dinamakan missed. Kalimat hasil ringkasan sistem yang tidak termasuk dalam ringkasan pakar dinamakan wrong. Gambar 3 di bawah ini menunjukkan hubungan ketiga variabel di atas.
Gambar 3. Hubungan Ringkasan Sistem dan Ringkasan Pakar
Dari ketiga variabel di atas, persamaan untuk menghitung akurasi sistem sebagai berikut:
Precision
Precision (𝑃) adalah perbandingan kalimat yang sama-sama muncul pada ringkasan sistem dan ringkasan pakar dengan banyak kalimat di ringkasan pakar.
𝑃 = 𝑐𝑜𝑟𝑟𝑒𝑐𝑡 𝑐𝑜𝑟𝑟𝑒𝑐𝑡 + 𝑤𝑟𝑜𝑛𝑔 Wrong Missed Correct (14) (15) Hasil Pakar Hasil Sistem
24 Recall
Recall (R) adalah perbandingan kalimat yang sama-sama muncul pada ringkasan sistem dan ringkasan pakar dengan banyak kalimat di ringkasan sistem.
𝑅 = 𝑐𝑜𝑟𝑟𝑒𝑐𝑡
𝑐𝑜𝑟𝑟𝑒𝑐𝑡 + 𝑚𝑖𝑠𝑠𝑒𝑑 F-Score
F-Score merupakan hubungan antara precision dan recall yang menyatakan akurasi sistem peringkasan.
F-Score
=
𝑃+𝑅2𝑃𝑅G. Sistem
Menurut Kadir (2003:54), sistem adalah sekumpulan elemen yang saling terkait atau terpadu untuk mencapai tujuan. Sedangkan menurut Jogiyanto (2005:2), sistem adalah sekumpulan elemen-elemen yang berinteraksi untuk mencapai suatu tujuan tertentu.
Berdasarkan pendapat di atas, sistem merupakan sekumpulan elemen yang saling terkait dan berinteraksi untuk mencapai tujuan tertentu. Menurut Jogiyanto (2005:3-5) sistem mempunyai karasteristik atau sifat-sifat tertentu, yaitu:
1. Komponen Sistem : suatu sistem terdiri dari sejumlah komponen yang saling berinteraksi, yang artinya saling kerjasama membentuk satu kesatuan.
(16)
25
2. Sifat-sifat : sistem itu terdiri untuk menjalankan fungsi tertentu dan mempunyai sistem yang lain secara keseluruhan.
3. Batasan (Boundary) Sistem : daerah yang membatasi antara suatu sistem dengan sistem yang lainnya.
4. Lingkungan Luar Sistem (Environment) : apapun diluar batasan sistem yang mempengaruhi operasi sistem, lingkungan luar sistem dapat bersifat menguntungkan dan juga dapat bersifat merugikan sistem tersebut.
5. Penghubung (Interface) Sistem : media penghubung antara suatu subsistem dengan subsistem lainya.
6. Masukkan Sistem (Input) : energi yang dimasukkan kedalam sistem, masukan dapat berupa masukkan perawatan (Maintenace Input), dan masukkan sinyal (Signal Input), maintenance input adalah energi yang dimasukkan supaya sistem tersebut dapat beroperasi. Sedangkan signal input adalah energi yang di proses untuk mendapatkan keluaran.
7. Keluaran Sistem (Output) : hasil energi yang diolah dan di klasifikasikan menjadi keluaran yang berguna dan sisa pembuangan keluaran dapat merupakan masukan untuk subsistem yang lain kepada supra sistem. 8. Sasaran Sistem : suatu sistem pasti memiliki sasaran atau tujuan (Goal).
Sasaran dari sistem sangat menentukan sekali masukan yang dibutuhkan sistem dan keluaran yang akan di hasilkan sistem.
H. Model Perancangan Sistem
Perancangan sistem merupakan pengembangan sistem baru untuk mengatasi masalah pada sistem yang lama. Model perancangan sistem yang akan
26
dipakai pada penelitian ini adalah metode analisis sistem terstruktur atau model Waterfall. Tahapan pada model Waterfall disusun bertingkat dan dilakukan secara berurutan. Ada empat tahapan pada model Waterfall, yakni: Analysis, Design, Code, dan Test (Pressman, 2001:28). Tahapan pada model Waterfall dapat disajikan pada Gambar 4 sebagai berikut:
Gambar 4. Tahapan Model Waterfall
Uraian tahap-tahap pada model Waterfall adalah sebagai berikut:
1. Analysis adalah tahap menganalisa hal-hal yang diperlukan dalam pelaksanaan perancangan sistem.
2. Design adalah tahap penerjemah atau tahap perancangan dari keperluan-keperluan yang dianalisis dalam bentuk yang lebih mudah dimengerti oleh pemakai.
3. Code adalah tahap implementasi dari hasil sistem yang telah dirancang dalam bahasa pemrograman yang telah ditentukan dan digunakan dalam pembuatan sistem.
4. Test adalah tahap pengujian terhadap program yang telah dibuat. Pengujian dilakukan agar fungsi-fungsi dalam sistem bebas dari error, dan hasilnya
System / Information Engineering
27
harus benar-benar sesuai dengan kebutuhan yang sudah didefinisikan sebelumnya.
I. Diagram Sequence
Diagram sequence menggambarkan interaksi antar objek secara berurutan di dalam sebuah sistem (Bell, 2004). Tujuan utama diagram sequence adalah untuk mendefinisikan urutan kejadian untuk mendapatkan output dari suatu proses. Diagram sequence terdiri atas dimensi vertikal (waktu) dan dimensi horizontal (objek yang terkait). Simbol-simbol yang digunakan dalam diagram sequence ditunjukkan pada Tabel 10 di bawah ini:
Tabel 10. Simbol Pada Diagram Sequence
Simbol Keterangan Actor Boundary Control Entity Object Message Message to Self Return Message Lifeline
Penjelasan masing-masing simbol adalah sebagai berikut:
Actor menggambarkan seseorang atau sesuatu yang berinteraksi dengan sistem.
28
Boundary menggambarkan interaksi antara satu atau lebih actor dengan sistem, memodelkan bagian dari sistem yang bergantung pada pihak di sekitarnya dan merupakan pembatas dari dunia luar.
Control menggambarkan “perilaku mengatur”, mengoordinasikan perilaku sistem dan dinamika dari suatu sistem, menangani tugas utama, dan mengontrol alur kerja suatu sistem.
Entity menggambarkan informasi yang harus disimpan oleh sistem. Object Message menggambarkan pesan/hubungan antar objek. Message to Self menggambarkan pesan/hubungan obyek itu sendiri. Return Message menggambarkan pesan/hubungan antar objek. Lifeline menggambarkan eksekusi objek.
J. Pengujian Sistem
Pengujian merupakan metode yang dilakukan untuk menjelaskan mengenai pengoperasian perangkat lunak. Pengujian sistem yang dilakukan adalah pengujian Betha. Pengujian ini bersifat objektif dan dilakukan oleh pengguna/user.
Hasil pengujian Betha berupa persentase dan dicari dengan menggunakan persamaan sebagai berikut:
𝑌 = (𝑃
𝑄) × 100% Keterangan :
𝑌 = Nilai persentase
𝑃 = Banyaknya jawaban responden tiap soal 𝑄 = Total responden
29
Ada beberapa faktor yang mempengaruhi kualitas sistem. Faktor yang sering digunakan oleh pengembang software adalah faktor McCall (Indrajit, 2012:2). Faktor-faktor McCall tersebut adalah:
1. Correctness: sejauh mana suatu perangkat lunak memenuhi keinginan dari user.
2. Reliability: sejauh mana suatu perangkat lunak dapat diharapkan untuk melaksanakan fungsinya dengan ketelitian yang diperlukan.
3. Efficiency: banyaknya sumber daya komputasi dan kode program yang dibutuhkan suatu perangkat lunak untuk melakukan fungsinya.
4. Integrity: sejauh mana akses ke perangkat lunak dan data oleh pihak yang tidak berhak dapat dikendalikan.
5. Usability: usaha yang diperlukan untuk mempelajari, mengoperasikan, menyiapkan input, dan mengartikan output dari perangkat lunak.
6. Maintainability: usaha yang diperlukan untuk menetapkan dan memperbaiki kesalahan dalam program.
7. Testability: usaha yang diperlukan untuk menguji program untuk memastikan bahwa program melaksanakan fungsi yang ditetapkan.
8. Flexibility: usaha yang diperlukan untuk memodifikasi program operasional. 9. Portability: usaha yang diperlukan untuk memindahkan program dari
perangkat keras / lingkungan sistem perangkat lunak tertentu ke yang lainnya. 10. Reusability: tingkat kemampuan program / bagian dari program yang dapat dipakai ulang dalam aplikasi lainnya, berkaitan dengan paket dan lingkup dari fungsi yang dilakukan oleh program.
30
11. Interoperability: usaha yang diperlukan untuk menggabungkan satu sistem dengan yang lainnya.
K. PHP
Pada mulanya, PHP merupakan singkatan dari Personal Home Page. PHP diciptakan oleh Rasmus Lerdorf pada tahun 1994 untuk melacak pengunjung resume online miliknya. Seiring meningkatnya kemampuan dan kegunaan PHP, PHP memiliki makna baru, yakni PHP: Hypertext Preprocessor (Ullman, 2011:ix). Berdasarkan situs resminya, PHP merupakan bahasa pemrograman yang cocok dengan web development dan dapat dilekatkan pada HTML.
PHP merupakan bahasa pemrograman pada sisi server, sehingga PHP berjalan di server dan mengirimkan informasi yang sesuai ke browser. PHP merupakan alat yang tepat untuk membuat halaman web dinamis. Diagram proses antara client, server, dan PHP ditunjukkan pada Gambar 5.
Gambar 5. Diagram Proses PHP Client PHP Server Script Request HTML URL Request HTML