Laporan Projek
Perbandingan Hasil Klasifikasi Teks Menggunakan Stopwords dan Tanpa
Stopwords Menggunakan SVM
ditulis untuk melengkapi tugas ujian akhir semester matakuliah teks dan web mining
Oleh
AHMAD ARIFUL AMRI 1108107010054
UNIVERSITAS SYIAH KUALA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
BANDA ACEH, DARUSSALAM
Pendahuluan
Pemanfaatan ilmu teks dan web mining pada projek ini yaitu mencari perbandingan hasil klasifikasi menggunakan SVM pada data uji yang diproses menggunakan stop removal dan tanpa menggunakan stopword removal. Himpunan data yang diuji adalah kumpulan teks hasil ekstrak file html yang didapatkan dari berbagai portal berita di dunia maya. Kumpulan teks tersebut dibagi menjadi kelas positif dan negatif. Untuk kelas positifnya mengambil tema mengenai korupsi, sedangkan kelas negatifnya mengenai segala hal selain korupsi (Kategori umum).
Menurut Liu (2007), web mining bertujuan untuk menemukan informasi atau pengetahuan yang bermanfaat dari struktur web hyperlinks, halaman web, dan data penggunaan web. Istilah lainnya yang berkaitan erat dengan web mining yaitu klasifikasi. Menurut Pramodiono (2003), classification(klasifikasi) adalah proses untuk menemukan model yang membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui. Namun pada projek ini hanya akan dibahas efek dari menggunakan stopword saja tanpa menerawang lebih lanjut label dari suatu objek menggunakan informasi hasil klasifikasi.
Projek ini dilakukan untuk mengetahui seberapa besar pengaruh hasil akurasi klasifikasi pada dataset yang memperhitungkan stopword dan tanpa stopword. Sehingga didapatkan perbandingan pengaruh stopword dalam klasifikasi. Stoplist/stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contoh
stopwords adalah “yang”, “dan”, “di”, “dari” dan seterusnya (Triawati, 2009).
Selain kata penghubung, stopword juga dapat terdiri dari beberapa kata keterangan atau yang lainnya. Menurut (Kabul, 2012) contoh dari Stopword List dalam bahasa indonesia antara lain:
1. Kata penghubung (sesudah,selesai,sebelum) 2. Kata tugas (bagi, dari, dengan, pada)
3. Kata keterangan (sangat, hanya, lebih) 4. Kata bilangan ( beberapa, banyak, sedikit) 5. Kata ganti ( kami, mereka, kita, itu) 6. dan lain sebagainya.
Kajian terkait
Ada beberapa kajian yang sudah pernah dilakukan dan telah dipublikasikan salah satunya para mahasiswa program pascasarjana dalam seminarnya mengenai klasifikasi yang di dalamnya menyinggung masalah penggunaan stopword pada seminar Elektro Nasional, Informatika dan Edukasi pada tahun 2009 yang mengangkat judul “Klasifikasi Dokumen
Teks Berbahasa Indonesia Menggunakan Naïve Bayes” oleh Joko Samodara, Surya Sumpeno
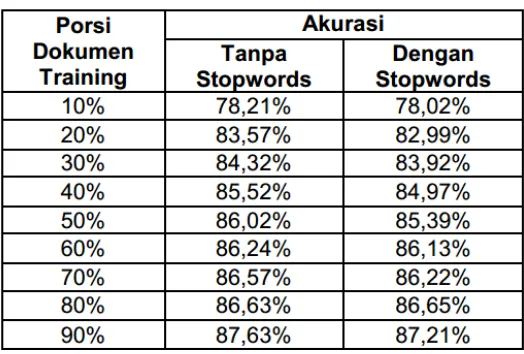
dan Mochamad Hariadi. Salah satu bagian yang dibahas dalam seminar tersebut yaitu nilai akurasi naïve bayes yang dibangun dari produk training tanpa stopword dan yang menggunakan stopword. Hasil yang didapatkan menunjukkan tingkat keakurasian hampir sama, perbedaannya kecil sekali.
Gambar 1 - tabel nilai akurasi naïve bayes dengan berbagai proporsi dokumen training. seminar Elektro Nasional, Informatika dan Edukasi, 2009 oleh ” oleh Joko Samodara, Surya Sumpeno dan Mochamad Hariadi
Kajian lainnya mengenai topik projek ini juga pernah disinggung dalam jurnal yang
berjudul “Pemanfaatan Teknik Supervised Untuk Klasifikasi Teks Berbahasa Indonesia”
Metodelogi
bangun fitur. Untuk percobaan yang menggunakan stopword akan dilakukan pengecekan pada file teks yang telah berisi kumpulan stopword. Untuk yang tidak menggunakan stopword, maka pengecekan kumpulan stopword akan dilewatkan.
Berikut langkah-langkah yang dilakukan dalam pengerjaan projek ini adalah sebagai berikut:
Pengumpulan data. Data diperoleh dengan mengunduh ribuan halaman web dari berbagai situs portal berita Indonesia yang membahas kategori korupsi sebagai label positif dan kategori non korupsi sebagai label negatif. Sehingga keseluruhannya diperoleh 11.000 data untuk label positif dan 11.000 data untuk label negatif.
Extractcontent, tahap ini yaitu melakukan pembersihan terhadap halaman web yang sudah didapatkan sebelumnya. Extracontent ini dilakukan untuk mengambil bagian konten atau isi artikel/berita suatu halaman web sekaligus menghilangkan sintaks-sintaks html yang ada didalamnya hingga menyisakan plain teks saja. Selain bagian konten bagian judul juga diambil untuk dinilai.
Membangun kamus 1-gram, 2-gram dan 3-gram untuk label positif dan negatif. Setiap kata gram yang dibangun memiliki bobot tersendiri yang akan mempengaruhi hasil klasifikasi. Untuk percobaan tanpa stopword, proses pengecekan dan penghapusan stopword dihilangkan. Setelah tahap ini dilanjutkan dengan mengeliminasi kata duplikat untuk rasio threshold 50% untuk masing-masing gram.
Rasio yang dimaksud adalah rasio antara jumlah frekuensi dari kata yang yang ditemukan di kamus label positif dan jumlah frekuensi dari kata yang sama di kelas negatif yang telah dinormalisasi. Cara kerjanya : bobot hasil normalisasi kedua kata dibandingkan, nilai terbesar dijadikan sebagai penyebut. Jadinya nilai terkecil akan membagi nilai terbesar. Didapatkan hasilnya, lalu dibandingkan dengan rasio yang telah ditentukan. Kedua kata akan dihilangkan dari kedua kamus jika hasil dari pembagian tersebut lebih besar dari nilai rasio threshold, karena kata umum di kedua kamus. Sebaliknya, jika didapatkan hasil baginya lebih kecil dari 0.5, maka lihat kembali nilai normalisasi kedua kata, bandingkan keduanya dan hapus nilai yang terkecilnya. Keluaran dari tahap ini yaitu kamus label positif dan negative tanpa ada kata yang duplikat di masing-masing kamus.
4 bagian x 3 jenisgram x 2 kategori = 24 fitur
Bagian konten dibagi 3 bagian yaitu bagian atas, tengah dan bawah. Setiap bagian diberi bobot yang berbeda dengan asumsi bagian atas konten Web lebih penting dari bagian tengah, dan bagian tengah konten lebih penting dari pada bagian bawah Web, pada permasalahan ini diberi bobot 0.5 untuk konten bagian atas, 0.3 untuk konten bagian tengah dan 0.2 untuk konten bagian bawah.
Klasifikasi, tahapan klasifikasi terbagi 2, ada training dan testing. data training digunakan untuk mencari pemodelan yang tepat. Sedangkan data testing digunakan untuk menguji pemodelan. Jumlah data training dalam pengerjaan projek ini berjumlah 5000 data dan data testing berjumlah 1000 data. Dalam pengujian menggunakan SVM light. Data training diuji mengunakan svm_learn dan data testing diuji menggunakan svm_classify.
Hasil
1. Menggunakan stopword removal
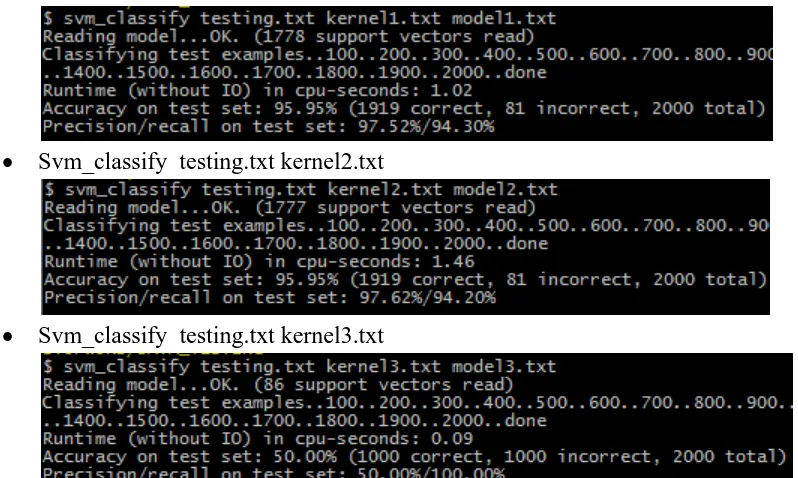
Ada 4 parameter fungsi kernel yang di uji coba, yaitu linear, polynomial, radial basis dan sigmoid tanh. Klasifikasi dilakukan menggunakan svm light. Berikut hasil yang didapatkan untuk menguji data training dan testing.
Data Training
Svm_learn –t 0 training.txt kernel0.txt
Svm_learn –t 1 training.txt kernel1.txt
Svm_learn –t 2 training.txt kernel2.txt
Svm_learn –t 3 training.txt kernel3.txt
Data Testing
Svm_classify testing.txt kernel0.txt model0.txt
Svm_classify testing.txt kernel2.txt
Svm_classify testing.txt kernel3.txt
Tabel hasil klasifikasi data uji dengan stopword removal menggunakan SVM Light
Kernel Recall Presisi Accuracy Correct Incorrect
Linear 93,50% 97,91% 95,75% 1915 85
Polynomial 94,30% 97,52% 95.95% 1919 81
Radial 94,20% 97,62% 95,95% 1919 81
Sigmoid 100% 50% 50% 1000 1000
2. Tanpa stopword removal
Data Traning
Svm_learn –t 0 training.txt kernel0.txt
Svm_learn –t 0 training.txt kernel1.txt
Svm_learn –t 0 training.txt kernel2.txt
Data Testing
Svm_classify testing.txt kernel0.txt model0.txt
Svm_classify testing.txt kernel1.txt model1.txt
Svm_classify testing.txt kernel2.txt model2.txt
Svm_classify testing.txt kernel3.txt model3.txt
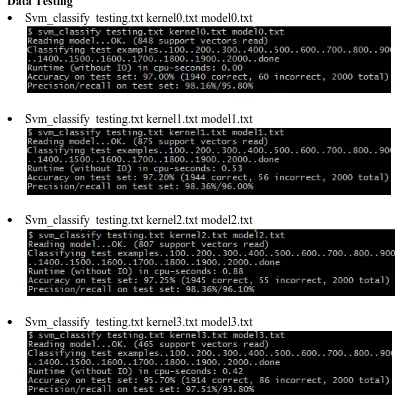
Tabel hasil klasifikasi data uji tanpa stopword removal menggunakan SVM Light
Kernel Recall Presisi Accuracy Correct Incorrect
Linear 95.80% 98,16% 97.00% 1940 60
Polynomial 96.00% 98,36% 97,0% 1944 56
Radial 96.10% 98,36% 98,36% 1945 55
Kesimpulan dan Saran
Kesimpulan
Dari hasil percobaan projek ini dan beberapa penelitian lainnnya menunjukkan penggunaan stopword memiliki pengaruh yang kecil terhadap hasil klasifikasi, walau memiliki perbedaan yang kecil ternyata hasil klasifikasi data uji tanpa stopword removal menunjukkan hasil yang lebih baik ketimbang menggunakan stopword removal. Seperti hasil yang terlihat pada tabel berikut.
Data Uji Kernel Recall Presisi Accuracy Correct Incorrect
Stopword berbeda. Untuk kasus menggunakan stopword removal, kernel Polynomial dan Radial memberikan hasil akurasi yang sama. Sedangkan untuk kasus tanpa stopword removal, hasil terbaik didapatkan melalui pengujian menggunakan kernel Radial yang memberikan hasil akurasi tertinggi yaitu 98,36%.
Saran
Daftar Pustaka
Liu, B., 2007, Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer Iko Pramudiono. "PengantarData Mining: Menambang Permata Pengetahuan di Gunung
Data". http://ilmukomputer.com. 2003
Candra Triawati. Metode Pembobotan Statistical Concept Based untuk Klastering dan Kategorisasi Dokumen Berbahasa Indonesia.