DENGAN ALGORITMA C4.5 PADA
PT. INDOSAFETY MANUFACTURE
SKRIPSI
Oleh:BAMBANG SUHERMAN
311410603
TEKNIK INFORMATIKA
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
IMPLEMENTASI DATA MINING UNTUK
MEMPREDIKSI PEMASARAN PRODUK HELMET
DENGAN ALGORITMA C4.5 PADA
PT. INDOSAFETY MANUFACTURE
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Menyelesaikan Program Strata Satu (S1) pada Program Studi Teknik Informatika
Oleh:
BAMBANG SUHERMAN
311410603
TEKNIK INFORMATIKA
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI
iii
PERNYATAAN KEASLIAN PENELITIAN
Saya yang bertandatangan dibawah ini menyatakan bahwa, skripsi ini merupakan karya saya sendiri (ASLI), dan isi dalam skripsi ini tidak terdapat karya yang pernah diajukan oleh orang lain untuk memperoleh gelar akademis di suatu institusi pendidikan tinggi manapun, dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis dan/atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka.
Segala sesuatu yang terkait dengan naskah dan karya yang telah dibuat adalah menjadi tanggungjawab saya pribadi.
Bekasi, ………
Materai 6.000
Bambang Suherman NIM: 311410603
iv
KATA PENGANTAR
Puji syukur penulis panjatkan ke hadiran Allah SWT. yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul “IMPLEMENTASI DATA MINING UNTUK MEMPREDIKSI PEMASARAN PRODUK HELMET DENGAN ALGORITMA C4.5 PADA PT. INDOSAFETY MANUFACTURE”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Suprianto, M.P selaku Ketua STT Pelita Bangsa
b. Bapak Aswan Sunge, S.E., M.Kom., selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Wiyanto, S.Kom, M.Kom selaku Pembimbing Utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Bapak Dodit Ardiatma, S.T., M.Sc., selaku Pembimbing Kedua yang telah memberikan arahan dan bimbingan kepada penulis dalam penyusunan skripsi ini.
e. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan dan ilmu di bidang teknik informatika.
f. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
g. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
v
h. Ibu dan Ayah tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
Akhir kata, penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, November 2018
vi
DAFTAR ISI
PERSETUJUAN i
PENGESAHAN ii
PERNYATAAN KEASLIAN PENELITIAN iii
KATA PENGANTAR iv DAFTAR ISI vi DAFTAR TABEL ix DAFTAR GAMBAR x ABSTRACT xi ABSTRAK xii BAB I PENDAHULUAN 1
1.1 Latar Belakang Masalah 1
1.2 Identifikasi Masalah 2
1.3 Batasan Masalah 2
1.4 Rumusan Masalah 3
1.5 Tujuan dan Manfaat Penelitian 3
1.6 Metodologi Pengumpulan Data 4
1.7 Sistematika Penulisan 5
BAB II LANDASAN TEORI 6
2.1 Implementasi 6
vii
2.2.1 Tahapan Data Mining 8
2.2.2 Fungsi Data Mining 11
2.2.3 Teknik Data Mining 12
2.2.4 Prediksi 15
2.2.5 Pohon Keputusan (Decision Tree) 16
2.2.6 Metode Algoritma C4.5 17 2.3 Aplikasi RapidMiner 23 2.4 PPIC 25 2.5 Pemasaran 26 2.6 Penelitian Sebelumnya 28 2.7 Kerangka Berfikir 29
BAB III METODOLOGI PENELITIAN 30
3.1 Tentang Perusahaan 30
3.1.1 Visi dan Misi Perusahaan 31
3.1.2 Struktur Organisasi Perusahaan 32
3.2 Tahapan Penelitian 33
3.2.1 Pemodelan 33
3.2.2 Pengujian Data Metode 35
3.2.3 Evaluasi dan Validasi Hasil 35
3.3 Instrument Penelitian 40
3.3.1 Bahan 40
3.3.2 Kebutuhan Perangkat Lunak (Software) 41 3.3.3 Kebutuhan Perangkat Keras (Hardware) 41
viii
BAB IV HASIL DAN PEMBAHASAN 42
4.1 Gambaran Umum Kerja Sistem 42
4.2 Tahap Pengujian Data Pengiriman 42
4.3 Data Pemasaran Helmet 43
4.4 Algoritma C4.5 44
4.5 Hasil dan Evaluasi menggunakan Tools Rapidminer 55
4.5.1 Proses Validation 55
4.5.2 Proses Training dan Testing 56
4.5.3 Accuracy Rapidminer 57
4.5.4 Precision RapidMiner 57
4.5.5 Recall RapidMiner 58
4.5.6 Pohon Keputusan RapidMiner 59
4.5.7 Decision Tree RapidMiner 60
BAB V PENUTUP 61
5.1 Kesimpulan 61
5.2 Saran 61
DAFTAR PUSTAKA LAMPIRAN
ix
DAFTAR TABEL
x
DAFTAR GAMBAR
xi
ABSTRACT
PT. Indosafety Manufacture is a Manufacture company that manufactures helmets for domestic and foreign companies. The company is capable of producing around 65,000 to 75,000 pcs of helmets for a month, with well-known brands such as: KYT, INK, BMC, and MDS. The Company's information service needs are very important, especially regarding marketing information from marketing to PPIC to avoid the dead stock of finish good products in warehouses that reach 25% of productions. So the authors propose to conduct a study of the implementation of data mining on helmet product marketing data using the C4.5 algorithm to find out which products are better sold, and do testing using the RapidMiner application. From the results of helmet marketing data processing, it can be concluded that the results of marketing data mining can be implemented using the C4.5 algorithm with RapidMiner tools to predict the best selling helmet products, that the open face helmet model is the best-selling product. With a ratio of 16: 1, with Accuracy 85%, Precision 94.12%, and Recall 84.21%.
xii
ABSTRAK
PT. Indosafety Manufacture adalah sebuah perusahaan Manufacture yang memproduksi helmet untuk dalam dan luar negeri, Perusahaan tersebut mampu memproduksi sekitar 65.000 sampai 75.000 pcs helmet perbulan, dengan merk ternama seperti : KYT, INK, BMC, dan MDS. Kebutuhan layanan informasi Perusahaan tersebut sangatlah penting, terutama tentang informasi pemasaran dari marketing kepada PPIC untuk menghindari adanya dead stock produk finish good di gudang yang mencapai 25% dari keseluruhan hasil produksi. Maka penulis mengusulkan untuk melakukan sebuah penelitian tentang implementasi data mining terhadap data pemasaran produk helmet dengan menggunakan algoritma C4.5 untuk mengetahui produk yang lebih laku terjual, serta melakukan pengujian dengan menggunakan aplikasi RapidMiner. Dari hasil pengolahan data pemasaran helmet, dapat diambil kesimpulan bahwa hasil mining data pemasaran dapat di implementasikan menggunakan algoritma C4.5 dengan tools RapidMiner untuk memprediksi produk helmet yang paling laku terjual, bahwa helmet model open face merupakan produk yang paling laku terjual. Dengan perbandingan 16 : 1, dengan tingkat Accuracy 85% , Precision 94,12%, dan Recall 84,21%.
1
BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
PT. Indosafety Manufacture adalah sebuah perusahaan Manufacture produksi Helm yang bertempat di Jl. Meranti III Blok L10 No. 7A Delta Silicon I, Lippo Cikarang Bekasi. Perusahaan tersebut mampu memproduksi sekitar 65.000 sampai 75.000 pcs helmet perbulan, dengan merk ternama seperti : KYT, INK, BMC, dan MDS. Kebutuhan layanan informasi PT.Indosafety Manufacture ini sangatlah penting, terutama tentang informasi pemasaran dari marketing kepada PPIC untuk menghindari adanya dead stock produk finish good di gudang yang mencapai 25% dari keseluruhan hasil produksi.
Dewasa ini forecast yang diturunkan Marketing kepada PPIC kurang akurat, sehingga planning dan hasil produksi tidak tepat sasaran pada produk yang lebih laku terjual. Oleh karena itu pihak perusahaan perlu melakukan analisa terhadap data pemasaran lebih lanjut.
Berdasarkan uraian masalah diatas penulis akan menggunakan metode yang berkaitan dengan prediksi, sehubungan dengan hal tersebut, maka dalam penelitian ini penulis mengambil sebuah judul “IMPLEMENTASI DATA
MINING UNTUK MEMPREDIKSI PEMASARAN PRODUK HELMET
DENGAN ALGORITMA C4.5 PADA PT. INDOSAFETY
2
1.2 Identifikasi Masalah
Berdasarkan pada latar belakang serta peninjauan masalah diatas dan untuk mempermudah dalam melakukan penelitian ini, maka penulis mengidentifikasi masalah sebagai berikut:
a) Data pemasaran hanya dijadikan arsip.
b) Hasil produksi banyak yang menjadi dead stock di gudang.
c) Forecast yang diterbitkan oleh Marketing kepada PPIC kurang tepat sasaran terhadap produk yang lebih laku terjual.
1.3 Batasan Masalah
Batasan masalah analisa dan mining data perlu di petakan agar pembahasan pokok dari analisa dan mining data pemasaran ini tidak melebar ke dalam masalah lain, oleh karena itu penulis menentukan batasan masalah pada penelitian ini adalah perlunya implementasi data mining untuk memprediksi pemasaran produk helmet yang paling laku terjual. Dengan menggunakan data jenis helm KYT, INK, BMC, dan MDS. Disertai dengan variable warna, model, dan serie yang di produksi pada PT.Indosafety Manufacture.
1.4 Rumusan Masalah
Berdasarkan latar belakang permasalahan diatas, apakah penelitian ini dapat di implementasikan kedalam proses data mining untuk memprediksi pemasaran produk helmet yang laku terjual dengan menggunakan algoritma C4.5?
1.5 Tujuan dan Manfaat Penelitian 1.5.1 Tujuan Penelitian
Tujuan dari penyusunan skripsi ini adalah untuk mengimplementasikan data mining dan memprediksi pemasaran produk helmet yang paling laku terjual dengan algoritma C4.5, berdasarkan data pemasaran produk helmet KYT, INK, BMC, dan MDS.
1.5.2 Manfaaat Penelitian
Manfaat dari pembuatan mining data ini, dapat dilihat dengan mengacu pada 2 sisi yaitu :
a) Individu
Memberikan pengalaman kepada penulis untuk menerapkan dan memperluas wawasan teori dan pengetahuan yang telah diterima di dalam perkuliahan pada kegiatan nyata.
Meningkatkan kinerja dan pola fikir penulis.
Penulis mudah beradaptasi dengan lingkungan kerja setelah menyelesaikan pendidikannya.
b) Umum
Memberikan kemudahan bagi user atau bagian staff maupun Pimpinan yang tergabung dalam lingkungan perusahaan, hingga data pemasaran terurai menjadi informasi ataun pengetahuan.
4
1.6 Metodologi Pengumpulan Data
Metodologi pengumpulan data sangat diperlukan untuk mendapatkan bukti kebenaran suatu konsep dan teori yang diperoleh serta untuk menemukan dan menguji suatu pengetahuan. Adapun penulis dalam hal ini menggunakan metode sebagai berikut:
1.6.1 Observasi
Disini penulis terjun langsung dengan cara mengamati langsung terhadap objek penelitian yang tentunya akan memudahkan untuk mendapatkan informasi yang dibutuhkan.
1.6.2 Wawancara
Selain metode observasi penulis juga melakukan pengumpulan data dengan cara tatap muka langsung dengan tanya jawab kepada bagian staff atau admin yang tentunya berkompetensi dibidangnya sehingga diperoleh penjelasan yang lebih rinci dan jelas.
1.6.3 Studi Kepustakaan
Mengumpulkan data-data yang diperlukan dengan mencarinya di dokumen-dokumen atau file-file yang tentunya berhubungan dengan topik pembahasan.
1.7 Sistematika Penulisan
Dalam laporan ini penulis membagi menjadi beberapa bab untuk mempermudah penulis dalam menyusun dan mempermudah bagi pembaca untuk memahaminya yang mana tiap-tiap bab terdiri dari sub-sub bab yang merupakan
penjelasan dari bab-bab sebelumnya, berikut pembagian bab-bab dalam laporan ini:
BAB I PENDAHULUAN
Bab ini meliputi uraian tentang latar belakang masalah, identifikasi masalah, batasan masalah, rumusan masalah, tujuan dan manfaat penelitian, metodologi pengumpulan data, dan sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini berisi tentang landasan teori yang menunjang didalam pembuatan karya ilmiah ini antara lain mengenai implementasi itu sendiri.
BAB III METODE PENELITIAN
Pada bab ini penulis akan membahas tentang metode yang akan digunakan dalam penelitian.
BAB IV HASIL DAN PEMBAHASAN
Pada bab ini penulis akan menguraikan masalah pokok dari objek penulisan laporan meliputi sejarah perusahaan, struktur organisasi, prosedur sistem yang berjalan, kamus data sistem berjalan, spesifikasi sistem berjalan, permasalahan pokok, dan alternatif pemecahan masalah.
BAB V KESIMPULAN DAN SARAN
Bab ke lima merupakan bab terakhir yang berisikan kesimpulan dan koreksi dari hasil penulisan disertai saran-saran dari hasil penelitian yang telah dilakukan oleh penulis.
6
BAB II
LANDASAN TEORI
2.8 Implementasi
Implementasi adalah yang bermuara pada aktivitas, aksi, tindakan, atau adanya mekanisme suatu sistem. Implementasi bukan sekedar aktivitas, tetapi suatu kegiatan yang terencana dan untuk mencapai tujuan kegiatan. Implementasi adalah perluasan aktivitas yang saling menyesuaikan proses interaksi antara tujuan dan tindakan untuk mencapai serta memerlukan jaringan-pelaksanaan, birokrasi yang efektif (Kenedi, 2018).
2.9 Data Mining
Data Mining adalah langkah analisis terhadap proses penemuan
pengetahuan didalam basisdata atau knowledge discovery in databases disingkat KDD. Pengetahuanya bisa berupa pola data atau relasi antar data yang valid yang berarti tidak diketahui sebelumnya. Data mining juga merupakan gabungan sejumlah disiplin ilmu komputer yang didefinisikan sebagai proses penemuan pola-pola baru dari kumpulan-kumpulan data yang sangat besar, meliputi metode-metode yang merupakan irisan dari artificial intelligence, machine learning,
statistics dan databases system (Suyanto, 2017).
Data mining adalah kegiatan mengekstrak informasi atau pengetahuan
(knowledge) penting dari suatu set data berukuran besar dengan menggunakan teknik tertentu. Informasi atau knowledge yang dihasilkan dari data mining bisa
dipakai untuk memperbaiki pengambilan keputusan. Dinamakan data mining atau penambangan data karena proses penemuan informasi atau knowledge dalam set data dilakukan seperti orang melakukan kegiatan penambangan. Banyak yang dilakukan dalam kegiatan penambangan untuk akhirnya menemukan “sebutir emas” atau “sejumlah banyak” (Budi, 2018).
Menurut (Bobby, 2013) Data Mining disebut juga Knowledge Discovery
in Database (KDD) didefenisikan sebagai ekstraksi informasi potensial, implisit
dan tidak dikenal dari sekumpulan data. Proses Knowlegde Discovery in Database melibatkan hasil proses data mining (proses pengekstrak kecenderungan suatu pola data), kemudian mengubah hasilnya secara akurat menjadi informasi yang mudah dipahami. Ada beberapa macam pendekatan yang berbeda yang diklasifikasikan sebagai teknik pencarian informasi/pengetahuan dalam KDD. Ada pendekatan kuantitatif, seperti pendekatan probabilistik seperti logika induktif, pencarian pola, dan analisis pohon keputusan. Pendekatan yang lain meliputi deviasi, analisis kecenderungan, algoritma genetik, jaringan saraf tiruan, dan pendekatan campuran dua atau lebih dari beberapa pendekatan yang ada. Pada dasarnya ada enam elemen yang paling esensial dalam teknik pencarian informasi/pengetahuan dalam KDD yaitu:
1. Mengerjakan sejumlah data besar.
2. Diperlukan efesiensi berkaitan dengan volume data 3. Mengutamakan ketepatan/keakuratan.
4. Membutuhkan pemakaian bahasa tingkat tinggi.
5. Menggunakan beberapa bentuk dari pembelajaran otomatis. 6. Menghasilkan hasil yang menarik.
8
Data Mining juga diartikan sebagai menambang data atau upaya untuk menggali informasi yang berharga dan berguna pada database yang sangat besar, Hal terpenting dalam teknik data mining adalah aturan untuk menemukan pola frekuensi tinggi antar himpunan itemset yang disebut fungsi Association Rules (Aturan Asosiasi). Beberapa algoritma yang termasuk dalam Aturan Asosiasi adalah seperti AIS Algoritma, Algoritma Apriori, DHP Algoritma, dan Partition Algoritma (Shuruti, 2013)
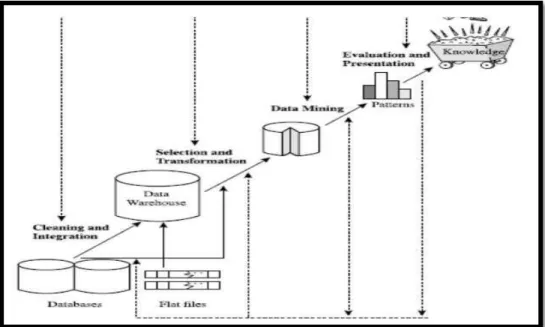
2.9.1 Tahapan Data Mining
Knoewledge Discovery In Database (KDD), adalah keseluruhan proses
non-trivial untuk mencari dan mengidentifikasi pola (pattern) dalam data, dimana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat dimengerti.
KDD berhubungan dengan teknik integrasi dan penemuan ilmiah,
interprestasi dan visualisasi dari pola-pola sekumpulan data. Pada proses data mining terdapat beberapa tahapan yang harus dilakukan.
Menurut (Retno, 2017), terdapat beberapa tahapan , antara lain sebagai berikut :
1. Data Selection
a. Menciptakan himpunan data target, pemilihan himpunan data, atau memfokuskan pada subset variabel atau sampel data, dimana penemuan (discovery) akan dilakukan.
b. Pemilihan data dari sekumpulan data opersional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dilmulai. Data hasil
seleksi yang akan untuk proses data mining disimpan dalam satu berkas, terpisah dari basis data operasional.
2. Data Preprocessing/Cleaning
a. Pemprosesan pendahuluan dan pembersihan data merupak operasi dasar seperti penghapusan noise dilakukan.
b. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi focus KDD.
c. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi).
d. Dilakukan proses enrichment, yaitu proses memperkaya data yang sudah ada dengan data atau informasi lain yang relavan.
3. Integrasi Data
Integrasi data merupakan penggabungan data dari beberapa sumber.
4. Transformasi Data
Transformasi data merupakan tahap pengubahan data, data diubah menjadi bentuk yang sesuai untuk di-mining. Tahap ini juga merupakan proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses ini merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
5. Aplikasi Teknik Data Mining
Proses data mining yaitu proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu.
10
Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan proses KDD secara keseluruhan
6. Interprestasi dan Evaluasi
a. Penerjemahan pola-pola yang dihasilkan dari data mining.
b. Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. c. Tahap ini merupakan bagian dari proses KDD yang mencakup apakah pola
atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya. Langkah terakhir KDD adalah mempresentasikan pengetahuan dalam bentuk yang mudah dipahami pengguna.
Gambar 2.1 Tahapan Data Mining (Retno, 2017) 2.9.2 Fungsi Data Mining
Manurut (Retno, 2017), ada beberapa fungsi yang diterapkan dalam data
mining antara lain sebagai berikut: 1. Classification
Classification merupakan proses penemuan model atau fungsi yang
menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui.
2. Clustering
Clustering adalah proses pengelompokan sejumlah data/obyek kedalam
kelompok data sehingga setiap kelompok berisi data yang mirip.
3. Association
Assosation adalah proses untuk menemukan aturan asosiasi antara suatu
kombinasi item dalm suatu waktu.
4. Regression
Regression adalah proses pemetaan data dalam suatu nilai prediksi. 5. Forecasting
Forecasting adalah suatu proses pengetimasian nilai prediksi berdasarkan
pola-pola didalm sekumpulan data.
6. Squence Analysis
Squence Analysis adalah proses untuk menemukan aturan asosiasi antar suatu
kombinasi item dalam suatu waktu dan diterapkan lebih dari stu periode.
7. Solution
Solution merupakan suatu proses penemuan akar masalah dan problem solving dari persoalan bisnis yang dihadapkan atau paling tidak sebagi
informasi dalam pengambilan keputusan.
2.9.3 Teknik Data Mining
12
Classification (Zaki, 2013) yaitu bagaimana mempelajari sekumpulan data
sehingga dihasilkan aturan yang bisa diklasifikasi atau mengenali data-data baru yang belum pernah dipelajari. Klasifikasi dapat didefinisakn sebagai proses untuk menyatakan suatu objek data sebagai salah satu kategori (kelas) yang telah didefinisikan sebelumnya. Klasifikasi banyak digunakan dalam berbagai aplikasi, diantaranya adalah deteksi kecurangan (fraud detection), pengelolaan pelanggan, diagnosis medis, prediksi penjualan, dan sebagainya.
Menurut (Suyanto, 2017) Classification adalah sebuah model data mining dimana classifier dikontruksi untuk memprediksi categorical label, seperti “aman” atau “beresiko” untuk data aplikasi peminjaman uang, “ya” atau “tidak” untuk data marketing, atau “treatment A”, “treatment B” atau “treatment C” untuk data medis. Kategori tersebut dapat dipresentasikan dengan nilai yang sesuai dengan kebutuhanya, dimana pengaturan dari nilai tersebut tidak memiliki arti terentu.
Classification juga dapat melakukan pengelompokan objek berdasarkan
kelompok yang sudah ada. Berbeda dengan klastering, klasifikasi ini mermerlukan data pelatihan yang sudah diberi label kelompok/kelas. Sebagai contoh, kita ingin mengelompokan data gambar kanker ringan dan akut, maka kita harus menyiapkan misalnya 1000 gambar data pelatihan (data training) dengan label kanker ringan dan 1000 gambar dengan label kanker akut. Prediksi pengelompokan dilakukan dengan membangun model terlebih dahulu melalui proses pelatihan menggunakan data yang sudah kita siapkan. Setelah model terbentuk dari proses pelatihan, data baru bisa dikelompokan menggunakan model tersebut (Budi, 2018).
2. Regresi (Regretion)
Regresi pada dasarnya mirip dengan klasikasi, yakni memerlukan data pelatihan yang sudah diberi label. Bedanya, outout klasifikasi adalah nilai diskrit, sedangkan output dari regresi adalah nilai kontinyu. Regresi ini mencari model hubungan antara atribut predictor dan atribut dependent, dimana atribut
dependent-nya juga berupa nilai kontinyu. Contoh regresi adalah memprediksi
nilai kurs rupiah terhadap dollar (Budi, 2018).
Regersi juga dapat didefinisikan sebagai cara merangkum data dalam melakukan analisis dengan cara melakukan akumulasi data, misalnya data yang semula perbulan diakumulasi menjadi pertahun (Suyanto, 2017).
3. Klastering(Clustering)
Klastering merupakan suatu pengelompokan obyek kedalam beberapa kelompok berdasarkan kemiripan antar obyek, dimana dalam satu klaster harus besisi obyek yang saling mirip dan antara klaster obyek saling tidak mirip. Klastering ini tidak memerlukan data pelatihan yang sudah diberi label (Budi, 2018).
Teknik klastering bisa digunakan untuk mereduksi data, ide dasarnya sangatlah sederhana. Obyek data dipartisi kedalam sejumlah kelompok atau
cluster, dimana obyek-obyek yang sangat mirip dikelompokan kelama satu calster
yang sama sedangkan obyek-obyek yang berbeda di cluster dengan obyek yang berbeda. Kemiripan antar obyek data dihitung dengan menggunakan fungsi jarak yang berupa similarity atau dissimilarity (Suyanto, 2017)
14
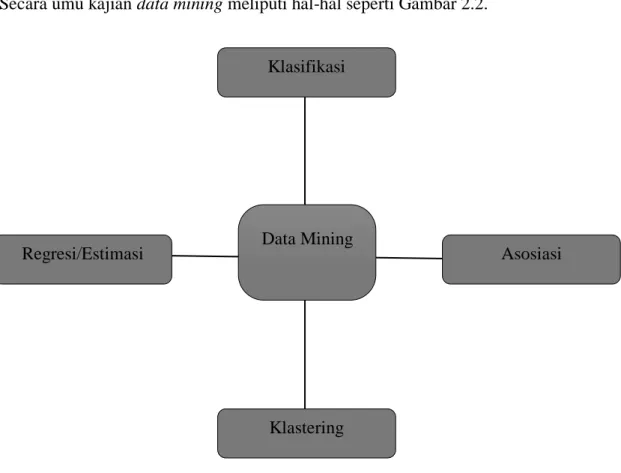
Asosiasi dilakukan dengan cara menghitung berapa kali dalam suatu set data suatu transaksi yang mengandung dua item atau lebih yang berhubungan satu sama lain. Sering ada yang menyebtu Market Basket Analysis. (Budi, 2018). Secara umu kajian data mining meliputi hal-hal seperti Gambar 2.2.
Gambar 2.2 Kajian Data Mining (Budi, 2018) 2.9.4 Prediksi
Prediksi merupakan bagian awal dari proses pengembalian suatu keputusan. Sebelum memprediksi, harus diketahui terlebih dahulu apa sebenarnya persoalan dalam pengambilan keputusan. Prediksi adalah pemikiran terhadap besaran, misalnya permintaan terhadap satu atau beberapa produk pada periode yang akan datang. Pada hakikatnya, prediksi hanya merupakan suatu perkiraan (Guess), tetapi dengan menggunakan teknik-teknik tertentu, maka memprediksi menjadi lebih sekedar perkiraan yang ilmiah (educated guess). Setiap
Data Mining Klasifikasi
Asosiasi Regresi/Estimasi
pengambilan keputusan yang menyangkut keadaan dimasa yang aka datang, maka pasti akan ada prediksi yang melandasi keputusan tersebut. Forecasting atau peramalan/prediksi adalah suatu usaha untuk memprediksi keadaan dimasa yang akan datang melalui pengujian keadaan dimasa lalu. Dalam prediksi data yang diproses adalah data historis yang digunakan sebagai data bahan acuan ditambah dengan data-data simulasi yang dapat diubah-ubah sesuai dengan kemungkinan-kemungkinan yang dapat terjadi. Prediksi mengetahui perkiraan nilai dari suatu barang diwaktu yangakan datang. Atau prediksi adalah kebutuhan akan prediksi semakin meningkat sejalan dengan keinginan manajemen untuk memberikan tanggapan yang cepatdan tepat terhadap peluang maupun perubahan dimasa mendatang. Perbedaan antara prediksi, peramalan dan prakiraan adalah prediksi dapat dilakukan secara kualitatif dan kuantitatif (Edy, 2013).
Prediksi kualitatif merupakan prediksiberdasarkan pendapat suatu pihak (judgement forcast) dan prediksi kuantitatif merupakan prediksi mendasarkan pada data masa lalu (data historis) dan dapatdibuat dalam bentuk angka yang biasa disebut sebagai data time series. Prediksi kuantitatif tidak lain adalah prediksi sedangkan prediksi kualitatif adalah peramalan, prakiraan dipandang sebagai proses prediksi variabel dima samendatang dengan berdasarkan data-data variabel yang bersangkutan dimasa sebelumnya. Data masa lampau tersebut, secara sistematik digabungkan melalui metode tertentu dan diolah untuk keadaan pada masa yang akan datang. Tujuan dari peramalan adalah menjadikan para pengambil keputusan dan pembuat kebijakan memahami ketidakpastian dan resiko yang mungkin muncul dapat dipertimbangkan sewaktu membuat perencanaan. Dengan melakukan prediksi tersebut para perencana dan pengambil keputusan akan dapat
16
mempertimbangkan pilihan-pilihan/alternatif lain. Dalam kenyataannya, hasil dari prediksi tidak pernah mutlak tepat, hal tersebut dikarenakankeadaan maupun kejadian dimasa depan tidak menentu. Meskipun demikian, jika semua faktor-faktor tersebut ditentukan dengan baik, maka hasilprediksi akan mendekati hasil sebenarnya. (Weneda, 2013).
2.9.5 Pohon Keputusan (Decision Tree)
Decision Tree adalah pemetaan mengenai alternatif-alternatif pemecahan
masalah yang dapat diambil dari masalah tersebut. Pohon tersebut juga melihatkan factor-faktor kemungkinan/probablitas yang akan mempengaruhi alternaitf-alternatif keputusan tersebut, disertai dengan estimasi hasil akhir yang akan didapat bila kita mengambil alternatif keputusan tersebut (Retno, 2017).
Menurut (Suyanto, 2017) Decision Tree adalah salah satu metode klasifikasi yang popular yang banyak digunakan secara praktis. Metode ini berusaha menemukan model klasifikasi yang tahan terhadap derau. Salah satu metode decision tree yang sangat popular adalah Iterative Dychotomizer version
3 (ID3). Dua varian lai yang popular adalah C4.5 dan ASSISTANT.
Pohon Keputusan atau Decision Tree merupakan representasi sederhana dari teknik klasifikasi untuk sejumlah kelas berhingga, dimana simpul internal maupun simpul akar ditandai dengan nama atribut, rusuk-rusuknnya diberi label nilai atribut yang mungkin dan simpul daun ditandai dengan kelas-kelas yang berbeda (Budi, 2018)
2.9.6 Metode Algoritma C4.5
Algoritma C4.5 adalah algoritma yang sudah banyak dikenal dan digunakan untuk klasifikasi data yang memiliki atribut-atribut numeric dan
kategorial. Hasil dari proses klasifikasi yang berupa aturan-aturan dapat digunakan untuk memprediksi nilai atribut bertipe diskret dari record yang baru (Elisa, 2017).
Algoritma data mining C4.5 merupakan salah satu algoritma yang digunakan untuk melakukan klasifikasi atau segmentasi atau pengelompokan yangb bersifat prediktif. Klasifikasi merupakan suatu proses data mining yang bertujuan untuk menemukan pola yang berharga dari data yang berukuran relatif besar hingga sangat besar. Algoritma C4.5 sendiri meruapakan pengembangan dari algoritma ID3 (Retno, 2017)
Secara umum algorima C4.5 untuk membangun pohon keputusan adalah sebagai berikut :
1. Pilih atribut sebagai node akar. 2. Buat cabang untuk tiap-tiap nilai. 3. Bagi kasus dalam cabang.
4. Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama (Kusrini & Luthfi, 2011)
Untuk memilih atribut sebagai node akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam persamaan berikut :
18
Setelah mendapatkan nilai Gain, ada satu hal lagi yang perlu kita lakukan perhitungan, yaitu mencari nilai Entropy. Entropy digunakan untuk menentukan seberapa informatif sebuah masukan atribut untuk menghasilkan keluaran atribut. Rumus dasar dari Entropy tersebut adalah sebagai berikut :
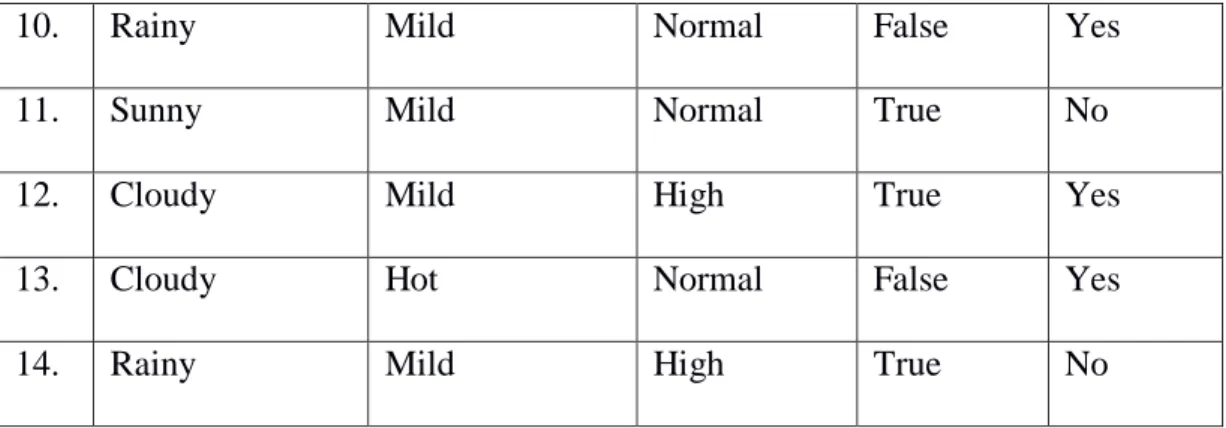
Untuk memudahkan penjelasan mengenai algoritma C4.5, berikut ini disertakan contoh kasus yang dituangkan dalam Tabel 2.1.
Tabel 2.1 Keputusan Bermain Tenis (Kusrini & Luthfi, 2011)
NO OUTLOOK TEMPERATUR HUMIDITY WINDY PLAY
1. Sunny Hot High False No
2. Sunny Hot High True No
3. Cloudy Hot High False Yes
4. Rainy Mid High False Yes
5. Rainy Cool Normal False Yes
6. Rainy Cool Normal True Yes
7. Cloudy Cool Normal True Yes
8. Sunny Mild High False Yes
10. Rainy Mild Normal False Yes
11. Sunny Mild Normal True No
12. Cloudy Mild High True Yes
13. Cloudy Hot Normal False Yes
14. Rainy Mild High True No
Dalam kasus yang tertera pada Tabel 2.1 akan dibuat pohon keputusan untuk menentukan main tenis atau tidak dengan melihat keadaan cuaca, temparatur, kelembaban dan keadaan angin. Selanjutnya data tersebut akan diproses sesuai langkah-langkah membentuk pohon keputusan. Berikut ini adalah penjelasan lebih terperinci: Hitung jumlah kasus, yakni jumlah kasus untuk keputusan Yes dan jumlah keputusan No, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut-atribut yang digunakan. Setelah itu lakukan perhitungan Gain untuk setiap atribut.
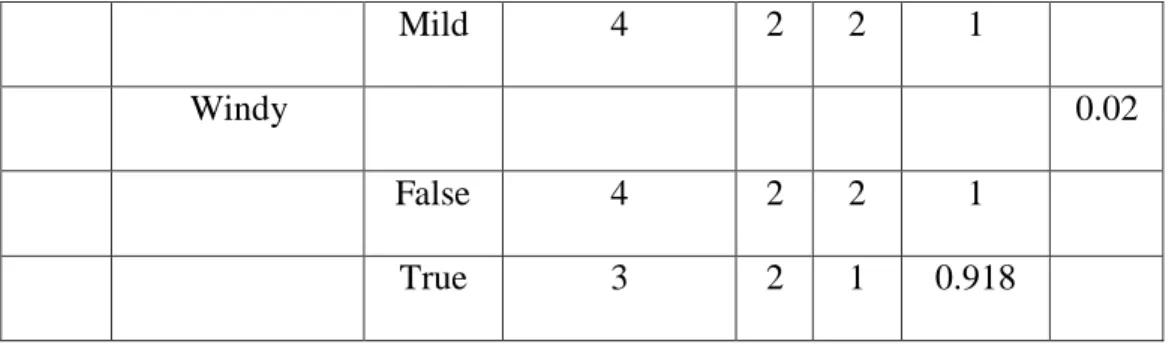
Tabel 2.2 Perhitungan Node 1 (Kusrini & Luthfi, 2011)
Node Jumlah Kasus No Yes Entropy Gain
1 Total 14 4 10 0.863 Outlook 0.258 Cloudy 4 0 4 0 Rainy 5 1 4 0.721 Sunny 5 3 2 0.97 Temperature 0.183 Cool 4 0 4 0 Hot 4 2 2 1
20 Mild 6 2 4 0.918 0.370 Humidity High 7 4 3 0.985 Normal 7 0 7 0 Windy 0.005 False 8 2 6 0.811 True 6 4 2 0.918
Dari hasil pada Tabel 2.2 dapat diketahui bahwa atribut dengan Gain tertinggi adalah Humidity yaitu sebesar 0.37. Dengan demikian Humidity dapat menjadi node akar. Ada dua nilai atribut dari Huminity yaitu High dan Normal. Dari kedua nilai atribut tersebut, nilai atribut Normal sudah mengklasifikasikan kasus menjadi satu keputusan Yes, sehingga tidak perlu dilakukan perhitungan lenih lanjut, tetapi untuk nilai atribut High masih perlu dilakukan perhitungan lagi. Setelah dilakukan perhitungan , maka terbentuklah pohon keputusan sementara seperti pada Gambar 2.3.
Gambar 2.3 Pohon Keputusan Hasil Perhitungan Node 1(Kusrini & Luthfi, 2011)
Hitung kembali jumlah kasus, Entropy dari semua kasus yang dibagi berdasarkan atribut yang dapat menjadi node akar dari nilai atribut Humidity-High. Setelah itu lakukan perhitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan pada Tabel 2.3.
Tabel 2.3 Perhitungan Node 1.1 (Kusrini & Luthfi, 2011)
Node Jumlah Kasus No Yes Entropy Gain
1.1 Humidity-Gain 7 4 3 0.965 Outlook 0.699 Cloudy 2 0 2 0 Rainy 2 2 1 1 Sunny 3 3 0 0 Temperature 0.02 Cool 0 0 0 0 Hot 3 2 1 0.918
22
Mild 4 2 2 1
Windy 0.02
False 4 2 2 1
True 3 2 1 0.918
Dari Tabel 2.3 dapat diketahui bahwa atribut dengan Gain tertinggi adalah Outlook yaitu sebesar 0,67. Dengan demikian Outlook dapat menjadi node cabang dari nilai atribut Humidiy – High . Dari ketiga nilai atribut Outlook, nilai atribut Cloudy sudah mengklasifikasi kasus 1 yaitu keputusan Yes dan nilai atribut Sunny sudah mengklasifikasi kasus 1 yaitu keputusan No. Pohon keputusan yang dihasilkan sampai tahap ini ditunjukkan pada Gambar 2.4.
Gambar 2.4 Pohon Keputusan Hasil Perhitugan Node 1.1.2 (Kusrini & Luthfi, 2011)
Dengan memperhatikan pohon keputusan pada Gambar 2.4, diketahui bahwa semua kasus sudah masuk dalam kelas. Dengan demikian, pohon keputusan pada Gambar 2.3 merupakan pohon keputusan terakhir yang terbentuk.
2.10 Aplikasi RapidMiner
RapidMiner adalah sebuah perangkat lunak ilmu data platform yang
dikembangkan oleh perusahaan dari nama yang sama yang menyediakan saran untuk mempelajari mesin dalam belajar, penambangan data, dan presdiksi analisa. Biasanya aplikasi ini digunakan untuk suatu bisnis komersial maupun untuk penelitian, pendidikan, dan pengembangan aplikasi yang mendukung semua langkah masin proses belajar termasuk persiapan data, hasil dan visualisasi, validasi dan optimasi. (Abhis hek, 2017)
Menurut Dennis (2017), “Perangkat lunak yang bersifat terbuka (open source). Rapidminer adalah sebuah solusi untuk melakukan analisis terhadap data mining, text mining dan analisis prediksi Rapidminer menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik”.
Rapidminer menyediakan GUI (Graphic User Interface) untuk merancang
sebuah pipeline analitis. GUI ini akan menghasilkan file XML (Extensible
Markup Language) yang mendefenisikan proses analitis keingginan pengguna
untuk diterpkan ke data. File ini kemudian dibaca oleh Rapidminer untuk menjalankan analis secara otomatis.
24
1. Ditulis dengan bahasa pemrograman java sehingga dapat dijalankan diberbagai sistem operasi
2. Proses penemuan pengetahuan dimodelkan sebagai operator trees.
3. Representasi XML internal untuk memastikan format standar pertukaran data.
4. Bahasa scripting memungkinkan untuk eksperimen skala besar dan otomatisasi eksperimen.
5. Konsep multi-layer untuk menjamin tampilan data yang efesien dan menjamin penanganan data.
6. Memiliki GUI, command line mode, dan Java API yang dapat dipanggil dari program lain.
2.11 PPIC
Divisi Production Planning and Inventory Control yang selanjutnya disingkat menjadi PPIC merupakan salah satu divisi yang ada di PT. Showa Indonesia Manufacturing. Divisi ini dibagi lagi menjadi dua departemen, yaitu departemen planning dan departemen warehouse. Departemen planning merupakan departemen yang menjembatani antara marketing dengan departemen lain, seperti produksi dan purchasing. Bagi marketing, planner harus menyediakan kebutuhan customer dengan tepat waktu, tepat barang, dan tepat jumlah. Sedangkan bagi produksi, planner harus memastikan produksi berjalan sesuai jadwal, seperti kapan produksi selesai dan kapan produk dapat release. Dan bagi purchasing, planner harus menyiapkan daftar kebutuhan material dengan tepat barang dan tepat jumlah.
Hubungan antara departemen planning dengan departemen-departemen lain dapat dijelaskan sebagai berikut. Tim marketing akan menyerahkan Purchase Order/forecasting kepada departemen planning. Planner kemudian menginput PO/forecasting tersebut kedalam master delivery schedule atau disingkat menjadi MDS. Selanjutnya planner akan membuat Master Production Planning atau disingkat menjadi MPP. MPP adalah penjadwalan produksi harian. MPP ini harus dicocokkan dengan MDS nya agar tidak terjadi perbedaan kalkulasi. MPP ini kemudian akan didistribusikan untuk dibuatkan Material Requirement Planning atau disingkat menjadi MRP. Planner dibantu dengan software IFS yang secara otomatis akan menghitung lead time material, pola delivery, struktur produk, level stock, dan parameterparameter lain dalam menyusun MRP. Daftar belanja ini kemudian akan diserahkan kepada tim purchasing untuk dibeli.
PO customer yang sering tidak sesuai dengan hasil forecasting PT Showa Indonesia Manufacturing ini mengindikasikan bahwa demand yang diajukan oleh customer sering mengalami fluktuasi. Hal ini dapat terjadi karena tingkat demand customer dipengaruhi oleh tingkat permintaan pasar yang juga fluktuatif seiring dengan perubahan tren mobil dan motor yang terjadi di masyarakat. Oleh karena itu, secara tidak langsung aktivitas produksi PT Showa Indonesia Manufacturing juga sangat dipengaruhi oleh trend mobil dan motor yang terjadi di masyarakat.
Sedangkan untuk kasus overstock, PT Showa Indonesia Manufacturing tentunya harus menyediakan inventory untuk menyimpan stok-stok tersebut. Dalam konsep just in time, inventory merupakan pemborosan karena artinya perusahaan harus mengeluarkan biaya lebih tinggi untuk perawatan persediaan tersebut. Overstock juga dapat berpotensi menjadi deadstock apabila tidak
26
terdapat permintaan dari customer untuk stok tersebut. Dikarenakan permintaan yang berfluktuatif, bisa saja customer tidak memesan varian shock breaker tertentu untuk waktu yang cukup lama walaupun kebutuhan komponen untuk shock breaker tersebut sudah dipesan sebelumnya. Akibatnya komponen tersebut tidak lagi dapat digunakan dan akhirnya menjadi deadstock.
Terdapat upaya yang dapat dilakukan untuk mengatasi masalah deadstock ini. Sebelumnya perusahaan akan menghitung umur barang tersebut, yaitu sampai kapan komponen ini dapat disimpan di inventory. Selama proses penyimpanan tersebut, perusahaan akan berusaha untuk menjual komponen tersebut ke cabang perusahaan Showa di negara lain. Namun, sayangnya tidak semua spesifikasi komponen yang diproduksi di PT. Showa Indonesia Manufacturing sama dengan spesifikasi yang dibutuhkan oleh perusahaan Showa di negara lain. Apabila upaya tersebut tidak berhasil, maka stok ini akan benar-benar menjadi deadstock yang artinya perusahaan akan mengalami kerugian sangat besar akibat biaya proses produksi dan biaya simpan yang telah dikeluarkan. (Arina, 2018).
2.12 Pemasaran
Inti dari pemasaran adalah mengidentifikasikan dan memenuhi kebutuhan dan keinginan konsumen. Definisi yang baik dan singkat dari pemasaran yang menurut (Kotler & Keller, 2016) adalah marketing is meeting needs profitability, maksud ungkapan tersebut adalah pemasaran merupakan hal yang dilakukan untuk memenuhi setiap kebutuhan (kebutuhan konsumen) dengan cara-cara yang menguntungkan semua pihak. Definisi formal yang ditawarkan America Marketing Association (AMA) yang dikutip oleh (Kotler & Keller, 2016) sebagai
berikut : Marketing is the activity, set of institutions, and processes for creating,
communicating, delivering, and exchanging offerings that have value for customers, clients, partners, and society at large. Arti dari definisi tersebut,
pemasaran adalah suatu fungsi organisasi dan serangkaian proses untuk menciptakan, mengkomunikasikan, menghantarkan dan memberikan nilai pelanggan yang unggul.
Menurut (Tjiptono, 2015), pemasaran adalah penentuan apa yang akan dijual kepada konsumen berupa produk atau jasa dengan mendapatkan laba, melalui cara-cara, kondisi dan sluran sidtribusi tertentu, serta penciptaan dan pengolahan program untuk menghasilkan, melayani dan memperluas penjualan.
2.13 Penelitian Sebelumnya
Beberapa penelitian mengenai prediksi pemasaran dan penjualan produk yang mendekati penelitian ini dapat digambarkan pada tabel berikut:
28
Tabel 2.4 Penelitian Sebelumnya
2.14 Kerangka Berfikir
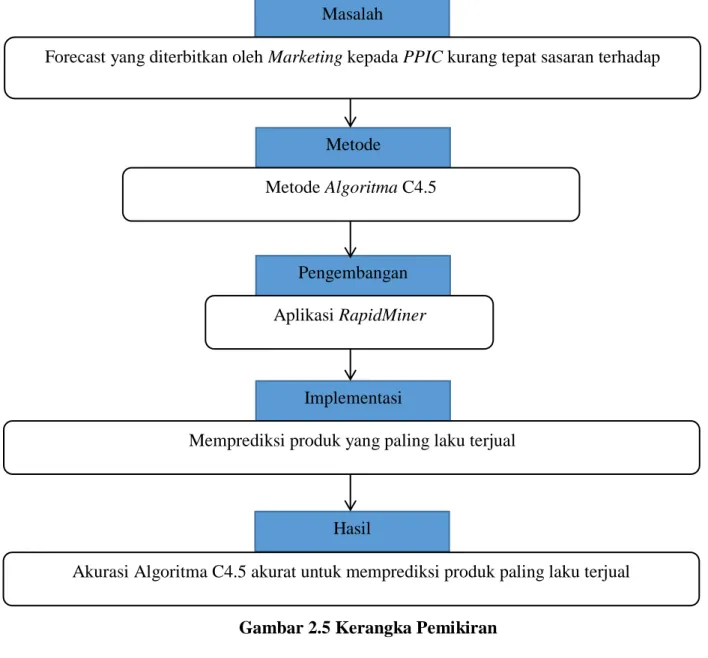
Dalam penelitina ini membuat sebuah kerangka pemikiran yang berguna sebagai pedoman penelitian sehingga dapat dilakukan secara konsisten. Untuk itu metode yang digunakan yaitu Algoritma C4.5 untuk memecahkan masalah dilakukan pengujian terhadap kinerja metode tersebut. Untuk pengembangan dan pengujian motede yang dipakai dangan menggunakan aplikasi RapidMiner. Gambar berikut ini merupakan kerangka pemikiran yang dilakukan.
No Penulis Judul Metode Penelitian Analisis 1 Asri Khoirunnisa, dkk. 2016. Analisa dan Implementasi
Perbandingan Algoritma C.45 dengan Naïve Bayes Untuk Prediksi Penawaran Produk
Algoritma C.45 dan Naïve Bayes
Implementasi kedua algoritma klasifikasi berhasil dilakukan, dimana kedua algoritma memberikan performa yang cukup dilihat dari akurasi 60% untuk algoritma Naïve Bayes, dan 48% untuk algoritma C4.5, pada kasus uji I dengan data uji terendah, yaitu 50 data. Pada kasus uji II dengan data uji sebanyak 120 data, performa algoritma Naïve Bayes mengalami peningktan menjadi 62%, sedangkan algoritma C4.5 menunjukan performa yang sema dengan sebelumnya yaitu 48%. Pada kasus uji III dengan data uji sebanyak 227 data, performa algoritm Naïve Bayes mengalami penurunan menjadi 49%, beigut juga dengan algoritma C4.5 menajdi 47%.
2 Fitriana Harahap, 2015. Penerapan Data Mining Dalam Memprediksi Pembelian Cat
Algoritma C.45 Berdasarkan hasil penelitian yang penulis lakukan pada Home Smart Medan, maka penulis dapat menarik kesimpulan bahwa pembelian cat dengan menggunakan metode Data Mining khususnya Algoritma C4.5 akan bermanfaat sekali dalam proses pengambilan keputusan dalam pembelian cat pada Home Smart Medan.
3 Nurul Azwanti, 2018 Analisa Algoritma C.45 Untuk Memprediksi Penjualan Motor Pada PT. Capella Dinamik Nusantara Cabang Muka Kuning
Algoritma C.45 Algoritma C4.5 dianggap sebagai algoritma yang sangat membantu dalam melakukan klasifikasi data karena karakteristik data yang diklasifikasi dapat diperoleh dengan jelas, baik dalam bentuk struktur pohon keputusan maupun aturan if-then, sehingga memudahkan pengguna dalam melakukan penggalian informasi terhadap data yang bersangkutan. Pada pemilihan atribut juga sangat mempengaruhi dalam pengolahan Algoritma C4.5 karena keputusan sangat bergantung pada atribut yang dipilih.
Gambar 2.5 Kerangka Pemikiran
Masalah
Metode
Pengembangan
Implementasi
Hasil
Forecast yang diterbitkan oleh Marketing kepada PPIC kurang tepat sasaran terhadap produk yang lebih laku terjual.
Metode Algoritma C4.5
Aplikasi RapidMiner
Memprediksi produk yang paling laku terjual
30
BAB III
METODOLOGI PENELITIAN
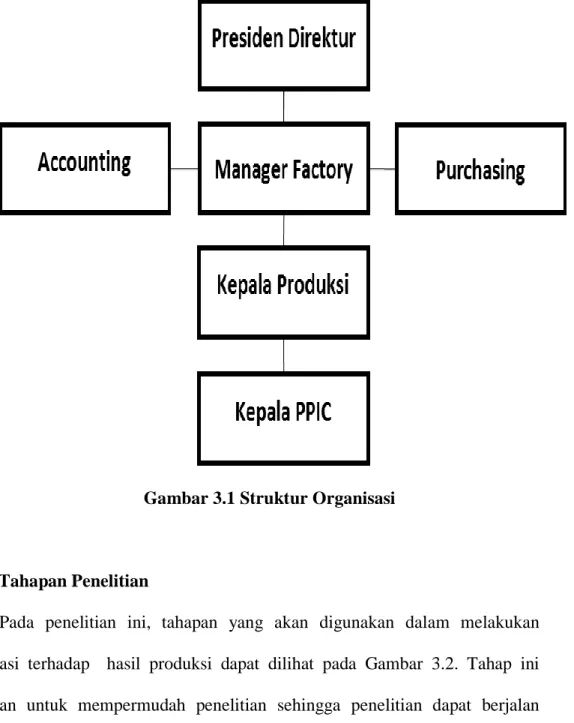
3.1 Tentang Perusahaan
Dimulai dari tahun 1980-an, melihat pentingnya keselamatan dalam berkendara khususnya kendaraan bermotor, PT. Indosafety Manufacture mulai mempelopori produksi helm motor roda dua pertama di Indonesia guna mendukung program keselamatan para pengendaran motor. PT. Indosafety Manufacture senantiasa berusaha memproduksi helm dengan kualitas produk dan proses yang mengedepankan keamanan dan didukung oleh kualitas bahan dasar terbaik yang telah melalui uji standar yang ketat sesuai dengan standar nasional dan internasional yang berlaku. PT. Indosafety Manufacture berusaha menciptakan helm dengan inovasi dan model terbaru, bukan hanya untuk menunjang keselamatan yang lebih baik, akan tetapi juga untuk menyesuaikan dengan gaya/karakter dan performa para pengguna sepeda motor.
PT. Indosafety Manufacture berlokasi di Kawasan Industri Lippo Cikarang, dengan luas wilayah 20.000 m (15.000 m), sekitar 45 menit perjalanan dari Pusat Kota Jakarta. Dalam hal proses produksi helm, PT. Indosafety Manufacture menggunakan teknologi terkini dan didukung oleh para ahli dari kerjasama teknik dengan produsen Eropa yang telah berpengalaman dalam industri helm. Dalam proses pembuatan produk, PT. Indosafety Manufacture memiliki proses produksi yang hampir seluruhnya in house.
Didukung dengan mesin-mesin memadai mulai dari proses Injection, Painting, Decal, EPS, Punch, Sewing (sarung padding) hingga proses assembling.
Semuanya dibawah kontrol ketat untuk memproduksi helm-helm label terkemuka merek lokal. Dalam pembuatan bahan dasar shell (batok) helm PT. Indosafety Manufacture memiliki proses teknologi thermoplastic (injection moulding). Untuk bagian riset dan teknologi, PT. Indosafety Manufacture mempunyai tim khusus dan kerja sama dengan produsen helm di Eropa & Amerika dalam melahirkan desain produk helm yang kontemporer, dari aspek teknologi, estetika, maupun keamanan dan kenyamanan.
Produk-produk PT. Indosafety Manufacture juga melalui tahap quality control yang tinggi dan sistematis dimulai dari hasil pembuatan shell hingga proses akhir assembling. In-house full laboratorium dengan standar internasional menguji produk-produk PT. Indosafety Manufacture secara berkala ketahanan bahan dasar shell, uji EPS maupun pengujian produk final sesuai dengan norma standar di dunia seperti Eropa (EC2205), USA (DOT FMVSS218 dan SNELL), Australia (SA AS 1698) hingga standar terakhir yang berlaku di Indonesia SNI 1811-2007. PT. Indo-Safety Manufacture mempunyai 750 orang karyawan dengan total kapasitas produksi helm yang mencapai lebih dari 2 juta unit per tahun, dengan berbagai pilihan model, warna dan corak/grafis yang inovatif.
3.1.1 Visi dan Misi Perusahaan
Adapun visi dan misi PT. Indosafety Manufacture adalah sebagai berikut:
a) Visi
Menjadi produsen helm terkemuka di tanah air dengan mengedepankan konsistensi dalam kualitas dan inovasi keamanan sempurna bagi pengguna sepeda motor.
32
b) Misi
Memproduksi helm secara bertanggung jawab dan mengedepankan kepuasan konsumen dengan senantiasa menjaga kualitas produk.
3.1.2 Struktur Organisasi Perusahaan
Gambar 3.1 Struktur Organisasi
3.2 Tahapan Penelitian
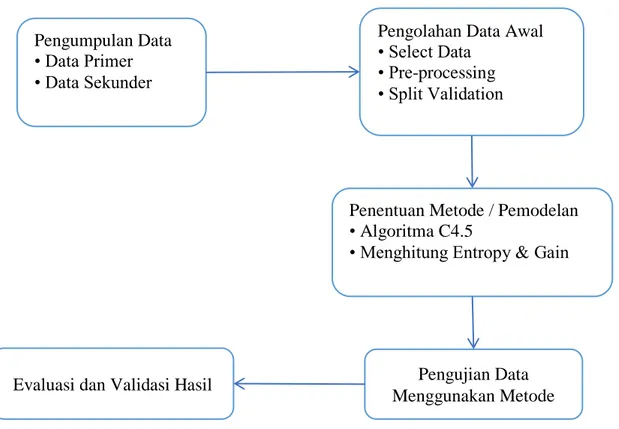
Pada penelitian ini, tahapan yang akan digunakan dalam melakukan klasifikasi terhadap hasil produksi dapat dilihat pada Gambar 3.2. Tahap ini dilakukan untuk mempermudah penelitian sehingga penelitian dapat berjalan dengan baik dan sistematis, serta memenuhi tujuan yang diinginkan. Berikut ini adalah langkah-langkah dalam tahapan yang dilakukan :
Gambar 3.2 Tahapan Penelitian
3.2.1 Pengumpulan Data
Pada tahap ini menjelaskan tentang bagaimana dan dari mana sumber data didapatka, diantaranya adalah :
1. Sumber Data Primer
Data-data yang penulis cantumkan disini merupakan data-data yang terdapat dari berbagai macam media yaitu : jurnal, buku, survey, internet dan lain-lain. Semua sumber data diambil dari sesi interview atau wawancara, dan studi pustaka untuk memperkuat bahan penelitian sebagai representasi teori.
Pengumpulan Data • Data Primer • Data Sekunder
Pengolahan Data Awal • Select Data
• Pre-processing • Split Validation
Penentuan Metode / Pemodelan • Algoritma C4.5
• Menghitung Entropy & Gain
Pengujian Data Menggunakan Metode Evaluasi dan Validasi Hasil
34
2. Sumber Data Sekunder
Dalam penulisan penelitian ini, penulis tidak hanya menggunakan metode pengumpulan data secara wawancara, studi literature dan internet saja. Tetapi mengunakan metode pengumpulan data yang diperoleh langsung dari sumber objek penelitian. Dalam hal ini, penulis mendapatkan data dari laporan hasil produksi yang ada pada perusahaan.
Pengumpulan data dilakukan dengan mempertimbangkan penggunaan data dari jenis dan sumbernya. Data yang digunakan dalam penelitian ini dalah data sekunder, data yang penulis dapatkan adalah data laporan hasil produksi yang akan dijadikan sebagai bahan penelitian. Data yang akan digunakan dalam penelitian ini adalah data yang sudah masuk pada
inventory gudang hasil tarikan dalam waktu tiga bulan terakhir pada PT.
Indosafety Manufacture. Jumlah data yang digunakan adalah 135 data, masing-masing diambil 15 data colour atau series dari 8 model helmet.
Gambar 3.3 Data Model Helmet
3.2.2 Pengolahan Data Awal
Pada tahap ini menjelaskan tentang tahap awal data mining. Data yang telah didapatkan akan diolah keformat yang dibutuhkan, pengelompokkan dan penentuan atribut data. Dalam melakukan pengolahan data awal, akan dilakukan
MON TUE WED THU FRI SAT MON TUE WED THU FRI SAT
#REF! #REF! #REF! #REF! #REF! #REF! #REF! #REF! #REF! #REF! #REF! #REF! 1 SOLID MDS SUPER PRO SOLID BLACK M 2 1 0 0 0 12 6 0 2 SOLID MDS SUPER PRO SOLID BLACK L 58 57 0 0 0 348 342 0 3 SOLID MDS SUPER PRO SOLID BLACK XL 11 11 0 0 0 66 66 0 4 SOLID MDS SUPER PRO SOLID GRAPHITE M 0 0 0 0 0 0 5 SOLID MDS SUPER PRO SOLID GRAPHITE L 1 1 0 0 0 6 6 0 6 SOLID MDS SUPER PRO SOLID GRAPHITE XL 0 0 0 0 0 0 7 SOLID MDS SUPER PRO SOLID RED FLUO M 0 0 0 0 0 0 8 SOLID MDS SUPER PRO SOLID RED FLUO L 0 0 0 0 0 0 9 SOLID MDS SUPER PRO SOLID RED FLUO XL 0 0 0 0 0 0 10 SOLID MDS SUPER PRO SOLID YELLOW FLUO M 16 15 0 0 0 96 90 0 11 SOLID MDS SUPER PRO SOLID YELLOW FLUO L 6 5 0 0 0 36 30 0 12 SOLID MDS SUPER PRO SOLID YELLOW FLUO XL 3 3 0 0 0 18 18 0 13 SOLID MDS SUPER PRO SOLID WHITE M 6 5 0 0 0 36 30 0 14 SOLID MDS SUPER PRO SOLID WHITE L 20 19 0 0 0 120 114 0 15 SOLID MDS SUPER PRO SOLID WHITE XL 41 41 0 0 0 246 246 0 16 STICKER MDS SUPER PRO #1 WHITE BLACK RED M 27 27 0 0 0 162 162 0 17 STICKER MDS SUPER PRO #1 WHITE BLACK RED L 27 27 0 0 0 162 162 0 18 STICKER MDS SUPER PRO #1 WHITE BLACK RED XL 1 1 0 0 0 6 6 0 19 STICKER MDS SUPER PRO #1 WHITE BLACK RED XXL 0 0
20 STICKER MDS SUPER PRO #1 WHITE BLACK RED FLUO M 15 15 0 0 0 90 90 0 21 STICKER MDS SUPER PRO #1 WHITE BLACK RED FLUO L 26 26 0 0 0 156 156 0 22 STICKER MDS SUPER PRO #1 WHITE BLACK RED FLUO XL 0 0 0 0 0 0 23 STICKER MDS SUPER PRO #1 WHITE BLACK BLUE M 1 1 0 0 0 6 6 0 24 STICKER MDS SUPER PRO #1 WHITE BLACK BLUE L 67 67 0 0 0 402 402 0 25 STICKER MDS SUPER PRO #1 WHITE BLACK BLUE XL 0 0 0 0 0 0 26 STICKER MDS SUPER PRO #1 WHITE BLACK YELLOW M 9 9 0 0 0 54 54 0 27 STICKER MDS SUPER PRO #1 WHITE BLACK YELLOW L 38 38 0 0 0 228 228 0 28 STICKER MDS SUPER PRO #1 WHITE BLACK YELLOW XL 4 4 0 0 0 24 24 0 29 STICKER MDS SUPER PRO #1 WHITE BLACK GUNMETAL M 0 0 0 0 0 0 30 STICKER MDS SUPER PRO #1 WHITE BLACK GUNMETAL L 46 46 0 0 0 276 276 0 31 STICKER MDS SUPER PRO #1 WHITE BLACK GUNMETAL XL 0 0 0 0 0 0 32 STICKER MDS SUPER PRO #2 ALL GREY MATT RED BLACK M 0 0 0 0 0 0 33 STICKER MDS SUPER PRO #2 ALL GREY MATT RED BLACK L 0 0 0 0 0 0 34 STICKER MDS SUPER PRO #2 ALL GREY MATT RED BLACK XL 0 0 0 0 0 0 35 STICKER MDS SUPER PRO #2 YELL FLUO RED BLACK M 0 0 0 0 0 0 36 STICKER MDS SUPER PRO #2 YELL FLUO RED BLACK L 4 4 0 0 0 24 24 0 37 STICKER MDS SUPER PRO #2 YELL FLUO RED BLACK XL 5 5 0 0 0 30 30 0 38 . TOTAL MDS SUPER PRO 0 0 0 434 428 0 0 0 0 2604 2568 0 39 SOLID KYT ROMEO SOLID BLACK M 55 35 0 0 0 330 210 0 40 SOLID KYT ROMEO SOLID BLACK L 0 0 0 0 0 0
GRAND TOTAL
PCS MB
COLOR TYPE MODEL NAME
36
beberapa tahapan agar didapatkan data yang bisa digunakan untuk tahap selanjutnya. Beberapa tahapan tersebut yaitu : select data, pre-processing, serta akan dilakukan split validation.
1. Select Data
Pada tahap ini akan dilakukan pemilihan variabel data yang akan dianalisis, karena sering ditemukan bawha tidak semua data yang dibutuhkan dengan mempertimbangkan tujuan penulisan, sehingga diperoleh beberapa variabel yang akan digunakan untuk menjadi masukan variabel input.
Dari 135 data record akan diambil 5 variable, yaitu : total, helmet, model, colour, type. Data hasil seleksi akan digunakan dalam proses data mining. 2. Pre-processing
Pada proses pre-processing akan dilaukan pembersihan data untuk membuang data yang missing value yaitu data yang tidak konsisten dan juga memperbaiki data yang rusak. Proses pemberihan data dilakukan secara manual untuk memastikan bahwa data yang telah dipilih layak untuk dilakuka proses permodelan.
3. Split Validation
Split Validation marupakan teknik validasi yang membagi data menjadi
dua bagi secara acak, sebagian data training dan sebagian data testing. Data yang sudah disipakan untuk klasifikasi dibagi menjadi dua untuk data
training dan data testing menggunakan sampling random sistematik
sistematik ini perandoman atau pengundian hanya dilakukan satu kali, yakni ketika menentukan unsur pertama dari sampling yang akan diambil. Penentuan unsur sampling selanjutnya ditempuh dengan cara memanfaatkan interval sampel. Interval sampel atau juga disebut sampling rasio diperoleh dengan cara membagi ukuran populasi dengan ukuran sampel yang dikehendaki (N/n). Hasil perhitungan untuk mengambil data testing adalah sebagai berikut:
Jumlah Data (N) = 135
Jumlah Data Testing = 20% x 135 = 27 Jumlah Sampel (n) = 27
Interval sampling = N/n = 135/27 = 5
Unsur pertama yang diambil untuk data testing (s) = 1 Unsur Kedua = s + k
Unsur Ketiga = s + 2k
Unsur Keempat = s+3k, dan sterusnya hingga unsur ke-n
Pembagian data menjadi data training dan data testing pada penelitian ini menggunakan split ratio 80% untuk data training dan 20% untuk data testing. Dari hasil diatas diperoleh data testing sebanyak 27 data, maka sisanya dijadikan data training 108 data.
38
Tabel 3.2.2 Data Testing
3.2.3 Pemodelan
Pada penelitian ini akan dilakukan pemodelan menggunakan metode Algoritma C4.5 untuk pengolahan data barang. Berikut ini tahapan proses permodelan dalam penelitian ini. Metode Algoritma C4.5 dipilih karena salah satu kelebihannya adalah dapat menangani data numerik dan diskret. Algoritma C4.5 menggunakan rasio perolehan (gain rasio). Sebelum menghitung rasio perolehan, perlu dilakukan perhitungan nilai informasi dalam satuan bits dari suatu kumpulan objek, yaitu dengan menggunakan konsep entropy untuk membentuk pohon
keputusan. Data kemudian dihitung menggunakan algoritma sesuai dengan metodenya kemudian dicari hasil akurasinya.
Ada beberapa tahap dalam membentuk pohon keputusan dengan algoritma C4.5 antara lain :
1. Menyiapkan data training, dimana data tersebut akan diklasifikasikan. 2. Menentukan akar dari pohon, akar akan diperoleh dari atribut yang terpilih
dengan cara menghitung nilai gain dari masing-masing atribut. Nilai gain tertinggi akan dijadikan akar pertama dalam pohon kepurusan. Sebelum menghitung nilai gain, hitung dulu nilai entropy dengan persamaan sebagai berikut :
3. Kemudian hitung nilai gain dengan persamaan sebagai berikut :
4. Untuk langkah 2 hinggga semua record terpartisi. 5. Proses partisi akan berhenti saat :
Semua record pada simpul N mendapat kelas yang sama.
Tidak ada atribut didalam record yang akan dipartisi lagi.
Tidak ada record di dalam cabang yang kosong.
3.2.4 Pengujian Data Metode
Pengujian metode dilakukan untuk mengetahui hasil perhitungan yang dianalisa dan untuk mengetahui apakah fungsi bekerja dengan baik atau tidak. Setelah data dihitung secara manual, kemudian data diuji menggunaka tools
40
RapidMiner untuk memastikan apakah hasil perhitungan manual dengan hasil yang diperoleh RapidMiner sama atau tidak.
3.2.5 Evaluasi dan Validasi Hasil
Evaluasi dapat dilakukan dengan cara mengamati dan menganalisa hasil dari algoritma yang digunakan untuk memastikan bahwa hasil pengujian benar-benar sesuai dengan pembahasan. Sedangkan validasi dilakukan dengan mengukur hasil prediksi untuk mengetahui tingkat akurasi, presisi dan recall.
Akurasi adalah presentase dari catatan yang diklasifikasikan dengan benar oleh pengujian dataset. Presisi adalah presentase data yang diklasifikasikan sebagai model yang baik yang sebenarnya juga baik. Recall adalah pengukuran tingkat pengenalan positif sebenarnya (Amin, Indwiarti, & Sibaroni, 2015).
3.3 Instrument Penelitian
Dalam penelitian dibutuhkan bahan dan peralatan untuk mendukung berjalannya penelitian.
3.3.1 Bahan
Bahan yang dibutuhkan dalam penelitian ini adalah data laporan hasil produksi PT. Indosafety Manufacture pada bulan juli sampai dengan agustus 2018.
3.3.2 Kebutuhan Perangkat Lunak (Software)
Perangkat lunak, versi dan fungsi dapat dilihat pada Tabel 3.3.2 dibawah ini :
Tabel 3.3.2 Perangkat Lunak (Software)
Software Versi Fungsi
Sistem Operasi Microsoft
Windows 10 Sebagai sistem operasi penelitian ini Microsoft Office Word 2010 Digunakan untuk mengolah laporan ini Microsoft Office Excel 2010 Digunakan sebagai media penulisan, dan
pengolahan dataset
RapidMiner Studio 8.1
Digunakan untuk mengolah dataset dan untuk melihat hasil akurasi dari
algoritma yang digunakan Microsoft Visio 2010 Digunakan sebagai media penulisan
3.3.3 Kebutuhan Perangkat Keras (Hardware)
Selain perangkat lunak (software) dibutuhkan pula perankat keras (Hardware) sebagai pendukung penelitian data mining , yaitu laptop. Adapun spesifikasi laptop dijelaskan pada tabel 3.3.3 dibawah ini :
Tabel 3.3.3 Perangkat Keras (Hardware)
Spesifikasi Hardware Keterangan
Processor Intel ® Celeron ® CPU @1.50 GHz
RAM 4,00 GB
42
BAB IV
HASIL DAN PEMBAHASAN
4.1 Gambaran Umum Kerja Sistem
Implementasi data mining dengan RapidMiner, untuk memprediksi pemasaran produk menggunakan Algoritma C4.5 berfungsi untuk melakukan perhitungan pemasaran produk helmet. Hal pertama yang dilakukan untuk melakukan proses perhitungan dengan menggunakan algoritma C4.5, menginput data pemasaran helmet kedalam sistem, Setelah memasukkan data, maka sistem melakukan proses perhitungan data testing sebagai bukti dari hasil akhir yang diperoleh.
4.2 Tahap Pengujian Data Pengiriman
Berdasarkan prosedur estimasi dalam melakukan proses mining untuk menghasilkan prediksi pemasaran, adalah sebagai berikut :
1. Pilih data pemasaran sebagai variabel. 2. Entrophy.
3. Information Gain.
4. Hasil perhitungan untuk memprediksi produk paling laku.
Untuk memilih data pemasaran sebagai atribut, untuk menghasilakan produk paling laku di pasaran barang. Berikut ini penjelasannya.
4.3 Data Pemasaran Helmet
Berikut ini adalah data testing yang diambil dari data pemasaran helmet dengan perbandingan 80%:20% dari 135 data, total 108 data training dan 27 data testing. Pengujian sistem yang dilakukan dengan data pemasaran menggunakan algoritma C4.5.
Gambar 4.3 Data Testing
4.4 Algoritma C4.5
Langkah awal perhitungan algoritma C4.5 adalah pertama mencari nilai entropy dan mencari nilai information gain berikut ini proses penentuan nilai entropy dan information gain, sebagai berikut:
44
1.
2.
3.
A. Perhitungan Nilai Total Diketahui :
Jumlah Kasus : 27 Jumlah Nila Laku : 18 Jumlah Nilai Tidak Laku : 9
( ) ( )
A. Perhitungan Nilai Helmet
Diketahui: MDS Super Pro Jumlah Kasus : 6 Laku : 3 Tidak Laku : 3 ( ) ( )
)
(
log
)
(
2 1 i m i ip
p
D
Info
)
(
|
|
|
|
)
(
1 j v j j AI
D
D
D
D
Info
(D) Info Info(D) Gain(A) ADiketahui: KYT Romeo Jumlah Kasus : 6 Laku : 5 Tidak Laku : 1 ( ) ( ) Diketahui: KYT SEVEN Jumlah Kasus : 3 Laku : 1 Tidak Laku : 2 ( ) ( ) Diketahui: KYT DJ Maru
46 Jumlah Kasus : 3 Laku : 3 Tidak Laku : 0 ( ) ( ) Diketahui: KYT XRocket Jumlah Kasus : 3 Laku : 1 Tidak Laku : 2 ( ) ( ) Diketahui: INK Centro Jet Jumlah Kasus : 6 Laku : 6 Tidak Laku : 0
( ) ( )
B. Perhitungan nilai Model
Diketahui: Full Face Jumlah Kasus : 10 Laku : 4 Tidak Laku : 6 ( ) ( ) Diketahui: Open Face Jumlah Kasus : 17 Laku : 16 Tidak Laku : 1 ( ) ( )
C. Perhitungan nilai Color
48
SOLID RED FLOU Jumlah Kasus : 3 Laku : 0 Tidak Laku : 3
( ) ( )
Diketahui:
# 1 White Black Red Jumlah Kasus : 3 Laku : 3 Tidak Laku : 0 ( ) ( ) Diketahui: SOLID BLACK Jumlah Kasus : 3 Laku : 3 Tidak Laku : 0
( ) ( )
Diketahui:
STREAM LINE RED FLOU BLACK Jumlah Kasus : 3
Laku : 2
Tidak Laku : 1
( ) ( )
Diketahui:
SOLID ALL GREY Jumlah Kasus : 3 Laku : 1 Tidak Laku : 2
50
Diketahui:
SOLID DEEP PURPLE Jumlah Kasus : 3
Laku : 3
Tidak Laku : 0
( ) ( )
Diketahui:
RETRO CRIMSON YELLOW BLACK
Jumlah Kasus : 3 Laku : 3
Tidak Laku : 0
( ) ( )
Diketahui:
#1 BLACK WHITE ORANGE
Jumlah Kasus : 3 Laku : 3
( ) ( )
D. Perhitungan nilai Type
Diketahui: SOLID Jumlah Kasus : 18 Laku : 11 Tidak Laku : 7 ( ) ( ) Diketahui: STICKER Jumlah Kasus : 9 Laku : 8 Tidak Laku : 1 ( ) ( )
52 Diketahui : Total : 27 Gain Helmet MDS Super Pro : ( 3,3 ) KYT Romeo : ( 5,1 ) KYT Seven : ( 1,2 ) KYT DJ Maru : ( 3,0 ) KTY XRocket : ( 1,2 ) INK Centro Jet : ( 6,0 )
( ) ( ) ( ( )) ( ( )) ( ( )) ( ( )) ( ( )) ( ( )) Diketahui : Total : 27 Gain Model Full Face : ( 4,6 ) Open Face : ( 16,1 ) ( ) ( ( )) ( ( ))
Diketahui : Total : 27 Gain Model Full Face : ( 4,6 ) Open Face : ( 16,1 ) ( ) ( ( )) ( ( )) Diketahui : Total : 27 Gain Color
Solid Red Flou : ( 0,3 ) # 1 White Black red : ( 3,0 )
Solid Black : ( 3,0 )
Stream Line Red flou Black : ( 2,1 )
Solid All Grey : ( 1,2 )
Solid Deep Purple : ( 3.0 )
Retro Crimson Yeleow Black : ( 3,0 ) #1 Black White Orange : ( 3,0 )
54 ( ( )) ( ( )) ( ( )) ( ( )) ( ( )) ( ( )) ( ( )) ( ( )) Diketahui : Total : 27 Gain Type Solid : ( 11,7 ) Sticker : ( 8,1 ) ( ) ( ( )) ( ( ))
Tabel 4.2.1 Hasil Entropy dan Gain
Langkah Jumlah Kasus Laku Tidak Laku Entropy Informasi Gain Total 27 18 9 0.918296 Helmet 0.347558444 MDS Super Pro 6 3 3 1 KYT Romeo 6 5 1 0.650022 KYT Seven 3 1 2 0.918296 KYT DJ Maru 3 3 0 0 KYT Xrocket 3 1 2 0.918296
INK Centro Jet 6 6 0 0
Model 0.355467158
Full Face 10 4 6 0.970951