Modul
Pengolaan
Data SPSS
Publish: September 24
2010
Metode Penelitian Dan Pengolahan Data Penelitian (Pendekatan Praktis)
Oleh: Hanif [email protected]
Modul
Bismillaahirrahmaanirrahiim,
Wabihii nasta’inu Subhaanaka laa ’ilmalana illaa maa ‘allamtana innaka antal ‘aliimul hakiim. Allahumma shalli ‘alaa sayyidina Muhammad wa ‘alaa alihi
washahbihi.
Pendahuluan
…….. Dalam suatu ujian skripsi, tujuh peserta ujian ditanya oleh penguji…. “Apa alasan anda memilih regresi berganda sebagai alat analisa ?..,” peserta 1, 2 dan 3 menjawab, dengan senyuman alias nggak ngerti, peserta 4 menjawab ikut skripsi yang lalu, peserta 5 dan 6 menjawab atas saran dosen pembimbing, peserta 7 menjawab karena pertimbangan masalah dan tujuan penelitian serta formulasi model penelitian.
….. mana kira-kira jawaban yang terbaik…….. !
Berdasarkan pengalaman penulis dalam membimbing dan menguji skripsi selama ini, masih ada beberapa mahasiswa yang telah lupa atau belum faham mengenai apa dan bagaimana proses analisis data itu dilakukan sebagai alat bantu pembuatan kesimpulan penelitian.
Suplemen ini merupakan pelengkap modul mata kuliah metode penelitian yang biasa digunakan oleh penulis dalam memberikan materi perkuliahan di kelas. Lebih lanjut, suplemen ini disusun atas dasar keinginan penulis untuk membantu mahasiswa STIEMARA yang sedang menyusun tugas akhir dan berkeinginan mengolah data secara mandiri.
Menurut pengamatan penulis, terdapat beberapa alat analisa yang umum digunakan mahasiswa S1 dalam menjawab permasalahan, tujuan serta hipotesis penelitian. Alat analisa tersebut antara lain analisis regresi berganda, analisis jalur, uji beda, analisis factor, analisis cluster dan diskriminan.
Bagian Satu
Analisa Regresi Berganda
Penggunaan Regresi Berganda
Regresi Berganda adalah bagian dari analisis multivariate. Tujuan utama analisis regresi berganda adalah untuk menduga besarnya koefisien regresi. Selanjutnya, koefisien regresi inilah yang akan menunjukkan besarnya pengaruh peubah bebas (independent variable/X) terhadap peubah tak bebas (dependent variable/Y).
Kata “berganda” diambil sebagai penjelas untuk menunjukkan bahwa peneliti dalam penelitiannya menggunakan lebih dari satu variabel bebas (di kampus tercinta ini variabel diistilahkan dengan kata peubah, pengertian keduanya mempunyai arti yang sama). Pemborosan yang sering dilakukan oleh mahasiswa dalam skripsinya ialah ia menyajikan semua analisa seperti regresi sederhana, korelasi sedehana, regresi berganda, korelasi berganda yang pada akhirnya mahasiswa bingung sendiri, figure statistik mana yang dipakai ?. Seiring kemajuan teknologi software, semua tujuan untuk uji hubungan maupun pengaruh baik secara bersama-sama maupun secara parsial dapat diselesaikan hanya dengan satu “click” yaitu “regression”. Semua tindakan olah data itu dapat dilakukan bahkan berulang-ulang dengan beberapa perbaikan yang dimungkinkan hanya dalam hitungan menit. Bersyukurlah kita karena sudah ada software pengolah data yang saudara kenal dengan sebutan SPSS for windows.
Jangan bayangkan statistic berwajah rumus yang “jlimet” dan seabrek perhitungan lain, disini statistik sebagai alat dan sebagai alat ia telah mengalamai metamorfosis, ibarat mengitung perkalian 2435364 x 647469865, dengan manual ?????, tetapi dengan calculator “no problem”. Demikian juga regresi berganda, dengan manual ??????, tetapi dengan SPSS “smile dan menantang”. Yang terpenting dari semua aspek teknis itu saudara bisa membaca hasil output SPSS tersebut untuk pengambilan kesimpulan atas masalah dan tujuan penelitian, misal untuk apa mengetahui nilai R, R square, nilai F, nilai b, nilai t, nilai Sig dan beberapa figure atau parameter lain yang diperlukan untuk pengujian hipotesis dan menjawab permasalahan penelitian.
Nah saudaraku mari kita santai sejenak dan perhatikan hiburan berikut ini……….
menghitung yang sebenarnya bukan tujuan utama saudara. Akibatnya pembahasan thesis, anti-thesis dan sintesa antara kajian teori dan temuan empiris menjadi tidak tajam karena anda lebih mengutamakan belajar darimana angka-angka tersebut tapi bukan belajar apa arti angka-angka tersebut. Fenomena ini sering penulis temui ketika menjelang ujian skripsi mahasiswa sibuk dan stress gara-gara rumus. Bukan sibuk mempersiapkan penjelasan yang logis atas temuan penelitiannya.
Mohon direnungkan……
Persiapan mengolah data penelitian.
Sebagai misal peneliti ingin mengetahui apakah ada pengaruh antara gaji karyawan dan Kedisiplinan kerja karyawan terhadap Prestasi kerja karyawan.
Lihat model teori penelitian berikut:1
Based on this model, dapat kita mengerti bahwa terdapat dua peubah bebas (x1 dan x2) dan satu peubah terikat (Y), yang selanjutnya ingin diketahui bagaimana bentuk hubungan dan pengaruhnya, tentunya dengan menggunakan analisis regresi berganda.
Apa yang perlu dipersiapkan ?
Setelah bangunan teori di susun dengan menyajikan argumen yang kuat dan relevan. Berikutnya perumusan hipotesis dilakukan sebagai dasar pengujian. Dalam contoh diatas peneliti mempunyai fokus pada peubah gaji karyawan (x1) dan Kedisiplinan karyawan (x2) keduanya sebagai peubah bebas yang berpengaruh pada prestasi kerja karyawan (Y) (lihat model hal 1). Selanjutnya peneliti harus menyusun pengukuran
1 Model penelitian dimaksudkan untuk membuat penyederhanaan permasalahan, sehingga pembaca dapat mengetahui alur atau arah cerita penelitian yang dilakukan.
didalam akhir bab II, gambar ini biasanya disajikan kerangka/ model teori penelitan
Gaji karyawan
Kedisiplinan kerja karyawan
dari peubah-peubah tersebut. (dalam skripsi saudara, perbincangan ini masuk pada bab III, Peubah dan Pengukuran). Untuk mempermudah penguasan peubah dan pengukuran, saudara lebih baik membuat tabel yang berisikan penjelasan atas peubah dan pengukuran tersebut, lihat contoh berikut:
Tabel 1. Peubah dan pengukuran
Peubah Penelitian Indikator peubah Skala pengukuran∗ Gaji karyawan (X1) 1. jumlah gaji
2.
kesesuaian dengan beban kerja3. unsur keadilan
1.
ordinal-interval 2. ordinal-interval 3. ordinal-intervalKedisiplinan karyawan (x2) 1. taat pada aturan 2. absensi
3.
pemanfaatan fasilitas kerja1. ordinal-interval 2. ordinal-interval 3. ordinal-interval Prestasi Kerja karyawan (Y) 1. kuantitas hasil kerja
2. kesesuaian dengan standart 3. ketepatan waktu
1. ordinal-interval 2. ordinal-interval 3. ordinal-interval
Setelah peubah dan pengukuran tersebut dikonsultasikan dengan pembimbing dan dinilai sudah tepat artinya sesuai dengan tujuan penelitian dan kondisi empiris/lapangan, maka indikator-indikator tersebut untuk selanjutnya digunakan sebagai bahan penyusunan kuesioner dalam bentuk pertanyaan-pertanyaan.
Selanjutnya kuesioner dibagikan kepada responden, dan jawaban-jawaban responden yang telah terdokumentasi didalam kuesioner dimasukkan kedalam SPSS editor dengan langkah-langkah sebagai berikut:
Langkah awal.
Susun terlebih dahulu peubah dan pengukurannya sebelum di input kedalam SPSS editor sbb. (lihat tabel hal 3)
Peubah Gaji karyawan (x1),
Indikatornya: x1.1 Jumlah gaji
X1.2 kesesuaian dengan beban kerja X1.3 unsur keadilan
Contoh pertanyaan didalam kuisioner:
1. Bagaimana pendapat bpk/ibu/sdr tentang jumlah gaji yang diterima perbulan dari perusahaan.
a. sangat memadai b. memadai c. cukup d. kurang
e. sangat tidak memadai
informasi lain : …… ……… ……. ………
Terkadang didalam kuesioner perlu diberikan pertanyaan terbuka untuk memperoleh informasi lain yang mungkin diperlukan dan berguna pada saat memperkuat penjelasan
Untuk Peubah kedisiplinan karyawan (x2), sbb:
Indikatornya: X2.1 Taat pada aturan X2.2 absensi
X2.3 pemanfaatan fasiltas
Untuk Peubah Prestasi kerja Karyawan (Y), sbb:
Indikatornya: Y.1 kuantitas hasil kerja
Y.2 kesesuaian dengan standart Y.3 Ketepatan waktu
(x1.1; x1.2 dst hanyalah pemberian istilah saja untuk mempermudah mengenali variabel beserta indikatornya. X1.1 artinya indikator ke 1 dari variable ke 1, x2.2 artinya indikator ke dua dari variable ke 2, dst)
Menjalankan SPSS.
1.
Buka SPSS , bisa open lewat program, windows explorer atau klik dua kali icon SPSS.Hasilnya akan nampak seperti ini:
setelah media spss editor dalam posisi ready, selanjutnya tinggal ketik nama-nama variable beserta masing-masing indikatornya dengan cara sbb: (untuk memulai memberi nama variable, klik variable view pada bagian paling bawah sebelah kiri) Hasilnya akan tampak sbb:
Data diatas berjumlah n=30 namun hanya tampak n=12
Setelah data lengkap disajikan didalam spss editor selanjutnya akan dilakukan analisis regresi, dengan tahapan sebagai berikut.
Tahap Awal.
Lakukan uji Validitas dan Reliabilitas seperti petunjuk di bawah ini
•
Arahkan pointer saudara pada menu Analyze•
Pilih Scale, selanjutnya pilih Reliability Analysis,,,,, (lihat kotak )Masukkan tiap peubah dan indikator ke dalam kotak item (pakai tanda untuk memasukkan dan mengeluarkan tiap peubah beserta indikatornya) sesuai dengan kelompoknya masing-masing, Gambar diatas adalah proses untuk menguji validitas dan reliabilitas untuk indikator-indikator X1, lakukan hal yang sama untuk x2 dan Y lakukan sesuai kelompoknya (lihat hal 5 )
Klik Ok dan hasilnya adalah
Reliability
****** Method 1 (space saver) will be used for this analysis ******
R E L I A B I L I T Y A N A L Y S I S - S C A L E (A L P H A)
Mean Std Dev Cases
1. X1.1 3.5667 .7279 30.0 2. X1.2 3.9333 .5833 30.0 3. X1.3 3.9333 .6915 30.0 4. X1TOTAL 11.4000 1.0372 30.0
Item-total Statistics
Scale Scale Corrected
Mean Variance Item- Alpha if Item if Item Total if Item Deleted Deleted Correlation Deleted
X1.1 19.2667 2.9609 .5157 .5404
X1.2 18.9000 3.4034 .5499 .5816
X1.3 18.9000 3.5414 .6007 .6758
X1TOTAL 11.4333 1.0816 .7746 .7698
Interpretasi hasil uji validitas dan reliabilitas.
Secara statistik, Instrumen penelitian dikatakan mempunyai tingkat validitas yang baik jika Nilai corrected item-total correlation dibandingkan dengan nila r kritik pada tabel harus lebih besar.
Instrumen penelitian dikatakan mempunyai tingkat reliabilitas yang tinggi jika nilai
Alpha lebih besar dari 0,6. Jadi instrument penelitian untuk merespon peubah gaji sudah “valid dan reliable”, lakukan interpretasi yang sama untuk x2 dan Y dengan bersandar pada ketentuan diatas.
Setelah melakukan uji validitas dan reliabilitas, berikutnya lakukan pengujian asumsi klasik2 (untuk uji asumsi klasik akan dijelaskan pada bagian akhir). Setelah semua asumsi dipenuhi ( multikolieritas, autokorelasi, heteroskedastisitas dan normalitas)
Proses uji asumsi klasik bisa dilakukan secara bersama dengan analisi regresi berganda. Dengan tahapan sebagai berikut:
Pilih menu Analyze, pilih Regression, pilih linear, tampilannya akan tampak sebagai berikut.
Klik linear maka akan tampak kotak perintah sbb: ikuti langkah berikut:
•
Masukkan peubah bebas (hanya nilai total saja, x1, x2 ) pada kotak independent• Masukkan peubah terikat (hanya nilai total Y) pada kotak dependent
•
Berikutnya klik icon “statistics….” Kemudian beri tanda check (√ ) pada kotak yang telah disediakan, sesuaikan dengan contohSelanjutnya klik continue dan klik Ok, maka spss sedang running… tunggu beberapa saat dan hasil analisis regresi berganda sudah bisa dilihat seperti tampilan berikut ini.
Regression
Variables Entered/Removedb
kedisiplina n, gaji karyawana
. Enter Model
1
Variables Entered
Variables
Removed Method
All requested variables entered. a.
Dependent Variable: prestasi kerja b.
Model Summaryb
.738a .544 .510 .9066 .544 16.103 2 27 .000 2.002
Model 1
R R Square Adjusted R Square
Std. Error of the Estimate
R Square
Change F Change df1 df2 Sig. F Change Change Statistics
Durbin-W atson
Predictors: (Constant), kedisiplinan, gaji karyawan a.
Dependent Variable: prestasi kerja b.
ANOVAb
26.473 2 13.237 16.103 .000a 22.194 27 .822
48.667 29 Regression
Residual Total Model 1
Sum of
Squares df Mean Square F Sig.
Predictors: (Constant), kedisiplinan, gaji karyawan a.
Dependent Variable: prestasi kerja b.
Coefficientsa
-4.35E-04 2.181 .000 1.000
.588 .179 .471 3.279 .003 .642 .534 .426 .819 1.220 .512 .183 .402 2.799 .009 .602 .474 .364 .819 1.220 (Constant)
gaji karyawan kedisiplinan Model
1
B Std. Error Unstandardized
Coefficients
Beta Standardi
zed Coefficien
ts
t Sig. Zero-order Partial Part Correlations
Tolerance VIF Collinearity Statistics
Berikutnya adalah melakukan interpretasi atas hasil analisis regresi. Dalam membaca print out SPSS tersebut, saudara harus bersandar pada rumusan masalah, tujuan dan hipotesis penelitian. Artinya tidak semua angka-angka/parameter diinterpretasikan. Dalam contoh ini telah disebutkan bahwa peneliti ingin mengetahui dan menguji: • Apakah ada pengaruh antara gaji karyawan (x1) dan kedisiplinan (x2) terhadap
prestasi kerja (Y) secara bersama-sama mapun secara parsial Dengan demikian hipotesis penelitian akan dinyatakan :
•
Ada pengaruh yang signifikan antara gaji karyawan (x1) dan kedisiplinan (x2) terhadap prestasi kerja (Y) secara bersama-sama mapun secara parsial.Atau bisa disusun secara terpisah, sbb.
•
Ada pengaruh yang signifikan antara gaji karyawan (x1) dan kedisiplinan (x2) terhadap prestasi kerja secara bersama-sama.•
Ada pengaruh yang signifikan antara gaji karyawan (x1) terhadap prestasi kerja (Y) (parsial)•
Ada pengaruh yang signifikan antara kedisiplinan (x2) terhadap prestasi kerja (y) (parsial)Jika dimungkinkan, saudara juga diperbolehkan menduga bahwa salah satu variabel mempunyai pengaruh paling dominan, asalkan saudara mempunyai argumen yang kuat berdasarkan teori maupun penelitian terdahulu, ingat harus punya argumen tidak sekedar menduga tanpa dasar.
Misalnya, Diduga gaji karyawan (x1) mempunyai pengaruh yang paling dominant terhadap prestasi kerja (Y), hal ini tentunya harus didukung dengan alasan yang kuat bukan sekedar ikut kebiasaan selama ini.
Sekarang marilah kita mulai dengan belajar membaca print out spss regresi berganda.
Pengujian hipotesis,
Ada pengaruh yang signifikan antara gaji karyawan (x1) dan kedisiplinan (x2) terhadap prestasi kerja (Y) secara bersama-sama.
Untuk pengujian penelitian, secara statistik biasanya ada prosedur sbb
1.
lihat nilai R (koefisien korelasi berganda) gunanya untuk mengetahui keeratan hubungan antara peubah x1 dan x2 (secara sumultan) terhadap peubah terikat (y). Nilai korelasi bisa bernotasi negative maupun positif, notasi ini mengindikasikan bentuk atau arah hunungan yang terjadi. Perhatikan Kriteria nilai korelasi pada tabel berikut:Nilai R (korelasi) Kriteria hubungan
0 Tidak ada hubungan
0 – 0,5 Korelasi lemah
0,5 – 0,8 Korelasi sedang/cukup kuat
0,8 – 1 Korelasi kuat
1 Korelasi sempurna
bersama-sama terhadap prestasi kerja (Y). Artinya jika x1 dan x2 meningkat maka Y juga akan meningkat (korelasi positif). (lihat tabel Model Summary hal 13)
2.
Lihat nilai R square (R2) juga disebut sebagai koefisien determinasi gunanya untuk mengetahui besarnya kontribusi peubah bebas (x) secara serempak didalam menjelaskan peubah terikat (Y). R Square juga dapat menunjukkan ragam naik atau turunnya peubah terikat (Y) yang diterangkan oleh pengaruh linier peubah bebas (X).
Ukuran nilai R Square adalah 0 ≤ R2 ( 1, artinya semakin mendekati angka satu berarti garis regresi yang terbentuk dapat meramalkan peubah terikat (Y) secara lebih baik menuju kesempurnaan (model fit)
Dalam tabel model summary (hal 13) kita lihat nilai R2 sebesar 0,544. Hal ini diartikan bahwa peubah bebas dalam hal ini gaji dan kedisiplinan secara bersama-sama menjelaskan peubah prestasi kerja sebesar 54,4 %, sedangkan sisanya 45,6 % dijelaskan oleh peubah lain yang tidak diteliti dalam penelitian ini atau model penelitian.
Semakin besar nilai R2 semakin menunjukkan ketepatan model yang telah disusun (model yang dimaksud adalah model teori penelitian ini).
3.
Lihat Nilai F statistic (biasa disebut Uji F) dan Nilai Sig. (lihat table ANOVA, hal 13) NIlai F statistic dapat digunakan untuk mengetahui tingkat signifikansi kontribusi peubah bebas (secara bersama-sama) dalam menjelaskan peubah terikat. Artinya apakah pengaruhnya nyata atau bermakna. Dengan membandingkan nilai F statistic dengan nilai F table dapat diketahui tingkat signifikansinya.Kita lihat dari table ANOVA bahwa nilai F stat sebesar 16.03 sedangkan F table dapat
di tentukan dengan cara sebagai berikut:
Lihat df (degree of freedom) atau derajat bebas (db) rumusnya k, n-k-1 atau langsung lihat di table anova, df nya adalah 2 (jumlah peubah bebas) , dan 27 (jumlah responden – peubah bebas -1 jadi 30-2-1=27) setelah diketahui df nya berikutnya lihat table F yang tersedia di setiap buku statistic. Cara baca tabelnya adalah sebagai berikut
Lihat angka 2 pada kolom db pembilang dan lihat angka 27 pada kolom db penyebut dan hubungkan perpotongan keduanya pada tingkat alpha (misal 0,05) maka akan terlihat angka sebesar 3,35.
Jika kita bandingkan antara F stat dengan F table maka 16,03>3.35, jadi
keputusannya adalah menerima hipotesis yang menyatakan bahwa terdapat pengaruh yang signifikan antara gaji karyawan (x1) dan Kedisiplinan karyawan (x2) secara bersama-sama terhadap prestasi kerja karyawan (Y)
Cara lain untuk melihat tingkat signifikansi.
prestasi kerja. Dua cara tersebut, yaitu membandingkan antara F stat dengan F table atau membandingkan Nilai Sig dengan Alpha, silahkan saudara pilih mana yang lebih mudah.
Setelah mengetahui pengaruh secara bersama-sama, selanjutnya kita akan analisis bagaimana pengaruhnya secara parsial (pengaruh secara sendiri-sendiri, artinya bagiamana pengaruh X1 thd Y dalam kondisi X2 dikontrol/tetap/cateris paribus).
Adapun manfaat lain mengetahui pengaruh secara parsial adalah untuk mencari informasi dari keseluruhan peubah bebas, peubah mana yang pengaruhnya paling dominan atau paling besar.
Untuk tujuan itu kita bisa lihat dari table coefficient berikut ini (sumber pada hal 13.)
Coefficientsa
-4.35E-04 2.181 .000 1.000
.588 .179 .471 3.279 .003 .642 .534 .426 .819 1.220
.512 .183 .402 2.799 .009 .602 .474 .364 .819 1.220
(Constant) gaji karyawan kedisiplinan Model
1
B Std. Error Unstandardized
Coefficients
Beta Standardi
zed Coefficien
ts
t Sig. Zero-order Partial Part Correlations
Tolerance VIF Collinearity Statistics
Dependent Variable: prestasi kerja a.
Secara parsial semua peubah bebas mempunyai pengaruh yang signifikan hal ini bisa dilihat dari nilai t stat maupun Sig, dimana nilai t stat lebih besar dari t table sedangkan nilai
Sig masih dibawah Alpha 0,05
Peubah gaji karyawan pengaruhnya signifikan terhadap prestasi kerja (t stat =3.279 > t table=2,056). Demikian juga nilai Sig=0.003 < 0,05 dengan koefisien regresi sebesar
0.588. Hal ini menyimpulkan bahwa hipotesis diterima.
Demikian juga dengan peubah kedisiplinan, dengan melihat nilai yang sama seperti diatas dapat disimpulkan bahwa, kedisiplinan mempunyai pengaruh signifikan terhadap prestasi kerja. Hal ini menyimpulkan bahwa hipotesis diterima.
Rekapitulasi hasil analisis regresi berganda
Jadi untuk tujuan penelitian ini beberapa parameter yang harus saudara ketahui ialah: Nilai R, R square, Nilai F(uji F), Nilai koefisien b atau beta, Nilai t (uji t), Nilai Sig
Ketika saudara mengartikan beberapa nilai statistik berdasarkan tabel-tabel pada halaman 13, itu berarti saudara sudah melakukan interpretasi secara statistik.
Pekerjaan saudara selanjutnya adalah menjelaskan atau interpretasi secara teoritis dan empiris. Artinya secara statistik terbukti ada pengaruh nyata (berdasarkan pada parameter-parameter tsb), berikutnya perlu penjelasan secara teori mengapa dan bagaimana itu terjadi, untuk itu kuasai landasan teori dan pertajam hasil observasi empiris.
Oh ya hampir lupa, terkadang pembimbing menghendaki ada asumsi klasik
dalam analisi regresi sebagai syarat, untuk urusan yang satu ini disarankan saudara berdiskusi secara langsung dengan dosen statistic yang ada atau berdiskusi dengan dosen pembimbing yang terhormat atau ke penulis.
Gaji karyawan (x1) B=0,588
t=3,279 Sig=0,003
Kedisiplinan kerja karyawan (x2) B=0,512 t=2,799 Sig=0,009
Prestasi kerja karyawan (Y).
R = 0,738 R2
= 0,544
F =16,03 Sig = 0,00
Semua Hipotesis diterima, pada : F tabel = 3,35
Bagian Dua
Path Analysis (Analisa Jalur)3
Prinsip dan keterbatasan
Path Analysis (analis jalur) pada dasarnya merupakan cabang dari multiple regression. Dalam analisis jalur terdapat suatu set variabel yang merupakan kumpulan atau rangkaian dari beberapa hubungan antar variabel yang telah membentuk sebuah model penelitian yang kita yakini variabel-variabel tersebut saling berpengaruh satu dengan yang lainnya. Tujuan path analysis adalah memberikan estimasi terhadap hubungan sebab akibat antara variabel-variabel yang diteliti. Disamping mengetahui hubungan, dengan path analysis peneliti akan mengetahui pengaruh secara langsung maupun pengaruh secara tidak langsung antar variabel tersebut.
Seperti halnya alat analisa yang lain, path analysis juga mempunyai keterbatasan. Keterbatasannya adalah : (1) tidak bisa digunakan untuk menguji pola hubungan timbal balik (feed back). Jadi gerak hubungan hanya dimungkinkan untuk lurus atau turun artinya satu tujuan. (2) setiap ada intervening variable, maka ia dianggap sebagai dependent variable. (3) skala pengukuran hanyalah interval atau rasio. Sedangkan untuk skala nominal, ordinal atau dichotomies tidak mungkin dilakukan.
Penggunaan
Sebagai contoh perhatikan figure 14 yang menjelaskan sebuah set variabel yang saling
berhubungan dengan survey tentang kepuasan kerja.
Diagram Input
3 Prosedur analisis jalur sama dengan regresi berganda yang telah dibahas pada bagian 1. 4 Model ini dikutip dari Bryman, A. & Cramer,D.(1990). Quantitative data analysis for social scientists, pp.246-251)
Masa kerja
otonomi
income
Tujuan penelitian adalah untuk menjelaskan bahwa peneliti ingin mengetahui bagaimana pengaruh masa kerja, otonomi dan income secara langsung maupun tidak langsung terhadap kepuasan kerja
Untuk mengetahui tujuan itu, kita harus menghitung path coefficients. Path coefficients ini bisa kita peroleh dari nilai standardized regression coefficient atau beta. Pada bahasan regresi berganda nilai beta terdapat pada table coefficient (misal hal 17).
Selanjutnya merumuskan persamaan dasar berdasarkan figure 1 sebagai berikut:
1.
kepuasan kerja=
β11masa kerja + β12 otonomi +
β13income + e1
2. Income
=
β21masa kerja +
β22otonomi + e2
3. Otonomi
=
β31masa kerja + e2
Keterangan:
β adalah path coefficient, yang diperoleh dari nilai beta.
e1, e2, e3 adalah error atau unexplained variance. Jika diperlukan nilai e1, e2, e3, diperoleh
dari 1-R2 (note: bukan 1-R2 adj)
Formulasi persamaan ini pada dasarnya sama dengan regresi berganda, namun nilai konstanta (a) tidak diperlukan. (bryman, A. & Cramer, D:1990:246-251)
Tahapan pengoalahan data.
Berdasarkan figure 1 maka, proses pengolahan untuk mencari nilai –nilai yang diperlukan seperti nilai β, R2 dane akan dilakukan secara bertahap. Lakukan analisis
regresi dengan formulasi sbb;
Indentifikasi variabel dan formulasi persamaan regresi
Tahap Variabel independent Variable dependent Persamaan 1
•
Masa kerja (x11)•
Otonomi (x12)•
Income (x13)•
Kepuasan kerja (Y1) β11masa kerja + β12otonomi+ β13income + e1
(regresi berganda)
2
•
Masa kerja (x21)•
Otonomi (x22)•
Income(Y2) β21masa kerja + β22otonomi+ e2
(regresi berganda) 3
•
Masa kerja (x31)•
Otonomi (Y3) β31masa kerja + e2(regresi sederhana) 4
•
Masa kerja (x)•
Kepuasan kerja (Y) βmasa kerja + e1Setelah diolah dengan spss, masukkan setiap nilai beta pada garis panah yang menghubungkan antar variable untuk mempermudah pembacaan hasil dan interpretasi hasil analisis. Sebagai misal lihat diagram output berikut:
Diagram output ( p<0.05)
Berdasarkan diagram output kita bisa menarik kesimpulan secara statistic sebagai berikut.
1.
Pengaruh secara langsung antara masa kerja dengan kepuasan adalah -0.08 (pola hubungan negative)2.
Pengaruh secara tidak langsung antara masa kerja dengan kepuasan kerja dapat dihitung sebagai berikut:masa kerja income kepuasan kerja = 0.57 x 0.47 = 0.26 masa kerja otonomi kepuasan kerja = 0.28 x 0.58 = 0.16 masa kerjaotonomi income kepuasan kerja = 0.28 x 0.22 x 0.47 = 0.03 Total pengaruh tidak langsung = 0.45
Total pengaruh adalah -0.08 + 0.45 = 0.37
Interpretasi
Hasil ini menjelaskan bahwa secara uji statistik pengaruh langsung antara masa kerja dengan kepuasan adalah kecil dan negative (-0.08), sedangkan pengaruh secara tidak langsung adalah positif dan lebih besar (0.37).
Berikutnya peneliti menjelaskan secara teoritis dan empiris mengapa hal itu terjadi. Menurut logika penulis hal ini sangat dimungkinkan sebab semakin lama masa kerja jika tidak diikuti oleh peningkatan peran akan menyebabkan pegawai merasa jenuh, kondisi ini mungkin menyebabkan pegawai merasa dirinya sudah tidak bisa lagi ikut berperan dalam dinamika organisasi sehingga kepuasan kerjanya menjadi menurun. Lain halnya jika masa kerja yang lama dibarengi juga dengan
Masa kerja
otonomi
income
Kepuasan kerja
β
- 0.08
β
0.28
β
0.57
β
0.58
β
0.47
peningkatan wewenang untuk mengatur aktivitasnya (otonomi), perbaikan pendapatan atau pergharaan lain (income), maka kepuasan kerja akan meningkat sebab pegawai merasa semakain dihargai senioritas dan pengabdiannya. Tentunya pendapat yang disampaikan akan lebih kuat jika didukung oleh teori maupun hasil penelitian terdahulu.
Bagian Tiga
Analisa Paired – Samples t tests dan Independent Samples t tests
(Uji Beda Untuk Sampel Berpasangan dan Tidak Berpasangan)
1. Analisa uji beda untuk sample berpasangan (Paired – Samples t tests)
Terkadang tujuan penelitian menyebutkan ingin mengetahui perbedaan antara dua kelompok yang diamati. Misalkan Peneliti ingin mengetahui apakah ada perbedaan rasa kopi antara merek A dan merek B. Untuk tujuan ini bisa digunakan Uji t atau uji beda untuk sample yang berpasangan. Perhatikan contoh berikut:
Contoh 1
Misal, peneliti ingin mengetahui apakah ada perbedaan antara rasa kopi merek A dan merek B. Untuk tujuan tersebut peneliti telah menyiapkan 10 orang relawan yang suka kopi untuk mencoba rasa kopi merek A dan merek B. kemudian diminta memberikan nilai dengan skala 1 sampai dengan 8 seperti berikut.
Skala pengukuran (semantic differential)
Tidak Enak Cukup
Sangat Enak
1 2 3 4 5 6 7 8
Hasil dari kuesioner ditampilkan dalam tabel sbb.
Relawan Kopi A Kopi B
1 8 6
2 8 7
3 6 7
4 7 5
5 6 5
6 8 7
7 8 8
8 5 6
9 8 7
10 6 5
Selanjutnya analisa dapat dimulai dengan langkah sbb:
Klik Analyze pilih Compare Means pilih Paired Samples T Test. Maka akan tampil BOX seperti berikut:
Selanjutnya klik merek a (a) dan merek b (b) kemudian klik tanda panah maka merek a dan merek b yang dibandingkan masuk dalam kotak Paired Variables, Kemudian OK,
Hasil pengolahan dengan menggunakan SPSS dapat dilihat pada output dibawah ini.
Paired Samples Statistics
7.0000 10 1.1547 .3651
6.3000 10 1.0593 .3350
merek a merek b Pair
1
Mean N Std. Deviation
Std. Error Mean
Paired Samples Correlations
10 .545 .103
merek a & merek b Pair 1
N Correlation Sig.
Dari hasil diatas dapat ditarik kesimpulan sebagai berikut:
Hipotesisnya
Ho: µa-µb = 0, artinya antara merek a dan merek b tidak ada perbedaan rasa Ha: µa-µb ≠ 0, artinya antara merek a dan merek b ada perbedaan yang significant tingkat signifikan menggunakan 0.05
Dari uji Paired - samples t test yang digunakan untuk menguji hipotesis menyatakan bahwa ada perbedaan nilai rata-rata, merek a dengan mean =7 merek b dengan mean=6.3, tetapi perbedaan tersebut tidak significant dimana t=2.09 dan p<0.066( pada significant level 0.05). Informasi lainnya adalah terdapat korelasi yang positif antara merek a dan merek b artinya peningkatan kepuasan merek a akan juga diikuti peningkatan kepuasan merek b, hal ini mengindikasikan antara merek a dan merek b mempunyai daya saing yang relative sama dari segi rasa. Atau bisa dikatakan diantara keduanya terdapat posisi market leader dan market chalanger.
Paired Samples Test
.7000 1.0593 .3350 -5.78E-02 1.4578 2.090 9 .066 merek a - merek b
Pair 1
Mean Std. Deviation
Std. Error
Mean Lower Upper 95% Confidence
Interval of the Difference Paired Differences
Contoh 2.
Misal peneliti ingin mengetahui apakah BPNN selaku badan penyehatan perbankan berhasil meningkatkan kinerja Bank yang menjadi pasiennya. Untuk tujuan itu diperlukan indikator untuk menilai kinerja bank tsb, misalnya CAR. Andaikan ada 10 bank yang telah diperbaiki dengan nilai CAR sebelum dan sesudah ditangani BPPN selengkapnya disajikan dalam tabel berikut.
Bank CAR (%)
Sebelum Masuk
BPPN
Sesudah Masuk
BPPN
A -2 3,5
B 1 4,6
C 0,5 3,7
D -4 2,1
E -4 1,2
F -3 2
G 0,5 3,8
H 2 6,6
I 1,3 4.8
J -1 3
Kriteria Hipotesis yang diajukan.
Ho: µa-µb = 0 maka usaha BPPN untuk meningkatkan nilai CAR Bank yang sakit, tidak berarti
Ha: µa-µb ≠ 0 maka usaha BPPN untuk meningkatkan CAR yang sakit, berarti. Tingkat signifikansi adalah 0.05
Dengan tahapan analisis seperti pada contoh satu maka didapat output spss sebagai berikut:
T-Test
Paired Samples Statistics
-.8700 10 2.2514 .7120
3.5300 10 1.5770 .4987
SEBELUM SESUDAH Pair
1
Mean N Std. Deviation
Std. Error Mean
Paired Sa mples Corre la tions
10 .917 .000
SEBELUM & SESUDAH Pair 1
Paired Samples Test
-4.4000 1.0220 .3232 -5.1311 -3.6689 -13.615 9 .000 SEBELUM - SESUDAH
Pair 1
Mean Std. Deviation Std. Error
Mean Lower Upper 95% Confidence
Interval of the Difference Paired Differences
t df Sig. (2-tailed)
Dari output diatas dapat ditarik suatu kesimpulan sebagai berikut:
Dilihat dari nilai rata-rata, ternyata ada perbedaan kinerja bank (CAR) antara sebelum (mean=-0.87) dan sesudah di tangani BPPN (mean=3.35). Perbedaan tersebut singnificant dengan t=-13.615 dan p>0.000. Sehingga BPPN patut mendapat pujian karena mampu meningkatkan nilai CAR bank sakit yang ditangani. Jadi Ha diterima. Informasi lainnya adalah dari nilai korelasi positif , sangat kuat dan significant (r=0.917; sig<p) artinya bank dengan posisi CAR baik(positif) cenderung akan semakin meningkat kinerjanya setelah ditangani BPPN. Atau bisa diartikan Usaha BPPN ditunjang juga oleh kinerja Bank yang ditangani sebelumnya.
Demikian mengenai Uji beda untuk sample yang berpasangan. Dua kasus tersebut hanyalah contoh, dan masih bisa dikembangkan untuk menjawab permasalahan penelitan yang lain.
2.
Uji beda untuk uji satu kelompok (one samples t test)Nah…Sekarang mari kembali pada contoh kasus 2, dimana peneliti ingin mengetahui apakah target BPPN untuk menyehatkan bank sakit mampu memiliki CAR sebesar 3% dapat dikatakan tercapai secara keseluruhan.
Dengan demikian maka hipotesis dapat dirumuskan sebagai berikut: Ho= µbank = 3%
Ha= µbank ≠ 3%
Tingkat signifikan menggunakan 0.05
Selanjutnya mari kita uji hipotesis tersebut, dengan langkah-langkah pengolahan sebagai berikut.
Pilih “variable sesudah” untuk dianalisa, dengan test value 3. dan confidence interval 95%. Klik OK, tunggu data sedang diolah .
Hasil pengolahan akan nampak sebagai berikut:
T-Test
One-Sample Statistics
10 3.5300 1.5770 .4987
SESUDAH
N Mean Std. Deviation
Std. Error Mean
One-Sample Test
1.063 9 .316 .5300 -.5981 1.6581
SESUDAH
t df Sig. (2-tailed)
Mean
Difference Lower Upper 95% Confidence
Interval of the Difference Test Value = 3
Kesimpulan yang dapat ditarik dari print out tersebut adalah:
Latihan
Sebuah industri Bola lampu ingin menguji apakah produknya mempunyai daya nyala selama 1000 jam nonstop. Untuk keperluan pengujian, telah diambil 10 bola lampu secara acak dari 2 lini produk masing-masing 5 unit dan dinyalakan secara bersama-sama dan daya tahan lampu tersebut didokumentasikan seperti dalam table berikut.
lampu Daya tahan (jam)
1 998
2 1050
3 1025
4 1068
5 998
6 1009
7 1016
8 935
9 1005
10 997
Dengan langkah yang sama maka hasil disajikan sebagai berikut
T-Test
One-Sample Statistics
10 1010.1000 35.4854 11.2215
WAKTU
N Mean Std. Deviation
Std. Error Mean
One-Sample Test
.900 9 .392 10.1000 -15.2847 35.4847
WAKTU
t df Sig. (2-tailed)
Mean
Difference Lower Upper
95% Confidence Interval of the
Difference Test Value = 1000
Bagian Empat Analisis Faktor
1.
Dasar pemikiranTerkadang dalam suatu penelitian kita dihadapkan pada beragam factor atau variable yang diduga mempunyai kaitan dengan suatu permasalahan yang ingin kita cari tahu jawabannya. Banyaknya factor atau variable ini terkadang bisa membuat bias dalam perumusan/formulasi permsalahan atau terkadang akan merepotkan peneliti karena harus mengendalikan banyaknya variable atau factor tersebut yang secara bangunan teori terkadang kurang kuat.
Berdasar pada situasi tersebut maka timbul pemikiran untuk mereduksi atau meringkas beragam factor atau variable tersebut menjadi suatu bentuk/model teori yang baru dengan harapan model tersebut nantinya akan dapat menjelaskan secara optimal tentang permasalahan yang ingin kita cari tahu jawabannya. Dengan demikian, merujuk pada pendapat Malhotra (1993), analisis factor adalah merupakan sekelompok prosedur untuk mengurangi dan meringkas data.
Dengan model matematisnya adalah :
Sedangkan faktor-faktor umum dapat dinyatakan sebagai berikut:
X
i= A
i1F
1┿ Ai2F2┿ Ai3F3┿ …………. ┿ AimFm┿ViUiKet:
Xi :variable standar ke-i
Aij :koefisien loading dari variable I pada factor umum j
F :factor umum
Vi :koefisienstandartized loading dari variable I pada factor khusus I
Ui : factor khusus bagi variable I
m :jumlah dari factor umum
F1 = Wi1Xi1+Wi2Xi2+Wi3Xi3+…………+WikXik
Ket:
F1 :estimasi factor loading ke-1
Wi :bobot atau koefisien nilai factor
2. Akurasi Model Faktor
Agar terdapat kesesuaian antara permasalahan yang akan dijawab beserta data yang diperoleh dengan alat analisis yang akan digunakan maka perlu dilakukan telaah akurasi model factor. Prosedur dalam analisis factor adalah mengikuti beberapa tahapan sebagai berikut:
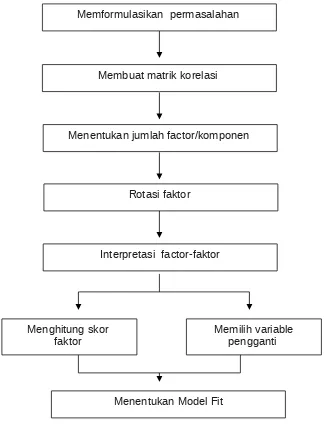
Gambar 1. Prosedur analisis faktor. (Malhotra:1996)
Memformulasikan permasalahan
Membuat matrik korelasi
Menentukan jumlah factor/komponen
Rotasi faktor
Interpretasi factor-faktor
Menghitung skor faktor
Memilih variable pengganti
Penjelasan Gambar 1.
1. Memformulasikan permasalahan
Beberapa yang perlu diperhatikan dalam memformulasikan permasalahan yaitu:
Mengidentifikasi tujuan analisis faktor
Variabel-variabel yang akan dimasukkan dalam analisis faktor berdasarkan pada penelitian terdahulu, teori dan keputusan peneliti.
Kesesuaian antara instrumen penelitian dengan sampel penelitian.
2. Membentuk matrik korelasi.
Proses analisis berdasarkan pada matriks korelasi antar variable-variabel yang diteliti. Agar analisis faktor dapat dilakukan variabel-variabel tersebut harus berkorelasi. Jika korelasi antar variabel kecil maka analisis faktor tidak dapat dilakukan. Pengujian korelasi antar variabel tersebut merupakan langkah pendahuluan sekaligus sebagai tindakan koreksi seperlunya. Selanjutnya diteruskan dengan penentuan metode yang cocok dalam analisis faktor. Metode yang lazim digunakan jika fokus tujuannya adalah untuk menentukan jumlah faktor minimum dari berbagai faktor yang ada yaitu: Principal Component analysis (PCA)
3. Menentukan jumlah factor
Dalam tahap ini informasi-informasi dalam variable-variabel awal diekstraksi menjadi factor-faktor yang lebih kecil. Dengan menggunakan criteria eigenvalues dimana dalam pendekatan ini, hanya factor yang mempunyai eigenvalues lebih besar dari 1 akan dipilih sedangkan yang laiinya tidak disertakan dalam model.
4. Rotasi factor.
Hasil penyederhanaan dalam matrik factor memperlihatkan hubungan antara factor dengan variable individual. Tetapi dengan banyaknya variable yang saling berkorelasi sehingga sulit untuk diinterpretasikan. Untuk itu harus dilakukan rotasi factor matrik yang hasilnya lebih sederhana sehingga mudah dibaca. Dalam rotasi matrik factor ini metode yang digunakan adalah Varimax yaitu metode rotasi orthogonal untuk meminimumkan jumlah variable dengan berpedoman pada nilai loading tertinggi.
5. Interprestasi faktor-faktor.
Interprestasi factor dapat dilakukan dengan mengelompokkan variable yang mempunyai factor loading tertinggi kedalam factor tersebut. Untuk interpretasi hasil perilaku ini, factor loading dengan nilai > 0,5 sedangkan yang < 0,5 dikeluarkan dari model.
6. Menentukan Model Fit
Beberapa Ketentuan Yang Harus Diketahui Dalam FA
1. Uji Bartlett
Yaitu uji tingkat independen dari variable-variabel. Hasil Bartlett test of sphericity dengan melihat tingkat signifikansi kesalahan untuk mengindikasikan sejauhmana antar variable tersebut berkorelasi.
2. Nilai KMO (kaiser-meyer-olkin)
Untuk mengetahui ketepatan dari analisis factor. Nilai KMO > 0,5 dianggap mempunyai ketepatan.
Tabel 1. Ukuran ketepatan KMO
Ukuran KMO Rekomendasi >0.9 Baik sekali >0.8 Baik
>0.7 Sedang/agak baik >0.6 Cukup
>0.5 Kurang <0.5 Ditolak
3. Penentuan jumlah factor.
Untuk menentukan jumlah factor biasanya digunakan ukuran sbb:
Eigenvalue > 1 (menurut pendapat kaiser) atau > 0,5 (menurut pendapat lawley and maxwell)
Persentase kumulatif > 60% atau mencapai 85%
4. Model FIT
Analisis ini sebenarnya untuk seberapa besar residual antara korelasi yang diamati dengan korelasi yang direproduksi. Sebagai ukuran jika terdapat banyak nilai residual melebihi nilai absolut 0.05 maka model tidak dapat diterima.
Petunjuk praktis teknis Analisis Faktor dengan SPSS. Utk pemula
Follow this direction
• Open SPSS
• Siapkan data yang akan diolah
• Klik menu analyze, pilih Data Reduction, pilih factor. • Muncul box menu berisikan:
Kotak variables (sebelah kiri berisikan variable, kanan kosong)
Descriptives (pada menu box, pilih coefficient dan KMO and Bartlett test atau klik semua pilihan), continue
Extraction ( pada menu box, pilih metode principal component, eigenvalue 1 atau 0,5. continue Rotation (pada menu box pilih method varimax )continue
Scores
Option
Tekan OK, output akan nampak seperti dibawah ini:
Contoh Print out factor analysis dari SPSS
KMO and Bartlett's Test Kaiser-Meyer-Olkin Measure of Sampling Adequacy.
,644
Bartlett's Test of Sphericity Approx. Chi-Square
562,809
df 153
Sig. ,000
Cara membaca table:
• Uji Bartlett's Test of Sphericity menyatakan sebesar 562,809 dengan Sig. 0,000. artinya peluang terjadi kesalahan untuk variable saling tidak independent sebesar 0% dengan demikian antar variable memiliki korelasi. (lihat penjelasan pada hal 3 tentang point 2)
• Nilai Kaiser-meyer-olkin / KMO measure of sampling adequacy sebesar 0,644 melebihi nilai baku 0,5 maka analisis factor memiliki ketepatan untuk digunakan.
Total Variance Explained Initial
Eigenvalues Rotation Sums of Squared Loadings
Componen t
Total % of Variance Cumulative %
Total % of Variance Cumulative %
1 3,920 21,779 21,779 2,526 14,032 14,032
2 2,700 15,002 36,781 2,307 12,817 26,849
3 2,279 12,662 49,444 2,273 12,626 39,475
4 1,909 10,604 60,048 1,994 11,079 50,554
5 1,382 7,678 67,726 1,625 9,026 59,580
6 ,980 5,447 73,173 1,280 7,109 66,689
7 ,907 5,040 78,213 1,162 6,456 73,145
8 ,708 3,932 82,145 1,155 6,416 79,561
9 ,598 3,321 85,466 1,063 5,905 85,466
10 ,489 2,719 88,185
11 ,397 2,204 90,388
12 ,335 1,863 92,251
13 ,327 1,817 94,069
14 ,293 1,630 95,699
15 ,266 1,480 97,179
16 ,219 1,219 98,398
17 ,166 ,924 99,323
18 ,122 ,677 100,000
Cara membaca table:
Dengan menggunakan metode principle component diperoleh 9 faktor dari 18 faktor yang telah diajukan. Hasil tersebut diperoleh dengan melihat nilai eigenvalue yang lebih besar dari 0,5. (ketika mengolah penulis menetapkan eigenvalue=0,5, namun jika yang ditetapkan sebesar 1 maka hanya terdapat 5 faktor yang akan membentuk model).
Reproduced Correlations
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11X12X13X14 X15X16 X17X18 Re pro duc ed Cor rela tion X1 , 839 ,786 , 627 , 346 , 335 - 4,322E-03 - 6,781E-02 2,933 E-02 , 313 -,160 - 7,704E-02 4,6 23E -02 , 137 , 125 - 5,107E-02 5,2 92E -02 ,126 , 263 X2 , 786 ,841 , 641 , 348 , 378 2,638E-02 - 9,256E-02 6,656 E-02 , 294 9,155 E-02 ,183 , 293 , 175 9,2 51E -02 - 3,397E-02 , 110 ,133 , 359 X3 , 627 ,641 , 794 , 573 , 642 - 2,050E-02 8,999E-03 3,426 E-02 , 196 2,196 E-02 8,035E-02 , 248 , 241 , 123 - 2,259E-02 4,6 22E -02 ,219 , 103 X4 , 346 ,348 , 573 , 912 , 483 - 2,026E-02 - 7,119E-02 ,210 , 354 -9,470 E-02 - 9,844E-02 , 240 , 179 9,5 45E -02 ,197 , 224 ,228 , 211 X5 , 335 ,378 , 642 , 483 , 896 - 1,901E-02
,151 ,175 , 133 -2,107 E-02 - 7,114E-03 9,7 84E -02 , 318 -3,9 69E -02 -,124-,14 4 6,005 E-02 , 310 X6 -4,3 22E -03 2,638 E-02 -2,0 50E -02 -2,0 26E -02 -1,9 01E -02
,760 ,659 ,668 , 350
,290 ,192 , 137 3,9 71E -02 , 212 - 1,225E-03 -8,2 16E -03 6,378 E-02 -7,7 24E -02 X7 -6,7 81E -02 -9,256 E-02 8,9 99E -03 -7,1 19E -02 , 151
,659 ,844 ,501 , 432 ,1766,762E-02 2,2 45E -02 , 171 , 331 5,272E-02 -,10 0 ,227 -2,0 59E -02 X8 2,9 33E -02 6,656 E-02 3,4 26E -02 , 210 , 175
X9 , 313 ,294 , 196 , 354 , 133
,350 ,432 ,255 , 896 3,747 E-02 - 5,108E-02 , 163 -4,6 44E -02 , 155 6,569E-02 -4,5 26E -02 ,218 , 440 X10-,16 0 9,155 E-02 2,1 96E -02 -9,4 70E -02 -2,1 07E -02
,290 ,176 8,641 E-02
3,7 47E -02
,841 ,693 , 711 , 177 , 216 -,108 -2,8 72E -02 -1,640 E-02 -2,8 02E -02 X11 -7,7 04E -02 ,183 8,0 35E -02 -9,8 44E -02 -7,1 14E -03 ,192 6,762E-02 6,678 E-02 -5,1 08E -02
,693 ,841 , 696 5,5 51E -05 -2,9 44E -02 ,233 , 329 ,297 2,1 44E -02 X12 4,6 23E -02 ,293 , 248 , 240 9,7 84E -02 ,137 2,245E-02 3,496 E-02 , 163
,711 ,696 , 805 , 191 , 198 ,164 , 253 ,251 , 134 X13 , 137 ,175 , 241 , 179 , 318 3,971E-02
,171 ,148 -4,6 44E -02 ,1775,551E-05 , 191 , 841 , 681 9,091E-02 7,7 77E -02 ,111 , 244 X14 , 125 9,251 E-02 , 123 9,5 45E -02 -3,9 69E -02
,212 ,331 8,463 E-02 , 155 ,216 - 2,944E-02 , 198 , 681 , 866 ,121 7,1 50E -02 ,211 -3,2 70E -02 X15 -5,1 07E -02 -3,397 E-02 -2,2 59E -02 , 197 -,12 4 - 1,225E-03 5,272E-02 ,126 6,5 69E -02
-,108 ,233 , 164 9,0 91E -02 , 121 ,885 , 823 ,772 , 156 X16 5,2 92E -02 ,110 4,6 22E -02 , 224 -,14 4 - 8,216E-03
-02 E-02 -02 X18 , 263 ,359 , 103 , 211 , 310 - 7,724E-02 - 2,059E-02 ,168 , 440 -2,802 E-02 2,144E-02 , 134 , 244 -3,2 70E -02 ,156 , 125 8,084 E-02 , 935 Res idu al
X8 -1,3 12E -02 1,131 E-02 1,8 23E -02 -4,4 88E -02 -1,6 91E -02 -,142 - 7,864E-03 3,0 70E -02 2,975 E-02 - 2,574E-02 1,5 88E -02 -1,7 40E -02 1,3 72E -02 - 2,798E-02 -2,7 48E -02 6,123 E-02 -2,9 24E -02 X9 -3,1 46E -02 2,957 E-03 1,8 99E -02 -5,2 68E -02 2,0 21E -02 - 1,629E-02 - 6,756E-02 3,070 E-02 -2,314 E-02 3,974E-02 -2,1 14E -02 6,4 51E -02 -2,2 35E -02 1,709E-02 6,1 36E -03 -2,191 E-02 -6,4 62E -02 X10 2,7 90E -02 -1,603 E-02 3,6 86E -02 1,7 53E -02 -2,8 97E -02 - 7,074E-02 3,609E-02 2,975 E-02 -2,3 14E -02 - 5,588E-02 -9,3 90E -02 -3,5 50E -02 -4,4 29E -03 7,926E-03 1,7 97E -02 1,863 E-02 2,3 67E -02 X11 1,7 18E -02 -2,662 E-02 -3,1 79E -02 4,9 15E -02 8,2 24E -03 2,390E-02 - 3,223E-02 -2,574 E-02 3,9 74E -02 -5,588 E-02 -9,2 48E -02 3,2 00E -02 2,5 04E -02 - 5,619E-03 -1,7 15E -02 -2,567 E-02 -1,1 86E -02 X12 1,3 42E -02 2,385 E-03 -2,8 71E -02 -5,9 95E -02 2,4 64E -02 1,453E-02 7,842E-03 1,588 E-02 -2,1 14E -02 -9,390 E-02 - 9,248E-02 -6,8 66E -04 -2,0 37E -02 5,166E-03 -1,4 35E -02 7,200 E-03 -1,6 43E -02 X13 -1,0 51E -03 9,050 E-03 -7,9 56E -03 3,4 66E -03 -4,8 45E -02 4,015E-02 - 3,576E-02 -1,740 E-02 6,4 51E -02 -3,550 E-02 3,200E-02 -6,8 66E -04 -,13 0 2,565E-02 -5,6 00E -02 2,042 E-02 -5,8 13E -02 X14 -1,2 40E -02 -7,707 E-03 -5,3 54E -03 -8,1 12E -03 6,5 94E -02 - 1,639E-02 - 1,078E-02 1,372 E-02 -2,2 35E -02 -4,429 E-03 2,504E-02 -2,0 37E -02 -,13 0 - 2,438E-02 4,4 40E -02 -2,414 E-02 3,4 40E -02 X15 2,2 04E -02 -1,269 E-02 1,1 68E -02 -1,6 02E -02 1,2 88E -02 4,655E-02 - 2,715E-02 -2,798 E-02 1,7 09E -02 7,926 E-03 - 5,619E-03 5,1 66E -03 2,5 65E -02 -2,4 38E -02 -5,1 86E -02 -5,747 E-02 -1,8 20E -02
2,3 05E -02 7,008 E-03 67E -02 1,6 12E -02 58E -02 2,826E-02 02 2,748 E-02 36E -03 E-021,715E-02 1,4 35E -02 5,6 00E -02 40E -02 5,186E-02 7,541 E-02 13E -02 X17 -2,8 32E -03 2,489 E-02 -4,3 39E -02 1,4 89E -02 -2,6 75E -02 - 1,909E-02 - 4,170E-02 6,123 E-02 -2,1 91E -02 1,863 E-02 - 2,567E-02 7,2 00E -03 2,0 42E -02 -2,4 14E -02 - 5,747E-02 -7,5 41E -02 -4,3 36E -04 X18 9,3 64E -03 -3,145 E-02 4,2 96E -02 2,6 31E -02 -2,2 56E -02 2,787E-02 3,141E-02 -2,924 E-02 -6,4 62E -02 2,367 E-02 - 1,186E-02 -1,6 43E -02 -5,8 13E -02 3,4 40E -02 - 1,820E-02 1,7 13E -02 -4,336 E-04
Extraction Method: Principal Component Analysis.
a Residuals are computed between observed and reproduced correlations. There are 25 (16,0%) nonredundant residuals with absolute values > 0.05.
Cara membaca table:
Pada tahap ini bertujuan untuk menetapkan Model Fit. Dari hasil perhitungan diatas disimpulkan sbb:
There are 25 (16,0%) nonredundant residuals with absolute values > 0.05. artinya nilai residual dari korelasi observasi dengan korelasi reproduksi yang mempunyai korelasi dengan nilai > 0,5 sangat sedikit yaitu sebesar 16 % sedangkan sisanya 84 % mempunyai korelasi < 0,05.
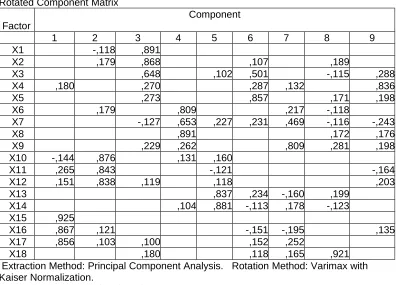
Rotated Component Matrix
Factor
Component
1 2 3 4 5 6 7 8 9
X1 -,118 ,891
X2 ,179 ,868 ,107 ,189
X3 ,648 ,102 ,501 -,115 ,288
X4 ,180 ,270 ,287 ,132 ,836
X5 ,273 ,857 ,171 ,198
X6 ,179 ,809 ,217 -,118
X7 -,127 ,653 ,227 ,231 ,469 -,116 -,243
X8 ,891 ,172 ,176
X9 ,229 ,262 ,809 ,281 ,198
X10 -,144 ,876 ,131 ,160
X11 ,265 ,843 -,121 -,164
X12 ,151 ,838 ,119 ,118 ,203
X13 ,837 ,234 -,160 ,199
X14 ,104 ,881 -,113 ,178 -,123
X15 ,925
X16 ,867 ,121 -,151 -,195 ,135
X17 ,856 ,103 ,100 ,152 ,252
X18 ,180 ,118 ,165 ,921
Extraction Method: Principal Component Analysis. Rotation Method: Varimax with Kaiser Normalization.
a Rotation converged in 9 iterations.
Cara membaca tabel:
Tabel diatas merupakan inti analisa factor yaitu menentukan ke sembilan factor yang telah teridentifikasi melalui beberapa tahapan diatas.
Cara menentukan factor adalah sbb:
Dalam tabel terdapat 9 komponen (lihat kolom), artinya ada 9 faktor yang akan direkomendasi menuju analisa lebih lanjut misal correl atau regress
Prosedur menentukan factor:
1. Pilih koefisien tertinggi pada masing-masing kolom (hanya nilai tertinggi) 2. Setelah semua kolom terpilih nilai tertingginya. Hubungkan nilai-nilai tersebut
Sebagai contoh
Pada kolom komponen 1 nilai tertinggi adalah ,925 nama factor atau variable adalah X15
Pada kolom komponen 9 nilai tertinggi adalah ,836 nama factor atau variable adalah X4
Penutup
Seperti pesan Imam As Syafii kepada para santrinya
Ra’yuna shawab yahtamil al khata’ Wa ra’yuna ghairina khata’ yahtamil al shawab
Bersandar pada pendapat ini, masihkan kita saling bertahan dengan pendapat pribadi dengan mengabaikan pendapat orang lain yang kemungkinan mengandung kebenaran dan membawa pencerahan….. Penulis yang masih kurang dalam segala hal sangat mengharapkan saran koreksi dari pembaca untuk perbaikan.
Semoga ada manfaatnya, Bagi adik-adik mahasiswa diberikan kesempatan seluas-luasnya untuk berdiskusi dengan penulis jika terdapat ketidakjelasan atau perbedaan pendapat.
Wallaahua’lam bisshawab Singosari, 27 Rajab 2003,
Hanif Mauludin,
e-mail:
[email protected]
. Web: www.stie-mce.ac.id/~hanifphone: STIE –MCE. 491813 ext 129 (ruang mce internet J-4)
Segera terbit suplemen tambahan untuk edisi mahasiswa ABM, analisis kluster dan diskriminan
REFERENCE
1. Everitt, B.S, & Dunn, G. (1991). Applied multivariate data analysis. London: Edward Arnold.
2.
Bryman, A & Cramer, D. (1990). Quantitative data analysis for social scientists. pp. 246-2513. Rietveld & Sunaryanto, (1994). 87 masalah pokok dalam regresi berganda 4. Sugiarto. (1992). Tahap awal dan Aplikasi analisis Regresi