BAB III
METODE PENELITIAN
3.1 Penelitian
Pada penelitian ini jenis penelitian yang digunakan adalah explanatory research.
Penelitian yang digunakan untuk mencari penjelasan dalam cause-effect antar beberapa variabel. Data yang diperlukan telah tersedia, maka penelitian ini termasuk studi empiris pada perusahaan-perusahaan di Bursa Efek Indonesia (BEI) yang termasuk dalam perusahaan pertambangan, yaitu sebanyak 39 perusahaan.
3.2 Jenis Data dan Sumber Data
Data adalah masukan (input) yang dapat diolah dan diproses untuk dijadikan sebagai sumber informasi. Data yang digunakan dalam penelitian ini adalah data sekunder dengan jenis data panel. Panel data adalah jenis data yang merupakan gabungan antara data runtut waktu (time series) dengan data seksi silang (cross section). Berikut adalah penjelasan jenis–jenis data yang digunakan dalam penelitian ini yang dilihat dari berbagai aspek:
1. Pembagian data menurut cara memperolehnya
Yang digunakan adalah data sekunder sebab data yang diterbitkan atau digunakan oleh organisasi yang bukan pengolahnya.
2. Pembagian data menurut sumbernya
Data eksternal adalah data yang berasal dari luar instansi.
3. Pembagian data menurut waktu pengumpulannya
Data yang digunakan dalam penelitian ini adalah laporan keuangan dan laporan tahunan perusahaan yang berasal dari www.idx.com dan website perusahaan terkait. Data laporan keuangan yang dipakai adalah dari tahun 2011 hingga 2014.
3.3 Teknik Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah dengan metode dokumentasi, metode dokumentasi adalah metode pengumpulan data dengan melihat dan memperlajari catatan–catatan atau dokumen perusahaan (data sekunder) yang sudah berlalu (Sugiyono, 2014). Data dalam penelitian ini berasal dari www.idx.com dan website perusahaan terkait.
3.4 Populasi
Populasi penelitian adalah gabungan peristiwa, hal atau orang yang memiliki karakteristik serupa yang menjadi perhatian seorang peneliti (Ferdinand, 2006).
Populasi dalam penelitian ini adalah perusahaan yang terdaftar dalam Bursa Efek Indonesia.
3.5 Sampel
Sampel adalah sebagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut (Sugiyono, 2014). Teknik pengambilan sampel dalam penelitian ini menggunakan non probability sampling dengan purposive sampling. Purposive sampling adalah teknik pengembalian sampel berdasarkan pertimbangan tertentu (Sugiyono, 2014). Teknik ini ditentukan untuk memilih anggota sampel secara khusus berdasarkan tujuan penelitian dan kesesuaian kriteria-kriteria yang ditetapkan oleh peneliti.
Kriteria pengambilan sampel dalam penelitian ini adalah sebagai berikut:
a. Perusahaan termasuk dalam perusahaan pertambangan pada Bursa Efek Indonesia periode 2011-2014.
b. Perusahaan mempublikasikan laporan keuangan auditan secara konsisten selama periode 2011-2014.
c. Perusahaan yang memiliki data lengkap mengenai variabel yang diteliti.
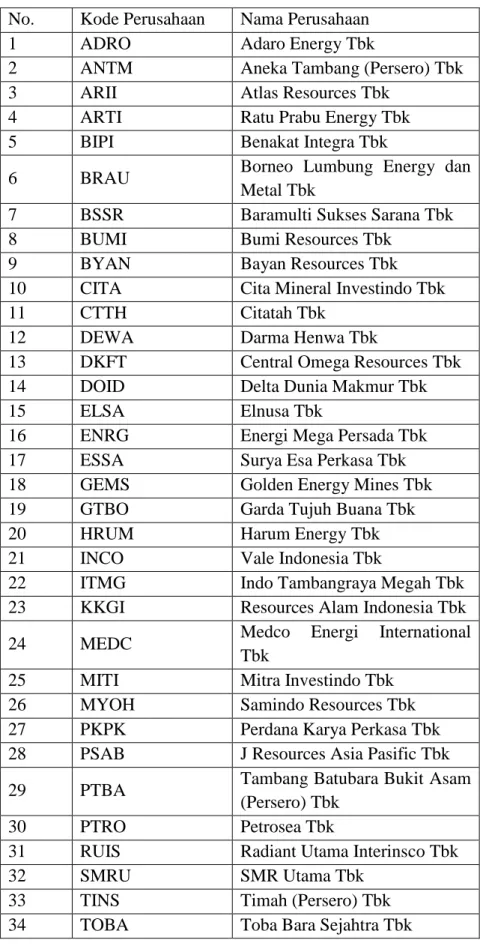
Berdasarkan tiga kriteria yang telah disebutkan diatas maka jumlah perusahaan pertambangan yang memenuhi tiga kriteria diatas berjumlah 34 perusahaan dan 5 perusahaan tidak memenuhi 3 kriteria diatas. Perusahaan-perusahaan yang telah memenuhi kriteria diatas dapat dilihat pada tabel dibawah ini:
Tabel 3.1 Sampel Perusahaan
No. Kode Perusahaan Nama Perusahaan
1 ADRO Adaro Energy Tbk
2 ANTM Aneka Tambang (Persero) Tbk
3 ARII Atlas Resources Tbk
4 ARTI Ratu Prabu Energy Tbk
5 BIPI Benakat Integra Tbk
6 BRAU Borneo Lumbung Energy dan
Metal Tbk
7 BSSR Baramulti Sukses Sarana Tbk
8 BUMI Bumi Resources Tbk
9 BYAN Bayan Resources Tbk
10 CITA Cita Mineral Investindo Tbk
11 CTTH Citatah Tbk
12 DEWA Darma Henwa Tbk
13 DKFT Central Omega Resources Tbk
14 DOID Delta Dunia Makmur Tbk
15 ELSA Elnusa Tbk
16 ENRG Energi Mega Persada Tbk
17 ESSA Surya Esa Perkasa Tbk
18 GEMS Golden Energy Mines Tbk
19 GTBO Garda Tujuh Buana Tbk
20 HRUM Harum Energy Tbk
21 INCO Vale Indonesia Tbk
22 ITMG Indo Tambangraya Megah Tbk
23 KKGI Resources Alam Indonesia Tbk
24 MEDC Medco Energi International
Tbk
25 MITI Mitra Investindo Tbk
26 MYOH Samindo Resources Tbk
27 PKPK Perdana Karya Perkasa Tbk
28 PSAB J Resources Asia Pasific Tbk
29 PTBA Tambang Batubara Bukit Asam
(Persero) Tbk
30 PTRO Petrosea Tbk
31 RUIS Radiant Utama Interinsco Tbk
32 SMRU SMR Utama Tbk
33 TINS Timah (Persero) Tbk
34 TOBA Toba Bara Sejahtra Tbk
3.6 Metode Pengumpulan Data
Metode pengambilan data yang digunakan dalam penelitian ini adalah metode studi pustaka dan dokumentasi. Metode dokumentasi merupakan metode pengumpulan data dengan cara memperlajari catatan-catatan atau dokumen.
Dalam hal ini, catatan atau dokumen perusahaan yang dimaksud adalah laporan keuangan perusahaan yang terdaftar di Bursa Efek Indonesia (BEI) yang berisi informasi berkaitan dengan variabel-variabel penelitian.
3.7 Definisi Oprasional Variabel 3.7.1 Variabel Dependen
Yaitu variabel yang dipengaruhi oleh variabel lain. Pada penelitian ini, Debt Maturity adalah variabel terikat.
𝐷𝑒𝑏𝑡 𝑀𝑎𝑡𝑢𝑟𝑖𝑡𝑦 = 𝐿𝑜𝑛𝑔 𝑇𝑒𝑟𝑚 𝐷𝑒𝑏𝑡 (𝐿𝑇𝐷)
𝑇𝑜𝑡𝑎𝑙 𝐷𝑒𝑏𝑡 𝑇𝐷 … … … .3.1
Dimana,
Debt Maturity = Maturitas Utang
Long Term Debt = Utang Jangka Panjang
Total Debt = Total Utang
3.7.2 Variabel Independen
Yaitu variabel yang mempengaruhi variabel lain. Pada penelitian ini ada 3 variabel independen, yaitu:
1. Tarif Pajak
𝑇𝑎𝑟𝑖𝑓 𝑃𝑎𝑗𝑎𝑘 = 𝑇𝑎𝑥 𝑃𝑎𝑖𝑑 𝑇𝑃
𝑃𝑟𝑒 𝑇𝑎𝑥 𝐼𝑛𝑐𝑜𝑚𝑒 𝑃𝑇𝐼 … … … 3.2
Dimana,
Tarif Pajak = Besarnya pajak
Tax Paid = Pajak yang dibayarkan
Pre Tax Income = Pendapatan Sebelum Pajak
2. Term Structure
Term = (Month end yield on 10 years govt. bond) – (Month yield on 6 month Govt. Bond matched to firm’s fiscal year end …………. 3.3
Dimana,
Term = Struktur Jangka Suku Bunga.
Month end yield on 10 years Govt. Bond = yield bulan terakhir obligasi pemerintah 10 tahun.
Month yield on 6 month Govt. Bond matched to firm’s fiscal year end = yield 6 bulan obligasi pemerintah yang sesuai dengan periode fiskal perusahaan.
3. Aset Varians
𝐴𝑠𝑠𝑒𝑡 𝑉𝑎𝑟𝑖𝑎𝑐𝑒 = 𝜎 𝐸𝐵𝐼𝑇𝐷𝐴
𝐵𝑜𝑜𝑘 𝑉𝑎𝑙𝑢𝑒 𝑜𝑓 𝐴𝑠𝑠𝑒𝑡 𝐵𝑉 … … … … 3.4
Dimana,
Asset Variance = Aset Varians.
𝜎𝐸𝐵𝐼𝑇𝐷𝐴= Standar Deviasi Pendapatan sebelum Pajak dan Amortation.
Book Value of Asset (BV) = Nilai Buku Aset.
3.7.3 Variabel Control
1. Growth Option
𝐺𝑟𝑜𝑤𝑡 = 𝑀𝑎𝑟𝑘𝑒𝑡 𝑉𝑎𝑙𝑢𝑒 𝑜𝑓 𝐴𝑠𝑠𝑒𝑡 (𝑀𝑉)
𝐵𝑜𝑜𝑘 𝑉𝑎𝑙𝑢𝑒 𝑜𝑓 𝐴𝑠𝑠𝑒𝑡 (𝐵𝑉) … … … … 3.5
Dimana,
Growth = Pilihan pertumbuhan Perusahaan.
MV = Nilai Pasar Aset
BV = Nilai Buku Aset
Tabel 3.2 Definisi Oprasional
No Variabel Indikator Skala
Pengukuran 1. Debt Maturity 𝐷𝑒𝑏𝑡 𝑀𝑎𝑡𝑢𝑟𝑖𝑡𝑦 = 𝐿𝑜𝑛𝑔 𝑇𝑒𝑟𝑚 𝐷𝑒𝑏𝑡 (𝐿𝑇𝐷)
𝑇𝑜𝑡𝑎𝑙 𝐷𝑒𝑏𝑡 𝑇𝐷 Rasio 2. Tarif Pajak 𝑇𝑎𝑟𝑖𝑓 𝑃𝑎𝑗𝑎𝑘 = 𝑇𝑎𝑥 𝑃𝑎𝑖𝑑 𝑇𝑃
𝑃𝑟𝑒 𝑇𝑎𝑥 𝐼𝑛𝑐𝑜𝑚𝑒 𝑃𝑇𝐼 Rasio
3. Term Structure
Term = (Month end yield on 10 years govt. bond) – (Month yield on 6 month Govt. Bond matched to firm’s fiscal year end)
Rasio
4. Aset Varians 𝐴𝑠𝑠𝑒𝑡 𝑉𝑎𝑟𝑖𝑎𝑐𝑒 = 𝜎 𝐸𝐵𝐼𝑇𝐷𝐴
𝐵𝑜𝑜𝑘 𝑉𝑎𝑙𝑢𝑒 𝑜𝑓 𝐴𝑠𝑠𝑒𝑡 𝐵𝑉 Rasio 5. Growth
Option 𝐺𝑟𝑜𝑤𝑡 =
𝑀𝑎𝑟𝑘𝑒𝑡 𝑉𝑎𝑙𝑢𝑒 𝑜𝑓 𝐴𝑠𝑠𝑒𝑡 (𝑀𝑉)
𝐵𝑜𝑜𝑘 𝑉𝑎𝑙𝑢𝑒 𝑜𝑓 𝐴𝑠𝑠𝑒𝑡 (𝐵𝑉) Rasio
3.8 Teknik Analisis Data 3.8.1 Analisis Statistik
Dalam melakukan penelitian ini penulis menggunakan analisis stratistik regresi linier berganda dengan metode penelitian secara kuantitatif. Dalam melakukan uji ini penulis menggunakan software Eviews 6.0.
3.8.2 Analisis Regresi Berganda Model Panel Data
Analisis yang digunakan dalam pengolahan data penelitian adalah analisis regresi linier berganda (multiple linier regression). Analisis regresi berganda digunakan untuk menguji pengaruh dari beberapa variabel bebas terhadap satu variabel terikat. Menurut Ghozali (2005) analisis regresi berganda pada dasarnya adalah studi mengenai ketergantungan variabel dependen (terikat) dengan satu atau lebih variabel independen (bebas), dengan tujuan untuk mengestimasi dan/atau memprediksi rata-rata populasi atau nilai rata-rata variabel dependen berdasarkan nilai variable independen yang diketahui. Hasil analisis regresi adalah berupa koefisien untuk masing-masing variabel independen. Koefisien ini, diperoleh dengan cara memprediksi nilai variabel dependen dengan suatu persamaan (Ghozali, 2005). Hal ini dapat dimodelkan dalam persamaan berikut:
𝑦 = 𝑎 + 𝑏1𝑥1 + 𝑏2𝑥2 + 𝑏3𝑥3 + 𝑏4𝑥4 + 𝑒 … … … … 3.6
Sumber : Ghozali (2005)
Dimana,
y = Debt Maturity
a = Konstanta
b1 = Koefisien Regresi Variabel Tarif Pajak
b2 = Koefisien Regresi Variabel Term Structure
b3 = Koefisien Regresi Variabel Aset Varians
x1 = Tarif Pajak
x2 = Term Structure
x3 = Aset Varians
e = error term
Menurut Ajija dan Dyah (2011), data panel atau pooled data merupakan kombinasi dari data time series dan cross-section. Dengan mengakomodasi informasi baik yang terkait dengan variabel-variabel cross-section maupun time series. Data panel secara substansial mampu menurunkan masalah omitted- variables, model yang mengabaikan variabel yang relevan. Menurut Djalal dan Usman (2006), untuk mengestimasi parameter dengan model data panel, terdapat beberapa teknik yang ditawarkan, yaitu:
1. Pooled Last Square atau Common
Teknik ini tidak ubahnya dengan membuat regresi dengan data cross-section atau time series. Akan tetapi, untuk data panel, sebelum membuat regresi kita harus menggabungkan data cross-section dengan data time-series (pool data).
Kemudian data gabungan ini diperlakukan sebagai satu kesatuan pengamatan
yang digunakan untuk mengestimasi model dengan metode PLS. Rumus estimasi dengan mengunakan Common sebagai berikut:
𝑌
𝑖𝑡= 𝛽
1+ 𝛽
2+ 𝛽
3𝑋
3𝑖𝑡+ ⋯ + 𝜇
𝑖𝑡… … … … 3.7
Sumber : Djalal (2006)
2. Metode Efek Tetap (fixed effect)
Adanya variabel-variabel yang tidak semuanya masuk dalam persamaan model mungkin adanya intercept yang tidak konstan. Atau dengan kata lain, intercept mungkin berubah untuk setiaap individu dan waktu. Pemikiran inilah yang menjadi dasar pemikiran pembentukan model tersebut. Persamaan model ini adalah sebagai berikut:
𝑌𝑖𝑡 = 𝑎1+ 𝑎2𝐷2+ ⋯ + 𝑎𝑛𝐷𝑛 + 𝛽2𝑋2𝑖𝑡+ ⋯ + 𝛽𝑛𝑋𝑛𝑖𝑡 + 𝜇𝑖… … … 3.8
Sumber : Djalal (2006)
3. Metode Efek Random (random effect)
Bila pada Model Efek Tetap, perbedaan antar individu dan atau waktu dicerminkan lewat intercept, maka pada Model Efek Random, perbedaan tersebut diakomodasi lewat error. Teknik ini juga memperhitungkan bahwa error mungkin berkolerasi sepanjang time-series dan cross-section. Rumus estimasi model ini sebagai berikut:
𝑌𝑖𝑡 = 𝛽1+ 𝛽2𝑋2𝑖𝑡+ ⋯ + 𝛽𝑛𝑋𝑛𝑖𝑡 + 𝜀𝑖𝑡 + 𝜇𝑖𝑡… … … … 3.9
Sumber : Djalal (2006)
Jalan tengah dikemukakan pula oleh beberapa ahli ekonometri yang tentunya telah membuktikan secara matematis (Djalal, 2006), dimana dikatakan bahwa:
a. Jika data panel yang dimiliki mempunyai jumlah waktu (T) lebih besar disbanding jumlah individu (N) maka disarankan untuk menggunakan fixed effect.
b. Jika data panel yang dimiliki mempunyai jumlah waktu (T) lebih kecil dibanding jumlah individu (N) maka disarankan untuk menggunakan random effect.
Memilih model yang tepat, ada beberapa uji yang perlu dilakukan. Pertama, menggunakan uji signifikan fixed effect uji F atau chow-test. Kedua, dengan uji Hausman. Chow-test atau likehood ratio test adalah pengujian F statistik untuk memilih apakah model yang digunakan Common atau fixed effect. Sedangkan uji Hausman adalah uji untuk memilih model fixed effect atau random effect.
1. Uji Chow-test (Common vs fixed effect)
Uji signifikansi fixed effect (uji F) atau chow-test adalah untuk mengetahui apakah teknik regresi data panel dengan fixed effect lebih baik dari model regresi data panel tanpa variabel dummy atau OLS. Adapun uji F statistiknya sebagai berikut (Harahap, 2009):
𝐶𝐻𝑂𝑊 =(𝑅𝑅𝑆𝑆 − 𝑈𝑅𝑆𝑆)/(𝑁 − 1)
𝑈𝑅𝑆𝑆/(𝑁𝑇 − 𝑁 − 𝐾) … … … … 3.10
Sumber : Harahap (2009)
Keterangan:
RRSS : restricted residual sum square (merupakan sum of square residual yang diperoleh dari estimasi data panel dengan metode common)
URSS : unrestricted residual sum square (merupakan sum of square residual yang diperoleh dari estimasi data panel dengan metode fixed effect)
N : jumlah data cross section
T : jumlah data time series
K : jumlah variabel penjelas
Dasar pengembalian keputusan menggunakan chow test atau likehood ratio test, yaitu:
a. Jika Ha ditolak dan Ho diterima, maka model pooled b. Jika Ha diterima dan Ho ditolak, maka model fixed effect
Jika hasil uji chow menyatakan Ho diterima, maka teknik regresi data panel menggunakan model pool (common effect) dan pengujian berhenti sampai disini.
Apabila hasil uji chow menyatakan Ho ditolak, maka teknik regresi data panel menggunakan model fixed effect dan untuk selanjutnya dilakukan uji hausman.
2. Uji Hausman
Uji hausman digunakan untuk memilih antara fixed effect atau random effect, uji hausman didapatkan memalui command eviews yang terdapat pada direktori panel (Winarno, 2009). Statistik uji hausman ini mengikuti distribusi statistic Chi Square dengan degree of freedom sebanyak k, dimana k adalah jumlah variabel
independen. Jika nilai statistik hausman lebih besar dari nilai kritisnya maka model yang tepat adalah model fixed effect. Sedangkan sebaliknya bila nilai statistik hausman lebih kecil dari nilai kritisnya maka model yang tepat adalah model random effect. Dasar pengambilan keputusan menggunakan uji hausman (random effect vs fixed effect), yaitu:
a. Jika Ha ditolak dan Ho diterima, maka model random effect.
b. Jika Ha diterima dan Ho ditolak, maka model fixed effect.
3.8.3 Koefisien Determinasi
Koefisien determinasi (R2) ini digunakan untuk menggambarkan kemampuan model menjelaskan variasi yang terjadi dalam variabel dependen (Ghozali, 2005).
Dengan pengukuran koefisien determinasi ini akan dapat diketahui seberapa besar variabel independen mampu menjelaskan variabel dependennya, sedangkan sisanya dijelaskan oleh faktor lain diluar model. Koefisien determinasi (R2) dinyatakan dalam persentase. Nilai koefisien korelasi (R2) ini berkisar antara 0 <
R2 < 1. Semakin besar nilai yang dimiliki, menunjukan bahwa semakin banyak informasi yang mampu diberikan oleh variabel-variabel independen untuk memprediksi variansi variabel dependen. Dan dapat dirumuskan sebagai berikut:
𝑅2 =𝑏1 𝑥1𝑦 + 𝑏2 𝑥2𝑦 + 𝑏3 𝑥3𝑦 𝑦2
Sumber : Ghozali (2005)
Dimana,
b1 = Koefisien Regresi variabel Tarif Pajak
b2 = Koefisien regresi variabel Term Structure
b3 = Koefisien regresi variabel aset varians
x1 = Tarif Pajak
x2 = Term Structure
x3 = aset varians
y = Debt Maturity
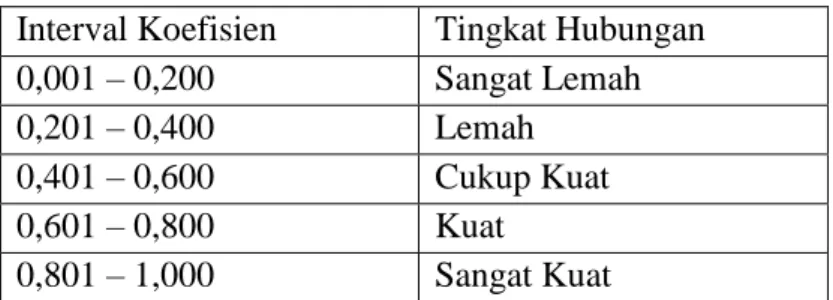
Tabel 3.3 Pedoman memberikan interpretasi terhadap koefisien korelasi
Interval Koefisien Tingkat Hubungan 0,001 – 0,200 Sangat Lemah
0,201 – 0,400 Lemah
0,401 – 0,600 Cukup Kuat
0,601 – 0,800 Kuat
0,801 – 1,000 Sangat Kuat
3.8.4 Uji Signifikansi Parameter Individual (Uji t)
Pada dasarnya menunjukan seberapa jauh pengaruh satu variabel independen secara individual dalam menerangkan variasi variabel dependen (Ghozali, 2005).
Membandingkan nilai statistik t dengan titik kritis menurut tabel. Apabila nilai – nilai statistik t hasil perhitungan lebih tinggi dibandingkan nilai t tabel, kita menerima hipotesis alternatif yang menyatakan bahwa suatu variabel independen secara individual mempengaruhi variabel dependen. Nilai t dapat dirumuskan sebagai berikut:
𝑡 =𝑋 − 𝜇 𝑆𝑥
Sumber : Ghozali (2005)
Dimana,
X = rata – rata hitung sampel 𝜇= rata – rata hitung populasi
Sx = strandar eror rata – rata nilai sampel
Pengujian denga uji t yaitu membandingkan antara t hitung dengan t tabel.
Uji ini dilakukan dengan syarat:
a. Jika t hitung < t tabel, maka Ho terima.
b. Jika t hitung > t tabel, maka Ho ditolak.
3.8.5 Uji Signifikansi Simultan (Uji F)
Pada dasarnya menunjukan apakah semua variabel independen atau bebas yang dimasukkan kedalam model mempunyai pengaruh secara bersama – sama terhadap variabel independen/terikat (Ghozali, 2005). Nilai F dapat dirumuskan sebagai berikut :
𝐹 = 𝑅2𝑘
1 −𝑅2
𝑛 − 𝑘 − 1
Sumber : Ghozali (2005)
Dimana :
n = jumlah sampel
k = jumlah variabel bebas
R2 = koefisien determinasi
Pengujian dengan uji F yaitu membandingkan antara uji F hitung dengan F tabel.
Uji ini dilakukan dengan syarat:
a. Jika F hitung < F tabel, maka Ho diterima.
b. Jika F hitung > F tabel, maka Ho ditolak.