BERBAHASA JAWA DENGAN HIERARCHICALK
MEANSCLUSTERING
ABSTRAK
Artikel memiliki berbagai jenis topik, sebagai contoh: berita ekonomi, kesehatan, dan sebagainya. Berdasarkan pada jenis artikel di atas ternyata dapat digali informasi yang dapat dimanfaatkan (knowledge discovery). Knowledge discoverypada data teks dapat dilakukan dengan proses awal berupa information retrieval. Proses dari information retrieval bertujuan untuk menemukan ciri dari dokumen, untuk selanjutnya dilakukan analisis keterhubungan antar dokumen dengan menggunakan metode pengelompokan. Sebelum dikelompokkan, data dokumen dari media cetak harus diubah ke bentuk text file. Selanjutnya masuk tahap
information retrievaluntuk memperoleh ciri dari suatu dokumen. Proses yang dilakukan adalah tokenizing, stop word, stemming, dan weighting. Berdasarkan proses information retrieval yang telah dilakukan, data dikelomopokan menggunakan Hierarchical K Means.
Metode Hierarchical K Means terdiri dari dua buah algoritma utama, yaitu K Means dan
agglomerative hierarchical clustering (AHC) khususnya teknik single linkage. Single linkage
dilakukan mencari centroid yang paling baik. Proses selanjutnya dilakukan K Means dengan menggunakan centroid hasil single linkage, guna menghasilkan cluster terbaik. Setiap hasil
cluster dievaluasi dengan metode evaluasi internal,metode yang digunakan adalah sum of square error (SSE). Cluster yang memiliki error minimum diuji kembali dengan evaluasi eksternal, yaitu dengan menggunakan (confusiion matrix). Berdasarkan percobaan pengelompokan yang dilakukan didapatkan pembentukan tiga cluster, yang memiliki error
USING HIERARCHICAL KMEANS
ABSTRACT
There are many kinds of topic article—economy, health, politic, etc. Within those articles,
there is useful information that can be found (knowledge discovery). Knowledge discovery
on the text data could be initiated by the initial process called information retrieval. The
information retrieval process aimed to collect the characteristic of a document in order to
analyze the connection between documents by using clustering method. Before conducting
the clustering process, document’sdata from printed media should be converted into text file.
The next step is information retrieval. In this step, the information retrieval collected the
characteristic of a document by using tokenizing, stop word, stemming, and weighting.
Documents data clustered by using Hierarchical K Means method based on information
retrieval. This method consisted of two main algorithms, which are K Means and
agglomerative hierarchical clustering (AHC) with single linkage technic. Single linkage
would collect the best centroid. In the next process, K Means was initiated using best centroid
from AHC to produce best cluster. Every cluster produced would be evaluated by internal
evaluation method. The internal evaluation method is sum of square error (SSE). Clusters
with minimum error would be retested by external evaluation method using confusion matrix.
There are three outcome of clusters based on the clustering trial, which have minimum error
19,84882 (internal evaluation) and maximum accuracy 80% (external evaluation). The
forming of these three clusters was corresponded with this paper’s objectives, which are
i
HALAMAN JUDUL
PENGELOMPOKAN ARTIKEL
BERBAHASA JAWA DENGAN HIERARCHICAL K MEANS
CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh :
Aluisius Bachtiar Bayu Saputra
115314076
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
HALAMAN JUDUL
JAVANESE LANGUAGE ARTICLES CLUSTERING
USING HIERARCHICAL K MEANS
A Final Project
Presented as Partial Fulfillment of The Requirements
To Obtain Sarjana Komputer Degree
In Informatics Engineering Study Program
By:
Aluisius Bachtiar Bayu Saputra
115314076
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
HALAMAN PERSETUJUAN SKRIPSI
PENGELOMPOKAN ARTIKEL
BERBAHASA JAWA DENGAN HIERARCHICAL K MEANS
CLUSTERING
Disusun oleh:
Aluisius Bachtiar Bayu Saputra
115314076
Telah disetujui oleh:
Dosen Pembimbing
iv
HALAMAN PENGESAHAN SKRIPSI
PENGELOMPOKAN ARTIKEL
BERBAHASA JAWA DENGAN HIERARCHICAL K MEANS
CLUSTERING
Dipersiapkan dan disusun oleh:
Nama : Aluisius Bachtiar Bayu Saputra
NIM : 115314093
Telah dipertahankan di depan panitia penguji
pada tanggal 23 Juli 2015
dan dinyatakan memenuhi syarat
Susunan Panitia Penguji:
Nama Lengkap Tanda Tangan
Ketua : JB Budi Darmawan, S.T., M.Sc. _____________
Sekretaris : Eko Hari Parmadi, S.Si., M.Kom. _____________
Anggota : Sri Hartati Wijono, S.Si., M.Kom. _____________
Yogyakarta, Juli 2015
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
v
HALAMAN PERSEMBAHAN
Tugas akhir ini saya persembahkan untuk:
Tuhan Yesus Yang Maha Baik
Bapak dan Ibu tercinta
Clothilde Arum ―si Gembul‖
Arzeta von A34
Renata Smile von Mentari
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi saya tulis ini tidak
memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam
kutipan dan daftar pustaka sebagaimana layaknya karya ilmiah.
Yogyakarta, 28 Juli 2015
Penulis
vii
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma :
Nama : Aluisius Bachtiar Bayu Saputra
Nomor Mahasiswa : 115314076
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
Pengelompokan Artikel Berbahasa Jawa dengan Hierarchical K Means
Clustering
beserta perangkat yang diperlukan. Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, me-ngalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal : 31 Juli 2015 Yang menyatakan
viii
ABSTRAK
PENGELOMPOKAN ARTIKEL
BERBAHASA JAWA DENGAN HIERARCHICAL K MEANS
CLUSTERING
ABSTRAK
Artikel memiliki berbagai jenis topik, sebagai contoh: berita ekonomi, kesehatan, dan sebagainya. Berdasarkan pada jenis artikel di atas ternyata dapat digali informasi yang dapat dimanfaatkan (knowledge discovery). Knowledge discovery
pada data teks dapat dilakukan dengan proses awal berupa information retrieval.
Proses dari information retrieval bertujuan untuk menemukan ciri dari dokumen, untuk selanjutnya dilakukan analisis keterhubungan antar dokumen dengan menggunakan metode pengelompokan. Sebelum dikelompokkan, data dokumen dari media cetak harus diubah ke bentuk text file. Selanjutnya masuk tahap
ix
ABSTRACT
JAVANESE LANGUAGE ARTICLES CLUSTERING
USING HIERARCHICAL K MEANS
ABSTRACT
There are many kinds of topic article—economy, health, politic, etc. Within those
articles, there is useful information that can be found (knowledge discovery).
Knowledge discovery on the text data could be initiated by the initial process
called information retrieval. The information retrieval process aimed to collect the
characteristic of a document in order to analyze the connection between
documents by using clustering method. Before conducting the clustering process,
document’s data from printed media should be converted into text file. The next
step is information retrieval. In this step, the information retrieval collected the
characteristic of a document by using tokenizing, stop word, stemming, and
weighting. Documents data clustered by using Hierarchical K Means method
based on information retrieval. This method consisted of two main algorithms,
which are K Means and agglomerative hierarchical clustering (AHC) with single
linkage technic. Single linkage would collect the best centroid. In the next
process, K Means was initiated using best centroid from AHC to produce best
cluster. Every cluster produced would be evaluated by internal evaluation method.
The internal evaluation method is sum of square error (SSE). Clusters with
minimum error would be retested by external evaluation method using confusion
matrix. There are three outcome of clusters based on the clustering trial, which
have minimum error 19,84882 (internal evaluation) and maximum accuracy 80%
(external evaluation). The forming of these three clusters was corresponded with
this paper’s objectives, which are to cluster the article and to find out the type of
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan atas kehadirat Tuhan Yang Maha Esa
atas berkat, rahmat serta kasih-Nya sehingga penulis dapat menyelesaikan skripsi
yang berjudul ―Pengelompokan Artikel Berbahasa Jawa dengan Hierarchical
K Means Clustering‖.
Penulisan skripsi ini bertujuan untuk memenuhi sebagian syarat
memperoleh gelar sarjana komputer program studi S1 jurusan Teknik Informatika
Universitas Sanata Dharma. Penulis menyadari bahwa skripsi ini masih jauh dari
sempurna oleh sebab itu penulis mengharapkan kritik dan saran yang bersifat
membangun dari semua pihak demi kesempurnaan skripsi ini.
Selesainya skripsi ini tidak lepas dari peran penting berbagai pihak,
sehingga pada kesempatan ini penulis dengan segala kerendahan hati serta rasa
hormat mengucapkan terima kasih yang sebesar – besarnya kepada semua pihak
yang telah memberikan dukungan baik secara langsung maupun tidak langsung
kepada penulis dalam penyusunan skripsi ini hingga selesai. Pada proses
penulisan tugas akhir ini, saya ucapkan banyak terima kasih kepada:
1. Tuhan Yesus selaku pembimbing iman dalam hidup yang selalu
memberi solusi di atas segala solusi.
2. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku pembimbing yang
memberikan pengarahan serta solusi dalam pengerjaan skripsi ini
hingga selesai.
3. Romo Dr. Cyprianus Kuntoro Adi, SJ, MA, M.Sc. yang rela
meluangkan waktunya untuk ngopi dan berbagi solusi.
4. Kedua orangtua, Bapak Y. Sumaryono dan Ibu Laurentina Suparmi yang selalu rela berkorban, mendoakan serta memberikan motivasi kepada penulis.
5. Romo Poldo Andreas Situmorang yang senantiasa tulus meluangkan waktunya untuk konsultasi mengenai penelitian ini.
xi
7. Semok Crew (Poldo, Ega, dan Nusa) yang senantiasa kompak dalam kerjasama team, baik siang, malam, maupun subuh menjelang, baik di kampus, base camp, maupun di bar.
8. Seluruh civitas akademika Teknik Informatika angkatan 2011,
terutama anggota C++ yang telah berjuang bersama dan saling memberi
semangat dan inspirasi.
9. Semua pihak, baik langsung maupun tidak, yang telah membantu
dalam proses penyelesaian skripsi ini.
Penulis menyadari bahwa masih banyak kekurangan yang terdapat dalam
skripsi ini. Saran dan kritik diharapkan untuk perbaikan-perbaikan pada masa
yang akan datang. Semoga bermafaat.
Penulis menyadari masih banyak kekurangan dalam menyusun skripsi ini,
namun penulis tetap berharap skripsi ini bermanfaat bagi pengembangan ilmu
pengetahuan.
Yogyakarta, 28 Juli 2015
Penulis
xii
BAB II LANDASAN TEORI ... 7
2.1 Information Retrieval ... 7
2.2 Clustering ... 19
2.3. Evaluasi ... 30
BAB III METODOLOGI PENELITIAN... 32
3.1 Data ... 32
3.2 Teknik Analisis Data ... 32
3.3 Desain User Interface ... 42
3.4 Spesifikasi Software dan Hardware ... 42
BAB IV IMPLEMENTASI DAN ANALISIS HASIL ... 43
4.1 Implementasi ... 43
xiii
4.1.2 Pengolahan Data... 50
4.2 Analisis Hasil ... 64
BAB V PENUTUP ... 80
5.1.Kesimpulan ... 80
5.2 Saran ... 82
DAFTAR PUSTAKA ... 83
xiv
DAFTAR GAMBAR
Gambar 2.1 Proses Information Retrieval (Manning, 2008)... 8
Gambar 2.2 Distribusi Zipf (Manning, 2008) ... 12
Gambar 2.3 Ilustrasi Penentuan Keanggotaan Kelompok Berdasarkan Jarak (Turban dkk, 2005)... 20
Gambar 2.4 Dendrogram ... 24
Gambar 2.5 Dendrogram singlelinkage untuk 5 obyek data ... 29
Gambar 3.1 Diagram Block Proses Clustering. ... 33
Gambar 3.2 Pembobotan tf-idf ... 35
Gambar 3.3 Langkah Menghitung Jarak Minimum pada single linkage ... 38
Gambar 3.4 Langkah Menghitung Menggabungkan Kelompok yang Berdekatan39 Gambar 3.5 Dendrogram ... 39
Gambar 3.6 Tampilan Menu Utama... 42
Gambar 4.1 Implementasi User Interface Awal (sebelum proses dilakukan) ... 44
Gambar 4.2 Implementasi User Interface (setelah dilakukan proses) ... 44
Gambar 4.3 Button Preprocessing dan Button Proses ... 45
Gambar 4.4 Hasil Kata Unik ... 46
Gambar 4.5 Hasil Pengelompokan Terbaik ... 47
Gambar 4.6 Anggota Cluster dari Pengelompokan Terbaik ... 48
Gambar 4.7 Hasil Centroid Terbaik yang Digunakan Pengelompokan ... 48
Gambar 4.8 Hasil Himpunan Centroid yang Divisualisasikan dengan Dendrogram ... 49
Gambar 4.9 Hasil Akurasi Berdasarkan Pengelompokan Terbaik... 49
Gambar 4.10 Peringatan/Informasi dari Aksi Menekan Button Preprocessing dan Proses ... 50
Gambar 4.11 Jumlah Data Dokumen yang Digunakan ... 51
Gambar 4.12 Salah Satu Contoh Data Dokumen ... 51
Gambar 4.13 Hasil Tokenizing ... 53
Gambar 4.14 Hasil Stop Word ... 54
Gambar 4.15 Hasil Stemming ... 56
Gambar 4.16 Hasil Indexing ... 57
Gambar 4.17 Dendrogram ... 59
Gambar 4.18 Centroid Awal ... 60
Gambar 4.19 Pembagian Cluster Beserta Anggotanya ... 62
Gambar 4.20 Pembagian Anggotanya Cluster ... 62
Gambar 4.21 Pemilihan SSE Minimum ... 63
Gambar 4.22 Hasil Akurasi ... 64
Gambar 4.23 Perbandingan Pemotongan Frekuensi Kata ... 78
xv
DAFTAR TABEL
Tabel 2.1 Rule untuk Suffix ... 14
Tabel 2.2 Rule untuk Prefix ... 14
Tabel 2.3 Rule untuk Infix ... 15
Tabel 2.4 Contoh Data Perhitungan hierarchical clustering ... 25
Tabel 2.5 Matriks jarak ... 26
Tabel 2.6 Matriks Jarak Pertama singlelinkage ... 27
Tabel 2.7 Matriks Jarak Kedua singlelinkage ... 27
Tabel 2.8 Matriks Jarak Ketiga singlelinkage ... 28
Tabel 3.1 Pembobotan ... 35
Tabel 3.2 Perhitungan Jarak antara Dokumen dengan Centroid... 37
Tabel 3.3 Hasil Himpunan Cluster Berdasarkan Pemotongan ... 40
Tabel 3.4 Hasil iterasi K Means yang Sudah Stabil ... 41
Tabel 4.1 Percobaan 1 dengan range term frekuensi 0-152 (tanpa pemotongan term) dengan jumlah kata unik 2.358 ... 66
Tabel 4.2 Hasil Akurasi 1 dengan tf 0-152(tanpa pemotongan) dengan jumlah kata unik 2.358 ... 67
Tabel 4.3 Percobaan 2 dengan range term frekuensi 20-130, dengan jumlah kata unik 236. ... 68
Tabel 4.4 Hasil Akurasi 2 dengan tf 20-130 dengan jumlah kata unik 236. ... 69
Tabel 4.5 Hasil Percobaan 3 dengan c=2 dan range 70-90 dengan jumlah kata unik 11. ... 70
Tabel 4.6 Hasil Akurasi 3 c=2 dan range 70-90 dengan jumlah kata unik 11. ... 70
Tabel 4.7 Hasil Percobaan 4 dengan c=4 dan range 70-90 dengan jumlah kata unik 11. ... 71
Tabel 4.8 Hasil Akurasi 4 c=4 dan range 70-90 dengan jumlah kata unik 11. ... 71
Tabel 4.9 Hasil Percobaan 5 dengan c=2 dan range 50-150 dengan jumlah kata unik 40. ... 72
Tabel 4.10 Hasil Akurasi 5 c=2 dan range 50-150 dengan jumlah kata unik 40. . 72
Tabel 4.11 Hasil Percobaan 6 dengan c=4 dan range 50-150 dengan jumlah kata unik 40. ... 73
Tabel 4.12 Hasil Akurasi 6 c=4 dan range 50-150 dengan jumlah kata unik 40. . 73
Tabel 4.13 Percobaan 7 dengan range term frekuensi 75-85 dengan jumlah kata unik 4. ... 74
1
1.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Media cetak adalah sarana menuangkan gagasan dan buah pikiran. Salah
satu jenis media cetak adalah majalah. Ada beberapa daerah yang memiliki
majalah dengan bahasa daerahnya, sebagai contoh: Jaka Lodhang, Mekar Sari,
Panjebar Semangat (Bahasa Jawa) dan Cupumanik, Manglé (Bahasa Sunda).
Seperti halnya Bahasa Inggris dan Bahasa Indonesia, artikel berbahasa Jawa juga
memiliki informasi tersembunyi yang dapat digali dan dimanfaatkan, yang
membedakannya adalah proses stemming dan aturan-aturan setiap bahasa.
Artikel memiliki berbagai jenis topik, sebagai contoh: berita ekonomi,
kesehatan, dan sebagainya. Berdasarkan pada jenis-jenis artikel di atas ternyata
dapat digali informasi yang dapat dimanfaatkan sebagai knowledge discovery.
Knowledge discovery adalah kegiatan menggali informasi dan pola tersembunyi
pada suatu sumber data. Knowledge discovery dengan data teks dapat dilakukan
dengan proses information retrieval (Han, 2011). Information retrieval adalah
sekumpulan algoritma dan teknologi untuk melakukan pemrosesan, penyimpanan,
dan menemukan kembali informasi (tertstruktur) pada suatu koleksi data yang
besar (Manning, 2008). Terdapat beberapa tahap yang harus dilakukan dalam
information retrieval, secara umum dapat dibagi ke dalam tahap seperti berikut:
2 Pengelompokan dokumen dapat dikerjakan dengan metode tertentu,
penelitian ini akan menggunakan salah satu metode clustering yaitu K Means.
Pemilihan algoritma K Means karena memiliki banyak keunggulan daripada
algoritma lainnya (Baswade, 2013), keunggulan K Means diantaranya:
1. Relatif efisien dengan O (knt) di mana k-jumlah cluster, n-jumlah objek,
t-jumlah iterasi.
2. Mudah untuk diimplementasikan dan dijalankan.
3. Waktu yang dibutuhkan untuk menjalankan pembelajaran ini relatif cepat.
4. Mudah untuk diadaptasi.
Keunggulan yang ditawarkan K Means membuat banyak penelitian yang
menggunakan metode tersebut, salah satu diantaranya: Analisa Perbandingan
Metode Hierarchical Clustering, K-means dan Gabungan Keduanya dalam
Cluster Data (Studi kasus : Problem Kerja Praktek Jurusan Teknik Industri ITS)
(Alfina, Santosa, Ridho Barakbah, 2012), Klasterisasi, Klasifikasi dan Peringkasan
Teks Berbahasa Indonesia (Raharjo dan Winarko, 2014), serta Deteksi Iris Mata
untuk Menentukan Kelebihan Kolesterol Menggunakan Ekstraksi Ciri Moment
Invariant dengan K-Means Clustering (Handini Rani, Supriyati, Khotimah,
2014). Berdasarkan keunggulan keunggulan dan penelitian yang telah dilakukan,
maka peneliti memilih metode K Means untuk digunakan sebagai metode
pengelompokan data, pada penerapannya akan digunakan Hierarchical clustering
untuk mengoptimalkan centroid awal sehingga diperoleh akurasi yang lebih tinggi
dibandingkan dengan random K Means dan tentunya proses pencarian dan
3 1.2 Rumusan Masalah
Bertolak dari uraian latar belakang di atas, maka peneliti mengambil
rumusan masalah sebagai berikut:
1. Bagaimana langkah mengelompokkan artikel berbahasa Jawa menurut
topiknya?
2. Sejauh mana pendekatan metode hierarchical K Means mampu
mengelompokkan artikel berbahasa Jawa dengan akurasi yang baik?
1.3 Batasan Masalah
Batasan masalah sangat penting dalam membuat suatu sistem agar
implementasinya nanti sesuai dengan yang diharapkan, maka batasan masalah
yang akan dibahas dan diaplikasikan dalam penulisan ini yaitu:
1. Data artikel memiliki jumlah 75 dokumen dimana dibatasi sumber yang
berasal dari majalah Djaka Lodhang, Praba, dan Mekarsari yang memiliki
tiga kelompok topik, yaitu ekonomi, kesehatan, dan pendidikan.
2. Pengelompokan artikel Bahasa Jawa dilakukan secara manual dan belum
melibatkan pakar atau ahli di bidang Bahasa Jawa.
3. Artikel menggunakan Bahasa Jawa.
4. Data artikel yang digunakan diubah dalam bentuk dokumen berekstensi
.txt.
5. Pengelompokan data artikel menggunakan metode K Means dimana
centroid awal ditentukan dengan metode Hierarichal Clustering (Single
4 1.4 Tujuan
Penelitian ini diharapkan dapat :
1. Mengetahui kelompok dari artikel dan dapat membantu untuk
mengetahui jenis topik artikel pada dokumen berbahasa Jawa.
2. Mengukur akurasi dari metode Hierarichal K Means pada
pengelompokan dokumen berbahasa Jawa.
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penelitian ini adalah studi
kasus dengan langkah-langkah sebagai berikut :
1. Studi Pustaka
Studi pustaka bertujuan untuk memberikan pengetahuan tentang
hal-hal yang berkaitan dengan pengelompokan dokumen. Studi pustaka
dilakukan dengan mempelajari buku referensi, jurnal dan artikel yang
berkaitan dengan pengelompokan dokumen teks, metode Hierarchical K
Means.
2. Pengumpulan Data
Pada tahap ini dilakukan pencarian dan pengumpulan data. Data
didapat dari majalah berbahasa Jawa Jaka Lodang, Mekarsaridan majalah
Praba.
3. Perancangan
5 4. Pembuatan Sistem
Berdasarkan hasil analisis dan perancangan sistem, maka tahapan
selanjutnya adalah membuat sistem yang akan digunakan.
5. Implementasi dan Pengujian
Implementasi sistem dengan cara menjalankan sistem yang telah
dibuat dan dilakukan pengujian dengan menampilkan pengelompokan
dokumen teks dalam Bahasa Jawa untuk mengetahui pengklasifikasiannya.
6. Evaluasi
Menganalisis hasil implementasi dan membuat kesimpulan
terhadap penelitian yang telah dikerjakan.
1.6 Sistematika Penulisan
Sistematika penulisan yang akan digunakan adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini akan menjelaskan latar belakang, perumusan masalah, batasan
masalah, tujuan penelitian, manfaat penelitian, dan sistematika penulisan.
BAB II DASAR TEORI
Bab ini akan menjelaskan dasar – dasar teori yang akan digunakan
sebagai landasan utama penelitian dan pembuatan sistem.
BAB III METODOLOGI
Bab ini membahas tentang teknik pengambilan, proses, hingga
6
BAB IV IMPLEMENTASI DAN ANALISIS HASIL
Bab ini berisi tentang implementasi berdasarkan metodologi yang
telah dipaparkan di bab sebelumnya.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan dan saran yang diberikan untuk
7
2.
BAB II
LANDASAN TEORI
2.1 Information Retrieval
Information Retrieval merupakan sekumpulan algoritma dan teknologi
untuk melakukan pemrosesan, penyimpanan, dan menemukan kembali informasi
(tertstruktur) pada suatu koleksi data yang besar (Manning, 2008). Data yang
digunakan dapat berupa teks, tabel, gambar maupun video. Sistem IR yang baik
memungkinkan pengguna menentukan secara cepat dan akurat apakah isi dari
dokumen yang diterima memenuhi kebutuhannya.
2.1.1 Arsitektur Information Retrieval
2.1.1.1 Proses Retrieval
Proses information retrieval secara garis besar digambarkan dalam
8 Gambar 2.1 Proses Information Retrieval (Manning, 2008)
Secara detail, penjelasan mengenai arsitektur information retrieval
terdiri dari beberapa langkah, yaitu :
1. Langkah pertama dalam proses retrieval adalah merancang dan
memodelkan bentuk dari data yang akan digunakan untuk
keperluan informationretrieval.
• Penentuan jenis dokumen yang akan digunakan (Semi
Structured dan Unstructured)
Semi–structured (dokumen yang memiliki struktur tree, misalnya dokumen XML)
biasanya memberikan tag tertentu pada term
9 Unstructured (dokumen yang tidak memiliki pola, misalnya artikel atau paragraf) proses
ini akan dilewati dan term pada dokumen
akan dibiarkan tanpa imbuhan tag.
• Operasi dasar yang akan dilakukan terhadap text pada isi
dokumen.
• Sistem akan membentuk indeks dari text.
2. Indeks merupakan bagian yang sangat kritikal karena akan
berpengaruh pada proses pencarian yang cepat dalam volume data
yang sangat besar. Struktur indeks dapat berbeda-beda, namun
yang paling popular untuk digunakan adalah invertedindex.
3. Ketika document data text selesai dibentuk, maka user sudah
dapat melakukan pencarian. Langkah-langkah yang harus
dilakukan pada pencarian adalah sebagai berikut :
Pada suatu kebutuhan pencarian data atau kebutuhan informasi pengguna akan merepresentasikan kebutuhan
tersebut dengan menggunakan query.
Query Operation akan dilakukan setelah user menginput
query.
10 Sebelum data dikembalikan ke user, dokumen yang
di-retrieved akan diranking berdasarkan kedekatan dokumen
dengan query.
2.1.1.2 Text Operation
Text Operation berperan penting dalam proses information
retrieval, karena seluruh proses yang berhubungan dengan penggalian
informasi dari sumber dokumen ataupun teks dilakukan pada proses text
operation. Textoperation memilki beberapa langkah yang dapat dilakukan
di dalam sebuah sistem Information Retrieval, berikut adalah
langkah-langkah pada textoperatrion:
Tokenisasi
Penghilangan Stop-word
Stemming
Indexing2.1.1.2.1 Tokenization
Tokenisasi merupakan proses pemenggalan kata dalam suatu
dokumen menjadi potongan – potongan kata yang berdiri sendiri (token).
Proses ini juga akan menghilangkan tanda baca atau karakter yang melekat
pada kata tersebut dan semua kata menjadi huruf kecil (Manning, 2008).
Contoh tokenisasi :
• Input :Friends, Romans, Countrymen, Lend, Me, Your, Eyes
11 Terkadang token dapat dikatakan juga sebagai term atau kata. Pemotongan
kumpulan karakter biasanya berdasarkan karakter spasi, namun beberapa
permasalahan yang terjadi dalam proses tokenisasi yaitu terdapat beberapa
kata yang akan berbeda arti bila dipotong berdasarkan spasi seperti San
Fransisco akan memiliki arti yang berbeda bila dipotong menjadi San dan
Fransisco. Setiap dokumen dan query direpresentasikan dengan model
bag-of-words, yaitu model yang mengabaikan urutan dari kata – kata dan
struktur yang ada di dalam dokumen. Dokumen diubah menjadi sebuah
wadah yang berisi kata – kata yang independen.
2.1.1.2.2 Penghilangan Stop Word
Stop-word didefinisikan sebagai term yang tidak berhubungan
(non-relevant) dengan subjek utama dari data meskipun kata tersebut
sering muncul di dalam dokumen. Penghilangan stop-word tidak bersifat
wajib pada beberapa desain dari modern information retrieval, dimana
memliki cara sendiri untuk menyelesaikan masalah kata-kata yang sering
digunakan dengan menggunakan data statistik. Contoh stop-word dalam
Bahasa Inggris adalah : a, an, the, this, that, these, those, her, his, its, my,
our, their, your, all, few, many, several, some, every, for, and, nor, bit, or,
yet, so, also, after, although, if, unless, because, on, beneath, over, of,
during, beside, dan etc. Contoh stop-word dalam bahasa Indonesia : yang,
juga, dari, dia, kami, kamu, aku, saya, ini, itu, atau, dan, tersebut, pada,
dengan, adalah, yaitu, ke, tak, tidak, di, pada, jika, maka, ada, pun, lain,
12
Stop-word juga bisa dilakukan dengan memotong kata berdasarkan
distribusi kata (Zipf Distrubution). Zipf Distrubution merupakan
pembagian/distribusi frekuensi kata, dapat digambarkan seperti gambar
2.2. Pada tahap ini dilakukan pemotongan kata yang memiliki frekuensi
sangat tinggi maupun rendah, dengan demikian dapat dikatakan Zipf
Distribution dapat memotong batas kata yang optimum untuk memberikan
ciri atau key word dari suatu dokumen.
Gambar 2.2 Distribusi Zipf (Manning, 2008)
2.1.1.2.3 Stemming
Sebuah kata kerja dalam dokumen sering kali memiliki banyak
bentuk atau tata bahasa yang berbeda, untuk mengatasinya dilakukan
stemming. Tujuan akhir dari stemming adalah mereduksi kata menjadi kata
dasar, proses ini dilakukan dengan pemotongan akhiran dan awalan kata.
Hasil dari langkah stemming diperoleh kelompok kata yang mempunyai
makna serupa tetapi berbeda wujud sintaktis satu dengan lainnya.
Kelompok tersebut dapat direpresentasikan oleh satu kata tertentu.
13 cara kerjanya. Stemming melakukan proses pemotongan akhiran dan
awalan untuk mencapai tujuan tersebut, sedangkan lemmatisasi melihat
penggunaan kata kerja serta analisis morfologi terlebih dahulu sebelum
melakukan pemotongan, hasil dari lemmatisasi biasa disebut dengan
lemma. Misalkan sebuah kata saw, stemming hanya akan mengembalikan
kata see, sedangkan lemmatisasi akan memotongnya ke bentuk see atau
saw tergantung pada penggunaan katanya sebagai verb atau noun. Setiap
bahasa tentunya memiliki norma stemming yang berbeda, maka tahap
stemming untuk Bahasa Jawa tentunya memiliki proses yang berbeda
(Ledy Agusta, 2009), berikut adalah langkah stemming untuk Bahasa
Jawa:
2.1.1.2.3.1 Aturan / Rule Stemming
Sebelum membuat aturan stemming untuk bahasa Jawa, diuraikan
terlebih dahulu penggunaan simbol-simbol dalam membuat stemmerrule
(Widjono, dkk, 2011) :
1. Aturan substitusi/penghapusan menggunakan tanda =>.
ny =>‖‖ (ny dihapus)
ny => s (ny diganti s)
2. Simbol <> digunakan untuk menyatakan tingkat affix yang mempengaruhi
urutan pengecekan di algoritma stemming. Rule yang digunakan adalah
14 Tabel 2.1 Rule untuk Suffix
SUFFIX
<1> e=>"",n=>"",a=>"",i=>"",ing=>"", ku=>"",mu=>""
<2> ke=>"", ki=>"",wa=>"", ya=>"",na=>"",ne=>"",en=>"",an=>"",ni=>"",nira=>"", ipun=>"",
on=>"u", ning=>""
<3> ake=>"", en=>"i", kna=>"n", kno=>"n", ana=>"", ono=>"", ane=>"", kne=>"", nan=>"",
yan=>"", nipun=>"", oni=>"u", eni=>"i"
<4> kake=>"n", ken=>"" ,kke=>"",nana=>"",nono=>"", nane=>"", nen=>"",kna=>"",kno=>"",
ekne=>"i", onan=>"u",enan=>"i"
<5> kake=>"",kken=>"",aken=>"",kke=>"n",enana=>"i",enono=>"i",onen=>"u",enen=>"i",onana=>
"u",onono=>"u", ekna=>"i",ekno=>"i",okno=>"u",okna=>"u"
<6> ekken=>"i",kaken=>"n",okken=>"u",ekake=>"i",ekke=>"i",okake=>"u",okke=>"u",
kaken=>"", kken=>"n"
<7> ekaken=>"i",okaken=>"u"
Tabel 2.2 Rule untuk Prefix
PREFIX
<1> dipun=>"",peng=>"",peny=>"",pem=>"",pam=>"",pany=>"",pra=>"",kuma=>"",kapi=>"",
bok=>"",mbok=>"",dak=>"",tak=>"",kok=>"",tok=>"",ing=>"",ang=>"",any=>"", am=>"",
sak=>"",
se=>"",su=>"",mang=>"",meng=>"",nge=>"",nya=>"",pi=>"",ge=>"",ke=>"",u=>"",
po=>"u",ke=>"u"
<2> mer=>"",mra=>"",mi=>"",sa=>"",ku=>"",an=>"",ka=>"",ny=>"s",ng=>"k",di=>"",peng=>"
k",pang=>"k",pany=>"c", pam=>"p",ke=>"i",mang=>"k",meng=>"k"
15
<4> n=>"t", pan=>"s", pen=>"s",man=>"s",men=>"s"
<5> pan=>"",pen=>"",man=>"t",men=>"t",n=>""
<6> pa=>"",pe=>"",man=>"",men=>""
<7> p=>"",ma=>"",me=>""
<8> m=>"w"
<9> m=>"p"
<10> m=>""
Tabel 2.3 Rule untuk Infix
INFIX
<1> gum=>"b",gem=>"b",kum=>"p",kem=>"p"
<2> kum=>"w", kem=>‖w‖
2.1.1.2.3.2 Algoritma Stemming
Algoritma untuk melakukan proses stemming terhadap kata tunggal atau
duplikasi.
1. Kata berimbuhan adalah word. Kata sebagai hasil adalah stemW
2. Cek jumlah karakter word, jika < 2. Keluar.
3. Jika word mengandung ―-―, maka pecah kata berdasar ―-― menjadi w1
dan w2. Dan lakukan langkah 4-13
4. w11 = w1 tanpa vokal dan w21 = w2 tanpa vokal.
5. Jika w11 = w21 dan panjang w1=w2 maka lakukan langkah 6-8
6. Jika w2 ada di kamus maka stemW=w2 dan keluar.
16 8. Jika w22 ada di kamus maka stemW=w22, jika tidak
stemW=w1-w2 dan keluar.
9. Jika w11 != w21, lakukan langkah 10-13
10.ws11=hilangkan imbuhan(w1) dan ws21 = hilangkan
imbuhan(w2).
11.Cek ws21 di kamus, jika ada maka stemW=ws21 dan
keluar.
12.Cek ws11 di kamus, jika ada maka stemW=ws11 dan
keluar.
13.Jika tidak maka stemW=ws11-ws21 dan keluar.
14.stemW = hilangkan imbuhan(stemW). Cek stemW di dictionary. Jika
ada stemW dikembalikan dan keluar.
Algoritma untuk menghilangkan afiks pada kata berimbuhan.
1. Kata yang akan dihilangkan imbuhan adalah word.
2. ws1=hapus suffix (word). Cek di dictionary. Jika ada kembalikan kata.
3. ws1s2=hapus suffix (ws1). Cek di dictionary. Jika ada kembalikan
kata.
4. ws1i1=hapus infix (ws1). Cek di dictionary. Jika ada kembalikan kata.
5. dws1= pengulangan parsial (ws1). Cek di dictionary. Jika ada
kembalikan kata.
6. dws1s2= pengulangan parsial (ws1s2). Cek di dictionary. Jika ada
kembalikan kata.
17 8. dwp1= pengulangan parsial (wp1). Cek di dictionary. Jika ada
kembalikan kata.
9. wp1s1=hapus suffix(wp1). Cek di dictionary. Jika ada kembalikan
kata.
10.dwp1s1= pengulangan parsial (wp1s1). Cek di dictionary. Jika ada
kembalikan kata.
11.wp1s1s2=hapus suffix (wp1s1). Cek di dictionary. Jika ada
kembalikan kata.
12.wp1p2=hapus prefix (wp1). Cek di dictionary. Jika ada kembalikan
kata.
13.wp1p2s1=hapus suffix (wp1p2). Cek di dictionary. Jika ada
kembalikan kata.
14.wp1p2s1s2=hapus suffix (wp1p2s1). Cek di dictionary. Jika ada
kembalikan kata.
15.wi1=hapus infix (word). Cek di dictionary. Jika ada kembalikan kata.
16.wi1s1=hapus suffix (wi1). Cek di dictionary. Jika ada kembalikan kata.
2.1.1.3 Indexing
Proses indexing adalah proses yang merepresentasikan document
collection ke dalam bentuk tertentu untuk memudahkan dan mempercepat
proses pencarian dokumen yang relevan. Pembuatan index dari document
collection adalah tugas pokok pada tahapan pre-processing di dalam
information retrieval. Efektitifitas dan efisiensi information retrieval
18 dokumen satu dengan dokumen yang lain yang berada di dalam satu
collection. Indeks dengan ukuran yang kecil dapat memberikan hasil yang
kurang baik dan bisa saja beberapa dokumen yang seharusnya relevan
terabaikan. Sementara indeks dengan ukuran yang besar memungkinkan
ditemukannya dokumen yang tidak relevan dan menurunkan kecepatan
pencarian. Pembuatan inverted index harus melibatkan konsep linguistic
processing yang bertujuan mengekstrak term-term penting dari dokumen
yang direpresentasikan sebagai bag-of-words.
Pada tahap indexing, dapat dilakukam pengindeksan terhadap term
frekuensi (tf), idf, tf-idf, atau fitur bobot tf-idf dapat dihitung sebagai
Contoh pembobotan kata pada dokumen:
Diberikan dokumen berisi kata A,B,C dengan frekuensi :
A(3), B(2), C(1)
Misal, ada koleksi berisi 10,000 dokumen dan frekuensi kata A, B, C
19 A(50), B(1300), C(250)
Maka :
A: tf = 3; idf = log(10000/50) = 2.3; tf-idf = 6.9
B: tf = 2; idf = log(10000/1300) = 0.88;tf-idf = 1.77
C: tf = 1; idf = log(10000/250) = 1.6; tf-idf = 1.6
2.2 Clustering
2.2. K Means Clustering
K Means clustering merupakan metode yang populer digunakan untuk
mendapatkan deskripsi dari sekumpulan data dengan cara mengungkapkan
kecenderungan setiap individu data untuk berkelompok dengan
individu-individu data lainnya. Kecenderungan pengelompokan tersebut didasarkan
pada kemiripan karakteristik tiap individu data yang ada. Ide dasar dari
metode ini adalah menemukan pusat dari setiap kelompok data yang mungkin
ada untuk kemudian mengelompokkan setiap data individu ke dalam salah
satu dari kelompok-kelompok tersebut berdasarkan jaraknya (Turban dkk,
2005). Semakin dekat jarak data individual, sebut saja X1 dengan salah satu
pusat dari kelompok yang ada , sebut saja A, maka semakin jelas bahwa X1
tersebut merupakan anggota dari kelompok yang berpusat di A dan semakin
jelas pula bahwa X1 bukan anggota dari kelompok-kelompok yang lainnya
(ilustrasi dapat dilihat pada gambar 1). Secara kuantitatif hal ini ditunjukkan
melalui fakta bahwa d1A yaitu jarak dari X1 ke A mempunyai nilai yang
20 Gambar 2.3 Ilustrasi Penentuan Keanggotaan Kelompok Berdasarkan Jarak
(Turban dkk, 2005)
Cara untuk menemukan pusat yang paling sesuai sebagai upaya
merepresentasikan posisi dari sebuah kelompok data terhadap kelompok data yang
lainnya dilakukan sebuah proses perulangan. Proses perulangan ini dimulai
dengan menentukan secara sembarang posisi dari pusat-pusat kelompok yang
telah ditetapkan. Selanjutnya ditentukan keanggotaan setiap individu data
berdasarkan jarak terpendek terhadap pusat-pusat tersebut. Pada iterasi kedua dan
seterusnya dilakukan pembaharuan posisi pusat untuk semua kelompok. Langkah
selanjutnya dilakukan pembaharuan keanggotaan untuk setiap kelompok.
2.2.1 Langkah K Means Clustering
Metode pengelompokkan K Means pada dasarnya melakukan dua proses yakni
tiap-21 tiap cluster dan proses pencarian anggota dari tiap-tiap cluster. Proses Algoritma
K Means sebagai berikut :
1. Tentukan K sebagai jumlah cluster yang ingin dibentuk.
2. Bangkitkan K centroid (titik pusat cluster) awal secara random.
3. Hitung jarak setiap data ke masing-masing centroid.
4. Setiap data memilih centroid yang terdekat.
5. Tentukan posisi centroid baru dengan cara menghitung nilai rata-rata
dari data-data yang terletak pada centroid yang sama.
6. Kembali ke langkah 3 jika posisi centroid baru kurang dari centroids
lama.
Berdasarkan cara kerjanya Algoritma K Means memiliki karakteristik sebagai
berikut :
1. K Means sangat cepat dalam proses clustering.
2. K Means sangat sensitif dalam proses pembangkitan centroid awal secara
random.
3. Memungkinkan suatu cluster tidak mempunyai anggota.
4. Hasil clustering dengan K Means bersifat tidak unik.
Proses pengelompokkan data ke dalam suatu cluster dapat dilakukan dengan cara
menghitung jarak terdekat dari suatu data ke sebuah titik centroid. Rumus untuk
menghitung jarak tersebut menggunakan euclidean matrix:
(2.3)
22 g = 2, untuk menghitung jarak euclidean
xi , xj adalah dua buah data yang akan dihitung jaraknya
p = dimensi dari sebuah data
Pembaharuan suatu titik centroid dapat dilakukan dengan rumus berikut:
(2.4)
dimana:
µk = titik centroid dari cluster ke-K
Nk = banyaknya data pada cluster ke-K
xq = data ke-q pada cluster ke-K
2.2.2 Hierarchical Clustering
Metode agglomerative hierarchical clustering adalah metode yang
menggunakan strategi disain bottom-up yang dimulai dengan meletakkan setiap
obyek sebagai sebuah cluster tersendiri (atomic cluster) dan selanjutnya
menggabungkan atomic cluster – atomic cluster tersebut menjadi cluster yang
lebih besar dan lebih besar lagi sampai akhirnya semua obyek menyatu dalam
sebuah cluster atau proses berhenti jika telah mencapai batasan kondisi tertentu
(Arai ,2007).
Sebelum dibentuknya sebuah cluster perlu melalui langkah menghitung
23 banyak digunakan adalah dengan perhitungan euclidean distance. Euclidean
distance sendiri adalah:
√ | | | | | | | | (2.5)
dapat disederhanakan dengan:
√∑ (2.6)
Keterangan:
adalah jumlah atribut atau dimensi
dan adalah data
Hierarchical clustering memiliki beberapa cara untuk perhitungan jarak
antar cluster, di antaranya adalah single linkage, average linkage, dan complete
linkage. Berikut ini adalah pendevinisian perhitungan jarak dengan cara single
linkage:
Perhitungan dengan teknik single linkage adalah untuk mencari jarak minimum
antar cluster. Dengan single linkage jarak antara dua cluster didevinisikan sebagai
berikut:
(2.7)
Keterangan:
adalah jarak antara data dan y dari masing-masing cluster A dan B.
Berdasarkan perhitungan rumus di atas akan didapatkan jarak antar cluster. Jarak
minimum antar data yang ditemukan pertama akan menjadi cluster yang pertama.
Perhitungan selanjutnya juga akan dilakukan untuk pembentukan cluster
24
J
a
r
a
k
0 1 2
0,5 1,5
a b c e d f
D a t a
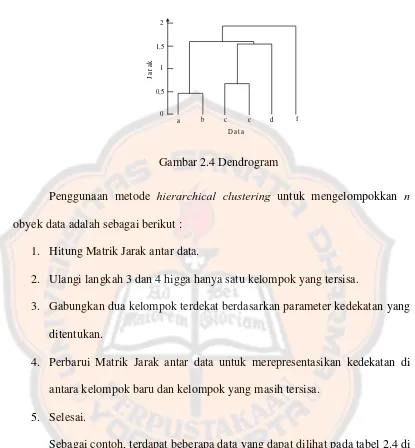
Gambar 2.4 Dendrogram
Penggunaan metode hierarchical clustering untuk mengelompokkan n
obyek data adalah sebagai berikut :
1. Hitung Matrik Jarak antar data.
2. Ulangi langkah 3 dan 4 higga hanya satu kelompok yang tersisa.
3. Gabungkan dua kelompok terdekat berdasarkan parameter kedekatan yang
ditentukan.
4. Perbarui Matrik Jarak antar data untuk merepresentasikan kedekatan di
antara kelompok baru dan kelompok yang masih tersisa.
5. Selesai.
Sebagai contoh, terdapat beberapa data yang dapat dilihat pada tabel 2.4 di
bawah ini. Data akan dibentuk dengan menggunakan hierarchical clustering
dengan perhitungan kemiripan obyek data menggunakan euclidean distance dan
25 Tabel 2.4 Contoh Data Perhitungan hierarchical clustering
Data X Y
A 1 1
B 4 1
C 1 2
D 3 4
E 5 4
Dihitung dengan euclidean distance setiap obyek data tersebut dihitung
jaraknya sebagai berikut:
√ | | | |
√ | | | |
√ | | | |
√ | | | |
√ | | | |
√ | | | |
√ | | | |
√ | | | |
√ | | | |
√ | | | |
Berdasarkan perhitungan tersebut dapat dibentuk matriks jarak seperti
26 Tabel 2.5 Matriks jarak
A B C D E
a 0 3 1 3.61 5
b 3 0 3.16 3.16 3.16
c 1 3.16 0 2.83 4.47
d 3.61 3.16 2.83 0 2
e 5 3.16 4.47 2 0
Single linkage
Selanjutnya dari tabel 2.5 dapat dilihat jarak obyek data yang paling dekat,
yaitu a dan c, berjarak 1. Kedua obyek data ini menjadi satu cluster pertama.
Kemudian untuk menemukan cluster berikutnya dicari jarak antar obyek data dari
sisa yang ada (b, d, e) dan berada paling dekat dengan cluster (ac). Untuk
pencarian jarak ini pertama digunakan single linkage.
Kemudian baris-baris dan kolom-kolom matriks jarak yang bersesuaian
dengan cluster a dan c dihapus dan ditambahkan baris dan kolom untuk cluster
27 Tabel 2.6Matriks Jarak Pertama singlelinkage
Ac B d E
Ac 0 3 2.83 4.47
B 0 3.16 3.16
D 0 2
E 0
Berdasar pada matriks jarak kedua (Tabel 2.6), dipilih kembali jarak
terdekat antar cluster. Ditemukan cluster (de) yang paling dekat, yaitu bernilai 2.
Kemudian dihitung jarak dengan cluster yang tersisa, (ac), dan b.
Kemudian baris-baris dan kolom-kolom matriks jarak yang bersesuaian
dengan cluster d dan e dihapus dan ditambahkan baris dan kolom untuk cluster
(de), sehingga matriks jarak menjadi seperti berikut ini:
Tabel 2.7 Matriks Jarak Kedua singlelinkage
Ac b De
Ac 0 3 2.83
B 0 3.16
28 Berdasar pada matriks jarak ketiga (Tabel 2.7), dipilih kembali jarak
terdekat antar cluster. Ditemukan cluster (acde) yang paling dekat, yaitu bernilai
2.83. Kemudian dihitung jarak dengan cluster yang tersisa, yaitu b.
Langkah selanjutnya yaitu menghapus dan menambahkan baris dan kolom
untuk cluster (acde) baris-baris dan kolom-kolom matriks jarak yang bersesuaian
dengan cluster (ac) dan (de), sehingga matriks jarak menjadi seperti berikut ini:
Tabel 2.8 Matriks Jarak Ketiga singlelinkage
acde B
Acde 0 3
B 0
Proses iterasi perhitungan jarak untuk pembentukan cluster sudah slesai
karena cluster sudah tersisa satu. Jadi cluster (acde) dan (b) digabung menjadi
satu, yaitu cluster (acdeb) dengan jarak terdekat adalah 3. Berikut ini adalah hasil
29 Gambar 2.5 Dendrogram singlelinkage untuk 5 obyek data
2.3 Hierarchical K Means
Menurut eksperimen yang telah dilakukan, metode K Means sudah
digunakan untuk metode pengelompokan data set. Hal itu dapat dibuktikan
dengan prosentase eror yang minimal, namun seiring berjalannya waktu,
eksperimen tentang clustering lebih berkembang dengan adanya metode
Hierarichal K Means yang dapat menentukan centroid awal yang akan
digunakan untuk clustering pada metode K Means. Ternyata metode
Hierarichal K Means dapat mengatasi pemilihan centroid secara random yang
memikiki tingkat eror lebih besar dan dalam penggunannya dianggap kurang
praktis karena harus melakukan beberapa eksperimen dalam menentukan
centroid awal yang tepat. Harapannya dengan diterapkan Hierarichal K Means
dapat meningkatkan akurasi dan menurunkan prosentasi erornya, disebutkan
dalam penelitian, ternyata eror pada metode K Means dengan centroid
random sebesar 32.5236%, sedangkan dengan metode Hierarichal K Means
30 Berikut adalah langkah dalam menentukan centoid awal dengan menggunakan
hierarchicalK Means :
1. Set X ={xi | i =1, ..., r} i setiap data A, dimana A {ai | i= 1, ..., n} dengan
n-dimensi vektor.
2. Set K sebagai jumlah _ cluster yang telah ditetapkan.
3. Tentukan p sebagai banyaknya perhitungan
4. Set i = 1 sebagai counter awal
5. Terapkan algoritma K Means.
6. Catat hasil centroid hasil Clustering sebagai Ci = {ij | j = 1, ..., K}
7. Tambahkan i = i + 1
8. Ulangi dari langkah 5 saat i <p.
9. Asumsikan C = {Ci | i = 1, ..., p} sebagai satu set data baru, dengan K
sebagai nomor _ cluster yang telah ditetapkan
10.Terapkan algoritma hirarki (singlelinkage)
11.Catat hasil centroid Clustering sebagai D = {di | i = 1, ..., K}
Langkah berikutnya adalah menerapkan D = {di | i = 1, ..., K} sebagai
pusat klaster awal untuk K Means. Penggunaan algoritma hirarki untuk
menemukan centroid awal dipilih single linkage, karena single linkage
penerapannya mudah selain itu ternyata tidak ada perbedaan signifikan
dibandingkan dengan average maupun completelinkage (Arai, 2007).
2.3. Evaluasi
Berkaitan dengan evaluasi yang digunakan pada penelitian ini, digunakan
31 eksternal. Evaluasi yang pertama adalah evaluasi internal sistem, dimana
berfungsi untuk mengukur kinerja K Means clustering ini menggunakan Sum
Square Erorr (SSE). Evaluasi bertujuan untuk menilai kualitas cluster yang
dibuat. Kinerja sistem yang dievaluasi dengan menghitung nilai akurasi, dari
perhitungan akurasi akan diketahui sejauh mana metode K Means dapat
mengelompokkan dokumen apa topik artikel Berbahasa Jawa. Semakin kecil nilai
SSE semakin baik hasil cluster yang dibuat.
∑ ∑ || || (2.8)
Keterangan:
adalah jarak data di indeks
adalah rata-rata semua jarak data di cluster
Evaluasi yang diterapkan berikutnya adalah evaluasi yang berkaitan
dengan eksternal sistem, yaitu mengukur akurasi dari pengelompokkan dokumen
hasil dari internal evaluasi. Langkah yang dilakukan adalah membandingkan
setiap anggota cluster dengan manual pengelompokkan yang sudah dibuat, dalam
hal ini sudah ditentukan pembagian cluster dokumen berdasarkan topik (ekonomi,
kesehatan, dan pendidikan), dimana masing-masing kelompok beranggotakan 25
dokumen. Metode pengukuran akurasi eksternal yang digunakan adalah
confussion matrix. Tabel matriks konfusi merupakan tabel yang digunakan untuk
menghitung tingkat akurasi setiap cluster, dimana setiap anggota cluster
dibandingkan dengan anggota cluster yang ideal (Prasetyo E, 2012).
32
3.
BAB III
METODOLOGI PENELITIAN
Berdasar pada landasan teori yang telah disampaikan pada bab kedua di
atas, pada bab ini akan membahas metodologi yang akan digunakan pada skripsi
ini. Bab ini berisi diagram blok, data, tatap muka pengguna dan evaluasi.
3.1 Data
Data yang digunakan adalah artikel yang bersumber dari majalah
berbahasa Jawa Mekarsari, Praba, dan Djaka Lodhang yang terlebih dahulu
diubah menjadi dokumen berekstensi .txt . Data yang digunakan berjumlah 75
dokumen, dengan jumlah kata unik yang digunakan 2.358 kata.
3.1.1 Jenis Data
Jenis data yang diambil adalah artikel dari majalah Djaka Lodhang, Praba,
dan Mekarsari diubah ke bentuk dokumen berkestensi .txt. Data yang dipilih,
berasal dari tiga kelompok, yaitu pendidikan, kesehatan, dan ekonomi.
3.2 Teknik Analisis Data
Secara umum, sistem yang akan dibangun dalam penelitian ini adalah
sebuah sistem dengan fungsi utama untuk melakukan pengelompokan dokumen
berbahasa Jawa. Dokumen yang akan dikelompokkan adalah artikel yang diambil
dari majalah berbahasa Jawa yaitu Djaka Lodhang, Praba, dan Mekarsari. Proses
pengelompokan yang digunakan pada sistem ini adalah metode Hierarchical K
Means. Praktiknya, dokumen-dokumen yang akan dikelompokkan dijadikan
33 diproses oleh sistem melalui proses tokenizing, stemming, indexing, pembobotan,
clustering, percobaan, dan evaluasi. Proses-proses tersebut dapat dilihat pada
Gambar 3.1 .
Gambar 3.1Diagram Block Proses Clustering.
Pada Gambar 3.1 dapat diketahui terdapat input data kemudian
dilakukan text operation. Pada proses tersebut didapat dari proses
tokenizing untuk memisah kata atau terms kemudian dilakukan
normalisasi dengan melakukan stopword, stemming, dan pembobotan
data model. Langkah berikutnya adalah dengan melakukan
pengelompokan dengan metode K Means untuk mendapatkan himpunan
centroid, dimana proses menghitung jarak dokumen dengan centroid
dilakukan menggunakan euclidean distance. Setelah mendapatkan hasil
Input
Data
Tokenizing
Stemming StopWord
Indexing
IR
Hierarchical
(Single Linkage)
K Means
K Means
Hiearchical Kmeans
Hasil Cluster
Output
SSE
Akurasi
34 himpunan centroid, langkah selanjutnya adalah melakukan langkah
hierarchical single linkage untuk mendapatkan centroid baru sejumlah
tiga buah (di rata-rata). Hal ini dilakukan untuk mendapatkan centroid
lebih tepat dibandingkan pemilihan centroid random. Langkah berikutnya
yaitu memproses pengelompokan dengan metode K Means dengan
centroid baru. Hasil dari K Means clustering dievaluasi dengan SSE guna
mendapatkan error minimum dan menemukan pembagian cluster yang
baik. SSE yang minimum akan membantu dalam dalam mengevaluasi
eksternal sistem, yaitu dengan menguji pengelompokan anggota
kelompok dari sistem yang kemudian dibandingkan dengan manual
cluster, dimana berisi anggota cluster yang ideal.
3.2.1 Text Operation
3.2.1.1 Information Retrieval (Tokenization,Stop Word, Steming, Indexing)
Pada tahap information retrieval dilakukan langkah untuk mencapai calon data
yang akan dikelompokkan. Langkah-langkah yang dilakukan adalah:
1. Tokenization
Proses yang dilakukan pada tahap ini adalah memenggal kata-kata yang
ada pada dokumen menjadi kata-kata yang berdiri sendiri.
2. Stop Word
Proses yang dilakukan pada tahap ini adalah menghilangkan kata yang
35 juga diterapkan Zipf Distrubution untuk menemukan range frekuensi kata
yang optimum untuk menemukan key word dari suatu dokumen.
3. Steming
Pada tahap ini setiap hasil kata yang sudah tereduksi dari proses stop word
dilakukan penghapusan kata menjadi kata dasar yang kemudia dicocokkan
ke kamus untuk menghasilkan kata unik.
4. Indexing
Pada tahap ini setiap kata unik diberi bobot kata dengan menggunakan
rumus weighting (tf.idf) seperti yang sudah dijelaskan di bab sebelumnya.
Gambar 3.2Pembobotan tf-idf
Tabel 3.1 Pembobotan
PEMBOBOTAN IDF TF IDF w=tf*idf
Pergok 1 1,77815125 1,77815125
Wong 1 1,77815125 1,77815125
Nandhang 1 1,77815125 1,77815125
Racun 2 1,477121255 1,477121255
Dhahar 2 1,477121255 2,954242509
*log yang digunakan basis 10
36 wong: tf = 1; idf = log(60/1) = 1,77815125; W = 1,77815125
nandhang: tf = 1; idf = log(60/1) = 1,77815125; W = 1,77815125
kemudian hasil pembobotan kata pada dokumen disimpan pada
matriks calonData sebagai berikut:
c
dimana w merupakan bobot dari term i sepanjang jumlah kata unik
(horizontal) dan yang vertikal sepanjang/sejumlah dokumen.
3.2.1.2 K Means (pertama)
Langkah setelah dilakukannya pembobotan adalah melakukan
pengelompokan, pengelompokan yang digunakan adalah
menggunakan K Means untuk mendapatkan himpunan centroid. Hal
ini diawali dengan memilih centroid awal = 3 centroid, dipilih tiga
centroid dikarenakan sudah dibatasi dengan pengelompokan topik
yang diasumsikan menjadi tiga kelompok/cluster, yaitu ekonomi,
kesehatan, dan pendidikan. K Means ini dilakukan sebanyak jumlah
computation/jumlah dilakukannya metode K Means (c=3),
computation 1 menghasilkan tiga centroid random yang
digunakan{c1,c3,c5}, computation 2 menghasilkan tiga centroid
random yang digunakan {c1,c4,c5}, dan computation 3 menghasilkan
tiga centroidrandom yang digunakan ={c2,c4,c6}. Berdasarkan proses
37 Kemudian dilanjutkan dengan menghitung euclidean distance untuk
menghitung jarak masing-masing centroid ke setiap dokumen.
Contoh menghitung euclidean distance dari dokumen 1 ke dokumen 1 dan dokumen 1 ke dokumen 2:
Tabel 3.2 Perhitungan Jarak antara Dokumen dengan Centroid
Pergok(w) Sum
doc1 1,778151 1,778151
doc2 0 0
Lakukan untuk semua himpunan centroid dan kemudian lanjutkan dengan proses
hierarchical single linkage.
W2 sum doc1 3,161822 3,161822 doc2 0 0
38 3.2.1.3 Hierarchical Centroid awal
Himpunan centroid yang diperoleh dari langkah sebelumnya digunakan
dalam proses hierarchical single linkage. Hal pertama yang dilakukan adalah
menghitung jarak minimum antar centroid dengan rumus:
(3.1)
Langkah berikutnya yaitu menggabungkan dua kelompok terdekat berdasarkan
jaraknya.
Gambar 3.3 Langkah Menghitung Jarak Minimum pada single linkage
Langkah berikutnya yaitu memperbarui matrik jarak antar data untuk
merepresentasikan kedekatan di antara kelompok baru dan kelompok yang masih
39 Gambar 3.4 Langkah Menghitung Menggabungkan Kelompok yang
Berdekatan
Berdasarkan proses menggabungkan kelompok terdekat yang sudah dilakukan
didapatkah dendrogram sebagai berikut:
40 Tahap ini bertujuan untuk mendapatkan tiga buah cluster, maka bisa dipotong
pada dendogram, sehingga diperoleh pusat cluster sebagai berikut:
Tabel 3.3 Hasil Himpunan Cluster Berdasarkan Pemotongan
Langkah di atas merupakan langkah pemilihan centroid dari himpundan centroid
hasil single linkage.Centroid yang dipilih adalah:
C1 adalah rata-rata dari feature dari indeks 1 dan 2
C2 adalah rata-rata dari feature dari indeks 3,4, dan 5
C3 adalah rata-rata dari feature dari indeks 6 (dapat langsung diambil
indeks 6).
3.2.1.4 K Means (kedua)
Langkah ini memerlukan centroid baru yang didapat dari proses
sebelumnya, maka ditentukan centroid baru sebagai berikut: c1, c2, dan c3.
Gunakan rumus euclidean distance untuk menghitung jarah terdekat dokumen
41 Tabel 3.4 Hasil iterasi K Means yang Sudah Stabil
Lakukan langkah K Means sampai anggota setiap centroid tidak terjadi peubahan,
dan ternyata iterasi berhenti di iterasi 1 (2 kali iterasi), sehingga didapatkan
pengelompokan dengan anggota cluster sebagai berikut:
Kelompok 1 : doc 1 dan 2
Kelompok 2 : doc 3,4, dan 5
Kelompok 3 : doc 6
3.2.1.5 Output
Output yang diharapkan pada penelitian ini adalah menampilkan pembagian
cluster, sehingga secara visual dapat dilihat hasil pembagian cluster-nya
3.2.1.6 Penghitungan Evaluasi
Penelitian ini menggunakan beberapa prosedur uji coba, di antaranya
variasi jenis range kata unik yang digunakan dan variasi computation(c) yang
merupakan jumlah dilakukan K Means pertama. Berdasarkan prosedur uji coba di
-42 nya. SSE dengan nilai yang paling rendah mengindikasikan bahwa cluster yang
terbentuk adalah yang paling baik. Nilai SSE terkecil dipilih sebagai pedoman
pengukuran akurasi eksternal sistem, yaitu pencocokan hasil pengelompokan
dokumen dengan dokumen yang sebenarnya. Pada pengujian eksternal sistem ini
dapat digunakan confussion matrix sebagai metodenya.
3.3 Desain User Interface
Gambar 3.6 Tampilan Menu Utama
3.4 Spesifikasi Software dan Hardware
Untuk proses membuat sistem dan data digunakan software dan hardware
sebagai berikut :
1. Software
a) Sistem Operasi : Windows 7 Ultimate 32-bit
b) Bahasa Pemprograman : Matlab version 8.0.0.783 (R2012b)
2. Hardware
a) Processor : Intel(R) Core(TM) i5-2430M CPU @ 2.40GHz
b) Memory : 2 GB
c) Hardisk : 500 GB
button button
Tabel Hasil
Pengujian
akurasi
43
4.
BAB IV
IMPLEMENTASI DAN ANALISIS HASIL
Berdasarkan metodologi yang dijelaskan pada bab sebelumnya, maka
penelitian ini dapat diimplementasikan dengan langkah-langkah sebagai berikut:
4.1 Implementasi
Implementasi yang diterapkan pada bab ini merupakan penerapan
metodologi yang telah dipaparkan pada bab sebelumnya. Implementasi mencakup
proses information retrieval, pengelompokan data dengan hierarchical K Means,
hinga pengukuran akurasi dari sistem dengan menggunakan SSE dan confussion
matrix. Pada tahap selanjutnya diimplementasi dengan ujicoba dan kemudian
dianalisis. Analisis implementasi meliputi user interface dan pengolahan data.
4.1.1 User Interface
Pembuatan user interface sistem pengelompokan artikel berbahasa Jawa
menggunakan sarana yang diberikan oleh Matlab version 8.0.0.783 (R2012b).
Desain user interface yang telah dipaparkan pada bab sebelumnya
diimplementasikan dan digunakan sebagai sarana untuk melakukan text operation
sampai untuk mengetahui akurasi dari pengelompokan data dengan Hierarchical
K Means. Sistem dapat langsung menampilkan hasil keseluruhan proses. User
interface tersimpan dengan file yang bernama GUI.m dan GUI.fig (lampiran 1 dan
2). Gambar 4.1 dan 4.2 adalah contoh tampilan keseluruhan sistem yang telah