PERNYATAAN ORISINALITAS
Karya ini adalah karya orisinal dan belum pernah disajikan sebagai salah satu tulisan untuk memperoleh suatu kualifikasi tertentu atau dimuat pada media publikasi lain.
Peneliti membedakan dengan jelas antara pendapat atau gagasan penulis dengan pendapat atau gagasan yang bukan berasal dari penulis dengan mencantumkan tanda kutip.
Medan, September 2020
Penulis
ABSTRAK
Utari, Sri. 2020. Perbandingan Pengindeksan Subjek Menggunakan Hukum Zipf’s Dengan Kata Kunci Artikel Pada Jurnal Library Management.
Penelitian ini bertujuan untuk mengetahui persamaan dan perbedaan istilah indeks subjek yang dihasilkan pengarang (kata kunci) dengan indeks subjek yang dihasilkan oleh Dalil Zipf dalam menentukan indeks subje yang terdapat pada Jurnal Library Management Vol. 36 issue 8/9 tahun 2015. Jenis penelitian ini adalah deskriptif dan penelitian ini menggunakan unit analisis. Unit analisis yang digunakan dalam penelitian ini adalah artikel yang dimuat dalam jurnal Library Management Vol. 36 issue 8/9 tahun 2015 yang dimuat dalam bentuk online dan berjumlah 11 artikel. Hasil dari penelitian ini menunjukkan bahwa penggunaan Dalil Zipf dalam pengindeksaan subjek dapat menghasilkan indeks tunggal (pra- koordinasi) yang berasal dari bahasa ilmiah (natural language) yang diambil langsung dari bahasa dokumen itu sendiri. Karena merupakan bahasa alamiah, maka indeks yang dihasilkan juga merupakan indeks subjek tak terkendali serta kata yang dihasilkan juga bersifat umum (general). Berdasarkan hasil penelitian diketahui bahwa pengindeksan menggunakan Dalil Zipf dan kata kunci artikel memiliki tingkat kesamaan relevan yang tinggi sebesar 54%, relevan marginal sebesar 37%, dan tidak relevan sebesar 9%.
Kata Kunci: Bibliometrik; Pengindeksan Subjek; Dalil Zipf.
UNIVERSITAS SUMATERA UTARA
KATA PENGANTAR
Segala puji dan syukur saya panjatkan kehadirat tuhan yang maha esa karena atas berkat rahmat-Nyalah peneliti mampu menyelesaikan skripsi ini. Adapun judul skripsi ini adalah “Perbandingan Pengindeksan Subjek Menggunakan Hukum Zipf’s Dengan Kata Kunci Artikel Pada Jurnal Library Management”, guna memenuhi satu syarat untuk memperoleh gelar Sarjana Sains Informasi.
Saya menyadari bahwa skripsi ini masih jauh dari kata sempurna, oleh karena itu saya mengharapkan kritik dan saran yang sifatnya membangun dari beberapa pihak.
Izinkanlah saya dengan segala kerendahan hati mengucapkan rasa terima kasih sebesar-besarnya kepada orang tua yang sangat peniliti sayangi Bapak M. Ikram dan Ibunda Fatimah Syam yang telah memberikan kasih dan cintanya kepada saya selama ini.
Selama penulisan skripsi ini peneliti banyak mendapat bimbingan, motivasi, dan bantuan dari berbagai pihak. Oleh karena itu dalam kesempatan ini peneliti mengucapkan terima kasih kepada pihak yang telah ikut membantu baik secara moral maupun material. Penulis mengucapkan terimakasih kepada:
1. Bapak Dr. Budi Agustono, M.S selaku Dekan Fakultas Ilmu Budaya Universitas Sumatera Utara.
2. Ibu Dr. Eva Rabita, M.Hum selaku Ketua Program Studi Perpustakaan dan Sains Informasi Fakultas Ilmu Budaya USU.
3. Bapak Dr. Jonner Hasugian, M.Si selaku pembimbing I, dimana beliau telah meluangkan waktunya dan memberikan banyak bimbingan dan kemudahan dalam penulisan skripsi ini.
4. Bapak Mas Irwansyah Putra, S.Sos yang telah memberikan arahan dan bantuan dalam penulisan skripsi ini.
5. Seluruh staf pengajar dan staf administrasi Program Studi Perpustakaan dan Sains Informasi yang telah mendidik dan membantu penulis selama masa perkuliahan.
UNIVERSITAS SUMATERA UTARA
6. Untuk keluarga tersayang yang telah memberikan dukungan dan doa kepada penulis (nenek tersayang, uwo daro, uwo kolat, uwo paet, K’ ayu yang cerewet, K’ ulan si tempat curhat skripsi ku, Andri, Gilang, Baim ganteng, dan Ripal gendut.
7. Buat Mociku yang teristimewa dan ku cinta Aulia Syarif Nasution yang selalu memberikan motivasi, semangat dan waktunya. Terima kasih ya sayang, atas perhatian dan kasih sayangnya.
8. Untuk para sahabat-sahabat terbaikku para wanita-wanita tangguh yaitu ada Sena Afrina Simbolon, Yemima Atania Surbakti, Natalia Cristauli Lubis, Crisna Agave Togatorop, Emia Yuni Nadeta Barus, Yenni Magdalena Butar- Butar, Devi Lestari Situmorang, dan Mayria Trifani Br. Ginting. Terima kasih buat persahabatan tangis dan tawa yang telah kita rasakan selama ini, oya cepat cepat nyusul buat kalian semua. Ingat tuh skripsi dikerjain bukan di anggurin aja jangan sampai aku keburu nikah baru kalian tamat.
9. Untuk teman-temanku seluruh stambuk 2016 yang baik, lucu, dan aneh-aneh (kadar, harkat, Immanuel, bg Ryan, Shola, ervina yang selalu sedia pas aku nanya soal skripsi, dan maruba temen satu doping ku yang selalu ada disaat aku butuh info tentang skripsi).
Peneliti juga mengucapakan terima kasih kepada semua pihak yang tidak dapat peneliti sebutkan satu persatu yang telah memberikan semangat, dukungan, bantuan dan do’a selama ini. Akhir kata saya berharap semoga skripsi ini bermanfaat bagi semua pihak yang membutuhkannya, terima kasih.
Medan, Agustus 2020
Penulis
DAFTAR ISI
Abstrak ……….…………...…… I
Kata Pengantar ………..…. II
Daftar Isi ………..…. IV
Daftar Tabel ……….. VI
Daftar Gambar ………... VII
BAB I PENDAHULUAN
1.1.Latar Belakang ……….. 1
1.2.Rumusan Masalah ……….. 2
1.3.Tujuan Penelitian ……….. 2
1.4.Manfaat Penelitian ……….. 2
1.5.Ruang Lingkup Penelitian ……….. 2
BAB II TINJAUAN LITERATUR 2.1. Information Retrival ……….. 3
2.2. Pengindeksan Subjek ……….. 3
2.2.1. Pengertian Pengindeksan Subjek ……….. 3
2.2.2. Tujuan Pengindeksaan Subjek ……….. 4
2.2.3. Pengindeksan Subjek Secara Manual (Human Indexer) ………….. 4
2.2.4. Pengindeksan Subjek Secara Otomatis (Machine Indexer) ………….. 5
2.3. Bibliometrika ……….. 7
2.3.1. Pengertian Bibliometrika ……….. 7
2.3.2. Dalil Bibliometrika ……….. 8
2.3.3. Pengertian dan Sejarah Zipf ……….. 8
2.3.4. Perkembangan dan Aplikasi Dalil Zipf ……….. 10
2.3.5. Titik Transisi dan Daerah Transisi Goffman ……….. 10
BAB III METODOLOGI PENELITIAN 3.1. Jenis Penelitian ……….. 12
3.2. Unit Analisis ……….. 12
3.3. Instrumen Penelitian ……….. 12
3.4. Teknik Pengumpulan Data ……….. 13
3.5. Teknik Analisis Data ……….. 13
BAB IV HASIL DAN PEMBAHASAN 4.1 Identitas Jurnal Library Management ... 15
4.2 Kode Untuk Masing-Masing Artikel ... 15
4.3 Kata Kunci Artikel ... 16
4.4 Pengindekasan Menggunakan Dalil Zipf ... 17
4.5 Jumlah Kata Pada Setiap Dokumen Uji dan Titik Transisinya ………….. 30
4.6 Daerah Transisi dan Indeks Dokumen Pada Dokumen Uji Menggunakan Dalil Zipf ……… 36
4.7 Relevansi Hasil Pengindeksan ……….. 59
BAB V KESIMPULAN DAN SARAN 5.1. Kesimpulan ……….. 65
5.2. Saran ……….. 65
DAFTAR PUSTAKA ……….. 66
LAMPIRAN ... 68
DAFTAR TABEL
Tabel 1 Kode Artikel dalam Dokumen Uji ……… 15
Tabel 2 Daftar Kata Kunci Artikel Dalam Dokumen Uji ……… 16
Tabel 3 Daerah Transisi dan Indeks Dokumen A01 ……… 37
Tabel 4 Daerah Transisi dan Indeks Dokumen A02 ……… 39
Tabel 5 Daerah Transisi dan Indeks Dokumen A03 ……… 41
Tabel 6 Daerah Transisi dan Indeks Dokumen A04 ……… 43
Tabel 7 Daerah Transisi dan Indeks Dokumen A05 ……… 45
Tabel 8 Daerah Transisi dan Indeks Dokumen A06 ……… 47
Tabel 9 Daerah Transisi dan Indeks Dokumen A07 ……… 49
Tabel 10 Daerah Transisi dan Indeks Dokumen A08 ……… 51
Tabel 11 Daerah Transisi dan Indeks Dokumen A09 ……… 53
Tabel 12 Daerah Transisi dan Indeks Dokumen A10 ……… 55
Tabel 13 Daerah Transisi dan Indeks Dokumen A11 ……… 57
Tabel-14 Relevansi Hasil Pengindeksan Subjek Menggunakan Dalil Zipf Dengan Kata Kunci Artikel ……… 60
DAFTAR GAMBAR
Gambar 1 Proses Convert file ………. 18
Gambar 2 Proses Convert file ………. 18
Gambar 3 Proses pemisahan kata secara otomatis ………. 19
Gambar 4 Proses pemisahan kata kedalam bentuk tabel …………. 20
Gambar 5 Proses pengurutan berdasarkan abjad ……….. 20
Gambar 6 Proses penghapusan karakter kosong sehingga pada awal tabel berisi kata “a” ……….. 20
Gambar 7 Proses salin data dari Microsoft Word ke Microsoft Excel ….. 21
Gambar 8 Proses Input rumus perhitungan jumlah kata yang sama …. 22 Gambar 9 Proses salin data dari Ms. Excel ke Ms. Word …………. 22
Gambar 10 Proses sortir data yang memiliki keterangan angka …………. 23
Gambar 11 Proses mengurutkan data dari angka terbesar sampai terkecil ... 24
Gambar 12 Proses menambah 2 kolom dan keterangannya ………….. 25
Gambar 13 Proses memberikan peringkat (r) serta perhitungan antara peringkat (r) × Frekuensi (f) ……….. 25
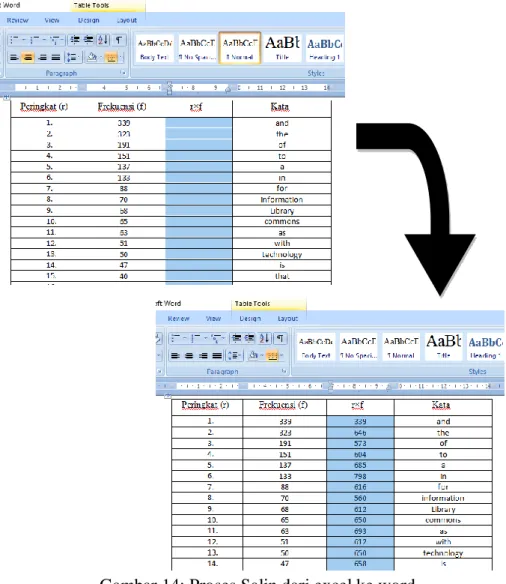
Gambar 14 Proses Salin dari excel ke word ……….. 26
Gambar 15 Proses Menentukan titik transisi ……….. 27
Gambar 16 Proses Penentuan Indeks Dokumen ……….. 28
Gambar 17 Proses Interpretasi Indeks Dokumen ……….. 29
BAB I PENDAHULUAN 1.1. Latar Belakang
Indeks dan pengindeksan merupakan bagian yang penting dalam keberlanjutan dan kemajuan sebuah informasi, sebuah jasa penyedia informasi seperti perpustakaan maupun Vendor jurnal elektronik harus mampu membuat sebuah data atau dokumen dapat ditemukan kembali secara cepat dan tepat.
Indexing digunakan untuk mempermudah pencarian suatu dokumen atau informasi ketika terjadinya ledakan dan kecepatan pertumbuhan dokumen.
Pengindeksaan Subjek berkonsentrasi pada pengambilan kata atau istilah yang ada dalam dokumen sehingga digunakan sebagai kata kunci atau inti sari dari dokumen tersebut.
Artikel dapat diakses secara online melalui internet, untuk mengakses artikel jurnal diperlukan sebuah kata kunci atau keyword yang menjadi titik akses ke artikel tersebut sehingga proses temu kembali dokumen bisa berjalan cepat dan tepat. Kata kunci dapat berupa kata yang mewakili isi dari dokumen tersebut.
Penentuan kata kunci artikel jurnal atau biasa disebut dengan proses pengindeksan jurnal dapat dilakukan dengan dua cara yaitu secara manual oleh seorang indekser/pengarang karya itu langsung dan pengindeksan subjek otomatis yang dilakukan dengan bantuan komputer atau biasa kita kenal dengan bantuan Dalil Zipf. Pembuatan indeks secara manual yang dilakukan oleh seorang indekser/pengarang karya itu langsung dilakukan dengan cara menganalisa dan mengevaluasi dokumen sehingga menghasilkan klasifikasi indeks dari dokumen tersebut. Hasil indeks yang di dapat kemudian di sesuaikan dengan LCSH (Library of Congress Subject Headings) sehingga menghasilkan kosa kata yang baku dan terkontrol. Pengindeksan subjek juga dapat dilakukan dengan menggunakan Hukum Zipf. Hukum ini lahir untuk membantu meringankan atau mempermudah tugas pustakawan dalam melakukan proses pengindeksan dengan cara menghitung jumlah atau frekuensi kemunculan kata atau istilah didalam dokumen sehingga menjadi wakil atau kata kunci untuk
proses temu kembali dokumen.
Berdasarkan data diatas penulis tertarik untuk mengakaji lebih dalam tentang Perbandingan Pengindeksan Subjek Menggunakan Hukum Zipf Dengan Kata Kunci Artikel Pada Jurnal Library Management.
1.2. Rumusan Masalah
Berdasarkan latar belakang di atas rumusan masalah dalam penelitian ini adalah “Bagaimanakah Perbandingan Pengindeksan Subjek Menggunakan Hukum Zipf Dengan Kata Kunci Artikel Pada Jurnal Library Management ? ”.
1.3. Tujuan Penelitian
Tujuan dalam penelitian adalah untuk “mengetahui Perbandingan Pengindeksan Subjek Menggunakan Hukum Zipf Dengan Kata Kunci Artikel Pada Jurnal Library Management”.
1.4. Manfaat Penelitian
Manfaat yang diharapkan dalam penelitian ini adalah sebagai berikut:
1. Menambah wawasan dan pengetahuan penulis tentang perbandingan Kata kunci pada artikel dan indeks subjek yang dihasilkan oleh Dalil Zipf’s.
2. Tulisan ini dapat dijadikan acuan oleh pustakawan atau pun pengarang dalam menentukan indeks subjek dokumen dengan menggunakan Dalil Zipf’s.
3. Menambah wawasan dan pengetahuan pembaca tentang penentuan indeks subjek dapat dilakukan dengan menghitung frekunsi kata yang muncul.
1.5. Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah bidang ilmu perpustakaan yaitu bibliometrika dengan kajian pengindeksaan subjek menggunakan Hukum Zipf.
Penelitian ini dilakukan pada Artikel Jurnal Library Management Vol.36, Issue 8/9, Tahun 2015.
BAB II
TINJAUAN LITERATUR 2.1. Information Retrival
Information retrival adalah sebuah proses temu kembali informasi yang diakses oleh pengguna pada data penyimpanan yang bertujuan untuk pencarian yang lebih cepat dan tepat. Sama hal nya dengan mengakses artikel jurnal secara online, diperlukan kata kunci yang dapat menjadi titik akses ke artikel tersebut.
Kata kunci adalah istilah yang ditetapkan sebagai kata utama untuk mencari dokumen di sistem temu kembali informasi. Menurut Rose, dkk (2010, 3) “Kata kunci merupakan urutan satu atau beberapa kata, yang memberikan representasi ringkas dari konten atau isi dokumen, sehingga dapat mewakili konten atau isi dari suatu dokumen”.
2.2. Pengindeksan Subjek
2.2.1. Pengertian Pengindeksan Subjek
Pengindeksan adalah sebuah kegiatan untuk mempermudah proses penelusuran informasi. Perpustakaan memiliki fungsi utama yaitu untuk membuat informasi yang di kumpulkan dapat tersedia bagi pengguna perpustakaan berdasarkan permintaan mereka. Maka untuk memenuhi fungsi tersebut perpustakaan harus bisa menyediakan bahan pustaka sebanyak mungkin dan sesuai dengan kebutuhan pengguna. Pengindeksan tentang subject atau yang lebih kita kenal dengan subject indexing. Pengindeksaan subjek berguna untuk mempercepat proses temu kembali dan pemanggilan dokumen.
Menurut Cleveland and Cleveland (2001, 97) bahwa, “Indexing is the process identyfying information in a knowledge record (text or nontext) an organizing the pointers to that information in to searchable file”. Artinya Pengindeksan merupakan proses pengidentifikasian informasi kedalam catatan pengetahuan (baik secara text maupun non text) yang memberikan petunjuk ke informasi file yang diinginkan atau dicari.
“The term indexing is used with several shades of meaning. we use it to cover all activities involved in the construction of indexes. as such, it is major activity supporting all aspects of information retrival. As you have seen, the process of information retrival is intiated by
requests in which information needs are expressed in a variety of ways, eg a document, or documents, by specified author, or about a specified subject” Brown (1976, 26)
Berdasarkan pendapat diatas menjelaskan bahwa Pengindeksan adalah seluruh kegiatan yang terlibat dalam proses pembuatan indeks dalam mempermudah pencarian informasi. Pencarian informasi dimulai dengan adanya permintaan akan kebutuhan informasi dengan berbagai cara seperti judul dokumen, pengarang, hingga subjek dari dokumen yang dicari.
Selain itu menurut pendapat Suwarno (2010, 97-98), menyatakan bahwa:
“Indeks adalah sebuah daftar yang sistematis, mengandung istilah atau frasa (menyatakan pengarang, judul, konsep, dan sebagainya) yang dilengkapi dengan penunjuk ke isi satu atau serangkaian dokumen, kelokasi di mana istilah atau frasa tersebut dapat ditemukan. Indeks dan pengindeksan merupakan hal penting bagi perpustakaan, mengingat efesiensi penyimpanan buku dan dokumentasi hanya bisa dicapai jika ada cara paling jitu dalam menemukan kembali buku atau informasi yang dikelola perpustakaan ketika pemustaka memerlukan”
Dari ketiga pendapat di atas maka dapat di simpulkan pengindeksan adalah proses pengidentifikasian sebuah dokumen dengan memilih istilah yang paling tepat untuk mewakili dokumen serta pengaturan informasi ke dalam pangkalan data sehingga data dapat ditemukan dengan mudah dalam proses penelusuran informasi.
2.2.2. Tujuan Pengindeksaan Subjek
Menurut Cleveland and Cleveland (2001, 3) yaitu:
“Index has two general purpose: minimize the time and effort in finding information, and to maximize the searching success of the user. both purpose are accomplished by choosing best word that will match a user's languange and by having a system of accurate and complete cross- references to related information”
Berdasarkan pendapat di atas indeks memiliki dua tujuan yaitu meminimalkan waktu dan pencarian, serta memaksimalkan tingkat keberhasilan dalam pencarian. Kedua tujuan tersebut dapat dicapai oleh pihak perpustakaan dengan cara mencocokkan indeks dokumen asli dengan bahasa pengguna dan sistem referensi silang serta informasi terkait.
2.2.3. Pengindeksan Subjek Secara Manual (Human Indexer)
Menurut Sensuse (2004, 22) bahwa, “Manual indexing refers to a process of assigning significant words or terms that is performed manually by trained subject experts and that involves a level of human intellect”. Artinya
Pengindeksan manual mengarah pada proses pemilihan kata-kata penting atau istilah yang dilakukan secara manual oleh seorang indexer terlatih dengan menggunakan tingkat kecerdasan tinggi untuk menghasilkan indeks subjek dokumen.
Selain itu Lancaster yang dikutip oleh White, Whillis, & Greenberg (1986, 308) juga mengemukakan pendapatnya tentang pengindeksan manual.
Yaitu:
“describes two distinct intellectual steps that occur during human subject indexing: conceptual analysis and translation. Conceptual analysis involves working with an information object to understand its subject matter and having knowledge of the needs of the system’s users. Translation is the act of converting knowledge derived from the conceptual analysis portion into a representative vocabulary choice.
During this translation process, human indexers may select
“appropriate” terms from indexing aids, such as thesauri or controlled vocabularies, or may choose words from the title, abstract, or text of the document as index terms”
Artinya ada dua langkah intelektual berbeda yang terjadi selama pengindeksan subjek secara manual yaitu: analisis konseptual dan terjemahan.
Analisis konseptual bekerja dengan objek informasi untuk memahami materi pelajarannya dan memiliki pengetahuan tentang kebutuhan pengguna sistem.
Penerjemahan adalah tindakan mengubah pengetahuan yang berasal dari bagian analisis konseptual menjadi pilihan kosa kata yang representatif. Selama proses penerjemahan ini, pengindeks dapat memilih istilah "sesuai" dari alat bantu pengindeksan, seperti tesaurus atau kosakata terkontrol, atau dapat "memilih kata- kata dari judul, abstrak, atau teks dokumen sebagai istilah indeks"
Dari ke dua pendapat diatas maka dapat disimpulkan pengindeksaan manual adalah proses pemilihan kata atau istilah secara manual yang dilakuakan seorang indexer untuk mendapatkan wakil dokumen atau kata indeks. Proses pengindeksan manual memiliki dua langkah yaitu: analisis konseptual atau pemahaman materi dokumen yang sesuai dengan kebutuhan pengguna dan terjemahan atau pencarian kosa kata yang sesuai dengan menggunakan alat bantu seperti thesaurus dan LCSH.
2.2.4. Pengindeksan Subjek Secara Otomatis (Machine Indexer)
Pengindeksan subjek otomatis berkaitan dengan pengindeksaan menggunakan komputer. Pengindeksaan otomatis dapat mempermudah pekerjaan
dan memperkecil beban kerja seorang indexer. Untuk itu seorang indexer harus mempunyai kemampuan dalam bidang komputer. Menurut tulic yang dikutip oleh Obaseki (2010,1) adalah:
“Automated indexing is the process of assigning and arranging index terms for natural language without human intervention.The index is produced using algorithms. These algorithms works on database containing document representations, inncluding full text or bibliographic records, but also on non-text data bases such as images or music”
Artinya pengindeksan otomatis adalah proses mengatur pemilihan istilah untuk kata indeks tanpa campur tangan manusia. Indeks dibuat dengan menggunakan prosedur pemecahan masalah yang sistematis. Prosedur ini bekerja pada basis data yang berisi wakil dokumen, seperti teks lengkap maupun non teks seperti gambar dan music. Menurut Seth yang dikutip oleh Obaseki yaitu :
“Argues for the use of automated indexing because it is faster and cheaper. Seth asserts that this is one way of achieving the goals of information centers. This view is welcomed by numerous scholars, because automated indexing can deal with the increasing amount of new material being produced that has made manual indexing slow and expensive”
Maka dapat diartikan bahwa, penggunaan pengindeksan secara otomatis lebih cepat dan lebih murah. Pengindeksaan otomatis adalah salah satu cara untuk mencapai tujuan pusat informasi. Pandangan ini disambut baik oleh banyak orang, karena pengindeksan otomatis dapat menangani peningkatan jumlah materi baru yang sebelumnya dibuat secara manual yang memiliki kekurangan dari segi efesiensi waktu yang lambat dan biaya yang mahal.
Selain pendapat di atas menurut Sebastiani dan Hlava yang dikutip oleh White, H., Whilis, C., & Greenberg, J. (2014, p. 309) menyatakan bahwa:
“Processes for automatic subject indexing fall into two broad categories: rule-based and statistical. Rule-based approaches rely on formalized languages for the assignment of terms from controlled vocabularies based on document text. Statistical and machine- learning approaches rely on techniques for learning the associations between words or other features in document text and indexing terms”
Dapat di jelaskan bahwa Proses pengindeksan subjek otomatis terbagi dalam dua kategori besar yaitu: Pendekatan berbasis aturan yang bergantung pada bahasa formal untuk penugasan istilah dari kosa kata terkontrol berdasarkan teks
dokumen dan Pendekatan statistik yang bergantung pada teknik untuk mempelajari hubungan antara kata dalam teks dokumen dan istilah pengindeksan.
Dari beberapa pendapat diatas maka dapat di simpulkan pengindeksaan secara otomatis adalah proses pemilihan kata indeks secara otomatis menggunakan komputer dengan menggunakan pendekatan berbasis aturan dan statistik. Pengindeksan subjek secara otomatis memiliki keuntungan diantaranya efesiensi waktu yang lebih cepat dan biaya yang lebih murah serta kemampuan menangani jumlah materi yang banyak dalam sekali waktu.
2.3. Bibliometrika
2.3.1. Pengertian Bibliometrika
Bibliometrika berasal dari dua kata yaitu “Biblio” yang memiliki arti buku dan “metrics” yang memiliki arti mengukur. Menurut Hasugian (2020, 2) yaitu
“bibliometrika adalah suatu bidang kajian yang menggunakan matematika dan teknik-teknik statistik untuk mempelajari atau meneliti berbagai publikasi/terbitan, pola komunikasi dan distribusi informasi”.
Menurut Powel yang dikutip oleh Fatmawati (2012, 3) yaitu “Bibliometrics is a special type of documentry research or inquiry into the tools of library and information science”. Hal ini berarti bibliometrika dapat didefenisikan sebagai metode matematika dan statistik dengan menggunakan alat riset pada buku dan media komunikasi lainnya.
Kemudian Bellis (2009, 3) menyatakan bahwa:
“the term “bibliometrics,” coined by Alan Pritchard in the late 1960s,2 stresses the material aspect of the undertaking: counting books, articles, publications, citations, in general any statistically significant manifestation of recorded information, regardless of disciplinary bounds”
Istilah "bibliometrics," diciptakan oleh Alan Pritchard pada akhir 1960-an, dia menekankan aspek material yaitu : menghitung buku, artikel, publikasi, kutipan, secara umum setiap manifestasi signifikan secara statistik dari informasi yang direkam , terlepas dari batasan disiplin.
Jadi dari beberapa pendapat diatas dapat dinyatakan bahwa bibliometrika adalah suatu bidang kajian yang digunakan sebagai alat ukur dengan memanfaatkan metode matematika dan statistik untuk mengidentifikasi atau
mempelajari berbagai publikasi/terbitan,serta pola media komunikasi dan distribusi informasi.
2.3.2. Dalil Bibliometrika
Tiga dalil atau hukum dasar dalam bibliometrika menurut Chen, Y. dan Ferdinand F. (1998, 2), yaitu sebagai berikut:
“ Lotka (1926): published a paper in which he examined patterns of productivity among chemists. he discovered that if he ranked his population of chemists according to how frequently the published, Bradford (1934): a librarian, first proposed the law bearing his name in 1934. according to bradford, if a comprehensive literature searche is conducted on some subject covering a specified period of time, often.
it will be found that the literature is scattered in a regular pattern over vary lage number of source, and Zipf (1933) : stated that if one takes the words making up an extended body of text and ranks them by frequency of occurrence, then the rank r multiplied by its frequency of occurrence, g(r) will be approximately constant"
Berdasarkan pendapat di atas bahwa ada 3 (tiga) hukum dasar dalam bibliometrik yaitu hukum Lotka yang dipergunakan untuk menghitung produktivitas pengarang, hukum Bradfoard adalah hukum yang dipergunakan untuk mengetahui subjek literatur yang tersebar dalam sebuah majalah, dan hukum Zipf adalah hukum yang berfungsi dalam proses pengindeksan subyek dokumen dengan memanfaatkan frekuensi kemunculan kata dalam dokumen tersebut.
2.3.3. Pengertian dan Sejarah Zipf
Menurut Hasugian (2020: 54) bahwa, “Dalil Zipf digunakan untuk pengindeksan berdasarkan kepada rangking atau peringkat kata atau istilah yang termuat dalam sebuah dokumen dan dihitung berdasarkan frekuensi kata atau istilah tertinggi”. Dari penjelasan tersebut dapat disimpulkan bahwa dalil Zipf dapat digunakan dalam proses pengindeksaan dengan cara memanfaatkan hasil frekuensi kemunculan kata.
Hukum ini adalah hasil karya dari George Kingsley Zipf (1902-1950) atau biasa disebut dengan panggilan Zipf. Zipf lahir di kota Illinois Freeport pada tanggal 7 Januari 1902 dengan lulusan predikat summa cum laude dari Harvard College pada tahun 1924, selanjutnya ia melanjutkan pendidikannya di Bonn Berlin kemudian kembali ke Harvard College dan melanjutkan studinya dan
lullus PhD (doktor) dengan disertasi Comparative Philology pada tahun 1929.
Kemudian ia menjadi seorang instruktur dan dosen pengajar linguistik di Harvard College pada tahun 1939 sampai ia meninggal pada tanggal 25 September 1950 dengan usia 48 tahun dikarenakan penyakit kanker yang dialaminya dan dia meninggalkan satu orang istri serta empat orang anak.
Pada masa hidupnya Zipf sangat tertarik dengan fenomena kuantitatif dan perilaku manusia yang cenderung untuk meminimalkan tindakannya dalam kehidupan sehari-hari seperti menghemat kata dalam berkomunikasi, sehingga dia menyusun sebuah hipotesis “kata” yang digunakan dalam dokumen sebagai media komunikasi baik yang ilmiah maupun non-ilmiah.
Zipf mulai terkenal dalam bidang ilmu bibliometrika setelah karyanya yang berjudul “Psycho-Biology Of Language” terbit pada tahun 1935. Melalui karyanya tersebut telah membawa studi bahasa ke dalam kondisi ilmu eksak dengan memakai prinsip-prinsip statistik.
Pada tahun 1949 buku Zipf yang berjudul “Human Behavior and Principle of Least Effort” membawa namanya semakin terkenal di mata dunia, karyanya tersebut berisi tentang seseorang yang lebih mudah memunculkan kata-kata umum yang familiar dalam berkomunikasi dari pada kata-kata yang tidak dikenalnya. Sehingga memungkinkan pemunculan kata dalam penyusunan sebuah karya ilmiah berasal dari kata-kata umum bukan dari kata-kata yang tidak dikenal oleh penulis. Karena ketertarikannya pada perhitungan frekuensi kata membuat dia melakukan observasi atau pemeriksaan terhadap sebuah novel yang berjudul “Ulysses” Karangan James Joyce.
Pada pengamatan Zipf ia menyatakan bahwa 29.899 kata yang berbeda dalam karya tersebut, sedangkan seluruh kata berjumlah 260.430. dalam observasinya ia menemukan beberapa kata yang berkali-kali diulang, banyak kata yang tingkat frekuensinya rendah, perkalian antara peringkat kata dengan frekuensi nya bersifat konsisten, dan nilai rata-rata simpangan baku dapat digunakan sebagai tolak ukur keserasian.
Ciri-ciri kata yang termasuk dalam batasan Zipf, yaitu sebagai berikut:
a. Kata adalah kumpulan huruf yang dipisah oleh dua spasi;
b. Kata yang bergaris hubung dianggap menjadi satu kata;
c. Kata yang memiliki Tanda kutip dianggap menjadi bagian dari satu kata;
d. Semua kata fonetik yang berbeda dianggap kata berbeda;
e. Kata-kata gelar, nama, jabatan, afiliasi, dan sebagainya dianggap diabaikan.
2.3.4. Perkembangan Dalil Zipf
Dalil atau hukum Zipf dikenal dengan perhitungan kata tertinggi sebagai istilah kata yang digunakan sebgai istilah atau kata yang digunakan dalaam penentuan indeks subyek atau indeks kata kunci sebuah dokumen yang di indeks.
Hukum pertama dalil Zipf adalah sebagai berikut:
“Hasil dari perhitungan sejumlah kata kemudian dituangkan kedalam sebuah tabel dengan menempatkan kata yang memiliki frekuensi pengulangan tertinggi sebagai peringkat pertama, kemudian diikuti peringkat lainnya yang lebih rendah frekuensi pengulangannya secara berturut. Susunan jajaran kata berdasarkan frekuensi pengulangan yang terurut tersebut dinamai peringkat atau rangking, yang diberi symbol “r”, sedangkan jumlah pengulangannya disebut frekuensi atau“f”, maka f×r =k (Konstan)” (Hasugian, 2009: 44)
Berdasarkan pendapat di atas bahwa, hukum pertama Zipf hanya berlaku pada kata-kata frekuensi tinggi. Sedangkan, untuk kata-kata dengan frekuensi rendah Zipf mengajukan rumus:
(𝑓2 − 1⁄4) = 𝑘
yang di mana n adalah kata yang muncul, f adalah frekuensi dan k adalah bilangan konstanta. Setelah diperbaharui oleh Boyce dengan rumus, yaitu sebagai berikut:
𝐼𝑛 𝐼1
⁄ = 2 𝑛(𝑛 + 1)⁄
Di mana:
n = jumlah seluruh kata
In = jumlah kata yang berbeda dengan frekuensi kemunculan n, 𝐼1 = jumlah kata yang berbeda dengan frekuensi kemunculan 1 kali.
2.3.5. Titik Transisi dan Daerah Transisi Goffman
Goffman adalah seorang peminat Hukum Zipf yang mengembangkan teori penentuan subyek atau isi dokumen berdasarkan hukum Zipf. Goffman
menemukan sebuah fenomena yang disebut sebagai “titik transisi”. Titik transisi adalah titik yang terjadi perubahan dari frekuensi tinggi ke frekuensi rendah yang diduga memuat kata-kata yang menunjukkan subyek dokumen.
Titik transisi Goffman adalah titik transisi yang dapat ditarik ke daerah atas dan bawah dengan jarak yang sama sehingga menghasilkan daerah transisi. Di daerah transisi terdapat kata-kata yang menunjukan isi dari suatu dokumen setelah kita menghilangkan kata-kata abai atau kata tidak bermakna yang tidak digunakan dalam pengindeksan (stopwords). Stopwords atau kata abai adalah kata yang berupa kata bantu seperti atau, dari, maka, untuk, dan lain sebagainya.
Kata yang digunakan dalam pengindeksan adalah jenis kata “content words”
yaitu kata yang mempunyai makna.
Goffman menawarkan:
Rumus-1:
𝑛 = (−1 + √1 + 8I1)/2 Di mana:
n = Titik transisi
I1 = Jumlah kata yang berbeda dengan frekuensi kemunculan 1 kali Rumus-2:
𝑛1.2 = 1 2⁄ (−𝑏 ± √(𝑏2− 4𝑎𝑐)) Atau
𝑛12 = 1/2{−𝑏 ± √(𝑏2− 4𝑎𝑐)}
Di mana:
𝑛12 = titik transisi yang akan dicari a = 1 (Konstanta)
b = 1 (Konstanta) c = -2 I1
I1 = jumlah kata yang berbeda dengan frekuensi kemunculan 1 kali.
BAB III
METODE PENELITIAN 3.1. Jenis Penelitian
Dalam penelitian ini, penulis menggunakan metode penelitian kuantitatif.
Penelitian Kuantitatif menurut Bryman (dalam Pendit, 2003:195) merupakan penelitian yang bertujuan untuk mengumpulkan data numeric dan menggunakan logika dalam pengembangan dan pengujian teori. Jenis penelitian yang digunakan dalam penelitian ini adalah deskriptif yang mendeskripsikan obyek penelitian berdasarkan fakta dan data yang ada. Menurut Arikunto (2000: 309)
“Penelitian deskriptif merupakan suatu penelitian yang dimaksudkan untuk mengumpulkan informasi mengenai status suatu gejala yang ada, yaitu keadaan gejala menurut apa adanya pada saat penelitian dilakukan”.
3.2. Unit Analisis
Unit analisis adalah satuan tertentu yang dijadikan sebagai subjek penelitian yang mengandung perilaku, karakteristik, dan informasi yang ingin diketahui. Menurut Rahmat (2009), Unit analisis diartikan sebagai sesuatu yang berkaitan dengan komponen yang diteliti. Unit analisis ini dilakukan oleh peneliti agar validitas dan reabilitas penelitian dapat terjaga.
Berdasarkan pendapat di atas maka penulis menentukan unit analisis penelitian ini adalah artikel yang dimuat dalam Jurnal Library Management Vol.
36 issue 8/9 tahun 2015 yang dimuat dalam bentuk online dan bersifat gratis (free). Jurnal ini terbit lima kali dalam satu tahun. Dari hasil observasi yang dilakukan oleh penulis, didapat data bahwa yang menjadi unit analisis penelitian ini adalah sebanyak 11 artikel. Karena unit analisis yang tidak terlalu besar maka penulis menjadikan semua artikel sebagai sampel. Teknik Pengambilan sampel yang digunakan pada penelitian ini adalah teknik sampel jenuh yaitu seluruh anggota populasi dijadikan sebagai sampel penelitian.
3.3. Instrumen Penelitian
Instrument penelitian adalah alat-alat yang diperlukan atau yang dipergunakan untuk mengumpulkan data. Instrument yang digunakan dalam penelitian ini adalah program aplikasi seperti; Microsoft Word, Microsoft Excel yang digunakan sebagai mesin proses perhitungan atau penjumlahan dan Mozilla
Firefox sebagai mesin pencari.
3.4. Teknik Pengumpulan Data
Metode yang digunakan dalam pengumpulan data pada penelitian ini adalah metode dokumentasi. Metode dokumentasi yaitu mencari data mengenai hal-hal atau variable yang berupa catatan, transkip, buku, surat kabar, majalah, prasasti, notulen rapat, lengger, agenda, dan sebagainya (Siyoto, S. & Ali S.
2015: 77-78) untuk mengumpulkan semua data. Maka, diperlukan proses
browsing pada situs dibawah ini
http://www.emerald.com/insight/publication/issn/0143-5124/vol/36/iss/8/9.
Selanjutnya artikel tersebut di download dan di konversi ke format word, kemudian file yang telah di dapat kemudian di cari indeksnya dengan menggunakan Dalil Zipf.
3.5. Teknik Analisis Data
Dalam proses menganalisis terlebih dahulu diperlukan data yang tepat, sehingga menghindari kemungkinan terjadinya kesalahan pada hasil akhir pengolahan data. Analisis data bertujuan untuk menata, menyusun dan memberikan makna dari kumpulan data. Hal penting yang sangat berkaitan dengan proses pengumpulan data adalah rasionalitas, deskripsi, ilustrasi, dan pendukung. Setelah data diperoleh maka langkah selanjutnya adalah mengolah data tersebut agar pertanyaan-pertanyaan dari penelitian dapat terjawab.
Analis data pada penelitian ini denagn menggunakan rumus dalil Zipf dan Transisi Goffman. Rumus dalil Zipf yang digunakan untuk pemeringkatan kata yaitu:
𝑐 = 𝑟 × 𝑓 Keterangan:
r = Peringkat kata;
f = Frekuensi kemunculan kata c = Konstanta
Sedangkan Rumus transisi Goffman yang digunakan untuk menentukan titik transisi yaitu:
n = (−1 + √1 + 8I1)/2
Keterangan:
n = titik transisi
Ii = Jumlah kata yang memiliki frekuensi kemunculan satu kali
Analisis hasil indeks menggunakan Dalil Zipf (machine indexer) dengan hasil indeks atau keyword dari pengarang pada artikel itu sendiri. Tingakt Relevansi Hasil pengindeksan pada dalil Zipf adalah sebagai berikut:
a. Relevan, apabila indeks yang dihasilkan dari dalil Zipf dengan kata kunci pada artikel jurnal benar-benar dan sama persis.
Indeks Dalil Zipf = Kata Kunci Artikel
b. Relevan marginal, apabila indeks yang dihasilkan memiliki kemiripan/
kesamaan.
Indeks Dalil Zipf < 𝐾𝑎𝑡𝑎 𝐾𝑢𝑛𝑐𝑖 𝐴𝑟𝑡𝑖𝑘𝑒𝑙
c. Tidak Relevan, apabila indeks yang dihasilkan sama sekali tidak memiliki kemiripan/ kesamaan.
Indeks Dalil Zipf ≠ Kata Kunci Artikel
BAB IV
HASIL DAN PEMBAHASAN 4.1 Identitas Jurnal Library Management
Jurnal Library Management adalah jurnal penelitian terbaru yang dilakukan di institusi akademis, pemerintah dan perusahaan dengan melaporkan pemikiran kontemporer, sambil mengeksplorasi implikasi praktis bagi mereka yang terlibat dalam penelitian tersebut. Jurnal ini diterbitkan oleh Emerald Publishing Limited dengan periode terbit sembilan kali dalam satu tahun.
Jurnal Library Management mengangkat tema terkait penelitian tentang management strategis, HRM/HRO, Keragaman budaya, penggunaan informasi, manajemen kualitas dan perubahan, masalah manajemen, pemasaran, outsourcing, otomatisasi, keuangan perpustakaan, pengukuran kinerja, serta perlindungan data dan hak cipta. Metode Informasi ini sangat berguna untuk manajer perpustakaan senior dan akademisi.
4.2 Kode Untuk Masing-Masing Artikel
Artikel dimuat dalam jurnal Library Management Vol. 36 issue 8/9 tahun 2015 berjumlah 11 artikel. Kode Artikel berfungsi sebagai wakil dari judul dokumen tersebut. Adapun Kode artikel adalah sebagai berikut:
Tabel-1: Kode Artikel dalam Dokumen Uji
No Judul Artikel Kode
Artikel 1. Library spaces in the 21st century Meeting the
challenges of user needs for information, technology, and expertise
A01
2. Commons consent Librarians, architects and community culture in co-creating academic library learning spaces.
A02
3. Choice of Library and Information Science in a rapidly changing information landscape A systematic literature review
A03
4. The odyssey of Flemish public libraries facing opportunities and threats when becoming strategic partners in urban development
A04
5. Evidence based organizational change: people surveys, strategies and structures
A05 6. Decision-making experiences of public library CEOs A06
A study exploring the roles of interpersonal influence and evidence in everyday practice
7. Trust me: the keys to success in cooperative collections ventures
A07 8. Factors affecting empowerment of female librarians,
views of female managers of Tehran public libraries
A08 9. Public library managers’ descriptions of political
attention
A09 10. Reducing library space can promote the shift from
storage of print-collections towards
a learning-centre without limiting the access to information
A10
11. Hong Kong JULAC common library card A11
4.3. Kata Kunci Artikel
Setiap artikel memiliki kata kunci berbeda-beda yang berasal dari pengarang atau penulis artikel itu sendiri. Berikut data kata kunci Artikel pada dokumen uji yang dimuat di jurnal Library Management Vol. 36 issue 8/9 tahun 2015 adalah sebagai berikut:
Tabel-2: Daftar Kata Kunci Artikel Dalam Dokumen Uji No Kode Artikel Kata Kunci Pada Artikel
1. A01 Library Management, Library spaces, Information commons
2. A02 Academic libraries, Co-creation in library construction, Librarians and architects, Library buildings, Library learning commons, Sensemaking in library construction
3. A03 Literature review, Library and Information Science, Systematic review, Career change, LIS career choice, LIS career motivations
4. A04 Flanders, Urban development, Public libraries, Strategic management,
Case-study research
5. A05 Library Management, Human relations,
ClimateQUAL, Library strategy, Library structures, Staff surveys
6. A06 Managers, Canada, Public libraries, Interpersonal influence, Evidence-based practice, Decision-making practices
7. A07 Collaboration, Collections, Consortia, Conspectus, RLG, TRLN
8. A08 Women, Management, Empowerment, Public libraries, Female librarian, Spreitzer’s model
9. A09 Public library, Public library directors, Public library managers, Municipalities, Local politicians,
Multinominal logistic regression analysis
10. A10 Collaboration, Medical libraries, Collection policy, Learning environment, Library space, National repositories
11. A11 Hong Kong, Collaboration, University libraries, Access services, Library card, Personal data privacy
Berdasarkan tabel diatas dapat diketahui bahwa jurnal Library Management Vol. 36 issue 8/9 tahun 2015 memiliki 11 artikel dengan kata kunci yang berbeda- beda dari segi kata maupun jumlah. 1 artikel memiliki 8 kata kunci yaitu artikel 9.
2 artikel memiliki 7 kata kunci yaitu artikel 4 dan artikel 8. 6 artikel memiliki 6 kata kunci yaitu artikel 2, artikel 5, artikel 6, artikel 7, artikel 10,dan artikel 11.
Serta 1 artikel yang memiliki 3 kata kunci yaitu artikel 1.
4.4. Pengindekasan Menggunakan Dalil Zipf
Dalil Zipf adalah salah satu metode dalam pengindeksan subjek otomatis dengan cara memanfaatkan hasil frekuensi kemunculan kata kemudian diurutkan berdasarkan peringkat kata mulai dari kata yang memiliki peringkat tertinggi sampai ke peringkat terendah.
Langkah-langkah yang dilakukan peneliti dalam menganalisis data adalah sebagai berikut:
1. Proses Dokumen
Terlebih dahulu proses masing-masing artikel menggunakan program Microsoft Word untuk mempermudah pengelompokan kata dalam bentuk tabel. Caranya adalah sebagai berikut:
a. Artikel yang digunakan harus dalam bentuk word. Jika, ada dalam bentuk pdf maka convert lah file pdf menjadi bentuk word.
Gambar 1: Proses Convert file
b. Hapus keyword atau kata kunci dan daftar pustaka pada artikel.
Gambar 2: Proses Convert file
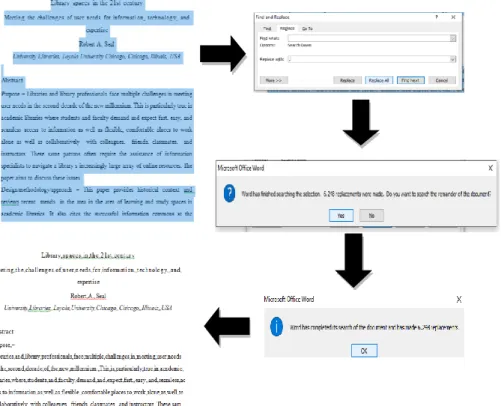
c. Blok seluruh kata kemudian Cari menu home klik fitur replace, kemudian akan muncul jendela find replace, pada find what tekan spasi dan pada replace input tanda koma (,) dan selanjutnya tekan replace all.
Gambar 3: Proses pemisahan kata secara otomatis
d. Blok seluruh teks, lalu buka menu insert dan pilih tabel>kemudian klik convert text to tabel selanjutnya isi jumlah kolom dengan angka 1 dan pilih separate text at dan pilih other dan input tanda koma (,) terakhir klik ok.
Gambar 4: Proses pemisahan kata kedalam bentuk tabel e. Blok seluruh tabel lalu klik home kemudian klik short, kemudian pilih
text and ascending, selanjutnya klik ok.
Gambar 5: Proses pengurutan berdasarkan abjad
f. Buang karakter kosong karena spasi, tanda-tanda, kutipan dan buang angka (bukan kata).
Gambar 6: Proses penghapusan karakter kosong sehingga pada awal tabel berisi kata “a”
2. Hitung Jumlah dan Frekuensi Kata dalam Dokumen
Setelah kata pada tabel didapatkan, maka kita memerlukan bantuan
Microsoft Excel untuk mempermudah dan mempercepat proses perhitungan kata.
Caranya adalah sebagai berikut:
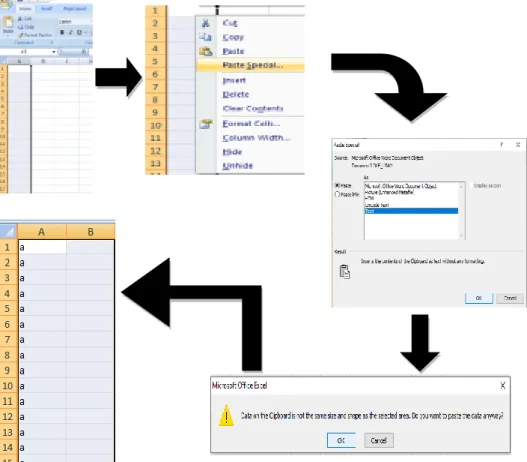
a. Copy seluruh tabel yang berisi urutan kata yang sesuai pada langkah pertama, kemudian paste pada tabel atau cel yang ada di Ms.excel sesuai dengan jumlah atau banyaknya kata dengan cara klik kanan tekan paste special > klik text > kemudian ok.
Gambar 7: Proses salin data dari Microsoft Word ke Microsoft Excel b. Untuk proses perhitungan kata yang sama masukkan rumus dibawah ini
pada cel kosong
= countif (range; ""kriteria")
Gambar 8: Proses Input rumus perhitungan jumlah kata yang sama c. Masukkan rumus tersebut pada setiap cel yang ingin diketahui jumlah
katanya, setelah jumlah seluruh kata yang sama telah di dapatkan.
Selanjutnya kita copy seluruh data yang telah didapat di excel ke word.
Gambar 9: Proses salin data dari Ms. Excel ke Ms. Word
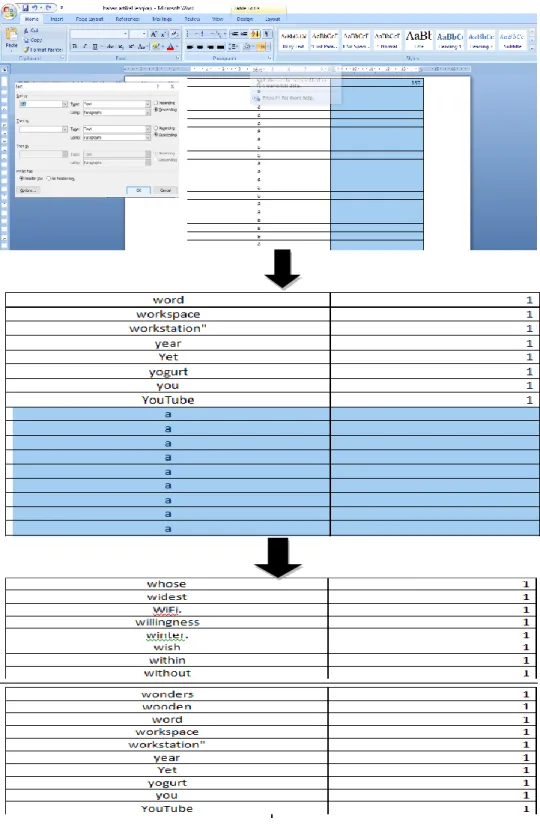
d. Kemudian blok tabel yang berisi angka-angka, kemudian klik short, pilih text and descending dan klik ok. Hapus kata-kata yang tidak memiliki keterangan jumlah kata.
Gambar 10: Proses sortir data yang memiliki keterangan angka
e. Kemudian blok tabel angka untuk di urutkan kembali, kemudian klik short, pilih text and descending dan klik ok.
Gambar 11: Proses mengurutkan data dari angka terbesar sampai terkecil
f. Setelah kata yang berisi keterangan jumlah di urutkan, kemudian tambahkan dua kolom disampingnya dan isi setiap kolom dengan keterangan Peringkat(r), Frekuensi(f), r×f, dan kata. Sehingga menghasilkan contoh tabel seperti di bawah ini.
Gambar 12: Proses menambah 2 kolom dan keterangannya
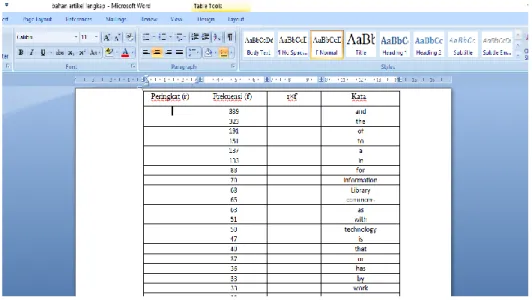
g. Copy seluruh data frekuensi dari Ms.word ke Ms.excel, kemudian Berikan peringkat dengan cara input angka 1 pada cel A1 kemudian input rumus (=A1+1) pada cel A2. Setelah itu tinggal tarik kursor ke bawah sehingga hasil peringkat telah didapatkan, kemudian hitung hasil perkalian antara peringkat dan frekuensi untuk mengisi pada kolom r×f dengan cara blok semua data ke Ms.excel kemudian masukkan rumus perkalian (=A1*B1) kemudian enter. Setelah itu tinggal tarik kursor ke bawah sehingga hasil perkalian telah didapatkan.
Gambar 13: Proses memberikan peringkat (r) serta perhitungan antara peringkat (r) × Frekuensi (f)
h. Blok hasil perkalian pada ms.excel dan pindahkan ke word serta masukkan data pada kolom r×f.
Gambar 14: Proses Salin dari excel ke word 3. Menentukan titik transisi
Cara menghitung titik transisi adalah sebagai berikut:
a. Hitung semua jumlah kata yang ada dalam dokumen (N)
Dengan cara hitung seluruh jumlah frekuensi menggunakan rumus
=SUM(B1:B1528) pada akhir cel B b. Hitung jumlah kata berbeda (In)
c. Hitung kata yang muncul satu kali atau frekuensi satu kali (I1)
Gambar 15: Proses Menentukan titik transisi 4. Menentukan Daerah Transisi
Masukkan ke Rumus:
n = (−1 + √1 + 8I1)/2
Setelah diperoleh angka transisi, maka tepatkan angka tersebut pada peringkat susunan kata. Dalam menentukan daerah transisi ambil 10 kata keatasnya dan 10 kata kebawahnya sesuai dengan angka transisi pada peringkat susunan kata.
𝒏 = (−𝟏 + √𝟏 + 𝟖𝐈𝟏)/𝟐 𝒏 = (−𝟏 + √𝟏 + 𝟖 × 𝟖𝟓𝟏)/𝟐 𝒏 = (−𝟏 + √𝟏 + 𝟔𝟖𝟎𝟖)/𝟐 𝒏 = (−𝟏 + √𝟔𝟖𝟎𝟗)/𝟐 𝒏 = (−𝟏 + 𝟖𝟐, 𝟓𝟏)/𝟐 𝒏 = (𝟖𝟏, 𝟓𝟏)/𝟐
𝑛 = 40,75 𝑝𝑒𝑚𝑏𝑢𝑙𝑎𝑡𝑎𝑛 𝑘𝑒 𝑎𝑡𝑎𝑠 = 41
Gambar 15: Proses Menentukan titik transisi 5. Menentukan Indeks Dokumen
Buang kata-kata tak bermakna (stopword) pada daerah transisi sehingga meninggalkan beberapa kata yang akan menjadi indeks dokumen.
Gambar 16: Proses Penentuan Indeks Dokumen 10 Kata diatas Titik Transisi dan 10 Kata dibawah
Titik Transisi
We, At, Access, Have, Not, Group, Study, Was, IC, University, First, Been, Its, Libraries, They,
From, New, Resources, Use, which, while.
We, At, Access, Have, Not,
Group, Study, Was, IC, University, First, Been, Its, Libraries, They, From, New,
Resources, Use, which, while. Access, Group, Study, IC, University, Libraries,
Resources.
Stopword “Function words” adalah kata bantu yang tidak memiliki arti
Interpretasi
6. Interpretasi Terhadap Indeks Dokumen
Setelah indeks dokumen diperoleh, maka selanjutnya diinterpretasikan atau dinilai apakah indeks tersebut benar-benar dapat menggambarkan isi atau subjek dari artikel atau dokumen yang sebenarnya.
Gambar 17: Proses Interpretasi Indeks Dokumen 7. Merelevasi Hasil Pengindeksan
Langkah selanjutnya adalah merelevansi hasil indeks menggunakan Dalil Zipf (machine indexer) dengan hasil indeks atau keyword dari pengarang pada artikel itu sendiri.
Hasil pengindeksan pada dalil Zipf akan diberi penilaian sebagai berikut:
a. Relevan, apabila indeks yang dihasilkan dari dalil Zipf dengan kata kunci pada artikel jurnal benar-benar dan sama persis.
Indeks Dalil Zipf = Kata Kunci Artikel
b. Relevan marginal, apabila indeks yang dihasilkan memiliki kemiripan/
kesamaan.
Indeks Dalil Zipf < 𝐾𝑎𝑡𝑎 𝐾𝑢𝑛𝑐𝑖 𝐴𝑟𝑡𝑖𝑘𝑒𝑙
c. Tidak Relevan, apabila indeks yang dihasilkan sama sekali tidak memiliki kemiripan/ kesamaan.
Indeks Dalil Zipf ≠ Kata Kunci Artikel Kata Kunci Artikel
Library management, Library spaces, Information commons
Indeks dari Dalil Zipf
Access, Group, Study, IC, University, Libraries, Resources.
Setiap Kata dapat di gabungkan membentuk kata yang memiliki arti khusus
IC (Information Commons) Kata berbeda yaitu singkatan dari kata kunci pengarang tetapi memiliki arti yang sama
Study Access dan Accses Libraries resources
Tidak ada dalam kata Kunci Artikel tetapi dapat menggambarkan isi dari artikel
4.5. Jumlah Kata Pada Setiap Dokumen Uji dan Titik Transisinya
Masing-masing artikel memiliki jumlah kata yang berbeda diantaranya adalah sebagai berikut:
1. A01
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 6105
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1528
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1
= 1528 − 677
= 851
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 851)/2
= (−1 + √1 + 6808)/2
= (−1 + √6809)/2
= (−1 + 82,51)/2
= (81,51)/2
= 40,75 pembulatan ke atas
= 41 2. A02
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi
= 5838
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1654
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1
= 1654 − 677
= 1021
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 1023)/2
= (−1 + √1 + 8184)/2
= (−1 + √8185)/2
= (−1 + 90,47)/2
= (89,47)/2
= 44,47 pembulatan ke atas
= 45 3. A03
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 5995
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1097
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1
= 1097 − 552
= 545
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 545)/2
= (−1 + √1 + 4360)/2
= (−1 + √4361)/2
= (−1 + 66,03)/2
= (65,03)/2
= 32,51 pembulatan ke atas
= 33 4. A04
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 6262
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1215
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 1215 − 589
= 626
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 626)/2
= (−1 + √1 + 5008)/2
= (−1 + √5009)/2
= (−1 + 70,77)/2
= (69,77)/2
= 34,88 pembulatan ke atas
= 35 5. A05
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 8348
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1741
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 1741 − 843
= 898
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 898)/2
= (−1 + √1 + 7184)/2
= (−1 + √7185)/2
= (−1 + 84,76)/2
= (83,76)/2
= 41,88 pembulatan ke atas
= 42 6. A06
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 3192
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 887
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 887 − 406
= 481
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 481)/2
= (−1 + √1 + 3848)/2
= (−1 + √3849)/2
= (−1 + 62,04)/2
= (61,04)/2
= 30,52 pembulatan ke atas
= 31 7. A07
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 4824
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1344
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 1344 − 553
= 791
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 791)/2
= (−1 + √1 + 6328)/2
= (−1 + √6329)/2
= (−1 + 79,55)/2
= (78,55)/2
= 39,27 pembulatan ke atas
= 40 8. A08
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 2523
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 765
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 765 − 312
= 453
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 453)/2
= (−1 + √1 + 3624)/2
= (−1 + √3625)/2
= (−1 + 60,20)/2
= (59,20)/2
= 29,6 pembulatan ke atas
= 30 9. A09
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi
= 5085
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 846
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 846 − 423
= 423
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 423)/2
= (−1 + √1 + 3384)/2
= (−1 + √3385)/2
= (−1 + 58,18)/2
= (57,18)/2
= 28,59 pembulatan ke atas
= 29 10. A10
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 2023
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 588
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 588 − 256
= 332
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 332)/2
= (−1 + √1 + 2656)/2
= (−1 + √2657)/2
= (−1 + 51,54)/2
= (50,54)/2
= 25,27 pembulatan ke atas
= 26 11. A11
Total Kata dalam Dokumen (N) = Jumlah seluruh frekuensi = 3825
Jumlah Kata Berbeda (In) = Angka terakhir peringkat = 1008
Total kata yang muncul 1 kali (I1) = Angka terakhir peringkat − total kata yang memiliki frekuensi lebih dari 1 = 1528 − 677
= 603
Titik transisi = (−1 + √1 + 8I1)/2
= (−1 + √1 + 8 × 603)/2
= (−1 + √1 + 4824)/2
= (−1 + √4825)/2
= (−1 + 69,46)/2
= (68,46)/2
= 34,23 pembulatan ke atas
= 35
4.6. Daerah Transisi dan Indeks Dokumen Pada Dokumen Uji
Menggunakan Dalil Zipf
Setiap artikel memiliki daerah transisi yang berbeda-berbeda tergantung pada titik transisi pada artikel itu sendiri dan untuk menghasilkan suatu indeks dokumen kita harus mengetahui daerah transisi lalu kemudian membuang kata yang yang tidak bermakna (stopword). Untuk itu daerah transisi dan indeks dokumen pada dokumen uji menggunakan dalil Zipf adalah sebagai berikut:
Tabel-3: Daerah Transisi dan Indeks Dokumen A01 Kode Artikel : A01
Titik Transisi (n) : 41
Peringkat (r) Frekuensi (f) r× f Kata
1. 339 339 And
2. 323 646 The
3. 191 573 Of
4. 151 604 To
5. 137 685 A
6. 133 798 In
7. 88 616 For
8. 70 560 Information
9. 68 612 Library
10. 65 650 Commons
11. 63 693 As
12. 51 612 With
13. 50 650 Technology
14. 47 658 Is
15. 40 600 That
16. 37 592 Or
17. 36 612 Has
18. 33 594 By
19. 33 627 Work
20. 32 640 An
21. 31 651 It
22. 31 682 Learning
23. 29 667 Academic
24. 29 696 Be
25. 29 725 On
26. 29 754 This
27. 28 756 More
28. 27 756 Are
29. 26 754 Our
30. 26 780 Students
31. 26 806 We
32. 25 800 At
33. 24 792 Access
34. 24 816 Have
35. 24 840 Not
36. 23 828 Group
37. 23 851 Study
38. 22 836 Was
39. 21 819 IC
40. 21 840 University
41. 20 820 First
42. 19 798 Been
43. 19 817 Its
44. 19 836 Libraries
45. 19 855 They
46. 18 828 From
47. 18 846 New
48. 18 864 Resources
49. 18 882 Use
50. 18 900 Which
51. 18 918 While
52. 17 884 Loyola
53. 17 901 Social
54. 17 918 Software
55. 16 880 Needs
56. 16 896 Other
57. 16 912 Place
58. 16 928 Services
59. 15 885 But
60. 15 900 Equipment
61. 15 915 Knowledge
62. 15 930 Model
63. 15 945 Space
64. 15 960 Such
65. 15 975 Their
66. 14 924 Can
67. 14 938 creation
68. 14 952 faculty
69. 14 966 second
70. 14 980 spaces
71. 13 923 Also
72. 13 936 Chicago
73. 13 949 Class
74. 13 962 digital
75. 13 975 librarians
76. 13 988 media
77. 13 1001 service
78. 13 1014 User
Hasil Daerah Transisi:
We, At, Access, Have, Not, Group, Study, Was, IC, University, First, Been, Its, Libraries, They, From, New, Resources, Use, which, while.
Indeks subjek perkata:
Access, Group, Study, IC, University, Libraries, Resources.
Indeks Subjek yang jika digabungkan membentuk kata-kata yang lebih khusus diantaranya:
IC(Information Commons), Study Access, Access Libraries Resources.