ANALISIS KAPASITAS SITUS CONTENT-SHARING ITERASI
KEDUA DI P.T. BDMN
KARYA AKHIR
TRI RAHMAT GUNADI
1106042416
FAKULTAS ILMU KOMPUTER
PROGRAM STUDI MAGISTER TEKNOLOGI INFORMASI
JAKARTA
HALAMAN JUDUL
ANALISIS KAPASITAS SITUS CONTENT-SHARING ITERASI
KEDUA DI P.T. BDMN
KARYA AKHIR
Diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Teknologi Informasi
TRI RAHMAT GUNADI
1106042416
FAKULTAS ILMU KOMPUTER
PROGRAM STUDI MAGISTER TEKNOLOGI INFORMASI
JAKARTA
Karya Akhir ini adalah hasil karya saya sendiri, dan semua sumber, baik yang dikutip maupun yang
dirujuk, telah saya nyatakan dengan benar.
Nama : Tri Rahmat Gunadi
NPM : 1106042416
Tanda Tangan :
iii
HALAMAN PENGESAHAN
KATA PENGANTAR
Puji syukur saya panjatkan kepada Tuhan Yang Maha Esa, karena berkat kuasa-Nya, saya dapat menyelesaikan Karya Akhir ini. Penulisan karya akhir ini dilakukan dalam rangka memenuhi syarat kelulusan untuk mencapai gelar Magister Teknologi Informasi dari Fakultas Ilmu Komunikasi Universitas Indonesia.
Saya menyadari bahwa, tanpa bantuan dan bimbingan dari berbagai pihak pada masa perkuliahan sampai penyusunan karya akhir, akan sangat sulit bagi saya untuk menyelesaikannya. Oleh karena itu, saya mengucapkan terimakasih kepada:
1. Bapak Rizal Fathoni Aji, S. Kom, M. Kom, selaku dosen pembingbing yang telah menyediakan waktu, ide dan bimbingan dalam penyelesaiaan karya akhir ini.
2. Bapak Bob Hardian, Ph.D dan Gladhi Guarddin, M.kom selaku penguji yang telah memberikan masukan yang bermanfaat untuk meningkatkan kualitas Karya Akhir ini.
3. Pihak perusahaan BDMN yang telah menyediakan topik permasalahan yang digali, serta informasi-informasi yang mendukung penyelesaian Karya Akhir ini.
4. Orang tua dan keluarga yang saya sayangi.
5. Staff MTI Fasilkom UI, untuk bantuannya dalam pengumpulan karya akhir ini 6. Teman-teman MTI Fasilkom.
Akhir kata, semoga karya akhir ini dapat membawa pengetahuan dan manfaat bagi pihak lain.
Jakarta, 10 Januari 2015 Tri Rahmat Gunadi
v
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademi Universitas Indonesia, saya yang bertanda tangan di bawah ini:
Nama : Tri Rahmat Gunadi
NPM : 1106042416
Program Studi : Magister Teknologi Informasi Departemen :
-Fakultas : Ilmu Komputer
Jenis Karya : Karya Akhir
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Indonesia Hak Bebas Royalti Noneksklusif(Non-exclusive Riyalty-Free Right) atas karya ilmiah saya yang berjudul:
Analisis Kapasitas Situs Ccntent-sharing Iterasi Kedua di P.T. BDMN Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Nonekslusif ini, Universitas Indonesia berhak menyimpan, mengalihmedia/formatkan, mengelola dalam bentuk pangkalan data (database), merawat dan mempublikasikan karya akhir saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Jakarta
Tanggal : 10 Januari 2015 Yang Menyatakan
Nama : Tri Rahmat Gunadi
NPM : 1106042416
Program Studi : Magister Teknologi Informasi
Judul Karya Akhir : Analisis Kapasitas Situs Content-sharing Iterasi Kedua di P.T. BDMN
PT. BDMN memutuskan untuk mempermudah akses DVN, salah satu aplikasinya, dengan mengembangkan situs yang mengakomodir request dari perangkat telepon genggam.
Setelah proses pengembangan, manajemen berharap bisa memiliki informasi yang cukup untuk mengelola server DVN. Sampai saat ini, pengelolaan infrastruktur masih berdasarkan estimasi, dan belum ada metodologi yang dianggap cukup untuk memperkirakan kapasitas server.
Oleh karena itu, kami memulai penelitian ini, dengan tujuan untuk mengetahui metodologi yang cocok dalam menilai kapasitas DVN dalam mengakomodir penggunanya, dan melakukan perhitungan atas kapasitas server, agar menjadi informasi yang berguna dalam proses perencanaan.
iii Universitas Indonesia ABSTRACT
Name : Tri Rahmat Gunadi
NPM : 1106042416
Study Program : Magister Teknologi Informasi
Title : Capacity Analisis for a Second-itteration Ccntent-sharing Site in P.T. BDMN
PT. BDMN decided to give mobile access to DVN, one of their application, by developing a mobile-friendly site as one of the accessible front-end.
After the development process, the management feels insufficient by the currently-available information concerning server capacity. Up to now, the capacity planning had been done using estimates by the developer, without proper methodology to came up with the numbers.
Thus, the purpose if this study is to find acceptable means to came up with capacity numbers. That is, the methodology to estimate DVN's server capacity to accommodate user's request. Additionally, to add relevant information to the planning process, we will also calculate the server's capacity based on the underlying methodology.
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN PERNYATAAN ORISINALITAS ... ii
HALAMAN PENGESAHAN ... iii
KATA PENGANTAR ... iv
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... v
ABSTRAK ... ii
ABSTRACT ... iii
DAFTAR ISI ... iv
DAFTAR GAMBAR ... vi
DAFTAR TABEL ... vii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Pertanyaan Penelitian ... 3
1.4 Batasan Penelitian ... 4
1.5 Tujuan dan Manfaat ... 4
1.5.1 Tujuan penelitian ... 4
1.5.2 Manfaat penelitian ... 4
BAB 2 STUDI LITERATUR ... 5
2.1 Tentang DVN ... 5
2.1.1 Arsitektur Aplikasi DVN ... 7
2.1.2 Arsitektur teknologi DVN ... 10
2.2 Penelitian Terdahulu ... 11
2.2.1 Perencanaan Kapasitas jaringan ... 11
2.2.2 Manajemen Kapasitas ... 11
2.2.3 Kapasitas web-server ... 12
2.3 Load Testing ... 13
2.4 Customer Behavior Model Graph ... 15
2.4.1 Interpretasi log-file ... 16
2.4.2 Clustering data sesi ... 18
2.4.3 Probabilitas Transisi ... 19
2.5 Customer Visit Model ... 19
2.6 Client Server Interaction Diagram ... 20
2.7 K-means clustering... 21
BAB 3 METODOLOGI PENELITIAN ... 24
3.1 Penyusunan Metode Perhitungan Kapasitas ... 25
3.2 Interpretasi Log ... 27
3.3 Clustering ... 27
v Universitas Indonesia
3.4 Pemetaan Komponen Server dan Perhitungan Utilisasi Komponen ... 30
3.5 Pengujian Hasil Perhitungan Kapasitas ... 31
BAB 4 PROFIL PEMILIK APLIKASI ... 32
4.1 Profil Pemilik Aplikasi ... 32
4.2 Area Operasional HR ... 33
4.3 Profil Vendor Server ... 36
BAB 5 ANALISA KAPASITAS ... 38
5.1 Proses Interpretasi Log-file ... 38
5.2 Proses Pembersihan log-file ... 41
5.3 Proses ektraksi sesi ... 41
5.4 Proses Clustering ... 43
5.5 Proses Pemetaan Komponen Fisik ... 44
5.6 Perhitungan Visit Ratio ... 44
5.7 Pemetaan Komponen Fisik ... 48
5.8 Hitung utilisasi komponen ... 52
BAB 6 PENGUJIAN HASIL ... 55
6.1 Modifikasi ApacheBenchmark (ab) ... 55
6.2 49 model perilaku pengguna. ... 58
6.3 Penyusunan URL ... 60
6.4 Perhitungan koneksi paralel ... 60
6.5 Benchmark ... 61
6.5.1 Setting Server ... 61
6.5.2 Hasil Benchmark ... 62
6.6 Akurasi perhitungan ... 64
6.6.1 Hasil perhitungan dan benchmark dengan k = 1 ... 65
6.7 Solusi yang ditawarkan ... 66
6.8 Hasil perhitungan K1 ... 67
BAB 7 KESIMPULAN DAN REKOMENDASI ... 69
7.1 Rekomendasi ... 69
DAFTAR PUSTAKA ... 71
Lampiran 1: Transkrip Wawancara ... 72
Lampiran 2: Matrix Transisi DVN ... 79
DAFTAR GAMBAR
Gambar 1.1 Aplikasi DVN ... 1
Gambar 1.2 DVN Iterasi Pertama ... 2
Gambar 1.3 DVN Iterasi Kedua ... 3
Gambar 2.1 Usecase DVN ... 6
Gambar 2.2 Arsitektur Aplikasi DVN ... 8
Gambar 2.3 Infrastruktur DVN ... 10
Gambar 2.4 Hubungan antara waktu respon dan jumlah permintaan ... 13
Gambar 2.5 Hubungan antara waktu respon dan permintaan ... 14
Gambar 2.6 Contoh CBMG ... 15
Gambar 2.7 Proses Interpretasi Log-file... 18
Gambar 2.8 Contoh CSID ... 21
Gambar 2.9 Proses K-Means Clustering ... 23
Gambar 3.1 Kerangka Berpikir ... 24
Gambar 3.2 Metodologi Perhitungan Kapasitas ... 26
Gambar 3.3 Jarak intracluster dan jarak intercluster ... 28
Gambar 4.1 Proses Pengelolaan Aset SDM ... 34
Gambar 4.2 Faktor Material dan Imaterial dalam proses pemeliharaan SDM ... 35
Gambar 5.1 Proses Perhitungan Visit Ratio ... 46
vii Universitas Indonesia DAFTAR TABEL
Tabel 2.1 Komponen Aplikasi DVN ... 9
Tabel 2.2 Frekwensi request dari setiap sesi didalam log-file ... 20
Tabel 4.1 Area Operasional HR BDMN ... 33
Tabel 5.1 Table Konversi URI ... 39
Tabel 5.2 Struktur tabel “access” untuk menampung baris log yang valid ... 41
Tabel 5.3 Contoh matrix transisi ... 45
Tabel 5.4 Visit Ratio untuk setiap titik navigasi ... 47
Tabel 5.5 Utilisasi Komponen Fisik ... 48
Tabel 5.6 Probabilitas Visit Ratio... 50
Tabel 5.7 Utilisasi yang dikalikan dengan PV ... 51
Tabel 5.8 Kapasitas sesi untuk setiap komponen ... 53
Tabel 6.1 Utilisasi server untuk 50 sampel ... 58
Tabel 6.2 Statistik dari hasil 50 sampel ... 59
Tabel 6.3 Perbedaan antara data terhitung dan data real ... 62
Tabel 6.4 Statstik delta CPUms ... 63
Tabel 6.5 Hasil benchmark untuk K1 ... 65
BAB 1
PENDAHULUAN
1.1Latar Belakang
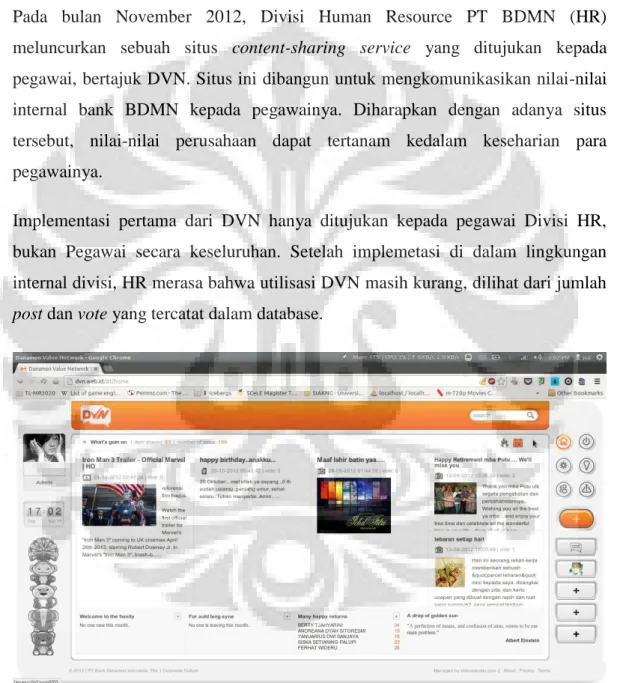
Pada bulan November 2012, Divisi Human Resource PT BDMN (HR) meluncurkan sebuah situs content-sharing service yang ditujukan kepada pegawai, bertajuk DVN. Situs ini dibangun untuk mengkomunikasikan nilai-nilai internal bank BDMN kepada pegawainya. Diharapkan dengan adanya situs tersebut, nilai-nilai perusahaan dapat tertanam kedalam keseharian para pegawainya.
Implementasi pertama dari DVN hanya ditujukan kepada pegawai Divisi HR, bukan Pegawai secara keseluruhan. Setelah implemetasi di dalam lingkungan internal divisi, HR merasa bahwa utilisasi DVN masih kurang, dilihat dari jumlah
post dan vote yang tercatat dalam database.
Gambar 1.1 Aplikasi DVN (Sumber: http://test.dvn.web.id)
Akhirnya, pada bulan Juli 2013, sebagai usaha untuk mempermudah akses aplikasi dan meningkatkan utilisasi DVN, HR meneruskan pengembangan DVN. pengembangan iterasi kedua ini difokuskan pada akses aplikasi lewat perangkat
mobile, dan perombakan tampilan untuk lebih menarik pengguna. Dengan adanya pembangunan iterasi kedua ini, diharapkan akses kepada aplikasi akan lebih mudah, dan ketertarikan pengguna akan meningkat.
1.2Rumusan Masalah
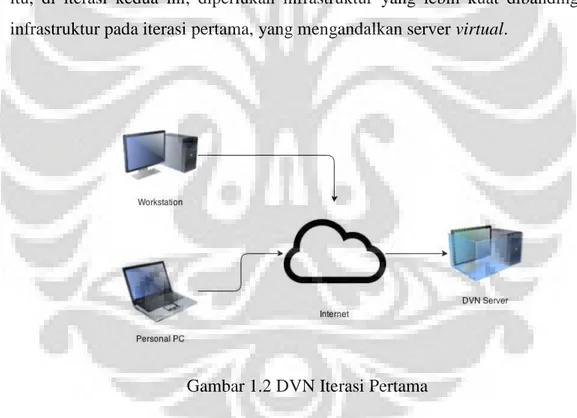
Iterasi pertama difokuskan pada pembangunan fitur-fitur seperti user-to-user chat, group chat, sharing text, video, dan gambar. Di iterasi kedua, pembangunan di fokuskan pada kemudahan akses dan perombakan tampilan aplikasi. Oleh karena itu, di iterasi kedua ini, diperlukan infrastruktur yang lebih kuat dibandingkan infrastruktur pada iterasi pertama, yang mengandalkan server virtual.
Gambar 1.2 DVN Iterasi Pertama
Pada iterasi kedua ini, pihak BDMN telah memilih ponsel dan tablet sebagai media akses untuk para penggunanya. Untuk pilihan server, karena jumlah akses yang diperkirakan akan lebih banyak, maka pihak HR telah memilih sebuah
dedicated server untuk mengirim data kepada pengguna.
DVN iterasi pertama difokuskan pada pengembangan fitur, maka kemudahan akses tidak menjadi masalah yang terlalu diperhitungkan. Oleh karena itu, di
iterasi kedua, yang mana pengembangan aplikasi lebih difokuskan ke pada akses lewat peramban ponsel, maka kapasitas server dipertanyakan.
Gambar 1.3 DVN Iterasi Kedua
Permasalahan yang ada saat ini adalah, cara mengestimasi batasan kapasitas server. Karena pengguna yang lebih banyak, maka hal ini menjadi perhatian. Perlu ada satu metodologi untuk mengkalkulasi jumlah pengguna yang dapat diakomodir oleh server saat ini.
1.3Pertanyaan Penelitian
Pertanyaan penelitian disusun berdasarkan masalah yang dihadapi. Jawaban dari pertanyaan penelitian ini harus dapat menjadi solusi untuk masalah tersebut. Berdasarkan pernyataan pada sub-bab sebelumya, bahwa perlu ada ada satu metodologi untuk mengkalkulasi jumlah pengguna yang dapat diakomodir oleh server, maka pertanyaan penelitian di susun sebagai berikut:
Dengan kondisi iterasi kedua yang memudahkan akses aplikasi, Bagaimana cara mengukur jumlah pengguna yang dapat diakomodir oleh server DVN?
1.4Batasan Penelitian
Penelitian dilakukan dengan melakukan studi literatur untuk mencari metode yang tepat dalam mengukur kapasitas server. Setelah itu, akan dilakukan simulasi pengukuran kapasitas dari sejarah penggunaan aplikasi, jumlah sesi paralel yang dapat diakomodir oleh server bisa diukur, atau sebaliknya, kapasitas server yang diperlukan untuk mengakomodir pengguna sejumlah n.
setelah dilakukan perhitungan, akan dilakukan pengujian terhadap hasil tersebut. Pengujian harus dilakukan dengan mencocokan hasil perhitungan dengan kondisi
real.
1.5Tujuan dan Manfaat
Dengan disusunnya pertanyaan penelitian, dan batasan penelitian, maka dapat dijabarkan tujuan dan manfaat penelitian dapat sebagai berikut:
1.5.1Tujuan penelitian
a. Merumuskan cara untuk mengkalkulasi kapasitas server dari aplikasi DVN. b. Mengestimasi kapasitas server, berdasarkan jumlah akomodasi pengguna.
1.5.2Manfaat penelitian
Hasil penelitian ini adalah suatu metode perhitungan kapasitas server yang memerlukan input tertentu dan menghasilkan angka estimasi. Oleh karena itu, hasil penelitian ini diharapkan dapat menghasilkan membantu proses perencanaan kapasitas dari aplikasi DVN.
Metode ini diharapkan dapat menggantikan proses benchmarking, sehingga untuk mengestimasi kapasitas server pada aplikasi yang sedang berjalan, tidak perlu melakukan benchmarking, yang biasanya memerlukan sumber daya dan memerlukan perubahan setelan pada web-server.
BAB 2
STUDI LITERATUR
Pertanyaan penelitian ini adalah: “Dengan kondisi iterasi kedua yang memudahkan akses aplikasi, Bagaimana cara mengukur jumlah pengguna yang dapat diakomodir oleh server DVN?” Untuk mengestimasi jumlah pengguna yang dapat diakomodir oleh sistem yang berjalan saat ini, perlu diketahui tentang teknik-teknik perhitungan kapasitas sebuah web server.
Untuk mempelajari hal tersebut, perlu dipelajari penelitian-penelitian terdahulu tentang analisis kapasitas, dan membahas topik-topik yang berhubungan dengan teknik perhitungan kapasitas: Load testing, Customer Behaviour Model Graph (CBMG), Customer Visit Model, Client-Server Interaction Diagram. Selain teknik perhitungan kapasitas, akan dibahas juga sedikit tentang K-means clustering, metode pengelompokan data yang dipergunakan dalam penyusunan CBMG dan
CVM.
Namun, sebelum membahas tentang penelitian-penelitian terdahulu dan teknik-teknik perhitungan kapasitas, ada baiknya mempelajari aplikasi yang bersangkutan terlebih dahulu. Oleh karena itu, di bab ini, akan diberikan penjelasan komponen aplikasi dan arsitetur teknologi yang digunakan.
2.1Tentang DVN
DVN merupakam situs content-sharing. Yang dimaksud dengan situs content-sharing adalah situs yang mengakomodir pengunggahan konten oleh pengguna, untuk diakses oleh pengguna lain.
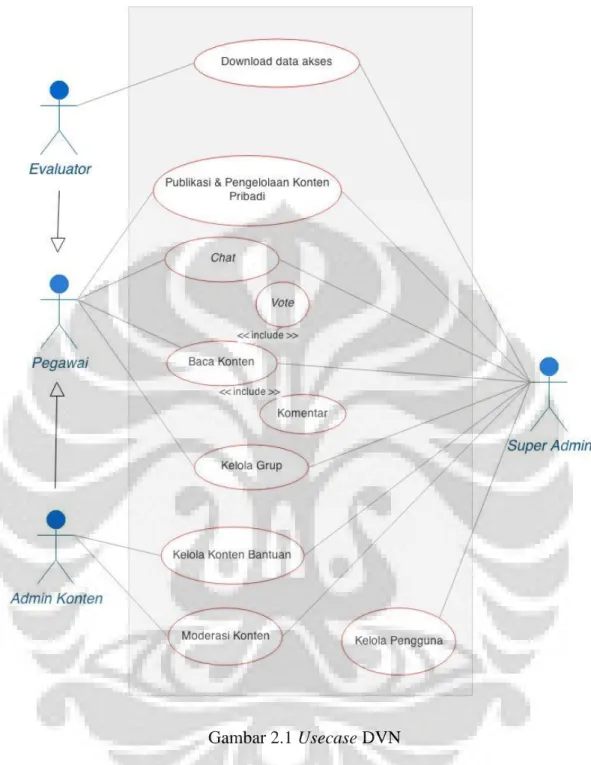
Jenis konten yang dapat di akses pun berbeda-beda: gambar, link-video, kuotasi, text, atau link-audio. Semua konten dapat di vote oleh pengguna lain, dan di beri komen. Penggambaran tetang fitur DVN Dapat dilihat pada use case dibawah:
Gambar 2.1 Usecase DVN
Gambar 2.1 adalah usecase yang digunakan dalam proses pengembangan iterasi pertama. Untuk pengembangan iterasi kedua, usecase tidak berubah. Beberapa hal yang mungkin perlu dijelaskan dalam (dan diluar) usecase diatas adalah: User-group, Live Notification, Konten Bantuan. Fitur lain dirasa cukup jelas.
a. User-grouping
Dalam DVN, setiap pengguna berada dalam grup. Minimal satu grup, yaitu sub-divisi dimana pengguna tersebut bekerja. Pengguna dapat menciptakan grup-grup baru, dan berkomunikasi sebagai grup dalam fitur chat.
b. Live Notification
Live Notification berfungsi sebagai sumber informasi instan pengguna mengenai konten baru yang di publikasikan oleh teman dalam group-nya, dan notifikasi mengenai pesan chat yang baru masuk.
c. Konten Bantuan
Konten bantuan adalah kumpulan narasi, yang disusun untuk membantu pengguna dalam menggunakan DVN. Narasi ini ditulis oleh pihak HR. Saat ditulisnya penelitian ini, belum tersedia konten bantuan yang dapat dibaca oleh pengguna.
2.1.1Arsitektur Aplikasi DVN
Pembahasan arsitektur DVN akan dimulai dengan membahas proses DVN dalam merespon request dari pengguna. Setelah itu, akan diinformasikan komponen-komponen aplikasi yang digunakan untuk menjalankan sistem tersebut.
Pembahasan ini bertujuan untuk mendapatkan konteks teknikal tentang aplikasi DVN, bagaimana aplikasi tersebut merespon, apa saja proses yang berperan dalam menciptakan respon, bagaimana pembagian tugas dalam server DVN untuk mengakomodir tipe request yang berbeda.
Konteks teknikal mungkin diperlukan untuk mengetahui faktor-faktor apa saja yang mempengaruhi performa sistem secara keseluruhan, sekaligus untuk menghindari kesalahan estimasi dengan meng-inklusi atau meng-ekslusi faktor.
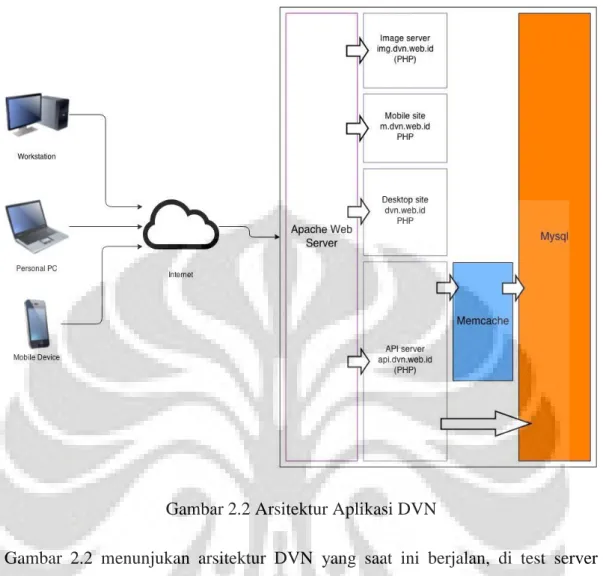
Gambar 2.2 Arsitektur Aplikasi DVN
Gambar 2.2 menunjukan arsitektur DVN yang saat ini berjalan, di test server DVN. Aplikasi diakses dengan browser, yang mengakses melalui internet, dengan access point yang random. Request dari browser ini kemudian diterima oleh
Apache web-server, yang berfungsi sebagai penerima request utama dan router untuk beberapa komponen lain:
Server halaman web (Desktop Site, Mobile Site).
Server API, berperan sebagai agen yang mengakses database.
Server gambar, berperan dalam manipulasi ukuran file gambar yang diakses. Hasil manipulasi gambar di simpan dalam hard-disk untuk mempermudah akses yang berulang, dan di hapus setiap harinya.
Panggilan ke database (MySql), khusus untuk operasi SELECT, di jembatani oleh
cache (memcache). Hal ini untuk meringankan beban database dalam mengakomodir panggilan berulang. Hasil operasi SELECT akan disimpan dalam
memory selama 10 detik, sehingga jika ada operasi SELECT yang sama dalam waktu kurang dari 10 detik, maka database tidak akan terbebani oleh operasi ini. Cukup mengambil hasil dari cache yang telah tersimpan. Jumlah data yang dapat disimpan dalam memory adalah 128MB.
Penggunaan cache untuk hasil operasi SELECT mengatasi bottleneck yang biasanya terjadi pada panggilan database karena jumlah row yang banyak dan operasi join. Memperkecil waktu respon, meningkatkan throughput, dan mempercepat durasi request. Proses pengelolaan juga dipermudah, karena peningkatan performa dapat dilakukan dengan menambah alokasi RAM. Atau,
scale-out pada server memori – memcache adalah sistem in-memory cache yang terdistribusi, sehingga menunda kebutuhan untuk scale-out pada server database.
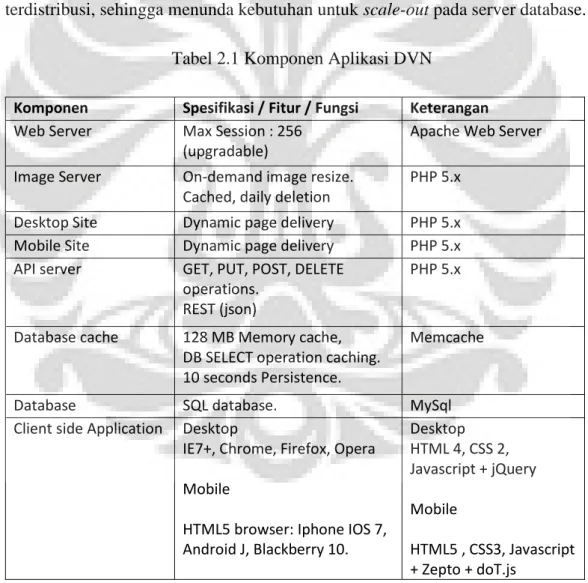
Tabel 2.1 Komponen Aplikasi DVN
Komponen Spesifikasi / Fitur / Fungsi Keterangan
Web Server Max Session : 256 (upgradable)
Apache Web Server Image Server On-demand image resize.
Cached, daily deletion
PHP 5.x
Desktop Site Dynamic page delivery PHP 5.x
Mobile Site Dynamic page delivery PHP 5.x
API server GET, PUT, POST, DELETE operations.
REST (json)
PHP 5.x
Database cache 128 MB Memory cache, DB SELECT operation caching. 10 seconds Persistence.
Memcache
Database SQL database. MySql
Client side Application Desktop
IE7+, Chrome, Firefox, Opera Mobile
HTML5 browser: Iphone IOS 7, Android J, Blackberry 10. Desktop HTML 4, CSS 2, Javascript + jQuery Mobile HTML5 , CSS3, Javascript + Zepto + doT.js
Tabel 2.1 diatas merincikan komponnen-kompoen yang digunakan oleh DVN. Mulai dari komponen untuk server-side sampai dengan komponen client-side.
2.1.2Arsitektur teknologi DVN
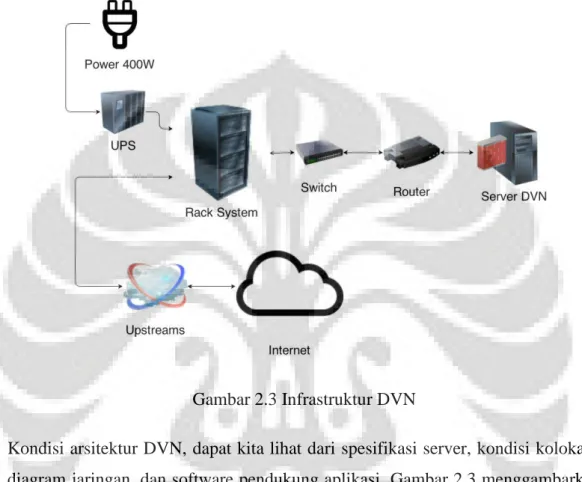
Gambar 2.3 Infrastruktur DVN
Kondisi arsitektur DVN, dapat kita lihat dari spesifikasi server, kondisi kolokasi, diagram jaringan, dan software pendukung aplikasi. Gambar 2.3 menggambarkan Kondisi DVN saat ini: Server menggunakan mesin rakitan, dengan CPU Intel Xeon E3; 3,3Ghz. Memory yang saat ini digunakan adalah 8GB. Ditempatkan di gedung Cyber 1, Jakarta. Lokasinya didukung oleh 400W listrik, dan arus listrik di setiap rack diamankan oleh UPS. Server DVN sendiri adalah server tower. Server dilengkapi, dengan firewall, sebagai pelindung utama dari traffic.
Sejauh ini kita membahas sedikit tentang aplikasi DVN. Selanjutnya kita akan mencoba mempelajari penelitian terdahulu yang terkait dengan kapasitas.
2.2Penelitian Terdahulu
Untuk mempelajari tentang kapasitas dan pengukurannya, perlu dibahas beberapa penelitian terdahulu yang tersedia. Penelitian-penelitian ini berhubungan dengan perencanaan kapasitas, manajemen kapasitas, dan analisis kapasitas web-server.
2.2.1Perencanaan Kapasitas jaringan
Siregar (2008) melakukan analisis kapasitas jaringan untuk menciptakan rancangan infrastruktur teknologi informasi yag lebih optimal. Hal ini dilakukan melalui 4 tahap:
1. Memonitor dan mengumpulkan data dari sistem berjalan. 2. Analisis terhadap hasil monitoring.
3. Menghitung bandwith yang diperlukan.
4. merancang infrastruktur yang dapat mengakomodir kebutuhan bandwith. Dari keempat tahap tersebut, kita dapat melihat bahwa proses perencanaan kapasitas memerlukan adanya pengumpulan data dari sistem berjalan, dan analisis terhadap data tersebut.
Dengan empat tahapan penelitian tersebut, kami berlanjut kepada penelitian lain. Karena penelitiaan Siregar ini berfokus pada jaringan, sulit bagi kami untuk menyetarakan dengan penelitian ini, sehingga masih dianggap perlu untuk mempelajari penelitian lain.
2.2.2Manajemen Kapasitas
Prihastuti (2012) menghitung kebutuhan server untuk menunjang kegiatan operasional sebuah bank. Perhitungan ini dilakukan dalam kerangka kerja manajemen kapasitas. Secara teknis, Prihastuti menyusun proyeksi pemakaian masa depan menggunakan garis regresi dari berbagai faktor bisnis dan teknis sebagai input.
Faktor-faktor bisnis yang dijadikan input adalah: Jumlah rekening dan transaksi, rencana pertumbuhan bisnis, jumlah produk bank. Sedangkan faktor-fator teknis yang digunakan sebagai input adalah: Data histori kinerja Server, dan IBM Performance Guideline. Faktor-faktor tersebut diproses secara terpisah untuk mendapatkan dua output: pertumbuhan rekening dan transaksi 2012-20014, dan kinnerja server 2011. Kedua output tersebut dikorelasikan, kemudian diproyeksikan. Dengan hasil proyeksi, maka kebutuhan masa depan di perkirakan. Dari kedua kategori faktor tersebut, terlihat adanya kesamaan dengan Siregar, yaitu penggunaan data pemakaian secara historis. Perhitungan kapasitas memang seharusnya menggunakan data real, hal tersebut wajar adanya. Yang membedakan antara kedua penelitian tersebut adalah: Siregar merancang sistem baru berdasarkan analisis atas data saat ini, sedangkan Prihastuti menyusun rencana pengembangan berdasarkan proyeksi kebutuhan masa depan.
Dari kedua penelitian tersebut, diketahui bahwa untuk mengukur kapasitas saat ini, memerlukan data historis penggunaan mesin. Dari data tersebut kita dapat mengukur jumlah respon yang dapat diharapkan dari request tertentu.
Kedua penelitian tersebut belum dirasa cukup untuk menjawab pertanyaan penelitian ini. Perlu penelitian lain yang dapat disejajarkan dengan penelitian ini. oleh karena itu, pembahasan selanjutnya adalah pembahasan mengenai pengukuran kapasitas web-server.
2.2.3Kapasitas web-server
Budianto (2009) menganalisis penggunaan web-server untuk mendapatkan kapasitas maksimum yang dapat diakomodir server. Budianto melakukan hal tersebut dengan cara mengukur probabilitas transisi antara titik navigasi. Transisi antara titik navigasi ini kemudian digunakan untuk mengukur utilisasi server. Metode yang digunakan untuk mengukur probabilitas transisi akan menghasilkan sebuah diagram yang dinamakan Customer Behavior Model Graph (CBMG), diagram yang menggambarkan probabilitas transisi dari satu titik navigasi ke titik navigasi lain. Probabilitas transisi tersebut akan digunakan untuk menghitung
utilisasi komponen fisik. perhitungan utilisasi komponen fisik tersebut akan menghasilkan diagram yang dinamakan Customer Server Interaction Diagram
(CSID).
Pada akhirnya, Budiono dapat mengukur jumlah sesi yang dapat diakomodir. Hal ini sesuai dengan pertanyaan penelitian ini. Dengan kesesuaian tersebut, maka penelitian Budiono membuka pembahasan mengenai teknik-teknik perhitungan kapasitas. Teknik-teknik dibawah ini merupakan teknik-teknik yang digunakan dalam menentukan kapasitas web-server. Selanjutnya akan dibahas secara umum proses yang dilalui dan hasil yang diharapkan dari setiap teknik.
2.3Load Testing
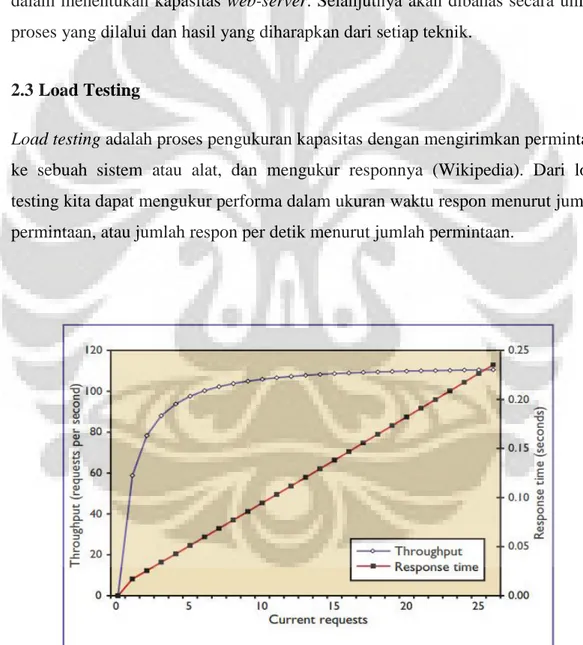
Load testing adalah proses pengukuran kapasitas dengan mengirimkan permintaan ke sebuah sistem atau alat, dan mengukur responnya (Wikipedia). Dari load testing kita dapat mengukur performa dalam ukuran waktu respon menurut jumlah permintaan, atau jumlah respon per detik menurut jumlah permintaan.
Gambar 2.4 Hubungan antara waktu respon dan jumlah permintaan (Sumber: Load Testing of Web Sites, Menascé, 2002)
Gambar 2.4 menunjukan data yang dihasilkan dari load testing. Dapat dilihat bagaimana server merespon dengan jumlah permintaan yang beragam.
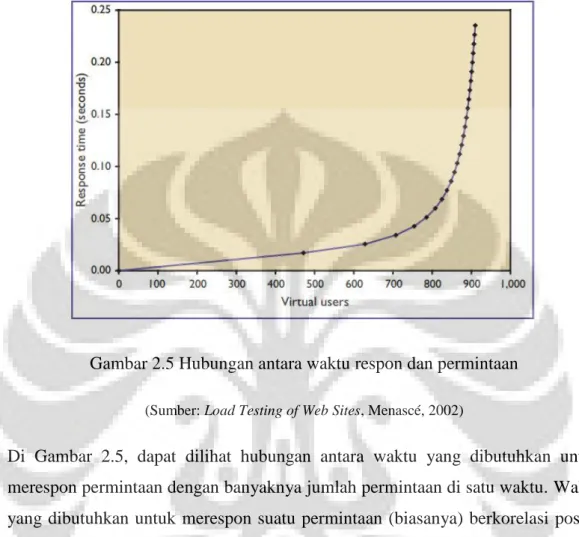
Gambar 2.5 Hubungan antara waktu respon dan permintaan (Sumber: Load Testing of Web Sites, Menascé, 2002)
Di Gambar 2.5, dapat dilihat hubungan antara waktu yang dibutuhkan untuk merespon permintaan dengan banyaknya jumlah permintaan di satu waktu. Waktu yang dibutuhkan untuk merespon suatu permintaan (biasanya) berkorelasi positif dengan banyaknya jumlah permintaan, yaitu: waktu yang dibutuhkan untuk merespon akan meningkat seiring dengan peningkatan jumlah permintaan (per-detik). Pengukuran dari kapasitas server dapat dilakukan dengan melihat slope dari grafik. Target dari testing ini biasanya adalah Slope yang landai. Semakin landai semakin bagus.
Hasil dari load-testing berguna dalam menetukan Quality-of-service dari sebuah situs. Artinya, kualitas sebuah service berbasis web dalam mengakomodir pengguna dalam hal availibilitas dan waktu respon.
Berikut adalah pertanyaan-pertanyaan yang dapat dijawab oleh hasil load testing: 1. Berapakah rata-rata waktu respon ketika n pengguna mengakses server?
2. Kapankah waktu respon mengalami peningkatan yang signifikan?
2.4Customer Behavior Model Graph
Customer Behavior Model Graph (CBMG) adalah diagram yang menunjukan pola perilaku pengguna dalam sebuah sistem. Pertama kali dikemukakan oleh Menascé & Almeida (1999) untuk menjabarkan pola perilaku pengguna dalam sebuah website.
Proses ekstraksi pola perilaku dirmulai dari interpretasi log-file. Log-file dari
server di konversi kedalam diagram yang menggambarkan probabilitas transisi dari satu titik navigasi ke titik navigasi lain. Dengan Metode CBMG, kita dapat menjawab pertanyaan-pertanyaan berikut:
1. Berapa kali modul A diakses dalam satu sesi?
2. Berapa kali modul A diakses setelah modul B dalam satu sesi?
Gambar 2.6 Contoh CBMG
Gambar 2.6 memperlihatkan contoh CBMG dari sebuah situs belanja online. Setiap titik navigasi diberikan hubungan dengan titik navigasi lain. Dengan hubungan tersebut, terdapat angka probabilitas transisi: probabilitas stuatu modul akan diakses setelah modul lain diakases. Gambar tersebut diciptakan melalui proses tertentu. Berikut adalah urutan proses untuk menyusun CBMG:
a. Interpretasi log-file b. Clustering data sesi
c. Perhitungan probabilitas transisi
2.4.1Interpretasi log-file
Sebuah log-file adalah catatan tentang sejarah akses oleh pengguna. Log-file
(minimal) berisi informasi tentang waktu kedatangan dan URL yang diakses di setiap barisnya. Biasanya, log-file diciptakan oleh aplikasi web-server. Namun, tidak menutup kemungkinan sebuah log-file diciptakan oleh proses lain. Contoh
log-file dapat dilihat sebagai berikut:
Figur 2.1 Contoh log-file
Log-file (L) diatas terdiri dari catatan request (r) yang datang ke server aplikasi. Setiap request dipisahkan kedalam baris yang berbeda, dimana setiap baris terdiri
dari: IP, Waktu akses, Jenis Koneksi HTTP dan URI, Status operasi, jumlah data-transfer, dan User-agent String. Sehingga r1 ... n∈ L.
Untuk mengetahui pola perilaku, log-file harus dipisahkan kedalam session, sebagai proxy dari pengguna. Karena biasanya tidak ada indikasi session, maka
session dapat diestimasi dari IP dan durasi koneksi. Durasi koneksi untuk memisahkan satu sesi dan sesi lain dapat diasumsikan, contoh: 30 menit, 1 jam, 2 jam, dll. Pemisahan baris log-file kedalam sesi akan menghasilkan sebuah session-log. Dengan sk sebagai sebuah sesi dalam session-log S, dan Ci,j sebagai transisi antara titik navigasi dalam suatu sesi, maka: Ci,j∈ sk ∈ S.
Dalam penyusunan CBMG, yang diperhitungkan adalah jumlah transisi antara titik navigasi dan waktu antar navigasi. Sehingga, Cij = (ci,j, wi,j). Frekwensi transisi antara titik navigasi i dan j, adalah ci,j dan waktu antar titik navigasi adalah
wi,j.
Katakanlah rk = ( Ik, tk, hk, xk ); dimana I adalah IP, t adalah waktu akses, h adalah halaman yang di request (Http-verb & Request URI) dan x adalah waktu eksekusi.
Ci,j dapat disusun dengan cara menginisialisasi seluruh titik transisi dengan
Cij = (0,0) dan mensortir request dalam satu sesi berdasarkan waktu, sehingga untuk setiap rk | k>1 , kita dapat menghitung:
(2.1) (2.2) dan untuk setiap r1 kita berikan
(2.3) Setelah menghitung semua Ci,j dalam semua sesi, kita tambahkan cn,exit= 1 untuk setiap sesi.
Gambar 2.7 Proses Interpretasi Log-file
Dari Gambar 2.7, dapat dilihat bahwa proses interpretasi log-file bertujuan untuk mendapatkan representasi sesi, dimana setiap sesi berisi informasi tentang transisi antara titik navigasi. Pada gambar diatas, Sesi U menunjukan informasi berupa frekwensi transisi antara titik navigasi: cxy adalah frekwensi transisi antara titik navigasi X dan Y, dan waktu yang lewat antara titik navigasi: wxy adalah waktu yang lewat disaat pengguna bertransisi dari X ke Y.
2.4.2Clustering data sesi
Setelah mendapatkan informasi mengenai sesi, dilakukan clustering untuk mencari grup pengguna yang ingin di teliti. Clustering ini dipergunakan untuk memfokuskan penelitian pada pengguna dengan karakteristik yang diinginkan.
Clustering dilakukan dengan metode K-means. Pembahassan tentang K-means
akan disediakan pada sub-bab lain. Berkaitan dengan CBMG, dalam melakukan
clustering, fungsi yang dipergunakan untuk menghitung jarak antara titik a dan b
(2.4) Di Persamaan (2.4) diatas, kita hanya menggunakan transisi navigasi. Karena kita hanya berfokus pada perilaku pengguna, transisi navigasi merupakan parameter yang cocok untuk mengukur perilaku pengguna.
Setelah semua cluster telah didapatkan, pemilihan cluster terbaik dapat dilakukan.
cluster terbaik adalah cluster sesuai dengan parameter yang dinginkan. Misalnya
cluster jumlah pembelian terbanyak, atau cluster dengan probabilitas transisi “Modul A” yang terbesar, dan lain-lain.
2.4.3Probabilitas Transisi
Probalitas transisi untuk semua titik navigasi dalam sebuah sesi dapat dihitung dengan rumus berikut:
(2.5)
dan waktu eksekusi di setiap transisi dapat dihitung sebagai berikut:
Zi,j = wi,j / ci,j (2.6) Setelah mendapatkan probabilitas transisi untuk semua titik navigasi, kita dapat mengkalkulasi Visit Ratio untuk setiap modul dengan operasi aljabar linear.
2.5Customer Visit Model
Seperti halnya CBMG, Customer Visit Model (CVM) juga menghitung probabilitas diaksesnya suatu modul dalam satu sesi. Perbedaannya adalah CVM memiliki proses yang lebih sederhana. CVM melihat frekwensi diaksesnya suatu titik navigasi dalam satu sesi, bukan transisi dari satu titik navigasi ke titik navigasi lain. Jadi, dari log-file, ditentukan frekwensi akses untuk setiap modul, lalu berdasarkan data frekwensi tersebut, dilakukan clustering untuk
mengelompokan sesi, dengan rumus perhitungan jarak antara a dan b sebagai berikut:
(2.7)
Setelah itu,gunakan centroid sebagai Visit ratio dari cluster tersebut. Tabel 2.2 Frekwensi request dari setiap sesi didalam log-file
Sesi Va Vb Vc 1 5 2 1 2 6 2 2 3 8 7 3 4 4 5 5 5 6 5 6 6 3 3 8 7 2 4 8
Tabel 2.2 diatas memberikan contoh hasil perhitungan frekwensi request untuk setiap titik navigasi dalam log-file. Dari tabel tersebut, dihitunglah Visit Ratio, untuk kemudian di proses kedalam pemetaan komponen fisik.
2.6Client Server Interaction Diagram
Client Server Interaction Diagram (CSID) adalah diagram yang menggambarkan interaksi pengguna dengan komponen-komponen sebuah sistem. Setiap request pasti berhubungan dengan satu atau lebih komponen, oleh karena itu dengan meneliti komponen yang merespon sebuah request, kita dapat mengetahui pengaruh dari suatu request terhadap beban server.
Contoh diagram CSID adalah sebagai berikut:
Gambar 2.8 Contoh CSID
(Sumber: Capacity Planning: an Essential Tool for Managing Web Services, Menasce 2002)
Gambar 2.8 diatas merupakan contoh CSID yang menggambarkan rute yang dapat diambil oleh sebuah request. Dapat terlihat bahwa ada kemungkinan 95% request
akan menuju Aplication server. Untuk menghitung kemungkinan terpakainya DB (database), dapat kita Telusuri di rute 1 – 2 – 4 – 7. Dengan probabilita 0.72 = 0.95 x 0.8, maka kemungkinan terpakainya DB dalam satu koneksi adalah 0.72 kali.
Dengan notasi CSID, penggunaan komponen dalam server dapat dilihat dengan jelas. Sehingga, dalam satu satuan sesi, beban suatu sistem dapat diestimasi. Dengan beragam probabilita rute yang dapat diambil oleh sebuah request, jumlah sesi paralel yang dapat di jalankan oleh sebuah sistem dalam suatu waktu dapat diestimasi. Begitu juga dengan besarnya sumber daya yang diperlukan untuk menjalankan satu sesi.
2.7K-means clustering
Pembahasan selanjutnya adalah tentang K-means clustering. Apa itu clustering?
Clustering adalah pengelompokan data berdasarkan properti dari data yang bersangkutan. Misalnya pengelompokan berdasarkan umur, atau letaknya dalam koordinat kartesian. Pada prakteknya, pengelompokan data lebih banyak menggunakan properti letak. Teknik pengelompokan ini berguna dalam
meng-klasifikasi pengguna dalam sistem, sehingga kita dapat berfokus pada pengguna dengan karakteristik tertentu.
K-means clustering adalah pengelompokan berdasarkan jarak antar data. K adalah jumlah cluster yang dinginkan. Jadi secara literal K-means dapat diartikan sebagai pengelompokan kedalam K cluster berdasarkan jaraknya terhadap K centroid.
Centroid adalah titik tengah dari kelompok data, yang berperan sebagai nilai rata-rata (mean) dari suatu cluster.
Untuk ilustrasi, katakanlah kita memiliki sejumlah data didalam koordinat cartesian { P = pi, pi+1 … pn | pi = (xi, yi) } Untuk melakukan clustering dengan metode K-means, kita lakukan beberapa langkah berikut:
a. Pilik K titik dari P secara random, dan anggap titik-titik tersebut sebagai
centroid dari cluster.
b. Untuk semua data dalam P, ukur jaraknya dengan titik-titik centroid, dan kelompokan data ke dalam centroid terdekat.
c. Dengan cluster sejumlah K, hitung letak centroid baru dengan cara menghitung rata-rata dari cluster ( , ). dengan masing nilai adalah:
(2.8)
(2.9)
d. Ulangi langkah 2 dan 3 sampai anggota cluster tidak berubah.
Gambar 2.9 Proses K-Means Clustering
24 Universitas Indonesia
BAB 3
METODOLOGI PENELITIAN
Pertanyaan penelitian ini adalah: Bagaimana cara mengukur jumlah pengguna yang dapat diakomodir oleh server DVN saat ini? Dalam kata lain, penelitian ini berusaha untuk mengukur kapasitas server DVN. Kata “kapasitas”, dalam kaitannya dengan sebuah sistem, memiliki dua komponen penting: “load” dan
“kualitas”.
Oleh karena itu, untuk menjawab pertanyaan penelitian ini, teknik-teknik perhitungan beban dan pengukuran performa (kualitas) dipelajari pada Bab 2, sehingga metode untuk menghitung kapasitas server DVN dapat disusun. Setelah proses perhitungan, hasilnya harus diuji. Oleh karena itu akan disediakan penjelasan mengenai pengujian yang dilakukan di akhir bab ini.
Berikut adalah gambar yang menjelaskan tentang kerangka berpikir untuk menjawab pertanyaan penelitian ini:
Gambar 3.1 Kerangka Berpikir
Penjelasan Gambar 3.1 adalah, dalam menjawab pertanyaan penelitian ada beberapa proses yang harus dilalui. Proses proses tersebut adalah (secara berurutan):
a. Melakukan studi literatur tentang perhitungan kapasitas b. Menyusun metode perhitungan
c. Lakukan pengujian atas metode perhitungan kapasitas yang telah disusun
3.1Penyusunan Metode Perhitungan Kapasitas
Studi literatur terkait dengan teknik perhitungan kapasitas telah dilakukan. Berikut adalah opini atas keempat metode yang telah dipelajari, dan metode yang akhirnya digunakan untuk menjawab pertanyaan penelitian.
Load testing merupakan cara termudah untuk mengukur performa sistem dan batas atas dari kinerja suatu sistem. Namun Load testing tidak dapat menangkap operasi aplikasi secara keseluruhan, dan tidak juga memperhitungkan jumlah komponen yang digunakan. Hanya memberikan informasi tentang kapasitas sistem dalam merespon satu, atau lebih, fungsi operasi yang diakses secara berulang-ulang atau bersamaan.
Dalam kenyataannya, load testing sering digunakan untuk mengukur kapasitas dengan menyusun skenario akses. Penyusunan skenario ini didasari oleh perkiraan atas fungsi-fungsi yang diakses. Jadi, tidak menggambarkan perilaku pengguna secara nyata. Hal tersebut berguna dalam memperkirakan kebutuhan kapasitas dalam sistem yang baru berdiri. Untuk sistem yang sedang berjalan, hal ini dapat menyebabkan perbedaan yang jauh antara performa yang terhitung dan performa yang terjadi dalam live-system.
Berhubung pertanyaan yang diajukan memiliki “pengguna” sebagai titik fokal, maka akan lebih baik jika jawaban penelitian melibatkan faktor pengguna dalam proses analisa.
CBMG dan CVM merupakan kandidat yang bagus untuk menciptakan pengukuran load, karena keduanya menggunakan log-file sebagai dasar perhitungan. Sehingga kita dapat mengestimasi kebutuhan kapasitas server berdasarkan pemakaian pengguna.
Yang mana yang harus dipilih? CBMG atau CVM. Secara intuitif, CBMG adalah kanditat pilihan, karena sifatnya yang organik. CBMG menjelaskan load dengan menghitung probabilitas transisi antara titik navigasi, sedangkan CVM menghitung load berdasarkan frekwensi akses suatu titik navigasi. Selain itu, CBMG berisi informasi yang mungkin akan diperlukan dalam pengambilan keputusan untuk perencanaan kapasitas, atau pengembangan aplikasi, untuk menjawab petanyaan seperti: Berapa probabilitas diaksesnya modul A setelah modul B?
Dengan CBMG (atau CVM), hasil yang dapat diharapkan adalah Visit Ratio, yaitu jumlah diaksesnya suatu titik navigasi dalam satu sesi pengguna. Visit Ratio
tersebut dapat digunakan untuk memetakan setiap titik navigasi kedalam utilisasi komponen fisik server (misalnya CPU, database dan memory) Dimana untuk setiap komponen, probabilitas utilisasi komponen oleh pengguna dapat dihitung. Pemetaan kedalam komponen ini menghasilkan CSID.
Jadi, proses terakhir adalah menghitung utilisasi komponen fisik dengan memetakan pola perilaku pengguna, yang disusun dengan metode CBMG, kedalam komponen fisik server. Berikut adalah tahapan yang dilakukan untuk menghitung kapasitas server DVN:
Gambar 3.2 Metodologi Perhitungan Kapasitas
Dalam Gambar 3.2 diatas, dapat terlihat urutan proses yang dapat dilakukan untuk mengestimasi kapasitas server. Pertama interprestasi log-file untuk menciptakan
pengguna yang diminati. Setelah ditemukan cluster yang diminati, centroid-nya dapat digunakan untuk menghitung Visit ratio, yang kemudian dapat digunakan dalam proses ketiga, yaitu pemetaan komponen fisik.
Setelah komponen fisik dipetakan dengan setiap titik navigasi, maka utilisasi untuk setiap komponen dapat dihitung dengan menjumlahkan utilisasi komponen tersebut oleh semua titk navigasi. Dengan hasil tersebut, maka kita dapat mengestimasi berapa jumlah waktu yang dibutuhkan untuk menyelesaikan satu
request oleh pengguna.
Untuk lebih memperjelas deksripsi metode, sub-bab selanjutnya akan mendeskripsikan langkah-langkah yang dilakukan dalam setiap proses.
3.2Interpretasi Log
Log yang digunakan adalah log aplikasi, log web-server tidak dapat didapatkan. Menyadari hal tersebut, perlu dijelaskan fitur log-file aplikasi DVN seperti berikut:
1. Log-file DVN memiliki User ID (uid), mengindikasikan log dicatat setelah proses login berhasil.
2. Log-file DVN tidak mencatat detik dari request, catatan waktu hanya mencakup menit, dengan format mm/dd/yyy hh:mm.
3. Catatan URI harus di konversi kedalam bentuk standar.
3.3Clustering
Clustering dilakukan dengan metode K-means. Tujuan dari clustering, secara umum, adalah mencari kelompok data yang optimum. Apakah yang disebut kelompok data yang optimum? Kelompok data yang optimum adalah kelompok data yang memiliki cluster dengan jarak intracluster yang kecil dan jarak
intercluster yang besar.
Apa itu jarak intracluster dan jarak intercluster? Jarak intracluster adalah jarak antara titik pengamatan dalam satu cluster. Sedangkan jarak intercluster adalah
jarak antara centroid satu dengan centroid lain. Jarak intracluster
mengindikasikan besarnya varian antara pengamatan satu dengan pengematan lain dalam satu cluster. Sedangkan jarak intercluster mengindikasikan jarak antar
cluster. Faktor tersebut diperhatikan karena proses clustering seharusnya menciptakan kelompok data yang memiliki karakteristik berbeda dengan anggota setiap kelompok memiliki perbedaan (varian) yang kecil.
Gambar 3.3 Jarak intracluster dan jarak intercluster
Pada Gambar 3.3, kita dapat melihat jarak intracluster ditandai dengan garis kuning, dan jarak intercluster dengan garis ungu. Untuk mencari jarak intercluster dan jarak intracluster, serta informasi lain yang berguna tentang kedua jarak ini, maka kita perlu mengilustrasikan Sebuah cluster Pk dengan jumlah anggota sejumlah nk, dan memiliki centroid . Rata-rata jarak antara pik dengan (jarak intracluser) dapat dihitung dengan rumus:
(3.1)
Sedangkan, rata-rata jarak intracluster dari semua cluster dapat dihitung dengan:
(3.2) Dengan adanya kita dapat menghitung sampel varians dari jarak intracluster dengan:
(3.3) dan covariance dari jarak intracluster adalah
(3.4) Untuk menghitung jarak intercluster, kita dapat menghitung jarak antara untuk semua Pk dengan:
(3.5) Sedangkan, sampel varians dari dengan:
(3.6) Oleh karena itu:
(3.7) Kelompok yang optimal dapat kita raih dengan nilai terkecil dari rasio antara varians jarak intracluster dengan varians jarak intercluster (βσ2), dan nilai terkecil
dari rasio antara covarians jarak intracluster dengan varians jarak intercluster
(βCo), yang masing-masing dapat dihitung dengan:
(3.8)
(3.9)
3.3.1Pemilihan Cluster
Setelah nilai K ditentukan, proses selanjutnya adalah pemilihan cluster dengan anggota terbanyak. Hal ini mengandung arti bahwa penelitian ini hanya tertarik dengan kelompok pengguna terbanyak.
3.4Pemetaan Komponen Server dan Perhitungan Utilisasi Komponen
Setelah Cluster dipilih, Visit ratio dari cluster tersebut di petakan ke dalam komponen fisik server, sehingga utilisasi komponen dari semua aktivitas pengguna dapat diukur.
Pemetaan CSID dimulai dari pemetaan setiap akitivitas kedalam notasi CSID. Dengan adanya Visit ratio untuk setiap aktivitas, maka rata-rata utilisasi komponen dapat dihitung dengan Ua = PVa ua dimana ua adalah besaran utilisasi komponen server oleh suatu titik navigasi dan PVa adalah ProbabilitasVisit Ratio dari titik navigasi (aktivitas) a, mengindikasikan probabilitas diaksesnya suatu titik navigasi dalam satu sesi. Dengan Va sebagai Visit Ratio dari modul a, maka
PVa dapat dihitung sebagai berikut:
(3.10) Estimasi utilisasi komponen dalam satu koneksi dapat dihitung dengan menghitung jumlah utilisasi dari seluruh aktivitas yang menggunakan komponen tersebut. Pada akhirnya, hasil yang dapat diharapkan adalah sebagai berikut: a. Jumlah sesi paralel yang dapat diakomodir oleh sistem selama satu detik
b. bottleneck yang terdapat dalam sistem, diindikasikan lewat akomodasi jumlah sesi yang paling kecil (per detik).
c. Biaya yang harus di keluarkan untuk mengakomodir satu sesi.
3.5Pengujian Hasil Perhitungan Kapasitas
Pengujian hasil perhitungan, dapat dilakukan dengan load test. Pada poin a diatas (Jumlah sesi paralel yang dapat diakomodir oleh sistem selama satu detik), dapat dilihat bahwa hasil dari metode ini adalah hasil numerik yang di hitung berdasarkan probabilitas utilisasi komponen fisik. Dengan kata lain, jumlah sesi yang dapat diakomodir, dengan Visit Ratio tertentu.
Jadi, load test, dapat dilakukan dengan menggunakan Probabilitas Visit Ratio saat mengirim request ke server DVN. Misalnya, pengiriman request ke URL “A“ harus sesuai dengan Probabilitas Visit Ratio URL ”A” yang telah di hitung sebelumnya.
Hal tersebut dapat dilakukan dengan menyusun URL untuk request sedemikian rupa, sehingga perilaku load test (URL yang di request) sama dengan perilaku pengguna yang sedang diteliti (pengguna dalam cluster terpilih).
Pengujian suatu metode tidak akan sah apabila pengujian hanya dilakukan terhadap satu kondisi variabel independen, oleh karena itu, pengujian harus dilakukan dengan berbagai kondisi variable indenpenden. Dengan “perilaku pengguna” sebagai variabel independen dari “kapasitas”, maka perlu disusun beberapa Probabilitas Visit Ratio dalam melakukan pengujian, selain menggunakan Probabilitas Visit Ratio yang telah didapatkan dari data real.
32 Universitas Indonesia
BAB 4
PROFIL PEMILIK APLIKASI
4.1Profil Pemilik Aplikasi
DVN Dimiliki oleh PT BDMN. Lebih spesifik lagi, divisi HR PT BDMN. Untuk itu, Kami akan membahas sedikit tentang PT BDMN dan HR. Berikut adalah kutipan dari website BDMN:
PT Bank BDMN Indonesia Tbk. didirikan pada 1956. Nama Bank BDMN berasal dari kata “dana moneter” dan pertama kali digunakan pada 1976, ketika perusahaan berubah nama dari Bank Kopra.
…
Saat ini, “BDMN” adalah salah satu institusi keuangan terbesar di Indonesia dari jumlah pegawai – sekitar 67,000 (termasuk karyawan anak perusahaan) pada Desember 2012 - yang berfokus untuk merealisasikan visinya: “Kita peduli dan membantu jutaan orang mencapai kesejahteraan.”
Dengan visi “Kita peduli dan membantu jutaan orang mencapai kesejahteraan.”, BDMN menerapkan Nilai-nilai perusahaan sebagai berikut: “caring, honesty,
passion to excel, teamwork and disciplined professionalism” (Peduli, Kejujuran,
Hasrat untuk performa, kerja tim, disiplin dan profesionalisme).
Selain itu, juga didefinikan “Brand Personality”: Enabling, Energetic, Proactive, Adaptive, Capable, Genuine.
Komponen – komponen yang mempengaruhi pengembangan aplikasi ini adalah: Visi, Nilai-nilai perusaahan, dan Brand Personality. Mengapa ketiga komponen tersebut penting? Karena ketiga komponen itu merupakan dasar pembangunan DVN sebagai media komunikasi internal.
HR, yang berperan dalam mengelola sumber daya manusia di dalam organisasi BDMN, tidak hanya berfungsi sebagai penyedia proses rekrutmen dan payroll,
tapi juga berfungsi sebagai pengelola proses bisnis, dan performa sumber daya manusia di BDMN. HR merasa perlu untuk mengkomunikasikan visi, nilai-nilai, dan brand personality dalam BDMN, dengan cara yang menyeluruh, sinambung, dan terkontrol. Oleh karena itu, perlu diciptakan suatu media yang mendukung tujuan komunikasi internal ini. Berikut kami jabarkan proses operasi, dari HR, untuk memperjelas bagian operasional yang di dukung oleh DVN.
4.2Area Operasional HR
Area operasional HR dibagi kedalam dua bagian besar: Personalia dan Pengelolaan Aset SDM. Kegiatan operasional yang dilakukan di kedua area tersebut dapat dilihat pada table dibawah.
Tabel 4.1 Area Operasional HR BDMN
Dari Tabel 4.1 diatas, terlihat pembagian area operasional dalam operasi HR BDMN. Dalam area Personalia, kegiatan yang dilakukan adalah kegiatan administratif seperti Gaji, Pensiun, Pencatatan sejarah karyawan, pelayanan pengajuan cuti, dan lain-lain. Kami tidak akan membahas area personalia lebih lanjut, karena area ini tidak berhubungan dengan DVN.
Dalam area Pengelolaan Aset SDM, proses-proses operasionalnya, dapat digambarkan sebagai berikut:
Gambar 4.1 Proses Pengelolaan Aset SDM
Pada Gambar 4.1 diatas, dapat terlihat bahwa DVN berada dalam sub-proses pemeliharaan. Untuk lebih memperjelas deskripsi sub-proses dalam area Operasional, berikut adalah penjelasan dari setiap proses:
a. Desain Organisasi (design)
Proses ini adalah proses perancangan organisasi, seperti struktur organisasi, penyusunan Deskripsi pekerjaan, dan kriteria SDM yang dibutuhkan dalam proses bisnis. Desain organisasi yang dibuat disusun berdasarkan kebutuhan proses bisnis dari suatu organisasi/divisi. Sehingga, proses ini pada akhirnya akan menciptakan desain organisasi dan kriteria SDM yang sejalan dengan kebutuhan proses bisnis.
b. Akuisisi
Setelah Proses desain, proses selanjutnya adalah proses akuisisi, dimana HR melakukan rekrutmen atas SDM yang diperlukan. Proses akuisis terdiri dari beberap sub-proses:
1. Brand Positioning BDMN terhadap calon pegawai 2. Analisis SWOT dari BDMN dalam dunia kerja
3. Formulasi Value Proposition dari BDMN terhadap calon pegawai. 4. Proses rekrutmen secara internal dan external.
Proses akuisisi ini bertujuan untuk merekrut SDM yang tepat, sesuai dengan desain yang telah di susun dalam proses Desain.
c. Pemeliharaan
Setelah diakuisisi, SDM dipelihara dengan mempertimbangkan dua faktor: material dan imaterial. Faktor material contohnya adalah Kompensasi dan manfaat. Sedangkan, faktor imateril adalah kebahagiaan pegawai dan perilaku pegawai.
Gambar 4.2 Faktor Material dan Imaterial dalam proses pemeliharaan SDM Dalam Gambar 4.2 diatas, kita dapat melihat bahwa pemeliharaan faktor imaterial diimplementasikan kedalam penyusunan budaya organisasi dan nilai-nilai perusahaan. Pemeliharaan faktor imaterial inilah yang melahirkan DVN. Dengan fungsi utama sebagai alat komunikasi dua arah dalam upaya komunikasi nilai-nilai perusahaan, DVN menyediakan saran komunikasi untuk membahas, mengaktualisasikan dan menyebarkan nilai-nilai perusahaan kepada pegawai BDMN.
Budaya organisasi yang diciptakan BDMN, bersandar pada empat pilar utama: Kepemimpinan, Komunikasi, Lingkungan Kerja, dan Peraturan perundangan.
Berhubungan dengan pilar-pilar tersebut, DVN bersandar pada pilar komunikasi, karena sifatnya yang berfungsi sebagai media komunikasi.
Sedangkan nilai-nilai perusahaan yang dianut oleh BDMN adalah: 1. Jujur
2. Peduli 3. Kerjasama
4. Mengupayakan yang terbaik 5. Disiplin dan profesionalisme
Dengan memperhitungkan faktor-faktor material dan imaterial, proses ini bertujuan untuk menciptakan keterlibatan karyawan (employee engagement) dalam menjalankan tugas sehari-hari.
d. Pengembangan
Proses pengembangan merupakan usaha untuk meningkatkan kemampuan pegawai secara individual ataupun organisasional. Kita dapat melihat proses perkembangan ini lewat seminar dan pelatihan. Proses ini berjalan bersamaan dengan proses Pemeliharan (setelah Akuisisi). Hasil yang diharapkan dari proses ini adalah peningkatan performa pegawai.
e. Pelepasan
Proses ini berusaha mengelola proses pelepasan pegawai, baik mengundurkan diri, pecat, atau pensiun. Proses pengelolaan ini dilakukan untuk meminimalisir resiko akibat pelepasan pegawai (seperti resiko legal), dan untuk menjaga hak-hak dari pegawai yang pergi.
4.3Profil Vendor Server
Saat ini, aplikasi DVN dikelola oleh PT Bitcribs Indonesia (Bitcribs, bitcribs.co.id) . Sebagai perusahaan yang bergerak di bidang Website Design, pengembangan IT, dan jasa kreatif, Bitcribs berkomitmen untuk mengelola
aplikasi DVN. Semenjak tahun 2013, yang sebelumnya dikembangkan dan dikelola oleh Visious Studio (PT Visious Indonesia).
Bitcribs dikelola oleh Ritchie Ned Hansel (Rici, founder), sebagai direktur, dan Goenawan Adhi (Adi, co-founder) sebagai pengelola aset SI & TI. Bitcribs merupakan perusahaan skala kecil dengan jumlah pegawai mencapai 10 orang.
38 Universitas Indonesia
BAB 5
ANALISA KAPASITAS
Perhitungan kapasitas dilakukan dengan menterjemahkan proses perhitungan kedalam bahasa pemrograman node.js. Mulai dari proses interpretasi log-file, sampai dengan kalkulasi utilisasi server, semua diterjemahkan kedalam bahasa pemrograman. Hal ini dilakukan untuk memudahkan proses kalkulasi, daripada harus mempelajari, memilih, dan kemungkinan, memodifikasi tools yang ada di pasaran. Pemilihan node.js sebagai bahasa pemrograman tidak didasari oleh analisa apapun. Tentunya, replikasi proses kalkulasi tidak harus menggunakan
node.js.
5.1Proses Interpretasi Log-file
Analisa kapasitas bermula dari interpretasi log-file. Dari server DVN, didapatkan
log-file seperti berikut:
Figur 5.1 Log-file Aplikasi DVN
Log-file yang didapatkan tersebut (Figur 5.1), berisi baris header, dan baris log
pada baris selanjutnya (penambahan baris kosong untuk memperjelas). Disetiap baris log terdapat informasi tentang IP pengguna, URI yang diakses, Referer,
User-Agent, User-ID, dan waktu dalam format mm/dd/yyyy HH:mm. Untuk memproses log-file tersebut kedalam sesi, kami melakukan hal-hal berikut:
a. Log-file sudah mengikut sertakan user-ID, sehingga sesi bisa disusun berdasarkan IP, user-ID, waktu. Dimana waktu per sesi adalah satu hari.
b. Waktu akses (t) terbatas pada menit, sehingga dalam menghitung delta-t (δt), kami mengasumsikan δt = 5 jika tk - tk-1 = 0
c. URI terkadang memiliki url-query sehingga kami harus melakukan konversi untuk mendapatkan nama standard untuk setiap URI.
d. Tidak semua baris dalam log-file dapat digunakan. Kami harus membersihkan
log-file sehingga dapat digunakan.
Dalam poin b diatas, URI harus dikonversi untuk mendapatkan informasi akses yang konsisten. Untuk itu perlu disusun sebuah tabel konversi sebagai dasar konversi. Proses konversi sendiri dapat dilakukan dengan regular expression.
Tabel 5.1 Table Konversi URI
Regex Aktivitas \/modul\/shared read \/modul.php\?(.+)?hash\=shared read \/api\/item\/\?(.+)?iid\= read-item \/api\/item\/itemcomment read-itemcomment \/api\/utils\/news\?(.+)?sort\= browse \/modul\/home home \/modul.php\?(.+)?hash\=home home \/api\/utils\/hometable hometable \/api\/currentstat currentstat \/api\/upload(\/|\?).+ upload \/modul\/share$ sharebase \/modul.php\?(.+)?hash\=share$ sharebase \/modul\/share\/.+ share \/modul.php\?(.+)?hash\=share.+ share \/modul\/divizen$ divizen
Tabel 5.1 Table Konversi URI (Sambungan) Regex Aktivitas \/modul.php\?(.+)?hash\=divizen divizen \/modul\/divizen\/story divizen-story \/modul\/profile\/userimage profile-image \/modul\/profile profile \/modul.php\?(.+)?hash\=profile$ profile \/modul.php\?(.+)?hash\=profile\%2Fshared profile-shareditem \/api\/user\/profile profile-data \/api\/user\/friends profile-friends \/api\/user\/points profile-points \/api\/user\/items profile-items \/api\/user\/photo profile-photo \/modul\/settings\/help settings-help \/modul.php\?(.+)?hash\=setting settings \/modul\/settings settings \/modul\/crowd$ crowd \/modul\/crowd\/list crowd-list \/modul\/crowd\/suggest crowd-suggest \/modul\/notification notification \/modul.php\?(.+)?hash\=notification notification \/modul\/search$ searchbase \/modul\/search search \/modul.php\?(.+)?hash\=search search \/modul\/help help \/modul.php\?(.+)?hash\=help help \/modul\/chat$ chat \/modul\/chat\/checkonline chat-checkonline \/modul\/chat\/active chat-active \/modul\/chat\/send chat-send \/api\/item\/itemcomment comment \/api\/item\/itemvote vote \/api\/item\/post publish
Tabel 5.1 diatas adalah tabel yang digunakan untuk melakukan konversi URI atas
log-file DVN. Dengan didefinisikan-nya tabel konversi tersebut, proses selanjutnya adalah pembersihan log-file.
5.2Proses Pembersihan log-file
Untuk Membersihkan log-file, tiap baris log divalidasi dengan parameter valid sebagai berikut:
a. Referer harus berasal dari test.dvn.web.id atau m.test.dvn.web.id, atau kosong. b. URI harus bisa di konversi kedalam bentuk standar, bila ada URI yang tidak
dikenal, maka baris tersebut dianggap tidak valid.
Validasi kolom referer harus dilakukan karena ada beberapa baris dengan nilai
referer: dvn.local. Bukan referer yang valid. Sedangkan, Uri yang tidak bisa di konversi dianggap tidak valid untuk menghindari inklusi URI seperti login, sekaligus membersihkan log-file dari panggilan bot, seperti googlebot. Setiap baris log yang valid, disimpan kedalam database (mysql), untuk memudahkan proses sortir dalam ekstraksi sesi.
5.3Proses ektraksi sesi
Baris log yang valid disimpan menggunakan mysql. Semua baris log tersebut disimpan dalam database “dvnlog” dengan table “access” yang memiliki struktur
seperti dibawah ini:
Tabel 5.2 Struktur tabel “access” untuk menampung baris log yang valid Field Type
id (PK) Number (Auto Incerement)
ip Varchar
uid Varchar
url Text
time datetime activity varchar
Tabel 5.2 diatas memberikan informasi tentang struktur tabel untuk menyimpan baris log yang valid. id adalah angka yang menyatakan urutan dalam log-file, ip
pengguna, url adalah URI yang diakses, time adalah waktu akses, dan activity
adalah nama standar untuk URI yang telah dikonversi.
Langkah selanjutnya adalah penyusunan sesi. Sesi dapat disusun dengan langkah-langkah berikut:
a. Panggil semua activity yang tersedia dalam database secara unik, dan simpan didalam Array activityIndex. tambahkan activity “entry” di depan Array dan activity “exit” di akhir Array.
b. Untuk setiap activity di dalam activityIndex berikan index [0 .. n]
c. Panggil semua baris log dari database, urutkan berdasarkan id, ip, uid dengan perintah: select * from `access` order by ip,uid,id
d. Untuk setiap baris log (i) lakukan hal berikut: d.1. Buat nama sesi: S = ( ipi , uidi , mmi /ddi /yyyyi )
d.2. Jika sesi dengan nama S belum ada, buat sesi baru dengan menginisialisasi CS dan WS sebagai matrix 0 dengan dimensi n x n (activityIndex memiliki dimensi 1 x n) dan lastActivityS = 'entry', serta
lastTimeS = mmi /ddi /yyyyi hhi:mmi d.3. Hitung nilai Ci dengan:
CS [ lastActivityS ] [ activityi ] = CS [ lastActivityS ] [ activityi ] + 1 d.4. Hitung waktu yang dibutuhkan dalam transisi:
δt= lastTimeS - timei
d.5. Asumsikan δt= 5 jika δt = 0 dan lastActivityi!='entry' d.6. Hitung nilai Wi dengan:
Wi [ lastActivityi ] [ activityi ] += δt d.7. Rubah nilai lastActivityS menjadi activityi.
LastActivityS = activityi e. Untuk semua sesi, tambahkan exit point dengan
CS [ lastActivityS ] [ exit ] = 1
Dengan operasi tersebut, utk log-file DVN, terdapat 650 sesi yang dapat digunakan. Proses selanjutnya adalah proses clustering.
5.4Proses Clustering
Clustering dilakukan dengan metode K-means. Data sesi yang sudah kita ekstrak sebelumnya digunakan sebagai input dari proses clustering. Untuk memperhitungkan jarak antara sesi a dan sesi b, kami menggunakan rumus yang direkomendasikan oleh Menasche (1999), tertera di Bab 2 (Persamaan 2.4):
Dengan rumus tersebut, metode clustering seperti yang tertera pada sub-bab 2.6 kemudian di lakukan, dan nilai K yang optimal dapat dicari dengan menghitung
instracluster variance dan intercluster variance (Sub-bab 3.3).
Kekurangan dari metode K-means adalah inisialisasi centroid yang random. Inisialisasi seperti ini menghasilkan hasil yang tidak konsisten. Untuk mengatasi ini, pemilihan nilai K optimal dapat dilakukan dengan cara berikut:
a. Lakukan clustering dengan K = { 3, 4, 5, 6 }
b. Untuk semua hasil K, identifikasi nilai K yang optimal dengan kondisi
min( βσ21 , ... , βσ2k) dan min( βCo1 , ... , βCok ) berada di nilai K yang sama. c. Jika hasil optimal tidak dapat ditemukan, kembali ke langkah 1.
Jadi, yang dilakukan adalah membatasi nilai K, sebatas nilai yang dianggap wajar, dan mengulangi proses clustering hingga ditemukan hasil cluster yang optimal.
Dengan proses tersebut (hasil dapat dilihat pada lampiran 3), nilai K yang optimal adalah K = 3. Memiliki nilai betaVar ( βσ2 ) dan betaCoVar ( βCo ) yang terkecil, dengan jumlah cluster terbesar adalah 639 anggota pengguna.
Dengan terpilihnya cluster terbesar, maka probabilitias transisi untuk setiap titik navigasi dapat dihitung dengan persamaan (2,5) dan waktu transisi dapat dihitung dengan persamaan (2,6). Proses ini menghasilkan matrix transisi yang dapat dilihat pada lampiran 2.
5.5Proses Pemetaan Komponen Fisik
Saat ini log-file telah di interpretasi dengan menyusun log-file tersebut kedalam sesi pengguna. Setelah itu clustering juga telah dilakukan untuk memilih tipe pengguna terbanyak, dan menghitung transisi untuk setiap titik navigasi dalam
cluster terpilih, sehingga matrix transisi dapat disusun.
Proses selanjutnya adalah menggunakan data transisi untuk memetakan utilisasi komponen fisik di server. Pertama, Visit Ratio (V) dari setiap titik navigasi harus dihitung. Perhitungan Visit Ratio dilakukan melalui proses aljabar linear. Untuk menterjemahkan proses ini kedalam bahasa pemrograman, operasi aljabar linear dapat dilakukan dengan melakukan operasi matrix.
5.6Perhitungan Visit Ratio
Sub-bab ini akan memberikan penjelasan proses operasi matrix yang dilakukan untuk menghitung Visit Ratio. Namun, karena persamaan yang diolah cukup panjang, maka akan lebih mudah apabila penjelasan dilakukan lewat contoh yang lebih sederhana.
Karena itu, Tabel dibawah telah disusun untuk men-simulasikan proses operasi matrix dalam menghitung Visit Ratio. Perlu diketahui bahwa tabel dibawah tidak berhubungan sama sekali dengan data sebenarnya.