PREDIKSI CALON MAHASISWA BARU UNIVERSITAS
SANATA DHARMA YANG TIDAK MENDAFTAR ULANG
MENGGUNAKAN ALGORITMA
NAIVE BAYESIAN
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
SRI PURWANTI
065314098
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
PREDICTION OF SANATA DHARMA UNIVERSITY’S
NEW STUDENTS ENROLLMENT
USING NAIVE BAYESIAN
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Computer Degree
In Study Program of Informatics Engineering
by:
SRI PURWANTI
065314098
STUDY PROGRAM OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
ABSTRAK
Dalam penerimaan mahasiswa baru Universitas Sanata Dharma
(USD), seringkali jumlah mahasiswa yang mendaftar ulang lebih sedikit
dari kapasitas penerimaan mahasiswa baru yang ditetapkan oleh USD.
Namun sebaliknya dapat juga terjadi mahasiswa baru yang mendaftar
ulang melebihi kuota. Untuk mengantisipasi masalah tersebut, USD perlu
mengetahui prediksi calon mahasiwa baru yang tidak melakukan daftar
ulang.
Banyak cara yang dapat digunakan untuk melakukan prediksi calon
mahasiswa baru yang tidak melakukan daftar ulang. Salah satu cara yang
digunakan adalah data mining menggunakan algoritma Naive Bayesian. Dalam skripsi ini dibangun sebuah sistem untuk memprediksi
apakah seorang mahasiswa baru akan mendaftar ulang atau tidak. Data
yang akan digunakan dalam proses prediksi adalah data PMB USD tahun
2009 untuk pendaftaran melalui jalur reguler tes tertulis dari gelombang 1
sampai gelombang 3 meliputi prioritas pilihan pada program studi tempat
calon mahasiswa diterima, gelombang masuk pendaftaran, jenis kelamin,
jurusan SMA, program studi tempat diterima, status daftar ulang yang
dilakukan dan nilai final tes masuk berdasarkan program studi. Data-data
ini digunakan sebagai himpunan data pelatihan dan data pengujian. Data
pelatihan digunakan untuk melakukan penghitungan nilai probabilitas
prior dan likelihood sedangkan himpunan data pengujian digunakan untuk melakukan penghitungan nilai probabilitas posterior. Pengujian dilakukan
ABSTRACT
USD often has less new students than the standar capacity of the
admission. Nevertheless, there is also a possibility of over quota. Henceforth,
USD needs to anticipate the unpredictable situation.
Several ways could be done to predict the numbers of new students who
do not enroll. One of them is data mining by using Naive Bayessian algorithm.
In this thesis, the writer developed a system to predict whether a new
student will enroll or not. The data was taken from Sanata Dharma University
Admission year 2009. The data consists of regular admission test which includes
the priority of the choosen study program, the enrollment period, sex, the previous
major in SMA, the study program in which the student is accepted, enrollment
status and the final test score based on the choosen study program. The data were
used as training data set and test data set as well. Training data set was used to
calculate prior probability and likelihood while the test data set was used to
calculate posterior probability. The system was test using fivefold cross-validation
and tenfold cross-validation with 1304 data row. The accuracy of the prediction
using fivefold cross-validation method is 65,57%, while the accuracy of the
tenfold cross-validation method is 65,64%.
KATA PENGANTAR
Puji syukur penulis haturkan kepada Tuhan Yang Maha Esa yang telah
melimpahkan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan
Tugas Akhir ini yang berjudul “Prediksi Calon Mahasiswa Baru Universitas
Sanata Dharma Yang Tidak Mendaftar Ulang Menggunakan Algoritma
Naive Bayesian”.
Dalam kesempatan ini penulis mengucapkan terima kasih kepada semua
pihak yang telah membantu penulis baik secara langung maupun tidak langsung,
yang telah memberikan dukungan serta semangat kepada penulis. Terima kasih
penulis ucapkan kepada :
1. Ibu P.H Prima Rosa, S.Si.,M.Sc. selaku dosen pembimbing yang selalu
memberikan waktu, kesabaran serta bimbingan yang telah diberikan
kepada penulis.
2. Ibu Ridowati Gunawan S.Kom, M.T. selaku dosen penguji.
3. Ibu Sri Hartati Wijono, S.Si.,M.Kom. selaku dosen penguji.
4. Staf BAPSI USD yang telah memberikan data mahasiswa baru.
5. Bapak, Ibu, Adik dan seluruh keluarga yang selalu memberikan dukungan
moril maupun material sehingga penulis dapat menyelesaikan skripsi ini.
6. Mas Didik Daryanto yang selalu memberikan dukungan kepada penulis.
7. Teman-teman penulis : Grace, Irene Leni, Novi Hartati, Rina Hapsari,
Novi Sulistyawati, Yosia Dwi Susetyo yang selalu memberikan semangat.
8. Semua pihak yang telah membantu penulis.
Penulis menyadari dalam penyusunan tugas akhir ini masih jauh dari
sempurna, sehingga dengan kerendahan hati penulis mengharapkan kritik dan
saran yang bersifat membangun untuk merperbaiki tugas akhir ini.
Akhir kata penulis mengucapkan terima kasih dan semoga tugas akhir ini
barmanfaat bagi semua pihak.
Yogyakarta 28 Januari 2011
DAFTAR ISI
HALAMAN JUDUL ……….
HALAMAN PERSETUJUAN ………..
HALAMAN PENGESAHAN ...
PERNYATAAN KEASLIAN KARYA ...
ABSTRAK ...
ABSTRACT ...
LEMBAR PERNYATAAN PERSETUJUAN ...
KATA PENGANTAR ...
DAFTAR ISI ...
DAFTAR GAMBAR ...
DAFTAR TABEL ...
BAB I PENDAHULUAN ………
1.1Latar Belakang Masalah ………..
1.2Rumusan Masalah ………...
1.3Tujuan ……….
1.4Batasan Masalah ……….
1.5Metodologi Penelitian ……….
1.6Sistematika Penelitian ……….
BAB II LANDASAN TEORI ………...
2.1Pengertian Data Mining ………..
2.2Teorema Bayes ………
2.3Naïve Bayes Clasifier ………..
2.4Conditional Independence ………...
2.5Contoh Klasifikasi Naïve Bayes ……….
BAB III ANALISIS DAN PERANCANGAN SISTEM ...………...
3.1Identifikasi Sistem …….………..
3.2Pembersihan Data ………...
3.3Integrasi Data ………..
3.4Seleksi Data ……….
3.6Analisis Kebutuhan Pengguna ………
3.6.1Diagram Model Usecase ……….…...
3.6.2Tabel Ringkasa Usecase ……….………..
3.6.3Narasi Usecase ……….
3.7Perancangan Umum Sistem ….………...
3.7.1Diagram Konteks ..…….……….…...
3.7.2Masukan Sistem ……….……….…...
3.7.3Proses Sistem ………...
3.7.4Keluran Sistem ……….
3.7.5Perancangan Basis Data ………...
3.7.5.1Perancangan Konseptual ...………….
3.7.5.2Perancangan Logikal ….………
3.7.5.3Perancangan Fisikal …….……….
3.7.6Diagram Aktifitas ……….
3.7.7Diagram Kelas ………..
3.7.7.1Diagram Kelas Usecase Memasukkan Data ………….
3.7.7.2Diagram Kelas Usecase Melihat Detail Atribut Data
Pelatihan ………….………...
3.7.7.3Diagram Kelas Usecase Melihat Detail Atribut Data
Pengujian………...
3.7.7.4Diagram Kelas Use Case Menghitung Nilai
Probabilitas Prior ………...
3.7.7.5Diagram Kelas Use Case Menghitung Nilai
Likelihood ………..………...
3.7.7.6Diagram Kelas Use Case Melakukan Prediksi Satu
Record ………...
3.7.7.7Diagram Kelas Use Case Melakukan Prediksi Semua
Record ………...
3.7.8Diagram Sequence ……...………
3.7.9Perancangan Metode Dalam Diagram Kelas ………..
3.7.9.1Perancangan Metode Diagram Kelas Kontrol Database
3.7.9.2 Perancangan Metode Diagram Kelas Pelatihan ……...
3.7.9.4Perancangan Metode Diagram Kelas ControlPelatihan
3.7.9.5Perancangan Metode Diagram Kelas ControlPengujian
3.7.10 Perancangan Antar Muka ………..
3.7.11 Perancangan Pengujian ……….
BAB IV IMPLEMENTASI DAN PEMBAHASAN ………
4.1Implementasi Basis Data …...………..
4.2Implementasi Program dan Pembahasannya ………...
4.2.1Halaman Utama ……...……….
4.2.2Use Case Memasukkan Data ………
4.2.3Use Case Lihat Detail Atribut Data Pelatihan ……….
4.2.4Use Case Lihat Detail Atribut Data Pengujian ………
4.2.5Use Case Menghitung Nilai Probabilitas Prior ………
4.2.6Use Case Menghitung Nilai Likelihood ………...
4.2.7Use Case Melakukan Prediksi Satu Record ……….
4.2.8Use Case Melakukan Prediksi Semua Record ……….
4.3Analisa Hasil ………...
4.3.1Pengujian Untuk Nilai Fold 5 ……...……..……….
4.3.2Pengujian Untuk Nilai Fold 10 ……...……..………..…….
BAB V KESIMPULAN DAN SARAN ………
5.1Kesimpulan ………...………..
5.2Saran ………
DAFTAR PUSTAKA ………...
LAMPIRAN ………..
1. Listing Program Memasukkan Data ...……….……….
2. Listing Program Lihat Detail Atribut Pelatihan ………
3. Listing Program Lihat Detail Atribut Pengujian .…..…………...
4. Listing Program Penghitungan Nilai Probabilitas Prior ……..…...
5. Listing Program Penghitungan Nilai Likelihood ...
6. Listing Program Penghitungan Nilai Probabilitas Posterior ……...
7. Listing Program Prediksi Satu Record …..………...
8. Listing Program Prediksi Semua Record …..………...
DAFTAR GAMBAR
Gambar 2.1 Langkah-langkah Dalam Penambangan Data ...………
Gambar 3.1 Diagram Use Case Sistem ………….……… Gambar 3.2 Diagram Konteks Sistem ………..
Gambar 3.3 Diagram Aktifitas Use Case Memasukkan Data ………... Gambar 3.4 Diagram Aktifitas Use Case Lihat Detail Atribut Data Pelatihan ……… Gambar 3.5 Diagram Aktifitas Use Case Lihat Detail Atribut Data Pengujian ……... Gambar 3.6 Diagram Aktifitas Use Case Menghitung Probabilitas Prior ……… Gambar 3.7 Diagram Aktifitas Use Case Menghitung Likelihood………. Gambar 3.8 Diagram Aktifitas Use Case Melakukan Prediksi Satu Record ... Gambar 3.9 Diagram Aktifitas Use Case Melakukan Prediksi Semua Record………. Gambar 3.10 Diagram Kelas Use Case Memasukkan Data ………... Gambar 3.11 Diagram Kelas Use Case Melihat Detail Atribut Data Pelatihan .…... Gambar 3.12 Diagram Kelas Use Case Melihat Detail Atribut Data Pengujian …... Gambar 3.13 Diagram Kelas Use Case Menghitung Nilai Probabilitas Prior …... Gambar 3.14 Diagram Kelas Use Case Menghitung Nilai Likelihood ... Gambar 3.15 Diagram Kelas Use Case Melakukan Prediksi Satu Record …………... Gambar 3.16 Diagram Kelas Use Case Melakukan Prediksi Semua Record ………... Gambar 3.17 Diagram Sequence Memasukkan Data ………...
Gambar 3.18 Diagram Sequence Lihat Detail Atribut Data Pelatihan ….………
Gambar 3.19 Diagram Sequence Lihat Detail Atribut Data Pengujian ………
Gambar 3.20 Diagram Sequence Menghitung Nilai Probabilitas Prior ………
Gambar 3.21 Diagram Sequence Menghitung Nilai Likelihood ……..………
Gambar 3.22 Diagram Sequence Melakukan Prediksi Satu Record ...
Gambar 3.23 Diagram Sequence Melakukan Prediksi Semua Record ...
Gambar 3.24 Desain Antar Muka Halaman Utama...
Gambar 3.25 Desain Antar Muka Tambah Data ...
Gambar 3.26 Desain Antar Muka Detail Tabel Pelatihan ...
Gambar 3.27 Desain Antar Muka Detail Tabel Pengujian ...
Gambar 3.28 Desain Antar Muka Menghitung Probabilitas Prior dan Likelihood ...
Gambar 3.29 Desain Antar Muka Pilih Pengujian ...
Gambar 3.30 Desain Antar Muka Prediksi Satu Record ...
Gambar 4.1 Halaman Utama ...
Gambar 4.2 Halaman Tentang Sistem ...
Gambar 4.3 Halaman Bantuan Sistem ...
Gambar 4.4 Halaman Memasukkan Data ...
Gambar 4.5 Halaman Detail Atribut Data ... ...
Gambar 4.6 Hasil Detail Atribut Data Pelatihan ...
Gambar 4.7 Hasil Detail Atribut Data Pengujian ...
Gambar 4.8 Pesan Penghitungan Nilai Probabilitas Prior dan Likelihood ...
Gambar 4.9 Pesan Selesai Penghitungan Nilai Probabilitas Prior dan Likelihood ...
Gambar 4.10 Halaman Hasil Menghitung Probabilitas Prior dan Likelihood ...
Gambar 4.11 Halaman Pilih Pengujian ...
Gambar 4.12 Halaman Prediksi Satu Record ...
Gambar 4.13 Hasil Prediksi Satu Record ...
Gambar 4.14 Pesan Proses Prediksi Semua Record ...
Gambar 4.15 Pesan Proses Prediksi Semua Record Selesai ...
Gambar 4.16 Halaman Hasil Prediksi Semua Record ...
Gambar 4.17 Halaman Hasil Prediksi Benar ... 69
70
70
71
72
73
74
74
74
75
76
77
78
78
79
79
DAFTAR TABEL
Tabel 2.1 Training Dataset Masalah Berolah Raga Atau Tidak ...
Tabel 3.1 Hasil Test Korelasi Bivariat Data PMB ...
Tabel 3.2 Data Sebelum Transformasi ...
Tabel 3.3 Data Setelah Transformasi ...
Tabel 3.4 Tabel Ringkasan Use Case ... Tabel 3.5 Deskripsi Atribut Tabel Data Pelatihan …...………...
Tabel 3.6 Deskripsi Atribut Tabel Data Pengujian ...
Tabel 3.7 Contoh Tabel Pengujian yang Akan Dilakukan Proses Prediksi ...
Tabel 3.8 Tabel Relasional Database ...
Tabel 3.9 Contoh Tabel Pelatihan ...
Tabel 3.10 Contoh Tabel Pengujian ...
Tabel 3.11 Contoh Tabel Temp ...
Tabel 3.12 Tabel Relasional Database Setelah Normalisasi ...
Tabel 3.13 Struktur Tabel Pelatihan ...
Tabel 3.14 Struktur Tabel Pengujian ...
Tabel 3.15 Struktur Tabel Temp ...
Tabel 3.16 Klasifikasi Use Case Memasukkan Data ... Tabel 3.17 Klasifikasi Use Case Lihat Detail Tabel Pelatihan ... Tabel 3.18 Klasifikasi Use Case Lihat Detail Tabel Pengujian ...
Tabel 3.19 Klasifikasi Use Case Menghitung Nilai Probabilitas Prior ... Tabel 3.20 Klasifikasi Use Case Menghitung Nilai Likelihood ... Tabel 3.21 Klasifikasi Use Case Melakukan Prediksi Satu Record ... Tabel 3.22 Klasifikasi Use Case Melakukan Prediksi Semua Record ... Tabel 4.1 Tabel Pelatihan ...
Tabel 4.2 Tabel Pengujian ...
Tabel 4.3 Tabel Temp ...
Tabel 4.4 Confunsion Matrix Pengujian I Fold 5 ... Tabel 4.5 Confunsion Matrix Pengujian II Fold 5 ... Tabel 4.6 Confunsion Matrix Pengujian III Fold 5 ... Tabel 4.7 Confunsion Matrix Pengujian IV Fold 5... Tabel 4.8 Confunsion Matrix Pengujian V Fold 5 ... Tabel 4.9 Pengujian Cross Validation Fold 5...
Tabel 4.10 Confunsion Matrix Pengujian I Fold 10... Tabel 4.11 Confunsion Matrix Pengujian II Fold 10 ... Tabel 4.12 Confunsion Matrix Pengujian III Fold 10 ... Tabel 4.13 Confunsion Matrix Pengujian IV Fold 10... Tabel 4.14 Confunsion Matrix Pengujian V Fold 10 ... Tabel 4.15 Confunsion Matrix Pengujian VI Fold 10 ... Tabel 4.16 Confunsion Matrix Pengujian VII Fold 10... Tabel 4.17 Confunsion Matrix Pengujian VIII Fold 10 ... Tabel 4.18 Confunsion Matrix Pengujian IX Fold 10 ... Tabel 4.19 Confunsion Matrix Pengujian X Fold 10 ... Tabel 4.20 Pengujian Cross Validation Fold 10...
84
84
84
85
85
85
86
86
86
87
BAB I
PENDAHULUAN
I.1.
Latar Belakang Masalah
Universitas Sanata Dharma (USD) adalah salah satu perguruan
tinggi swasta di Yogyakarta. Setiap tahunnya USD menerima mahasiswa
baru lebih dari seribu mahasiswa. Dalam prosedur pendaftaran mahasiswa
baru, ketika sudah diumumkan mahasiswa tersebut diterima, langkah
selanjutnya adalah mahasiswa baru itu melakukan daftar ulang. Jumlah
mahasiswa baru yang diterima selalu lebih dari kuota yang ada. Hal ini
dilakukan untuk mengantisipasi mahasiswa yang sudah diterima tetapi
mahasiswa tersebut tidak melakukan daftar ulang. Namun demikian
kadang kala jumlah mahasiswa yang mendaftar ulang lebih sedikit dari
kapasitas penerimaan mahasiswa baru yang ditetapkan oleh USD.
Sebaliknya, dapat juga terjadi mahasiswa baru yang mendaftar ulang
melebihi kuota.
Untuk mengantisipasi masalah perlu dilakukan suatu prediksi
untuk menentukan mahasiswa baru yang tidak melakukan daftar ulang.
Banyak hal yang bisa dilakukan untuk melakukan prediksi ini, salah
satunya menggunakan data mining. Data mining adalah percobaan untuk
memperoleh informasi yang berguna yang tersimpan di dalam basis data
yang sangat besar (Mitra & Acharya, 2003). Salah satu algoritma yang
digunakan menggunakan algoritma naive bayesian. Naïve bayes adalah metode klasifikasi yang berdasarkan probabilitas dan teorema bayesian dengan asumsi bahwa setiap variabel bersifat bebas (independent). Dengan kata lain, naïve bayesian classifier mengasumsikan bahwa keberadaan sebuah variabel tidak ada kaitannya dengan keberadaan variabel lain.
Dengan prediksi mahasiswa yang tidak melakukan daftar ulang di
USD ini, maka akan membantu USD untuk menentukan kuota secara lebih
tepat. Dengan demikian jumlah mahasiswa baru yang sudah diprediksikan
oleh USD tidak jauh berbeda dengan mahasiswa yang benar-benar
I.2.
Rumusan Masalah
1. Bagaimana mengimplementasikan algoritma Naive Bayesian untuk memprediksi calon mahasiwa baru yang tidak melakukan daftar ulang ?
2. Berapakah tingkat keakuratan prediksi yang dihasilkan dalam
memprediksi calon mahasiswa baru yang tidak melakukan daftar ulang ?
I.3.
Tujuan
Tujuan dari penelitian ini adalah bagaimana menerapkan algoritma
Naive Bayesian sebagai salah satu algoritma dalam data mining untuk mengetahui calon mahasiswa baru Universitas Sanata Dharma yang tidak
melakukan daftar ulang.
I.4.
Batasan Masalah
Dalam prediksi yang akan dilakukan dalam tugas akhir ini memiliki
batasan-batasan masalah :
1. Dalam mengimplementasikan prediksi ini, algoritma yang digunakan
memakai algoritma Naive Bayesian.
2. Data yang digunakan dalam proses prediksi adalah data penerimaan
mahasiswa baru Universitas Sanata Dharma tahun 2009 untuk
pendaftaran melalui jalur reguler tes tertulis dari gelombang 1 sampai
gelombang 3.
3. Data PMB USD meliputi prioritas pilihan pada program studi tempat
calon mahasiswa diterima, gelombang masuk pendaftaran, jenis
kelamin, jurusan SMA, program studi tempat diterima, status daftar
ulang yang dilakukan dan nilai final tes masuk berdasarkan program
studi.
4. Berdasarkan input data penerimaan mahasiswa baru Universitas Sanata
Dharma tahun 2009, output program ini adalah prediksi apakah
mahasiswa baru itu melakukan daftar ulang atau tidak, tingkat
keakuratan prediksi yang dihasilkan, serta hasil prediksi untuk satu data
mahasiswa tertentu.
I.5.
Metodologi Penelitian
1. Melakukan pencarian data penerimaan mahasiswa baru di Universitas
Sanata Dharma.
2. Melakukan proses pembersihan data untuk membuang data yang tidak
konsisten dan noise.
3. Melakukan proses integrasi data yaitu menggabungkan tabel dari
beberapa sumber agar seluruh data terangkum dalam satu tabel utuh.
4. Melakukan proses seleksi dan transformasi yaitu data dipilih untuk
selanjutnya diubah menjadi bentuk yang sesuai untuk ditambang.
5. Melakukan proses pencarian pola pada training data menggunakan
algoritma Naive Bayesian. 6. Uji coba program.
I.6.
Sistematika Penulisan
Bab I. PendahuluanBab ini membahas mengenai latar belakang, rumusan masalah, batasan
masalah, tujuan, manfaat, metodologi dan sistematika penulisan.
Bab II. Landasan Teori
Bab ini membahas mengenai implementasi penambangan data
menggunakan algoritma Naive Bayesian.
Bab III. Perancangan Sistem
Bab ini berisi tentang identifikasi sistem, pembersihan data, integrasi
data, seleksi data, transformasi data, analisis kebutuhan pengguna, serta
perancangan umum sistem.
Bab IV. Implementasi Program
Berisi implementasi algoritma Naive Bayesian dalam menentukan prediksi calon mahasiswa baru yang tidak melakukan daftar ulang serta
analisa hasil prediksi.
Bab V. Kesimpulan dan Saran
2.1
Pengertian Dat
Data mining adala
data yang besar y
merupakan bagian
tahap-tahap dalam
Gam
Secara garis besa
KDD adalah:
alah suatu proses untuk menentukan informas
r yang disimpan dalam database penyimpana ian dari knowledge discovery in databases ( am proses penambangan data adalah:
mbar 2.1 Langkah-langkah dalam Penambangan D Sumber: Jiawei Han and Micheline Kamber
http://www.cs.sfu.ca/~han/dmbook
sar, langkah-langkah utama penambangan dat
terhadap domain aplikasi, relevansinya terhad
tujuan dari end-user.
himpunan target data: pemilihan himpunan dat
data dan Preprocessing : untuk membuang an noise.
n pengurangan data: pencarian fitur-fitur yang
asikan data bergantung kepada tujuan yang ingin
5. Pemilihan fungsi penambangan data : pemilihan tujuan dari proses KDD
misalnya klasifikasi, regresi, clustering, dll.
6. Pemilihan algoritma penambangan data.
7. Penambangan data : pencarian pola-pola yang diinginkan.
8. Evaluasi pola-pola yang dihasilkan dari penambangan data (langkah 7).
9. Menggunakan informasi yang didapatkan.
2.2
Teorema Bayes
Misalnya pertandingan sepak bola antara persaingan dua regu: tim 0 dan tim 1.
Diumpamakan tim 0 kemenangannya 65% untuk saat ini dan kemenangan tim
1 untuk pertandingan sisanya. Diantara pertandingan yang dimenangkan oleh
regu 0, hanya 30% untuk mereka yang datang dari tim yang bermain di area
Team 1. Pada sisi lain, 75% kemenangan untuk tim 1 diperoleh ketika
menjadi tuan rumah. Jika tim 1 adalah tuan rumah pertandingan berikutnya
antara kedua regu, regu yang akan hampir bisa dipastikan muncul sebagai
pemenang dapat dicari dengan menggunakan teorema Bayes. Misalnya, X
dan Y menjadi sepasang variabel acak. Menggabungkan kemungkinan,
P(X=x, Y=y), mengacu pada kemungkinan bahwa variabel X akan menerima
nilai x dan variabel Y akan menerima nilai y. Sebuah kemungkinan bersyarat
adalah kemungkinan bahwa suatu variabel acak akan menerima nilai tertentu
yang diberikan yang mana hasil untuk variabel acak lain diketahui. Sebagai
contoh, conditional probability (kemungkinan bersyarat) P(Y=Y|X=X) mengacu pada kemungkinan bahwa variabel Y akan menerima nilai y,
variabel X diamati untuk memiliki nilai x. Conditional probability untuk X dan Y terkait sebagai berikut:
P(Y|X)=
- X adalah sampel dengan klas (label) yang tidak diketahui.
- Y merupakan hipotesis bahwa X adalah data dengan klas(label).
- P(Y) adalah peluang (Prior probability) dari hipotesa Y. - P(X) adalah bahwa data sampel diamati.
- P(X|Y) adalah peluang data sampel X, bila diasumsikan bahwa
Teorema Bayes dapat digunakan untuk memecahkan masalah prediksi. X menjadi variabel acak yang menjadi tim tuan rumah pertandingan dan Y
variabel acak yang menjadi pemenang pertandingan. Kedua nilai X dan Y
di-set { 0,1}. Kita dapat meringkas informasi dalam masalah sebagai berikut:
- Kemungkinan tim 0 kemenangannya adalah P(Y=0)= 0.65
- Kemungkinan tim 1 kemenangannya adalah
P(Y=1)=1-P(Y=0)=0.35
- Kemungkinan tim 1 menjadi tuan rumah pertandingan itu
dimenangkan adalah P(X=1|Y=1)=0.75
- Kemungkinan Regu 1 menjadi tuan rumah pertandingan
dimenangkan oleh tim 0 adalah P(X=1|Y=0)=0.3
Objek ini adalah menghitung P(Y=1|X=1), yang mana conditional probability kemenangan tim 1 adalah pertandingan berikutnya ketika menjadi tuan rumah, dan bandingkan kembali P(Y=0|X=1). Penggunaan teorema
Bayes, diperoleh:
P(Y=1|X=1)>P(Y=0|X=1), tim 1 mempunyai suatu kesempatan lebih baik
2.3 Naïve Bayes Clasifier
Naïve Bayes adalah metode klasifikasi yang berdasarkan probabilitas dan teorema Bayesian dengan asumsi bahwa setiap variable bersifat bebas (independence). Dengan kata lain, Naïve Bayesian Classifier mengasumsikan bahwa keberadaan sebuah variable tidak ada kaitannya dengan keberadaan
variable lain. Karena setiap variabel tidak ada kaitanya dengan variabel lain
maka rumus 2.1 berubah sebagai berikut:
P(X|Y=y)=
∏
==
d i
i Y y
X P
1
) |
( ………(2.2)
Dimana masing-masing set atribute X={X1, X2,....,Xd} terdiri dari d atribut.
2.4Conditional Independence
Contoh conditional independence adalah hubungan antara panjang lengan
tangan seseorang dan ketrampilan membacanya. Seseorang mungkin
mengamati orang itu dengan lengan tangan yang lebih panjang cenderung
mempunyai ketrampilan membaca lebih tinggi. Hubungan ini dapat ditentukan
oleh faktor umur. Seorang anak muda cenderung mempunyai lengan yang
lebih pendek dan ketrampilan membacanya lebih rendah untuk orang dewasa.
Jika umur seseorang ditetapkan, maka hubungan yang diamati antara panjang
lengan tangan dan ketrampilan membaca tidak ada. Seperti itu, dapat
disimpulkan panjang lengan tangan dan ketrampilan membaca adalah kondisi
2.5Contoh Klasifikasi Naïve Bayes
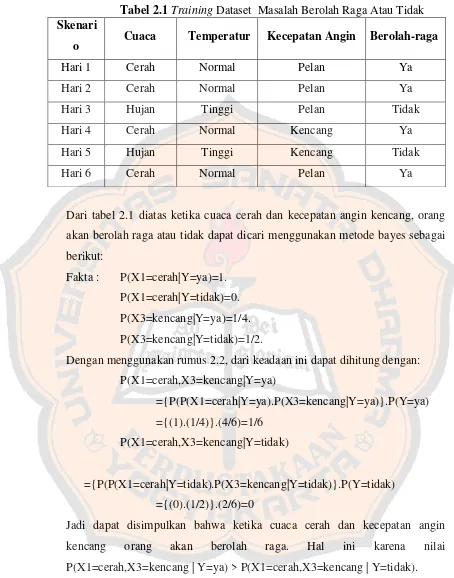
Tabel 2.1 Training Dataset Masalah Berolah Raga Atau Tidak
Skenari
o Cuaca Temperatur Kecepatan Angin Berolah-raga
Hari 1 Cerah Normal Pelan Ya
Hari 2 Cerah Normal Pelan Ya
Hari 3 Hujan Tinggi Pelan Tidak
Hari 4 Cerah Normal Kencang Ya
Hari 5 Hujan Tinggi Kencang Tidak
Hari 6 Cerah Normal Pelan Ya
Dari tabel 2.1 diatas ketika cuaca cerah dan kecepatan angin kencang, orang
akan berolah raga atau tidak dapat dicari menggunakan metode bayes sebagai
berikut:
Fakta : P(X1=cerah|Y=ya)=1.
P(X1=cerah|Y=tidak)=0.
P(X3=kencang|Y=ya)=1/4.
P(X3=kencang|Y=tidak)=1/2.
Dengan menggunakan rumus 2.2, dari keadaan ini dapat dihitung dengan:
P(X1=cerah,X3=kencang|Y=ya)
={P(P(X1=cerah|Y=ya).P(X3=kencang|Y=ya)}.P(Y=ya)
={(1).(1/4)}.(4/6)=1/6
P(X1=cerah,X3=kencang|Y=tidak)
={P(P(X1=cerah|Y=tidak).P(X3=kencang|Y=tidak)}.P(Y=tidak)
={(0).(1/2)}.(2/6)=0
Jadi dapat disimpulkan bahwa ketika cuaca cerah dan kecepatan angin
kencang orang akan berolah raga. Hal ini karena nilai
BAB III
PERANCANGAN SISTEM
3.1Identifikasi Sistem
Setiap tahunnya Universitas Sanata Dharma menerima mahasiswa baru
lebih dari seribu mahasiswa baru. Dalam prosedur pendaftaran mahasiswa
baru, ketika sudah diumumkan mahasiswa tersebut diterima, langkah
selanjutnya adalah mahasiswa baru itu melakukan daftar ulang. Dalam
menentukan jumlah mahasiswa baru yang diterima, Universitas menentukan
jumlah yang diterima lebih dari kuota yang ada. Hal ini dilakukan untuk
mengantisipasi mahasiswa yang sudah diterima tetapi mahasiswa tersebut
tidak melakukan daftar ulang. Akan tetapi kadang kala jumlah mahasiswa
yang mendaftar ulang lebih sedikit dari kapasitas penerimaan mahasiswa baru
yang ditetapkan olah pihak Universitas. Sebaliknya, dapat juga terjadi ketika
mahasiswa baru yang mendaftar ulang melebihi kuota.
Untuk mengantisipasi masalah diatas maka perlu dilakukan suatu
prediksi untuk menentukan mahasiswa baru yang tidak melakukan daftar
ulang. Salah satu solusi yang digunakan adalah menggunakan data mining. Algoritma yang digunakan adalah algoritma naive bayesian. Data-data penerimaan mahasiswa baru yang ada, diolah dan diproses yang nantinya
menghasilkan suatu informasi. Data yang akan digunakan dalam proses
prediksi adalah data penerimaan mahasiswa baru tahun 2009 yang meliputi
data prioritas pilihan pada program studi tempat calon mahasiswa diterima,
gelombang masuk pendaftaran, jenis kelamin, jurusan SMA, program studi
tempat diterima, status daftar ulang yang dilakukan dan nilai final tes masuk
berdasarkan program studi. Data-data tersebut nantinya akan dibagi menjadi
dua. Data tersebut digunakan sebagai data pelatihan dan data pengujian.
Data-data yang ada nantinya diproses untuk memprediksi mahasiswa baru yang
3.2Pembersihan data
Dalam proses pembersihan data ini, data yang didapatkan dari BAPSI
universitas Sanata Dharma dibersihkan untuk menghilangkan data-data yang
tidak konsisten, data yang kosong ataupun noise. Data-data itu misalnya dalam penulisan jurusan_SMA ada yang menuliskan SMA IPS, dan ada yang
menuliskan IPS. Sebenarnya data tersebut memiliki arti yang sama, tetapi jadi
tidak konsisten jika data tersebut ditulis berbeda, sehingga data tersebut perlu
diseragamkan. Misalnya data tersebut diubah menjadi IPS.
3.3Integrasi Data
Dalam proses integrasi data data-data dalam beberapa tabel perlu disatukan
supaya menjadi tabel yang utuh.
3.4Seleksi Data
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan
sebelum tahap penggalian informasi dalam knowledge discovery in databases (KDD) dimulai. Seleksi data dilakukan menggunakan tes korelasi bivariat
menggunakan program SPSS agar data-data yang digunakan bersifat
independent ( berdiri sendiri ). Hasil seleksi data yang dilakukan sebagai berikut:
Dari hasil test korelasi yang dilakukan jika nilai signifikan hasil korelasi lebih
besar dari 0,05 maka data tersebut bersifat independent sedangkan nilai signifikan lebih kecil dari 0,05 maka data tersebut akan berkorelasi. Misalnya
untuk data gelombang dan jenis kelamin menghasilkan angka 0,899 hal ini
berarti bahwa nilai signifikan yang dihasilkan lebih besar dari 0,05 sehingga
data ini tidak berkorelasi. Untuk data gelombang dengan pilihan diterima
menghasilkan angka 0,015 hal ini berarti bahwa nilai signifikan hasil korelasi
lebih kecil dari 0,05 sehingga data antara gelombang dengan pilihan diterima
berkorelasi. Seberapa erat hubungan korelasi antara gelombang dengan pilihan
diterima adalah ketika nilai koefisien korelasi lebih kecil dari 0,5 maka
korelasi yang dihasilkan lemah, tetapi jika nilai koefisien korelasi lebih besar
dari 0,5 maka korelasi yang dihasilkan kuat. Untuk data gelombang dan
prioritas menghasilkan angka koefisien korelasi -0,067 hal ini berarti lebih
kecil dari 0,5 sehingga korelasinya lemah. Ketika nilai korelasi lemah
dianggap tidak ada hubungan sehingga bisa diabaikan. Tanda – menunjukkan
arah hubungan yang berlawanan, sedangkan untuk tanda + menunjukkan arah
hubungan yang sama. Dari hasil pengujian test korelasi bivariat yang
dilakukan hubungan atara semua variabel bersifat independen atau berdiri
sendiri.
3.5Transformasi Data
Dalam proses transformasi, data-data yang akan ditambang diubah kedalam
bentuk yang sesuai. Salah satu data penerimaan mahasiswa baru yaitu data
nilai final tes masuk memiliki nilai kontinyu. (Ernawati, 2007) Diasumsikan
data nilai final tes berdistribusi normal. Maka perlu dilakukan proses
transformasi, yaitu nilai final tes masuk dipartisi menjadi 4 interval.
Masing-masing interval dinyatakan dalam bilangan bulat 1, 2, 3, dan 4. Atribut nilai
final tesmasuk dinyatakan sebagai berikut :
1 nilai tesmasuk < rata nilai_tes – 1,5 * st_devnilai_tes
2 ratanilai_tes – 1,5 * st_devnilai_tes ≤ nilai tesmasuk < ratanilai_tes
3 ratanilai_tes ≤ nilai tesmasuk < ratanilai_test +1,5 * st_devnilai_tes
Untuk data prioritas pilihan data diubah menjadi nilai 1, 2, 3 tergantung dari
program studi diterima. Misalnya untuk data prioritas pilihan 1 : PBSID,
pilihan 2 : PAK, pilihan 3 : PEK, sedangkan calon mahasiswa, diterima di
program studi PBSID maka nilai prioritas pilihan setelah transformasi menjadi
nilai 1. Data sebelum dan sesudah proses transformasi tercantum dalam tabel
3.2 dan 3.3 berikut :
Tabel 3.2 Data Sebelum Transformasi
3.6Analisis Kebutuhan Pengguna
3.6.1Diagram Model Use Case
3.6.2 Tabel Ringkasan Use Case
Tabel 3.4 Tabel Ringkasan Use Case
Nama Use Case Keterangan Pelaku
Memasukkan data Melakukan penambahan data yang
terdiri dari data pelatihan dan data
pengujian.
Petugas
Lihat detail atribut
data pelatihan
Melihat detail data-data pelatihan
yang telah dimasukkan.
Petugas
Lihat detail atribut
data pengujian
Melihat detail data-data pengujian
yang telah dimasukkan.
Petugas
Menghitung nilai
probabilitas prior
Melakukan penghitungan nilai
probabilitas prior berdasarkan data
pelatihan yang telah dimasukkan.
Petugas
Menghitung nilai
likelihood
Melakukan penghitungan nilai
likelihood berdasarkan data pelatihan
yang telah dimasukkan.
Petugas
Melakukan prediksi
satu record
Melakukan prediksi dengan memilih
data yang diinginkan. Proses prediksi
hanya untuk satu record.
Petugas
Melakukan prediksi
semua record
Melakukan prediksi semua data
pengujian yang telah dimasukkan.
3.6.3 Narasi Use Case
Pengarang : Sri Purwanti Tanggal : 15 November 2009
Versi :
Pemicu Aktor memilih menu memasukan data pelatihan.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1: Petugas
memilih menu input data pada sistem.
Langkah 3: Petugas memilih data yang akan dimasukkan dengan
Bidang alternatif Petugas memilih tombol cancel. Tombol ini digunakan untuk membatalkan pemasukan data dan jika tombol cancel dipilih maka program akan kembali ke menu utama
Kesimpulan Use case ini selesai jika sistem sudah menampilkan halaman detail tabel.
Pascakondisi Sistem masuk ke halaman detail tabel.
Pengarang : Sri Purwanti Tanggal : 15 November 2009 Versi :
Nama Use Case Melihat Detail Atribut Data Pelatihan
Prakondisi Pengguna sudah menekan tombol ok pada halaman input data
Pemicu Aktor memilih menu lihat data pelatihan.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1: menekan
Bidang alternatif -
Kesimpulan Use case ini selesai jika sistem sudah menampilkan data yang dimasukkan sebelumnya.
Pascakondisi Sistem menampilkan detail atribut data pelatihan.
Pengarang : Sri Purwanti Tanggal : 15 November 2009 Versi :
Nama Use Case Melihat Detail Atribut Data Pengujian
Prakondisi Pengguna sudah menekan tombol ok pada halaman input data.
Pemicu Aktor memilih menu lihat data pelatihan.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1: Petugas
Bidang alternatif -
Kesimpulan Use case ini selesai jika sistem sudah menampilkan data pengujian.
Pengarang : Sri Purwanti Tanggal : 15 November 2009 Versi :
Nama Use Case Menghitung nilai probabilitas prior
Deskripsi Use case ini merupakan proses menghitung nilai probabilitas prior. Petugas menekan tombol hitung probabilitas prior dan likelihood pada tampilan halaman detail tabel.
Prakondisi Petugas sudah memilih menu lihat detail atribut.
Pemicu Aktor menekan tombol hitung probabilitas prior.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1: Menekan
tombol hitung probabilitas prior dan
likelihood. Langkah 2: Sistem merespon dengan melakukan
penghitungan nilai probabilitas prior dan menampilkan nilai probabilitas prior pada halaman probabilitas prior dan likelihood.
Bidang alternatif -
Kesimpulan Use case ini selesai jika sistem sudah menampilkan nilai probabilitas prior.
Pascakondisi Pada halaman hitung probabilitas prior dan likelihood, sistem manampilkan nilai probabilitas prior pada tabel probabilitas prior.
Pengarang : Sri Purwanti Tanggal : 15 November 2009 Versi :
Nama Use Case Menghitung nilai likelihood
Deskripsi Use case ini merupakan proses menghitung nilai likelihood. Dengan menekan tombol hitung probabilitas prior dan likelihood pada tampilan halaman detail tabel.
Prakondisi Petugas sudah mengeksekusi use case lihat detail tabel.
Pemicu Aktor menekan tombol hitung likelihood.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1: Petugas tersebut pada halaman hitung likelihood..
Bidang alternatif -
Kesimpulan Use case ini selesai jika sistem sudah menampilkan nilai likelihood.
Pengarang : Sri Purwanti Tanggal : 15 November 2009 Versi :
Nama Use Case Melakukan prediksi satu record.
Deskripsi Use case ini merupakan proses untuk melakukan prediksi hanya untuk satu record saja.
Prakondisi Petugas memilih menu prediksi sau record pada halaman pengujian..
Pemicu Aktor menekan tombol prediksi satu record.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1: Petugas
memilih data yang
akan diprediksi. Langkah 2: Sitem merespon dengan
Bidang alternatif -
Kesimpulan Use case ini selesai jika sudah menampilkan hasil prediksi untuk satu record.
Pengarang : Sri Purwanti Tanggal : 15 November 2009 Versi :
Nama Use Case Melakukan prediksi semua record
Deskripsi Usecase ini mendeskripsikan tentang prediksi semua record.
Prakondisi Petugas sudah menekan tombol prediksi semua record pada halaman pengujian.
Pemicu Aktor menekan tombol prediksi semua record.
Langkah Umum Kegiatan Pelaku Respons Sistem Langkah 1 : Petugas
menekan tombol prediksi
keakuratan prediksi.
Bidang Alternatif -
Kesimpulan Use case ini selesai jika sistem sudah menampilkan semua hasil prediksi dalam halaman hasil prediksi semua record beserta nilai tingkat keakuratan prediksi.
Pascakondisi Sistem menampilkan halaman hasil prediksi semua record.
Aturan bisnis -
Batasan Dan Spesifikasi Implementasi
-
Asumsi -
Masalah Terbuka -
3.7 Perancangan Umum Sistem
3.7.1Diagram Konteks
Gambar 3.2 Diagram konteks sistem
3.7.2 Masukan Sistem
Pada masukan sistem, tabel masukan sistem akan terdiri dari dua tabel yaitu
tabel data pelatihan dan tabel data pengujian. Masukan tabel data pada
sistem terdiri dari atribut gelombang_masuk, prioritas_pilihan,
program_studi, jenis_kelamin, jurusan_SMA, nilai_final dan atribut status.
Atribut-atribut ini akan menjadi tabel data pelatihan. Dalam atribut-atribut
data pelatihan atribut status akan menjadi atribut keputusan. Deskripsi dari
Tabel 3.5 Deskripsi atribut tabel data pelatihan
No Nama Atribut Keterangan Nilai Atribut
1 gelombang_masuk Gelombang tes masuk. 1, 2, 3
2 prioritas_pilihan Prioritas pilihan tempat
mahasiswa tersebut
diterima.
1, 2, 3
3 program_studi Program studi tempat
mahasiswa diterima.
4 jenis_kelamin Jenis kelamin mahasiswa. Laki-laki, Perempuan
5 jurusan_SMA Jurusan pada saat berada
berdasarkan program studi
mahasiswa diterima
Selain tabel pelatihan, terdapat juga masukan tabel data pengujian yang
terdiri dari atribut gelombang_masuk, prioritas_pilihan, program_studi,
jenis_kelamin, jurusan_SMA, nilai_final, status, dan atribut hasil_prediksi.
Atribut hasil_prediksi digunakan sebagai atribut penyimpanan data hasil
prediksi. Deskripsi dari atribut data pengujian adalah sebagai berikut:
Tabel 3.6 Deskripsi atribut tabel data pengujian
No Nama Atribut Keterangan Nilai Atribut
1 gelombang_masuk Gelombang tes masuk. 1, 2, 3
2 prioritas_pilihan Prioritas pilihan tempat
mahasiswa tersebut
diterima.
3 program_studi Program studi tempat
mahasiswa diterima.
4 jenis_kelamin Jenis kelamin mahasiswa. Laki-laki, Perempuan
5 jurusan_SMA Jurusan pada saat berada di
SMA
IPA, IPS, BAHASA,
SMK, STM, SMF,
LAIN-LAIN
5 nilai_final Nilai final tes masuk
berdasarkan program studi
mahasiswa diterima.
7 Hasil_prediksi Berisi prediksi mahasiswa
yang melakukan daftar
ulang atau tidak.
Daftar Ulang,
Tidak Daftar Ulang
3.7.3Proses Sistem
Algoritma proses untuk sistem adalah sebagai berikut:
a) Menentukan kelas-kelas yang muncul dari atribut target. X1 untuk kelas
status = Daftar Ulang, X2 untuk kelas status = tidak Daftar Ulang.
b) Menghitung probabilitas prior untuk masing-masing kelas X1 dan kelas
X2 dengan menggunakan rumus 2.1, yaitu sebagai berikut:
P(X1=Daftar Ulang) =
P(X2=tidak Daftar Ulang)=
c) Setelah itu menghitung nilai likehood untuk setiap kelas kelas X1 dan kelas X2 yaitu sebagai berikut:
- Likelihood Gelombang_masuk:
- Likelihood prioritas_pilihan:
- Likekelihood untuk jenis_kelamin:
d) Proses prediksi (Posterior Probability)
Ketika nilai dari probabilitas prior dan likelihood sudah didapatkan, maka langkah selanjutnya adalah melakukan proses prediksi. Proses
prediksi dilakukan dengan menghitung nilai probabilitas posterior dari
data yang akan dilakukan prediksi. Misalnya model data tabel pengujian
yang akan diprediksi ditampilkan dalam tabel berikut ini:
Tabel 3.7 : Contoh Tabel Pengujian yang Akan Dilakukan Proses Prediksi
gelombang_mas uk
prioritas_pilih an
program_stu di
jenis_kelami n
jurusan_SM A
nilai_fin al
1 2 TI P IPA 4
Dari data tersebut maka dengan menggunakan algoritma Naive Bayesian dapat diprediksi dengan menghitung nilai probabilitas posterior sebagai
berikut:
Probabilitas posteriorstatus= daftar ulang:
Probabilitas posteriorstatus= tidak DU:
e) Ketika nilai probabilitas posterior sudah didapatkan, maka langkah
selanjutnya adalah membandingkan nilai probabilitas posterior yang
telah dihitung. Nilai prediksi yang diambil adalah nilai probabilitas
posterioryang paling besar.
f) Setelah hasil prediksi didapatkan, maka sistem akan melakukan
perhitungan keakuratan proses prediksi yang dilakukan. Penghitungan
keakuratan dilakukan hanya untuk prediksi semua record.
Penghitungan keakuratan prediksi dilakukan dengan membandingkan
3.7.4 Keluaran Sistem
Keluaran sistem yang akan dibangun adalah sebagai berikut:
a. Menampilkan himpunan data pelatihan dan pengujian.
b. Tabel pengujian yang akan dilakukan proses prediksi beserta nilai
kejadiannya.
c. Jumlah prediksi benar dan jumlah prediksi salah.
d. Hasil prediksi yang dilakukan serta tingkat keakuratan prediksi.
3.7.5 Perancangan Basis Data
Dalam perancangan basis data terdiri dari tiga tabel yaitu tabel
pelatihan, pengujian dan tabel temp. Tabel pelatihan memiliki atribut
NoPelatihan sebagai primary key, kelompok_data, gelombang_masuk,
prioritas_pilihan, program_studi, jenis_kelamin, jurusanSMA,
nilai_final dan status. Tabel pelatihan digunakan untuk menyimpan
data pelatihan yang dimasukkan oleh pengguna. Tabel pengujian
memiliki atribut NoPengujian sebagai primary key, kelompok_data,
gelombang_masuk, prioritas_pilihan, program_studi, jenis_kelamin,
jurusanSMA, nilai_final, status, hasil_prediksi dan keterangan. Tabel
pengujian digunakan untuk menyimpan data pengujian yang sudah
dimasukkan oleh pengguna, selain itu tabel pengujian digunakan untuk
menyimpan hasil prediksi dengan menyimpan hasil prediksi kedalam
atribut hasil prediksi. Sedangkan untuk tabel temp memiliki atribut
NoUrut sebagai primary key, likelihood dan probabilitas_prior dan
keterangan. Tabel Temp ini digunakan untuk menyimpan nilai
likelihood dan probabilitas prior sementara. Nilai likelihood dan
probabilitas prior yang sudah dilakukan penghitungan disimpan
kedalam atribut likelihood untuk hasil perhitungan nilai likelihood dan
3.7.5.1Perancangan Konseptual
Tabel 3.8 Tabel Relasional Database
3.7.5.2Perancangan Logikal
Pelatihan : NoPelatihan, kelompok_data, gelombang_masuk, prioritas_pilihan, program_studi, jenis_kelamin, jurusan_SMA, nilai_final, status
Pengujian : NoPengujian, kelompok_data, gelombang_masuk, prioritas_pilihan, program_studi, jenis_kelamin, jurusan_SMA, nilai_final, status ,hasil_prediksi, keterangan.
Temp : NoUrut,likelihood, probabilitas_prior, Keterangan
Normalisasi:
Tabel 3.9 Contoh Tabel Pelatihan
Pada setiap perpotongan baris dan kolom untuk tabel di atas hanya
terdapat satu harga data, sehingga memenuhi bentuk normal 1.
Atibut-atribut bukan kunci benar-benar tergantung pada kunci primer, sehingga
memenuhi bentuk normal 2. Tabel di atas tidak mempunyai field yang
bergantung transitive, sehingga memenuhi bentuk normal 3.
Tabel 3.10 Contoh Tabel Pengujian
Pada setiap perpotongan baris dan kolom untuk tabel di atas hanya
terdapat satu harga data, sehingga memenuhi bentuk normal 1.
Atibut-atribut bukan kunci benar-benar tergantung pada kunci primer, sehingga
memenuhi bentuk normal 2. Tabel di atas tidak mempunyai field yang
bergantung transitive, sehingga memenuhi bentuk normal 3.
Pada setiap perpotongan baris dan kolom untuk tabel di atas hanya
terdapat satu harga data, sehingga memenuhi bentuk normal 1.
Atibut-atribut bukan kunci benar-benar tergantung pada kunci primer, sehingga
memenuhi bentuk normal 2. Tabel di atas tidak mempunyai field yang
bergantung transitive, sehingga memenuhi bentuk normal 3.
Tabel relasional database setelah normalisasi:
Tabel 3.12 Tabel Relasional Database Setelah Normalisasi
3.7.5.3 Perancangan Fisikal
Struktur tabel pada database mahasiswa sebagai berikut:
Tabel 3.13 Struktur Tabel Pelatihan
Nama Field Tipe Deskripsi
NoPelatihan Int (11) Primary key
Kelompok_data Varchar (50)
Gelombang_masuk Int(11)
Prioritas_Pilihan Int(11)
Program_Studi Varchar(50)
Nilai_Final Int(11)
Status Varchar(50)
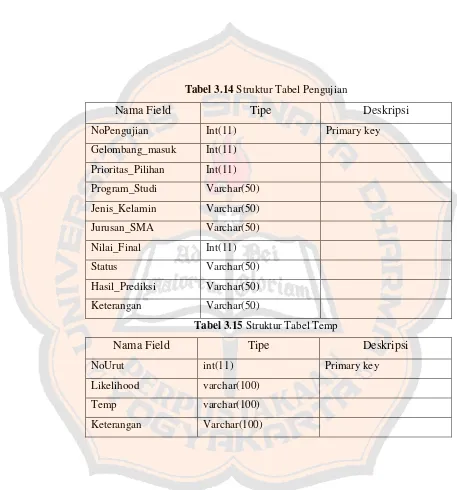
Tabel 3.14Struktur Tabel Pengujian
Nama Field Tipe Deskripsi
NoPengujian Int(11) Primary key
Gelombang_masuk Int(11)
Prioritas_Pilihan Int(11)
Program_Studi Varchar(50)
Jenis_Kelamin Varchar(50)
Jurusan_SMA Varchar(50)
Nilai_Final Int(11)
Status Varchar(50)
Hasil_Prediksi Varchar(50)
Keterangan Varchar(50)
Tabel 3.15Struktur Tabel Temp
Nama Field Tipe Deskripsi
NoUrut int(11) Primary key
Likelihood varchar(100)
Temp varchar(100)
3.7.6Diagram Aktivitas
Diagram Aktifitas Use Case Memasukkan Data
Gambar 3.3 Diagram Aktifitas Use Case Memasukkan Data
Gambar 3.4 Diagram Aktifitas Use Case Lihat Detail Atribut Data pelatihan
Diagram Aktifitas Use Case Lihat Detail Atribut Data Pengujian
Diagram Aktifitas Use Case Menghitung Probabilitas Prior.
Gambar 3.6 Diagram Aktifitas Use Case Menghitung Probabilitas Prior
Diagram Aktifitas Use Case Menghitung Likelihood
Gambar 3.7 Diagram Aktifitas Use Case Menghitung Likelihood
Gambar 3.8 Diagram Aktifitas Use Case Melakukan Proses Prediksi satu record
Diagram Aktifitas Use Case Melakukan Proses Prediksi Semua Record
Record
3.7.7 Diagram Kelas
3.7.7.1Diagram Kelas Use Case Memasukkan Data
Gambar 3.11 Diagram Kelas Use Case Lihat Detail Atribut Data Pelatihan
3.7.7.3 Diagram Kelas Use Case Lihat Detail Data Pengujian
Gambar 3.12 Diagram Kelas Use Case Lihat Detail Atribut Data Pengujian
Gambar 3.13 Diagram Kelas Use Case Menghitung Probabilitas Prior
Gambar 3.14 Diagram Kelas Use Case Hitung Likelihood
Gambar 3.15 Diagram Kelas Use Case Prediksi Satu Record
3.7.7.7Kelas Diagram Usecase Prediksi Semua Record
Tabel 3.16 Klasifikasi Use Case Memasukkan Data
Kelas Interface, Controller dan Entity usecase memasukkan data pelatihan Kelas Interface Kelas Controller Kelas Entity H-001 tambah data KontrolDatabase
Gambar 3.17 Diagram Sequence Memasukkan Data
Kelas Interface, Controller dan Entity usecase memasukkan data pelatihan Kelas Interface Kelas Controller Kelas Entity H-002 detail data KontrolDatabase Pelatihan
Kelas Interface, Controller dan Entity usecase memasukkan data pelatihan Kelas Interface Kelas Controller Kelas Entity H-002 detail tabel KontrolDatabase Pengujian
Gambar 3.19 Diagram Sequence Lihat Detail Tabel Pengujian
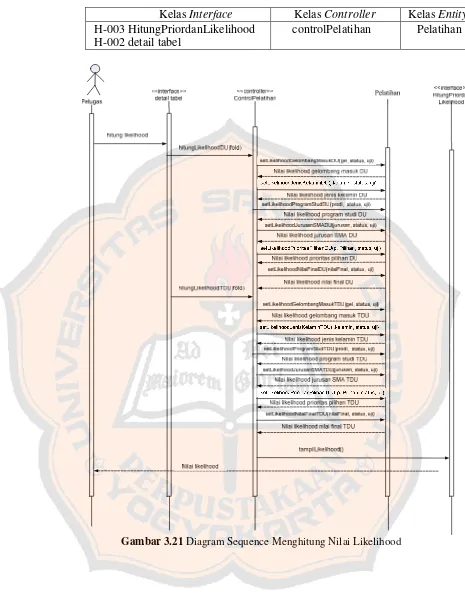
Kelas Interface, Controller dan Entity usecase memasukkan data pelatihan Kelas Interface Kelas Controller Kelas Entity H-003 Hitung PriordanLikelihood
H-002 Detail tabel
controlPelatihan Pelatihan
Kelas Interface Kelas Controller Kelas Entity H-003 HitungPriordanLikelihood
H-002 detail tabel
controlPelatihan Pelatihan
Gambar 3.21 Diagram Sequence Menghitung Nilai Likelihood
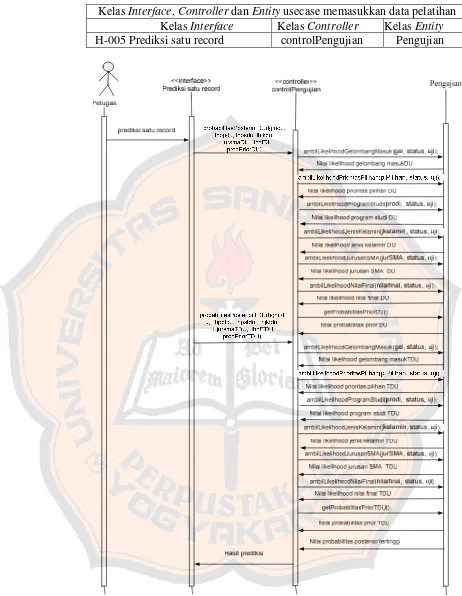
Kelas Interface, Controller dan Entity usecase memasukkan data pelatihan Kelas Interface Kelas Controller Kelas Entity H-005 Prediksi satu record controlPengujian Pengujian
Kelas Interface, Controller dan Entity usecase memasukkan data pelatihan Kelas Interface Kelas Controller Kelas Entity H-004 Pilih pengujian
H-006 Prediksi semua record
controlPengujian Pengujian
Gambar 3.23 Diagram Sequence Melakukan Prediksi Semua Record
3.7.9 Perancangan Metode Dalam Diagram Kelas
a. Menyimpan Data Pelatihan
hasil = 0
query = insert into pelatihan
(NoPelatihan,gelombang_masuk,prioritas_pilihan, jenis_kelamin,jurusan_SMA,program_studi,
nilai_final,status) values(no, gelombangMasuk, prioritasPilihan, jenisKelamin, jurusanSMA, programStudi,
nilaiFinal, status) hasil = query
return hasil
b. Menyimpan Data Pengujian
hasil = 0
query = insert into pengujian
(NoPengujian,gelombang_masuk,prioritas_pilihan, jenis_kelamin,jurusan_SMA,program_studi,
nilai_final,status)
c. Menghapus Data Pengujian
delete from pelatihan
d. Menghapus Data Pelatihan
delete from pengujian
e. Mengelompokkan Data Pelatihan Untuk Status Daftar Ulang Berdararkan Nilai Fold
`jurusan_SMA`= getjurusan_SMA and
f. Mengelompokkan Data Pelatihan Untuk Status Daftar Ulang Berdararkan Nilai Fold
3.7.9.2 Perancangan Metode Diagram Kelas Pelatihan
LengthAngs = Data.size()
for i=0 to i< LengthAngs increment i do
baris.addElement(Data.elementAt(i))
end for
b. SetProbabilitas Prior DU
nilaiPriorDU = jduuji / jDatauji
sql = insert into temp (NoUrut,keterangan,Prob_Prior)
values("no",'Pengujian: "nomor pengujian" Nilai Prior X1=Daftar Ulang', " nilaiPriorDU ")
c. SetProbabilitas Prior TDU
nilaiPriorTDU = jtduuji / jDatauji
sql = insert into temp (NoUrut,keterangan,Prob_Prior) values("no",'Pengujian: "nomor pengujian" Nilai Prior
X1='Tidak Daftar Ulang', " nilaiPriorDU ")
d. SetLikelihood Gelombang Masuk DU
jLHGMDU = 0
sql = Select count(*) from pelatihan where gelombang_masuk like '%gel%' and
nilaiLHGMDU = jLHGMDU / getJDUUji()
sql2 = insert into temp (NoUrut,Keterangan,likelihood) values('Pengujian "+uji+":
Gelombang tes="gel"|status="status"', 'getLHGMDU()')
e. SetLikelihood Jenis Kelamin DU
jumlahJKDU = 0
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "+uji+":Jenis kelamin="sex"| status="status"', 'getLHJKDU()')
sql = Select count(*) from pelatihan where
nilaiLHPSDU = jPSDU / getJDUUji()
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Program studi= "progStudi"|status="status "',
'getLHPSDU()')
g. SetLikelihood Jurusan SMA DU
jSMADU = 0
sql = Select count(*) from pelatihan where jurusan_SMA like '%jur%' and
nilaiLHJSMADU = jSMADU / getJDUUji()
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Jurusan SMA="jur" |status='status','getLHJurSMADU()')
h. SetLikelihood Nilai Final DU
jNFDU = 0
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Nilai final="nf" |status="status"','getLHNFDU()')
i. SetLikelihood Prioritas Pilihan DU
jPPDU = 0
nilaiLHPPDU = jPPDU / getJDUUji()
values("no",'Pengujian "uji": Prioritas pilihan= "prioritas "|status=" status "',
'getLHPPDU()')
j. SetLikelihood Gelombang Masuk DU
jLHGMDU = 0
sql = "Select count(*) from pelatihan where gelombang_masuk like '%gel%' and
nilaiLHGMDU = jLHGMDU / getJDUUji()
sql2 = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "+uji+":
Gelombang tes="gel"|status="status"', 'getLHGMDU()')
k SetLikelihood Jenis Kelamin TDU
jumlahJKTDU = 0;
nilaiLHJKTDU = jJKTDU / getJTDUUji()
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "+uji+":
Jenis kelamin=" sex "|status="status"', 'getLHJKTDU()')
l. SetLikelihood Program Studi TDU
jPSTDU = 0
sql = Select count(*) from pelatihan where program_studi='progStudi' and
nilaiLHPSTDU = jPSTDU / getJTDUUji()
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Program studi= "progStudi"|status="status "',
jSMATDU = 0
sql = Select count(*) from pelatihan where jurusan_SMA like '%jur%' and
nilaiLHJSMATDU = jSMATDU / getJTDUUji()
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Jurusan SMA="jur" |status='status','getLHJurSMATDU()')
n. SetLikelihood Nilai Final TDU
jNFTDU = 0
sql = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Nilai final="nf" |status="status"','getLHNFTDU()')
o. SetLikelihood Prioritas Pilihan TDU
jPPTDU = 0
nilaiLHPPTDU = jPPTDU / getJTDUUji()
sql2 = insert into temp (NoUrut,Keterangan,likelihood) values("no",'Pengujian "uji": Prioritas pilihan= "prioritas "|status=" status "',
'getLHPPTDU()')
a. Mengambil Nilai Likelihood Gelombang Masuk
return nilaiLHGM
b. Mengambil Nilai Likelihood Jenis Kelamin
nilaiLHJK = 0
sql = select likelihood from temp where keterangan like 'Pengujian "uji": Jenis kelamin="jk"|
c. Mengambil Nilai Likelihood Program Studi
nilaiLHPS = 0
sql = select likelihood from temp where keterangan like 'Pengujian "uji": Program studi="+prodi+"|
status="status"' group by keterangan while rs.next()
nilaiLHPS = getnilailhps Endwhile
return nilaiLHPS
d. Mengambil Nilai lLikelihood Jurusan SMA
nilaiLHJSMA = 0
sql = select likelihood from temp where keterangan like 'Pengujian "uji": Jurusan SMA="jur"|
e. Mengambil Nilai Likelihood Nilai Final
nilaiLHNF = 0
sql = select likelihood from temp where keterangan like 'Pengujian "uji": Nilai final="nf"|
status="status"' group by keterangan while (rs.next()) {
nilaiLHNF = getnilailhnf Endwhile
nilaiLHPP = 0
sql = select likelihood from temp where keterangan like 'Pengujian "uji": Prioritas pilihan="p"|
status="status"' group by keterangan while rs.next()
nilaiLHPP = getnilailhpp Endwhile
return nilaiLHPP
i. Mengambil Nilai Probabilitas Prior DU
sql = select Probabilitas_Prior from temp where keterangan like 'Pengujian: "uji"
j. Mengambil Nilai Probabilitas Prior TDU
sql = select Probabilitas_Prior from temp where keterangan like 'Pengujian: "uji"
k. Ambil data pengujian
LengthAngs = Data.size() for i=0 to i< LengthAngs do
baris.addElement(Data.elementAt(i)) end for
3.7.9.4 Perancangan Metode Diagram Kelas ControlPelatihan
a. Menghitung Probabilitas Prior TDU
for int j = 1 to j <= fold increment j
c. Menghitung Probabilitas Prior DU
status = Daftar Ulang
f. Menghitung Likelihood TDU
status = Tidak Daftar Ulang
daftar.setLHPPTDU(prioritas, status,j)
3.7.9.5 Perancangan Metode Diagram Kelas ControlPengujian
a.Menghitung Probabilitas Posterior TDU
probPosteriorTDU = hgmtdu x lhpptdu x lhpstdu x lhjktdu x LHjursmaTDU x lhnfTDU x probPriorTDU
return probPosteriorTDU
b. Menghitung Probabilitas Posterior DU
probPosteriorDU = hgmdu x lhppdu x lhpsdu x lhjkdu x LHjursmaDU x lhnfDU x probPriorDU
return probPosteriorDU
3.7.10 Perancangan Antar Muka
Halaman Tam
Halaman Deta
Gambar 3.24 Desain Antar Muka Halaman
mbah Data
Gambar 3.25 Desain Antar Muka Tambah
etail Tabel Pelatihan:
n Utama
Halaman Deta
Halaman Hitun
Gambar 3.26 Desain Antar Muka Detail Tabel etail Tabel Pengujian
Gambar 3.27 Desain Antar Muka Detail Tabel
itung Nilai Probailitas Prior dan likelihood
el Pelatihan
Gambar 3.28 Desain Antar Muka Menghitung Probabilitas Prior dan Likelihood
Halaman Pilih Pengujian
Ga
Halaman Pred
Gambar 3.30 Desain Antar Muka Hasil Prediksi S
ediksi Semua Record
Gambar 3.31 Desain Antar Muka Prediksi Sem
Satu Record
3.7.11 Perancangan Pengujian
Untuk melakukan proses analisa program, menggunakan metode
cross_validation . Metode ini membagi data menjadi beberapa bagian dimana setiap bagian memiliki bagian yang sama banyaknya. Analisis program yang
digunakan menggunakan metode n_fold validation dimana data penerimaan mahasiswa baru yang telah diinputkan sebelumnya dibagi menjadi beberapa
bagian. Nilai n berarti bahwa pengguna bisa memasukan nilai fold sesuai dengan keinginan pengguna. Pembagian data didasarkan pada atribut data
status. Setiap bagian memiliki bagian yang sama. Satu bagian akan menjadi
data pengujian sedangkan bagian yang lain akan menjadi tabel pelatihan.
Misalnya angka fold yang dimasukkan adalah 5 jadi pengujian pertama,
bagian pertama menjadi tabel pengujian maka bagian kedua, ketiga, keempat
dan kelima akan menjadi tabel pelatihan. Pengujian kedua bagian kedua
menjadi tabel pengujian maka bagian pertama, ketiga, keempat dan kelima
akan menjadi tabel pelatihan, begitu seterusnya sampai setiap bagian tepat
digunakan sekali menjadi tabel pengujian.
Algoritma pengujian yang dilakukan adalah sebagai berikut:
1. Mengambil semua data yang telah dimasukkan untuk atribut status
daftar ulang.
2. Data yang sudah diambil diberi kelompok berdasarkan nilai fold,
misalnya nilai fold yang dimasukkan adalah 5, maka data dengan status
daftar ulang dari data pertama sampai lima diberi kelompok satu sampai
lima, lalu mengambil data dengan status daftar ulang dari data ke enam
sampai sepuluh diberi kelompok satu sampai lima, begitu seterusnya
sampai semua data dengan status daftar ulang diberi kelompok semua.
3. Mengambil semua data dengan status tidak daftar ulang.
4. Data yang sudah diambil diberi kelompok berdasarkan nilai fold. Proses
pemberian kelompok status tidak daftar ulang ini sama dengan
pemberian kelompok status daftar ulang seperti pada langkah ke dua.
5. Data yang telah dikelompokkan, satu bagian atau satu kelompok menjadi
tabel pengujian sedangkan kelompok yang lain menjadi tabel pelatihan.
Lalu dilakukan proses prediksi. Begitu seterusnya sampai setiap bagian
IMPL
4.1
Implementasi B
Proses ini dilakuk
yog. Database yan
tabel yang akan
melakukan daftar
Berikut sintaks pe mahasiswa:
kukan pembuatan database pada MySQL men
ang dibuat bernama mahasiswa. Database ini a
n diperlukan oleh program prediksi mahasi
ar ulang atau tidak.
Tabel 4.1 Tabel Pelatihan
Tabel 4.2 Tabel Pengujian
Tabel 4.3 Tabel Temp
pembuatan database mahasiswa dan tabel-tabe
ase if not exists `mahasiswa`;
wa`;
cture for table `pelatihan` */
F EXISTS `pelatihan`;
`pelatihan` (
an` int(11) NOT NULL,
data` varchar(50) default NULL, _masuk` int(11) default NULL,
AN
enggunakan SQL
i akan berisi
tabel-asiswa baru yang