i TUGAS AKHIR – KI141502
IMPLEMENTASI
FITUR
TEMU
KEMBALI
INFORMASI SLiMS PADA WEB MANAJEMEN
RBTC
RAHARDIAN DEWA BIMANTARA NRP. 5112 100 067
Dosen Pembimbing 1
Diana Purwitasari, S.Kom., M.Sc. Dosen Pembimbing 2
Abdul Munif, S.Kom., M.Sc.
JURUSAN TEKNIK INFORMATIKA
Fakultas Teknologi Informasi
Institut Teknologi Sepuluh Nopember
Surabaya 2017
ii
iii HALAMAN JUDUL
TUGAS AKHIR – KI141502
IMPLEMENTASI
FITUR
TEMU
KEMBALI
INFORMASI SLiMS PADA WEB MANAJEMEN
RBTC
RAHARDIAN DEWA BIMANTARA NRP. 5112 100 067
Dosen Pembimbing 1
Diana Purwitasari, S.Kom., M.Sc. Dosen Pembimbing 2
Abdul Munif, S.Kom., M.Sc.
JURUSAN TEKNIK INFORMATIKA
Fakultas Teknologi Informasi
Institut Teknologi Sepuluh Nopember
iv
v Halaman Judul
UNDERGRADUATE THESIS – KI141502
IMPLEMENTATION OF SLiMS INFORMATION
RETRIEVAL FEATURE ON INFORMATICS ITS
DIGITAL LIBRARY SYSTEM
RAHARDIAN DEWA BIMANTARA NRP. 5112 100 067
Supervisor 1
Diana Purwitasari, S.Kom., M.Sc. Supervisor 2
Abdul Munif, S.Kom., M.Sc.
DEPARTMENT OF INFORMATICS Faculty of Information Technology Institut Teknologi Sepuluh Nopember
vi
viii
ix
IMPLEMENTASI FITUR TEMU KEMBALI INFORMASI SLiMS PADA WEB MANAJEMEN RBTC
Nama : Rahardian Dewa Bimantara
NRP : 5112100067
Jurusan : Teknik Informatika
Fakultas Teknologi Informasi ITS Dosen Pembimbing I : Diana Purwitasari, S.Kom., M.Sc. Dosen Pembimbing II : Abdul Munif, S.Kom., M.Sc.
ABSTRAK
Ruang Baca Teknik Informatika ITS menggunakan Senayan Library Management System (SLiMS) sebagai dasar arsitektur pembangunan sistem informasi perpustakaan digital guna mempermudah mahasiswa maupun staf untuk mencari informasi. Seiring bertambahnya jumlah dokumen dalam repositori digital, Fitur temu kembali informasi yang ada tidak dapat mengimbangi sehingga mahasiswa menemukan banyak kendala dalam mendapatkan informasi. Mahasiswa sering mencari referensi guna memilih topik tugas akhir dan tesis yang sedang populer. Fitur temu kembali informasi tambahan perlu dibangun sebagai solusi permasalahan tersebut. Clustering topik-topik tugas akhir dan tesis juga bisa menjadi salah satu cara untuk menggali informasi bagi rencana pengembangan kurikulum maupun perencanaan pengambilan topik tugas akhir dan tesis yang sedang populer sebagai rekomendasi.
Fitur temu kembali informasi yang dibangun diharapkan bisa mempermudah mahasiswa untuk memperoleh informasi dan pengetahuan yang menjadi kebutuhannya. Fitur pencarian yang baru dibangun dengan metode yang biasa digunakan dalam sistem temu kembali informasi, yakni Vector Space Model. Proses clustering topik tugas akhir dan tesis menggunakan K-Means Clustering, dan membagi topik-topik menjadi beberapa kelompok sesuai dengan bidang minat Teknik Informatika ITS.
x
Fitur pencarian yang dibangun dapat mencari dengan kriteria yang lebih detil dari yang ada di RBTC. Abstrak tercluster secara merata pada tiap cluster yang terbentuk, tetapi nilai kualitas cluster masih sangat rendah untuk jumlah kelompok delapan, tetapi tinggi untuk jumlah kelompok tiga karena pembagian bidang minat Teknik Informatika juga masih belum sepenuhnya terpisah.
Kata Kunci: Text Mining, Tugas Akhir, Tesis, Dokumen, K-Means Clustering, Vector Space Model.
xi
IMPLEMENTATION OF SLiMS INFORMATION RETRIEVAL FEATURE ON INFORMATICS ITS
DIGITAL LIBRARY SYSTEM
Name : Rahardian Dewa Bimantara
NRP : 5112100067
Department : Department of Informatics
Faculty of Information Technology ITS Supervisor I : Diana Purwitasari, S.Kom., M.Sc. Supervisor II : Abdul Munif, S.Kom., M.Sc.
ABSTRACT
ITS Informatics Engineering Reading Room uses Senayan Library Management System (SLiMS) as the basic architecture of digital library information system in order to facilitate students and staff to find information. With increasing number of documents in the digital repository, feature information retrieval cannot be offset so that the students do not find many obstacles in getting information. Students often find references to elect the undergraduate thesis and thesis topics that are popular. Additional features of information retrieval needs to be built as a solution to these problems. Clustering topics of undergraduate thesis and thesis could also be one way to gather information for planning, curriculum development and planning decision and the undergraduate thesis and thesis topic that is popular as a recommendation.
Features built by information retrieval expected to facilitate students to acquire information and knowledge into their needs. The new search feature is built with a method commonly used in information retrieval system, the Vector Space Model. Clustering process undergraduate thesis topic and thesis using the K-Means Clustering, and split the topics into certain amount of groups according to their areas of interest ITS Informatics Engineering. The new search feature can search by more detailed
xii
criteria than in RBTC. Abstracts are clustered almost evenly on each cluster, but the value of the quality of the cluster is very low for eight groups yet high for three, because of the division of areas of interest of Informatics is still not completely separated. Keywords: Text Mining, Undergraduate Thesis, Thesis, Document, K-Means Clustering, Vector Space Model
xiii
KATA PENGANTAR
Segala puji dan syukur kepada Tuhan Yang Maha Esa yang telah melimpahkan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul “IMPLEMENTASI FITUR TEMU KEMBALI INFORMASI SLiMS PADA WEB MANAJEMEN RBTC”.
Tugas akhir ini dilakukan dengan tujuan agar penulis dapat menghasilkan sesuatu atau menerapkan apa yang telah dipelajari selama pada masa perkuliahan dan untuk memenuhi salah satu syarat memperoleh gelar Sarjana di Jurusan Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember Surabaya.
Penulis mengucapkan banyak terima kasih kepada semua pihak yang telah memberikan dukungan dan bimbingan kepada penulis, baik secara langsung maupun tidak langsung dalam proses pengerjaan tugas akhir ini, yaitu kepada:
1. Keluarga dari penulis yang sudah mendukung sepanjang waktu pembuatan tugas akhir.
2. Ibu Diana Purwitasari, S.Kom., M.Sc. dosen pembimbing I yang telah memberikan bimbingan dan arahan kepada penulis dalam pengerjaan tugas akhir ini.
3. Bapak Abdul Munif, S.Kom., M.Sc. sebagai dosen pembimbing II yang telah memberikan arahan dan bantuan kepada penulis dalam pengerjaan tugas akhir dan penulisan buku tugas akhir ini hingga selesai.
4. Bapak Dwi Sunaryono, S.Kom., M.Kom. sebagai dosen wali yang telah membimbing selama masa perkuliahan. 5. Dan kepada seluruh pihak yang tidak bisa penulis sebutkan
satu persatu yang telah memberikan dukungan dan semangat kepada penulis untuk menyelesaikan tugas akhir ini.
Penulis menyadari bahwa masih terdapat banyak kekurangan dalam pengerjaan tugas akhir ini. Penulis sangat mengharapkan kritik dan saran dari pembaca untuk perbaikan dan
xiv
pembelajaran kedepannya. Semoga tugas akhir yang penulis buat dapat memberikan manfaat.
Surabaya, Januari 2017
xv
DAFTAR ISI
LEMBAR PENGESAHAN ... Error! Bookmark not defined.
ABSTRAK ... ix
ABSTRACT ... xi
KATA PENGANTAR ... xiii
DAFTAR ISI ... xv
DAFTAR GAMBAR ... xix
DAFTAR TABEL ... xxi
DAFTAR KODE SUMBER ... xxiii
BAB I PENDAHULUAN……….. ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 2 1.3 Batasan Masalah ... 3 1.4 Tujuan ... 3 1.5 Manfaat ... 3 1.6 Metodologi ... 4
1.7 Sistematika Penulisan Laporan Tugas Akhir ... 5
BAB II TINJAUAN PUSTAKA ... 9
2.1 Algoritma Pemrosesan Teks ... 9
Tokenisasi ... 9
Penghapusan Stopword ... 9
Stemming ... 10
2.2 Algoritma Vector Space Model ... 10
2.3 Algoritma Reduksi Dimensi ... 12
2.4 Algoritma Clustering Tugas Akhir dan Tesis ... 14
2.5 Algoritma Silhouette Coefficient ... 15
2.6 Senayan Library Management System... 17
2.7 Pustaka Visualisasi Cluster ... 17
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 21
3.1 Analisis Sistem ... 21
xvi
Deskripsi Umum Sistem ... 22
3.2 Perancangan Sistem ... 23
Praproses Data ... 23
Fitur Pencarian... 24
Clustering Tugas Akhir dan Tesis ... 26
Perancangan Basis Data ... 31
Perancangan Antar Muka ... 33
BAB IV IMPLEMENTASI SISTEM ... 39
4.1 Lingkungan Implementasi ... 39
Perangkat Keras ... 39
Perangkat Lunak ... 39
4.2 Penggunaan Pustaka dan Kerangka Kerja ... 40
Kerangka Kerja SLiMS ... 40
MySQLdb ... 41
Scikit-learn (Sklearn) ... 42
Data Driven Documents ... 42
4.3 Implementasi Praproses Data ... 43
Tokenisasi ... 43
Penghapusan stopword ... 44
Stemming ... 44
4.4 Implementasi Fungsi Pencarian ... 45
Implementasi Praproses Query Masukan ... 45
Implementasi Pembentukan Vektor Query ... 46
Implementasi Cosine Similarity dan Ranking .... 47
4.5 Implementasi Clustering Tugas Akhir dan Tesis ... 48
Implementasi Pembentukan Matriks Frekuensi Kata 48 Implementasi Pembentukan Vektor Dokumen ... 48
Implementasi Reduksi Dimensi ... 49
Implementasi K-Means Clustering ... 50
xvii
4.7 Implementasi Basis Data ... 52
4.8 Implementasi Antar Muka ... 58
BAB V UJI COBA DAN EVALUASI ... 59
5.1 Deskripsi Uji Coba ... 59
Lingkungan Uji Coba ... 59
Dataset Uji Coba ... 60
Threshold Uji Coba ... 60
5.2 Skenario Uji Coba 1 ... 60
Tahapan Uji Coba ... 61
Hasil Uji Coba ... 61
Analisis dan Evaluasi ... 63
5.3 Skenario Uji Coba 2 ... 63
Tahapan Uji Coba ... 64
Hasil Uji Coba ... 65
Analisis dan Evaluasi ... 68
5.4 Skenario Uji Coba 3 ... 70
Tahapan Uji Coba ... 70
Hasil Uji Coba ... 71
Analisis dan Evaluasi ... 75
5.5 Skenario Uji Coba 4 ... 75
Tahapan Uji Coba ... 75
Hasil Uji Coba ... 76
Analisis dan Evaluasi ... 78
BAB VI KESIMPULAN DAN SARAN ... 79
6.1 Kesimpulan ... 79 6.2 Saran ... 80 DAFTAR PUSTAKA ... 81 LAMPIRAN A ... 83 LAMPIRAN B ... 85 LAMPIRAN C ... 89 BIODATA PENULIS ... 93
xviii
xix
DAFTAR GAMBAR
Gambar 2.1 Vektor dokumen dengan query ... 10
Gambar 2.2 Matriks term document ... 11
Gambar 2.3 Contoh Berkas JSON ... 18
Gambar 2.4 Contoh Code Flower 1 ... 19
Gambar 2.5 Contoh Code Flower 2 ... 19
Gambar 3.1 Deskripsi Umum Sistem ... 22
Gambar 3.2 Proses pencarian metode Vector Space Model ... 26
Gambar 3.3 Diagram Alur K-Means Clustering ... 29
Gambar 3.4 Conceptual Data Model Tabel Tambahan ... 31
Gambar 3.5 Physical Data Model Tabel Tambahan ... 32
Gambar 3.6 Antar Muka Visualisasi Cluster Tesis ... 34
Gambar 3.7 Antar Muka Visualisasi Cluster Kata Tugas Akhir . 35 Gambar 3.8 Antar Muka Pencarian Spesifik ... 36
Gambar 4.1 Folder Kerangka kerja SLiMS ... 40
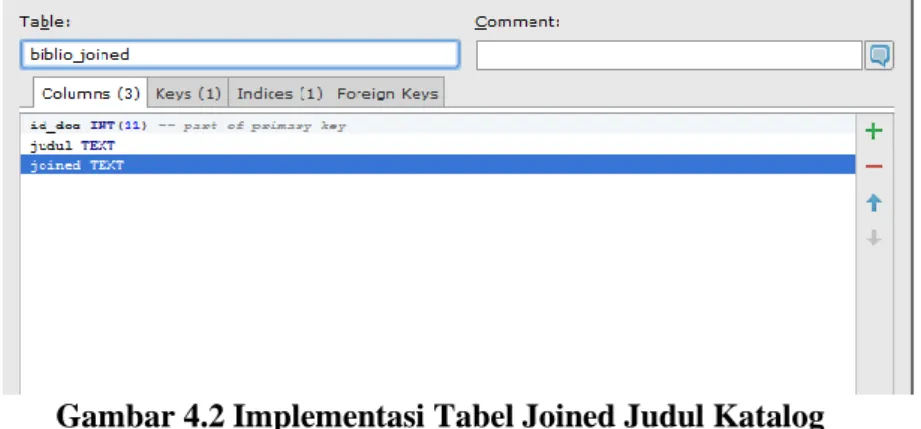
Gambar 4.2 Implementasi Tabel Joined Judul Katalog ... 53
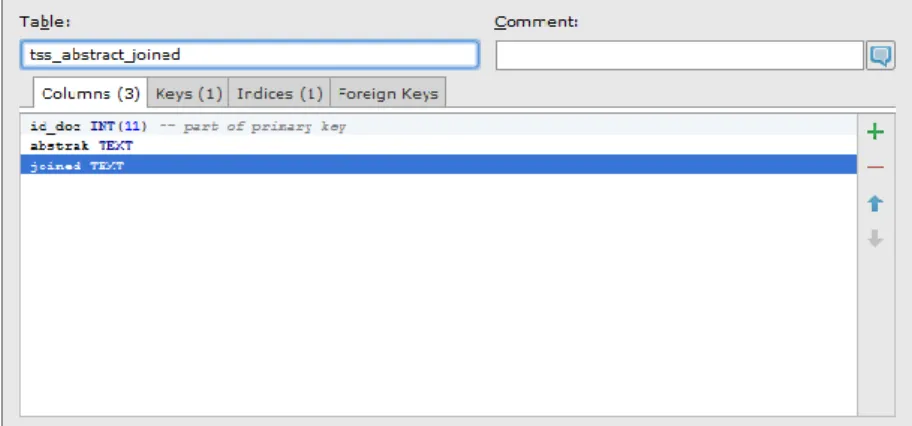
Gambar 4.3 Implementasi Tabel Joined Abstrak Tugas Akhir ... 53
Gambar 4.4 Implementasi Tabel Joined Abstrak Tesis ... 54
Gambar 4.5 Implementasi Tabel kata Judul katalog ... 54
Gambar 4.6 Implementasi Tabel Kata Abstrak Tugas Akhir ... 55
Gambar 4.7 Implementasi Tabel Kata Abstrak Tesis ... 55
Gambar 4.8 Implementasi Tabel tf-idf Judul Katalog ... 56
Gambar 4.9 Implementasi Tabel tf-idf Abstrak Tugas Akhir ... 56
Gambar 4.10 Implementasi Tabel tf-idf Abstrak Tesis ... 57
Gambar 4.11 Implementasi Tabel Hasil Clustering Tugas Akhir ... 57
Gambar 4.12 Implementasi Tabel Hasil Clustering Tesis ... 58
Gambar 5.1 Hasil Clustering dengan 8 kelompok ... 73
xx
Gambar 5.3 Pemetaan clustering tugas akhir 8 kelompok tanpa reduksi dimensi ... 76 Gambar 5.4 Pemetaan clustering tugas akhir 3 kelompok tanpa reduksi dimensi ... 77 Gambar 5.5 Pemetaan clustering tugas akhir 8 kelompok dengan reduksi dimensi ... 77 Gambar 5.6 Pemetaan clustering tugas akhir 3 kelompok dengan reduksi dimensi ... 78
xxi
DAFTAR TABEL
Tabel 2.1 Nilai Silhouette Coefficient ... 16
Tabel 3.1 Contoh Matriks Frekuensi Kata ... 27
Tabel 3.2 Contoh Matriks Vektor Dokumen ... 28
Tabel 3.3 Tabel Antar Muka Pencarian Spesifik ... 36
Tabel 5.1 Hasil Waktu Eksekusi ... 62
Tabel 5.2 Hasil Proses ... 62
Tabel 5.3 Hasil Pencarian dengan query 1 ... 65
Tabel 5.4 Hasil pencarian dengan query 2 ... 66
Tabel 5.5 Hasil pencarian dengan query 3 ... 67
Tabel 5.6 Clustering Tugas Akhir 8 Kelompok ... 71
Tabel 5.7 Clustering Tesis 8 Kelompok ... 71
Tabel 5.8 Clustering Tugas Akhir 3 Kelompok ... 72
xxii
xxiii
DAFTAR KODE SUMBER
Kode Sumber 4.1 Penggunaan MySQLdb ... 42 Kode Sumber 4.2 Penggunaan Data Driven Documents ... 42 Kode Sumber 4.3 Tokenisasi Abstrak Tugas Akhir dan Tesis ... 43 Kode Sumber 4.4 Tokenisasi Judul Katalog ... 43 Kode Sumber 4.5 Menghapus Stopword Tugas Akhir dan Tesis44 Kode Sumber 4.6 Menghapus Stopword Judul Katalog ... 44 Kode Sumber 4.7 Proses Stemming ... 44 Kode Sumber 4.8 Kode Sumber Pemisahan proses query ... 46 Kode Sumber 4.9 Pembentukkan Vektor Query ... 46 Kode Sumber 4.10 Penghitungan Cosine Similarity... 47 Kode Sumber 4.11 Pembentukan Matriks Frekuensi Kata ... 48 Kode Sumber 4.12 Pembentukan Vektor Dokumen ... 49 Kode Sumber 4.13 Implementasi PCA ... 49 Kode Sumber 4.14 Implementasi K-Means Clustering ... 50 Kode Sumber 4.15 Pembangkitan Berkas JSON untuk Visualisasi Cluster ... 51 Kode Sumber 4.16 Contoh JSON Hasil Clustering ... 52
xxiv
1
BAB I
PENDAHULUAN
1.
1.1 Latar Belakang
Perpustakaan digital adalah sebuah sistem yang memiliki beragam layanan dan objek informasi yang mendukung akses objek informasi tersebut melalui perangkat digital. Layanan ini diharapkan dapat mempermudah temu kembali informasi di dalam koleksi objek informasi seperti dokumen, gambar dan database dalam format digital dengan cepat, tepat, dan akurat. Perpustakaan digital itu tidak berdiri sendiri, melainkan terkait dengan sumber-sumber lain dan pelayanan informasinya terbuka bagi pengguna di seluruh dunia.
Senayan Library Management System atau biasa disingkat SLiMS adalah Open Source Software (OSS) berbasis web untuk memenuhi kebutuhan otomasi perpustakaan (library automation) skala kecil hingga skala besar [1]. Dengan fitur yang cukup lengkap dan masih terus aktif dikembangkan. SLiMS sangat cocok digunakan bagi perpustakaan yang memiliki koleksi, anggota dan staf banyak di lingkungan jaringan, baik itu jaringan lokal (intranet) maupun internet. SLiMS memiliki beberapa fitur, antara lain:
Online Public Access Catalog (OPAC) dengan pembuatan thumbnail yang dibangkitkan on-the-fly. Thumbnail berguna untuk menampilkan sampul buku
Mode penelusuran tersedia untuk yang sederhana (Simple Search) dan tingkat lanjut (Advanced Search). Mendukung Boolean Logic, temu kembali menggunakan suara dan saran kata kunci.
Detail record juga tersedia format XML (Extensible Markup Language) standar MODS untuk kebutuhan layanan web. Manajemen data bibliografi yang efisien meminimalisasi
pengulangan data.
Pengelolaan dokumen multimedia, inventarisasi koleksi, manajemen anggota, laporan dan statistik.
Sirkulasi dengan fitur:
Transaksi peminjaman dan pengembalian, Reservasi koleksi,
Aturan peminjaman yang fleksibel, dan Informasi keterlambatan dan denda.
SLiMS digunakan sebagai arsitektur dasar perangkat lunak perpustakaan digital Ruang Baca Teknik Informatika ITS (RBTC). Web manajemen RBTC menggunakan SLiMS versi 3 sebagai template dasar, dimana sudah dilakukan empat kali pembaruan sesuai dengan kebutuhan pengguna RBTC.
Perbandingan ketersediaan fitur pada SLiMS dan web manajemen RBTC sangat besar, banyak fitur baru yang belum terimplementasi pada web RBTC. Web RBTC memerlukan fitur tambahan untuk memenuhi kebutuhan pengguna yang semakin bervariasi dan tidak dapat dipenuhi dengan fitur yang telah ada sehingga diperlukan fitur tambahan mengimbangi perkembangan kebutuhan pengguna RBTC. Tugas akhir ini akan membahas implementasi penambahan fitur-fitur baru yang terkait temu kembali informasi yang masih belum terdapat di situs web RBTC.
1.2 Rumusan Masalah
Rumusan masalah yang diangkat pada tugas akhir ini adalah sebagai berikut:
1. Bagaimana implementasi fitur-fitur temu kembali informasi SLiMS pada web manajemen RBTC?
2. Bagaimana clustering topik tugas akhir dan tesis sesuai bidang minat mata kuliah?
3. Bagaimana perubahan antarmuka pengguna sistem informasi RBTC setelah fitur temu kembali diimplementasikan?
3
1.3 Batasan Masalah
Batasan masalah dalam pengerjaan tugas akhir ini adalah sebagai berikut:
1. Aplikasi yang dibangun pada tugas akhir ini adalah aplikasi berbasis web.
2. Fitur temu kembali informasi yang diimplementasikan berdasarkan SLiMS dan metode information retrieval.
3. Data uji yang digunakan berasal dari basis data Ruang Baca Teknik Informatika ITS dan basis data Tugas Akhir Teknik Informatika.
4. Algoritma yang dipakai dalam tugas akhir ini adalah Vector Space Model untuk pembuatan fitur temu kembali dan K-Means clustering untuk clustering tugas akhir dan tesis. 5. Bahasa pemrograman yang digunakan adalah Python untuk
implementasi fitur temu kembali informasi dan PHP untuk pembuatan web.
1.4 Tujuan
Tujuan dalam pengerjaan tugas akhir ini adalah sebagai berikut: 1. Mengimplementasikan fitur-fitur pada SLiMS terkait temu kembali informasi yang belum ada dalam sistem perpustakaan digital Ruang Baca Teknik Informatika ITS.
2. Clustering topik tugas akhir dan tesis yang terkait berdasarkan bidang minat Teknik Informatika ITS.
3. Membuat antarmuka pengguna baru untuk beradaptasi pada fitur temu kembali yang diimplementasikan.
1.5 Manfaat
Manfaat dari hasil pembuatan tugas akhir ini adalah penambahan fitur-fitur yang berhubungan dengan sistem temu kembali informasi pada situs web Ruang Baca Teknik Informatika yaitu rbtc.if.its.ac.id sesuai dengan kelengkapan fitur SLiMS dan kebutuhan pengguna web manajemen RBTC.
1.6 Metodologi 1. Studi Literatur
Pada tahap ini dilakukan pembelajaran dan pemahaman tentang metode-metode dan pustaka-pustaka yang digunakan dalam proses pengerjaan tugas akhir pada tahap implementasi sistem. Metode-metode dan pustaka-pustaka tersebut adalah sebagai berikut:
a. Metode penghitungan kedekatan antar kata, Vector Space Model.
b. Metode clustering kata dan dokumen, K-Means clustering. c. Pustaka pembobotan kata, Scikit-learn
d. Pustaka K-Means clustering, Scikit-learn.
e. Pustaka penampilan data hasil clustering, data-driven documents.
2. Analisis dan perancangan sistem
Pada tahap ini dilakukan analisis permasalahan yang diangkat dan perancangan sistem berdasarkan studi literatur yang telah dilakukan. Tahap ini merancang alur implementasi yang akan dilakukan, seperti merancang modul-modul yang dibuat, melakukan perancangan untuk menampilkan hasil clustering, perancangan basis data dan perancangan antar muka. Fitur temu kembali yang dibangun memiliki dua modul utama, yaitu: a. Modul praproses data, yaitu modul yang digunakan untuk melakukan ekstraksi kata pada setiap abstrak tugas akhir dan tesis, serta seluruh judul katalog RBTC.
b. Modul fungsi pencarian, yaitu modul yang digunakan untuk melakukan proses pencarian katalog pada RBTC. Proses pencarian terbagi dalam dua kategori, yakni pencarian sederhana dengan menggunakan kata kunci dan metode Vector Space Model dan pencarian spesifik dengan filter judul, pengarang, subjek, tahun, issn/isbn, dan GMD. c. Modul pembentukan cluster tugas akhir dan tesis, yaitu
5
menjadi beberapa cluster dan untuk menghitung nilai kemiripan antar kata pada suatu cluster.
3. Implementasi sistem
Pada tahap ini dilakukan implementasi fitur temu kembali informasi yang ada pada SLiMS, penambahan fitur clustering tugas akhir dan tesis, metode-metode dan pustaka-pustaka yang telah dipelajari menjadi sistem yang dapat digunakan. Bahasa pemrograman yang digunakan adalah PHP dan Python dengan menggunakan basis data MySQL untuk menyimpan data-data bibliografi perpustakaan di RBTC, dan pemisahan data abstrak skripsi dan tesis untuk Clustering topik, serta Apache sebagai web server.
4. Pengujian dan evaluasi
Pengujian aplikasi menggunakan black box testing. Pengujian fungsionalitas aplikasi dinilai berdasarkan akurasi dari hasil proses fitur temu kembali yang diimplementasikan dan evaluasi hasil clustering tugas akhir dan tesis yang dibangun. Akurasi hasil dihitung dari perbandingan hasil temu kembali dengan query masukan dan rekomendasi kata kunci.
5. Penyusunan buku tugas akhir
Pada tahap ini dilakukan penyusunan buku tugas akhir sebagai dokumentasi pengerjaan tugas akhir dari keseluruhan proses pengerjaan. Mencakup tinjauan pustaka pengerjaan tugas akhir, analisis dan perancangan, implementasi, uji coba dan evaluasi, kesimpulan dan saran terhadap sistem yang telah dibangun.
1.7 Sistematika Penulisan Laporan Tugas Akhir
Buku tugas akhir ini disusun dengan tujuan untuk memberikan gambaran tentang pengerjaan tugas akhir yang telah dilakukan. Buku tugas akhir ini terbagi menjadi enam bab, yaitu:
Bab I Pendahuluan
Bab yang berisi mengenai latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat pembuatan tugas akhir, serta metodologi dan sistematika penulisan buku tugas akhir. Bab II Tinjauan Pustaka
Bab yang berisi penjelasan metode-metode dan pustaka-pustaka yang digunakan sebagai dasar dan penunjang pengerjaan tugas akhir. Metode-metode yang digunakan meliputi beberapa algoritma, yaitu algoritma pemrosesan teks, algoritma clustering dokumen dan algoritma penghitungan kemiripan. Sedangkan pustaka yang digunakan yaitu pustaka pembangkitan array, pustaka clustering dokumen dan pustaka untuk menampilkan hasil clustering dokumen.
Bab III Analisis dan Perancangan Sistem
Bab yang berisi tentang analisis masalah yang diangkat, mendefinisikan alur proses implementasi, merancang modul-modul, algoritma, tahapan sistem hingga terbentuk suatu rancangan sistem yang siap dibangun.
Bab IV Implementasi Sistem
Bab yang berisi implementasi perancangan sistem yang telah dibuat berupa algoritma dan tahapan pada bab perancangan sehingga menjadi sistem yang dilakukan uji coba dan evaluasi. Bab V Uji Coba dan Evaluasi
Bab yang berisi skenario uji coba, hasil uji coba, analisis dan evaluasi yang dilakukan terhadap sistem sehingga dapat diketahui performa dan kebenaran yang dihasilkan oleh sistem.
7
Bab VI Kesimpulan dan Saran
Bab yang berisi kesimpulan dari hasil uji coba terhadap sistem yang dibuat dan saran untuk pengembangan sistem pada tugas akhir ini untuk kedepannya.
9
BAB II
TINJAUAN PUSTAKA
2.
Bab ini membahas metode dan pustaka yang digunakan dalam implementasi fitur temu kembali informasi tambahan. Penjelasan ini bertujuan untuk memberikan gambaran secara umum terhadap fitur temu kembali yang dibangun dan menjadi acuan dalam proses pembangunan dan pengembangan .
2.1 Algoritma Pemrosesan Teks
Algoritma pemrosesan teks digunakan untuk melakukan ekstraksi kata pada kumpulan abstrak tugas akhir dan tesis dan seluruh judul katalog dalam basis data RBTC. Algoritma ini bisa disebut sebagai tahapan praproses data.
Tokenisasi
Tokenisasi adalah suatu proses untuk membagi suatu teks berupa kalimat atau paragraf menjadi unit-unit kecil berupa kumpulan kata atau token [2]. Sebagai contoh pada kalimat “Sistem temu kembali informasi” menghasilkan empat token, yaitu: “Sistem”, “temu”, “kembali”, “informasi”. Pada proses tokenisasi, yang menjadi acuan pemisah antar kata adalah tanda baca dan spasi.
Penghapusan Stopword
Setelah dilakukan proses tokenisasi pada artikel berita, proses yang dilakukan selanjutnya yaitu penghapusan stopword. Stopword adalah kata-kata sering muncul pada suatu dokumen yang tidak memberikan informasi penting, seperti kata penghubung dan kata ganti orang [2]. Penghapusan stopword ini bertujuan agar kata-kata yang digunakan hanya kata-kata yang memiliki arti penting dan memberikan suatu informasi.
Stemming
Stemming adalah proses untuk mengembalikan bentuk kata menjadi bentuk dasarnya [2]. Membuang awalan, sisipan atau akhiran hingga menjadi kata dasar yang sesuai dengan bahasa Indonesia yang baik dan benar.
2.2 Algoritma Vector Space Model
Vector Space Model (VSM) adalah metode untuk melihat tingkat kedekatan atau kesamaan (similarity) istilah (term) dengan cara pembobotan [3]. Dokumen dipandang sebagai sebuah vektor yang memiliki jarak (magnitude) dan arah (direction). Pada Vector Space Model, sebuah term direpresentasikan dengan sebuah dimensi dari ruang vektor. Relevansi sebuah dokumen ke sebuah query didasarkan pada similaritas di antara vektor dokumen dan vektor query. Bobot term yang akhirnya digunakan untuk menghitung tingkat kesamaan antara setiap dokumen yang tersimpan dalam sistem dan permintaan pengguna. Dokumen yang terambil diurutkan berdasarkan kemiripan yang dimiliki. Model vektor memperhitungkan pertimbangan dokumen yang relevan dengan permintaan pengguna. Sebuah dokumen dj dan sebuah
query direpresentasikan sebagai vektor t-dimensi seperti pada Gambar 2.1.
11
Gambar 2.2 Matriks term document
Koleksi dokumen direpresentasikan sebagai sebuah matriks term document. Setiap sel dalam matriks menyimpan bobot yang diberikan dari term dalam dokumen yang ditentukan. Nilai 0 berarti bahwa term tersebut tidak ada dalam dokumen.
Gambar 2.2 menunjukkan matriks term document dengan n dokumen dan t term. Di mana D1 hingga Dn adalah dokumen ke-1 hingga n, T1 hingga Tt adalah term ke-1 hingga t sehingga Wtn adalah bobot dari term ke-t pada dokumen ke-n. Proses penghitungan VSM melalui tahapan penghitungan Term Frequency Inverse Document Frequency (tfidf) menggunakan Persamaan 2.1.
𝑊𝑖𝑗 = 𝑡𝑓 ∙ 𝑖𝑑𝑓 = 𝑡𝑓𝑖𝑗∙ log𝑑𝑓𝑁
𝑖 (2.1)
Dengan tf adalah Term Frequency atau bisa diartikan sebagai frekuensi kemunculan term dalam suatu dokumen, idf adalah Inverse Document Frequency, N adalah jumlah dokumen yang terambil oleh sistem, tfij adalah banyaknya kemunculan term
ti pada dokumen dj, dan dfi adalah banyaknya dokumen dalam
digunakan untuk mengetahui banyaknya term yang dicari yang muncul dalam dokumen lain dalam basis data. Wij adalah bobot dokumen dihitung dari dot product antara term frequency (tf) dan Inverse Document Frequency (idf). Penghitungan pengukuran similaritas query dan dokumen menggunakan Persamaan 2.2.
𝑠𝑖𝑚(𝑞, 𝑑
𝑗) =
|𝑞|∗|𝑑𝑞∙𝑑𝑗𝑗|
=
∑𝑡𝑖=1 𝑊𝑖𝑞 ∙ 𝑊𝑖𝑗
√∑𝑡𝑖=1(𝑊𝑞𝑗)2∗√∑𝑡𝑖=1(𝑊𝑖𝑗)2
(2.2)
Dengan |q| adalah jarak query, dan Wqj adalah bobot query
dokumen ke-j, maka jarak query (|q|) dihitung untuk mendapatkan jarak query dari bobot query dokumen (Wiq) yang terambil oleh
sistem. Jarak query bisa dihitung dengan persamaan akar jumlah kuadrat dari bobot query dokumen ke-j. |dj| adalah jarak dokumen, dan Wij adalah bobot dokumen ke-j, maka jarak dokumen (|dj|) dihitung untuk mendapatkan jarak dokumen dari bobot dokumen (Wij) yang terambil oleh sistem. Jarak dokumen bisa dihitung
dengan persamaan akar jumlah kuadrat dari bobot dokumen ke-j. 2.3 Algoritma Reduksi Dimensi
Sebelum melakukan clustering dokumen, dilakukan reduksi dimensi terhadap data abstrak tugas akhir maupun tesis. Hal ini dikarenakan jumlah fitur pada data masukan abstrak yang berupa kata dasar memiliki dimensi yang sangat tinggi sehingga penghitungan jarak antar kata dengan pusat kelompok menjadi rancu, dan clustering dokumen menjadi tidak jelas. Algoritma untuk mereduksi dimensi dari data masukan pada Tugas Akhir ini adalah Principal Component Analysis (PCA).
PCA adalah sebuah teknik statistika yang berguna pada bidang pengenalan, klasifikasi dan kompresi data dokumen. PCA juga merupakan teknik yang umum digunakan untuk menarik fitur-fitur dari data pada sebuah skala berdimensi tinggi. Dengan cara mentransformasikan dokumen ke dalam eigenfaces secara linier, proyeksikan matriks kata ke dalam bentuk skala berdimensi n,
13
yang menampakkan properti dari sampel yang paling jelas sepanjang koordinat. PCA memproyeksikan kata ke dalam subspace, dan menghitung variasi dari kata tersebut.
Dengan kata lain, PCA adalah transformasi linear untuk menentukan sistem koordinat yang baru dari dataset. Teknik PCA dapat mengurangi dimensi dari dataset tanpa tidak menghilangkan informasi penting dari dataset [4]. Alur algoritma PCA adalah sebagai berikut:
1. Normalisasi data, di mana tiap data akan dikurangi dari rata-rata seluruh data dan dibagi dengan standar deviasi (σ).
2. Membentuk matriks kovarian data menggunakan Persamaan 2.3.
𝑐𝑜𝑣(𝑋, 𝑌) = ∑𝑛𝑖−1(𝑥𝑖−𝑥̅)(𝑦𝑖 −𝑦̅)
𝑛−1 (2.3)
Nilai dari tiap elemen matriks kovarian berada dalam rentang nilai antara -1 hingga 1.
3. Mencari nilai eigenvalue (λ) dari matriks kovarian menggunakan Persamaan 2.4.
|𝐶 − 𝜆𝐼| = 0 (2.4)
C adalah matriks kovarian dan I adalah matriks identitas. λ adalah nilai eigenvalue dari C jika nilai determinan dari Persamaan 2.4 bernilai nol.
4. Membentuk matriks eigenvector menggunakan eigenvalue yang telah dihasilkan seperti pada Persamaan 2.5.
𝐶𝑣 = 𝜆𝑣 (2.5)
C adalah matriks kovarian, λ adalah nilai eigenvalue dan v adalah matriks eigenvector yang memenuhi Persamaan 2.5.
5. Mencari nilai principal component baru berdasarkan eigenvalue dan eigenvector dari langkah-langkah sebelumnya menggunakan Persamaan 2.6.
𝑧𝑖= 𝑒𝑣𝑖∗ 𝑋 (2.6)
zi adalah principal component ke i, X adalah dataset awal
dan evi adalah eigenvector ke i.
Algoritma PCA pada tugas akhir ini akan diimplementasikan menggunakan pustaka Scikit-learn pada modul
sklearn.decomposition.
2.4 Algoritma Clustering Tugas Akhir dan Tesis
Clustering kata pada dokumen adalah proses penting untuk mengatur koleksi dokumen dan temu kembali dokumen. K-Means merupakan salah satu algoritma pengelompokan (clustering). Tujuan algoritma ini yaitu untuk membagi data menjadi beberapa kelompok. Algoritma ini menerima masukan berupa data tanpa label kelas. Alur algoritma K-Means adalah sebagai berikut:
1. Pilih K buah titik centroid secara acak.
2. Kelompokkan data sehingga terbentuk K buah cluster dengan titik dari setiap cluster merupakan titik centroid yang telah dipilih sebelumnya.
3. Perbarui nilai titik centroid. Dilakukan dengan menggunakan Persamaan 2.7.
𝑈𝑘 = 𝑁1
𝑘 ∑ 𝑋𝑞
𝑁𝑘
𝑞=1 (2.7)
Dengan Uk adalah titik centroid dari cluster ke-k, Nk adalah banyak data pada cluster ke-k, dan Xq adalah data ke-q pada cluster ke-k.
4. Ulangi langkah 2 dan 3 sampai nilai dari titik centroid tidak lagi berubah.
15
𝐷(𝑋𝑖, 𝑋𝑗) = √∑𝑝𝑘=1(𝑋𝑖𝑘− 𝑋𝑗𝑘)2 (2.8)
Variabel p adalah dimensi data, Xi dan Xj adalah dua buah data yang akan dihitung jaraknya, D(Xi,Xj) adalah jarak hasil penghitungan. Pustaka K-Means clustering yang digunakan pada bahasa pemrograman Python adalah Scikit-learn. Pustaka tersebut memiliki modul untuk melakukan K-Means clustering, yaitu modul sklearn.cluster.KMeans. Scikit-learn adalah sebuah pustaka bahasa pemrograman Python yang dapat digunakan untuk penghitungan scientific [5], contohnya adalah penghitungan integral, diferensial numerik, interpolasi dan lain sebagainya.
Fungsi pada modul sklearn.cluster.KMeans yang digunakan untuk melakukan K-Means clustering adalah
KMeans(n_clusters=true_k).fit(matrix) [5]. Penjelasan beberapa
parameter fungsi KMeans() adalah sebagai berikut:
1. matrix adalah variabel yang menampung hasil pembangkitan matriks pembobotan TF-IDF pada sejumlah dokumen input yang disimpan dalam sebuah array. 2. n_clusters adalah parameter yang menyimpan nilai dari
jumlah cluster yang dibentuk dengan metode K-Means. 3. true_k adalah nilai opsional yang menentukan jumlah
cluster yang dibentuk.
2.5 Algoritma Silhouette Coefficient
Metode evaluasi yang akan digunakan pada sistem ini adalah metode Silhouette Coefficient. Metode ini berfungsi untuk menguji kualitas dari cluster yang dihasilkan. Metode ini merupakan metode validasi cluster yang menggabungkan metode cohesion dan Separation [6]. Untuk menghitung nilai Silhouette Coefficient diperlukan jarak antar dokumen dengan menggunakan rumus Euclidean Distance. Setelah itu tahapan untuk menghitung nilai Silhouette Coefficient adalah sebagai berikut:
1. Untuk setiap objek i, hitung rata-rata jarak dari objek i dengan seluruh objek yang berada dalam satu cluster. Akan didapatkan nilai rata-rata yang disebut ai.
2. Untuk setiap objek i, hitung rata-rata jarak dari objek i dengan objek yang berada di cluster lainnya. Dari semua jarak rata-rata tersebut ambil nilai yang paling kecil. Nilai ini disebut bi.
3. Setelah itu maka untuk objek i memiliki nilai Silhouette Coefficient:
𝑠𝑖 = (𝑏𝑖 − 𝑎𝑖) max (𝑎⁄ 𝑖, 𝑏𝑖) (2.9)
Hasil perhitungan nilai Silhouette Coefficient pada Persamaan 2.9 dapat bervariasi antara -1 hingga 1. Hasil clustering dikatakan baik jika nilai Silhouette Coefficient bernilai positif (ai < bi) dan ai mendekati 0, sehingga akan menghasilkan nilai Silhouette Coefficient yang maksimum yaitu 1 saat ai = 0. Maka dapat
dikatakan, jika si = 1 berarti objek i sudah berada dalam cluster
yang tepat. Jika nilai si = 0 maka objek i berada di antara dua cluster
sehingga objek tersebut tidak jelas harus dimasukkan ke dalam cluster A atau cluster B. Akan tetapi, jika si = -1 artinya struktur cluster yang dihasilkan overlapping, sehingga objek i lebih tepat dimasukan ke dalam cluster yang lain.
Nilai rata-rata Silhouette Coefficient dari tiap objek dalam suatu cluster adalah suatu ukuran yang menunjukan seberapa ketat data dikelompokan dalam cluster tersebut. Tabel 2.1 adalah nilai silhoutte berdasarkan Kaufman dan Rousseeuw.
Tabel 2.1 Nilai Silhouette Coefficient Nilai Silhouette Coefficient Keterangan
0.7 < SC <= 1 Struktur Kuat 0.5 < SC <= 0.7 Struktur Normal 0.25 < SC <= 0.5 Struktur Lemah
17
2.6 Senayan Library Management System
Ruang Baca Teknik Informatika menggunakan SLiMS versi 3 sebagai dasar perancangan web manajemen perpustakaan. Fitur temu kembali dalam Senayan Library Management System (SLiMS) ini terdiri dari Simple Search (temu kembali sederhana), dan Advanced Search (temu kembali tingkat lanjut). Pada Simple Search, temu kembali dapat dilakukan dengan mengetikkan kata kunci (judul, pengarang, tahun atau subjek) pada kolom yang tersedia. Sedangkan pada Advanced Search terdapat empat kolom temu kembali yaitu: khusus Title, khusus Author, ISBN/ISSN dan khusus Subjek. Untuk memperoleh ketepatan temu kembali disediakan pula pilihan General Material Designation (GMD).
Hasil pencarian pada SLiMS dibatasi dengan hanya tampilan 10 hasil pencarian per halamannya, di mana urutan hasil berdasarkan data yang terakhir kali dimasukkan ke dalam basis data. Tabel “biblio” menjadi tabel utama dalam seluruh proses pencarian yang menyimpan seluruh data dokumen, dan dapat dimodifikasi melalui back-end SLiMS pada modul bibliografi. Tugas akhir ini juga akan memodifikasi beberapa alur proses temu kembali informasi RBTC yakni bagian pemisahan proses query pada modul pencarian, proses memasukkan data katalog baru ke dalam basis data, dan antarmuka yang beradaptasi dengan fitur temu kembali informasi tambahan.
2.7 Pustaka Visualisasi Cluster
Visualisasi hasil cluster akan menggunakan Data Driven Documents. Data-Driven Documents atau D3.js adalah pustaka bahasa JavaSript untuk memanipulasi dokumen berdasarkan data pada tampilan situs web. D3.js memungkinkan untuk mengikat suatu data pada Document Object Model (DOM) dan menerapkan transformasi data pada dokumen. Contohnya adalah menghasilkan sebuah tabel pada suatu tampilan HTML dari kumpulan angka atau menggunakan data yang sama untuk membuat grafik batang interaktif dengan berbagai macam transisi pada interaksi yang
dilakukan pengguna [7]. Tugas akhir ini menggunakan salah satu contoh penerapan D3.js yaitu Code Flower. Code Flower menampilkan data kelompok-kelompok berupa lingkaran yang saling berkumpul dalam suatu cluster.
Data yang ditampilkan berasal dari berkas JSON yang berisi tiga parameter yaitu name, children dan size seperti pada Gambar 2.4. Parameter name berisi nama dari kelompok atau nama anggota kelompok. Jika parameter name tersebut memiliki child, maka name berisi nama kelompok, jika tidak maka name berisi nama anggota kelompok. Children adalah parameter untuk menentukan suatu name merupakan nama kelompok atau nama anggota dari kelompok. Sedangkan size adalah ukuran dari lingkaran yang ingin dibuat. Data yang ditampilkan menggunakan D3.js pada tugas akhir ini adalah data hasil clustering kata, sehingga dapat dilihat kelompok-kelompok kata yang terbentuk. Pembangkitan berkas JSON dilakukan menggunakan data hasil dari clustering kata dengan bahasa pemrograman Python.
{ "name": "flare", "children": [ { "name": "analytics", "children": [ { "name": "cluster", "children": [
{"name": "AgglomerativeCluster", "size": 3938}, {"name": "CommunityStructure", "size": 3812}, {"name": "HierarchicalCluster", "size": 6714}, {"name": "MergeEdge", "size": 743}
] }
} }
19
Gambar 2.5 dan Gambar 2.6 adalah contoh tampilan visualisasi data menggunakan pustaka D3 Code Flower.
Gambar 2.4 Contoh Code Flower 1
21
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.
Bab ini membahas analisis dan perancangan sistem manajemen Ruang Baca Teknik Informatika baru yang disesuaikan dengan penambahan fitur temu kembali informasi yang dibangun. Analisis sistem membahas permasalahan yang diangkat pada tugas akhir dan gambaran secara umum fitur temu kembali informasi yang dibangun. Sedangkan perancangan sistem menjelaskan perancangan dua proses utama penambahan fitur temu kembali informasi pada web Ruang Baca teknik Informatika ITS, yaitu praproses data dan pembentukan cluster dokumen yang menjadi acuan untuk menentukan tren topik tugas akhir dan tesis. Selain perancangan dua proses utama, juga terdapat perancangan basis data serta perancangan antar muka.
3.1 Analisis Sistem
Analisis sistem terbagi menjadi dua bagian, yaitu analisis permasalahan yang diangkat pada tugas akhir dan gambaran umum sistem yang dibangun.
Analisis Permasalahan
Permasalahan yang diangkat pada tugas akhir ini adalah fitur pencarian pada web manajemen Ruang Baca Teknik Informatika ITS (RBTC) yang masih kurang lengkap dan kurang dapat memenuhi kebutuhan pencarian pengguna di mana kriteria dalam pencarian secara spesifik masih hanya dapat dilakukan berdasarkan jenis dokumen saja. Selain itu, untuk membantu rekomendasi topik tugas akhir dan tesis, ditambahkan fitur clustering topik dokumen untuk menentukan tren topik yang dipilih oleh mahasiswa Teknik Informatika ITS.
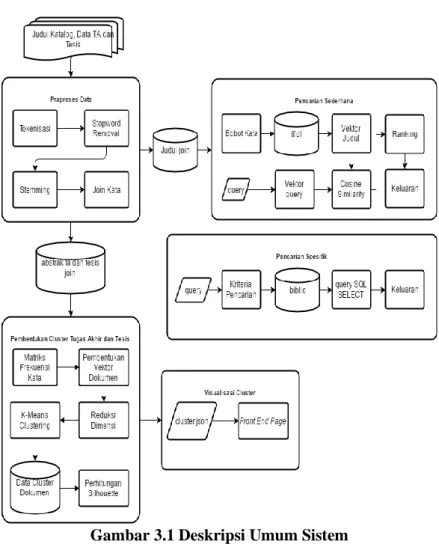
Deskripsi Umum Sistem
Fitur temu kembali yang diimplementasikan pada tugas akhir ini terbagi menjadi tiga proses utama, yaitu praproses data, fitur pencarian dan pembentukan cluster. Gambar 3.1 adalah bentuk dari deskripsi umum sistem.
23
Praproses data berfungsi untuk melakukan ekstraksi kata dari kumpulan data abstrak tugas akhir dan tesis RBTC, fitur pencarian berfungsi untuk memudahkan pengguna dalam mencari katalog RBTC, sedangkan pembentukan cluster kata berfungsi untuk mengetahui tren topik tugas akhir dan tesis yang ada di jurusan Teknik Informatika ITS.
3.2 Perancangan Sistem
Perancangan sistem menjelaskan perancangan tiga proses utama sistem, yaitu praproses data, fitur pencarian dan pembentukan cluster tugas akhir dan tesis.
Praproses Data
Praproses data adalah proses awal yang dilakukan untuk melakukan ekstraksi kata-kata dari kumpulan dokumen tugas akhir dan tesis dari basis data RBTC. Tiga tahapan praproses data yang dilakukan adalah sebagai berikut:
1. Tokenisasi
Proses tokenisasi dilakukan pada seluruh judul katalog dokumen, dan setiap data abstrak dokumen tugas akhir dan tesis dari basis data RBTC. Tokenisasi adalah suatu proses untuk membagi suatu teks berupa kalimat atau paragraf menjadi unit-unit yang lebih kecil berupa kata-kata atau token. Sebelum melakukan tokenisasi, kalimat atau paragraf yang ada pada data abstrak tugas akhir dan tesis disimpan pada suatu array. Tokenisasi dilakukan dengan menggunakan pustaka pada bahasa pemrograman Python, yaitu Natural Language Toolkit (nltk). Fungsi spesifik yang digunakan dari pustaka nltk yakni word_tokenize(). Fungsi word_tokenize() digunakan untuk memisahkan kata pada suatu kalimat berdasarkan tanda baca dan spasi.
2. Stemming
Stemming adalah proses mengembalikan bentuk dari suatu kata ke bentuk dasar kata tersebut. Proses stemming pada abstrak tugas akhir dan tesis dilakukan sebelum proses penghapusan stopword dikarenakan adanya penambahan stopword yang berkaitan dengan jurusan teknik informatika. Stemming dilakukan terlebih dahulu untuk mendapatkan kata baku dari stopword tersebut. Stemming dilakukan dengan menggunakan pustaka bahasa pemrograman Python yaitu Sastrawi, stemmer untuk kata dalam Bahasa Indonesia.
3. Penghapusan Stopword
Proses selanjutnya adalah melakukan penghapusan stopword yang terdapat pada kumpulan kata-kata hasil tokenisasi. Terdapat suatu berkas kumpulan stopword yang sering muncul pada suatu artikel atau dokumen. Berkas kumpulan stopword tersebut didapatkan dari penelitian yang dilakukan oleh F. Z. Tala tentang efek stemming untuk temu kembali informasi pada bahasa Indonesia [8]. Kemudian, yang dilakukan pada isi dari berkas kumpulan stopword tersebut adalah membandingkannya dengan variabel array yang menyimpan hasil tokenisasi. Jika kata yang tersimpan pada variabel array terdapat pada berkas kumpulan stopword, kata tersebut dihapus dari variabel array. Tujuan dari proses ini adalah agar kata yang digunakan dalam pembentukan cluster kata dan fitur pencarian merupakan kata yang penting sehingga mampu mewakili sebuah dokumen dengan baik.
Fitur Pencarian
Fitur pencarian pada SLiMS memiliki dua jenis, yaitu pencarian sederhana dan pencarian spesifik. Kedua pencarian tersebut menggunakan dua algoritma yang berbeda. Pencarian
25
sederhana akan diimplementasikan menggunakan algoritma Vector Space Model, di mana query pencarian dan dokumen akan direpresentasikan dalam bentuk vektor, kemudian tingkat kesamaan vektor query dan vektor dokumen akan dihitung menggunakan jarak sudut cosinus antara kedua vektor [3].
Penghitungan bobot dan cosinus dari dokumen disimpan dalam basis data. Tabel “biblio_joined” menyimpan kumpulan hasil praproses data yang meliputi tokenisasi, stemming, dan penghapusan stopword, kemudian digabungkan ke dalam satu string. Tabel “kata” menyimpan seluruh kata yang muncul pada katalog RBTC dan hasil penghitungan frekuensi kemunculan kata tersebut dalam keseluruhan dokumen. Tabel “tfidf” menyimpan identifier dokumen, kelompok kata dasar yang mewakili dokumen, hasil penghitungan frekuensi masing-masing kata pada dokumen, dan penghitungan TF-IDF sebagai bobot dokumen. Penmbentukan vektor query juga dilakukan dengan menggunakan metode Vector Space Model yang telah dijelaskan pada Bab II.
Nilai cosine similarity dihitung nilai cosinus antara bobot query dan bobot dokumen, dan disimpan ke dalam array jika nilainya lebih besar dari nol karena dianggap masih memiliki keterkaitan. Hasil penghitungan cosine similarity diurutkan dimulai dari yg bernilai paling tinggi hingga paling rendah (descending) dan ditampilkan ke antarmuka RBTC (OPAC). Secara garis besar alur proses pencarian sederhana dapat dilihat di Gambar 3.2.
Pencarian spesifik akan diimplementasikan menggunakan query SQL “LIKE” untuk membandingkan query masukan dengan bagian dokumen yang sama pada beberapa kriteria, yakni Judul, Pengarang, ISBN/ISSN, topik/subjek, tahun, dan jenis dokumen (GMD).
Gambar 3.2 Proses pencarian metode Vector Space Model
Clustering Tugas Akhir dan Tesis
Pembentukan cluster tugas akhir dan tesis dilakukan setelah melakukan penghitungan bobot per dokumen. Pembobotan dokumen akan dilakukan dengan menggunakan algoritma Term Frequency – Inverse Document Frequency (TF-IDF).
27
3.2.3.1. Pembentukan Matriks Frekuensi Kata
Setelah melakukan tokenisasi pada tiap abstrak tugas akhir dan tesis, dilakukan penghitungan frekuensi kemunculan kata pada tiap abstrak tugas akhir dan tesis. Hasil penghitungan tersebut akan disimpan dalam bentuk matriks frekuensi kata. Matriks frekuensi kata terdiri dari kata (baris) dan dokumen (kolom). Matriks yang dihasilkan menyerupai matriks sparse karena hampir sebagian besar nilai dari matriks berupa nol. Matriks frekuensi kata dibuat dan kemudian disimpan ke dalam basis data, penyimpanannya juga akan disisipkan identifier dokumen tugas akhir dan tesis sebagai tanda bahwa kumpulan kata dalam matriks mewakili suatu dokumen tugas akhir maupun tesis tertentu. Tabel 3.1 adalah contoh hasil matriks frekuensi kata.
Tabel 3.1 Contoh Matriks Frekuensi Kata
id_dokumen id_kata kata TF
171 100 Perangkat 0,014705 171 101 Vektor 0,035714 171 157 Fitur 0,020408 228 203 Ekstraksi 0,015873 228 157 Input 0,045454 228 300 pusat 0,020408
Nilai TF pada masing-masing kata dihitung dari kemunculan kata dalam abstrak dibagi dengan jumlah seluruh kata baku dari hasil praproses abstrak.
3.2.3.2. Pembentukan Vektor Dokumen
Setelah pembuatan matriks frekuensi kata, maka akan dibuat matriks vektor dokumen di mana isinya adalah kumpulan hasil penghitungan TF-IDF dari masing-masing kata yang tersimpan di dalam matriks kata. Tabel 3.2 adalah contoh matriks vektor dokumen.
Tabel 3.2 Contoh Matriks Vektor Dokumen Id
dokumen
Id_kata kata TF TF-IDF
171 100 Perangkat 0,0147059 0,024417 171 101 Vektor 0,0357143 0,115213 171 157 Fitur 0,0204082 0,104222 228 203 Ekstraksi 0,015873 0,050869 228 157 Input 0,0454545 0,097797 228 300 pusat 0,0204082 0,0704191 Penghitungan TF-IDF yakni nilai TF pada matriks frekuensi kata dikalikan dengan nilai invers dari frekuensi kemunculan kata pada kumpulan abstrak tugas akhir dan tesis. Proses pembentukan vektor dokumen pada bahasa pemrograman Python dilakukan dengan mengubah array yang menyimpan tiap bobot vektor dokumen menjadi matriks sparse dokumen dan kata. 3.2.3.3. Reduksi Dimensi
Fitur-fitur yang dihasilkan praproses abstrak tugas akhir dan tesis memiliki dimensi yang berjumlah sangat banyak. Jika fitur-fitur tersebut langsung dikelompokkan, maka hasil Clustering menjadi kacau. Algoritma PCA dipakai untuk mengurangi dimensi fitur menjadi hanya dua dimensi, sehingga dapat divisualisasikan. Pustaka Scikit-learn pada bahasa pemrograman python digunakan untuk melakukan reduksi dimensi dari fitur-fitur yang telah diekstraksi sebelumnya. Modul yang digunakan untuk algoritma PCA adalah sklearn.decomposition.PCA.
Penjelasan penggunaan pustaka Scikit-learn khususnya modul sklearn.decomposition.PCA dan bahasa pemrograman Python untuk reduksi dimensi yang lebih detil akan dijelaskan pada Bab IV.
29
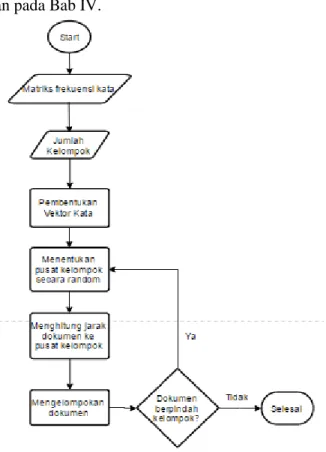
3.2.3.4. K-Means Clustering
Proses setelah pembentukan vektor dan reduksi dimensi fitur adalah proses mengelompokkan hasil penghitungan tersebut menggunakan K-Means Clustering. Seluruh proses pembentukan cluster dimulai dari membangun matriks frekuensi kata hingga Clustering menggunakan bahasa pemrograman Python dengan pustaka Scikit-learn. Gambar 3.3 adalah diagram alur K-Means Clustering.
Penjelasan penggunaan pustaka Scikit-learn dan bahasa pemrograman Python untuk clustering yang lebih detil akan dijelaskan pada Bab IV.
Langkah-langkah untuk melakukan proses clustering menggunakan K-Means clustering adalah sebagai berikut:
1. Impor pustaka Python yang digunakan untuk menghubungkan berkas Python dengan basis data MySQL, MySQLdb.
2. Mengambil isi dari kolom “joined” dari tabel “ta_abstract_join” dan “tss_abstract_join”, yakni string hasil penggabungan seluruh kata baku yang dihasilkan dari praproses tiap abstrak tugas akhir dan tesis dan disimpan ke dalam sebuah array.
3. Membangun matriks frekuensi kata dari array penyimpanan kata-kata baku hasil praproses menggunakan modul dari pustaka Scikit-learn, yakni
sklearn.feature_extraction.text.CountVectorizer().
4. Membangun vektor-vektor dokumen dari matriks frekuensi kata yang telah dibuat sebelumnya menggunakan
sklearn.feature_extraction.text.TfidfTransformer(),
kemudian simpan ke dalam sebuah array baru.
5. Ubah array vektor dokumen menjadi matriks vektor dokumen menggunakan fungsi todense(), kemudian gunakan modul sklearn.decomposition.PCA untuk mereduksi dimensi tinggi fitur-fitur yang dihasilkan. 6. Setelah semua nilai dimasukkan ke dalam array, maka
array tersebut dimasukkan ke dalam fungsi pada pustaka Scikit-learn untuk melakukan clustering, yaitu
sklearn.cluster.KMeans().
7. Menggunakan fungsi labels pada modul KMeans() untuk mendapatkan posisi kelompok hasil clustering tiap abstrak tugas akhir dan tesis, disimpan ke dalam array agar hasilnya dapat divisualisasikan.
8. Mengevaluasi cluster yang telah dibangun menggunakan metode Silhouette Coefficient. Scikit-learn menyediakan modul penghitungan nilai koefisien silhouette, yakni
31
Perancangan Basis Data
Setiap proses yang dilakukan pada tugas akhir ini menghasilkan suatu keluaran seperti kata pada proses ekstraksi kata judul katalog RBTC, proses ekstraksi kata abstrak tugas akhir dan tesis, hasil penghitungan TF-IDF, dan hasil clustering. Hasil penghitungan TF-IDF digunakan untuk melakukan proses pembentukan cluster kata atau clustering sehingga hal tersebut menyebabkan diperlukan tempat untuk menyimpan nilai keluaran-keluaran sehingga dapat digunakan pada proses yang lain.
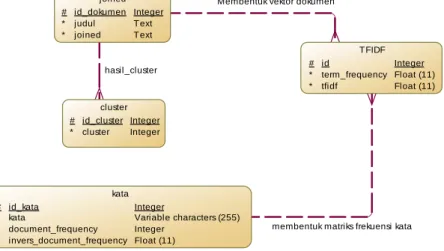
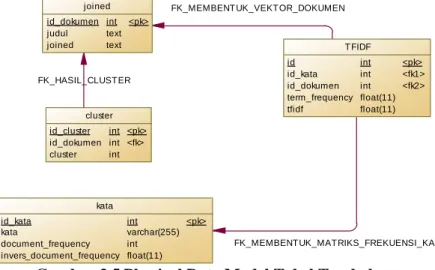
Gambar 3.4 adalah Conceptual Data Model (CDM) dan Gambar 3.5 adalah Physical Data Model (PDM) perancangan tabel basis data tambahan untuk mengimplementasikan fitur temu kembali informasi pada tugas akhir ini.
Gambar 3.4 Conceptual Data Model Tabel Tambahan
hasil_cluster
Membentuk vektor dokumen
membentuk matriks frekuensi kata joined # * * id_dokumen judul joined Integer Text Text kata # * * * id_kata kata document_frequency invers_document_frequency Integer Variable characters (255) Integer Float (11) TFIDF # * * id term_frequency tfidf Integer Float (11) Float (11) cluster # * id_cluster cluster Integer Integer
Gambar 3.5 Physical Data Model Tabel Tambahan Terdapat 11 tabel tambahan yang akan digunakan selama proses implementasi fitur temu kembali informasi, yaitu tiga tabel kata, tiga tabel vektor dokumen, dan tiga tabel “join” untuk menyimpan ekstraksi kata hasil praproses dan penghitungan bobot kata untuk judul katalog, abstrak tugas akhir, dan abstrak tesis, serta dua tabel hasil cluster untuk menyimpan kelompok abstrak tugas akhir dan tesis. Masing-masing kegunaan tabel adalah sebagai berikut:
1. Tiga tabel “joined” untuk judul katalog, abstrak tugas akhir, dan abstrak tesis digunakan untuk menyimpan hasil praproses tiap data dan diubah menjadi satu string berisi seluruh kata baku untuk mempercepat penghitungan TF-IDF karena tidak perlu memerlukan praproses berulang-ulang. Memiliki tiga atribut, yaitu id_dokumen, judul/abstrak, joined.
2. Tiga tabel kata untuk judul katalog, abstrak tugas akhir, dan abstrak tesis digunakan untuk menyimpan seluruh kata baku hasil praproses data, penghitungan Document Frequency (kemunculan kata pada keseluruhan dokumen), dan nilai invers Document Frequency.
FK_HASIL_CLUSTER FK_MEMBENTUK_VEKTOR_DOKUMEN FK_MEMBENTUK_MATRIKS_FREKUENSI_KATA joined id_dokumen judul joined int text text <pk> kata id_kata kata document_frequency invers_document_frequency int varchar(255) int float(11) <pk> TFIDF id id_kata id_dokumen term_frequency tfidf int int int float(11) float(11) <pk> <fk1> <fk2> cluster id_cluster id_dokumen cluster int int int <pk> <fk>
33
Memiliki empat atribut, yaitu id_kata, kata, document_frequency, inverse_document_frequency. 3. Tiga tabel “tfidf” penyimpanan vektor dokumen untuk
judul katalog, abstrak tugas akhir, dan abstrak tesis digunakan untuk menyimpan hasil penghitungan TF-IDF sebagai bobot kata. Memiliki lima atribut, yaitu id, id_dokumen, id_kata, term frequency, tf_idf.
4. Dua tabel hasil cluster untuk abstrak tugas akhir dan abstrak tesis digunakan untuk menyimpan hasil clustering. Memiliki tiga atribut, yaitu id_cluster, id_dokumen, dan cluster.
Perancangan Antar Muka
Antar muka RBTC baru dibuat sebagai perantara fitur temu kembali informasi tambahan dan pengguna RBTC untuk memberikan kemudahan pada pengguna menggunakan fitur temu kembali informasi yang telah dibangun. Beberapa modifikasi antar muka yang akan dibuat adalah penambahan menu visualisasi cluster dan modul pencarian spesifik.
1. Antar Muka Visualisasi Cluster
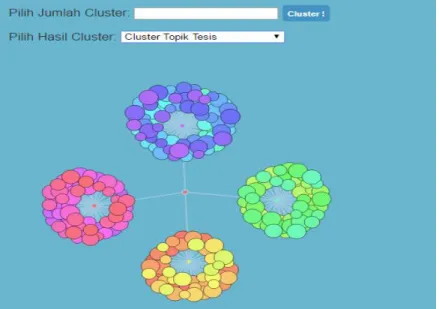
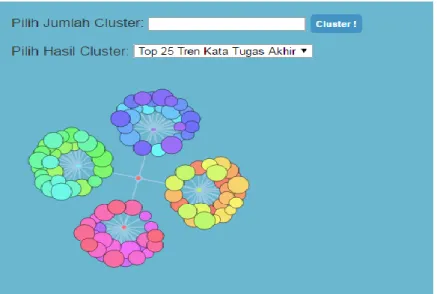
Antar muka ini adalah antar muka dari menu tambahan pada web RBTC untuk visualisasi hasil clustering tugas akhir dan tesis berdasarkan abstrak. Hal yang dapat dilakukan pengguna pada halaman ini adalah menampilkan visualisasi cluster tugas akhir dan tesis, baik judul maupun kata. Terdapat menu dropdown yang dapat digunakan untuk memilih visualisasi cluster yang akan ditampilkan, dan textarea yang digunakan untuk menampilkan isi berkas JSON dari visualisasi cluster. Sebagai contoh, Gambar 3.6 adalah antar muka untuk visualisasi cluster topik tesis, sedangkan Gambar 3.7 adalah antar muka untuk visualisasi cluster tren kata pada tugas akhir. Visualisasi cluster menggunakan pustaka d3 Code Flower, di mana tiap kelompok cluster yang
terbentuk akan divisualisasikan dalam bentuk sekumpulan node dengan gradasi warna yang berbeda untuk tiap kelompoknya. Fungsi mouseover digunakan untuk menampilkan label pada masing-masing node sebagai identitas anggota kelompok topik jika mouse diletakkan pada node tertentu.
35
Gambar 3.7 Antar Muka Visualisasi Cluster Kata Tugas Akhir 2. Antar Muka Pencarian Spesifik Baru
Antar muka ini adalah antar muka yang digunakan untuk menampilkan menu pencarian spesifik baru yang dibangun dengan spesifikasi yang lebih lengkap dan akurat sepertiyang ditunjukkan pada Gambar 3.8. Penjelasan detail tentang antar muka pencarian kata dapat dilihat pada Tabel 3.3.
Gambar 3.8 Antar Muka Pencarian Spesifik
Tabel 3.3 Tabel Antar Muka Pencarian Spesifik
No Nama Jenis Fungsi Masukan
/
Keluaran
1 label_judul Label Menampil
kan label judul
-
2 textbox_judul Textbox Menampu ng query
Teks kata pencarian
37
No Nama Jenis Fungsi Masukan
/
Keluaran pencarian
judul 3 label_pengarang Label Menampil
kan label pengaran g
-
4 textbox_pengarang Textbox Menampu ng query pencarian pengaran g Teks kata pencarian
5 label_subjek Label Menampil
kan label subjek
-
6 textbox_subjek Textbox Menampu ng query pencarian subjek
Teks kata pencarian
7 label_tahun Label Menampil
kan label tahun
-
8 textbox_tahun Textbox Menampu ng query pencarian tahun
Teks kata pencarian
9 label_isbn Label Menampil
kan label isbn/issn
-
10 textbox_isbn Textbox Menampu ng query pencarian isbn/issn
Teks kata pencarian
No Nama Jenis Fungsi Masukan /
Keluaran
11 label_gmd Label Menampil
kan label gmd - 12 dropdown_gmd Dropdown List Menampil kan daftar GMD Daftar GMD
13 btn_cari Button Menjalan
kan fungsi pencarian
39
BAB IV
IMPLEMENTASI SISTEM
4.
Bab ini membahas proses implementasi yang dilakukan berdasarkan hasil perancangan fitur temu kembali informasi yang dibangun pada Bab III. Penjelasan proses implementasi terbagi menjadi enam bagian, yaitu lingkungan implementasi, penggunaan pustaka dan kerangka kerja, implementasi praproses data, implementasi fungsi pencarian, implementasi clustering tugas akhir dan tesis, implementasi visualisasi hasil clustering, implementasi basis data, dan implementasi antar muka.
4.1 Lingkungan Implementasi
Lingkungan implementasi adalah lingkungan di mana fitur temu kembali informasi dibangun. Lingkungan implementasi dibagi menjadi dua yaitu perangkat keras dan perangkat lunak.
Perangkat Keras
Lingkungan implementasi perangkat keras dari tugas akhir ini adalah sebagai berikut:
Tipe : ASUS A45V
Prosesor : Intel® Core(TM) i5-3210M CPU @ 2.50GHz
Memori(RAM) : 4.00 GB
Perangkat Lunak
Lingkungan implementasi perangkat lunak dari tugas akhir ini adalah sebagai berikut:
Sistem operasi : Windows 7 Ultimate 64-Bit Bahasa Pemrograman : PHP 5.6.3, Python 2.7.12 Text Editor : Sublime Text 3, PyCharm
Kerangka Kerja : Framework SLiMS Web Server : Apache 2.4.4 Basis Data : MySQL 5.5.32
Kakas Bantu Basis Data : DataGrip 2016.3 (64-bit) 4.2 Penggunaan Pustaka dan Kerangka Kerja
Penggunaan pustaka-pustaka bahasa pemrograman Python merupakan salah satu hal penting dalam proses implementasi K-Means Clustering. Hal tersebut menjadi penting karena dapat membantu untuk menyediakan fungsi-fungsi yang dapat digunakan dalam penerapan perancangan vektor dokumen dan cluster yang telah dibuat pada Bab III.
Kerangka Kerja SLiMS
Kerangka kerja SLiMS menggunakan sistem Model, View, Controller (MVC) yang sedikit berbeda dari kerangka kerja yang lainnya. Gambar 4.1 adalah tampilan folder kerangka kerja SLiMS.
41
Model berfungsi untuk menjadi penghubung antara sistem dan basis data yang digunakan untuk melakukan fungsi yang pencarian, penambahan, penghapusan dan pembaruan data. View berfungsi untuk mengatur tampilan yang ingin ditampilkan pada pengguna. Sedangkan controller berfungsi untuk melakukan pemrosesan pada data dan menjadi penghubung antara model dan view. Kode sumber Model, View, Controller pada kerangka kerja SLiMS tidak tersimpan pada folder yang menggunakan nama proses secara spesifik.
Folder “template” digunakan untuk menyimpan kode sumber View. Template yang digunakan oleh RBTC untuk menampilkan halaman depan web manajemen menggunakan folder template 191. Folder “lib” digunakan untuk menyimpan kode sumber Controller dan Model. Dalam folder “lib”, tersimpan kelas-kelas yang digunakan untuk modifikasi data dalam basis data. Data- data yang digunakan oleh RBTC berupa data katalog/bibliografi, data berita, data statistik pengunjung, data clustering tugas akhir dan tesis, data keanggotaan, data inventaris, dan data-data lainnya yang diperlukan dalam sistem informasi perpustakaan digital.
MySQLdb
MySQLdb pada kode sumber 4.1 digunakan untuk menghubungkan antara basis data MySQL pada bahasa pemrograman Python. Parameter yang digunakan pada fungsi
MySQLdb.connect() adalah user, password, host dan database. User dan password digunakan untuk memasukkan nama pengguna dan kata sandi yang digunakan pada basis data. Parameter host digunakan untuk memasukkan alamat dari basis data MySQL yang akan dihubungkan dengan bahasa pemrograman Python, jika terdapat pada jaringan lokal atau localhost, masukkan alamat IP dari localhost yaitu 127.0.0.1. Sedangkan parameter database digunakan untuk memasukkan nama basis data yang akan digunakan.
import MySQLdb
connection = MySQLdb.connect (host = "localhost", user = "root", passwd = "", db = "new_rbtc") cursor = connection.cursor()
Kode Sumber 4.1 Penggunaan MySQLdb
Scikit-learn (Sklearn)
Scikit-learn atau biasa disebut sklearn adalah pustaka bahasa pemrograman Python yang digunakan untuk pengolahan dan analisis data. Sklearn dibangun menggunakan tiga pustaka penghitungan numerik, yakni SciPy untuk penghitungan metode numerik, NumPy untuk pembangkitan array n-dimensi yang serbaguna, dan matplotlib untuk ilustrasi dua dimensi hasil proses machine-learning. Modul-modul milik sklearn yang digunakan untuk tugas akhir ini adalah modul ekstraksi fitur, modul reduksi dimensi, dan clustering. Modul ekstraksi fitur menggunakan fungsi
CountVectorizer() untuk pembentukan matriks frekuensi kata pada
tiap dokumen dan TfidfTransformer() untuk pembentukan matriks vektor dokumen.
Data Driven Documents
...
<script src="assets/js/d3.js"></script> <script src="assets/js/d3.min.js"></script> ...
<script>
...
d3.json("json/data.json", function(error, root) {…… }
</script>
Kode Sumber 4.2 Penggunaan Data Driven Documents Implementasi Data-Driven Documents atau D3.js seperti pada kode sumber 4.2 adalah dengan mengunduh berkas d3.js dan d3.min.js pada situs resmi D3.js [7] dan mengimpornya ke dalam