PREDIKSI STATUS KEAKTIFAN STUDI MAHASISWA DENGAN ALGORITMA C5.0 DAN K-NEAREST NEIGHBOR
IIN ERNAWATI
G651044054
SEKOLAH PASCA SARJANA INSTITUT PERTANIAN BOGOR
BOGOR
2008
PERNYATAAN MENGENAI TESIS DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa Tesis Prediksi Status Keaktifan Studi Mahasiswa dengan Algoritma C5.0 dan K-Nearest Neighbor, adalah karya saya sendiri dan belum diajukan dalam bentuk apapun kepada Perguruan Tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Juni 2008 Iin Ernawati NRP. G651044054
ABSTRAK
IIN ERNAWATI. Prediksi Status Keaktifan Studi Mahasiswa dengan Algoritme C5.0 dan K-Nearest Neighbor (KNN). Dibimbing oleh Irman Hermadi dan Hari Agung Adrianto.
Diperlukan suatu metode data mining yang bisa memanfaatkan gunungan data yang dihasilkan oleh sebuah sistem dalam sebuah organisasi maupun lembaga, sehingga menjadi informasi yang bernilai strategis. Dalam penelitian ini teknik data mining digunakan untuk membantu menemukan karakteristik mahasiswa aktif maupun tidak aktif pada sebuah fakultas di sebuah Perguruan Tinggi Swasta di Jakarta selatan, sehingga untuk selanjutnya dapat digunakan dalam memprediksi status studi mahasiswa yang akan datang.
Penggunaan perangkat lunak weka sebagai alat bantu dalam proses klasifikasi memberikan hasil bahwa atribut Indeks Prestasi Kumulatif (IPK) adalah atribut yang menentukan status studi mahasiswa. Hasil percobaan memberikan informasi bahwa Algoritme C5.0 lebih baik dibandingkan algoritme KNN.
Kata kunci : Karakteristik mahasiswa aktif dan tidak aktif , C5.0, K-Nearest Neighbor, weka classifier.
ABSTRACT
IIN ERNAWATI. Prediction of University Student Status Using C5.0 and K- Nearest Neighbor Algorithms (KNN). Under the direction of Irman Hermadi and Hari Agung Adrianto.
Data mining methods are required to explore pyramid of data such that strategic information is uncovered. In this thesis, data mining techniques are used to find student characteristics whom is active or inactive academically. Further, these characteristics can be employed to classify students based on their academic status one semester in advance.
This research made use an open source data mining application software named WEKA Classifier. The experimental results showed that C5.0 Algorithm is better than KNN and Grade Point Average (GPA) contributes significantly in determining next coming semester student status.
Keywords: inactive student, active student, C5.0, K-Nearest Neighbor, weka classifier.
RINGKASAN
IIN ERNAWATI. Prediksi Status Keaktifan Studi Mahasiswa dengan Algoritme C5.0 dan K-Nearest Neighbor. Dibimbing oleh IRMAN HERMADI dan HARI AGUNG ADRIANTO.
Teknologi komputasi dan media penyimpanan telah memungkinkan manusia untuk mengumpulkan dan menyimpan data dari berbagai sumber dengan jangkauan yang amat luas. Meskipun teknologi basis data modern telah menghasilkan media penyimpanan yang besar, teknologi untuk membantu menganalisis, memahami, atau bahkan memvisualisasikan data belum banyak tersedia. Hal inilah yang melatarbelakangi dikembangkannya konsep data mining.
Klasifikasi sebagai salah satu teknik dalam data mining yang digunakan dalam penelitian ini untuk mengolah data akademik mahasiswa dalam sebuah fakultas sehingga diperoleh aturan klasifikasi untuk prediksi status studi mahasiswa pada waktu yang akan datang. Sebanyak 3.366 data diperoleh dari sistem akademik fakultas namun setelah melalui tahap pembersihan data (data cleaning), hanya sebanyak 1.175 data yang berhasil digunakan untuk proses klasifikasi. Sebanyak 925 data diklasifikasi sebagai data mahasiswa aktif dan sebanyak 250 data diklasifikasi sebagai data mahasiswa tidak aktif.
Algoritme C5.0 yang digunakan dalam klasifikasi model decision tree (pohon keputusan) memberikan hasil dalam bentuk if-then dan bentuk pohon keputusan yang menyatakan bahwa aktif dan tidak aktif seorang mahasiswa ditentukan oleh Indeks Prestasi Kumulatif (IPK) mahasiswa yang bersangkutan.
Hasil klasifikasi yang diperoleh dari algoritme C5.0 ini menunjukkan bahwa apabila seorang mahasiswa memperoleh IPK 1,77 maka dapat diprediksi bahwa mahasiswa yang bersangkutan berpotensi untuk tidak aktif pada semester yang akan datang. Keberhasilan klasifikasi yang diperoleh dari algoritme C5.0 mencapai lebih dari 90%, yang menyatakan bahwa algoritme C5.0 mampu melakukan klasifikasi data akademik dengan memberikan output berupa aturan klasifikasi.
K-Nearest Neighbor melakukan klasifikasi dengan menghitung jarak antara data yang sudah terklasifikasi ke data yang belum terklasifikasi dengan menentukan jumlah tetangga data k yang dipilih yaitu k=1, k=3 dan k=5 sehingga diperoleh hasil yang reasonable dari ketiga nilai k yang diberikan tadi. Persentase klasifikasi tertinggi diperoleh dari k=1 yaitu mencapai lebih dari 90%, yang menyatakan bahwa untuk menentukan kelas bagi data baru maka data baru tersebut dihitung jaraknya ke setiap data yang sudah diketahui kelasnya. Berbeda dengan hasil yang diperoleh dari algoritme C5.0, K-Nearest Neighbor tidak dapat menunjukkan karakteristik data yang diklasifikasi sebagai mahasiswa aktif dan mahasiswa tidak aktif.
Algoritme C5.0 tetap dianggap sebagai algoritma yang sangat membantu dalam melakukan klasifikasi data karena karakteristik data yang diklasifikasi dapat diperoleh dengan jelas baik dalam bentuk struktur pohon keputusan maupun aturan if-then, sehingga memudahkan pengguna dalam melakukan penggalian informasi terhadap data yang bersangkutan.
Kata kunci : status aktif dan tidak aktif, algoritme C5.0, K-Nearest Neighbor
© Hak cipta milik IPB, tahun 2008 Hak cipta dilindungi
Dilarang mengutip dan memperbanyak tanpa izin tertulis dari Institut Pertanian Bogor, sebagian atau seluruhnya dalam bentuk apapun, baik cetak, fotokopi,
microfilm, dan sebagainya
PREDIKSI STATUS KEAKTIFAN STUDI MAHASISWA DENGAN ALGORITMA C5.0 DAN K-NEAREST NEIGHBOR
IIN ERNAWATI
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCA SARJANA INSTITUT PERTANIAN BOGOR
BOGOR
2008
Judul Tesis : Prediksi Status Keaktifan Studi Mahasiswa dengan Algoritme C5.0 dan K-Nearest Neighbor
Nama : Iin Ernawati
NIM : G651044054
Disetujui Komisi Pembimbing
Irman Hermadi, S.Kom, MS Hari Agung Adrianto, S.Kom, MSi Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr. Sugi Guritman Prof. Dr.Ir. Khairil Anwar Notodiputro, MS
Tanggal Lulus : Tanggal Ujian: 20 Juni 2008
RIWAYAT HIDUP
Penulis dilahirkan di Madiun, pada tanggal 2 Januari 1976 dari ayah S.
Soegiarto dan ibu Sri Lestari. Penulis merupakan putri pertama dari tiga bersaudara.
Pada tahun 1993 penulis lulus dari MAN (Madrasah Aliyah Negeri) 1 Tangerang, dan pada tahun 2000 berhasil menyelesaikan pendidikan S1 jurusan Manajemen Informatika pada Universitas Pembangunan Nasional “veteran”
Jakarta.
Penulis diterima sebagai staf laboratorium komputer Fakultas Ilmu Komputer, UPN “veteran” Jakarta pada tahun 2001 sampai dengan sekarang.
Penguji Luar Komisi pada Ujian Tesis: Aziz Kustiyo, S.Si, M.Kom.
PRAKATA
Syukur Alhamdulillah penulis panjatkan kehadirat Allah SWT, karena atas segala karunia-Nya penulisan tesis dengan judul Prediksi Status Keaktifan Studi Mahasiswa dengan Algoritme C5.0 dan K-Nearest Neighbor.
Tesis ini disusun sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada Program Studi Ilmu Komputer, Sekolah Pascasarjana Institut Pertanian Bogor.
Pada kesempatan ini penulis menyampaikan penghargaan dan ucapan terima kasih kepada :
1. Bapak Irman Hermadi, SKom, MS selaku ketua komisi pembimbing dan Hari Agung Adrianto, SKom, Msi selaku anggota komisi pembimbing yang telah meluangkan waktu, tenaga dan pikiran sehingga tesis ini dapat diselesaikan.
2. Bapak Aziz Kustiyo, SSi, Mkom selaku dosen penguji yang telah memberikan arahan dan masukan untuk perbaikan tesis ini.
3. Bapak Dr. Sugi Guritman selaku Ketua Program Studi Ilmu Komputer atas kerjasamanya selama studi dan penelitian.
4. Staff Pengajar Program Studi Ilmu Komputer yang telah memberi bekal pengetahuan.
5. Staff Departemen Ilmu Komputer atas kerjasamanya selama studi dan penelitian.
6. Rekan mahasiswa Program Studi Ilmu Komputer mulai dari angkatan 2 sampai dengan angkatan 8.
7. Ayah, ibu, adik-adik dan kekasihku tercinta Bambang Dwi Raharjo atas dorongan semangat, doa dan kesabaran yang telah dicurahkan.
Penulis menyadari masih banyak kekurangan dalam penyajian tesis ini.
Meskipun demikian penulis berharap semoga tesis ini bermanfaat bagi bidang ilmu komputer dan dunia pendidikan.
Bogor, Juli 2008
Iin Ernawati
DAFTAR ISI
Halaman DAFTAR TABEL ………...
DAFTAR GAMBAR ………..
DAFTAR LAMPIRAN ………...
PENDAHULUAN
Latar Belakang ………...
Tujuan Penelitian ………
Ruang Lingkup ………
Output dan Manfaat Penelitian ………
TINJAUAN PUSTAKA
Definisi Data Mining ………..
Klasifikasi ………...
Model Klasifikasi ………..
Decision Tree (Pohon Keputusan) ………
Algoritme C5.0 ………..
K-Nearest Neighbor Algorithm ………
Membangun model prediksi ………
Alat ukur dalam evaluasi ………
Review Riset yang Relevan ………
DATA DAN METODE
Data ……….
Metode ………
Kerangka Pemikiran ………..
Tata Laksana ……….
Waktu dan Tempat Penelitian ………...
HASIL DAN PEMBAHASAN
Praproses Data ………
Data Mining ………
iii iv v
1 2 2 3
4 5 6 7 9 10 12 13 14
16 18 18 21 22
23 30
Evaluasi ………...
KESIMPULAN DAN SARAN
Kesimpulan ……….
Saran ………
DAFTAR PUSTAKA ………..
LAMPIRAN ………
38
43 43 45 46
DAFTAR TABEL
Halaman
1 2 3 4 5 6 7 8 9 10 11 12 13
14
15
16
Tabel klasifikasi kualitas baik atau tidak baik sebuah kertas tisu ...
Perbedaan hasil yang diperoleh dari dua kelas prediksi ………..
Contoh instances dengan missing value pada sebagian atributnya ...
Contoh redundancy data ………..
Contoh data pada dataset mahasiswa ...
Contoh data pada dataset IPK ...
Contoh instances dengan beberapa atribut pada dataset mahasiswa ..
Contoh instances dengan atribut pada dataset IPK ...
Contoh instances dengan atribut yang akan diubah tipe datanya ...
Keterangan kode pada atribut PkOrtu dan JenisSLA ...
Contoh instances dengan tipe data dan nama atribut yang baru ...
Contoh instances dengan atribut terpilih ……….
Kombinasi dataset hasil pemisahan dengan metode 3-fold cross vali-dation...
Contoh data dengan kelas mahasiswa aktif dan tidak aktif berdasar- kan atribut JnsSLA ...
Nilai gain seluruh atribut pada kelompok data training dan data testing………
Persentase hasil klasifikasi berdasarkan alat ukur evaluasi confusion matrix (overall success rate, lift chart, dan recall precision)...
12 14 17 17 23 23 24 24 26 27 27 28
30
31
32
39
DAFTAR GAMBAR
Halaman 1
2
3 4 5 6 7 8
9
10
11
12
13
Data Mining sebagai salah satu tahapan dalam proses KDD ………..
Klasifikasi sebagai pemetaan sebuah himpunan atribut input x ke dalam label kelasnya ………..
Contoh penggunaan metode Decision Tree untuk menentukan jenis buah..
Ilustrasi 1-, 2-, 3-nearest neighbor terhadap data baru (x) ………..
Kerangka pemikiran penelitian ………
Gambar hasil klasifikasi data testing 3 menggunakan weka classifier……..
Aturan-aturan klasifikasi hasil data testing 3 ...
Hasil klasifikasi dengan algoritma C5.0 menggunakan weka classifier dalam bentuk struktur pohon keputusan ...
Hasil klasifikasi dengan KNN=1 pada data testing 3 menggunakan Weka classiFier………
Grafik Overall Success Rate pada dataset akademik menggunakan metode decision tree (C5.0) dan KNN ...
Grafik Lift Chart pada dataset akademik menggunakan metode
decision tree (5.0) dan KNN ...
Grafik Recall Precision pada dataset akademik menggunakan
metode decision tree (5.0) dan KNN ...
Grafik persentase true classified dan missclassified ……….
5
6 8 11 18 34 35
36
37
40
40
41 42
DAFTAR LAMPIRAN
Halaman
1 2 3 4 5 6 7
8
9
Atribut dataset mahasiswa ...
Atribut dataset IPK ...
Dataset Mahasiswa ...
Dataset IPK ...
Sample data training ...
Sample data testing ...
Hasil klasifikasi dengan C5.0 menggunakan weka classifier dalam bentuk if-then ...
Hasil klasifikasi C5.0 menggunakan weka classifier dalam bentuk pohon keputusan ...
Grafik klasifikasi KNN dengan k=1 (a), k=3 (b), k=5 (c) pada
atribut IPK ...
47 49 50 56 57 58
59
60
61
PENDAHULUAN
Latar Belakang
Teknologi komputasi dan media penyimpanan telah memungkinkan manusia untuk mengumpulkan dan menyimpan data dari berbagai sumber dengan jangkauan yang amat luas. Meskipun teknologi basis data modern telah menghasilkan media penyimpanan yang besar, teknologi untuk membantu menganalisis, memahami, atau bahkan memvisualisasikan data belum banyak tersedia. Hal inilah yang melatarbelakangi dikembangkannya konsep data mining.
Sejak awal berdiri 1980, sebuah fakultas pada sebuah Perguruan Tinggi Swasta di Jakarta telah menghasilkan gunungan data akademik. Diketahui dalam jangka waktu enam tahun terakhir (1999-2005) banyaknya mahasiswa yang melakukan registrasi ulang pada hampir tiap semester berkurang dibandingkan saat registrasi pada semester awal (satu). Misal, pada semester 1 total mahasiswa baru sebanyak 335 mahasiswa, lalu pada saat semester ke dua menjadi 280 mahasiswa, semester ke tiga menjadi 276 mahasiswa, semester ke empat 260 mahasiswa, demikian pula selanjutnya. Banyaknya mahasiswa yang tidak aktif selalu ditemukan pada hampir tiap semester dan pada setiap program studi, dan jumlahnya cenderung bertambah. Berdasarkan panduan akademik tahun 2004- 2007 dijelaskan bahwa mahasiswa tidak aktif adalah mahasiswa yang masih tercatat sebagai mahasiswa dari program studi masing-masing namun tidak memenuhi semua persyaratan administrasi keuangan dan akademik dalam jangka waktu tertentu, sedangkan mahasiswa aktif adalah mahasiswa yang telah memenuhi semua persyaratan administrasi keuangan dan akademik serta berhak dan wajib mengikuti semua kegiatan akademik [UPNVJ, 2004].
Tidak tersedianya data yang cukup dan informasi yang terkait dengan status keaktifan studi mahasiswa menyebabkan tidak dapat ditemukannya karakteristik mahasiswa yang aktif dan tidak aktif, sehingga mendorong dilakukannya penelitian tentang karakteristik mahasiswa yang aktif dan tidak aktif. Berdasarkan hal tersebut maka penulis melakukan penelitian terhadap data-data akademik untuk menemukan ciri atau karakteristik mahasiswa yang aktif dan tidak aktif.
Diharapkan penelitian yang dilakukan dapat memberikan hasil berupa informasi yang bermanfaat dalam melakukan pengambilan keputusan manajerial, terutama yang berkaitan dengan prediksi status keaktifan studi mahasiswa.
Salah satu alternatif solusi dari masalah tersebut adalah dengan menerapkan teknik data mining sehingga dapat dilakukan penelusuran pada data historis untuk mengidentifikasi karakteristik data yang dimiliki terhadap subyek yang diteliti yang didasarkan pada sifat-sifat data yang teridentifikasi sebelumnya. Adapun teknik yang dipilih untuk menganalisis data yang dimiliki adalah klasifikasi dengan algoritma C5.0 dan K-Nearest Neighbor. Diketahui klasifikasi merupakan bentuk analisis data yang dapat digunakan untuk mengekstrak model dari data yang berisi kelas-kelas atau untuk memprediksi trend data yang akan datang.
Sehingga diharapkan dengan menggunakan teknik ini maka diperoleh karakteristik dari seorang mahasiswa terhadap status keaktifannya dalam masa studi yang ditempuh.
Tujuan penelitian
Beberapa tujuan yang dilakukan dalam penelitian adalah diantaranya:
1. Menerapkan dan melakukan analisis algoritma C5.0 dan K-Nearest Neighbor pada dataset akademik untuk melihat karakteristik mahasiswa yang tidak aktif.
2. Membentuk aturan klasifikasi untuk memprediksi status studi mahasiswa pada waktu yang akan datang.
Ruang lingkup
1. Menerapkan proses Knowledge Discovery in Database (KDD) untuk mengolah data akademik mahasiswa dan melakukan analisis terhadap penerapan algoritma C5.0 dan K-Nearest Neighbor.
2. Data penelitian berasal dari data identitas mahasiswa dan data Indeks prestasi Kumulatif (IPK) pada tiga program studi (S1-SI, S1-TI, D3-MI) tahun angkatan 2000 sampai dengan 2005.
3. Transformasi & pengolahan data menggunakan weka classifier.
Output dan manfaat penelitian
Output yang dihasilkan dari penelitian ini adalah informasi karakteristik mahasiswa aktif dan tidak aktif.
Manfaat yang dapat diambil dengan tersedianya karakteristik mahasiswa aktif dan tidak aktif adalah:
1. Membantu sistem dalam mengambil tindakan untuk mengatasi mahasiswa yang berpotensi untuk tidak aktif pada waktu yang akan datang.
2. Membantu untuk memperbaiki standar kualitas mahasiswa yang melamar sehingga jumlah mahasiswa yang berpotensi tidak aktif dapat dikurangi.
TINJAUAN PUSTAKA
Definisi Data Mining
Sistem Manajemen Basis Data tingkat lanjut dan teknologi data warehousing mampu untuk mengumpulkan “banjir” data dan untuk mentransformasikannya ke dalam basis data yang berukuran besar. Diperlukan teknik baru yang secara pintar dan otomatis mentransformasikan data-data yang diproses untuk menghasilkan informasi dan pengetahuan yang berguna. Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Kata mining berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar (Pramudiono, 2003). Data mining merupakan proses pencarian pola dan relasi-relasi yang tersembunyi dalam sejumlah data yang besar dengan tujuan untuk melakukan klasifikasi, estimasi, prediksi, association rule, clustering, deskripsi dan visualisasi (Han dan Kamber, 2001).
Secara garis besar data mining dapat dikelompokkan menjadi 2 kategori utama, yaitu (Tan et al, 2005) :
1. Descriptive mining, yaitu proses untuk menemukan karakteristik penting dari data dalam suatu basis data. Teknik data mining yang termasuk dalam descriptive mining adalah clustering, association, dan sequential mining.
2. Predictive, yaitu proses untuk menemukan pola dari data dengan menggunakan beberapa variabel lain di masa depan. Salah satu teknik yang terdapat dalam predictive mining adalah klasifikasi.
Secara sederhana data mining bisa dikatakan sebagai proses menyaring atau
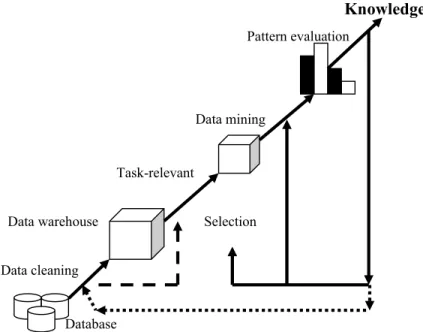
“menambang” pengetahuan dari sejumlah data yang besar. Istilah lain untuk data mining adalah Knowledge Discovery in Database atau KDD. Walaupun sebenarnya data mining sendiri adalah bagian dari tahapan proses dalam KDD, seperti yang terlihat pada Gambar 1 (Han dan Kamber, 2001).
Knowledge Pattern evaluation
Data mining
Task-relevant
Data warehouse Selection
Data cleaning
Database
Gambar 1. Data mining sebagai salah satu tahapan dalam proses Knowledge Discovery
Tujuan dari adanya data mining adalah (Thomas, 2004) :
1. explanatory, yaitu untuk menjelaskan beberapa kegiatan observasi atau suatu kondisi.
2. confirmatory, yaitu untuk mengkonfirmasi suatu hipotesis yang telah ada.
3. exploratory, yaitu untuk menganalisis data baru suatu relasi yang janggal.
Klasifikasi
Klasifikasi dan prediksi adalah dua bentuk analisis data yang bisa digunakan untuk mengekstrak model dari data yang berisi kelas-kelas atau untuk memprediksi trend data yang akan datang. Klasifikasi memprediksi data dalam bentuk kategori, sedangkan prediksi memodelkan fungsi-fungsi dari nilai yang kontinyu. Misalnya model klasifikasi bisa dibuat untuk mengelompokkan aplikasi peminjaman pada bank apakah berisiko atau aman, sedangkan model prediksi bisa dibuat untuk memprediksi pengeluaran untuk membeli peralatan komputer dari pelanggan potensial berdasarkan pendapatan dan lokasi tinggalnya.
Prediksi bisa dipandang sebagai pembentukan dan penggunaan model untuk menguji kelas dari sampel yang tidak berlabel, atau menguji nilai atau rentang
nilai dari suatu atribut. Dalam pendangan ini, klasifikasi dan regresi adalah dua jenis masalah prediksi, dimana klasifikasi digunakan untuk memprediksi nilai- nilai diskrit atau nominal, sedangkan regresi digunakan untuk memprediksi nilai- nilai yang kontinyu. Untuk selanjutnya penggunaan istilah prediction untuk memprediksi kelas yang berlabel disebut classification, dan penggunaan istilah prediksi untuk memprediksi nilai-nilai yang kontinyu sebagai prediction (Han &
Kamber, 2001).
Model Klasifikasi
Data input untuk klasifikasi adalah koleksi dari record. Setiap record dikenal sebagai instance atau contoh, yang ditentukan oleh sebuah tuple (x,y), dimana x adalah himpunan atribut dan y adalah atribut tertentu, yang dinyatakan sebagai label kelas (juga dikenal sebagai kategori atau atribut target).
Klasifikasi adalah tugas pembelajaran sebuah fungsi target f yang memetakan setiap himpunan atribut x ke salah satu label kelas y yang telah didefinisikan sebelumnya.
Fungsi target juga dikenal secara informal sebagai model klasifikasi.
Model klasifikasi berguna untuk keperluan berikut :
Pemodelan Deskriptif. Model klasifikasi dapat bertindak sebagai alat penjelas untuk membedakan objek-objek dari kelas-kelas yang berbeda. Sebagai contoh untuk para ahli Biologi, model deskriptif yang meringkas data.
Pemodelan Prediktif. Model klasifikasi juga dapat digunakan untuk memprediksi label kelas dari rekord yang tidak diketahui. Seperti pada Gambar 2 tampak sebuah model klasifikasi dapat dipandang sebagai kotak hitam yang secara otomatis memberikan sebuah label ketika dipresentasikan dengan himpunan atribut dari record yang tidak diketahui.
Input Output
Attribut set (x) Class label (y)
Gambar 2. Klasifikasi sebagai pemetaan sebuah himpunan atribut input x ke dalam label kelasnya
Classification model
Beberapa teknik klasifikasi yang digunakan adalah decision tree classifier, rule-based classifier, neural-network, support vector machine, dan naive Bayes classifier. Setiap teknik menggunakan algoritme pembelajaran untuk mengidentifikasi model yang memberikan hubungan yang paling sesuai antara himpunan atribut dan label kelas dari data input.
Pendekatan umum yang digunakan dalam masalah klasifikasi adalah, pertama, training set berisi record yang mempunyai label kelas yang diketahui haruslah tersedia. Training set digunakan untuk membangun model klasifikasi, yang kemudian diaplikasikan ke test set, yang berisi record-record dengan label kelas yang tidak diketahui.
Decision Tree (Pohon Keputusan)
”Apakah yang dimaksud dengan decision tree?” Decision tree (pohon keputusan) adalah sebuah diagram alir yang mirip dengan struktur pohon, di mana setiap internal node menotasikan atribut yang diuji, setiap cabangnya merepresentasikan hasil dari atribut tes tersebut, dan leaf node merepresentasikan kelas-kelas tertentu atau distribusi dari kelas-kelas (Han & Kamber, 2001).
Klasifier pohon keputusan merupakan teknik klasifikasi yang sederhana yang banyak digunakan. Bagian ini membahas bagaimana pohon keputusan bekerja dan bagaimana pohon keputusan dibangun.
Seringkali untuk mengklasifikasikan obyek, kita ajukan urutan pertanyaan sebelum bisa kita tentukan kelompoknya. Jawaban pertanyaan pertama akan mempengaruhi pertanyaan berikutnya dan seterusnya. Dalam decision tree, pertanyaan pertama akan kita tanyakan pada simpul akar pada level 0. Jawaban dari pertanyaan ini dikemukakan dalam cabang-cabang. Jawaban dalam cabang akan disusul dengan pertanyaan kedua lewat simpul yang berikutnya pada level 1.
Dengan memperhatikan decision tree dalam Gambar 3 akan nampak ada 4 level pertanyaan. Dalam setiap level ditanyakan nilai atribut melalui sebuah simpul.
Jawaban dari pertanyaan itu dikemukakan lewat cabang-cabang. Langkah ini akan berakhir di suatu simpul jika pada simpul tersebut sudah ditemukan kelas atau jenis obyeknya. Kalau dalam satu tingkat suatu obyek sudah diketahui termasuk
warna
Ukuran? Bentuk? Ukuran?
Semangka Anggur
Apel
Ukuran? Pisang Apel Rasa
Level 0
Level 1
Level 2
Level 3
dalam kelas tertentu, maka kita berhenti di level tersebut. Jika tidak, maka dilanjutkan dengan pertanyaan di level berikutnya hingga jelas ciri-cirinya dan jenis obyek dapat ditentukan (Santosa, 2007).
Gambar 3. Contoh penggunaan metode Decision Tree untuk menentukan jenis buah
Walaupun banyak variasi model decision tree dengan tingkat kemampuan dan syarat yang berbeda, pada umumnya beberapa ciri kasus cocok untuk diterapkan decision tree (Santosa, 2007) :
1. Data dinyatakan dengan pasangan atribut dan nilainya. Misalnya atribut satu data adalah temperatur dan nilainya adalah dingin. Biasanya untuk satu data nilai dari satu atribut tidak terlalu banyak jenisnya. Dalam contoh atribut warna buah ada beberapa nilai yang mungkin yaitu hijau, kuning, merah.
2. Label/output data biasanya bernilai diskrit. Output ini bisa bernilai ya atau tidak, sakit atau tidak sakit, diterima atau ditolak. Dalam beberapa kasus mungkin saja outputnya tidak hanya dua kelas, tetapi penerapan decision tree lebih banyak untuk kasus binary.
3. Data mempunyai missing value. Misalkan untuk beberapa data, nilai dari suatu atributnya tidak diketahui. Dalam keadaan seperti ini decision tree masih mampu memberi solusi yang baik.
Algoritme C5.0
Algoritme C5.0 adalah salah satu algoritme yang terdapat dalam klasifikasi data mining disamping algoritme CART, yang khususnya diterapkan pada teknik decision tree. C5.0 merupakan penyempurnaan algoritme terdahulu yang dibentuk oleh Ross Quinlan pada tahun 1987, yaitu ID3 dan C4.5. Dalam algoritme C5.0, pemilihan atribut yang akan diproses menggunakan information gain. Secara heuristik akan dipilih atribut yang menghasilkan simpul yang paling bersih (purest). Kalau dalam cabang suatu decision tree anggotanya berasal dari satu kelas maka cabang ini disebut pure. Kriteria yang digunakan adalah information gain. Jadi dalam memilih atribut untuk memecah obyek dalam beberapa kelas harus kita pilih atribut yang menghasilkan information gain paling besar.
Ukuran information gain digunakan untuk memilih atribut uji pada setiap node di dalam tree. Ukuran ini digunakan untuk memilih atribut atau node pada pohon. Atribut dengan nilai information gain tertinggi akan terpilih sebagai parent bagi node selanjutnya. Formula untuk information gain adalah (Kantardzic, 2003):
( ) ∑
=
−
= m
i
i i
m p p
s s s I
1
2 2
1, ,...., log ( ) (2.1) S adalah sebuah himpunan yang terdiri dari s data sampel. Diketahui atribut class adalah m dimana mendefinisikan kelas-kelas di dalamnya, Ci (for i= 1, …, m), si adalah jumlah sampel pada S dalam class Ci. untuk mengklasifikasikan sampel yang digunakan maka diperlukan informasi dengan menggunakan aturan seperti di atas (2.1). Dimana pi adalah proporsi kelas dalam output seperti pada kelas Ci dan diestimasikan dengan si /s. Atribut A memiliki nilai tertentu {a1, a2,
…, av}. Atribut A dapat digunakan pada partisi S ke dalam v subset, {S1, S2, …, Sv}, dimana Sj berisi sample pada S yang bernilai aj pada A. Jika A dipilih sebagai atribut tes (sebagai contoh atribut terbaik untuk split), maka subset ini akan berhubungan pada cabang dari node himpunan S. Sij adalah jumlah sample pada class Ci dalam sebuah subset Sj. Untuk mendapatkan informasi nilai subset dari atribut A tersebut maka digunakan formula,
(
j mj)
y j
mj
j I s s
s s A s
E ... ,...
)
( 1
1
∑
1=
+
= + (2.2)
s
s s1j+ ..+ mj
adalah jumlah subset j yang dibagi dengan jumlah sampel pada S, maka untuk mendapatkan nilai gain, selanjutnya digunakan formula
Gain(A)=I(s1,s2,...,sm)–E(A) (2.3) C5.0 memiliki fitur penting yang membuat algoritme ini menjadi lebih
unggul dibandingkan dengan algoritme terdahulunya dan mengurangi kelemahan yang ada pada algoritme decision tree sebelumnya. Fitur tersebut adalah (Quinlan, 2004) :
1. C5.0 telah dirancang untuk dapat menganalisis basis data subtansial yang berisi puluhan sampai ratusan record dan satuan hingga ratusan field numerik dan nominal.
2. untuk memaksimumkan tingkat penafsiran pengguna terhadap hasil yang disajikan, maka klasifikasi C5.0 disajikan dalam dua bentuk, menggunakan pohon keputusan dan sekumpulan aturan IF-then yang lebih mudah untuk dimengerti dibandingkan neural network.
3. C5.0 mudah digunakan dan tidak membutuhkan pengetahuan tinggi tentang statistik atau machine learning.
K-Nearest Neighbor Algorithm
Seperti halnya decision tree, K-Nearest Neighbor sangat sering digunakan dalam klasifikasi dengan tujuan dari algoritme ini adalah untuk mengklasifikasi objek baru berdasarkan atribut dan training samples (Larose, 2002 ).
Algoritme k-nearest neighbor (k-NN atau KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Teknik ini sangat sederhana dan mudah diimplementasikan. Mirip dengan teknik klastering, pengelompokkan suatu data baru berdasarkan jarak data baru itu ke beberapa data/tetangga
(neighbor) terdekat. Dalam hal ini jumlah data/tetangga terdekat ditentukan oleh user yang dinyatakan dengan k. Misalkan ditentukan k=5, maka setiap data testing dihitung jaraknya terhadap data training dan dipilih 5 data training yang jaraknya paling dekat ke data testing. Lalu periksa output atau labelnya masing-masing, kemudian tentukan output mana yang frekuensinya paling banyak. Lalu masukkan suatu data testing ke kelompok dengan output paling banyak. Misalkan dalam kasus klasifikasi dengan 3 kelas, lima data tadi terbagi atas tiga data dengan output kelas 1, satu data dengan output kelas 2 dan satu data dengan output kelas 3, maka dapat disimpulkan bahwa output dengan label kelas 1 adalah yang paling banyak. Maka data baru tadi dapat dikelompokkan ke dalam kelas 1. Prosedur ini dilakukan untuk semua data testing (Santosa, 2007). Gambar 4 berikut ini adalah bentuk representasi K-NN dengan 1, 2 dan 3 tetangga data terhadap data baru x (Pramudiono, 2003).
(a)1-nearest neighbor (b)2-nearest neighbor (c)3-nearest neighbor Gambar 4. Ilustrasi 1-, 2-, 3-nearest neighbor terhadap data baru (x)
Untuk mendefinisikan jarak antara dua titik yaitu titik pada data training (x) dan titik pada data testing (y) maka digunakan rumus Euclidean,
∑
=−
=
ni
i
i
y
x y
x d
1
) (
) ,
(
2 (2.4)dengan d adalah jarak antara titik pada data training x dan titik data testing y yang akan diklasifikasi, dimana x=x1,x2,…,xi dan y=y1,y2,…,yi dan I merepresentasikan nilai atribut serta n merupakan dimensi atribut (Han &
Kamber, 2001). Sebagai ilustrasi, pada Tabel 1 berikut ini disajikan contoh penerapan rumus Euclidean, pada empat data klasifikasi kualitas baik dan tidak baik sebuah kertas tisu yang dinilai berdasarkan daya tahan kertas tersebut dan fungsinya. Sebanyak tiga data yang sudah terklasifikasi yaitu data no 1,2, dan 3
- - - - - - - - - - + +
- + - - + +
- + - x
- - - - - - - - - + +
- + - - + +
+ - x + - - - -
- - - + + - + - - + +
- x
masing-masing data dihitung jaraknya ke data no 4 untuk mendapatkan kelas yang sesuai bagi data no 4 maka k=1 (Teknomo, 2006).
Tabel 1. Tabel klasifikasi kualitas baik atau tidak baik sebuah kertas tisu No Fungsi Daya Tahan Klasifikasi
1 7 7 Tidak baik
2 7 4 Tidak baik
3 3 4 Baik
4 1 4 ?
Berikut ini disajikan pula perhitungan yang dilakukan terhadap tiga data yang sudah terklasifikasi dengan data yang belum terklasifikasi pada Tabel 1 di atas.
Jarak data no satu ke data no empat:
07 . 6 45 3
6 ) 4 7 ( ) 1 7
( 2 2 2 2
4 ,
1 = − + − = + = =
d
Jarak data no dua ke data no empat:
6 36 0
6 ) 4 4 ( ) 1 7
( 2 2 2 2
4 ,
2 = − + + = + = =
d
Jarak data no tiga ke data no empat:
2 4 0
2 )
4 4 ( ) 1 3
( 2 2 2 2
4 ,
3 = − + + = + = =
d
Dari hasil perhitungan di atas diperoleh jarak antara data no tiga dan data no empat adalah jarak yang terdekat maka kelas data no empat adalah baik.
Teknik ini akan diujicobakan terhadap dataset akademik yang belum terklasifikasi atau data yang belum dikenal, untuk menemukan kelas yang sesuai dengan berdasarkan pada data tetangga terdekatnya yang sudah terklasifikasi.
Tingkat ketepatan klasifikasi terhadap data dari kedua algoritma yang digunakan menjadi titik fokus analisa dalam penelitian.
Membangun Model Prediksi
Secara umum, proses dasar dalam membangun model prediksi adalah sama, terlepas dari teknik data mining yang akan digunakan. Keberhasilan dalam membangun model lebih banyak tergantung pada proses bukan pada teknik yang
digunakan, dan proses tersebut sangat tergantung pada data yang digunakan untuk menghasilkan model. Hal ini terkait dengan tahapan praproses data dalam data mining yaitu pembersihan data (data cleaning) yang harus dikerjakan sebelum melakukan tahap pengolahan data dengan tujuan membersihkan data yang akan diolah dari redudancy dan missing value.
Tantangan utama dalam membangun model prediksi adalah mengumpulkan data awal yang cukup banyak jumlahnya. Data preclassified, hasilnya sudah diketahui, dan oleh karena itu data preclassified digunakan untuk melatih model, sehingga disebut model set. Data dibagi secara acak menggunakan teknik 3-fold cross validation ke dalam kelompok data training dan data testing. Masing- masing kelompok akan diujicobakan ke dalam kedua algoritma yang dipakai.
Alat ukur dalam evaluasi
Evaluasi model merupakan tahapan yang juga dikerjakan dalam penelitian dengan tujuan untuk memperoleh informasi yang terdapat pada hasil klasifikasi terhadap kedua algoritma yang digunakan. Dalam weka classifier hasil klasifikasi yang diperoleh disertakan dengan beberapa alat ukur yang tersedia di dalamnya, diantaranya adalah sebagai berikut :
- Confusion matrix
Dalam penelitian ini dipilih alat ukur evaluasi berupa confusion matrix yang terdapat pada weka classifier dengan tujuan untuk mempermudah dalam menganilisis performa algoritma karena confusion matrix memberikan informasi dalam bentuk angka sehingga dapat dihitung rasio keberhasilan klasifikasi. Confusion matrix adalah salah satu alat ukur berbentuk matrik 2x2 yang digunakan untuk mendapatkan jumlah ketepatan klasifikasi dataset terhadap kelas aktif dan tidak aktif pada kedua algoritma yang dipakai. Dalam kasus dengan dua klasifikasi data keluaran seperti contoh : ya dan tidak, pinjam atau tidak pinjam, atau contoh lainnya, tiap kelas yang diprediksi memiliki empat kemungkinan keluaran yang berbeda, yaitu true positives (TP) dan true negatives (TN) menunjukkan ketepatan klasifikasi.
Jika prediksi keluaran bernilai positif sedangkan nilai aslinya adalah negatif
maka disebut dengan false positive (FP) dan jika prediksi keluaran bernilai negatif sedangkan nilai aslinya adalah positif maka disebut dengan false negative (FN). Berikut ini pada Tabel 2 disajikan bentuk confusion matrix seperti yang telah dijelaskan sebelumnya.
Tabel 2. Perbedaan hasil yang diperoleh dari dua kelas prediksi Predicted Class
Yes No Yes True Positive False Negative
Actual
Class No False Positive True Negative
Beberapa kegiatan yang dapat dilakukan dengan menggunakan data hasil klasifikasi dalam confusion matrix diantaranya :
- menghitung nilai rata-rata keberhasilan klasifikasi (overall success rate) ke dalam kelas yang sesuai dengan cara membagi jumlah data yang terklasifikasi dengan benar, dengan seluruh data yang diklasifikasi.
- Selain itu dilakukan pula penghitungan persentase kelas positif ( true positive & false positive ) yang diperoleh dalam klasifikasi, yang disebut dengan lift chart.
- Lift chart terkait erat dengan sebuah tehnik dalam mengevaluasi skema data mining yang dikenal dengan ROC (receiver operating characteristic) yang berfungsi mengekspresikan persentase jumlah proporsi positif dan negatif yang diperoleh.
- Recall precision berfungsi menghitung persentase false positive dan false negative untuk menemukan informasi di dalamnya .
Review Riset yang Relevan
Moertini (2003) melakukan penelitian menggunakan algoritma C4.5 yang merupakan algoritma pendahulu dari C5.0. Hasil dari penelitian tersebut menyebutkan bahwa algoritma C4.5 memiliki performa yang baik dalam
mengkonstruksi sebuah pohon keputusan dan menghasilkan aturan-aturan yang dapat digunakan pada waktu yang akan datang. Salah satu kesimpulan yang diperoleh mempertegas alasan bahwa algoritma ini digunakan untuk klasifikasi data yang memiliki atribut-atribut numerik dan kategorikal.
Sufandi (2007) melakukan penelitian untuk memprediksi kemajuan belajar mahasiswa aktif yaitu dengan melakukan pengujian menggunakan data dengan kategori mahasiswa aktif dengan metode Neural Network Multi Layer Perceptron namun tidak selesai dikejakan karena hasil klasifikasi mahasiswa aktif & tidak aktif tidak diperoleh dengan jelas .
DATA DAN METODE
Data
Sumber data yang digunakan dalam penelitian berasal dari data mahasiswa tahun angkatan 2000 sampai dengan 2005, dan dari tiga program studi yaitu S1- Sistem Informasi, S1-Teknik Informatika, serta D3-Manajemen Informatika.
Beberapa jenis data diperoleh dari sistem yang berjalan namun hanya data identitas mahasiswa dan data IPK mahasiswa saja yang digunakan untuk penelitian, dikarenakan informasi yang terkandung di dalamnya sudah mewakili informasi yang dibutuhkan untuk dijadikan indikator penentu dalam klasifikasi data keluaran yang diinginkan.
Jumlah data yang diperoleh adalah sebanyak 2.115 record data yang berasal dari dataset identitas mahasiswa dan 1.088 record data yang berasal dari dataset IPK. Dataset mahasiswa terdiri dari 64 atribut yang menjelaskan identitas diri mahasiswa dan informasi tentang keadaan mahasiswa yang bersangkutan saat mendaftarkan diri pada UPNVJ. Atribut-atribut tersebut diantaranya adalah nama, tanggal lahir, alamat, asal sekolah, nama orangtua, pekerjaan orangtua, gelombang daftar, no ujian, dan no registrasi pokok (NRP). Sedangkan dataset IPK hanya terdiri dari 7 atribut, dimana memberikan informasi mengenai prestasi akademik dan beban studi yang sudah diambil mahasiswa yang bersangkutan. Atribut- atribut tersebut adalah NRP, tahun akademik, semester, sks semester, IP semester, sks kumulatif, dan IP Kumulatif. Keterangan atribut pada dataset mahasiswa dan contoh datanya dapat dilihat pada lampiran yang terdapat dalam tesis ini. Dan untuk keterangan atribut pada dataset IPK dan contoh datanya dapat dilihat pula pada lampiran yang terdapat dalam tesis ini.
Seluruh atribut pada kedua dataset di atas selanjutnya akan diseleksi untuk mendapatkan atribut-atribut yang berisi nilai yang relevan, tidak missing value, dan tidak redundant, dimana ketiga syarat tersebut merupakan syarat awal yang harus dikerjakan dalam data mining sehingga akan diperoleh dataset yang bersih untuk digunakan pada tahap mining data. Dikatakan missing value jika atribut-
atribut dalam dataset tidak berisi nilai atau kosong, sementara itu data dikatakan redundant jika dalam satu dataset yang sama terdapat lebih dari satu record yang berisi nilai yang sama. Relevan tidaknya sebuah atribut dapat ditentukan oleh keluaran yang ingin dihasilkan, misalnya untuk mengetahui bahwa seorang mahasiswa tidak aktif, tidak relevan jika indikator yang dilihat adalah agamanya.
Contoh dataset dengan atribut yang missing value dapat dilihat pada Tabel 3 di bawah ini.
Tabel 3. Contoh instances dengan missing value pada sebagian atributnya
NAMA TGLHR ALMHS KDPOS
MAYA YULIETNA 7/19/1982 PERUM. I KARAWACI
RACHMAD NUR RIFAI 10/23/1981 12520 MUHAMNAD ICHSAN KURNIA 8/31/1983 JL.MENTENG 14270
ATIKAH 4/10/1985 KEL. BAKTI JAYA 16418
WAHMI ARDIANSYAH 10/31/1984 16418
MULTARINI
CHANDRA SEVILLA 1/7/1983 GG.ALI ANDONG 16516
URUPAN MAGDALENA 1/10/1984 12320
OVIRINA PUTRI WARDHANI 10/31/1984 BLOK AA XI, RENI JAYA 15417
HARDIANTO 1/26/1985 12790
Pada tabel di atas terlihat bahwa record ke 1, 2, 5, 6, 8 dan 10, beberapa atributnya tidak berisi data atau kosong. Maka keadaan seperti diatas dikatakan bahwa atribut tersebut missing value. Selain atribut yang missing value, disajikan pula contoh dataset dengan data yang redundant seperti pada Tabel 4 di bawah ini.
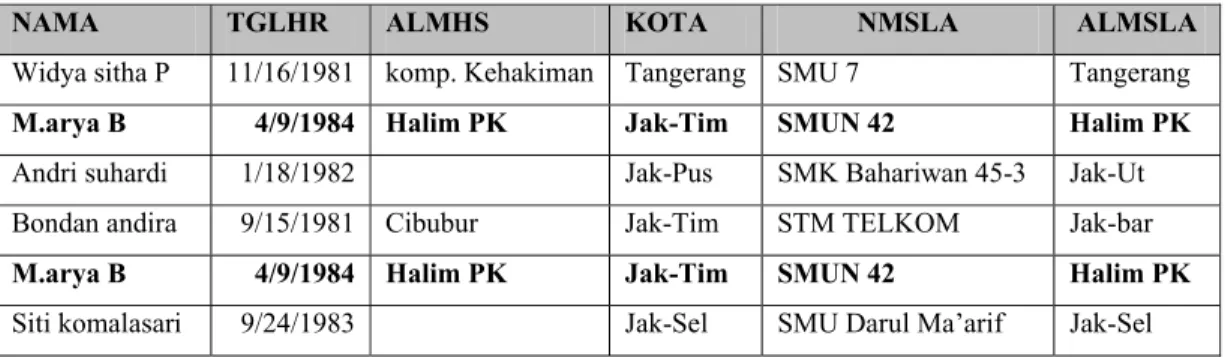
Tabel 4. Contoh redundancy data
NAMA TGLHR ALMHS KOTA NMSLA ALMSLA
Widya sitha P 11/16/1981 komp. Kehakiman Tangerang SMU 7 Tangerang M.arya B 4/9/1984 Halim PK Jak-Tim SMUN 42 Halim PK Andri suhardi 1/18/1982 Jak-Pus SMK Bahariwan 45-3 Jak-Ut Bondan andira 9/15/1981 Cibubur Jak-Tim STM TELKOM Jak-bar M.arya B 4/9/1984 Halim PK Jak-Tim SMUN 42 Halim PK Siti komalasari 9/24/1983 Jak-Sel SMU Darul Ma’arif Jak-Sel
Record 2 dan record 5 pada tabel di atas berisi data yang sama, maka dikatakan record tersebut redundant.
Metode
Kerangka Pemikiran
Sebagai langkah awal maka perlu adanya identifikasi masalah berkenaan dengan masalah yang di bahas. Kemudian dilakukan pengumpulan data berkaitan dengan permasalahan yang akan diteliti dan studi literatur untuk menentukan metode data mining untuk pengolahan data dan penentuan alternatif solusi.
Selanjutnya dilakukan pengumpulan data untuk menentukan parameter-parameter yang menyebabkan berkurangnya jumlah mahasiswa FIK-UPNVJ dalam hampir tiap semesternya. Kerangka pemikiran dalam pengembangan model sistem pada penelitian ini dapat digambarkan dalam suatu diagram alir penelitian seperti pada Gambar 5.
Gambar 5. Kerangka pemikiran penelitian Selesai
Mulai
Identifikasi Masalah
Feature Selection
Dataset C5.0
Studi Literatur Pengumpulan Data
Data Praproses
Evaluasi Hasil
KNN
Dengan demikian diharapkan dapat diperoleh gambaran yang lengkap dan menyeluruh tentang tahap-tahap penelitian yang akan dilaksanakan serta keterkaitan antara satu tahap dengan tahap selanjutnya.
1. Identifikasi Masalah
Menggali permasalahan yang ditemukan pada obyek yang di teliti guna mencari alternatif solusi yang terkait dengan permasalahan, diantaranya,
a. Jumlah mahasiswa tidak aktif yang bertambah.
b. Karakteristik mahasiswa tidak aktif yang tidak tersedia.
2. Studi Literatur
Kegiatan mempelajari dan memahami fungsi-fungsi data mining, teknik-teknik dan algoritma yang digunakan dalam data mining. Adapun literatur yang digunakan berasal dari buku-buku data mining dan jurnal penelitian bidang data mining untuk teknik klasifikasi dengan algoritma C5.0 dan K-Nearest Neighbor. Penelitian yang dilakukan sebelumnya oleh Moertini, Beikzadeh dan Phon menggunakan C5.0 & KNN menunjukkan bahwa kedua algoritma ini dapat melakukan klasifikasi data di atas 80%.
3. Pengumpulan data
Tahap pengumpulan data untuk mendapatkan sejumlah informasi yang dibutuhkan dengan mengambil data akademik mahasiswa pada Sistem Informasi Akademik FIK-UPNVJ. Maka diperolehlah dataset mahasiswa dan dataset IPK untuk digunakan dalam penelitian karena kedua dataset ini sudah mewakili informasi yang dibutuhkan.
4. Data Praproses
Adalah tahap seleksi data bertujuan untuk mendapatkan data yang bersih dan siap untuk digunakan dalam penelitian. Tahapan yang dikerjakan adalah dengan melakukan perubahan terhadap beberapa tipe data pada atribut dataset dengan tujuan untuk mempermudah pemahaman terhadap isi record, juga melakukan seleksi dengan memperhatikan konsistensi data, missing value, dan redundant pada data. Beberapa atribut yang bertipe numeric diubah menjadi string, dan atribut Tgllhr yang
bertipe data date menjadi numeric. Untuk atribut Tgllhr selanjutnya berubah nama menjadi Usia. Atribut Anakke dan Dari digabung dengan nama Anakke dan tipe data string. Sebanyak 6 atribut terpilih yang berasal dari 64 atribut dataset mahasiswa dan 7 atribut dataset IPK.
5. Feature Selection
Adalah tahapan seleksi atribut, dimana atribut-atribut yang diperoleh dari tahap praproses selanjutnya diseleksi lagi menggunakan formula Information Gain yang menghasilkan nilai Gain dari seluruh atribut dalam dataset yang mana formula ini terdapat dalam algoritma C5.0 dengan fungsinya untuk mendapatkan atribut yang berfungsi sebagai root atau akar pada decision tree, node dan leaf .
6. Teknik Data Mining
Tahap pengolahan data dengan memfungsikan algoritma dan teknik yang telah ditentukan sebelumnya, yaitu klasifikasi menggunakan algoritma C5.0 dan KNN. Algoritma C5.0 bekerja untuk menghasilkan aturan-aturan klasifikasi dalam bentuk pohon keputusan (decision tree) yang selanjutnya aturan-aturan tersebut akan digunakan pada dataset yang baru. KNN berfungsi sebagai algoritma pembanding yang akan melakukan prediksi klasifikasi data dengan menentukan sejumlah data tetangga yang sudah terklasifikasi.
7. Dataset
Tahap seleksi atribut menghasilkan himpunan data akhir yang digunakan untuk tahap klasifikasi data berupa dataset akademik. Dataset akademik adalah data yang sudah tidak lagi mengandung data dengan missing value dan redundant. Dengan menggunakan teknik 3-fold cross validation, data dibagi menjadi dua bagian sebagai data training dan satu bagian sebagai data testing, yang mana training dan testing dilakukan sebanyak 3 kali.
8. Hasil
Klasifikasi dengan algoritma C5.0 memberikan hasil berupa aturan-aturan klasifikasi dalam bentuk if-then dan dalam bentuk pohon
keputusan (decision tree) serta menunjukkan karakteristik data yang diklasifikasi, sedangkan KNN hanya memberikan hasil berupa jumlah ketepatan dan ketidaktepatan data yang diklasifikasi namun tidak dapat menunjukkan karakterisitk dari data yang di klasifikasi. Sehingga dapat dikatakan bahwa telah diperoleh sebanyak dua model yang berasal dari kedua penerapan algoritma yang dipilih.
9. Evaluasi
Analisis terhadap hasil klasifikasi yang diperoleh dengan menggunakan kedua algoritma menunjukkan bahwa rata-rata lama waktu yang dibutuhkan sangat singkat yaitu 0.01 seconds. Dilakukan pula analisis dengan beberapa alat evaluasi yang lain dengan menggunakan tabel confusion matrix, yaitu hasil klasifikasi dengan proporsi positif dan negatif yang diperoleh akan dievaluasi sehingga diperoleh persentase kelas positif dalam lift chart, persentase jumlah proporsi positif dan negatif dalam ROC, dan nilai rata-rata keberhasilan klasifikasi ke dalam kelas yang sesuai dalam overall success rate.
Tata Laksana
Kegiatan yang dilakukan dalam penelitian ini diantaranya adalah pembentukan model klasifikasi untuk memperoleh aturan-aturan yang dibutuhkan. Proses dimulai dengan pendefinisian masalah serta mempelajari bisnis proses dari sistem yang sedang berjalan. Pada tahap selanjutnya melakukan uji coba terhadap dataset baru yang belum terklasifikasi dengan menggunakan aturan-aturan yang diperoleh dari tahap sebelumnya.
Metodologi data mining didasarkan pada tiga tahapan yang dilakukan untuk mendeteksi mahasiswa yang berpotensi untuk tidak aktif pada waktu yang akan datang dengan memperhatikan karakteristik data dalam dataset. Ketiga tahapan tersebut adalah a) seleksi atribut dataset b) menangani data yang tidak konsisten, redundant dan missing value c) rule mining dan klasifikasi.
Pada tahap pertama, seleksi atribut dalam dataset untuk mendapatkan atribut dengan record yang relevan terhadap keluaran yang diinginkan. Pada tahap kedua, pemrosesan awal data mahasiswa dilakukan untuk menghapus data atau record yang tidak konsisten, redundant dan missing value dan mengekstrak data yang akan digunakan untuk mengelompokkan mahasiswa ke dalam klas aktif dan tidak aktif. Pada tahap ketiga, algoritme decision tree classifier digunakan untuk menghasilkan aturan-aturan yang berguna untuk mendeteksi mahasiswa yang tidak aktif.
Waktu dan Tempat Penelitian
Penelitian dilaksanakan mulai bulan Juli 2006 hingga Januari 2007, dan bertempat di Laboratorium Komputer Pascasarjana Ilmu Komputer IPB serta Laboratorium Komputer FIK-UPNVJ.
HASIL DAN PEMBAHASAN
Praproses Data
Tahap pertama yang dilakukan adalah menyeleksi seluruh data pada kedua dataset dengan memperhatikan keberadaan setiap record data pada keduanya. Jika terdapat record tertentu pada salah satu dataset namun record tersebut tidak terdapat pada dataset yang lain, maka record yang dimaksud akan dihapus karena record tersebut dinilai tidak konsisten. Pada Tabel 5 dan Tabel 6 di bawah ini berisi contoh ketidak-konsistenan data pada dataset mahasiswa dan dataset IPK.
Tabel 5. Contoh data pada dataset mahasiswa
NRP NAMA TGLHR ALMHS1 KOTA NMSLA
200502113 Ikrar Achmad B 10/28/1981 Komp. Kopassus Depok SMU 105 Jkt 200502114 Cindy Rahmawati 7/23/1982 Delima I Blok K-3 Depok SMUN 103
200502115 Dyah Andri M 1/4/1981 Sukatani Cimanggis Depok SMU Islam PB.Sudirman 200502116 Siti Maesaroh 10/19/1981 Jakarta SMUN 97 Ciganjur 200502117 Yanuar Tri P 1/8/1982 Pinang Kp. Baru Jakarta SMU Borobudur 200502118 Fransiskus Ony F 2/23/1983 Laki Cimanggis Bogor SMUN I Cimanggis
Tabel 6. Contoh data pada dataset IPK
I_NRP I_THAK I_SMT I_IPS I_JSKSS I_IPK I_JSKSK 200502113 0001 1 1.90 20 1.90 20 200502114 0001 1 2.00 16 2.00 16 200502116 0001 1 2.50 20 2.50 20 200502117 0001 1 2.00 14 2.00 14 200502118 0001 1 2.10 20 2.10 20 200502119 0001 1 1.70 20 1.70 20
Record dengan NRP=200502115 yang terdapat pada dataset mahasiswa tidak terdapat pada dataset IPK, maka record tersebut dihapus karena dinilai tidak konsisten keberadaan informasinya.
Yang dilakukan selanjutnya adalah seleksi terhadap atribut dataset, dimana diketahui sebanyak 64 atribut terdapat pada dataset mahasiswa dan 7 atribut pada dataset IPK. Seleksi ini dilakukan untuk mendapatkan atribut-atribut
dengan nilai yang relevan terhadap status keaktifan studi mahasiswa sehingga untuk selanjutnya atribut-atribut yang dinilai berisi nilai yang tidak relevan tidak lagi disertakan dalam dataset. Di bawah ini disajikan contoh instances dengan beberapa atribut pada dataset mahasiswa seperti tampak pada Tabel 7.
Tabel 7. Contoh instances dengan beberapa atribut pada dataset mahasiswa NoForm NoUjiGel NoUji NRP Nama PilJur1 PilJur2 TglDft TryOut 0049 30076 WIDYA SIST 311 511 3/30/2001 FALSE 0067 50013 M.ARYA NUG 511 512 4/3/2001 TRUE 0070 50016 ANDRI SUHA 512 502 4/3/2001 FALSE 0082 50005 BONDAN AND 511 414 4/4/2001 FALSE 0088 50026 SITI KOMAL 512 502 4/5/2001 FALSE 0097 30038 ASNIDA RAT 311 511 4/6/2001 TRUE 0120 5 ACHMAD DJO 502 4/10/2001
0122 5 EDO TIAS R 511 4/10/2001
0131 50039 IKA MARYAN 512 4/10/2001 FALSE 0147 50062 ANGELA RUS 512 112 4/12/2001 FALSE
NoForm, NoUjiGel, NoUji, NRP, Nama adalah atribut-atribut yang tidak digunakan dalam penelitian karena menjadi tidak relevan jika seorang mahasiswa berpotensi tidak aktif pada waktu yang akan datang ditentukan oleh atribut-atribut tersebut. PilJur1, PilJur2, TglDft dan TryOut dapat dipilih sebagai atribut dalam penelitian, namun tidak terdapat keterangan atau penjelasan yang berkaitan dengan atribut-atribut tersebut baik berupa nilai hasil ujian masuk, lama waktu yang disediakan untuk mendaftar pada setiap gelombang daftar, dan lembaga yang melaksanakan tryout serta kapan dilaksanakannya, maka atribut-atribut yang tertera pada tabel di atas tidak dipilih untuk digunakan dalam penelitian. Pada Tabel 8 di bawah ini, disajikan contoh instances dengan atribut pada dataset IPK.
Tabel 8. Contoh instances dengan atribut pada dataset IPK I_NRP I_THAK I_SMT I_IPS I_JSKSS I_IPK I_JSKSK 201511027 0102 1 2.42 19 2.42 19 201511029 0102 1 1.59 17 1.59 17 201511030 0102 1 1.63 19 1.63 19 201511031 0102 1 1.68 19 1.68 19
I_NRP I_THAK I_SMT I_IPS I_JSKSS I_IPK I_JSKSK 201511048 0102 1 2.58 19 2.58 19 201511001 0102 2 2.62 21 2.75 40 201511003 0102 2 2.48 21 2.50 40 201511004 0102 2 2.71 21 2.85 40 201511005 0102 2 3.28 25 3.41 44 201511007 0102 2 2.83 23 2.90 42
Contoh dataset di atas digunakan untuk melihat prestasi akademik yang diperoleh oleh setiap mahasiswa pada tiap semester yang diambil. Atribut I_IPK adalah satu-satunya atribut yang dipilih karena dinilai sudah mewakili informasi prestasi akademik mahasiswa hingga saat masa akhir studi yang ditempuh. Pada sistem yang berjalan, masa studi yang telah ditempuh oleh setiap mahasiswa dapat dilihat pada atribut I_THAK, I_SMT dan I_JSKSK. Jika mahasiswa dengan NRP tertentu tidak muncul pada tahun akademik selanjutnya baik pada semester ganjil maupun genap maka mahasiswa tersebut dianggap tidak menyelesaikan masa studi yang harus ditempuh. Misal masa studi D3 adalah 7 semester dengan total sks 115 sks, namun mahasiswa yang dimaksud tidak melakukan registrasi pada tahun akademik dan semester yang sedang berjalan dan pada semester selanjutnya hingga masa studi yang berlaku dan total sks yang telah diambil lebih kecil atau sama dengan separuh dari total sks yang berlaku .
Tahap seleksi atribut tidak hanya dilakukan untuk mendapatkan konsistensi dan relevansi isi dari atribut yang dimiliki namun juga dilakukan seleksi terhadap atribut yang mengandung missing value atau nilai yang hilang atau kosong, serta atribut yang mengandung data yang redudancy atau data yang duplikat. Jika ditemukan dalam kedua dataset terdapat atribut dengan nilai kosong atau missing value ataupun atribut dengan data yang redudancy, maka data tersebut dihapus, demikian halnya seperti seleksi yang dilakukan sebelumnya terhadap atribut-atribut dalam dataset. Hal ini dilakukan karena atribut yang missing value tidak memberikan informasi apapun jika dipertahankan keberadaannya, demikian pula dengan atribut yang redundancy, maka cukup dipilih salah satunya saja dari data yang redundant karena data tersebut berisi informasi yang sama. Tahap seleksi ini disebut juga dengan tahap pembersihan data atau data cleaning yang bertujuan mendapatkan data yang bersih, sehingga
data tersebut dapat digunakan untuk tahap selanjutnya yaitu transformasi data.
Pada Gambar 2 telah diperlihatkan bahwa proses data cleaning adalah proses awal yang dikerjakan sebelum melakukan tahap mining.
Dari tahap seleksi atribut yang telah dilakukan di atas diperoleh beberapa atribut sementara yang akan digunakan dalam penelitian, yaitu : NRP, Tgllhr, Alamat, Pekerjaan Orangtua, JenisSLA, WilSMU, Anakke, dan Dari yang berasal dari dataset mahasiswa dan atribut IPK dari dataset IPK. Dan jumlah data akhir yang diperoleh adalah sebanyak 1.175 record data dari total data sebelumnya adalah 3.203 record data.
Selanjutnya adalah menghapus atribut NRP , dimana pada tahap sebelumnya atribut ini digunakan untuk melihat kemunculannya pada tiap semester dan tahun akademik pada dataset IPK, setelah diperoleh informasi yang dicari maka atribut ini sudah tidak lagi diperlukan. Sehingga atribut-atribut yang digunakan hanya tinggal atribut Tgllhr, JenisSLA, PkOrtu, Anakke dan Dari.
Tahap berikutnya adalah merubah tipe data dari beberapa atribut tadi, diantaranya adalah atribut Tgllhr, JenisSLA, PkOrtu, Anakke dan atribut Dari. Hal ini dilakukan dengan tujuan agar isi pada setiap atribut lebih mudah dipahami oleh pengguna data maupun pengguna informasi. Pada Tabel 9 di bawah ini ditampilkan contoh instances dengan atribut-atribut yang disebutkan tadi.
Tabel 9. Contoh instances dengan atribut yang akan dirubah tipe datanya TGLLAHIR PK_ORTU JNSSLA AKKE DARI
3/4/1983 1 1 1 2
8/3/1982 1 1 1 3
9/23/1981 3 1 2 4
9/24/1979 4 1 5 7
11/19/1981 4 1 1 2
1/11/1983 4 1 2 2
2/1/1981 2 1 3 3
9/7/1982 4 1 1 3
7/13/1982 4 1 4 4
4/1/1983 4 1 1 1
7/11/1980 2 1 3 3
5/28/1981 3 1 3 3
TGLLAHIR PK_ORTU JNSSLA AKKE DARI
10/25/1981 2 1 2 2
3/23/1981 4 1 2 4
Tipe data atribut TglLhr yang semula adalah date diubah menjadi atribut Usia dengan tipe data numeric, sehingga tidak lagi berisi tanggal lahir mahasiswa melainkan berisi usia mahasiswa pada saat awal kuliah pada semester satu. Tipe data JenisSLA, PkOrtu, Anakke dan Dari diubah menjadi bertipe data string, sehingga dapat lebih mudah dipahami isi atribut yang dikandung dan tipe data ini dan sesuai dengan tipe data yang digunakan dalam algoritma decision tree.
Atribut Anakke dan atribut Dari dijadikan dalam satu atribut baru bernama Anakke yang berisi informasi kategori urutan anak dalam keluarga.
Beberapa atribut pada tabel di atas masih berisi data dalam bentuk kode angka, seperti nampak pada atribut PkOrtu dan JenisSLA. Berikut ini pada Tabel 10 disajikan keterangan kode pada kedua atribut tersebut.
Tabel 10. Keterangan kode pada atribut PkOrtu dan JenisSLA Atribut Kode Keterangan
PkOrtu 1 TNI
2 PNS
3 Swasta
4 Purnawirawan
JenisSLA 1 SMU
2 SMK
3 MA/MAN
Setelah perubahan tipe data dan pemberian nama baru dilakukan kepada beberapa atribut maka isi dari atribut yang bersangkutanpun berubah. Berikut ini tampak pada Tabel 11 adalah contoh instances dengan tipe data dan nama atribut yang baru.
Tabel 11. Contoh instances dengan tipe data dan nama atribut yang baru USIA PKORTU JNSSLA Anakke
17 TNI smu sulung
18 TNI smu sulung
19 SWASTA smu tengah