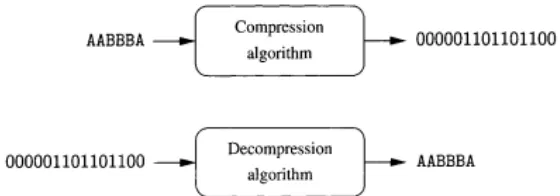
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Mencapai Gelar Strata Satu Jurusan Informatika
Disusun Oleh :
ANDREAS DONY MARHENDRA STIAWAN M0508084
JURUSAN INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SEBELAS MARET
SURAKARTA
ii
ALGORITMA
BWT-RLE-MTF-HUFFMAN
DAN
BWT-MTF-RLE-HUFFMAN
PADA KOMPRESI
FILE
Disusun Oleh :
ANDREAS DONY MARHENDRA STIAWAN M0508084
iii
RLE-HUFFMAN
PADA KOMPRESI
FILE
Disusun Oleh :
ANDREAS DONY MARHENDRA STIAWAN M0508084
Telah dipertahankan di hadapan Dewan Penguji pada tanggal : 4 Desember 2012
iv
“D an segala sesuat u yang kamu lakukan dengan perkat aan at au perbuat an, lakukanlah semuanya it u dalam nama Tuhan Yesus sambil mengucap syukur oleh D ia kepada Allah,
Bapa kit a” (K olose 3 : 17)
“M usuh yang paling berbahaya di at as dunia ini adalah penakut dan bimbang. Teman yang paling set ia, hanyalah keberanian dan keyakinan yang t eguh”
(Andrew Jackson)
“Banyak kegagalan dalam hidup ini dikarenakan orang-orang t idak menyadari bet apa dekat nya mereka dengan keberhasilan saat mereka menyerah”
(Thomas Alva E dison)
“K it a melihat kebahagiaan it u sepert i pelangi, t idak pernah berada di at as kepala kit a sendiri, t et api selalu berada di at as kepala orang lain”
v
Karya ini kupersembahkan kepada :
Tuhan Yesus Kristus, yang senantiasa memberikan cinta kasih dan anugerah karunia yang berlimpah…
Bapak yang sedang berjuang dalam pemulihannya dan senantiasa menemani serta memberi semangat dalam penyusunan skripsi ini…
Ibu, Budhe, dan kakak-kakak yang selalu membimbing, mendukung dan mencurahkan kasih sayang dan cintanya…
vi
Puji dan syukur atas segala limpahan rahmat dan anugerah Tuhan Yang
Maha Esa sehingga penulis dapat menyelesaikan skripsi yang berjudul “Analisis
Perbandingan Kinerja Kombinasi Algoritma BWT-RLE-MTF-Huffmandan
BWT-MTF-RLE-Huffmanpada KompresiFile”.
Penulis menyadari akan keterbatasan yang penulis miliki dalam penyusunan skripsi ini, sehingga begitu banyak bantuan dari berbagai pihak yang diberikan kepada penulis.
Melalui kesempatan ini penulis ingin mengucapkan terima kasih kepada semua pihak yang telah membantu, memberikan bimbingan, dukungan moral dan semangat dalam penyusunan skripsi ini. Terima kasih yang mendalam penulis ucapkan kepada :
1. Bapak Ir. Ari Handono Ramelan, M.Sc.(Hons), Ph.D., Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sebelas Maret. 2. Ibu Umi Salamah, S.Si, M.Kom., Ketua Jurusan Informatika Fakultas
Matematika dan Ilmu Pengetahuan Alam Universitas Sebelas Maret. 3. Ibu Esti Suryani, S.Si, M.Kom., Dosen Pembimbing I yang telah bersedia
meluangkan waktunya untuk membimbing, mengarahkan, serta memberikan motivasi kepada penulis dalam penyusunan skripsi ini. 4. Bapak Abdul Aziz, S.Kom, M.Cs., Dosen Pembimbing II yang telah
bersedia meluangkan waktunya untuk membimbing, mengarahkan, serta memberikan motivasi kepada penulis dalam penyusunan skripsi ini. 5. Bapak Wiharto, S.T, M.Kom., Pembimbing Akademik atas bimbingan dan
kesabarannya dalam perkuliahan.
6. Kedua orang tua, kakak-kakak dan segenap keluarga yang senantiasa mendoakan dan memberikan banyak bantuan serta dukungan kepada penulis.
vii
sempurna. Oleh karena itu penulis mengharapkan saran dan kritik yang bersifat membangun untuk perbaikan di masa mendatang. Akhir kata penulis berharap semoga tulisan ini dapat berguna bagi penulis pada khususnya dan bagi para pembaca pada umumnya.
Surakarta, 12 Desember 2012
viii
ANDREAS DONY MARHENDRA STIAWAN
Jurusan Informatika. Fakultas MIPA. Universitas Sebelas Maret
ABSTRAK
Penerapan teknik-teknik kompresi data sering kali digunakan dalam penyimpanan (storage) data maupun dalam hal transmisi data (data transmission). Keuntungan data yang terkompresi diantaranya adalah penyimpanan data lebih hemat ruang, mempersulit pembacaan data oleh pihak yang tidak berkepentingan, memudahkan distribusi data, serta dapat mengurangi bottleneck pada transmisi data.
Berdasarkan keuntungan dari kompresi data, penulis dalam tugas akhir ini mencoba menerapkan beberapa algoritma kompresi data, serta dilakukan pengujian secara multiple files untuk tipe file (.txt), (.rtf), (.doc), (.exe), (.dll), (.tif), dan (.bmp). Algoritma yang digunakan merupakan kombinasi beberapa algoritmalossless compression, yaitu Burrows-Wheeler Transform (BWT), Run-Length Encoding(RLE),Move-To-Front(MTF) sertaHuffman Coding. Pengujian dilakukan untuk mengetahui besar rasio kompresi, waktu kompresi dan waktu dekompresi. Serta dilakukan perbandingan kinerja pada 2 jenis kombinasi algoritma.
Penelitian menghasilkan suatu sistem kompresi data dan hasil perbandingan kinerja kompresi file menggunakan kombinasi BMRH (BWT –
MTF – RLE – Huffman) dan BRMH (BWT – RLE – MTF – Huffman). Hasil pengujian diperoleh untuk kombinasi BMRH memiliki rasio kompresi 70.44 %, waktu kompresi 9.6 × 10 second/byte, dan waktu dekompresi 22.4 × 10 second/byte, sedangkan untuk kombinasi BRMH memiliki rasio kompresi 66.57 %, waktu kompresi9.2 × 10 second/byte, dan waktu dekompresi15.8 × 10 second/byte. Berdasarkan hasil yang didapat, maka kombinasi BMRH lebih unggul dalam performansi kompresi data dibanding kombinasi BRMH.
ix
ANDREAS DONY MARHENDRA STIAWAN
Department of Informatic. Mathematic and Science Faculty. Sebelas Maret University
ABSTRACT
Application of data compression techniques often be used in data storage and in data transmission. The advantages of compressed data include more efficient data storage space, complicate the reading of data by unauthorized parties, facilitate the distribution of data, and can reduce the bottleneck in data transmission.
Based on the advantage of data compression, the authors in this thesis try to apply some data compression algorithm, and tested in multiple files for the file type (.txt), (.rtf), (.doc), (.exe), (. dll. ), (.tif), and (.bmp). The algorithm used is a combination of several lossless compression algorithm, the Burrows-Wheeler Transform (BWT), Run-Length Encoding (RLE), Move-To-Front (MTF) and Huffman Coding. Tests performed to determine the compression ratio, compression time, and decompression time. As well, the performance of the two type algorithm combinations.
The study resulted in a system of data compression and file compression performance comparison results using a combination BMRH (BWT – MTF –
RLE – Huffman) and BRMH (BWT– MTF– RLE – Huffman). The test results were obtained for the combination BMRH have 70.44% compression ratio, compression time 9.6 × 10 second / byte, and a decompression time 22.4 × 10 second / bytes, whereas for the combination BRMH have 66.57% compression ratio, compression time of 9.2 × 10 second / byte, and a decompression time15.8 × 10 second / byte. Based on the results obtained, the combination BMRH superior in performance compared to a combination of data compression BRMH.
x
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... iii
MOTTO ... iv
PERSEMBAHAN ... v
KATA PENGANTAR ... vi
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiii
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang Masalah ... 1
1.2. Rumusan Masalah ... 2
1.3. Batasan Masalah ... 3
1.4. Tujuan Penelitian ... 3
1.5. Manfaat Penelitian ... 3
1.6. Sistematika Penulisan ... 4
BAB 2 TINJAUAN PUSTAKA ... 5
2.1 Landasan Teori ... 5
2.1.1 Kompresi Data ... 5
2.1.2 Burrows-Wheeler Transform(BWT) ... 8
2.1.3 Run-Length Encoding(RLE) ... 12
2.1.4 Move-To-Front(MTF) ... 14
2.1.5 Huffman Coding ... 16
2.2 Penelitian Terkait ... 20
2.3 Rencana Penelitian ... 24
xi
3.2.2 Perancangan Proses Sistem ... 28
3.2.2.1 Tahap Kompresi ... 28
3.2.2.2 Tahap Dekompresi ... 30
3.3 Pengujian dan Analisis ... 32
BAB 4 HASIL DAN PEMBAHASAN ... 35
4.1 Spesifikasi Perangkat Implementasi dan Pengujian ... 35
4.2 Hasil Pengujian ... 35
4.2.1 Hasil Pengujian Rasio dan Waktu Kompresi ... 36
4.2.2 Hasil Pengujian Waktu Dekompresi ... 45
4.2.3 Analisis Perbandingan Kinerja ... 52
4.2.4 Pengujian Kualitas Hasil ... 60
BAB 5 PENUTUP ... 61
5.1 Kesimpulan ... 61
5.2 Saran ... 62
DAFTAR PUSTAKA ... 63
xii
Gambar 2.2. Alur Perilaku Kompresi ... 6
Gambar 2.3. Klasifikasi Teknik Kompresi Data ... 7
Gambar 2.4. MatriksString“BANANA”... 9
Gambar 2.5. MatriksString“BANANA” Diurutkan Secaralexicographic... 9
Gambar 2.6. HasilEncodingMatriksString“BANANA” ... 10
Gambar 2.7. Proses PembentukanStringAsliS ... 11
Gambar 2.8. Format Kode Algoritma RLE ... 13
Gambar 2.9. Pohon AlgoritmaHuffman ... 18
Gambar 2.10. Proses Dekompresi dengan Pohon AlgoritmaHuffman ... 19
Gambar 2.11. Alur Pikir Penelitian oleh Plipus Telaumbanua ... 21
Gambar 2.12. Alur Pikir Penelitian oleh Muhammad Husli Khairi ... 22
Gambar 3.1. Alur Pikir Proses Penelitian ... 27
Gambar 3.2.FlowchartProses Kompresi Kombinasi BMRH ... 29
Gambar 3.3.FlowchartProses Kompresi Kombinasi BRMH ... 29
Gambar 3.4.FlowchartProses Dekompresi Kombinasi BMRH ... 31
Gambar 3.5.FlowchartProses Dekompresi Kombinasi BRMH ... 31
Gambar 4.1. Grafik Rasio KompresiFile0–1 MB ... 40
Gambar 4.2. Grafik Waktu KompresiFile0–1 MB ... 41
Gambar 4.3. Grafik Rasio KompresiFile1–3 MB ... 42
Gambar 4.4. Grafik Waktu KompresiFile1–3 MB ... 42
Gambar 4.5. Grafik Rasio KompresiFile3–6 MB ... 43
Gambar 4.6. Grafik Waktu KompresiFile3–6 MB ... 44
Gambar 4.7. Grafik Waktu DekompresiFile0–1 MB ... 50
Gambar 4.8. Grafik Waktu DekompresiFile1–3 MB ... 51
Gambar 4.9. Grafik Waktu DekompresiFile3–6 MB ... 52
Gambar 4.10. Grafik Perbandingan Rata-rata Total Rasio Kompresi ... 53
Gambar 4.11. Grafik Perbandingan Rata-rata Total Waktu Kompresi ... 56
xiii
Tabel 2.2. Proses Algoritma ... 15
Tabel 2.3. ProsesDecodingAlgoritmaMove-To-Front ... 16
Tabel 2.4. Konversi Karakter dalam Kode Biner ASCII ... 17
Tabel 2.5. Frekuensi Kemunculan Karakter ... 18
Tabel 2.6. Kode Bit Hasil Kompresi ... 18
Tabel 4.1. Rata-rata Rasio dan Waktu KompresiFile (.txt) ... 36
Tabel 4.2. Rata-rata Rasio dan Waktu KompresiFile (.rtf)... 37
Tabel 4.3. Rata-rata Rasio dan Waktu KompresiFile (.doc)... 37
Tabel 4.4. Rata-rata Rasio dan Waktu KompresiFile (.dll) ... 38
Tabel 4.5. Rata-rata Rasio dan Waktu KompresiFile (.exe) ... 38
Tabel 4.6. Rata-rata Rasio dan Waktu KompresiFile (.tif) ... 39
Tabel 4.7. Rata-rata Rasio dan Waktu KompresiFile (.bmp)... 39
Tabel 4.8. Rata-rata Rasio dan Waktu Kompresi 0–1 MB ... 40
Tabel 4.9. Rata-rata Rasio dan Waktu Kompresi 1–3 MB ... 41
Tabel 4.10. Rata-rata Rasio dan Waktu Kompresi 3–6 MB ... 43
Tabel 4.11. Rata-rata Waktu DekompresiFileTerkompresi(.txt) ... 46
Tabel 4.12. Rata-rata Waktu DekompresiFileTerkompresi(.rtf)... 46
Tabel 4.13. Rata-rata Waktu DekompresiFileTerkompresi(.doc)... 47
Tabel 4.14. Rata-rata Waktu DekompresiFileTerkompresi(.dll) ... 47
Tabel 4.15. Rata-rata Waktu DekompresiFileTerkompresi(.exe) ... 48
Tabel 4.16. Rata-rata Waktu DekompresiFileTerkompresi(.tif) ... 48
Tabel 4.17. Rata-rata Waktu DekompresiFileTerkompresi(.bmp)... 49
Tabel 4.18. Rata-rata Waktu Dekompresi 0–1 MB ... 49
Tabel 4.19. Rata-rata Waktu Dekompresi 1–3 MB ... 50
Tabel 4.20. Rata-rata Waktu Dekompresi 3–6 MB ... 51
xv
1
Penggunaan data digital yang semakin merambah di berbagai aspek sering menimbulkan masalah dalam hal ruang penyimpanan dan transmisi data. Oleh karena itu, pengembangan teknik kompresi perlu dilakukan. Pengembangan algoritma kompresi seringkali didasari algoritma yang sudah ada atau berusaha mengkombinasikan dua atau lebih algoritma. Beberapa algoritma dasar yang sering dikembangkan diantaranya adalah Run-Length Encoding (RLE) dan Huffman.
Huffman Coding merupakan algoritma kompresi lossless entropi yang menggunakan metode spesifik dengan memanfaatkan frekuensi kemunculan (probabilitas) simbol, yang kemudian disajikan dalam suatu prefix-tree dan kemudian dikodekan dalam kode biner (Al-laham & El Emary, 2007). Huffman Coding ini dapat digunakan dalam lingkup yang luas karena kesederhanaan, kecepatan serta fleksibel pada media kompresi apapun, juga biasa digunakan
sebagai algoritma “back-end” pada beberapa metode kompresi yang lainnya (Sharma, 2010). Lain halnya dengan Run-Length Encoding (RLE), RLE merupakan algoritma kompresi data yang paling sederhana yang memanfaatkan deretan simbol berulang yang panjangnya dikodekan dalaminteger. Masalah yang muncul dalam RLE terletak padaworst caseyang dapat menghasilkanoutput data yang lebih besar dari input data. Untuk meminimalkan masalah tersebut maka dapat dikombinasikan dengan algoritma seperti Huffman Coding (Shanmugasundaram & Lourdusamy, 2011).
Penelitian tentang kompresi data saat ini sering mengkombinasikan algoritma satu dengan yang lainnya untuk mendapatkan performansi kompresi yang lebih tinggi. Michael Dipperstein (2010) menyatakan bahwa
(MTF) dapat meningkatkan kompresi dari metode statistical encoder / entropy seperti metode dasar Huffman atau Arithmetic Coding. Bahkan Burrows & Wheeler (1994) dalam penelitiannya mencoba melakukan penambahan algoritma MTF setelah algoritma BWT format data yang dihasilkan menjadi lebih kompresibel oleh metode RLE maupun statistical encoder (seperti Huffman, Arithmetic, danShannon-Fano) bahkan dengan ordo“0”sekalipun.
Berdasarkan pemaparan masalah dan pertimbangan dari keunggulan metode-metode tersebut maka pada kesempatan ini penulis mencoba melakukan penelitian dengan mempertimbangkan pernyataan sebelumnya dari Michael Dipperstein (2010) dan penelitian dari Telaumbanua (2011) mengenai keunggulan kombinasi BWT – RLE dan MTF – Huffman kemudian menggabungkan kedua kombinasi tersebut menjadi satu kesatuan yaitu, BRMH (BWT – RLE – MTF –
Huffman). Penulis juga mengangkat kombinasi kedua dengan mempertimbangkan
pernyataan Burrows & Wheeler (1994) mengenai keunggulan menggabungkan BWT dan MTF kemudian digabungkan dengan algoritma RLE serta memanfaatkanHuffman codingsebagai“back-end”dalam kombinasi seperti yang diungkapkan Sharma (2010) dan Shanmugasundaram & Lourdusamy (2011). Oleh karena itu penulis mengangkat kombinasi BMRH (BWT – MTF – RLE –
Huffman) sebagai kombinasi kedua dalam penelitian ini.
Kombinasi algoritma BRMH dan BMRH tersebut nantinya akan dilakukan pengujian kinerja berdasarkan rasio kompresi, waktu kompresi dan dekompresi untuk mengetahui tingkat efektivitas dalam kompresi kemudian dilakukan analisis perbandingan antara BRMH dan BMRH.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan di atas, berikut ini adalah beberapa rumusan masalah yang akan dibahas lebih lanjut dalam penelitian ini :
1. Bagaimana proses encoding dan decoding yang diterapkan dalam kombinasiBMRH (BWT–MTF–RLE–Huffman) dan BRMH (BWT–RLE–
2. Pola Kombinasi algoritma manakah antara BMRH (BWT – MTF– RLE –
Huffman) dan BRMH (BWT–RLE–MTF–Huffman)yang lebih baik dalam
kompresi file dilihat dari segi kecepatan kompresi dan dekompresi serta rasio kompresi?
1.3 Batasan Masalah
Batasan masalah yang digunakan dalam penulisan ini adalah :
1. File uji kompresi yang akan digunakan dalam kasus ini adalah file berekstensi Text (.txt), Rich Text Format (.rtf), Document (.doc), Application (.exe), Bitmap (.bmp), Tagged Image Format (.tif) dan Application Extension / Library(.dll).
2. Ruang lingkup dalam penelitian ini hanya sebatas dalam cakupan Data
Compression.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dalam tugas akhir ini adalah :
1. Merancang dan mengimplementasikan kombinasi algoritma kompresi BMRH (BWT – MTF– RLE –Huffman) dan BRMH (BWT– RLE – MTF–
Huffman).
2. Mengetahui hasil perbandingan pengaplikasian kedua metode kombinasi tersebut ditinjau dari rasio performansi kompresi, waktu kompresi dan waktu dekompresi pada beberapa jenis ekstensifile.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini diharapkan dapat memberikan pemilihan pola kombinasi algoritma yang optimal antaraBWT–MTF–RLE–Huffmandan BWT–
RLE –MTF–Huffman berdasarkan batasan yang telah dipaparkan serta dari hasil
1.6 Sistematika Penulisan
Sistematika penulisan yang digunakan dalam penyusunan skripsi ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini menjelaskan latar belakang masalah, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, dan sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini menguraikan teori-teori yang menjadi landasan topik penelitian ini, yaitu meliputi definisi-definisi serta model alur kompresi yang terkait dengan masalah yang diteliti, penelitian terkait yang mendukung penelitian ini.
BAB III METODE PENELITIAN
Bab ini berisi tentang metode atau langkah-langkah dalam penyelesaian masalah, meliputi metode dan algoritma yang digunakan dalam penelitian, serta metode pengujian.
BAB IV HASIL DAN PEMBAHASAN
Bab ini berisi hasil pembahasan hasil pengujian yang telah dilakukan dan dilakukan analisis dan perbandingan hasil pengujian tersebut dengan memperhatikan variabel-variabel terkait.
BAB V PENUTUP
5 2.1 Landasan Teori
Bagian landasan teori ini menjelaskan konsep-konsep dasar yang diangkat oleh penulis dan akan dijelaskan secara mendalam baik berupa lingkup kasus maupun metode-metode yang digunakan dalam penyelesaian masalah.
2.1.1 Kompresi Data
Kompresi Data merupakan cabang ilmu komputer yang bersumber dari Teori Informasi. Teori Informasi mengfokuskan pada berbagai metode tentang informasi termasuk penyimpanan dan pemrosesan pesan. Teori Informasi mempelajari pula tentang redundancy (informasi tak berguna) pada pesan. Semakin banyak redundancy semakin besar pula ukuran pesan, upaya mengurangi redundancy inilah yang akhirnya melahirkan subyek ilmu tentang Kompresi Data (Widhiartha, 2008).
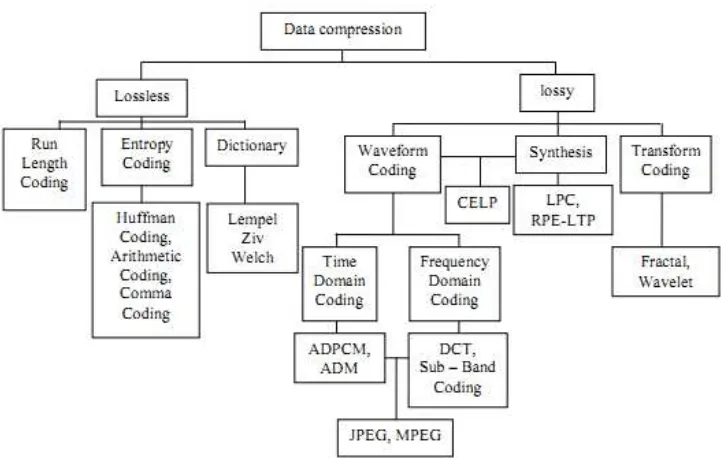
Apabila dilihat secara perilaku dan hasil output yang dihasilkan teknik kompresi data dapat dibagi menjadi dua kategori besar, yaitu :
1. KompresiLossless
Gambar 2.1. Alur Perilaku KompresiLossless(Pu Ida Mengyi, 2006)
2. KompresiLossy
Kompresi lossy adalah kompresi yang menekankan pada perubahan atau hilangnya beberapa informasi atau bit pada data, sehingga hasil kompresi tidak bisa lagi dikembalikan ke bentuk semula (irreversible). Namun, hasil kompresi masih bisa mempertahankan informasi utama pada data. Kompresi ini cocok diaplikasikan pada file suara, gambar atau video. Umumnya teknik ini menghasilkan kualitas hasil kompresi yang rendah, namun rasio kompresinya cenderung tinggi. Contoh algoritma kompresi
lossy adalah Fractal Compression, Wavelet Compression, Wyner-Ziv Coding (WZC), dan lain-lain. Gambar 2.1 berikut menunjukkan contoh perilaku dalam kompresilossy.
Gambar 2.2. Alur Perilaku KompresiLossy(Pu Ida Mengyi, 2006)
Gambar 2.3. Klasifikasi Teknik Kompresi Data (Fauzi, 2003)
Selain secara teknik kompresi dan output, kompresi data dapat dikategorikan Berdasarkan tipe peta kode yang digunakan untuk mengubah pesan awal (isi file input) menjadi sekumpulan codeword, metode kompresi terbagi menjadi dua kelompok (Linawati & Panggabean, 2004), yaitu :
1. Metode statik : menggunakan peta kode yang selalu sama. Metode ini membutuhkan dua fase (two-pass) : fase pertama untuk menghitung probabilitas kemunculan tiap simbol / karakter dan menentukan peta kodenya, dan fase kedua untuk mengubah pesan menjadi kumpulan kode yang akan ditransmisikan. Contoh: algoritmaHuffmanstatik.
1. Metode symbolwise : menghitung peluang kemunculan dari tiap symbol dalam file input, lalu mengkodekan satu simbol dalam satu waktu, dimana simbol yang lebih sering muncul diberi kode lebih pendek dibandingkan simbol yang lebih jarang muncul, contoh: algoritmaHuffman.
2. Metode dictionary : menggantikan karakter / fragmen dalam file input dengan indeks lokasi dari karakter / fragmen tersebut dalam sebuah kamus (dictionary), contoh: algoritma LZW.
3. Metode predictive : menggunakan model finite-context atau finite-state untuk memprediksi distribusi probabilitas dari simbol-simbol selanjutnya; contoh: algoritma DMC.
2.1.2 Burrows-Wheeler Transform(BWT)
Algoritma BWT merupakan algoritma proses melakukan transformasi terhadap blok data teks menjadi suatu bentuk baru yang tetap mengandung karakter yang sama, hanya saja urutannya yang berbeda.
Transformasi ini cenderung mengelompokan karakter secara berurut sehingga peluang untuk menemukan karakter yang sama secara berurutan akan meningkat sehingga akan lebih mudah dikompresi oleh algoritma kompresi sepertiRun-Length Encoding,Move-To-Front, atau Huffman Coding.
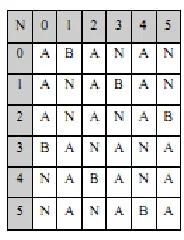
Sebagai contoh untuk melakukan transformasi (encoding) pada string
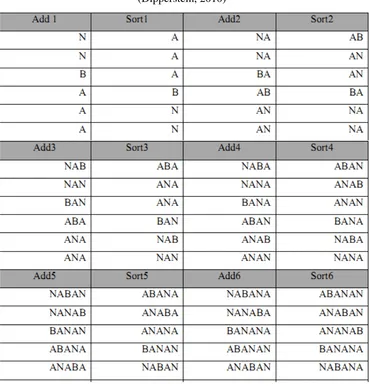
“BANANA” dapat dilihat pada langkah-langkah berikut (Dipperstein, 2010) : 1. Melakukan rotasi (cyclic shift) pada string “BANANA” sebanyak N-1
kali, sehingga diperoleh matrik yang berordoNxN:
Gambar 2.4. MatriksString“BANANA”(Dipperstein, 2010)
2. Mengurutkan matriks hasil rotasi secara lexicographic pada baris-baris matriks. :
Gambar 2.5. MatriksString“BANANA”Diurutkan Secaralexicographic (Dipperstein, 2010)
function BWT (string s)
create a table, rows are all possible rotations of s sort rows alphabetically
return (last column of the table)
function inverseBWT (string s) create empty table
repeat length(s) times
insert s as a column of table before first column of the table
// first insert creates first column
sort rows of the table alphabetically
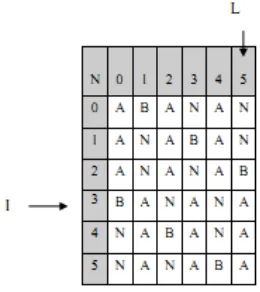
3. Berdasarkan Gambar 2.6 tersebut diperoleh string L yang dibentuk dari karakter terakhir setiap baris matriks, dan index Iyang menyatakan posisi string yang asli, sehingga hasilencoding adalah(L, I)yang dalam hal ini adalah (NNBAAA, 3).
Gambar 2.6. HasilEncodingMatriksString“BANANA”(Dipperstein, 2010) ProsesDecoding(pembalikkan transformasi) pada algoritma BWT sedikit berbeda dengan encoding. Jika pada encodingsebuah matriks dibuat secara utuh, akan tetapi pada decoding, matriks yang dibuat hanya terdiri dari kolom pertama F dan kolom terakhirL. Dimana F diperoleh dengan cara mengurutkan L secara lexicographic. Dalam pembalikkan diperlukan paasangan L dan I yang akan digunakan sebagai masukan untuk membentukstring asli SsepanjangN karakter dengan langkah-langkah sebagai berikut (Dipperstein, 2010) :
1. Membentuk karakter pertama dari rotasi
Langkah ini akan membentuk kolom pertama F dari matriks M. Hal ini dapat dilakukan dengan cara mengurutkan karakter-karakter string L membentuk string F. Mengingat setiap kolom matriks M merupakan permutasi dari string asli S maka baik L maupun F juga merupakan permutasi dari string S. Oleh karena string F adalah kolom pertama dari matriksMmaka setiap karakter dalam Fjuga terurut. Maka stringFyang diperoleh yaituF=‘AAABNN
2. Membentuk kembalistringasliS
sebelumnya. IndeksIadalah merupakan kunci yang memungkinkanstring asli S dibentuk kembali karena I menunjukkan karakter pertama dari string asli. Semenjak permutasi blok data teks telah diurut secara lexicograpical, sehingga karakter karakter pada kolom pertama dan kolom terakhir dari blok data tersebut memiliki urutan posisi yang sama pula. Berdasarkan sifat yang dimiliki oleh blok data teks inilah maka karakter kedua dan seterusnya dari string asli S dapat diketahui. Berikut ini merupakan gambaran dari proses pembentukkanstringasli S berdasarkan stringL,F, dan indeksI
Gambar 2.7. Proses PembentukanStringAsliS(Dipperstein, 2010)
Tabel 2.1. Pembalikkan Transformasi BWT Berdasarkan Pengurutan (Dipperstein, 2010)
Berdasarkan tabel pembalikan transformasi di atas maka didapat hasil stringsemula yaitu “BANANA” dengan melihat indeksI= “3” dari hasil sorting.
2.1.3 Run-Length Encoding(RLE)
keberhasilan kompresi algoritma RLE. Secara garis besar format kode yang dihasilkan oleh algoritma RLE dituliskan sebagai berikut :
Gambar 2.8. Format Kode Algoritma RLE (Telaumbanua, 2011)
Keterangan gambar di atas yaitu, dimana m adalah penanda (marker byte), n adalah jumlah deret karakter yang berulang, dan ssebuah karakter yang berulang tersebut.
Sebagai contoh apabila string: “AAAABBCDEEEEEFGHHHIJ”
dikompresi dengan algoritma RLE maka hasilnya adalah : “^4A^2B^1C^1D^5E^1F^1G^3H^1I^1J”. Karena panjang kode yang dihasilkan
oleh RLE untuk setiap deret karakter minimal 3 byte, maka jumlah perulangan karakter harus lebih dari 3 (tiga) kali agar pengkodean bisa dilakukan. Satu hal yang perlu diperhatikan untuk penanda m adalah, sebaiknya yang dipilih adalah karakter yang jarang digunakan pada data (seperti tanda #, ^, |, atau ~). Berikut adalah langkah-langkah yang dilakukan dalamencodingRLE (Khairi, 2010) :
1. Cek apakah terdapat deretan karakter yang sama secara berurutan lebih dari tiga karakter, jika memenuhi dilakukan pemampatan.
2. Berikan bit penanda (marker Byte) pada file pemampatan, bit penanda digunakan secara konsisten pada proses kompresi. Bit penanda ini berfungsi untuk menandai bahwa karakter selanjutnya adalah karakter pemampatan sehingga tidak membingungkan pada saat mengembalikan fileyang sudah dimampatkan ke file aslinya.
3. Tambahkan deretan bit untuk menyatakan jumlah karakter yang sama berurutan.
4. Tambahkan deretan bit yang menyatakan karakter yang berulang.
1. Lihat karakter pada hasil pemampatan satu-persatu dari awal sampai akhir, jikaditemukan bit penanda, lakukan proses pengembalian.
2. Lihat karakter setelah bit penanda, konversikan ke bilangan desimal untuk menentukan jumlah karakter yang berurutan.
3. Lihat karakter berikutnya, kemudian lakukan penulisan karakter tersebut sebanyak bilangan yang telah diperoleh pada karakter sebelumnya (point 2).
Misalnya, apabila hasil kompresi adalah
“^4A^2B^1C^1D^5E^1F^1G^3H^1I^1J” maka hasil dekompresi
“AAAABBCDEEEEEFGHHHIJ”.
Pada umumnya algoritma RLE optimal digunakan pada file-file yang memiliki karakter-karakter yang cenderung homogen. Oleh karena itu, jika algoritma tersebut dipergunakan secara universal maka perlu dilakukan pengelompokan atau transformasi karakter-karakter / simbol-simbol yang sejenis.
2.1.4 Move-To-Front(MTF)
Move-To-Front (MTF) coding adalah algoritma transformasi yang tidak mengkompres data, tetapi dapat membantu untuk membuat data menjadi lebih seragam (Campos, 1999). Move-To-Front (MTF) menggunakan teknik yang mengkodekan aliran simbol berdasarkan pada kode adaptasi. Simbol dikodekan oleh posisinya sendiri di daftar setiap simbol dalam alfabet. Awalnya daftar diurutkan secara lexicographic (atau cara lain yang ditentukan). Setelah simbol dalam aliran data dikodekan, simbol tersebut dipindahkan dari posisi semula ke depan daftar dan simbol terdepan dipindahkan satu posisi ke belakang (Langer, 2008). Misalnya diambil suatuinput string“cbad” dengan ketentuansymbol list:
List : 0 1 2 3
a b c d
maka output yang dihasilkan menurut symbol list adalah angka “2” karena karakter “c” berada pada list ke-2. Kemudian karakter “c” pada list dipindahkan ke posisi terdepan (posisi ke-0) dan isi list posisi yang ke-0 (list[0]) hingga ke posisi simbol-1 (list[simbol-1]) dipindahkan ke posisi selanjutnya.
Input Character : “c”
List : 0 1 2 3
c a b d
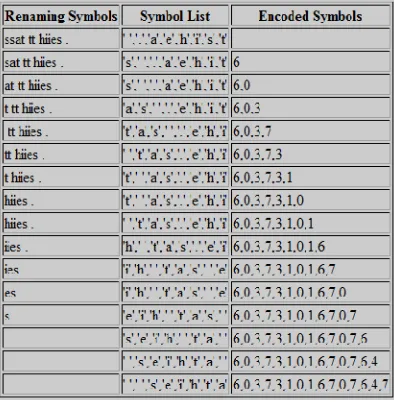
Sebagai contoh detail diberikan daftar urutan alfabet sebagai acuan dalam pengkodean, yaitu(' ','.','a','e','h','i','s','t')denganinput"ssat tt hiies ."berikut prosesencodingberlangsung :
Tabel 2.2. ProsesEncodingAlgoritmaMove-To-Front(Dipperstein, 2010)
Berdasarkan proses encoding input "ssat tt hiies ." di atas didapat hasil
outputberupa kode“603731016707647”.
dapat secaralexicographic(atau cara lain yang telah ditentukan). Data yang telah dikodekan menunjukkan posisi simbol diterjemahkan. Setelah simbol dilakukan decoding, simbol dipindahkan ke bagian depan daftar. Berikut ini tabel decode dari ketentuan sebelumya :
Tabel 2.3. ProsesDecodingAlgoritmaMove-To-Front(Dipperstein, 2010)
2.1.5 Huffman Coding
Algoritma Huffman adalah salah satu metode yang paling terkenal dalam kompresi teks, algoritma ini dibuat oleh David Huffman pada tahun 1952. Algoritma Huffman menggunakan prinsip pengkodean yang mirip dengan kode Morse, yaitu tiap karakter dikodekan hanya dengan rangkaian beberapa bit, dimana karakter yang sering muncul dikodekan dengan rangkaian bit yang pendek dan karakter yang jarang muncul dikodekan dengan rangkaian bit yang lebih panjang (Septin, 2010).
Algoritma kompresi Huffman menghasilkan kode bit yang lebih sedikit atau efisien untuk karakter-karakter yang sering muncul dalam data teks. Untuk membuktikan hal tersebut, maka dibuatlah pohon biner Huffman. Kode tersebut diperoleh dengan cara memyusun sebuah pohon biner Huffman untuk masing-masing simbul berdasarkan nilai probabilitasnya. Simpul yang memiliki probabilitas terbesar akan dekat dengan root dan simpul yang memiliki probabilitas terkecil akan terletak jauh dari root (Dipperstein, 2010). Langkah-langkah pembuatan pohon binerHuffmanadalah (Dipperstein, 2010) :
1. Pengurutan keluaran sumber berdasarkan frekuensi kemunculan. 2. Menggabungkan dua keluaran yang memiliki frekuensi terendah.
3. Memberikan nilai kode bit 0 di sebelah kiri dan kode bit 1 di sebelah kanan. 4. Apabila sebuah keluaran merupakan hasil dari penggabungan dua keluaran,
maka berikan kode bit 0 dan 1 untuk kode word-nya, lakukan proses ini hingga terbentuk akar.
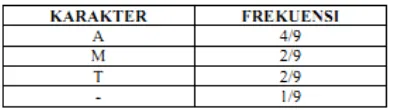
Berikut ini adalah contoh penerapan algoritma kompresiHuffman. Sebuah file berisi karakter “MATA-MATA” dimana jika diuraikan berdasarkan kode ASCII, maka akan terlihat sebagai berikut :
Tabel 2.4. Konversi Karakter dalam Kode Biner ASCII (Septin, 2010)
Sehingga menjadi :
M A T A - M A T A
01001101 01000001 01010100 01000001 00101101 01001101 01000001 01010100 01000001 = 72 bit
Tabel 2.5. Frekuensi Kemunculan Karakter (Septin, 2010)
Penghitungan selesai, langkah berikutnya adalah membuat pohon Huffman.
Gambar 2.9. Pohon algoritmaHuffman(Septin, 2010) Didapat kode baru untuk masing-masing karakter adalah sebagai berikut :
Tabel 2.6. Kode Bit Hasil Kompresi (Septin, 2010)
Maka hasil kompresi yang didapat adalah :
M A T A - M A T A
001 1 01 1 000 001 1 01 1
= 17 bit
Rasio kompresi = Bit sesudah kompresi : Bit sebelum dikompresi
= 17 bit : 72 bit
Dekompresi teks dapat dilakukan dengan dua cara, yang pertama dengan menggunakan pohon biner Huffman dan yang kedua dengan menggunakan tabel kode biner Huffman. Langkah-langkah mengdekompresi suatu kode biner yang merupakan hasil dari proses kompresi dengan menggunakan pohon binerHuffman adalah sebagai berikut :
1. Baca sebuah bit dari kode biner.
2. Menelusuri pohon mulai dari atas atau akar, periksa ke kanan dan kekiri. 3. Ulangi langkah 1 dan 2 sampai bertemu daun. Kodekan rangkaian bit yang
telah dibaca dengan karakter daun.
4. Ulangi dari langkah 1 sampai semua bit di dalam kode biner terbaca semua dan berubah menjadi karakter-karakter yang sesuai pada daun.
Sebagai contohmengkompresi string biner yang bernilai “001”
Gambar 2.10. Proses Dekompresi dengan Pohon AlgoritmaHuffman(Septin, 2010)
Setelah menelusuri pohon dari akar, maka akan ditemukan bahwa string yang mempunyai kode bit “001” adalah karakter M. Cara yang kedua adalah dengan menggunakan tabel kode biner Huffman.
mudah. Misal ditemukan kode biner 00110110000011011, kode tersebut di ubah ke kode ASCII menjadi karakter “MATA-MATA”.
2.2 Penelitian Terkait
Penelitian ini mengacu pada beberapa penelitian maupun studi sejenis yang telah dilakukan sebelumnya mengenai kompresi data. Berikut uraian singkat dari penelitian maupun studi tersebut.
2.2.1 Analisis Perbandingan Algoritma Kompresi Lempel Ziv Welch, Arithmetic Coding, Dan Run-Length Encoding Pada File Teks, oleh Plipus Telaumbanua (Telaumbanua, 2011)
Penelitian Plipus Telaumbanua ini membandingkan tiga algoritma kompresi data yaitu Lempel Ziv Welch (LZW), Arithmetic Coding, dan Run-Length Encoding(RLE), dimana algoritma RLE dibantu oleh algoritma Burrows-Wheeler Transform (BWT) untuk memaksimalkan kinerjanya. Algoritma-algoritma tersebut dipilih karena semuanya dalam kategori Algoritma-algoritma lossless, dan mewakili masing-masing teknik pengkodean. Parameter yang digunakan untuk perbandingan adalah kompleksitas algoritma, rasio kompresi, dan waktu untuk proses kompresi dan dekompresi, sedangkan fileuji yang digunakan adalah fileplaintext ASCII (*.txt) dengan berbagai ukuran dan pola masukan.
Gambar 2.11. Alur Pikir Penelitian oleh Plipus Telaumbanua (Telaumbanua, 2011)
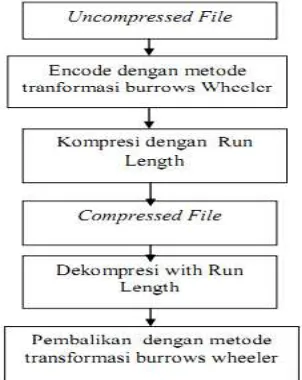
2.2.2 Implementasi Run Length Pada Kompresi File Text Dengan Menggunakan Transformasi Burrows Wheeler, oleh Muhammad Husli Khairi (Khairi, 2010)
Pokok bahasan dalam penelitian Muhammad Husli Khairi ini melakukan uji kasus tentang penyempurnaan metode kompresiRun-Length Encodingdengan algoritma Transformasi Burrows-Wheeler dengan tujuan untuk meningkatkan efektivitas kompresi dan menutupi kekurangan algoritma RLE sendiri.
Penelitian Khairi ini menitikberatkan implementasinya dalam program komputer dengan platform atau bahasa pemrograman Visual Basic 6.0 dengan data uji yang digunakan berupa file-file ekstensi (*.doc), (*.rft), (*.txt), dan file (*.html) yang selanjutnya dilakukan dilakukan analisis waktu baik dalam
encodingdan decodingserta efektivitas kompresi dilihat dari rasio kompresi yang dihasilkan.
menemukan karakter yang sama secara berurutan akan meningkat. Transformasi Burrows-Wheeler ini juga memiliki sifat reversible yaitu dapat mengembalikan data teks yang telah ditransformasikan kenbetuk yang sama persis dengan data aslinya (Khairi, 2010). Gambar 2.12. menunjukkan alur pikir oleh Muhammad Husli Khairi :
Gambar 2.12. Alur Pikir Penelitian oleh Muhammad Husli Khairi (Khairi, 2010)
2.2.3 Compression Using Huffman Coding, oleh Mamta Sharma (Sharma, 2010)
Jurnal internasional yang ditulis oleh Mamta Sharma ini membahas mengenai algoritma Huffman yang dianalisa dan dijelaskan secara mendalam dilihat dari berbagai aspek meliputi teknik dasar Huffman, fungsi utama yang digunakan, pengaplikasian, kelebihan dan kekurangan, serta sedikit penjelasan singkat mengenai Adaptive Huffman Coding.
Setelah dilakukan pembelajaran mengenai berbagai teknik untuk kompresi dan membandingkan berdasarkan penggunaannya dalam berbagai aplikasi dan kelebihan serta kekurangan. Disimpulkan bahwa pengkodean Arithmetic Coding efisien jika lebih sering muncul urutan piksel dengan bit yang rendah dan mengurangi ukuran file secara signifikan. RLE merupakan algoritma yang mudah dalam implementasi dan cepat dalam eksekusi. Algoritma LZW lebih efektif digunakan untuk TIFF, GIF dan File Tekstual, sedangkan algoritma Huffman lebih cocok digunakan dalam kompresi JPEG. Keunggulannya Huffman menghasilkan kode yang optimal tetapi relatif lambat (Sharma, 2010).
2.2.4 A Comparative Study Of Text Compression Algorithm, oleh Senthil Shanmugasundaram dan Robert Lourdusamy (Shanmugasundaram & Lourdusamy, 2011)
Penelitian dari Senthil Shanmugasundaram dan Robert Lourdusamy ini membahas mengenai survei terhadap algoritma dasar kompresi data lossless yang berbeda. Hasil percobaan dan perbandingan algoritma kompresi lossless menggunakan teknik Statistical Compression dan teknik Dictionary Based
Compression dilakukan pada data teks. Teknik pengkodean statistik yang diperbandingkan diantaranya algoritma seperti Shannon-Fano coding, Huffman coding, Adaptive Huffman coding, Run-Length EncodingsertaArithmetic coding. PolaLempel Zivyang merupakan teknikDictionary Basedjuga dibandingkan dan dibagi menjadi dibagi menjadi dua bagian: yang merupakan derivasi dari LZ77 (LZ77, LZSS, LZH dan LZB) dan yang merupakan derivasi dari LZ78 (LZ78, LZW dan LZFG).
Dari hasil survei dan perbandingan yang telah dilakukan maka didapat algoritma-algoritma yang memiliki efisiensi yang cukup tinggi diantaranya Arithmetic Coding (untuk teknik Statistical Compression), LZB (untuk teknik
Dictionary Based Compression derivasi LZ77), serta LZFG (untuk teknik Dictionary Based Compression derivasi LZ78) (Shanmugasundaram & Lourdusamy, 2011).
2.2.5 Comparative Study Between Various Algorithms of Data Compression Techniques, oleh Mohammed Al-laham dan Ibrahiem M. M. El
Emary(Al-laham & El Emary, 2007)
Penelitian Al-laham dan El Emary ini membahas mengenai survei terhadap algoritma-algoritma teknik kompresi data. Penelitian ini menitikberatkan pada pola data yang menonjol kompresi, diantaranya yang cukup populer yaitu .DOC, .TXT, .BMP, .TIF, .GIF, dan .JPG. Dengan menggunakan beberapa algoritma kompresi yang berbeda, didapatkan beberapa hasil dan sehubungan dengan hasil tersebut ditarik kesimpulan mengenai algoritma yang efisien untuk digunakan pada jenis file tertentu yang akan dilakukan proses kompresi dengan mempertimbangkan rasio kompresi dan ukuran file terkompresi..
Beberapa algoritma yang digunakan dalam penelitian ini adalah algoritma LZW, Huffman, LZH (LZW – Huffman) serta HLZ (Huffman – LZW). Hasil yang di dapat berdasarkan parameter ukuran output hasil kompresi dan rasio kompresi didapat bahwa algoritma Huffman dan algoritma LZH (kategori algoritma kombinasi) lebih unggul untuk kompresi file .DOC, .TXT, dan .BMP dibandingkan algoritma LZW dan HLZ. Sedangkan untuk file .TIF, .GIF, dan .JPG semua algoritma yang diujikan menampilkan performansi yang buruk (Al-laham & El Emary, 2007).
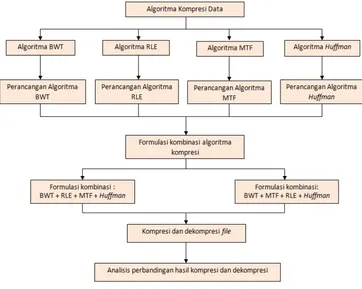
2.3 Rencana Penelitian
Transformasi Burrows-Wheeler dan Run-Length Encoding yang sebelumnya dilakukan oleh Khairi (2010) dikombinasikan kembali dengan algoritma Huffman Codingdan Move-To-Frontatas dasar saran penelitian Telaumbanua (2011) serta menggunakan penelitian Sharma (2010), Shanmugasundaram dan Lourdusamy (2011), serta Al-laham dan El Emary (2007) sebagai pertimbangan dalam menerapkan teknik-teknik kompresi.
26
Studi ini dilaksanakan dengan melakukan studi kepustakaan dengan cara mencari dan membaca berbagai literatur serta karya-karya penelitian mengenai Data Compression terutama yang berkonsentrasi pada algoritma-algoritma Burrows-Wheeler Transform (BWT), Run-Length Encoding (RLE), Move-To-Front(MTF) danHuffman, serta data-data yang berhubungan dengan sistem yang akan dibuat. Literatur pendukung ini dapat berupa jurnal, paper, makalah, artikel, buku, atau sumber lainnya. Output yang ingin dihasilkan dari tahap ini adalah rangkuman dasar teori serta tinjauan penelitian sebelumnya.
3.2 Analisis dan Perancangan
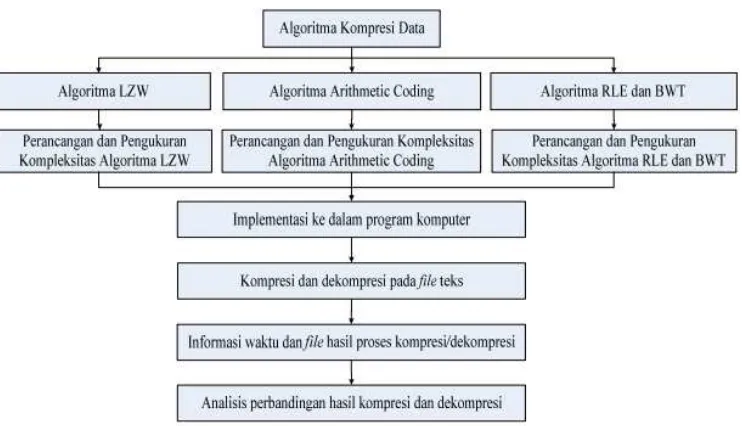
Tahap ini dilakukan analisis dan perancangan kombinasi algoritma. Perancangan sistem dilakukan dengan menggunakan diagram alir (flowchart) agar lebih memperjelas alur dan cara kerja sisitem yang akan dibangun. Pembangunan sistem menggunakan bahasa pemrogramanVisual C++dan memanfaatkansource
Gambar 3.1. Alur Pikir Proses Penelitian
3.2.1 Analisis Proses Sistem dan Kombinasi Algoritma
3.2.2 Perancangan Proses Sistem
Perancangan proses dilakukan dengan menggunakan diagram alir (flowchart). Terdapat dua proses utama yang dijalankan, yaitu kompresi dan dekompresi. Sesuai dengan batasan masalah proses yang akan dibahas dalam kasus ini adalah proses kompresi dan dekompresi untuk kombinasi algoritma BMRH dan BRMH yang terdiri dari 2 algoritma transformasi, yaitu BWT (Burrows-Wheeler Transform) dan MTF (Move-To-Front) serta 2 algoritma Kompresi, yaitu RLE (Run-Length Encoding) danHuffmanCoding.
Algoritma BWT yang digunakan pada kasus ini merupakan algoritma block-sorting dengan ukuran 128 KB. Algoritma BWT ini bersifat transformatif yang mendukung RLE dalam kompresi. Dengan kata lain algoritma ini tidak melakukan pengurangan atau penambahan informasi pada file input, hanya saja padafile inputterjadi proses sorting/ pengurutan karakter pada tiap ukuran blok. Oleh karena itu, ukuran yang dihasilkan masih tetap sama (bila ada perbedaan hanya terpaut beberapa byte) hanya saja letak karakter dalam suatu file yang berbeda. Selain algoritma BWT, algoritma MTF juga bersifat transformatif. MTF melakukan transformasi input file dengan memindahkan suatu stream karakter
input ke depan stream. Algoritma ini bersifat mendukung Huffman yang memanfaatkan kode numerik serta frekuensi kemunculan karakter dalam kompresi.
Implementasi RLE sama sederhananya dengan MTF dan merupakan algoritma kompresif. Algoritma ini memanfaatkan input file yang memiliki kesamaan karakter secara berturut-turut. Apabila berdiri sendiri algoritma ini kurang fleksibel dalam kompresi bahkan kurang menguntungkan. Oleh karena itu digunakan algoritma BWT sebelum dioperasikan dengan RLE karena BWT bersifat mengelompokkan karakter sejenis.
3.2.2.1 Tahap Kompresi
ditunjukkan oleh Gambar 3.2 untuk kombinasi BMRH dan Gambar 3.3 untuk kombinasi BRMH.
Gambar 3.2.FlowchartProses Kompresi Kombinasi BMRH
Tahap Kompresi ini, sebuah file (*.txt), (*.rtf), (*.doc), (*.dll), (*.exe), (*.tif) dan (*.bmp) akan dikompresi menggunakan kombinasi algoritma BMRH dan BRMH sehingga akan menghasilkan sebuah output file yang berekstensi (.bmrh) untuk kombinasi BMRH dan (.brmh) untuk kombinasi BRMH.
Kombinasi BMRH dan BRMH diimplementasikan secara berantai dan akan menghasilkan suatuoutput file. Apabilafile input telah dioperasikan dengan suatu algoritma selanjutnya output yang dihasilkan oleh algoritma sebelumnya kemudian dijadikan input oleh berikutnya. Operasi tersebut terus dilakukan hingga algoritma terakhir atau dengan kata lain kombinasi algoritma telah mencapai operasi terakhir sesuai denganflowchartpada Gambar 3.2 dan Gambar 3.3. File output akhir tersebut akan dilakukan pengolahan data yang nantinya menjadi tolok ukur dalam pengujian suatu kombinasi algoritma.
Ciri khas file yang telah melalui proses kompresi ini tentunya memiliki ukuran yang lebih kecil dari ukuran aslinya dan oleh karena algoritma yang digunakan bersifat lossless maka informasi dan data didalam file juga akan berubah dan tidak dapat dibaca /parsignprogram yang mendukung.
3.2.2.2 Tahap Dekompresi
Gambar 3.4.FlowchartProses Dekompresi Kombinasi BMRH
Gambar 3.5.FlowchartProses Dekompresi Kombinasi BRMH
berekstensi (.ubmrh) untuk kombinasi BMRH dan (.ubrmh) untuk kombinasi BRMH.
Proses operasi pada tahap dekompresi secara berturut-turut sama dengan ahap kompresi hanya saja fungsi-fungsi yang dilakukan pada setiap algoritma adalah proses kebalikannya yaitu mengubah file untuk menjadi seperti semula (proses decoding) yang identik dengan file aslinya dikarenakan algoritma kompresi yang bersifat lossless. Proses dekompresi untuk tiap kombinasi baik kombinasi BMRH dan BRMH dapat dilihat pada Gambar 3.4 dan 3.5.
Ciri khas file terkompresi yang telah melalui proses dekompresi ini tentunya memiliki ukuran yang lebih besar dari ukuran yang terkompresi dan informasi dan data didalam file juga akan kembali seperti file asli yang belum terkompresi juga dapat memberikan data dan informasi seperti semula.
3.3 Pengujian dan Analisis
Tahap Pengujian dan Analisis ini merupakan tindak lanjut dan pembuktian hipotesa awal, apakah hasil pengujian sesuai dengan yang diharapkan atau tidak. Pengujian akan dilakukan dengan skenario pengujian sebagai berikut : 1. Melakukan pengujian kinerja tiap algoritma padafileuji
Setelah kombinasi algoritma selesai diimplementasikan maka pada bagian ini dilakukan perhitungan kinerja dengan beberapa ketentuan dan parameter pengujian sebagai tolok ukur efektivitas algoritma serta beberapa jenisfileuji yang sudah ditentukan dan pada batasan masalah, seperti berikut ini :
Perhitungan performansi dengan rasio performansi kompresi dengan rumus sebagai berikut (Pu Ida Mengyi, 2006) :
= − ( )
( ) × % ( )
untuk tiap ukuran file dengan rumus sebagai berikut (Pu Ida Mengyi, 2006) :
= ( )
( ) ( )
= ( )
( ) ( )
File-file yang akan diujikan untuk proses kompresi dan dekompresi menggunakan format Text (.txt), Rich Text Format (.rtf), Document (.doc), Application(.exe), Bitmap(.bmp), Tagged Image Format(.tif) dan
Application Extension / Library (.dll). Pengujian dilakukan sebanyak 420 kali meliputi uji kompresi maupun dekompresi pada kedua algoritma (BMRH dan BRMH), dengan menggunakan 105 file uji rincian sebagai berikut :
1. File dengan format Text (.txt) dilakukan pengujian sebanyak 60 kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 0-1 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB 2. File dengan format Rich Text Format (.rtf) dilakukan pengujian
sebanyak 60 kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 0-1 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB 3. File dengan formatDocument (.doc) dilakukan pengujian sebanyak 60
kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 0-1 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB 4. File dengan format Application (.exe) dilakukan pengujian sebanyak
60 kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB 5. File dengan format Application Extension / Library (.dll) dilakukan
pengujian sebanyak 60 kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 0-1 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB 6. File dengan format Tagged Image Format (.tif) dilakukan pengujian
sebanyak 60 kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 0-1 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB 7. File dengan format Bitmap (.bmp) dilakukan pengujian sebanyak 60
kali, dengan rincian :
Pengujian sebanyak 4 kali untuk 5fileyang berukuran 0-1 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 1-3 MB Pengujian sebanyak 4 kali untuk 5fileyang berukuran 3-6 MB
2. Membandingkan kinerja algoritma yang diuji
35
tiap jenis kombinasi algoritma ditinjau dari segi rasio kompresi, waktu kompresi
dan waktu dekompresi dengan rasio kompresi sebagai tolok ukur utama pada
beberapa jenis file uji. Setelah kinerja tiap kombinasi, selanjutnya dilakukan
perbandingan kinerja kedua kombinasi yang disajikan dalam bentuk grafik.
4.1 Spesifikasi Perangkat Implementasi dan Pengujian
Perangkat dan sarana yang digunakan untuk implementasi dan pengujian
rancangan yang telah dibuat meliputi perangkat lunak dan perangkat keras
diantaranya, yaitu :
Programming Package : Code::Blocks IDE 10.05
Compiler
GUI C++ Library
=
=
GNU (MinGW) C++
wxWidgets 2.8.12
Documentation Tools : Microsoft Word 2007
Microsoft Visio 2007
Operating Sistem : Microsoft Windows 7 Ultimate SP 1 32-bit (6.1,
Build 7600)
Hardware Specification : Intel®CoreTMi3 CPU M 330 2.13 GHz
Memory DDR3 1024 MB RAM
4.2 Hasil Pengujian
Pengujian dilakukan dengan cara menghitung rasio kompresi, waktu
kompresi, dan waktu dekompresi. Pengujian dilakukan pada beberapa tipe file
dan ukuran file yang bervariasi untuk tiap kombinasi sesuai dengan skenario
pengujian yang telah dipaparkan pada metode penelitian dengan konsepmultiple
file. Beberapa tipe file yang akan diujikan untuk proses kompresi ini
Application (.exe), Bitmap (.bmp), Tagged Image Format (.tif) dan Application
Extension / Library(.dll).
4.2.1 Hasil Pengujian Rasio dan Waktu Kompresi
Pengujian hasil kinerja kompresi kombinasi BMRH dan BRMH pada
beberapafile yang ditinjau dari dua variabel kinerja yaitu, Waktu Kompresi (per
Byte) (Rumus 2 pada BAB III) dan Rasio Kompresi (Rumus 1 pada BAB III)
yang telah dikelompokkan berdasar ukuranfile. Setelah itu dilakukan perhitungan
rata-rata rasio (Rumus 3) dan waktu kompresi (Rumus 4).
− = ( )
− = ( )
Pengujian kompresi yang dilakukan pada 15 file (.txt) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
filedan selanjutnya dilakukan perhitungan rata-rata rasio dan waktu kompresi tiap
kelas yang terlihat pada Tabel 1, 2, 3, 43, 44, dan 45 di halaman LAMPIRAN I.
Berikut Tabel 4.1 ditampilkan hasil rata-rata tiap kelas ukuran.
Tabel 4.1. Rata-rata Rasio dan Waktu KompresiFile (.txt)
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Text (.txt) 0 - 1 MB 67.73 65.43 0.0000036 0.0000040
Text (.txt) 1 - 3 MB 70.90 64.88 0.0000109 0.0000110
Text (.txt) 3 - 6 MB 56.35 47.41 0.0000050 0.0000044
Rata - Rata 64.99 59.24 0.0000065 0.0000065
Pengujian kompresi yang dilakukan pada 15 file (.rtf) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
kelas yang terlihat pada Tabel 4, 5, 6, 46, 47, dan 48 di halaman LAMPIRAN I.
Berikut Tabel 4.2 ditampilkan hasil rata-rata tiap kelas ukuran.
Tabel 4.2. Rata-rata Rasio dan Waktu KompresiFile (.rtf)
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Document (.rtf) 0 - 1 MB 86.02 85.09 0.0000049 0.0000041
Document (.rtf) 1 - 3 MB 89.72 89.20 0.0000041 0.0000035
Document (.rtf) 3 - 6 MB 90.01 88.61 0.0000043 0.0000035
Rata - Rata 88.58 87.64 0.0000044 0.0000037
Pengujian kompresi yang dilakukan pada 15 file (.doc) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
filedan selanjutnya dilakukan perhitungan rata-rata rasio dan waktu kompresi tiap
kelas yang terlihat pada Tabel 7, 8, 9, 49, 50, dan 51 di halaman LAMPIRAN I.
Berikut Tabel 4.3 ditampilkan hasil rata-rata tiap kelas ukuran.
Tabel 4.3. Rata-rata Rasio dan Waktu KompresiFile (.doc)
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Document (.doc) 0 - 1 MB 66.92 64.12 0.0000068 0.0000058
Document (.doc) 1 - 3 MB 69.69 66.92 0.0000065 0.0000054
Document (.doc) 3 - 6 MB 63.35 55.60 0.0000089 0.0000076
Rata - Rata 66.65 62.21 0.0000074 0.0000063
Pengujian kompresi yang dilakukan pada 15 file (.dll) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
filedan selanjutnya dilakukan perhitungan rata-rata rasio dan waktu kompresi tiap
kelas yang terlihat pada Tabel 10, 11, 12, 52, 53, dan 54 di halaman LAMPIRAN
Tabel 4.4. Rata-rata Rasio dan Waktu KompresiFile (.dll)
File
Rasio (%) Waktu Kompresi perByte (second)
BMRH BRMH BMRH BRMH
Executable (.dll) 0 - 1 MB 47.82 33.03 0.0000054 0.0000067
Executable (.dll) 1 - 3 MB 53.15 49.75 0.0000077 0.0000075
Executable (.dll) 3 - 6 MB 44.26 27.52 0.0000073 0.0000067
Rata - Rata 48.41 36.77 0.0000068 0.0000070
Pengujian kompresi yang dilakukan pada 15 file (.exe) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
filedan selanjutnya dilakukan perhitungan rata-rata rasio dan waktu kompresi tiap
kelas yang terlihat pada Tabel 13, 14, 15, 55, 56, dan 57 di halaman LAMPIRAN
I. Berikut Tabel 4.5 ditampilkan hasil rata-rata tiap kelas ukuran.
Tabel 4.5. Rata-rata Rasio dan Waktu KompresiFile (.exe)
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Executable (.exe) 0 - 1 MB 47.31 46.54 0.0000064 0.0000069
Executable (.exe) 1 - 3 MB 37.34 30.22 0.0000099 0.0000097
Executable (.exe) 3 - 6 MB 39.02 40.80 0.0000058 0.0000055
Rata – Rata 41.22 39.19 0.0000074 0.0000074
Pengujian kompresi yang dilakukan pada 15 file (.tif) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
filedan selanjutnya dilakukan perhitungan rata-rata rasio dan waktu kompresi tiap
kelas yang terlihat pada Tabel 16, 17, 18, 58, 59, dan 60 di halaman LAMPIRAN
Tabel 4.6. Rata-rata Rasio dan Waktu KompresiFile (.tif)
File
Rasio (%) Waktu Kompresi perByte (second)
BMRH BRMH BMRH BRMH
Bitmap (.tif) 0 - 1 MB 92.62 92.54 0.0000046 0.0000039
Bitmap (.tif) 1 - 3 MB 95.18 94.91 0.0000066 0.0000062
Bitmap (.tif) 3 - 6 MB 93.84 92.59 0.0000437 0.0000431
Rata – Rata 93.88 93.35 0.0000183 0.0000178
Pengujian kompresi yang dilakukan pada 15 file (.bmp) dengan
menggunakan kombinasi BMRH dan BRMH yang dibagi ke dalam 3 kelas ukuran
filedan selanjutnya dilakukan perhitungan rata-rata rasio dan waktu kompresi tiap
kelas yang terlihat pada Tabel 19, 20, 21, 61, 62, dan 63 di halaman LAMPIRAN
I. Berikut Tabel 4.7 ditampilkan hasil rata-rata tiap kelas ukuran.
Tabel 4.7. Rata-rata Rasio dan Waktu KompresiFile (.bmp)
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Bitmap (.bmp) 0 - 1 MB 84.43 79.51 0.0000056 0.0000036
Bitmap (.bmp) 1 - 3 MB 94.15 93.62 0.0000034 0.0000034
Bitmap (.bmp) 3 - 6 MB 89.42 89.73 0.0000410 0.0000408
Rata - Rata 89.34 87.62 0.0000166 0.0000159
Berdasarkan Tabel 4.1 hingga Tabel 4.7 dapat dilakukan perhitungan
rata-rata rasio dan waktu kompresi tiap kelas ukuran. Perhitungan dan
perbandingan rata-rata rasio dan waktu kompresi pada kelas ukuranfile 0 – 1 MB
Tabel 4.8. Rata-rata Rasio dan Waktu Kompresi 0 – 1 MB
File
Rasio (%) Waktu Kompresi perByte (second)
BMRH BRMH BMRH BRMH
Text (.txt) 0 - 1 MB 67.73 65.43 0.0000036 0.0000040
Document (.rtf) 0 - 1 MB 86.02 85.09 0.0000049 0.0000041
Document (.doc) 0 - 1 MB 66.92 64.12 0.0000068 0.0000058
Executable (.dll) 0 - 1 MB 47.82 33.03 0.0000054 0.0000067
Executable (.exe) 0 - 1 MB 47.31 46.54 0.0000064 0.0000069
Bitmap (.tif) 0 - 1 MB 92.62 92.54 0.0000046 0.0000039
Bitmap (.bmp) 0 - 1 MB 84.43 79.51 0.0000056 0.0000036
Rata - Rata 70.40 66.61 0.0000053 0.0000050
Gambar 4.2. Grafik Waktu KompresiFile0 – 1 MB
Perhitungan dan perbandingan rata-rata rasio dan waktu kompresi pada
kelas ukuranfile1 – 3 MB ditunjukkan oleh Tabel 4.9 serta Gambar 4.3 dan 4.4.
Tabel 4.9. Rata-rata Rasio dan Waktu Kompresi 1 – 3 MB
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Text (.txt) 1 - 3 MB 70.90 64.88 0.0000109 0.0000110
Document (.rtf) 1 - 3 MB 89.72 89.20 0.0000041 0.0000035
Document (.doc) 1 - 3 MB 69.69 66.92 0.0000065 0.0000054
Executable (.dll) 1 - 3 MB 53.15 49.75 0.0000077 0.0000075
Executable (.exe) 1 - 3 MB 37.34 30.22 0.0000099 0.0000097
Bitmap (.tif) 1 - 3 MB 95.18 94.91 0.0000066 0.0000062
Bitmap (.bmp) 1 - 3 MB 94.15 93.62 0.0000034 0.0000034
Gambar 4.3. Grafik Rasio KompresiFile1 – 3 MB
Perhitungan dan perbandingan rata-rata rasio dan waktu kompresi pada
kelas ukuranfile3 – 6 MB ditunjukkan oleh Tabel 4.10 serta Gambar 4.5 dan 4.6.
Tabel 4.10. Rata-rata Rasio dan Waktu Kompresi 3 – 6 MB
File Rasio (%)
Waktu Kompresi perByte
(second)
BMRH BRMH BMRH BRMH
Text (.txt) 3 - 6 MB 56.35 47.41 0.0000050 0.0000044
Document (.rtf) 3 - 6 MB 90.01 88.61 0.0000043 0.0000035
Document (.doc) 3 - 6 MB 63.35 55.60 0.0000089 0.0000076
Executable (.dll) 3 - 6 MB 44.26 27.52 0.0000073 0.0000067
Executable (.exe) 3 - 6 MB 39.02 40.80 0.0000058 0.0000055
Bitmap (.tif) 3 - 6 MB 93.84 92.59 0.0000437 0.0000431
Bitmap (.bmp) 3 - 6 MB 89.42 89.73 0.0000410 0.0000408
Rata - Rata 68.04 63.18 0.0000166 0.0000160
Gambar 4.6. Grafik Waktu KompresiFile3 – 6 MB
Berdasarkan Tabel 4.8 hingga 4.10 dan Gambar 4.1 hingga 4.6 dapat
ditarik beberapa poin-poin yaitu.
1. Pengujian kinerja kombinasi BMRH menunjukkan besarnya rata-rata
rasio kompresi dari terbesar hingga terkecil untuk kelas ukuran 0 – 1 MB
berturut-turut padafile(.tif), (.rtf), (.bmp), (.txt), (.doc), (.dll), dan (.exe)
sedangkan kelas ukuran 1 – 3 MB berturut-turutfile(.tif), (.bmp), (.rtf),
(.txt), (.doc), (.dll), dan (.exe) serta kelas ukuran 3 – 6 MB berturut-turut
file (.tif), (.rtf), (.bmp), (.doc), (.txt), (.dll), dan (.exe). Sedangkan
Pengujian kinerja kombinasi BRMH rasio kompresi dari terbesar hingga
terkecil untuk kelas ukuran 0 – 1 MB berturut-turut padafile(.tif), (.rtf),
(.bmp), (.txt), (.doc), (.exe), dan (.dll) sedangkan kelas ukuran 1 – 3 MB
berturut-turutfile(.tif), (.bmp), (.rtf), (.doc), (.txt), (.dll), dan (.exe) serta
kelas ukuran 3 – 6 MB berturut-turut file (.tif), (.bmp), (.rtf), (.doc),
(.txt), (.exe), dan (.dll).
2. Rata-rata rasio kompresi untukfileberukuran 0 – 1 MB, 1 – 3 MB, dan 3
– 6 MB untuk kombinasi BMRH berturut-turut adalah 70.40 %, 72.88 %
dan 68.04 %, sedangkan untuk kombinasi BRMH berturut-turut adalah
66.61 %, 69.93 % dan 63.18 % serta waktu kompresi per Byte yang
seluruhnya nilai rata-rata yang naik berdasar kelas ukuran untuk
kombinasi BMRH berturut-turut adalah 5.3 × 10 second/byte,
7.0 × 10 second/byte, dan16.6 × 10 second/byte, sedangkan untuk
kombinasi BRMH berturut-turut adalah 5.0 × 10 second/byte,
6.7 × 10 second/byte, dan16.0 × 10 second/byte..
4.2.2 Hasil Pengujian Waktu Dekompresi
Pada poin ini dilakukan pengujian hasil kinerja dekompresi kombinasi
BMRH dan BRMH pada beberapa file yang ditinjau dari variabel Waktu
Dekompresi (per Byte) (Rumus 3 pada BAB III) yang telah dikelompokkan
berdasar ukuran file. Setelah itu dilakukan perhitungan rata-rata waktu
dekompresi per kelompok (Rumus 6).
− = ( )
Pengujian dekompresi yang dilakukan pada 15 file (.txt) terkompresi
dengan menggunakan kombinasi BMRH dan BRMH serta skenario pengujian
yang sama dengan pengujian kompresi (detail hasil pada Tabel 22, 23, 24, 64, 65,
dan 66 di halaman LAMPIRAN I). Berikut Tabel 4.11 ditampilkan hasil rata-rata
Tabel 4.11. Rata-rata Waktu DekompresiFileTerkompresi(.txt)
File
Waktu Dekompresi perByte
(second)
BMRH BRMH
Compressed(.txt) 0 - 1 MB 0.0000130 0.0000115
Compressed(.txt) 1 - 3 MB 0.0000126 0.0000116
Compressed(.txt) 3 - 6 MB 0.0000123 0.0000114
Rata – Rata 0.0000126 0.0000115
Pengujian dekompresi yang dilakukan pada 15 file (.rtf) dengan
menggunakan kombinasi BMRH dan BRMH serta skenario pengujian yang sama
dengan pengujian kompresi (detail hasil pada Tabel 25, 26, 27, 67, 68, dan 69 di
halaman LAMPIRAN I). Berikut Tabel 4.12 ditampilkan hasil rata-rata waktu
dekompresi perBytetiap kelas ukuran.
Tabel 4.12. Rata-rata Waktu DekompresiFileTerkompresi(.rtf)
File
Waktu Dekompresi perByte
(second)
BMRH BRMH
Compressed(.rtf) 0 - 1 MB 0.0000237 0.0000170
Compressed(.rtf) 1 - 3 MB 0.0000239 0.0000182
Compressed(.rtf) 3 - 6 MB 0.0000237 0.0000185
Rata - Rata 0.0000237 0.0000179
Pengujian dekompresi yang dilakukan pada 15 file (.doc) dengan
menggunakan kombinasi BMRH dan BRMH serta skenario pengujian yang sama
dengan pengujian kompresi (detail hasil pada Tabel 28, 29, 30, 70, 71, dan 72 di
halaman LAMPIRAN I). Berikut Tabel 4.13 ditampilkan hasil rata-rata waktu
Tabel 4.13. Rata-rata Waktu DekompresiFileTerkompresi(.doc)
File
Waktu Dekompresi perByte
(second)
BMRH BRMH
Compressed(.doc) 0 - 1 MB 0.0000182 0.0000168
Compressed(.doc) 1 - 3 MB 0.0000186 0.0000169
Compressed(.doc) 3 - 6 MB 0.0000173 0.0000164
Rata - Rata 0.0000181 0.0000167
Pengujian dekompresi dilakukan pada 15file (.dll)dengan menggunakan
kombinasi BMRH dan BRMH dengan skenario pengujian sama dengan pengujian
kompresi (detail hasil pada Tabel 31, 32, 33, 73, 74, dan 75 di halaman
LAMPIRAN I). Berikut Tabel 4.14 ditampilkan hasil rata-rata waktu dekompresi
perBytetiap kelas ukuran.
Tabel 4.14. Rata-rata Waktu DekompresiFileTerkompresi(.dll)
File
Waktu Dekompresi perByte
(second)
BMRH BRMH
Compressed(.dll) 0 - 1 MB 0.0000132 0.0000147
Compressed(.dll) 1 - 3 MB 0.0000161 0.0000150
Compressed(.dll) 3 - 6 MB 0.0000479 0.0000135
Rata – Rata 0.0000257 0.0000144
Pengujian dekompresi yang dilakukan pada 15 file (.exe) dengan
menggunakan kombinasi BMRH dan BRMH dengan skenario pengujian sama
dengan pengujian kompresi (detail hasil pada Tabel 34, 35, 36, 76, 77, dan 78 di
halaman LAMPIRAN I). Berikut Tabel 4.25 ditampilkan hasil rata-rata waktu