PENERAPAN DATA MINING UNTUK MENGOLAH DATA PENEMPATAN
BUKU DI PERPUSTAKAAN SMK TI PAB 7 LUBUK PAKAM
DENGAN METODE ASSOCIATION RULE
Dian Wirdasari#1 dan Ahmad Calam*2
#Program Studi Ilmu Komputer, Universitas Sumatera Utara
*Program Studi Sistem Informasi, STMIK Triguna Dharma
1dianws, 2[email protected]
ABSTRAK: Pertumbuhan yang pesat dari akumulasi data telah menciptakan kondisi kaya akan data tapi minim informasi. Data mining merupakan penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data dalam jumlah besar yang diharapkan dapat mengatasi kondisi tersebut. Dengan memanfaatkan data kunjungan perpustakaan, dapat menggali informasi tentang buku-buku apa yang sering dipinjam oleh siswa dan keterkaitan antar masing – masing peminjaman sehingga dapat melakukan penyusunan buku sesuai dengan tingkat support dan confidence. Kemudian setelah itu dibuat suatu aplikasi yang dapat menujukkan lokasi buku secara lebih spesifik sehingga memudahkan pencarian bagi para pengunjung.
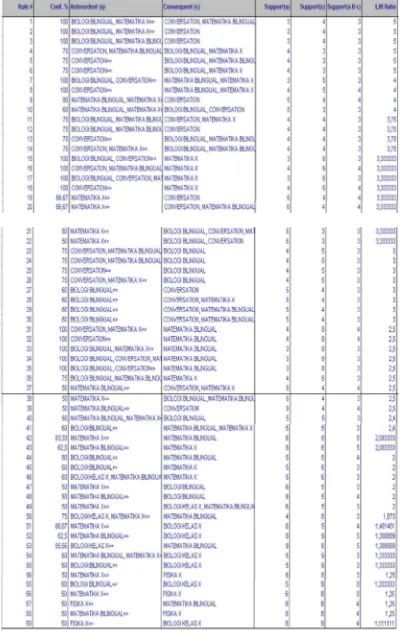
Penelitian yang dibuat di SMK TI PAB 7 Lubuk Pakam ini dibuat dengan menggunakan beberapa software seperti XL Miner untuk data mining dan Visual Basic 6.0 untuk aplikasi pencari buku. Sementara untuk basis data digunakan Microsoft Access dan software – software pendukung lainnya.Hasil penelitian ini adalah, pertama, dalam tumpukan data kunjungan perpustakaan, terdapat pengetahuan yang bermanfaat bagi perpustakaan itu dan para pengunjung perpustakaan tersebut, kedua, hasil mining data kunjungan perpustakaan SMK TI PAB 7 Lubuk Pakam didapatkan informasi bahwa buku yang paling sering dipinjam oleh siswa dengan nilai support 9 adalah buku Biologi Kelas X, ketiga, terdapat beberapa aturan asosiasi yang memiliki nilai confidence 100% misalnya jika meminjam Conversation dan matematika bilingual maka meminjam Matematika X. Artinya jika meminjam buku Conversation dan matematika maka kemungkinan meminjam matematika bilingual adalah 100%.
Kata kunci : data mining, association rules, support, confidence.
A. PENDAHULUAN
Dengan kemajuan teknologi informasi dewasa ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari, sehingga informasi akan menjadi suatu elemen penting dalam perkembangan masyarakat saat ini dan waktu mendatang. Namun kebutuhan informasi yang tinggi kadang tidak diimbangi dengan penyajian informasi yang memadai, sering kali informasi tersebut
masih harus digali ulang dari data yang jumlahnya sangat besar. Kemampuan teknologi informasi untuk mengumpulkan dan menyimpan berbagai tipe data jauh meninggalkan kemampuan untuk menganalisis, meringkas dan mengekstrak pengetahuan dari data. Metode tradisional untuk menganalisis data yang ada, tidak dapat menangani data dalam jumlah besar.
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
138
pengambilan keputusan, tidak cukup hanya mengandalkan data operasional saja, diperlukan suatu analisis data untuk menggali potensi-potensi informasi yang ada. Para pengambil keputusan berusaha untuk memanfaatkan gudang data yang sudah dimiliki untuk menggali informasi yang berguna membantu mengambil keputusan, Hal ini mendorong munculnya cabang ilmu baru untuk mengatasi masalah penggalian informasi atau pola yang penting atau menarik dari data dalam jumlah besar, yang disebut dengan Data Mining. Penggunaan teknik data mining diharapkan dapat memberikan pengetahuan-pengetahuan yang sebelumnya tersembunyi di dalam gudang data sehingga menjadi informasi yang berharga.
Di SMK TI PAB 7 Lubuk Pakam, sebagai sekolah Teknologi Informasi dilengkapi dengan fasilitas berupa perpustakaan. Perpustakaan ini memiliki koleksi buku yang cukup banyak dari mulai buku pelajaran sampai buku – buku ensiklopedi. Pengunjung perpustakaan pun cukup banyak. Setiap akhir semester diberikan penghargaan kepada siswa- siswa yang paling sering mengunjungi perpustakaan. Hal ini tentu saja mendorong siswa untuk lebih sering mengunjungi perpustakaan.
1.1 Rumusan Masalah
Permasalahan yang akan dibahas dalam hal ini adalah :
1. Bagaimana mengolah data peminjaman buku diperpustakaan sehingga menjadi informasi yang berguna.
2. Bagaimana mengukur tingkat support dan confidence dari peminjaman buku sehingga dapat dilakukan penyusunan buku dengan lebih baik.
1.2 Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini adalah:
1. Mengolah data peminjaman buku diperpustakaan sehingga menjadi informasi yang berguna.
2. Mengukur tingkat support dan confidence dari peminjaman buku
sehingga dapat dilakukan penyusunan buku dengan lebih baik.
B. DATA WAREHOUSE
Data warehouse adalah sebuah sistem yang mengambil dan menggabungkan data secara periodik dari sistem sumber data ke penyimpanan data bentuk dimensional atau normal (Reinardi, 2008). Data warehouse merupakan penyimpanan data yang berorientasi objek, terintegrasi, mempunyai variant waktu,dan menyimpan data dalam bentuk nonvolatile sebagai pendukung manejemen dalam proses pengambilan keputusan.(Han. 2006)
Data warehouse menyatukan dan menggabungkan data dalam bentuk multidimensi. Pembangunan data warehouse meliputi pembersihan data, penyatuan data dan transformasi data dan dapat dilihat sebagai praproses yang penting untuk digunakan dalam data mining. Selain itu data warehouse mendukung On-line Analitycal Processing (OLAP), sebuah kakas yang digunakan untuk menganalisis secara interaktif dari bentuk multidimensi yang mempunyai data yang rinci. Sehingga dapat memfasilitasi secara efektif data generalization dan data mining. Banyak metode-metode data mining yang lain seperti asosiasi, klasifikasi, prediksi, dan clustering, dapat diintegrasikan dengan operasi OLAP untuk meningkatkan proses mining yang interaktif dari beberapa level dari abstraksi. Oleh karena itu data warehouse menjadi platform yang penting untuk data analisis dan OLAP untuk dapat menyediakan platform yang efektif untuk proses data mining.
Empat karakteristik dari data warehouse meliputi :
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
139 Oleh karena itu data warehouse
mempunyai karakter menyediakan secara singkat dan sederhana gambaran seputar subjek lebih detail yang dibuat dari data luar yang tidak berguna dalam proses pendukung keputusan.
2. Integrated : Data warehouse biasanya dibangun dari bermacam-macam sumber yang berbeda, seperti database relasional, flat files, dan on-line transaction records. Pembersihan dan penyatuan data diterapkan untuk menjamin konsistensi dalam penamaan, struktur kode, ukuran atribut, dan yang lainnya.
3. Time Variant : data disimpan untuk menyajikan informasi dari sudut pandang masa lampau (misal 5 – 10 tahun yang lalu). Setiap struktur kunci dalam data warehouse mempunyai elemen waktu baik secara implisit maupun eksplisit
4. Nonvolatile : sebuah data warehouse secara fisik selalu disimpan terpisah dari data aplikasi operasional. Penyimpanan yang terpisah ini, data warehouse tidak memerlukan proses transaksi, recovery dan mekanisme pengendalian konkurensi. Biasanya hanya membutuhkan dua operasi dalam akses data yaitu initial load of data dan access of data
Dari pengertian tersebut, sebuah data warehouse merupakan penyimpanan data tetap sebagai implementasi fisik dari pendukung keputusan model data. Data warehouse juga biasanya dilihat sebagai arsitektur, pembangunan dan penyatuan data dari bermacam macam sumber data yang berbeda untuk mendukung struktur dan atau query tertentu, laporan analisis, dan pembuatan keputusan.
Extract, transform, dan load (ETL) merupakan sebuah sistem yang dapat membaca data dari suatu data store, merubah bentuk data, dan menyimpan ke data store yang lain. Data store yang dibaca ETL disebut Data Source, sedangkan data store yang disimpan ETL disebut Target. Proses pengubahan data
digunakan agar data sesuai dengan format dan kriteria, atau sebagai validasi data dari source system. Proses ETL tidak hanya menyimpan data ke data warehouse, tetapi juga digunakan untuk berbagai proses pemindahan data. Kebanyakan ETL mempunya mekanisme untuk membersihkan data dari source system sebelum disimpan ke warehouse. Pembersihan data merupakan proses identifikasi dan koreksi data yang kotor. Proses pembersihan ini menerapkan aturan-aturan tertentu yang mendefinisikan data bersih.
C. DATA MINING
Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar (Davies. 2004). Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data (Pramudiono, 2007).
Data mining, sering juga disebut Sebagai Knowledge Discovery In Database (KDD). KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar (Santoso, 2007).
Data mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan dengan bidang ilmu – ilmu lain, seperti database system, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing
(Han, 2006).
Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semiotomatis (Witten,
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
140
arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi.
Karakteristik data mining sebagai berikut 1. Data mining berhubungan dengan
penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
2. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
3. Data mining berguna untuk membuat keputusan yang kritis, terutama dalam strategi (Davies, 2004).
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Datamining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan database. Beberapa metode yang sering disebut-sebut dalam literatur data mining antara lain clustering, classification, association rules mining, neural network, genetic algorithm dan lain-lain
(Pramudiono, 2007).
D. TAHAP-TAHAP DATA MINING
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yang diilustrasikan di Gambar . Tahap-tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base.
Tahap-tahap data mining ada 6 yaitu : 1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada
umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang. Pembersihan data juga akan mempengaruhi performasi dari teknik data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya. 2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. Sebagai contoh, sebuah kasus yang meneliti faktor kecenderungan orang membeli dalam kasus market basket analysis, tidak perlu mengambil nama pelanggan, cukup dengan id pelanggan saja.
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
141 asosiasi dan clustering hanya bisa menerima
input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5. Proses mining,
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern evaluation),
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi pengetahuan (Knowledge Presentation),
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil Data Mining (Han, 2006)
E. SUPPORT DAN CONFIDENCE
a. Support, suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu item atau itemset dari keseluruhan transaksi. b. Confidence, suatu ukuran yang
menunjukkan hubungan antar dua item secara conditional.
F. METODE ASSOCIATION RULES
Association rules (aturan asosiasi) atau affinity analysis (analisis afinitas) berkenaan dengan studi tentang “apa bersama apa”. Sebagai contoh dapat berupa studi transaksi di supermarket, misalnya seseorang yang membeli susu bayi juga membeli sabun mandi. Pada kasus ini berarti susu bayi bersama dengan sabun mandi. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis (Santoso,2007).
Aturan asosiasi ingin memberikan informasi tersebut dalam bentuk hubungan “ if-then” atau “jika-maka”. Aturan ini dihitung dari data yang sifatnya probabilistik Analisis asosiasi dikenal juga sebagai salah satu metode data mining yang menjadi dasar dari berbagai metode data mining lainnya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frekuensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang) yaitu prosentase kombinasi item tersebut. Dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan assosiatif. Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence) (Pramudiono, 2007)
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
142
ada satu algoritma klasik yang sering dipakai yaitu algoritma apriori. Ide dasar dari algoritma ini adalah dengan mengembangkan frequent itemset. Dengan menggunakan satu tersebut. Secara umum, mengembangkan set dengan fc-item menggunakan frequent set dengan k – 1 item yang dikembangkan dalam langkah sebelumnya. Setiap langkah memerlukan sekali pemeriksaan ke seluruh isi database.
Dalam asosiasi terdapat istilah antecedent dan consequent, antecedent untuk mewakili bagian “jika” dan consequent untuk mewakili bagian “maka”. Dalam analisis ini, antecedent dan consequent adalah sekelompok item yang tidak punya hubungan secara bersama (Santoso, 2007) .
Dari jumlah besar aturan yang mungkin dikembangkan, perlu memiliki aturan-aturan yang cukup kuat tingkat ketergantungan antar item dalam antecedent dan consequent. Untuk mengukur kekuatan aturan asosiasi ini, digunakan ukuran support dan confidence. Support adalah rasio antara jumlah transaksi yang memuat antecedent dan consequent dengan jumlah transaksi. Confidence adalah rasio antara jumlah transaksi yang meliputi semua item dalam antecedent dan consequent dengan jumlah transaksi yang meliputi semua item dalam antecedent.
mengandung antecedent danconsequencent
∑ (Ta+Tc)= Jumlah transaksi yang mengandung antecedent dan consequencent
Σ(Ta) = Jumlah transaksi yang mengandung antecedent
G. ANALISA DAN PERANCANGAN
Tabel 1 berikut ini adalah tabel contoh transaksi peminjaman buku dengan menggunakan data fiktif. Hal ini dimaksudkan untuk memberikan gambaran bagaimana melakukan mining data sehingga menghasilkan aturan asosiasi.
Tabel 1. Tabel Transaksi Peminjaman Buku
No Nama Buku Yang di Pinjam
Inggris x Kehidupan Bakteri
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
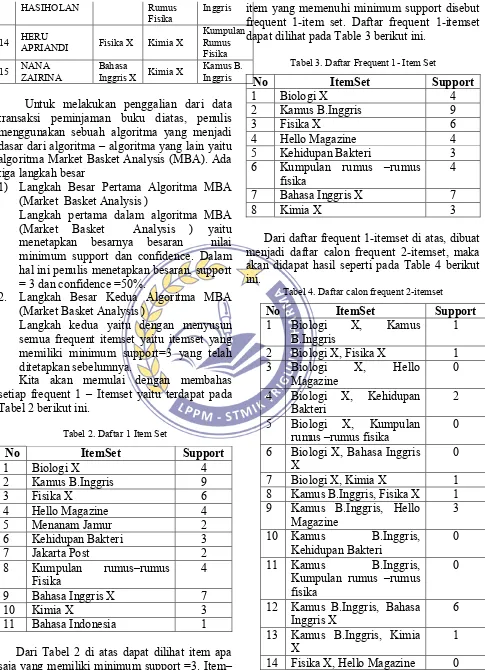
143 HASIHOLAN Rumus
Fisika Inggris
14 HERU APRIANDI Fisika X Kimia X Kumpulan Rumus Fisika 15 NANA ZAIRINA Bahasa Inggris X Kimia X Kamus B. Inggris
Untuk melakukan penggalian dari data transaksi peminjaman buku diatas, penulis menggunakan sebuah algoritma yang menjadi dasar dari algoritma – algoritma yang lain yaitu algoritma Market Basket Analysis (MBA). Ada tiga langkah besar
1) Langkah Besar Pertama Algoritma MBA (Market Basket Analysis )
Langkah pertama dalam algoritma MBA (Market Basket Analysis ) yaitu menetapkan besarnya besaran nilai minimum support dan confidence. Dalam hal ini penulis menetapkan besaran, support = 3 dan confidence =50%.
2. Langkah Besar Kedua Algoritma MBA (Market Basket Analysis )
Langkah kedua yaitu dengan menyusun semua frequent itemset yaitu itemset yang memiliki minimum support=3 yang telah ditetapkan sebelumnya.
Kita akan memulai dengan membahas setiap frequent 1 – Itemset yaitu terdapat pada Tabel 2 berikut ini.
Tabel 2. Daftar 1 Item Set
No ItemSet Support
1 Biologi X 4
2 Kamus B.Inggris 9
3 Fisika X 6
4 Hello Magazine 4
5 Menanam Jamur 2
6 Kehidupan Bakteri 3
7 Jakarta Post 2
8 Kumpulan rumus–rumus
Fisika 4
9 Bahasa Inggris X 7
10 Kimia X 3
11 Bahasa Indonesia 1
Dari Tabel 2 di atas dapat dilihat item apa saja yang memiliki minimum support =3. Item–
item yang memenuhi minimum support disebut frequent 1-item set. Daftar frequent 1-itemset dapat dilihat pada Table 3 berikut ini.
Tabel 3. Daftar Frequent 1- Item Set
No ItemSet Support
1 Biologi X 4
2 Kamus B.Inggris 9
3 Fisika X 6
4 Hello Magazine 4
5 Kehidupan Bakteri 3
6 Kumpulan rumus –rumus
fisika 4
7 Bahasa Inggris X 7
8 Kimia X 3
Dari daftar frequent 1-itemset di atas, dibuat menjadi daftar calon frequent 2-itemset, maka akan didapat hasil seperti pada Table 4 berikut ini.
Tabel 4. Daftar calon frequent 2-itemset
No ItemSet Support
1 Biologi X, Kamus
B.Inggris 1
2 Biologi X, Fisika X 1 3 Biologi X, Hello
Magazine 0
4 Biologi X, Kehidupan
Bakteri 2
5 Biologi X, Kumpulan
rumus –rumus fisika 0 6 Biologi X, Bahasa Inggris
X 0
7 Biologi X, Kimia X 1
8 Kamus B.Inggris, Fisika X 1 9 Kamus B.Inggris, Hello
Magazine 3
10 Kamus B.Inggris,
Kehidupan Bakteri 0
11 Kamus B.Inggris, Kumpulan rumus –rumus fisika
0
12 Kamus B.Inggris, Bahasa
Inggris X 6
13 Kamus B.Inggris, Kimia
X 1
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
144
15 Fisika X, Kehidupan
Bakteri 0
16 Fisika X, Kumpulan
rumus –rumus fisika 4 17 Fisika X, Bahasa Inggris
X 0
18 Fisika X, Kimia X 0
19 Hello Magazine,
Kehidupan Bakteri 1
20 Hello Magazine, Kumpulan rumus –rumus fisika
0
21 Hello Magazine, Bahasa
Inggris X 4
22 Hello Magazine, Kimia X 1 23 Kehidupan Bakteri,
Kumpulan rumus –rumus fisika
1
24 Kehidupan Bakteri,
Bahasa Inggris X 1
25 Kehidupan Bakteri, Kimia
X, 1
26 Kumpulan rumus –rumus
fisika, Kimia X 0
27 Kumpulan rumus –rumus
fisika, Bahasa Inggris X 1 28 Bahasa Inggris X, Kimia
X 0
Dari table diatas dapat dilihat bahwa yang memenuhi syarat minimum support atau yang berhak menjadi frequent 2-itemset adalah seperti terlihat pada Tabel 5 berikut.
Tabel 5. Daftar frequent 2-itemset
No ItemSet Support
1 Kamus B.Inggris, Hello
Magazine 3
2 Kamus B.Inggris, Bahasa
Inggris X 6
3 Fisika X, Kumpulan rumus
–rumus fisika 4
4 Hello Magazine, Bahasa
Inggris X 4
Kemudian daftar frequent 2-itemset diatas dibuat menjadi daftar calon frequent 3-itemset yaitu seperti terlihat pada Tabel 6 berikut.
Tabel 6. Daftar calon frequent 3-itemset
No ItemSet Support
1 Kamus B.Inggris, Hello
Magazine, Bahasa Inggris X 3 2 Kamus B.Inggris, Hello
Magazine, Fisika X 0
3 Kamus B.Inggris, Hello Magazine, Kumpulan rumus –rumus fisika
0
4 Kamus B.Inggris, Bahasa
Inggris X, Fisika X 0
5 Kamus B.Inggris, Bahasa Inggris X, Kumpulan rumus –rumus fisika
0
Dari table di atas, dapat dilihat bahwa yang berhak menjadi frequent 3-itemset adalah seperti terlihat pada Tabel 7 berikut.
Tabel 7. Daftar frequent 3-itemset
No ItemSet Support
1 Kamus B.Inggris, Hello
Magazine, Bahasa Inggris X 3 Kemudian frequent 3-itemset = frequent 4-itemset = frequent 5-iteset
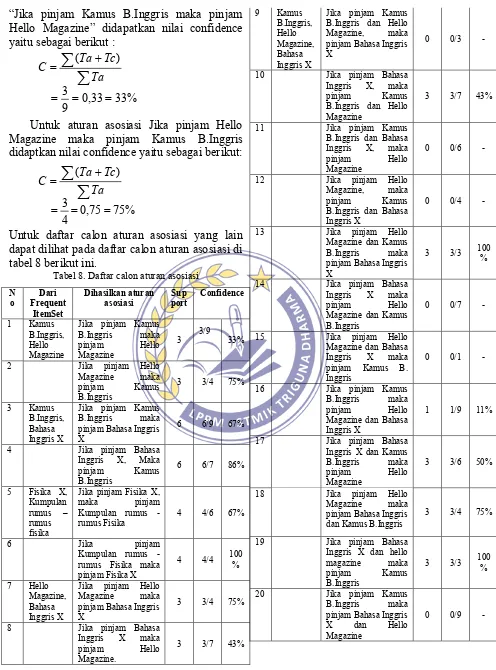
Setelah itu kita hitung nilai confidence dari masing – masing frequent itemset sehingga muncul calon aturan asosiasi. Untuk menghitung nilai confidence digunakan rumus sebagai berikut:
Keterangan : C = Confidence
∑ (Ta+Tc) = Jumlah transaksi yang
mengandung antecedent dan
consequencent
Σ(Ta) = Jumlah transaksi yang mengandung antecedent
Misalnya untuk itemKamus B.Inggris, Hello Magazine dihasilkan calon aturan asosiasi
Ta Tc Ta
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
145 “Jika pinjam Kamus B.Inggris maka pinjam
Hello Magazine” didapatkan nilai confidence yaitu sebagai berikut :
Untuk aturan asosiasi Jika pinjam Hello Magazine maka pinjam Kamus B.Inggris didaptkan nilai confidence yaitu sebagai berikut:
Untuk daftar calon aturan asosiasi yang lain dapat dilihat pada daftar calon aturan asosiasi di tabel 8 berikut ini.
Tabel 8. Daftar calon aturan asosiasi
N
o Frequent Dari ItemSet
Dihasilkan aturan
asosiasi port Sup Confidence
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
146
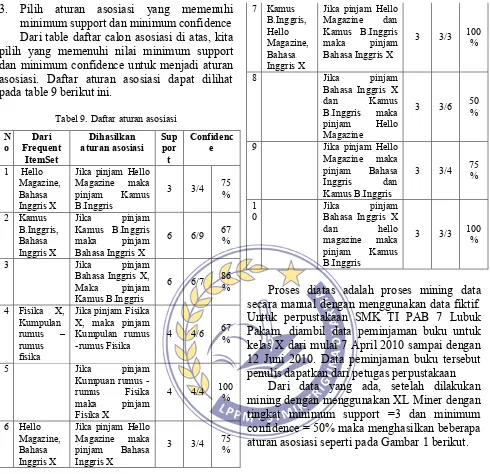
3. Pilih aturan asosiasi yang memenuhi minimum support dan minimum confidence Dari table daftar calon asosiasi di atas, kita pilih yang memenuhi nilai minimum support dan minimum confidence untuk menjadi aturan asosiasi. Daftar aturan asosiasi dapat dilihat pada table 9 berikut ini.
Tabel 9. Daftar aturan asosiasi
N
o Frequent Dari ItemSet
Dihasilkan
aturan asosiasi Suppor t secara manual dengan menggunakan data fiktif. Untuk perpustakaan SMK TI PAB 7 Lubuk Pakam, diambil data peminjaman buku untuk kelas X dari mulai 7 April 2010 sampai dengan 12 Juni 2010. Data peminjaman buku tersebut penulis dapatkan dari petugas perpustakaan
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
148
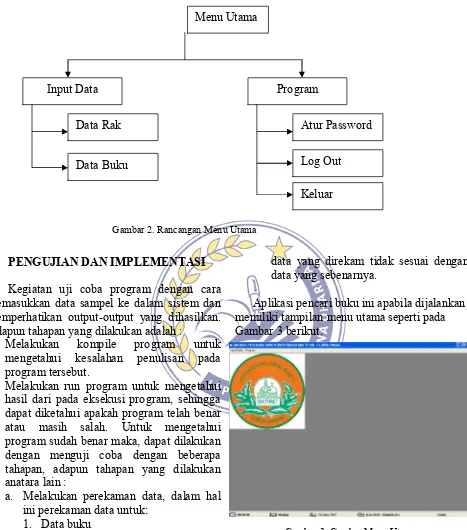
Untuk menu utama , rancangan formnya seperti pada Gambar 2 berikut.
H. PENGUJIAN DAN IMPLEMENTASI
Kegiatan uji coba program dengan cara memasukkan data sampel ke dalam sistem dan memperhatikan output-output yang dihasilkan. Adapun tahapan yang dilakukan adalah :
1. Melakukan kompile program untuk mengetahui kesalahan penulisan pada program tersebut.
2. Melakukan run program untuk mengetahui hasil dari pada eksekusi program, sehingga dapat diketahui apakah program telah benar atau masih salah. Untuk mengetahui program sudah benar maka, dapat dilakukan dengan menguji coba dengan beberapa tahapan, adapun tahapan yang dilakukan anatara lain :
a. Melakukan perekaman data, dalam hal ini perekaman data untuk:
1. Data buku 2. Data Rak
b. Melakukan perbaikan data untuk menghindari apabila ada data yang direkam tidak benar maka, dapat dilakukan sesuai dengan yang sebenarnya
c. Melakukan penghapusan data bila data yang direkam tidak dibutuhkan lagi atau
data yang direkam tidak sesuai dengan data yang sebenarnya.
Aplikasi pencari buku ini apabila dijalankan memiliki tampilan menu utama seperti pada Gambar 3 berikut.
Menu utama memiliki dua menu utama yaitu menu Input Data dan menu Program. Input data memiliki dua submenu yaitu Data Buku dan Data Rak. Sementara menu Program memiliki tiga submenu yaitu Pengaturan Password, Log Out dan Keluar.
Dalam aplikasi ini, sebelum kita dapat menginputkan data, terlebih dahulu kita Log in. Menu Utama
Input Data Program
Data Rak
Data Buku
Atur Password
Log Out Keluar
Gambar 2. Rancangan Menu Utama
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
149 Kita dapat log in sebagai user ataupun sebagai
admin. Perbedaannya kalau kita masuk sebagai user, beberapa tombol dalam form input data akan dibekukan. Hal ini dilakukan untuk menghindari pemodifikasian oleh orang – orang yang tidak berhak. Tetapi kalau kita masuk sebagai admin semua form akan berfungsi normal tanpa ada tombol yang dalam keadaan beku.
Untuk masuk sebagai user cukup diketikan ”user” kemudian masukkan passwordnya kemudian klik tombol log in. Untuk masuk sebagai admin, ketik pada kolom user ”admin” kemudian ketikkan passwordnya kemudian klik log in.
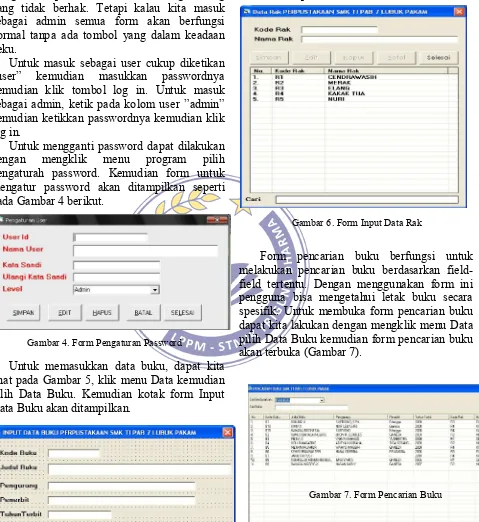
Untuk mengganti password dapat dilakukan dengan mengklik menu program pilih pengaturah password. Kemudian form untuk mengatur password akan ditampilkan seperti pada Gambar 4 berikut.
Untuk memasukkan data buku, dapat kita lihat pada Gambar 5, klik menu Data kemudian pilih Data Buku. Kemudian kotak form Input Data Buku akan ditampilkan.
Untuk menginputkan data rak, dapat kita lakukan dengan mengklik menu Data kemudian kita pilih Data Rak. Kemudian form input data rak akan tampil (Gambar 6).
Form pencarian buku berfungsi untuk melakukan pencarian buku berdasarkan field-field tertentu. Dengan menggunakan form ini pengguna bisa mengetahui letak buku secara spesifik. Untuk membuka form pencarian buku dapat kita lakukan dengan mengklik menu Data pilih Data Buku kemudian form pencarian buku akan terbuka (Gambar 7).
Gambar 4. Form Pengaturan Password
Gambar 5. Form Input Data Buku
Gambar 6. Form Input Data Rak
Jurnal SAINTIKOM Vol. 10 / No. 2 / Mei 2011
150
I. SIMPULAN
Adapun kesimpulan yang diperoleh dari penelitian ini adalah :
1. Dari tumpukan data kunjungan perpustakaan, terdapat pengetahuan yang bermanfaat bagi perpustakaan itu sendiri dan para pengunjung perpustakaan tersebut. 2. Dari hasil mining data kunjungan perpustakaan SMK TI PAB 7 Lubuk Pakam didapatkan informasi bahwa buku yang paling sering dipinjam oleh siswa dengan nilai support 9 adalah buku Biologi Kelas X.
3. Terdapat beberapa aturan asosiasi yang memiliki nilai confidence 100% misalnya jika meminjam Conversation dan matematika bilingual maka meminjam Matematika X. Artinya jika memnjam buku Conversation dan matematika maka kemungkinan meminjam matematika bilingual adalah 100%.
J. DAFTAR PUSTAKA
Arhami, Muhammad. 2005. Konsep Dasar Sistem Pakar. Yogyakarta: Penerbit Andi. Hartati, Iswanti. 2008. Sistem Pakar dan
Pengembangannya. Yogyakarta: Graha Ilmu.
http://journal.unair.ac.id/filerPDF/PERPUSTAK AAN%20DIGITAL.pdf diakses pada 9/01/2011 11:00
http://blogs.msdn.com/azazr/archive/2008/05/09 /populate-time-dimension-of
adventureworksdw-sample-database-and-use-it-in-your-datawarehouse-cube.aspx. Diakses pada 12/10/2011 08:25
Jogiyanto H. M. 1999. Analisa dan Desain. Yogyakarta: Andi Offset.
Kusrini, Emha Taufiq Luthfi. 2009. Algoritma Data Mining. Yogyakarta : Penerbit Andi Kusrini. 2008. Aplikasi Sistem Pakar,
Yogyakarta: Penerbit Andi.
----. 2006. Sistem Pakar Teori dan Aplikasi. Yogyakarta: Penerbit Andi.
Laboratorim Data Mining. 2011. Klasifikasi Decision Tree dalam “http://datamining-lab.com”. Yogyakarta : Fakultas Teknologi Industri Universitas Islam Indonesia
Larose, Daniel T. 2005. Discovering Knowledge in Data: An Introduction to Data Mining. John Willey & Sons, Inc.
Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.