3.1 Jenis dan Sumber Data
Pada penelitian ini terdapat dua variabel yang merupakan data dunia dan satu variabel yang merupakan data nasional. Variabel yang merupakan data dunia yaitu harga minyak dunia dan harga pangan dunia, sedangkan variabel yang merupakan data nasional yaitu jumlah uang beredar. Penggunaan data harga minyak dunia dan harga pangan dunia mengacu pada penelitian-penelitian terdahulu dan dimaksudkan untuk melihat dampak fenomena guncangan luar negeri terhadap perekonomian regional. Penggunaan data jumlah uang beredar pada level nasional, disebabkan tidak tersedianya data jumlah uang beredar pada level provinsi. Selebihnya penggunaan variabel lainnya merupakan data pada level provinsi.
Pengguanaan data IHK hanya pada lingkup ibu kota provinsi sebagai proksi dari inflasi mengacu pada penelitian Subekti (2011), yang menganggap bahwa ibukota provinsi sebagai pusat pertumbuhan yang akan mempengaruhi daerah lainnya yang berada pada provinsi yang sama cukup merepresentasikan tingkat harga pada level provinsi.
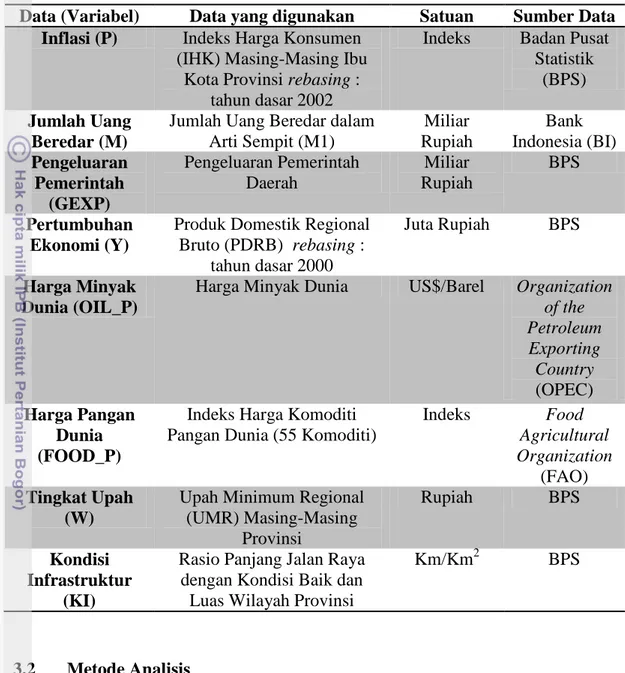
Data yang digunakan dalam penelitian ini merupakan data sekunder berupa data tahunan periode 2001-2010 yang diambil dari publikasi resmi pemerintah. Variabel, data, satuan dan sumber data yang digunakan dalam penelitian ini dapat dilihat pada Tabel 3.1. Proses pengolahan data pada penelitian ini dilakukan dengan menggunakan bantuan paket program software Microsoft Office Excel 2007 dan Eviews 6.
Tabel 3.1 Variabel, Data yang Digunakan dan Sumbernya
Data (Variabel) Data yang digunakan Satuan Sumber Data Inflasi (P) Indeks Harga Konsumen
(IHK) Masing-Masing Ibu Kota Provinsi rebasing :
tahun dasar 2002
Indeks Badan Pusat Statistik
(BPS) Jumlah Uang
Beredar (M)
Jumlah Uang Beredar dalam Arti Sempit (M1) Miliar Rupiah Bank Indonesia (BI) Pengeluaran Pemerintah (GEXP) Pengeluaran Pemerintah Daerah Miliar Rupiah BPS Pertumbuhan Ekonomi (Y)
Produk Domestik Regional Bruto (PDRB) rebasing :
tahun dasar 2000
Juta Rupiah BPS
Harga Minyak Dunia (OIL_P)
Harga Minyak Dunia US$/Barel Organization of the Petroleum Exporting Country (OPEC) Harga Pangan Dunia (FOOD_P)
Indeks Harga Komoditi Pangan Dunia (55 Komoditi)
Indeks Food Agricultural Organization (FAO) Tingkat Upah (W)
Upah Minimum Regional (UMR) Masing-Masing Provinsi Rupiah BPS Kondisi Infrastruktur (KI)
Rasio Panjang Jalan Raya dengan Kondisi Baik dan Luas Wilayah Provinsi
Km/Km2 BPS
3.2 Metode Analisis 3.2.1 Analisis Deskriptif
Metode analisis deskriptif merupakan suatu metode analisis sederhana yang dapat digunakan untuk menggambarkan kondisi suatu observasi dengan menyajikannya dalam bentuk tabel, grafik maupun narasi dengan tujuan untuk memudahkan pembaca dalam menafsirkan hasil observasi.
Metode analisis deskriptif dalam penelitian ini dilakukan untuk mengetahui gambaran umum mengenai perkembangan laju inflasi yang terjadi di Pulau Jawa selama kurun waktu 2001-2010 dan juga untuk menggambarkan
hubungan antara inflasi dengan variabel-variabel yang memengaruhi pada peneltian ini.
3.2.2 Analisis Ekonometrika
Metode analisis ekonometrika yang digunakan pada penelitian ini adalah metode analisis regresi data panel (pooled data). Data panel adalah gabungan dari data time series dan data cross section. Penggunaan metode data panel sudah banyak dipakai saat ini sebab adanya kelemahan dalam pendekatan metode cross
section saja atau pendekatan time series. Jika hanya menggunakan metode cross
section saja, pengamatan yang diamati hanya pada titik tertentu saja, sehingga
perkembangan pengamatan tersebut dalam kurun waktu tertentu tidak dapat diestimasi. Pada pendekatan metode time series juga menimbulkan persoalan yaitu peubah-peubah yang diobservasi secara agregat hanya dari satu unit individu sehingga memberi peluang untuk menghasilkan estimasi yang sifatnya bias. Penggunaan data panel ini merupakan konsekuensi dari kemampuan dan keterbatasan kedua metode analisis diatas. Penggabungan data cross section dan
time series dalam studi data panel digunakan untuk mengatasi kelemahan dan
menjawab pertanyaan yang tidak dapat dijawab oleh pendekatan metode cross
section dan time series murni. Data cross section yang sama diobservasi menurut
waktu. Jika setiap unit cross section memiliki observasi time series yang sama maka disebut sebagai balanced panel, sebaliknya jika jumlah observasi berbeda maka disebut sebagai unbalanced panel.
Beberapa keunggulan dari penggunaan data panel dalam analisis ekonometrika dikemukakan oleh Baltagi (2005) yaitu, pertama mengontrol heterogenitas individu. Data panel menyatakan bahwa individu, perusahaan, tempat atau negara adalah heterogen. Dalam data panel terdiri dari besaran dan waktu sehingga ada banyak variabel-variabel lain yang mungkin menjadi
state-invariant atau time-invariant yang dapat memengaruhi variabel dependen. Data
panel memberikan peluang perlakuan setiap unit-unit individu yang dianalisis adalah heterogen. Kedua, data panel memberikan informasi yang lebih banyak dan beragam, meminimalisasi masalah kolinieritas antar variabel, meningkatkan
derajat bebas dan lebih efisien. Pendekatan metode time series dapat menyebabkan multikoliniearitas, dengan data cross section menambah banyak variabilitas, menambah lebih banyak informasi sehingga dapat menghasilkan parameter estimasi yang dapat diandalkan. Ketiga, data panel lebih baik dalam mempelajari dynamics of adjustment. Distribusi cross section yang kelihatan stabil dapat menyembunyikan banyak perubahan yang sulit untuk diidentifikasi. Masa pengangguran, pergantian pekerjaan, tempat tinggal dan pergerakan pendapatan merupakan contoh data yang lebih baik dipelajari dengan data panel. Data panel juga cocok untuk mempelajari durasi dari variabel besaran ekonomi seperti pengangguran, kemiskinan dan inflasi dan juga dapat menjelaskan dalam kecepatan respon perubahan kebijakan ekonomi.
Data panel juga dibutuhkan untuk mengestimasi hubungan antar massa, siklus hidup dan intergenerasi (intergenerational). Data panel ini dapat menghubungkan pengalaman individu dan tingkah laku dalam satu titik waktu dengan pengalaman dan tingkah laku dalam titik waktu yang berbeda. Keempat, data panel lebih baik dalam mengidentifikasi dan mengukur efek yang tidak dapat dideteksi oleh cross section murni maupun time series murni. Seperti contoh, dalam menentukan apakah anggota serikat buruh dapat meningkatkan atau menurunkan upah. Hal ini dapat dijawab dengan mengobservasi seorang pekerja yang bergerak dari serikat buruh ke nonserikat buruh atau sebaliknya. Dengan mengasumsikan karakteristik individu yang konstan, dilengkapi dengan variabel yang lain untuk menentukan apakah keanggotaan serikat buruh memengaruhi upah dan dengan berapa banyak upah tersebut bisa berpengaruh terhadap keanggotaan serikat buruh (Friedman dalam Baltagi (2005)). Kelima, model data panel dapat digunakan untuk mengkonstruksi dan menguji model perilaku secara kompleks apabila dibandingkan dengan cross section atau time series murni. Pada kenyataanya, indikator dalam perekonomian sebagian besar bersifat dinamis. Hubungan dinamis ini dapat diketahui dengan adanya lag variabel endogen yang terdapat pada variabel eksogen. Verbeek (2004) menjelaskan kelebihan dari penggunaan metode data panel bila dibandingkan dengan metode cross section
dan time series murni. Kombinasi data cross section dan time series membuat
lebih besar bila dibandingkan dengan model cross section dan time series murni. Selain itu, variabel penjelas dalam model data panel lebih bervariasi atau
marginal effect dalam dua dimensi (ruang atau individu dan waktu), sehingga
selain dapat dianalisis variasi antar ruang (individu) dan waktu, penduga yang didasari oleh data panel lebih akurat dibandingkan cross section dan time series
murni. Menurut Baltagi (2005), permasalahan tersebut antara lain: (i) relatif terbatasnya data karena melibatkan komponen cross section dan time series
menimbulkan masalah desain survei panel, pengumpulan dan manajemen data (masalah yang umumnya dihadapi diantaranya: coverage, nonresponse,
kemampuan daya ingat responden (recall), frekuensi dan waktu wawancara); (ii) distorsi kesalahan pengamatan (measurement error) yang umumnya terjadi karena kegagalan respon (contoh: pertanyaan yang tidak jelas, ketidaktepatan informasi, dan lain-lain); (iii) masalah selektivitas, yakni: selfselectivity, nonresponse,
attrition (jumlah responden yang terus berkurang pada survei lanjutan); (iv) cross
section dependence (contoh: apabila macropanel data dengan unit analisis negara
atau wilayah dengan deret waktu yang panjang mengabaikan cross-country
dependence maka dapat mengakibatkan kesimpulan-kesimpulan yang tidak tepat
(misleading inference)).
Umumnya terdapat tiga pendekatan yang biasa diaplikasikan pada metode data panel, yaitu Pooled Least Square (PLS), Fixed Effect Model (FEM) dan
Random Effect Model (REM). Selain itu, didalam melakukan pengolahan data
panel juga terdapat kriteria pembobotan yang berbeda-beda yaitu No weighting
(semua observasi diberi bobot sama), Cross section weight (Generalized Least
Square (GLS) dengan menggunakan estimasi varians residual cross section,
digunakan apabila terdapat pelanggaran asumsi cross section heteroskedasticity),
dan Seemingly Uncorrelated Regression (SUR) (GLS dengan menggunakan
covariance matrix cross section). Metode ini mengoreksi baik heteroskedastisitas
3.2.2.1 Pooled Least Square
Pada prinsipnya, pendekatan ini adalah menggunakan gabungan dari seluruh data (pooled), sehingga terdapat N × T observasi, dimana N menunjukkan
jumlah unit cross-section dan T menunjukkan jumlah time-series yang digunakan. Persamaan pada estimasi yang menggunakan Pooled Least Square (PLS) dapat dituliskan dalam bentuk sebagai berikut (Baltagi, 2005):
...(3.1) dimana :
= nilai variabel terikat (dependent variable) untuk setiap unit cross section = nilai variabel penjelas (explanatory variable) ke-j untuk setiap cross section α = intercept yang konstan antar waktu dan cross section
= slope untuk variabel ke-j yang konstan antar waktu dan cross section
= komponen error untuk setiap unit cross section ke-i pada periode waktu t. N adalah jumlah unit cross section, T adalah jumlah periode waktunya dan K adalah jumlah variabel penjelas.
Keunggulan dalam penggunaan metode PLS adalah dengan mengkombinasikan semua data cross-section dan data time-series, dapat meningkatkan derajat kebebasan sehingga dapat memberikan hasil estimasi yang lebih efisien. Sementara, kelemahan pada metode PLS terletak pada dugaan parameter akan bias. Parameter yang bias ini disebabkan karena PLS tidak dapat membedakan observasi yang berbeda pada periode yang sama, atau tidak dapat membedakan observasi yang sama pada periode yang berbeda (Firdaus, 2011).
3.2.2.2 Fixed Effect Model
Fixed effect model (FEM) memasukkan unsur variabel dummy sehingga
intersept α bervariasi antar individu maupun antar unit waktu. FEM lebih tepat digunakan jika data yang diteliti ada pada tingkat individu serta jika terdapat korelasi antara εit dan xit. Persamaan pada estimasi menggunakan FEM dapat dituliskan dalam bentuk sebagai berikut (Baltagi, 2005):
Yit = β1i + β2X2it + β3X3it + uit
Kelebihan pendekatan FEM adalah dapat menghasilkan dugaan parameter yang tidak bias dan efisien. Tetapi kelemahannya adalah jika jumlah unit observasinya besar maka akan mengurangi derajat bebas model, sehingga akan mengurangi tingkat keakuratan model (Firdaus, 2011).
...(3.2)
3.2.2.3 Random Effect Model
Random Effect Model (REM) muncul ketika antara efek individu dan
regresor tidak memiliki korelasi. Asumsi ini membuat komponen error dari efek individu dimasukkan ke dalam error pada persamaan regresi. Persamaan estimasi pada REM adalah sebagai berikut (Baltagi, 2005):
………(3.3) dengan
dimana : ~ N (0, δu2 ~ N (0, δv
) = komponen cross section error
2
~ N (0, δw
) = komponen time series error
2
Asumsinya adalah bahwa error secara individual tidak saling berkorelasi begitu juga dengan error kombinasinya.
) = komponen error kombinasi
3.2.2.4 Pengujian Model
Untuk memilih model mana yang paling tepat digunakan untuk pengolahan data panel, maka terdapat beberapa pengujian yang dapat dilakukan, antara lain:
1. Chow Test
Chow Test merupakan pengujian untuk memilih apakah model yang
digunakan PLS atau FEM. Dalam pengujian ini dilakukan dengan hipotesis sebagai berikut:
H0 H
: PLS 1
Dasar penolakan terhadap hipotesis nol tersebut adalah dengan menggunakan F-statistic seperti yang dirumuskan oleh Chow (1967):
: FEM
……...………(3.4) dimana:
RRSS = Restricted Residual Sum Square (Sum Square Residual PLS)
URSS = Unrestricted Residual Sum Square (Sum Square Residual FEM)
N = jumlah data cross section
T = jumlah data time series
K = jumlah variabel independen
Dimana pengujian ini mengikuti distribusi F yaitu . Jika nilai Chow Test (F-statistic) hasil pengujian lebih besar dari F-Tabel, maka cukup bukti bagi kita untuk melakukan penolakan terhadap H0
2. Hausman Test
sehingga model yang kita gunakan adalah FEM, begitu juga sebaliknya.
Hausman Test adalah pengujian statistik sebagai dasar pertimbangan kita
dalam memilih apakah menggunakan FEM atau REM. Pengujian ini dilakukan dengan hipotesis sebagai berikut:
H0 H
: REM 1
Sebagai dasar penolakan H : FEM
0
…………....(3.5) maka digunakan statistik Hausman dan membandingkannya dengan Chi square. Statistik Hausman dirumuskan dengan:
dimana M adalah matriks kovarians untuk parameter β dan k adalah derajat bebas yang merupakan jumlah variabel independen.
Jika nilai statistik Hausman hasil pengujian lebih besar dari , maka cukup bukti untuk melakukan penolakan terhadap H0 sehingga model yang digunakan adalah FEM, begitu juga sebaliknya.
3.2.2.5 Metode Evaluasi Model
Setelah selesai melakukan pengolahan data dengan metode analisis data panel, harus dilakukan evaluasi terhadap model estimasi yang dihasilkan. Metode estimasi yang dihasilkan melalui metode analisis data panel tersebut harus dievaluasi berdasarkan tiga kriteria sebagai berikut:
I. Kriteria Ekonometrika II. Kriteria Statistik III. Kriteria Ekonomi
I. Kriteria Ekonometrika
Model estimasi regresi linear yang ideal dan optimal harus menghasilkan estimator yang memenuhi kriteria Best Linear Unbiased Estimator (BLUE), antara lain sebagai berikut :
a. Estimator linear artinya adalah estimator merupkan sebuah fungsi linear atas sebuah variabel dependen yang stokastik.
b. Estimator tidak bias artinya nilai ekspektasi sesuai dengan nilai yang sebenarnya.
c. Estimator harus mempunyai varians yang minimum. Estimator yang tidak bias dan memiliki varians minimum disebut estimator yang efisien.
Terdapat beberapa permasalahan yang dapat menyebabkan sebuah estimator dikatakan tidak memenuhi kriteria BLUE jika melanggar beberapa asumsi antara lain sebagai berikut:
1. Normalitas
Pengujian asumsi normalitas dilakukan untuk melihat apakah error term
maka prosedur pengujian dengan menggunakan uji t-statistic menjadi tidak sah. Pengujian asumsi normalitas dilakukan dengan Jarque Bera Test atau dengan melihat plot dari sisaan. Hipotesis dalam pengujian normalitas adalah:
H0 H
: Residual berdistribusi Normal 1
Dasar penolakan H
: Residual tidak berdistribusi Normal
0 dilakukan dengan membandingkan nilai Jarque Bera dengan taraf nyata α sebesar 0,05, dimana jika nilai Jarque Bera Test lebih besar dari taraf nyata α 0,05 menandakan H0
2. Multikolinearitas
tidak ditolak dan residual berdistribusi normal.
Istilah multikolinearitas berarti terdapat hubungan linier sempurna antar peubah bebas dalam suatu model regresi. Dalam prakteknya, kita sering dihadapkan dengan masalah peubah-peubah bebas yang tingkat multikoliniearitasnya tidak sempurna tetapi tinggi. Jika kita berhadapan dengan adanya peubah-peubah bebas yang seperti ini, maka dugaan parameter koefisien regresi masih mungkin diperoleh, tetapi interpretasinya akan menjadi sulit. Gujarati (2003) menyatakan indikasi terjadinya multikolinearitas dapat terlihat melalui:
a. Nilai R2
b. Korelasi berpasangan yang tinggi antara variabel-variabel independennya. yang tinggi tetapi sedikit rasio yang signifikan.
c. Melakukan regresi tambahan (auxiliary) dengan memberlakukan variabel independen sebagai salah satu variabel dependen dan variabel independen lainnya tetap diberlakukan sebagai variabel independen.
Menurut Juanda (2009), ada beberapa cara untuk mendeteksi adanya multikolinearitas di dalam suatu model. Pertama atau merupakan syarat cukup
(sufficient condition) adalah melalui Uji koefisien korelasi sederhana (Pearson
correlation coefficient), jika korelasi antar peubah-peubah bebas sangat tinggi dan
nyata, dapat dikatakan terjadi multikolinearitas. Menurut Gujarati (2003), batas terjadinya korelasi antar variabel bebas adalah tidak boleh lebih dari tanda mutlak 0,8. Kedua atau merupakan syarat perlu (necessary condition) apabila syarat cukup tidak terpenuhi yaitu, dapat dilakukan dengan melihat nilai Variance
………(3.6) nilai VIF ini menggambarkan kenaikan varians dari dugaan parameter antar peubah penjelas. Apabila nilai VIF lebih dari 5 atau 10, maka taksiran parameter kurang baik atau terjadi multikoliniearitas.
Perlu diingat jika tujuan pemodelan hanya untuk peramalan nilai peubah tak bebas dan bukan untuk mengkaji hubungan atau pengaruh peubah-peubah bebas terhadap peubah tak bebas, maka masalah multikolinearitas bukan masalah yang serius. Akan tetapi jika tujuan pemodelan adalah untuk menduga hubungan atau pengaruh peubah-peubah bebas terhadap peubah tak bebas, maka masalah multikoliniearitas menjadi masalah yang serius. Oleh karena itu terdapat beberapa cara yang dapat digunakan untuk mengatasi multikoliniearitas, antara lain (Juanda, 2009):
a. Memanfaatkan informasi sebelumnya (prior information).
b. Mengeluarkan peubah dengan koliniearitas tinggi, tetapi dapat menimbulkann bias spesifikasi model.
c. Melakukan transformasi terhadap peubah-peubah dalam model menjadi bentuk first difference.
d. Menggunakan regresi komponen utama (principal component).
e. Penambahan data baru. 3. Heteroskedastisitas
Salah satu asumsi dasar dari metode regresi linear adalah varians tiap unsur erroradalah suatu angka konstan yang sama dengan δ2
a. Dugaan parameter koefisien regresi tetap tidak bias dan masih konsisten, tetapi standar errornya dapat bias ke bawah.
. Heteroskedastisitas terjadi ketika varians tiap unsur error tidak konstan. Guajarati (2003) menyatakan heteroskedastisitas memiliki beberapa konsekuensi, diantaranya adalah :
b. Perhitungan standar error tidak lagi dapat dipercaya kebenarannya karena varians tidak minimum sehingga dapat menghasilkan estimasi regresi yang tidak efisien.
c. Uji hipotesis yang didasarkan pada uji F-statistic dan t-statistic tidak dipercaya.
Cara mendeteksi adanya pelanggaran asumsi heteroskedastisitas dalam metode data panel dapat dilakukan dengan menggunakan grafik standardized
residual, apabila secara grafis menunjukkan bahwa ragam sisaan menyebar
normal maka dapat dinyatakan tidak terjadi pelanggaran asumsi heteroskedastisitas.
4. Autokorelasi
Gujarati (2003) menyatakan autokorelasi adalah korelasi antara anggota serangkaian observasi yang diurutkan menurut waktu seperti dalam data time
series atau diurutkan menurut ruang seperti dalam data cross section. Suatu model
dikatakan memiliki autokorelasi jika error dari periode waktu (time series) yang berbeda saling berkorelasi. Masalah autokorelasi ini akan menyebabkan model menjadi tidak efisien meskipun masih tidak bias dan konsisten. Autokorelasi menyebabkan estimasi standar error dan varian koefisien regresi yang diperoleh akan underestimate, sehingga R2
Untuk mendeteksi masalah autokorelasi yang paling umum dapat dilakukan dengan melihat nilai Durbin-Watson statistic pada model dibandingkan dengan nilai DW-Tabel. Sebuah model dapat dikatakan terbebas dari autokorelasi jika nilai Durbin-watson statistic terletak di area nonautokorelasi. Penentuan area tersebut dibantu dengan nilai tabel D
akan besar tetapi di uji t-statistic dan uji F-statistic menjadi tidak valid.
L dan DU.
H
Jumlah observasi (N) dan jumlah variabel independen (K). Dengan menggunakan hipotesis pengujian sebagai berikut:
0 H
: Tidak terdapat autokorelasi 1
Maka aturan pengujiannya adalah sebagai berikut : : Terdapat autokorelasi
0 < d < DL : tolak H0
D
, ada autokorelasi positif L≤ d ≤ DU
D
: daerah ragu-ragu, tidak ada keputusan U < d < 4 – DU : terima H0
4 - D
, tidak ada autokorelasi U≤ d ≤ 4-DL
4 – D
: daerah ragu-ragu, tidak ada keputusan
II. Kriteria Statistik
Evaluasi model berdasarkan kriteria statistik dilakukan dengan beberapa pengujian antara lain sebagai berikut:
a. Koefesien Determinasi (R2 Nilai R
) 2
digunakan untuk mengukur seberapa besar tingkat variabel independen yang digunakan dalam penelitian dapat menjelaskan variabel dependen. Nilai tersebut menunjukkan seberapa dekat garis regresi yang kita estimasi dengan data yang sesungguhnya. Nilai R2
b. Uji F-statistic
terletak antara nol hingga satu dimana semakin mendekati satu maka model akan semakin baik.
Uji F-statistic digunakan untuk mengetahui apakah variabel-variabel
independen yang digunakan dalam penelitian secara bersama-sama signifikan memengaruhi variabel dependen. Nilai F-statistic yang besar lebih baik dibandingkan dengan F-statistic yang rendah. Nilai Prob(F-statistic) merupakan tingkat signifikansi marginal dari F-statistic. Dengan menggunakan hipotesis pengujian sebagai berikut:
H0 : β1=β2=…=βk H
=0
1 : minimal ada salah satu βj Tolak H
yang tidak sama dengan nol
0 jika F-statistic > F α(k-1,NT-N-K) atau Prob(F-statistic) < α. Jika H0
c. Uji t-statistic
ditolak, maka artinya dengan tingkat keyakinan 1-α kita dapat menyimpulkan bahwa variabel independen yang digunakan di dalam model secara bersama-sama signifikan memengaruhi variabel dependen.
Uji t-statistic digunakan untuk mengetahui apakah variabel-variabel
independen secara parsial berpengaruh signifikan terhadap variabel dependen. Dengan menggunakan hipotesis pengujian sebagai berikut:
H0 : βj H = 0 1 : βj Tolak H ≠ 0
0 jika t-statistic > t α/2(NT-K-1) atau (t-statistic) < t-tabel. Jika H0 ditolak, maka artinya dengan tingkat keyakinan 1-α kita dapat menyimpulkan bahwa variabel independen ke-i secara parsial memengaruhi variabel dependen.
III. Kriteria Ekonomi
Evaluasi model estimasi berdasarkan kriteria ekonomi dilakukan dengan membandingkan kesesuaian tanda dan nilai estimator dengan teori ekonomi dan kesesuaian dengan logika.
3.2.3 Aplikasi Regresi Data Panel
Analisis data panel pada umumnya menggunakan data dalam bentuk level
dengan tujuan untuk memudahkan interpretasi model, namun jika kemudian penelitian menggunakan data time series yang mengandung tren, maka sebaiknya dilakukan pengujian unit root, untuk memastikan bahwa hubungan antara peubah tak bebas dan peubah bebas tidak menunjukkan spurious regression. Bila hasil pengujian unit root menunjukkan adanya tren pada data level, maka seperti biasanya, harus dilakukan pembedaan pertama (first differencing) untuk menghindari hasil yang misleading. Perlu diingat bahwa metode yang digunakan dalam penelitian ini adalah metode regresi data panel, maka pengujian unit root
yang digunakan bukan menggunakan metode biasa, tetapi menggunakan panel
unit root. Pengujian ini disarankan oleh Baltagi (2005) untuk data panel dengan N
dan T yang relatif tidak besar.
Hipotesis nol yang digunakan dalam pengujian panel unit root sama seperti pada pengujian unit root untuk data time series murni, hanya saja statistik uji yang digunakan merupakan pengembangan lebih lanjut dari statistik uji
Augmented Dickey-Fuller (ADF) dan Phillips-Perron (PP). Statistik uji yang
digunakan dalam menguji panel unit root terdiri dari dua jenis, yaitu common unit root yang terdiri dari statistik uji Levin, Lin and Chu (LLC) dan Breitung’s test; serta individual unit root yang terdiri dari statistik uji Im, Pesaran and Shin (IPS), ADF - Fisher test dan PP - Fisher test. Setelah diperoleh hasil pengujian yang menyatakan bahwa series dari data panel tidak mengandung unit root maka estimasi bisa dilakukan.
3.3 Perumusan Model Penelitian
Rancangan model yang akan diajukan adalah mengacu pada penelitian Lestari (2003) dengan melakukan beberapa modifikasi pada variabel. Pada model penelitian ini terdapat tujuh variabel independen, dengan variabel dependennya P dan variabel independennya adalah M, GEXP, Y, W, KI, OIL_P dan FOOD_P. Data yang diperoleh pada variabel-variabel tersebut ternyata berbeda satuan dan berada dalam nilai yang sangat besar. Oleh karena itu, untuk memudahkan dalam mengolah data dan interpretasi hasil akhir, seluruh variabel yang berbeda satuan akan ditransformasi sehingga menjadi bentuk satuan yang sama, yaitu dalam bentuk logaritma natural. Dengan model tersebut diharapkan bahwa hasil regresi yang diperoleh akan lebih efisien dan mudah untuk diinterpretasikan.
Sesuai dengan keterangan di atas, maka spesifikasi model tersebut secara ekonometrika akan menjadi model sebagai berikut :
Ln(Pit) = α +β1 Ln(Mit) + β2 Ln(GEXPit) + β3 ln(Yit) + β4 Ln(Wit β
) +
5 Ln(KIit) + β6 Ln(OIL_Pit) + β7 Ln(FOOD_Pit) + εit
Model pada persamaan (3.7) merupakan model pada data level, jika kemudian terdapat unit root pada data level, maka persamaan (3.8) harus dirubah menjadi persamaan pada first differencing, sehingga akan diperoleh persamaan sebagai berikut :
………..…..(3.7)
Ln(∆Pit) = α +β1 Ln(∆Mit) + β2 Ln(∆GEXPit) + β3 ln(∆Yit) + β4 Ln(∆Wit β
) +
5 Ln(∆KIit) + β6 Ln(∆OIL_Pit) + β7 Ln(∆FOOD_Pit) + εit
dimana:
…………...……..…(3.8)
∆P : Perubahan harga (Inflasi) ∆M : Perubahan jumlah uang beredar
∆GEXP : Perubahan pengeluaran pemerintah daerah ∆Y : Perubahan pertumbuhan ekonomi daerah ∆W : Perubahan upah minimum regional ∆KI : Perubahan kondisi infrastruktur daerah
∆OIL_P : Perubahan harga minyak dunia ∆FOOD_P : Perubahan harga pangan dunia
Subskrip (i) menandakan kondisi pada provinsi ke-i dan (t) menandakan pengamatan pada tahun ke-t.