BAB 2
LANDASAN TEORI
2.1 Analisis Regresi
Perubahan nilai suatu variabel tidak selalu terjadi dengan sendirinya, namun perubahan nilai variabel itu dapat pula disebabkan oleh berubahnya variabel lain yang berhubungan dengan variabel tersebut. Untuk mengetahui pola nilai suatu variabel yang disebabkan oleh variabel lain diperlukan alat analisis yang memungkinkan kita untuk membuat perkiraan nilai variabel tersebut pada nilai tertentu variabel yang mempengaruhinya.
Teknik yang umum digunakan untuk menganalisis hubungan antara dua atau lebih variabel dalam ilmu statistik adalah analisis regresi. Analisis regresi adalah teknik statistik yang berguna untuk memeriksa dan memodelkan hubungan diantara variabel-variabel. Analisis regresi berguna dalam menelaah hubungan dua variabel atau lebih dan terutama untuk menelusuri pola hubungan yang modelnya belum diketahui dengan sempurna, sehingga dalam penerapannya lebih bersifat eksploratif.
Persamaan regresi yang digunakan untuk membuat taksiran mengenai nilai variabel terikat disebut persamaan regresi estimasi, yaitu suatu formula matematis yang menunjukkan hubungan keterkaitan antara satu atau beberapa variabel yang nilainya sudah diketahui dengan satu variabel yang nilainya belum diketahui. Sifat hubungan antarvariabel dalam persamaan regresi merupakan hubungan sebab akibat.
Regresi yang berarti peramalan, penaksiran atau pendugaan pertama kali diperkenalkan pada tahun 1877 oleh Sir Francis Galton (1822 – 1911) sehubungan
dengan penelitiannya terhadap manusia. Penelitian tersebut membandingkan antara tingggi anak laki-laki dan tinggi badan orang tuanya. Istilah regresi pada mulanya bertujuan untuk membuat perkiraan nilai suatu variabel (tinggi badan anak) terhadap suatu variabel yang lain (tinggi badan orang tua). Pada perkembangan selanjutnya, analisis regresi dapat digunakan sebagai alat untuk membuat perkiraan nilai suatu variabel dengan menggunakan beberapa variabel lain yang berhubungan dengan variabel tersebut.
2.1.1 Regresi Linier Sederhana
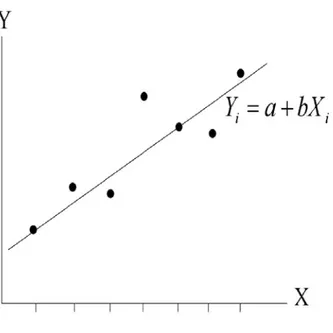
Regresi linier sederhana adalah analisis regresi yang melibatkan hubungan fungsional antara satu variabel terikat dengan satu variabel bebas. Variabel terikat merupakan variabel yang nilainya selalu bergantung dengan nilai variabel lain. Dalam hal ini variabel terikat yang nilainya selalu dipengaruhi oleh variabel bebas, sedangkan variabel bebas adalah variabel yang nilainya tidak bergantung pada nilai variabel lain. Dan biasanya variabel terikat dinotasikan dengan Y, sedangkan variabel bebas dinotasikan dengan X. Hubungan-hubungan tersebut dinyatakan dalam model matematis yang memberikan persamaan-persamaan tertentu.
Bentuk umum persamaan regresi linier sederhana yang menunjukkan hubungan antara dua variabel, yaitu variabel X sebagai variabel bebas dan variabel Y sebagai variabel terikat adalah
i i a bX
Y = + (2.1) dimana:
Yi = variabel terikat ke-i
Xi = variabel bebas ke-i
a = intersep (titik potong kurva terhadap sumbu Y) b = kemiringan (slope) kurva linier
Gambar 2.1 Diagram pencar
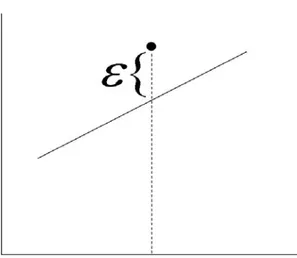
Metode kuadrat terkecil adalah suatu metode untuk menghitung a dan b sebagai perkiraan A dan B, sedemikian rupa sehingga jumlah deviasi kuadrat
(
=∑
2)
i e
SSD memiliki nilai terkecil.
Model sebenarnya : Y = A + BX + ε Model perkiraan : Y = a + bX + e
Dimana a, b merupakan perkiraan / taksiran atas A, B.
Jika X dikurangi dengan rata-ratanya
(
xi = Xi−X)
akan diperoleh variabel baru x dengan∑
xi =0. Maka persamaannya menjadi:(
i)
i i i i i bx a Y e e bx a Y + − = + + =(
)
[
]
∑
=∑
− + = 2 2 i i i Y a bx e SSD (2.2)Metode meminimumkan jumlah deviasi kuadrat (regresi kuadrat terkecil) yang didasarkan pada pemilihan a dan b, sehingga meminimalkan jumlah kuadrat deviasi titik-titik data dari garis yang dicocokkan.
Gambar 2.2 Suatu pengamatan (data) yang tidak tepat pada garis regresi
Kemudian akan ditaksir a dan b sehingga jika taksiran ini disubstitusikan ke dalam persamaan (2.2), maka jumlah deviasi kuadrat menjadi minimum. Dengan mendifferensialkan persamaan (2.2) terhadap a dan b dengan menetapkan derivatif parsial yang dihasilkan sama dengan nol, diperoleh:
(
)
2 0 0 2∑
∑
∑
∑
∑
− − = − − = → = ∂ ∂ = ∂ ∂ i i i i i i x x b na Y bx a Y a a e Y n Y a= i = ⇒ ˆ∑
(2.3)(
)
2 2 0 0 2 = → = − − = − − ∂ ∂ = ∂ ∂∑
∑
∑
∑
∑
∑
i i i i i i i i x x b x a Y x bx a Y b b e∑
∑
= ⇒ ˆ 2 i i i x Y x b (2.4)Nilai aˆ dan bˆ yang diperoleh dengan cara ini disebut taksiran kuadrat terkecil
masing-masing dari a dan b. Dengan demikian, taksiran persamaan regresi dapat ditulis sebagai, Yˆ =aˆ+bˆX yang disebut persamaan prediksi.
Garis regresi berguna untuk menentukan hubungan pengaruh perubahan variabel yang satu terhadap variabel yang lainnya. Selanjutnya dari hubungan dua variabel ini dapat dikembangkan untuk analisa tiga variabel atau lebih.
2.1.2 Multiple Regresi
Multiple regresi (regresi linier ganda) merupakan regresi linier yang melibatkan hubungan fungsional antara sebuah variabel terikat dengan dua atau lebih variabel bebas. Semakin banyak variabel bebas yang terlibat dalam suatu persamaan regresi semakin rumit menentukan nilai statistik yang diperlukan hingga diperoleh persamaan regresi estimasi. Regresi linier berganda berguna untuk mendapatkan pengaruh dua variabel kriteriumnya atau untuk mencari hubungan fungsional dua variabel prediktor atau lebih dengan variabel kriteriumnya, atau untuk meramalkan dua variabel prediktor atau lebih terhadap variabel kriteriumnya.
Hubungan linier lebih dari dua variabel yang bila dinyatakan dalam bentuk persamaan matematis adalah:
ε β β β + + + + = X kXk Y 0 1 1 dimana: Y = variabel terikat
X1,…, Xk = variabel bebas pada variabel ke-1sampai variabel ke-k
k
β β
β0, 1,..., = parameter regresi ε = nilai kesalahan (error)
Metode kuadrat terkecil dari estimasi β yang terdiri dari minimum
∑
εi2 yang berkenaan dengan β, dimana minimum ε'ε = Y −Xβ 2 mengenai β, yaitu:(
) (
)
β β β β β ε ε X X Y X Y Y X Y X Y ' ' ' ' 2 ' ' ' + − = − − =Perbedaan ε'ε mengenai β dan persamaan ' =0
∂ ∂ β ε ε , diperoleh: 0 ' 2 ' 2 + = − X Y X Xβ atau X'Xβ = X'Y (2.5)
(
X'X)
X'Y ˆ= −1 β (2.6) Kemudian untuk β,(
) (
)
[
(
)
]
[
(
)
]
(
) (
) (
)
(
)
(
β) (
β)
β β β β β β β β β β β β β β ˆ ' ˆ ˆ ' ' ˆ ˆ ' ˆ ˆ ˆ ' ˆ ˆ ' X Y X Y X X X Y X Y X X Y X X Y X Y X Y − − ≥ − − + − − = − + − − + − = − −Minimum dari
(
Y −Xβ) (
' Y −Xβ)
adalah(
Y −Xβˆ) (
' Y−Xβˆ)
dicapai pada β =βˆ. Solusi ini untuk melihat minimum ε'ε.2.2 Estimasi
Estimasi adalah menaksir ciri-ciri tertentu dari populasi atau memperkirakan nilai populasi (parameter) dengan memakai nilai sampel (statistik). Dengan statistika kita berusaha menyimpulkan populasi. Dalam kenyataannya, mengingat berbagai faktor untuk keperluan tersebut diambil sebuah sampel yang representatif dan berdasarkan hasil analisis terhadap data sampel kesimpulan mengenai populasi dibuat. Cara pengambilan kesimpulan tentang parameter berhubungan dengan cara-cara menaksir harga parameter. Jadi, harga parameter sebenarnya yang tidak diketahui akan diestimasi berdasarkan statistik sampel yang diambil dari populasi yang bersangkutan.
Sifat atau ciri estimator yang baik yaitu tidak bias, efisien dan konsisten:
1. Estimator yang tidak bias
Estimator dikatakan tidak bias apabila ia dapat menghasilkan estimasi yang mengandung nilai parameter yang diestimasikan. Misalkan, estimator θˆ dikatakan estimator yang tidak bias jika rata-rata semua harga θˆ yang mungkin akan sama dengan θ. Dalam bahasa ekspektasi ditulis E
( )
θˆ =θ .2. Estimator yang efisien
Estimator dikatakan efisien apabila hanya dengan rentang nilai estimasi yang kecil saja sudah cukup mengandung nilai parameter. Estimator bervarians minimum ialah estimator dengan varians terkecil diantara semua estimator untuk parameter yang sama. Jika θˆ1 dan θˆ2 dua estimator untuk θ dimana varians untuk θˆ1 lebih kecil dari varians untuk θˆ2, maka θˆ1 merupakan estimator bervarians minimum.
3. Estimator yang konsisten
Estimator dikatakan konsisten apabila sampel yang diambil berapa pun besarnya, pada rentangnya tetap mengandung nilai parameter yang sedang di estimasi. Misalkan, θˆ estimator untuk θ yang dihitung berdasarkan sebuah sampel acak berukuran n. Jika ukuran sampel n makin besar mendekati ukuran populasi menyebabkan θˆ mendekati θ, maka θˆ disebut estimator konsisten.
Estimasi nilai parameter memiliki dua cara, yaitu estimasi titik (point
estimation) dan estimasi selang (interval estimation).
a. Estimasi titik (point estimation)
Estimasi titik adalah estimasi dengan menyebut satu nilai atau untuk mengestimasi nilai parameter.
b. Estimasi interval (interval estimation)
Estimasi interval dengan menyebut daerah pembatasan dimana kita menentukan batas minimum dan maksimum suatu estimator. Metode ini memuat nilai-nilai estimator yang masih dianggap benar dalam tingkat kepercayaan tertentu (confidence interval).
2.2.1 Estimasi Maksimum Likelihood
Suatu cara yang penting untuk mendapat estimator yang baik adalah metode maksimum likelihood yang diperkenalkan oleh R. A. Fisher. Maksimum likelihood merupakan suatu cara mendapat estimator a untuk parameter b yang tidak diketahui dari populasi dengan memaksimumkan fungsi kemungkinan.
Untuk data sampel x1,…, xn dari distribusi yang kontinu dengan fungsi padat
f(x ; α) ditentukan fungsi likelihood sebagai L(x1,…, xn; α) = f(x1;α) … f(xn; α).
Untuk data sampel distribusi yang diskrit dengan nilai kemungkinan p(X = xi)
= pi(α), i = 1,…r dan frekuensi f1,…,fr ditentukan dengan fungsi likelihood sebagai:
(
)
(
( )
)
(
( )
)
∑
= = = n i i f r f i n p p f n x x L r 1 1,..., ; ... , 1 α α αKarena ln L merupakan transformasi yang monoton naik daripada L, maka ln L mencapai maksimumnya pada nilai α yang sama. Menurut hitung differensial persamaannya menjadi ln =0
∂ ∂
α
L
. Suatu akar persamaan ini αˆ =a
(
x1,...,xn)
yangmemaksimumkan L, disebut estimasi maksimum likelihood untuk α.
2.2.2 Maksimum Likelihood dalam Multiple Regresi
Maksimum likelihood adalah metode yang dapat digunakan untuk mengestimasi suatu parameter dalam regresi.
Jika X dikurangi dengan rata-ratanya, maka akan diperoleh variabel baru x
(
xi = Xi−X)
dan selisih antara Xidengan X merupakan perhitungan yang sederhana karena jumlah dari nilai xi tersebut adalah sama dengan nol
∑
= = 0 1 n i i x .ε β β β + + + + = k k i x x Y 0 1 1 (2.7) dimana:
Yi = variabel terikat ke-i
x1i,…, xki = selisih antara variabel bebas X dengan nilai rata-ratanya pada
pengamatan ke-i
k
β β
β0, 1,..., = parameter regresi ε = nilai kesalahan (error)
Teknik estimasi maksimum likelihood mempertimbangkan berbagai populasi yang mungkin dengan perpindahan garis regresi dan regresi tersebut mengelilingi distribusi untuk semua posisi yang mungkin. Perbedaan posisi yang berhubungan dengan perbedaan nilai percobaan untuk β0,β1,...,βk. Dalam hal ini, pengamatan likelihood Y1, Y2,…, Yn akan di estimasi. Untuk estimasi maksimum likelihood
dipilih hipotesis populasi yang maksimum dalam likelihood. Secara umum, andaikan kita mempunyai sampel berukuran n dan kita ingin mengetahui kemungkinan sampel yang diamati. Diperlihatkan fungsi nilai kemungkinan untuk β0,β1,...,βk:
(
Y Y Yn k)
p 1, 2,..., β0,β1,...,β (2.8) Mengingat kemungkinan nilai pertama Y adalah:
( )
( ) 2 1 1 0 1 2 1 1 2 1 − − + + + = σ β β β π σ ki k i x x Y e Y p (2.9)Hal di atas adalah distribusi normal sederhana dengan rata-rata
ki k i x x β β β0 + 1 1 ++ dan varians
( )
2σ yang disubstitusi ke dalam
( )
2 2 1 2 1 − − = σ µ π σ x e xp . Kemungkinan nilai kedua Y sama dengan (2.9), kecuali
Untuk nilai Y bebas dengan mengalikan semua kemungkinan bersama dalam (2.8), dimana:
(
Y Y Yn k)
p 1, 2,..., β0,β1,...,β ( ) ( ) = − + + + − − + + + − 2 1 1 0 2 2 1 1 0 1 2 1 2 1 2 1 2 1 β β σ β β β σ β π σ π σ ki k i ki k i x Y x x x Y e e ( )∏
= − + + + − = n i x x Yi i k ki e 1 2 1 2 1 1 0 2 1 β β σ β π σ (2.10) Dengan∏
= n i 1menyatakan hasil kali n kemungkinan bersama untuk nilai Yi
yang penggunaannya dikenal untuk eksponensial. Hasil (2.10) dapat diperlihatkan dengan penjumlahan eksponen:
(
)
( ) ( ) 2 1 1 1 0 2 1 1 0 2 1 2 1 ,..., , ,..., , ∑= − − + + + = n i ki k i i x x Y n k n e Y Y Y p σ β β β π σ β β β (2.11)Mengingat Yi amatan yang diberikan dipertimbangkan untuk berbagai nilai
k
β β
β0, 1,..., . Sehingga persamaan (2.11) dinamakan fungsi likelihood:
(
)
(
)
∑ = = − − − − − n i ki k i i x x Y n k e L 1 2 1 1 0 2 1 1 0 2 1 ,..., , σ β β β π σ β β β (2.12) dimana:(
k)
L β0,β1,...,β = fungsi maksimum likelihood pada parameter β0,β1,...,βk σ = parameter yang merupakan simpangan baku untuk distribusi π = nilai konstan (π = 3,1416)
n = banyak data sampel
e = bilangan konstan (e = 2,7183) Yi = variabel terikat ke-i
i
Dari persamaan (2.12) diperoleh ln L(β0,β1,...,βk), yaitu:
(
)
( )
∑
= − − − − − − − = = Λ n i ki k i i k x x Y n n L 1 2 1 1 0 1 0 2 1 ln 2 ln 2 ,..., , ln σ β β β σ π β β β (2.13)Dengan mendifferensialkan Λ terhadap setiap parameter β0,β1,...,βk dan menetapkan derivatif parsial yang dihasilkan sama dengan nol, diperoleh:
(
)
0 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 0 2 0 = = → = − − − − = = − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i ki n i i n i ki k n i i n i i n i ki k i i x x x x n Y x x Y β β β β β β σ β Y n Y n i i = = ⇒∑
=1 0 ˆ β (2.14)(
)
0 0 0 1 1 1 1 1 1 2 1 1 1 1 0 1 1 1 1 1 0 1 2 1 = → = + + + + − = = − − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i i n i ki i k n i i n i i n i i i n i ki k i i i x x x x x Y x x x Y x β β β β β β σ β 0 1 1 1 2 1 1 1 1 + + + = − ⇒∑
∑
∑
= = = n i ki i k n i i n i i iY x x x x β β (2.15)
(
)
0 0 0 1 1 1 2 1 1 1 1 0 1 1 1 1 0 2 = → = + + + + − = = − − − − − = ∂ Λ ∂∑
∑
∑
∑
∑
∑
= = = = = = n i ki n i ki k n i ki i n i ki n i i ki n i ki k i i ki k x x x x x Y x x x Y x β β β β β β σ β 0 1 2 1 1 1 1 = + + + − ⇒∑
∑
∑
= = = n i ki k n i ki i n i i kiY x x x x β β (2.16)Maka hasil yang diperoleh dari penurunan parsial di atas dapat dihitung nilai parameter βˆ0,βˆ1,,βˆk.