PENGEMBANGAN DAN IMPLEMENTASI SEGMENTASI WARNA
PADA PENGENALAN MEREK MINUMAN KALENG
MENGGUNAKAN METODE K-MEANS
Khaidir Aswad 1,Tulus 2, Sajadin Sembiring 3
Program Studi Teknik Informatika, Sekolah Tinggi Teknik Harapan Medan Jl. H.M. Jhoni No 70 Medan, Indonesia
ABSTRAK
K-means merupakan salah satu metode clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster. Segmentasi citra (image segmentation) mempunyai arti membagi suatu citra menjadi wilayah-wilayah yang homogen berdasarkan kriteria keserupaan yang tertentu antara tingkat keabuan suatu piksel dengan tingkat keabuan piksel - piksel tetangganya, kemudian hasil dari proses segmentasi ini akan digunakan untuk proses identifikasi objek atau pengenalan objek. Pada penelitian ini penulis menggunakan metode K-Means dan jumlah cluster ditetapkan sejumlah empat buah. Keempat pusat cluster dijadikan sumber pembelajaran untuk mengenali objek. Objek yang digunakan adalah citra kaleng minuman.
Kata kunci : Segmentasi Citra, Pengolahan Citra, K-Means.
ABSTRACT
K-means is a non hierarchical clustering method that seeks to partition the data into the form of one or more clusters. Image segmentation (image segmentation) is of dividing an image into regions homogeneous criteria similarity certain between the gray level of a pixel with a gray level of pixels - pixel neighbor, then the result of the segmentation process will be used for the identification of objects or object recognition , In this study the authors use the method of K-means and the number of clusters was determined at four. The fourth cluster center used as a source of learning to recognize objects. The object used is the image of beverage cans.
Keywords: Image Segmentation, Image Processing, K-Means .
1. PENDAHULUAN
Pada era sekarang ini komputer digunakan sebagai alat bantu dalam banyak hal. Seiring perkembangannya, komputer hampir dapat mengerjakan seluruh pekerjaan manusia. Kecerdasan komputer merupakan hasil dari penciptaan oleh manusia dari waktu-kewaktu. Istilah yang sering muncul dari pemanfaatan teknologi komputer adalah otomatisasi. Dimana hampir semua pekerjaan sudah dikerjakan oleh mesin.
Citra adalah gambar pada bidang dua dimensi. Citra merupakan suatu representasi (gambaran), kemiripan, atau imitasi dari suatu objek [4]. Citra merupakan data yang dapat diolah menjadi informasi. Proses pengolahan data menjadi informasi sangat diperlukan untuk keperluan tertentu. Dalam penelitian ini diupayakan citra dapat dapat dikelali oleh komputer. Melalui sebuah teknik pengolahan citra, komputer dapat menyajikan informasi berupa merek minuman yang terdapat di dalam citra.
Segmentasi citra (image segmentation)
mempunyai arti membagi suatu citra menjadi wilayah-wilayah yang homogen berdasarkan kriteria keserupaan yang tertentu antara tingkat keabuan suatu piksel dengan tingkat keabuan piksel - piksel tetangganya, kemudian hasil dari proses
segmentasi ini akan digunakan untuk proses identifikasi objek atau pengenalan objek.
Pada penelitian ini, penulis mencoba menggunakan algoritma k-means untuk melakukan segmentasi citra. K-means merupakan salah satu metode clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster. Metode ini mempartisi data ke dalam cluster sehingga data yang memiliki karakteristik yang sama dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karateristik yang berbeda di kelompokan ke dalam cluster yang lain. Algoritma ini cukup efektif untuk meng clusterkan data atau piksel.
Hasil dari sebuah proses segmentasi citra adalah informasi berupa cluster-cluster warna.
Cluster-cluster adalah berupa kumpulan warna
homogen yang memiliki ciri khas yang dapat dijadikan sumber informasi untuk pembelajaran komputer. Dari hasil pembelajaran diharapkan komputer dapat mengenali merek-merek minuman kaleng yang di inputkan.
Metode pembelajaran komputer yang
digunakan adalah pencocokan pusat cluster akhir citra pembelajaran dengan citra uji. Pusat cluster pembelajaran akan dijadikan acuan untuk mengenali objek uji coba pengenalan merek minuman kaleng.
Pada sebuah penelitian dengan judul Segmentasi Buah Menggunakan Metode K-Means
Clustering Dan Identifikasi Kematangannya Menggunakan Metode Perbandingan Kadar Warna dibuat menggunakan matlab, meneliti tentang pengenalan kematangan buah. Penelitian lain yaitu Analisis Segmentasi Citra USG Hati Menggunakan Metode Fuzzy C-Means. Penilitian yang penulis buat mengangkat tentang bagaimana mengenali merek minuman menggunakan perbandingan kadar warna menggunakan bahasa pemrograman visual
basic.
a. Rumusan Masalah
Berdasarkan uraian dari latar belakang di atas, yang menjadi rumusan masalah dalam tugas akhir ini adalah segmentasi citra menggunakan metode K-Means untuk pengenalan merek minuman kaleng.
b. Tujuan Penelitian
Adapun tujuan dari penulisan tugas akhir ini adalah mengimplementasikan segmentasi citra untuk pengenalan merek.
2. METODE PENELITIAN
a. Tahapan Metode Penelitian
Dalam menulis tugas akhir ini penulis melakukan penelitian terhadap sistem yang sedang diterapkan. Adapun langkah – langkah penelitian adalah sebagai berikut :
1. Studi Pustaka
Tahap ini adalah tahap pencarian informasi dan studi literatur yang diperlukan untuk mengumpulkan data dan memahami metode yang akan digunakan. Informasi didapat melalui buku-buku, jurnal teori-teori
pendukung yang berhubungan dengan
penelitian yang didapat dari internet. 2. Analisa Metode
Pada tahap ini dilakukan analisa metode yang akan digunakan. Seperti menghitung rumus-rumus matematika secara lebih detil. Kemudian melakukan perancangan langkah-langkah yang harus dilakukan dalam bentuk algoritma.
3. Implementasi Metode
Pada tahap ini yaitu pembuatan program dengan menggunakan bahasa pemrograman Visual Studio 2010. Yang merupakan inplementasi metode yang digunakan dalam bentuk bahasa pemrograman yang dimengerti oleh sistem komputer.
4. Uji Coba dan Evaluasi
Pada tahap ini dilakukan ujicoba terhadap aplikasi yang dibuat, tujuannya untuk
menemukan kesalahan-kesalahan yang
mungkin terjadi serta melakukan perbaikan atas kesalahan aplikasi.
b. Spesifikasi Perangkat Keras
Tahap analisis ini ialah berupa tahap identifiksi kebutuhan-kebutuhan apa saja yang dibutuhkan dalam merancang aplikasi pengenalan merek minuman kaleng menggunakan metode k-means. Kebutuhan-kebutuhan tersebut akan meliputi kebutuhan perangkat keras dan kebutuhan perangkat lunak dalam membangun aplikasi. Berikut kebutuhan-kebutuhan sistem yang akan dibangun.
Dalam membangun aplikasi ini diperlukan beberapa perangkat keras dalam impelemtasinya. Berikut ialah beberapa perangkat keras yang dibutuhkan dalam merancang aplikasi pengenalan merek minuman kaleng menggunakan metode k-means meliputi:
1. Satu unit PC dengan spesifikasi antara lain: 2. Prosesor : Intel(R) Core(TM) i3 CPU 3. Memori : 2 Gb
4. Ruang Penyimpan : 500 Gb
Selain perangkat keras diatas, dalam membangun aplikasi ini diperlukan pula beberapa perangkat lunak termasuk bahasa pemrograman yang digunakan dalam impelemtasinya. Berikut ialah beberapa perangkat lunak yang dibutuhkan dalam merancang aplikasi pengenalan merek minuman kaleng menggunakan metode k-means meliputi:
1. Sistem Operasi Microsoft Windows 7 Ultimate 32 bit.
2. Visual Basic 2010
c. Pengenalan Citra
Citra (image) atau istilah lain untuk gambar sebagai salah satu komponen multimedia memegang peranan sangat penting sebagai bentuk informasi visual. Secara umum, pengolahan citra digital menunjuk pada pemrosesan gambar 2 dimensi menggunakan komputer. Dalam konteks yang lebih luas, pengolahan citra digital mengacu pada pemrosesan setiap 2 data dimensi. Citra digital merupakan larik (array) yang berisi nilai-nilai real maupun komplek yang di representasikan dengan bit tertentu [1].
Meskipun sebuah citra kaya akan informasi, namun sering kali citra yang dimiliki mengalami penurunan mutu, misalnya mengandung cacat atau
noise. Tentu saja citra semacam ini menjadi lebih
sulit untuk diinterpretasikan karena informasi yang disampaikan oleh citra tersebut menjadi berkurang, agar citra yang mengalami gangguan mudah diinterprestasikan (baik oleh manusia maupun dengan mesin) maka citra perlu di olah atau dimanipulasi sehingga kualitas dan hasil lebih baik. Sebuah citra mempunyai karakterisrik yang tidak dimiliki oleh data teks yaitu, citra kaya dengan informasi karena dapat menyampaikan informasi yang imajinatif (dapat dihayalkan) [1].
Citra yang baik merupakan citra yang dapat menampilkan gambar yang bersih dan secara utuh, seperti pada keindahan gambar dan kejelasan gambar tanpa mengurangi dan tanpa mengubah informasi yang terkandung pada sebuah gambar atau citra.
d. Pengertian Citra Analog
Citra analog adalah citra yang bersifat kontinu, seperti gambar pada monitor televisi, foto sinar X, foto yang tercetak di kertas foto, lukisan, pemandangan alam, hasil CT scan, gambar-gambar yang terekam pada pita kaset, dan lain sebagainya. Citra analog tidak dapat direpresentasikan dalam komputer sehingga tidak bisa diproses di komputer secara langsung. Oleh sebab itu, agar citra ini dapat diproses di komputer, proses konversi analog ke digital harus dilakukan terlebih dahulu. Citra analog dihasilkan dari alat-alat analog, seperti video kamera analog, seperti video kamera analog, kamera foto analog, WebCam, CT scan, sensor rontgen untuk foto thorax, sensor gelombang pendek pada sistem radar, sensor ultrasound pada sistem USG, dan lain sebagainya [2].
Hampir semua kejadian alam boleh diwakili sebagai perwakilan analog seperti bunyi, cahaya, air, elektrik, angin dan sebagainya. Jadi citra analog adalah citra yang terdiri dari sinyal–sinyal frekuensi elektromagnetis yang belum dibedakan sehingga pada umumnya tidak dapat ditentukan ukurannya [5].
e. Pengertian Citra Digital
Secara umum, pengolahan citra digital menunjuk pada pemrosesan gambar 2 dimensi menggunakan komputer. Dalam konteks yang lebih luas, pengolahan citra digital lebih mengacu pada pemrosesan setiap 2 data dimensi. Citra digital merupakan sebuah larik (array) yang berisi nilai-nilai real maupun kompleks yang di representasikan dengan deretan bit tertentu.
Suatu citra dapat didefenisikan sebagai fungis f (x,y), berukuran M baris dan N kolom, dengan x dan y adalah koordinat spasial, dan amplitudo f dititik koordinat (x,y) dinamakan intensitas atau tingkat kaabuan dari citra pada titik tersebut. Apabila nilai x,y dan nilai amplitudo f secara keseluruhan berhingga (finite) dan bernilai diskrit maka dapat dikatakan bahwa citra tersebut adalah citra digital.
Sebuah citra digital terdiri dari sejumlah element yang berhingga, dimana masing-masing mempunyai lokasi dan nilai tertentu. Elemen – elemen ini disebut sebagai picture element, image element, pels, atau pixel [1].
Citra digital adalah gambar dua dimensi yang dihasilkan dari gambar analog dua dimensi yang kontinus menjadi gambar diskrit melalui proses sampling. Agar dapat direpresentasikan secara numeric dengan nilai-nilai diskrit. Representasi citra dari fungsi malar (kontinu) menjadi nilai-nilai diskrit disebut digitalisasi. Citra yang dihasilkan inilah yang disebut digital (Digital Image) [4].
Komputer digital bekerja dengan angka-angka presisi terhingga, dengan demikian hanya citra dari kelas diskrit yang dapat diolah dengan komputer. Citra dari kelas tersebut lebih dikenal sebagai citra digital. Citra digital dinyatakan dalam suatu array dua dimensi atau suatu matriks yang
elemen-elemennya menyatakan tingkat keabuan
(grayscale) dari warna masing-masing pixel. Pixel merupakan elemen terkecil dari suatu citra, yakni berupa titik-titik warna yang membentuk citra. Citra digital tidak selalu harus merupakan hasil langsung dari rekaman suatu sistem digital, namun ada juga rekaman data bersifat kontinu seperti pada gambar monitor televisi, foto sinar-X, dapat juga berasal dari yang telah mengalami suatu konversi, sehingga citra tersebut selanjutnya dapat diproses melalui komputer.
f. Segmentasi Citra
Segmentasi citra adalah proses pengolahan citra yang bertujuan memisahkan wilayah (region) objek dengan wilayah latar belakang agar objek mudah dianalisis dalam rangka mengenali objek yang banyak melibatkan persepsi visual [8].
Segmentasi citra merupakan proses yang ditujukan untuk mendapatkan objek-objek yang terkandung di dalam citra atau membagi citra ke dalam beberapa daerah dengan setiap objek atau daerah yang memiliki kemiripan atribut (homogen). Pada citra yang hanya mengandung satu objek, objek dibedakan dari latar belakangnya. Teknik segmentasi citra didasarkan pada dua properti dasar nilai aras keabuan:
ketidaksinambungan dan kesamaan antarpiksel. Pada bentuk pertama, pemisahan citra didasarkan pada perubahan mendadak pada aras keabuan. Contoh yang menggunakan pendekatan seperti itu adalah detektor garis dan detektor tepi pada citra. Cara kedua didasarkan pada kesamaan antar piksel dalam suatu area. Termasuk dalam cara kedua ini yaitu :
a. Pengambangan berdasarkan histogram b. Pertumbuhan area
c. Pemisahan dan penggabungan area d. Pengelompokan atau klasifikasi e. Pendekatan teori graf
f. Pendekatan yang dipadukan pengetahuan atau berbasis aturan
Berdasarkan teknik yang digunakan, segmentasi dapat dipagi menjadi empat kategori, yaitu :
(1) Teknik peng-ambangan (2) Metode berbasis batas (3) Metode berbasis area
(4) Motode hibrid yang mengkombinasikan kriteria batas dan area
Segmentasi biasa dilakukan sebagai langkah awal untuk melaksanakan klasifikasi objek. Setelah segmentasi citra dilaksanakan, fitur yang terdapat pada objek diambil. Selanjutnya melalui klasifikasi, jenis objek dapat ditentukan.
Prinsip kerja segmentasi adalah membagi citra ke dalam daerah intensitasnya masing-masing sehingga dapat dibedakan antara objek dan background-nya. Pembagian ini tergantung pada masalah yang akan diselesaikan. Segmentasi harus dihentikan apabila masing-masing objek telah terisolasi atau terlihat dengan jelas.
Secara umum algoritma segmentasi citra terbagi dalam dua macam:
a. Diskontinuitas, yaitu berdasarkan perbedaan dalam intensitasnya, seperti titik, garis atau tepi (edge).
b. Similaritas, yaitu berdasarkan kesamaan-kesamaan kriteria yang dimilikinya, seperti algoritma Thresholding, Region Merging, Region Splitting dan Region Growing [2]. Algoritma Thresholding adalah segmentasi citra berbasis histogram, dimana bila sebuah citra terbagi menjadi dua wilayah, maka global thresholding dapat digunakan untuk mendapatkan nilai threshold T yang tepat sehingga bagian objek dan latar belakang citra dapat ditentukan.
Algoritma Region Merging adalah segmentasi yang melakukan proses perhitungan karakteristik masing-masing daerah (region). Bagian citra yang memiliki karakteristik yang sama akan digabung dan dianggap satu bagian, sedangkan bagian yang memiliki karakteristik yang berbeda dilakukan pembagian dan perhitungan karakteristik kembali sampai seluruh bagian citra mempunyai karakteristik yang sama..
Dengan membandingkan kedua algoritma segmentasi citra diatas, maka akan dapat diketahui parameter yang tepat untuk setiap algoritma.
Parameter yang tepat berguna untuk
memaksimumkan kinerja algoritma dalam melakukan perbaikan citra [7]/
g. Clustering K-Means
K-means clustering merupakan metode yang
paling populer digunakan untuk mendapatkan deskripsi dari sekumpulan data dengan cara mengungkapkan kecenderungan setiap data lainnya.
Kecenderungan pengelompokkan tersebut
didasarkan pada kemiripan karakteristik individu-individu data yang ada. Ide dasar dari teknik ini adalah menemukan pusat dari setiap kelompok data
yang mungkin ada untuk kemudian
mengelompokkan setiap data individu kedalam salah satu dari kelompok-kelompok tersebut berdasarkan jaraknya. Untuk menentukan pusat
yang paling sesuai sebagai upaya
merepresentasikan posisi dari sebuah kelompok data terhadap kelompok data yang lainnya dilakukan sebuah proses perulangan. Proses perulangan ini dimulai dengan menentukan secara sembarang posisi dari pusat-pusat kelompok yang telah ditetapkan. Selanjutnya ditentukan keanggotaan setiap individu data berdasarkan jarak terpendek terhadap pusat-pusat tersebut. Pada iterasi kedua dan seterusnya dilakukan pembaharuan posisi pusat untuk semua kelompok. Selanjutnya dilakukan pembaharuan keanggotaan untuk setiap kelompok.
K-Means merupakan metode klasterisasi yang
paling terkenal dan banyak digunakan di berbagai
bidang karena sederhana, mudah
diimplementasikan, memiliki kemampuan untuk mengklaster data yang besar, mampu menangani data outlier, dan kompleksitas waktunya linear
O(nKT) dengan n adalah jumlah dokumen, K adalah jumlah kluster, dan T adalah jumlah iterasi.
K-means merupakan metode pengklasteran secara
partitioning yang memisahkan data ke dalam kelompok yang berbeda. Dengan partitioning secara iteratif, Kmeans mampu meminimalkan rata-rata jarak setiap data ke klasternya. Metode ini dikembangkan oleh Mac Queen pada tahun 1967.
K-means clustering merupakan salah satu
metode data clustering non-hirarki yang mengelompokan data dalam bentuk satu atau lebih
cluster/kelompok. Data-data yang memiliki karakteristik yang sama dikelompokan dalam satu
cluster/kelompok dan data yang memiliki karakteristik yang berbeda dikelompokan dengan
cluster/kelompok yang lain sehingga data yang
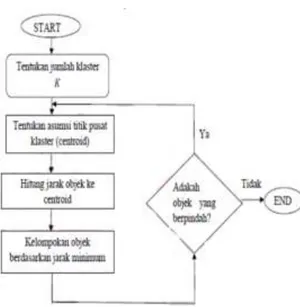
berada dalam satu cluster/kelompok memiliki tingkat variasi yang kecil [6], langkah-langkah melakukan clustering dengan metode K-Means adalah sebagai berikut:
a. Pilih jumlah cluster k.
b. Inisialisasi k pusat cluster ini bisa dilakukan dengan berbagai cara. Namun yang paling sering dilakukan adalah dengan cara random. Pusat-pusat cluster diberiduberi nilai awal dengan angka-angka random,
c. Alokasikan semua data / objek ke cluster terdekat. Kedekatan dua objek ditentukan berdasarkan jarak kedua objek tersebut. Demikian juga kedekatan suatu data ke cluster tertentu ditentukan jarak antara data dengan pusat cluster. Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat cluster. Jarak paling antara satu data dengan satu cluster tertentu akan menentukan suatu data masuk dalam cluster mana. Untuk menghiutng jarak semua data ke setiap tiitk pusat cluster dapat menggunakan teori jarak Euclidean yang dirumuskan sebagai berikut:
dimana:
D (i,j) = Jarak data ke i ke pusat cluster j Xki = Data ke i pada atribut data ke k Xkj = Titik pusat ke j pada atribut ke k
d. Hitung kembali pusat cluster dengan keanggotaan cluster yang sekarang. Pusat cluster adalah rata-rata dari semua data/ objek dalam cluster tertentu. Jika dikehendaki bisa juga menggunakan median dari cluster tersebut. Jadi rata-rata (mean) bukan satu-satunya ukuran yang bisa dipakai.
e. Tugaskan lagi setiap objek memakai pusat cluster yang baru. Jika pusat cluster tidak berubah lagi maka proses clustering selesai. Atau, kembali ke langkah nomor 3 sampai pusat cluster tidak berubah lagi [3].jak
Gambar 1. Algoritma K-Means
[3]
3. HASIL DAN PEMBAHASAN
Implementasi dari perancangan aplikasi pengenalan merek minuman kaleng menggunakan metode K-Means.
a. Implementasi Sistem
Tahap implementasi sistem ini merupakan tahap dimana sistem yang telah di rancang kemudian dapat diimplementasikan. Agar sistem yang dirancang dapat berjalan dengan baik atau tidak, maka perlu dilakukan pengujian terhadap sistem yang dirancang. Dalam tahap implementasi sistem ini penulis akan memaparkan hasil penelitian ini yaitu aplikasi pengenalan merek minuman kaleng menggunakan metode K-Means dengan meliputi penjelasan mengenai persiapan aplikasi, dan pengujian aplikasi yaitu dengan menampilkan hasil dari layout/desain antarmuka sistem yang telah dibangun menggunakan bahasa pemrograman Visual Basic 2010.
b. Pengujian Sistem
Tahap pengujian sistem ini akan dijelaskan bagaimana proses pengujian aplikasi yang telah dibangun, dimana tahap pengujian akan dilakukan dalam 2 tahap yaitu pengujian hasil berupa pengujian melalui tampilan hasil aplikasi dan pengujian melalui salah satu teknik pengujian sistem berupa pengujian blackbox.
c. Form Utama
Pada saat pertama kali program dijankan form utama akan tampil pertama kali. Fungsinya sebagai form induk bagi form-form lain. Berikut adalah tampilan form utama:
Gambar 2. Tampilan Form Utama
Pada form utama terdapat empat menu yaitu Training, Pengujian, Petunjuk dan Tentang.
d. Form Training
Form ini fungsinya untuk melakukan pembelajaran komputer untuk mengenali citra minuman kaleng yang akan diuji, berikut tampilan formnya:
Gambar 3. Tampilan Form Pembelajaran
Pada gambar 3 diatas adalah tampilan form pembelajaran pengenalan merek minuman kaleng. Pada iterasi ke-7 pusat cluster tidak berubah lagi, sehingga proses berhenti. Pada pembelajaran diatas data yang akan disimpan sebagai pembelajaran adalah data pusat cluster terakhir.
e. Form Pengujian
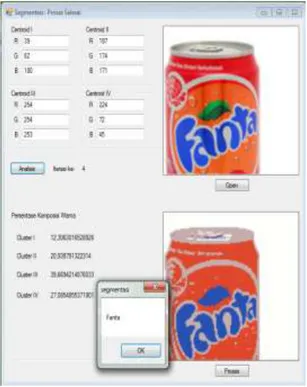
Form ini digunakan untuk menguji aplikasi dalam mengenali merk minuman kaleng. Berikut adalah tampilannya:
Gambar 4. Pengujian pengenalan merek minuman
Fanta
Pada gambar 4 dapat dilihat citra kaleng fanta di crop dan selanjutnya diproses. Titik pusat
cluster pembelajaran dan pengujian memiliki
kemiripan. Setelah dibandingkan dengan seluruh data didapat hasil merek adalah Fanta sehingga pengujian ini dikatakan berhasil.
Untuk pengujian pengenalan merek
berdasarkan persentase jumlah warna. Hasil kurang akurat dibandingkan dengan pusat cluster terakhir.
f. Form Petunjuk
Form petunjuk ini isinya petunjuk penggunaan aplikasi pengenalan merek minuman kaleng. Berikut tampilan formnya:
Gambar 5. Tampilan Form Petunjuk
g. Form Tentang
Form tentang ini fungsinya untuk menampilkan tentang pembuat aplikasi. Berikut tampilan form tentang:
Gambar 6. Tampilan Form Tentang
h. Analisis Hasil Pengujian Pengujian
Pengujian akan dilakukan pada lima buah citra yang dilakukan dua tahap yaitu pengujian proses pembelajaran dan pengujian proses pengenalan merek.
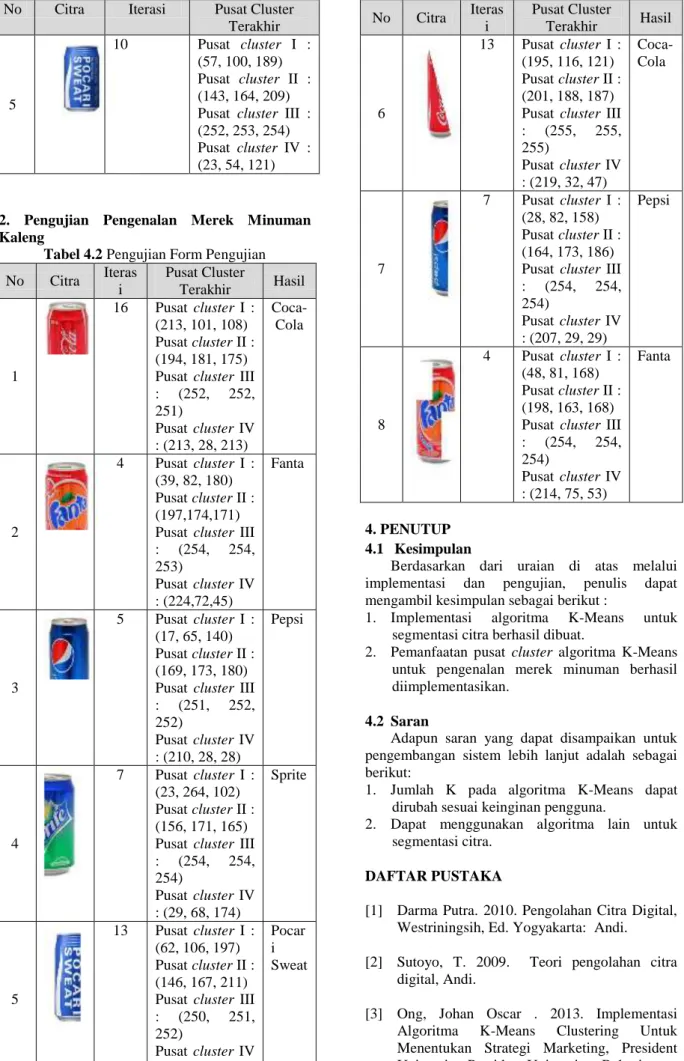
1. Pengujian pembelajaran
Tabel 4.1 Pengujian Form Pembelajaran
No Citra Iterasi Pusat Cluster
Terakhir 1 19 Pusat cluster I : (203, 112, 117) Pusat cluster II : (198, 187, 183) Pusat cluster III : (255, 254, 254) Pusat cluster IV : (217, 31, 45) 2 7 Pusat cluster I : (43, 83, 178) Pusat cluster II : (194, 166, 165) Pusat cluster III : (254, 254, 254) Pusat cluster IV : (223, 72, 51) 3 6 Pusat cluster I : (21, 77, 157) Pusat cluster II : (160, 168, 177) Pusat cluster III : (253, 253, 253) Pusat cluster IV : (208, 28, 28) 4 7 Pusat cluster I : (22, 165, 104) Pusat cluster II : (159, 172, 165) Pusat cluster III : (254, 254, 254) Pusat cluster IV : (31, 72, 175)
No Citra Iterasi Pusat Cluster Terakhir 5 10 Pusat cluster I : (57, 100, 189) Pusat cluster II : (143, 164, 209) Pusat cluster III : (252, 253, 254) Pusat cluster IV : (23, 54, 121)
2. Pengujian Pengenalan Merek Minuman Kaleng
Tabel 4.2 Pengujian Form Pengujian
No Citra Iteras i Pusat Cluster Terakhir Hasil 1 16 Pusat cluster I : (213, 101, 108) Pusat cluster II : (194, 181, 175) Pusat cluster III : (252, 252, 251) Pusat cluster IV : (213, 28, 213) Coca-Cola 2 4 Pusat cluster I : (39, 82, 180) Pusat cluster II : (197,174,171) Pusat cluster III : (254, 254, 253) Pusat cluster IV : (224,72,45) Fanta 3 5 Pusat cluster I : (17, 65, 140) Pusat cluster II : (169, 173, 180) Pusat cluster III : (251, 252, 252) Pusat cluster IV : (210, 28, 28) Pepsi 4 7 Pusat cluster I : (23, 264, 102) Pusat cluster II : (156, 171, 165) Pusat cluster III : (254, 254, 254) Pusat cluster IV : (29, 68, 174) Sprite 5 13 Pusat cluster I : (62, 106, 197) Pusat cluster II : (146, 167, 211) Pusat cluster III : (250, 251, 252) Pusat cluster IV : (25, 65, 153) Pocar i Sweat No Citra Iteras i Pusat Cluster Terakhir Hasil 6 13 Pusat cluster I : (195, 116, 121) Pusat cluster II : (201, 188, 187) Pusat cluster III : (255, 255, 255) Pusat cluster IV : (219, 32, 47) Coca-Cola 7 7 Pusat cluster I : (28, 82, 158) Pusat cluster II : (164, 173, 186) Pusat cluster III : (254, 254, 254) Pusat cluster IV : (207, 29, 29) Pepsi 8 4 Pusat cluster I : (48, 81, 168) Pusat cluster II : (198, 163, 168) Pusat cluster III : (254, 254, 254) Pusat cluster IV : (214, 75, 53) Fanta 4. PENUTUP 4.1 Kesimpulan
Berdasarkan dari uraian di atas melalui implementasi dan pengujian, penulis dapat mengambil kesimpulan sebagai berikut :
1. Implementasi algoritma K-Means untuk segmentasi citra berhasil dibuat.
2. Pemanfaatan pusat cluster algoritma K-Means untuk pengenalan merek minuman berhasil diimplementasikan.
4.2 Saran
Adapun saran yang dapat disampaikan untuk pengembangan sistem lebih lanjut adalah sebagai berikut:
1. Jumlah K pada algoritma K-Means dapat dirubah sesuai keinginan pengguna.
2. Dapat menggunakan algoritma lain untuk segmentasi citra.
DAFTAR PUSTAKA
[1] Darma Putra. 2010. Pengolahan Citra Digital, Westriningsih, Ed. Yogyakarta: Andi. [2] Sutoyo, T. 2009. Teori pengolahan citra
digital, Andi.
[3] Ong, Johan Oscar . 2013. Implementasi Algoritma K-Means Clustering Untuk Menentukan Strategi Marketing, President University, President University : Bekasi.
[4] Achmad, Balza dan Kartika Firdausy. 2005.
Teknik Pengolahan Citra Digital
Menggunakan Delphi, Yogyakarta: Ardi Group.
[5] Munir, R. 2004. Pengolahan Citra Digital, Informatika. Bandung.
[6] Nurullah. 2012. Perancangan Dan Pembuatan Sistem Informasi Akuntansi Pada Stmik U’budiyah Menggunakan Vb.Net, Vol1.No.7 Hal.39-69.
[7] Anhar, 2009, PHP & MySQL Secara Otodidak, Mediakita, Jakarta.
[8] Destyningtias B., Heranurweni S. dan T. Nurhayati. 2010. Segmentasi Citra Dengan Metode Pengambangan, Jurnal Elektrika. Vol.2, No.1, 2010: 39– 49.