1274
KLASIFIKASI CITRA FORMULIR MENGGUNAKAN METODE SUPPORT
VECTOR MACHINE (SVM) PADA PROSES DIGITALISASI FORMULIR
Dewi Pramudi Ismi 1), Ardiansyah 2) 1
Program Studi Teknik Informatika, Fakultas Teknologi Industri, Universitas Ahmad Dahlan email: [email protected]
2 Program Studi Teknik Informatika, Fakultas Teknologi Industri, Universitas Ahmad Dahlan
email: [email protected] Abstract
Dalam berbagai keperluan administrasi, pengisian formulir/borang secara manual masih banyak dilakukan di Indonesia. Hal ini menyebabkan terdapat banyak data yang masih tersimpan dalam bentuk kertas (hardcopy). Data-data tersebut perlu diubah ke dalam bentuk digital agar dapat disimpan dan diolah lebih lanjut menggunakan komputer. Pada kondisi saat ini, peng-input-an data dari kertas (hardcopy) ke dalam bentuk softcopy pada komputer pada umumnya dilakukan oleh operator manusia. Proses ini tentunya membutuhkan waktu, tenaga dan biaya yang tidak sedikit jika data yang harus diubah ke dalam bentuk digital berjumlah banyak. Penelitian ini adalah bagian awal dari penelitian besar yang bertujuan untuk melakukan digitalisasi data formulir/borang secara otomatis. Penelitian ini memiliki objektif yaitu melakukan klasifikasi citra hasil scan dokumen formulir/borang. Metode yang digunakan pada klasifikasi ini adalah Support Vector Machine (SVM). Klasifikasi citra dilakukan dengan menggunakan 100 data training dan 50 data testing yang terdiri dari citra formulir/borang dan citra non formulir/borang. Output dari penelitian ini adalah perangkat lunak yang mampu mengidentifikasi citra yang merupakan citra formulir/borang dan citra non formulir/borang. Dari hasil pengujian yang dilakukan, ketepatan klasifikasi citra formulir/borang dengan metode SVM ini mencapai 98%.
Keywords: pengolahan citra, klasifikasi, support vector machine, digitalisasi formulir/borang
1. PENDAHULUAN
Salah satu tujuan dari e-government menurut [1] adalah terciptanya managemen yang efisien bagi pemerintah sehingga dapat menekan biaya operasional, transparansi data, dan meningkatnya kenyamanan birokrasi. Di negara Republik Indonesia kebijakan mengenai e-government tertuang dalam Peraturan Presiden no. 3 tahun 2003 yang meliputi (a) pengembangan pelayanan atau servis yang terpercaya dan dapat dijangkau, (b) restrukturisasi sistem management dan proses kerja pemerintah daerah dan pemerintan pusat, (c) pemanfaatan teknologi informasi yang optimal, (d) peningkatan partisipasi dari sektor bisnis serta
perkembangan industri TIK, (e)
pengembangan sumber daya manusia pada instansi pemerintah dan peningkatan e-literacy, serta (f) pengembangan
e-government yang sistematis, realistis dan terukur.
Peraturan Presiden tersebut dilengkapi dengan guideline tentang pengembangan
e-government yang dikeluarkan oleh
Departemen Komunikasi dan Informatika pada tahun 2003. Guideline yang dikeluarkan tersebut berkaitan dengan (a) pengembangan infrastruktur portal pemerintah, (b) pengelolaan dokumen elektronik pemerintah, (c) rencana pengembangan e-government, (d)
pelatihan TIK untuk mendukung
implementasi e-government, (e) serta implementasi website dari pemerintah daerah.
Berkaitan dengan pengelolaan dokumen elektronik pemerintah, pada berbagai instansi di Indonesia, dokumen-dokumen yang berupa hardcopy masih digunakan. Dalam berbagai keperluan administrasi, pengisian formulir/borang secara manual masih
1275
dilakukan. Penyebab terbesar penggunaan dokumen hardcopy adalah belum adanya implementasi aplikasi paperless pada instansi-instansi terkait. Sebagai contoh, untuk pembuatan Kartu Tanda Penduduk (KTP) yang baru atau untuk mengubah informasi pada KTP, seseorang harus mengisi formulir/borang permohonan yang berbentuk hardcopy. Tidak hanya pembuatan KTP, dalam administrasi kependudukan yang
lainnya juga masih menggunakan
formulir/borang hardcopy. Hal ini menyebabkan terdapat banyak data yang masih tersimpan dalam bentuk kertas (hardcopy) pada instansi pemerintah.
Data-data yang berbentuk hardcopy tersebut perlu diubah ke dalam bentuk digital agar dapat disimpan dan diolah lebih lanjut menggunakan komputer. Pada kondisi saat ini, peng-input-an data dari kertas (hardcopy) ke dalam bentuk softcopy pada komputer pada umumnya dilakukan oleh operator manusia. Proses ini tentunya membutuhkan waktu, tenaga dan biaya yang tidak sedikit jika data yang harus diubah ke dalam bentuk digital berjumlah banyak. Pemanfaatan teknologi informasi secara umum, dan sistem cerdas
secara khusus, dapat membantu
menyelesaikan permasalahan digitalisasi formulir/borang secara otomatis.
Penelitian ini merupakan bagian awal dari penelitian besar yaitu membangun sistem yang dapat membaca dan mengekstrak data yang terdapat pada citra hasil scan formulir (digitalisasi formulir /smart paperwork system). Pada penelitian ini, dilakukan klasifikasi citra formulir dan citra non formulir. Hasil yang diharapkan adalah sebuah sistem yang mampu mengindentifikasi citra yang merupakan hasil scan formulir dan citra non formulir.
2. KAJIAN LITERATUR
Pada bagian ini akan dipaparkan kajian teori tentang klasifikasi, metode Support Vector Machine, dan klasifikasi citra.
a. Klasifikasi
Klasifikasi merupakan proses analisis data untuk memperoleh label atau kelas dari data yang belum
diketahui label/kelasnya berdasarkan data-data historis yang telah diketahui label atau kelasnya [2]. Label atau kelas bersifat diskret dan jumlahnya terbatas. Pada klasifikasi, model atau classifier dibagun dengan data-data historis yang diketahui label/kelasnya melalui proses training. Data yang digunakan pada fase training disebut data training.
Setelah model dibentuk,
pengujian dilakukan untuk
mengetahui kualitas model/classifier.
Pengujian dapat dilakukan
menggunakan data-data baru, yaitu data-data yang tidak digunakan pada proses training. Pengujian juga dapat dilakukan dengan data-data yang sudah digunakan pada proses training sejumlah porsi tertentu. Pengujian yang kedua ini disebut sebagai cross validation [3].
b. Support Vector Machine (SVM) Support Vector Machine (SVM) pertama kali diperkenalkan oleh Vladimir Vapnik, Bernhard Boser, dan Isabell Guyon pada tahun 1972.
Konsep dasar SVM adalah
menggunakan garis lurus untuk memisahkan dua kelas data yang berbeda. Karena menggunakan garis lurus, maka dua kelas data yang dapat dipisahkan dengan cara demikian disebut sebagai linearly separable. Sedangkan dua kelas yang tidak dapat dipisahkan dengan menggunakan garis lurus disebut sebagai non linearly separable.
Untuk memisahkan dua kelas data yang berbeda, terdapat banyak garis lurus yang mungkin dibuat. Oleh karena itu, pada SVM dipilih sebuah garis lurus yang dapat memisahkan kedua kelas data dengan minimal kesalahan pengelompokan (mis-classification) yang dihasilkan. Dengan kata lain garis lurus yang dipilih adalah garis lurus yang
1276
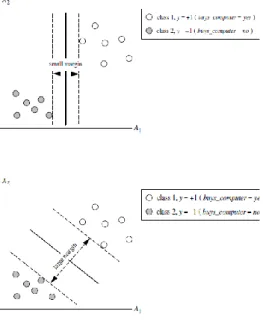
memiliki margin terbesar untuk memisahkan kedua kelas data. Garis lurus yang demikian adalah garis lurus dimana jarak terpendek antara garis tersebut dengan data di kelas pertama sama dengan jarak terpendek garis tersebut dengan data pada kelas kedua. Gambar 1 berikut ini menunjukkan garis lurus yang memiliki margin yang besar dan garis lurus yang memiliki margin yang kecil.
Gambar 1. Garis lurus pemisah dua kelas yang memiliki margin kecil dan margin besar
Pada data yang lebih dari dua dimensi (memiliki lebih dari dua atribut/fitur), maka garis pemisah antar kelas adalah sebuah bidang yang disebut sebagai hyperplane.
Fungsi hyperplane atau garis lurus didefinisikan seperti pada persamaan (1).
w0+w1x1+w2x2 = 0
……….(1)
Kelas pertama berada di atas garis lurus, sedangkan kelas kedua berada di bawah garis lurus.
Persamaan (2) dan persamaan (3) adalah adjustment (lihat garis putus-putus pada Gambar 2) dari persamaan 1 sehingga terlihat margin
yang memisahkan kelas pertama dan kelas kedua:
H1 :w0+w1x1+w2x2 ≤1 untuk yi = +1
..(1)
H2 :w0+w1x1+w2x2 ≤-1 untuk yi = -1
..(2)
Data yang terletak di atas H1 termasuk dalam kategori kelas pertama, sedangkan data yang terletak di bawah H2 termasuk ke dalam kategori kelas kedua.
c. Klasifikasi Citra
Klasifikasi yang dilakukan pada data yang berbentuk citra pada umumnya ditempuh dengan langkah-langkah sebagai berikut:
1. Komputasi deskriptor (dense sift descriptor) dari setiap data citra
2. Membangun visual
vocabulary dari data citra yaitu dengan memasukkan sampel dari deskriptor ke dalam k-means clustering
atau kdtree. Visual
vocabulary didapatkan
dengan menggunakan hasil clustering.
3. Komputasi histogram spasial dan feature map dari setiap data citra
4. Feature map digunakan sebagai data training pada model classifier yang digunakan
5. Menguji model klasifikasi yang dibentuk dengan data citra testing
3. METODE PENELITIAN
Penelitian ini dikerjakan melalui tahapan-tahapan berikut ini:
a. Pengumpulan Data Training dan Data Testing
1277
Data training yang digunakan untuk membangun model classifier adalah citra scan formulir sejumlah 50 citra dan citra non-formulir yang diambil random sejumlah 50 citra. Baik citra formulir maupun citra non formulir yang digunakan pada penelitian ini diambil dari internet. Berikut ini Gambar 2 adalah contoh sebagian dari citra formulir yang digunakan pada penelitian ini.
(a)
(b)
(c)
(d)
Gambar 2. (a)(b)(c)(d) merupakan contoh
data citra formulir yang digunakan untuk training
Sedangkan citra non formulir yang digunakan sebagai data training
adalah gambar yang bukan
merupakan formulir seperti gambar benda-benda.
b. Preprocessing Citra
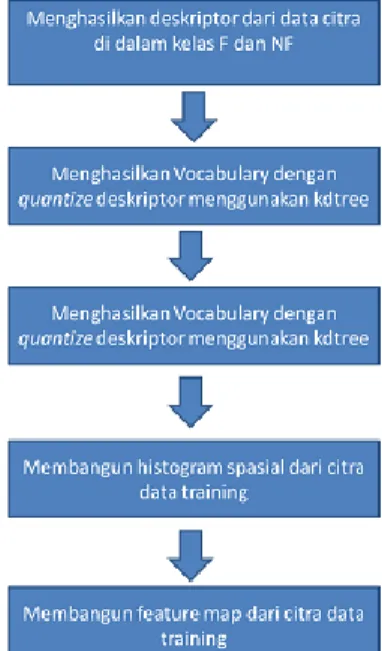
Sebelum dilakukan pembangunan model SVM, dilakukan preprocessing citra yang akan dipakai sebagai data training. Preprocessing yang dimaksud meliputi tahap-tahap pada Gambar 3 berikut ini:
Gambar 3. Tahap-tahap preprocessing data citra sebelum digunakan untuk training
Pada tahap preprocessing ini, semua
proses dilakukan dengan
menggunakan library vl_feat [4] yang merupakan library untuk pemrosesan citra.
c. Training Model Klasifikasi : SVM Training dilakukan untuk membangun model klasifikasi. Pada penelitian ini model yang akan dibangun untuk klasifikasi citra formulir dan citra non formulir adalah Support Vector
1278 Machine (SVM), yang tergolong dalam supervised learning. Sehingga, pada saat training, disediakan label untuk masing-masing data citra.
Training dilakukan dengan
menggunakan 100 data citra, terdiri dari 50 citra formulir yang diberi label F, dan 50 citra non formulir yang diberi label NF.
Pada penelitian ini, SVM yang digunakan berasal dari library liblinear
[5].
d. Pengujian Model
Pengujian model classifier pada penelitian ini menggunakan dua metode, yaitu
1. Pengujian menggunakan data di luar data training
Pada pengujian ini digunakan 50 data citra yang terdiri dari 25 citra formulir dan 25 citra non formulir. Semua data citra tersebut tidak termasuk pada data citra yang digunakan untuk training model classifier.
2. Pengujian menggunakan data training dengan metode 10 fold cross validation
4. HASIL DAN PEMBAHASAN
Klasifikasi citra formulir menggunakan metode Support Vector Machine memberikan akurasi yang cukup tinggi yaitu di atas 90%. Hal ini berarti bahwa tingkat kesalahan prediksi citra formulir rendah yaitu kurang dari 10% pada setiap iterasi pengujian.
a. Pengujian dengan 50 Data Citra Di luar Data Training
Hasil pengujian menggunakan 50 citra yang tidak termasuk dalam data training menghasilkan akurasi sebesar 98%. Citra sejumlah 50 ini terdiri dari 25 citra formulir dan 25 citra non formulir. Terdapat satu buah citra formulir yang diklasifikasi sebagai citra non formulir (klasifikasi yang
salah). Confusion matrix untuk hasil pengujian ini pada Tabel 1 sebagai berikut:
Tabel 1 Confusion Matrix Pengujian
Prediksi Formulir Prediksi Non-Formulir Aktual Formulir 24 1 Aktual Non-Formulir 0 25
Citra formulir yang salah diklasifikasikan sebagai non formulir adalah citra berikut:
Gambar 4. Citra formulir yang salah diprediksi sebagai non formulir oleh SVM
Meskipun citra di atas adalah citra formulir namun karena adanya watermark yang dominan pada badan formulir sehingga classifier mengkategorikan citra tersebut pada kelas NF.
b. Pengujian dengan Metode 10 fold cross validation
Selain menggunakan data yang telah digunakan untuk proses training, pengujian juga dilakukan dengan metode 10 fold cross validation. Pada pengujian ini dilakukan 10 iterasi, dimana masing-masing iterasi menggunakan 50% dari data training (50 data citra) yang dipilih secara
1279
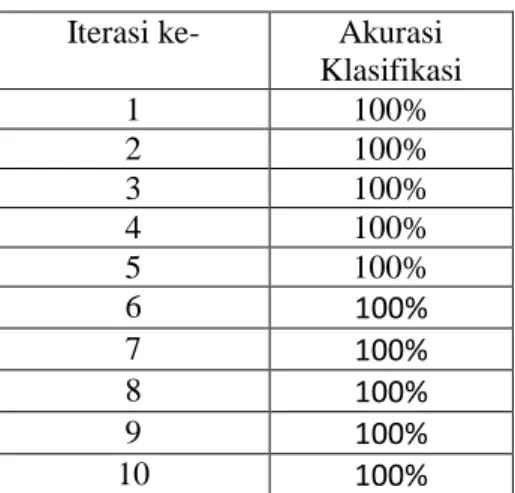
random dan terdiri dari citra formulir dan citra non formulir untuk diprediksi masing-masing kelasnya. Akurasi klasifikasi yang diperoleh melalui pengujian ini seperti pada Tabel 2 sebagai berikut:
Tabel 2 Akurasi Klasifikasi Pengujian 10 Fold Cross Validation
Iterasi ke- Akurasi Klasifikasi 1 100% 2 100% 3 100% 4 100% 5 100% 6 100% 7 100% 8 100% 9 100% 10 100%
Pengujian dengan menggunakan 10 fold cross validation menghasilkan akurasi sempurna yaitu 100%. Hasil ini dapat dipahami karena pengujian dilakukan menggunakan data yang sebelumnya telah digunakan untuk training.
5. KESIMPULAN DAN SARAN
Pada penelitian ini metode Support Vector Machine (SVM) telah digunakan untuk melakukan klasifikasi citra hasil scan formulir dan membedakan citra formulir dan citra non formulir. Akurasi yang didapatkan tinggi yaitu 98%, sehingga Support Vector Machine dapat disimpulkan efektif untuk melakukan klasifikasi citra formulir. Hasil penelitian ini
merupakan langkah awal untuk
pengembangan smart paperwork system. Untuk selanjutnya, penelitian ini dapat dikembangkan dengan melakukan segmentasi nama field dan segmentasi isi field pada citra formulir/borang.
[1] A. Rokhman, E-government Adoption in Developing Countries: the Case of Indonesia, Journal of Emerging Trends in Computing and Information Sciences, Vol.2, No.5, May 2011, pp 228-236.
[2] J. Han, M.Kamber, Data Mining Concepts and Techniques, 2nd Edition, Morgan Kaufmann, San Fransisco: 2006.
[3] E. Alpaydin, Introduction to Machine Learning, 3nd Edition, MIT Press, 2004. [4] VLFeat library: http://www.vlfeat.org/ [5] Liblinear library :https://www.csie.ntu.edu.tw/~cjlin/libli near/ 6. DAFTAR PUSTAKA