PENENTUAN KONDISI OPTIMUM PADA
PEMBENTUKAN POHON TERBAIK DENGAN
METODE POHON KLASIFIKASI (CLASSIFICATION
TREE)
A. Efendi dan H. Kusdarwati
Program Studi Statistika, FMIPA Universitas Brawijaya, Malang 65145
Masuk 12 Nopember 2006; diterima untuk diterbitkan 19 Pebruari 2007
Abstrak
Penelitian ini bertujuan untuk menentukan nilai maksimum fungsi keheterogenan pada proses pemilahan dan menentukan nilai penduga validasi silang lipat V yang sesuai. Pada penelitian ini digunakan data bangkitan yang berfungsi sebagai variabel dengan kelas tertentu dan sebagai respon-prediktor. Dari hasil analisis diperoleh bahwa fungsi keheterogenan φ hanya mencapai nilai maksimum pada (1,0,0,..,0), (0,1,0,... ,0), ..., (0,0,0, ...,1), yaitu ketika hanya memuat amatan-amatan yang berasal dari satu kelas. Fungsi keheterogenan φ akan mencapai nilai minimum pada (1/J, 1/J, ... , 1/J) yaitu ketika memuat amatan-amatan dari seluruh kelas secara berimbang. Nilai maksimum fungsi keheterogenan akan menurun dengan bertambahnya jumlah kelas pada masing-masing variabel. Nilai penduga validasi silang lipat V yang bernilai 10 sampai 20 memberikan hasil ketepatan penglasifikasian yang sama untuk beberapa kombinasi prediktor dengan jumlah kelas yang tetap pada respon.
Kata kunci: Pohon klasifikasi; Fungsi keheterogenan; Validasi silang lipat Abstract
The aims of this research are to determine the maximum value of heterogeneity function in splitting process and to determine the suitable cross validation value V. In this research it is used generating data whose functions are as variable with certain class and as response-predictor. In the result of analysis, it is known that the heterogeneity function φ will reach the maximum value in (1,0,0, ...,0), (0,1,0,... ,0), ..., (0,0,0, ...,1), when variable contains data from one class. The heterogeneity function φ will reach the minimum value in (1/J, 1/J, ..., 1/J), when variable contains data from all class in balance condition. The maximum value of heterogeneity function will decrease when the number of class in each variable increases. The cross validation estimator V which has value 10 until 20 gives the same misclassification cost for some predictor combinations with the fixed number of class in response.
1. Pendahuluan
Analisis regresi merupakan cara pemodelan statistika parametrik yang paling dikenal dan populer, yang penggunaannya antara lain ditujukan untuk prediksi, pemilihan variabel bebas, pencarian model terbaik dan pendugaan parameter [1]. Pembentukan model terutama untuk pembedaan kelas dengan menghitung probabilitas masing-masing kelas [2]. Pada pemodelan regresi parametrik, konsekuensi yang harus terpenuhi adalah asumsi dari residual, sedangkan dalam kenyataaannya asumsi-asumsi tersebut sulit terpenuhi.
Metode pohon klasifikasi, yang merupakan metode nonparametrik, dapat menjadi alternatif karena memiliki beberapa kelebihan yakni, robust terhadap outlier, kesederhanaan model, interpretasi secara visual yang mudah, dan bebas dari asumsi-asumsi klasik. Metode pohon kasifikasi mulai banyak dipakai terutama oleh beberapa pengguna dan peneliti di bidang kedokteran, keperawatan, aktuaria dan perbankan, biologi konservasi, kependudukan dan lain-lain [3][juga Timofeev].
Metode ini digunakan untuk menggambarkan hubungan antara variabel respon dengan satu set variabel prediktor. Metode pohon klasifikasi dikenal sebagai metode penyekatan rekursif biner [4], yang prinsip utamanya adalah aturan-aturan dalam penyekatan setiap simpul, penetapan simpul akhir dan penentuan nilai dugaan respon bagi setiap simpul akhir [3][juga Timofeev].
Tujuan dari metode pohon klasifikasi adalah untuk menduga atau memprediksi kelas y berdasarkan vektor x. Untuk pendugaan kelas y, diasumsikan tersedia L = {( , ),x jn n n=1, 2,..., }N yang dibentuk dari vektor penjelas dan vektor label kelas yang berkaitan. L dinamakan sampel pembelajaran (learning sampel) yang terdiri dari sejumlah N amatan di mana xn
∈
X dan jn∈
C , n = 1,2, ... , N. Berdasarkan aturan keputusan, metode pohon klasifikasi merupakan sebuah fungsi d(x) yang memetakan X pada C atau ∀ x∈
X, ∃ y∈
C ∋ y = d(x) [3]. Jadi pengklasifikasi d(x) mempartisi ruang X menjadi J himpunan bagian saling lepas A1, A2, ... , Aj sedemikian hingga:• j j A =X
∪
• Ai∩ Aj = ∅, 1≤ i ≠ j ≤ J • ∀ x ∈ X, d(x) = j ⇔ x∈AjDalam penerapannya, banyak pengguna metode pohon klasifikasi ini yang menemukan beberapa permasalahan, diantaranya adalah kesulitan dalam menemukan kriteria kondisi optimum untuk masing-masing fungsi keheterogenan [5][juga Chipman]. Untuk itu diperlukan upaya untuk mengetahui masalah tersebut yang dapat berlaku umum pada tahap pemilahan.
Di samping itu, ada dua jenis penduga pengganti, penduga sampel uji (test sample estimate) dan penduga validasi silang lipat V yang digunakan untuk mendapatkan tipologi pohon optimum, yaitu pohon yang sederhana dengan tingkat ketepatan penglasifikasian tinggi. Penduga pengganti yang sering dipakai dalam pembentukan pohon klasifikasi adalah penduga validasi silang lipat V. Permasalahannya, sampai saat ini belum ada kesepakatan nilai penduga validasi silang lipat V yang sesuai sebagai penduga pengganti dalam penentuan pohon klasifikasi optimum. Nilai 10 merupakan nilai aman dengan ukuran sampel learning yang kurang lebih sama besar untuk setiap
kelasnya [6][juga Angelopoulus]. Sayangnya nilai ini hanya berlaku pada penentuan pohon klasifikasi optimum untuk variabel respon dengan 2 level kategori.
Gambar 1 Pemetaan oleh Fungsi d(x), diambil dari Bachtiar [7].
Sehingga tujuan penelitian adalah untuk menentukan kriteria kondisi optimum fungsi keheterogenan pada proses pemilahan dan menentukan nilai penduga validasi silang lipat V yang sesuai pada penentuan pohon klasifikasi optimum.
2. Metode Penelitian
2.1 Menentukan Kriteria Kondisi Optimum Fungsi Keheterogenan pada Proses Pemilahan
1. Membangkitkan data secara acak dengan menggunakan 10 data menyebar kontinu (0,1) yang mewakili proporsi kelas untuk variabel 1 dan 10 data menyebar kontinu (0,1) yang mewakili proporsi kelas untuk variabel 2.
2. Membagi tiap sel data pada variabel 1 dan variabel 2 dengan jumlah sel dalam satu variabel untuk mendapatkan proporsi masing-masing kelas.
3. Menggunakan indeks Gini, I(t) =
∑
p i t p j t( | ) ( | ) untuk memperoleh nilai fungsi keheterogenan karena Indeks Gini ini sesuai dan mudah untuk diterapkan dalam berbagai kasus juga mempunyai perhitungan sederhana dan cepat [7].4. Melakukan langkah 1 sampai 3 sebanyak 10000 kali dengan program Macro Minitab.
5. Mendapatkan nilai maksimum fungsi keheterogenan dan mengetahui proporsi masing-masing kelas dalam satu variabel.
2.2 Menentukan Nilai Penduga Validasi Silang Lipat V yang Sesuai pada Penentuan Pohon Klasifikasi Optimum
1. Dipilih nilai penduga validasi silang lipat V (nilai validasi silang lipat) sebesar 10 sampai 20 (dipilih 11 macam nilai V). Amatan dalam L (banyak sampel data learning) dibagi menjadi V bagian yang saling lepas untuk setiap kelas.
2. Mengkombinasikan masing-masing nilai penduga pengganti V untuk data variabel respon dengan jumlah level dan jumlah data yang berbeda.
3. Proses penglasifikasian dihitung dengan software CART 5.
4. Memilih nilai V pada pemilihan pohon sederhana dan optimum yang menghasilkan tingkat ketepatan penglasifikasian maksimum.
5. Pohon sederhana yang optimum menghasilkan tingkat ketepatan penglasifikasian yang maksimum.
3. Hasil dan Pembahasan
3.1 Penentuan Kriteria Optimum Fungsi Keheterogenan Rumus yang digunakan dalam program adalah:
( ) ( | ) ( | ) ( (1| ), (2 | ), , ( | )) I t p i t p j t p t p t p J t φ = =
∑
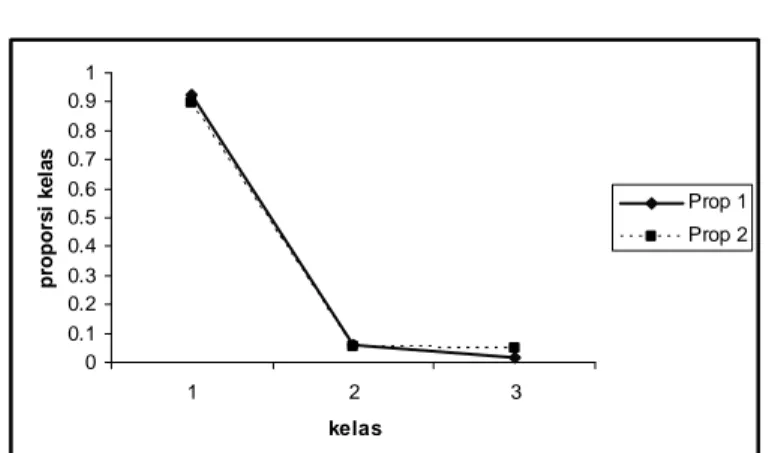
… (1)Dari hasil running program Macro Minitab didapatkan nilai maksimum fungsi keheterogenan 0,96992 untuk variabel yang hanya memuat dua kelas. Nilai maksimum fungsi keheterogenan akan menurun dengan bertambahnya kelas dalam variabel yang akan membentuk simpul. Plot proporsi masing-masing kelas dengan nilai fungsi keheterogenannya adalah sebagai berikut:
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 2 3 kelas p ro p o rs i k e la s Prop 1 Prop 2
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 1 2 3 4 5 6 7 8 9 10 kelas p ro p o rs i k e la s Prop 1 Prop 2
Gambar 3 Plot proporsi kelas untuk fungsi keheterogenan maksimum 10 kelas.
Dari Gambar 2 dan 3 dapat diketahui informasi tentang nilai maksimum fungsi keheterogenan, yaitu: terdapat sebagian kecil kelas dengan proporsi yang lebih besar dari yang lain dengan besar proporsi kelas yang seletak memiliki besar yang hampir sama. Dengan demikian fungsi keheterogenan φ hanya mencapai nilai maksimum pada (1,0,0,..,0), (0,1,0,... ,0), ..., (0,0,0, ...,1) yaitu ketika hanya memuat amatan-amatan yang berasal dari satu kelas. Dan fungsi keheterogenan φ akan mencapai nilai minimum pada (1/J, 1/J, ... , 1/J) yaitu ketika memuat amatan-amatan dari seluruh kelas secara berimbang.
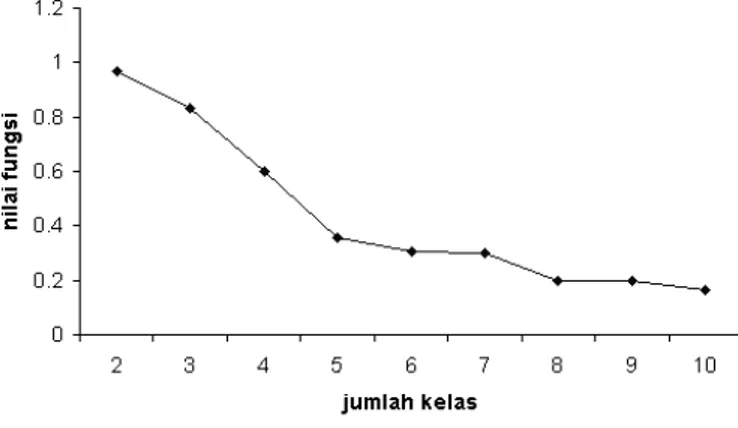
Gambar 4 Plot nilai maksimum fungsi keheterogenan untuk masing-masing jumlah kelas.
Nilai maksimum fungsi keheterogenan akan mencapai nilai tertinggi pada saat jumlah kelas sama dengan 2 untuk masing-masing variabel yang berpasangan. Kemudian nilai tersebut akan menurun dengan bertambahnya jumlah kelas pada masing-masing variabel. Kondisi tersebut berlaku untuk variabel kategorik yang memuat beberapa kelas, sedangkan untuk variabel kontinu mengikuti, dengan
pemilahan terjadi pada median. Terdapat catatan penting yaitu ketika variabel kategorik dengan jumlah kelas lebih dari 15, maka akan menghasilkan nilai maksimum fungsi keheterogenan mendekati nilai nol sehingga variabel kategorik dengan jumlah kelas sebanyak itu akan memiliki kemiripan dengan variabel kontinu.
3.2 Penentuan Nilai Penduga Validasi Silang Lipat V yang Sesuai pada Pembentukan Pohon Klasifikasi Optimum
0 0.2 0.4 0.6 0.8 1 1.2 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 RC MC
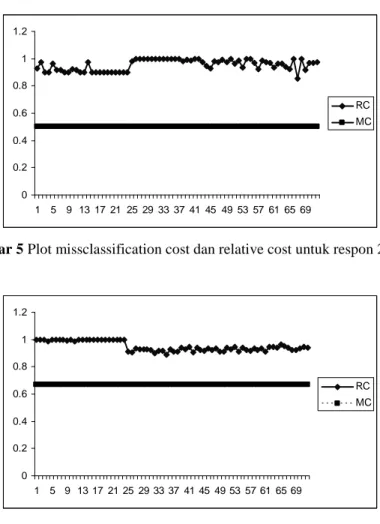
Gambar 5 Plot missclassification cost dan relative cost untuk respon 2 kelas.
0 0.2 0.4 0.6 0.8 1 1.2 1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 RC MC
Gambar 6 Plot missclassification cost dan relative cost untuk respon 3 kelas. Dari hasil perhitungan penglasifikasian untuk nilai penduga validasi silang lipat 10 sampai 20 dengan CART 5 didapatkan nilai Relatif Cost (RC) dan proporsi kesalahan penglasifikasian (Misclassification Cost, MC) yang diplotkan seperti Gambar 5 dan 6 diatas. Dari dua gambar tersebut juga dapat diketahui bahwa ketidaktepatan penglasifikasian, MC, bernilai sama dan mengalami kenaikan jika jumlah kelas dalam respon bertambah. Hal ini tampak pada nilai kesalahan penglasifikasian yang bernilai
0,5 untuk respon 2 kelas, 0,667 untuk respon 3 kelas dan 0,75 untuk respon 4 kelas. Hasil ini menjadi realistis karena semakin banyak jumlah kelas dalam respon maka proses kombinasi tiap-tiap kelas dalam prediktor dengan respon juga semakin banyak sehingga peluang kesalahannya juga akan semakin besar.
Plot diatas juga memperlihatkan bahwa nilai relatif cost (RC) bernilai relatif sama yaitu antara 0,8 sampai dengan 1 untuk penduga validasi silang lipat bernilai 10 sampai dengan 20. Hal ini bisa diartikan bahwa tingkat kesalahan penglasifikasian pada simpul kiri relatif terhadap tingkat kesalahan penglasifikasian pada simpul kanan cenderung sama karena nilai relatifnya berkisar 0,8 sampai 1.
Secara umum, nilai penduga validasi silang lipat V yang bernilai 10 sampai 20 memberikan hasil ketepatan penglasifikasian yang sama untuk beberapa kombinasi prediktor dengan jumlah kelas yang tetap dalam respon. Sedangkan kesalahan penglasifikasian akan meningkat justru dikarenakan penambahan kelas dalam respon.
4. Kesimpulan dan Saran
4.1 Kesimpulan
Kesimpulan yang dapat diambil dari penelitian ini adalah:
1. Fungsi keheterogenan φ hanya mencapai nilai maksimum pada (1,0,0,..,0), (0,1,0,... ,0), ..., (0,0,0, ...,1) yaitu ketika hanya memuat amatan-amatan yang berasal dari satu kelas. Dan φ akan mencapai nilai minimum pada (1/J, 1/J, ... , 1/J) yaitu ketika memuat amatan-amatan dari seluruh kelas secara berimbang. Nilai maksimum fungsi keheterogenan akan menurun dengan bertambahnya jumlah kelas pada masing-masing variabel.
2. Nilai penduga validasi silang lipat V yang bernilai 10 sampai 20 memberikan hasil ketepatan penglasifikasian yang sama untuk beberapa kombinasi prediktor dengan jumlah kelas yang tetap dalam respon.
4.2 Saran
Untuk menentukan dampak perubahan nilai validasi silang lipat pada tingkat kesalahan penglasifikasian pohon, sebaiknya digunakan data dengan jumlah kelas yang tetap dalam respon. Selanjutnya, penelitian lebih lanjut diperlukan untuk menentukan nilai validasi silang lipat dengan nilai lebih dari 20 yang sesuai dan dengan tingkat kesalahan penglasifikasian yang terkecil.
Daftar Pustaka
[1] R.H. Myers, (1993), Classical and Modern Regression with Applications, PWS-Kent Pub. Co., Boston.
[2] A. Agresti, (1990), Categorical Data Analysis, John Wiley & Sons, New York. [3] L. Breiman, J.H. Freidman, R.A. Olshen dan C.J. Stone, (1993), Classification and
Regression Trees, Chapman and Hall, New York.
[4] R.J. Lewis, (2000), An introduction to Classification and Regression Tree (CART) analysis, makalah disajikan dalam The 2000 Annual Meeting of the Society for Academic Emergency Medicine of San Francisco, San Francisco, California.
[5] D. Steinberg dan P. Colla, (1998), Clasification and Regression Trees, Salford System, San Diego.
[6] S. Pingit dan B.W. Otok, (2004), Penerapan dan perbandingan regresi pohon dan regresi logistik pada data kategorik, Laporan Penelitian DIKS Institut Teknologi Sepuluh Nopember, Surabaya.
[7] A. Bachtiar, (2004), Studi klasifikasi data IPK mahasiswa pada jurusan yang memperoleh program DUE-Like Batch 1 dengan metode pohon klasifikasi, Skripsi S1, Jurusan Statistika, Institut Teknologi Sepuluh Nopember, Surabaya.
![Gambar 1 Pemetaan oleh Fungsi d(x), diambil dari Bachtiar [7].](https://thumb-ap.123doks.com/thumbv2/123dok/4843740.3464314/3.892.333.585.197.418/gambar-pemetaan-fungsi-d-x-diambil-bachtiar.webp)