SISTEM KLASIFIKASI KHASIAT FORMULA JAMU
DENGAN METODE SUPPORT VECTOR MACHINE
ARIES FITRIAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Sistem Klasifikasi Khasiat Formula Jamu dengan Metode Support Vector Machine adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Aries Fitriawan NIM G64090063
ABSTRAK
ARIES FITRIAWAN. Sistem Klasifikasi Khasiat Formula Jamu dengan Metode Support Vector Machine. Dibimbing oleh WISNU ANANTA KUSUMA dan RUDI HERYANTO.
Jamu adalah obat yang dibuat dari bahan-bahan alami seperti akar-akaran, daun-daunan, kayu-kayuan, dan buah-buahan. Komposisi jamu biasanya didasarkan pada data empiris atau pengalaman pribadi. Jamu terdiri atas banyak variasi formula sehingga proses klasifikasi jamu berdasarkan komposisi tanaman masih merupakan permasalahan yang menarik untuk diteliti. Tujuan penelitian ini adalah membuat sistem klasifikasi khasiat jamu berdasarkan komposisi tanaman menggunakan metode Support Vector Machine (SVM). Hasil dari penelitian ini dibandingkan dengan penelitian sebelumnya yang menggunakan metode Partial Least Squares Discriminant Analysis (PLS-DA). Model terbaik dihasilkan oleh SVM dengan Radial Basis Function (RBF) kernel. Metode SVM memiliki nilai akurasi pelatihan 5-fold cross validation lebih tinggi dibandingkan dengan PLS-DA untuk data yang sudah direduksi maupun untuk pelatihan menggunakan balanced dataset.
Kata kunci: jamu, klasifikasi, machine learning, support vector machine.
ABSTRACT
ARIES FITRIAWAN. A Classification System for Jamu Efficacy Using Support Vector Machine. Supervised by WISNU ANANTA KUSUMA and RUDI HERYANTO.
Jamu is made from natural materials such as roots, leaves, wood and fruits. The composition of jamu formula is usually constructed based on empirical data or personal experiences. Jamu has many variations of formula. Thus, the classification of jamu efficacy based on its composition of plants remains an interesting task. The purpose of this research is to develop a classification system for jamu efficacy based on the composition of plants using Support Vector Machine (SVM). This method were compared to those of previous research using Partial Least Squares Discriminant Analysis (PLS-DA). The results show that the SVM method with Radial Basis Function (RBF) kernel using data reduction and balanced dataset obtains higher accuracy than those of PLS-DA.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
SISTEM KLASIFIKASI KHASIAT FORMULA JAMU
DENGAN METODE SUPPORT VECTOR MACHINE
ARIES FITRIAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2013
Penguji: Dr Farit Mochamad Afendi, SSi MSi Sony Hartono Wijaya, SKom MKom
Judul Skripsi : Sistem Klasifikasi Khasiat Formula Jamu dengan Metode Support Vector Machine
Nama : Aries Fitriawan NIM : G64090063
Disetujui oleh
Dr Wisnu Ananta Kusuma, ST MT Pembimbing I
Rudi Heryanto, SSi MSi Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas rahmat dan karunia-Nya sehingga skripsi ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan November 2012 sampai Mei 2013 ini adalah pendekatan machine learning pada klasifikasi khasiat formula jamu, dengan judul Sistem Klasifikasi Khasiat Formula Jamu dengan Metode Support Vector Machine.
Terima kasih penulis ucapkan kepada Bapak Dr Wisnu Ananta Kusuma, ST MT dan Bapak Rudi Heryanto, SSi MSi atas bimbingannya, Bapak Dr Farit Mochamad Afendi, SSi MSi dan Bapak Sony Hartono Wijaya, SKom MKom, yang telah memberikan data dan masukan ide untuk penelitian ini, serta Bapak Ahmad Ridha, SKom MSc yang telah memberi saran. Ungkapan terima kasih juga disampaikan kepada kedua orang tua penulis Yuyus Ruslan dan Tati Mulyati serta adik penulis, Adrie Maulana atas doa, dukungan dan kasih sayangnya. Tidak lupa penulis mengucapkan terima kasih kepada Aussie Komala Rani dan keluarga atas bantuan dan dukungannya. Penulis juga mengucapkan terima kasih kepada Ariny, Aditrian, Gita, Rangga, Papank, Kak Isnan, Kak Chawang serta seluruh keluarga besar Ilkomerz 46 dan kakak angkatan Ilkomerz 45 dan Ilkomerz 44 yang tidak dapat penulis tuliskan satu demi satu yang secara langsung dan tidak langsung telah membantu penulis dalam melakukan penelitian ini.
Besar harapan penulis agar laporan penelitian ini dapat dimanfaatkan dan dikembangkan dengan lebih baik lagi.
Bogor, Juni 2013
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 3
Data dan Penyiapan Data 3
Data Balancing 5
K-Fold Cross Validation 5
Pelatihan Support Vector Machine 6
Uji dan Klasifikasi Support Vector Machine 7
Evaluasi dan Perbandingan Hasil 7
Implementasi Sistem 7
HASIL DAN PEMBAHASAN 8
Hasil 8
Pembahasan 12
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 15
DAFTAR PUSTAKA 15
LAMPIRAN 17
DAFTAR TABEL
1 Rincian Percobaan 1 dan Percobaan 2 8
2 Perbandingan hasil akurasi training dari Data I dan Data II 9 3 Perbandingan akurasi PLS-DA dengan SVM menggunakan Data I dan
Data II 10
DAFTAR GAMBAR
1 Skema metode penelitian untuk perbandingan akurasi PLS-DA dengan
SVM 3
2 Skema metode penelitian untuk mengetahui pengaruh imbalanced data 3 3 Grafik penyebaran data jamu yang digunakan dalam penelitian 4 4 Ilustrasi representasi data hubungan antara jamu, tanaman dan khasiat
jamu 4
5 Contoh ilustrasi pemodelan SVM yang bersifat linear 7 6 Hasil perbandingan akurasi pencarian nilai d Data I dengan C=1 dan
γ=2 (a), hasil perbandingan akurasi pencarian nilai d Data II dengan
C=2 dan γ=2 (b) 9
7 Hasil grid search pada model RBF Kernel menggunakan grid.py dari
Data I (a) dan Data II (b) 10
8 Hasil perbandingan akurasi pencarian nilai d Data III dengan C=0.5 dan
γ=2 11
9 Hasil grid search pada model RBF Kernel menggunakan grid.py dari
Data III 11
10 Hasil akurasi training 5-fold cross validation pada setiap jenis data 11
11 Penyebaran data jamu baru hasil prediksi 14
12 Ilustrasi pengelompokan data hasil prediksi sistem dengan diagram
irisan 14
DAFTAR LAMPIRAN
1 Daftar tanaman jamu yang paling signifikan berdasarkan kelasnya 17 2 Ilustrasi proses penambahan dan pengurangan data 19
3 Langkah dan tampilan penggunaan aplikasi 22
PENDAHULUAN
Latar BelakangJamu adalah obat herbal tradisional Indonesia yang terbuat dari bahan alami seperti akar, daun, kayu, dan buah-buahan. Menurut Mahady (2001), penggunaan jamu sebagai pengobatan alternatif mengalami peningkatan. Orang-orang mulai mempertimbangkan jamu sebagai obat yang aman dan manjur yang telah terbukti secara empiris selama ratusan tahun.
Adam et al. (2006) yang meneliti sel prostat menunjukkan bahwa penggunaan kombinasi dari beberapa ekstrak tanaman memiliki interaksi sinergi yang lebih baik daripada hanya menggunakan satu ekstrak tanaman saja. Oleh sebab itu, jamu memiliki banyak variasi formula. Setiap wilayah di Indonesia mengembangkan formula jamu sendiri berdasarkan bahan-bahan alami yang ada di wilayah itu (Beers 2001). Namun, meski secara empiris jamu telah terbukti dapat menyembuhkan beberapa penyakit, belum ada cukup bukti ilmiah yang dapat menjelaskan hubungan antara formula atau komposisi tanaman dengan khasiatnya.
Upaya sistematis untuk menemukan hubungan antara komposisi dan khasiat jamu telah dilakukan oleh Afendi et al. (2010) dengan menggunakan pendekatan statistik. Penelitian ini menunjukkan bahwa jamu dengan khasiatnya memiliki aktivitas farmakologi tertentu. Selanjutnya, Afendi et al. (2010) mengembangkan hipotesis bahwa formula jamu terdiri atas tanaman utama dan tanaman pendukung. Tanaman utama memiliki efek langsung pada penyakit sehingga menjadi tanaman yang langsung dihubungkan dengan khasiat tertentu (Afendi et al. 2010). Sementara itu, tanaman pendukung didefinisikan paling tidak harus memiliki tiga karakteristik, yaitu analgesik, antimikroba, dan anti-peradangan.
Afendi et al. (2012) menggunakan metode Partial Least Squares Discriminant Analysis (PLS-DA) untuk mengembangkan sebuah model klasifikasi formula jamu. Penelitian tersebut difokuskan pada pengamatan 3138 sampel jamu yang diklasifikasikan ke dalam 9 jenis khasiat. Khasiat yang dapat diprediksi oleh metode ini adalah urinary related problems (URI), disorder of apetite (DOA), disorder of mood and behavior (DMB), gastrointestinal disorders (GST), female reproductive organ problems (FML), muskuloskeletal and connective tissue disorders (MSC), pain and inflammation (PIN), respiratory disease (RSP), dan wounds and skin infections (WND). Sampel jamu yang digunakan mengandung 1 sampai 16 tanaman yang diambil dari 465 tanaman obat. Dengan demikian, variasi formula jamu yang dihasilkan sangat tinggi. Hasil klasifikasi menunjukkan bahwa akurasi dengan 5-fold cross validation adalah 71.6%. Akurasi meningkat secara signifikan setelah dilakukan data cleaning (94.21%) (Afendi et al. 2012).
Dalam bidang ilmu komputer, masalah klasifikasi dapat diselesaikan dengan menggunakan teknik machine learning, salah satunya dengan menggunakan Support Vector Machine (SVM). SVM adalah salah satu teknik machine learning yang mampu mengklasifikasikan problem di dunia nyata dengan hasil akurasi yang tinggi (Byun dan Lee 2003). Berdasarkan penelitian yang telah dilakukan, SVM juga mampu menghasilkan akurasi tinggi untuk
2
mengklasifikasikan potongan metagenome dari komunitas kecil mikroba (Kusuma dan Akiyama 2011). Dalam penelitian ini, akan diterapkan metode SVM untuk mengklasifikasikan khasiat jamu berdasarkan komposisi tanamannya. Hasil pengklasifikasian dengan menggunakan SVM pada penelitian ini akan dibandingkan dengan hasil dari metode PLS-DA yang diperoleh Afendi et al. (2012). Oleh sebab itu, untuk melakukan perbandingan yang adil, digunakan dataset yang sama seperti yang digunakan dalam penelitian Afendi et al. (2012). Pada penelitian ini juga dilakukan teknik undersampling dan oversampling untuk mengatasi masalah imbalanced dataset pada saat proses pelatihan. Teknik ini diharapkan dapat menjadi dasar untuk mengembangkan sistem klasifikasi khasiat formula jamu baru.
Perumusan Masalah
Adapun masalah yang akan diangkat dalam penelitian ini adalah pencarian metode klasifikasi lain yang dapat digunakan dalam klasifikasi khasiat formula jamu. Dari perbandingan metode PLS-DA dengan metode SVM diharapkan dapat menghasilkan sebuah metode terbaik untuk memprediksi khasiat formula jamu baru.
Tujuan Penelitian
Tujuan dari penelitian ini ialah:
1 menganalisis dan membuat sistem klasifikasi khasiat jamu berdasarkan komposisi tanaman dengan metode Support Vector Machine (SVM)
2 membandingkan nilai akurasi antara metode SVM dan metode Partial Least Squares Discriminant Analysis (PLS-DA)
3 menerapkan teknik undersampling dan oversampling untuk mengatasi permasalahan imbalanced dataset.
Manfaat Penelitian
Hasil dari dilakukannya penelitian ini diharapkan dapat menjadi sebuah konsep dasar dalam mengembangkan sistem penentuan khasiat formula jamu baru. Pada akhirnya, hasil dari penelitian ini dapat menjadi dasar dalam menangani solusi permasalahan pencatatan data jamu beserta khasiatnya di Indonesia.
Ruang Lingkup Penelitian
Ruang lingkup dalam penelitian ini adalah:
1 tanaman yang dikenali terbatas pada 465 jenis tanaman dari 3138 jamu hasil praproses dari penelitian sebelumnya (Afendi et al. 2010)
2 data reduksi menggunakan data yang sama dengan penelitian sebelumnya, data ini terdiri atas 231 jenis tanaman dari 2748 jamu (Afendi et al. 2010)
3 3 implementasi metode klasifikasi SVM menggunakan bantuan library LibSVM
3.14 (Hsu et al. 2010).
METODE
Untuk menghasilkan penelitian yang baik, diperlukan sebuah metode dan rencana penelitian. Skema metode penelitian ini dapat dilihat pada Gambar 1 dan Gambar 2.
Data dan Penyiapan Data
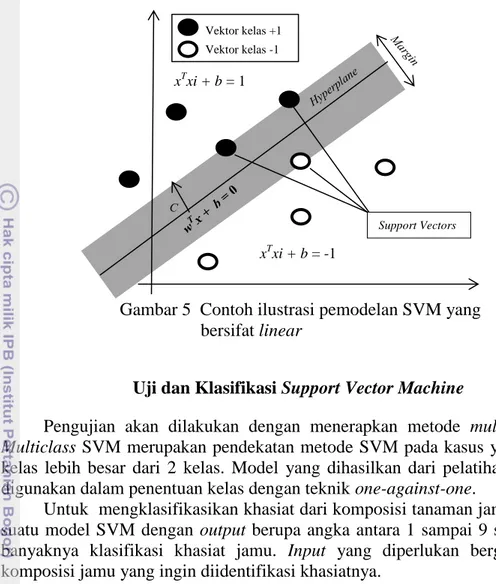
Data yang digunakan pada penelitian ini menggunakan data yang sama dengan penelitian yang dilakukan oleh Afendi et al. (2010). Data yang digunakan terdiri atas data jamu berjumlah 3138 buah jamu yang terdaftar di Badan Pengawasan Obat dan Makanan (Badan-POM) yang disertai komposisi masing-masing jamu dari 465 jenis tanaman. Data ini telah melalui praproses data dari jumlah awal 6533 buah jamu. Praproses data yang dikerjakan terdiri atas penghapusan redudansi data jamu sebanyak 1223 buah jamu. Dari sisa 5310 buah jamu hanya diambil sebanyak 3138 buah jamu yang dianggap dapat mewakili data yang dibutuhkan untuk analisis (Afendi et al. 2010) (Data I). Penelitian ini juga menggunakan data yang telah direduksi melalui proses data cleaning yang didapatkan dari hasil penelitian sebelumnya. Data ini terdiri atas 231 jenis tanaman dari 2748 jamu (Data II). Selanjutnya, untuk melihat pengaruh dari imbalanced data, penelitian ini menggunakan data yang telah melalui proses pemerataan data yang akan dijelaskan pada bagian Data Balancing. Data ini terdiri atas 231 jenis tanaman dari 2745 jamu (Data III). Data tersebut tersebar ke dalam 9 jenis khasiat (lihat Gambar 3).
Data yang digunakan pada penelitian ini merupakan hasil representasi data dari jamu yang beredar di Indonesia. Data yang digunakan berupa hubungan antara jamu, tanaman yang digunakan dalam komposisi jamu, dan khasiat dari jamu tersebut. Komposisi tanaman didefinisikan dengan menetapkan nilai biner untuk masing-masing tanaman. Jika tanaman tertentu dimasukkan ke dalam
Gambar 1 Skema metode penelitian untuk perbandingan akurasi PLS-DA dengan SVM
Gambar 2 Skema metode penelitian untuk mengetahui pengaruh imbalanced data Pengumpulan dan Praproses Data 5-Fold Cross Validation Support Vector Machine Model Evaluasi Hasil Implementasi Praproses Data 5-Fold Cross Validation Support Vector Machine Model Evaluasi Hasil Data Balancing
4
sampel jamu, nilai pada tanaman ini ditetapkan sebagai 1, sebaliknya penetapan nilainya adalah 0. Penelitian ini hanya dapat menetapkan nilai fitur dengan nilai biner karena belum mendapatkan informasi yang lebih akurat dari formulasi bahan-bahan jamu. Gambar 4 menunjukkan contoh fitur data jamu, J1 sampai JN mewakili sampel jamu dan P1 sampai Pk mewakili komposisi tanaman yang digunakan. Sebagai contoh, jamu J2 disusun oleh P2 dan P3 memiliki khasiat yang diwakili dengan urutan khasiat ke-5 (FML).
Ekstraksi data yang dilakukan pada Data I menghasilkan matriks berukuran 465 x 3138, Data II menghasilkan matriks berukuran 231 x 2748, dan Data III menghasilkan matriks berukuran 231 x 2745. Data ini kemudian diproses agar bisa diolah menggunakan LibSVM 3.14 (Hsu et al. 2010).
72 249 22 980 398 840 311 107 159 66 228 19 720 377 798 292 105 143 305 305 305 305 305 305 305 305 305 0 100 200 300 400 500 600 700 800 900 1000
URI DOA DMB GST FML MSC PIN RSP WND
B a ny a k Da ta Khasiat Jamu Data I Data II Data III
Gambar 3 Grafik penyebaran data jamu yang digunakan dalam penelitian
Gambar 4 Ilustrasi representasi data hubungan antara jamu, tanaman dan khasiat jamu
5
Data Balancing
Dari penelitian ini ditemukan masalah imbalanced data pada setiap jenis data. Imbalanced data terjadi karena penyebaran data setiap kelas yang tidak sama. Imbalanced data akan mengakibatkan pendekatan pada data set yang tidak seimbang sehingga membuat hyperplane yang dibentuk berada lebih jauh dari kelas positifnya (Akbani et al. 2004).
Pada penelitian ini dilakukan oversampling dan undersampling untuk menangani imbalanced data. Teknik ini dilakukan untuk mengatur ulang jumlah distribusi dataset sehingga memungkinkan jumlah data yang merata pada setiap kelas.
Pemerataan jumlah data ini dilakukan pada Data II. Penentuan jumlah data per kelas diambil dari rata-rata data per kelas pada Data II. Pemerataan jumlah data per kelas pada Data II yang memiliki jumlah awal 2748 data jamu menghasilkan jumlah data yang baru sebanyak 2745 data jamu, dengan jumlah data rata-rata per kelas sebanyak 305 data jamu (Data III).
Dari perbandingan jumlah data dapat dilihat ada kelas yang mendapatkan penambahan jumlah data dan yang mengalami pengurangan data. Pada penelitian ini, penambahan data dilakukan dengan pertimbangan sebagai berikut:
1 tidak menggunakan data yang berulang
2 data yang ditambahkan dipilih dari kombinasi komposisi tanaman yang berjumlah 1 sampai dengan 10 tanaman
3 komposisi tanaman yang dipilih pada setiap kelasnya menyesuaikan dengan kecenderungan tanaman yang lebih signifikan terhadap khasiatnya, daftar tanaman ini merupakan hasil dari penelitian yang dilakukan oleh Afendi et al. (2012) dan dapat dilihat pada Lampiran 1
4 jumlah data dan jumlah tanaman dalam setiap komposisi beragam dan merata pada setiap kelasnya bergantung pada kekurangan data pada kelas tersebut.
Pengurangan data dilakukan dengan pertimbangan sebagai berikut: 1 penghapusan data yang masih berulang
2 pengurangan data dilakukan merata di setiap kelompok data dengan jumlah komposisi tanaman tertentu.
Ilustrasi dari proses penambahan dan pengurangan data dapat dilihat pada Lampiran 2.
K-Fold Cross Validation
Data dilatih dengan metode SVM. Untuk mencari akurasi data latih digunakan metode pengujian K-fold cross validation dengan nilai K sebesar 5. Seluruh data set yang ada akan dibagi menjadi lima subset, yaitu: fold 1, fold 2, fold 3, fold 4, dan fold 5. Pelatihan akan dilakukan secara berulang dan pada setiap pengulangannya empat fold akan dijadikan data latih dan satu fold akan dijadikan data uji. Proses ini dilakukan sebanyak lima kali sampai setiap fold pernah berperan sebagai data latih dan data uji. Dalam setiap pengulangan nilai akurasi akan dihitung dan akurasi terakhir didapat dari rata-rata nilai akurasi dari seluruh pengulangan. Hal ini dilakukan dengan tujuan mencari akurasi yang
6
terbaik. Data latih yang digunakan dalam penelitian ini terbagi menjadi tiga, yaitu Data I, Data II, dan Data III.
Pelatihan Support Vector Machine
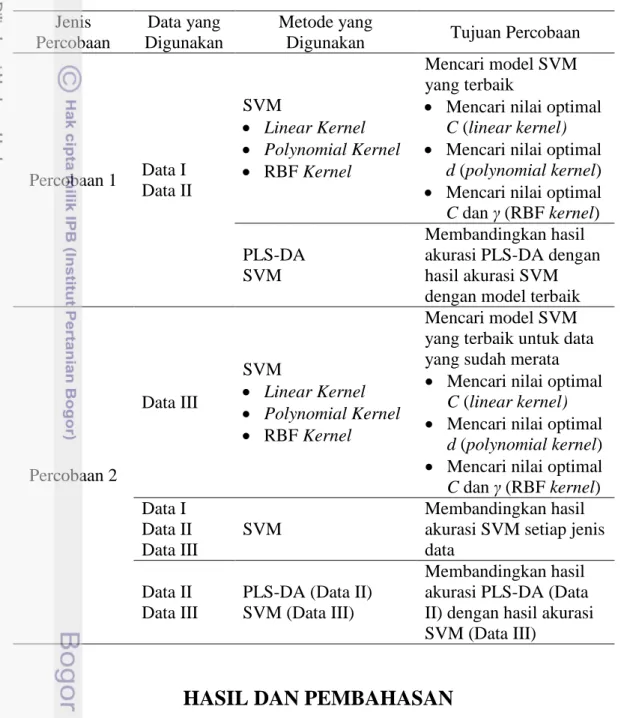
Support Vector Machine (SVM) adalah suatu sistem pembelajaran menggunakan ruang hipotesis dari suatu fungsi linear dalam suatu ruang dimensi berfitur tinggi. Tujuan utama SVM ialah menemukan fungsi pemisah (hyperplane) yang terbaik untuk memisahkan dua buah kelas pada input space.
Hyperplane terbaik antara dua kelas dapat ditemukan dengan pengukuran margin hyperplane yang maksimal antara ruang input non-linear dengan ruang ciri menggunakan fungsi kernel (Cortes dan Vapnik 1995).
Menurut Byun dan Lee (2003), fungsi kernel yang umum digunakan adalah: 1 linear kernel
( ) 2 polynomial kernel
( ) d
3 Radial Basis Function (RBF) kernel
( ) - ‖ - ‖ , dengan
Dari ketiga fungsi kernel tersebut xi merepresentasikan vektor dari setiap data, d merepresentasikan jumlah derajat dari fungsi polinomial, dan γ merepresentasikan ukuran rentangan pada kurva gaussian. SVM menerapkan kernel yang digunakan untuk merepresentasikan data ke dimensi yang lebih tinggi. Data yang sudah berada di dimensi lebih tinggi tersebut dapat dengan mudah dipisahkan dengan hyperplane yang linear (Boswell 2002). Hyperplane yang baik adalah hyperplane yang dapat memaksimumkan jarak antara geometri hyperplane dengan support vector. Jarak tersebut diistilahkan dengan margin seperti diilustrasikan pada contoh ilustrasi pemodelan SVM yang bersifat linear (lihat Gambar 5).
Pelatihan data dilakukan dengan LibSVM 3.14 menggunakan 3 kernel, yaitu:
1 linear kernel, hanya membutuhkan peubah C
2 polynomial kernel yang membutuhkan peubah C dan d 3 RBF kernel yang membutuhkan peubah C dan γ.
Beberapa peubah yang digunakan merupakan peubah yang hanya digunakan di LibSVM 3.14. Peubah C dalam LibSVM 3.14 merepresentasikan error penalty dalam komputasi pembentukan model.
Masing-masing kernel dicoba dengan nilai peubah fungsi kernel yang diterapkan untuk fungsi polynomial kernel dan RBF kernel. Dari hasil percobaan akan didapatkan beberapa model SVM yang memiliki akurasi pelatihan 5-fold cross validation.
7
Uji dan Klasifikasi Support Vector Machine
Pengujian akan dilakukan dengan menerapkan metode multiclass SVM. Multiclass SVM merupakan pendekatan metode SVM pada kasus yang memiliki kelas lebih besar dari 2 kelas. Model yang dihasilkan dari pelatihan SVM akan digunakan dalam penentuan kelas dengan teknik one-against-one.
Untuk mengklasifikasikan khasiat dari komposisi tanaman jamu diperlukan suatu model SVM dengan output berupa angka antara 1 sampai 9 sesuai dengan banyaknya klasifikasi khasiat jamu. Input yang diperlukan bergantung pada komposisi jamu yang ingin diidentifikasi khasiatnya.
Evaluasi dan Perbandingan Hasil
Evaluasi dan perbandingan hasil dilakukan untuk mengevaluasi kekurangan dan kelebihan dari metode yang digunakan serta membandingkannya dengan metode sebelumnya. Perbandingan hasil dapat dilihat dari perbandingan akurasi metode PLS-DA dengan metode SVM.
Penelitian ini dilakukan dalam 2 tahap. Percobaan 1 dilakukan untuk mencari model SVM terbaik dan membandingkannya dengan hasil dari PLS-DA. Percobaan 2 dilakukan untuk menganalisa dan membandingkan pengaruh balanced dataset terhadap akurasi. Rincian percobaan dapat dilihat pada Tabel 1.
Implementasi Sistem
Implementasi sistem dilakukan dalam lingkungan pengembangan aplikasi menggunakan bahasa pemrograman PHP, library komputasi LibSVM 3.14, dan MySQL sebagai database management system.
Gambar 5 Contoh ilustrasi pemodelan SVM yang bersifat linear Vektor kelas +1 Vektor kelas -1 xTxi + b = -1 xTxi + b = 1 Support Vectors
8
Sistem yang dikembangkan memiliki fungsi melakukan prediksi khasiat jamu dari formula jamu baru yang dimasukkan oleh pengguna menggunakan bantuan model hasil training SVM yang tersedia.
Tabel 1 Rincian Percobaan 1 dan Percobaan 2 Jenis
Percobaan
Data yang Digunakan
Metode yang
Digunakan Tujuan Percobaan
Percobaan 1 Data I Data II SVM Linear Kernel Polynomial Kernel RBF Kernel Mencari model SVM yang terbaik
Mencari nilai optimal C (linear kernel) Mencari nilai optimal
d (polynomial kernel) Mencari nilai optimal C dan γ (RBF kernel) PLS-DA
SVM
Membandingkan hasil akurasi PLS-DA dengan hasil akurasi SVM dengan model terbaik
Percobaan 2 Data III SVM Linear Kernel Polynomial Kernel RBF Kernel Mencari model SVM yang terbaik untuk data yang sudah merata Mencari nilai optimal
C (linear kernel) Mencari nilai optimal
d (polynomial kernel) Mencari nilai optimal C dan γ (RBF kernel) Data I Data II Data III SVM Membandingkan hasil akurasi SVM setiap jenis data
Data II Data III
PLS-DA (Data II) SVM (Data III)
Membandingkan hasil akurasi PLS-DA (Data II) dengan hasil akurasi SVM (Data III)
HASIL DAN PEMBAHASAN
HasilPercobaan 1
Langkah awal dalam penelitian ini ialah mengolah data agar dapat digunakan untuk proses komputasi dengan menggunakan LibSVM 3.14. Data
9 yang digunakan untuk perbandingan perhitungan akurasi ialah Data I dan Data II. Akurasi yang dicari adalah akurasi hasil 5-fold cross validation.
Setelah data siap untuk diuji menggunakan LibSVM 3.14, dilakukanlah proses grid search untuk mendapatkan nilai C dan γ yang optimal. Teknik grid search adalah teknik yang diterapkan oleh LibSVM 3.14 untuk mencari nilai peubah yang optimal dilihat dari hasil akurasi yang didapatkan menggunakan perangkat grid.py dari LibSVM 3.14. Untuk linear kernel dicari nilai peubah C yang optimal, dari hasil pencarian didapatkan nilai C sebesar 1 untuk Data I dan 2 untuk Data II. Untuk polynomial kernel perlu dicari juga nilai d yang optimal. Pencarian nilai d yang optimal dilakukan dengan percobaan menggunakan 5-fold cross validation terhadap data dengan rentang nilai d dari 2 sampai 4. Nilai d yang dipilih adalah nilai d dengan akurasi training tertinggi. Dari perbandingan hasil percobaan Data I menggunakan nilai C sebesar 1 dan γ sebesar 2 dan Data II menggunakan nilai C sebesar 2 dan γ sebesar 2, didapatkan nilai d yang sama, yaitu 2 (lihat Gambar 6). Untuk RBF kernel perlu dicari nilai C dan γ yang optimal. Dari hasil pencarian menggunakan Data I didapatkan nilai C sebesar 2 dan nilai γ sebesar 0.125, sedangkan Data II didapatkan nilai C sebesar 2 dan nilai γ sebesar 0.5. Perbandingan hasil grid search pada model RBF kernel menggunakan grid.py dapat dilihat pada Gambar 7.
Dengan menggunakan nilai dari setiap peubah yang telah didapatkan, dilakukanlah proses training menggunakan LibSVM 3.14 dengan percobaan pada 3 jenis kernel. Hasil akurasi dari training Data I dan Data II menggunakan metode 5-fold cross validation dapat dilihat pada Tabel 2.
Tabel 2 Perbandingan hasil akurasi training dari Data I dan Data II
Data
Akurasi dari hasil training SVM (%) Linear kernel Polynomial kernel RBF kernel Data I (3138 jamu, 465 tanaman) 68.19 66.63 71.00 Data II (2748 jamu, 231 tanaman) 94.32 93.85 95.34 66.63 65.14 63.00 0 20 40 60 80 100 d = 2 d = 3 d = 4 Ak u rasi (%) (a) 93.85 93.12 92.79 0 20 40 60 80 100 d = 2 d = 3 d = 4 Ak u rasi (%) (b)
Gambar 6 Hasil perbandingan akurasi pencarian nilai d Data I dengan C=1 dan γ=2 (a), hasil perbandingan akurasi pencarian nilai d Data II dengan C=2 dan γ=2 (b)
10
Pada percobaan ini dipilih model terbaik yang dihasilkan oleh RBF kernel, karena di setiap jenis data RBF kernel selalu menghasilkan akurasi pelatihan yang tertinggi. Hasil dari setiap akurasi yang dihasilkan oleh model SVM menggunakan RBF kernel akan digunakan sebagai pembanding dengan metode PLS-DA. Hasil perbandingan antara metode SVM dengan metode PLS-DA dapat dilihat pada Tabel 3.
Dataset PLS-DA (%) SVM RBF Kernel (%) Data I 71.60 71.00 Data II 94.21 95.34 Percobaan 2
Langkah awal yang dilakukan dalam percobaan ini ialah mencari model terbaik untuk Data III. Pencarian dilakukan dengan teknik grid search menggunakan LibSVM 3.14. Untuk linear kernel didapatkan nilai C yang optimal sebesar 0.5. Pada percobaan menggunakan polynomial kernel menggunakan nilai C sebesar 0.5 dan γ sebesar 2, Data III mendapatkan nilai d yang optimal sebesar 2. Pada percobaan menggunakan RBF kernel, didapatkan nilai C sebesar 2 dan nilai γ sebesar 0.5. Hasil perbandingan pencarian nilai d dapat dilihat pada Gambar 8. Hasil grid search pada model RBF kernel menggunakan grid.py untuk Data III dapat dilihat pada Gambar 9.
Pada percobaan ini dilakukan proses training menggunakan LibSVM 3.14 dengan percobaan pada 3 jenis kernel menggunakan Data III. Hasil yang
(a) (b)
Gambar 7 Hasil grid search pada model RBF Kernel menggunakan grid.py dari Data I (a) dan Data II (b)
Tabel 3 Perbandingan akurasi PLS-DA dengan SVM menggunakan Data I dan Data II
11 didapatkan akan dibandingkan dengan hasil akurasi dari Data I dan Data II. Hasil perbandingan dari akurasi dapat dilihat pada Gambar 10.
Gambar 10 Hasil akurasi training 5-fold cross validation pada setiap jenis data
92.53 89.39 88.92 0 20 40 60 80 100 d = 2 d = 3 d = 4 Ak u rasi (%) 68.19 66.63 71.00 94.32 94.21 93.85 92.53 95.34 95.70 0 20 40 60 80 100
Linear Kernel Polynomial Kernel RBF Kernel
Ak u rasi (%) Jenis Model Data I Data II Data III
Gambar 8 Hasil perbandingan akurasi pencarian nilai d Data III dengan C=0.5 dan γ=2
Gambar 9 Hasil grid search pada model RBF Kernel menggunakan grid.py dari Data III
12
Dari hasil yang diperoleh, dapat dilihat bahwa model SVM telah memberikan hasil yang baik. Jika dirata-ratakan dari ketiga model kernel, akurasi yang diperoleh dari penggunaan Data I sebesar 68.61%, Data II sebesar 94.5%, dan Data III sebesar 94.15%. Pada penelitian ini dipilih model terbaik yang dihasilkan oleh RBF kernel, karena di setiap jenis data RBF kernel selalu menghasilkan akurasi pelatihan yang tertinggi. Hasil dari akurasi Data III menggunakan RBF kernel akan digunakan sebagai pembanding dengan metode PLS-DA untuk mengetahui pengaruh dari imbalanced data. Dari hasil penelitian sebelumnya, PLS-DA memiliki akurasi tertinggi menggunakan Data II sebesar 94.21%. Hasil yang diperoleh dari metode SVM menggunakan Data II memiliki akurasi sebesar 95.34%, dan hasil terbaik dimiliki oleh metode SVM menggunakan Data III yang menghasilkan akurasi sebesar 95.70%. Dari hasil yang didapatkan dapat dilihat penggunaan Data III hasil data balancing memiliki akurasi yang tertinggi dengan model SVM menggunakan RBF kernel.
Implementasi Sistem
Tahap implementasi sistem menghasilkan program yang dapat memprediksi komposisi jamu yang baru.Tampilan dan tahapan dalam penggunaan sistem ini dapat dilihat pada Lampiran 3.
Pembahasan
Percobaan 1
Dilihat dari hasil training 5-fold cross validation, akurasi terbaik didapat dari model SVM dengan menggunakan RBF kernel. RBF kernel selalu menghasilkan akurasi tertinggi pada setiap jenis data. Hal ini menunjukkan bahwa daerah setiap kelas dari data yang digunakan membentuk wilayah yang lebih cocok dipisahkan dan dipetakan dengan Radial Basis Function (RBF). Dilihat dari bentuk fungsinya RBF cocok digunakan dalam masalah estimasi fungsi non-linear. Salah satu keuntungan dari RBF terletak pada penerapannya di hampir semua dimensi (fleksibilitas). Keuntungan lainnya adalah akurasi yang tinggi dan konvergensi cepat untuk mendapatkan fungsi sasaran dalam banyak kasus ketika penyelesaiannya dalam bentuk dimensi data yang sangat padat (Buhmann 2010).
Dilihat dari perbandingan hasil akurasi metode yang dilakukan oleh Afendi et al. (2012) menggunakan PLS-DA tanpa melakukan data cleaning, metode SVM memiliki nilai akurasi sedikit lebih rendah. Tingkat akurasi PLS-DA untuk data ini sebesar 71.6% sedangkan SVM sebesar 71%. Sedangkan untuk data yang telah direduksi, metode SVM memiliki tingkat akurasi yang lebih tinggi. Tingkat akurasi PLS-DA sebesar 94.21%, sedangkan metode SVM memiliki nilai akurasi sebesar 95.34%.
Peningkatan tingkat akurasi pada SVM ini dikarenakan data yang digunakan telah diproses untuk mendukung hasil prediksi yang lebih baik untuk metode PLS-DA dengan membuang beberapa jamu dan tanaman yang dianggap tidak begitu signifikan. Pembuangan data ini dilakukan dengan proses simplifikasi jamu dengan cara pembuangan data jamu yang hanya mengarah ke satu khasiat dan diikuti dengan simplifikasi tanaman jamu dengan cara pembuangan jumlah tanaman yang tidak begitu signifikan dalam penentuan khasiat jamu. Proses data
13 cleaning ini telah dilakukan pada penelitian oleh Afendi et al. (2012) dan tidak diulangi pada penelitian ini sehingga data yang digunakan sama. Dari hasil penggunaan data tersebut, dapat dikatakan bahwa SVM memiliki akurasi yang lebih baik pada penerapan data cleaning terhadap data yang tidak signifikan.
Percobaan 2
Pada penelitian ini masalah imbalanced data yang menyebabkan proses pelatihan data dengan SVM kurang optimal diatasi dengan melakukan teknik undersampling dan oversampling. Hasil yang diperoleh dari pelatihan data menunjukkan bahwa Data III memiliki nilai akurasi yang lebih tinggi dari data lainnya. Hal ini menggambarkan pengaruh imbalanced data yang dapat mengurangi hasil dari akurasi data.
Dilihat dari perbandingan hasil akurasi metode penelitian yang dilakukan oleh Afendi et al. (2012) menggunakan PLS-DA dan metode SVM dengan imbalanced data, metode SVM dengan jumlah data yang sudah seimbang memiliki nilai akurasi yang lebih tinggi. Jadi, dari percobaan ini telah dihasilkan model terbaik yang dicapai dengan melakukan undersampling dan oversampling dari data yang sudah melalui data cleaning. Tujuan dari prosedur ini ialah untuk mengatasi efek dari imbalanced data dari data sebelumnya.
Pengujian Prediksi Sistem
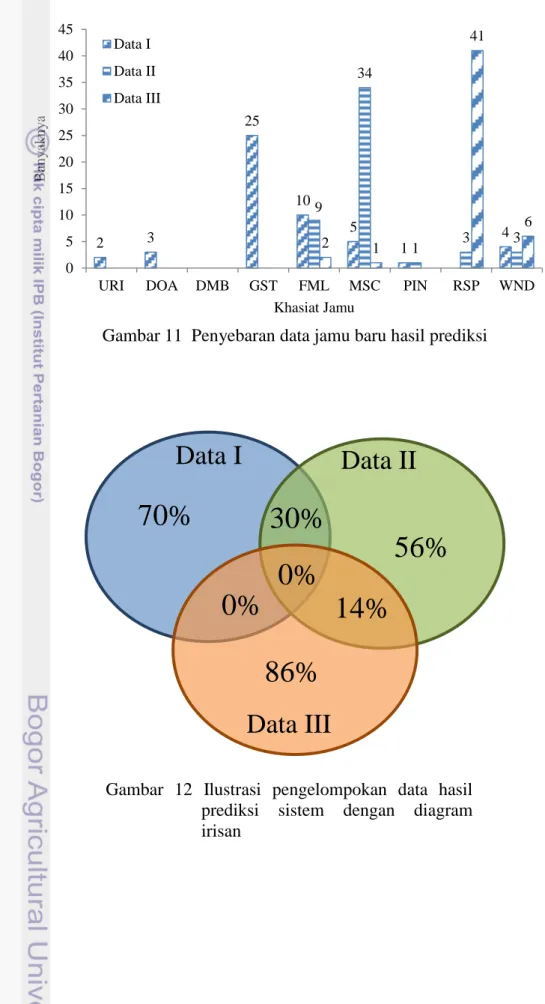
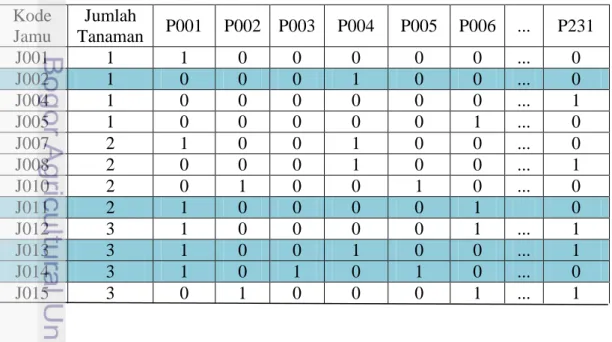
Untuk mengetahui hasil prediksi, sistem yang dibuat telah dicoba untuk memprediksi 50 jenis formula jamu baru yang dapat dilihat pada Lampiran 4. Model yang digunakan dalam memprediksi formula jamu adalah model yang dihasilkan dengan RBF kernel. Hasil dari prediksi ini dapat dilihat pada Lampiran 4. Setiap formula jamu yang digunakan memiliki komposisi yang terdiri atas 4 jenis tanaman. Prediksi dilakukan terhadap 3 jenis model, yaitu model yang dihasilkan dengan menggunakan data latih Data I, Data II, dan Data III. Hasil prediksi ini diharapkan dapat menjadi pembanding antar model klasifikasi SVM yang telah dibentuk oleh masing-masing data. Penyebaran kelas hasil prediksi dapat dilihat pada Gambar 11. Hasil prediksi masih menampilkan hasil yang beragam untuk setiap model. Model yang dihasilkan dari data latih Data I menghasilkan hasil prediksi yang dominan pada khasiat GST, Data II dominan pada khasiat MSC, sedangkan Data III dominan pada khasiat RSP. Penyebaran dan gambaran irisan hasil prediksi setiap data dapat dilihat pada Gambar 12. Dari hasil yang ditunjukkan oleh Gambar 10 belum terlihat adanya irisan yang menghasilkan nilai prediksi yang sama dari semua jenis data. Hasil prediksi yang diperoleh menghasilkan jumlah data sebesar 30% dari jumlah data yang memiliki hasil prediksi yang sama antara Data I dengan Data II dan 14% antara Data II dengan Data III. Hal ini menggambarkan kedekatan bentuk model antara Data I dengan Data II dan Data II dengan Data III.
Tidak adanya irisan yang sama antara ketiga model data tersebut menunjukkan bahwa data yang digunakan belum menunjukkan konsistensi pada setiap model data dalam melakukan prediksi dan masih perlu diuji lebih lanjut. Oleh sebab itu, pengujian sistem ini adalah upaya untuk memunculkan kandidat-kandidat formula jamu baru yang dapat membantu peneliti untuk memilih kandidat formula jamu untuk diuji secara in-vivo dan in-vitro untuk dibandingkan dengan hasil prediksi dari setiap model SVM. Setelah sistem dapat dibandingkan
14
dengan pengujian tersebut, model yang terbaik untuk memprediksi formula jamu yang baru diharapkan dapat diketahui.
2 3 25 10 5 1 4 9 34 1 3 3 2 1 41 6 0 5 10 15 20 25 30 35 40 45
URI DOA DMB GST FML MSC PIN RSP WND
B an y ak n y a Khasiat Jamu Data I Data II Data III
Data I
Data II
Data III
30%
0%
0%
14%
%
86%
56%
70%
Gambar 12 Ilustrasi pengelompokan data hasil prediksi sistem dengan diagram irisan
15
SIMPULAN DAN SARAN
SimpulanPenelitian ini berhasil membandingkan akurasi sistem klasifikasi khasiat jamu antara metode SVM dengan PLS-DA. Akurasi metode SVM lebih rendah dibandingkan dengan metode PLS-DA pada data yang belum direduksi, yaitu sebesar 71%, tetapi memiliki akurasi yang lebih tinggi pada data yang telah direduksi, yaitu sebesar 95.34%. Dari hasil tersebut dapat disimpulkan bahwa metode SVM memberikan kinerja yang lebih baik dari metode PLS-DA pada data yang telah melalui data cleaning. Terkait dengan masalah imbalanced data, proses undersampling dan oversampling yang dilakukan mampu meningkatkan akurasi. Dari hasil tersebut, model SVM yang terbaik dapat diperoleh dari penerapan data cleaning dan penggunaan data pelatihan yang seimbang.
Penelitian ini juga telah berhasil mengimplementasikan sistem klasifikasi jamu sederhana dengan metode SVM yang dapat digunakan untuk memprediksi kandidat-kandidat formula jamu baru. Kandidat yang dihasilkan dari sistem klasifikasi ini dapat membantu peneliti untuk memilih kandidat formula jamu yang akan diuji dalam tahap selanjutnya, yaitu uji in vivo dan in vitro.
Saran
Saran untuk penelitian selanjutnya adalah:
1 mencoba penelitian dengan data jamu yang lebih representatif dengan komposisi berupa persentase formula setiap tanaman
2 menerapkan metode lain untuk menangani masalah imbalanced data pada metode SVM terhadap data jamu yang digunakan seperti metode SMOTE atau menerapkan teknik Weighted-SVM agar menghasilkan hasil yang lebih baik 3 menggunakan metode lain untuk mencari nilai akurasi klasifikasi dan prediksi
yang lebih akurat
4 melakukan pengujian in vivo dan in vitro untuk data komposisi jamu baru untuk mengetahui akurasi prediksi dari setiap model.
DAFTAR PUSTAKA
Adam LS, Navindra PS, Mary LH, Catherine C, David H. 2006. Analysis of the interactions of botanical extract combinations againts the viability of prostate cancer cell lines. Evid Based Complement Alternat Med. 3(1): 117-124.
Afendi FM, Darusman LK, Hirai A, Amin MA, Takahashi H, Nakamura K, Kanaya S. 2010. System biology approach for elucidating the relationship between Indonesia herbal plants and the efficacy of jamu. Di dalam: Fan W, Hsu W, Webb GI, Liu B, Zhang C, Gunopulos D, Wu X, editor. 2010 IEEE International Conference on Data Mining Workshops; 2010 Des 14; Sydney, Australia. Sydney (AU): Conference Publishing Services.
16
Afendi FM, Darusman LK, Morita AH, Altaf-Ul-Amin M, Takahashi H, Nakamura K, Tanaka K, Kanaya S. 2012. Efficacy prediction of jamu formulations by PLS modeling. Curr Comput Aided Drug Des. 9(1):46-59. PubMed PMID: 23106776.
Akbani R, Kwek S, Japkowicz N. 2004. Applying support vector machines to imbalanced datasets. Di dalam: Jaime G, Siekmann J, editor. Machine Learning: ECML; 2004 Sept 20-24; Pisa, Italia. Berlin (DL): Springer-Verlag Berlin Heidelberg.
Beers SJ. c2001. Jamu the Ancient Indonesian Art of Herbal Healing. Singapore (SG): Periplus Editions (HK) Ltd.
Boswell D. 2002. Introduction to Support Vector Machine [Internet]. [diacu 2013 Mar 19]. Tersedia dari: http://www.work.caltech.edu/~boswell/IntroTo SVM.pdf
Buhmann M. 2010. Radial basis function. Scholarpedia, 5(5):9837. doi:10.4249/scholarpedia.9837.
Byun H, Lee SW. 2003. A survey on pattern recognition application of support vector machines. Int J Patt Recogn Artif Intell. 17(3):459-486.
Cortes C, Vapnik V. 1995. Support-vector networks. Machine Learning. 20(3):273-297.
Hsu CW, Chang CC, Lin CJ. 2010. A Practical Guide to Support Vector Machine [Internet]. [diacu 2012 Des 1]. Tersedia dari : http://www.cs.sfu.ca/people/Faculty/teaching/726/spring11/svmguide.pdf Kusuma WA, Akiyama Y. 2011. Metagenome fragment binning based on
characterization vectors. Di dalam: Proceedings of 2011 International Conference on Bioinformatics and Biomedical Technology; 2011 Mar 25-27; Sanya, China. hlm 50-54.
Mahady GB. 2001. Global harmonization of herbal health claim. J Nutr. 131: 1120S-1123S.
17 Lampiran 1 Daftar tanaman jamu yang paling signifikan berdasarkan kelasnya
18
Lampiran 1 lanjutan
(Sumber : Afendi FM, 2012. Statistical Model of Plants Function in Jamu Medicine, NAIST)
19 Lampiran 2 Ilustrasi proses penambahan dan pengurangan data
1 proses penambahan data
Ilustrasi data awal yang masih memiliki jumlah data kurang dari jumlah rata-rata (contoh: 10 data) Kode Jamu Jumlah Tanaman P001 P002 P003 P004 P005 P006 ... P231 J001 1 1 0 0 0 0 0 ... 0 J002 1 0 0 0 1 0 0 ... 0 J003 1 0 0 0 0 0 0 ... 1 J004 2 1 0 0 1 0 0 ... 0 J005 2 0 0 0 1 0 0 ... 1 J006 3 1 0 0 0 0 1 ... 1 J007 3 1 0 0 1 0 0 ... 1 J008 4 1 0 0 1 0 1 ... 1
*keterangan = tanaman yang signifikan di kelasnya
Penambahan data dilakukan dengan pertimbangan jumlah tanaman yang digunakan dalam formula dan tanaman yang digunakan merupakan tanaman yang diambil dari kelompok tanaman yang signifikan di kelasnya serta tidak menggunakan data yang berulang
Kode Jamu Jumlah Tanaman P001 P002 P003 P004 P005 P006 ... P231 J001 1 1 0 0 0 0 0 ... 0 J002 1 0 0 0 1 0 0 ... 0 J003 1 0 0 0 0 0 0 ... 1 xxxx 1 0 0 0 0 0 1 0 J004 2 1 0 0 1 0 0 ... 0 J005 2 0 0 0 1 0 0 ... 1 xxxx 2 1 0 0 0 0 0 1 J006 3 1 0 0 0 0 1 ... 1 J007 3 1 0 0 1 0 0 ... 1 J008 4 1 0 0 1 0 1 ... 1
*keterangan = tanaman yang signifikan di kelasnya
20
Lampiran 2 lanjutan
2 proses pengurangan data
Ilustrasi data awal yang masih memiliki jumlah data lebih dari jumlah rata-rata yang diinginkan (contoh: 10 data).
Kode Jamu Jumlah Tanaman P001 P002 P003 P004 P005 P006 ... P231 J001 1 1 0 0 0 0 0 ... 0 J002 1 0 0 0 1 0 0 ... 0 J003 1 1 0 0 0 0 0 ... 0 J004 1 0 0 0 0 0 0 ... 1 J005 1 0 0 0 0 0 1 ... 0 J006 1 0 0 0 0 0 0 ... 1 J007 2 1 0 0 1 0 0 ... 0 J008 2 0 0 0 1 0 0 ... 1 J009 2 1 0 0 1 0 0 ... 0 J010 2 0 1 0 0 1 0 ... 0 J011 2 1 0 0 0 0 1 0 J012 3 1 0 0 0 0 1 ... 1 J013 3 1 0 0 1 0 0 ... 1 J014 3 1 0 1 0 1 0 ... 0 J015 3 0 1 0 0 0 1 ... 1 J016 3 1 0 0 1 0 0 ... 1 J017 3 1 0 1 1 0 0 ... 0 J018 4 1 0 0 1 0 1 ... 1 J019 4 1 0 0 1 0 1 ... 1
*keterangan = data yang berulang
Langkah awal melakukan pengurangan data dengan penghapusan data yang berulang (redudansi data)
Kode Jamu Jumlah Tanaman P001 P002 P003 P004 P005 P006 ... P231 J001 1 1 0 0 0 0 0 ... 0 J002 1 0 0 0 1 0 0 ... 0 J004 1 0 0 0 0 0 0 ... 1 J005 1 0 0 0 0 0 1 ... 0 J007 2 1 0 0 1 0 0 ... 0 J008 2 0 0 0 1 0 0 ... 1 J010 2 0 1 0 0 1 0 ... 0 J011 2 1 0 0 0 0 1 0 J012 3 1 0 0 0 0 1 ... 1 J013 3 1 0 0 1 0 0 ... 1 J014 3 1 0 1 0 1 0 ... 0 J015 3 0 1 0 0 0 1 ... 1
21 Lampiran 2 lanjutan
J017 3 1 0 1 1 0 0 ... 0
J018 4 1 0 0 1 0 1 ... 1
Setelah penghapusan data yang masih berulang, penghapusan dilakukan pada data dengan pertimbangan pemerataan jumlah tanaman yang dipakai jika data masih melebihi nilai rata-rata.
Kode Jamu Jumlah Tanaman P001 P002 P003 P004 P005 P006 ... P231 J001 1 1 0 0 0 0 0 ... 0 J004 1 0 0 0 0 0 0 ... 1 J005 1 0 0 0 0 0 1 ... 0 J007 2 1 0 0 1 0 0 ... 0 J008 2 0 0 0 1 0 0 ... 1 J010 2 0 1 0 0 1 0 ... 0 J012 3 1 0 0 0 0 1 ... 1 J015 3 0 1 0 0 0 1 ... 1 J017 3 1 0 1 1 0 0 ... 0 J018 4 1 0 0 1 0 1 ... 1
22
Lampiran 3 Langkah dan tampilan penggunaan aplikasi 1 pemilihan model SVM yang diinginkan.
2 pemilihan dari tanaman untuk formula jamu baru
23 Lampiran 3 lanjutan
24
Lampiran 4 Hasil prediksi komposisi jamu baru
No. Jamu Tanaman Hasil dari Model Data I (3138 data jamu) Hasil dari Model Data II (2748 data jamu) Hasil dari Model Data III (2745 data jamu, balance) 1 2 3 4 1 Jb0001 Tamarindus
indica Curcuma longa
Languas
galanga Piper betle 5 5 8
2 Jb0002 Piper retrofractum Terminalia bellirica Helicteres isora Notopterygium incisum 6 6 8
3 Jb0003 Mentha piperita alternifolia Melaleuca Syzygium cumini officinale Zingiber 7 7 8 4 Jb0004 Gaultheria
punctata Panax ginseng
Eclipta prostrata Commiphora myrrha 6 6 8 5 Jb0005 Zanthoxylum acanthopodium Commiphora myrrha Cola acuminata Panax pseudoginseng 6 6 8
6 Jb0006 Borreria hispida Terminalia bellirica Cinchona succirubra Solanum verbacifolium 5 5 8 7 Jb0007 Hydrocotyle
asiatica Syzygium cumini
Quercus
lusitanica Messua ferrea 5 5 8
8 Jb0008 Illicium verum Helicteres isora Notopterygium incisum Echinacea purpurea 4 8 8 9 Jb0009 Eriobotrya japonica Pistacia lentiscus Mentha arvensis Wolfiporia extensa 4 8 8
10 Jb0010 Sida rhombifolia Spatholobus suberectus
Canangium
odoratum Ocimum sanctum 6 6 8
11 Jb0011 Schisandra chinensis Crataegus pinnatifida Phellodendron chinense Parameria laevigata 5 5 8
12 Jb0012 Curcuma longa Piper nigrum Aloe vera Tamarindus
indica 5 5 8
13 Jb0013 Apium graveolens Santalum album Zingiber officinale
Canangium
odoratum 9 9 8
14 Jb0014 Aloe vera Oryza sativa Trifolium pratense
Theobroma
cacao 9 9 8
15 Jb0015 Nigella sativa Lavandula angustifolia
Foeniculum vulgare
Glycyrrhiza
uralensis 4 8 8
16 Jb0016 Thymus vulgaris Punica
granatum Panax ginseng
Coriandrum
sativum 5 5 9
17 Jb0017 flagelliforme Typhonium Piper nigrum Foeniculum vulgare Plantago major 6 6 8 18 Jb0018 Psidium guajava Curcuma longa Alpinia
galanga Languas galanga 4 5 5
19 Jb0019 Melaleuca leucadendra Myristica fragrans Hydrocotyle asiatica Curcuma xanthorrhiza 4 6 6 20 Jb0020 Kaempferia pandurata Syzygium aromaticum Phaleria papuana Hibiscus sabdariffa 4 6 8
21 Jb0021 Theae sinensis Curcuma xanthorrhiza
Melaleuca
leucadendra Curcuma longa 4 6 8
22 Jb0022 Mentha piperita Garcinia atroviridis Psidium guajava Anacardium occidentale 4 6 9 23 Jb0023 Zingiber officinale Coriandrum sativum Phaleria papuana Garcinia atroviridis 4 6 8 24 Jb0024 Dioscorea opposite Anacardium occidentale Orthosiphon stamineus Morinda citrifolia 1 6 9
25 Jb0025 Curcuma longa Piper nigrum Tamarindus indica
Melaleuca
leucadendra 5 6 8
26 Jb0026 Psidium guajava Curcuma longa Carica papaya Garcinia
atroviridis 4 5 8
27 Jb0027 Tamarindus
indica Cassia alata
Phaleria papuana
Cymbopogon
nardus 4 9 9
28 Jb0028 Psidium guajava Caesalpinia sappan
Orthosiphon
stamineus Languas galanga 1 6 8
29 Jb0029 Coriandrum sativum Morinda citrifolia Syzygium aromaticum Aquilaria sinensis 4 6 8
25 Lampiran 4 lanjutan 30 Jb0030 Guazuma ulmifolia Melaleuca leucadendra Orthosiphon stamineus Merremia mammosa 2 6 8 31 Jb0031 Amomum
compactum Aloe vera
Morinda citrifolia Tamarindus indica 4 6 8 32 Jb0032 Syzygium aromaticum Guazuma ulmifolia Melaleuca
leucadendra Cassia alata 2 6 8
33 Jb0033 Amomum compactum Orthosiphon stamineus Phaleria papuana Zanthoxylum acanthopodium 4 6 8 34 Jb0034 Amomum compactum Melaleuca leucadendra Languas galanga Andrographis paniculata 4 6 8 35 Jb0035 Orthosiphon
stamineus Curcuma longa
Morinda citrifolia Syzygium aromaticum 4 6 8 36 Jb0036 Guazuma ulmifolia Cinchona
succirubra Aloe vera
Phaleria
papuana 2 6 8
37 Jb0037 Canangium
odoratum Piper betle
Curcuma xanthorrhiza
Melaleuca
leucadendra 5 6 8
38 Jb0038 Mentha piperita Theae sinensis Daucus carota Psidium guajava 4 6 8 39 Jb0039 Orthosiphon
stamineus
Hydrocotyle asiatica
Melaleuca
leucadendra Cassia alata 4 6 9
40 Jb0040 Curcuma xanthorrhiza
Syzygium aromaticum
Zingiber
officinale Psidium guajava 4 6 8
41 Jb0041 Aloe vera Phaleria papuana
Mentha piperita
Merremia
mammosa 9 6 8
42 Jb0042 Psidium guajava Canangium odoratum Mentha piperita Hibiscus sabdariffa 4 6 9 43 Jb0043 Kaempferia pandurata Curcuma xanthorrhiza Melaleuca
leucadendra Curcuma longa 4 5 5
44 Jb0044 Phaleria papuana Piper betle Curcuma xanthorrhiza Zanthoxylum acanthopodium 5 6 8 45 Jb0045 Tamarindus indica Phaleria papuana Mentha
piperita Theae sinensis 4 6 8
46 Jb0046 Piper betle Psidium guajava Piper nigrum Mentha piperita 5 6 8 47 Jb0047 Phaleria papuana Mentha piperita Theae sinensis Daucus carota 4 6 8 48 Jb0048 Curcuma xanthorrhiza Syzygium aromaticum Zingiber officinale Morinda citrifolia 4 6 8
49 Jb0049 Aloe vera Mentha piperita Merremia
mammosa Psidium guajava 9 6 8
50 Jb0050 Psidium guajava Mentha piperita Theae sinensis Tamarindus
indica 4 6 8
keterangan indeks prediksi
1 = urinary related problems (URI) 2 = disorder of apetite (DOA)
3 = disorder of mood and behavior (DMB) 4 = gastrointestinal disorders (GST)
5 = female reproductive organ problems (FML)
6 = muskuloskeletal and connective tissue disorders (MSC) 7 = pain and inflammation (PIN)
8 = respiratory disease (RSP)
26
RIWAYAT HIDUP
Penulis dilahirkan di Lampung Selatan pada tanggal 15 April 1991 dari pasangan Yuyus Ruslan dan Tati Mulyati. Penulis adalah putra pertama dari dua bersaudara. Tahun 2009 penulis lulus dari SMA Negeri 5 Bogor dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui Undangan Seleksi Masuk IPB dan diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis aktif menjadi asisten praktikum Algoritme dan Bahasa Pemrograman pada tahun ajaran 2011/2012 dan 2012/2013, asisten praktikum Basis Data pada tahun ajaran 2011/2012 dan 2012/2013, asisten praktikum Struktur Data pada tahun ajaran 2011/2012, asisten praktikum Bahasa Pemrograman pada tahun ajaran 2012/2013, dan asisten praktikum Sistem Pakar pada tahun ajaran 2012/2013. Penulis juga aktif mengajar mata kuliah Pengantar Matematika, Landasan Matematika, Kalkulus, Kalkulus II, dan Matematika Diskret di bimbingan belajar Katalis. Kegiatan lain penulis adalah sebagai assistant sound engineer di salah satu perusahaan entertainment AAC Indonesia. Pada bulan Juli-Agustus 2012 penulis melaksanakan Praktik Kerja Lapang di PT. Praisindo Teknologi dan membantu dalam pengembangan user interface framework untuk aplikasi portofolio management. Penulis juga mandapatkan peringkat juara ke-2 dalam perlombaan aplikasi Rock Star Dev 2013 kategori New Rock Star Dev bersama tim AppSynthesis pada tahun 2013.