Fakultas Ilmu Komputer
Universitas Brawijaya
4477
Prediksi Rating Pada Review Produk Kecantikan Menggunakan Metode
Semantic Orientation Calculator dan Regresi Linier
Bastian Dolly Sapuhtra1, M. Ali Fauzi2, Bayu Rahayudi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Ramainya produsen produk kecantikan menghasilkan produk yang bagus dan beragam. Hal ini menarik konsumen untuk menggunakan produk-produk kecantikan tersebut. Semakin banyak konsumen yang menggunakan produk kecantikan tersebut, membuat produsen mencoba berbagai inovasi pada produk mereka. Inovasi dapat diperoleh dari banyaknya komentar, saran, atau review yang dibuat oleh konsumen pada berbagai macam produk. Manfaat dari review produk bagi konsumen juga berguna untuk memperoleh informasi sebelum membeli suatu produk. Banyak hasil review yang ada tidak disertai dengan rating. Hal ini membuat produsen sulit dalam mengelompokkan review pada sentiment tertentu. Penelitian ini bertujuan untuk pengelompokan review kedalam sentiment tertentu secara otomatis dalam bentuk rating. Pada penelitian ini dibangun sebuah sistem menggunakan metode penghitungan Semantic Orientation Calulator dan Regresi Linier. Pemecahan kalimat pada review kedalam bentuk n-gram (bigram dan trigram) dan satu kalimat bertujuan meningkatkan hasil prediksi. Hasil Pengujian pada sistem ini adalah 23%, 71%, 67% pada akurasi bigram, 24%, 71%, 67% pada akurasi trigram, dan paling rendah 24%, 67%, 64% pada akurasi satu kalimat dengan menggunakan model pengujian toleransi 0, toleransi 1, dan sentiment review. Hasil pengujian terbaik pada pemecahan kalimat menggunakan n-gram (bigram dan trigram) cukup baik menyelesaikan masalah pada penelitian.
Kata kunci: prediksi rating, review, semantic orientation calculator, regresi linier, n-gram Abstract
Crowded producers of beauty product produce good and varied products. This has attracted consumers to use these beauty products. More and more consumers are using these beauty products, making producers try various innovations on their products. Innovation can be obtained from many comments, advices, or reviews made by consumers on variety of products. Benefits of product reviews for consumers are also useful to obtain information before buy a product. Many results of the review are not accompanied by rating. This makes it difficult for producers to classify reviews into certain sentiments. In this research aims to classify review into certain sentiments automatically into rating. In this research built a system using Semantic Orientation Calculator and Linear Regression methods. Breaking sentences in a review into n-gram (bigram and trigram) and one sentence aims to improve the results of predictions. Results of testing on this system are 23%, 71%, 67% on accuracy of bigram, 24%, 71%, 67% on accuracy of trigram, and lowest 24%, 67%, 64% on accuracy of one sentence with tolerance 0, tolerance 1, and sentiment reviews. The best result of testing on breaking sentence using n-gram (bigram and trigram) was good enough to solve problem in this research.
Keywords: rating prediction, review, semantic orientation calculator, linear regression, n-gram
1. PENDAHULUAN
Saat ini konsumen yang menulis dan
membaca review secara online semakin meningkat. Membaca review tersebut secara keseluruhan dapat memakan waktu, namun jika hanya sedikit review yang dibaca tidak akan
mendapatkan evaluasi yang bagus. Beberapa review tentang produk dapat membantu konsumen dalam mengetahui kualitas merk produk tersebut layak atau tidak untuk digunakan. Produk yang beredar di pasaran saat ini sangat beragam, baik dari segi jenis maupun merk. Namun tidak semua produk memiliki
kualitas yang baik sesuai kebutuhan konsumen dan hal ini yang harus diperhatikan oleh para konsumen.
Salah satu website terkenal khusus wanita di Indonesia yang memiliki banyak konten seputar dunia kecantikan adalah femaledaily.com, yang berisi artikel serta review produk kecantikan. Terdapat banyak produk kecantikan yang siap untuk di-review oleh konsumen yang ingin menceritakan pengalamannya dalam menggunakan produk tersebut pada website ini. Pada website femaledaily.com sendiri terdapat rating pada masing-masing review. Rating adalah sebuah wujud tingkat kepuasan dari pengalaman seorang pe-review (Jong, 2011). Rating yang diberi oleh pe-review menjadi suatu pandangan bagi para konsumen terhadap produk tersebut. Banyaknya review yang ada terhadap suatu produk tanpa adanya rating yang diberikan oleh pengulas, membuat produsen agak kesulitan dalam mengkategorikan ulasan ke rating agar diketahui kualitas produk. Oleh sebab itu, dibutuhkan sistem untuk prediksi rating dari review yang diberi sehingga hasil yang didapat bisa digunakan untuk evaluasi dan meningkatkan kualitas produk.
Penelitian ini menerapkan analisis sentimen yang bertujuan untuk mengelompokkan review pengguna menjadi opini positif atau negatif secara otomatis (Zhang, et al, 2011). Untuk itu perlunya pengkajian ulang tentang review produk dengan cara pengklasifikasian review tersebut ke dalam kelas positif dan negatif supaya pada akhirnya konsumen dapat mengetahui tanggapan konsumen lain tentang produk tersebut secara cepat dan tepat, tetapi pengklasifikasian review dengan analisis sentimen hanya dibagi menjadi dua kelas yaitu sentimen positif dan sentimen negatif, akan tetapi review dapat diukur, sehingga tidak hanya menghasilkan sentimen positif dan sentimen negatif saja melainkan dapat menghasilkan sentimen kurang positif, sangat positif, sangat negatif, dan tidak terlalu negatif, kemudian mengukur rentang sentimen dari sangat negatif hingga sangat positif kedalam bentuk rating. Penghitungan dalam menentukan rating ini tidak langsung hanya pada sebuah review tetapi akan dilakukan proses N-gram.
Pada penelitian sebelumnya yang berjudul Sentiment Analysis with N-gram oleh Thiel dengan menggunakan n-gram untuk pengklasifikasian dokumen ke dalam sentimen negatif atau postif. Dalam klasifikasi sentimen pada penelitian ini terdapat kesalahan karena
fitur term tunggal. Sebuah fitur term tunggal yang diklasifikasikan dalam sentimen positif tidak selalu positif dan term tunggal yang diklasifikasikan dalam sentimen negatif tidak selalu negatif. Contohnya kata “baik” termasuk sentimen positif tetapi jika digabungkan dengan kata negasi menjadi “tidak baik” dan masuk kedalam sentimen negatif. Dengan penerapan n-gram ini diharapkan dapat menangani masalah tersebut. Pada penelitian ini didapat nilai akurasi yang lebih baik ketika menggunakan n-gram pada term tunggal dari 70% menjadi 84% setelah menerapkan n-gram (Thiel, 2016).
Pada penelitian ini menggunakan sebuah metode yang belum pernah diterapkan dalam memprediksi rating yaitu sebuah metode yang berhubungan dengan analisis sentimen yaitu metode Semantic Orientation Calculator (SO-CAL). Metode ini memiliki kamus yang masing-masing kata memiliki bobot dalam bentuk bahasa inggris, oleh sebab itu semua review akan diterjemahkan ke bahasa inggris menggunakan Google Translate API. Metode SO-CAL ini bertujuan untuk menghitung orientasi sentimen dari sebuah review dengan acuan pada kamus SO-CAL, yang menghasilkan nilai berupa bobot dari review yang diberikan. Nilai bobot ini tidak dapat langsung digunakan untuk memprediksi atau mengklasifikasi nilai rating, maka dari itu diterapkan suatu metode untuk mengkonversi nilai SO-CAL ke dalam kelas rating, yaitu regresi linier. Pada penelitian sebelumnya oleh Imtiyaz, Henryranu, dan Hidayat dengan judul Sistem Pendukung Keputusan Budidaya Tanaman Cabai Berdasarkan Prediksi Curah Hujan, penelitian ini menggunakan data curah hujan pada tahun-tahun sebelumnya dengan regresi linier, dari penelitian ini didapatkan tingkat akurasi sebesar 91,6% (Imtiyaz, Henryranu, & Hidayat, 2017). Tingkat akurasi yang tinggi ini menjadi acuan menerapkan regresi linier dalam memprediksi rating, dengan menggunakan data berupa nilai rating pada review sebelumnya dan nilai bobot dari proses pembobotan menggunakan SO-CAL.
Oleh sebab itu pada penelitian ini menggunakan metode perhitungan Semantic Orientation Calculator (SO-CAL) pada review yang diberikan pada proses pemecahan kalimat untuk menghitung bobot, lalu berdasarkan perhitungan yang sudah dilakukan dengan metode SO-CAL, selanjutnya nilai rating diprediksi menggunakan metode regresi linier.
2. METODE PENELITIAN 2.1 DATA
Data yang digunakan dalam penelitian ini dikumpul dari website www.femaledaily.com. Metode pengumpulan data adalah dengan pengumpulan data sekunder. Dataset yang digunakan dalam penelitian ini adalah data yang telah ada sebelumnya dan telah digunakan dalam penelitian sebelumnya oleh Irma (2017). Data ini digunakan sebagai data latih sebanyak 900 data dan data uji sebanyak 100 data. Pada data latih terdapat nilai rating dari 1-5 dengan komposisi yang sama pada masing-masing data, yaitu terdapat 180 rating pada kelas yang sama. Data ini digunakan karena memiliki studi kasus yang serupa.
2.2 DESKRIPSI UMUM SISTEM
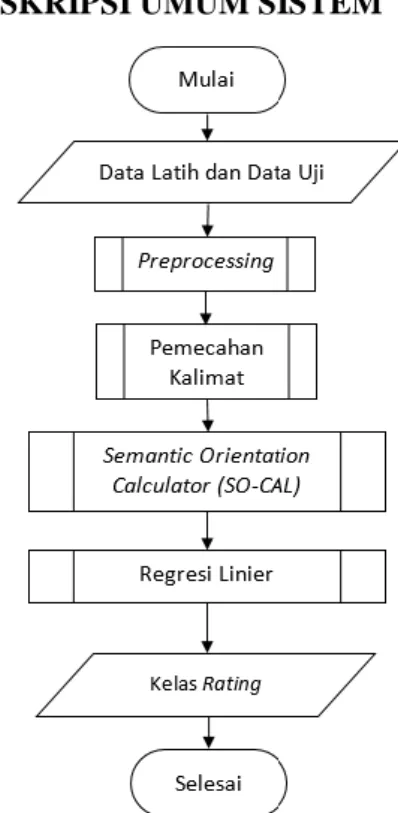
Gambar 1. Diagram alir sistem
Pada gambar diagram alir sistem prediksi rating pada review produk kecantikan dimulai dengan melakukan preprocessing untuk menghasilkan data yang terstruktur. Kemudian hasil preprocessing digunakan untuk proses prediksi rating dengan menggunakan metode semantic orientation calculator dan regresi linier.
2.3 PRE-PROCESSING
Tahap ini adalah bagian awal dari pemrosesan teks, terutama dalam proses
klasifikasi rating. Pre-processing merupakan proses menghilangkan kata-kata tidak berbobot, tidak penting, atau tidak memiliki arti dari sebuah teks atau dokumen, sehingga data menjadi lebih terstruktur dan dapat diolah (Harjanta, 2015). Pada penelitian ini pre-processing untuk mendapatkan teks terstruktur meliputi proses case folding dan tokenizing. Proses case folding adalah mengonversikan huruf kapital yang ada pada dokumen menjadi huruf kecil atau sebaliknya. Pada penelitian ini semua huruf dikonversikan menjadi huruf kecil (Harjanta, 2015). Proses tokenizing bertujuan untuk memisahkan kalimat menjadi pecahan kata, yang sesuai dengan kata penyusunnya, dan biasanya pada batas akhir dari kata tersebut ditandai dengan karakter spasi (Hartanti & Hartanti, 2016).
2.4 N-GRAM
Dalam tata Bahasa, terkadang suatu Bahasa tidak hanya terbentuk dari kata individu, namun terkadang terdiri dari urutan kata frase dan individu, baik frase dua, tiga, atau bahkan lebih yang biasa dikenal dengan n-gram. Huruf “n” pada n-gram sendiri memiliki arti banyaknya kata yang ada pada susunan kata tersebut, untuk penerapan n-gram, khusunya bigram pada kalimat “i very like that” menjadi “i very”, “very like”, dan “like that” (Ha, et al., 2003). Pada penelitian ini menggunakan n-gram yang memecah sebuah review menjadi sekelompok kata dengan “n=2” yang disebut bigram yaitu pemecahan kalimat menjadi dua kata pada masing-masing kelompok dan “n=3” yang disebut trigram yaitu pemecahan kalimat menjadi tiga kata pada masing-masing kelompok.
2.5 SEMANTIC ORIENTATION
CALCULATOR
Pada SO-CAL ditujukan untuk analisis orientasi semantik dari masing-masing kata (Taboada et al, 2011). Proses pertama yang dilakukan adalah mengekstrasi kata-kata dari sebuah dokumen berupa kalimat kedalam kata sifat, kata benda, kata kerja, dan keterangan. Kemudian menggunakan nilai orientasi semantik untuk masing-masing kata dari kamus SO-CAL untuk menghitung nilai dari keseluruhan dokumen. Kamus SO-CAL yang terdapat kata sifat, kata benda, kata kerja, dan keterangan memiliki nilai sentimen antara +5 dan -5 (tanda + mengartikan sentimen positif
dan tanda – mengartikan sentimen negatif). Model SO-CAL yang digunakan adalah Galadriel, pada model ini terdapat enam model yang bernama sent1, sent2, dan selanjutnya.
Pada model sent1 (Aggregating SO Scores) memiliki kamus SO-CAL yang terdiri dari kata sifat, kata kerja, kata benda, dan keterangan dengan nilai bobot antara +5 dan -5. Kemudian model sent2 (Intensification) atau disebut intensifier yang bukan termasuk sentimen tetapi memberikan tambahan nilai sentimen pada satu kata, dan apabila terdapat intensifier akan mengubah nilai sentimen pada kata tersebut, contoh intensifier adalah “very” , “less”, “really”, dan lainnya. Selanjutnya model sent3 (Negation) berfungsi sebagai negator pada kata. Kata-kata yang termasuk negator adalah “not”, “never”, “no”, “nobody”. Sama seperti intensifier, negator tidak memiliki nilai Semantic Orientation (SO), jika terdapat negator maka kata akan mempengaruhi suatu kata dengan mengurangi nilai SO sejumlah 4 apabila kata tersebut bernilai positif dan akan ditambah 4 apabila kata tersebut bernilai negatif. Model sent4 (Irrealis Blocking) Suatu kalimat akan dianggap nol atau mengabaikan nilai sentimen apabila terdapat kata blocking, contoh kata blocking adalah penanda bersyarat (if), kata kerja tertentu, kata “doubt” dan “expect”, quotes, dan kalimat tanya. Model sent5 dan sent6 (Text Level Features) total nilai yang dihitung dari semua bobot pada masing-masing kata dan sekaligus mengakhiri proses perhitungan SO-CAL. Proses SO-CAL dapat dilihat pada Tabel 1.
Tabel 1 Proses SO-CAL
Word it is not very good
SO-CAL Kamus 0 0 0 0 3 3 Intensifier 0.2 3.6 Negation 4 -0.4 Blocking Text-Level -0.6 2.6 REGRESI LINIER
Regresi linier adalah variabel yang tergantung pada satu atau lebih variabel lainnya, dan disebut variabel eksplanatori yang berfungsi memprediksi atau membuat estimasi rata-rata populasi atau nilai rata-rata variabel tergantung dengan semua nilai variabel yang
telah didapat dari variabel eksplanatorinya (Gujarati, 2009).
Regresi linier memiliki persamaan yaitu persamaan regresi. Pada umumbya persamaan regresi menggambarkan hubungan linier antara variabel kriteria / variabel tergantung dengan simbol Y dan satu atau lebih variabel prediktor / variabel bebas dengan simbol X, apabila memiliki banyak prediktor diberi simbol X1, X2, hingga Xn (Crammer & Howitt, 2006). Model Persamaan Regresi Linear 1 adalah seperti berikut ini :
Y = a + bX (1)
Keterangan :
Y = Variabel Response atau Variabel Akibat (Dependent)
X = Variabel Predictor atau Variabel Faktor Penyebab (Independent)
a = konstanta
b = koefisien regresi (kemiringan); besaran Response yang ditimbulkan oleh Predictor. Nilai-nilai a dan b dapat dihitung dengan menggunakan Rumus dibawah ini :
a = (Σy) (Σx²) – (Σx) (Σxy)
n(Σx²) – (Σx)² (2) b = n(Σxy) – (Σx) (Σy)
n(Σx²) – (Σx)² (3)
3. HASIL DAN PEMBAHASAN
Hasil dari sistem ini diuji dengan dua model pengujian yaitu dengan menggunakan pengujian toleransi 0, toleransi 1, sentiment review dan pengujian k-fold (cross validation).
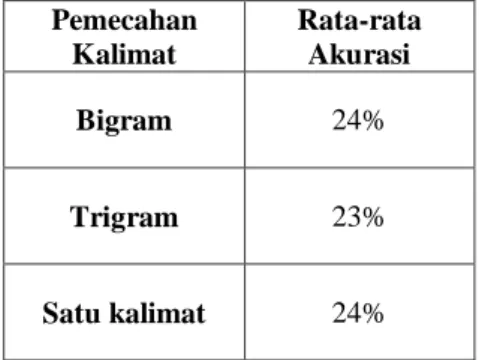
Tabel 2 Hasil Pengujian Akurasi Dengan K-Fold Pada Toleransi 0
Pemecahan Kalimat Rata-rata Akurasi Bigram 24% Trigram 23% Satu kalimat 24%
Tabel 3 Hasil Pengujian Akurasi Dengan K-Fold Pada Toleransi 1
Pemecahan Kalimat Rata-rata Akurasi Bigram 71% Trigram 71% Satu kalimat 67%
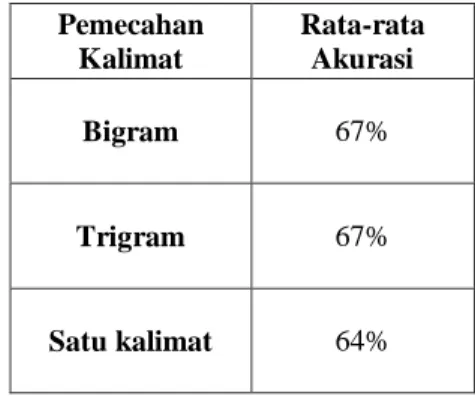
Tabel 4 Hasil Pengujian Akurasi Dengan K-Fold Pada Sentiment Review
Pemecahan Kalimat Rata-rata Akurasi Bigram 67% Trigram 67% Satu kalimat 64%
Berdasarkan hasil pengujian secara keseluruhan prediksi rating dengan menggunakan metode SO-CAL dan Regresi linier, memiliki akurasi yang kurang pada model pengujian toleransi 0 tetapi memiliki akurasi yang cukup baik pada model pengujian toleransi 1 dan sentiment review. Tabel di atas adalah hasil pengujian pemecahan kalimat menjadi bentuk n-gram (bigram dan trigram) dan satu kalimat yang merupakan skenario pengujian. Hasil yang didapatkan dari pengujian pada data bigram, data trigram dan data satu kalimat memiliki selisih yang sangat kecil. Pengujian pada data bigram yang mengelompokkan suatu data dengan berisi dua kata yang melakukan proses n-gram pada dokumen review, pada data bigram ini menghasilkan nilai akurasi yang sedikit lebih tinggi dari dokumen data trigram, tetapi memiliki akurasi yang sesuai dengan data satu kalimat. Nilai akurasi yang sedikit lebih tinggi ini kurang bisa dibandingkan karena memiliki selisih yang tidak besar yaitu 1%. Kemudian pada data trigram, yang mengelompokkan suatu data dengan berisi tiga kata yang dilakukan n-gram pada suatu dokumen review, pada data trigram ini
menghasilkan nilai akurasi yang paling rendah dibanding pengujian pada data bigram dan data review, tetapi nilai akurasi yang paling rendah ini juga tidak dapat dibandingkan dengan skenario yang lain karena selisih 1% tersebut. Pada skenario ketiga adalah pengujian pada data satu kalimat yang berisi dokumen dengan pemecahan kalimat, pada data satu kalimat ini menghasilkan nilai akurasi yang sama dengan data bigram dan lebih tinggi sebesar 1% dengan data trigram, sehingga tiga skenario pengujian akurasi dengan nilai rata-rata dari k-fold tidak dapat dibandingkan karena selisih yang kecil dari masing-masing skenario.
Skenario pengujian yang sudah mendapatkan hasil, kemudian dimodelkan dengan tiga model pengujian yaitu toleransi 0, toleransi 1, dan sentiment review. Model pengujian ini yang digabungkan dengan k-fold dilakukan untuk mengetahui kemampuan dari sistem yang telah dibuat. Model pengujian pertama adalah toleransi 0 yang mendapatkan hasil prediksi rating sistem harus sesuai dengan hasil rating yang ada pada data uji. Pada model pengujian pertama di dapat paling tinggi adalah sebesar 24% pada data bigram dan satu kalimat, dan 23% pada data trigram dengan akurasi rata-rata dari k-fold. Hasil akurasi dari pengujian toleransi 0 ini relatif rendah karena suatu nilai rating dari sistem harus sesuai dengan nilai rating sebenarnya atau yang diberikan oleh pe-review, tetapi dari beberapa hasil prediksi rating tersebut memiliki hasil yang memiliki selisih satu tingkat rating, dari hasil prediksi rating ini memiliki kesalahan karena nilai rating yang berdekatan, contohnya rating 1 dengan rating 2, atau rating 3 dengan rating 4, karena itu perlu dilakukan model pengujian toleransi 1. Pengujian model toleransi 1 adalah dengan mentolerir hasil prediksi selisih satu. Pada model pengujian toleransi 1 ini mendapatkan nilai akurasi terbaik yang sangat signifikan dibanding model pengujian sebelumnya sebesar 71% pada data bigram dan trigram, dan 67% pada data satu kalimat. Hasil pengujian dengan model toleransi 1 ini menunjukkan bahwa kesalahan prediksi yang dilakukan oleh sistem kebanyakan hanya karena selisih 1 rating. Hal ini disebabkan karena beberapa review dengan rating yang berdekatan memiliki banyak kesamaan kata-kata, contoh pada review yang terdapat kalimat “very good” dengan nilai rating 4 pada hasil sistem tetapi pada rating sebenarnya adalah 5. Pada model pengujian terakhir dengan sentiment review,
didapatkan nilai akurasi terbaik tetapi menurun dari model pengujian sebelumnya yaitu 67% pada data bigram dan trigram, dan 64% pada data satu kalimat. Hasil dari model pengujian terakhir ini membuktikan bahwa sistem ini dapat melakukan analisis sentiment dengan kemampuan yang baik saat menggunakan dua kelompok, yaitu positif dan negatif saja. Menurunnya tingkat akurasi dari model pengujian toleransi 1 ke sentiment review menunjukkan ada pengelompokan hasil prediksi rating yang kurang sesuai, model pengujian toleransi 1 yang mentolerir hasil prediksi dengan selisih satu dan model pengujian sentiment review yang mengelompokkan menjadi positif yaitu rating 4 dan 5, dan negatif yaitu rating 1 hingga 3. Pada model pengujian sentiment review menurun dari model pengujian toleransi 1 disebabkan adanya beberapa hasil prediksi rating yang salah pada rating 3 dan 4, rating tersebut menjadi pemisah dua kelompok sentiment positif dan negatif, sehingga nilai rating yang seharusnya termasuk pada sentiment positif tetapi dari hasil prediksi sistem termasuk sentiment negatif.
Berdasarkan pengujian akurasi menggunakan metode k-fold pada hasil prediksi rating, menghasilkan nilai yang stabil pada setiap fold atau tidak terjadi fluktuasi yang menyebabkan sistem ini sudah handal, meskipun memiliki nilai akurasi yang sangat rendah pada pengujian toleransi 0 dan tidak terlalu tinggi pada pengujian toleransi 1 atau sentimen review.
4. KESIMPULAN
Berdasarkan hasil pengujian dan analisis dari penelitian implementasi metode Semantic Orientation Calculator dan Regresi Linier untuk prediksi rating pada review produk kecantikan, bisa disimpulkan bahwa metode ini dapat diterapkan dalam memprediksi rating, dengan langkah-langkahnya adalah preprocessing, pemecahan kalimat, semantic orientation calculator (SO-CAL), dan regresi linier. Pengaruh pemecahan kalimat menggunakan n-gram (bigram dan trigram) berpengaruh positif. Hal ini dapat dilihat dari lebih tingginya akurasi dari pada pemecahan kalimat menjadi satu kalimat sebesar 71% dengan model pengujian toleransi 1 dan 67% pada model pengujian sentiment review, sedangkan pada pemecahan satu kalimat sebesar 67% pada model pengujian toleransi 1 dan 64% pada model pengujian sentiment
review. Hasil akurasi pada bigram dan trigram sangat kompetitif hanya memiliki selisih 1% pada model pengujian toleransi 0, yaitu 24% pada akurasi bigram dan 23% pada akurasi trigram. Dengan kata lain akurasi pada bigram merupakan hasil akurasi yang terbaik. Pemecahan kalimat menggunakan n-gram meningkatkan akurasi karena pemecahan kalimat menjadi gabungan kata yang lebih banyak.
5. DAFTAR PUSTAKA
A. & Hartanti, L. . P. S., 2016. Naive Baiyes Implementation Into Bahasa Indonesia Stemmer For Content Based Web Page Classification. Ijaber.
Cramer, D., & Howitt, D., 2006, The Sage
Dictionary of Statistics. London: Sage Publication
Gujarati, Damodar N., & Porter, Dawn C., 2012. Basic Econometric 5th Edition. McGraw –Hill: New York
Ha, L. Q., Sicilia-Garcia, E. I., Ming, . J. & . Smith, F. J., 2003. Extension of Zipf's Law to Word and Character. Journal of Computational Linguistics and Chinese Language Processing.
Harjanta, A. T. J., 2015. Preprocessing Text untuk Meminimalisir Kata yang Tidak Berarti. Jurnal Informatika Upgris. Imtiyaz, Hilal., Henryranu, Barlian Prasetio.,
Hidayat, Nurul., 2017. Sistem Pendukung Keputusan Budidaya Tanaman Cabai Berdasarkan Prediksi Curah Hujan. [Online] tersedia di: http://j-ptiik.ub.ac.id/index.php/j-ptiik/article/view/214 [diakses 15 Februari 2019].Jong, J., 2011. Predicting Rating with Sentiment Analysis. [Online] tersedia di: https://scholar.google.co.id/ [diakses 22 September 2018].
Pujadayanti, Irma., Ali, Mochammad Fauzi., Arum, Yuita Sari., 2018. Prediksi Rating Otomatis pada Ulasan Produk Kecantikan dengan Metode Naive Bayes dan N-gram. [Online] tersedia di: http://j-ptiik.ub.ac.id/index.php/j-ptiik/article/view/2921 [diakses 2 Desember 2018].
Taboada, Maite., Broke, Julian., Tofiloski, Milan., 2011. Lexicon-Based Methods for Sentiment Analysis. Computational
Linguisitics.
Thiel, K., 2016. Sentiment Analysis with N-gram. [Online] tersedia di: https://www.knime.com/blog/sentiment -analysis-with-n-grams [diakses 11 November 2018].
Zhang., Ye, Q., Zhang, Z., & Li, Y., 2011. Sentiment classification of Internet
restaurant reviews written in Cantonese. Expert Systems with Applications, 38, 7674–7682.