TUGAS II
TUGAS II
TEKNOLOGI SISTEM BASIS DATA
TEKNOLOGI SISTEM BASIS DATA
Semester Genap 2015/2016
Semester Genap 2015/2016
Kelas 2015FA
Kelas 2015FA
EENNNN! ! II""NNA A EE##A A SSAA""II 11550066$$112211$$00 "
"AANNGGGGA A KK%%AA""IISSMMA A &&UUTT""AA 11550066$$1122''((55 T
TAANSNSA A T"T"ISISNA NA AASTSTONONO &UO &UT"T"II 15150606$1$12)2)(6(6
MAGISTE" TEKNOLOGI INFO"MASI MAGISTE" TEKNOLOGI INFO"MASI
FAKULTAS ILMU KOM&UTE" FAKULTAS ILMU KOM&UTE"
UNI#E"SITAS INDONESIA UNI#E"SITAS INDONESIA
2016 2016
Pu
Puji ji syusyukur kur kehkehadiadirat rat TuTuhan Yahan Yang ng MahMaha a Esa Esa atas atas segsegala ala rahmrahmat-Nat-Nya ya dandan karunia-Nya sehingga kami dapat menyelesaikan Tugas Teknologi Sistem Basis Data karunia-Nya sehingga kami dapat menyelesaikan Tugas Teknologi Sistem Basis Data mengenai Data Mining. Tidak lupa kami juga mengucapkan anyak terima kasih mengenai Data Mining. Tidak lupa kami juga mengucapkan anyak terima kasih kepada Dosen kami! D". #chmad Ni$ar %idayanto! S.&om.! M.&om! yang telah kepada Dosen kami! D". #chmad Ni$ar %idayanto! S.&om.! M.&om! yang telah memiming dan menjelaskan kami mengenai materi Data Mining.
memiming dan menjelaskan kami mengenai materi Data Mining.
Terlepas dari semua itu! kami menyadari sepenuhnya ah'a masih terdapat Terlepas dari semua itu! kami menyadari sepenuhnya ah'a masih terdapat eerapa
eerapa kekurangan kekurangan dari dari segi segi penulisan! penulisan! tata tata ahasa! ahasa! maupun maupun kekurangan kekurangan dalamdalam pendalaman
pendalaman materi materi mengenai mengenai data data mining. mining. (leh (leh karena karena itu! itu! kami kami menerima menerima segalasegala saran dan kritik dari pemaca maupun dari pak dosen! agar kami dapat memperaiki saran dan kritik dari pemaca maupun dari pak dosen! agar kami dapat memperaiki tugas kami.
tugas kami. #k
#khihir r kakata ta kakami mi eerhrhararap ap sesemomoga ga tutugagas s kakami mi memengngenenai ai DaData ta MiMininingng men
mengguggunaknakan an aplaplikaikasi si ))eeka ka ini ini dapdapat at memmemererikan ikan manman*aat *aat dan dan solsolusi usi kepkepadaada permasalahan mengenai Data Mining.
permasalahan mengenai Data Mining.
+akarta!
+akarta! +uni +uni ,/,/
Penulis Penulis
ABST"AK
ABST"AK
Teknologi yang semakin erkemang di segala aspek telah menyeakan peruahan Teknologi yang semakin erkemang di segala aspek telah menyeakan peruahan terutama dalam idang perdagangan. Perdagangan yang semula ialah transaksi terutama dalam idang perdagangan. Perdagangan yang semula ialah transaksi
tukar-menukar arang! lalu menggunakan mata uang seagai nilai arang yang dijual! dan untuk saat ini telah erkemang perdangan online di dunia internet atau yang iasa diseut dengan e-commerce. Dalam e-commerce! penjual dan pemeli tidak memerlukan tatap muka! dan transaksi pemayaran dilakukan dengan menggunakan metode transfer atau metode pemayaran lainnya.
Selain e*ekti0itas 'aktu dan jarak! teknologi e-commerce memiliki kelemahan yaitu ketidaksesuaian arang yang diinginkan dengan yang dieli oleh konsumen. %al terseut dapat mempengaruhi tingkat kepuasan konsumen dalam memilih metode pemelian online! yang dapat dilihat dari proailitas arang yang dikemalikan
dengan arang yang tidak dikemalikan oleh konsumen. %al ini dapat diprediksi dan dianalisis menggunakan data mining dengan melihat pada data order e-commerce.
Data order ialah sekumpulan data yang didalamnya masih terdapat kemungkinan nilai yang tidak terinput 1 missing value2. Nilai ini dapat mengurangi tingkat kualitas data dan akan mempengaruhi hasil akhir analisis terhadap data yang masih memiliki missing value. 3ntuk menndapatkan hasil yang leih akurat dan e*isiensi 'aktu komputasi! dapat dilakukan proses preprocessing yaitu proses trans*ormasi data ke suatu *ormat yang prosesnya leih mudah dan e*ekti* unutk keutuhan pemakai.
#nalisis dilakukan dengan memandingkan metode klasi*ikasi dengan menggunakan tools )E&# 4.5 diantaranya algoritma Bayesian Net'ork! Na60e Bayes! #DTree! dan 7ero". %asil pengujian mendapatkan akurasi tertinggi terhadap data train seesar /5.8/9 dengan menggunakan model klasi*ikasi Bayesian Net'ork. %asil prediksi yang memiliki nilai tertinggi seesar ::.589 dilakukan dengan metode Bayesian Net'ork.
&ata kunci; data mining, missing value, Bayesian Network, Naïve Bayes, AD Tree, ZeroR, decision tale
DAFTA" ISI
KATA &ENGANTA"...2
ABST"AK...3
DAFTA" ISI...4
BAB I &ENDA%ULUAN...5
1*1* Latar Bela+an,...5 1*2* T-.-an...6 1*'* "-an, Ln,+-p...6BAB II TINAUAN &USTAKA
...7
2*1* Data Mnn,...7
2*1* Data &repressn,...9
,... "epresentasi dari Data Mentah...9
,..,. &arakteristik dari Data Mentah...9
,..4. Trans*ormasi dari Data...10
,..<. Penanganan dari Data yang %ilang...12
,..=. #nalisa (utlier ... 13
BAB III ANALISIS KEBUTU%AN DAN METODE &ENELITIAN
...15
'*1* Analss Ke-t-3an Sstem...15
'*2* Keran,+a &eneltan...15
'*'* Dataset...16
'*)* &repressn,...16
'*5* 4a+t- an Tempat &eneltan...17
BAB I# ANALISIS %ASIL &ENELITIAN
...18
)*1* &eneltan...18
<... #nalisis Data...18
<..,. Data Preprocessing...19
<..,.. "eplace Missing >alue...20
<..,.,. Mendeteksi (utlier ...20
<..,.4. #ttriute Selection...21
<..,.<. Discreti$e...22
<..4. &lasi*ikasi Data Training... 23
<..<. &lasi*ikasi Data Testing...25
)*2* Analss %asl &en,-.an...27
BAB I# KESIM&ULAN DAN SA"AN
...28
5*1* Kesmp-lan...28
5*2* Saran...28
1* BAB I
2* &ENDA%ULUAN
1*1* Latar Bela+an,
Transaksi secara online !e-commerce" merupakan salah satu cara metode erelanja dan erdagang secara online atau direct selling yang meman*aatkan *asilitas internet. Sistem pemayaran pada transaksi e-commerce menggunakan metode trans*er secara digital! seperti account paypal! kartu kredit! transfer e-anking ! dll. Metode e-commerce telah anyak diimplementasikan dan digunakan oleh perusahaan yang ergerak di idang arang dan jasa. Tujuan utama perusahaan dari metode e-commerce ialah untuk memperluas pangsa pasar 1market e#posure2 dan meningkatkan pro*it perusahaan. Bagi konsumen! teknologi e-commerce juga memerikan keuntungan yaitu transaksi pemelian dapat dilakukan kapan saja! dan dapat memeli arang dari mana saja karena arang akan dikirim langsung menggunakan ekspedisi.
Selain man*aat yang dierikan dari teknologi e-commerce! terdapat juga eerapa masalah yang dihadapi dari penggunaan metode terseut! salah satunya adalah ketidaksesuian arang yang ditampilkan?dijual dengan arang yang diharapkan oleh konsumen. %al ini erakiat menurunnya kepuasan konsumen serta meningkatnya item penjualan yang dikemalikan.
Data order konsumen dalam e-commerce dapat diolah dan dianalisis untuk melihat proailitas arang yang dikemalikan dengan arang yang tidak dikemalikan oleh konsumen. Data order terseut masih terdapat adanya kemungkinan missing value! yang erupa null value yaitu data yang diisikan tidak sesuai *ormat maupun kesalahan input data. %al ini dapat mempengaruh tingkat akurasi prediksi dari data order yang diolah dan dianalisis.
3ntuk mengantisipasi hal terseut! diperlukan penerapan proses Data Mining seperti pre-processing ! melakukan pengujian terhadap eerapa classifier ! dan analisis prediksi yang mengatasi permasalahan prediksi pengemalian arang sehingg tujuan perusahaan dengan menggunakan sistem e-commerce dapat tercapai.
1*2* T-.-an
Tujuan dari penyusunan tugas ini adalah seagai erikut;
a2 Melakukan proses analisis! perhitungan akurasi! serta dokumentasi pada data training kemudian dapat digunakan untuk melakukan prediksi pada data order. 2 Menggunakan tools data mining dengan melakukan eerapa percoaan
terhadap eerapa classifier untuk mencari hasil prediksi yang memiliki tingkat keakuratan yang paling tinggi.
1*'* "-an, Ln,+-p
Berikut ini ruang lingkup dari proses analisis dan penghitungan hasil prediksi;
a2 Data yang digunakan merupakan data orders training dan data order DM@ ,< yang didapatkan dari Scele MTA
2 Pemilihan uji coa algoritma klasi*ikasi yang digunakan terhadap data orders diatasi menjadi algoritma Bayesian Net'ork! Na60e Bayes! dan #DTree.
2* BAB II
'* TINAUAN &USTAKA
2*1* Data Mnn,
Data Mining memang salah satu caang ilmu komputer yang relati* aru. Dan sampai sekarang orang masih memperdeatkan untuk menempatkan data mining di
idang ilmu mana! karena data mining menyangkut dataase! kecerdasan uatan 1artificial intelligence2! statistik! ds. #da pihak yang erpendapat ah'a data mining tidak leih dari mac$ine learning atau analisa statistik yang erjalan di atas dataase. Namun pihak lain erpendapat ah'a dataase erperanan penting di data mining karena data mining mengakses data yang ukurannya esar 1isa sampai terayte2 dan disini terlihat peran penting dataase terutama dalam optimisasi uery-nya. Calu apakah data mining itu #pakah memang erhuungan erat dengan dunia pertamangan! tamang emas! tamang timah! ds. De*inisi sederhana dari data mining adalah ekstraksi in*ormasi atau pola yang penting atau menarik dari data yang ada di dataase yang esar. Dalam jurnal ilmiah! data mining juga dikenal dengan nama %nowledge Discovery in Dataases 1&DD2.
&ehadiran data mining dilatarelakangi dengan prolema data e#plosion yang dialami akhir-akhir ini dimana anyak organisasi telah mengumpulkan data sekian tahun lamanya 1data pemelian! data penjualan! data nasaah! data transaksi ds.2. %ampir semua data terseut dimasukkan dengan menggunakan aplikasi komputer yang digunakan untuk menangani transaksi sehari-hari yang keanyakan adalah (CTP 1&n 'ine Transaction (rocessing 2. Bayangkan erapa transaksi yang dimasukkan oleh %ypermarket semacam @arre*our atau transaksi kartu kredit dari seuah ank dalam seharinya dan ayangkan etapa esarnya ukuran data mereka jika nanti telah erjalan eerapa tahun. Pertanyaannya sekarang! apakah data terseut akan diiarkan menggunung! tidak erguna lalu diuang! ataukah kita dapat me- namangF-nya untuk mencari emasF! erlianF yaitu in*ormasi yang erguna untuk organisasi kita. Banyak diantara kita yang keanjiran data tapi miskin in*ormasi.
Gamar 2*1 &rama
Dari gamar di atas terlihat ah'a teknologi data 'arehouse digunakan untuk melakukan (C#P! sedangkan data mining digunakan untuk melakukan information discovery yang in*ormasinya leih ditujukan untuk seorang Data #nalyst dan Business #nalyst 1dengan ditamah 0isualisasi tentunya2. Dalam prakteknya! data mining juga mengamil data dari data 'arehouse. %anya saja aplikasi dari data mining leih khusus dan leih spesi*ik diandingkan (C#P mengingat dataase ukan satu-satunya idang ilmu yang mempengaruhi data mining! anyak lagi idang ilmu yang turut memperkaya data mining seperti; information science 1ilmu in*ormasi2! $ig$ performance computing ! visualisasi! mac$ine learning ! statistik! neural networks 1jaringan syara* tiruan2! pemodelan matematika! information retrieval dan information e#traction serta pengenalan pola. Bahkan pengolahan citra 1image processing 2 juga digunakan dalam rangka melakukan data mining terhadap data image)spatial . Dengan memadukan teknologi (C#P dengan data mining diharapkan pengguna dapat melakukan hal-hal yang iasa dilakukan di (C#P seperti drilling)rolling untuk melihat data leih dalam atau leih umum! pivoting, slicing dan dicing* Semua hal terseut diharapkan nantinya dapat dilakukan secara interakti* dan dilengkapi dengan 0isualisasi. Data mining tidak hanya melakukan mining terhadap data transaksi saja. Penelitian di idang data mining saat ini sudah meramah ke sistem dataase lanjut seperti o+ect oriented dataase! image)spatial dataase!
time- series data)temporal dataase! teks 1dikenal dengan nama te#t mining 2! we 1dikenal dengan nama we mining 2 dan multimedia dataase. GH
2*2* Data &repressn,
2*1*1* "epresentas ar Data Menta3
Data yang elum diproses diseut data mentah. Data mentah peru disiapkan terleih dahulu agar isa dipakan dalam proses Data Mining. G=H
#da , tipe data secara umum; . Numerik
Nilai numerik termasuk nilai real 1pecahan2 dan integer 1ilangan ulat2. Iitur dengan nilai numerik memiliki , properti penting! yaitu; setiap nilai memiliki urutan dan memiliki relasi jarak.
,. &ategorikal 1simolik2
Dinyatakan dengan sama dengan atau tidak sama dengan.. 0ariael kategori yang memiliki , nilai dapat dikon0ersi menjadi 0ariael numerik dengan , nilai 0alues 1 atau 2. >ariael pengkodean dengan N uah nilai dapat dikon0ersikan ke dalam N uah 0ariael ertipe numerik yang memiliki nilai iner untuk setiap kategorikal. Pengkodean ini diseut Jdummy 0arialesJ. Misal 0ariael mata memiliki empat uah nilai; hitam! iru! hijau! dan cokelat! maka dapat dikodekan ke dalam empat digit iner;
Nilai 0ariael kode
%itam
Biru
%ijau
@okelat
2*1*2* Kara+terst+ ar Data Menta3
Pada data mentah sering ditemukan anyaknya nilai yang hilang 1 missing value", distorsi nilai! tidak tersimpannya nilai 1misrecording", sampling yang tidak cukup agus dan seagainya. 3ntuk itu perlu ditingkatkan kualitasnya dengan melakukan penyiapan data 1 preprocessing"*
Penyea kurang aiknya kualitas data mentah adalah karena adanya kesalahan dalam penyimpanan dan pengukuran! tapi isa juga karena tidak adanya nilai me'akili yang tersedia.
(utlier atau adanya nilai yang tidak iasa 1lain dari umumnya2 muncul karena anyak hal! antara lain kesalahan pada entri data dan adanya data yang tidak
tersimpan sehingga nilai de*ault otomatis tersimpan. G=H 2*1*'* Transrmas ar Data
Data mentah perlu dilakukan proses trans*ormasi untuk meningkatkan per*ormanya. Salah satu trans*ormasi yang umum digunakan adalah dengan
melakukan normalisasi. G/H @ontoh ;
Pada tael erikut ini! tiap *aktor memiliki skala yang tidak sama! ada yang esar dan ada yang kecil.
Tael E7al-as erasar+an tap a+tr
Dari tael diatas! dapat dilihat tidak adil karena skala yang dimiliki oleh maing-masing *aktor ereda.
3ntuk mendapatkan hasil yang leih adil mengunakan , cara; . Merangking Pilihan dari tiap *aktor
@aranya;
• Memeri rangking per aris
Tael E7al-as erasar+an ran,+n,
,. Menguah nilai sehingga tiap *aktor mempunyai nilai yang sama @aranya;
• 3ntuk menguahnya supaya mempunyai range -! menggunakan
cara geometri sederhana pada garis lurus.
Dimana;
Na ; atas atas nilai aru N ; atas a'ah nilai aru Naa ; atas atas nilai asli Na ; atas a'ah nilai asli
2*1*)* &enan,anan ar Data 9an, %lan,
Metode data mining seringkali mensyaratkan semua nilai data lengkap atau tidak ada yang hilang. Padahal pada kenyataannya anyak atriut atau field dari eerapa record yang tidak diketahui nilainya. Solusi paling sederhana adalah dengan menghapus semua record yang erisi nilai yang kosong. 3ntuk data yang esar mungkin cara ini tidak erpengaruh terhadap model data mining yang dihasilkannya. #kan tetapi lain hasilnya jika data-data yang dihapus ini memiliki potensi yang sangat esar.
Solusi untuk menangani data yang hilang adalah data miner ersama-sama dengan pakar domain secara manual menguji data-data yang kosong kemudian memperkirakan nilai yang tepat untuk data terseut. #kan tetapi metode ini akan memutuhkan 'aktu yang lama apalagi jika data yang ditangani erukuran esar dan erdimensi anyak.
Pendekatan kedua dilakukan dengan cara penggantian suatu nilai konstanta terhadap nilai yang hilang terseut. G/H
Selain itu ada lagi cara yang isa dilakukan! yaitu dengan mengintepretasikan nilai yang hilang seagai nilai JdonFt careJ. Dengan cara ini! suatu sample data dengan nilai yang kosong akan digantikan oleh eerapa data dari himpunan sample uatan yang erisi semua kemungkinan yang ada dari domain nilai terseut. Seagai contoh! jika sampel K merupakan sampel 4 dimensi dan dinyatakan KL!!4! dimana nilai *itur kedua adalah nilai yang hilang! maka proses akan menggenerate lima sampel uatan yang domain *iturnya adalahL
KL !!4! K,L !!4! KL !,!4! K4L !4!4! K<L !<!4 2*1*5* Analsa O-tler
Seringkali pada data set! terdapat suatu nilai yang ereda dari iasanya dan tidak mencerminkan karakteristik data secara umum. Nilai yang tidak konsisten itu dinamakan outlier G,H
Berikut ini metode untuk melakukan deteksi terhadap outlier; . Deteksi outlier erdasarkan teknik statistik
@ara paling sederhana adalah dengan cara statistik. Perlu dilakukan perhitungan rata-rata dan standar de0iasi. &emudian erdasarkan nilai terseut diuat *ungsi t$res$old erpotensi untuk dinyatakan seagai outlier
Maka semua data yang erada diluar range -=.<! 4., adalah Tres$$old . Pada contoh diatas terdapat 4 nilai yang termasuk outlier; =/! 4:! -/8
2. Distance Based &utlier Detection
Metode yang kedua ini erusaha mengeliminasi keteratasan dari pendeteksian erdasarkan teknik statistik. Metode ini cocok digunakan untuk data yang multidimensi. @ara yang dilakukan adalah dengan menge0aluasi nilai jarak diantara semua sampel data set yang erukuran n-dimensi.
2*2* 4e+a
)eka adalah kumpulan algoritma mac$ine learning untuk pengerjaan proyek data mining* #lgoritma dalam )eka dapat digunakan secara langsung terhadap dataset yang kita miliki. )eka erisi tools untuk data preprocessing, klasi*ikasi! regresi! klastering! dan 0isualisasi. )eka juga isa digunakan untuk mengemangkan skema mac$ine learning* G4H
BAB III
ANALISIS KEBUTU%AN DAN METODE &ENELITIAN
'*1* Analss Ke-t-3an Sstem
a. Spesi*ikasi Perangkat Cunak
Dalam penelitian ini diutuhkan eerapa perangkat lunak seperti erikut ;
• Sistem (perasi ; M#@ (S K
• Perangkat lunak pendukung ; )eka! +D&
• Dataase ; dataset dalam *ormat cs0
. Spesi*ikasi Perangkat &eras
Dalam penelitian ini diutuhkan eerapa perangkat keras seperti erikut ;
• Processor ; Antel @ore i= • "#M ; <OB
'*2* Keran,+a &eneltan
Tahapan yang dilakukan dalam proses memprediksi returnShipment! adalah seagai erikut ;
a. Preprocessing
Tahap preprocessing yang dilakukan dalam penelitian ini adalah dengan menggunakan teknik data-cleaning . Dengan menggunakan teknik terseut! maka dalam tahap ini dilakukan proses untuk menghilangkan nilai-nilai data yang salah! memperaiki kekacauan data dan memeriksa data yang tidak konsisten.
. Training
Pada tahap ini dilakukan proses training dengan mengimplementasikan algoritma dalam tools )eka terhadap data train yaitu orderstrain.cs0. Tahapan ini ertujuan agar tools memiliki pengetahuan 1mac$ine-learning 2 terhadap metode klasi*ikasi pada data training yang kemudian akan isa mengimplementasikannya ke data testing .
c. Testing
Pada tahap ini dilakukan proses testing atau prediksi nilai return$ipment pada data tes ordersclass.cs0 dengan menggunakan metode klasi*ikasi yang sudah digunakan pada tahap training seelumnya.
Ani merupakan tahap akhir dalam penelitian ini! yaitu menge0aluasi per*ormansi metode atau algoritma klasi*ikasi yang sudah dipakai dalam penelitian ini.
'*'
* DatasetDataset yang digunakan pada penelitian ini erasal dari Data Mining @up 1DM@2 pada tahun ,<. Dataset yang disediakan terdiri atas orderstrain.cs0 seagai data training dan ordersclass.cs0 seagai data testing dalam penelitian ini. Data ini merupakan data order pada suatu e-commerce yang kemudian akan dilakukan prediksi apakah arang yang dieli customer akan dikemalikan atau tidak.
Data training yaitu orderstrain.cs0 terdiri atas < atriut dan <5:, instances sedangkan data testing ordersclass.cs0 terdiri atas 4 atriut dan =85 instances. Peredaannya adalah pada ordersclass.cs0 tidak memiliki atriut returnShipment seperti pada orderstrain.cs0.
'*)* &repressn,
(reprocessing merupakan tahap untuk memperaiki data seelum dilakukan proses klasi*ikasi. Tujuannya adalah untuk menghasilkan nilai per*ormansi klasi*ikasi yang leih aik lagi. #dapun penyea data yang kurang aik adalah seagai erikut ;
• Ancomplete ; kekurangan nilai-nilai atriut atau atriut tertentu lainnya • Noisy ; erisi kesalahan atau nilai-nilai outlier yang menyimpang • Anconsistent; ketidakcocokan dalam penggunaan kode atau nama
3ntuk menja'a permasalahan diatas! maka dilakukan tahapan seagai erikut dalam tahap preprocessing untuk data training dan data testing pada penelitian ini ;
. Melakukan analisis untuk mencari apakah ada atriut outlier ! atriut yang tidak memiliki isi 1missing value2 dan atriut yang salah kode atau nama. ,. Memperaiki atriut yang kurang aik terseut.
4. Melakukan filter terhadap satu atau leih atriut untuk mendapatkan per*ormansi klasi*ikasi yang leih aik lagi.
'*5* 4a+t- an Tempat &eneltan
Penelitian dilaksanakan selama hari pada ulan Mei ,/ ertempat di 3ni0ersitas Andonesia Salema! +akarta Pusat.
BAB I#
)*1* &eneltan
)*1*1* Analss Data
Berdasarkan dari dataset yang digunakan! yaitu orderstrain*csv seagai data training dan ordersclass*csv seagai data testing, maka didapatkan analisis atriut pada masing-masing dataset seagai erikut.
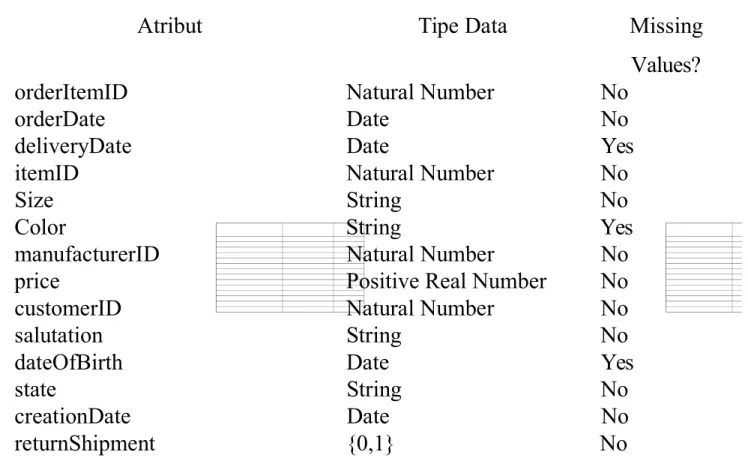
Tabel 1 Analisis Atribut orders_train.csv
#triut Tipe Data Missing
>alues
orderAtemAD Natural Numer No
orderDate Date No
deli0eryDate Date Yes
itemAD Natural Numer No
Si$e String No
@olor String Yes
manu*acturerAD Natural Numer No
price Positi0e "eal Numer No
customerAD Natural Numer No
salutation String No
date(*Birth Date Yes
state String No
creationDate Date No
returnShipment ! No
Tabel 2 Analisis Atribut orders_class.csv
#triut Tipe Data Missing
>alues
orderAtemAD Natural Numer No
orderDate Date No
deli0eryDate Date Yes
itemAD Natural Numer No
Si$e String No
@olor String No
manu*acturerAD Natural Numer No
price Positi0e "eal Numer No
customerAD Natural Numer No
date(*Birth Date Yes
state String No
creationDate Date No
Selain ditemukan atriut yang mengandung missing values seperti yang ditunjukkan pada tael diatas! juga ditemukan eerapa masalah pada atriut dalam dataset! antara lain ;
. Pada atriut color, ditemukan data yang mengalami pengejaan yang salah seperti Qoli0J! Qro'nJ! QlauJ! QdarklueJ.
,. Pada atriut deliveryDate ditemukan tanggal pengiriman yang ereda dari yang lainnya. Pada rekor data yang lain! tanggal pengiriman dimulai pada tahun ,,! dan ditemukan data yang menunjukkan tahun ,:.
)*1*2* Data &repressn,
Data preprocessing ertujuan untuk memperaiki data seelum dilakukan proses klasi*ikasi. Tahap-tahap preprocessing yang dilakukan dalam penelitian ini antara lain! replace missing value, mendeteksi oulier, attriute selection, discreti.e. Data preprocessing ini dilakukan terhadap data training dan juga data testing*
4.1.2.1. Replace Missing Value
Tahap ini dilakukan untuk menggantikan nilai yang kosong yang dimiliki oleh satu atau leih atriut dalam dataset. Tahap ini dilakukan dengan menggunakan tools )eka. Replace /issing 0alue dapat dilakukan pada )eka dengan menggunakan *ilter Replace/issing0alues seperti gamar <.. di a'ah ini.
Gambar 4.2 Replace Missing Values
4.1.2.2. Mendeteksi Outlier
Salah satu proses untuk memperaiki dataset adalah dengan melakukan pendeteksian outlier* &utlier merupakan data yang ereda jauh
dengan yang lainnya dan dapat mempengaruhi per*ormansi algoritma data mining . &utlier isa diseakan oleh kesalahan pengetikan atau penginputan pada dataset sehingga menjadikannya seagai outlier*
Tahap pendeteksian outlier ini dilakukan dengan menggunakan tools )eka dan ditunjukkan pada gamar <., erikut.
Gambar 4.3 ete!si "utlier
Iilter 1nter2uartileRange akan menghasilkan atriut &utlier dan 3#treme0alue. #triut terseut dapat dihapus dengan menggunakan
*ilter remove*
4.1.2.3. Attribute Selection
Tahap attriute selection dilakukan dengan menggunakan )eka. Tahapan ini ertujuan untuk meningkatkan per*ormansi dan keakuratan training data dengen algoritma data mining . Tahap ini menggunakan *ilter Attriuteelection dan menggunakan e0aluator 4ainRatio seagai evaluator-nya dan diurutkan dari yang paling tinggi sampai yang paling rendah! isa dilihat pada gamar <.4 dia'ah ini.
Gambar 4.4 Attribute #electi$n
4.1.2.4. Discretize
Tahap ini dilakukan untuk mengurangi angka dari nilai-nilai yang akan dianalisis untuk memerikan atriut selanjutnya dengan cara melakukan pemagian range atriut menjadi inter0al. Tahapan ini dilakukan dengan menggunakan )eka dan dapat dilihat pada gamar <.< dia'ah ini.
Gambar 4.5 iscreti%e
)*1*'* Klas+as Data Trann,
Proses klasi*ikasi adalah proses untuk memprediksi atriut return$ipment pada data train orderstrain*csv. Proses klasi*ikasi ini dilakukan dengan
menggunakan 4 algoritma data mining untuk mengetahui algoritma mana yang memiliki tingkat akurasi per*ormansi yang paling tinggi. 4 algoritma terseut adalah Na60e Bayes! Bayesian Net'ork dan #DTree. Proses klasi*ikasi ini dilakukan dengan menggunakan )eka dengan menggunakan percentage split seesar //9 isa dilihat pada gamar <.=! <./! dan <.8 dia'ah ini.
Gambar 4.6 &ai'e (a)es
Gambar 4.7
Gambar 4.8 ATree
Berdasarkan dari percoaan yang sudah dilakukan diatas! dapat ditampilkan dalam tael seperti dia'ah ini.
Tabel 3 +asil A!urasi Alg$ritma pa,a ata Training
#lgoritma %asil #kurasi &lasi*ikasi
Bayesian Net'ork /5.8/9
Na60e Bayes /5./,9
#DTree /.,89
)*1*)* Klas+as Data Testn,
Setelah dilakukan prediksi dengan menggunakan data training orderstrain*csv langkah selanjutnya adalah melakukan prediksi dengan menggunakan data testing ordersclass*csv. Cangkah ini dilakukan dengan menggunakan )eka dan menggunakan supplied test set setelah melakukan klasi*ikasi dengan data training dan pilih ordersclass*csv.
Gambar 4.8 -lasi!asi ata Testing
Proses testing ini dilakukan setelah proses klasi*ikasi data training untuk memerikan pengetahuan terleih dahulu kepada algoritma sehingga dapat menerapkannya pada *ile data testing sesuai dengan rule pada data training* Setelah proses klasi*ikasi data testing dengan menggunakan < algoritma yang sama dengan klasi*ikasi data training, maka didapatkan hasil seagai erikut pada tael <.
Tabel 4 +asil A!urasi Alg$ritma pa,a ata Testing
#lgoritma %asil #kurasi &lasi*ikasi
Bayesian Net'ork ::.589
Na60e Bayes ::.5<9
#DTree :5.9
)*2*
Analss %asl &en,-.an
Berdasarkan dari penelitian dan percoaan yang sudah dilakukan! didapatkan eerapa analisis yaitu seagai erikut ;
. (reprocessing pada dataset yang dilakukan di a'al seelum melakukan proses klasi*ikasi dengan menggunakan algoritma data mining mempengaruhi per*ormansi algoritma terseut.
,. Dari ketiga algoritma yang dilakukan percoaan didapatkan ah'a algoritma Bayesian Net'ork leih aik per*ormansi diandingkan dengan algoritma lainnya.
4. &ualitas data yang aik juga mempengaruhi per*ormansi algoritma data mining dalam menentukan atriut kelasnya.
BAB I#
KESIM&ULAN DAN SA"AN
5*1* Kesmp-lan
. Proses preprocessing perlu dilakukan untuk meningkatkan akurasi per*ormansi algoritma data mining dalam proses klasi*ikasi.
,. Tahapan yang dilakukan dalam proses preprocessing juga mempengaruhi aik atau tidaknya hasil dari proses preprocessing terseut. Maka dari itu! diperlukan juga analisis terhadap dataset untuk mengetahui kekurangan yang ada pada dataset sehingga dapat diperaiki pada proses preprocessing*
4. Tingkat akurasi per*ormansi algoritma klasi*ikasi yang paling aik dimiliki oleh algoritma Bayesian Net'ork yaitu seesar /5.8/9 untuk data training dan ::.589 untuk data testing*
<. Berdasarkan dari hasil terseut! maka dapat disimpulkan ah'a Bayesian Net'ork adalah algoritma klasi*ikasi yang paling aik digunakan untuk data training dan data testing*
5*2* Saran
3ntuk saran pengemangan selanjutnya adalah menggunakan dataset untuk studi kasus yang lain untuk mengetahui apakah kesimpulan yang didapatkan erlaku untuk semua jenis dataset.
DAFTA" &USTAKA
GH Iadli! #ri 1,2. &onsep Data Mining. Almu &omputer. 3ni0ersitas Oadjah Mada. Yogyakarta.
G,H &norr! Ed'in and T.! "aymond 1::52. #lgorithms *or Mining Distance-Based (utliers in Carge Datasets. 3ni0ersity o* British. @anada.
G4H )esite )E&#. '''.cs.ccsu.edu?Rmarko0?:e+a-t-tral.pd* diakses pada tanggal ,: Mei ,/.
G<H )esite. https;??'''.researchgate.net?*ile.PostIileCoader.html diakses pada tanggal ,: Mei ,/
G=H )esite. http;??eritati.logspot.co.id?,<??jenis-jenis-atriut-data-dalam-data.html diakses pada tanggal 4 Mei ,/
G/H )esite. https;??rencanait.'ordpress.com?,?4?5?data-mining-data- preprocessing? diakses pada tanggal 4 Mei ,/