SISTEM APLIKASI KAMUS PENERJEMAH BAHASA INDONESIA – AKSARA LONTARA BUGIS DENGAN MENGGUNAKAN METODE
BINARY SEARCH DAN PARSING TREE
DICTIONARY TRANSLATOR APPLICATION SYSTEM INDONESIAN– AKSARA BUGIS LONTARA METHOD USING BINARY SEARCH AND
PARSING TREE
Jumadil Nangi1, Nadjamuddin Harun2, Syafaruddin2
1Program Studi Teknik Informatika Politeknik Indotec Kendari 2
Program Studi Teknik Informatika Fakultas Teknik, Universitas Hasanuddin
Alamat Korespondensi :
Jumadil Nangi
Jurusan Teknik Informatika Politeknik Indotec Kendari
Jl. Tunggala II, No 24, Sulawesi Tenggara HP :085241723346
Abstrak
Latar belakang penelitian ini adalah bagaimana mengembangkan aplikasi kamus penerjemah bahasa Indonesia - Aksara Lontara Bugis sebagai sarana proses pengenalan penulisan Aksara Lontara Bugis kepada masyarakat umum. Penelitian ini bertujuan untuk membangun aplikasi kamus penerjemah bahasa Indonesia – Aksara Lontara Bugis dengan mengenalkan perbendaharaan kosakata dalam bahasa Indonesia dan bahasa Bugis beserta penulisan Aksara Lontara Bugis pada masyarakat umum. Aplikasi kamus penerjemah bahasa Indonesia – Aksara Lontara Bugis dibuat dengan menggunakan metode binary search dan parsing tree. Metode parsing tree digunakan untuk memecah kalimat menjadi kata-kata serta menggabungkan kata-kata menjadi kalimat, sedangkan binary search digunakan untuk melakukan proses pencarian kosakata berdasarkan nilai index dari masing-masing kosakata pada kamus. Hasil penelitian ini menunjukan bahwa aplikasi kamus penerjemah dapat menerjemahkan bahasa Indonesia– Aksara Lontara Bugis dalam bentuk kata maupun kalimat yang diinputkan ke dalam aplikasi kamus, serta dapat menampilkan pemecehan kalimat menjadi kata beserta arti dari kata tersebut. Waktu yang dibutuhkan dalam pencarian kata dengan binary search kurang dari 0.1 milidetik, kompleksitas waktu terbaiknya adalah 1 kali, yaitu ketika kata yang dicari berada di bagian tengah daftar urut kata. Kesimpulan dari penelitian ini adalah aplikasi kamus penerjemah bahasa Indonesia – Aksara Lontara Bugis dapat menerjemahkan kata atau kaliamat dalam bahasa Indonesia ke Aksara Lontara Bugis dan sebaliknya.
Kata Kunci : aplikasi kamus, Lontara Bugis, Binary Search, Parsing Tree
Abstract
The background of this research is how to develop applications Indonesian translator dictionary - Lontara Bugis script as a means of introduction to the process of writing the script Lontara Bugis to the general public. This study aims to build applications Indonesian translator dictionary - Literacy Lontara Bugis by introducing vocabulary vocabulary and language in Indonesian Bugis Bugis Lontara script writing along with the general population. Indonesian translator dictionary applications - Lontara Bugis script created using the method of binary search and parsing tree. Parsing tree method is used to break the sentence into words and combine words into sentences, whereas binary search is used to make the search process vocabulary based on the value of the index of each of the vocabulary in the dictionary. These results indicate that the application dictionary translator can translate Indonesian Bugis Lontara-script in the form of the word or phrase is entered into the application dictionary, and can display pemecehan sentence into words and their meaning of the word.The time needed to search a word with binary search is less than 0.1 milliseconds, its best time complexity is 1 times, ie when the search terms are in the middle of the waiting list. The conclusion of this research is the application dictionary translator Indonesian - Lontara Bugis script can translate words in Indonesian or kaliamat Lontara script to Bugis and vice versa.
PENDAHULUAN
Aksara Bahasa Bugis secara tekstual dituliskan dalam bentuk huruf-huruf yang dikenal dengan istilah Aksara Lontara. Namun harus dipahami bahwa aksara lontara digunakan pada 2 (dua) etnis besar di sulawesi selatan yakni etnis Bugis dan etnis Makassar. Aksara Lontara juga merupakan lambang identitas daerah dan alat transformasi nilai-niiai luhur yang sangat berharga atau indigenous knowledge (Supriadi, 2012).
Tidak tersedianya alat yang secara fleksibel dapat menterjemahkan bahasa Indonesia ke Aksara Lontara Bugis dan sebaliknya merupakan salah satu penyebab berkurangnya pengetahuan generasi muda tentang penulisan Aksara Lontara Bugis. Sehingga dengan pembuatan Aplikasi Kamus penerjemah Bahasa Indonesia – Aksara Lontara Bugis dengan
binary Search dan parsing tree bisa menjadi salah satu alat yang bermanfaat untuk
menterjemahkan bahasa Indonesia ke Aksara Lontara Bugis dan sebaliknya. Aplikasi kamus penerjemah ini dirancang untuk bisa dijalankan secara lokal maupun secara Online dengan memanfaatkan media internet, sehingga bisa digunakan dari mana saja selama masih terkoneksi dengan jaringan internet.
BAHAN DAN METODE Metode Penerjemah Binary Search
Algoritma pencarian (searching algorithm) adalah algoritma yang menerima sebuah argumen kunci dengan langkah-langkah tertentu akan mencari rekaman dengan kunci tersebut. Setelah proses pencarian dilaksanakan, akan diperoleh salah satu dari dua kemungkinan, yaitu data yang dicari ditemukan (successfull) atau tidak ditemukan (unsuccessfull) (Tri, 2012). Binary Search adalah algoritma pencarian untuk data yang terurut. Pencarian dilakukan dengan cara menebak apakah data yang dicari berada di tengah-tengah data, kemudian membandingkan data yang dicari dengan data yang ada di tengah-tengah (Dewi, 2009).
Apabila data yang di tengah sama dengan data yang dicari berarti data ditemukan. Namun, bila data yang di tengah lebih besar dari data yang dicari, maka dapat dipastikan bahwa data yang dicari kemungkinan berada di sebelah kiri dari data tengah dan data di sebelah kanan data tengah dapat diabaikan. Upper bound dari bagian data kiri yang baru adalah indeks dari data tengah itu sendiri. Sebaliknya, bila data yang di tengah lebih kecil dari data yang dicari, maka dapat dipastikan bahwa data yang dicari kemungkinan besar berada di
sebelah kanan dari data tengah. Lower bound data di sebelah kanan dari data tengah adalah
indeks dari data tengah itu sendiri ditambah satu (Lovinta, 2007).
Prinsip dari pencarian biner dapat dijelaskan sebagai berikut: mula-mula diambil posisi awal 0 dan posisi akhir = N - 1, kemudian dicari posisi data tengah dengan rumus (posisi awal + posisi akhir) / 2. Kemudian data yang dicari dibandingkan dengan data tengah. Jika lebih kecil, proses dilakukan kembali tetapi posisi akhir dianggap sama dengan posisi tengah –1. Jika lebih besar, proses dilakukan kembali tetapi posisi awal dianggap sama dengan posisi tengah + 1. Demikian seterusnya sampai data tengah sama dengan yang dicari (Suyanto, 2011).
Pada intinya, algoritma ini menggunakan prinsip divide and conquer, di mana sebuah masalah atau tujuan diselesaikan dengan cara mempartisi masalah menjadi bagian yang lebih kecil. Algoritma ini membagi sebuah tabel menjadi dua dan memproses satu bagian dari tabel itu saja. Algoritma ini bekerja dengan cara memilih record dengan indeks tengah dari tabel dan membandingkannya dengan record yang hendak dicari. Jika record tersebut lebih rendah atau lebih tinggi, maka tabel tersebut dibagi dua dan bagian tabel yang bersesuaian akan diproses kembali secara rekursif (Kusumadewi, 2005).
Parsing Tree
Parsing adalah suatu cara memecah-mecah suatu rangkaian masukan (misalnya dari
berkas atau keyboard) yang akan menghasilkan suatu pohon uraian (parse tree). Parse Tree berfungsi untuk menggambarkan bagaimana memperoleh suatu string dengan cara menurunkan simbol-simbol variabel menjadi simbol-simbol terminal, sampai tidak ada simbol yang belum tergantikan. Algoritma untuk proses parsing banyak digunakan adalah
Top-down parsing dan Bottom-up parsing (James, 2004).
Top-down parsing
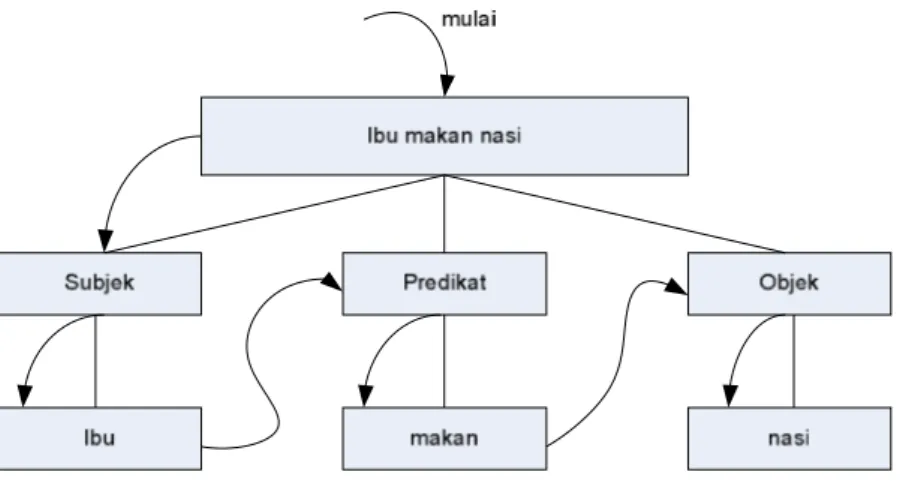
Top-down parsing bekerja dengan cara menguraikan sebuah kalimat mulai dari constituent yang terbesar yaitu sampai menjadi constituent yang terkecil. Hal ini dilakukan
terus-menerus sampai semua komponen yang dihasilkan adalah constituent terkecil dalam kalimat, yaitu kata. Sebagai contoh dapat dilakukan proses top-dowm parsing untuk kalimat “ibu makan nasi” sesuai gambar 1.
Bottom-up parsing
Bottom-up parsing bekerja dengan cara mengambil satu demi satu kata dari kalimat
terus-menerus sampai constituent yang terbentuk ialah kalimat. Sebagai contoh dilakukan proses bottom-up parsing dengan kata “ibu”, “makan”, “nasi”.
Mekanisme Penerjemah Lontara Bugis
Dilakukan pembacaan string perkarakternya dan kata tersebut langsung dicompare terhadap kosakata contohnya masukan kata yaitu “manre”, dimana kata tersebut dibentuk dari susunan huruf : m-a-n-r-e yang diawali dengan huruf “m” yang ada pada database. Pada
event pertama proses compare menuju ke huruf “m”, karena input berupa kata “manre” yang
berawalan huruf “m” (Junus, 2004).
Pada gambar 4 di atas menjelaskan rangkaian state kata “manre” dimana karakter “ma” diubah ke Lontara Bugis menjadi “ ”, dan untuk karakter “nre” diubah menjadi huruf “nra” atau “ ”. Apabila hufuf vokal “e” di dalam penulisan Lontara Bugis akan berada pada awalan huruf Lontara sehingga untuk penulisan huruf “nre” akan menjadi “enra” atau “ ” dalam penyebutan Aksara Lontara Bugis. Untuk penulisan kata “manre” akan diubah ke dalam penulisan Aksara Lontara Bugis yang menjadi” ”. Untuk huruf vokal ”e” atau” ” dalam penulisan Aksara Lontara Bugis akan berada di depan huruf Lontara Bugis untuk semua jenis kosakata penulisan Aksara Lontara Bugis (Jamal, 2013).
HASIL
Pada database kamus untuk kata/kalimat bahasa Indonesia ke bahasa Bugis, terdapat 702 kosakata. Berikut adalah rekap jumlah kata yang mewakili awalan huruf atau karakter yang sama sesuai pada Tabel 1. Pada Tabel 1 terlihat, bahwa nilai probabilitas kata berawalan huruf “B”, memiliki nilai probabilitas paling kecil yaitu “0,00885” dengan jumlah kata yang berawalan huruf “B” sebanyak 113 kosakata. Nilai total probabilitas dari setiap awalan huruf (α) selalu berjumlah 1, sehingga nilai 1 tersebut akan terbagi nilai probabilitasnya terhadap banyaknya jumlah kosakata yang ada pada database kamus. Pada Tabel 2 terlihat ada perbedaan antara sebutan penulisan Aksara Lontara untuk aplikasi kamus dengan penulisan Lontara umum.
Gambar 3 menunjukan pencarian kata bahasa Indonesia-Aksara Bugis “ibu makan nasi”. Dimana, kalimat/kata yang diinputkan akan dilakukan proses parsing pertama kali yaitu “Ibu”,”makan”,”nasi” kemudian hasil dari parsing yang berupa kata akan melakukan proses pencarian dengan binary search. Hasil dari parsing dan pencarian binary search dilakukan kembali proses penggabungan kata menjadi kalimat.
PEMBAHASAN
Pengenalan kata/kalimat penulisan bahasa Indonesia - Aksara Lontara Bugis terlihat bahwa adanya perbedaan antara sebutan penulisan Aksara Lontara untuk aplikasi kamus dengan penulisan Lontara umum. Pada kata “baik”, ”jahat”, “mandi” dan kata “ibu” penulisan Aksara Lontara pada aplikasi kamus berbeda dengan penulisan umum Aksara Lontara, yang membedakannya apabila terdapat huruf mati di dalam kosakata bahasa Bugis. Contohnya dalam bahasa Bugis “majak” pada aplikasi kamus huruf mati “k” dihilangkan sehingga menjadi kata “maja” atau “mj” sedangkan penulisan Lontara umum kata “majak” tidak mempunyai huruf mati jadi semua huruf ditulis dalam penulisan Aksara Lontara Bugis menjadi “mjk”.
KESIMPULAN DAN SARAN
Dari penelitian yang dilakukan, aplikasi kamus penerjemah yang telah diuji diperoleh hasil sesuai yang diharapkan yaitu aplikasi dapat menerjemahkan kata atau kalimat dalam bahasa Indonesia - Aksara Lontara Bugis dan sebaliknya. Aplikasi kamus penerjemah dengan menggunakan metode binary search dan parsing tree yang dihasilkan bisa digunakan dan dijadikan solusi untuk masyarakat yang ingin mempelajari bahasa daerah Bugis beserta penulisan Aksara Lontara Bugisnya. Pengujian basisdata dilakukan untuk menguji beberapa karakter tanda pemisah kosakata pada database, dan beberapa karakter yang tidak bisa digunakan antara lain “+”,”&”,”%”,”#” tanda tersebut menimbulkan kerancuan ketika dilakukan proses pencarian kosakata ke database karena tanda tersebut telah digunakan untuk fungsi lain. Diharapkan melalui hasil penelitian ini mampu menjadi tolak ukur pemilihan metode bagi peneliti yang ingin membangun aplikasi kamus berikutnya. Perlunya pengembangan lebih lanjut dari perangkat lunak aplikasi kamus penerjemah bahasa Indonesia-Aksara Lontara Bugis dengan menggunakan metode binary search dan parsing
tree. Mulai dari jumlah kosakata yang disajikan serta nantinya bisa dikembangkan dengan
DAFTAR PUSTAKA
Dewi,Martina Andayani. (2009).Pembuatan Kamus Elektronik Kata-Kata Bahasa
Indonesia-Jawa Menggunakan Metode Binary Search Berbasis Perangkat Lunak. PENS-ITS,
Surabaya.
Jamal,Imran. (2013).BelajarMenulisAksaraBugis.
James, Suciadi. (2004).“Studi Analisis Metode-Metode Parsing dan Interpretasi Semantik
Pada Natural Language Processing (NLP)”. Teknik Informatika, Fakultas Teknologi
Industri, Universitas Kristen Petra.
Junus, H.A. M. (2004). Morfologi Bahasa Bugis. Makassar: Badan Penerbit Universitas Negeri Makassar.
Kusumadewi, Sri. (2005). Artificial Intelligence (Teknik dan Aplikasinya). Bandung: Penerbit Graha Ilmu.
Lovinta Happy Atrinawati, (2007). Analisis Kompleksitas Algortima untuk Berbagai Macam
Metode Pencarian Nilai (Searching) dan Pengurutan Nilai (Sorting) Pada Tabel”,
Teknik Informatika, ITB, Bandung.
Presman, Roger S. (2004). Rekayasa Perangkat Lunak. Andi dan McGrow-Hill Book Co. Sugiarti, yuni. (2012). Analisis dan Perancangan UML (unified Modelling Langunge).
Yogyakarta: Penerbit Graha Ilmu
Supriadi,Wawan. (2012). Mengenal Aksara Lontara.
Suyanto. (2011). Artificial Intelegence. Bandung: Penerbit Informatika.
Tri, Antika. (2012).“Keanekaragaman Budaya Indonesia Yang Mulai Luntur (Upaya
Melestarikan Budaya)”.
Tabel 1 Rekap Kosakata
Huruf (α)
Jumlah Nilai Probalitas Kata
Berawalan Huruf (α) A 47 0,02127 B 113 0,00885 C 38 0,02631 D 69 0,01449 E 2 0,5 F 1 1 G 14 0,07142 H 14 0,07142 I 12 0,08334 J 25 0,04 K 45 0,02222 L 19 0,05263 M 99 0,0101 N 9 0,11111 O 2 0,5 P 52 0,19231 Q 0 0 R 20 0,05 S 68 0,01471 T 46 0,02173 U 6 0,16667 V 0 0 W 0 0 X 0 0 Y 1 1 Z 0 0 Total 702 -
Tabel 2 Pengujian Bahasa Indonesia – Lontara Bugis
Kata Indonesia Aplikasi Kamus Penulisan Umum
Bugis Sebutan Lontara sebutan Lontara
Kata Benda
Baju Wajju Waju wju
Kursi Kadera Kaedara kedr
Matahari mataesso Mataeso mteso
Kata Sifat
Jahat Majak Maja mjk
Malu Masiri Masiri msiri
Baik Makanja Makaja mknj
Kata Kerja
Tidur Tinro Itinrao Tinrao
Makan manre Maenra menra
Mandi cemme Ecema ecem
S-P Ibu makan Indo’
manre
Iado Maenra
indo menra
SPO Ibu makan
nasi Indo’ manre nanre Iado Maenra naenra Indo menra nenra
Gambar 1 Top-Down Parsing
Gambar 2 Proses Penerjemahan Lontara Bugis