Skripsi
Oleh Muhammad Nur NIM : 11160910000058
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
1443 H / 2022 M
Data Mining Untuk Memprediksi Kelulusan Mahasiswa Jurusan Teknik Informatika UIN Syarif Hidayatullah
Jakarta Menggunakan Metode Klasifikasi C4.5
Skripsi
Diajukan sebagai salah satu syarat untuk memperoleh gelar S.Kom.
Oleh :
Muhammad Nur 11160910000058
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
1443 H / 2022 M
ii
LEMBAR PENGESAHAN
PERNYATAAN ORISINALITAS
iv
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI
Sebagai sivitas akademik UIN Syarif Hidayatullah Jakarta, saya yang bertanda tangan di bawah ini:
Nama : Muhammad Nur
NIM : 11160910000058
Program Studi : Teknik Informatika Fakultas : Sains dan Teknologi Jenis Karya : Skripsi
demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti Noneksklusif (Non-exclusive Royalty Free Right) atas karya ilmiah saya yang berjudul :
“Data Mining Untuk Memprediksi Kelulusan Mahasiswa Jurusan Teknik Informatika UIN Syarif Hidayatullah Jakarta Menggunakan Metode
Klasifikasi C4.5 “
beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Noneksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/fomatkan, mengelola dalam bentuk pangkalan data (database), merawat, dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di: Jakarta
Pada tanggal: Jakarta, 28 Januari 2022 Yang menyatakan
(Muhammad Nur)
Nama : Muhammad Nur Program Studi : Teknik Informatika
Judul : Data Mining Untuk Memprediksi Kelulusan Mahasiswa Jurusan Teknik Informatika UIN Syarif Hidayatullah Jakarta Menggunakan Metode Klasifikasi C4.5
ABSTRAK
UIN Syarif Hidayatulah Jakarta merupakan salah satu perguruan tinggi negeri yang
berakreditasi A menurut BAN-PT dengan nomor SK
25/SK/BANPT/Akred/PT/II/2018. Akan tetapi tingkat kelulusan mahasiswa tepat waktu masih sangat rendah. Hasil laporan Biropt UIN Jakarta pertanggal 30 November 2019 menyebutkan jumlah mahasiswa yang lulus dari tahun 2014 hingga 2018 mengalami penurunan. Hal ini berdampak buruk bagi penilaian akreditasi kampus. Karena tingkat lulusan tepat waktu menjadi salah satu instrumen BAN-PT melakukan akreditasi pengguruan tinggi. Sehingga penting untuk mencari tahu variabel yang memengaruhi mahasiswa lulus tepat waktu. Agar proses akreditasi kampus berjalan dengan baik. Solusi yang coba ditawarkan adalah melakukan uji korelasi dan klasifikasi variabel yang memengaruhi mahasiswa lulus tepat waktu.
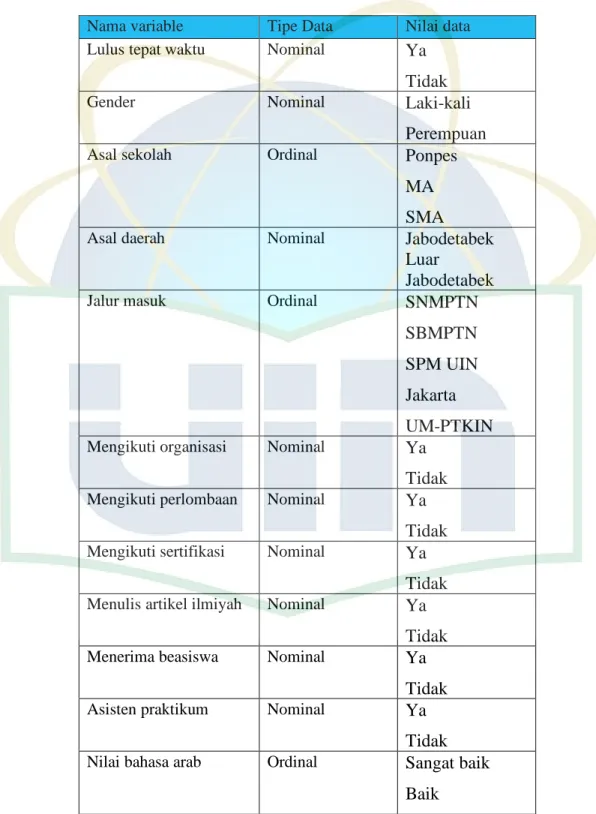
Variabel yang digunakan adalah jenis kelamin, asal sekolah, asal daerah, jalur masuk, pernah mengukuti organisasi, pernah mengikuti perlombaan, pernah mengikuti sertifikasi, pernah menulis artikel ilmiyah, menerima beasiswa, asisten praktikum, nilai bahasa arab, nilai bahasa ingris, nilai praktikum qiroah, nilai praktikum ibadah, jumlah sks persemester, jenis/tipe skripsi, dosen pembimbing, indeks prestasi kumulatif. Hasil nilai akurasi dari penelitian ini adalah 91% dan nilai kappa yang didapatkan adalah 82%.
Kata Kunci : Kelulusan Tepat Waktu, Decision Tree, C4.5 Jumlah Pustaka : 20 e-book, 32 jurnal, dan 1 website
Jumlah Halaman : VI BAB + Halaman + Halaman
vi
KATA PENGANTAR
Puji syukur atas kehadirat Allah Subhanahu wa Ta’ala yang telah memberikan rahmat dan nikmat yang besar kepada penulis sehingga dapat menyelesaikan skripsi ini. Penulisan skripsi ini disusun sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri (UIN) Syarif Hidayatullah Jakarta.
Penulis sangat menyadari bahwa skripsi ini tidak akan bisa terselesaikan tanpa bantuan dan dukungan dari berbagai pihak. Maka pada kesempatan ini penulis bermaksud mengucapkan terima kasih yang sebesar-besarnya kepada semua pihak, diantaranya :
1. Allah SWT, Tuhan yang Maha Pengasih lagi Maha Penyayang yang telah memberikan nikmat yang tak kunjung henti kepada penulis serta diberikan kelancaran dalam menyelesaikan skripsi.
2. Nashrul Hakiem, S.Si., M.T., Ph.D selaku Dekan Fakultas Sains dan Teknologi.
3. Dr. Imam Marzuki Shofi, M.T selaku Ketua Program Studi Teknik Informatika Fakultas Sains dan Teknologi.
4. Rizal M.Kom. dan Luh Kesuma Wardhani S.T., M.T. selaku Dosen Pembimbing I dan II yang senantiasa membimbing, mengarahkan, dan memotivasi penulis selama penyusunan skripsi.
5. Orang tua dan keluarga yang selalu mendoakan dan mendukung penulis.
6. Teman – teman seperjuangan kelas TI Angkatan 2016 yang senantiasa memberikan dukungan semangat satu sama lain.
7. Teman – Teman BaseCamp Susu yang senantiasa memberi dukungan dan semangat kepada penulis.
8. Teman – Teman BaseCamp E-Sport yang senantiasa memberi dukungan dan semangat kepada penulis.
9. Teman – Teman BaseCamp Kapitalis yang senantiasa memberi dukungan dan semangat kepada penulis.
10. Ayu Laynda Saputri yang selalu mendoakan dan mendukung penulis.
11. Serta semua pihak yang telah membantu penyelesaian skripsi ini yang tidak dapat disebut namanya satu per satu.
Tidak menutup kemungkinan bahwa skripsi ini tidak luput dari kekurangan dan kesalahan. Oleh karena itu, penulis memohon maaf atas segala kekurangan ataupun kesalahan baik dari segi keilmuan atau penulisan. Bila ada kritik dan saran yang tentunya dibutuhkan untuk penelitian ini, dapat dikirimkan ke email [email protected]. Akhir kata, semoga skripsi ini dapat bermanfaat bagi para pembaca pada umumnya dan penulis pada khususnya. Amin.
Jakarta, 28 Januari 2022
Muhammad Nur
viii DAFTAR ISI
LEMBAR PERSETUJUAN ... i
LEMBAR PENGESAHAN ... ii
PERNYATAAN ORISINALITAS ... iii
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI...iv
ABSTRAK ... v
KATA PENGANTAR ...vi
DAFTAR ISI ... viii
DAFTAR GAMBAR ...xii
DAFTAR TABEL ... xiii
BAB I ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 4
1.3 Batasan Masalah ... 4
1.3.1 Metode ... 4
1.3.2 Tools ... 4
1.3.3 Proses ... 5
1.4 Tujuan ... 6
1.5 Manfaat ... 6
1.5.1 Bagi Penulis... 6
1.5.2 Bagi Universitas ... 6
1.6 Metode Penelitian ... 6
1.6.1 Metode Pengumpulan Data ... 6
1.7 Sistematika Penulisan ... 7
BAB II ... 9
2.1 Data Mining ... 9
2.1.1 Pengetian Data Mining ... 9
2.1.2 Teknik Dasar Data Mining ... 9
2.2 Decision Tree ... 10
2.2.1 Algoritama ID3 ... 12
2.2.2 Algoritma C 4.5 ... 13
2.3 Pra Proses Data ... 15
2.3.1 Pembersihan Data ... 15
2.3.2 Integrase Data ... 19
2.3.3 Reduksi data ... 19
2.3.4 Penambahan data ... 21
2.3.5 Normalisasi data ... 21
2.3.6 Distribusi data... 22
2.4 Model Data Mining ... 23
2.4.1 Metode Hold-Out ... 23
2.4.2 Metode SubSampling Acak... 23
2.4.3 Metode k-Fold Cross-Validation ... 23
2.4.4 Metode Leave-One-Out Cross-Validation ... 24
2.5 Mengevaluasi Kualitas Model ... 24
2.5.1 Akurasi ... 25
2.5.2 Presisi ... 25
2.5.3 Daya ingat atau sensitivitas ... 26
2.6 Analisa Statistik ... 26
2.6.1 Pengertian Statistik ... 26
2.6.2 Teknik Dasar Statistik ... 27
2.7 Uji Korelasi ... 28
2.7.1 Korelasi Univariate ... 28
2.7.2 Korelasi Bivariate ... 29
2.7.3 Korelasi Multivariate ... 30
2.8 Korelasi Bivariate ... 31
2.8.1 Korelasi Pearson Product Moment ... 31
2.8.2 Korelasi Kendall-Tau ... 32
x
2.8.3 Korelasi Spearman Rank ... 33
2.9 Uji Signifikasi ... 34
2.9.1 Uji-T (t−𝑻𝑬𝑺𝑻) ... 34
2.9.2 Uji-T (t−𝑻𝑬𝑺𝑻) Dua Sampel ... 35
2.9.3 Uji Anova ... 36
2.9.4 Anova Dua Jalur (Two Ways – Anova) ... 37
2.10 Bahasa Pemrograman Data Mining ... 37
2.10.1 Bahasa R ... 37
2.10.2 Bahasa Python ... 38
2.10.3 Bahasa Matlab ... 38
2.10.4 Bahasa Julia ... 39
2.10.5 Bahasa Scala ... 40
2.11 Metode Pengumpulan Data... 41
2.11.1 Studi Pustaka ... 41
2.11.2 Observasi ... 42
2.11.3 Kuesioner ... 42
2.11.4 Wawancara ... 43
2.12 Studi Literatur Sejenis ... 44
BAB III ... 51
3.1 Metode Pengumpulan Data ... 51
3.1.1 Observasi ... 51
3.1.2 Studi Pustaka ... 51
3.2 Penentuan Metode ... 51
3.3 Penentuan Variabel ... 52
3.4 Akurasi Data ... 52
3.5 Pembagian Data ... 53
3.6 Metode Klasifikasi C4.5 ... 53
3.7 Perhitungan Akurasi ... 54
3.8 Peralatan Penelitian... 55
3.7.1 Perangkat keras ... 55
3.7.2 Perangkat lunak ... 55
3.9 Kerangka Penelitian ... 55
BAB IV ... 57
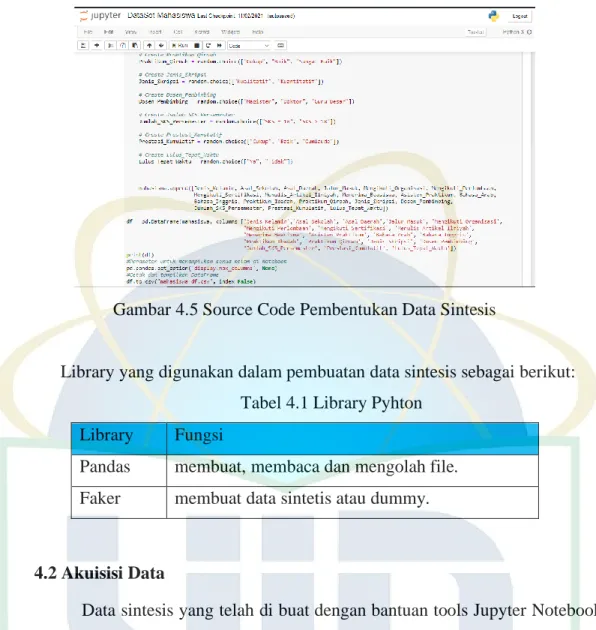
4.1 Pembentukan Data Sintesis ... 57
4.1.1 Penentuan Metode ... 57
4.1.2 Penentuan Variabel ... 58
4.1.3 Pembentukan Data Sintesis Jupyter ... 58
4.2 Akuisisi Data ... 60
4.3 Metode Klasifikasi C4.5 ... 62
4.3.1 Entropy ... 62
4.3.2 Information Gain ... 65
4.3.3 Decision Tree C4.5 ... 67
BAB V ... 70
5.1 Hasil Metode Klasifikasi C4.5 ... 70
BAB VI ... 72
6.1 Kesimpulan... 72
6.2 Saran ... 72
DAFTAR PUSTAKA ... 73 LAMPIRAN ... Error! Bookmark not defined.
xii
DAFTAR GAMBAR
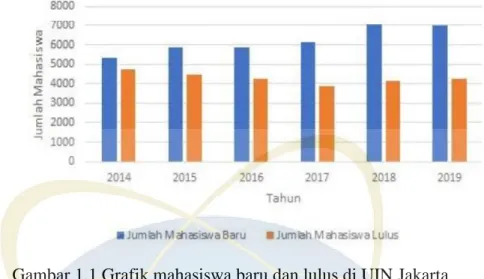
Gambar 1.1 Grafik mahasiswa baru dan lulus di UIN Jakarta ... 3
Gambar 2.1 Tahapan Data Mining ... 8
Gambar 3.1 Alur Penelitia ... 55
Gambar 4.1 Source Code Pembentukan Data Sintesis ... 56
Gambar 4.2 Source Code Pembentukan Data Sintesis ... 56
Gambar 4.3 Source Code Pembentukan Data Sintesis ... 57
Gambar 4.4 Rstudio Decision Tree C4.5 ... 62
Gambar 4.5 Rstudio Decision Tree C4.5 ... 63
Gambar 4.6 Pohon keputusan lulus tepat waktu ... 64
Gambar 5.1 Hasil Akurasi & Kappa ... 66
DAFTAR TABEL
Tabel 1.1 Jumlah mahasiswa baru dan lulus di UIN Jakarta ... 2
Tabel 2.1 Interpretasi Nilai R ... 31
Tabel 2.2 Studi Literatur ... 43
Tabel 4.1 Library Pyhton ... 57
Tabel 4.2 Rincian variabel pada data yang digunakan ... 58
Table 4.3 Hasil perhitungan Entropy dan Information gain ... 61
Tabel 4.4 Library R ... 63
1 BAB I
PENDAHULUAN
1.1 Latar Belakang
Dalam dunia pendidikan mahasiswa merupakan objek utama dari setiap penyelenggaraan pendidikan yang senantiasa mengedepankan kedisiplinan ilmu yang bermanfaat untuk mahasiswa itu sendiri ataupun orang lain, biasanya banyak hal yang terjadi kepada mahasiswa ketika proses pendidikan itu dilaksanakan, mulai ketidak patuhan akan aturan, ketidak nyamanan dalam belajar, ketidak seriusan dalam belajar, kemampuan dan bakat yang dimiliki yang tidak menunjang pada bidang yang diterimanya, kesenjangan sosial, ketidak mampuan secara financial, dan lain-lain, itu semua menyebabkan terjadinya ketidak konsitenan dalam proses belajar, sehingga dampak yang ditimbulkannya cukup kompleks, mulai dari kesiapan untuk menerima materi yang kurang, banyaknya mahasiswa yang mengulang, drop out dan berhenti sebelum lulus.
Dari dasar tersebutlah penulis mencoba melakukan sebuah penelitian dalam memprediksi kelulusan mahasiswa sebagai bahan pertimbangan dan bahan untuk melakukan kebijakan akademik, sehingga dapat menekan tingkat putus kuliah, drop out dan mengulang pada mahasiswa. Sebaiknya data yang digunakan adalah data real atau data sesungguhnya. Namun karena terkendela waktu dan birokrasi, maka data yang digunakan adalah data sintesis. Dari data- data tersebutlah penulis melakukan prediksi dengan menggunakan Decision Tree sebagai metode untuk mendapatkan hasil prediksi variable apa saja yang terkait dengan kelulusan mahasiswa dan mencari akurasi dari perhitungan tersebut.
UIN Syarif Hidayatullah Jakarta atau sering disebut sebagai UIN Jakarta merupakan salah satu Perguruan Tinggi Negeri (PTN). Menurut laporan Badan Akreditasi Nasional Perguruan Tinggi No SK 25/SK/BAN- PT/Akred/PT/II/2018, UIN Jakarta mendapat akreditasi A (BAN-PT, 2018).
UIN Jakarta memiliki tujuh puluh lima jurusan yang terbagi lima puluh
empat jurusan sarjana, enam belas jurusan magister, tiga jurusan pendidikan profesi, dua jurusan doktor. Salah satu masalah pada UIN Jakarta adalah Penerimaan mahasiswa baru mengalami peningkatan namun kelulusan mahasiswa cenderung turun.
Hal ini sesuai dengan laporan Biro Perencanaan dan Keuangan UIN Jakarta tanggal 30 Novemver 2019 tentang jumlah mahasiswa baru dan lulus.
Tabel 1.1 Jumlah mahasiswa baru dan lulus di UIN Jakarta (http://biropk.uinjkt.ac.id/jumlah-data-mahasiswa-baru-dan-lulus/)
(Biropk.Uinjkt, n.d.) Tahun Jumlah Mahasiswa
Baru
Jumlah Mahasiswa Lulus
2019 7009 4268
2018 7038 4129
2017 6133 3854
2016 5849 4243
2015 5861 4449
2014 5310 4731
Berdasarkan data tersebut, jumlah mahasiswa baru mengalami peningkatan tahun 2014-2019 dan jumlah kelulusan mahasiswa mengalami penurunan tahun 2014-2017.
3
UIN Syarif Hidayatullah Jakarta
Gambar 1.1 Grafik mahasiswa baru dan lulus di UIN Jakarta
Terdapat beberapa metode klasifikasi yang umum digunakan, seperti Decision Tree, Random Forest, K-Nearest Neighbor, Naïve Bayes, Neural Network, Logistic Regression, Support Vector Machine, Fuzzy Logic (Purnama, 2019), (Pramana et al., 2018), (Suyanto, 2017). Berikut beberapa hasil penelitian tentang kinerja metode klasifikasi:
A. (Anam & Santoso, 2018) akurasi C4.5 96,40 % dan Naïve Bayes 95,11%.
B. (Arisandy, 2017) akurasi C4.5 89,46% dan Naïve Bayes 79,39%.
C. (Wibisono & Fahrurozi, 2019) akurasi C4.5 80,33%, Naïve Bayes 80,33%, KNN 69,67%, Random Forest 85,66.
D. (Astuti, 2016) akurasi C4.5 92,89%, KNN 77,78%, Neural Network 91,10%.
Berdasarkan hasil tersebut, metode Decision Tree memiliki kecendurngan yang lebih baik apabila dibandingkan dengan metode lain.
Oleh karena itu, penulis melakukan penelitian tentang prediksi kelulusan mahasiswa tepat waktu pada mahasiswa menggunakan metode klasifikasi Decision Tree dengan menggunakan algoritma C4.5.
Berdasarkan pembahasan di atas, maka penulis tertarik untuk melakukan penelitian dengan judul “Data Mining Untuk Memprediksi Kelulusan Mahasiswa Jurusan Teknik Informatika UIN Syarif Hidayatullah Jakarta Menggunakan Metode Klasifikasi C4.5”.
1.2 Rumusan Masalah
1. Berdasarkan latar belakang tersebut maka rumusan masalah dalam penelitian ini yaitu Berapa akurasi yang dihasilkan oleh metode Decision Tree C4.5 dalam melakukan klasifikasi?
2. Bagaimana hasil teknik data mining dengan metode Decision Tree C4.5 untuk menampilkan informasi dalam memprediksi kelulusan mahasiswa Teknik Informatika UIN Syarif Hidayatullah Jakarta?
1.3 Batasan Masalah 1.3.1 Metode
1. Metode pengumpulan data yang digunakan adalah observasi, studi pustaka, dan pembuatan data sintesis.
2. Mengumpulan data dengan data sintesis dilakukan dengan menggunakan aplikasi Jupyter Notebook dengan bahasa pyhton.
3. Metode analisis dalam penelitian ini menggunakan metode Decision Tree C4.5.
4. Prediksi yang dihasilkan adalah tepat atau tidak tepat waktunya mahasiswa dalam menyelesaikan masa studinya
5. Variabel dalam penelitian ini dibagi menjadi dua, pertama variabel bebas dan variabel terikat. Variabel bebas terdiri dari jenis kelamin, asal sekolah, asal daerah, jalur masuk, pernah mengukuti organisasi, pernah mengikuti perlombaan, pernah mengikuti sertifikasi, pernah menulis artikel ilmiyah, menerima beasiswa, asisten praktikum, nilai bahasa arab, nilai bahasa ingris, nilai praktikum qiroah, nilai praktikum ibadah, jumlah sks persemester, jenis/tipe skripsi, dosen pembimbing, indeks prestasi kumulatif dan variable bebas adalah lulus tepat waktu.
1.3.2 Tools
1. Perangkat lunak yang digunakan untuk pembuatan data adalah Jupyter Notebook dengan bahasa Pyhton.
5
UIN Syarif Hidayatullah Jakarta
2. Perangkat lunak yang digunakan untuk analisis Decision Tree C4.5 adalah Rstudio 1.4.1103.
3. Penelitian ini menggunakan aplikasi Microsof Word 2016 sebagai alat penulisan.
4. Penelitian ini menggunakan aplikasi Mendeley1.19.3 sebagai alat bantu mengelola, berbagi, dan mencari referensi.
5. penelitian ini menggunakan laptop dengan spesifikasi AMD A8- 7410 APU with AMD Radeon R5 Graphics 2.20 GHz, RAM 4GB, sistem operasi Windows 10 1903 V2 English x64.
1.3.3 Proses
1. Pengumpulan Data
Penulis melakukan observasi yang dilakukan pada data mahasiswa jurusan teknik informatika pada tahun 2014-2019, lalu penulis melakukan pembuatan data sintesis atau dummy yang dilakukan menggunakan aplikasi jupyter notebook menggunakan bahasa python.
2. Penentuan Variabel
Penulisa melakukan penentuan variabel dilakukan dengan cara melihat studi literatur yang penulis gunakan lalu dikombinasikan dengan variabel yang menjadi sarat kelulusan yang ada di UIN Jakarta.
3. Akurasi Data
Sebaiknya data yang digunakan menggunakan data sesungguhnya.
Namun karena terkendela waktu dan birokrasi, maka data yang digunakan adalah data sintesis.
4. Metode Klasifikasi C4.5
Metode klasifikasi menggunakan metode C4.5. Hasil C4.5 pada penelitian berupa pohon keputusan berdasarkan empat variabel bebas yang memiliki korelasi yang paling besar dari variabel bebas lainnya.
1.4 Tujuan
Berdasarkan rumusan masalah yang sudah dijelaskan, dengan menggunakan metode klasifikasi Decision Tree algoritma C4.5 diharapkan dapat meningkatkan keberhasilan dan keinginan lembaga untuk memberikan pikiran, pandangan, dan kebijakan baru kepada mahasiswa, dengan kata lain memaksimalkan kinerja lembaga kepada mahasiswa dalam upaya peningkatan persentase kelulusan mahasiswa.
1.5 Manfaat
1.5.1 Bagi Penulis
1. Menerapkan ilmu yang telah diperoleh selama perkuliahan dalam menyelesaikan permasalahan di dunia nyata.
2. Memberikan informasi prediksi kelulusan mahasiswa yang lulus tepat waktu maupun yang tidak tepat waktu.
3. Memenuhi salah satu syarat kelulusan untuk memperoleh gelar Sarjana Komputer pada Program Studi Teknik Informatika UIN Syarif Hidayatullah Jakarta.
1.5.2 Bagi Universitas
1. Sebagai bahan untuk evaluasi kinerja Lembaga Pendidikan yang bersangkutan dalam menghadapi era globalisasi yang sangat komplek dan penuh dengan persaingan.
1.6 Metode Penelitian
1.6.1 Metode Pengumpulan Data
Pada penelitian ini, penulis mengumpulkan data dan informasi terkait penelitian dengan menggunakan beberapa metode yaitu : 1.6.1.1 Observasi
Observasi adalah mengumpulkan data dan informasi dengan cara mengamati dan meninjau data kelulusan mahasiswa pada tahun 2014-
7
UIN Syarif Hidayatullah Jakarta
2019 dan melakukan pembuatan data sintesis dikarenakan terkendela waktu dan birokrasi.
1.6.1.2 Studi Pustaka
Studi pustaka merupakan metode pengumpulan data dengan mencari informasi yang relevan dengan tujuan penelitian. Informasi tersebut dapat diperoleh dari berbagai referensi seperti buku, jurnal, skripsi/tesis, situs internet, dan sumber-sumber lain.
1.6.1.3 Metode Perancangan Sistem
Metode perancangan sistem yang digunakan pada penelitian ini adalah:
1. Pengumpulan Data 2. Penentuan Variabel 3. Akurasi Data
4. Metode Klasifikasi C4.5
1.7 Sistematika Penulisan
Penelitian ini dikelompokkan menjadi beberapa bab dengan sistematika penyampaian sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisi uraian mengenai latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode yang digunakan, dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini berisi penjelasan mengenai berbagai teori yang berkaitan dengan penelitian.
BAB III METODE PENELITIAN
Bab ini menjelaskan metode yang digunakan penulis dalam pengumpulan data dan perancangan pada penelitian ini.
BAB IV ANALISIS DAN PERANCANGAN
Bab ini membahas proses analisis dan uji korelasi sesuai dengan metode yang digunakan.
BAB V HASIL DAN PEMBAHASAN
Bab ini memaparkan hasil pengujian desain dan pembahasannya.
BAB VI PENUTUP
Bab ini merupakan penutup yang berisi kesimpulan dari hasil penelitian dan saran yang kiranya dapat dijadikan acuan untuk pengembangan yang lebih baik lagi di masa yang akan datang.
9 BAB II
LANDASAN TEORI
2.1 Data Mining
2.1.1 Pengetian Data Mining
Data Mining adalah Sebuah disiplin ilmu yang mempelajari metode untuk mendapatkan pengetahuan atau menemukan pola dari suatu data.
Teknologi Data Mining sendiri di cetuskan pada tahun 1990 di bidang ilmu komputer (Pramana et al., 2018). Informasi yang dihasilkan diperolehdengan cara mengekstaksi dan mengenali pola yang penting atau menarik dari data yang terdapat pada basis data. Data mining terutama digunakan untuk mencari pengetahuan yang terdapat dalam basis data yang besar sehingga sering disebut Knowledge Discovery Database (KDD)(Retno Tri Vulandari, S.Si., 2017).
Gambar 2.1 Tahapan Data Mining Sumber: (Hendrickx et al., 2015)
2.1.2 Teknik Dasar Data Mining 1. Asosiasi
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan suatu kombinasi item. Salah satu tahap analisis asosiasi yang menarik perhatian banyak peneliti
untuk menghasilkan algoritma yang efisien adalah analisis pola frequensi tinggi (frequent pattern mining).
2. Klasifikasi
Klasifikasi digunakan untuk memberikan label dari suatu data/objek baru. Dengan menerapkan merode pohon keputusan, kita dapat sebuah “pengetahuan” berupa pohon keputusan. Jika ada pelanggan baru, maka cukup diproses datanya ke pohon keputusan tersebut untuk memutuskan/mengklasifikasikan apakah pelanggan ini nanti layak mendapatkan peminjaman uang atau tidak.
3. Pengelompokan (Clustering)
Pengelompokan (Clustering) dapat digunakan untuk mengidentifikasi klaster/daerah yang padat, pola-pola distribusi objek secara umum, dan keterkaitan yang menarik antar artibut objek. Pada analisis klaster, objek-objek dikelompokkan berdasarkan informasi atribut dari objek tersebut.
4. Prediksi
Prediksi adalah peran data mining untuk “meramalkan” di masa depan nilai kira-kira dari suatu data. Misal kita memiliki data harga saham dari tanggal 1 januari 2017 hingga 31 januari 2017. Dengan menerapkan metode artificial neural network kita bisa
“meramalkan”kira-kira nanti pada tanggal 1 november 2017 berapa harga saham yang akan terjadi (Pramana et al., 2018).
2.2 Decision Tree
Proses pada pohon keputusan adalah mengubah bentuk data atau tabel menjadi model pohon, mengubah model pohon menjadi rule, dan menyederhanakan rule. Metode decision tree mengubah fakta yang sangat besar menjadi pohon keputusan yang merempresentasikan aturan (Sri WahyuniKana Saputra S, 2017). Langkah pertama yang dilakukan dalam pembuatan pohon keputusan yaitu menghitung nilai Entropy total dari jumlah data yang dijadikan sampel, selanjutnya yaitu mengelompokkan
11
UIN Syarif Hidayatullah Jakarta
variabel dan menghitung nilai Informasi Gain pada tiap atribut. Setelah dihitung menggunakan rumus algoritma C4.5 maka atribut yang mempunyai nilai Informasi Gain akan menjadi akar dan atribut lainnya menjadi cabang, kemudian dari cabang akan dihitung kembali atribut apa lagi yang mempunyai nilai Gain tertinggi.
Manfaat utama dari penggunaan pohon keputusan adalah kemampuannya untuk membreak down proses pengambilan keputusan yang kompleks menjadi lebih simpel sehingga pengambil keputusan akan lebih menginterpretasikan solusi dari permasalahan. Pohon Keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target. Pohon keputusan memadukan antara eksplorasi data dan pemodelan, sehingga sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain. Decission Tree juga disebut sebagai diagram alir yang berbentuk seperti struktur pohon yang mana setiap internal node menyatakan pengujian terhadap suatu atribut, setiap cabang menyatakan output dari pegujian tersebut dan node daun (leaf node) menyatakan distribusi kelas. Node yang paling atas disebut sebagai node akar (root node). Decission Tree digunakan untuk mengklasifikasikan suatu sampel data yang belum diketahui kelasnya ke dalam kelas-kelas yang sudah ada.
Jalur pengujian data adalah pertama semua data harus melalui root node dan terakhir adalah melalui leaf node yang akan menyimpulkan prediksi kelas bagi data tersebut. Atribut data harus berupa data kategorik, bila kontinu maka atribut harus didiskretisasi terlebih dahulu. Metode decission Tree memiliki beberapa keunggulan dibandingkan metode lainnya untuk database yang besar yaitu:
1. Memiliki kecepatan yang relatif lebih cepat.
2. Dapat diubah menjadi rule klasifikasi dengan mudah dan sederhana.
3. Dapat menggunakan query SQL untuk mengakses database.
4. Dapat dibandingkan tingkat akurasinya dengan metode lainnya.
2.2.1 Algoritama ID3
Iterative Dichotomizes 3 (ID3) adalah algoritma decision tree learning (algoritma pembelajaran pohon keputusan) yang paling dasar. Algoritma ini melakukan pencarian secara merata /menyeluruh (greedy) pada semua kemungkinan pohon keputusan.
Salah satu algoritma induksi pohon keputusan yaitu ID3 (Iterative Dichotomizes 3). ID3 dikembangkan oleh J. Ross Quinlan. (Safii, 2018). Kelebihan menggunakan Algoritma ID3 adalah daerah pengambilan keputusan yang kompleks dan global dapat diubah menjadi lebih simpel dan mengerucut, fleksibel untuk memilih fitur dari internal node yang berbeda serta menghapus perhitungan- perhitungan yang tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sample diuji hanya berdasarkan kriteria atau kelas tertentu. ID3 terbentuk dari rumus entropy dan information Gain. Entropy didefinisikan sebagai suatu paramater untuk mengukur heterogenitas (keberagaman) dalam suatu himpunan data(Suyanto, 2017). Information Gain untuk menentukan suatu variabel menjadi akar dalam pembentukan pohon keputusan (Pramana et al., 2018). Rumus Entropy dan Information gain:
Entropy (S) = − ∑ 𝑃𝑗 ∗ 𝐿𝑜𝑔2𝑃𝑗
𝑛
𝑗=1
S = Himpunan kasus
N = jumlah nilai yang terdapat pada variabel target 𝑃𝑗 = rasio antara jumlah sampel dikelas i dengan
jumlah semua sampel pada himpunan data.
13
UIN Syarif Hidayatullah Jakarta
Gain (S, A) = Entropy(S) − ∑ |Sv|
|𝑆| ∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖)
V∈Value(A)
S = ruang (data) sampel A = varibael yang digunakan
V = suatu nilai yang mungkin untuk variabel A Value(A) = himpunan nilai yang mungkin untuk
variabel A
|𝑆𝑣| = jumlah sampel untuk nilai v
|𝑆| = jumlah seluruh sampel data
2.2.2 Algoritma C 4.5
Banyak algoritma yang dapat dipakai dalam pembentukan pohon keputusan, antara lain ID3, dan C.4.5. Algoritma C4.5 digunakan untuk mengklasifikasi data yang melihat variable bebas yang mempengaruhinya. Algoritma C4.5 dimulai dari proses memilih atribut dengan gain tertinggi sebagai akar pohon, kemudian membuat cabang untuk tiap-tiap nilai, lalu membagi kasus dalam cabang, setelah itu mengulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama (Yudha Aditya Fiandra, Sarjon Defit, 2017). Algoritma C4.5, yang juga ditemukan oleh Jhon Ross Quinlan, merupakan pengembangan dari algoritma ID3. Berbeda dengan ID3 yang menggunakan information Gain, algoritma C4.5 menggunakan Gain Ratio agar tidak bias dalam penentuan atribut pemilihan terbaik (the best split attribure) (Suyanto, 2018).
Pada ID3 tipe data yang digunakan berupa kategori, sedangkan C4.5 tipe data yang digunakan dapat berupa numerik dan kategori. Pada saat pembentukan akar dengan menggunakan information Gain masih terdapat nilai bias dikarenakan algoritma ini mengklasifikasikan data berdasarkan konsep impurity oleh karena itu Jhon Rose Quinlan memperbaiki ID3 menjadi C4.5 dengan menambahkan rumus Gain Rasio untuk memperbaiki hasil bias dari rumus information Gain. Rumus Entropy dan Information gain:
Entropy (S) = − ∑ 𝑃𝑗 ∗ 𝐿𝑜𝑔2𝑃𝑗
𝑛
𝑗=1
S = Himpunan kasus
N = jumlah nilai yang terdapat pada variabel target 𝑃𝑗 = rasio antara jumlah sampel dikelas i dengan
jumlah semua sampel pada himpunan data.
𝐼𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛 𝐺𝑎𝑖𝑛(S, A) = Entropy(S) − ∑ |Sv|
|𝑆| ∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖)
V∈Value(A)
S = ruang (data) sampel A = varibael yang digunakan
V = suatu nilai yang mungkin untuk variabel A Value(A) = himpunan nilai yang mungkin untuk
variabel A
|𝑆𝑣| = jumlah sampel untuk nilai v
|𝑆| = jumlah seluruh sampel data
15
UIN Syarif Hidayatullah Jakarta
𝐺𝑎𝑖𝑛𝑅𝑎𝑡𝑖𝑜(𝑆, 𝐴) = 𝐺𝑎𝑖𝑛(𝑆, 𝐴)
𝑠𝑝𝑙𝑖𝑡 𝑖𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛(𝑆, 𝐴)
Dimana rumus dari Split Info adalah:
𝑆𝑝𝑙𝑖𝑡𝐼𝑛𝑓𝑜𝑚𝑎𝑡𝑖𝑜𝑛(𝑆, 𝐴) = ∑|𝑆𝑖|
|𝑆| 𝑥𝑙𝑜𝑔₂(|𝑆𝑖|
|𝑆|
𝑐
𝑖=1
S = himpunan sampel data
𝑆1 sampai 𝑆𝑠 = sub himpunan sampel data yang terjadi berdasarkan jumlah variasi nilai pada atribut A.
2.3 Pra Proses Data
Saat ini data meningkat secara eksponensial, cepat luar biasa. Berbagai sistem e-commerce, e-government, media elektronik dan sebagainya, menghasilkan basis data sangat besar. Namun, basis data yang besar (hingga Gigabytes atau lebih) umumnya memiliki derai, tidak lengkap, dan tidak konsisten karna berasal dari sumber berbeda. Apalgi mesin pencarian semacam Google dan sejumlah media social, seperti Facebook, Twitter, Line, dan sebagainya, yang menghasilkan miliaran data tidak teratur:
dengan jutaan symbol, singkatam, dan bahasa gaul yang sangat beragam di setiap wilayah, komunitas, dan kelompok (Suyanto, 2017).
2.3.1 Pembersihan Data
Sebuah data dikatakan tidak bersih jika mengandung kotoran yang berupa nilai kotor dan /atau pencilan dan/atau inkonsistensi.
Semakin banyak kandungan kotoran pada suatu data semakin tinggi pula tingkat kekotoran data tersebut. Data mining terhadap data yang masih kotor (tidak dibersihkan lebih dulu) umumnya memberikan hasil yang kurang baik. Hingga saat ini belum ada teknik data mining
yang memberikan hasil baik untuk data kotor. Kalua pun ada biasanya teknik tersebut tidak stabil dan tidak selalu tahan (robust) untuk semua jenis data kotor.
A. Membersihkan nilai kosong
Jika anda memiliki data yang mengandung tuple dengan satu atau lebih atribut tanpa nilai (kosong), anda dapat mebersihkan data dengan cara:
1. Abaikan tuple tersebut: cara ini digunakan jika tuple tersebut tidak memiliki label kelas (dalam kasus klasifikasi data).
Cara ini efektif jika tuple tersebut memiliki banyak atribut kosong. Namun, metode ini kurang sesuai untuk data yang mempunyai banyak tuple dengan sedikit atribut kosong.
Mengapa? Karna dengan mengabaikan tuple- tuple tersebut, berarti banyak atribut lain yang memiliki nilai tidak dipergunakan sama sekali.
2. Isi atribut kosong secara manual: cara ini dapat digunakan untuk mengatasi kelemahan metode pertama. Namun, cara ini tentu saja memerlukan banyak waktu dan seringkali tidak layak untuk himpunan data besar yang mengandung banyak atribut kosong.
3. Gunakan sebuah konstanta global untuk mengisi atribut kosong; isi semua atribut kosong dengan nilai yang berupa sebuah konstanta yang sama, seperti label “Tak dikenal” atau -∞.
4. Gunakan sebuah nilai tendensi sentral (missal rata-rata atau median) untuk mengisi atribut kosong: rata-rata biasanya digunakan untuk himpunan data yang memiliki distribusi normal (simetris) sedangkan median umumnya digunakan untuk himpunan data yang memiliki distribusi condong ke kiri atau ke kanan (asimetris).
17
UIN Syarif Hidayatullah Jakarta
5. Gunakan rata-rata atau median sari suatu atribut untuk mengisi semua sampel dalam semua kelas yang sama dengan tuple tersebut: gunakan rata-rata untuk himpunan data yang memiliki distribusi normal (simetris) dan median untuk himpunan data yang asimetris.
6. Gunakan nilai yang paling mungkin untuk mengisi atribut kosong: nilai yang paling mungkin dapat ditentukan menggunakan regresi atau inferensi (seperti Bayesian atau Decision Tree).
B. Menghaluskan data berderau
Derau dalam himpunan daa bisa berupa kesalahan atau variasi yang bersifat acak, misalnya suatu nilai yang jauh lebih kecil atau lebih besar disbanding yang lain. Jika anda memiliki sebuah data yang berderau, anda dapat membersihkannya dengan cara:
1. Binning (pewadahan): metode sederhana ini sangat mudah dilakukan dengan cara mengurutkan nilai-nilai pada suatu atribut, lalu membaginya ke dalam sejumlah wadah (bin) secara merata, dan akhirnya penghalusan dapat dilakukan menggunakan tiga cara, yaitu: rat-rata (ganti semua nilai dengan rata-rata pada setiap bin), median (ganti semua nilai dengan median pada setiap bin), atau batas nilai minimum dan maksimum (ganti semua nilai dengan nilai minimum dan maksimum yang terdekat pada setiap bin).
2. Regresi: suatu regresi linier biasa mencari persamaan garis
“terbaik” yang paling mendekati nilai-nilai dari dua buah atribut sedemikian hingga suatu atribut dapat digunakan
untuk memperdiksi atribut yang lain. Jika anda memiliki lebih dari dua atribut, anda bisa menggunakan linear regresi jamak (multiple linier regression) untuk menentukan persamaan permukaan multi-dimensi sedemikian hingga dua atu lebih atribut dapat digunakan untuk memprediksi suatu atribut yang anda inginkan.
3. Clustering (pengelompokan data): teknik ini memungkinkan anda dapat mempraktisi data secara lebih baik, tidak harus merata berdasarkan frekuensi seperti pada teknik binning.
Dengan cara ini, penghalusan nilai-nilai atribut dapat dilakukan secara lebih mulus.
C. Membuang pencilan
Data-data pencilan dapat ditemukan menggunakan tendensi sentral, grafik statistic boxplot, berbagai teknik visualisasi. Jika anda menemukan sejumlah data pencilan, anda dapat membuang tuple tersebut.
D. Memperbaiki inkonsistensi
Inkonsistensi data dapat disebabkan oleh beberapa faktor, di antaranya adalah: kurang bagusnya desan formulir pemasukan data (misalnya, terlalu banyak kolom pilihan sehingga membingungkan pengguna), kesalahan operator dalam memasukkan data, kesalahan yang disengaja oleh pengguna (mungkin saja pengguna tidak ingin membocorkan informasi
19
UIN Syarif Hidayatullah Jakarta
data pribadinya), data kadaluwarsa (alamat yang sudah tidak digunakan lagi karena sudah pindah rumah), representasi data
yang inkonsisten, penggunaan kode yang inkonsisten, kesalahan dalam perangkat perekam data, kesalahan sistem, dan
integrase data yang inkonsisten (misal, suatu atribut dapat memiliki nama yang tidak sama dalam basis data berbeda).
2.3.2 Integrase Data
Dalam data mining, secara praktis integrase atau penggabungan sejumlah basis data berbeda sering kali harus dilakukan. Intergasi data yang baik akan menghasilkan data gabungan dengan sedikit redudansi dan/atau inkonsistensi sehingga meningkatkan akurasi dan kecepatan proses data mining. Permaslahan utama dalam integrase data adalah hiterogenitas semantik dan struktur dari semua data yang diintegrasikan.
2.3.3 Reduksi data
Pada banyak kasus, mungkin saja anda menghadapi masalah dengan himpunan data sangat besar secara jumlah, dimensi, maupun keberbilangan (numerosity). Analisis dan penambahan data pada himpunan data yang sangat besar tentu saja membutuhkan waktu lama, yang bahkan tidak realistis jika anda dituntut untuk membangun sebuah sistem waktu nyata (real time system). Pada buku ini dibahas dua belas stategi reduksi data yang dapat dikelompokkan kedalam tiga teknik, yaitu:
A. Reduksi dimensi
Teknik ini mereduksi dimensi (jumlah atribut) data. Pada kasus tertentu, reduksi dimensi memungkinkan sebaran data menjadi lebih sederhana, dimana data yang tadinya tersebar acak dan tumpeng tindih dapat dikelompokkan secara teratur dengan sedikit (bahkan tidak ada) tumpeng tindih lagi, sehingga lebih mudah di analisis dan ditambang.
B. Reduksi keberbilangan
Teknik ini mengganti data asli dengan reprsentasi baru yang lebih sederhana, yang bisa berupa parametrik (data baru hamya berupa parameter-parameter) atau nonparametrik (data baru berupa representasi data yang tereduksi). Terdapat banyak strategi yang masuk kedalam teknik ini.
C. Kompresi data
Teknik ini umumnya menggunakan metode-metode tranformasi, yang bisa berupa lossless (data asli dapat di rekontruksi dari data terkompres tanpa kehilangan informasi) atau lossy (data asli hanya dapat diaproksimasi, dengan kehilangan sebagian informasi). Stategi yang termasuk kompresi data lossless adalah Agregasi Kubus Data sedangkan yang termasuk kedalam kompresi data lossy adalah tranformasi wavelet, principal compenent analysis, independent component analysis, singular value decomposition, seleksi subhimpunan
21
UIN Syarif Hidayatullah Jakarta
fitur, model regresi linier, model log-linier, histogram, klasterisasi, dan sampling.
2.3.4 Penambahan data
Penambahan dimensi baru terkadang perlu dilakukan justru untuk mempermudah (bukan mempersulit) proses data mining.
`Pertanyaannya, bagaimana stategi menambahkan dimensi baru?
Anda hanya perlu meramu fungsi logaritma atau ekponensial secara tepat. Logaritma terhadap bilangan kecil akan memperbesar jarak keduanya sedangkan ekponensial akan memperkecil.
2.3.5 Normalisasi data
Nilai-nilai atribut data yang berbeda-beda rentangnya seringkali perlu dinormalisasi atau distandarisasikan agar proses data mining tidak bias. Biasanya normalisasi data dilakukan kedalam rentang yang kecil, seperti [0,1] atau [-1,1], sehingga semua atribut akan memiliki bobot yang sama.
A. Normalisasi min-maks
Sesuai namanya, metode ini menggunakan nilai minimum dan maksimum untuk melakukan konversi data secara linier. Metode ini banyak digunakan secara praktis. Namun, metode ini memiliki kelemahan pada dua kondisi, yaitu: jika terdapat nilai pencilan yang medominasi dan menjadi minᴀ atau maksᴀ (yang jaul lebih besar atau lebih kecil disbanding nilai-nilai lainnya) atau jika suatu saat ada nilai-nilai atribut yang lebih besar dari
pada maksᴀ atau lebih kecil dari pada minᴀ, maka nilai-nilai tersebut akan berada diluar rentang [minbaruᴀ, maksbaruᴀ].
B. Normalisasi dengan penskalaan decimal
Metode ini menggunakan cara paling sederhana dibandingkan metode lain, yaitu dengan membagi nilai-nilai atribut 𝐴 dengan sebuah bilangan 10ᵈ (dimana d adalah bilangan bulat yang membuat max|𝐴|
10ᵈ <1 dipenuhi). Dengan cara ini semua nilai atribut 𝐴 akan dipetakan kedalam rentang [0,1] jika atribut 𝐴 tidak memiliki nilai negative atau rentang [-1,1] jika atribut 𝐴 memiliki nilai negative. Metode ini memiliki kelemahan pada
dua kondisi seperti pada metode normalisasi min-maks.
C. Normalsasi z-score
Metode yang disebut juga zero-mean ini menormalisasi sesuatu nilai xᵢ pada atribut 𝐴 menjadi nilai baru 𝑥ᵢ1 berdasarkan nilai rata-rata Ā dan deviasi standar σᴀ menggunakan formula 𝑥ᵢ1 =
𝑥ᵢ−Ā
σᴀ dengan memanfaatkan nilai rata-rata dan deviasi standar, metode ini lebih stabil terhadap nilai pencilan maupun adanya nilai-nilai baru yang lebih besar dari pada maksᴀ atau lebih kecil dari pada minᴀ.
2.3.6 Distribusi data
Pada kasus tertentu, mungkin saja anda perlu mentranformasikan nilai-nilai atribut bertipe numerik menjadi nominal, ordinal, atau bahkan biner. Anda mungkin juga perlu
23
UIN Syarif Hidayatullah Jakarta
mentranformasikan nilai-nilai kontinu menjadi diskrit. Hal ini seringkali disebut diskritisasi data. Banyak metode diskritisasi data yang bisa anda gunakan di antarnya adalah: binning, histogram, clustering, decision tree, dan analisis korelasi.
2.4 Model Data Mining 2.4.1 Metode Hold-Out
Pada umumnya metode holdout membagi himpunan data D secara acak kedalam dua subhimpunan yang paling besar (tidak tumpeng tindih), yaitu: data latih D₁ (biasanya 2/3 bagian) dan data uji D₂ (biasanya 1/3 bagian sisanya). Penggunaan metode holdout dengan membagi himpunan data secara acak kedalam dua subhimpunan (data latih dan data uji) kurang sesuai dengan metode klasifikasi yang berbasis pembelajaran, seperti ANN. Karena ANN seringkali terjebak pada optimum lokal (Suyanto, 2017).
2.4.2 Metode SubSampling Acak
Metode holdout terlalu pesimis karena hanya sebuah data awal yang digunakan untuk melatih model klasifikasi padahal metode klasifikasi yang umumnya berbasis pembelajaran umumnya bersifat data-driven (disetir data). Artinya, dengan data yang berbeda, anda akan menghasilkan model klasifikasi yang berbeda juga. Untuk mengatasi masalah tersebut, anda dapat menggunakan metode random subsampling. Caranya? Jalankan metode holdout beberapa kali, misalnya sejumlah k iterasi, kemudian evaluasi kualitas model klasifikasi berdasarkan rata-rata dari setiap iterasi (Suyanto, 2017).
2.4.3 Metode k-Fold Cross-Validation
Sesuai dengan namanya, metode k-Fold Cross-Validation mempartisi himpunan data D secara acak menjadi k fold
(subhimpunan) yang saling bebas: f₁, f₂, …, fₖ, sehingga masing- masih fold berisi 1/k bagian data (Suyanto, 2017).
2.4.4 Metode Leave-One-Out Cross-Validation
Metode Leave-One-Out Cross-Validation (LOOCV) adalah varian dari k-fold cross-validation. Pada metode ini, (N-1) objek data digunakan untuk pelatihan dan satu sisanya untuk pengujian. Dalam hal ini N adalah jumlah seluruh objek data. Proses tersebut dilakukan sebanyak N kali sehingga dihasilkan N ekperimen (Suyanto, 2017).
2.5 Mengevaluasi Kualitas Model
Metrik evaluasi memberi kita cara untuk mengevaluasi secara kuantitatif seberapa baik model kita tampil. Performa model pada data pelatihan dievaluasi untuk mendapatkan akurasi set pelatihan, sedangkan performanya pada data pengujian dievaluasi untuk mendapatkan pengujian akurasi data ketika model memprediksi target dari contoh yang sebelumnya tidak terlihat. Evaluasi pada data pengujian membantu kita mengetahui ukuran kinerja sebenarnya dari model kita.
Masalah pembelajaran menentukan jenis metrik evaluasi yang akan digunakan. Sebagai seorang Misalnya, untuk masalah prediksi regresi, biasanya menggunakan root mean squared error (RMSE) untuk mengevaluasi besarnya kesalahan yang dibuat oleh model. Untuk masalah klasifikasi, salah satu metrik evaluasi umum adalah menggunakan kebingungan matriks untuk mendapatkan gambaran tentang berapa banyak sampel yang diklasifikasikan dengan benar atau salah klasifikasi. Dari matriks kebingungan, dimungkinkan untuk mendapatkan metrik lain yang
25
UIN Syarif Hidayatullah Jakarta
berguna untuk evaluasi masalah klasifikasi seperti akurasi, presisi, dan recall.
Ada empat nilai utama yang bisa didapat langsung dari pemeriksaan kebingungan matriks, dan mereka adalah positif benar, positif palsu, negatif benar, dan nilai negatif palsu.
1. Positif benar: Positif benar adalah jumlah sampel yang diperkirakan positif (atau benar) ketika kelas sebenarnya positif.
2. Positif palsu: Positif palsu adalah jumlah sampel yang diprediksi sebagai positif (atau benar) ketika kelas sebenarnya negatif.
3. Negatif benar: Negatif benar adalah jumlah sampel yang diprediksi menjadi negatif (atau salah) dan kelas sebenarnya adalah negatif.
4. Negatif palsu: Negatif palsu adalah jumlah sampel yang diperkirakan menjadi negatif (atau salah) ketika kelas yang sebenarnya adalah positif. Ini adalah akurasi, positif nilai prediksi (atau presisi), dan sensitivitas (atau penarikan kembali).
2.5.1 Akurasi
Akurasi adalah bagian dari prediksi benar yang dibuat oleh algoritma pembelajaran. Ini direpresentasikan sebagai rasio jumlah true positif, TP, dan negatif benar, TN, terhadap total populasi (Bisong, 2019).
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃 + 𝑇𝑁 𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁
2.5.2 Presisi
Presisi atau nilai prediksi positif: Presisi adalah rasio benar positive, TP, dengan penjumlahan dari true positive, TP, dan false
positive, FP. Dengan kata lain, presisi mengukur sebagian kecil dari hasil yang ada diprediksi dengan benar sebagai positif atas semua hasil yang algoritma memprediksi sebagai positif. Jumlah TP + FP juga disebut prediksi kondisi positif (Bisong, 2019).
𝑃𝑟𝑒𝑠𝑖𝑠𝑖 = 𝑇𝑃 𝑇𝑃 + 𝐹𝑃
2.5.3 Daya ingat atau sensitivitas
Daya ingat atau sensitivitas adalah rasio dari positif benar, TP, dengan jumlah dari positif benar, TP, dan negatif palsu, FN. Dengan kata lain, ingat mengambil bagian hasil yang diprediksi dengan benar sebagai positif atas semua hasil yang positif. Jumlah TP + FN juga diketahui sebagai kondisi positif (Bisong, 2019).
𝐷𝑎𝑦𝑎 𝑖𝑛𝑔𝑎𝑡 = 𝑇𝑃 𝑇𝑃 + 𝐹𝑁
2.6 Analisa Statistik
2.6.1 Pengertian Statistik
Pengertian statistik itu sendiri berasal dari kata state (Yunani) yaitu negara dan digunakan untuk urusan negara. Dari uraian ini dapat dikatakan bahwa statistic adalah rekaputulasi dari fakta yang berbentuk angka-angka disusun dalam bentuk tabel dan diagram yang mendiskripsikan suatu permasalahan. Adapun jenis tabel, yaitu: tabel biasa, tabel kontigensi, dan tabel distribusi frekuensi, sedangkan jenis diagram, yaitu: (diagram batang, diagram garis, atau
27
UIN Syarif Hidayatullah Jakarta
grafik, diagram lambing, lingkaran, diagram pastel, diagram peta dan diagram pencar) (Dr. Riduwan, 2010).
2.6.2 Teknik Dasar Statistik 2.6.2.1 Statistik Deskriptif
Metode-metode yang berkaitan dengan pengumpulan dan penyajian suatu gugus data sehingga memberikan informasi yang berguna. Perlu kiranya dimengerti bahwa statistic deskriptif memberikan infomasi hanya mengenai data yang dipunyai dan sama sekali tidak menarik inferensi atau kesimpulan apapun tentang gugus data induknya yang lebih besar (Walpole, 1993).
2.6.2.2 Statistik Inferensial
Inferensia statistik mencakup semua metode yang berhubungan dengan analisis sebagian data untuk kemudian sampai pada peramalan atau penarikan kesimpulan mengenai keseluruhan gugus data induknya (Walpole, 1993).
2.6.2.3 Statistik Parametrik
Statistik Parametrik digunakan untuk analisa dengan menggunakan parameter-parameter populasi seperti rata-rata dan sebagainya, biasanya digunakan untuk mengolah data kuantitatif (numerikal / diskrit / kontinu) yaitu data jenis interval atau ratio dengan memastikan distribusi data adalah distribusi normal atau mendekati normal.
2.6.2.4 Statistik Non Parametrik
Statistik Non Parametrik digunakan untuk analisa yang tidak menggunakan parameter-parameter populasi biasanya digunakan untuk mengolah data kualitatif (kategorikal dan kategori bertingkat) yaitu data jenis nominal atau ordinal dengan distribusi data yang tidak diketahui atau tidak normal.
2.7 Uji Korelasi
2.7.1 Korelasi Univariate
ANOVA satu arah antar-subjek adalah bentuk umum dari kelompok independen uji t. Uji t melibatkan perbandingan hanya dua kelompok yang mewakili satu indeks tunggal. variabel independen;
ANOVA memungkinkan kita untuk membandingkan dua atau lebih kelompok. Nama dari desain ANOVA berasal dari pertimbangan berikut:
1. Ini adalah desain satu arah karena hanya ada satu variabel independen sejumlah kelompok atau level yang mewakili variabel independen tersebut dimasukkan.
2. Ini adalah desain antar-subjek di mana kasus di setiap kelompok harus independen satu sama lain, artinya, mereka harus merupakan entitas yang berbeda.
Desain ANOVA yang berbeda mempartisi varians variabel dependen menjadi beberapa sumber perbedaan yang berbeda. Dalam desain satu arah antara subjek, dua sumber dari varians di mana total varians dari variabel dependen dipartisi adalah sebagai berikut:
1. Varians Antar-Grup. Ini mencerminkan perbedaan rata-rata antara kelompok dan didefinisikan dalam istilah perbedaan antara kelompok berarti dan arti agung. Ini mewakili pengaruh variabel independen. Namun, jika ada kesalahan eksperimental sistematis (perancu) yang dihasilkan dari beberapa kesalahan lain sumber yang meliputi efek
29
UIN Syarif Hidayatullah Jakarta
pengobatan, perbedaan rata-rata juga akan mengirim sumber kesalahan eksperimental (Keppel & Wickens, 2004). Varians terkait dengan varians antarkelompok adalah pembilang rasio F.
2. Varians Dalam-Grup. Ini mencerminkan variabilitas dalam setiap kelompok dan didefinisikan dalam istilah perbedaan antara rata-rata kelompok dan setiap skor dalam kelompok itu. Ini mewakili kesalahan pengukuran dalam penelitian. Itu varians yang terkait dengan sumber varians ini adalah penyebut dari F perbandingan (Meyers et al., 2013).
2.7.2 Korelasi Bivariate
Dalam pengertian yang paling umum, korelasi mengindeks sejauh mana variabel dalam analisis terkait. Ada beberapa koefisien korelasi yang dapat digunakan untuk penelitian ini dilakukan dalam ilmu perilaku, sosial, dan kedokteran, namun yang paling banyak digunakan adalah Pearson Product Moment Correlation, biasanya disebut sebagai korelasi Pearson atau just yang Pearson r. Ini mengasumsikan bahwa variabel mewakili perkiraan pengukuran interval dan bahwa mereka kira-kira terdistribusi normal; pencilan dapat mendistorsi file nilai korelasi, dan karenanya harus ditangani dengan tepat sebelum analisis data.
Pearson r dikembangkan oleh Karl Pearson (1896) berdasarkan pengembangan awal gagasan gagasan oleh Sir Francis Galton (1886,
1888). Ini menilai sejauh mana dua variabel terkait secara linier.
Sampai sejauh itu hubungan kedua variabel tersebut tidak linier (misalnya, fungsi berbentuk U), Pearson r secara substansial akan meremehkan seberapa kuat kedua variabel terkait (dalam kasus fungsi berbentuk U yang simetris, Pearson r akan menjadi nol).
Untuk mengatakan bahwa dua variabel terkait berarti mereka saling melengkapi. Salah satu cara untuk memikirkan kovariat adalah variasi dalam satu variabel sinkron dengan variabel lain.
Misalnya, kasus dengan nilai yang lebih tinggi pada satu variabel mungkin cenderung memiliki nilai yang lebih rendah variabel lainnya. Cara terkait untuk memikirkan kovarian adalah nilai dari satu variabel dapat diprediksi dengan beberapa margin lebih baik daripada kebetulan dari pengetahuan yang sesuai nilai di sisi lain.
Pearson 𝑟2 mengindeks kekuatan hubungan, yaitu jumlah varian yang dibagi antara dua variabel (Meyers et al., 2013).
2.7.3 Korelasi Multivariate
ANOVA didefinisikan sebagai prosedur univariat karena hanya ada satu variabel dependen dalam analisis. Namun dalam banyak konteks penelitian, kasus-kasus dalam penelitian ini lebih terpengaruh dari satu cara oleh variabel independen, dan jika ini adalah kemungkinan, itu berguna untuk menilai kasus pada beberapa variabel dependen. Saat kami membandingkan kasus di masing- masing tingkat variabel independen terhadap kinerja mereka pada dua atau lebih variabel dependen, desain yang kami gunakan adalah multivariate ANOVA (MANOVA). Fitur utama dari MANOVA adalah, setidaknya di bagian awal analisis, variabel dependen
31
UIN Syarif Hidayatullah Jakarta
diperlakukan bersama sebagai satu set dari pada dianalisis secara terpisah satu sama lain.
Tujuan statistik dalam MANOVA adalah membentuk komposit linier berbobot (variate) dari variabel dependen analog dengan apa yang terjadi dalam regresi berganda. Dalam MANOVA, bagaimanapun, bobot dihasilkan sedemikian rupa sehingga kelompoknya maksimal dibedakan. Nilai yang dihasilkan dari penyelesaian fungsi diskriminan (pembobotan komposit linier dari variabel dependen) adalah skor diskriminan (yaitu, diskriminan skor dihitung untuk setiap kasus), dan bobot diberikan untuk setiap variabel dependen mencapai tujuan untuk secara maksimal memisahkan (membedakan) kelompok berdasarkan mereka skor diskriminan rata-rata. Kelompok-kelompok tersebut kemudian dibandingkan menggunakan ANOVA tetapi dengan skor diskriminan (mewakili variate atau "variabel super") sebagai dependen variabel dalam analisis (Meyers et al., 2013).
2.8 Korelasi Bivariate
2.8.1 Korelasi Pearson Product Moment
Kegunaan Uji Pearson Product Moment atau analisis korelasi adalah untuk mencari hubungan variable bebas (X) dengan variabel terikat (Y) dan data berbentuk interval dan ratio. Karena sangat mudah dalam pengerjaan, maka uji ini lebih terkenal dengan analisis korelasi Pearson Product Moment (Dr. Riduwan, 2010). Rumus yang dikemukakan adalah:
𝑟 = 𝑛. (∑ 𝑋𝑌) − (∑ 𝑋). (∑ 𝑌)
√{. ∑ 𝑋2− (∑ 𝑋)2}. {𝑁. ∑ 𝑌2− (∑ 𝑌)2}
Korelasi PPM dilambangkan (r) dengan ketentuan nilai r tidak lebih dari harg (-1 ≤ r ≤ + 1). Apabila r = -1 artinya korelasinya negatif sempurna, r = 0 artinya tidak ada korelasi, dan r = 1 berarti korelasinya sempurna positif (sangat kuat). Sedangkan harga r akan dikonsultasikan dengan tabel interpretasi nilai r sebagai berikut:
Tabel 2.1 Interpretasi Nilai R Interval koefisien Tingkat hubungan
0,00-0,199 Sangat rendah
0,20-0,399 Rendah
0,40-0,599 Cukup
0,60-0,799 Kuat
0,80-1,000 Sangat kuat
Sedangkan untuk menyatakan besar kecilnya sumbangan variabel X terhadap Y dapat ditentukan dengan rumus koefisien diterminan sebagai berikut r (Dr. Riduwan, 2010):
KP = 𝑟2𝑥100%
KP = besarnya koefisien penentu (diterminan) r = koefisien korelasi
2.8.2 Korelasi Kendall-Tau
Tau Kendall dikemukakan oleh Maurice Kendall (1938) sebagai ukuran asosiasi dari dua variabel acak kontinyu yang didistribusikan bersama. Ini didefinisikan sebagai perbedaan antara probabilitas
33
UIN Syarif Hidayatullah Jakarta
konkordansi dan ketidaksesuaian dua variabel acak. Sepasang observasi dikatakan sesuai jika nilai X lebih besar kemungkinannya terkait dengan nilai Y yang lebih besar. Pasangan tersebut sumbang jika nilai X lebih besar lebih mungkin terkait dengan nilai Y yang lebih kecil.
𝜏 = 𝑃[(𝑋1− 𝑋2)(𝑌1− 𝑌2) > 0] − 𝑃[(𝑋1− 𝑋2)(𝑌1− 𝑌2) < 0],
P (konkordansi) P (perselisihan)
Dimana (𝑋2, 𝑌2) adalah replikasi independen dari (𝑋1, 𝑌1).
Sebagai perbedaan dua probabilitas, - 1 ≤ 𝜏 ≤ 1 dengan 𝜏 positif menunjukkan hubungan positif antara variabel dan nilai absolut yang lebih tinggi menunjukkan asosiasi yang lebih kuat. Untuk (X, Y) mengikuti distribusi normal bivariat dengan koefisien korelasi ρ, Kruskall (1958) mempresentasikan hubungan antara korelasi Pearson koefisien dan tau Kendall.
𝜏 = 4 ∫ ∫ 𝐻(𝑥, 𝑦)𝑑𝐻(𝑥, 𝑦) − 1 =2 𝜋
∞
−∞
𝑎𝑟𝑐𝑠𝑖𝑛(ρ).
∞
−∞
Untuk mendapatkan estimasi tau, misalkan (𝑋1) 𝑌1), ..., (𝑋𝑛, 𝑌𝑛) menjadi sampel acak dari distribusi gabungan (X, Y) (Silva Pimentel
& Silva, 2009).
2.8.3 Korelasi Spearman Rank
Uji Rank Spearman digunakan untuk menguji hipotesis korelasi dengan skala pengukuran variabel minimal ordinal. Uji Rank
Spearman diperkenalkan oleh Spearman pada tahun 1904. Dalam Uji Rank Spearman, skala data untuk kedua variabel yang akan dikorelasikan dapat berasal dari skala yang berbeda (skala data ordinal dikorelasikan dengan skala data numerik) atau sama (skala data ordinal dikorelasikan dengan skala data ordinal). Data yang akan dikorelasikan tidak harus membentuk distribusi normal. Jadi Uji korelasi Rank Spearman adalah uji yang bekerja untuk skala data ordinal atau berjenjang atau rangking, dan bebas distribusi. Korelasi rank spearman terutama digunakan untuk memecahkan masalah yang menyangkut data nominal dan data sekuensial. Ini diterapkan pada dua kolom variabel dan memiliki properti variabel peringkat dan bahan dengan variabel peringkat property dan hubungan linier.
(Tan et al., 2018).
2.9 Uji Signifikasi
2.9.1 Uji-T (t−𝑻𝑬𝑺𝑻)
Uji t sampel ini tergolong hipotesis deskriptif. Uji t ini terdapat dua rumus yang dapat digunakan, yaitu:
• Jika standar deviasi populasi diketahui, maka yang digunakan ialah rumus 𝑍ℎ𝑖𝑡𝑢𝑛𝑔.
𝑍ℎ𝑖𝑡𝑢𝑛𝑔=𝑥−𝜇0 𝜎
√𝑛
Dimana:
𝑍ℎ𝑖𝑡𝑢𝑛𝑔= harga yang dihitung dan menunjukkan nilai standar deviasi pada distribusi normal (Tabel z).
𝑋 = Rata-rata nilai yang diperoleh dari hasil pengumpulan data.
35
UIN Syarif Hidayatullah Jakarta
𝜇0 = Rata-rata nilai yang dihipotesiskan
𝜎 = Standar deviasi populasi yang telah diketahui.
n = jumlah populasi penelitian.
Jika standar deviasi populasi tidak diketahui, maka yang digunakan ialah rumus 𝑡ℎ𝑖𝑡𝑢𝑛𝑔.
𝑡ℎ𝑖𝑡𝑢𝑛𝑔=𝑥−𝜇0 𝑆
√𝑛
Dimana:
𝑡ℎ𝑖𝑡𝑢𝑛𝑔 = harga yang dihitung dan menunjukkan nilai standar deviasi pada distribusi t (Tabel t).
𝑋 = Rata-rata nilai yang diperoleh dari hasil pengumpulan data.
𝜇0 = Rata-rata nilai yang dihipotesiskan
𝑆 = Standar deviasi populasi yang telah diketahui.
n = jumlah populasi penelitian.
Adapun standar deviasi sampel dapat dihitung berdasarkan data yang terkumpul. Pada umumnya standar deviasi setiap populasi jarang diketahui, maka penggunaan rumus 𝑍ℎ𝑖𝑡𝑢𝑛𝑔 kurang digunakan (Dr. Riduwan, 2010).
2.9.2 Uji-T (t−𝑻𝑬𝑺𝑻) Dua Sampel
Uji t dua sampel ini dapat tergolong uji perbandingan (uji komparatif) tujuan dari uji ini adalah untuk membandingkan (membedakan) apakah kedua data (variabel) tersebut sama atau berbeda. Gunakan uji komparatif adalah untuk menguji kemampuan
generalisasi (signifikasi hasil penelitian yang berupa perbandingan keadaan variabel dari dua rata-rata sampel (Dr. Riduwan, 2010).
Rumus uji t dua sampel:
𝑡ℎ𝑖𝑡𝑢𝑛𝑔= 𝑥1−𝑥̅̅̅̅2
√𝑆12 𝑛1+𝑆22
𝑛2−2.𝑟.(𝑆1
√𝑛1)+(𝑆2
√𝑛2)
r = nilai korelasi 𝑋1dengan 𝑋2 𝑛1𝑑𝑎𝑛 𝑛2 = jumlah sampel
𝑋1
̅̅̅ = rata-rata sampel ke-1 𝑋2
̅̅̅ = rata-rata sampel ke-2 𝑆1 = standar deviasi sampel ke 1 𝑆2 = standar deviasi sampel ke 2 𝑆12 = varians deviasi sampel ke 1 𝑆22 = varians deviasi sampel ke 2 2.9.3 Uji Anova
Uji Anova adalah anonym dari analisis varian terjemahan dari analysis of variance, sehingga banyak orang yang menyebutnya dengan anova. Anova merupakan bagian dari metode analisis statistika yang tergolong analisis komparatif (perbandingan) lebih dari dua rata-rata. Tujuan dari uji Anova satu jalur ialah untuk membandingkan lebih dari dua rata-rata. Sedangkan gunanya untuk menguji kemampuan generalisasi. Maksudanya dari signifikasi hasil penelitian (anova satu jalur). Jika terbukti berbeda dua sampel tersebut dapat digeneralisasikan artinya (data sampel dianggap dapat
37
UIN Syarif Hidayatullah Jakarta
mewakili [populasi]). Anova pengembangan atau penjabaran lebih lanjut dari Uji-T (t−ℎ𝑖𝑡𝑢𝑛𝑔). Uji-t atau uji-z hanya dapat melihat perbandingan dua kelompok data saja. Sedangkan anova satu jalur lebih dari dua kelompok data. Anova lebih dikenal dengan uji-F (Fisher Test), sedangkan ari variasi atau variasi itu asal usulnya dari pengertian konsep “Mean Square” atau kuadrat rerata (KR) (Dr.
Riduwan, 2010), rumus sistematisnya:
𝐾𝑅 =𝐽𝐾 𝑑𝑏
JK = jumlah kuadrat (some of square) db = derajat bebas (degree of freedom)
2.9.4 Anova Dua Jalur (Two Ways – Anova)
Anova dua jalur digunakan untuk menguji hipotesis perbandingan lebih dari dua sampel dan setiap sampel terdiri atas dua jenis atau lebih secara bersama-sama.
Dalam kasus ini terdapat tiga hipotesis yang akan diuji:
kemungkinan terjadi interaksi, tidak terjadi interaksi, dan tidak ada interaksi terhadap suatu yang dibandingkan (Dr. Riduwan, 2010).
2.10 Bahasa Pemrograman Data Mining 2.10.1 Bahasa R
R adalah bahasa pemrograman lengkap dengan fitur pemrograman fungsional dan pemrograman berorientasi objek.
Bahwa untuk menggunakan R untuk analisis data, Anda jarang perlu melakukan banyak pemrograman. Setidaknya, jika Anda
melakukannya jenis pemrograman yang tepat, Anda tidak perlu banyak pemrograman (Mailund, 2017).
2.10.2 Bahasa Python
Python adalah bahasa pemrograman yang banyak digunakan di kalangan ilmiah karena jumlahnya yang besar perpustakaan menyediakan seperangkat alat lengkap untuk analisis dan manipulasi data. Dibandingkan dengan bahasa pemrograman lain yang umumnya digunakan untuk analisis data, seperti R dan Matlab, Python tidak hanya menyediakan platform untuk pengolahan data tetapi juga memiliki beberapa fitur yang membuatnya unik dibandingkan dengan bahasa lain dan aplikasi khusus.
Perkembangannya pun terus meningkat jumlah pustaka pendukung, penerapan algoritma dari metodologi yang lebih inovatif, dan kemampuan untuk berinteraksi dengan bahasa pemrograman lain (C dan Fortran) membuat Python unik di antara jenisnya. Lebih jauh lagi, Python tidak hanya dikhususkan untuk analisis data, tetapi juga memiliki banyak aplikasi lain, seperti pemrograman umum, skrip, antarmuka ke database, dan pengembangan web baru-baru ini seperti baik, berkat kerangka web seperti Django (Nelli, 2018).
2.10.3 Bahasa Matlab
MATLAB (laboratorium matriks) adalah bahasa pemrograman tingkat tinggi generasi keempat dan lingkungan interaktif untuk komputasi numerik, visualisasi, dan pemrograman. MATLAB dikembangkan oleh MathWorks. Ini memungkinkan manipulasi