자동화된 한국어 작문 채점에 적용하기 위한 형태소 분석 및 품사 첨부. 해외 자동 채점 시스템은 형태소 분석, 품사 첨부, 종속 구문 분석을 사용합니다.

한국어의 특성
수식어는 다른 단어를 수식하는 역할을 하는 품사입니다. 동사는 주로 문장에서 술어로 기능하는 품사이며 형용사와 동사를 포함합니다.
한국어 형태소 분석 기법
형태학적 분석의 방향은 상향식 분석과 하향식 분석으로 구분할 수 있다. 단위 형태소만 사전에 포함되어 있는 경우 정보에 접근합니다.
한국어 형태소 품사 부착
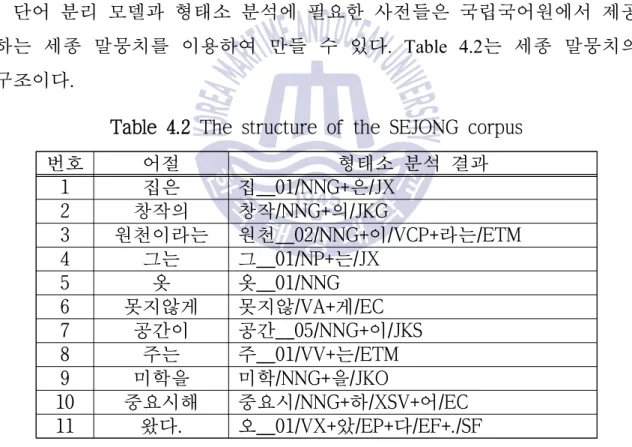
또한, 자주 사용하는 단어에 대한 형태소 분석 결과를 저장하는 경석사전을 구축하여 사용할 수 있습니다. 본 방법의 품사부착기법은 각 단어나 형태소의 확률정보를 추출한 후, 각 단어나 형태소의 확률정보를 추출한다.
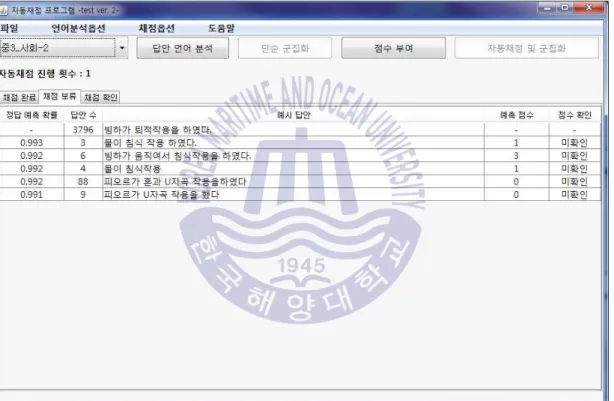
한국어 서답형 문항 자동채점 시스템
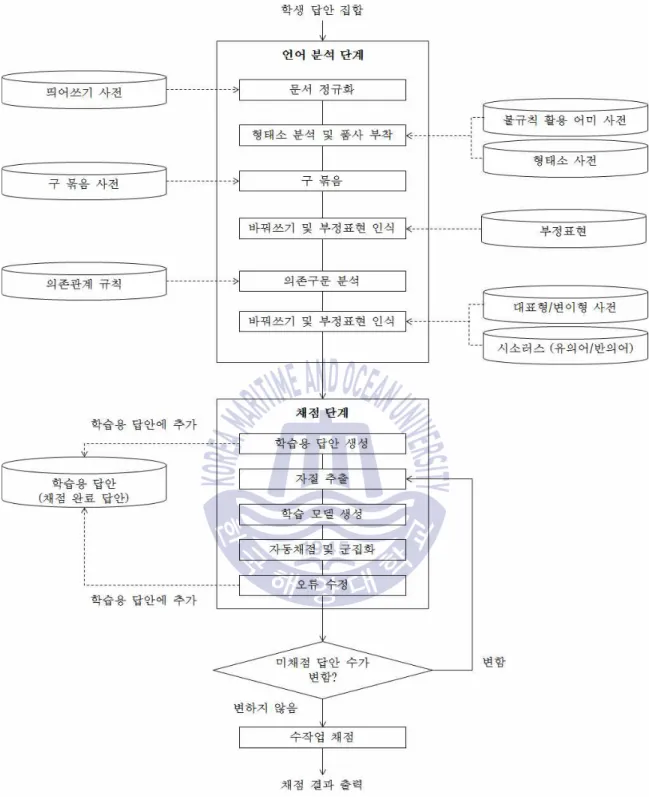
한국어 단답형 자동 채점 시스템은 그림 1에 나와 있다. 언어분석 단계는 학생의 응답을 입력으로 받아 자동채점에 필요한 언어정보를 분석, 처리하는 단계이다. 언어분석 단계의 결과와 완벽하게 일치하는 답변을 유형으로 정의합니다.
평가 단계에서 평가자는 초기 훈련 응답을 생성하기 위해 많은 응답을 포함하는 유형을 수동으로 평가한 다음 훈련 응답에서 유용한 기능을 추출하고 자동 평가를 수행합니다.
기존 시스템의 형태학적 분석 과정을 위한 의사코드. 형태소 분석 및 단어 음성 첨부 과정에서 한 학생의 오류가 발생했습니다. 형태소 분석 및 단어 음성 매핑 기술의 대표적인 예입니다.
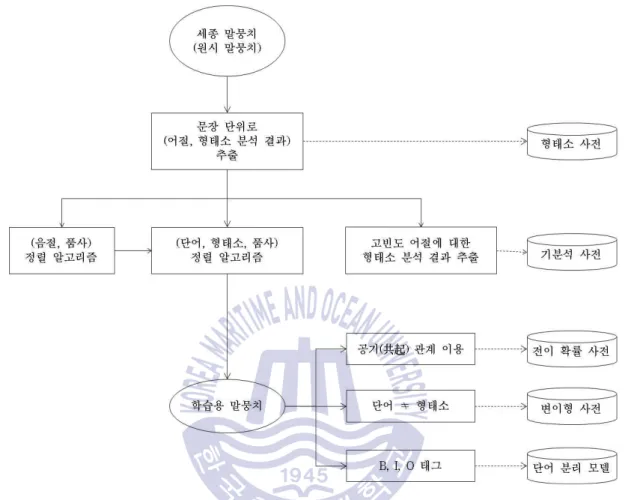
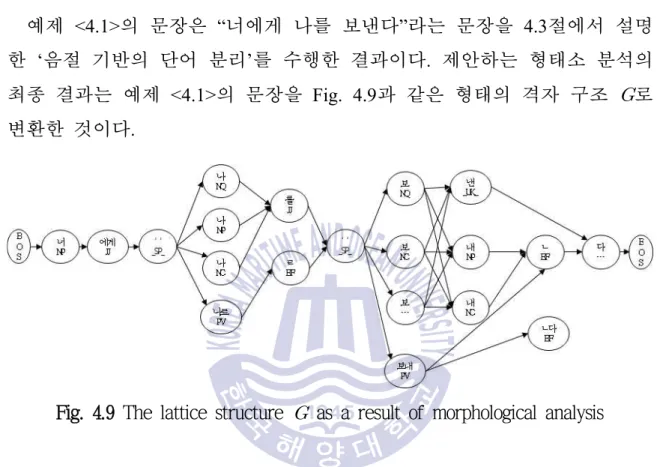
이 정렬 결과를 이용하여 형태소 분리 모델과 변형형 G를 생성하고, 단어별로 형태소 사전을 검색한다. 형태소사전에서 검색한 결과가 있는 경우 Fig.
한국어 형태분석 및 정보검색, 홍릉과학출판사. 형태소 분석기 사용을 제외한 음절 수준의 한국어 품사.

기존 형태소 분석기 및 품사기의 문제점
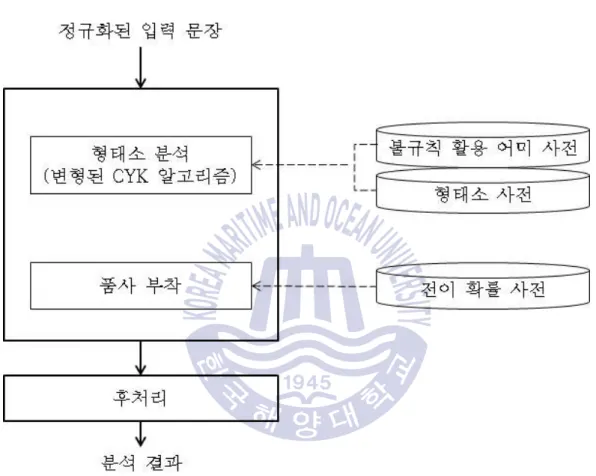
이 방법은 기존 자동 채점 시스템에서 사용되는 형태소 분석 및 품사 확인 기법과 유사하다. 제안하는 형태소 분석 및 품사 확인 기법에서는 세종 코퍼스에서 생성된 음절 기반 단어 분리 모델을 사용하여 기계 학습 방법인 CRF를 이용한 “음절 기반 단어 분리”를 수행한다. 그런 다음 무드스톤 사전을 단어별로 검색하여 분석 후보를 생성합니다.
형태소 분석이 완료되면 전이확률 사전을 이용하여 가장 적절한 품사부착 결과를 생성하고, 후처리를 거쳐 최종 분석결과를 출력한다.
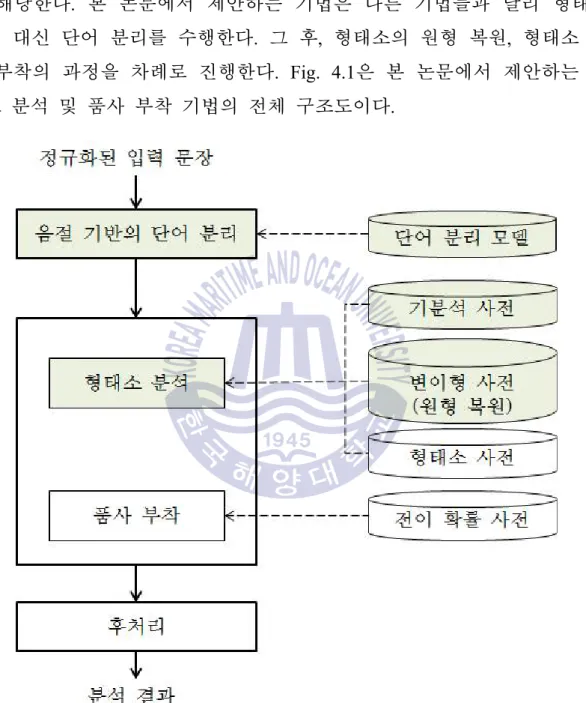
이후 분리된 단어를 변형사전에서 검색하여 원래의 형태소를 복구하고, 형태소사전을 이용하여 추가적인 분석 후보를 생성한다. 현재는 기분 분석을 위한 사전 구축을 위해 빈도가 높은 단어에 대한 형태소 분석 결과를 추출하고 있다. 학습 코퍼스에서 단어와 형태소가 일치하지 않는 결과는 변형 사전에 추가됩니다.
단어 분리 모델의 경우 'equal'과 'replace'의 정보를 이용하여 표 4.7과 같은 학습 코퍼스를 생성한다.
음절 기반의 단어 분리
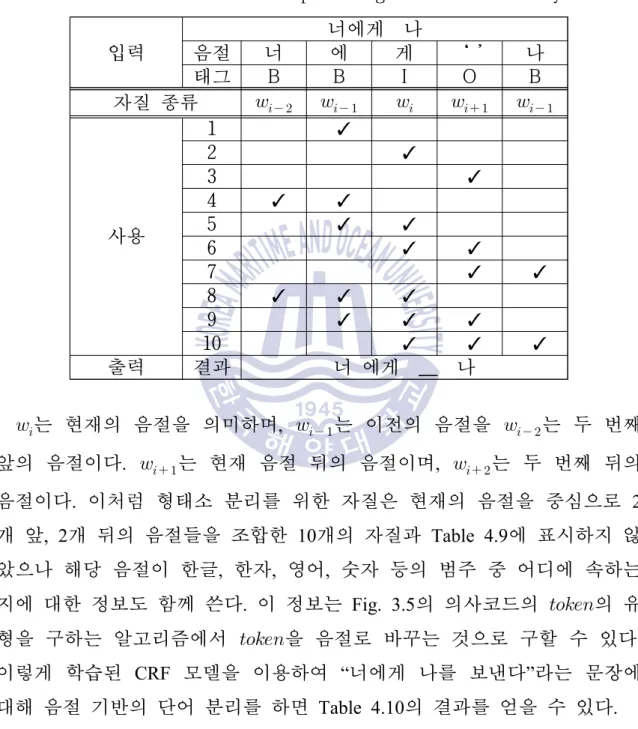
단어 문맥 확률 대신 품사 문맥 확률을 사용하는 이유는 한국어 단어의 종류가 셀 수 없이 많고 지속적으로 생성되기 때문에 전체 단어에 대한 전이 확률을 구하기가 어렵기 때문이다. CRF를 이용한 음절 단어 분리 함수는 음절 공간 함수와 동일한 기능을 사용한다. 업무 내용 결과서를 입력해서 보내드립니다.
제안하는 형태소 분석 기법
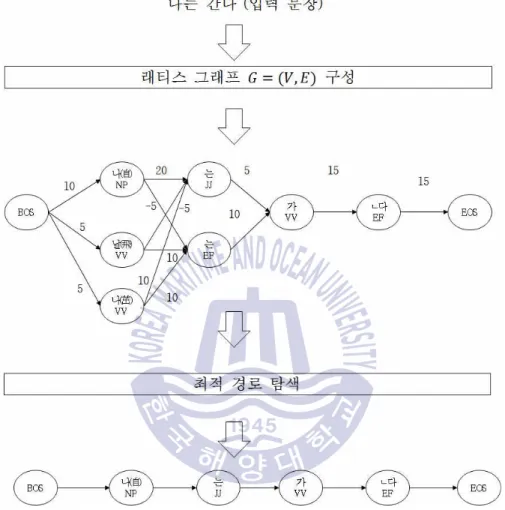
경석사전의 검색단위는 단어이다. 해당 단어에 대한 형태소사전에 검색결과가 없는 경우. 이형사전에서 검색결과가 있는 경우 해당 이형사전을 대상으로 형태소사전 검색을 수행하고 그 결과를 정점으로 추가한다.
이때, 형태소사전에 검색결과가 없는 복합어는 정점으로 추가되지 않는다.
통계기반의 품사 부착
찾아낸 최적의 경로를 '형태소/품사' 형식으로 출력하면 그 결과가 품사부착이 된다. 본 장에서는 기존에 제안된 형태소 분석과 품사부착기법의 성능을 평가하고, 오류 유형을 분석하며, 향후 연구방향을 모색한다.
성능 평가 대상
세종 말뭉치
본 답변은 교육과정평가원과 함께 진행한 '한국어 단답형 자동 채점 프로그램 실기 성적 개발 및 검증' 프로젝트의 예시 답변이며, 학생 정보는 보안상의 이유로 블라인드 처리되어 있습니다.
성능 평가 척도
형태소 분석 성능 평가 척도인 회상 속도는 시스템의 후보 형태소 분석 결과에 단어 대 단어가 올바른 형태소가 포함되어 있는지 확인하여 측정됩니다. 품사 기법의 정확성은 평가 코퍼스의 정답이 시스템 품사 첨부의 단어 대 단어 결과와 얼마나 잘 일치하는지 확인합니다. 제안된 형태소 분석과 품사 확인 기법의 비교를 위한 근거는 기존의 형태소 분석과 품사 확인 기법7)이다.
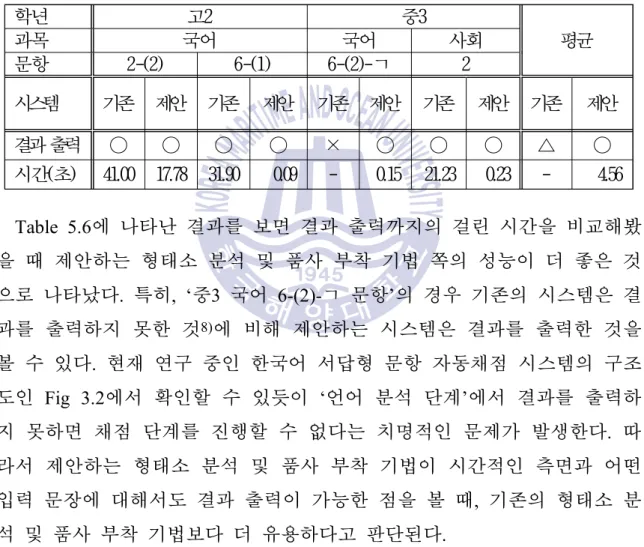
성능 평가 결과
시스템의 올바른 형태소 수에 대한 정확도 시간(초)입니다. 단어 음성부착기의 성능은 문장을 단어 단위로 분리하는 시스템에서 출력되는 형태소의 수와 실제 정답과 일치하는 형태소의 비율(정확도)을 기준으로 평가하였다. 앞서 언급한 바와 같이 본 실험에는 정답이 없으므로 형태소 분석의 출력과 단어 음성에 대한 부착 결과 및 그 결과 시간을 평가지표로 설정하였다.
컴퓨터 사양과 시간이 충분하다면 계산이 완료돼 형태소 분석 결과가 언젠가 나올 것으로 예상된다.
오류분석
“의미정보를 이용한 한국어 복합명사 분석,” 한국정보과학회지, 논문집. “가중 네트워크를 이용한 한국어 품사 태깅,” Journal of Information Science and Technology. “한국어 복합명사의 의미기반 분석,” 한국정보과학회지, 학회지.
"그래서", 한국정보과학회지, 학회지.