저작자표시-비영리-변경금지 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게
l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. 다음과 같은 조건을 따라야 합니다:
l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다.
l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다.
저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다.
Disclaimer
저작자표시. 귀하는 원저작자를 표시하여야 합니다.
비영리. 귀하는 이 저작물을 영리 목적으로 이용할 수 없습니다.
변경금지. 귀하는 이 저작물을 개작, 변형 또는 가공할 수 없습니다.
공학석사학위논문
동시에 실행되는 워크로드 조합에 따른 GPGPU 성능 분석
및 워크로드 GPGPU에 분배
Analysis of the GPGPU Performance for Various Combinations
of Workloads Executed Concurrently and Balancing Their Load
2017 년 2 월
서울대학교 대학원
컴퓨터 공학부
김 동 환
공학석사학위논문
동시에 실행되는 워크로드 조합에 따른 GPGPU 성능 분석
및 워크로드 GPGPU에 분배
Analysis of the GPGPU Performance for Various Combinations
of Workloads Executed Concurrently and Balancing Their Load
2017 년 2 월
서울대학교 대학원
컴퓨터 공학부
김 동 환
동시에 실행되는 워크로드 조합에 따른 GPGPU 성능 분석
및 워크로드 GPGPU 에 분배
Analysis of the GPGPU Performance for Various Combinations
of Workloads Executed Concurrently and Balancing Their Load
지도교수 엄 현 상
이 논문을 공학석사 학위논문으로 제출함
2016 년 10 월
서울대학교 대학원
컴퓨터 공학부
김 동 환
김동환의 공학석사 학위논문을 인준함
2016 년 12 월
위 원 장 이 광 근 (인)
초록
높은연산처리능력을가진GPGPU를활용하여길고복잡한계산을하려는시
도가많이 있다.하지만연산을하기위해host와device사이에메모리복사가필요 하며이는매우큰오버헤드로서latency를길어지게만든다.이latency를줄이기 위해메모리복사량을줄이려는노력이 있었다.하지만이를위해서추가적인CPU 연산이 선행되거나GPGPU 어플리케이션을 수정하는등의노력이 필요하다.하 지만최신GPGPU들과그에따른device driver를포함한software들이GPGPU 를공유 자원으로서여러개의어플리케이션들이함께사용할수있도록허용하고 있다. 그리고 서로 다른 어플리케이션의 메모리 복사구간과 kernel 실행 구간은 동시에 실행이 가능하다. 이를 이용하면 메모리 복사를 하기위해 GPGPU가 기 다리는 구간을줄일수있고이를latency hiding 효과라고 한다. Latency hiding 효과가 많이 발생할수록 GPGPU의 utilization이 향상되기 때문에 GPGPU의 성능이 증가된다. 본 논문에서는 latency hiding 효과에 영향을 미치는 GPGPU 프로그램들의특성을분석하고이를바탕으로성능향상예측시뮬레이션을제안 한다. 워크로드 m개를n 개의 GPGPU들에배치할때 배치 가능조합에따라서 latency hiding 효과의발생 정도가달라지고이는성능과직결됨을 보인다.성능 향상예측시뮬레이션을 이용하여워크로드들을배치하면 모든배치가능조합의 평균성능 향상 대비 약11.6% 더 성능이 향상되고,성능향상이가장적게되는 조합대비약25% 더높아진다.
주요어: GPGPU, CUDA, Performance analysis, Multi-GPGPU, heterogeneous device
목차
초록 i
제 1 장 서론 1
제 2 장 배경 지식 3
2.1 GPGPU 구조및GPGPU프로그래밍. . . 3
2.2 Pinned memory와pageable memory . . . 4
2.3 GPGPU 공유 . . . 5
제 3 장 GPGPU 성능 분석 6 3.1 워크로드소개 . . . 6
3.2 워크로드의특성분석 . . . 6
3.3 워크로드조합에따른성능변화 . . . 7
3.4 워크로드특성에따른동시 실행실험분석 . . . 9
제 4 장 성능 향상 예측 시뮬레이션 및워크로드 분배 11 4.1 GPGPU의제약사항을 이용한성능향상예측 시뮬레이션. . . 11
4.2 성능향상예측시뮬레이션을 이용한워크로드분배 . . . 14
제 5 장 실험 결과 및 분석 17 5.1 성능향상예측시뮬레이션 . . . 17
5.2 성능향상예측시뮬레이션을 이용한워크로드분배 . . . 18
5.3 오버헤드측정 . . . 21
제 6 장 관련 연구 22
6.1 동시kernel수행. . . 22 6.2 멀티어플리케이션스케줄링 . . . 22 6.3 데이터전송과kernel의동시 수행 . . . 23
제 7 장 결론 24
참고문헌 25
Abstract 28
표 목차
표3.1 GPGPU 성능분석실험에사용한워크로드 . . . 7
표3.2 테스트환경 . . . 7
표5.1 성능향상예측실험에사용한워크로드 . . . 17
표5.2 워크로드개수에따른함께수행하는워크로드조합 . . . 18
그림 목차
그림2.1 메모리할당방식에따른메모리복사 . . . 4 그림3.1 워크로드특성및특성에따른실행시간변화 . . . 8 그림5.1 워크로드들을동시 실행할때각조합에따른실제성능향상
및성능향상예측결과 . . . 19 그림5.2 다섯 개의워크로드들을 두개의GPGPU들에 배치할 때모
든가능조합에대한실제성능향상정도,시뮬레이션을통한 성능향상예측값그리고시뮬레이션오버헤드 . . . 20
제 1 장 서론
GPGPU는수천개의core들을가진이기종의디바이스로서높은연산처리량
으로인해주목을받고여러분야의복잡한문제를풀기위해사용되고있다[10].
또한Nvidia에서Kepler 아키텍처를이용한 GPGPU의발표이후 GPGPU공유 기반의멀티어플리케이션동시 실행이가능해졌다[9].
GPGPU(device)는CPU(host)와는별개로독립된메모리를갖기때문에GPGPU 를연산자원으로이용하려면연산에필요한 입력데이터를GPGPU의메모리로 복사해야 한다(host to device copy). 그리고 연산이 끝난 후에는 연산된 결과를 CPU의메모리로복사해야한다(device to host copy).이는굉장히큰오버헤드로 서 GPGPU연산의latency를길게만드는요인이다.이를줄이기위해CPU에서
일부분연산을하여복사할메모리의양을줄이거나메모리복사와kernel의수행
이 중첩될 수 있도록 GPGPU 프로그램을 수정하는 등의 노력이 있었지만 이는
추가의 노력이필요하다.이러한 노력 대신에 여러개의워크로드들을동시에실 행시키면 메모리복사와GPGPU연산이중첩이되게되고latency hiding효과가 일어난다.본논문에서는워크로드들을독립적으로실행시켰을때실행시간과두 개를 매칭시켜서 동시에 실행시켰을때의실행시간을 비교했다.그리고두워크 로드를 독립적으로순차실행시켰을 때대비동시에실행시켰을 때얼마나실행 시간이 줄어드는지 테스트했다. 워크로드들은 특성에 따라 compute-intensive와 memory-intensive로분류할수있는데같은특성을가진워크로드들을매칭시키는 것보다 다른 특성의워크로드들을매칭시킬때실행시간이더 많이,최고75.1%
까지감소하였다.
Host에서 pinned memory를 직접적으로 할당 받는 경우에는 host 내부에서
CPU를이용한 메모리 복사를 생략하여 성능 향상이 있지만 메모리복사 API가 DMA 독점적으로 사용하기때문에 메모리 복사가 끝날 때까지 다른 어플리케이 션은 메모리 복사를 할 수 없다. 하지만 이 구간 동안에 다른 어플리케이션들이 kernel을수행할수있다.이러한특성을바탕으로하나의GPGPU에서여러개의 워크로드들이 동시에 실행되는 경우를 시뮬레이션할 수 있다. 그리고 전체 수행
시간중에kernel수행과메모리복사가얼마나많이중첩되었는지계산하여성능
향상을 예측할 수있다.다섯개의 워크로드들을 두 개의 GPGPU들에서 실행할 때 배치 가능 방법은15가지 조합이 있다.각조합에따라GPGPU의 utilization 이 달라지게 됨을 보이고 성능 향상 예측 시뮬레이션을 기반으로 워크로드들을 GPGPU들에배치하게되면 모든경우의 평균 성능향상대비약 11.6%더성능 향상이 있고,최악의경우대비성능향상이25% 높음을 보인다.
제 2 장 배경 지식
2.1 GPGPU 구조 및 GPGPU 프로그래밍
GPGPU는구조적으로크게두가지분류가있다.첫번째는CPU에GPGPU 가하나의칩으로통합되어있는경우[8]이고두번째는GPGPU가CPU와독립적 으로구성되어있는경우이다.전자의경우에는CPU와GPGPU가하나의물리적 메모리를 사용하며 on-chip network로 서로가 연결되어 있다. 후자의 경우에는 CPU와GPGPU가서로독립된물리메모리를소유하고PCI express bus로연결 되어 있다 [11]. 본 논문에서 사용할 GPGPU는 Kepler 아키텍처 기반의 Nvidia GK110 chip이내장되어있는Tesla K20c이고위분류중에후자이다[9].
일반적인GPGPU프로그래밍은CPU(host)에서연산되는부분과GPGPU(device) 에서연산되는부분으로구분할수있다.특히GPGPU에서연산되는부분을ker- nel이라고부른다. Kernel이실행되기전에입력데이터를host에서device로복사 하고kernel수행후에결과 데이터를host에서device로복사한다.따라서“CPU 연산– host to device 메모리복사(H2D) – kernel 실행(KE, kernel execution) – device to host메모리복사(D2H)”를반복한다.
Host와device사이의 메모리복사는매우큰오버헤드로서이를줄이기위한 연구가 활발하게 진행되었다. 모든 연산을 GPGPU에서 하는 것이 아니라 많은
입력 데이터 대비 출력 데이터가 적은 부분은 CPU에서 수행하도록 프로그램을
수정하는노력이 있었다.또kernel의비동기적인특성을 이용하여메모리복사를
쪼갠 뒤 먼저 복사된 부분의 데이터에 대해서 kernel을 수행하도록 프로그램하
여 GPGPU의 utilization을 향상시키려는시도가있었다. 하지만 이러한 기법은 기존의GPGPU 프로그램을수정해야한다는 단점이 있다[17].
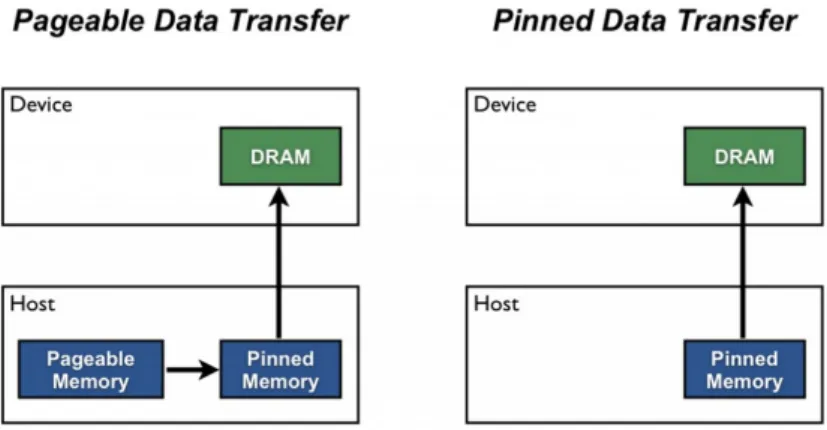
2.2 Pinned memory와 pageable memory
Host에서malloc()함수로할당받은메모리영역은기본적으로pageable mem- ory이다. 이메모리영역의data를 device로 복사하기 위해서는 그림 2.1과 같이 host의pageable memory에서pinned memory로CPU복사한후에DMA를사용 하여device로다시복사한다[6].하지만cudaHostAlloc()함수를이용하면pinned memory 영역을직접적으로할당받기때문에host내부에서CPU 메모리복사를 생략하여성능을향상시킬수있다. Pageable memory를이용하는컴퓨터의CPU 성능이 좋지 않은 경우에 메모리 복사가 CPU 성능에 바운드되기도 한다. 또한 pinned memory 영역의데이터를 device memory로 복사하는 경우에는DMA를 독점적으로 사용하기때문에 안정적인bandwidth를보장하고, CPU를사용하는
host 내부 메모리 복사가 없기 때문에 CPU 성능이 메모리 복사 성능에 영향을
주지않는다는장점이 있다.이에반해단점으로는DMA를독점적으로사용하기 때문에 메모리 복사가 시작되면 복사가 끝날 때까지는 다른프로세스 혹은쓰레 드에서 DMA를 사용할 수 없다. 하지만 pageable memory의 경우에는 data의 일부만pinned memory 영역으로복사한뒤DMA로복사할수있기때문에 여러 어플리케이션들의메모리복사가동시에일어나는것처럼보일수있다.
그림2.1메모리할당방식에따른메모리복사
2.3 GPGPU 공유
Nvidia GPGPU는 kernel의 동시 실행, CUDA stream 그리고Hyper-Q[9]를 통해여러개의어플리케이션들이GPGPU를공유 자원으로사용할수있는방법 을제공하고있다.
Nvidia의 Fermi 아키텍처부터 GPGPU SM(Streaming Multiprocessor)들의 utilization을 높이기 위해 kernel들의 동시 실행이 가능해졌다. Nvidia thread block (TB) 스케줄러는 TB단위로 idle 상태인 SM에 명령어를 전달한다. 실행 중인 kernel의 실행시킬 잔여 TB의 개수가 현재 idle인 SM 수보다 적으면 TB scheduler는kernel의동시 실행을허용한다.
CUDA API는여러개의GPGPU어플리케이션들을동시에실행할수있도록 CUDA stream을 제공한다. Stream은서로 의존성이 없는kernel들을동시 실행 하기 위한 SW queue이다. 각 stream은 id를 가지고 있어서 서로 구분이 되고 프로그래머가kernel을런칭할때파라미터로값을전달해야한다.만약해당값을 생략할경우에는stream id가0이된다.같은stream에쌓인명령어들은서로의존 성이 있으므로순차적으로실행되어야 하는반면다른stream에속한명령어들은 병렬적수행이가능하다.단각명령어를수행할 때필요로하는자원이사용가능 해야한다.예를들어PCI express bus및SM들이 있다.
다수의stream에쌓인명령어들이GPGPU에전달되는과정에서하나의queue 로들어가게된다면false dependency가발생한다. Hyper-Q는이를방지하기위해 여러개의HW queue들을제공한다[9]. GPGPU의디바이스드라이버는stream 과Hyper-Q를연결시켜준다.
제 3 장 GPGPU 성능 분석
3.1 워크로드 소개
본논문에서는 다양한도메인을 포괄하고 여러가지 memory access pattern 을 이용하고 있는 Rodinia V.2.4 벤치마크에 속한 워크로드들을 이용했다 [1].
Rodinia 벤치마크는 실제로 GPGPU를 사용하고 있는 많은 분야들의 최적화된
워크로드들로서여러 논문에서 많이 이용하고 있으므로 GPGPU 프로그램분석 을 위한실험에적합하다.또한Rodinia벤치마크의configuration을변경해서워 크로드들의 실행 시간을 다양화하였다. Rodinia는 CUDA[2], OpenCL[3] 그리고
OpenMP[4]를 각각 지원하는데 이중에 CUDA를 이용해서 테스트를 하였다. 표
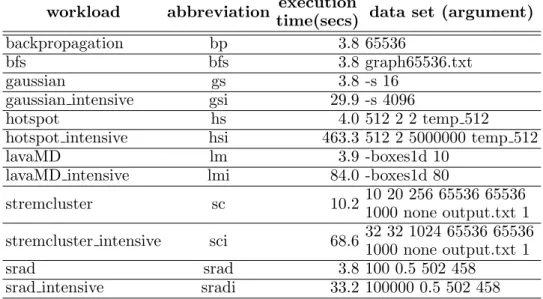
3.1은Rodinia 벤치마크중에서실험에사용한벤치마크들을나열하여보여준다. 그리고 configuration을 달리하여이를 data set(argument) 열에 표기했다.벤치 마크 이름 뒤에 “ intensive”가 붙은 것들은 큰 데이터 세트를 이용하거나 반복 횟수를늘려서실행시간을길게설정한워크로드들이다.실험은표3.2의환경에 서수행하였다.
3.2 워크로드의 특성 분석
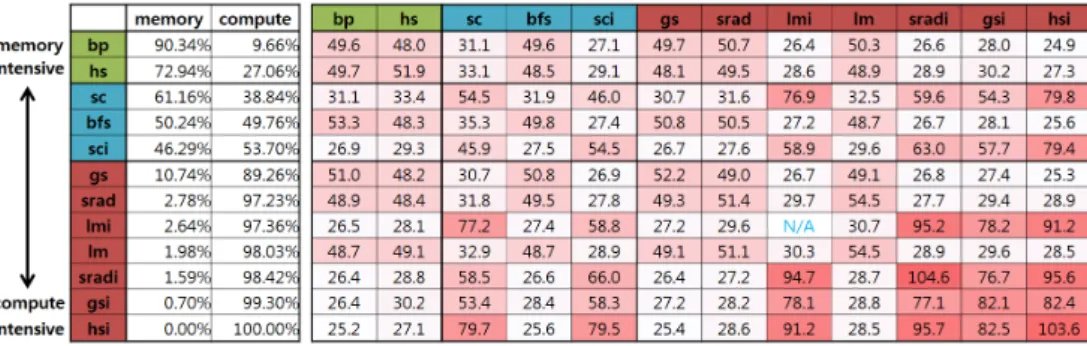
Kernel이 실행되기 전에 입력 데이터를 host에서 device로 복사하고 kernel 수행후에 결과 데이터를 host에서device로 복사한다. 이때 kernel의수행부분 과메모리복사부분의비율을 기준으로compute-intensive워크로드와memory- intensive워크로드로구분할수있다.이비율은nvprof[5]로측정이가능한데이는 Nvidia에서제공하는profiling tool이다.그림3.1의memory및compute열의값
workload abbreviation execution
time(secs) data set (argument)
backpropagation bp 3.8 65536
bfs bfs 3.8 graph65536.txt
gaussian gs 3.8 -s 16
gaussian intensive gsi 29.9 -s 4096
hotspot hs 4.0 512 2 2 temp 512
hotspot intensive hsi 463.3 512 2 5000000 temp 512
lavaMD lm 3.9 -boxes1d 10
lavaMD intensive lmi 84.0 -boxes1d 80
stremcluster sc 10.2 10 20 256 65536 65536
1000 none output.txt 1 stremcluster intensive sci 68.6 32 32 1024 65536 65536
1000 none output.txt 1
srad srad 3.8 100 0.5 502 458
srad intensive sradi 33.2 100000 0.5 502 458 표3.1 GPGPU성능분석실험에사용한워크로드
specification
CPU 2 sockets Intel Xeon E5-2690 (2.9GHz, 8-cores)
RAM 128GB
GPGPU Nvidia Tesla K20c
표3.2테스트환경
것이다.각행마다 두값의 합은100%이고메모리복사부분의값을기준으로내 림차순 정렬하였다. hotspot intensive 벤치마크의 경우 메모리 복사 부분이 0%, kernel실행부분이100%로되어있다.이는메모리복사하는데걸린시간이kernel 실행시간보다극히짧다는것을 의미한다.
3.3 워크로드 조합에 따른 성능 변화
우선 각워크로드들을 독립적으로실행하였을 때 실행 시간을측정하고워크 로드들을 짝지어 실행했을 때의 실행 시간을 측정하였다. 각 워크로드들은 실행 시간이 모두 상이하므로두 개의워크로드들 중실행시간이 긴워크로드가끝날
그림3.1워크로드특성및특성에따른실행시간변화
때까지 실행 시간이 짧은 워크로드를 반복하여 실행하는 방법을 이용했다. 그에
따른예상실행시간과 실제 실행 시간을 비교하였다. 각워크로드를 독립적으로 실행하였을 때의 실행 시간과 각 워크로드의실행 횟수를곱하여 더하면두워크 로드를 연달아독립적으로실행하였을 때의 실행 시간이된다. 이것이예상실행 시간이고수식3.1과 같이표현할수있다.
texp =
n
X
num=1
(twnum ×exec countwnum) (3.1)
두개의워크로드들을함께실행하면 메모리복사부분과kernel 실행부분이 중첩되는현상이발생하고이로인해서GPGPU의 utilization이향상된다.그결 과 실제 실행 시간이 예상 실행 시간보다 짧아지게 된다. lavaMD intensive(w1) 와gaussian intensive(w2)가함께수행되는경우를예로들어보자.각워크로드를 독립적으로 실행시켰을 때의 실행 시간을 각각 tw1과 tw2로 표기한다. 표 3.1을 참조하면 해당 값은 각각 84초 및 29.9초이다. 실험 수행 시 w1의 실행 시간이 더길어서w1의실행이끝날 때까지w2가2번실행되었으므로 exec countw1은1 이고 exec countw2는 2가 된다. 수식 3.1에 따라서 texp는 약 143.8초가 된다. 두 워크로드를동시 실행할때w1가1번수행될때걸리는시간과w2가2번실행되는 시간이정확히같지않기때문에오차가있다.하지만실행시간이짧은워크로드
의 실행 시간보다 작은값의오차이기때문에 실험을통해서 실행시간의변화를 측정하는데있어서큰영향이없다.
각워크로드조합에따라예상실행시간에대한실제실행의비를수식3.2와 같이계산하였다. 이는 실제 실행 시간을예상 실행 시간으로 나누고100을곱한 값이다.따라서해당값이100이면실제실행시간과예상실행시간이같은것이고 해당값이 작을수록실제실행시간이예상실행시간보다적게 걸린것이다.
ratio= treal
texp ×100 (3.2)
lavaMD intensive와gaussian intensive를동시에실행시킨테스트결과실행 시간은112.4초가 걸렸다.즉treal이112.4초인것이다.그렇다면수식3.2에의해서 ratio는약78.2%가된다.모든워크로드들의조합에따른실험결과는그림3.1에 보이고있다.
lavaMD intensive 벤치마크 두 개를 동시에 실행시키는 경우에는 GPGPU
memory가 부족하기 때문에 실험을 할 수 없었다. 하지만 전체 실험의 경향을
살펴보는데크게지장이없기때문에그대로실험을진행했다.
3.4 워크로드 특성에 따른 동시 실행 실험 분석
실험 결과를보면좌측 상단과우측하단에 비교적큰값들이 몰려 있고좌측 하단과우측상단에비교적작은값들이치우쳐있는경향을찾아볼수있다.이는 함께 수행하는 워크로드들의 조합에 따라서 실행시간이 달라진다는 것을 알 수 있는증거이다.
Memory-intensive한워크로드와 compute-intensive한 워크로드를 함께수행 할때실행시간이예상시간보다많이줄었고특히intensive 정도가심한워크로 드들의조합에서는그경향이더뚜렷하다.
Ratio의 평균값은 45.0으로 실행 시간이 55% 줄었다는 것을 의미한다. 그리 고backpropagation과hotspot intensive를함께수행했을때ratio는24.9로실험 결과 중에 가장 작은 값이다. 이는 실행 시간이 75.1% 줄었다는 것을 의미한다. 이 두워크로드는 각각 테스트한 워크로드들 중에서 가장 memory-intensive하고 가장compute-intensive하는점에서의미가있다.
Compute-intensive한 워크로드들의 조합의 경우에는 latency-hiding이 거의 발생하지않은것을알수있었을뿐만아니라공유 자원경쟁으로인해서오히려 실행시간이 예상 실행시간보다길어지는경우도 발생하게 되었다는 것을 알수 있었다.
제 4 장 성능 향상 예측 시뮬레이션 및 워크로드 분배
4.1 GPGPU의 제약 사항을 이용한 성능 향상 예측 시뮬레이션
앞의 실험을 통해 여러 개의 워크로드들이 동시에 실행될 때 latency hiding 효과가 발생하고 이는성능향상으로이어짐을알 수있었다.워크로드들이동시
에수행되는상황에서몇가지GPGPU의제약사항을 이용한다면시뮬레이션을
통해성능향상정도를예측할수있다.
워크로드들은 “CPU 연산(CC, CPU computation) – host to device 메모리 복사(H2D) – kernel 실행(KE, kernel execution) – device to host 메모리 복사 (D2H)”를반복적으로수행하는특성이 있다.각각을job이라고하고4가지job의 묶음을 task라고한다 [7].예를들어 표5.1의streamcluster의경우task가2,988 번 반복한다.이때task의각메모리복사(H2D및D2H), CPU연산(CC) 그리고 kernel 실행(KE)시간을미리측정하여활용할수있다.
Pinned memory를사용할때메모리복사API는DMA를독점적으로사용한 다.따라서여러워크로드들이메모리복사를동시에요청하더라도특정시점에한 개의메모리 복사 요청만수행이 가능하다는 제약이 있다. Kernel실행의경우에 는동시에 여러워크로드가GPGPU를공유하여사용이가능하다.다만GPGPU 의코어를독점적으로사용하지않고나누어사용하기때문에그에따라서kernel 수행 시간이 길어진다. 이 특성을 이용하면 시뮬레이션을 통해 동시에 실행되는 워크로드에따른성능향상정도를예측할수있다.
함께수행할 워크로드들의CC, H2D, KE 그리고D2H를기반으로실행시간 을더해가며시뮬레이션을한다.메모리복사와kernel의수행이동시에실행되는
부분들의수행시간합을총수행시간으로나눈값을구하고,그값으로성능향상 정도를예측한다.이를알고리즘으로표현하면Algorithm 1과 같다.
Algorithm 1에서사용하는변수들은다음과 같다.CopyingW orkload는DMA 를 사용하여 메모리 복사 작업을 하고 있는 워크로드를 저장한다. N umKernel 과N umM emCopy는 각각kernel을수행하고있는워크로드들의 개수와메모리 복사를수행하고있는워크로드들의개수로서while 문이반복될때마다0으로초 기화된다. timeshortest는모든워크로드들이수행해야하는job들 중에 가장짧은 remaining time을가진job의remaining time을저장한다.
Algorithm 1이 실행되면 가장먼저수행시간이가장긴 워크로드(wlongest)를 찾고그워크로드가 끝날때까지시뮬레이션을 진행한다 (1,3줄). 그리고 각워크 로드의현재수행할job들에대하여kernel수행및메모리복사의개수를확인한다 (6-13줄).그다음에각워크로드의현재수행할job들의남은실행시간이가장짧 은것(timeshortest)을찾는다.이때기존에실행중인메모리복사job이존재하면 더 짧은 잔여 시간을 가진 메모리 복사 job이 있더라도 기존 job이 끝날 때까지
기다려야 한다 (17-23줄). 이는 모든 워크로드들이 메모리 복사를 위한 DMA를
상호 배제적으로 공유하기 때문이다. tempCopyingW orkload를 이용하여 현재 실행중인메모리 복사워크로드가없으면현재까지검사한 모든 메모리복사워 크로드중에가장짧은메모리복사job을저장한다.모든워크로드들을검사한후 CopyingW orkload에저장을 하여19줄의if문이정상적으로동작하도록보장한 다(34줄).
실행할 job들 중에 kernel 수행 job들이 2개 이상이면 그 수의 배만큼 kernel
수행 시간이 길어진다. 따라서 timeshortest를 찾을 때 동시에 수행되는 kernel의
개수를 remaining time에 곱하여 비교한다. 이는 수행될 kernel들이 GPGPU의 모든core들을공유하여사용해서 속도가느려지기때문이다(24-27줄). CPU job 의 경우에는 kernel 수행 및 메모리 복사에 영향을 미치지 않으므로 timeshortest
보다remaining time이 작은지만검사한다(28-32줄).
Rodinia와 같이 병렬 정도가 높은 워크로드들의 경우에는 GPGPU가 소유
한 모든SM을 다 이용하기때문에함께 수행될kernel의 개수배로 수행 시간이 늘어난다. 만약병렬정도가낮고MPS(Multi-Process Service)를이용하여 여러 워크로드가 GPGPU를 공유하면 수행시간이 워크로드 개수에 비례하지 않는다. 많은연구에서자신의연구를평가하기위해GPGPU프로그램으로Rodinia벤치 마크를 많이 사용한다.따라서본 논문에서는Rodinia 벤치마크가최신GPGPU 프로그램을대표한다고 가정하고실험을진행하였다.즉병렬도가낮아서GPGPU
자원을충분히활용하지못하는GPGPU 프로그램은배제하였다.
가장 짧은 remaining time을 가진 job이 kernel일 경우(35줄)에는 각 kernel 들에대해서 그remaining time만큼 수행되는 동안GPGPU core를나누어사용
하기때문에실제시간은timeshortest ∗N umKernel만큼소비가된다(36-37줄).
반대로가장짧은remaining time을가진job이메모리복사혹은CPU job일경우
(38줄)에는커널들이수행할수있는계산량이함께수행할 커널들의개수에반비
례한다.이계산량을시간으로역산하였다(39-40줄). 위에서계산한실제수행된 시간(timekernel 및timeactual)을 각워크로드들의remaining 시간에서 빼서해당 값을업데이트한다(46-57줄).메모리복사의경우에는remaining time이0이되면 CopyingW orkload를NULL으로세팅하여 새로운메모리복사job을시작할 수 있다.
한 개 이상의 kernel과 메모리 복사가 함께 수행될 때만 해당 시간만큼을
timeoverlapped에 더한다 (42-44줄). Kernel 수행 부분과 메모리 복사 부분이 겹
치는것과상관없이모든수행시간은timetotal에더한다(45줄). timeoverlapped의
값이상대적으로크다는것은latency hiding효과가많이발생했다는것이며이는 GPGPU의 utilization이 높음을 의미한다. 즉 성능 향상이 많이 될 것을 예측할
수 있다. 따라서 timetotal 중에 timeoverlapped의 비율을 통해서 성능 향상 정도를
예측할수있다(59줄).
4.2 성능 향상 예측 시뮬레이션을 이용한 워크로드 분배
워크로드m개를n개의GPGPU들에분배할때여러가지분배가능조합이
존재한다.예를들어다섯개의워크로드들을두개의GPGPU들에분배하게되면 분배가능한 조합은15가지이다.각 조합에따라서함께수행하게될 워크로드가 달라지게되고이는성능에영향을 미친다. 즉워크로드의 분배에따라서 성능이 달라지게된다.
본 논문에서 제안한 성능 향상 예측 시뮬레이션으로 각 조합에 대하여 미리 성능을 예측해보고 이를 바탕으로 가장 성능 향상이 많이 되는 조합으로 실제 워크로드를GPGPU에분배하면성능의향상을기대할수있다.
Algorithm 1 Performance Increase Anticipation
1: find longest workloadwlongest
2: CopyingW orkload = NULL
3: while ! end ofwlongest do
4: N umKernel=N umM emCopy = 0
5: timeshortest = MAX
6: for each workloadwi do
7: jobi = current job of wi
8: if jobi == copythen
9: N umM emCopy += 1
10: else if jobi == kernelthen
11: N umKernel+= 1
12: end if
13: end for
14: for each workloadwi do
15: jobi = current job of wi 16: time = remaining time of jobi
17: if jobi == copythen
18: if time <timeshortest then
19: if CopyingW orkload == NULL or CopyingW orkload ==
wi then
20: timeshortest =time
21: tempCopyingW orkload =wi
22: end if
23: end if
24: else if jobi == kernelthen
25: if time ∗ N umKernel <timeshortest then
26: timeshortest =time
27: end if
28: else//CPU job case
29: if time <timeshortest then
30: timeshortest =time
31: end if
32: end if
33: end for
34: CopyingW orkload= tempCopyingW orkload
35: if jobshortest == kernelthen
36: timekernel =timeshortest
37: timeacutal =timeshortest ∗ N umKernel
38: else// copy and CPU job case
39: timekernel =timeshortest / N umKernel
40: timeactual =timeshortest
41: end if
42: if N umKernel >0 and N umM emCopy >0 then
43: timeoverlapped += timeactual
44: end if
45: timetotal +=timeactual 46: for each jobjobi do
47: if jobi == copy and wi ofjobi ==CopyingW orkload then
48: remaining time ofjobi −=timeactual 49: if remaining time ofjobi == 0 then
50: CopyingW orkload = NULL
51: end if
52: else if jobi == kernelthen
53: remaining time ofjobi −=timekernel
54: else//CPU job case
55: remaining time ofjobi −=timeactual
56: end if
57: end for
58: end while
59: return timeoverlapped /timetotal
제 5 장 실험 결과 및 분석
5.1 성능 향상 예측 시뮬레이션
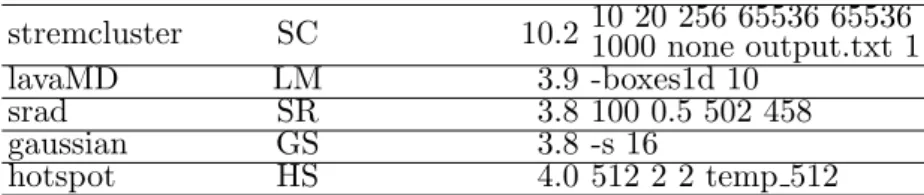
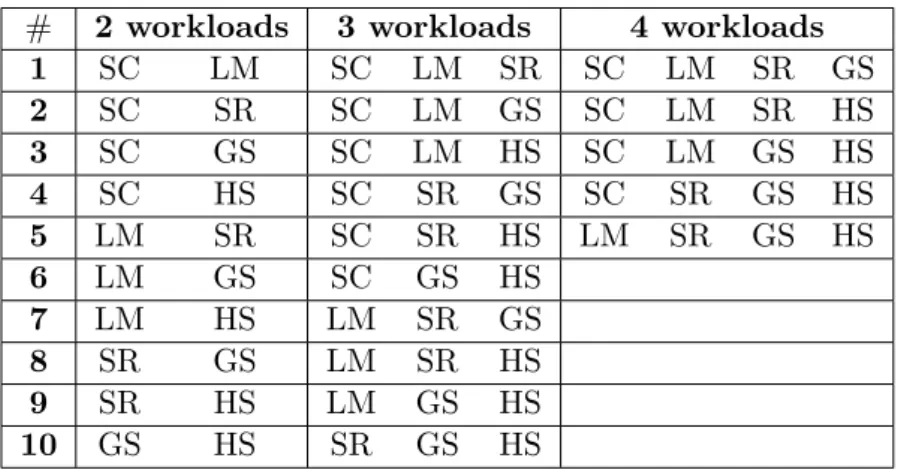
여러개의워크로드들이한개의GPGPU를공유하여함께수행될때,시뮬레 이션을 통한성능 향상 예측과 실제성능 향상 정도를 비교하였다.이를 위해 표 5.1에 있는 다섯 개의 워크로드들로 만들 수 있는 조합을모두 구하였다. 그리고 같은개수의워크로드가한개의GPGPU에서수행되는경우끼리비교를하였다. 따라서다섯개모두수행되는경우는제외하였다.또한워크로드가함께수행되면 서 성능향상이 일어나기때문에한개의워크로드가수행되는경우도제외하였다. 테스트할워크로드의조합은표5.2와같고총25가지경우이다.
각조합에대하여600초동안워크로드들을동시에수행하였고,해당시간동안 에각워크로드들이몇번씩수행되었는지측정하였다.이를수식 3.1에적용하면 모든워크로드들이 600초 동안병렬적으로 수행한 연산의총량을상대적인값으 로 계산할 수있다.즉 해당 값이클수록 성능향상이 많이된 것이다.이는함께 수행한워크로드들이병렬적으로수행하여성능이향상된정도라고할수있다.
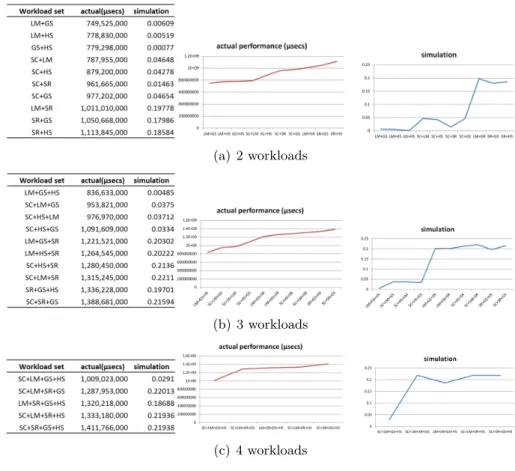
표5.2의모든조합에 대하여시뮬레이션을통한성능향상예측실험을하였 다. 실험환경은 표 3.2와 같다. 두 개, 세 개 그리고 네 개의 워크로드들을 함께
workload abbreviation execution
time(secs) data set (argument) stremcluster SC 10.2 10 20 256 65536 65536
1000 none output.txt 1
lavaMD LM 3.9 -boxes1d 10
srad SR 3.8 100 0.5 502 458
gaussian GS 3.8 -s 16
hotspot HS 4.0 512 2 2 temp 512
표5.1 성능향상예측실험에사용한워크로드
# 2 workloads 3 workloads 4 workloads
1 SC LM SC LM SR SC LM SR GS
2 SC SR SC LM GS SC LM SR HS
3 SC GS SC LM HS SC LM GS HS
4 SC HS SC SR GS SC SR GS HS
5 LM SR SC SR HS LM SR GS HS
6 LM GS SC GS HS
7 LM HS LM SR GS
8 SR GS LM SR HS
9 SR HS LM GS HS
10 GS HS SR GS HS
표5.2워크로드개수에따른함께수행하는워크로드조합
수행한 경우에 대한 결과 값을 각각 그림 5.1의 (a), (b) 그리고 (c)에 보이고 있 다. 수식 3.1을 바탕으로 성능 향상 정도를 수치화하여 actual 열에 보이고 성능 향상 예측 시뮬레이션의 결과를 simulation 열에 나타내었다. Actual 열의 값을 기준으로오름차순정렬하여성능의향상이적은것부터많은순서로나열하였다. 그리고 actual의값들과simulation의 값을그래프로 표현하였다. Actual의값을 오름차순으로정렬하였기때문에그래프가오른쪽으로갈수록값이올라가는것을 볼 수있다. 또한simulation 값은상대적인값으로actual 그래프와 같은 경향으 로 대체적으로오른쪽값이왼쪽의 값보다높음을 보인다. 워크로드들 사이에각 CPU 연산이 서로 영향을 주기 때문에 시뮬레이션을 통한 완벽한 성능 향상 예 측은어려우나대체적으로 실제 성능향상과성능 향상 예측 값의경향이같음을 보인다.
5.2 성능 향상 예측 시뮬레이션을 이용한 워크로드 분배
워크로드m개를n개의GPGPU들에분배할때성능향상시뮬레이션을활용
할수있다.다섯개의워크로드들을두개의GPGPU들에분배하려고할때분배
가능조합은15가지이다.한 개의 GPGPU에는워크로드를 한 개배치하고다른
(a) 2 workloads
(b) 3 workloads
(c) 4 workloads
그림 5.1 워크로드들을 동시 실행할 때 각 조합에 따른 실제 성능 향상 및 성능 향상예측결과
GPGPU에는 나머지 워크로드 네 개를 배치할 수 있다. 혹은 첫 번째 GPGPU
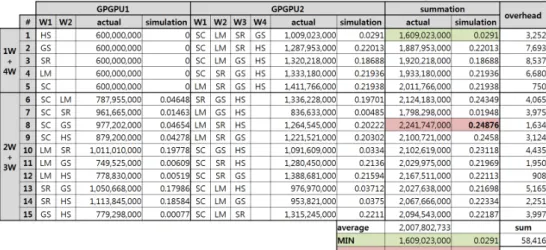
에는워크로드 두 개를배치하고두 번째 GPGPU에는나머지 워크로드 세개를 배치할수있다.이와같이배치할때가능조합을그림5.2가보여준다.그리고 각 조합마다실제성능향상정도를actual열에표기하고성능향상예측시뮬레이션 을 통해 계산한 값을 simulation 열에 보인다. 오른쪽sum 열에 두GPGPU들의 실제성능향상값과 시뮬레이션을통해 계산한값을각각 더하여전체시스템에 해당하는각 값을계산하였다.
8번 행에 해당하는 조합(GPGPU1 : SC+GS 및 GPGPU2 : LM+SR+HS)
의 시뮬레이션 결과 값이 0.24876으로 가장 높았기 때문에 가장 성능 향상이 많 이 될 것으로 예상된다. 실제로 첫 번째 GPGPU에 SC와 GS를 배치하고 두 번 째 GPGPU에 LM, SR그리고 HS를 배치하는 경우가2,241,747,000 마이크로초 로 가장 성능 향상이 많이 되었다. 또한 시뮬레이션 결과를 통해 가장 성능 향 상이 적게 될 것으로 예상되었던 1번 행의 조합(GPGPU1 : HS 및 GPGPU2 : SC+LM+SR+GS)이실제로1,609,023,000마이크로초로성능향상이가장적었 다.
시뮬레이션결과를바탕으로8번행에해당하는조합으로각워크로드를배치 하면실제성능향상정도가모든가능조합의평균대비약11.6%높다.그리고성 능향상이가장적게되는조합(GPGPU1 : HS및GPGPU2 : SC+LM+SR+GS) 보다는약25% 높음을 보인다.
그림 5.2 다섯 개의 워크로드들을두 개의 GPGPU들에 배치할 때 모든 가능 조 합에 대한 실제 성능 향상 정도, 시뮬레이션을 통한 성능 향상 예측 값 그리고 시뮬레이션오버헤드
5.3 오버헤드 측정
그림 5.2의 overhead 열은 각 조합의 성능 향상 예측 값을 계산하기 위해 필 요한 시간을 보인다. 15가지의 가능 조합의 성능 향상 예측을 계산하기 위해 총 58,416 마이크로초가소요된다.
그림5.2의actual열평균값은2,007,802,733마이크로초이고이는1,200,000,000 마이크로초에대한상대값이다.여기서1,200,000,000마이크로초는두개의GPGPU 들이연산에사용된시간의총량으로각GPGPU가600,000,000마이크로초씩사 용되었다.즉평균적으로약1.673배성능이향상되었다.다섯개의워크로드들을 독립적으로 실행하였을 때의 각 소요 시간을 모두 더하면 140,604,000 마이크로 초이고,이값에평균성능향상정도를적용하면약235,254,246마이크로초이다. 시뮬레이션결과를바탕으로워크로드들의배치조합을선택하면성능향상정도 가 평균 성능 향상 대비 약 11.6%가 더 높으므로 약 27,289,492 마이크로초만큼 성능향상이 이루어진것이다.즉총오버헤드는성능향상대비약0.2%이고이는 성능향상대비매우적은시간으로성능에영향이미미하다.
제 6 장 관련 연구
6.1 동시 kernel 수행
J.T. Adriaens 외4명이 연구한내용[13]에 따르면적은 수의 thread block을
가진 작은 kernel들이 있는 환경에서 HW 기반의 공간적 공유 기법을 이용하여
utilization을 향상시켰다. 하드웨어를 이용하여 thread block을 대체시키기위한 선점수행 정책을제안하였다. S.Pai 외3명의 연구[14]에서는 kernel들의 특성에 따라다른정책으로GPGPU를공유하는방법을제안하였고이를Elastic kernels 이라고 명명했다. I. Tanasic 외 5명이 연구한 내용[11]에서는 HW 기반의 2가지 선점방식을개발하였다. 이는 컨텍스트 스위칭과드레인이고, 이를 통하여수행 중인thread block을다른것으로교체할수있다.
6.2 멀티 어플리케이션 스케줄링
T. B. Jablin외4명이진행한연구[15]와M.Becchi 외5명이진행한 연구[16]
에서는 CPU에서수행되는코드와kernel들사이에 데이터 의존성을 트래킹하여
데이터를위한메모리 공간 할당 및전송을 동시에하는SW를제안하였다.이를 통하여 human error를줄일수 있다. 비슷한 방법으로 K. Sajjapongse 외2명이 진행한 연구[12]에서는 kernel 의존성에 따른 대기 시간을 줄이기 위해 kernel을
여러개의GPGPU들에분배하는기법을제안하였다.
6.3 데이터 전송과 kernel의 동시 수행
Belviranli 외 4명이 진행한 연구[7]에서는 동시에 여러 개의 어플리케이션들 이 한 개의GPGPU에서 수행될 때 데이터 복사와 kernel의 수행이 겹치게되어
latency가줄어들게되는현상을극대화하기위해어플리케이션들의실행순서를
바꾸는방법을제안하였다.
제 7 장 결론
GPGPU는 throughput이 높아 복잡하고 오래 걸리는 연산을 빠르게 처리할 수있고최신아키텍처에서는여러개의어플리케이션들이공유 자원으로사용할 수있다.여러어플리케이션이동시에GPGPU를사용하면latency hiding효과로 인해 성능이 향상된다. 성능 향상 예측 시뮬레이션을 통해 두 개 이상의 어플리 케이션이동시에 수행될때 성능 향상 정도를예측할수있다. 이를 통해 m개의 워크로드들을 n 개의 GPGPU들에 배치하면 모든 배치 가능 조합의 평균 성능 향상대비약11.6%더성능이향상된다.이를통해여러개의GPGPU들을사용 하는많은컴퓨터시스템에서하드웨어의업그레이드없이성능향상을기대할수 있다.
본 논문에서는 Ronidia와 같이 병렬도가 높은 워크로드들이 GPGPU를 공
유하여 kernel이 동시에수행되는경우에 대하여시분할 방식과 같이 수행시간이
함께수행되는kernel의개수만큼배수로늘어난다고했다.하지만legacy GPGPU 프로그램들중에서는병렬도가낮아서최신GPGPU의SM들을모두사용하지못
하는경우가많다.이럴경우에서kernel이중첩되어도수행시간이함께수행되는
kernel들의 개수 배만큼 늘어나지 않을 수 있다. 즉 kernel이 GPGPU가 소유한 SM을 나누어 사용해서 GPGPU의 SM utilization을 높인다. 따라서 GPGPU를 독립적으로사용하는것대비성능향상이된다.이러한경우에대해서추가적으로 연구가필요하다.이에대하여미래에 연구할예정이다.
참고문헌
[1] S. Che, M. Boyer, J. Meng, D. Tarjan, J. Sheaffer, S.-H. Lee, and K.
Skadron, “Rodinia: A benchmark suite for heterogeneous computing.”Pro- ceedings of the 2009 IEEE International Symposium on Workload Charac- terization (IISWC), pp. 44–54. 2009.
[2] NVIDIA. Accelerated Computing, https://developer.nvidia.com/accelerated- computing
[3] Khronos. OpenCL, https://www.khronos.org [4] OpenMP, http://openmp.org/
[5] NVIDIA. CUDA Toolkit Documentation, http://docs.
nvidia.com/cuda/profiler-users-guide
[6] NVIDIA, How to Optimize Data Transfers in CUDA C/C++, https://devblogs.nvidia.com/parallelforall/how-optimize-data-transfers- cuda-cc
[7] Belviranli, Mehmet E., Khorasani, F., Bhuyan, Laxmi N., Gupta R.,
“CuMAS: Data Transfer Aware Multi-Application Scheduling for Shared GPUs.” Proceedings of the 2016 International Conference on Supercom- puting, Article No. 31, ACM,2016.
[8] A. Branover, D. Foley and M. Steinman, “AMD Fusion APU: Llano.”
Micro, IEEE, vol. 32, no. 2, pp. 28–37, 2012.
[9] NVIDIA, Next generation CUDA computer architecture Kepler GK110, 2012 https://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler- GK110-Architecture-Whitepaper.pdf
[10] J. D. Owens, M. Houston, D. Luebke, S. Green, J. E. Stone, and J. C.
Phillips, “GPU computing.” Proceedings of the IEEE, vol. 96, no. 5, pp.
879–899, 2008.
[11] I. Tanasic, I. Gelado, J. Cabezas, A. Ramirez, N. Navarro, and M. Valero,
“Enabling preemptive multiprogramming on gpus.”Proceeding of the 41st annual international symposium on Computer architecuture, Pages 193- 204, 2014.
[12] K. Sajjapongse, X. Wang, and M. Becchi, “A preemption-based run- time to efficiently schedule multi-process applications on heterogeneous clusters with gpus.” Proceedings of the 22nd international symposium on High-performance parallel and distributed computing, pages 179–190. ACM, 2013.
[13] J. T. Adriaens, K. Compton, N. S. Kim, and M. J. Schulte, “The case for gpgpu spatial multitasking.” Proceedings of the High Performance Com- puter Architecture (HPCA), 2012, pages 1–12. IEEE, 2012.
[14] S. Pai, M. J. Thazhuthaveetil, and R. Govindarajan, “Improving gpgpu concurrency with elastic kernels.” Proceedings of the eighteenth interna- tional conference on Architectural support for programming languages and operating systems, pages 407–418. ACM, 2013.
[15] T. B. Jablin, J. A. Jablin, P. Prabhu, F. Liu, and D. I. August, “Dy- namically managed data for cpu-gpu architectures.” Proceedings of the Tenth International Symposium on Code Generation and Optimization, pages 165–174. ACM, 2012.
[16] M. Becchi, K. Sajjapongse, I. Graves, A. Procter, V. Ravi, and S. Chakrad- har, “A virtual memory based runtime to support multi-tenancy in clus- ters with gpus.”Proceedings of the 21st international symposium on High- Performance Parallel and Distributed Computing, pages 97–108. ACM, 2012.
[17] NVIDIA. CUDA C Best Practices Guide,
http://docs.nvidia.com/cuda/cuda-c-best-practices- guide/axzz4WwkPCpDu
Abstract
There have been many studies on utilizing GPGPU (General-Purpose Graphic Processing Unit) and its high computing power to perform complex tasks. Due to the characteristics of GPGPU programs, the operations of memory copy be- tween the host and device are necessary. The latency can affect the program performance if it is high. In order to reduce the latency, there have been many attempts, which are adding the CPU computation for reducing the amount of memory copy, modifying GPGPU applications, etc. A recent generation GPGPU can be a shared computing resource. Many applications can be ex- ecuted concurrently in a single GPGPU, when the memory copy operations of the applications can be overlapped with the kernel executions. The overlap- ping between the memory copy and the kernel execution is called the latency hiding effect, and the GPGPU utilization increases as the latency hiding effect increases. We analyzed the GPGPU workloads and factors which lead to the latency hiding. Based on the result of the analysis, we have proposed a simu- lation method for anticipating the performance improvement. When executing M workloads in N GPGPUs, the latency hiding effect varies depending on the combination of workloads, and this leads to the performance variation. Via the simulation for the performance increase anticipation, the best combination of workloads shows an 11.6% performance improvement compared to the average for all possible combinations of workloads.
neous device
Student Number: 2015-21229