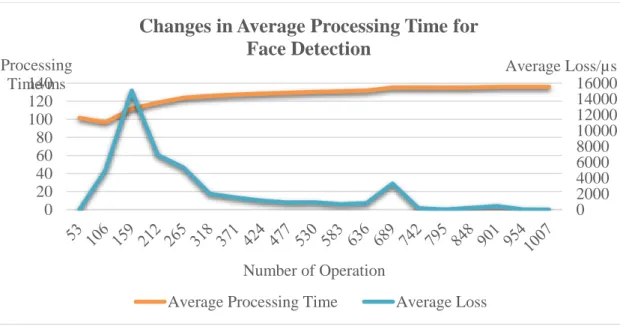
Figure 4.5.4.1 The Index Keys of Trained Model Prediction Array 55 Figure 5.1.1 Flow of Measuring Time of Image Processing 62 Figure 5.1.2 Flow of Measuring Time Elapsed to Access AWS. 67 Figure 5.2.1.1 Changes in average processing time for face detection 69 Figure 5.2.2.1 Bandwidth requirements for different types of images.
Motivation
Problem Statement
Objectives
2 in every query and minimizes the time it takes to obtain the input image and produce the output result. Design optimizations for processing the input frames to maintain FER results with acceptable accuracy while minimizing the time that elapses between acquiring the image input and providing the FER output and the cost and amount of data transfer when sending the recognition request to a third party.
Project Scope and Direction
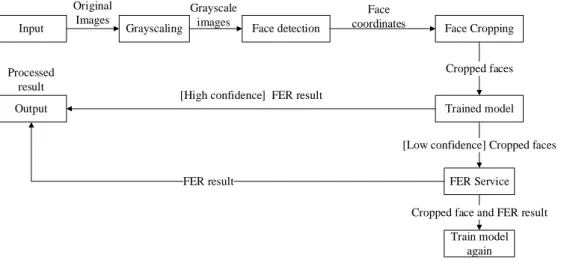
The new input will be predicted by the model and then sent to the third-party FER service only when the prediction is not reliable. By designing the FER procedure, the Android application implementing the optimization techniques of downsampling, spatial trimming and FER technique will be provided, targeted to help people who are emotionally disabled or visually impaired.
Contributions
At the same time, a basic FER model will classify input frames and only send them to the FER service for recognition when the model is not sure of the predicted result. Each time a new expression is sent to the paid service for recognition, the base FER model is retrained using the datasets added to the new expression, which the recognition results as its true value.
Report Organization
Face Acquisition
Two different techniques are used for estimating head posture: 2-dimensional image-based and 3-dimensional model-based methods. 7 (LBP) algorithm to detect the faces in its proposed system, which turns the image into an arrangement of micropatterns.
Feature Extraction
Feature extraction plays a critical role in facial expression recognition, as feature vectors are generated at this stage as inputs to the next stage where the emotion recognition outcome is determined. Therefore, various pre-processing can be performed before the feature extraction to improve the extraction, such as cropping, resizing and intensity normalization on the raw images to remove extra expression information not used in emotion recognition [4].
Emotion Recognition
On the contrary, sequence-based facial expression recognition analyzes the temporal information in the input sequence to recognize the emotion of various frames. With these services, the process of facial expression recognition can be outsourced and save some operational requirements in building and launching a desired system.
Beyond touch
In 2012, a book reading application was developed where the application acquires the users' natural facial expressions to control the device [8]. It could be extended to cover several different AUs and improve the interaction between the device and users' facial expressions.
AffdexMe
11 was supposed to work as a test prototype that explored the interaction between the devices and users' facial expressions, such as smiling, blinking, and moving the head. While AffdexMe, this app demonstrates and allows participants to map their facial expressions into real-time virtual experiences.
Real-Time Mobile Facial Expression Recognition System
However, some other SDKs and APIs still need to be explored, and they may be useful later in development. 14 displacement of non-neutral and neutral features made the system less sensitive to peak frames.
Critical Remarks of Previous Works
Design Specification
Methodologies and General Work Procedures
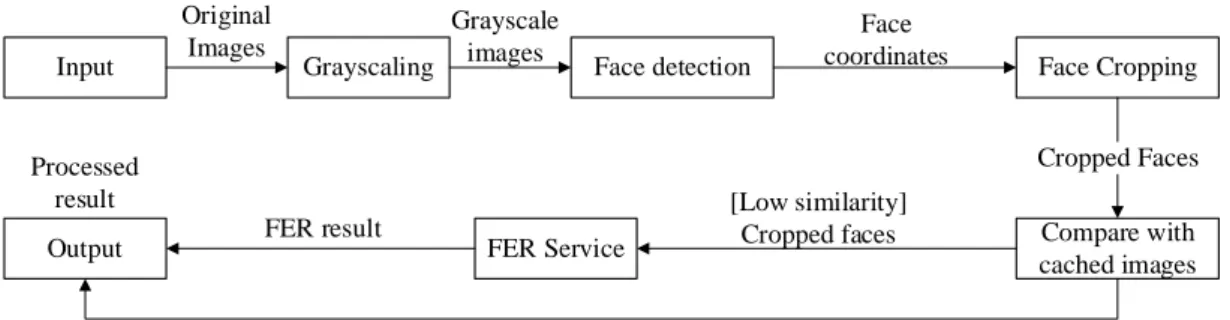
If an image with high similarity is found, the input frame will be classified as the same expression of the image in the cache. After repeatedly training the local model over time, it will become more and more accurate, reducing the number of requests to send the image to a third-party FER service.
Tools to Use
As a result, Python was chosen to support development and all other experiments on Jupyter Notebook, such as the deep learning model for teachers and students and measuring the bandwidth reduction for this project's facial expression recognition. In the project, the Jupyter Notebook will be used to test and demonstrate image processing, face cropping and FER API call.
System Performance Definition
Local training of the FER model may take too much time due to the large amount of data required, the time required to process the data, the time required to train the model, the time required to improve the model, and the time required to evaluate the model performance. Consequently, online FER will be used to determine the user's facial expressions in this project.
System Overview
FER Service
The system performance requirement is critical in the proposed project, as it ensures that a reliable online FER service can be accessed with an acceptable amount of bandwidth and minimal battery consumption, while allowing real-world FER services to be implemented at a bearable cost. Finally, the system displays the FER results with bounding boxes of the faces on the phone screen, and the word describing the FER result is played to alert the visually impaired.
Mobile Application Implementation
Potential optimization
Caching Methodologies
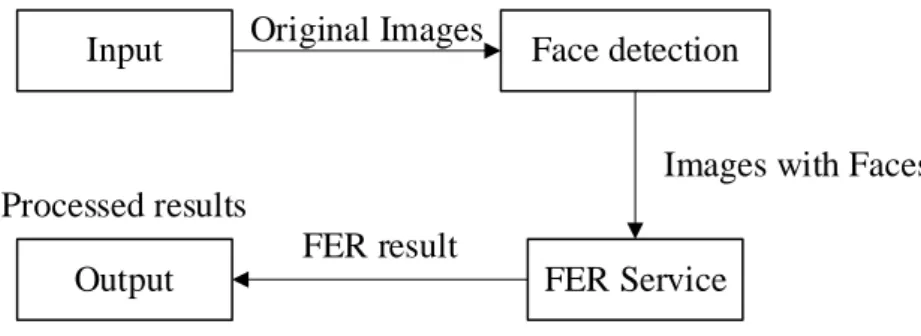
Rather, the faceted input frame is submitted to an external FER service for recognition. For predictions with low confidence, the cropped image is sent to the FER service for recognition.
Methodology and Tools
The results of the mobile application include the label of the identified facial expression, a square box that identifies the coordinates of the face in the input frame, and the output of the voice. In this project, the library is used to authenticate AWS service access by creating the AWS Credential object so that the recognition service can be used to recognize the facial expression captured by the camera in the android project.
Requirement
This project uses Keras, a Python-based deep learning API that runs on top of the TensorFlow machine learning framework, to build a machine learning model between teachers and students.
Android Application Implementation
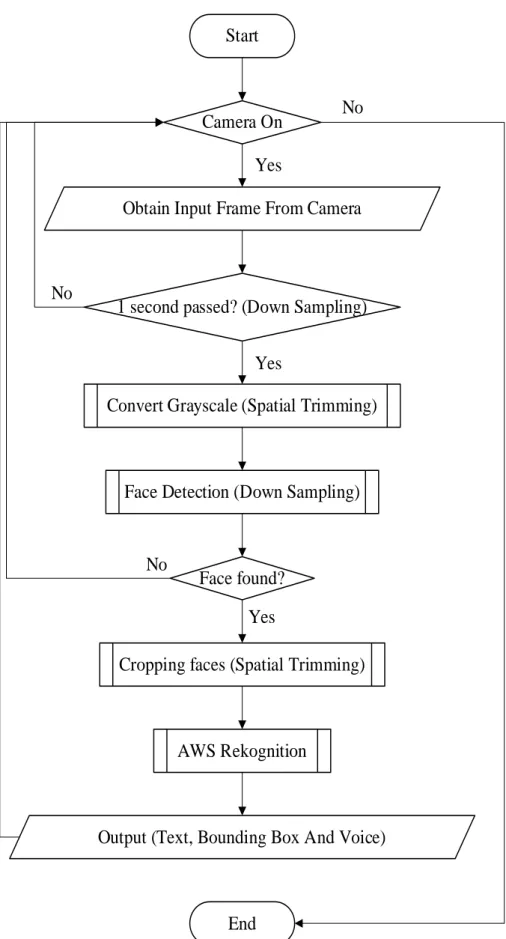
- Input frames from the camera
- Down Sampling - Time Interval
- Spatial Trimming – Grayscaling
- Spatial Trimming - Face cropping
- Output
The expression object is initialized in the facialExpressionRecognition class to store the information about detected facial expressions for a one-second interval when the input frame is not processed for recognition. The frame size, display FPS and also enable camera display are configured in the callback function.
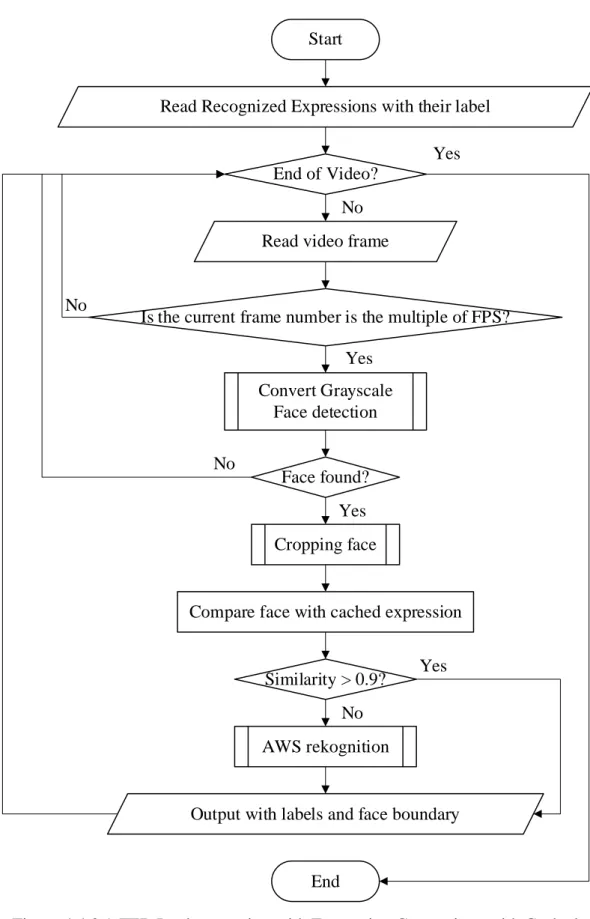
Caching Methodology 1 - Comparing with Cached Images
- Library Import
- Reading the input video
- Down Sampling & Spatial Trimming
- Comparing the Cropped Face with Cached Expression
- Block Diagram
- Library Import
- Base Model Training
- Prediction using the Model
- Dataset preparation for down sampling and spatial trimming
- Dataset preparation for Cache Methodologies (video)
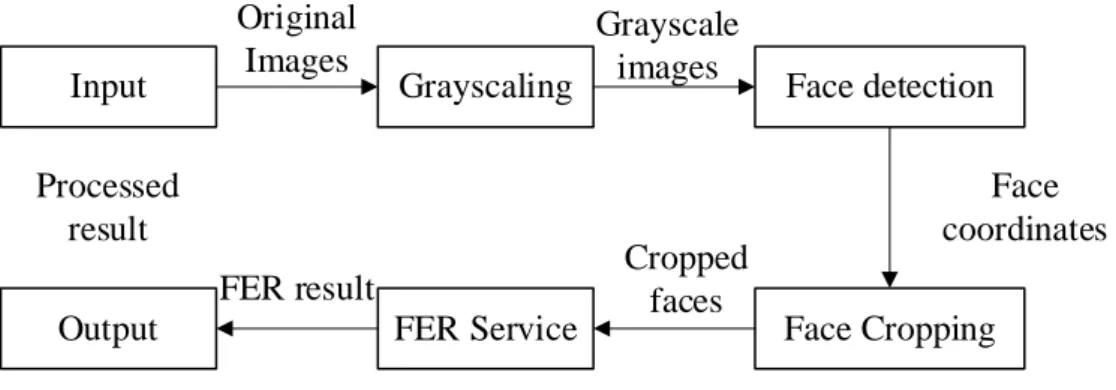
Then the cropped face is compared to the cached expression in the device. Then the OpenCV is also used in the Jupyter Notebook to read the video input. When faces are detected, a rectangle is drawn on the video frame to represent the detected face, and the face is cropped out of the video frame to be used in a comparison or later sent to the AWS Recognizer.
The face_cascade object is initialized before it starts reading the video frame by specifying the model directory.
Experimental design
Measuring Reduced Requests with Caching Methodologies
As suggested, the caching methodologies were implemented with the aim of minimizing the number of AWS requests required by sending them only when the caching methodologies could not provide reliable recognition results. As a result, the number of AWS requests that can be reduced after implementing caching methodologies should also be evaluated. The total number of video frames detected with at least one face will be calculated by adding the number of reliable recognitions obtained by caching methodologies and AWS recognition.
Thus, the total number of AWS requests that are reduced can be determined, which shows the effect of caching methodologies on the total number of AWS requests.
Experimental results
- Time of Image Processing
- Bandwidth Required to Access AWS Rekognition
- Time Elapsed to Access AWS Rekognition
- Accuracy for Teacher-Student Machine Learning Model
- Reduced Requests with Caching Methodologies
This evaluation sent all the images, including the originals, grayscale images, face-cropped images, and finally face-cropped grayscale images to the AWS Rekognition service to determine the amount of bandwidth consumed. To determine the difference in AWS recognition processing time with different types of images, this evaluation sent all the images to the AWS Rekognition service, including the originals, grayscale images, face-cropped images, and finally face-cropped grayscale images. 74 While comparing the face-cropped images with the original images, there are even more images that have been misclassified.
First, the sad expression is still the same misclassified expression in the grayscale image and face cropped image sections.
Summary
In short, the basic trained ResNet50 FER model is still very unreliable and is expected to predict the expression with a low confidence value and get the true value from the AWS recognition to train the model, again and again, the so-called teacher-student machine learning . Among the 17 frames, there are 11 frames detected by the trained FER model with confidence higher than 80%, and only six frames are sent to AWS recognition for recognition. Therefore, it is still adopted in the final implementation even though it also tends to decline in AWS recognition accuracy.
Finally, the teacher-learner machine learning model is chosen from the memorization methodology to continuously improve the classification model with the AWS recognition result in implementation.
Project Review, Discussions and Conclusions
This is also the same in the face crop to exclude a smaller part of the face due to the face recognition algorithm, which makes the cropped expression appear different from the original image. Based on this finding, AWS recognition analyzes the images without applying any image pre-processing to the images before analyzing them. Lesson learned, expanding the view to include theoretical expectations of how a thing works with the typical approach may not always be correct; instead, it is necessary to be hands-on and only know exactly how something works.
Novelties and Contributions
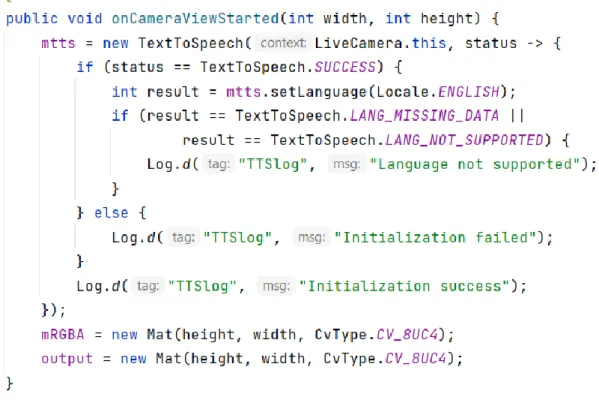
When the FER results are received, the mobile application will convert them into voice messages via text-to-speech technology. The voice alert is intended for visually impaired users and allows other users to listen to the FER results via headphones instead of playing the voice results publicly.
Future Work
Python Codes of Teacher-Student Machine Learning Model Splitting dataset into training, validation and testing data
Dataset Used in Down Sampling and Spatial Trimming Facial Expression Images
Dataset Used in Caching Methodologies Facial Expression Images
WORK DONE
WORK TO BE DONE
PROBLEMS ENCOUNTERED
SELF EVALUATION OF THE PROGRESS
Try calling the AWS recognition for recognizing the facial expression from the camera frame and the images from the gallery. Select a new set of data to get 100% accuracy of the AWS recognition using the original images. The elapsed time for the AWS recognition to respond using the original images and the face-cropped grayscale images have no major differences and the reduced time is less than 0.1 seconds.
Based on the above results, I hereby declare that I am satisfied with the originality of the Final Year Project Report submitted by my student(s) as mentioned above.
UNIVERSITI TUNKU ABDUL RAHMAN