時間序列分析
– 總體經濟與財務金融之應用 –
共整合與向量誤差修正模型
陳旭昇
2013.12
1 共整合關係
2 共整合與共同隨機趨勢
3 向量誤差修正模型
4 共整合分析
5 共整合分析I: Engle-Granger兩階段程序
6 共整合分析II: Johansen程序
7 共整合分析的實例應用:利率期限結構
共整合關係
共整合關係
我們將定態時間序列稱為零階整合(integrated of order zero)序列, 簡稱I(0)序列,並以 yt ∼I(0)代表yt為一個零階整合序列。
如果一個序列經過一階差分後為定態,則稱此序列稱為一階整合 (integrated of order one)序列,亦即I(1)序列,並以zt∼I(1)表示 之。
∆zt= (1−L)zt ∼I(0), 則zt∼I(1);同理,當
∆dxt= (1−Ld)xt ∼I(0), 則xt為I(d)序列。
共整合關係
共整合關係
定義(共整合關係)
給定k×1的向量序列yt,如果yt∼I(1),且存在一個k×γ矩陣β使得 β′yt ∼I(0)
則我們稱yt中的k個序列具共整合關係,而矩陣β中的γ個向量就稱做共整合向量 (cointegrating vectors)。
簡單地說,共整合關係的意義就是,將一群I(1)序列做某一線性組合後變 成一個新序列,而該新序列竟然變成I(0)序列!
共整合關係
例子 : 貨幣需求函數
mt=β0+β1pt+β2yt+β3rt+et,
其中mt,pt,yt以及rt分別代表 貨幣需求,物價水準,實質所得與名目利 率。除了名目利率之外,其他變數均已取對數。 由於實證上發現
mt,pt,yt與rt均為I(1)序列,而貨幣需求的干擾 et =mt−β0−β1pt−β2yt−β3rt 必須是I(0)序列。
共整合關係
例子 : 貨幣需求函數
如果et不是定態,則代表貨幣市場均衡的偏離(deviation)不會消殆。 因 此,mt,pt,yt與rt具共整合關係,且共整合向量為
⎡⎢⎢⎢
⎢⎢⎢⎢
⎢⎣
1
−β1
−β2
−β3
⎤⎥⎥⎥
⎥⎥⎥⎥
⎥⎦
共整合關係
例子 : 消費函數
Ct=Ctp+Ctt,
=β ytp+Ctt,
其中Ctp是恆常消費(permanent consumption),為恆常所得 (permanent income)的函數,Ctt則是短暫消費(transitory
consumption)。 由於ytp∼I(1),Ct ∼I(1),則根據短暫消費的定義, Ctt=Ct−β ytp
是I(0)序列。 因此,Ct與ytp具共整合關係,且共整合向量為
[ 1
−β ]
共整合關係
例子 : 遠期外匯不偏假說
根據Engel (1996a),在理性預期(rational expectations)與風險中立 (risk neutrality)的假設下,遠期外匯應為未來匯率的不偏估計式
Et[st+1]= ft,
其中st為名目匯率, ft為遠期外匯匯率。 因此, FRUH可以改寫成 st+1= ft+ut+1, Et(ut+1)=0.
給定s ∼I(1), f ∼I(1),則u ∼I(0)。
共整合關係
例子 : 遠期外匯不偏假說
如果說ut+1非定態,亦即,
ut+1=ut+et+1,
et∼i.i.d. (0,σ2). 則
st+1 = ft+ut+1,
= ft+ut+et+1,
共整合關係
例子 : 遠期外匯不偏假說
Et(st+1)= ft+ut,
代表遠期外匯匯率並沒有包含所有資訊,或是說市場不具效率性。 因此, FRUH隱含ut+1∼I(0),也就是說st+1與 ft具共整合關係,且共整合向量 為
[ 1
−1 ]
相關討論詳見Hakkio and Rush (1989)與Zivot (2000)。
共整合關係
例子 : 購買力平價說
根據購買力平價,
qt =st+p∗t −pt
必須是一個定態的數列,qt∼I(0)。 因此, PPP隱含st,p∗
t,與pt具共整合
關係,且共整合向量為
⎡⎢⎢⎢
⎢⎢⎢⎣
1 1
−1
⎤⎥⎥⎥
⎥⎥⎥⎦
因此,檢定購買力平價說有兩種方法, (1)直接對qt應用單根檢定; (2)檢 定st,p∗
t,與pt是否具共整合關係。
共整合與共同隨機趨勢
共整合與共同隨機趨勢
根據Stock and Watson(1988),考慮
xt=[ yt
zt ]=[ µyt+eyt µzt+ezt ]
其中µyt與µzt 為隨機漫步序列(random walk series),eyt與ezt為 定態序列(stationary component)。顯而易見地,yt與zt均為I(1) 序列。
假設yt與zt具共整合關係:β′xt∼I(0).亦即, β′xt =β1 yt+β2 zt
共整合與共同隨機趨勢
共整合與共同隨機趨勢
如果β′xt∼I(0),則前一項(β1µyt+β2µzt)必須消失。 也就是說, β1µyt+β2µzt =0,
或是說
µyt= −β2
β1 µzt. 令µzt =µt,我們可以得到
[ yt zt ]=⎡⎢
⎢⎢⎣
−β2
β1
1
⎤⎥⎥⎥
⎦µt+[ eyt
ezt ] (1)
共整合與共同隨機趨勢
共整合與共同隨機趨勢
根據第(1)式,序列若具有共整合關係,則它們具有共同的隨機趨勢 (common stochastic trend)。 因此,「共整合」一詞聽起來很玄,事實上就 是說序列具有相同的隨機趨勢,亦步亦趨地一起移動。
共整合與共同隨機趨勢
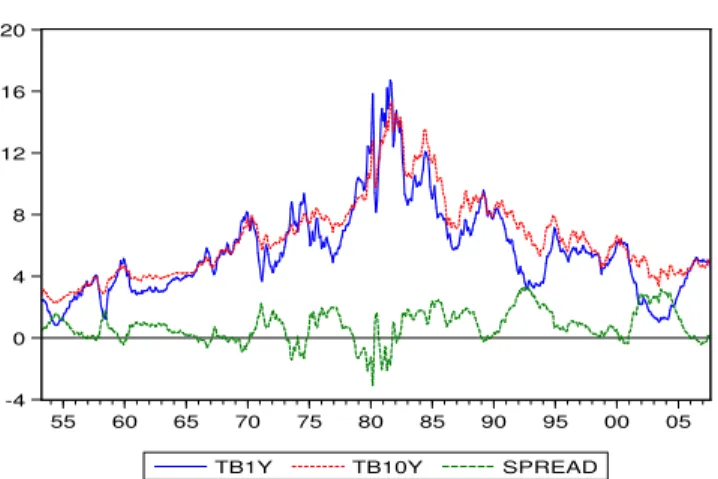
例子 : 共整合與共同隨機趨勢
圖:美國1年期與10年期的國庫券利率(TB1Y與TB10Y)以及利差
-4 0 4 8 12 16 20
55 60 65 70 75 80 85 90 95 00 05
TB1Y TB10Y SPREAD
向量誤差修正模型
向量誤差修正模型
考慮一個VAR(p)模型,
Φ(L)yt=εt, yt∈Rk 且 εt∼i.i.d. (0, Ω). 亦即
(I−Φ1L−Φ2L2− ⋯ −ΦpLp)yt =εt.
向量誤差修正模型
向量誤差修正模型
因此,
yt=Φ1yt−1−Φ2yt−2− ⋯ −Φpyt−p,
=⎡⎢⎢⎢
⎢⎣
⎛
⎝
p
∑j=1
Φj⎞
⎠L−∑p
j=2
Φj(1−L)L−∑p
j=3
Φj(1−L)L2− ⋯
⋯ −∑p
j=p
Φj(1−L)Lp−1⎤⎥⎥⎥
⎥⎦yt+εt
向量誤差修正模型
向量誤差修正模型
注意到上式可由以下算式驗證:
(Φ1+Φ2+Φ3⋯ +Φp) L
− (Φ2+Φ3⋯ +Φp) L(1−L)
− (Φ3⋯ +Φp) L2(1−L)
− ⋮ ⋮
− Φp Lp−1(1−L) Φ1L+Φ2L2+ ⋯ +ΦpLp
向量誤差修正模型
向量誤差修正模型
令
Dj=− ∑p
s=j+1
Φs=−(Φj+1+Φj+2+ ⋯ +Φp), 則yt可以改寫成
yt=⎡⎢
⎢⎢⎢⎣
∑p j=1
Φj⎤⎥
⎥⎥⎥⎦yt−1+∑p−1
j=1
Dj∆yt−j+εt
向量誤差修正模型
向量誤差修正模型
左右兩邊都減去yt−1可得
∆yt=⎡⎢
⎢⎢⎢⎣−I+∑p
j=1
Φj⎤⎥
⎥⎥⎥⎦yt−1+∑p−1
j=1
Dj∆yt−j+εt
=−Φ(1)
´¹¹¹¹¸¹¹¹¹¹¶
Π
yt−1+∑p−1
j=1
Dj∆yt−j+εt
=Πyt−1+∑p−1
j=1
Dj∆yt−j+εt
向量誤差修正模型
向量誤差修正模型
假設yt的自積階次最高為一階, I(1),則∆yt∼I(0)。 如果∆yt,
∑p−1j=1 Dj∆yt−j與εt均為定態,則
Πyt−1 =∆yt−∑p−1
j=1
Dj∆yt−j−εt 一定也是定態。
向量誤差修正模型
向量誤差修正模型
根據Π矩陣的秩(rank)的性質可以決定三種不同情況。
1 rank(Π)=k,Π為滿秩(full rank)。 因此,yt−1所有的線性組合都是 定態時間序列,亦即yt∼I(0)。 在這種情況下,我們直接以yt估計 VAR模型。
2 rank(Π)=0。 因此,沒有任何一個yt−1的線性組合是定態時間序 列,亦即yt∼I(1),且不存在共整合關係。 在這種情況下,我們直接以
∆yt估計VAR模型。
向量誤差修正模型
向量誤差修正模型
3 rank(Π)=r<k。 因此,yt−1部分的線性組合是定態時間序列,更精 確地說,存在r個共整合關係,且r稱為共整合秩(cointegration rank)。
在第3種情況下,稱之為減秩(reduced rank),則我們可以將Π分解為 Π=αβ′
其中α與β均為k×r矩陣,且
rank(α)=rank(β)=r.
向量誤差修正模型
向量誤差修正模型
定理(Granger Representation定理)
給定yt∈Rk,yt∼I(1)具有r<k個共整合關係,若且為若rank(Π)=r且Π可以分解 成Π=αβ′,其中β與α為k×r矩陣,rank(β)=rank(α)=r且VAR(p)模型可以寫成 向量誤差修正模型(vector error correction model, VECM),或是稱共整合VAR模型 (cointegrated VAR model)
∆yt=αβ′yt−1+p
−1
∑
j=1
Dj∆yt−j+εt.
向量誤差修正模型
Granger Representation 定理
1 Granger Representation定理告訴我們,對於任何具共整合關係的 一組序列,共整合關係與向量誤差修正模型為一體之兩面。
2 由於Π=−Φ(1),所有長期影響(long-run effects)的資訊已經包含 在Π矩陣中。
3 Π衡量長期影響,而Dj衡量短期影響。
4 β為共整合向量所組成的矩陣。
5 β′yt−1稱做 「均衡誤差」(equilibrium error)或是「誤差修正 項」(error correction)。
向量誤差修正模型
例子 : 誤差修正模型
xt與zt有如下向量誤差修正模型 [ ∆xt
∆zt ]=[ −1 1
0 0 ] [ xt−1
zt−1 ] + [ εx t
εz t ] 或是寫成
∆yt=Πyt−1+εt, 其中
yt=[ xt
zt ] Π=[ −1 1
0 0 ] 且 εt=[ εx t
εz t ]∼(0, Ω).
向量誤差修正模型
例子 : 誤差修正模型
首先,我們可以輕易得到
zt=zt−1+εz t,
=
∑t j=1
εz j+εz0,
且
xt =zt−1+εx t =
t−1
∑
j=1
εz j+εz0+εx t,
=(∑t
j=1
εz j−εz t) +εz0+εx t,
=
∑t j=1
εz j+εz0+ (εx t−εz t).
向量誤差修正模型
例子 : 誤差修正模型
我們有如下的觀察,
1 ∑tj=1εz j為一隨機趨勢,所以xt與zt都是I(1)序列。
2 ∑tj=1εz j稱為xt與zt的共同隨機趨勢。
3 xt與zt的某一線性組合可以消除此共同隨機趨勢:
xt−zt=(zt−1+εxt)−(zt−1+εzt)=εxt−εzt ∼I(0).
4 注意到Π可以寫成
Π=[ −1 1
]=[ −1
][ 1 −1 ]=αβ′
共整合分析
共整合分析
共整合分析有兩種主要的程序。 第一種係由Robert Engle以及
Clive Granger所提出,他們假設變數之間只存在一個共整合關係,
並且採取兩階段程序,以第一階段的殘差在第二階段檢定共整合關 係以及建構誤差修正模型。
第二種方法則是由Soren Johansen所提出,此方法容許多個共整 合關係存在,並以最大概似法從事檢定與估計。
共整合分析I: Engle-Granger兩階段程序
共整合檢定
Engle and Granger(1987)在只存在一個共整合關係的假設下,提出一
種兩階段檢定法以檢定一組I(1)序列是否具有共整合關係。 以兩個序列 xt與zt為例,說明如何執行Engle-Granger檢定。
1 估計共整合關係:
xt=β0+β1zt+et.
2 對{eˆt}做ADF檢定,
∆ ˆet=a0+a1eˆt−1+∑n ai+1∆ ˆet−i+εt.
共整合分析I: Engle-Granger兩階段程序
共整合檢定
3 欲檢定的假設(hypothesis)為
{ H0 ∶a1=0 不具共整合關係 H1∶a1 <0 具共整合關係
4 如果我們拒絕虛無假設,代表xt與zt具有共整合關係。 反之,如果 我們無法拒絕虛無假設,代表xt與zt不具共整合關係(更精確地說, 是我們找不到證據支持xt與zt具有共整合關係)。
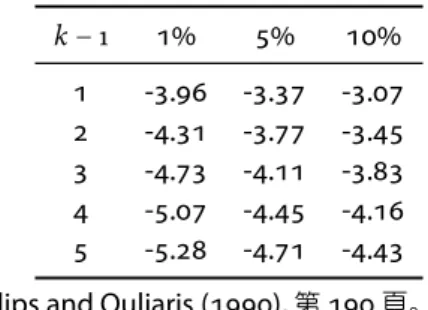
5 Engle-Granger檢定中的ADF檢定不能使用傳統的ADF統計量的
臨界值,其漸近分配由Phillips and Ouliaris (1990)推導出來。
共整合分析I: Engle-Granger兩階段程序
共整合檢定
表:Engle-Granger統計檢定量臨界值
k−1 1% 5% 10%
1 -3.96 -3.37 -3.07 2 -4.31 -3.77 -3.45 3 -4.73 -4.11 -3.83 4 -5.07 -4.45 -4.16 5 -5.28 -4.71 -4.43 參見Phillips and Ouliaris (1990),第190頁。
共整合分析I: Engle-Granger兩階段程序
估計共整合關係與向量誤差修正模型
xt與zt的向量誤差修正模型為
∆xt=α1+αx[xt−1−β1zt−1]+ ∑
i=1
α11i∆xt−i+ ∑
i=1
α12i ∆zt−i+εx t
∆zt=α2+αz[xt−1−β1zt−1]+ ∑
i=1
α21i ∆xt−i+ ∑
i=1
αi22∆zt−i+εz t
透過第一階段估計出共整合關係後,令迴歸殘差為 eˆt=xt−βˆ0+βˆ1zt,
共整合分析I: Engle-Granger兩階段程序
估計共整合關係與向量誤差修正模型
Engle and Grangerv(1987)建議估計向量誤差修正模型如下,
∆xt=α1+αxeˆt−1+ ∑
i=1
αi11∆xt−i+ ∑
i=1
αi12∆zt−i+εy t,
∆zt=α2+αzeˆt−1+ ∑
i=1
α21i ∆xt−i+ ∑
i=1
α22i ∆zt−i+εz t.
1 無論選擇哪一個變數(xt或zt)當作共整合關係中的被解釋變數,理 論上(大樣本性質)不會影響我們對是否存在共整合關係的推論,然 而,實務上如果樣本數較小,統計推論會因不同的變數選擇而不同。
共整合分析I: Engle-Granger兩階段程序
估計共整合關係與向量誤差修正模型
2 Engle-Granger兩階段程序無法處理多個共整合關係的存在。
3 兩階段程序可能會不具效率性。 在第一階段估計共整合關係時,產 生的估計誤差會被帶到下一個階段。
4 由於Engle-Granger兩階段檢定是對殘差做檢定,是故又稱殘差式
檢定(residual-based tests)。
5 對於共整合關係的估計,利用OLS所得到的係數估計式βˆ0,βˆ1具一 致性,在某些情況下(譬如誤差項et具序列相關)其t比率(t-ratio) 的漸近分配不是標準常態。Stock and Watson (1993)建議一種簡 單的解決方法:動態OLS (dynamic OLS, DOLS),
xt =β0+β1zt+ ∑p
j=−p
δj∆zt−j+et.
共整合分析II: Johansen程序
共整合檢定
考慮VAR(p),
yt=Φ1yt−1+Φ2yt−2+ ⋯ +Φpyt−p+εt. yt∈Rk 令
Dj=− ∑p
s=j+1
Φs,
Π=−Φ(1)=−(I−Φ1−Φ2− ⋯ −Φp), 則VAR(p)可以改寫成VECM
∆yt=Πyt−1+p
−1
∑j 1
Dj∆yt−j+εt.
共整合分析II: Johansen程序
共整合檢定
給定yt的階次最高為一。
1 如果rank(Π)=0,意指沒有任何yt的線性組合為I(0),則yt不存 在共整合關係。此外,若rank(Π)=0,則隱含Π=0(零矩陣),因此,
∆yt=∑p−1j=1 Dj∆yt−j+εt為I(0),亦即yt為I(1)。
2 如果rank(Π)=k,意指yt的所有線性組合都是I(0),則所有的yt 都是I(0)。換句話說,yt不存在共整合關係。 事實上,由於
rank(Π)=k,Π矩陣為滿秩(full rank),則Π矩陣可逆,且 yt−1=Π−1∆yt−Π−1
∑p−1 j=1
Dj∆yt−j−Π−1εt 為定態。
共整合分析II: Johansen程序
共整合檢定
3 如果rank(Π)=r<k,則yt存在共整合關係。
因此,我們可以用Π矩陣的秩來檢定是否存在共整合關係,這樣的檢定 方式一般稱為Johansen檢定(Johansen test)。
性質(矩陣秩的重要性質)
Π矩陣的秩等於其異於零的特性根數目。
假設Π矩陣的特性根為λ1,λ2,⋯,λk,
1 如果
rank(Π)=0⇒λ1=λ2=⋯=λk=0
⇒log(1−λi)=0 ∀i
共整合分析II: Johansen程序
共整合檢定
2 如果rank(Π)=r,且假設
{ λ1,λ2, . . . ,λr ≠0
λr+1=λr+2=...=λk=0 亦即,
{ log(1−λi)≠0 fori=1, 2...r
log(1−λi)=0 fori=r+1,r+2, ...k 則yt存在共整合關係。
共整合分析II: Johansen程序
共整合檢定
實務上,我們只能透過資料找出估計式Π,ˆ 進而找出rank(Πˆ)。 在給定 rank(Π)=r, Johansen (1988)以最大概似法估計VECM,亦即,在 Π=αβ′的限制下,估計
∆yt=Πyt−1+p
−1
∑
j=1
Dj∆yt−j+εt,
欲檢定共整合階次,給定特性根
1>λˆ1>ˆλ2> ⋯ >λˆr >λˆr+1 > ⋯ >ˆλk>0,
共整合分析II: Johansen程序
共整合檢定
定義(跡檢定, Trace Test)
1 檢定之假設為
{ H0∶最大共整合階次為r(最多只有r個共整合關係) H1∶最大共整合階次為k(最多只有k個共整合關係)
2 跡檢定量
λtrace(r)=−T
∑k j=r+1
log(1−ˆλj)
如果虛無假設H0為真,則ˆλr+1, ˆλr+2, . . . , ˆλk都會很接近零,則跡檢定量λtrace(r)會 很小。當對立假設成立時,有更多的log(1−ˆλj)<0被加進跡檢定量,由於檢定量前面 乘上一個負號,亦即在對立假設成立時,跡檢定量會較大。
共整合分析II: Johansen程序
共整合檢定
定義(最大特性根檢定, Max Test)
1 檢定之假設為
{ H0 ∶最大共整合階次為r(最多只有r個共整合關係) H1∶最大共整合階次為r+1(最多只有r+1個共整合關係)
2 最大特性根檢定量
λmax(r,r+1)=−Tlog(1−λˆr+1) ˆ
共整合分析II: Johansen程序
最大特性根檢定
步驟一:檢定H0∶r=0vs.H1∶r=1,如果無法拒絕H0,代表我們無 法拒絕沒有共整合關係。 反之,如果我們拒絕H0,則須執行下一步 驟。
步驟二:檢定H0∶r=1vs.H1∶r=2,如果無法拒絕H0,代表有一個 共整合關係。 反之,如果我們拒絕H0,則須繼續執行H0∶r=2vs.
H1∶r=3的檢定...一直做下去,直到無法拒絕虛無假設為止。
此兩種檢定量的臨界值可參考Osterwald-Lenum (1992),或是參考 Maddala and Kim (1998)頁213的表6.5。
共整合分析II: Johansen程序
VECM 的設定
關於VECM的設定,有以下五種設定。
1 設定1, VAR與ECM都沒有常數項。
∆yt=αβ′yt−1+p−1∑
j=1
Dj∆yt−j+εt.
2 設定2, VAR沒有常數項而ECM有常數項。
∆yt=α(β′yt−1−γ2) +∑p−1
j=1
Dj∆yt−j+εt.
共整合分析II: Johansen程序
VECM 的設定
3 設定3, VAR與ECM都有常數項。
∆yt =γ1+α(β′yt−1−γ2) +∑p−1
j=1
Dj∆yt−j+εt.
4 設定4, VAR有常數項而ECM有常數項與時間趨勢項。
∆yt=γ1+α(β′yt−1−γ2−δ2t) +∑p−1
j=1
Dj∆yt−j+εt.
共整合分析II: Johansen程序
VECM 的設定
5 設定5, VAR與ECM都有常數項與時間趨勢項。
∆yt=γ1+δ1t+α(β′yt−1−γ2−δ2t) +∑p−1
j=1
Dj∆yt−j+εt.
EViews提供了一個很好的彙整功能。跡檢定與最大特性根檢定可
能會給我們不一致的檢定結果。 遇到這種情況, Johansen and
Juselius(1990)建議採用最大特性根檢定。
共整合分析的實例應用:利率期限結構
實例應用 : 利率 期限結構
令Rk,t代表k年期長期利率,Rt代表1年期短期利率,et代表I(0)的期 限溢價(term premium)。 根據利率期限結構的預期理論(the
expectations theory of the term structure of interest rates),長期利率 與短期利率之間的關係為
Rk,t= ∑kj=1Et(Rt+j) k +et,
其中,Et(Rt+j)為對於第t+j期的1年期短期利率以第t期的資訊集合所做的預期。
假設Rt為一隨機漫步序列:
Rt =Rt−1+ut, ut ∼i.i.d. N(0, 1).
共整合分析的實例應用:利率期限結構
實例應用 : 利率 期限結構
我們知道
Et(R1,t+j)=Rt, 因此,根據以上模型,
Rk,t= ∑kj=1Et(Rt+j) k +et,
= ∑kj=1Rt k +et,
= kRt k +et,
共整合分析的實例應用:利率期限結構
實例應用 : 利率 期限結構
亦即
Rk,t−Rt=et∼I(0).
也就是說,經濟理論告訴我們長期利率與短期利率之間存在共整合關係, 且共整合向量為
[ 1
−1 ]
關於共整合分析
關於共整合分析
1 根據Clive W. Granger教授之說法,他當初會發現共整合這個概念是為了證明
「沒有共整合這種現象」。
A colleague, David Hendry, stated that the difference between a pair of integrated series could be stationary. My response was that it could be proved that he was wrong, but in attempting to do so, I showed that he was correct, and generalized it to cointegration, and proved the consequences such as the error-correction representation.
關於共整合分析
關於共整合分析
2 對於共整合分析的適當應用為:給定一經濟模型,模型中的I(1)變數 根據經濟理論在某些線性組合下可為定態,接下來以共整合檢定驗 證經濟理論。一般常見的不適當做法為隨意找一組I(1)變數,做共 整合分析並得到統計上共整合關係,就冒然宣稱變數之間存在的經 濟關係。統計上的共整合關係只是建議變數之間存在一個看不見的 共同變因,至於這個共同變因是什麼,則有賴經濟理論,經濟制度,或 是總體經濟環境等之啟迪。
關於共整合分析
關於共整合分析
3 舉例來說,最常被誤用的概念就是,錯把統計上的共整合與經濟整合 或是金融整合混在一起。你把不同國家的股票價格(或是匯率)找來 做共整合檢定,發現共整合關係,然後就下結論說亞洲各國的股票市 場(外匯市場)具有相當程度的金融整合,顯然是不適當的。 除非你 能夠建構一個經濟模型說明金融整合隱含各國股票價格(或是匯率) 有共整合關係,接下來再以共整合檢定驗證之。
關於共整合分析
關於共整合分析
4 再從另外一個角度來看,假設各國股票價格為I(1)序列且存在共整 合關係;則各國股票報酬為I(0),自然沒有所謂的共整合關係。 如果 我們貿然地將共整合關係詮釋為金融整合,則弔詭的是,同樣的股票 市場,何以 「價格」 告訴我們有金融整合,而「報酬」卻又隱含金融整 合不存在?此外,另外一個常見的不適當應用,就是將共整合與市場 效率性混在一起。
關於共整合分析
關於共整合分析
5 共整合分析只能應用在所有序列均為I(1),要應用共整合分析前,我 們必須先透過單根檢定確認序列為I(1),而單根檢定的檢定力已於 第五章討論過,令人堪慮。
6 實務上我們常會碰到研究的變數有的為I(0),有的為I(1), VAR體系 中有I(0)與I(1)序列的混合,此時應用共整合分析就不恰當。