FAKTOR-FAKTOR YANG MEMPENGARUHI KEPUTUSAN
BEROBAT DENGAN METODE REGRESI LOGISTIK
(Studi Kasus RSU Mitra Sejati Medan)
SKRIPSI
EVA YULIANA
040803019
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
FAKTOR-FAKTOR YANG MEMPENGARUHI KEPUTUSAN BEROBAT DENGAN METODE REGRESI LOGISTIK
(Studi Kasus RSU Mitra Sejati Medan)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
EVA YULIANA 040803019
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : FAKTOR-FAKTOR YANG MEMPENGARUHI
KEPUTUSAN BEROBAT DENGAN METODE REGRESI LOGISTIK
Kategori : SKRIPSI
Nama : EVA YULIANA
Nomor Induk Mahasiswa : 040803019
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juni 2010
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Henry Rani Sitepu, M.Si Dra. Rahmawati Pane, M.Si
NIP. 195303031983031002 NIP. 195602191985032001
Diketahui oleh
Departemen Matematika FMIPA USU Ketua,
PERNYATAAN
FAKTOR-FAKTOR YANG MEMPENGARUHI KEPUTUSAN BEROBAT DENGAN REGRESI LOGISTIK
(Studi Kasus RSU Mitra Sejati Medan)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juni 2010
PENGHARGAAN
Dengan mengucapkan puji syukur kehadirat Allah swt, yang telah limpahan karunia-Nya skripsi ini dapat diselesaikan dengan sebaik-baiknya. Skripsi ini merupakan salah satu syarat untuk menyelesaikan perkuliahan di Departemen Matematika FMIPA USU.
Penulis mengucapkan terimakasih kepada Dra. Rahmawati Pane, M.Si dan Drs. Henry Rani Sitepu, M.Si sebagai dosen pembimbing yang telah membimbing dan mengarahkan penulis serta kebaikanya untuk meluangkan waktu, tenaga, dan bantuannya sehingga skripsi ini dapat terselesaikan. Ucapan terimakasih juga penulis sampaikan kepada Ketua Departemen Matematika, Dr. Saib Suwilo, M.Sc, Dekan dan Pembantu Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara, semua dosen FMIPA USU, serta para pegawai di FMIPA USU. Saya juga mengucapkan terimakasih kepada Uci, Nova, Ija, Baity, Masna, Diana, Dani, Darto, Indra, dan teman-teman seperjuangan lainnya khususnya stambuk 2004 yang tidak dapat penulis sebutkan namanya satu persatu atas motivasi dan bantuannya, abang dan adik-adik yang kusayangi Ivan, Putri, Tria, Alvi. Akhirnya terimakasihku yang sebesar-besarnya kepada kedua orangtua tercinta Alm.Budi Situmeang dan Sarifaini Hutabarat atas semua doa, motivasi, dan bantuan baik moril maupun materril yang selama ini diberikan kepada penulis.
Medan, Juni 2010
Penulis
ABSTRAK
ABSTRACT
DAFTAR ISI
1.2 Perumusan Masalah 4
1.3 Pembatasan Masalah 4
1.4 Tujuan Penelitian 4
1.5 Tinjauan Pustaka 4
1.6 Metode Penelitian 6
Bab 2 Landasan Teori
2.1 Data 7
2.1.1 Menurut Sifat 7
2.1.2 Menurut Sifat Kekontinyuannya 8
2.1.3 Menurut Sumber 8
3.2 Pengumpulan Data 29
3.2.1 Sumber Data 29
3.2.2 Populasi dan Sampel 31
3.3 Pengolahan Data 31
3.3.1 Uji Validitas 31
3.3.2 Uji Reliabilitas 35
3.4 Analisis Data 38
3.4.1 Analisa Tipe Data 38
3.4.2 Menganalisis Data Menggunakan Program SPSS 43
3.5 Menafsirkan Hasil Analisis Data 44
3.5.1 Persamaan Regresi Logistik 44
3.5.2 Uji Model Persamaan Regresi Logistik 46
3.5.3 Negelkerke R 2 47
3.5.4 Odds Rasio 48
Bab 4 Kesimpulan dan Saran
4.1 Kesimpulan 51
4.2 Saran 52
Daftar Pustaka 53
DAFTAR TABEL
Halaman
Tabel 3.1 Tabel Karakteristik Pasien 29
Tabel 3.2 Uji Validitas Variabel Individu 33
Tabel 3.3 Uji Validitas Variabel Komunikasi 33
Tabel 3.3 Uji Validitas Variabel Fasilitas 34
Tabel 3.4 Uji Validitas Variabel Paramedis 35
Tabel 3.5 Uji Reliablitas Variabel Individu 36
Tabel 3.6 Uji Reliabilitas Variabel Komunikasi 36
Tabel 3.7 Uji Reliabilitas Variabel Fasilitas 37
Tabel 3.8 Uji Reliabilitas Variabel Paramedis 37
Tabel 3.9 Tabel Transformasi Karakteristik Pasien 41
Tabel 3.10 Tabel Nilai Variabel 44
Tabel 3.11 Tabel Hosmer dan Lemeshow 47
Tabel 3.12 Tabel Negelkerke R 2 47
ABSTRAK
ABSTRACT
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Seiring dengan kemajuan ilmu pengetahuan dan teknologi mendorong masyarakat untuk semakin memperlihatkan derajat kesehatan demi peningkatan kualitas hidup yang lebih baik. Tersedianya pelayanan kesehatan yang berkualitas bagi masyarakat menjadi hal yang harus mendapat perhatian dari pemerintah sebagai salah satu upaya dalam pembangunan di bidang kesehatan. Pelayanan kesehatan kepada masyarakat bertujuan membentuk masyarakat yang sehat. Diperlukan upaya-upaya kesehatan yang menyeluruh dan terpadu untuk mencapai tujuan pembangunan kesehatan tersebut (Siregar, 2003).
Rumah sakit merupakan rujukan pelayanan kesehatan untuk pusat kesehatan masyarakat, terutama upaya penyembuhan dan pemulihan, sebab rumah sakit memiliki fungsi utama menyelenggarakan upaya kesehatan yang bersifat penyembuhan dan pemulihan bagi penderita. Rumah sakit terutama rumah sakit milik pemerintah harus dapat menjadi sarana kesehatan bagi masyarakat luas. Pelayanan kesehatan yang diberikan harus berkualitas agar memuaskan masyarakat sebagai konsumen (Siregar, 2003). Pelayanan kesehatan yang bermutu adalah pelayanan kesehatan yang dapat memuaskan setiap pemakai jasa pelayanan sesuai dengan tingkat kepuasan rata-rata penduduk serta penyelenggarannya sesuai dengan kode etik dan standar pelayanan yang telah ditetapkan (Azwar, 1996).
Rumah sakit kini sudah menjadi bagian integral dari keseluruhan sistem pelayanan kesehatan. Departemen Kesehatan RI telah menggariskan bahwa rumah sakit mempunyai tugas melaksanakan upaya kesehatan secara berdayaguna dan berhasilguna dengan mengutamakan upaya penyembuhan dan pemulihan yang dilaksanakan secara serasi dan terpadu dengan upaya peningkatan dan pencegahan serta melaksanakan upaya rujukan (Aditama, 2002).
Rumah sakit adalah suatu organisasi yang kompleks, menggunakan gabungan alat ilmiah khusus dan rumit, dan difungsikan oleh berbagai kesatuan personel terlatih dan terdidik dalam menghadapi dan menangani masalah medik modern, yang semuanya terikat bersama-sama dalam maksud yang sama, untuk pemulihan dan pemeliharaan kesehatan yang baik. Menurut Keputusan Menteri Kesehatan Republik Indonesia Nomor: 983/ Menkes/ SK/ XI/ 1992, tentang Pedoman Organisasi Rumah Sakit Umum, yang menyebutkan bahwa tugas rumah sakit mengutamakan upaya penyembuhan dan pemulihan yang dilaksanakan secara serasi dan terpadu dengan upaya peningkatan dan pencegahan serta melaksanakan upaya rujukan (Siregar, 2003).
Sesuai dengan peraturan perundang-undangan yang berlaku, rumah sakit di Indonesia dapat dibedakan atas beberapa macam. Ditinjau dari pemiliknya, maka rumah sakit di Indonesia dapat dibedakan menjadi dua yaitu: Rumah Sakit Pemerintah dan Rumah Sakit Swasta. Rumah Sakit Pemerintah yang dimaksudkan di sini dapat dibedakan atas dua macam yaitu: Rumah Sakit Pemerintah Pusat dan Rumah Sakit Pemerintah Daerah. Rumah Sakit Umum Pemerintah Pusat dan Daerah diklasifikasikan menjadi Rumah sakit umum kelas A, B, C, dan kelas D. Klasifikasi tersebut didasarkan pada unsur pelayanan, ketenagaan, fisik, dan peralatan.
umum, dengan tujuan utama melayani masyarakat dalam hal kesehatan. Sehingga kemudian berdirilah rumah sakit yaitu RSU Mitra Sejati Medan yang berlokasi di Jl. Jendral Besar A.H Nasution No. 7 Medan, dengan ketua yayasan dr. Parambir Singh.
Rumah sakit sudah begitu banyak berdiri di Indonesia tetapi ada juga sebagian masyarakat yang lebih memilih melakukan pengobatan bukan di rumah sakit. Mereka lebih memilih melakukan penyembuhan di tempat-tempat lain seperti klinik-klinik, puskesmas, puskesmas pembantu, bahkan tempat pengobatan alternatif. Faktor-faktor seperti lingkungan, pendapatan, kepercayaan dari diri sendiri menjadi alasan yang dikemukakan oleh masyarakat tersebut. Selain itu juga masih terdapat beberapa alasan yang menjadi standar masyarakat untuk tidak berobat ke rumah sakit. Oleh karena besarnya pengaruh faktor-faktor terhadap pengambilan keputusan masyarakat dalam berobat ke rumah sakit, maka dirasa sangat perlu melakukan penelitian terhadap faktor-faktor tersebut. Penelitian ini akan menggunakan regresi logistik sebagai alat analisisnya.
Regresi logistik ini tidak seperti pada regresi linier biasa. Regresi logistik tidak mengasumsikan hubungan antara variabel bebas dan terikat secara linier. Regresi logistik merupakan regresi non linier dimana model yang ditentukan akan mengikuti pola data yang berupa data kategorik. Metode regresi logistik ini lebih fleksibel dibanding teknik lain. Regresi logistik memiliki beberapa kelebihan yaitu tidak memiliki asumsi normalitas atas variabel bebas yang digunakan dalam model, variabel-variabel bebas dalam regresi logistik bisa merupakan campuran dari variabel kontinu, diskrit, dan dikotomis, serta regresi logistik sangat bermanfaat digunakan apabila distribusi respon atas variabel hasil diharapkan nonlinier dengan satu atau lebih variabel bebas (Kuncoro, 2001, hal: 217).
Berdasarkan uraian diatas, penulis tertarik memilih judul “Faktor-faktor yang Mempengaruhi Keputusan Berobat dengan Regresi Logistik”.
1.2 Perumusan Masalah
Yang menjadi permasalahan dalam penelitian ini adalah faktor-faktor apa saja yang berpengaruh terhadap keputusan masyarakat untuk berobat ke Rumah Sakit Mitra Sejati Medan.
1.3 Pembatasan Masalah
Permasalahan ini dibatasi pada penelusuran faktor-faktor apa saja yang berpengaruh terhadap keputusan masyarakat berobat ke rumah sakit dengan menggunakan metode regresi logistik.
1.4 Tujuan Penelitian
Tujuan penelitian ini adalah untuk mengetahui faktor-faktor yang berpengaruh terhadap keputusan masyarakat berobat ke rumah sakit, serta mengetahui faktor yang dominan.
1.5 Tinjauan Pustaka
tidak linear, ketidaknormalan sebaran dari Y, keragaman respon yang tidak konstan dan tidak dapat dijelaskan oleh model regresi linear biasa (Agresti, 1990).
Metode regresi logistik adalah suatu metode analisis statistika yang mendeskripsikan hubungan antara peubah respon yang memiliki dua kategori atau lebih dengan satu atau lebih peubah penjelas berskala kategori atau interval (Hosmer dan Lemeshow, 1989). Sedangkan menurut David (1989) uji regresi logistik adalah metode statistik yang mempelajari tentang pola hubungan secara matematis antara satu variabel dependen dengan satu atau lebih variabel independen.
Model logistik dirancang untuk melakukan prediksi keanggotaan grup. Regresi logistik digunakan bila variabel-variabel prediktor (predictors) merupakan campuran antara variabel diskrit dan kontinu dan distribusi data yang digunakan tidak normal (Wahyuddin, 2004:34). Uji ini bertujuan memprediksi variabel dependen yang berupa sebuah variabel biner dengan menggunakan data variabel independen yang sudah diketahui besarnya (Santoso, 2001).
Ada beberapa metode pendugaan parameter dalam regresi logistik, salah satunya yaitu metode maksimum likelihood. Keuntungan menggunakan metode maksimum likelihood adalah bahwa uji rasio likelihood dapat diimplementasikan untuk menaksir kesesuaian dari kelebihan pendugaan parameter regresi logistik dengan menggunakan MLE (Maksimum Likelihood Estimation). MLE adalah suatu fungsi dari parameter yang memaksimumkan peluangnya untuk menduga parameter (Hosmer, 1989).
Untuk menguji hipotesis digunakan model Hosmer and Lemeshow’s goodness of fit test. Jika nilai Hosmer and Lemeshow’s goodness of fit test statistik sama dengan atau kurang dari 0,05, maka hipotesis nol ditolak yang berari ada perbedaan signifikan antara model dengan nilai observasinya, yang goodness fit model tidak baik, karena model tidak dapat memprediksi nilai observasinya. Jika nilai statistik Hosmer and Lemeshow’s goodness of fit lebih besar dari 0,05, maka hipotesis nol tidak dapat ditolak dan berarti model mampu memprediksikan nilai obsevasinya atau dapat dikatakan model dapat ditemui karena cocok dengan observasinya (Ghozali, 2001, hal: 218).
Berdasarkan Hosmer dan Lemeshow (1990) untuk menguji keberartian koefisien secara parsial digunakan uji Wald. Pengujian ini dilakukan untuk menguji koefisien tiap variabel secara individual. Hasil pengujian secara individual ini akan menunjukkan kelayakan suatu variabel prediktor untuk masuk dalam model.
1.6 Metode Penelitian
Adapun metodologi penelitian ini adalah sebagai berikut :
1. Pengumpulan data berupa data primer berdasarkan kuesioner yang diperoleh dari data pasien Rumah Sakit Mitra Sejati Medan.
2. Pengolahan data yang meliputi pengujian kelayakan data dan analisis regresi logistik biner dengan menggunakan SPSS, dimana bentuk umum regresi logistik tersebut adalah
BAB 2
LANDASAN TEORI
2.1 Data
Data merupakan bentuk jamak dari datum, yang mempunyai arti pemberian atau penyajian. Secara definitif dapat diartikan sebagai kumpulan angka, fakta, fenomena atau keadaan yang merupakan hasil pengamatan, pengukuran, atau pencacahan terhadap karakteristik atau sifat dari obyek yang dapat berfungsi untuk membedakan obyek yang satu dengan lainnya padasifat yang sama (Solimun, 2001, hal: 2).
2.2.1 Menurut Sifat
Data terbagi atas dua golongan berdasarkan sifatnya, yaitu :
a. Data Kualitatif
Data kualitatif adalah data yang sifatnya hanya menggolongkan saja. Termasuk dalam klasifikasi data tipe ini adalah data yang berskala ukur nominal dan ordinal. Sebagai contoh adalah data kepuasan pelanggan (tinggi, sedang, rendah).
b. Data Kuantitatif
2.2.2 Menurut Sifat Kekontinyuannya
Berdasarkan sifat kekontinyuannya data hasil pengamatan dapat dibedakan menjadi dua, yaitu :
a. Data Diskrit
Data diskrit adalah data hasil pengamatan yang hanya menempati angka-angka tertentu pada sebuah garis. Sebagai contoh adalah data jumlah mahasiswa STAIN Malang dari tahun 2001-2005. Jumlah mahasiswa tersebut hanya berada pada angka-angka tertentu saja, yaitu : 5000, 5200, 5500, 5600, dan 6000 orang.
b. Data Kontinyu
Data kontinyu adalah data yang menempati seluruh angka pada sebuah garis. Sebagai contoh data ini adalah data pendapatan orangtua mahasiswa = Rp 1.000.000 – Rp 3.000.000. Data ini tentu saja menempati semua angka yang berada pada rentang nilai tersebut.
2.2.3 Menurut Sumber
Menurut sumbernya data terbagi atas dua bagian, yaitu :
a. Data Internal
Data internal adalah data yang didapat dari dalam perusahaan atau organisasi dimana riset dilakukan. Sebagai contoh adalah data keadaan produksi pabrik.
b. Data Eksternal
Data eksternal adalah data yang menggambarkan keadaan di luar organisasi. Data eksternal itu sendiri terbagi atas dua bagian, yaitu :
1. Data Primer
2. Data Sekunder
Data sekunder adalah data primer yang diperoleh dari pihak lain atau data primer yang telah diolah lebih lanjut dan disajikan. Sebagai contoh adalah data nilai siswa di sebuah sekolah.
2.2 Skala Pengukuran Data
Pengukuran dapat didefinisikan sebagai suatu proses sistimatik dalam menilai dan membedakan sesuatu obyek yang diukur. Pengukuran tersebut diatur menurut kaidah-kaidah tertentu. Kaidah-kaidah-kaidah yang berbeda menghendaki skala serta pengukuran yang berbeda pula. Skala merupakan suatu prosedur pemberian angka atau simbol lain kepada sejumlah ciri tersebut. Skala pengukuran oleh S.S Steven (1976) dibagi atas empat bagian, yaitu :
1. Skala Nominal
Skala Nominal merupakan skala yang paling lemah/rendah di antara skala pengukuran yang ada. Skala nominal hanya bisa membedakan benda atau peristiwa yang satu dengan yang lainnya berdasarkan nama (predikat) dan tidak diasumsikan adanya tingkatan antara satu kategori dan kategori lainnya dalam satu variabel. Oleh karena itu skala ini sering dikenal dengan skala yang mengandung unsur penamaan. Skala ini digunakan untuk mengklasifikasikan obyek-obyek atau kejadian-kejadian ke dalam kelompok (kategori) yang terpisah untuk menunjukkan kesamaan atau perbedaan ciri-ciri tertentu dari obyek yang diamati. Kategori tersebut biasanya dilambangkan dengan huruf atau simbol.
Contoh :
Jenis kelamin 1 = Pria 2 = Wanita 2. Skala Ordinal
peringkat. Angka-angka tersebut tidak menunjukkan kuantitas absolut, tidak pula memberikan petunjuk bahwa interval-interval antara setiap dua angka itu sama.
Contoh :
Seorang anggota ABRI dapat dikelompokkan menurut pangkatnya, yaitu mayor, kapten, letnan. Dimana hubungan antar kelas-kelas terdapat urutan tertentu (mayor > kapten > letnan).
3. Skala Interval
Skala interval adalah skala suatu variabel yang selain membedakan dan mempunyai tingkatan, juga diasumsikan mempunyai jarak yang pasti antara satu kategori dengan kategori yang lain dalam satu variabel.
Contoh :
Nilai prestasi yang telah ditransfer dalam bentuk huruf A, B, C, D, E. Selanjutnya diberi bobot masing-masing 4, 3, 2, 1, dan 0. Sehingga interval A dan B sama dengan interval D dan E, juga interval A dan C sama dengan antara C dan E.
4. Skala Rasio
Skala rasio adalah skala suatu variabel yang selain membedakan dan mempunyai tingkatan serta jarak antara suatu nilai dengan nilai yang
lainnya, juga diasumsikan bahwa setiap nilai variabel diukur dari suatu keadaan atau titik yang sama (mempunyai titik nol mutlak). Angka-angka pada skala menunjukkan besaran sesungguhnya dari sifat yang diukur. Contoh :
Berat benda A adalah 30 kg dan berat benda B adalah 60 kg.
2.3 Skala Instrumen (Model Skala Sikap)
Bentuk-bentuk skala instrumen (model skala sikap) yang sering digunakan dalam penelitian ada 5 macam, yaitu :
a. Skala Likert
skala likert variabel yang akan diukur dijabarkan menjadi subvariabel. Kemudian subvariabel dijabarkan lagi menjadi indikator-indikator yang terukur ini yang mana menjadi titik tolak untuk membuat item instrumen yang berupa pertanyaan yang perlu dijawab responden. Setiap jawaban diungkapkan dengan kata-kata, misalnya :
Sangat Setuju (SS) = 5 multidimensi. Skala Gutman ialah skala yang digunakan untuk jawaban yang bersifat jelas (tegas) dan konsisten.
Misalnya : yakin-tidak yakin, benar-salah, setuju-tidak setuju, dan sebagainya.
c. Skala Diferensial Semantik
Skala diferensial semantik atau skala perbedaan semantik berisikan serangkaian bipolar (dua kutub). Responden diminta untuk menilai suatu obyek atau konsep pada suatu skala yang mempunyai dua ajektif yang bertentangan.
Misalnya : panas-dingin, popular-tidak popular, bagus-buruk, dan sebagainya.
d. Rating Scale
Rating scale yaitu data mentah yang didapat berupa angka kemudian ditafsirkan dalam pengertian kualitatif.
Misalnya : ketat-longgar, lemah-kuat, positif-negatif. e. Skala Thurstone
2.4 Teknik Pengumpulan Data
Di dalam suatu penelitian diperlukan teknik-teknik untuk pengumpulan data. Menurut Iqbal Hasan (2002, hal :38) teknik pengumpulan data terbagi atas :
a. Kuesioner
Kuesioner adalah teknik pengumpulan data dengan menyerahkan atau mengirimkan daftar pertanyaan untuk diisi sendiri oleh responden. Dalam penelitian survei pemakaian kuesioner merupakan hal penting untuk mengumpulkan data. Analisis data kualitatif dan kuantitatif berdasarkan kuesioner tersebut. Sebuah kuesioner yang baik adalah sebuah kuesioner yang mengandung pertanyaan yang baik pula, dalam arti sedemikian sehingga tidak menimbulkan arti yang lain pada diri responden. Pertanyaan-pertanyaan yang ada pada sebuah kuesioner harus jelas dan mudah dimengerti sehingga mengurangi tingkat kesalahan interprestasi responden dalam pengisian kuesioner. Berdasarkan jenis pertanyaan kueisoner dapat
dibedakan menjadi 3 macam, yaitu: 1. Pertanyaan Tertutup
Pertanyaan tertutup yaitu pertanyaan yang telah disertai pilihan
jawaban. Responden tinggal memilih salah satu jawaban yang tersedia. Pertanyaan tertutup dapat berupa pertanyaan pilihan berganda atau skala.
2. Pertanyaan Terbuka
Pertanyaan tertutup yaitu pertanyaan yang telah disertai pilihan jawaban. Responden tinggal memilih salah satu jawaban yang tersedia. Pertanyaan tertutup dapat berupa pertanyaan pilihan berganda atau skala.
3. Pertanyaan Kombinasi Tertutup dan Terbuka
Pertanyaan kombinasi tertutup dan terbuka telah diberi jawaban tetapi kemudian disertai dengan jawaban terbuka.
Pertanyaan semi tertutup yaitu pertanyaan yang sudah disertai pilihan jawaban namun masih memungkinkan untuk menambahkan jawaban terbuka.
b. Wawancara
Wawancara adalah teknik pengumpulan data dengan mengajukan pertanyaan secara langsung oleh pewawancara kepada responden dan jawaban responden dicatat atau direkam dengan alat perekam.
c. Observasi
Secara luas, observasi atau pengamatan berarti setiap kegiatan untuk melakukan pengukuran. Akan tetapi observasi atau pengamatan disini diartikan lebih sempit, yaitu pengamatan dengan menggunakan indera pengeliatan yang berarti tidak mengajukan pertanyan-pertanyaan.
2.5 Populasi dan Sampel
2.5.1 Populasi
Populasi adalah himpunan unit penelitian yang lengkap/utuh yang terdiri dari
nilai/skor/ukuran peubah-peubah yang bersifat majemuk. Selain itu terdapat juga beberapa pengertian populasi yang lain, diantaranya yaitu populasi adalah wilayah generalisasi yang terdiri atas obyek/subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya (Sugiyono, 2009, hal: 61).
Sedangkan menurut Santoso dan Tjiptono (2002, hal: 79) populasi merupakan sekumpulan orang atau objek yang memiliki kesamaan dalam satu atau beberapa hal dan yang membentuk masalah pokok dalam suatu riset khusus. Populasi yang akan diteliti harus didefinisikan dengan jelas sebelum penelitian dilakukan. Sehingga dapat disimpulkan bahwa populasi tidak hanya terbatas pada manusia, tetapi juga obyek dan benda-benda alam yang lain. Populasi juga bukan sekedar jumlah yang ada pada obyek/subyek yang dipelajari, tetapi meliputi seluruh karakteristik/sifat yang dimiliki oleh subyek atau obyek itu.
2.5.2 Sampel
Sampel adalah bagian dari populasi yanng memberikan keterangan atau data untuk suatu penelitian yang terdiri dari nilai/skor/ukuran peubah-peubah yang bersifat terbatas jumlahnya. Tidak semua anggota dari populasi target diteliti. Penelitian hanya dilakukan terhadap sekelompok anggota populasi yang mewakili populasi. Kelompok kecil yang secara nyata kita teliti dan tarik kesimpulan dari padanya disebut sampel (Nana Syaodih Sukmadinata, 2008, hal: 250).
Pengertian lainnya yaitu sampel adalah bagian dari jumlah dan karakteristik populasi. Misalnya karena keterbatasan dana, tenaga dan waktu, maka peneliti dapat menggunakan sampel yang diambil dari populasi itu. Kesimpulan sampel akan berlaku untuk populasi. Untuk itu sampel yang diambil dari populasi harus betul-betul representatif (mewakili) (Sugiyono, 2009, hal: 62).
2.6 Teknik Sampling
2.6.1 Teknik Sampling Random (Probability Sampling)
Pada tipe pengambilan sampel secara random ini setiap unit populasi mempunyai kesempatan yang sama untuk diambil sebagai sampel. Faktor pemilihan atau penunjukan sampel yang diambil semata-mata karena pertimbangan peneliti akan dihindarkan. Karena jika maka akan mengakibatkan terjadinya bias.
Dengan cara random, bias pemilihan dapat diperkecil sekecil mungkin. Ini merupakan salah satu usaha untuk mendapatkan sampel yang representatif. Selain itu pemilihan sampel dengan cara ini juga memiliki beberapa keuntungan, yaitu derajat kepercayaan terhadap sampel dapat ditentukan, beda penaksiran parameter populasi dengan statistik sampel dapat diperkirakan, serta besar sampel yang akan diambil dapat dihitung secara statistik. Pemilihan sampel dengan teknik sampling random ini mempunyai lima cara, yaitu :
a. Sampel Random Sederhana (Simple Random sampling)
Sampel random sederhana adalah teknik pengambilan sampel secara acak dimana masing-masing subjek atau unit dari populasi memiliki peluang yang sama dan independen (tidak bergantung) untuk terpilih sebagai sampel. Keuntungan dari teknik ini adalah memungkinkan peneliti mengetahui besarnya sampling error (margin of error) penelitian dan memberikan sampel yang secara rata-rata representatif terhadap populasi. Sedangkan kerugiannya, peneliti harus memiliki daftar (sampling frame) setiap subjek yang ada dalam populasi dan skema sampling random ini membutuhkan perencanaan lebih matang serta biaya yang besar jika populasi besar.
b. Stratified Random Sampling
dari populasi yang dipandang penting oleh peneliti dapat terwakili secara proporsional.
c. Cluster sampling
Cluster sampling adalah teknik pengambilan sampel dimana unit tempat pengambialn adalah kelompok atau klaster subjek dan bukan individu. Meskipun unit pengambilan adalah klaster, namun pengamatan/pengukuran variabel dilakukan pada masing-masing individu dalam klaster terpilih, sesuai dengan batasan populasi sasaran (Streiner et
al, 1989).
d. Systematic Sampling
Systematic sampling menuntut kepada peneliti untuk memilih unsur populasi secara sistematis, yaitu unsur populasi yang bisa dijadikan sampel adalah yang keberapa. Pengambilan sampel ini lebih menekankan pada sistem interval dari hasil proses random. Pengambilan sampel sistematik lebih menghemat waktu dan lebih sederhana. Jika peneliti dihadapkan pada ukuran populasi yang banyak dan tidak memiliki alat pengambil data secara random maka cara pengambilan sampel sistematis dapat digunakan. e. Area Sampling
Teknik ini dipakai ketika peneliti dihadapkan pada situasi bahwa populasi penelitiannya tersebar di berbagai wilayah.
2.6.2 Teknik Sampling Non-Random (Non Probability Sampling)
Teknik sampling nonrandom adalah teknik pengambilan sampel yang tidak memberi peluang/kesempatan sama bagi setiap unsur atau anggota populasi untuk dipilih menjadi sampel. Pemilihan sampel dengan teknik sampling nonrandom ini mempunyai empat cara, yaitu :
a. Sampling Purposive
tertentu, atau mendapatkan kelompok-kelompok penelitian yang sebanding sehingga dapat dianalisis dengan valid.
b. Sampling Kuota
Sampling kuota merupakan teknik pemilihan sampel nonrandom dimana peneliti membagi populasi ke dalam kategori (strata), lalu memberikan jatah jumlah subjek untuk masing-masing stratum tersebut (Kothari, 1990; Vogt, 1993; Polgar dan Thomas, 2000).
c. Sampling Aksidental
Ini merupakan tipe pemilihan sampel yang sampelnya diambil atas dasar seandainya saja, tanpa direncanakan lebih dahulu. Juga jumlah sampel yang dikehenadaki tidak berdasrkan pertimbangan yang dapat dipertanggung jawabkan, melainkan asal memenuhi keperluan saja. Kesimpulan yang diperoleh bersifat kasar dan sementara saja.
d. Snawball Sampling
Snawball sampling atau sampling bola salju merupakan sebuah metode pemilihan sampel dengan pertama-tama menghubungi seseorang atau sekelompok responden, lalu meminta mereka untuk memberikan saran tentang orang yang dipandang memiliki informasi penting dan bersedia untuk berpartisipasi dalam penelitian (Rice dan Ezzy, 2000). Teknik pengambilan sampel ini dapat digunakan untuk penelitian kuantitatif maupun kualitatif (Utarini et al, 2003).
2.7 Variabel
2.7.1 Menurut Sifat
Berdasarkan sifatnya variabel terbagi atas dua, yaitu :
1. Variabel Kualitatif
metode statistika maka data kualitatif tersebut harus dikuantitatifkan melalui cara pemberian skor (skoring). Hal ini diperlukan mengingat metode statistika merupakan metode komputasi dengan pendekatan kuantitatif. Data demikian ini termasuk data diskrit dengan skala ukur nominal atau ordinal. 2. Variabel Kuantitatif
Variabel Kuantitatif, adalah variabel yang menujukkan sifat kuantitas, akan menghasilkan data kuantitatif melalui cara pencacahan, atau pengukuran, atau pemeriksaan laboratorium dll, yang bisa berupa data diskrit atau kontinyu dengan skala ukur interval dan rasio.
2.7.2 Menurut Keberadaan, Keterkaitan, dan Struktur Pengaruhnya
Berdasarkan keberadaan, keterkaitan, serta struktur pengaruhnya, variabel terbagi atas
1. Variabel Bergantung
Variabel bergantung (dependen variabel) adalah suatu variabel yang menjadi pusat perhatian peneliti (tercakup dalam hipotesis penelitian), yang keragamannya (variabilitasnya) ditentukan atau bergantung/dipengaruhi oleh variabel lain.
2. Variabel Bebas
Variebel bebas (independent variabel) adalah suatu variabel yang menjadi pusat perhatian peneliti (termuat dalam permasalahan penelitian) yang keragamannya sebagai akibat dari manipulasi atau intervensi peneliti atau merupakan suatu keadaan atau kondisi atau fenomena yang ingin diselidiki, diteliti dan dikaji. Variabel ini mempengaruhi variabel tergantung.
3. Variabel Pembaur
4. Variabel Penyerta
Variabel penyerta (Concomitant) adalah suatu variabel dalam penelitian yang tidak merupakan pusat perhatian peneliti, akan tetapi muncul dan berpengaruh terhadap keragaman variabel tergantung dan pengaruh tersebut membaur (cofounding) dengan variabel bebas. Variabel ini tidak dapat dikendalikan , sehingga tetap menyertai (terikut) dalam proses penelitian, dengan konsekuensi data harus diamati dan pengaruh baurnya harus dieliminir. Pengaruh baur tersebut dapat dihilangkan (dieliminasi) pada tahap analisi data, misalnya dengan anova atau manova.
5. Variabel Kendali
Variabel Kendali (Control Variabel) adalah variabel yang bukan merupakan pusat perhatian peneliti, akan tetapi berpengaruh terhadap keragaman variabel tergantung dan pengaruh tersebut dapat dikendalikan. Pengendalian ini biasanya dilakukan dengan cara blocking, yaitu mengelompokkan obyek penelitian menjadi kelompok-kelompok yang relatip homogen atau dengan cara ekxklusi (mengeluarkan obyek yang tidak memenuhi kriteria) dan inklusi (memilih dan menjadikan obyek yang memenuhi kriteria untuk diikutkan dalam penelitian / kajian). Bilamana dilakukan dengan cara pengelompokan (blocking), maka pada tahap analisis data pengaruh blocking ini harus dihilangkan, misalnya dengan ANOVA Two Way.
2.8 Analisis Data
2.8.1 Uji dalam Pengolahan Data
a. Uji Validitas
Validitas terbagi atas empat macam, yaitu : 1. Validitas Isi (Content Validity)
Sebuah tes dikatakan memiliki validitas isi apabila mengukur tujuan khusus tertentu yang sejajar dengan materi atau isi pelajaran yang diberikan. Misalnya seorang peneliti ingin mengukur bagaimana persepsi konsumen terhadap suatu produk.
2. Validitas Konstruk (Construct Validity)
Sebuah tes dikatakan memiliki validitas konstruksi apabila butir-butir soal yang membangun tes tersebut mengukur setiap aspek berpikir seperti yang disebutkan dalam tujuan instruksional khusus. 3. Validitas “ada sekarang” (Concurrent Validity)
Validitas ini lebih umum dikenal dengan validitas empiris. Sebuah tes dikatakan memiliiki validitas empiris jika hasilnya sesuai dengan pengalaman. Misalnya seorang guru ingin mengetahui apakah tes sumatif yang disusun sudah valid atau belum.
4. Validitas Prediksi (Predictive Validity)
Memprediksi artinya meramal, dan meramal selalu mengenai hal yang akan datang, sehingga sekarang ini belum terjadi. Sebuah tes dikatakan memiliki validitas prediksi apabila mempunyai kemampuan untuk meramalkan apa yang akan terjadi pada masa yang akan datang.
b. Uji Reliabilitas
Reliabilitas adalah indeks yang menunjukkan sejauh mana suatu alat pengukur dapat dipercaya atau diandalkan. Bila suatu alat pengukur dipakai dua kali untuk mengukur gejala yang sama dan hasil pengukuran diperoleh relatif koefisien, maka alat pengukur tersebut reliabel. Adapun teknik perhitungan reliabel ada beberapa cara, yaitu sebagai berikut :
1. Teknik Pengukuran Ulang (Testretest)
perhitungannya adalah dengan mengkorelasikan jawaban pada wawancara pertama dengan jawaban pada wawancara kedua. 2. Teknik Belah Dua
Untuk menggunakan teknik belah dua sebagai cara menghitung reliabilitas alat pengukur, maka alat pengukur yang disususn harus memiliki cukup banyak item pertanyaan yang mengukur aspek yang sama.
3. Teknik Bentuk Paralel.
Perhitungan reliabilitas dilakukan dengan membuat dua jenis alat pengukur yang mengukur aspek yang sama. Kedua alat ukur tersebut diberikan pada responden yang sama, kemudian dicari validitasnya untuk masing-masing jenis.
4. Internal Consistency Reliability
Internal consistency reliability berisi tentang sejauh mana item-item instrumen bersifat homogen dan mencerminkan konstruk yang sama sesuai dengan yang melandasinya. Suatu variabel dikatakan reliabel jika memberikan nilai cronbach alpha > 0,60 (Ghozali, 2005) atau nilai cronbach alpha > 0,80 (Kuncoro, 2003).
2.8.2 Metode Analisis Data
Kualitas data yang digunakan sangat menentukan hasil atau kesimpulan yang diperoleh. Bila datanya berkualitas baik maka informasi yang akan diperoleh juga baik dan sebaliknya. Kualitas data ditentukan oleh akurasinya. Data yang tidak akurat ditunjukkan oleh adanya data pencilan (outliers). Data ini harus dibuang agar tidak merusak hasil. Selain itu juga diperlukan pemeriksaan normalitas data. Baberapa analisis data diantaranya sebagai berikut :
a. Analisis Deskriptif
atau penelitian demikian bisa jadi dalam bentuk studi kasus. Contoh bentuk penyajiannya adalah histogram, diagram pastel, dan sebagainya.
b. Analisis Parametrik Dan Nonparametrik
Pada dasarnya data statistik terbagi menjadi dua macam, yaitu statisitik parametrik dan statistik nonparametrik. Statistik parametrik dilakukan jika sampel yang akan dipakai berasal dari populasi yang berdistribusi normal. Jumlah data yang digunakan dalam analisis ini minimal 30 sampel dan menggunakan yang berupa data interval dan ratio. Sedangkan statistik non parametrik digunakan untuk menganalisis data yang jumlahnya dibawah 30 (sangat sedikit) serta datanya berupa data ordinal dan nominal. Disamping itu metode non parametrik tidak mengharuskan data berdistribusi normal, karena itu metode ini sering dinamakan uji distribusi bebas (distribution free test). Dengan demikian metode ini dapat dipakai untuk segala distribusi data dan lebih luas penggunaanya.
c. Analisis Hubungan
Analisis hubungan secara garis besar dibedakan menjadi analisis keeratan hubungan (korelasi), bentuk hubungan (regresi atau model aritmatika) dan analisis sebab akibat (analisis jalur atau path analisis, LISREL). Pada tulisan ini akan diuraikan kesesuaian setiap metode dengan jenis data berdasarkan skala pengukurannya. Disamping itu juga akan kelihatan kesetaraan berbagai metode analisis, misalnya parametrik dengan non parametrik.
d. Analisi Perbandingan (Komparatif)
Analisis perbandingan dapat dibedakan menjadi pembandingan satu populasi (terhadap nilai tertentu / standar yang dihipotesiskan), pembandingan dua populasi dan pembandingan lebih dari dua populasi. Disamping itu juga dibedakan menjadi parametrik dengan non parametrik, dan univariate dengan multivariat.
dalam suatu penelitian melibatkan banyak variabel dan antar variabel tersebut saling berkorelasi, maka analisis yang tepat adalah analisis peubah ganda (multivariat).
2.9 Analisis Regresi
Analisis regresi adalah teknik statstika yang berguna untuk memerikas dan memodelkan hubungan diantara variabel-variabel. Analisis regresi dapat digunakan untuk dua hal pokok, yaitu :
a. Untuk memperoleh suatu persamaan dari garis yang menunjukkan persamaan hubungan antara dua variabel. Persamaan dan garis yang dihasilkan bisa berupa persamaan garis bentuk linier maupun nonlinier.
b. Untuk menaksir suatu variabel yang disebut variabel tak bebas (terikat) dengan variabel lain yang disebut variabel bebas berdasarkan hubungan yang ditunjukkan persamaan regresi tersebut.
Berdasarkan amatan dan analisis data, penyelesaian regersi ini dapat berupa persamaan linier maupun nonlinier. Oleh karena itu analisis regresi ini terbagi atas regresi linier dan regresi nonlinier. Yang termasuk ke dalam regresi linier adalah regresi linier sederhana, regresi linier berganda, dan sebagainya. Ssedangkan yang termasuk regresi nonlinier adalah regresi model parabola kuadratik, model parabola kubik, model eksponen, model geometrik, regresi logistik, dan sebagainya.
2.10 Analisis Regresi Logistik
penjelas. Pada umumnya analisis regresi digunakan untuk menganalisis data dengan variabel respon berupa data kuantitatif. Akan tetapi sering juga ditemui kasus dengan variabel responnya bersifat kualitatif/kategori. Untuk mengatasi masalah tersebut maka dapat digunakan model regresi logistik.
Pendekatan model persamaan regresi logistik digunakan karena dapat menjelaskan hubungan antara variabel bebas dan peluangnya yang bersifat tidak linear, ketidaknormalan sebaran dari variabel terikat, serta keragaman respon yang tidak konstan dan tidak dapat dijelaskan oleh model regresi linear biasa (Agresti, 1990). Menurut Hosmer (1989), metode regresi logistik adalah suatu metode analisis statistika yang mendeskripsikan hubungan antara peubah respon yang memiliki dua kategori atau lebih dengan satu atau lebih peubah penjelas berskala kategori atau interval. Yang dimaksud dengan peubah kategorik yaitu peubah yang berupa data nominal dan ordinal.
Menurut Kleinbaum (1994) regresi logistik merupakan pendekatan model matematika yang dapat digunakan untuk menjelaskan hubungan antara beberapa variabel prediktor X terhadap variabel respon yang bersifat dikotomus atau biner Y. Model regresi logistik diperlukan pada saat data respon bersifat kategorik (variabel indikator) karena akan ada beberapa permasalahan yang muncul yang tidak memungkinkan untuk tetap menggunakan regresi klasik (Kutner et al., 2004)
Regresi logistik biner adalah salah satu metode statistika yang sering digunakan untuk mengklasifikasikan sejumlah pengamatan dengan respon biner ke dalam beberapa kelompok berdasarkan satu atau lebih variabel prediktor. Melalui metode ini akan dihasilkan peluang dari masingmasing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian dan suatu pengamatan akan masuk kedalam respon kategori tertentu berdasarkan nilai peluang yang terbesar.
(2001, hal: 217) regresi logistik cukup baik dan sering digunakan. Hal ini karena regresi logistik memiliki beberapa keuntungan dibandingkan regresi lainnya, yaitu :
1. Regresi logistik tidak memiliki asumsi normalitas atas variabel bebas yang digunakan dalam model. Artinya variabel penjelas tidak harus memiliki distribusi normal, linier, maupun memiliki varian yang sama dalam setiap group.
2. Variabel dalam regresi logistik dapat berupa campuran dari variabel kontinyu, diskrit, dan dikotomis.
3. Regresi logistik amat bermanfaat digunakan apabila distribusi respon atas variabel terikat diharapkan non linier dengan satu atau lebih variabel bebas.
Adapun bentuk umum regresi logistik tersebut adalah :
)
2.10.1 Uji Model Persamaan Regresi Logistik
H0 : ( )
Untuk menguji hipotesis digunakan model Hosmer and Lemeshow’s goodness
of fit test. Jika nilai Hosmer and Lemeshow’s goodness of fit test statistik sama dengan atau kurang dari 0,05, maka hipotesis nol ditolak yang berari ada perbedaan
signifikan antara model dengan nilai observasinya atau goodness fit model tidak baik, karena model tidak dapat memprediksi nilai observasinya. Jika nilai statistik Hosmer and Lemeshow’s goodness of fit lebih besar dari 0,05, maka hipotesis nol diterima dan berarti model mampu memprediksikan nilai obsevasinya atau dapat dikatakan model cocok dengan observasinya (Ghozali, 2001:218).
2.10.2 Negelkerke R 2
Nilai Negelkerke R2 ini akan menunjukkan seberapa besar variabel-variabel bebas
penelitian ini menjelaskan variabel terikatnya. Nilai Negelkerke R2 biasanya dibentuk dalam persen agar dapat mengetahui dengan pasti seberapa jauh penjelasan variabel-variabel bebas terhadap variabel-variabel terikatnya.
2.10.3 Odds Rasio
Odds ratio didefinisikan sebagai perbandingan dari nilai variabel sukses terhadap variabel bernilai gagal. Dengan kata lain odds rasio menjelaskan seberapa besar
BAB 3
PEMBAHASAN
3.1 Gambaran Umum
Rumah sakit merupakan rujukan pelayanan kesehatan untuk pusat kesehatan masyarakat, terutama upaya penyembuhan dan pemulihan, sebab rumah sakit memiliki fungsi utama menyelenggarakan upaya kesehatan yang bersifat penyembuhan dan pemulihan bagi penderita. Rumah sakit terutama rumah sakit milik pemerintah harus dapat menjadi sarana kesehatan bagi masyarakat luas. Pelayanan kesehatan yang diberikan harus berkualitas agar memuaskan masyarakat sebagai konsumen (Siregar, 2003).
Rowland juga menyatakan bahwa rumah sakit adalah tempat dimana orang sakit mencari dan menerima pelayanan kedokteran serta tempat dimana pendidikan klinik untuk mahasiswa kedokteran, perawat, dan berbagai tenaga profesi kesehatan lainnya diselenggarakan. (Rowland, 1984). Keputusan masyarakat untuk berobat ke rumah sakit dipengaruhi oleh beberapa faktor. Faktor-faktor tersebut merupakan variabel bebas yang mempengaruhi variabel terikat dalam penelitian. Berikut akan dikemukakan faktor-faktornya. Selain itu juga akan diberikan definisi operasional dari tiap-tiap variabel bebas dan variabel terikatnya :
a. Individu (X ) adalah predisposisi atau kecenderungan yang dipelajari dari 1
seorang individu untuk merespon secara positif atau negatif dengan intensitas yang moderat dan atau memadai terhadap objek, situasi, konsep, atau orang lain (Aiken, 1970).
b. Komunikasi (X ) adalah proses penyampaian pesan oleh seseorang kepada 2
baik secara lisan (langsung) ataupun tidak langsung (melalui media) (Onong Cahyana Effendi, 2001).
c. Fasilitas (X ) adalah kelengkapan dalam suatu instansi yang dalam 3
penelitian ini adalah rumah sakit.
d. Paramedis (X ) adalah orang yang bekerja di lingkungan kesehatan. 4
e. Pendapatan (X ) adalah jumlah rata-rata penghasilan perbulan dalam 5
enam bulan terakhir yang diperoleh sesorang (dalam rupiah).
f. Tingkat Pendidikan (X ) adalah jenjang pendidikan formal responden 6
yang tertinggi.
g. Keputusan Berobat (Y) adalah kemampuan dalam proses pengambilan keputusan yang optimal melalui analisa menyeluruh terhadap suatu informasi mengenai pengobatan dan tempatnya.
3.2 Pengumpulan Data
3.2.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data primer yang bersumber dari hasil wawancara terstruktur terhadap responden dengan menggunakan kuesioner. Responden pada penelitian adalah pasien RSU Mitra Sejati Medan. Dibawah ini adalah data yang diperoleh dari penelitian dan untuk mempermudah analisa selanjutnya data akan ditandai dengan nomor respondennya saja.
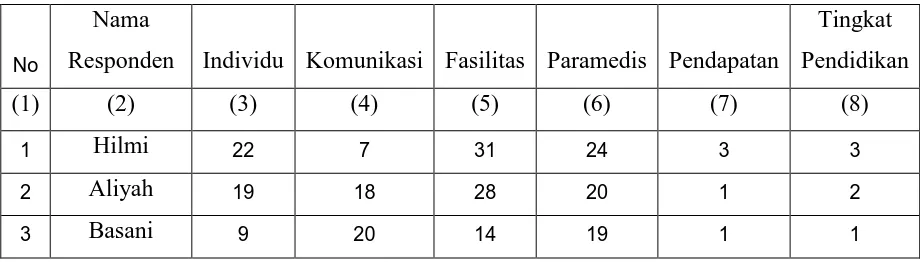
Tabel 3.1 Tabel Karakteristik Pasien
No
Nama
Responden Individu Komunikasi Fasilitas Paramedis Pendapatan
Tingkat Pendidikan
(1) (2) (3) (4) (5) (6) (7) (8)
1 Hilmi 22 7 31 24 3 3
2 Aliyah 19 18 28 20 1 2
(1) (2) (3) (4) (5) (6) (7) (8) pada populasi ini dibatasi pada pasien yang masih dapat diajak berkomunikasi (tidak dalam keadaan sekarat), bukan merupakan pasien rujukan, dan bukan pasien dadakan (menjadi pasien karena berada di lokasi rumah sakit tersebut). Penentuan sampel menggunakan sampel secara acak (simple random sampling). Adapun rumusan metode tersebut sebagai berikut :
Dengan :
Berdasarkan rumusan tersebut diperoleh jumlah sampel sebagai berikut :
Dengan α = 0.5 sehingga diperoleh
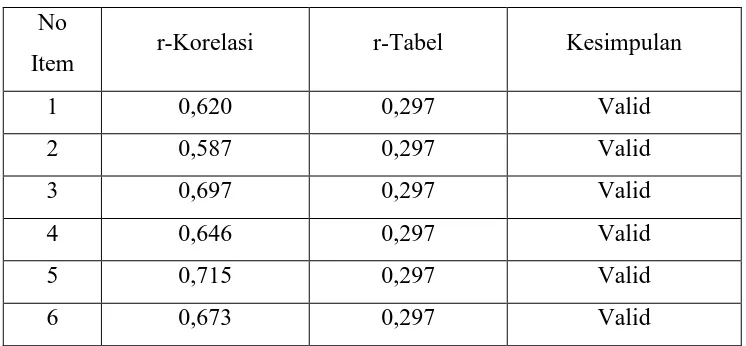
Tabel 3.2 Uji Validitas Variabel Individu
No
Item r-Korelasi r-Tabel Kesimpulan
1 0,620 0,297 Valid
2 0,587 0,297 Valid
3 0,697 0,297 Valid
4 0,646 0,297 Valid
5 0,715 0,297 Valid
6 0,673 0,297 Valid
Dari hasil uji validitas diatas terlihat bahwa seluruh butir item pertanyaan dinyatakan valid, karena nilai r-korelasinya lebih besar dari 0,297. Selanjutnya dapat dilanjutkan uji reliabilitas.
b. Variabel Komunikasi (X ) 2
Berdasarkan kuesioner yang diberikan pada sampel contoh, terdapat lima butir pertanyaan yang valid. Sama halnya seperti pada variabel individu, pengujian terhadap variabel komunikasi ini juga dilakukan pada 23 responden. Setelah dilakukan uji validitas dengan bantuan program SPSS diperoleh hasil sebagai berikut :
Tabel 3.3 Uji Validitas Variabel Komunikasi
No Item r-Korelasi r-Tabel Kesimpulan
1 0,678 0,297 Valid
2 0,730 0,297 Valid
3 0,656 0,297 Valid
4 0,621 0,297 Valid
Tabel uji validitas diatas memperlihatkan bahwa kelima item pertanyaan dinyatakan valid, karena nilai r-korelasinya lebih besar dari 0,297. Untuk selanjutnya dapat dilakukan uji reliabilitas.
c. Variabel Fasilitas (X ) 3
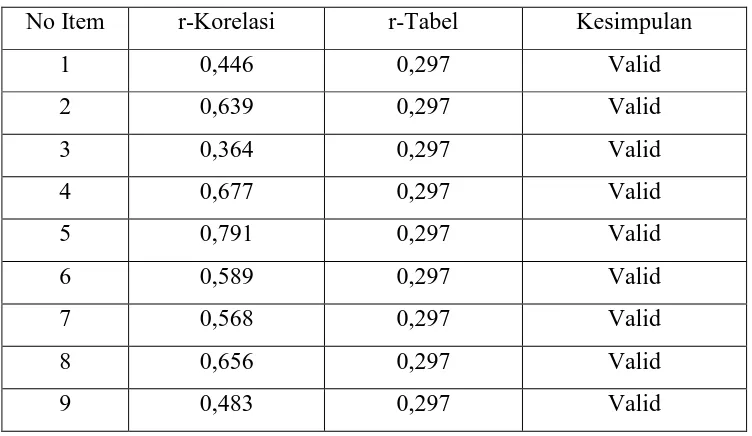
Berdasarkan kuesioner yang diberikan pada sampel contoh, terdapat sembilan butir pertanyaan yang valid. Pengujian ini juga dilakukan terhadap 23 responden. Setelah dilakukan uji validitas dengan bantuan program SPSS diperoleh hasil sebagai berikut :
Tabel 3.3 Uji Validitas Variabel Fasilitas
No Item r-Korelasi r-Tabel Kesimpulan
1 0,446 0,297 Valid
2 0,639 0,297 Valid
3 0,364 0,297 Valid
4 0,677 0,297 Valid
5 0,791 0,297 Valid
6 0,589 0,297 Valid
7 0,568 0,297 Valid
8 0,656 0,297 Valid
9 0,483 0,297 Valid
Dari hasil uji validitas diatas terlihat bahwa seluruh butir item pertanyaan dinyatakan valid, karena nilai r-korelasinya lebih besar dari 0,297. Selanjutnya dapat dilanjutkan uji reliabilitas.
d. Variabel Paramedis (X ) 4
pengujian terhadap variabel paramedis ini juga dilakukan kepada 23 responden. Setelah dilakukan uji validitas dengan bantuan program SPSS diperoleh hasil sebagai berikut :
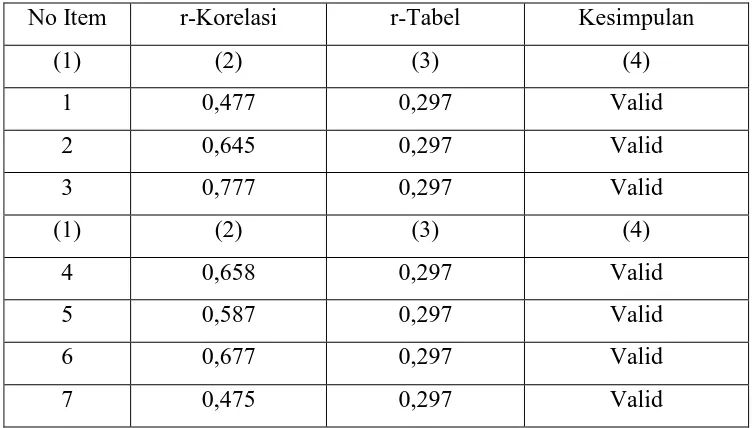
Tabel 3.4 Uji Validitas Variabel Paramedis
No Item r-Korelasi r-Tabel Kesimpulan
(1) (2) (3) (4)
1 0,477 0,297 Valid
2 0,645 0,297 Valid
3 0,777 0,297 Valid
(1) (2) (3) (4)
4 0,658 0,297 Valid
5 0,587 0,297 Valid
6 0,677 0,297 Valid
7 0,475 0,297 Valid
Tabel uji validitas diatas memperlihatkan bahwa ketujuh item pertanyaan dinyatakan valid, karena nilai r-korelasinya lebih besar dari 0,297. Untuk selanjutnya dapat dilakukan uji reliabilitas.
3.3.2 Uji Reliabilitas
a. Variabel Individu (X ) 1
Tabel 3.5 Uji Reliablitas Variabel Individu
No Item Alpha Cronbach Kesimpulan
1 0,837 Reliabel
2 0,834 Reliabel
3 0,814 Reliabel
4 0,828 Reliabel
5 0,810 Reliabel
6 0,826 Reliabel
Berdasarkan tabel diatas terlihat bahwa seluruh butir item pertanyaan reliabel karena tiap butir item tersebut memberikan nilai alpha cronbach yang lebih besar dari 0,80.
Sehingga dapat disimpulkan bahwa pertanyaan pada kuesioner variabel individu (X ) 1
adalah reliabel.
b. Variabel Komunikasi (X ) 2
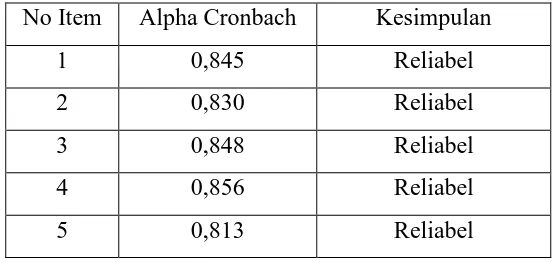
Tabel 3.6 Uji Reliabilitas Variabel Komunikasi
No Item Alpha Cronbach Kesimpulan
1 0,845 Reliabel
2 0,830 Reliabel
3 0,848 Reliabel
4 0,856 Reliabel
5 0,813 Reliabel
c. Variabel Fasilitas (X ) 3
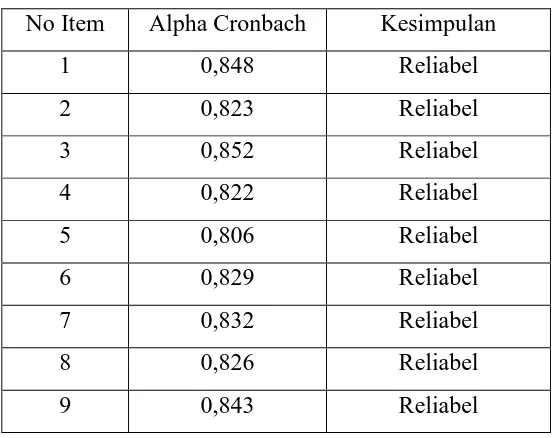
Tabel 3.7 Uji Reliabilitas Variabel Fasilitas
No Item Alpha Cronbach Kesimpulan
1 0,848 Reliabel
2 0,823 Reliabel
3 0,852 Reliabel
4 0,822 Reliabel
5 0,806 Reliabel
6 0,829 Reliabel
7 0,832 Reliabel
8 0,826 Reliabel
9 0,843 Reliabel
Berdasarkan tabel diatas terlihat bahwa seluruh butir item pertanyaan reliabel karena tiap butir item tersebut memberikan nilai alpha cronbach yang lebih besar dari 0,80.
Sehingga dapat disimpulkan bahwa pertanyaan pada kuesioner variabel fasilitas (X ) 3
adalah reliabel.
d. Variabel Paramedis (X ) 4
Tabel 3.8 Uji ReliabilitasVariabel Paramedis
No Item Alpha Cronbach Kesimpulan
1 0,842 Reliabel
2 0,819 Reliabel
3 0,803 Reliabel
4 0,817 Reliabel
5 0,827 Reliabel
6 0,817 Reliabel
Berdasarkan tabel diatas terlihat bahwa seluruh butir item pertanyaan reliabel karena tiap butir item tersebut memberikan nilai alpha cronbach yang lebih besar dari 0,80. Sehingga dapat disimpulkan bahwa pertanyaan pada kuesioner variabel paramedis (X ) adalah reliabel. 4
3.4 Analisis Data
3.4.1 Analisa Tipe Data
Data variabel independen pada penelitian ini terdiri atas dua tipe data. Data variabel individu, variabel komunikasi, variabel fasilitas, serta variabel paramedis pada variabel independen adalah data interval. Data ini diperoleh berdasarkan pengukuran variabel-variabel indikator yang berupa item-item pertanyaan menuju suatu variabel latennya dengan menggunakan skala likert. Sedangkan dua variabel independen lainnya, yaitu variabel pendapatan dan variabel tingkat pendidikan merupakan data ordinal. Selain itu diketahui juga bahwa data variabel dependen pada penelitian ini yang merupakan keputusan berobat pasien adalah tipe data nominal.
Karena perbedaan tipe data pada variabel-variabel tersebut, maka perlu adanya transformasi tipe data. Pada kasus ini tipe data variabel yang akan dirubah adalah variabel independen. Data pada variabel individu, variabel komunikasi, variabel fasilitas, serta variabel paramedis yang berupa data interval akan dirubah menjadi tipe data ordinal. Sedangkan dua variabel lainnya pada variabel independen, yaitu variabel pendapatan dan variabel tingkat pendidikan tidak mengalami perubahan tipe data (tetap dalam tipe data ordinal). Transformasi tipe data ini mengikuti ketentuan-ketentuan untuk setiap variabelnya. Tiap variabel akan terbagi ke dalam tiga kategori, yaitu 0 untuk kategori rendah, 1 untuk kategori sedang, dan 2 untuk kategori tinggi. Sedangkan kriteria penggolongan data ke dalam kategori itu sendiri bergantung pada jumlah skor hasil pengisian kuesioner setiap variabelnya.
dan akan digolongakan ke dalam kategori sedang (1) jika jumlah skor responden berkisar pada nilai 11 sampai 20. Sedangkan penggolongan data menjadi kategori tinggi (2) terjadi apabila jumlah skor responden berada pada rentang nilai 21 sampai 30.
Variabel kedua adalah variabel komunikasi dengan lima item pertanyaan. Data akan digolongkan ke dalam kategori rendah (0) apabila jumlah skor responden kurang dari 9 (jumlah skor ≤ 8), dan akan digolongakan ke dalam kategori sedang (1) jika jumlah skor responden berkisar pada nilai 9 sampai 17. Sedangkan penggolongan data menjadi kategori tinggi (2) terjadi apabila jumlah skor responden berada pada rentang nilai 18 sampai 25.
Variabel selanjutnya adalah variabel fasilitas dengan sembilan pertanyaan. Penggolongan data ke dalam kategori rendah terjadi jika jumlah skor responden kurang dari 16 (jumlah skor ≤ 15). Sedangkan penggolongan kategori sedang adalah jika jumlah skor responden berkisar pada nilai 16 sampai 30, dan kategori tinggi pada rentang nilai 31 sampai 45.
Variabel terakhir yang mengalami transformasi tipe data adalah variabel paramedis. Variabel ini memiliki tujuh pertanyaan dan akan digolongkan ke dalam kategori rendah (0) apabila jumlah skor responden kurang dari 12 (jumlah skor ≤ 11). Sedangkan penggolongan data menjadi kategori sedang (1) terjadi pada jumlah skor responden berkisar pada nilai 12 sampai 24, dan kategori tinggi (2) apabila jumlah skor responden berada pada rentang nilai 18 sampai 25. Berikut ini adalah tabel karakteristik pasien sebelum dan sesudah mengalami transformasi tipe data :
Tabel Karakteristik Pasien
No
Responden Individu Komunikasi Fasilitas Paramedis Pendapatan
Tingkat Pendidikan
(1) (2) (3) (4) (5) (6) (7)
1 22 7 31 24 3 3
(1) (2) (3) (4) (5) (6) (7)
34 23 23 38 30 0 3
35 21 23 32 26 1 2
36 27 21 39 33 2 3
37 15 14 26 19 0 3
38 21 22 40 23 2 3
39 20 18 29 24 3 2
40 21 23 32 33 3 4
41 15 22 29 24 1 3
42 19 13 25 27 2 2
43 11 18 28 16 1 1
44 9 13 37 29 1 2
45 23 10 32 26 2 3
46 24 21 40 30 3 3
47 10 21 37 27 1 1
48 24 22 38 29 2 3
49 24 23 35 28 2 3
50 20 20 34 28 2 3
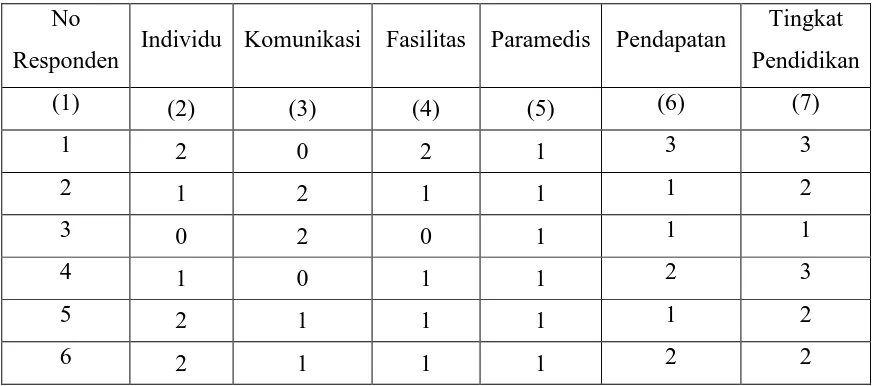
Tabel 3.9 Tabel Transformasi Karakteristik Pasien
No
Responden Individu Komunikasi Fasilitas Paramedis Pendapatan
Tingkat Pendidikan
(1) (2) (3) (4) (5) (6) (7)
1 2 0 2 1 3 3
2 1 2 1 1 1 2
3 0 2 0 1 1 1
4 1 0 1 1 2 3
5 2 1 1 1 1 2
(1) (2) (3) (4) (5) (6) (7)
3.4.2 Menganalisis Data Menggunakan Program SPSS
Setelah transformasi tipe data variabel-variabel independen, untuk selanjutnya dapat dilakukan analisis regresi untuk mengetahui pengaruh tiap-tiap variabel independen terhadap variabel dependennya. Karena variabel dependennya berskala nominal, maka proses analisisnya dilakukan dengan menggunakan regresi logistik. Adapun bentuk persamaan regresi logistik tersebut adalah :
2
X = variabel komunikasi
3
X = variabel fasilitas
4
X = variabel paramedis
5
X = variabel pendapatan
6
X = variabel tingkat pendidikan
Proses analisis data dilakukan dengan menggunakan program SPSS. Hasil analisis data dapat dilihat pada lampiran di halaman belakang.
3.5 Menafsirkan Hasil Analisis Data
3.5.1 Persamaan Regresi Logistik
Berdasarkan hasil analisis data menggunakan SPSS diperoleh sebagai berikut :
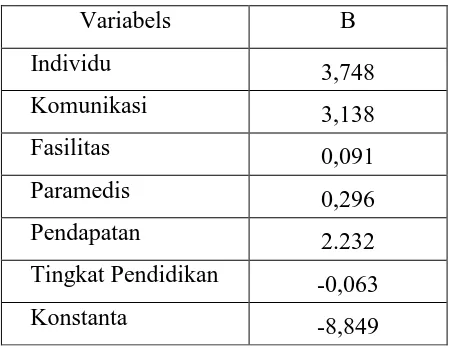
Tabel 3.10 Tabel Nilai Variabel
Variabels B
Individu 3,748
Komunikasi 3,138
Fasilitas 0,091
Paramedis 0,296
Pendapatan 2.232
Tingkat Pendidikan -0,063
Konstanta -8,849
a) Variabel Individu (β1 = 3,748)
Dari nilai ini dapat disimpulkan bahwa jika variabel komunikasi (X ), variabel 2
fasilitas (X ), variabel paramedis (3 X4), variabel pendapatan (X ), dan variabel 5
tingkat pendidikan (X ) dianggap konstan maka akan meningkatkan keputusan 6
masyarakat untuk berobat ke RSU Mitra Sejati sebesar 3,748. b) Variabel Komunikasi (β2 = 3,138)
Artinya bahwa jika variabel individu (X ), variabel fasilitas (1 X ), variabel 3
paramedis (X4), variabel pendapatan (X ), dan variabel tingkat pendidikan (5 X ) 6
dianggap konstan maka akan meningkatkan keputusan masyarakat untuk berobat ke RSU Mitra Sejati sebesar 3,138.
c) Variabel Fasilitas (β3 = 0,091)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel paramedis (2 X4), variabel pendapatan (X ), dan 5
variabel tingkat pendidikan (X ) dianggap konstan maka akan meningkatkan 6
keputusan masyarakat untuk berobat ke RSU Mitra Sejati sebesar 0,091. d) Variabel Paramedis (β4 = 0,296)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel fasilitas (2 X ), variabel pendapatan (3 X ), dan variabel 5
tingkat pendidikan (X ) dianggap konstan maka akan meningkatkan keputusan 6
masyarakat untuk berobat ke RSU Mitra Sejati sebesar 0,296.
e) Variabel Pendapatan (β5 = 2.232)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel fasilitas (2 X ), variabel paramedis (3 X4), dan variabel
tingkat pendidikan (X ) dianggap konstan maka akan meningkatkan keputusan 6
masyarakat untuk berobat ke RSU Mitra Sejati sebesar 2.232. f) Variabel Tingkat Pendidikan (β6 = -0,063)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
pendapatan (X ), dianggap konstan maka akan menurunkan keputusan 5
masyarakat untuk berobat ke RSU Mitra Sejati sebesar 0,063.
Berdasarkan nilai-nilai koefisien hasil analisis tersebut dengan segera didapatkan model persamaan logistik penelitian ini, yaitu :
)
p(x) = peluang memutuskan berobat ke Rumah Sakit
1
3.5.2 Uji Model Persamaan Regresi Logistik
Uji ini sering disebut juga sebagai uji ketepatan model. Uji ini digunakan untuk mengatahui apakah model regresi logistk sudah sesuai dengan data observasi yang diperoleh. Untuk menilai ketepatan model regresi logistik dalam penelitian ini diukur dengan nilai chi square dengan uji Hosmer dan Lemeshow. Pengujian ini akan melihat nilai goodness of fit test yang diukur dengan nilai chi square pada tingkat signifikansi 5%. Adapun model pengujiannya adalah sebagai berikut :
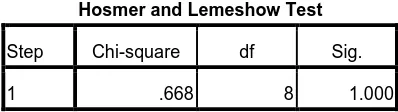
Agar dapat membandingkannya dengan nilai chi square pada uji Hosmer dan Lemeshow, berikut akan diberikan tabel Hosmer dan Lemeshow hasil analisis data penelitian ini :
Tabel 3.11 Tabel Hosmer dan Lemeshow
Hosmer and Lemeshow Test
Step Chi-square df Sig.
1 .668 8 1.000
Berdasarkan tabel diatas diperoleh bahwa nilai chi square adalah 0,668. Angka
tersebut lebih besar dari 0,05, sehingga H0 diterima. Hal ini berarti model regresi
logistik tersebut sesuai dengan data.
3.5.3 Negelkerke R 2
Nilai Negelkerke R ini akan menunjukkan seberapa besar variabel-variabel bebas 2
penelitian ini menjelaskan variabel terikatnya. Untuk dapat membandingkannya
berikut diberikan tabel nilai Negelkerke R hasil analisa data penelitian : 2
Tabel 3.12 Tabel Negelkerke R 2
Model Summary
Step -2 Log likelihood
Cox & Snell R
Square
Nagelkerke R
Square
1 14.518a .358 .689
Dari tabel diatas diperoleh nilai Negelkerke R adalah 0,689. Ini menunjukkan 2
bahwa variabel individu (X ), variabel komunikasi (1 X ), variabel fasilitas (2 X ), 3
variabel paramedis (X4), variabel pendapatan (X ), dan variabel tingkat pendidikan 5
Sejati Medan sebesar 69%. Bisa dikatakan bahwa variabel-variabel bebas tersebut sudah menjelaskan 70% terhadap variabel terikatnya dan sisanya dijelaskan oleh variabel-variabel lain diluar model.
3.5.4 Odds Rasio
Selain itu hasil analisis data juga mengahasilkan nilai odds rasio untuk masing-masing variabel bebas persamaan. Berikut ini adalah tabel odds rasio hasil analisis data penelitian :
Tabel 3.13 Tabel Odds Rasio
Variabels Exp (B)
Individu 42,451
Komunikasi 23,052
Fasilitas 1,095
Paramedis 1,345
Pendapatan 9,317
Tingkat Pendidikan 0,939
Konstanta 0,000
Berdasarkan tabel diatas dapat disimpulkan sebagai berikut :
a) Variabel Individu (Exp (B) = 42,451)
Dari nilai ini dapat disimpulkan bahwa jika variabel komunikasi (X ), variabel 2
fasilitas (X ), variabel paramedis (3 X4), variabel pendapatan (X ), dan variabel 5
tingkat pendidikan (X ) dianggap konstan maka kepercayaan individu yang baik 6
b) Variabel Komunikasi (Exp (B) = 23,052)
Artinya jika variabel individu (X ), variabel fasilitas (1 X ), variabel paramedis 3
(X4), variabel pendapatan (X ), dan variabel tingkat pendidikan (5 X ) dianggap 6
konstan maka komunikasi yang baik mengenai RSU Mitra Sejati Medan akan mempengaruhi responden untuk berobat ke rumah sakit tersebut 23 kali lebih besar dibandingkan dengan komunikasi yang buruk.
c) Variabel Fasilitas (Exp (B) = 1,095)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel paramedis (2 X4), variabel pendapatan (X ), dan 5
variabel tingkat pendidikan (X ) dianggap konstan maka fasilitas RSU Mitra 6
Sejati Medan yang lengkap akan mempengaruhi responden untuk berobat ke rumah sakit tersebut 1 kali lebih besar dibandingkan dengan fasilitas yang kurang lengkap.
d) Variabel Paramedis (Exp (B) = 1,345)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel fasilitas (2 X ), variabel pendapatan (3 X ), dan variabel 5
tingkat pendidikan (X ) dianggap konstan maka faktor paramedis RSU Mitra 6
Sejati Medan yang baik akan mempengaruhi responden untuk berobat ke rumah sakit tersebut 1 kali lebih besar dibandingkan dengan paramedis yang buruk. e) Variabel Pendapatan (Exp (B) = 9,317)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel fasilitas (2 X ), variabel paramedis (3 X4) dan variabel
tingkat pendidikan (X ) dianggap konstan maka pendapatan yang besar akan 6
mempengaruhi responden untuk berobat ke RSU Mitra Sejati Medan 9 kali lebih besar dibandingkan dengan pendapatan yang kecil.
f) Variabel Tingkat Pendidikan (Exp (B) = 0,939)
Dari nilai ini dapat disimpulkan bahwa jika variabel individu (X ), variabel 1
komunikasi (X ), variabel fasilitas (2 X ), variabel paramedis (3 X4), dan variabel
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil penelitian di RSU Mitra Sejati Medan, maka dapat diambil
kesimpuan bahwa :
1. Pengaruh masing-masing variabel bebas terhadap terhadap variabel terikat
yaitu keputusan berobat masyarakat ke RSU Mitra Sejati Medan adalah
berturut-turut adalah variabel individu sebesar 3,748; variabel komunikasi
sebesar 3,138; variabel fasilitas sebesar 0,091; variabel paramedis sebesar
0,296; variabel pendapatan sebesar 2,232; variabel tingkat pendidikan
sebesar -0.063.
2. Berdasarkan hasil analisis data diketahui bahwa pengaruh terbesar ada
pada variabel individu, yaitu sebesar 3,748. Dapat disimpulkan bahwa
faktor individu paling mempengaruhi keputusan masyarakat dalam berobat
ke RSU Mitra Sejati Medan. Hal ini juga dapat dilihat dari nilai odds rasio
variabel individu yang menunjukkan bahwa keputusan berobat masyarakat
dapat meningkatkan 42 kali lebih besar.
3. Variabel komunikasi menempati urutan kedua setelah variabel individu
dalam hal meningkatkan keputusan berobat ke rumah sakit tersebut,
mempengaruhi responden untuk berobat ke rumah sakit tersebut 23 kali
lebih besar dibandingkan dengan komunikasi yang buruk.
4. Pengaruh variabel lain diluar model terhadap keputusan berobat ke RSU
Mitra Sejati sebesar 0,311.
4.2 Saran
1. Pihak Rumah Sakit diharapkan lebih memfokuskan pada peningkatan
kualitas agar citra baik Rumah Sakit dapat terus terjaga bahkan meningkat
sehingga menimbulkan kepercayaan yang tinggi dari masyarakat. Selain
itu juga diharapkan untuk meningkatkan sosialisasi Rumah Sakit, agar
keberadaan serta pelayanan Rumah Sakit ini dapat diketahui masyarakat
luas.
2. Diharapkan pada peneliti selanjutnya untuk dapat mencari faktor-faktor lain