KAJIAN PENERAPAN JARINGAN SYARAF TIRUAN
DALAM METODE KUADRAT TERKECIL PARSIAL
OLEH : RUSLAN
PROGRAM PASCASARJANA
INSTITUT PERTANIAN BOGOR
"Sesuqjyuhnya setehh &&tan
ad2
~mulibliaq
sesunaguhn. setehh &nrCitan
ad2 ~m&han."
~endzsan
ini saya persem6ahkan untuk
ABSTRAK
RUSLAN. Kajian Penerapan Jaringan Syaraf Tiruan dalam Metode Kuadrat Terkecil Parsial. Dibimbing oleh AJI HAMIM WIGENA dan ASEP SAEFUDDIN.
SURAT PERNYATAAN
Dengan ini saya menyatakan bahwa tesis yang berjudul :
KAJIAN PENERAPAN JARINGAN SYARAF TIRUAN DALAM METODE KUADRAT TERKECIL PARSIAL
adaiah benar merupakan hasil karya saya sendiri dan belum pernah dipublikasikan.
Semua sumber data dan informasi yang digunakan telah dinyatakan secara jelas dan
dapat diperiksa kebenarannya.
Bogor, 5 Juni 2002
KAJIAN PENERAPAN JARINGAN SYARAF TIRUAN
DALAM METODE KUADRAT TERKECIL PARSIAL
OLEH
:RUSLAN
Tesis
sebagai salah satu syarat untuk memperoleh gelar
Magister Sains pada
Program Studi Statistika
PROGRAM PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul : Kajian Penerapan Jaringan Syaraf Tiruan dalam
Metode Kuadrat Terkecil Parsiai
Nama Mahasiswa : Ruslan
Nomor Poltok : 98124
Program Studi : Stat,istil<a
Menyetujui
,
1. Komisi Pembimbing
1r.H. A.ji Hamim Wigena
,
M.Sc. Dr. Ir. Asep Saefuddin,
M.Sc.Ketua Anggo ta
1 1 JUN 2002
RIWAYAT HIDUP
Penulis dilahirkan di Bandung, Propinsi Jawa Barat pada tanggal 14 Agustus
1974 oleh seorang ibu yang bernarna Tjutju Surtini (Almah) dan Ayah Abas, sebagai
anak ketujuh dari tujuh saudara.
Pendidikan formal yang penulis tempuh sebagai berikut :
1. Sekolah Dasar di SD Negeri Tilil I Bandung lulus tahun 1986
2. Sekolah Menengah Pertama Negeri 2 Bandung lulus tahun 1989
3. Sekolah Menengah Atas Negeri 14 Bandung lulus tahun 1992
4. Pendidikan Sarjana Statistika Universitas Padjadjaran Bandung lulus tahun
1997
Penulis mendapatkan beasiswa DUE Project untuk melanjutkan pendidikan di
Program Pascasarjana IPB pada tahun 1998, dan ditugaskan oleh DIKTI dan diangkat
PRAKATA
Segala puji bagi Allah SWT yang masih berkenan memberikan karunia dan
rahmat-Nya sehingga penelitian dalam rangka penulisan tesis yang berjudul " Kajian
Penerapan Jaringan Syaraf Tiruan Dalam Metode Kuadrat Terkecil Parsial" dapat
diselesaikan.
Penelitian ini merupakan pengenalan metode yang bernama Artificial Neural Network dan penerapannya dalam metode Statistika.
Penelitian ini tidak terlepas dari bantuan berbagai pihak, oleh karena itu dalam
kesempatan ini disampaikan terimakasih kepada :
1. Bapak 1r.H. Aji Hamim Wigena , M.Sc. dan Dr. Ir. Asep Saefbddin
,
M.Sc.selaku komisi pembimbing yang telah mencurahkan waktu, tenaga dan
pikirannya selama ini.
2. Bapak Dr.Ir. Budi Susetyo, M.S. selaku ketua Program Studi Statistika
Pascasarj ana IPB.
3. Para staf Dosen Pengajar Program Studi Statistika Pascasarjana IPB yang
telah memberikan ilmu statistika.
4. Orangtua, kakak-kakak, terimakasih atas segala perhatian dan
pengorbanannya sehingga penulis mampu melewati saat-saat sulit.
5. Teman-teman yang telah menemani dalam suka maupun duka selama ,-
6. Intan, Heni Silva.L., Olivia, Shinta terimakasih atas do'a dan dukungannya
sehingga penulis mampu melewati saat-saat sulit.
7. Dan berbagai pihak lain yang tidak dapat disebut satu persatu.
Penulisan ini telah dilakukan secara maksimal, tetapi penulis menyadari masih
terdapat banyak kekurangan. Oleh karena itu kritik dan saran selalu karni harapkan
dan akan diterima senang hati.
Bogor, Mei 2002
DAFTAR IS1
Halaman
DAFTAR TABEL
...
xiDAFTAR
GAMBAR
...
xii...
DAFTAR LAMPIRAN ... xi11
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 2
TINJAUAN PUSTAKA ... 3
...
Metode Kuadrat Terkecil Parsial 3
...
Algoritma Metode Kuadrat Terkecil Parsial 4
Jaringan Syaraf Tiruan ... 5
...
Algoritma Pembelajaran Propagasi Balik 9
...
Pemeriksaan Pembelajaran dalam Jaringan Syaraf Tiruan 13
...
Metode Pembelajaran Gradien Descent 14
Metode NNPLS ... 15
Algoritma NNPLS ... 16
METODE PENELITIAN ... 18
Data ... 18
Metodologi ... 18
HASIL DAN PEMBAHASAN ... 19
...
Penentuan banyaknya komponen dengan Validasi Silang 19
...
Penentuan pendugaan dengan MKTP 20
...
Penentuan pendugaan dengan NNPLS 21
Perbandingan RMSE antara MKTP dengan NNPLS ... 23
KESIMPULAN ... 24
SARAN ... 24
DAFTAR PUSTAKA ... 25
DAFTAR TABEL
Halaman
... 1 . Hasil Prosedur Silang untuk menentukan banyaknya komponen h 19
...
2 . Persentase Variasi yang dihasilkan untuk menjelaskan variasi peubah 20
...
DAFTAR
GAMBAR
Halaman
1 . Skema Algoritma MKTP ... 5 2 . Struktur sel syaraf ... 7
3
.
Skema arsitektur dari jaringan syaraf tiruan untuk satu output ... 84 . Skema Algoritma NNPLS ... 17
DAFTAR LAMPIRAN
Halaman
1 . Tabel data Sekunder Flourense ... 27
[image:87.580.75.532.69.714.2]2 . Korelasi antar peubah data Flourense ... 32
...
3 . Makro Program untuk Metode NNPLS 34
... 4 . Tabel vektor u dan t hasil metode MKTP linier 42
...
5 . Tabel hasil Y prediksi untuk metode MKTP 44
6 . Tabel vektor u dan t hasil dari NNPLS
...
45... 7 . Tabel vektor u dan t untuk metode internal Neural Network 47
...
8 . Tabel hasil Y prediksi untuk metode NNPLS 49
. ...
9 Tabel antilogaritma hasil Y prediksi untuk MKTP 50
...
.
PENDAHULUAN
Latar Belakang
Suatu pendekatan analisis statistika dapat digunakan terhadap data dengan asumsi
yang sesuai. Salah satunya adalah Analisis Regresi Ganda dengan kendala bahwa :
(1) jumlah peubah relatif sedikit, (2) tidak ada kolinieritas antar peubah penjelas, dan
(3) peubah penjelas berhubungan erat dengan peubah respon. Analisis Regresi Ganda
digunakan untuk mengetahui model hubungan antara peubah respon dengan peubah-
peubah penjelas yang sesuai dengan asumsinya (Tobias, 1995).
Jika jumlah peubah penjelas maupun peubah respon besar, tetapi jumlah
pengamatan lebih kecil daripada jumlah peubah penjelas, serta ada korelasi antar peubah,
maka analisis regresi tersebut tidak menghasilkan model yang kekar. Pendekatan yang
sesuai adalah Metode Kuadrat Terkecil Parsial (MKTP). MKTP dapat mengatasi peubah
penjelas yang berkorelasi serta jumlah pengamatan terbatas, tetapi hanya mampu
mengatasi data dengan informasi yang linier, sehingga diperlukan suatu pendekatan yang
dapat memodelkan hubungan nonlinier (kenonlinieran dapat ditunjukan pada plot antara
vektor skor u dan vektor skor t) . Pendekatannya adalah mengintegrasikan MKTP dengan
metode Jaringan Syaraf Tiruan (Artzficial Neural Network) yang mampu mengatasi
kenonlinieran.
Metode Jaringan Syaraf Tiruan merupakan suatu pendekatan nonlinier yang *
dapat memodelkan hubungan antara peubah respon dengan peubah penjelas. Namun
pengamatan terbatas, pendekatan yang dilakukan akan mengarah pada overfitting (Qin & McAvoy, 1992).
Untuk mengatasi masalah - masalah tersebut diperlukan suatu pendekatan yang
dapat mengintegrasikan MKTP dengan metode Jaringan Syaraf Tiruan, yaitu metode
Neural Network Parsial Least Square W L S ) .
Dalarn penggunaannya, model jaringan syaraf banyak dilakukan pada berbagai
bidang, khususnya dalam statistika , dalam Analisis Gerombol dan Diskriminan, Analisis
Regresi, Analisis Deret Waktu, dan Pemodelan Bayes (Cheng & Titterington, 1994).
Tujuan Penelitian
Berdasarkan latar belakang yang telah dikemukakan, tujuan penelitian ini adalah
mengkaji penerapan metode Jaringan Syaraf Tiruan dalam MKTP (metode NNPLS) dan
TINJAUAN PUSTAKA
Metode NNPLS merupakan integrasi antara MKTP dengan Jaringan Syaraf
Tiruan. Pada bab ini dibahas mengenai teori dan algoritma MKTP, Jaringan Syaraf
Tiruan, dan metode NNPLS.
Metode Kuadrat Terkecil Parsial (MKTP)
MKTP merupakan suatu metode regresi ganda linier yang dapat mengatasi
kolinieritas dan data terbatas. MKTP menggambarkan hubungan eksternal (outer) dan
hubungan internal (inner) antara peubah bebas (X) dan peubah tak bebas (Y). Hubungan
eksternal ditulis dengan persamaan berikut:
Y = U Q ' + F = 2 u h q , + F
h=l
dimana X adalah peubah bebas, Y adalah peubah tak bebas, T dan U adalah vektor skor
faktor komponen pertama, P dan Q adalah vektor pembobot, E adalah matriks residu
peubah X, F adalah matriks residu peubah Y, th dan uh adalah vektor skor faktor
komponen pertama ke-h, ph dan qh adalah vektor pembobot ke-h. Keempat vektor
tersebut diperoleh dengan meminimumkan matriks residu E dan matriks residu F.
Hubungan antara
X
dan Y terbaik diperoleh pada kondisiI(E11
danllFll
yang minimum.Hubungan internal ditulis dengan persamaan sebagai berikut:
Uh = bhth
Matriks residu ditulis dengan persaman sebagai berikut:
Eh=X-thPh
Fh = Y - bhthq;,
Faktor kedua dihitung berdasarkan residu El dan F1 yang diperoleh dengan cara yang
sama untuk faktor pertama, dengan h =1,2,3 ..., a. Cara yang sama diulang sampai dengan
faktor terakhir a. Banyaknya faktor a ditentukan oleh metode validasi silang yang
berguna untuk mengatasi overJitting. OverJitting terjadi jika banyaknya peubah lebih
besar dibandingkan dengan banyaknya pengamatan, sehingga mode1 yang dibentuk
sesuai dengan data contoh, tetapi tidak dapat digunakan untuk memprediksi.
Algoritma Metode Kuadrat Terkecil Parsial Linier
Menurut Geladi & Kowalski (1986) algoritma MKTP linier adalah sebagai
berikut:
Untuk peubah X :
1. to = x,, t, = to
2. p; = tjX/ tit,
3. p;+, = P; 1
1 1 ~ ;
11
4. t,+l = X p i + ~ l pi+, pi+l
5. Jika ti = t,+l, maka proses berhenti, tetapi jika t, # kembali ke langkah 2.
Untuk peubah Y :
1. Uo=yj,Ui=Uo
5. jika u, = u,+l , maka proses berhenti, tetapi jika ui
+
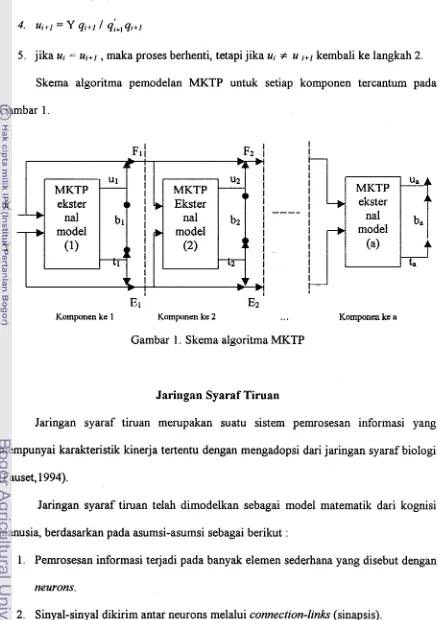
u kembali ke langkah 2. [image:92.572.70.508.76.696.2]Skema algoritma pemodelan MKTP untuk setiap komponen tercantum pada
Gambar 1 .
Gambar 1. Skema algoritma MKTP
I
plj
F2I
Ir lI
T
I IJaringan Syaraf Tiruan
Jaringan syaraf tiruan merupakan suatu sistem pemrosesan informasi yang
mempunyai karakteristik kinerja tertentu dengan mengadopsi dari jaringan syaraf biologi
(Fauset, 1994).
Jaringan syaraf tiruan telah dimodelkan sebagai model matematik dari kognisi
manusia, berdasarkan pada asumsi-asumsi sebagai berikut :
1. Pemrosesan informasi terjadi pada banyak elemen sederhana yang disebut dengan
neurons.
2. Sinyal-sinyal dikirim antar neurons melalui connection-links (sinapsis). X
U a 4
A ba MKTP (a) ta MKTP L I I
1 I I
E 1
E2
Komponen ke 1 Komponen ke 2 ... Komponen ke a
nal model I I I I I I nal model Y I I
I
--+
(1)ekster
3. Setiap sinapsis mempunyai bobot tertentu, tergantung tipe jaringan syaraf.
4. Setiap neuron mempunyai fungsi aktivasi (biasanya tak linier) yang merupakan
penjumlahan dari sinyal-sinyal input untuk sinyal-sinyal output.
Jaringan syaraf dibedakan menurut ha1 berikut :
1. Pola koneksi antar neuron (arsitektur).
2. Metode penentuan pembobot pada koneksi-koneksi (pelatihan, pembelajaran dan
algoritma).
3 . Fungsi aktivasi.
Jaringan syaraf tiruan mendistribusikan sistem proses informasi yang menyusun
beberapa perhitungan elemen tunggal berinteraksi dengan menghubungkan
pembobotannya (Patterson, 1996).
Dua fakta yang mendasar dari jaringan syaraf tiruan. Pertama jaringan syaraf
tiruan diilhami oleh sistem jaringan biologi. Kedua jaringan syaraf tiruan terdiri atas
banyak elemen yang disebut neurons, unit sel yang saling terhubung satu dengan yang
lain melalui sinapsis dan mempunyai bobot yang berkaitan. Sedangkan sinapsis adalah
daerah sambungan khusus antar neuron. Bobot mewakili informasi yang akan digunakan
oleh jaringan untuk menyelesaikan fbngsi tertentu.
Jaringan syaraf tiruan menyimpan sinyal dari unit sel lainnya (neurons) melewati
hubungan input yaitu dendrit (dendrite) dan sinapsis (synapse). Bobot untuk tiap
hubungan input (kekuatan sinapsis) dapat menjadi positif atau negatif. Bobot input
ditambahkan dan ditransformasikan oleh fungsi aktivasi untuk sebuah sinyal output
(pembebasan neuron). Sinyal adalah transmisi yang melewati hubungan output (akson
Jaringan syaraf tiruan dapat dibentuk dalam suatu model sel syaraf. Model sel
syaraf merupakan pembentuk jaringan syaraf tiruan yang disusun berdasarkan pilihan
arsitektur dan konsep pembelajaran. Sistem syaraf biologi terdiri dari susunan sel-sel
syaraf yang disebut neurons. Struktur utarna dari neuron dalam sebuah sistem saraf pusat terdiri dari dendrit, tubuh sel (cell body/soma), dan sebuah akson (axon) tunggal. Akson berfbngsi sebagai daerah output sel yang panjang dan bercabang. Sebuah impulse dapat
dipicu oleh sel dan dikirim ke sepanjang percabangan akson sampai akhir serat. Dendrit,
yang berupa sekumpulan serat cabang, berhngsi sebagai input sel. Titik penghubung
antara dendrit dan akson adalah sinapsis. Ketika impulse diterima dendrit, maka terjadi
peningkatan kemungkinan target neuron untuk mengaktifkan impulse menuju akson.
Sinapsis adalah daerah sambungan khusus antar neuron. Dalam sistem syaraf, pola
interkoneksi sel ke sel beserta fenomena komunikasi antar unit pemroses tersebut
menentukan kemampuan komputasi jaringan secara keseluruhan. Dengan kata lain
sinapsis merupakan bagian penting dalam komputasi neural (neurocomputing) (Skapura,
1990). Gambar 2 memperlihatkan sebuah struktur sel syaraf (neuron).
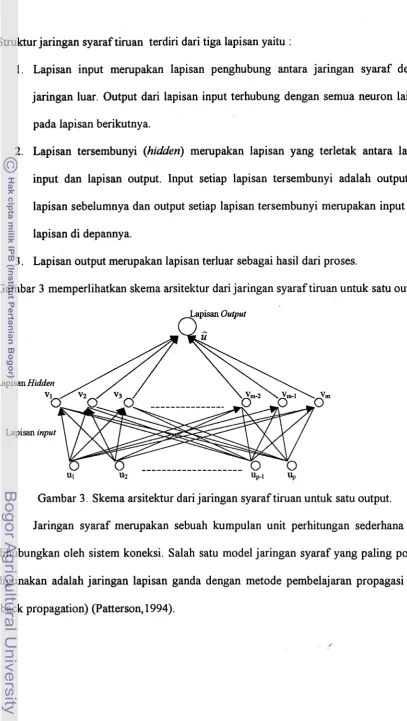
Struktur jaringan syaraf tiruan terdiri dari tiga lapisan yaitu :
1. Lapisan input merupakan lapisan penghubung antara jaringan syaraf dengan
jaringan luar. Output dari lapisan input terhubung dengan semua neuron lainnya
pada lapisan berikutnya.
2. Lapisan tersembunyi (hidden) merupakan lapisan yang terletak antara lapisan
input dan lapisan output. Input setiap lapisan tersembunyi adalah output dari
lapisan sebelumnya dan output setiap lapisan tersembunyi merupakan input bagi
lapisan di depannya.
[image:95.572.64.472.23.746.2]3 . Lapisan output merupakan lapisan terluar sebagai hasil dari proses.
Gambar 3 memperlihatkan skema arsitektur dari jaringan syaraf tiruan untuk satu output.
Lapisan Output
n
Gambar 3 . Skema arsitektur dari jaringan syaraf tiruan untuk satu output.
Jaringan syaraf merupakan sebuah kumpulan unit perhitungan sederhana yang
dihubungkan oleh sistem koneksi. Salah satu model jaringan syaraf yang paling popular
digunakan adalah jaringan lapisan ganda dengan metode pembelajaran propagasi balik
Algoritrna Pernbelajaran Propagasi Balik
Algoritma pembelajaran Propagasi Balik membagi proses belajar menjadi 3 tahap
yang dilakukan secara iteratif sehingga jaringan menghasilkan perilaku yang diinginkan.
Tiga tahap tersebut adalah :
1. Tahap umpan maju Cfeedforward) yaitu jaringan diberi suatu input x (xl,xz,.-.,xJ
sehingga jaringan menghasilkan output y (y1,y2, ...,yn) Setelah output jaringan
diperoleh, tahap selanjutnya adalah tahap penentuan nilai galat.
2. Tahap penentuan nilai galat (error); galat diperoleh dengan cara membandingkan
output jaringan y dengan nilai output yang diinginkan tk (tl,tz, ..., t,) yaitu :
E(t) = Y(t)
-
tk3 . Melakukan adaptasi bobot jaringan berdasarkan nilai galat yang diperoleh. Tujuan
dari adaptasi bobot ini adalah untuk memperkecil nilai galat pada iterasi
berikutnya sehingga nilai galatnya pada suatu saat akan menuju ke 0. Untuk
mengetahui kriteria tampilan jaringan dengan rumus berikut :
Kriteria tampilan jaringan semakin baik jika nilai J minimum. Karena tujuan dari
adaptasi bobot adalah meminimumkan nilai galat total E, maka besar perubahan bobot
jaringan disesuaikan dengan besar sumbangan tiap-tiap nilai pembobot terhadap nilai
galat total yang terjadi.
Pada lapisan tersembunyi (hidden) berlaku :
Pada lapisan keluaran berlaku :
sehingga :
Yk = f(y-ink)
dimana :
Xi = unit masukan ke-i, i = 1,2,3 ,..., n.
Vij = bobot unit masukan ke-i pada unit tersembunyi (hidden) ke-j, (i=1,2,. ..,p).
Voj = bobot bias unit masukan pada unit hidden ke-j.
z-inj = unit hidden ke-j dari masukan ke-j.
zj = unit hidden ke-j, (i=1,2,. ..,p).
4.)
= fbngsi aktivasiWjk = bobot unit hidden ke-j pada unit keluaran ke-k, (k=1,2,
...,
m).wok = bobot (bias) unit hidden pada unit keluaran ke-k.
y-ink = unit keluaran ke-k dari unit hidden ke-k.
y k = unit keluaran ke-k, (k=1,2,.. .,m).
Fungsi aktivasi yang digunakan dalam penelitian ini adalah fungsi sigmoid (logistik)
dengan rumus berikut:
Pada lapisan keluaran kesalahan pada sebuah unit keluaran didefinisikan sebagai :
dengan :
YL = keluaran jaringan
tk = keluaran yang diiinginkan
Misalkan jaringan yang diberi pola belajar p menyebabkan kesalahan sebesar Ep.
sehingga :
dimana
sehingga persamaan (5) dapat ditulis menjadi :
Parameter jaringan yaitu bobot-bobot koneksi dari sel j ke sel i, Wij
,
harus diubahsebanding dengan fbngsi kesalahan gradien negatif terhadap perubahan bobot :
dimana,
AW,, = perubahan bobot unit ke-j ke unit ke-k dengan pola pembelajar p.
77 = konstanta pembelajaran dengan nilai ( 0 5 q < 1 )
Dengan mensubstitusikan Persamaan ( 6 ) dalam Persamaan (7) diperoleh persamaan
perubahan bobot sebagai berikut :
Bobot yang baru pada lapisan keluaran adalah :
W n e w ) = Fk(old)
+
AWjkUntuk menyederhanakan Persamaan (8) diambil konstanta baru yaitu :
6, = (Yk - tk)f (y-ink )
Sehingga Persamaan (8) menjadi :
Kk
(new) = W / k (old) + 77 Jkzj = q k (old) + AWjkPada lapisan tersembunyi (hidden), keluaran dari lapisan tersembunyi (hidden), zj
menentukan kesalahan total Ep, menjadi :
Sehingga negatif turunan kesalahan total
E,
terhadap bobot koneksi lapisan tersembunyi(hidden) vij sebagai berikut :
(10)
Dari Persamaan (1) sampai Persamaan (4) , maka Persamaan (10) menjadi :
Dengan menggunakan definisi Sk pada Persamaan (9)
,
Persamaan (12) menjadi :rn
Avii = nf
'
( z
- in, )x,C
Sk Wjkk=l
Persamaan tersebut menunjukan konsep Propagasi Kesalahan Balik (Back Error
Propagation) yaitu setiap perubahan bobot lapisan tersembunyi ( A j k ) bergantung pada
semua kesalahan (Sk) pada lapisan keluaran. Dengan pengertian kesalahan lokal pada
semua lapisan keluaran disebarkan balik ke setiap lapisan tersembunyi untuk
mendapatkan perubahan bobot yang sesuai. Dengan mendefinisikan konstanta :
Persamaan penyesuaian bobot pada lapisan tersembunyi -adalah :
vii (new) = vii (old)
+
vS,xiPemeriksaan Pembelajaran dalam Jaringan Syaraf Tiruan
Jaringan syaraf tiruan tidak hanya diklasifikasikan menurut aplikasinya, tapi juga
tergantung metode pembelajarannya. Ada tiga kategori paling penting dari metode
pembelajaran, yaitu : (1) supervised (e.g aturan delta, back propagation, hebbian,
stokastik); (2) unsupervised (e.g. kompetitif, hebbian) dan (3) reinforcement learning
(Patterson, 1996).
Dalam pembelajaran supervised gugus data pelatihan terdiri dari input dan target
output. Aturan pembobotan (dan bias) dari jaringan syaraf tiruan untuk meminimumkan
perbedaan antara output yang dicapai dan target output. Selisih ini dipergunakan untuk
Dalam pembelajaran unsupervised gugus data pelatihan hanya berisi vektor input.
Aturan pembobot (dm bias) dari jaringan syaraf tiruan dalam mengadaptasi respons
selanjutnya tergantung pada penurunan dan hubungan yang dideteksi dalam vektor
masukan, tanpa mempunyai beberapa indikasi apakah benar atau salah.
Reinforcement learning adalah gabungan antara pembelajaran supervised dan
unsupervised. Gugus data pelatihan terdiri dari input d m target output, tapi jaringan
syaraf tidak mempunyai indikasi pada output dari prosedur yang benar atau
salah,mengenai aturan pembobotan (dan bias) merupakan dasar (Patterson, 1996).
Pada kasus dimana terjadi integrasi antara kerangka kerja jaringan syaraf dengan
MKTP, metode pembelajaran yang digunakan adalah supervised dengan metode
pembelaj aran propagasi balik gradien descent.
Metode Pembelajaran Grndien Descent
Metode pembelajaran gradien descent merupakan salah satu metode pembelajaran
Propagasi Balik yang digunakan dalam NNPLS. Metode gradien descent merupakan
metode pertarna dalam mengatur koefisien pembobotan sehingga mempunyai
pengurangan tercepat dari fbngsi galat. Algoritma pembelajaran propagasi balik gradien
descent diperkenalkan oleh Rummelhart dan McClelland pada tahun 1986.
Dalam pembelajaran propagasi balik gradien descent, fbngsi galat E(w) yang
diminimumkan adalah jumlah kuadrat kekeliruan antara aktual (target) dengan keluaran
dimana :
P = jumlah dari pola pelatihan
EP
= hngsi galat tiap pola ke-po = jumlah unit dalam lapisan keluaran
t ij = keluaran yang diinginkan dari pola ke-i pada unit keluaran lapisan ke-j
Yij = keluaran aktual (target) dari pola ke-i pada unit lapisan keluaran ke-j
rij = galat antara keluaran yang diiinginkan tij, dan keluaran aktual (target) yij
Fungsi galat yang digunakan adalah total jumlah kuadrat (m=l) dan satu keluaran (o = 1)
yaitu sebagai berikut :
dimana, R(t) adalah matriks pxl dalam ri.
Metode
NNPLS
( Neural Network Partial Least Square)Metode NNPLS merupakan suatu metode yang dapat mengatasi kolinieritas antar
peubah, pengamatan yang terbatas, dan kenonlinieran. Pendekatan metode NNPLS
menggunakan jaringan syaraf sebagai hubungan internal dalam persamaan berikut :
UI, =
N
(6,) +a
dimana
N(.)
merupakan model hubungan nonlinier yang dihasilkan oleh jaringan syaraf.Hubungan eksternal tetap membentuk peubah skor dari data, kemudian ul, dan tl,
digunakan untuk melatih model internal dengan menggunakan jaringan syaraf Pada
umumnya, hampir semua tipe jaringan syaraf yang membentuk pemetaan nonlinier dari
yang digunakan adalah tipe jaringan yang mempunyai satu lapisan tersembunyi sigmoidal
dan satu lapisan keluaran linier.
Algoritma NNPLS
Algoritma NNPLS dapat dirumuskan sebagai berikut :
1. Bakukan X dan Y, dengan Eo = X dan Fo = Y.
2. Untuk tiap-tiap faktor h, uh = yj.
/*Hu bungan elisfernal*/
3 . W; = u; Ebl / u; uh
4 Wh = Wh llwhll
5 . th = Eh-1 . Wh
6 . th = th IIthII
7. q; = t ; Fh-1 1 t ; th
qh = qh llqhll
9. Uh = Fh-1 qh
10. P; = t ; Eh-1 1 t ; th
11. Ph = Ph 1
1 1 ~ ~ 1 1
/*Model internal
*/
Zih
= N ( t , ) = a ( t h .w;,+
e A h ) w Z h+
ePZh,...
dimana:
-
o,,
danozh
merupakan vektor bobot untuk lapisan input dan lapisan output.-
p,,
danP,,
merupakan bobot bias untuk lapisan input dan lapisan output.-
h adalah banyaknya unit lapisan tersembunyi untuk model network inner ke-h.-
a (.) adalah fbngsi sigmoid dengan persamaan berikut :13. Jh = I1uh - Ghll
I* Hitung residu untuk faktor h *I
14. El, = E h q l -th
PL
1 +
15. Fh = Fh-l
-
uh qh16. Jika h = h
+
1, kembali pada tahap 2 sampai semua faktor utarna dihitung.Penentuan banyaknya faktor h ditentukan dengan metode validasi silang.
Skema algoritma metode NNPLS (lihat Gambar 4) menunjukan data
ditransformasi menjadi peubah skor u dan t, kemudian jaringan syaraf tiruan digunakan
untuk menghasilkan output dari input vektor skor u dan t.
[image:104.572.64.514.56.713.2]Komponen ke 1 Komponen ke 2 ... Komponen he a
METODE PENELITIAN
Data
Data yang digunakan dalam penelitian ini (Lampiran 1) merupakan data sekunder
hasil penelitian Mc Avoy pada tahun 1989 (Umetrics,1995). Tiga zat kimia yaitu tingkat
total konsentrasi, tingkat tyrosine dan tingkat tryptophan yang diukur konsentrasinya
dengan menggunakan 30 macam panjang gelombang dan jumlah pengamatan sebanyak
33. Data dianalisis dengan menggunakan program SAS 6.12 dan Minitab 13.0.
Metodologi
Metodologi yang digunakan didasarkan pada bab sebelumnya dengan langkah-
langkah sebagai berikut:
1. Menghitung korelasi antar peubah panjang gelombang (Xl,X2, ..., X30), antar
peubah Zat kimia (Yl,Y2,Y3) dan antar peubah panjang gelombang dengan
peubah zat kimia.
2. Membakukan data.
3. Menentukan banyakny a komponen dengan metode Validasi Silang.
4. Melakukan perhitungan sesuai dengan algoritma NNPLS.
5. Melakukan perhitungan dari data yang sama dengan algoritma MKTP.
6. Melakukan perbandingan hasil perhitungan RMSE metode NNPLS dengan
HASIL DAN PEMBAHASAN
Penentuan banyaknya komponen dengan Validasi Silang
Langkah pertama adalah menghitung korelasi antar peubah untuk data yang
terdapat pada Lampiran 1. Korelasi yang cukup tinggi telah diperlihatkan seperti pada
Lampiran 2. Langkah selanjutnya adalah membakukan data. Metode Validasi silang
digunakan untuk menentukan banyaknya komponen. Tabel 1 memperlihatkan hasil
validasi silang untuk menentukan banyaknya komponen.
Akar rata-rata PRESS minimum = 0.2349 terdapat pada 6 peubah laten dengan
nilai p > 0.1. Hasil tersebut menunjukkan bahwa model yang dibentuk dapat dijelaskan
oleh persentase variasi dari 6 peubah laten. Hasil dari persentase variasi peubah yang
dihasilkan dari 6 peubah laten dapat dilihat pada Tabel 2.
Tabel 2. Porsentase variasi yang dihasilkan untuk menjelaskan variasi peubah
Enam komponen tersebut dapat menjelaskan variasi peubah dimana untuk
pengaruh model dijelaskan dengan total 99.8 % dan untuk peubah tak bebas dijelaskan
dengan total 97.8 %. Hasil ini menunjukkan kecukupan variasi dari model yang dapat
dijelaskan dengan 6 peubah laten.
Penentuan pendugaan dengan MKTP
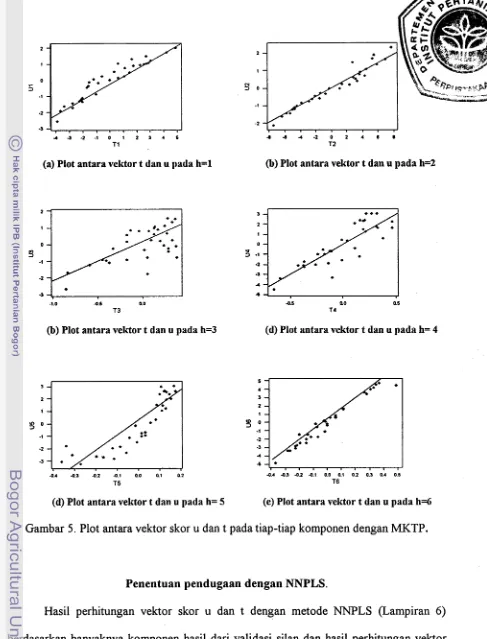
Hasil perhitungan vektor skor u dan t (Lampiran 4) berdasarkan banyak
komponen hasil dari validasi silang. Plot antara vektor skor u dan t dengan menggunakan
metode MKTP dapat dilihat pada Gambar 5.
Pada Gambar 5 ditunjukkan bahwa plot antara vektor skor u dan t pada tiap
komponen yang dibentuk memiliki model internal yang linier. Hasil pendugaan Y untuk
ketiga peubah yang dihasilkan terdiri dari 3 peubah dan 33 pengamatan (Lampiran 5).
Banyak Peubah Laten
1 2 3
Peuball Tak Bebas
(a) Plot antara vektor t dan u pada h=l
(b) Plot antara vektor t dan u pada h=3
[image:108.572.59.546.45.684.2](d) Plot antara vektor t dan u pada h= 5
Gambar 5. Plot antara vektor skor u dan t
(b) Plot antara vektor t dan u pada h=2
pada
(d) Plot antara vektor t dan u pada h= 4
(e) Plot antara vektor t dan u pada h=6
tiap-tiap komponen dengan MKTP.
Penentuan pendugaan dengan NNPLS.
Hasil perhitungan vektor skor u dan t dengan metode NNPLS (Lampiran 6 )
lib
dengan h =1,2,...,
6 dan vektor t untuk model internal (Lampiran 7). Gambar 6memperlihatkan bahwa plot antara vektor skor u dan t untuk model eksternal dan vektor
skor tih dan vektor skor t untuk model internal dengan metode NNPLS .
(a). plot antara u dan t pada h=l @). plot antara u dan t pada h = 2
t3
(c). plot antara u dan t pada h = 3
u
(d). plot antara u dan t pada h = 4
tS
(e). plot antara u dan t pada h = 5
Keterangan :
16
[image:109.578.66.514.50.666.2](f). plot antara u dm t pada 11 = 6
Gambar 6. Plot antara vektor skor u dan t hasil dari metode NNPLS
Gambar 6 menunjukan bahwa plot yang dibentuk memiliki model internal yang
nonlinier. Hasil pendugaan Y untuk ketiga peubah yang diukur tersebut memperoleh hasil
seperti pada Lampiran 10. Pendugaan yang dihasilkan terdiri dari 3 peubah dan 33
seperti pada Lampiran 10. Pendugaan yang dihasilkan terdiri dari 3 peubah dan 33
pengamatan.
Perbandingan RMSE antara MKTP dengan NNPLS
Untuk mengetahui metode yang terbaik, maka hasil pendugaan ketiga peubah
(Yl, Y2, dan Y3) dari metode MKTP (Lampiran 9) dan metode NNPLS (Lampiran 10)
akan dibandingkan berdasarkan nilai akar kuadrat tengah galat. Metode terbaik adalah
metode yang memiliki akar kuadrat tengah galat terkecil. Tabel 3 menunjukan bahwa
NNPLS memiliki nilai akar kuadrat tengah galat yang lebih kecil dibandingkan dengan
pendekatan metode MKTP. Hal ini terlihat pada h ke 6 dari hasil kedua metode yang
dibentuk dalam Tabel 3.
Tabel 3. Perbandingan RMSE MKTP dengan RMSE NNPLS
Tabel 3 memperlihatkan bahwa metode NNPLS lebih baik dibandingkan dengan
metode MKTP. Hal tersebut diperlihatkan dengan lebih kecilnya RMSE NNPLS
dibandingkan RMSE MKTP pada tiap-tiap peubah. Metode Pendekatan
MKTP NNPLS
KESIMPULAN
Penelitian ini merupakan suatu kajian untuk membandingkan dua metode yaitu
Metode Kuadrat Terkecil Parsial (MKTP) dengan Metode Neural Network Partial Least Square (NNPLS). Metode pembelajaran yang digunakan dalam metode NNPLS adalah metode pembelajaran propagasi balik Gradien Descent dengan satu input dan satu output.
Berdasarkan hasil dan pembahasan dari data yang digunakan, maka pada penelitian ini
dapat disimpulkan bahwa RMSE untuk pendekatan metode NNPLS lebih kecil
dibandingkan dengan metode MKTP. Hal ini menunjukkan bahwa NNPLS lebih baik
dibandingkan dengan metode MKTP dalam kasus data yang bersifat nonlinier.
SARAN
Metode pembelajaran propagasi balik tidak hanya metode pembelajaran
Gradien Descent saja, tetapi terdapat metode pembelajaran lainnya yaitu Conjugate Gradient dan lain-lain. Untuk itu disarankan untuk meneliti lebih lanjut dengan menerapkan jaringan syaraf tiruan dalam MKTP dengan menggunakan metode
pembelajaran propagasi balik lainnya, dengan tujuan untuk mengetahui apakah metode
DAFTAR PUSTAKA
Cheng B, Titterington DM. 1994, Neural Network: A Review fiom a Statistical
Prespective, Statistical Science, Vol9. No. 1,2-54.
Fauset L, 1994. Fundamental of Neural Network : Architecture, Algorithms and
Applications. New Jersey. Prentice Hall Inc.
Geladi P
,
Kowalski BR, 1986. Partial Least Square : A tutorial, Analitica ChiiicaActa, 1985 : 1-17.
Martens H, Naes T, 1989. Multivariate Calibration, John Willey & Sons, Chichester,
England.
Patterson DW. 1996. Artificial Neural Network : Theory and Applications. Simon &
Schuster. Prentice Hall, New York.
Qin SJ, Mc Avoy TJ, 1992. Nonlinier PLS Modelling using Neural Networks,Computer
Chemical Engeneering, Vol 16, No.4,379-39 1.
Ripley BD, 1996. Pattern Recognition and Neural Network, Cambridge University
Press, University of Oxpord, Melbourne, Australia.
Sarle WS, 1994. Neural Network and Statistical Models. Proceddings of the Nineteenth
Annual SAS User Group International Conference.
Skapura MD, Freeman JA. 1992. Neural Network : Algorithms, Application and
Tobias R, 1995. An Introduction to Partial Least Squares Regression, in Proccedding of
the Twentieth Annual SAS Users Group International Conferences, Carry,
NC:SAS Institute In., 1250-1257.
Lampiran
Lampiran
Lampiran
Lampiran
Lampiran
Lampiranl. Lanj utan
Y1 Y2 Y 3
-6.00000 -8.00000 -6.00000
-6.00000 -7.00000 -6.04576
-6.00000 -6.60206 -6.12494
-6.00000 -6.30103 -6.30103
-6.00000 -6.12494 -6.60206
-6.00000 -6.04576 -7.00000
-6.00000 -6.00000 -8.00000
-5.00000 -8.00000 -5.00000
-5.00000 -6.00000 -5.04576
-5.00000 -5.60206 -5.12494
-5.00000 -5.30103 -5.30103
-5.00000 -5.12494 -5.60206
Lampiran
Lampiran
Lampiran
Lampiran 3. Makro Program Untuk Metode NNPLS
/* Prosedur menentukan model outer dengan metode MKTP*/ proc iml;
start pls;
u=Y [,2];print,'(u=Y [,2])=',u[format= 10.51;
u2=(u')*u;print,'(u2=(u')*u=',u2[format=l0.5];
w==((u')*X)#(l/u2);print,
'(w-((u')*X)#((l/u2))=',w[format=
10.51; w2=w*w' ;printYy(w2= (w*w')=',w2[format=l0.5];sw=SQRT(w2);print,
'(sw=SQRT(w2))=',sw[format=
10.51;w=w#(l/sw);print,'(w=w#(l/sw))=', w[format= 10.51;
w2-w*w';print,'(w2=w*w')=', w2[format=10.5];
t=(X*w')#(l/w2);print, '(t=(X*w')#((l/w2))=',t[format=10.5];
t2=(t')*t;printyy(t2=(t')*t=',t2[f0rmat=l 0.51;
q=(t' *Y)#(l/t2);print,'(q=(t' *Y)#((l/t2))=',q[format=lO. 51;
q2=q*q';print,'(q2=q*q')=',q2[format=l0.5];
sq=SQRT(q2);printY'(sq=SQRT(q2))=',sq[format=l
0.51;q=q#( l/sq);print, '(q=q#( l/sq))=', q[format= 10.51; q2=q*q';print, '(q2=q*q')=',q2[format= 10.51;
u=(Y*q')#(l/q2);print,'(u=(Y*q')#(l/q2))=',u[fo~at=lO.5];
p=(t' *X)#(ll(t' *t));print,'(p=(t' *X)#(ll(t'*t)))=',p[format=l0.5];
p2=p*p';printY'(p2=p*p')=',p2[format= 10.51;
sp=
SQRT(p2);print,'(sp=SQRT(p2))=',sp[format=lO.
51;p=p#(l /sp);print,'(p=p#(l/sp))=', p[format=lO. 51;
t=t#(l/sp);print,'(t=t#(l/sp))=', t[format=10.5];
w=w#(l/sp);print,'(w=w#(l/sp))=', q[format=lO. 51;
xl=X-t*p;print,'(xl=X-t*p)=',xl
[format=10.5];/*mencetak hasil PLS outer*/
print,'pembobot w=', w[format=lO. 51; print,'laten X =', t[format=lO. 51; print, 'laten Y =', u[format=10.5];
print, 'vektor loading X=',p[format= 10.51; print, 'vektor loading Y=',q[format= 10.51; print,'residu X=',xl [format=10.5];
finish; /*data*/
/* Prosedur menentukan model inner dengan neural network *I
%macro tnn-nlp( /* Simple example of fitting a neural network (multilayer perceptron) using PROC NLP */
Lampiran
Lampiran 3. Lanjutan
nx=NX???, I* Number of inputs */
xvar=XVAR???, I* List of variables that are inputs. Do not use abbreviated lists with
--
or :. *Iny=NY???, I* Number of outputs */
yvar=YVAR???, I* List of variables that have training values. Do not use abbreviated lists with
--
or :. */hidden=2, I* Number of hidden nodes *I
bound=30, I* Bound on absolute values of weights *I inest=, I* Data set containing initial weight estimates.
If not specified, random initial estimates are used. *I
random=O, I* Seed for random numbers for initial weights */
outest=-EST, I* Data set containing estimated weights *I
nlpopt=SHORT HISTORY);
I* Additional options to be passed to PROC NLP,
such as MAXITER=, TECH=, ABSCONV=, etc. Do NOT put commas between the NLP options! */
%*
* * *
*
*
names of internal variables for output and residuals; %let predict=q 1 -q&ny;%let residual=-r 1 --r&ny ;
%*
* *
* *
*
size of each parameter array; %let na=&hidden;%let nb=%eval(&nx*&hidden); %let nc=&ny;
%let nd=%eval(&hidden*&ny);
%****** list of all parameters;
%let parrns=-a 1 --a&na -b 1 --b&nb -c 1 -c&nc -d 1 --d&nd;
%
* *
* * * *
get default data set name;%if %qupcase(&data)=-LAST %then %let data=&syslast;
%*
* * * *
*
random initial values. only the input-to-hidden weightsand hidden bias need to be nonzero; %if %bquote(&inest)= %then %do;
%let inest=-INEST; data &inest(type=est);
retain &parms 0;
Lampiran
Lampiran 3. Lanjutan
array -ab -a1 --a&na -b 1 --b&nb; do over -ab;
ab=ranuni(&random)-. 5; end;
output; run; %end;
%*
* ** **
training;proc nlp data=&data inest=&inest outest=&outest &nlpopt; lsq &residual;
parms &parms;
bounds -&bound
<
&parms < &bound; %tnn-arrrun;
%**
***
*
save number of hidden nodes and training data set name; data &outest(type=est);set &outest; length -data- $17; retain -hidden- &hidden
data- "&data";
label data ='Training Data'
h:lddei- umber
of Hidden Nodes'-
7
run;
%mend tnn-nlp;
%macro tnn-run( I* Simple example of simulating a neural network (multilayer perceptron) using a DATA step *I
data=DATA???, /* Data set containing inputs and training values *I
nx=NX???, I* Number of inputs */
xvar=X???, I* List of variables that are inputs. Do not use abbreviated lists with
--
or :. *Iny=NY???, I* Number of outputs */
yvar=, I* List of variables that have training values. may be omitted if you don't want residuals or fit statistics.
Do not use abbreviated lists with
--
or :. *Iest=-EST, I* Data set containing weights *I
predict=, /* Names of variables to contain outputs *I
Lampiran
Lampiran 3. Lanjutan
outfit=-FIT, I* Data set to contain fit statistics *I
out=-DATAJ; I* Data set to contain outputs and residuals *I
%*
** * * *
get number of hidden nodes and training data set name; data -null-;set &est;
call symput(" hidden",trim(leR(put(-hidden, 12.)))); call symput("tdata",-data_);
stop; run;
%*
*
* * *
*
names of variables for output and residuals; %if %bquote(&predict)= %then%let predict=g 1 -q&ny;
%if %bquote(&yvar)"= %then %if %bquote(&residual)= %then %let residual=-r 1 --r&ny;
%*
*
* * * *
size of each parameter array; %let na=&hidden;%let nb=%eval(&nx*&hidden); %let nc=&ny;
%let nd=%eval(&hidden*&ny);
%*
*
* * * *
number of parameters;%let nparm=%eval(&na+&nb+&nc+&nd);
%*
* * * * *
list of all parameters;%let parms-a 1 --a&na -b 1 --b&nb -c 1 --c&nc -d 1 --d&nd;
%****
**
variables to drop from both output data sets;%let drop=&parms -ih -ix -iy -n -sum -type- -tech- -name- -rhs-
-
data- -iter-;data
/
&out(drop=&drop -np-
-nabs-
-sse- -df- -mse- -rmse- -hidden- ,%if %qupcase(&data)=%qupcase(&tdata) %then -sbc- -rfpe-; -
1
Lampiran
Lampiran 3. Lanjutan
*
read estimated weights; if -n-=l then do;do untilctype-='PARMS1); set &est;
end; end;
*
read input and training values; set &data end=end;*
compute outputs and residuals; %tnn-arroutput &out;
*
compute fit statistics;%if %bquote(&yvar)"= %then %do;
-
n=n(of &residual);if -n then do; nobs-+-n;
-
do -iy=l to &ny; sse-+-r[-iyl* *2;
end; end;
if end then do; -np-=&nparm;
%*
*
* * * *
training data;%if %qupcase(&data)=%qupcase(&tdata) %then %do;
-
df-=max(O,-nobs---npJ;sbc-=-no bs-* log(sse-1-nobsJ+-np-* log(nobsJ; %end;
%****** test data; %else %do;
df-=-nobs-; %end;
Lampiran
Lampiran 3. Lanjutan
-
mse-=-sse-1-df-; rmse-=sqrt(mse_);%if %qupcase(&data)=%qupcase(&tdata) %then %do; -@e-=-rmse-* sqrt(Cnobs-+-npJ1-nobsJ;
%end; end; output; end;
label -np- ='Number of Parameters'
%if %qupcase(&data)=%qupcase(&tdata) %then %do; nobs-='Number of Training Values'
-
rfpe-='Root Final Prediction Error'
-
sbc- ='Schwarzl's Bayesian Criterion' %end;
%else %do;
nobs-='Number of Test Values' %end;
d f ='Degrees of Freedom for Error'
-
-
sse- ='Sum of Squared Errors' mse- ='Mean Squared Error'-
rmse-='Root Mean Squared Error'
-
> %end; run;
%if %bq~ote(&yvar)~= %then %do; proc print label data=&outfit; run; %end;
%mend tnn-run;
%macro tnn-act(out,in); %* activation function; if &in<-45 then &out=O;
*
avoid overflow; else if &in>45 then &out=l ;*
or underflow; else &out=l/(l+exp(-&in));*
logistic function; %mend tnn act;%macro tnnLarr; I* code for 3-layer perceptron using arrays *I array -x[&nx] &xvar; I* input *I
array -a[&hidden] al--a&na; /*.bias for hidden layer *I
array -b[&nx,&hidden] -bl--b&nb; I* weights from input to hidden layer *I
Lampiran
Lampiran 3. Lanjutan
array -d[&hidden,&ny] -dl-d&nd; I* weights fiom hidden layer to output *I
array j [ & n y ] &predict; I* output (predicted values) *I
%if %bq~ote(&yvar)~= %then %do;
array y[&ny] &yvar; I* training values *I
array -r[&ny] &residual; I* residuals
*I
%end;
*
compute hidden layer; do-
ih=l to &hidden;- sum=-a[-ih] ;
do
-
ix=l to &nx;- sum=~sum+~x[~ix]*~b[~ix,~ih];
end;
*
apply activation function to hidden nodes; %tnn-act(-hLih],-sum)end;
*
compute output; do -iy= 1 to &ny;-
sum=-c[-iy] ; do -ih=l to &hidden;sum=-sum+-h[-ih] *-d[ih,-iy] ; end;
*
apply activation function to output; %ttnn_actCp[iy] ,-sum)end;
%if %bquote(&yvar)/'= %then %do;
*
compute residuals;end; %end; %mend tnn-arr;
title 'Data florense'; data flour;
input t u @ @; cards;
%tnn - nlp(data=flour, nx= 1, xvar=t, ny= 1, y v w , hidden=l ,
random= 12, nlpopt=short history maxiter-125); %tnn-run(data=flour, nx=l, xvar=t, ny= 1, yvar-u,
Lampiran
Lampiran 3. Lanjutan
run;
Lampiran
Lampiran
Lampiran
Lampiran
Lampiran
Lampiran
Lampiran
Larnpiran
Lampiran