i
KAJIAN PENGKLASIFIKASI TUNGGAL
DAN GABUNGAN DARI POHON KLASIFIKASI
DAN
SUPPORT VECTOR MACHINE
IUT TRI UTAMI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN SUMBER INFORMASI SERTA
PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Kajian Pengklasifikasi
Tunggal dan Gabungan dari Pohon Klasifikasi dan
Support Vector Machine
adalah
benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam
bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal
atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain
telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir
tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Januari 2014
Iut Tri Utami
NRP
G152110031
ii
RINGKASAN
IUT TRI UTAMI. Kajian Pengklasifikasi Tunggal dan Gabungan dari Pohon Klasifikasi dan Support Vector Machine. Dibimbing oleh KUSMAN SADIK dan BAGUS SARTONO.
Pengklasifikasi adalah sebuah aturan yang digunakan untuk mengelompokkan objek ke dalam kelompok atau kelas yang telah ditentukan berdasarkan atributnya. Pendekatan metode klasifikasi ada dua yaitu parametrik dan nonparametrik. Metode parametrik membutuhkan asumsi tertentu untuk mendapatkan klasifikasi terbaik tetapi tidak semua asumsi dapat terpenuhi sehinga menyulitkan para peneliti. Pelanggaran asumsi pada metode parametrik mengakibatkan hasil yang kurang memuaskan. Berbagai metode nonparametrik seperti support vector machine (SVM) dan pohon klasifikasi sebagai pengklasifikasi tunggal telah dikembangkan untuk menyelesaikan masalah pelanggaran asumsi pada metode parametrik.
Beberapa penelitian menunjukkan bahwa pengklasifikasi gabungan bisa menjadi suatu metode yang efektif untuk meningkatkan akurasi pengklasifikasian dan mengurangi keragaman dugaan pengklasifikasi tunggal (Valentini dan Dietterich 2000). Pengklasifikasi gabungan adalah aturan penggabungan dugaan beberapa pengklasifikasi tunggal menjadi satu dugaan akhir dengan suatu algoritma yang disebut combiner. Salah satu teknik gabungan yang populer digunakan adalah metode bagging (bootstrap agregating) yang diperkenalkan oleh Breiman (1966). Metode ini merupakan suatu teknik yang paling sederhana tetapi mempunyai performa yang sangat baik. Tujuan dalam penelitian ini adalah mengkaji pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM dengan melakukan simulasi pada berbagai struktur data. Selain itu, membandingkan performa pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM berdasarkan salah klasifikasi pada tabel ketepatan klasifikasi. Data yang akan digunakan pada penelitian ini adalah data simulasi dan data terapan. Data simulasi digunakan untuk mengkaji dan membandingkan performa pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM pada beberapa struktur data yang berbeda dengan menggunakan tabel ketepatan klasifikasi. Data simulasi terdiri dari data yang dibangkitkan dari dua kelas berbeda dengan tiga skenario yaitu (1) anggota dari dua kelas berbeda yang terpisahkan linier secara sempurna (linearly separable), (2) anggota dari dua kelas berbeda yang terpisahkan linier secara tidak sempurna (linearly non separable) dan (3) anggota dari dua kelas berbeda yang terpisahkan secara tidak linier (nonlinearly separable). Pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM akan diterapkan pada data mahasiswa Pascasarjana IPB Program Studi Statistika pada tahun masuk 2000-2010 yang bertujuan untuk mengklasifikasi keberhasilan studi mahasiswa.
iii performa terbaik untuk mengklasifikasikan keberhasilan studi mahasiswa Pascasarjana Program Studi Statistika tahun masuk 2000-2010.
iv
SUMMARY
IUT TRI UTAMI. Study of Single and Ensemble Classifiers of Classification Tree and Support Vector Machine. Supervised by KUSMAN SADIK and BAGUS SARTONO.
A classifier is such a rule that can be used to group an object into predetermined group or classs based on its attributes. There are two types of approach to develop a classifier rules are a parametric and a nonparametric. Parametric method requires certain assumptions to obtain the best classification but not all assumptions are met so that makes it difficult for researchers. The violation of the assumptions might lead to the lack of the effectiveness and the validity results. Recently, people pay more attention to non parametric classifiers such as Support Vector Machine (SVM) and Classification Tree (CT) to overcome the violation of the assumptions of parametric method.
Some resent research figured out that an ensemble of classifiers could be an effective way to improve the classification accuracy and reduce the prediction variation of a single classifier (Valentini dan Dietterich 2000). The ensemble method is combining the class predictions resulted by a set of single classifiers into a single prediction by applying a majority vote rule. Among some popular techniques a method of bagging (bootstrap agregating) by Breiman (1996) is the simplest but powerful technique.
The data used in this research are simulation data and real-life data. Simulation data are used to assess and compare the performance of single and ensemble classifiers of classification tree and SVM in three different data structures: (1) a situation where the members of different classes are perfectly linear separable, (2) a situation where the members of different classes are liner-separable but not perfect and (3) a situation where the members of different classes could not be separated by a linear function. Single and ensemble classifiers of classification trees and SVM will be applied to classify the successful study of postgraduate IPB students in Statistics department enrollment 2000-2010.
Our research revealed that SVM resulted better classifier compared to Classification Tree. It is valid for all three data structure under consideration. Moreover, ensemble treatment to the classifier succeeded in improving the classification performance, especiality when radial kernel function is embedded in the procedure. Ensemble SVM in real-life data with a radial kernel function has the best performance compared to other methods and is the most appropriate method to classify the successful study of postgraduate IPB students in Statistics department enrollment 2000-2010.
v
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
i
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
KAJIAN PENGKLASIFIKASI TUNGGAL
DAN GABUNGAN DARI POHON KLASIFIKASI
DAN
SUPPORT VECTOR MACHINE
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2014
ii
iii Judul Tesis : Kajian Pengklasifikasi Tunggal dan Gabungan dari Pohon
Klasifikasi dan Support Vector Machine Nama : Iut Tri Utami
NRP : G152110031
Disetujui oleh Komisi Pembimbing
Dr Kusman Sadik, MSi Ketua
Dr Bagus Sartono, MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr Ir Anik Djuraidah, MS
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
v
PRAKATA
Puji dan syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan karya ilmiah yang berjudul “Kajian Pengklasifikasi Tunggal dan Gabungan dari Pohon Klasifikasi dan Support Vector Machine”. Keberhasilan penulisan karya ilmiah ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak.
Terima kasih penulis ucapkan kepada:
1. Ayahanda (alm Amirul Iksan), Ibunda (Suharti), suami (Sudigdo M), anak (Attaya Fathan M), serta seluruh keluarga atas doa, dukungan dan kasih sayangnya.
2. Bapak Dr Kusman Sadik, MSi selaku pembimbing I dan Bapak Dr Bagus Sartono MSi selaku pembimbing II yang telah banyak memberi bimbingan, arahan serta saran dalam penyusunan karya ilmiah ini.
3. Penguji luar komisi dan ketua Program Studi Pascasarjana Statistika Terapan Ibu Dr Anik Djuraidah MS pada ujian tesis yang telah memberikan kritik dan saran dalam perbaikan penyusunan karya ilmiah ini.
4. Seluruh staf pengajar di Program Studi Statistika Terapan IPB atas ilmu yang diberikan selama perkuliahan.
5. Teman-teman Statistika (S2 dan S3) dan Statistika Terapan (S2) atas bantuan dan kebersamaannya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2014
vi
DAFTAR ISI
1. PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2. TINJAUAN PUSTAKA 3
SVM sebagai Pengklasifikasi Tunggal 3
Pohon Klasifikasi 8
Metode Gabungan 10
Ukuran Performa Pengklasifikasi Tunggal dan Gabungan 11
3. METODE 12
Data 12
Metode Analisis 15
4. HASIL DAN PEMBAHASAN 17
Data Simulasi 17
Data Terapan 21
5. SIMPULAN DAN SARAN 22
Simpulan 22
Saran 23
DAFTAR PUSTAKA 23
LAMPIRAN 26
vii
DAFTAR TABEL
1 Ketepatan klasifikasi 12
2 Skenario data simulasi pada tiga struktur data 14 3 Karakteristik peubah penjelas pada data terapan 15 4 Persentase rataan salah klasifikasi dan simpangan baku pada data
terapan 22
DAFTAR GAMBAR
1 Ilustrasi SVM pada struktur data terpisahkan linier secara sempurna 4 2 Ilustrasi SVM pada struktur data yang terpisahkan linier secara tidak
sempurna 5
3 Pemetaan data yang terpisah secara non linier dari ke dalam 7
4 Struktur pohon klasifikasi 9
5 Alur kerja metode penelitian 16
6 Hasil bangkitan data simulasi pada struktur data yang terpisahkan
linier secara sempurna 17
7 Plot perbandingan (a) persentase rataan salah klasifikasi dan (b) simpangan baku pada struktur data terpisahkan linier secara
sempurna 18
8 Hasil bangkitan data simulasi pada struktur data yang terpisahkan
linier secara tidak sempurna 18
9 Plot perbandingan (a) persentase rataan salah klasifikasi dan (b) simpangan baku pada struktur data terpisahkan linier secara tidak
sempurna 19
10 Hasil bangkitan data simulasi pada struktur data yang terpisahkan
secara tidak linier 20
11 Plot perbandingan (a) persentase rataan salah klasifikasi dan (b) simpangan baku pada struktur data terpisahkan secara tidak linier 20 12 Plot perbandingan (a) persentase rataan salah klasifikasi dan
viii
DAFTAR LAMPIRAN
1. Persentase rataan dan simpangan baku kesalahan klasifikasi pada struktur data terpisahkan secara linier sempurna (ulangan = 50) 26 2. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara linier sempurna (ulangan=100) 26 3. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara linier sempurna (ulangan = 500) 27 4. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara linier sempurna (ulangan = 1000) 27 5. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara linier sempurna (ulangan = 5000) 28 6. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan linier secara tidak sempurna
(ulangan = 50) 28
7. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan linier secara tidak sempurna
(ulangan = 100) 29
8. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan linier secara tidak sempurna
(ulangan = 500) 29
9. Persentase rataan dan simpangan baku kesalahan klasifikasi pada struktur data terpisahkan linier secara tidak sempurna
(ulangan = 1000) 30
10. Persentase rataan dan simpangan baku kesalahan klasifikasi pada struktur data terpisahkan linier secara tidak sempurna
(ulangan = 5000) 30
11. Persentase rataan dan simpangan baku kesalahan klasifikasi pada struktur data terpisahkan secara tidak linier (ulangan = 50) 31 12. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara tidak linier (ulangan = 100) 31 13. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara tidak linier (ulangan = 500) 32 14. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara tidak linier (ulangan = 1000) 32 15. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
struktur data terpisahkan secara tidak linier (ulangan = 5000) 33 16. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
data terapan (ulangan = 50) 33
17. Persentase rataan dan simpangan baku kesalahan klasifikasi pada
data terapan (ulangan = 100) 34
18. Jumlah mahasiswa Pascasarjana IPB Program Studi Statistika
1
1.
PENDAHULUAN
Latar Belakang
Pengklasifikasian suatu objek sangat umum dilakukan dalam berbagai bidang. Metode klasifikasi memungkinkan peneliti untuk mengklasifikasikan pengamatan baru, yaitu menetapkan objek baru masuk ke dalam kelompok tertentu berdasarkan nilai atribut-atributnya (Salazar et al. 2012). Pendekatan metode klasifikasi ada dua yaitu parametrik dan nonparametrik. Metode parametrik membutuhkan asumsi tertentu untuk mendapatkan klasifikasi terbaik tetapi pada kasus riil tidak semua asumsi dapat terpenuhi sehinga menyulitkan para peneliti dalam analisis. Terpenuhinya asumsi-asumsi pada metode parametrik akan menghasilkan data dapat diklasifikasikan dengan baik sehingga memiliki kesalahan klasifikasi yang kecil (Johnson & Wichern 2007).
Metode klasifikasi parametrik yang sering digunakan adalah analisis diskriminan dan regresi logistik. Penerapan kedua metode tersebut memerlukan asumsi-asumsi untuk mendapatkan hasil yang optimal. Analisis diskriminan linier dikembangkan untuk populasi yang berdistribusi normal dengan matriks ragam peragamnya sama dan digunakan hanya untuk peubah penjelas yang kuantitatif dengan skala pengukuran interval atau rasio. Metode parametrik lain yang sering digunakan yaitu analisis regresi logistik yang memiliki kelebihan tidak memerlukan asumsi normalitas apabila dibandingkan dengan analisis diskriminan tetapi diasumsikan tidak terdapat multikolinieritas antar peubah penjelas.
Metode nonparametrik merupakan metode alternatif untuk mengatasi masalah pelanggaran asumsi tertentu dalam mengklasifikasikan data. Metode nonparametrik yang telah dikembangkan antara lain k-nearest neighbors (k-NN), classification and regression tree (CART), artificial neural network (ANN), dan support vector machine (SVM) (Scholkopf & Smola 2002). Pohon klasifikasi dan SVM merupakan metode nonparametrik yang populer digunakan dalam berbagai penelitian, karena kedua metode tersebut memiliki kemampuan yang baik dalam mengklasifikasikan data. Kedua metode tersebut termasuk pengklasifikasi tunggal yang dapat digunakan pada ukuran data yang besar dengan peubah penjelas yang banyak dan data yang terpisahkan secara tidak linier, selain itu metode ini kekar terhadap pencilan (Steinberg & Colla 1995). Pengklasifikasi tunggal adalah aturan mengelompokkan objek yang berbeda ke dalam kelompok tertentu.
2
pengklasifikasi tunggal (Valentini & Dietterich 2000). Metode gabungan lebih akurat dan dipercaya mampu untuk meningkatkan performa pengklasifikasi dibandingkan pengklasifikasi tunggal apabila pengklasifikasi tunggal yang membangun pengklasifikasi gabungan saling bebas dan beragam (Hansen & Salamon 1990).
Berbagai metode telah dikembangkan untuk membangun metode gabungan diantaranya adalah memanipulasi data training untuk membangkitkan data yang beragam yang bertujuan mengurangi korelasi antar pengklasifikasi tunggal. Teknik yang sering digunakan untuk memanipulasi data training antara lain bagging, boosting dan random forest. Pada penelitian ini digunakan teknik bagging karena teknik ini merupakan teknik yang paling sederhana tetapi mempunyai performa yang sangat baik. Prinsip metode ini adalah mengambil contoh dari data contoh dengan teknik bootstrap yang selanjutnya menggabungkan banyak nilai dugaan yang diperoleh menjadi satu nilai dugaan dengan suara terbanyak. Penggunaan bagging banyak digunakan pada metode klasifikasi untuk mengurangi ragam dan memperbaiki stabilitas dugaan seperti pada pohon klasifikasi.
Penelitian tentang pengklasifikasi gabungan dengan berbagai pengklasifikasi tunggal telah dilakukan oleh beberapa peneliti (misalnya ensemble neural network oleh Hansen dan Salamon (1990), bagging tree oleh Breiman (1996) dan ensemble SVM oleh Wang et al. (2009). Penelitian lain yang bisa digunakan sebagai rujukan adalah Opitz & Maclin (1999) dan Dietterich (2000) yang membandingkan metode yang berbeda dari beberapa metode gabungan. Sebagian besar penelitian sebelumnya menggunakan metode gabungan pada data terapan, penelitian ini menggunakan data simulasi dan data terapan untuk membandingkan performa pengklasifikasi tunggal dan gabungan. Performa dari masing-masing metode dapat dilihat dalam hal kemampuan untuk memberikan tingkat kesalahan klasifikasi yang rendah dan stabilitas suatu metode. Evaluasi performa dari pengklasifikasi tunggal dan gabungan dilakukan dengan menggunakan tabel ketepatan klasifikasi.
Data yang akan digunakan pada penelitian ini adalah data simulasi dan data terapan. Data simulasi digunakan untuk mengkaji dan membandingkan performa pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM pada beberapa struktur data yang berbeda. Data simulasi yang akan digunakan pada penelitian ini merupakan data yang dibangkitkan dari dua kelas berbeda dengan tiga struktur data yaitu struktur data yang terpisahkan secara linier sempurna (linearly separable), struktur data yang terpisahkan linier secara tidak sempurna (linearly non separable) dan struktur data yang terpisahkan secara tidak linier (nonlinearly separable). Pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM akan diterapkan pada data mahasiswa Pascasarjana IPB Program Studi Statistika pada tahun masuk 2000-2010 yang bertujuan untuk mengklasifikasi keberhasilan studi mahasiswa.
Tujuan Penelitian
Tujuan penelitian ini adalah
3 2. Membandingkan performa pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM berdasarkan persentase rataan kesalahan klasifikasi pada tabel ketepatan klasifikasi.
2.
TINJAUAN PUSTAKA
SVM sebagai Pengklasifikasi Tunggal
SVM diperkenalkan oleh Vapnik (1995). Konsep dasar SVM merupakan gabungan dari teori komputasi yang telah ada sebelumnya seperti margin hyperplane (Cover 1965, Duda et al. 1973) dan teori kernel yang dikembangkan oleh Aronszjan (1950). Ide dasar dari SVM adalah pencarian hyperplane terbaik yang berfungsi sebagai pemisah dua kelas data. Hyperplane terbaik antara kedua kelas terletak di tengah-tengah diantara dua bidang kendala kelas dan untuk mendapatkan hyperplane terbaik dilakukan dengan cara memaksimalkan jarak antara hyperplane dari titik terdekat (support vector) dari masing-masing kelas. Andaikan M adalah jarak tersebut, didefinisikan besaran margin sebagai 2M.
SVM pada Struktur Data Terpisahkan Linier secara Sempurna
Misalkan sebuah gugus data berisi n pasangan data pengamatan yang dinotasikan sebagai (x1,y1), (x2,y2), ..., (xn,yn) dengan xiRp untuk i = 1, 2, ..., n. Label kelas dinotasikan sebagai: yi{-1,1}. Bentuk umum hyperplane adalah
w x b (2.1) dengan w adalah vektor normal dengan ukuran 1p dan tegak lurus dengan hyperplane dan xmerupakan vektor data pengamatan yang berukuran p1. Skalar b disebut dengan simpangan. Fungsi klasifikasi didefinisikan sebagai:
( ) ( )
f x sign w x b (2.2)
Keckman (2005) menyatakan bahwa apabila f(x) > 0, maka data pengamatan diklasifikasikan ke dalam Grup 1, sedangkan apabila f(x) < 0, maka data pengamatan diklasifikasikan ke dalam Grup 2. Hyperplane dengan margin maksimum diperoleh dengan menemukan solusi dari permasalahan primal (Cortes & Vapnik 1995) yaitu :
2 1 min
2 w (2.3)
dengan kendala
( ) 1
i i
4
x2 w x b 1
Grup 1 w x b 1 M
support vectors
M
Margin = 2M = 2
w
Grup 2 w x b 0
x1
SVM pada Data Terpisahkan Linier Tidak secara Sempurna
Masalah SVM dapat diperoleh dengan menyelesaikan pemrograman kuadratik dengan menggunakan fungsi optimasi Lagrangian sebagai berikut :
2
1 1
( , , ) 1
2
n
i i i
i
L b y
w w w x (2.5)
dengan i adalah pengali Lagrange non negatif. Dengan memperhatikan sifat gradien maka diperoleh :
1
( , , ) n
i i i i L b y
ww x 0
w dan 1
( , , ) 0 n i i i L b y b
w (2.6) Persamaan (2.5) dapat dimodifikasi dengan memaksimumkan . Modifikasi ini memudahkan untuk menyelesaikan fungsi obyektif pada persamaan (2.3) dengan mengubah masalah primal menjadi masalah dual. Masalah pada dual mempunyai nilai yang sama dengan masalah primal (Strang 1986). Fungsi Lagrange akan diubah menjadi:2
1 1 1
1 ( , , )
2
n n n
i i i i i i
i i i
L b y b y
w w x w (2.7)
Substitusikan persamaan (2.6) ke dalam fungsi Lagrange (2.5) sehingga menjadi:
1 1 1 1 1
1
( , , ) 0
2
n n n n n
i i i j j j i i i j j j i
i j i j i
L b y y y y
w x x x x
1 1 1 1 1
1
( ) ( )
2
n n n n n
i j i j i j i j i j i j i
i j i j i
y y y y
x x x x
1 1 1 1
( )
2
n n n
i i j i j i j
i i j
y y
x x (2.8)5 dengan kendala ∑ni , i 0, i, j = 1, ..., n. Persamaan (2.8) merupakan fungsi masalah pengoptimuman dual. Nilai i didapatkan dengan cara memaksimumkan fungsi Lagrange pada persamaan (2.8). Gugus data yang memiliki nilai i > 0 dinamakan support vector. Gugus data tersebut akan digunakan untuk menghitung bobot ∑ i dan b = (w xi) – yi untuk i = 1, ..., nSV, dengan nSV adalah banyaknya support vector.
SVM pada Struktur Data Terpisahkan Linier secara Tidak Sempurna
Masalah klasifikasi sesungguhnya muncul pada ruang dimensi tinggi terutama pada data yang terpisahkan linier tidak secara sempurna. Struktur data yang terpisahkan linier tidak secara sempurna adalah data yang berada di dalam margin atau berada pada sisi yang salah dari batas keputusan. Hal ini menyebabkan proses optimisasi tidak dapat diselesaikan, karena tidak ada w dan b yang memenuhi pertidaksamaan (2.5).
Persamaan (2.3) dan (2.4) akan dimodifikasi dengan memasukkan peubah slacki (i > 0), sehingga menjadi :
2
1 1
min 2
n
i i C
w
(2.9) dengan kendala :
( ) 1
i i
y w x b ,
i 0; i = 1, ..., n (2.10) C adalah parameter yang menentukan besar penalti akibat kesalahan klasifikasi. Nilai C yang besar akan menghasilkan kesalahan klasifikasi yang kecil. Pada struktur data yang dapat dipisahkan linier secara tidak sempurna, peubah slack didefinisikan sebagai penyimpangan dari batas margin. Ilustrasi SVM pada struktur data terpisahkan linier secara tidak sempurna dapat dilihat pada Gambar 2. x2Grup 1 Margin
k xk
l xl
Grup 2 x1
Dua titik data xl dan xk pada Gambar 2 memperlihatkan dua titik yang menggambarkan kasus pada data terpisahkan linier secara tidak sempurna dengan Gambar 2 Ilustrasi SVM pada struktur data yang terpisahkan linier secara tidak
6
penambahan peubah slack l dan k. Titik xl adalah kesalahan klasifikasi karena berada di sisi yang salah batas keputusan. Titik xk merupakan titik yang berada di dalam margin tetapi diklasifikasikan dengan benar. Fungsi Lagrange dengan i dan βi untuk masalah primal pada kasus data terpisahkan secara linier tidak sempurna adalah :
2
1 1 1
1
( , , , , ) ( ) 1
2
n n n
i i i i i i i
i i i
L b C y b
w w w x (2.11)
Dengan memperhatikan sifat gradien diperoleh :
1
( , , , , ) n
i i i i L b y
ww x 0
w dan 1
( , , , , ) 0 n i i i L b y b
w (2.12) L( , , , , )b 0
w
menghasilkan i i C i([(w x ) b] 1 i)0, i = 1,..., n
0 i i
, untuk i = 1,..., n0i C, i 0, i 0, i 0 untuk i = 1, ..., n Substitusi persamaan (2.12) ke dalam persamaan fungsi Lagrange (2.11) akan didapatkan fungsi tujuan masalah dual sebagai berikut :
1 1 1
max ( ) ( )
n n n
i i j i j i j
i i j
L y y
x x (2.13)dengan kendala : ∑ , 0i C untuk i = 1, ..., n. Fungsi keputusan dari struktur data yang terpisahkan linier secara tidak sempurna adalah sama dengan struktur data yang dapat dipisahkan secara linier sempurna yaitu :
1 ( )
nSV i i i i
f sign y b
x x x (2.14)
dengan koefisien i merupakan solusi dari masalah dual dan SV merupakan himpunan dari support vector. Nilai didapatkan dari persamaan :
1
(1 ) ( )
nSV
i i i i j
i
b y y
x xSVM pada Struktur Data Terpisahkan secara Tidak Linier
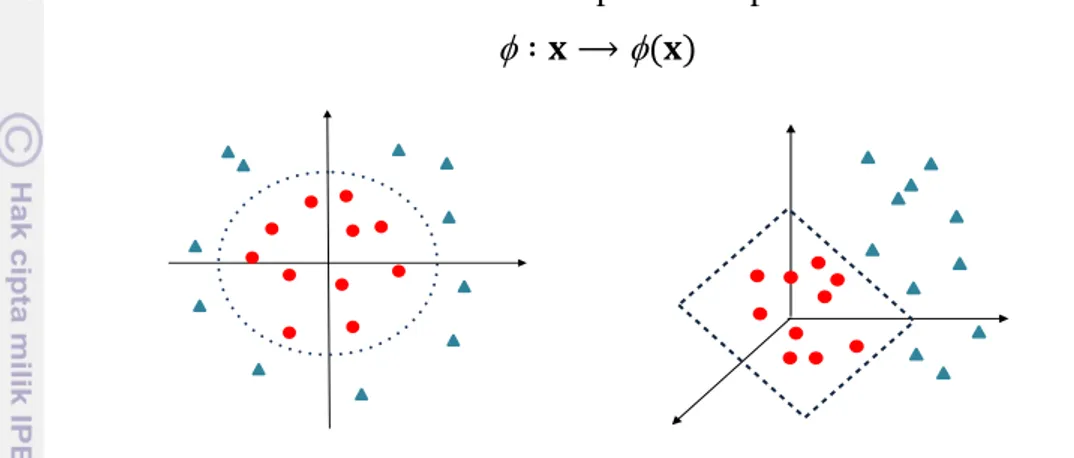
7 Secara umum metode kernel memiliki dua bagian utama. Bagian pertama adalah sebuah modul yang mentransformasikan data dari ruang awal ke dalam ruang baru yang berdimensi tinggi. Bagian kedua adalah suatu algoritma yang berfungsi untuk menemukan pola linier di dalam ruang baru yang terbentuk (Cristianini & Shawe-Taylor 2004). Ilustrasi pemetaan data yang terpisahkan secara non linier dari ke dalam dapat dilihat pada Gambar 3.
Pada Gambar 3 memperlihatkan tentang pemisahan non linier dalam ruang input yang dipetakan ke dalam ruang berdimensi tinggi dengan fungsi non linier yang disebabkan oleh fungsi kernel k sehingga didapatkan permukaan yang linier. Misalkan fungsi vektor non linier (x) = (1(x1), 2(x2), …, n(xn))‟ yang memetakan vektor ruang awal x ke dalam ruang yang berdimensi tinggi melalui fungsi vektor non linier . Fungsi keputusan pada ruang berdimensi tinggi adalah:
( ) ( ( ) )
f x sign w x b (2.15)
Pada struktur data terpisahkan linier secara tidak sempurna, vektor w merupakan kombinasi linier dari support vector di ruang berdimensi tinggi. Hal ini berarti :
1
( ) n
i i i i
y
w x
Fungsi klasifikasi f(x) pada persamaan (2.15) bergantung pada hasil kali dalam
(xi) dan (xj) yaitu :
1
( ) ( ( ) ) ( ), ( )
n
i i i i
f sign b sign y b
x w x x x (2.16)
SVM dibangun berdasarkan bentuk umum dari hasil kali dalam ruang Hilbert (Anderson & Bahadur 1966) yaitu :
( )u ( )v K u v( , )
Fungsi pemetaan (x) yang memetakan ruang awal ke dalam ruang berdimensi tinggi memenuhi:
( ,i j) ( )i ( j)
K x x x x
Gambar 3 Pemetaan data yang terpisah secara non linier dari ke dalam
8
dengan (xi) dan (xj) gambaran dari ruang berdimensi tinggi dan vektor xi dan xj sebagai ruang awal. Keuntungan menggunakan fungsi kernel adalah memperlihatkan transformasi non linier secara eksplisit. Teknik ini biasa dikenal kernel trick. Gunakan kernel trick untuk memaksimumkan masalah dual pada ruang berdimensi tinggiyaitu :
1 1 1
max ( ) ( )
n n n
i i j i j i j
i i j
L y y K
x x (2.17)dengan kendala : ∑ , 0 i C untuk i = 1, ..., n. Fungsi keputusan dari masalah dual adalah
1
( ) ( )
nSV
i i i i
f sign y K b
x x x (2.18)
dengan b diperoleh dari :
1
( )
nSV
i i i i
i
b y y K
x xFungsi kernel ( ,K x xi j) yang biasa digunakan dalam SVM (Meyer 2013) adalah : 1) Polinomial : K( ,x xi j)
(xixj) 1
ddengan d adalah derajat polinom. Pada software R i386 3.0.1 dengan package e1071 digunakan default dengan d = 3.
2) Radial basis function (RBF) : K( ,i j)exp i j2
x x x x
dengan merupakan parameter positif yang mengontrol radius. Pada software R i386 3.0.1 dengan package e1071 menggunakan default = (1/dimensi). 3) Tangent hyperbolic (sigmoid) : K( ,x xi j) tanh[ ( vx xi j)b]
untuk nilai parameter v, b telah ditentukan. Pada software R i386 3.0.1 dengan package e1071 menggunakan default dengan v = (1/dimensi) dan b = 0.
Pohon Klasifikasi
9
Node/simpul
Ya Tidak xi
Cabang Ya Tidak
xi
Simpul akhir
Langkah-langkah yang digunakan dalam pembentukan pohon klasifikasi (Breiman et al. 1993) adalah :
1. Pemilihan pemilah
Pada tahap ini dicari pemilah dari setiap simpul yang menghasilkan penurunan tingkat keheterogenan paling tinggi. Keheterogenan suatu simpul diukur berdasarkan nilai impurity-nya. Fungsi impuritas () yang dapat digunakan adalah indeks Gini. Semakin besar impuritas suatu simpul maka semakin heterogen simpul tersebut (Breiman et al. 1993). Nilai impuritas menggunakan indeks Gini pada simpul t yang dinotasikan dengan i(t) dan diformulasikan sebagai berikut:
( ) (1| ), (2 | ),..., ( | )
i t p t p t p j t (2.20) dengan p(j|t) adalah dugaan peluang unit pengamatan dalam kelas ke-j dan berada pada simpul t yang dinyatakan sebagai berikut:
j
j j j
j j j
N t N
N t N t
j p
/ ) (
/ ) ( )
(
(2.21)
dengan j adalah peluang awal kelas ke-j dan Nj adalah banyaknya unit pengamatan dalam kelas ke-j, dan Nj(t) adalah banyaknya unit pengamatan dalam kelas ke-j pada simpul t. Misalkan terdapat calon pemilah s yang memilah simpul t menjadi tL(dengan proporsi pL) dan tR (dengan proporsi pR), maka kebaikan dari s didefinisikan sebagai penurunan impuritas:
Δi(s,t) = i(t) –p
L i(tL) –pR i(tR) (2.22) Pengembangan pohon dilakukan dengan cara, pada simpul t1 carilah s* yang memberikan nilai penurunan impuritas tertinggi yaitu:
*
1 ( , ) max ( , )
s S
i s t i s t
(2.23) maka t1 dipilah menjadi t2 dan t3 dengan menggunakan s*. Dengan cara yang sama dilakukan juga pemilah terbaik pada t2 dan t3 secara terpisah, dan seterusnya.
2. Penentuan simpul terminal
Suatu simpul t akan menjadi simpul terminal atau tidak akan dipilah kembali, apabila banyaknya pengamatan kurang dari batas minimum yang telah
Gambar 4 Struktur pohon klasifikasi a
b
d e
10
ditentukan. Pada umumnya banyak pengamatan minimum pada simpul sebesar 5 dan terkadang sebesar 1 (Breiman et al. 1993). Selanjutnya t tidak akan dipilah lagi tetapi dijadikan simpul terminal dan hentikan pembuatan pohon. 3. Penandaan label kelas
Label kelas dari simpul terminal ditentukan berdasarkan aturan jumlah terbanyak, yaitu jika P(j0|t) = maxj P(j|t) dengan j = 1, ..., j maka label kelas untuk simpul terminal t adalah j0. Andaikan max�P(�|�) dicapai oleh dua atau lebih kelas yang berbeda, maka label kelas untuk simpul terminal t dipilih secara acak dari kelas maksimum tersebut (Breiman et al. 1993).
4. Penentuan pohon optimum
Pohon klasifikasi tidak dibatasi jumlahnya. pohon terbesar memiliki nilai salah pengklasifikasian terkecil, sehingga kita cenderung memilih pohon tersebut untuk perkiraan. Pohon yang besar cukup kompleks dalam menggambarkan struktur data sehingga perlu dipilih pohon optimal yang lebih sederhana tetapi memiliki kesalahan pengklasifikasian yang cukup kecil. Breiman et al. (1993) menyatakan bahwa salah satu cara mendapatkan pohon optimum yaitu dengan pemangkasan (pruning). Pemangkas berturut-turut memangkas pohon bagian yang kurang penting dengan tujuan untuk memperoleh pohon yang berukuran sederhana. Ukuran pemangkasan yang digunakan untuk memperoleh ukuran pohon yang optimum adalah biaya kompleksitas (cost-complexity). Persamaan ukuran biaya kompleksitas adalah:
|̃ | (2.24) dengan adalah tingkat salah klasifikasi pada pohon bagian Tk untuk k = 1,
̃ adalah himpunan simpul terminal pada Tk, |̃ | adalah banyaknya simpul terminal pada Tk, dan adalah parameter biaya kompleksitas. Hasil proses pemangkasan berupa sederet pohon klasifikasi Tk dan dengan validasi silang v -lipatan (RCV(Tk)) dapat ditentukan pohon optimum Tko (Venables & Ripley 2002) sebagai berikut:
( ) min ( )
CV CV
ko k
k
R T R T (2.25)
Metode Gabungan
Gagasan utama metodologi gabungan adalah mengkombinasikan beberapa pola pengklasifikasi tunggal seperti NN, SVM dan lain-lain dan menggabungkan pola tersebut menjadi satu nilai dugaan. Proses penggabungan yang biasa digunakan untuk kasus klasifikasi adalah suara terbanyak. Keberhasilan penerapan metode gabungan dapat ditemukan di berbagai bidang, seperti: keuangan (Leigh et al. 2002), bioinformatika (Tan et al. 2003), kesehatan (Mangiameli et al. 2004), geografi (Bruzzone et al. 2004) dan lain-lain.
Bagging merupakan singkatan dari bootstrap aggregrating. Berdasarkan namanya, maka dapat diperkirakan ada dua tahapan utama dalam analisis ini, yaitu bootstrap dan aggregating yaitu menggabungkan banyak nilai dugaan menjadi satu nilai dugaan. Teknik bootstrap diperkenalkan oleh Efron (1979).
11 (resampling). Bootstrap meletakkan dasar pada dua metode gabungan yaitu bagging dan random forest. Bagging pertama kali diperkenalkan oleh Breiman (1996). Ide dasar dari bagging adalah menggunakan teknik bootstrap pada data asli, membuat dugaan klasifikasi terpisah pada setiap data contoh bootstrap, dan menggabungkan dugaan klasifikasi tersebut dengan menggunakan suara terbanyak (Breiman 1996).
Misalkan terdapat himpunan data = {(xn; yn)|i = n … N}, dengan y berupa label kelas atau respon kategorik. Jika input adalah x maka y diduga dengan φ(x, ) dengan φ(x, ) merupakan prediktor yang diperoleh dengan menggunakan pengulangan bootstrap yang dinotasikan dengan Pengulangan bootstrap dilakukan sebanyak k kali sehingga menjadi dan dibentuk prediktor φ(x, )denganteknik pengambilan contoh dengan pemulihan (resampling) (Breiman 1996).
Prosedur pada teknik Bagging menurut Breiman (1996) adalah : 1) Data dibagi menjadi dua yaitu gugus data tes T dan gugus data training . 2) Tarik contoh acak dengan pengembalian sebanyak n* dari gugus data training
(tahapan bootstrap) dengan n*adalah ukuran contoh bootstrap.
3) Bentuk pengklasifikasi tunggal seperti SVM dan pohon klasifikasi berdasarkan contoh acak tersebut.
4) Ulangi langkah 2 dan 3 sebanyak k kali sehingga sehingga diperoleh k buah pengklasifikasi tunggal dan dugaan.
5) Lakukan pendugaan gabungan berdasarkan k buah pengklasifikasi tunggal tersebut dengan menggunakan suara terbanyak (tahapan aggregasi).
Hastie et al. (2008) menyatakan bahwa proses bagging dapat mengurangi galat baku dugaan yang dihasilkan oleh pengklasifikasi tunggal. Hal ini jelas terlihat karena dengan melakukan rata-rata misalnya maka ragam dugaan akan mengecil sedangkan tingkat bias dugaan tidak terpengaruh. Breiman (1996) mencatat bahwa pada banyak gugus data yang telah dicobakan, bagging mampu mengurangi tingkat kesalahan klasifikasi pada kasus klasifikasi. Hal ini tentu tidak berlaku secara keseluruhan. Berk (2008) mencatat beberapa kasus yang mungkin menyebabkan dugaan bagging memiliki ragam dugaan yang lebih besar atau juga bias yang lebih besar pula. Hal ini terjadi antara lain pada kasus dengan kategori peubah respon yang sangat tidak seimbang. Breiman (1996) menyebutkan bahwa banyaknya pengulangan bootstrap yang diperlukan menunjukkan bahwa 50 kali untuk kasus klasifikasi dan 25 kali untuk kasus regresi dapat memberikan hasil yang memuaskan. Semakin banyak resampling dan pengulangan dilakukan maka akurasi pengklasifikasi semakin meningkat walaupun peubahannya tidak terlalu signifikan.
Ukuran Performa Pengklasifikasi Tunggal dan Gabungan
12
yang diharapkan yaitu y = 1 sebesar a/n1 100%. Ketepatan klasifikasi total (akurasi) dalam menduga kejadian secara tepat dapat diduga oleh pengklasifikasi yang nilainya (a + d)/n 100%.
Tabel 1 Ketepatan klasifikasi
Amatan Dugaan Total Proporsi
Ketepatan
1 0
1 a b n1 a / n1
0 c d n0 d / n0
Total n1 n0 n (a + d) / n
Proporsi Kesalahan c / n1 d / n0 (b + c) / n
Selain ketepatan klasifikasi dapat pula diketahui persentase besarnya kesalahan klasifikasi (misclassification rate atau MCR). Kesalahan positif nilainya sebesar c/n1100% adalah persentase besarnya kesalahan ketika respon yang diduga adalah y = 1 tapi amatan sebenarnya bernilai y = 0 dan kesalahan negatif yang bernilai d/n0 100% dinyatakan sebagai persentase besarnya kesalahan ketika respon diduga adalah y = 0 namun amatan sebenarnya bernilai y = 1. Kesalahan klasifikasi total diartikan sebagai besarnya kesalahan klasifikasi terhadap kesalahan keseluruhan kejadian yang dapat diperoleh dengan cara merasiokan total klasifikasi yang tidak terkoreksi dengan jumlah keseluruhan data yaitu sebesar (b+c)100%.
3.
METODE
Data
Data Simulasi
Data simulasi yang digunakan untuk mengkaji dan membandingkan metode pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM terdiri dari tiga skenario yaitu (1) apabila anggota kelas berbeda dapat dipisahkan secara linier sempurna, (2) apabila anggota kelas berbeda dapat dipisahkan linier secara tidak sempurna dan (3) anggota kelas berbeda dipisahkan secara tidak linier. Ukuran data simulasi yang digunakan pada penelitian ini adalah 120 data pengamatan. Data simulasi terdiri dari dua kelompok yaitu Grup 1 dan 2.
Pada skenario pertama, ukuran contoh pada Grup 1 sebanyak 60 data pengamatan dan Grup 2 sebanyak 60 data pengamatan. Data dibangkitkan dari dua sebaran yang berdistribusi normal ganda sebagai Grup 1 dan Grup 2 dengan vektor rataan masing-masing adalah
1 2
2 8
,
2 8
μ μ
dengan matriks ragam peragam yang sama yaitu
1 2
2 0 0 2
13 Pemilihan vektor rataan pada skenario pertama disebabkan karena jarak antara dua populasi yang berjauhan menyebabkan data dapat terpisahkan secara linier sempurna tanpa ada error didalamnya sehingga tidak terdapat salah klasifikasi. Dengan menggunakan ragam yang sama maka ragam peubah penjelas akan merata pada setiap populasi.
Ukuran contoh pada Grup 1 pada skenario kedua adalah 60 data pengamatan dan 60 data pengamatan pada Grup 2. Data dibangkitkan dari dua sebaran yang berdistribusi normal ganda dengan vektor rataan masing-masing adalah
1 2
2 3
,
2 3
μ μ
dengan matriks ragam peragam yang sama yaitu
1 2
2 0 0 2
Σ Σ Σ
Pemilihan vektor rataan pada skenario kedua disebabkan karena jarak antara kedua populasi yang berdekatan menyebabkan terdapat beberapa titik yang tumpang tindih sehingga struktur data sulit dipisahkan secara linier sempurna. Dengan menggunakan ragam yang sama maka ragam peubah penjelas akan merata pada setiap populasi.
Pada skenario yang ketiga, ukuran contoh pada Grup 1 sebanyak 40 data pengamatan dan 80 data pengamatan sebagai Grup 2. Pada Grup 1, data dibangkitkan dari sebaran yang berdistribusi normal ganda dengan vektor rataan dan matriks ragam peragam masing-masing adalah
1
1 1
μ , dan 1 1 0.7
0.7 1
Σ
sedangkan pada Grup 2 dengan ukuran contoh sebanyak 80 data pengamatan. Data dibangkitkan dari campuran dua sebaran berdistribusi normal ganda dengan vektor rataan masing-masing adalah
2
1 3
μ dan 3 3
1
μ
dan matriks ragam peragam
2 3
1 0.7 0.7 1
Σ Σ
sehingga:
2 3 2 3 2 2 3 3
| ,w , , , ~ 0.5MVN( ; , ) 0.5 MVN( ; , )
x μ μ Σ Σ x μ Σ x μ Σ
dengan MVN(x; i, i) adalah fungsi kepadatan peluang yang berdistribusi normal ganda dengan i adalah vektor rataan ke-i dan i adalah matriks ragam peragam ke-i. Pemilihan vektor rataan pada skenario ketiga didasarkan sebagai ilustrasi untuk struktur data terpisahkan secara tidak linier pada dimensi dua. Dengan menggunakan ragam yang sama maka ragam peubah penjelas akan merata pada setiap populasi.
14
Simulasi dilakukan dengan dua kondisi ukuran contoh bootstrap (n*) dan ukuran contoh data training (n). Kondisi tersebut adalah ukuran contoh yang sama antara bootstrap dan data trainingnya dan ukuran contoh bootstrap lebih kecil daripada data trainingnya. Teknik bootstrap sebagai bagian dari pendekatan metode gabungan dilakukan dengan melakukan resampling sebanyak 50, 100, dan 500 kali. Prosedur resampling digunakan untuk mengenali pengaruh frekuensi resampling terhadap performa klasifikasi. Langkah-langkah pada pembentukan pengklasifikasi gabungan akan diulang sebanyak 50, 100, 500, 1000 dan 5000 kali. Ketiga skenario data simulasi terangkum pada Tabel 2.
Tabel 2 Skenario data simulasi pada tiga struktur data
Skenario Parameter Ukuran
contoh Struktur data terpisahkan linier secara sempurna
Grup 1 : 1 2
2
μ
Grup 2 : 2 8
8
μ
Matriks ragam-peragam: 1 2 2 0
0 2
Σ Σ Σ
n1 = 60 n2 = 60
Struktur data terpisahkan linier secara tidak sempurna
Grup 1 : 1 2
2
μ
Grup 2 : 2 3
3
μ
Matriks ragam-peragam: 1 2 2 0
0 2
Σ Σ Σ
n1 = 60 n2 = 60
Struktur data terpisahkan tidak secara
linier
Grup 1 : 1 2
2
μ
Grup 2 : 2 1
3
μ dan 3 3
1
μ
Matriks ragam-peragam: 1 2 1 0.7
0.7 1
Σ Σ Σ sehingga:
2 3 2 3 2 2 3 3
| , , , , ~ 0.5 ( ; , ) 0.5 ( ; , )
i i i
x wμ μ Σ Σ MVN x μ Σ MVN x μ Σ
n1 = 40 n2 = 80
Data Terapan
Data terapan yang akan digunakan pada penelitian ini adalah data mahasiswa Pascasarjana IPB Program Studi Statistika yang diperoleh dari Divisi Akademik Sekolah Pascasarjana IPB. Data tersebut akan digunakan untuk mengklasifikasikan keberhasilan studi mahasiswa Pascasarjana IPB Program Studi Statistika. Data terapan yang digunakan adalah semua data mahasiswa Pascasarjana IPB Program Studi Statistika yang berhasil lanjut ke semester dua. Kriteria mahasiswa yang berhasil lanjut ke semester dua adalah mahasiswa dengan IPK 3.00 yang berstatus percobaan dan mahasiswa dengan status biasa.
15 akhir semester 2. Data mahasiswa Pascasarjana IPB Program Studi Statistika berjumlah 188 mahasiswa tetapi hanya 162 mahasiswa yang memenuhi syarat lanjut ke semester dua dengan kriteria mahasiswa yang berhasil sebanyak 143 mahasiswa dan 19 mahasiswa kurang berhasil. Karakteristik peubah penjelas yang digunakan pada penelitian ini terangkum pada Tabel 3.
Tabel 3 Karakteristik peubah penjelas pada data terapan Peubah Penjelas Keterangan Jenis Kelamin 1 = Laki-laki
2 = Perempuan Usia Pada Saat Masuk Sekolah
Pascasarjana IPB
Status Perkawinan Pada Saat Masuk Sekolah Pascasarjana IPB
1 = Menikah 2 = Belum Menikah Pekerjaan pada saat tahun masuk 1 = Dosen
2 = Non Dosen Asal Perguruan Tinggi Pada Saat Sarjana 1 = PTN Jawa
2 = PTS Jawa
3 = PTN/PTS Non Jawa Program Studi Pada Saat Sarjana 1 = Statistika
2 = Matematika
3 = Pendidikan Matematika 4 = Lainnya
IPK Pada Saat Sarjana
Sponsor Pendidikan Pada Saat Menjadi Mahasiswa Pascasarjana IPB
1 = Sendiri 2 = BPPS/BU
3 = Instansi/Lembaga
Metode Analisis
Kajian Simulasi
Pada data simulasi langkah-langkah yang akan dilakukan dalam menganalisis pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM adalah :
1) Menggunakan data simulasi yang dibangkitkan dengan ketiga struktur data 2) Membentuk pengklasifikasi tunggal yaitu SVM dan pohon klasifikasi
3) Membentuk pengklasifikasi gabungan yaitu ensemble tree dan ensemble SVM. Tahapan ini terdiri dari beberapa lang
kah-langkah sebagai berikut :
i. Membagi data menjadi dua yaitu gugus data training dan data tes.
ii. Menarik contoh acak dengan pengembalian sebanyak n* dari gugus data training (tahapan bootstrap). Ukuran contoh bootsrap yang dicobakan adalah 84 dan 60 data pengamatan.
iii. Membuat dugaan pada pengklasifikasi SVM dan pohon klasifikasi berdasarkan data tersebut.
16
v. Melakukan pendugaan gabungan berdasarkan k buah pengklasifikasi tunggal tersebut dengan menggunakan suara terbanyak (tahapan aggregasi). 4) Mengevaluasi dan membandingkan performa pengklasifikasi tunggal dan
gabungan dengan menggunakan tabel ketepatan klasifikasi dengan menggunakan gugus data tes.
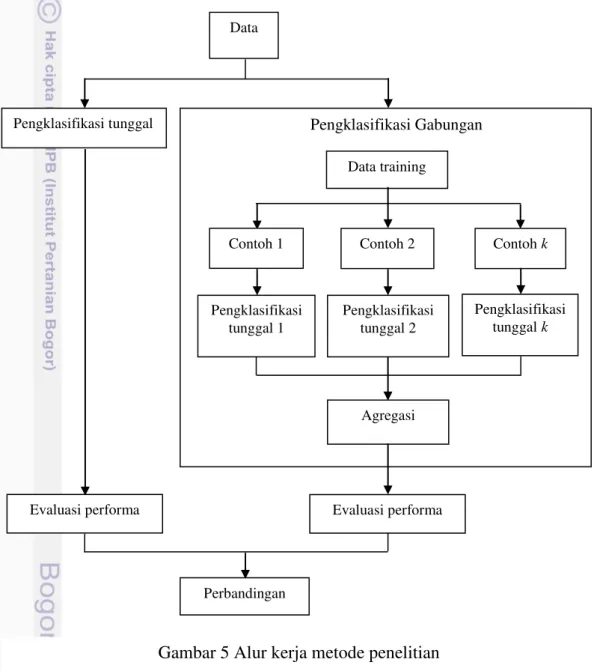
Keseluruhan proses analisis dilakukan menggunakan software R i386 3.0.1 dengan package MASS, e1071 dan rpart. Alur kerja metode penelitian disajikan pada Gambar 5.
Kajian Terapan
Prosedur yang dilakukan untuk contoh penerapan terdiri atas :
1) Menerapkan metode pengklasifikasi tunggal dan gabungan dari pohon klasifikasi dan SVM.
2) Mengevaluasi kinerja pengklasifikasi tunggal dan gabungan dengan tabel ketepatan klasifikasi.
Gambar 5 Alur kerja metode penelitian
Pengklasifikasi tunggal
Data
Pengklasifikasi Gabungan
Data training
Contoh 1 Contoh 2 Contoh k
Pengklasifikasi tunggal 1
Pengklasifikasi tunggal 2
Pengklasifikasi
tunggal k
Agregasi
Evaluasi performa Evaluasi performa
17
4.
HASIL DAN PEMBAHASAN
Data Simulasi
Data pembangkitan kasus simulasi merupakan data yang dibangkitkan dengan mengikuti distribusi tertentu dengan rataan dan ragam tertentu. Setiap kasus simulasi juga dihitung simpangan baku untuk melihat kestabilan model. Hasil pembangkitan data akan dilakukan disetiap skenario data simulasi untuk melihat kondisi data yang terbentuk.
Setiap data akan dibagi menjadi dua yaitu data training dan data tes. Data training digunakan untuk pembentukan pengklasifikasi tunggal dan gabungan sedangkan data tes digunakan untuk validasi model. Guna melihat efektifitas dari pengklasifikasi tunggal dan gabungan dihitung rataan kesalahan klasifikasi tiap-tiap model. Semakin kecil rataan tingkat kesalahan klasifikasi yang dihasilkan maka metode akan semakin efektif dalam mengklasifikasikan kasus simulasi.
Struktur Data yang Terpisahkan secara Linier Sempurna
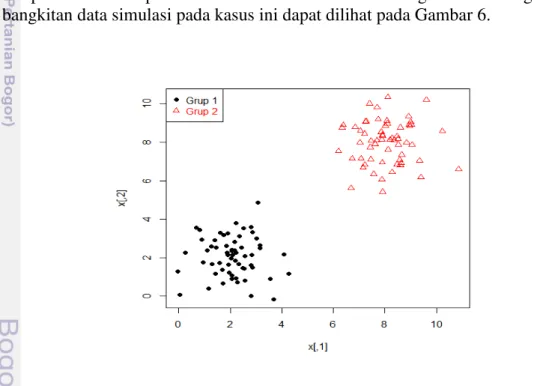
Struktur data yang terpisahkan secara linier sempurna dapat diartikan bahwa setiap anggota dari dua kelompok berbeda dapat dipisahkan secara linier sempurna dan setiap titik berada di luar atau sama dengan batas margin. Hasil bangkitan data simulasi pada kasus ini dapat dilihat pada Gambar 6.
Hasil simulasi pada skenario pertama menunjukkan bahwa persentase rataan kesalahan klasifikasi pada dua kondisi ukuran contoh bootstrap dan data training memiliki hasil yang sama sehingga akan disajikan hasil dengan kondisi ukuran contoh bootstrap lebih kecil data training. Plot perbandingan persentase rataan dan simpangan baku salah klasifikasi dengan ulangan 5000 pada struktur data terpisahkan linier secara sempurna dapat dilihat pada Gambar 7.
18
Pada pengklasifikasi tunggal, metode SVM memiliki persentase rataan tingkat kesalahan klasifikasi lebih rendah dibandingkan dengan pohon klasifikasi. Semakin banyak resampling dan pengulangan dilakukan maka persentase rataan salah klasifikasi dan simpangan baku SVM pada ketiga fungsi kernel tetap konstan yaitu sebesar 0. Metode SVM pada skenario ini tidak memiliki salah klasifikasi sehingga merupakan metode yang lebih baik dan lebih stabil dibandingkan pohon klasifikasi. Pada pengklasifikasi gabungan terjadi penurunan persentase rataan kesalahan klasifikasi dan nilai simpangan baku baik pada SVM maupun pohon klasifikasi. Hal ini menunjukkan bahwa metode gabungan meningkatkan akurasi dan menurunkan ragam pada pengklasifikasi tunggal.
Sruktur Data yang Terpisahkan Linier secara Tidak Sempurna
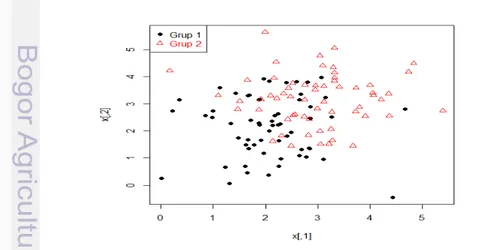
Struktur data yang terpisahkan linier secara tidak sempurna dapat diartikan bahwa setiap anggota dari dua kelompok berbeda dapat dipisahkan secara linier tetapi ada titik-titik yang berada di dalam batas margin meskipun diklasifikasikan secara benar serta titik-titik yang diklasifikasikan secara salah. Hasil bangkitan data simulasi pada kasus ini dapat dilihat pada Gambar 8.
Gambar 8 Hasil bangkitan data simulasi pada struktur data yang terpisahkan linier secara tidak sempurna
(a) (b)
0 0.2 0.4 0.6 0.8 1
Tunggal 50 100 500
M
CR
(%
)
Banyaknya resampling Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
0 0.005 0.01 0.015 0.02
Tunggal 50 100 500
S
im
p
a
n
g
a
n
b
a
k
u
Banyaknya resampling Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
19 Hasil simulasi pada skenario pertama menunjukkan bahwa persentase rataan kesalahan klasifikasi pada dua kondisi ukuran contoh bootstrap dan data training memiliki hasil yang sama sehingga akan disajikan hasil dengan kondisi ukuran contoh bootstrap lebih kecil data training. Plot perbandingan persentase rataan dan simpangan baku salah klasifikasi dengan ulangan 5000 pada struktur data terpisahkan linier secar tidak sempurna ditunjukkan pada Gambar 9.
Pada pengklasifikasi tunggal, metode SVM dengan ketiga fungsi kernel memiliki persentase rataan tingkat kesalahan klasifikasi lebih rendah dibandingkan dengan pohon klasifikasi. SVM semakin menurun dengan semakin banyaknya ulangan dengan persentase penurunan rataan tingkat kesalahan klasifikasi sebesar 1.39-1.75. Metode SVM dengan fungsi kernel radial mempunyai persentase rataan kesalahan klasifikasi terkecil sehingga merupakan metode pengklasifikasi tunggal yang mempunyai performa paling baik dibandingkan pohon klasifikasi.
Pada pengklasifikasi gabungan terjadi penurunan persentase rataan kesalahan klasifikasi dan nilai simpangan baku baik pada SVM maupun pohon klasifikasi. Hal ini menunjukkan bahwa metode gabungan meningkatkan akurasi dan menurunkan ragam pada pengklasifikasi tunggal. Ensemble SVM dengan fungsi kernel radial paling baik digunakan untuk mengelompokkan objek apabila dibandingkan dengan ensemble SVM dengan fungsi kernel lainnya.
Struktur Data yang Terpisahkan secara Tidak Linier
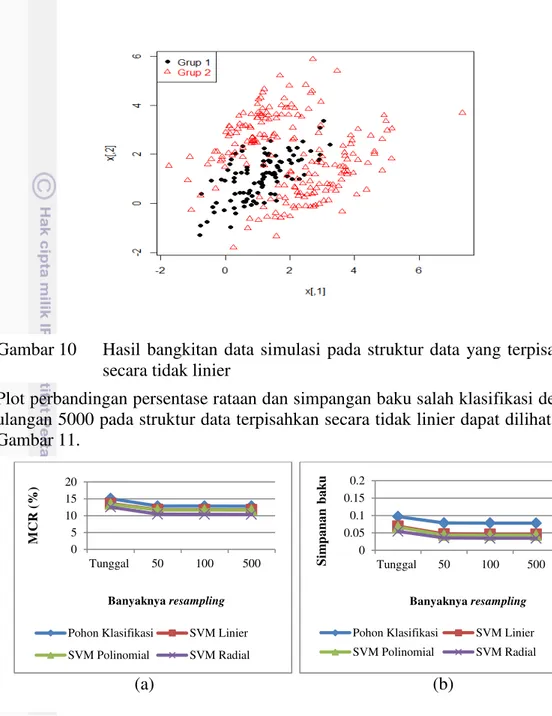
Struktur data yang terpisahkan secara tidak linier dalam hal ini merupakan setiap anggota dari dua kelompok berbeda tidak dapat dipisahkan secara linier sehingga perlu ditransformasi ke dimensi yang lebih tinggi dengan menggunakan fungsi kernel sehingga anggota kelas yang ada lebih mudah dipisahkan secara linear. Fungsi kernel yang digunakan pada kasus ini adalah linier, polinomial dan radial. Hasil simulasi pada skenario pertama menunjukkan bahwa persentase rataan kesalahan klasifikasi pada dua kondisi ukuran contoh bootstrap dan data training memiliki hasil yang sama sehingga akan disajikan hasil dengan kondisi ukuran contoh bootstrap lebih kecil data training. Hasil bangkitan data simulasi pada skenario untuk struktur data yang terpisahkan secara tidak linier dapat dilihat pada Gambar 10.
(a) (b)
0 10 20 30 40
Tunggal 50 100 500
M
CR
(%
)
Banyaknya resampling Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
0 0.02 0.04 0.06 0.08 0.1
Tunggal 50 100 500
S
im
p
a
n
g
a
n
b
a
k
u
Banyaknya resampling Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
20
Plot perbandingan persentase rataan dan simpangan baku salah klasifikasi dengan ulangan 5000 pada struktur data terpisahkan secara tidak linier dapat dilihat pada Gambar 11.
Pada pengklasifikasi tunggal, metode SVM dengan ketiga fungsi kernel memiliki persentase rataan tingkat kesalahan klasifikasi lebih rendah dibandingkan dengan pohon klasifikasi. SVM semakin menurun dengan semakin banyaknya ulangan dengan persentase penurunan rataan tingkat kesalahan klasifikasi sebesar 1.77-2.18. Metode SVM dengan fungsi kernel radial mempunyai persentase rataan kesalahan klasifikasi terkecil sehingga merupakan metode pengklasifikasi tunggal yang mempunyai performa paling baik dibandingkan pohon klasifikasi.
Pada pengklasifikasi gabungan terjadi penurunan persentase rataan kesalahan klasifikasi dan nilai simpangan baku baik pada SVM maupun pohon Gambar 10 Hasil bangkitan data simulasi pada struktur data yang terpisahkan
secara tidak linier
(a) (b)
0 5 10 15 20
Tunggal 50 100 500
M
CR
(%
)
Banyaknya resampling
Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
0 0.05 0.1 0.15 0.2
Tunggal 50 100 500
S
im
p
a
n
a
n
b
a
k
u
Banyaknya resampling
Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
21 klasifikasi. Hal ini menunjukkan bahwa metode gabungan meningkatkan akurasi dan menurunkan ragam pada pengklasifikasi tunggal. Ensemble SVM dengan fungsi kernel radial paling baik apabila dibandingkan dengan ensemble SVM dengan fungsi kernel yang lainnya.
Data Terapan
Data terapan yang akan digunakan pada penelitian ini adalah data mahasiswa Pascasarjana IPB Program Studi Statistika tahun masuk 2000-2010 yang diperoleh dari Divisi Akademik Sekolah Pascasarjana IPB. Mahasiswa Pascasarjana IPB Program Studi Statistika tahun masuk 2000-2010 berjumlah 188 mahasiswa. Data yang dibutuhkan pada penelitian ini adalah semua mahasiswa berstatus biasa dan mahasiwa berstatus percobaan yang mempunyai IPK lebih besar dari 3.00 pada semester satu.
Data mahasiswa Pascasarjana IPB Prdogram Studi Statistika tahun masuk 2000-2010 terdiri dari delapan peubah penjelas dan mempunyai ukuran populasi sebanyak 162 orang. Penerapan metode tunggal dan gabungan dari SVM dan pohon klasifikasi akan diulang sebanyak 50 dan 100. Banyaknya resampling yang akan digunakan adalah 50, 100 dan 500.
Sebagian besar mahasiswa Pascasarjana IPB Program Studi Statistika tahun masuk 2000-2010 diminati oleh mahasiswa berjenis kelamin perempuan, belum menikah, mempunyai pekerjaan sebagai dosen, berasal dari Perguruan Tinggi Negri di Jawa, berasal dari Program Studi Statistika saat sarjana dan mempunyai sponsor pendidikan sendiri ataupun beasiswa BBPS atau BU. Jumlah mahasiswa Pascasarjana IPB Program Studi Statistika tahun masuk 2000-2010 adalah 162 orang, 101 orang berjenis kelamin perempuan dan sisanya adalah laki-laki. Mahasiswa perempuan hampir mendominasi setiap angkatan pada Program Studi Statistika kecuali pada angkatan 2003, 2004 dan 2006. Sponsor pendidikan pada saat masuk Sekolah Pascasarjana IPB berimbang antara biaya sendiri dan beasiswa BPPS atau BU yang disebabkan sebagian besar mahasiswa Pascasarjana IPB Program Studi Statistika merupakan seorang dosen. Deskripsi data mahasiswa Pascasarjana IPB Program Studi Statistika tahun masuk 2000-2010 disajikan pada Lampiran 18.
Pada pengklasifikasi tunggal, metode SVM dengan ketiga fungsi kernel memiliki persentase rataan tingkat kesalahan klasifikasi lebih rendah dibandingkan dengan pohon klasifikasi. SVM semakin menurun dengan semakin banyaknya ulangan dengan persentase penurunan rataan tingkat kesalahan klasifikasi sebesar 0.32-1.00. Metode SVM dengan fungsi kernel radial mempunyai persentase rataan kesalahan klasifikasi terkecil sehingga merupakan metode pengklasifikasi tunggal yang mempunyai performa paling baik dibandingkan pohon klasifikasi.
22
mengklasifikasikan keberhasilan studi mahasiswa Pascasarjana IPB Program Studi Statistika tahun masuk 2000-2010. Plot perbandingan persentase rataan dan simpangan baku salah klasifikasi dengan ulangan 100 pada data terapan dapat dilihat pada Gambar 12.
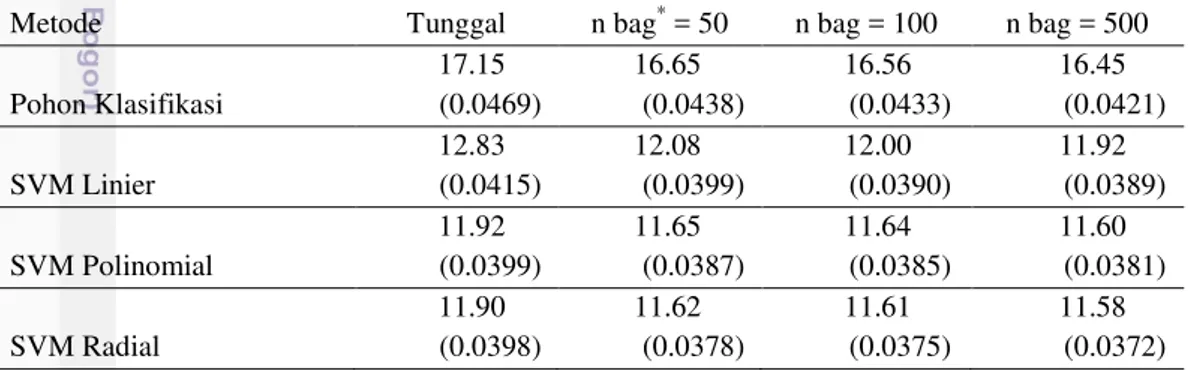
Tabel persentase rataan salah klasifikasi dan simpangan baku pada data terapan dengan ulangan 100 dapat dilihat pada Tabel 4.
Tabel 4 Persentase rataan salah klasifikasi dan simpangan baku pada data terapan
Metode Tunggal n bag* = 50 n bag = 100 n bag = 500
Pohon Klasifikasi 17.15 (0.0469) 16.65 (0.0438) 16.56 (0.0433) 16.45 (0.0421) SVM Linier 12.83 (0.0415) 12.08 (0.0399) 12.00 (0.0390) 11.92 (0.0389) SVM Polinomial 11.92 (0.0399) 11.65 (0.0387) 11.64 (0.0385) 11.60 (0.0381) SVM Radial 11.90 (0.0398) 11.62 (0.0378) 11.61 (0.0375) 11.58 (0.0372)
*n bag = banyaknya resampling
5.
SIMPULAN DAN SARAN
Simpulan
Simpulan yang dapat diambil pada penelitian ini adalah :
1. Metode SVM pada ketiga struktur data mempunyai persentase rataan tingkat kesalahan klasifikasi lebih rendah dibandingkan dengan pohon klasifikasi. - Pada struktur data yang terpisahkan linier secara sempurna, SVM dengan
ketiga fungsi kernel tidak memiliki salah klasifikasi sehingga mempunyai performa paling baik dibandingkan dengan pohon klasifikasi.
(a) (b)
0 5 10 15 20
Tunggal 50 100 500
M
CR
(%
)
Banyaknya resampling
Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
0 0.01 0.02 0.03 0.04 0.05
Tunggal 50 100 500
S im p a n g a n b a k u
Banyaknya resampling Pohon Klasifikasi SVM Linier SVM Polinomial SVM Radial
23 - Pada struktur data yang terpisahkan linier secara tidak sempurna, persentase rataan tingkat kesalahan klasifikasi SVM semakin menurun dengan semakin banyaknya ulangan dengan kisaran sekitar 1.39-1.75. SVM dengan fungsi kernel radial mempuyai performa yang paling baik dibandingkan dengan fungsi kernel lainnya.
- Pada struktur data yang terpisahkan secara tidak linier, persentase rataan tingkat kesalahan klasifikasi SVM semakin menurun dengan semakin banyaknya ulangan dengan kisaran sekitar 1.77-2.18. SVM dengan fungsi kernel radial mempuyai performa yang paling baik dibandingkan dengan fungsi kernel lainnya.
2. Metode gabungan lebih stabil