Lampiran A CONTOH BERITA
ID: 3530
Judul: Sate Maranggi Cibungur: Manis Gurih Sate Daging yang Bikin Ketagihan Ringkasan menggunakan TextTeaser:
Bisa pilih sate kambing, sate sapi atau sate ayam. Sate ini berbeda dengan sate yang umumnya berupa potongan daging yang dibakar langsung. Sate tanpa bumbu kacang dan direndam bumbu sebelum dibakar merupakan ciri khas sate maranggi. Konon nama maranggi diberikan oleh pelanggannya karena 25 tahun silam saat ia membuka warung sate, sate racikannya tak punya nama. Rasa sate yang khas ini membuat banyak orang menjual sate yang mirip dengan sate Cibungur.
Ringkasan menggunakan TextRank:
Bisa pilih sate kambing, sate sapi atau sate ayam. Sate ini berbeda dengan sate yang umumnya berupa potongan daging yang dibakar langsung. Sate tanpa bumbu kacang dan direndam bumbu sebelum dibakar merupakan ciri khas sate maranggi. Konon nama maranggi diberikan oleh pelanggannya karena 25 tahun silam saat ia membuka warung sate, sate racikannya tak punya nama. Rasa sate yang khas ini membuat banyak orang menjual sate yang mirip dengan sate Cibungur.
Teks asli:
Yeti ini tak punya cabang di lokasi lain. Konon nama maranggi diberikan oleh pelanggannya karena 25 tahun silam saat ia membuka warung sate, sate racikannya tak punya nama. Disebut maranggi karena mirip dengan sate dari Eretan, Kedunghaur, Indramayu. Kalau suka, bisa disantap dengan nasi hangat yang disajikan dalam bungkusan daun pisang (Rp. 6. 000). Beberapa orang suka menambahkan kecap manis. Namun, jika disantap begitu saja rasa manisnya sudah pas. Jodoh paling pas buat mengiringi santapan sate ini adalah es kelapa muda (Rp. 15. 000) yang disajikan dalam gelas stainless steel. Kelapa muda yang dikeruk halus diberi sirop vanili yang wangi dan es batu. Sebagai pendamping tutut yang direbus dengan bumbu gurih pedas juga enak. Disedot-sedot sambil mencungkili dagingnya yang kenyal. Sebagai pencuci mulut bisa memilih potongan buah segar atau colenak. Tape bakar yang diberi siraman sirop gula merah dan taburan kelapa parut. Rasa sate yang khas ini membuat banyak orang menjual sate yang mirip dengan sate Cibungur. Karenanya hampir di seluruh pelosok Purwakarta mudah ditemui sate ini. Namun, kalau mau yang asli Anda harus ke Cibungur. Lokasinya mudah dicari. Kalau dari arah Jakarta, keluar tol Cikampek, belok ke kanan, dan sekitar 3,3 km warung sate yang tak pernah sepi ini ada di sisi kiri. Ke Purwakarta, jangan lupa mampir ke sate maranggi ini!
ID: 5898
Judul: 2016, Komisi VIII Targetkan Pengesahan Dua RUU Ringkasan menggunakan TextTeaser:
Komisi VIII DPR RI menargetkan pembahasan dua Rancangan Undang-Undang (RUU) selesai pada 2016. Dua RUU itu adalah RUU Penyandang Disabilitas dan RUU Penyelenggaraan Haji dan Umroh, "Sampai masa akhir persidangan 2015, pembahasan kedua RUU sudah selesai dilaksanakan pada tingkat komisi," ujar Ketua Komisi VIII DPR Saleh Partaonan Daulay di Jakarta, Jumat (1/1/2016). Politisi Partai Amanat Nasional (PAN) itu mengatakan, Komisi VIII tinggal menunggu hasil pembahasan RUU Penyandang Disabilitas yang dilakukan pemerintah untuk selanjutnya dibahas lagi bersama DPR. "Sepanjang 2015, Komisi VIII fokus untuk menyelesaikan pembahasan dua RUU yang telah diamanatkan dalam Program Legislasi Nasional (Prolegnas) 2015 tersebut," tuturnya. Baleg DPR juga telah menyetujui dua RUU dalam Prolegnas 2016 yang akan dibahas Komisi VIII yaitu RUU Tanggung Jawab Sosial Perusahaan dan RUU Pekerja Sosial.
Ringkasan menggunakan TextRank:
Komisi VIII DPR RI menargetkan pembahasan dua Rancangan Undang-Undang (RUU) selesai pada 2016. Dua RUU itu adalah RUU Penyandang Disabilitas dan RUU Penyelenggaraan Haji dan Umroh, "Sampai masa akhir persidangan 2015, pembahasan kedua RUU sudah selesai dilaksanakan pada tingkat komisi," ujar Ketua Komisi VIII DPR Saleh Partaonan Daulay di Jakarta, Jumat (1/1/2016). Politisi Partai Amanat Nasional (PAN) itu mengatakan, Komisi VIII tinggal menunggu hasil pembahasan RUU Penyandang Disabilitas yang dilakukan pemerintah untuk selanjutnya dibahas lagi bersama DPR. Baleg DPR juga telah menyetujui dua RUU dalam Prolegnas 2016 yang akan dibahas Komisi VIII yaitu RUU Tanggung Jawab Sosial Perusahaan dan RUU Pekerja Sosial.
Teks asli:
DAFTAR PUSTAKA
Aristoteles. 2011. Pembobotan fitur teks pada peringkasan teks bahasa Indonesia menggunakan algoritme genetika. Tesis. Institut Pertanian Bogor.
Aristoteles. 2014. Text Feature Weighting for Summarization of Documents Bahasa Indonesia by Using Binary Logistic Regression Algorithm. International Journal of Computer Science and Telecommunications 5(7): 29-33.
Balabantaray, R. C., Sahoo, B., & Sahoo, D. K. 2012. Odia text summarization using stemmer. International Journal of Applied Information Systems (IJAIS) 1(3): 21-24.
Balbin, J. P. 2011. Automatic summarization of senate bills for dissemination in a social network environment. Master Thesis. De La Salle University.
Belica, M. 2015. Sumy 0.4.0: Module for automatic summarization of text documents and HTML pages. https://pypi.python.org/pypi/sumy. (diakses 11 Januari 2016).
Bird, S., Loper, E., & Klien, E. 2009. Natural Language Processing with Python. California: O'Reilly Media Inc.
Deshpande, A. R., & Lobo, L. M. 2013. Text Summarization using Clustering Technique. International Journal of Engineering Trends and Technology (IJETT) 4(8): 3348-3351.
Erkan, G., & Radev, D. R. 2004. LexRank: Graph-based lexical centrality as salience in text summarization. Journal of Artificial Intelligence Research: 457-479.
Fachrurrozi, M., Yusliani, N., & Yoanita, R. U. 2013. Frequent Term based Text Summarization for Bahasa Indonesia. International Conference on Innovations in Engineering and Technology: 30-32.
Google Developers. 2015. Google Cloud Messaging: Overview. https://developers.google.com/cloud-messaging/gcm (diakses 1 Desember 2015).
Hu, M., Sun, A., & Lim, E.-P. 2007. Comments-oriented blog summarization by sentence extraction. Proceedings of the sixteenth ACM conference on Conference on information and knowledge management, pp. 901-904.
Mihalcea, R., & Tarau, P. 2004. TextRank: Bringing order into texts. Association for
Computational Linguistics. (Online)
https://web.eecs.umich.edu%2F~mihalcea%2Fpapers%2Fmihalcea.emnlp04.p df (2 Desember 2015).
Mustaqhfiri, M., Abidin, Z., & Kusumawati, R. 2012. Peringkasan Teks Otomatis Berita Berbahasa Indonesia Menggunakan Metode Maximum Marginal Relevance. MATICS.
Pfeiffer, J. 2014. Home · GravityLabs/goose Wiki · GitHub. https://github.com/GravityLabs/goose/wiki (diakses 22 Desember 2015).
PhoneArena. 2013. Android's Google Play beats App Store with over 1 billion apps, now officially largest. http://www.phonearena.com/news/Androids-Google-
Play-beats-App-Store-with-over-1-million-apps-now-officially-largest_id45680 (diakses 22Desember 2015).
Riandayani, D., Putra, I., & Buana, P. 2014. Comparing fuzzy logics and fuzzy c-means (FCM) on summarizing indonesian language document. Journal of Theoretical and Applied Information Technology 59(3): 718-724.
Ridha, A. 2002. Pengindeksan otomatis dengan istilah tunggal untuk dokumen berbahasa indonesia. Tesis. Institut Pertanian Bogor.
Ridok, A. 2014. Peringkasan dokumen bahasa Indonesia berbasis non-negative matrix factorization (NMF). Jurnal Teknologi Informasi dan Ilmu Komputer: 39-44.
Saxena, S. 2013. 5 Characteristics of a Good News Report. http://www.easymedia.in/5-characteristics-good-news-report/ (diakses 27 Nepember 2015)
Setiawan, D. T. 2014. Peringkasan Teks Berita Secara Otomatis Menggunakan Term Frequency Inverse Document Frequency (TF-IDF). Skripsi. Universitas Sumatera Utara.
Smith, C. 2014. Introduction to Celery. http://pyvideo.org/speaker/1340/caleb-smith (diakses 30 Desember 2015).
Solem, A. 2015. Periodic Tasks.
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html (diakses 29 Desember 2015).
Steinberger, J., & Ježek, K. 2012. Evaluation measures for text summarization. Computing and Informatics 28(2): 251-275.
Torres-Moreno, J. 2014. Automatic Text Summarization. USA: John Wiley & Sons, Inc.
Valstar, M., Mehu, M., Jiang, B., Pantic, M., & Scherer, K. 2012. Meta-Analysis of the First Facial Expression Recognition Challenge. Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on 42(4): 966-979.
Zaman, B., & Winarko, E. 2011. Analisis Fitur Kalimat untuk Peringkas Teks Otomatis pada Bahasa Indonesia. IJCCS-Indonesian Journal of Computing and Cybernetics Systems 5(2).
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini akan menjelaskan beberapa hal di antaranya arsitektur umum sistem, sumber data yang digunakan, tampilan aplikasi serta analisis perancangan yang bertujuan untuk mengidentifikasi permasalahan yang ada pada sistem tersebut. Analisis ini diperlukan sebagai dasar perancangan sistem untuk mengimplementasikan algoritma TextTeaser dalam meringkas teks berita.
Arsitektur Umum
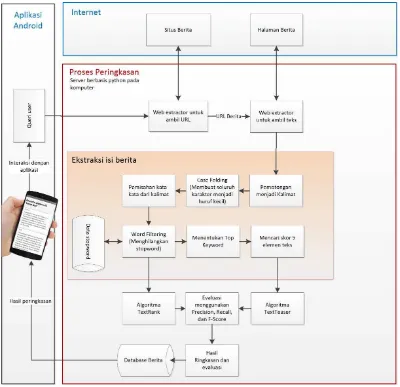
Pada awalnya sistem menyediakan konten (teks utuh berita, teks ringkasan, URL berita asli, URL gambar berita) dengan mengambil data berita dari situs berita (di internet) secara berkala menggunakan celery periodic tasks. Pada proses tersebut terdapat beberapa tahap antara lain yang pertama web data extraction untuk mengambil URL dari sebuah halaman yang diberikan, selanjutnya menggunakan URL berita yang didapatkan diproses lagi menggunakan web data extraction untuk mengambil isi berita (teks isi berita dan URL gambar terkait untuk keperluan penyajian aplikasi Android). Kemudian tahap yang kedua adalah melakukan pembersihan teks berita sehingga teks berita siap untuk memulai proses algoritma (TextTeaser dan TextRank). Seterusnya tahap ketiga setelah ringkasan teks baik menggunakan TextTeaser maupun TextRank diperoleh adalah mengevaluasi hasil ringkasan kedua algoritma, dan yang terakhir menyimpan data dalam database.
Aplikasi yang terpasang pada perangkat Android berguna membaca konten yang sudah disediakan oleh sistem. Pengguna aplikasi dapat memilih dan mendapatkan berita melalui kategori default yang sudah ada. Kategori default yang diberikan merupakan kategori umum yang biasa ada pada situs berita online misalnya kategori Economy, National, Technology, dan sebagainya. Kemudian pengguna bisa
server akan dicari judul berita berdasarkan query yang dikirim. Berita yang didapatkan kemudian diubah dalam bentuk string JSON. Terakhir aplikasi akan mengolah data JSON dari server untuk ditampilkan. Berikut pada gambar 3.1 arsitektur umum sistem peringkas berita online yang akan dibuat.
Gambar 3.1 Arsitektur umum sistem peringkas berita Analisis Data
Data Berita
Data berita seperti judul, berita dan teks berita diperoleh dari situs berita online. Data berita diambil menggunakan teknik web data extraction halaman berita. Beberapa contoh daftar halaman berita yang akan diproses dapat dilihat pada tabel 3.1. Terdapat dua kriteria data yang akan diambil melalui teknik web data extraction seperti data URL berita dan data berita.
Tabel 3.1 Contoh URL situs berita No. Kategori Berita Sumber Berita URL
1. Gaya Hidup Liputan6.com http://lifestyle.liputan6.com 2. Teknologi Liputan6.com http://tekno.liputan6.com 3. Ekonomi Kompas http://ekonomi.kompas.com 4. Internasional Kompas http://internasional.kompas.com
5 Otomotif Kompas http://otomotif.kompas.com
Web data extraction merupakan teknik untuk mengambil data tertentu dari sebuah halaman website di internet untuk kemudian disimpan pada media penyimpan lokal atau database. Pada penelitian ini, web data extraction bekerja dengan dua tujuan yaitu yang pertama mengambil semua URL pada halaman target seperti “http://otomotif.kompas.com”. Pada halaman tersebut akan diambil semua URL dengan domain yang sama untuk menghindari pengambilan URL yang tidak relevan dengan halaman seperti URL iklan atau media sosial. Kemudian tujuan kedua adalah untuk mengambil isi berita baik teks berita maupun gambar berita.
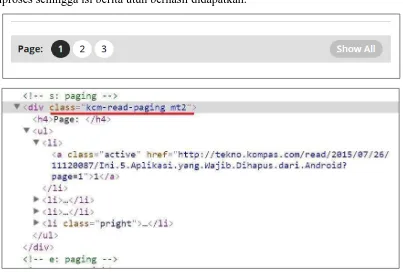
Kemudian hasil dari pengambilan data melalui web data extraction berupa URL berita. Diproses lagi untuk untuk memperoleh judul dan teks berita. Namun masalah terjadi ketika sebuah URL berita yang berisi hanya sebagian isi berita keseluruhan. Untuk itu dokumen HTML yang diperoleh dari Python Goose terlebih dahulu
ditentukan lokasi indikator berita bersambung. Pada berita kompas.com ditemukan lokasi indikator berita bersambung dengan tampilan seperti gambar 3.2. Kemudian pada dokumen HTML, secara manual lokasi indikator tersebut dicari sehingga ditemukan pada tag "div" dengan class "kcm-read-paging mt2". Berita bersambung pada kompas.com memiliki opsi untuk membuka halaman berita utuh berdasarkan berita bersambung yang dideteksi.
Misalnya pada halaman berita bersambung kompas.com:
jika ditelusuri halaman satu per satu diperoleh URL:
“http://tekno.kompas.com/read/2015/07/26/11120087/Ini.5.Aplikasi.yang.Wajib.Diha pus.dari.Android?page=2”
untuk menuju halaman kedua berita (ditandai dengan akhiran “?page=nomor_halaman”). Karena berita kompas.com menyediakan URL untuk menuju halaman utuh berita tersebut yaitu:
“http://tekno.kompas.com/read/2015/07/26/11120087/Ini.5.Aplikasi.yang.Wajib.Diha pus.dari.Android?page=all”.
Maka selanjutnya dari URL berita utuh (dengan akhiran “?page=all”) yang didapatkan diproses sehingga isi berita utuh berhasil didapatkan.
Gambar 3.2 Indikasi berita bersambung tekno.kompas.com
Selanjutnya untuk berita liputan6.com, lokasi indikator berita bersambung
Gambar 3.3 Indikasi berita bersambung health.liputan6.com
Berbeda dengan berita kompas.com, berita liputan6.com tidak menyediakan opsi untuk membuka berita utuh. Sehingga, tahapan yang dilakukan setelah URL dideteksi sebagai berita bersambung adalah mengambil URL dari indikator. Misalnya untuk berita bersambung dengan URL:
“http://health.liputan6.com/read/2396905/13-cara-sayangi-jantung”
Pada indikator akan ditemukan URL untuk menuju halaman selanjutnya seperti: “http://health.liputan6.com/read/2396905/13-cara-sayangi-jantung?p=0”, “http://health.liputan6.com/read/2396905/13-cara-sayangi-jantung?p=1”,
dan seterusnya dengan indikator halaman berupa akhiran “?p=nomor_halaman”. Selanjutnya semua URL diproses dengan dengan menggunakan web data extraction, kemudian hasil dari masing-masing URL disatukan.
Untuk berita detik.com, proses yang dilakukan sedikit berbeda. Pada indikator berita bersambung yang dideteksi, detik.com tidak menyediakan daftar URL berita
lainnya. Sehingga URL akan dibuat sendiri pada sistem. URL yang dibuat berjumlah sesuai jumlah halaman berita yang ada. Misalnya dideteksi sebuah URL berita detik.com bersambung:
“http://health.detik.com/read/2 015/12/23/201611/3103649/766/5-alasan-tidur-kelamaan-tidak-lebih-baik-dari-kurang-tidur”.
Alamat URL kemudian dipotong menjadi dua bagian:
Setelah lokasi indikator pada tampilan ditemukan terlebih dahulu, kemudian mencari lokasi kode program tampilan tersebut. Sehingga dari indikator yang ditemukan tag “div” per-class “multipage multipage2” seperti gambar 3.4. Di dalam kode tersebut terdapat tag “span” dengan nilai jumlah berita keseluruhan. Misalnya pada gambar 3.4, tag “span” terdapat teks “1 dari 6”, berarti halaman berita terdiri dari 6 halaman. Selanjutnya pada sistem kedua URL hasil pemotongan sebelumnya disatukan dengan penambahan indikasi halaman berita selanjutnya di tengah, misalnya dengan potongan pertama:
“http://health.detik.com/read/2015/12/23/201611/3103649/766”,
kemudian disambung dengan nomor_halaman misalnya “/2/”, seterusnya disambung dengan potongan kedua sehingga akan diperoleh beberapa alamat URL seperti:
“ http://health.detik.com/read/2015/12/23/201611/3103649/766/2/5-alasan-tidur-kelamaan-tidak-lebih-baik-dari-kurang-tidur”
“ http://health.detik.com/read/2015/12/23/201611/3103649/766/3/5-alasan-tidur-kelamaan-tidak-lebih-baik-dari-kurang-tidur”, dan seterusnya.
Dari URL yang dibuat terdapat indikasi halaman berita (cetak tebal, miring, dan garis bawah).
Gambar 3.4 Indikasi berita bersambung health.detik.com
Setelah semua alamat URL berhasil dibuat, langkah selanjutnya memproses alamat URL untuk memperoleh isi berita kemudian isi berita dari masing-masing alamat URL disatukan untuk disimpan ke dalam database.
Data stopword
Kata-kata umum (common word) yang yang tidak bermakna (stopword) berguna untuk mengurangi kompleksitas kalkulasi penghitungan skor fitur teks (text feature).. Stopword yang digunakan berasal dari penelitian (Tala, 2003). Pada penelitian tersebut daftar stopword ditentukan berdasarkan hasil analisis frekuensi kata pada total 3160 dokumen berita berbahasa Indonesia. Dari dokumen tersebut, setelah nama orang, nama
<div class="multipage multipage2"> <span class="fl">... </span> <span>1 dari 6</span>
kota, nama organisasi, nama negara, dan sebagainya dihilangkan, diperoleh 50000 (lima puluh ribu) kata unik.
Pada penelitian yang dilakukan Tala (2003), terbukti dengan menghilangkan stopword dari dokumen yang akan diteliti akan meningkatkan nilai Precision dan R-Precision (indikator pengukuran kualitas hasil). Contoh kata-kata tersebut dapat dilihat pada tabel 3.2. Daftar kata stopword disimpan dalam file teks (*.txt).
Tabel 3.2 Contoh stopword No. Kata
1 akan 2 di 3 dengan 4 pada 5 yang
Analisis Sistem
Setiap pembangunan sebuah sistem aplikasi diperlukan perancangan tahap-tahap (alur) bagaimana sistem bekerja. Salah satunya adalah identifikasi masalah. Identifikasi permasalahan yang ada pada sistem mencakup software, user, hingga output yang dihasilkan sistem (Setiawan, 2014).
Penelitian ini memiliki tiga proses utama yaitu ekstraksi isi berita, pembersihan isi berita, peringkasan isi berita.
Ekstraksi isi berita
URL berita yang diperoleh akan diproses lagi untuk mendapatkan teks berita. Untuk mendapatkannya digunakan Python Newspaper dan Python Goose yang secara otomatis menentukan bagian halaman berita yang merupakan teks berita. Karena pada umumnya halaman berita memiliki bagian-bagian yang bukan isi berita seperti navigasi halaman, kumpulan link berita terkait, hingga banner iklan. Kemudian pada tahap ini berita berpotong-potong juga akan ditangani.
Pembersihan teks berita
Untuk menghindari mengolah data yang bukan merupakan isi berita. Hasil ekstraksi isi berita terlebih dahulu dibersihkan. Beberapa data yang perlu dibersihkan meliputi judul atau keterangan di bawah gambar (caption gambar), selipan link berita terkait, inisial penulis, inisial sumber berita yang biasanya berada pada awal kalimat, hingga penyelipan inisial sumber berita pada judul berita. Karena setiap sumber berita memiliki kriteria data yang berbeda, maka masing-masing sumber berita akan dibersihkan cara yang berbeda pula.
Persiapan proses peringkasan
Setelah isi berita dibersihkan tahap selanjutnya adalah mempersiapkan teks untuk proses peringkasan (text preprocessing).
Pada tahap text preprocessing, teks berita terlebih dahulu dipotong menjadi kalimat. Pemotongan ini disebut sentence tokenizing yang menggunakan NLTK sentence tokenizer. Tujuan menggunakan NLTK sentence tokenizer adalah untuk memastikan
deteksi pembatas kalimat yang lebih baik. Hal ini tentu jauh lebih efektif daripada memotong kalimat hanya berdasarkan pembatas (delimiter) seperti titik, tanda seru,
tanda tanya. Contoh sentence tokenizing ini adalah:
“Saya bertemu dengan Prof. Robert, MD, dan Dr. Abdullah tadi pagi di laboratorium” Kalimat tersebut jika menggunakan pemotongan menggunakan tanda baca (contohnya tanda titik) sebagai indikator pemotongan, maka hasilnya terdapat tiga kalimat: “Saya bertemu dengan Prof”, “Robert, MD, dan Dr”, “Abdullah tadi pagi di laboratorium”. Berbeda jika menggunakan NTLK sentence tokenizer, hasil yang didapatkan hanya ada satu kalimat: “Saya bertemu dengan Prof. Robert, MD, dan Dr. Abdullah tadi pagi di laboratorium”.
Dari kalimat-kalimat hasil pemotongan, selanjutnya tanda baca seperti tanda seru (!), tanda tanya (?), tanda titik (.), dan karakter lainnya yang bukan merupakan huruf abjad dihilangkan. Untuk menghilangkan semua tanda baca yang bukan abjad tersebut digunakan fungsi pemeriksa karakter “isalnum”. Setiap karakter yang diperiksa dengan fungsi ini dan ternyata bukan huruf abjad, akan dihapus.
berupa spasi. Setelah itu semua huruf dalam kata diubah menjadi huruf kecil dengan menggunakan fungsi “lower”. Kemudian yang terakhir adalah menghilangkan stopword dengan mencocokkan setiap kata dalam teks berita dengan daftar kata stopword yang sudah disediakan. Setiap kata yang ada pada daftar stopword akan dihapus.
Proses text preprocessing dapat digambarkan dalam gambar 3.5 :
Judul dan isi berita
Pemotongan teks menjadi kalimat
Menghilangkan pungtuasi pada
teks
Mengubah kalimat menjadi kata Menghilangkan
stopword Mulai
Berhenti
Gambar 3.5 Flowchart text preprocessing
Contoh bagaimana penerapan text preprocessing, misalkan sebuah kalimat seperti pada gambar 3.6.
Gambar 3.6 Contoh input teks
Kalimat pada gambar 3.6, setelah melalui proses pemotongan kalimat (sentence tokenizing) akan menghasilkan dua kalimat:
i. “Saya bertemu dengan Prof. Robert, MD dan Dr. Abdullah tadi pagi di laboratorium”,
ii. “Setelah itu saya masuk ke kelas Interaksi Manusia dan Komputer (IMK)”. Proses selanjutnya adalah menghilangkan tanda baca pada teks hingga menghasilkan seperti gambar 3.7.
Gambar 3.7 Teks setelah menghilangkan tanda baca
Saya bertemu dengan Prof. Robert, MD, dan Dr. Abdullah tadi pagi di laboratorium. Setelah itu saya masuk ke kelas Interaksi Manusia dan Komputer (IMK).
Teks pada gambar 3.7 selanjutnya dipisahkan menjadi kata dengan menggunakan pemisahan berupa tanda spasi sehingga menghasilkan 24 kata. Kata-kata tersebut kemudian diubah menjadi huruf kecil. Sehingga menghasilkan kumpulan kata seperti gambar 3.8.
Gambar 3.8 Hasil penguraian kata dari teks dan huruf kecil
Proses text preprocessing yang terakhir adalah menghilangkan stopword. Hal ini dilakukan dengan cara membandingkan ke koleksi stopword dari penelitian Tala (2003). Setiap kata pada gambar 3.8 yang sama dengan koleksi stopword (Tala, 2003) akan dihapus sehingga kata yang tersisa adalah kata yang ada pada gambar 3.9.
Gambar 3.9 Kata-kata setelah penghapusan stopword Menentukan frekuensi keyword
Sebelum memulai proses peringkasan, keyword atau kata yang sering muncul pada teks didapatkan terlebih dahulu. Untuk mendapatkannya, seluruh kata berulang dalam teks hasil text preprocessing dijadikan satu. Seterusnya setiap kata dihitung jumlah kemunculannya pada teks asli sehingga dihasilkan kata unik dan berapa kali kata tersebut muncul. Misalkan input teks berita seperti gambar 3.10.
Judul: Kapolri Bela Anak Buah di Kerusuhan Banyuwangi
Teks: Kapolri Jenderal Badrodin Haiti tak menyoalkan tembakan yang dilepaskan anak
buahnya saat kerusuhan anti tambang di Kabupaten Banyuwangi, Jawa Timur. Insiden melukai tiga warga, satu di antaranya bocah. "Boleh-boleh saja (menembak)", kata Badrodin di Mabes Polri, Jalan Trunojoyo, Kebayoran Baru, Jakarta Selatan. Kapolri mengatakan, seharusnya warga tak berlaku anarkis. Apalagi, penambangan di sana berizin. Resmi. Menurut Badrodin, saat kerusuhan posisi anak buahnya melindungi dan menjaga agar tak ada perusakan. "Siapa yang melanggar hukum harus ditindak tegas" ujar Kapolri.
Gambar 3.10 Input judul dan teks berita
"saya", "bertemu", "dengan", "prof", "robert", "md", "dan", "dr", "abdullah", "tadi", "pagi", "di", "laboratorium", "setelah", "itu", "saya", "masuk", "ke", "kelas", "interaksi", "manusia", "dan", "komputer", "imk"
“bertemu”, “prof”, “robert”, “md”, “dr”, “abdullah”, “pagi”, “laboratorium”, “setelah”,
Dari teks yang diberikan akan diperoleh tujuh kalimat yaitu:
K.1. Kapolri Jenderal Badrodin Haiti tak menyoalkan tembakan yang dilepaskan anak buahnya saat kerusuhan antitambang di Kabupaten Banyuwangi, Jawa Timur.
K.2. Insiden melukai tiga warga, satu di antaranya bocah.
K.3. "Boleh-boleh saja (menembak)," kata Badrodin di Mabes Polri, Jalan Trunojoyo, Kebayoran Baru, Jakarta Selatan.
K.4. Kapolri mengatakan, seharusnya warga tak berlaku anarkis. K.5. Apalagi, penambangan di sana berizin resmi.
K.6. Menurut Badrodin, saat kerusuhan posisi anak buahnya melindungi dan menjaga agar tak ada perusakan.
K.7. "Siapa yang melanggar hukum harus ditindak tegas," ujar Kapolri.
Dari teks berita juga diperoleh total 48 kata dan 40 kata unik (kata tanpa perulangan). Selanjutnya 40 kata unik diurutkan dari terbesar ke terkecil, sepuluh dari kata unik diambil seperti tabel 3.3.
Tabel 3.3 Contoh top keyword Kata Frekuensi
kapolri 3
badrodin 3
buahnya 2
warga 2
kerusuhan 2
anak 2
posisi 1
kabupaten 1
mabes 1
ditindak 1
Kemudian dari top keyword yang diperoleh dihitung skor masing-masing kata menggunakan persamaan (4) dan variabel total kata unik dalam teks (|�|) bernilai 48
Tabel 3.4 Skor keyword Kata Frekuensi Skor
kapolri 3 0.09375
badrodin 3 0.09375
buahnya 2 0.0625
warga 2 0.0625
kerusuhan 2 0.0625
anak 2 0.0625
posisi 1 0.03125
kabupaten 1 0.03125
mabes 1 0.03125
ditindak 1 0.03125
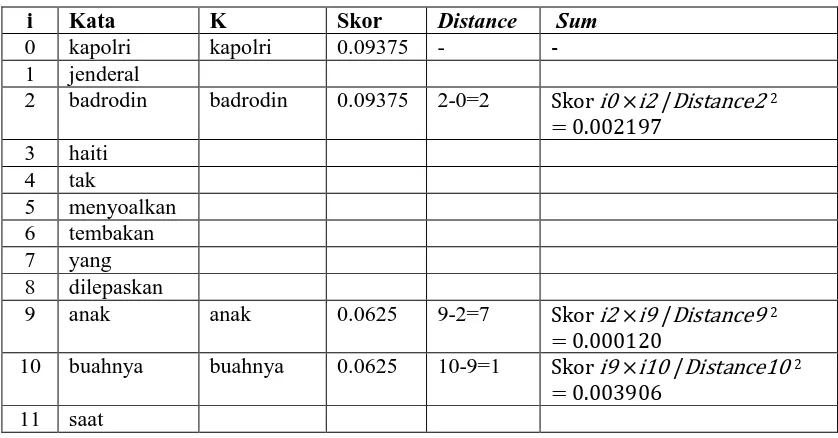
Top keyword sudah diperoleh, proses selanjutnya adalah menghitung skor fitur teks density-based selection (DBS) dan summation-based selection (SBS). Langkah pertama menghitung skor fitur DBS pada setiap kalimat dalam teks. Misalkan untuk mencari skor DBS untuk kalimat pertama (K1) teks berita pada gambar 3.10, “Kapolri Jenderal Badrodin Haiti tak menyoalkan tembakan yang dilepaskan anak buahnya saat kerusuhan antitambang di Kabupaten Banyuwangi, Jawa Timur”. Kalimat tersebut di
ubah ke huruf kecil dan dipilah menjadi kata. Kemudian setiap kata dalam kalimat dibandingkan dengan kata yang ada dalam top keyword. Total kata yang ada pada kalimat dan top keyword merupakan nilai pada persamaan (5). Proses tersebut dapat diilustrasikan pada tabel 3.5.
Tabel 3.5 Menghitung nilai variabel DBS i Kata K Skor Distance Sum 0 kapolri kapolri 0.09375 - - 1 jenderal
2 badrodin badrodin 0.09375 2-0=2 Skor i0 ×i2 /Distance2 2 = 0.002197
3 haiti 4 tak
5 menyoalkan 6 tembakan 7 yang 8 dilepaskan
9 anak anak 0.0625 9-2=7 Skor i2 ×i9 /Distance9 2 = 0.000120
10 buahnya buahnya 0.0625 10-9=1 Skor i9 ×i10 /Distance10 2 = 0.003906
Tabel 3.5 Menghitung nilai variabel DBS (lanjutan) i Kata K Skor Distance Sum
12 kerusuhan kerusuhan 0.0625 12-10=2 Skor i10 ×i12 /Distance12 2 = 0.000977
13 antitambang 14 di
15 kabupaten kabupaten 0.03125 15-12=3 Skor i12 ×i15 /Distance15 2 = 0.000217
16 banyuwangi 17 jawa 18 timur
Total K 6+1 = 7 Total = 0.007417
Pada tabel 3.5, Skor diperoleh dari top keyword sesuai dengan kata terkait misalnya pada baris pertama tabel (kata “kapolri”), pada top keyword memiliki skor 0.09375. Distance mengacu pada indeks kata sekarang (misalnya kata “badrodin” pada indeks ke 2, i2) di kurang indeks kata bagian dari K sebelumnya (misalnya kata “kapolri” pada indeks pertama, i0). Kemudian kolom Sum adalah hasil perhitungan Skor indeks sekarang (misalnya indeks ke-15 atau i15) dikalikan dengan Skor indeks bagian dari K sebelumnya (indeks ke-12 atau i12), hasilnya dibagi Distance indeks sekarang pangkat dua.
Contoh menghitung skor pada indeks ke-15 (i15) kata “kabupaten”:
Diketahui, Skor i12 (sebelumnya) = 0.0625, Skor i15 (sekarang) = 0.03125, Distance i15 = 3, jadi 0.0625 × 0.03125 ÷ 32 = 0.000217.
Langkah selanjutnya adalah menghitung skor DBS dengan nilai total K dan total skor (Sum) didapatkan.
Diketahui, Total K: 7
Total Sum: 0.007417
Jadi,
Nilai yang diperoleh merupakan hasil akhir skor fitur DBS kalimat pertama input teks pada gambar 3.10. Begitu juga seterusnya untuk kalimat-kalimat lain dalam teks.
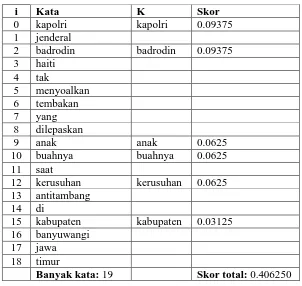
Fitur teks selanjutnya yang akan dihitung adalah SBS. Menggunakan kalimat yang sama (kalimat K1) seperti pada penghitungan DBS. Setelah kalimat diubah menjadi huruf kecil dan dipilah menjadi kata-kata. Setiap kata pada kalimat yang juga berada pada top keyword akan diambil skornya untuk selanjutnya ditotalkan. Hal ini dapat dilihat pada tabel 3.6.
Tabel 3.6 Skor total SBS
i Kata K Skor
0 kapolri kapolri 0.09375 1 jenderal
2 badrodin badrodin 0.09375 3 haiti
4 tak
5 menyoalkan 6 tembakan 7 yang 8 dilepaskan
9 anak anak 0.0625
10 buahnya buahnya 0.0625 11 saat
12 kerusuhan kerusuhan 0.0625 13 antitambang
14 di
15 kabupaten kabupaten 0.03125 16 banyuwangi
17 jawa 18 timur
Banyak kata: 19 Skor total: 0.406250
K pada tabel 3.6 memiliki keterangan yang sama seperti yang ada pada tabel 3.5 yaitu kata-kata pada kalimat yang juga ada dalam top keyword. Kemudian skor total dan banyak kata yang diperoleh seperti pada tabel 3.6 dihitung dengan:
Diketahui,
Banyak kata (| |): 19 Skor total: 0.406250
Jadi,
= | | ×
= × .
Sehingga diperoleh skor SBS yaitu 0.021382. Begitu juga selanjutnya untuk kalimat-kalimat lainnya dalam teks berita.
Skor fitur DBS dan fitur SBS sudah diperoleh, langkah berikutnya adalah menghitung fitur frekuensi keyword menggunakan persamaan (7) seperti:
= . ×+ .
= 0.149289
Sehingga diperoleh skor elemen frekuensi keyword = 0.149289. Kesimpulannya, untuk memperoleh skor frekuensi keyword, yang pertama dicari adalah top keyword pada teks, kemudian skor fitur DBS dan SBS setiap kalimat dalam teks.
Menentukan skor judul teks
Untuk mendapatkan skor judul teks, setiap kalimat dalam teks dipilah menjadi kata Contohnya pada kalimat K.1, stopword pada kata-kata yang dihasilkan dihilangkan, hasilnya dibandingkan lagi dengan kata-kata dalam judul teks seperti tabel 3.7.
Tabel 3.7 Hitung fitur judul berita
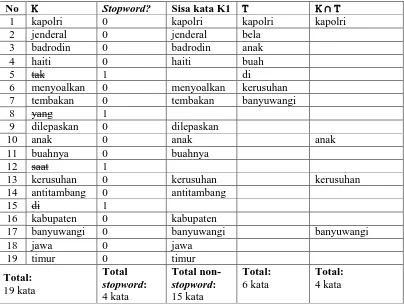
No K Stopword? Sisa kata K1 T K ∩ T
1 kapolri 0 kapolri kapolri kapolri
2 jenderal 0 jenderal bela
3 badrodin 0 badrodin anak
4 haiti 0 haiti buah
5 tak 1 di
6 menyoalkan 0 menyoalkan kerusuhan
7 tembakan 0 tembakan banyuwangi
8 yang 1
9 dilepaskan 0 dilepaskan
10 anak 0 anak anak
11 buahnya 0 buahnya
12 saat 1
13 kerusuhan 0 kerusuhan kerusuhan
14 antitambang 0 antitambang
15 di 1
16 kabupaten 0 kabupaten
17 banyuwangi 0 banyuwangi banyuwangi
18 jawa 0 jawa
19 timur 0 timur
Dari tabel K merupakan semua kata (termasuk stopword) yang ada pada kalimat K1, T adalah setiap kata (bukan stopword) yang terdapat pada judul, kemudian K∩T adalah setiap kata pada K yang juga ada pada T.
Untuk memperoleh skor judul teks pada kalimat K1, digunakan persamaan (1). Substitusi nilai yang didapat dari tabel 3.7 ke dalam persamaan (1) adalah = ×4 , sehingga diperoleh nilai 0,666667. Begitu juga seterusnya untuk kalimat-kalimat
lainnya dalam teks berita.
Menentukan skor panjang kalimat
Untuk mendapatkan skor panjang kalimat, digunakan nilai ideal 20 (Balbin, 2011) dan jumlah semua kata pada kalimat (termasuk stopword). Misalkan kalimat yang akan dipakai adalah kalimat K1, berdasarkan tabel 3.7 diketahui jumlah semua kata pada kalimat | | adalah 19. Selanjutnya nilai dapat dihitung menggunakan persamaan (3),
− − 9
. Jadi, skor panjang kalimat untuk kalimat K1 adalah 0,950000.
Menentukan skor posisi kalimat
Dalam proses text preprocessing, terdapat sentence tokenizing yang akan menghasilkan list kalimat dari teks yang diberikan. Dalam list, setiap kalimat memiliki nomor indeks yang dimulai dari nol (zero-based numbering). Misalkan dari teks dalam gambar 3.10,
kalimat yang akan diringkas adalah kalimat pertama (K.1). Indeks kalimat tersebut dalam list adalah 0. Berdasarkan persamaan (2), maka nilai o adalah 0 (nol),
dan nilai S (jumlah kalimat dalam teks) adalah 7 sehingga dari
× didapat 0. Kemudian nilai sentence position tersebut dibandingkan pada tabel 2.1 dan diperoleh distributed probability yang bernilai 0 (nilai skor posisi kalimat).
Menentukan skor total
Setelah semua skor dari kalimat K.1 sudah didapatkan, maka skor tersebut dihitung menggunakan persamaan (8) seperti:
Diketahui,
Skor judul teks (TS): 0,666667
Jadi,
= + . + � ∙ . + ∙ . + � ∙ . .
= , + . + , × . + , × . + × .. = ,
Jadi, total skor untuk kalimat K.1 adalah 0,443394. Selanjutnya skor, kalimat yang diproses, dan indeks kalimat disimpan dalam list untuk diproses. Kemudian untuk kalimat K.2 sampai K.7, proses penghitungan skor sama seperti kalimat K.1.
Langkah terakhir untuk memperoleh ringkasan adalah dengan mengurutkan list berdasarkan skor total secara descending (dari besar ke kecil). Kemudian lima kalimat
pertama diambil untuk disimpan dalam database.
Setelah hasil ringkasan menggunakan TextTeaser didapatkan, selanjutnya meringkas teks menggunakan TextRank. Untuk hal tersebut digunakan Sumy, library Python untuk meringkas teks. Teks asli berita yang diperoleh seperti pada gambar 3.9, selanjutnya diproses menggunakan class “TextRankSummarizer” sehingga menghasilkan teks ringkasan untuk selanjutnya disimpan dalam database.
Perancangan Sistem
Penelitian ini mencakup pembuatan sebuah sistem peringkas berita online yang terdiri dari server dan aplikasi untuk end-user. Server pada sistem bekerja untuk mengambil berita dari internet, kemudian meringkasnya. Kemudian aplikasi Android untuk end-user yang secara umum berguna untuk menyaji hasil ringkasan.
Perancangan antarmuka sistem
Sistem peringkas berita yang akan dibangun terdiri dari server dan aplikasi klien (aplikasi Android). Tampilan aplikasi server hanya berupa console yang menampilkan
proses request atau logging seperti gambar 3.11.
Gambar 3.11 Tampilan console server sistem peringkas (1) ũGET /peber_api/news/7540/ HTTP/1.1Ū 200 2534
(2) ũGET /peber_api/news/?news_category=Lifestyle HTTP/1.1Ū 200 40656 (3) ũPATCH /peber_api/update_user_desc/15/ HTTP/1.1Ū 200 124
Pada gambar 3.11, terdapat empat jenis tampilan untuk setiap metode akses server (GET, POST, PATCH) di mana masing-masing memiliki bagian (misalnya untuk jenis pertama (1)) yang dapat diuraikan menjadi seperti tabel 3.8.
Tabel 3.8 Keterangan bagian-bagian tampilan server GET /peber_api/news/7540/ HTTP/1.1 200 2534
Metode akses Alamat yang diakses Protokol yang digunakan
Kode respons dari server
Ukuran data respons (Byte)
Kemudian aplikasi klien berupa aplikasi Android memiliki beberapa halaman aplikasi yaitu halaman sign in, sign up, home, news details, settings, choose news source.
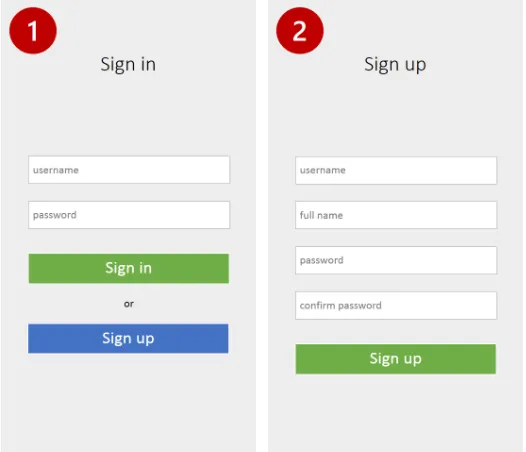
1. Sign In
Halaman sign in terbuka ketika aplikasi dibuka untuk yang pertama kalinya. Rancangan halaman sign in terlihat pada gambar 3.12 (1) terdapat dua text box dan dua tombol. Dua text box berfungsi untuk input username dan password pengguna. Kemudian dua tombol masing-masing berfungsi untuk lanjut proses sign in dan sign up jika belum ada username dan password.
2. Sign Up
Halaman sign up berguna untuk mendaftar dalam sistem. Rancangan halaman sign up dapat lihat pada gambar 3.12 (2), memiliki empat text box untuk username, full name, password, dan confirm password kemudian terdapat satu tombol untuk lanjut proses.
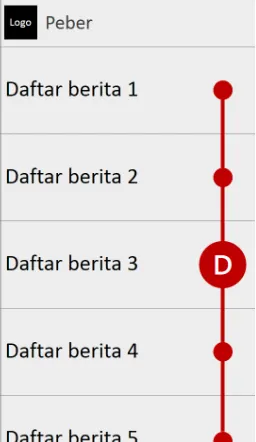
3. Home
Halaman home merupakan halaman utama penyajian daftar berita pada aplikasi. Pada halaman ini terdapat bagian logo aplikasi, judul aplikasi, dan daftar berita. Pada gambar 3.13, tanda merah dengan label (D) merupakan bagian daftar (list) berita. List berita yang disajikan terdiri dari judul berita, sumber berita, dan tanggal publikasi berita.
Gambar 3.13 Rancangan halaman home 4. News Details
Halaman news details menampilkan sebuah data berita yang lebih lengkap seperti teks ringkasan, gambar berita bersangkutan. Perancangan untuk halaman ini dapat dilihat
Gambar 3.14 Rancangan halaman news details 5. Settings
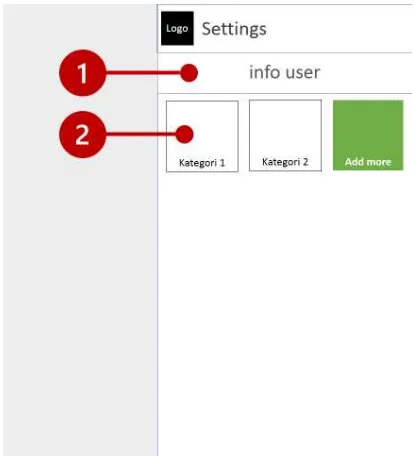
Halaman settings berisi informasi user dan kategori-kategori berita yang dipilihnya. Perancangan antarmuka untuk halaman settings dapat dilihat pada gambar 3.15. Pada rancangan yang dibuat, terdapat dua bagian yaitu bagian untuk informasi user (1), kemudian daftar kategori berita yang dipilih (2). Pada bagian daftar kategori terpilih terdapat sebuah tombol yang berfungsi untuk membuka halaman untuk memilih kategori berita.
6. Choose News Source
Halaman choose news source merupakan halaman untuk memilih kategori berita yang akan ditampilkan di halaman home. Perancangan halaman choose news source berdapat dua objek, daftar kategori dan tombol untuk konfirmasi pilihan. Objek daftar kategori menampilkan semua kategori berita yang ada pada sistem. Kemudian objek tombol Choose untuk mengirim kategori berita yang dipilih. Rancangan choose news source dapat dilihat pada
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab ini akan dijelaskan tentang proses implementasi algoritma TextTeaser, sesuai perancangan sistem yang telah dilakukan di bab 3 serta melakukan pengujian sistem yang telah dibangun.
Implementasi Sistem
Berdasarkan hasil analisis dan perancangan sistem yang telah dilakukan, maka dilakukan implementasi sistem peringkasan teks berita secara otomatis menggunakan algoritma TextTeaser ke dalam bentuk program komputer.
Spesifikasi perangkat keras yang digunakan
Dalam membangun sistem peringkasan berita, penelitian ini menggunakan dua jenis perangkat, komputer laptop dan Android Smartphone. Komputer laptop bertindak sebagai pemroses keseluruhan sistem seperti ekstraksi isi berita, jalankan algoritma, kelola database, hingga untuk menyediakan RESTful API untuk digunakan aplikasi klien (aplikasi Android). Spesifikasi perangkat keras komputer terdiri dari:
1. Prosesor AMD A6-4455M APU with Radeon™ HD Graphics 2.1GHz 2. Kapasitas Hardisk 500GB
3. Memori RAM 4GB
Selain komputer laptop, pada penelitian ini juga digunakan perangkat keras untuk uji aplikasi Android berupa Smartphone Android dengan spesifikasi:
Spesifikasi perangkat lunak yang digunakan
Pada penelitian ini digunakan spesifikasi perangkat lunak seperti:
1. Microsoft Windows™ 8.1 Pro 2. Python 2.7.10
3. Android OS, v4.1 (Jelly Bean) 4. Eclipse IDE (Luna)
5. JetBrains PyCharm (4.5.4)
Implementasi Perancangan Antarmuka
Tampilan halaman sign in
Halaman ini merupakan halaman pertama yang ditampilkan kepada pengguna sebelum
masuk ke dalam sistem. Pengguna dapat memasukkan username dan password pada kotak teks yang tersedia. Tampilan sign in dapat dilihat di gambar 4.1, bagian nomor (1) merupakan formulir untuk memasukkan username dan password kemudian bagian nomor (2) terdapat dua tombol yaitu sign in dan sign up. Tombol sign in berfungsi untuk melanjutkan proses pemeriksaan autentikasi data pengguna. Tombol berikutnya yaitu sign up yang berguna untuk mendaftarkan akun baru jika pengguna belum terdaftar dalam sistem.
Gambar 4.1 Tampilan halaman sign in Tampilan halaman sign up
bagian yaitu (1) formulir untuk mengisi data pengguna kemudian (2) tombol untuk melanjut proses pendaftaran.
Gambar 4.2 Tampilan halaman sign up Tampilan halaman home
Halaman ini merupakan halaman utama untuk menampilkan daftar judul berita yang
baru diproses. Berita yang ditampilkan merupakan berita dengan kategori yang telah dipilih oleh user. Tampilan halaman home dapat dilihat pada gambar 4.3. Pada halaman
ini terdapat tiga bagian utama seperti (1) daftar berita, (2) tombol pencarian berita, dan (3) tombol settings. Bagian daftar berita berisi beberapa informasi tentang berita seperti judul berita, gambar cuplikan berita, penerbit/kategori berita, serta tanggal publikasi berita. Kemudian bagian tombol pencarian berita berfungsi untuk mencari berita dalam database. Terakhir bagian tombol untuk membuka halaman settings.
[image:30.595.219.412.547.731.2]Tampilan halaman news details
[image:31.595.161.476.199.392.2]Halaman news details pada gambar 4.4 ditujukan untuk menampilkan informasi lebih rinci tentang berita yang dipilih user. Informasi yang terdiri dari (1) gambar berita terkait, (2) judul berita/sumber berita/tanggal dipublikasikan, kemudian (3) hasil ringkasan berita.
Gambar 4.4 Tampilan halaman news details Tampilan halaman settings
Halaman settings berguna untuk melihat informasi user seperti username dan kategori berita yang dipilih. Seperti pada gambar 4.5, halaman settings terdapat dua bagian yaitu (1) bagian informasi user, dan (2) kategori berita yang dipilih pengguna.
[image:31.595.187.453.528.739.2]Tampilan halaman choose news source
[image:32.595.196.437.242.464.2]Halaman ini menyediakan fitur untuk pengguna supaya bisa memilih kategori berita yang diminatinya. Kategori berita pilihan akan menentukan berita apa saja yang akan ditampilkan pada halaman Home. Halaman choose news source seperti pada gambar 4.6., memiliki dua bagian yaitu (1) daftar pilihan kategori berita dan (2) tombol “Choose” untuk konfirmasi pilihan.
Gambar 4.6 Tampilan halaman choose news source
Hasil Ringkasan
Pada bagian ini akan diberikan beberapa contoh hasil ringkasan yang dihasilkan oleh sistem. Di antara contoh tersebut adalah:
1. Judul: Microsoft Kritik Internet Gratis Facebook Ringkasan TextTeaser:
seragam, bukan berdasarkan konten, pengguna atau aplikasi yang digunakan. Layanan internet gratis Facebook di India bernama Free Basics.
Teks asli:
Bos Microsoft India Bashkar Pramanik mengkritik layanan internet gratis yang diberikan Facebook. Menurutnya, raksasa media sosial itu tak semestinya menyejajarkan layanan mereka dengan net neutrality. "Saya pikir tindakan Facebook tidak berkaitan dengan net neutrality. Mereka cuma membantu first time user untuk mengenal internet dan mesti menyebutnya seperti itu," terangnya. Net neutrality sendiri berarti prinsip yang meminta penyedia akses internet dan pemerintah untuk memperlakuan semua data setara dan tanpa diskriminasi. Penyedia layanan internet
serta pemeintah, menurut konsep ini, mesti memberikan tarif seragam, bukan berdasarkan konten, pengguna atau aplikasi yang digunakan. Layanan internet gratis Facebook di India bernama Free Basics. Ini adalah bagian dari Internet.org. Perusahaan asal Amerika Serikat itu bekerja sama dengan operator lokal untuk memberikan akses internet dengan harga sangat murah. Namun, sebagaimana dilansir KompasTekno dari Business Insider, Rabu (30/12/2015), sebagian pihak khawatir
Facebook terlalu kuat dalam mengendalikan Free Basics serta layanannya. Akibatnya regulator telekomunikasi India memerintahkan operator untuk memblokir akses ke Internet.org. Sementara itu mereka kini tengah membahas persoalan batas harga yang boleh dibebankan ke pungguna. "Jika pengguna mesti membayar lebih karena memiliki sepaket aplikasi pilihan sendiri, lalu diarahkan ke paket tertentu karena operator mengatakan akan memberikan gratis, di bagian manakah net neutrality itu?" tanya Pramanik.
2. Judul: Barong Bangkung Daur Ulang Hibur Turis Pantai Kuta di Awal 2016 Ringkasan TextTeaser:
ulang tersebut. "Sebelumnya saya pernah ke Pantai Kuta, tapi baru kali ini menyaksikan Tari Barong di Pantai Kuta.
Teks Asli:
Suguhan spesial disiapkan petugas Dinas Kebersihan dan Pertamanan (DKP) Kabupaten Badung, Bali, di hari perdana 2016. Wisatawan domestik dan mancanegara tidak hanya bisa menikmati keindahan pantai yang bersih dan indah di kawasan Kuta, mereka juga bisa menikmati Tari Barong khas Bali. Pertunjukan Tari Barong kali ini istimewa. Barong berjenis barong bangkung itu tidak terbuat dari kayu seperti biasa, tetapi berasal dari limbah sampah plastik daur ulang. "Untuk tahun ini, kami memang sengaja membuat atraksi yakni Barong Bangkung yang terbuat dari plastik. Kami sebut barong bangkung recycle," kata Kepala DKP Kabupaten Badung Putu Eka Martawan, di Kuta, Jumat (01/01/2016). Putu Eka berharap, pertunjukan itu bisa menghibur wisatawan pascaperayaan pergantian tahun. Itu disebabkan kondisi pantai yang sangat kotor akibat tumpukan berton-ton sampah. "Dengan pertunjukan ini, kami mengucapkan selamat tahun baru untuk para wisatawan. Kami juga mohon maaf kondisi pantai tidak sebersih biasanya. Sampah ini bukan hanya karena ulah manusia,
tapi juga akibat faktor alam angin barat," tutur dia. Dengan pertunjukan itu, DKP juga ingin menyisipkan pesan tentang pentingnya mengelola sampah dengan baik. Pengelolaan sampah itu penting agar bisa memberikan manfaat, bukan memunculkan masalah baru. "Pesan yang kami sampaikan itu adalah sampah plastik itu diolah bisa menjadikan berkah, tapi kalau tidak diolah akan menjadi petaka," ucap Putu Eka. Wisatawan mengapresiasi sajian para petugas kebersihan itu. Mereka mengaku terhibur dengan pertunjukan Barong Bangkung daur ulang tersebut. "Sebelumnya saya pernah ke Pantai Kuta, tapi baru kali ini menyaksikan Tari Barong di Pantai Kuta. Sempat takut juga sih saat berfoto sama barong," kata Dinda, seorang wisatawan asal Jombang, Jawa Timur.
potongan kalimat tersebut, kata “memperlakuan” dan “pemeintah” akan diproses seperti kata-kata tidak bermasalah lainnya.
Pengujian Hasil Ringkasan
Pada penelitian ini, pengujian hasil ringkasan sistem dilakukan pada 3075 data berita. Data tersebut diperoleh dari proses web data extraction pada tanggal 19 Januari 2016. Setelah data diproses kemudian dievaluasi dengan hasil ringkasan yang menggunakan algoritma TextRank dengan metode recall (R), precision (P), F-Score (F). Penghitungan menggunakan metode-metode tersebut menghasilkan nilai terkecil 0 (nol) yang berarti hasil ringkasan tidak sama dan nilai terbesar 1 yang menunjukkan hasil ringkasan sama
[image:35.595.130.504.389.578.2]persis dengan hasil ringkasan yang dievaluasi. Pada tabel 4.1 dapat dilihat beberapa contoh bagaimana kinerja hasil ringkasan menggunakan algoritma TextTeaser yang dievaluasi dengan hasil ringkasan algoritma TextRank.
Tabel 4.1 Contoh hasil evaluasi sistem
No. ID Berita
Jumlah kata
F-Score Precision Recall
Asli TextTeaser TextRank
1. 3530 552 71 71 1.000000 1.000000 1.000000 2. 5898 236 123 102 0.909091 0.833333 1.000000 3. 5578 240 104 101 0.833333 0.714286 1.000000 4. 6014 223 109 65 0.769231 0.625000 1.000000 5. 5134 191 119 83 0.666667 0.571429 0.800000 6. 5386 219 115 88 0.615385 0.500000 0.800000
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
7. 5424 344 91 125 0.200000 0.200000 0.200000 8. 5730 267 93 154 0.181818 0.166667 0.200000 9. 5283 210 92 35 0.153846 0.100000 0.333333 10. 1438 351 86 235 0.000000 0.000000 0.000000
Kolom ID Berita pada hasil evaluasi dalam tabel 4.1 menunjukkan nomor identifikasi berita dalam database (contoh dapat dilihat pada Lampiran A). Pada hasil tersebut diperoleh hasil ringkasan menggunakan algoritma TextTeaser dapat mencapai nilai F-Score hingga 1 jika di evaluasi dengan hasil ringkasan TextRank. Kemudian
berhasil dalam menentukan kalimat-kalimat penting dari teks asli. Selanjutnya, menurut Valstar et al. (2012) yang menyatakan bahwa hasil F-Score yang cukup baik adalah di atas 0.7 (>0.7) sehingga untuk nilai tersebut diperoleh total 31,36% (884 berita) dari keseluruhan data.
Tabel 4.2 Frekuensi nilai F-Score pada seluruh data
Kemudian evaluasi selanjutnya pada masing-masing sumber berita baik kompas.com, detik.com, atau liputan6.com. Evaluasi dilakukan dengan cara menghitung persentase setiap nilai F-Score dengan total berita secara menyeluruh, misalnya dari tabel 4.3 pada nilai F-Score 1 diperoleh persentase 2,02% dari 3075 data. Hal ini bertujuan untuk mengetahui lebih jelas sumber berita mana yang memiliki kontribusi untuk meningkatkan persentase nilai F-Score ≥ 0,5 pada keseluruhan sistem.
Hasil evaluasi pada sumber pertama yaitu kompas.com dapat dilihat seperti pada tabel 4.3, di mana diperoleh total 776 data berita. Nilai F-Score ≥ 0,5 data ini yaitu
Rentang
F-Score F-Score
Frekuensi (berita)
Persentase
(%) Total Frekuensi (%)
Total
F-Score ≥ 0,5 (%)
0.8-1
1 233 7.58
28.75
60.11 0.909091 36 1.17
0.888889 1 0.03 0.833333 7 0.23
0.8 607 19.74
0.5-0.7
0.769231 5 0.16
31.36 0.727273 82 2.67
0.714286 2 0.07 0.666667 20 0.65
0.625 1 0.03
0.615385 8 0.26
0.6 696 22.63
0.588235 2 0.07 0.571429 6 0.20 0.545455 108 3.51 0.533333 2 0.07
0.5 32 1.04
0.461538 8 0.26
⋮ ⋮ ⋮ ⋮ ⋮ ⋮
Total:
sebesar 16,51% (dari 3075 data) atau 65,34% untuk cakupan 776 data (kompas.com), kemudian untuk nilai F-Score yang lebih baik (>0,7) diperoleh pada 8,37% dari keseluruhan data dalam sistem atau 33,12 % dari 776 data data berita kompas.com.
Tabel 4.3 Frekuensi nilai F-Score berita kompas.com Rentang
F-Score F-Score
Frekuensi (berita) Persentase (%) Total Frekuensi (%) Total
F-Score ≥ 0,5 (%)
0.8-1
1 62 2.02
8.37
16.51
0.909091 6 0.20
0.833333 4 0.13
0.8 185 6.02
0.5-0.7
0.769231 2 0.07
8.14 0.727273 15 0.49
0.714286 1 0.03
0.666667 5 0.16
0.625 1 0.03
0.615385 3 0.10
0.6 193 6.28
0.588235 2 0.07
0.571429 2 0.07
0.545455 17 0.55
0.533333 1 0.03
0.5 8 0.26
0.461538 3 0.10
⋮ ⋮ ⋮ ⋮ ⋮ ⋮
Total: 776 Total: 100%
Tabel 4.4 Frekuensi nilai F-Score berita detik.com Rentang
F-Score F-Score
Frekuensi (berita) Persentase (%) Total (%) Total
F-Score ≥ 0,5 (%)
0.8-1
1.000.000 137 4.46
14.21
25.75
0.909091 9 0.29
0.888889 1 0.03
0.833333 1 0.03
0.8 289 9.40
0.5-0.7
0.769231 1 0.03
11.54
0.727273 12 0.39
0.666667 4 0.13
0.615385 1 0.03
0.6 325 10.57
0.545455 11 0.36
0.5 1 0.03
0.461538 1 0.03
⋮ ⋮ ⋮ ⋮ ⋮ ⋮
Total: 1278 Total: 100%
Untuk berita liputan6.com diperoleh data sebanyak 1021 berita. Kemudian dari data tersebut terdapat nilai F-Score ≥ 0,5 pada 17,87% dari keseluruhan data atau 53,79% dari 1021 data berita liputan6.com. Seterusnya nilai F-Score yang lebih baik (>0,7) diperoleh 6,19% berdasarkan keseluruhan data sistem atau 18,62% dari 1021 data berita liputan6.com.
Tabel 4.5 Frekuensi nilai F-Score berita liputan6.com Rentang
F-Score F-Score
Frekuensi (berita) Persentase (%) Total (%) Total F-Score ≥ 0,5
0.8-1
1.000.000 34 1.11
6.19
17.87 ⋮ ⌵ 0.909091 21 0.68
0.833333 2 0.07
0.8 133 4.33
0.5-0.7 ⋮ ⌵
0.769231 2 0.07
11.68 ⋮ ⌵ 0.727273 55 1.79
0.714286 1 0.03 0.666667 11 0.36 0.615385 4 0.13
0.6 178 5.79
[image:38.595.142.491.546.757.2]Tabel 4.5 Frekuensi nilai F-Score berita liputan6.com (lanjutan) Rentang
F-Score F-Score
Frekuensi (berita)
Persentase (%)
Total (%)
Total F-Score ≥ 0,5 ⋮
0.5-0.7
0.545455 80 2.6
⋮ 11.68
⋮ 17.87 0.533333 1 0.03
0.5 23 0.75
0.461538 4 0.13
⋮ ⋮ ⋮ ⋮ ⋮ ⋮
Total:
1021 Total: 100%
Dari ketiga sumber berita baik kompas.com, detik.com, ataupun liputan6.com dapat ditarik kesimpulan bahwa frekuensi nilai F-Score akan meningkat berdasarkan jumlah berita yang diperoleh. Seperti data dari detik.com yang berjumlah 1278 data berita menghasilkan nilai F-Score ≥ 0,5 pada 25,75%, kemudian untuk berita liputan.com yang terdapat 1021 data berita menghasilkan nilai F-Score ≥ 0,5 pada 17,87% dan data berita kompas.com yang berjumlah 776 didapatkan nilai F-Score ≥ 0,5 pada 16,51%.
BAB 5
KESIMPULAN DAN SARAN
Bab ini membahas mengenai kesimpulan dan saran berdasarkan analisis dan pengujian yang dilakukan dalam menyelesaikan permasalahan untuk meringkas teks berita online secara otomatis menggunakan algoritma TextTeaser.
Kesimpulan
Dari penelitian yang telah dilakukan dapat disimpulkan bahwa:
1. Dari 3075 data berita yang dicoba, peringkasan menggunakan algoritma
TextTeaser mampu memperoleh nilai F-Score lebih besar dan atau sama dengan 0.5% (≥ 0.5%) pada total 60,11% data. Seterusnya data tersebut terdapat nilai F-Score yang dianggap baik (>0,7) pada 31,36% atau sekitar 884 berita. Hal ini berarti peringkasan menggunakan algoritma memiliki nilai evaluasi yang cukup tinggi pada lebih dari 50% total data. Dengan kata lain algoritma TextTeaser cukup berhasil dalam menentukan kalimat-kalimat penting dalam teks berita. 2. Kesalahan penulisan (kata) yang disebabkan oleh jurnalis berita (human error)
akan diproses seperti kata yang tidak salah lainnya. Sehingga kemungkinan kata yang salah akan tetap ada pada hasil peringkasan.
Saran
Masih banyak sekali yang perlu ditingkatkan dalam penelitian tentang sistem peringkas berita online ini. Namun menurut penulis, ada beberapa hal yang perlu untuk ditingkatkan lagi pada penelitian selanjutnya yaitu:
1. Pengambilan teks berita menggunakan teknik yang secara otomatis memperbaiki kesalahan penulisan oleh jurnalis (human error).
ringkasan berdasarkan kriteria pengguna. Sehingga diharapkan pengguna mendapatkan hasil ringkasan yang sesuai dengan kebutuhannya.
BAB 2
LANDASAN TEORI
Berita
Berita merupakan informasi yang baru saja terjadi dan berguna untuk publikasikan terhadap khalayak melalui berbagai media baik cetak maupun digital atau bahkan dari mulut ke mulut. Kata berita sendiri berasal dari Sanskerta yaitu “vṛtta” yang berarti
terjadi atau ada.
Berita tertulis pertama kali dibuat pada abad ke-8 SM di Cina (Zhang, 2007). Pada abad ke-21 gaya penyampaian berita mengalami perubahan yang dramatis, yang membuat setiap kejadian yang baru saja terjadi secara instan akan diketahui oleh semua orang yang terhubung ke Internet.
Karakteristik berita
Setiap berita memiliki perbedaan satu sama lain, namun menurut Saxena (2013) minimal setiap berita harus memiliki beberapa karakteristik berikut :
1. Adil dan seimbang maksudnya berita disampaikan dari berbagai sudut pandang dan tidak mengacu hanya pada satu sudut pandang saja.
2. Akurat, informasi dalam berita ditulis dengan informasi seakurat mungkin. Sehingga berita yang ditulis semestinya sudah melalui proses cross-check atau proses peninjauan kembali.
3. Sumber, berita memiliki sumber informasi yang jelas. Walaupun pada beberapa jenis berita tertentu yang mewajibkan sumber anonim.
4. Ringkas, penulisan berita tidak boleh bertele-tele. Berita harus ditulis singkat namun tetap berisi fakta-fakta penting.
Penyampaian berita tentu harus memperhatikan nilai-nilai yang terkandung di dalamnya. Sehingga kualitas berita dapat ditingkatkan. Menurut Setiawan (2014) yang merujuk kepada (Djuroto, 2004) bahwa berita harus mengandung sepuluh nilai yaitu:
1. Magnitude, pengaruh yang ditimbulkan dengan menyebar luaskan berita pada khalayak.
2. Significant, tingkat kepentingan berita sehingga layak untuk dipublikasikan. 3. Actuality, kejadian yang benar-benar terjadi baru-baru ini.
4. Proximity, jarak kejadian yang semakin dekat dengan khalayak semakin perlu untuk diberitakan.
5. Prominence, kejadian yang menonjol untuk diberitakan.
6. Surprise, unsur kejutan dan isi berita yang tidak mudah ditebak.
7. Clarity, peristiwa harus benar-benar terjadi dan informasi yang akan disampaikan harus jelas dan tidak terlalu banyak opini.
8. Impact, kejadian yang akan diberikan memberikan dampak yang terasa untuk khalayak.
9. Conflict, suatu masalah yang terjadi perlu untuk diberitakan sehingga masalah
tersebut diketahui.
10.Human Interest, berita yang mencakup setiap ketertarikan seperti bidang olah raga, teknologi, dan sebagainya.
Berita yang akan dipublikasikan akan lebih berarti jika berita paling tidak memuat sepuluh nilai tersebut.
Peringkasan Teks Otomatis
Memahami isi tulisan yang panjang bukanlah hal yang mudah (Aristoteles, 2014), karena informasi dalam teks bacaan hanya bisa diperoleh dengan membaca seluruh isinya dan hal ini tentu memerlukan waktu yang relatif lama (Fachrurrozi, et al. 2013). Ringkasan teks akan mempercepat pengguna untuk mendapatkan informasi yang dibutuhkan tanpa harus menghabiskan waktu yang banyak dan upaya keras dalam membaca keseluruhan teks (Deshpande & Lobo, 2013). Oleh karena itu peringkasan
teks otomatis sangat diperlukan untuk masalah tersebut. Hal ini sudah diketahui sebagai bidang riset yang penting oleh beberapa organisasi seperti defense advanced research
Ringkasan teks dapat diperoleh melalui peringkasan secara manual dan peringkasan secara otomatis. Peringkasan teks yang dilakukan secara manual oleh manusia melibatkan pemahamannya tentang topik yang akan diringkas, penafsiran dan proses lainnya. Sehingga akan menghasilkan sesuatu yang baru, yang tidak terdapat dalam teks asli karena dalam proses peringkasan telah dipadukan dengan pengetahuan orang yang meringkas.
Peringkasan teks otomatis atau automatic text summarizaton (ATS) adalah program komputer berisi perintah atau algoritma yang mampu memilih kalimat-kalimat penting dalam suatu teks dan menghimpunnya dalam teks baru yang lebih ringkas sehingga bisa langsung digunakan. Peringkasan ini akan menggunakan pendekatan selection-based yang mengekstraksi dan menganalisis fitur-fitur dalam teks.
ATS terbagi menjadi dua tipe yaitu generic summary (text-driven) dan user-focused (query-driven). Tipe yang pertama, generic summary berisi kalimat ringkasan yang berasal dari teks asli. Kalimat yang termasuk dalam ringkasan ditentukan dengan menghitung bobot feature penting dalam teks. Tipe yang kedua, query driven menghasilkan ringkasan sesuai dengan kriteria informasi yang dibutuhkan oleh user
seperti query atau topik.
Keuntungan ATS dibandingkan dengan peringkasan manual adalah kecepatan dalam meringkas dokumen yang banyak, distribusi hasil ringkasan yang cepat dan mudah serta biaya yang relatif rendah (Torres-Moreno, 2014).
ATS memiliki tiga tahapan pengerjaan yaitu yang pertama pembuatan tafsiran dari teks sumber untuk mendapatkan perwakilannya (interpretation), kedua mengubah teks dari tahap pertama menjadi representasi hasil ringkasan (tranformation), terakhir yang ketiga pembuatan ringkasan dari representasi teks (generation).
Secara umum peringkasan teks terbagi dua yaitu:
1. Abstraktif
2. Ekstraktif
Hasil ringkasan dengan menggunakan teknik ekstraktif merupakan hasil seleksi kalimat-kalimat yang penting dari teks asli tanpa ada modifikasi pada kalimat tersebut (Kalita, Saharia, & Sharma, 2012). Teknik ekstraktif menggunakan beberapa metode seperti statistik, linguistik, heuristik, graph-based (Ridok, 2014). Di mana semua metode yang digunakan memanfaatkan fitur-fitur yang ada dalam teks untuk menentukan tingkat kepentingan suatu kalimat dalam keseluruhan teks. Kebanyakan yang digunakan dalam penelitian adalah ekstraktif karena memberikan hasil yang relatif lebih baik dari teknik abstraktif berdasarkan perkembangan teknologi peringkas teks otomatis yang ada sekarang ini (Erkan & Radev, 2004).
Algoritma TextTeaser
Algoritma TextTeaser pertama kali dipublikasikan pada Tahun (2011) dalam penelitian Juan Paolo Balbin. Algoritma tidak ditujukan untuk mengganti teks asli yang ada melainkan untuk memberikan gambaran isi teks. Seperti teaser pada film yang tidak berisi keseluruhan isi cerita film tersebut. Algoritma TextTeaser juga ditujukan untuk memberikan gambaran singkat (teaser) tentang isi teks.
TextTeaser meringkas teks secara ekstraktif sehingga kalimat-kalimat ringkasan yang dihasilkan merupakan bagian dari teks asli tanpa ada modifikasi. Untuk menentukan kalimat mana yang termasuk dalam ringkasan, algoritma bekerja dengan menghitung empat elemen dalam teks yang terdiri dari judul teks, posisi kalimat, panjang kalimat, dan frekuensi keyword (Balbin, 2011).
1. Judul teks berita
Penghitungan skor kalimat ditentukan dengan menghitung setiap kalimat dalam teks berita yang memiliki kesamaan dengan judul berita. Untuk menghitung skor berdasarkan judul teks, terlebih dahulu stopword pada kalimat dalam teks dan judul teks dihilangkan. Hal ini bertujuan untuk menghindari penghitungan kata yang tidak perlu sehingga proses kalkulasi skor lebih efisien. Selanjutnya bobot dihitung menggunakan
persamaan (1).
� = | ∩ |
Metode penghitungan skor memperoleh kalimat dalam teks , adalah
kata-kata dalam kalimat , adalah kata-kata-kata-kata dalam judul , kemudian dihitung jumlah
kata dalam kalimat dan juga kata yang berada dalam judul. Jumlah kata yang
didapatkan selanjutnya dibagi jumlah kata dalam judul dikali 1 (satu).
2. Posisi kalimat
Menentukan skor kalimat berdasarkan posisinya dalam teks. Dari penelitian yang dilakukan oleh Balbin (2011) mendapatkan bahwa skor posisi kalimat pada teks berita memiliki nilai yang lebih tinggi pada kalimat pembukaan atau kesimpulan daripada kalimat-kalimat lainnya .
� � � , = ∙ (2)
Dari persamaan (2) diketahui adalah posisi kalimat dalam teks, adalah
jumlah semua kalimat. Kemudian nilai � � � , ditentukan berdasarkan tabel 2.1.
Tabel 2.1 Nilai berdasarkan skor posisi kalimat (Balbin, 2011)
Sentence
position 0. < x ≤ 0.1 . < x ≤ 0.2 . < x ≤ 0.3 0.3 < x ≤ 0.4 0.4 < x ≤ 0.5
Distributed
Probability 0.17 0.23 0.14 0.08 0.05
Sentence
position 0.5 < x ≤ 0.6 0.6 < x ≤ 0.7 0.7 < x ≤ 0.8 0.8 < x ≤ 0.9 0.9 < x ≤ 1.0
Distributed
Probability 0.04 0.06 0.04 0.04 0.15
3. Panjang kalimat
Skor elemen ini ditentukan dengan menghitung banyak kata dalam kalimat. Untuk menghitung nilai panjang setiap kalimat dalam teks digunakan persamaan (3).
� ℎ = − − | | (3)
Dari persamaan (3), diketahui adalah kalimat dalam teks kemudian | | adalah jumlah semua kata dalam kalimat tersebut termasuk stopword, sedangkan merupakan
4. Frekuensi keyword
Frekuensi kemunculan kata pada keseluruhan teks berita. Untuk skor frekuensi keyword digunakan fitur teks (text feature) yang dihitung dengan dua metode yaitu density-based selection (DBS) dan summation-based selection (SBS).
Sebelum menghitung DBS dan SBS, keyword teks dan skornya ditentukan dengan mencari kata-kata unik (tanpa duplikat dan bukan stopword). Kemudian menghitung frekuensi setiap kata unik. Sampai tahap ini keyword dan frekuensi kemunculannya sudah diperoleh.
Langkah selanjutnya keyword beserta frekuensi yang diperoleh diurutkan dari bobot yang terbesar ke bobot yang terkecil. Untuk mendapatkan keyword paling sering muncul (top keyword), sepuluh data terurut diambil kemudian diproses untuk memperoleh skor masing-masing keyword. Skor setiap keyword dapat hitung dengan menggunakan persamaan (4).
= ∙ | | ÷ |�| ∙ . (4)
Dari persamaan (4), diketahui merupakan keyword yang akan dihitung, | | merupakan frekuensi kemunculan keyword dalam teks, dan |�| adalah jumlah semua
kata-kata unik dalam teks. Setelah skor masing-masing keyword diperoleh, barulah DBS dan SBS bisa dihitung.
Metode pertama, DBS adalah metode untuk menentukan peringkat (rank) pada teks berdasarkan beberapa parameter antara lain kumpulan keyword yang sudah diberi skor (Hu, Sun, & Lim, 2007), kata-kata pada kalimat yang akan dihitung, kata-kata pada kumpulan keyword. Kemudian kumpulan parameter tersebut dihitung dengan menggunakan persamaan (5).
= ∙ + ∙ ∑ � ( ) ∙ , ++
�−
=
(5)
Dari persamaan (5), adalah jumlah kata dalam yang juga ada dalam top
keyword tambah 1, adalah bobot keyword , dan � ( , + ) adalah
nilai dua keyword yang berdampingan ( dan + ) dan bukan keyword atau stopword
Metode kedua adalah SBS. Metode ini berfungsi untuk memberikan bobot kalimat yang lebih tinggi apabila kalimat mengandung kata-kata yang mewakili teks keseluruhan (atau disebut dengan top keyword). Untuk menghitung bobot yang dimaksud digunakan persamaan (6).
= | | ∙ ∑ �
��∈��
� (6)
Pada persamaan (6) adalah kalimat dalam teks, | | adalah jumlah kata-kata
yang terkandung dalam , kemudian parameter untuk mengambil bobot kata ( ) yang
merepresentasikan isi t