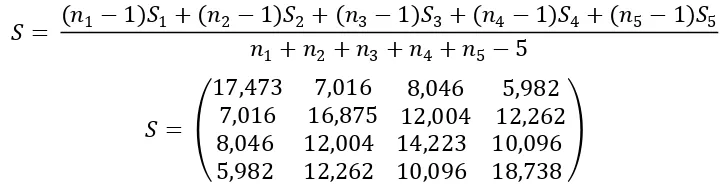DAFTAR PUSTAKA
Azwar, Saifuddin.1997. Reabilitas dan Validitas. Yogyakarta: Pustaka Pelajar Gie, The Liang. 1987. Liberty : Yogyakarta
Hair, Anderson. 1995.Tatham, Black.
Hamalik, Oemar. 2001. Proses Belajar Mengajar. Jakarta: PT. Bumi Aksara Riduan. 2002. Skala pengukuran Variabel-variabel Penelitian. Alfabeta: Bandung Santoso, Singgih 2010. Statistik Multivariat Konsep dan Aplikasi dengan SPSS. Jakarta: PT Elex Media Komputindo
Sardiman. 2011. Interaksi dan Motivasi Belajar Mengajar. Jakarta: Raja Grafindo Persada
Simamora, B. 2005. Analysis Multivariat Pemasaran. Jakarta: PT Gramedia Pustaka Utama
Slameto. 2003. Belajar dan Faktor-Faktor yang mempengaruhi I. Jakarta: PT Rineka Cipta
Susetyo, Budi. 2010.Statistika untuk Analisis Data Penelitian, Bandung : PT RefikaAditama
Sudjana. 1996. Teknik Analisis Regresi dan Korelasi. Bandung: Penerbit Tarsito Sudjana, Nana. 2005
Sugiarto, dkk. 2001. Teknik Sampling. Jakarta. Gramedia Pustaka Utama.
Sugiono. 2005. Statistika Penelitian Pendidikan. Alfabeta: Bandung
BAB 3 PEMBAHASAN
3.1 Populasi Penelitian
Populasi adalah keseluruhan objek penelitian. Dalam penelitian ini populasinya adalah seluruh siswa kelas tiga SMP Negeri 10 Medan berjumlah 387 siswa dari 11 kelas.
Tabel 3.1 Populasi Penelitian
No Kelas Jumlah
1 IX-A 30
2 IX-B 35
3 IX-C 34
4 IX-D 37
5 IX-E 35
6 IX-F 34
7 IX-G 36
8 IX-H 37
9 IX-I 35
10 IX-J 38
11 IX-K 36
Jumlah 387
3.2 Sampel Penelitian
Sampel merupakan sebagian atau wakil dari populasi yang diteliti. Untuk mengetahui jumlah sampel minimum yang akan diambil dalam penelitian ini, peneliti menggunakan rumus Slovin yaitu :
=
1 + �2 Keterangan:
n : Jumlah Sampel Minimal N : Populasi
pengambilan sampel yang masih ditaksir atau diinginkan 10 % maka pengambilan sampel dilakukan secara proporsional random sampling dan didapat jumlah sampel yang akan diteliti adalah 80 siswa. Adapun banyak sampel yang diambil dari masing-masing kelas dapat dilihat dari perhitungan pada tabel 3.2
11 IX-K 36 36
387×80 = 7,44 7
Jumlah 387 80
3.3 Validitas dan Reliabilitas Penelitian
Pada penelitian ini menggunakan alat ukur. Alat ukur ini harus baik dan berkualitas supaya memenuhi syarat validitas dan reliabilitas dari alat ukur yang digunakan. Validitas adalah suatu ukuran yang menunjukkan tingkatan-tingkatan kevalidan atau kesahihan suatu instrumen. Validitas bertujuan untuk mengetahui apakah pertanyaan yang digunakan baik atau tidak.
Adapun hasil perhitungan validitas instrumen penelitian yang diujikan pada 80 responden dengan pengerjaan manual adalah sebagai berikut:
1. Uji validitas dan reliabilitas dari motivasi belajar
Pengujian validitas tiap item pertanyaan dilakukan dengan menggunakan rumus product moment pearson :
= −
2− 2 2− 2
a. Menghitung besarnya koefisien korelasi pada pertanyaan 1
1, =
80 × 8990−318 × 2220
80 × 1314− 318 2 80 × 62950− 2220 2
1, = 719200−705960
105120−101124 5036000−4928400
1, =
13240
3996 107600 1, = 0,638
b. Menghitung besarnya koefisien korelasi pada pertanyaan 2
2, =
80 × 9264−325 × 2220
80 × 1391− 325 2 80 × 62950− 2220 2
2, = 741120−721500
2, =
19620
5655 107600 2, = 0,795
c. Menghitung besarnya koefisien korelasi pada pertanyaan 3
3, =
d. Menghitung besarnya koefisien korelasi pertanyaan 4
4, =
e. Menghitung besarnya koefisien korelasi pertanyaan 5
5, =
6, =
80 × 8921−312 × 2220
80 × 1296− 312 2 80 × 62950− 2220 2
6, = 713680−692640
103680−97344 5036000−4928400
6, =
21040
6336 107600
6, = 0,805
�. Menghitung besarnya koefisien korelasi pertanyaan 7
7, = 80 × 9002−321 × 2220
80 × 1331− 321 2 80 × 62950− 2220 2
7, = 720160−712620
106480−103041 5036000−4928400
7, =
7540
3439 107600 7, = 0,392
Setelah setiap item pertanyaan dicari rhitung, maka selanjutnya
dibandingkan dengan nilai rtabel. Dengan kriteria jika rhitung < rtabel maka item
pernyataan tersebut tidak valid, sebaliknya jika rhitung ≥ rtabel maka item pernyataan
tersebut valid dan dapat digunakan. Nilai rtabel tabel dapat diperoleh dari tabel r
dengan alfa 5% dan derajat kebebasan 80. Dengan demikian dapat dirangkum semua perhitungan dan pengujian validitas untuk setiap item sebagai berikut:
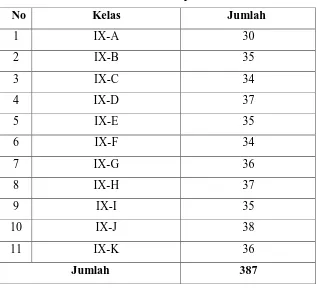
Tabel 3.3.1 Rangkuman analisis validitas dari motivasi belajar Item rhitung rtabel Keterangan
1 0,638 0,219 Valid
2 0,795 0,219 Valid
3 0,635 0,219 Valid
5 0,798 0,219 Valid
6 0,805 0,219 Valid
7 0,392 0,219 Valid
Setelah menguji validitas dari setiap item, maka selanjutnya dilakukan uji realibilitas dengan menggunakan rumus Cronbach Alpha:
11 =
� =62950−61605 80
� =1345
80
� = 16,812
Kemudian menjumlahkan varians semua item instrument dengan rumus: � = �1+�2 +�3+�4+�5 + �6 + �7
� = 0,624 + 0,884 + 0,644 + 0,634 + 0,725 + 0,99 + 0,537
� = 5,038
Dengan demikian dapat dicari nilai Cronbach Alpha :
11 = −
1 1−
� �
11 =
7
7−1 1−
5,038 16,812
11 =
7
6 1−0,299628
11 = 1,66667 (0,700372) 11 = 0,8171
Untuk melihat apakah instrument tersebut reliable atau tidaknya maka diperlukan pengujian. Dengan kriteria jika nilai Cronbach Alpha ≥ 0,60 maka instrument tersebut reliable, sebaliknya jika nilai Cronbach Alpha < 0,60 maka instrument tersebut tidak reliable. Dari hasil yang telah diperoleh maka dapat dilihat bahwa nilai Cronbach Alpha yang diperoleh lebih besar daripada 0,60, ini berarti instrument tersebut reliabel.
Tabel 3.3.2 Rangkuman analisis validitas kreativitas guru dalam PBM Item rhitung rtabel keterangan
1 0,763 0,219 Valid
2 0,682 0,219 Valid
3 0,725 0,219 Valid
4 0,771 0,219 Valid
5 0,585 0,219 Valid
6 0,762 0,219 Valid
7 0,582 0,219 Valid
Dari tabel dapat dilihat bahwa setiap itemnya itu valid, kemudian setelahnya dilakukan uji realibitas dengan mencari nilai Cronbach Alphanya dan diperoleh sebesar 0,819. Dan dengan kriteria yang telah ditetatpkan maka dapat disimpulkan bahwa intrumen tersebut reliabel.
3. Uji validitas dan reliabilitas untuk lingkungan keluarga
Hasil yang diperoleh untuk uji validitasnya dapat dilihat pada tabel.
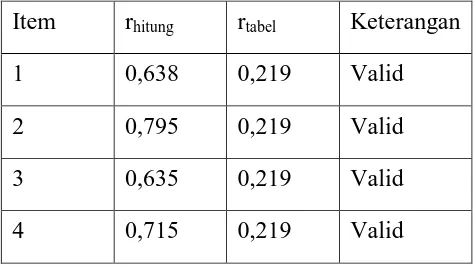
Tabel 3.3.3 Rangkuman analisis validitas lingkungan keluarga Item rhitung rtabel keterangan
1 0,658 0,219 Valid
2 0,352 0,219 Valid
3 0,607 0,219 Valid
4 0,639 0,219 Valid
5 0,801 0,219 Valid
6 0,645 0,219 Valid
Pada tabel dapat dilihat bahwa setiap item tersebut valid. Setelahnya dicari nilai Cronbach Alpha dan diperoleh hasilnya sebesar 0,752 dan lebih besar dari 0,60 maka untuk instrument ini dikatakan reliabel.
4. Uji validitas dan reliabilitas untuk cara belajar
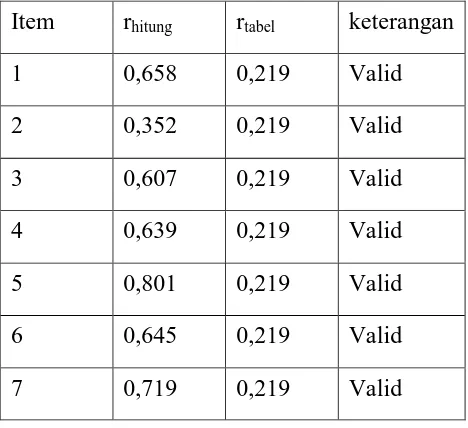
Hasil yang diperoleh untuk uji validitasnya dapat dilihat pada tabel. Tabel 3.3.4 Rangkuman analisis validitas cara belajar
Item rhitung rtabel keterangan
1 0,709 0,219 Valid
2 0,679 0,219 Valid
3 0,617 0,219 Valid
4 0,671 0,219 Valid
5 0,714 0,219 Valid
6 0,696 0,219 Valid
7 0,739 0,219 Valid
Pada tabel dapat dilihat bahwa setiap item tersebut valid. Setelahnya dicari nilai Cronbach Alpha dan diperoleh hasilnya sebesar 0,810 dan lebih besar dari 0,60 maka untuk instrument ini dikatakan reliable.
3.4 Transformasi Data Ordinal menjadi Interval
3.4.1 Transformasi Data Ordinal menjadi Interval dengan Excel
Metode Successive Interval (MSI) adalah salah satu metode untuk mentransformasikan data skala ordinal ke skala interval dengan menggunakan excel dapat dilakukan dengan cara berikut ini:.
1. Buka Microsoft Excel
klik Enable Macros
3. Masukkan data yang akan ditransformasikan
4. Pilih Add In lalu klik statistics pilih susccessive interval
5. Pada saat kursor di Data Range blok data yang ada sampai selesai 6. Kemudian isi cell output dengan mengklik kolom baru pada microsoft excel lihat di lampiran 5.
3.4.2 Transformasi Data Ordinal menjadi Interval dengan Perhitungan Manual
Langkah-langkah transformasi data ordinal ke data interval sebagai berikut : a. Menghitung frekuensi skor jawaban dalam skala ordinal.
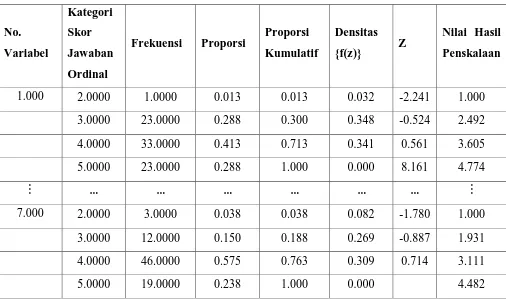
alternatif jawaban 1 = 0 alternatif jawaban 2 = 1 alternatif jawaban 3 = 23 alternatif jawaban 4 = 33 alternatif jawaban 5 = 23
b. Menghitung proporsi untuk masing-masing skor jawaban. 1=
1 = 0.0000 + 0.0000 = 0.0000 proporsi kumulatif dianggap mengikuti distribusi normal baku. Nilai Z diperoleh dari Tabel Distribusi Normal Baku.
Nilai Z = 0.5 – 0.0125 = 0.488 ; disesuaikan dengan Tabel Z diperoleh
f. Menghitung Scale Value (SV) dengan rumus :
� = � � − � �
h. Menentukan nilai skala dengan menggunakan rumus : Y = SV + |� |
3 = -1,101+ 3,462= 2.492 4 = -0,017+ 3,462= 3.605 5 = 1,188+ 3,462= 4.774
Tabel 3.4 Transformasi ke Data Interval untuk Variabel Motivasi Belajar
No.
Data Penskalaan secara lengkap dapat dilihat pada lampiran 9
3.5 Analisis Data
Analisis diskriminan dimulai dari : Pertama, pemilihan variabel dependen dan independen, di mana variabel dependen harus merupakan variabel kategorik sedangkan variabel independen merupakan variabel numerik. Variabel dependen diperoleh dari jumlah nilai rata- rata siswa mulai dari semester I hingga semester V. Hasil rata-rata nilai siswa tersebut akan diurutkan mulai dari urutan terbesar hingga urutan terkecil, yang akan diperoleh ranking siswa tertinggi hingga ranking siswa terendah. Di mana variabel dependen dibagi menjadi 5 (lima) kelompok dari keseluruhan jumlah sampel, yaitu :
b. Kelompok II dengan ranking “Baik” yaitu urutan ranking 17 hingga 32
c. Kelompok III dengan ranking “Cukup Baik” yaitu urutan ranking 33 hingga 48
d. Kelompok IV dengan ranking “Kurang Baik” yaitu urutan ranking 49 hingga 64
e. Kelompok V dengan ranking “Tidak Baik” yaitu urutan ranking 65 hingga 80
Sedangkan variabel independen pada penelitian ini adalah 1 = Motivasi Belajar
1 =
menyatakan nilai siswa yang mempunyai ranking baik untuk i = 1,2,3,4: dan j = 17,18, … , 32.
Sama halnya dengan untuk ranking siswa “cukup baik”, “kurang baik” dan ,”tidak baik”. Sehingga untuk mencari matriks varians-kovarians maka data dari kelompok I (sangat baik) dapat dibentuk matriks sebagai berikut :
(lihat lampiran 5)
Hal pertama dilakukan adalah menjumlahkan dan mengalikan nilai dari setiap variabel kelompok pertama. Dari matrik 1di atas maka diperoleh nilai-nilai sebagai berikut :
Kemudian dicari nilai varians digunakan rumus :
�11 = Sedangkan untuk mencari nilai kovarians digunakan rumus dibawah ini :
� = =1 − =1 =1 Kemudian nilai varian dan kovarian dari kelompok I disusun dalam bentuk matrik, sehingga dapat diperoleh matriks varians-kovarians untuk kelompok pertama:
�2 =
4 6.905 13.599 10.941 18.816
Kelima matriks varians-kovarians ini bisa dihitung matriks varians-kovarians gabungan, diberi lambang S dengan rumus :
�= ( 1−1)�1+ ( 2 −1)�2+ ( 3−1)�3+ ( 4−1)�4 + ( 5−1)�5
Penulis menggunakan bantuan SPSS dalam penyelesaian fungsi diskriminan ini. Sebelum melakukan analisis diskriminan terlebih dahulu akan dilakukan analisis univariat untuk mengetahui kenormalan data. Selanjutnya melakukan uji kesamaan yaitu untuk memenuhi asumsi bahwa faktor independen harus sama dilihat pada tingkat signifikan dari wilks’Lambda. Jika nilai p > 0,05 menunjukkan faktor yang sama.
Untuk menguji kenormalan data, dapat dilihat dari uji Kolmogorv Smirnov dan dengan menggunakan pendekatan grafik. Pendekatan kolmogorv smirnov (1 sample KS) dengan melihat data residualnya apakah berdistribusi normal atau tidak. Maka hasil pengujiannya ditunjukkan pada tabel di bawah ini:
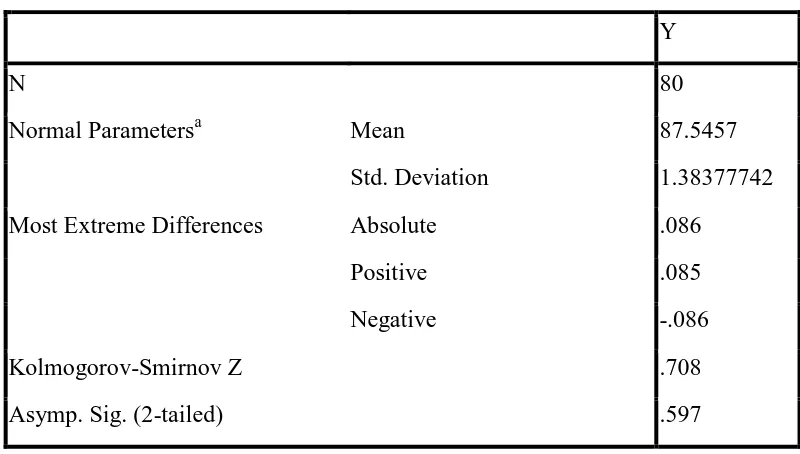
Tabel 3.7 Uji Kolmogorv-Smirnov (1 sample KS) One-Sample Kolmogorov-Smirnov Test
Y
N 80
Normal Parametersa Mean 87.5457
Std. Deviation 1.38377742
Most Extreme Differences Absolute .086
Positive .085
Negative -.086
Kolmogorov-Smirnov Z .708
Asymp. Sig. (2-tailed) .597
Berdasarkan output tabel 3.7 di atas, diketahui bahwa nilai Asymp.Sig.(2-tailed) sebesar 0,597 lebih besar dari 0,05 sehingga dapat disimpulkan bahwa data yang diuji berdistribusi normal.
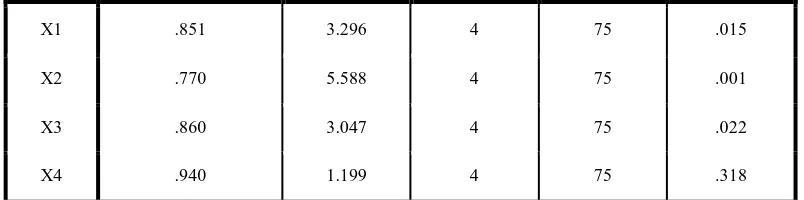
Tabel 3.8 Uji Kesamaan Rata-rata Tests of Equality of Group Means
X1 .851 3.296 4 75 .015
X2 .770 5.588 4 75 .001
X3 .860 3.047 4 75 .022
X4 .940 1.199 4 75 .318
Tabel 3.8 digunakan untuk menguji perbedaan antar kelompok untuk setiap faktor yang ada. Dengan angka Wilks’Lambda yang berkisar 0 sampai 1. Jika angka mendekati 0 maka data tiap kelompok cenderung berbeda, sedangkan jika angka mendekati 1, data tiap kelompok cenderung sama. Dari tabel 3.7 terlihat angka Wilks’Lambda berkisar antara 0,940 sampai 0,851 (mendekati1).
Dari kolom signifikan bisa dilihat bahwa dengan kriteria: Jika Sig.> 0,05 berarti tidak ada perbedaan antar kelompok Jika Sig.≤ 0,05 berarti ada perbedaan antar kelompok
Dari tabel tersebut bisa dilihat bahwa keempat faktor tersebut mempengaruhi ranking siswa.
Tabel 3.9 Hasil Uji Box’s M Test Results
Box's M 4.151
F Approx. 0.011
df1 4
df2 8437.500
Sig. 0.400
Uji Kesamaan matriks kovarian (group covariance matrices) memiliki nilai yang relatif sama dapat diuji dengan Box‟s M dengan ketentuan hipotesis:
� : group covariance matrices adalah relatif sama
�1 : group covariance matrices adalah berbeda secara nyata
dari semua faktor independen sama (equal) dan tidak ada masalah kolineritas pada faktor independen maka dapat dilakukan analisis diskriminan, adapun langkah-langkah dalam melakukan analisis diskriminan dengan SPSS adalah:
1. Klik Analys 2. Pilih Classify. 3. Pilih Diskriminant.
4. Masukkan faktor dependen kedalam kotak gruping variabel dan faktor- faktor independen yang memenuhi syarat kedalam kotak independent (S).
5. Pada define range, isi minimum dan maksimum faktor dependen.
6. Pada statistics pilih descriptive : Means dan pada Function Coeffisients: Fishers’s dan Unstandardized; pada matrices pilihwithin-grups
correlation dan within-grups covariance lalu klik continue.
7. Pada bagian tengah kotak katolog dialog utama, pilih Use Stepwise Method, maka secara otomatis icon method akan aktif.
8. Pada Method pilih Mahalanibis Distance, merupakan metode yang digunakan untuk mengukur menganalisis kasus pada analisa diskriminan, dimana metode ini juga dapat mengidentifikasi multivariate outlier. Mahalanibis Distance adalah jarak antara kasus dengan centroid pada setiap kelompok factor dependen. Setiap kasus mempunyai satu jarak Mahalanibis untuk setiap kelompok dan akan diklasifikasikan ke dalam kelompok dimana jarak tersebut paling kecil
9. Pada Criteria pilih Use Probability of F, tetapi jangan mengubah isi yang sudah ada. Disini lolos tidaknya sebuah faktor yang akan diuji dengan uji F, dengan batasan signifikan 5% lalu klik continue.
10.Pada bagian tengah kotak dialog utama, klik icon classify.
11.Pada Display, pilih Casswise result & Leave-one-out-classification lalu klik continue.
12.Klik OK
3.6Interpretasi Output SPSS
utama, yaitu rata-rata dan standar deviasi dari lima kelompok. Dari Tabel 3.10 terlihat ada 16 siswa ranking tidak baik, 16 siswa ranking kurang baik, 16 siswa ranking cukup baik, 16 siswa ranking baik dan 16 siswa ranking sangat baik.
Tabel 3.10 Kelompok Statistik Group Statistics
RANKING Mean Std. Deviation
Valid N (listwise) Unweighted Weighted
Tidak Baik 1 25.2221 3.33180 16 16.000
2 24.1138 3.45096 16 16.000
3 21.3673 3.84747 16 16.000
4 23.6804 3.96209 16 16.000
Kurang Baik 1 20.5298 5.57390 16 16.000
2 20.3401 4.37939 16 16.000
3 17.9249 3.33912 16 16.000
4 22.7573 4.18106 16 16.000
Cukup Baik 1 25.0133 4.10906 16 16.000
2 24.7198 4.20927 16 16.000
3 21.5952 3.64823 16 16.000
4 24.5251 4.33777 16 16.000
Baik 1 22.9303 3.88699 16 16.000
2 19.0066 3.16946 16 16.000
3 18.5180 3.15030 16 16.000
4 21.5334 4.16988 16 16.000
Sangat Baik 1 23.2731 3.63390 16 16.000
2 22.0319 5.05211 16 16.000
4 24.0451 4.93007 16 16.000
Total 1 23.3937 4.41641 80 80.000
2 22.0424 4.56014 80 80.000
3 19.8677 3.96188 80 80.000
4 23.3083 4.35045 80 80.000
Tabel variabel entered dari analisis stepwise akan memperlihatkan variabel mana saja yang akan masuk ke dalam fungsi diskriminan, dimana p < 0,05. Karena menggunakan metode analisis stepwise discriminant analysis dapat dilihat langkah-langkah pemilihan faktor yang masuk ke dalam fungsi diskriminan seperti tabel 3.11
Tabel 3.11 Variabel-variabel yang Dimasukkan Variables Entered/Removeda,b,c,d
Step Entered
Min. D Squared
Statistic
Between Groups
Exact F
Statistic df1 df2 Sig.
1 2 0.022 Tidak Baik
and Cukup Baik
0.174 1 75 0.678
At each step, the variable that maximizes the Mahalanobis distance between the two closest groups is entered.
a. Banyaknya langkah maksimum adalah 8. b. Nilai signifikan maksimum F adalah 0.05. c. Nilai minimum signifikan F adalah 0.10.
d. Toleransi tingkat F atau VIN tidak cukup untuk perhitungan selanjutnya.
yang mempunyai F hitung terbesar. Pada kasus ini banyak terjadi satu tahap, di mana variabel terpilih dan signifikan adalah 2 (Kreativitas guru). Atau bisa dikatakan 2 (Kreativitas Guru) mempengaruhi ranking siswa di SMP Negeri 10 Medan.
Tabel Variabel in the Analysis (lihat Lampiran 6) sebenarnya hanyalah perincian dari proses stepwise pada tabel sebelumnya. Di mana hanya ada satu step, variabel 2 adalah variabel pertama masuk dan yang masuk ke dalam model diskriminan.
Tabel Variables Not in the Analysis (lihat Lampiran 6) adalah kebalikan dari tabel sebelumnya, di mana pada tabel ini justru yang ditayangkan adalah proses pengeluaran variabel secara bertahap:
1. Pada step 0, keempat variabel secara lengkap ditayangkan dengan angka Sig. of F to Remove sebagai faktor penguji. Terlihat angka Sig. of F to Remove yang paling kecil adalah pada variabel 2 dengan angka 0,001. Maka variabel 2 dikeluarkan dari step 0, yang berarti variabel tersebut termasuk variabel yang dianalisis.
2. Pada step 1, sekarang terlihat empat variabel dan terlihat ketiga variabel tersebut mempunyai angka Sig. of F to Remove diatas 0,05, yaitu 1 (0,158), 3 (0,507), dan 4 (0,395). Karena sudah tidak ada variabel yang memenuhi syarat maka proses pengeluaran variabel terhenti, ketiga variabel tersebut tidak dikeluarkan, yang berarti ketiga termasuk pada Variabel Not in the Analysis, atau variabel yang tidak masuk dalam model.
3.6.1 Nilai Korelasi Kanonikal Eigenvalue
Dari nilai eigen terlihat bahwa fungsi 1 dengan nilai eigenvalue sebesar 0,298 dapat menjelaskan 100% varians. Fungsi 1 menjelaskan bahwa terdapat satu fungsi yang digunakan dalam proses diskriminan tersebut. Canonical Correlation pada tabel 3.12, angka ini akan mengukur keeratan hubungan antara discriminant score dengan kelompok. Nilai sebesar 0,479 menunjukkan keeratan yang relatif tinggi dengan ukuran skala asosiasi antara 0 sampai 1.
Eigenvalues
Function Eigenvalue % of Variance Cumulative % Canonical Correlation
1 .298a 100 100 0.479
3.6.2 Uji Signifikansi
Dari tabel Wilks’Lambda, pada kolom test of function (s), I through 2 menguji hipotesa :
� : Tidak ada perbedaan rata-rata (centroid) dari kedua fungsi diskriminan �1 : Ada perbedaan rata-rata (centroid) dari kedua fungsi diskriminan
Untuk menguji hipotesa, angka Wilks‟Lambda ditransformasikan ke angka Chi-square, dengan ketentuan: Angka Sig > 0,05, maka � diterima dan sebaliknya Angka Sig ≤ 0,05, maka � ditolak.
Tabel 3.13 Wilks’Lambda Wilks' Lambda Test of
Function(s)
Wilks'
Lambda Chi-square df Sig.
1 0.770 19.823 4 0.001
Pada Tabel 3.13 Wilk’s Lambda di atas menyatakan angka akhir dari
Wilks’ Lambda, yang sebenarnya sama saja dengan angka terakhir dari step
pembuatan model diskriminan. Angka Chi-Square sebesar 19,823 dengan tingkat signifikansi 0,001 jauh dibawah 0,05 maka cukup bukti untuk menolak H0, dengan
tingkat signifikan yang tinggi menunjukkan perbedaan yang jelas antara lima kelompok.
3.6.2 Koefisien Fungsi Diskriminan Kanonik
persamaan regresi berganda, yang dalam analisis diskriminan disebut fungsi diskriminan.
Tabel 3.14 Koefisien Fungsi Diskriminan Kanonik Canonical Discriminant Function Coefficients
2 (Constant)
Function 1 0.243 -5.366
Dengan menggunakan koefisien fungsi diskriminan kanonik maka dapat dibentuk fungsi diskriminan yaitu :
D = -5,366 + 0,243 2
3.6.3 Peluang Utama Kelompok
Pada tabel 3.15 peluang utama untuk kelompok memperlihatkan komposisi responden pada fungsi diskriminan. Tabel 3.14 memperlihatkan komposisi ke 80 responden dengan fungsi diskriminan menghasilkan masing-masing 16 responden berada pada setiap kelompok yaitu 16 responden di kelompok tidak baik, 16 responden di kelompok kurang baik, 16 responden di kelompok cukup baik, 16 responden di kelompok baik, 16 responden di kelompok sangat baik. Setiap kelompok memiliki peluang sebesar 0,2 yaitu pada kelompok tidak baik 0,2; pada kelompok kurang baik 0,2; pada kelompok cukup baik 0,2; pada kelompok baik 0,2; dan pada kelompok sangat baik 0,2.
Tabel 3.15 Peluang Utama Untuk Kelompok Prior Probabilities for Groups
Unweighted Weighted
3.6.4 Menguji Ketepatan Hasil Klasifikasi Fungsi Diskriminan
Menguji ketepatan klasifikasi fungsi diskriminan untuk mengetahui ketepatan klasifikasi fungsi diskriminan dilihat dari hasil klasifikasi (Classification Result) dari output terlihat bahwa ketepatan prediksi dari model adalah 60,3 %. Untuk menghitung kemungkinan berbagai bisa dilakukan uji kekuatan prediksi dengan metode leave-one-out-cros validation dan diperoleh hasil 60,3 %.
Kurang
Baik 6.3 31.3 18.8 37.5 6.3 100
Cukup
Baik 6.3 6.3 62.5 12.5 12.5 100
Baik 6.3 6.3 6.3 68.8 12.5 100
Sangat
Baik 6.3 12.5 31.3 31.3 18.8 100
Cross-validated
Count
Tidak Baik 2 1 7 2 4 16
Kurang
Baik 1 5 3 6 1 16
Cukup
Baik 1 1 10 2 2 16
Baik 1 1 1 11 2 16
Sangat
Baik 1 2 5 5 3 16
%
Tidak Baik 12.5 6.3 43.8 12.5 25.0 100 Kurang
Baik 6.3 31.3 18.8 37.5 6.3 100
Cukup
Baik 6.3 6.3 62.5 12.5 12.5 100
Baik 6.3 6.3 6.3 68.8 12.5 100
Sangat
Baik 6.3 12.5 31.3 31.3 18.8 100 a.Cross validation is done only for those cases in the analysis. In cross validation, each case is classified by the function derived from all cases other than that case. b. 60.3% of original grouped cases correctly classified.
c. 60.3% of cross-validated grouped cases correctly classified.
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil penelitian di SMP Negeri 10 Medan, maka diperoleh kesimpulan sebagai berikut:
1. Berdasarkan penelitian ini diperoleh dari 4 variabel independen yang mempengaruhi ranking siswa. Dalam penelitian ini dilihat hasil dari tabel uji kesamaan rata-rata dimana nilai signifikan dari masing-masing variabel. Variabel 1(0,15), 2(0,001), 3(0,22), dan 4(0,318). Dari hasil uji kesamaan rata-rata, variabel yang paling dominan yang mempengaruhi ranking siswa di SMP Negeri 10 Medan adalah Kreativitas guru dalam dalam proses belajar mengajar. Hal ini dapat dilihat dari tabel uji kesamaan rata-rata dimana nilai variabel 2 memiliki nilai signifikan lebih kecil yaitu 0,001. Yang berarti tinggi atau rendahnya ranking siswa dipengaruhi oleh kreativitas guru dalam proses belajar mengajar.
2. Ada perbedaan signifikan pada kelima kelompok. Hal ini dibuktikan dengan analisis Wilk’s Lambda. Dapat dilihat dari Wilk’s Lambda berasosiasi sebesar 0,770 dengan fungsi diskriminan. Angka ini kemudian ditransformasikan menjadi chi-square sebesar 19,823.
3. Fungsi diskriminan yang diperoleh berdasarkan kuisioner dari para siswa adalah:
D = -5,366 + 0,243 2
Yang mana interpretasi dari fungsi diskriminan yg diperoleh adalah : a. Jika kreativitas guru konstan, maka persentase ranking menurun
sebesar -5,366%.
b. Jika kreativitas guru meningkat sebesar 1%, maka persentase ranking bertambah sebesar 0,243%.
hasil klasifikasi spss berarti setiap siswa terklasifikasi dengan tepat dalam kelompok nya secara tepat sebesar 60,3%.
4.2 Saran
1. Sebaiknya pihak sekolah maupun orangtua siswa lebih memperhatikan faktor-faktor yang mempengaruhi ranking siswa. Di mana kreativitas guru dalam proses belajar mengajar yang menjadi faktor yang mempengaruhi ranking siswa agar dapat lebih ditingkatkan, sedangkan motivasi belajar, lingkungan keluarga, dan cara belajar, siswa perlu diperhatikan dan diperbaiki sehingga siswa dapat memberikan hasil yang lebih memuaskan sebagai generasi penerus bangsa.
BAB 2
LANDASAN TEORI
2.1 Variabel
Variabel adalah suatu konsep yang memiliki nilai yang bervariasi dalam setiap penelitian. Variabel dapat merupakan sebuah konsep yang telah diubah, hal ini dilakukan dengan memusatkan aspek tertentu dari variabel itu sendiri. Dengan demikian, variabel adalah merupakan objek yang berbentuk apa saja yang ditentukan oleh peneliti dengan tujuan untuk memperoleh informasi agar bisa ditarik suatu kesimpulan. Secara teori, defenisi variabel penelitian adalah merupakan suatu objek, sifat, atau atribut nilai dari orang, atau kegiatan yang mempunyai bermacam macam variasi antara satu dengan yang lainnya yang ditetapkan oleh peneliti.
Menurut J.Supranto, Variabel merupakan suatu yang nilainya berubah-ubah menurut waktu atau berbeda menurut elemen/tempat. Oleh sebab itu, setiap variabel dapat diberi nilai dan nilai itu berubah-ubah. Nilai itu berupa nilai kuantitatif maupun kualitatif. Nilai variabel dapat dibedakan menjadi 4 tingkatan skala yaitu nominal, ordinal, interval, dan rasio. Nominal ialah angka yang berfungsi hanya untuk membedakan dan merupakan identitas. Ordinal ialah angka yang selain berfungsi sebagai nominal juga menunjukkan urutan, bahwa sesuatu lebih baik, lebih bagus. Interval ialah angka yang selain berfungsi sebagai nominal dan ordinal juga menunjukkan jarak yang sama. Rasio ialah angka yang selain berfungsi sebagai nominal, ordinal dan interval, juga menunjukkan berapa kali, sebab angka nol letaknya tidak sembarang. Dilihat dari segi nilainya, variabel dibedakan menjadi dua, yaitu variabel diskrit dan variabel kontinu. Variabel diskrit nilai kuantitatifnya selalu berupa bilangan bulat. Variabel kontinu nilai kuantitatifnya bias berupa pecahan. Sugiarto, (2001) dalam bukunya mengemukakan kaitan hubungan suatu variabel dengan variabel lainnya, dikenal adanya bermacam-macam bentuk variabel, sebagai berikut:
tak bebas). Variabel independen atau variabel bebas, atau peubah bebas sering juga disebut dengan variabel stimulus atau predictor, atau variabel antecedent.
2. Variabel dependen (dependent variable) atau variabel tak bebas, yaitu variabel yang nilainya dipengaruhi oleh variabel independen. Variabel ini juga sering disebut sebagai variabel terikat.
3. Variabel moderator yaitu variabel yang memperkuat atau memperlemah hubungan antara suatu variabel dependen dengan independen.
4. Variabel intervening, seperti variabel moderator, tetapi nilainya tidak dapat diukur, seperti kecewa, gembira, sakit hati, dan sebagainya.
5. Variabel kontrol, yaitu variabel yang dapat dikendalikan oleh peneliti.
Dalam penelitian ini yang menjadi variabel independen atau variabel bebas yaitu :
1 = Motivasi belajar
2 = Kreativitas guru dalam proses belajar mengajar
3 = Lingkungan keluarga
4 = Cara belajar
2.2 Data
Istilah data berasal dari bahasa Latin yaitu datum yang merupakan bentuk jamak berarti sesuatu yang diberi. Pengertian Data merupakan sekumpulan fakta yang diperoleh dan kemudian diperuntukan menjadi sebuah data untuk diproses atau diolah sehingga menjadi sesuatu yang dapat dimengerti oleh orang lain. Data adalah sesuatu yang belum memiliki arti bagi penerimanya dan masih membutuhkan adanya suatu pengolahan. Data dapat berwujud suatu kondisi atau keadaan, suara, huruf, simbol, gambar, angka, ataupun bahasa lainnya yang dapat digunakan sebagai bahan untuk melihat objek, lingkungan, kejadian ataupun suatu konsep. Jenis data berdasarkan cara memperolehnya dapat dibagi atas dua bagian, yaitu:
Data primer merupakan data yang didapat dari sumber pertama, baik dari individu atau perseorangan seperti hasil wawancara atau pengisian kuisioner yang biasa dilakukan oleh peneliti. Biasanya data primer secara langsung diambil dari objek-objek penelitian oleh peneliti, baik perorangan maupun organisasi.
2.2.2 Data Sekunder
Data sekunder merupakan data primer yang diperoleh oleh pihak lain atau data primer yang telah diolah lebih lanjut dan disajikan baik oleh pengumpul data primer atau pihak lain yang pada umumnya disajikan dalam bentuk tabel-tabel atau diagram-diagram. (Sugiarto, dkk, 2001).
Di samping pembedaan data atas dasar cara perolehannya, data yang diperoleh dapat diklasifikasikan menurut jenisnya berdasarkan kriteria-kriteria berikut:
2.2.3 Data Kualitatif
Data kualitatif adalah data yang sifatnya hanya menggolongkan saja. Termasuk dalam klasifikasi data kualitatif adalah data yang berskala ukur nominal dan ordinal. Sedangkan data kuantitatif adalah data yang berbentuk angka termasuk dalam klasifikasi data kualitatif adalah data yang berskala ukur interval dan rasio.
2.2.4 Data Internal dan Eksternal
Data internal merupakan data yang didapat dari dalam perusahaan atau organisasi dimana riset dilakukan. Sedangkan data eksternal adalah data yang menggambarkan keadaan diluar organisasi.
2.2.5 Data time series dan data cross section
Data time series atau data deret waktu merupakan data yang dikumpulkan dari beberapa tahapan waktu secara kronologis. Sedangkan data cross section atau data kerat lintang adalah data yang dikumpulkan pada waktu dan tempat tertentu saja.
Menurut Supranto (2010), Populasi ialah kumpulan yang lengkap dari seluruh elemen yang sejenis, tetapi dapat dibedakan karena karakteristiknya. Populasi berarti keseluruhan unit atau individu dalam ruang lingkup yang ingin diteliti. Populasi dibedakan menjadi populasi sasaran (target population) dan populasi sampel (sampling population). Populasi sasaran adalah keseluruhan individu dalam areal/wilayah/lokasi/kurun waktu yang sesuai dengan tujuan penelitian. Populasi sampel adalah keseluruhan individu yang akan menjadi satuan analisis dalam populasi yang layak dan sesuai untuk dijadikan atau ditarik sebagai sampel penelitian sesuai dengan kerangka sampelnya (sampling frame).
1.3.2 Sampel
Sampel adalah sebagian anggota dari populasi yang dipilih dengan menggunakan prosedur tertentu sehingga diharapkan dapat mewakili populasinya. Banyaknya anggota suatu sampel disebut ukuran sampel, sedangkan suatu nilai yang menggambarkan ciri sampel disebut statistik.
Santoso (2010), Sampel bisa diartikan sebagai bagian dari populasi, bisa sebagian dari populasi namun tidak semua elemen populasi. Sampel diadakan karena pertimbangan penghematan waktu, biaya dan tenaga daripada jika semua elemen populasi harus diteliti.
2.3.3 Penentuan Jumlah Sampel
diambil dengan cara undian Untuk mendapatkan sampel yang benar-benar mewakili seluruh populasi, maka dalam penelitian ini teknik penentuan jumlah sampel menggunakan rumus Slovin:
=
1+ �2 (2.1)
Keterangan :
n = Jumlah sampel N = Populasi
e = Persentase kelonggaran ketelitian karena kesalahan pengambilan sampel
2.4 Ranking
Ranking adalah suatu tingkat atau kedudukan yang diraih oleh siswa dalam suatu pencapaian hasil belajar dikelas. Maksud kedudukan siswa dalam kelompok adalah letak seseorang siswa di dalam urutan tingkatan. Ketika dalam rangkaian kegiatan belajar mengajar guru atau dosen sebagai seorang pendidik dihadapkan pada tugas untuk melaporkan atau menyampaikan informasi, baik kepada atasan, maupun kepada wali murid, mengenai dimanakah letak urutan kedudukan seorang peserta didik jika dibandingkan dengan peserta didik yang lainnya. Dari penjabaran di atas dapat dikatakan jika ranking itu adalah hasil belajar siswa selama proses belajar.
Belajar yaitu suatu proses usaha yang dilakukan seseorang untuk memperoleh suatu perubahan yaitu perubahan tingkah laku sebagai hasil dari interaksi dengan lingkungannya dalam memenuhi hidup (Slameto, 2003). Sedangkan menurut Sardiman (2011) pengertian prestasi adalah kemampuan yang merupakan hasil interaksi antara berbagai faktor yang mempengaruhinya baik dari dalam maupun dari luar individu itu sendiri dalam belajar. Sehingga dapat ditarik kesimpulan bahwa pengertian prestasi belajar adalah hasil belajar siswa yang dapat diketahui dari perubahan tingkah laku, pengetahuan, serta dapat dilihat dari hasil belajar itu sendiri (nilai angka yang diberikan guru).
dapat digolongkan menjadi dua, yaitu:
1. Faktor internal, yaitu faktor yang ada dalam diri individu yang sedang belajar, yang terdiri dari: faktor jasmaniah (kesehatan dan cacat tubuh), faktor psikologis (inteligensi, perhatian, minat, bakat, motif, dan kesiapan), faktor kelelahan
2. Faktor eksternal, yaitu faktor dari luar individu yang terdiri dari: faktor keluarga, faktor sekolah, faktor masyarakat.
Dalam penelitian ini, penulis akan membagi empat faktor yang mempengaruhi ranking siswa yaitu: motivasi belajar, kreativitas guru dalam proses belajar mengajar (PBM), lingkungan keluarga dan cara belajar.
2.4.1Pengertian Motivasi Belajar
Motivasi menurut Mc. Donald (Hamalik, 2011) adalah perubahan energi dalam diri seseorang yang ditandai dengan timbulnya perasaan dan reaksi untuk mencapai tujuan. Motivasi memiliki dua komponen yaitu komponen dalam dan komponen luar, komponen dalam ialah kebutuhan yang ingin dipuaskan sedangkan komponen luar ialah tujuan yang hendak dicapai. Motivasi sangat diperlukan di dalam belajar. Hasil belajar akan menjadi optimal, jika ada motivasi. Makin tepat motivasi yang diberikan, akan makin berhasil pula pelajaran itu. Motivasi mempunyai fungsi yang sangat penting dalam belajar siswa, karena motivasi akan menentukan intensitas usaha belajar yang dilakukan oleh siswa.
Menurut Keke T. Aritonang (Hamalik, 2008:14) motivasi belajar siswa meliputi:
1. Ketekunan dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu: a) Kehadiran di sekolah
b)Mengikuti PBM di kelas c) Belajar di rumah
2. Minat dan ketajaman perhatian dalam belajar
a) Kebiasaan dalam mengikuti pelajaran b) Semangat dalam mengikuti PBM 3. Berprestasi dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu: a) Keinginan untuk berprestasi
b) Kualifikasi hasil belajar 4. Mandiri dalam belajar
Indikator pada subvariabel ketekunan dalam belajar yaitu: a) Penyelesaian tugas/PR
b) Menggunakan kesempatan di luar jam pelajaran
2.4.2 Pengertian Kreativitas Guru dalam Proses Belajar dan Mengajar Salah satu yang mempengaruhi Proses Belajar Mengajar (PBM) adalah guru, yang merupakan faktor eksternal sebagai penunjang pencapaian hasil belajar yang optimal. Untuk mencapai hasil belajar yang optimal diperlukan peran guru, terutama kreativitas guru dalam proses belajar mengajar. Kreativitas bagi seorang guru dalam proses pembelajaran betul-betul diperlukan guna menemukan nilai-nilai ajaran pada anak didik. Kreativitas yang dimaksud adalah kemampuan untuk menciptakan suatu produk baru, baik yang benar-benar baru sekali maupun yang merupakan modifikasi atau perubahan dengan mengembangkan hal-hal yang sudah ada. Bila hal ini dikaitkan dengan kreativitas guru, guru yang bersangkutan mungkin menciptakan suatu strategi mengajar yang benar-benar baru dan orisinil (asli ciptaan sendiri) atau dapat saja merupakan modifikasi dari berbagai strategi yang sudah ada sehingga menghasilkan bentuk baru.
Kreativitas guru sangat dibutuhkan guna memotivasi semangat belajar peserta didik mempunyai minat belajar. Sebab guru dipandang sebagai orang yang mengetahui kondisi belajar dan permasalahan belajar yang dihadapi oleh anak didik. Guru yang kreatif selalu mencari bagaimana agar proses belajar mengajar mencapai hasil belajar dengan tujuan yang direncanakan.
1. Cara guru merencanakan PBM 2. Cara guru melaksanakan PBM
3. Invensi adalah kegiatan menciptakan suatu hal yang belum pernah ada. 4. Fleksibilitas
2.4.3 Pengertian Lingkungan Keluarga
Keluarga adalah lembaga pendidikan yang pertama dan utama. Anak-anak pertama kali mendapatkan didikan dan bimbingan didalam keluarga. Pengaruh keluarga dalam pendidikan anak sangat besar dalam berbagai macam sisi. Keluargalah yang menyiapkan potensi pertumbuhan dan pembentukan kepribadian anak. Lebih jelasnya, kepribadian anak tergantung pada pemikiran dan tingkah laku kedua orang tua serta lingkungannya.
Kedua orang tua memiliki peran yang sangat penting dalam mewujudkan kepribadian anak. Orang tua harus berperan aktif dalam mendukung keberhasilan siswa, orang tua disamping menyediakan alat-alat yang dibutuhkan anak untuk belajar, yang lebih penting bagaimana memberikan bimbingan, pengarahan agar anak lebih bersemangat untuk berprestasi dan tidak melanggar tata-tertib sekolah.
Menurut Slameto (2003:60) lingkungan keluarga akan member pengaruh pada siswa. Dari penjelasan diatas dapat disimpulkan bahwa indikator-indikator lingkungan keluarga yang dapat mempengaruhi prestasi anak adalah sebagai berikut:
1. Cara orang tua dalam mendidik anak
Cara orangtua mendidik anaknya besar pengaruhnya terhadap belajar anak. Hal ini jelas dipertegas oleh Sutjipto Wirowidjojo dengan pernyataannya yang menyatakan bahwa keluarga adalah lembaga pendidikan yang pertama dan utama. Orang tua yang tidak atau kurang perhatian misalnya keacuhan orang tua tidak menyediakan peralatan sekolah, akan menyebabkan anak kurang berhasil dalam belajar. Orang tua dapat menolong anak yang mengalami kesulitan dalam belajar dengan bimbingan tersebut.
Relasi antar anggota keluarga yang terpenting adalah relasi orang tua dengan anaknya. Selain itu relasi anak dengan saudaranya atau dengan anggota keluarga yang lain pun turut mempengaruhi belajar anak.Sebetulnya relasi antar anggota keluarga ini erat hubungannya dengan cara orang tua mendidik. Demi kelancaran keberhasilan belajar siswa, perlu diusahakan relasi yang baik dalam keluarga tersebut.
3. Suasana rumah
Suasana rumah yang dimaksudkan adalah kejadian atau situasi yang sering terjadi di keluarga. Suasana rumah juga merupakan faktor yang penting yang tidak termasuk faktor yang disengaja. Agar anak dapat belajar dengan baik perlulah diciptakan suasana rumah yang tenang dan tentram sehingga anak betah di rumah dan dapat belajar dengan baik.
4. Keadaan ekonomi keluarga
Keadaan ekonomi anak erat kaitannnya dengan belajar anak. Pada kondisi ekonomi keluarga yang relative kurang menyebabkan orang tua tidak dapat memenuhi kebutuhan anak, tetapi faktor kesulitan ekonomi dapat menjadi pendorong keberhasilan anak. Keadaan ekonomi yang berlebih juga dapat menimbulkan masalah dalam belajar.
2.4.4 Pengertian Cara Belajar
Belajar ialah suatu proses usaha yang dilakukan seseorang untuk memperoleh suatu perubahan tingkah laku yang baru secara keseluruhan, sebagai hasil pengalamannya sendiri dalam interkasi dengan lingkungannya sendiri.
mandiri yang dilakukan, pola belajar mereka, cara mengikuti ujian.
Cara atau kebiasaan belajar yang baik harus dilaksanakan oleh siswa. Dengan kebiasaan belajar yang baik akan lebih bermakna dan tujuan untuk memperoleh prestasi belajar yang baik dapat sesuai dengan harapan. Menurut Nana Sudjana (2005: 165-173) ada beberapa indikator cara pelajar meliputi beberapa aspek berikut:
1. Cara mengikuti pelajaran
Cara mengikuti pelajaan di sekolah merupakan bagian penting dari proses belajar, siswa dituntut untuk dapat menguasai bahan pelajaran. Jika guru memberikan PR, ajaklah teman untuk diskusi pokok-pokok tugas yang diberikan.
2. Cara belajar mandiri di rumah
Belajar mandiri di rumah merupakan tugas pokok setiap siswa. Syarat utama belajar di rumah adalah keteraturan belajar yaitu memiliki jadwal belajar meskipn waktunya terbatas.
3. Cara belajar kelompok
Cara belajar sendiri di rumah sering menimbulkan kebosanan dan kejenuhan. Perlu adanya variasi cara belajar bersama dengan teman yang bisa dilakukan di sekolah, perpustakaan, di rumah teman, ataupun tempat yang nyaman untuk belajar.
4. Menghadapi ujian
2.5 Uji Validitas dan Reliabilitas
a. Uji Validitas
Validitas menunjukkan sejauh mana suatu alat pengukur itu mengukur apa yang ingin diukur. Untuk mengetahui valid atau tidaknya suatu item pertanyaan dapat dihitung koefisien korelasinya. Ukuran yang dipakai untuk mengetahui derajat hubungan, terutama untuk data kuantitatif, dinamakan koefisien korelasi. Koefisien korelasi adalah statistik yang menunjukkan kuat dan arah saling hubungan antara variasi dua distribusi skor. Pengujian validitas tiap item pertanyaan dilakukan dengan menggunakan rumus product moment pearson :
= −
2− 2 2− 2
Keterangan :
= koefisien korelasi n = jumlah sampel
X = skor variabel bebas pada data ke i dimana i = 1,2,...,n Y = skor variabel terikat
b. Uji Reliabilitas
Reliabilitas adalah indeks yang menunjukkan sejauh mana suatu alat pengukur dapat dipercaya atau diandalkan. Bila suatu alat pengukur dipakai dua kali untuk mengukur gejala yang sama dan hasil pengukuran diperoleh relatif koefisien, maka alat pengukur tersebut reliable.
Suatu variabel dikatakan reliabel jika memberikan nilai cronbach alpha > 0,60.
Rumus Cronbach Alpha (CA) adalah sebagai berikut :
11 = −
1 1−
� �
Keterangan :
11 = Koefisien realibilitas
k = Banyaknya pertanyaan dalam setiap variabel
�2 = Jumlah varians setiap variabel
St = Varians total
2.6 Transformasi Data Ordinal menjadi Interval
Proses transformasi merupakan upaya yang dilakukan untuk merubah data ordinal menjadi data interval misalnya analisis diskriminan dimana variabel bebasnya harus berskala interval. Data ordinal yang ditransformasikan menjadi data interval adalah data penelitian yang diperoleh menggunakan instrumen berupa angket yang memiliki jawaban berupa skala likert. Cara melakukan proses transformasi data ordinal menjadi data interval menggunakan Metode MSI (Method Of successive Interval). Adapun langkah-langkahnya sebagai berikut:
1. Mencari f (frekuensi) jawaban responden.
2. Setiap frekuensi dibagi dengan banyaknya responden dan hasilnya disebut proporsi.
3. Menentukan nilai proporsi kumulatif dengan menjumlahkan nilai proporsi secara berurutan perkolom skor.
4. Menghitung nilai Z untuk setiap proporsi dengan menggunakan tabel distribusi Normal.
5. Menentukan nilai densitas untuk setiap nilai Z yang diperoleh dengan menggunakan tabel densitas.
6. Menentukan SV (Scale Value = nilai skala) dengan rumus sebagai berikut:
�
=
� � − � �� � � − � � �
Keterangan :
SV = Interval rata-rata
Densitas at Upper Limit = Kepadatan batas atas Area Below Upper Limit = Daerah di bawah batas atas Area Below Lower Limit = Daerah di atas batas bawah
7. Menentukan nilai transformasi dengan rumus
Y SV
1SVmin
2.7 Analisis Diskriminan
Analisis diskriminan merupakan suatu analisis multivariat yang digunakan untuk mengelompokkan suatu individu atau objek kedalam suatu individu atau objek kedalam suatu kelompok yang telah ditentukan sebelumnya berdasarkan variabel-variabel tertentu. Analisis diskriminan dapat digunakan jika variabel dependen terdiri dari dua kelompok atau lebih kelompok. Pengelompokkan pada analisis bersifat apriori, artinya seorang peneliti sudah mengetahui sebelumnya individu atau objek mana saja yang masuk ke dalam kelompok 1, 2, 3, 4 dan 5.
Analisis diskriminan adalah salah satu teknik analisa statistika dependensi yang memiliki kegunaan untuk mengklasifikasikan objek beberapa kelompok. Pengelompokan dengan analisis diskriminan ini terjadi karena ada pengaruh satu atau lebih variabel lain yang merupakan variabel dependen.
Analisis diskriminan mirip dengan analisis regresi linier berganda (multivariable regression). Perbedaannya analisis digunakan apabila variabel independennya menggunakan skala kategoris (digunakan apabila menggunakan skala nominal dan ordinal) dan variabel independennya menggunakan skala metrik (interval dan rasio). Sedangkan dalam regresi berganda variabel dependennya harus metrik dan variabelnya independen dapat metrik maupun nonmetrik.
terjamin akurasinya.
2.7.1 Tujuan Analisis Diskriminan
Tujuan analisis diskriminan secara umum adalah :
1. Membuat suatu fungsi diskriminan atau kombinasi linear, dari predictor atau variabel bebas yang bisa mendiskriminasi atau membedakan katagori variabel tak bebas, artinya mampu membedakan suatu objek (responden) masuk kelompok yang mana.
2. Menguji apakah ada perbedaan signifikan antara kelompok, dikaitkan dengan variabel bebas.
3. Menentukan variabel bebas yang mana yang memberikan sumbangan terbesar terhadap terjadinya perbedaan antar kelompok.
4. Mengklasifikasi atau mengelompokkan responden ke dalam suatu kelompok didasarkan pada nilai variabel bebas.
5. Mengevaluasi keakuratan klasifikasi (the accuracy of classification).
2.7.2 Proses Dasar Analisis Diskriminan
Proses dasar Analisis Diskriminan adalah:
1. Memisahkan variabel-variabel menjadi variabel dependen dan variabel independen.
2. Menentukan metode untuk membuat fungsi diskriminan. Pada dasarnya ada dua metode dasar untuk itu, yaitu:
a. Simultaneous Estimation, dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses diskriminan.
b. Stepwise Estimation, dimana variabel dimasukkan satu persatu kedalam model diskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model dan ada kemungkinan satu atau lebih variabel independen yang dibuang dari model.
4. Melakukan interpretasi terhadap fungsi diskriminan tersebut.
5. Menguji ketepatan klasifikasi dari fungsi diskriminan, termasuk mengetahui ketepatan klasifikasi secara individual dengan casewise diagnostics.
2.7.3 Asumsi dalam Analisis Diskriminan
Berikut ini asumsi yang harus dipenuhi agar model diskriminan dapat digunakan:
1. Multivariat Normality, atau variabel independen yang seharusnya berdistribusi normal. Jika data tidak berdistribusi normal, hal ini akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan. Regresi logistik bisa dijadikan alternatif metode jika memang data tidak berdistribusi normal. Tujuan uji normal adalah ingin mengetahui, apakah distribusi dengan berbentuk lonceng (bell shapped). Data yang baik adalah data yang mempunyai pola seperti distribusi normal, yaitu distribusi data tersebut tidak menceng ke kiri atau menceng ke kanan. Uji normalitas pada multivariat sebenarnya kompleks, karena harus dilakukan pada seluruh variabel secara bersama-sama. Namun, uji ini bisa juga dilakukan pada setiap variabel dengan logika bahwa jika secara individual masing-masing variabel memenuhi asumsi normalitas, maka secara bersama-sama (multivariat) variabel-variabel tersebut juga dianggap memenuhi asumsi normalitas. Adapun kriteria pengujiannya adalah:
a. Angka signifikansi (Sig.) > 0,05, maka data tersebut berdistribusi normal. b. Angka signifikansi (Sig.) < 0,05, maka data tersebut tidak berdistribusi
normal.
2. Matriks Kovarian dari semua variabel independen seharusnya sama atau equal. 3. Tidak ada korelasi antara dua variabel independen.
4. Tidak adanya data yang sangat ekstrim pada variabel independen.
2.7.4 Model Analisis Diskriminan
dalam analisis diskriminan dilambangkan dengan “D”. Model analisis diskriminan adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai variabel independen, (Supranto,2004) yaitu:
= 0+ 1 1+ 2 2 + 3 3+
+
keterangan :
= Nilai ( skor) diskriminan dari responden ( objek ) ke – i . i = 1,2,...,n. D merupakan variabel tak bebas.
0 = Intercep atau konstanta
= Variabel ( atribut ) ke – j dari responden ke – i.
= Koefisien atau timbangan diskriminan dari variabel atau atribut ke j.
Yang diestimasi adalah koefisien bj, koefisien fungsi diskriminan bj
diperkirakan sedemikian rupa sehingga nilai D kelompok mempunyai nilai fungsi diskriminan yang sangat berbeda. Ini terjadi kalau rasio jumlah kuadrat antar-kelompok (between group sum of squares) dengan jumlah kuadrat dalam kelompok (within group sum of squares) untuk skor fungsi diskriminan menacapai maksimum atau rasio varian antar-kelompok dengan varian dalam kelompok sebesar mungkin (maksimum). Objek dalam kelompok homogen atau relatif homogen, sedangkan antar-kelompok sangat heterogen. Berdasarkan nilai D itulah keanggotaan seseorang diprediksi.
Suatu fungsi diskriminan layak untuk dibentuk bila terdapat perbedaan nilai rataan di antara kelompok-kelompok yang ada. Oleh karena itu sebelum fungsi diskriminan dibentuk perlu dilakukan pengujian terhadap perbedaan vektor nilai rataan dari kelompok-kelompok tersebut. Pada data pengamatan ke-i yang berukuran n (i = 1,2,3…,n) yang terdiri atas j buah variabel yaitu 1,
2, 3,…, . Data pengamatan tersebut dapat disajikan dalam bentuk matriks-matriks
� = =1 − =1 =1 ( −1)
Apabila semua ada
j 2 1
buah kovarians, dimana i = j maka � =� diberi lambang � . Varians dan kovarians ini disusun dalam sebuah matriks yang disebut dengan matriks varians-kovarians (� ) dengan bentuk sebagai� = Matriks varians-kovarians gabungan
�1,2,…, = Matriks varians-kovarians tiap kelompok 1,2,…, = Jumlah sampel tiap kelompok
= Jumlah kelompok
1 =
1 = menyatakan variabel X ke-j dalam kelompok ke-1 2 = menyatakan variabel X ke-j dalam kelompok ke-2
Dari setiap kelompok berukuran 1dari kelompok ke-I dan berukuran 2 dari kelompok ke-2. Data pengamatan akan berbentuk matriks yang bentuknya seperti di bawah ini :
Tabel 2.2 Matriks Data Pengamatan dari Kelompok I
Variabel 11 12 13 ... 1
11 = Kelompok ke-1, variabel X ke-1
Tabel 2.3 Matriks Data Pengamatan dari Kelompok II
21 = Kelompok ke-2, variabel X ke-1
211 = Kelompok ke-2, variabel X ke-1 yang berukuran 1 2 2 = Kelompok ke-2, variabel X ke-j yang berukuran 2 21 = Rata-rata variabel ke-1 dalam kelompok ke-2
Hasil pengamatan ini akan menghasilkan rata-rata untuk tiap variabel yang dalam bentuk vektor dapat ditulis sebagai berikut:
1=
1 1 = Kelompok ke-1, variabel X ke-j yang berukuran 1 2 1 = Kelompok ke-1, variabel X ke-j yang berukuran 2 1 = Rata-rata variabel ke-j dalam kelompok ke-1
Dari masing-masing rata-rata dari kelompok I dan rata-rata dari
�2 = matriks varians kovarians dari kelompok ke-2
Meskipun dalam �1 dan �2 digunakan � yang sama namun jelas besarnya berlainan antar � dalam �1 dan � dalam �2 . Kedua datanya juga
berlainan yaitu � dalam �1 diambil dari kelompok 1 dan � dalam �2 diambil
dari kelompok II. Kedua buah matriks varians-kovarians gabungan yang diberi lambang S dengan rumus :
�= 1− 1 �1+ 2− 1 �2
1+ 2− 2
Keterangan :
S = Matriks varian-kovarian gabungan
�1,�2 = Matriks varians kovarians dari kelompok ke-1 dan kelompok ke-2 1, 2 = Jumlah sampel kelompok ke-1 dan ke-2
Secara ringkas, langkah-langkah dari analisis diskriminan adalah:
1. Pengecekan adanya kemungkinan hubungan linier antara variabel bebas. Pengecekan dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada hasil output SPSS, matriks korelasi dapat dilihat pada Pooled Within-Groups Matrices.
2. Uji vektor rata-rata kedua kelompok
Pengujian terhadap vektor nilai rataan antar kelompok dilakukan dengan hipotesis:
H0 : µ1 = µ2 (Tidak ada perbedaan antar kelompok)
H1 : µ1≠ µ2 (Ada perbedaan antar kelompok)
Angka signifikan:
Jika angka Sig > 0,05, tidak ada perbedaan antar kelompok Jika angka Sig ≤ 0,05, ada perbedaan antar kelompok
Jika dari hasil pengujian diperoleh adanya perbedaan vektor nilai rataan, fungsi diskriminan layak disusun untuk mengkaji hubungan antar kelompok serta berguna untuk mengelompokkan objek ke salah satu kelompok tersebut. Pada SPSS, uji ini dilakukan secara univariate (yang diuji bukan berupa vektor), dengan bantuan tabel Tests of Equality of Group Means.
3. Pemeriksaan asumsi homoskedastisitas dengan uji Box’s M
Pengujian terhadap kesamaan matriks kovarians (∑) antar kelompok dilakukan dengan hipotesis:
H0 : Matriks kovarians kelompok adalah sama
H1 : Matriks kovarians kelompok adalah berbeda secara nyata
Keputusan dengan dasar signifikansi bias dilihat dari angka signifikannya Jika Sig > 0,05 berarti H0 diterima
Sama tidaknya grup kovarian matriks juga dapat dilihat dari tabel output Log Determinant. Jika dalam pengujian ini H0 ditolak maka proses
selanjutnya seharusnya tidak bisa dilakukan.
4. Pembentukan Model Diskriminan a. Pembentukan Fungsi Linier
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model dapat dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient bagia Unstandardized diaktifkan.
b. Menghitung Discriminant Score
Setelah fungsi liniernya dibentuk, maka dapat dihitung skor diskriminan untuk tiap observasi dengan cara memasukkan nilai-nilai variabel penjelasnya.
c. Menghitung Cutting Score
Untuk memprediksi responden masuk ke dalam kelompok yang mana, maka dapat menggunakan Optimum Cutting Score. Memang dari komputer informasi ini sudah diperoleh. Untuk cara mengerjakan secara manual Cutting Score dapat dihitung dengan rumus sebagai berikut dengan ketentuan:
1. Untuk dua kelompok yang mempunyai ukuran yang sama cutting score dinyatakan dengan rumus (Simamora, 2005):
� = +2
Keterangan:
� = Cutting score untuk kelompok yang mempunyai ukuran yang
sama
= Centroid kelompok A
2. Untuk dua kelompok yang mempunyai ukuran yang berbeda, rumus cutting score yang digunakan adalah:
= +
+
Keterangan:
= Cutting score untuk kelompok yang mempunyai ukuran yang berbeda
= Jumlah sampel kelompok A = Jumlah sampel kelompok B = Centroid kelompok A
� = Centroid kelompok B
Centroid adalah nilai rata-rata skor diskriminan untuk kelompok tertentu. Kemudian nilai-nilai discriminant score tiap observasi akan dibandingkan dengan nilai cutting score, sehingga dapat diklasifikasikan suatu obsevasi akan termasuk kedalam kelompok yang mana. Dapat dihitung dengan bantuan tabel Function at Group Centroids dari output SPSS.
d. Perhitungan Hit Ratio
2.7.6 Pengujian Hipotesis
Intepretasi hasil analisis diskriminan tidak berguna jika fungsinya tidak signifikan. Hipotesis yang diuji adalah H0 yang menyatakan bahwa rata-rata semua variabel dalam semua kelompok adalah sama. Dalam SPSS, uji dilakukan dengan menggunakan wilks’lambda. Jika dilakukan pengujian sekaligus beberapa fungsi sebagaimana dilakukan pada analisis diskriminan, statistik wilks’lamda adalah hasil lamda univariat untuk setiap fungsi. Kemudian, tingkat signifikan diestimasi berdasarkan chi-square yang telah ditransformasi secara statistik. Setelah analisis diketahui, kemudian dilihat apakah wilks’lambda berasosiasi dengan fungsi diskriminan. Selanjutnya angka ini ditransformasi menjadi chi-square dengan derajat kebebasan (df) yang akan digunakan dalam pengambilan keputusan dengan uji kriteria hipotesis berikut.
Jika Fhitung > Ftabel maka H0 ditolak dan H1 diterima
Jika Fhitung≤ Ftabel maka H0 diterima dan H1 ditolak
Selanjutnya dengan menggunakan nilai Fhitung, dapat diambil keputusan
untuk menerima atau menolak H0. . Jika H0 diterima maka akan diberikan
kesimpulan bahwa tidak ada perbedaan pada faktor yang mempengaruhi rangking siswa. Sebaliknya jika H0 ditolak maka terdapat perbedaan faktor yang
mempengaruhi rangking siswa, dengan nilai signifikan < α. H0 ditolak. Sehingga
BAB 1
PENDAHULUAN 1.1Latar Belakang
Pendidikan adalah salah satu bentuk interaksi manusia, sekaligus tindakan sosial yang dimungkinkan berlaku melalui suatu jaringan hubungan kemanusiaan melalui peranan-peranan individu di dalamnya yang diterapkan melalui proses pembelajaran. Belajar dan pembelajaran adalah suatu kegiatan yang tidak terpisahkan dari kehidupan manusia. Dengan belajar manusia dapat mengembangkan potensi-potensi yang dibawanya sejak lahir. Tanpa belajar manusia tidak mungkin dapat memenuhi kebutuhannya.
Menurut Hamalik (2001), belajar merupakan suatu proses usaha yang dilakukan seseorang untuk memperoleh suatu perubahan tingkah laku yang baru secara keseluruhan sebagai hasil pengalamannya sendiri dalam interaksi dengan lingkungannya, yang secara ideal harus mengacu pada tiga aspek yaitu kognitif (perubahan pengetahuan), psikomotorik (perubahan ketrampilan) dan afektif (perubahan nilai dan sikap). Setiap orang mempunyai pandangan yang berbeda tentang belajar, belajar merupakan suatu proses usaha yang dilakukan seseorang untuk memperoleh suatu perubahan tingkah laku. Perubahan yang terjadi dalam diri seseorang banyak sekali baik sifat maupun jenisnya, oleh karena itu tidak setiap perubahan dalam diri seseorang merupakan perubahan dalam arti belajar. Hasil belajar dapat dipengaruhi berbagai faktor kecakapan dan ketangkasan belajar yang berbeda secara individual.
faktor-faktor yang mempengaruhi keberhasilan pendidikan. Salah satu parameter yang digunakan untuk mengukur tingkat keberhasilan pendidikan adalah prrestasi belajar siswa. Prestasi belajar di pengaruhi oleh dua faktor, yaitu faktor intern dan faktor extern. Faktor intern yaitu, faktor yang berasal dari dalam diri manusia yang terdiri dari : faktor biologis (karna sakit, kurang sehat, cacat tubuh). Faktor ekstern yaitu, faktor yang berasal dari luar diri manusia yang terdiri dari lingkungan keluarga, lingkungan sekolah, lingkungan masyarakat dan media massa. Prestasi belajar adalah hasil suatu penelitian dibidang pengetahuan, ketrampilan dan sikap sebagai hasil belajar yang dinyatakan dalam bentuk nilai.
Untuk mengevaluasi prestasi belajar, pemerintah melaksanakan Ujian Nasional, yang merupakan kegiatan pengukuran dan penilaian kompetensi peserta didik secara nasional pada jenjang pendidikan. Pendidikan merupakan investasi jangka panjang yang memerlukan usaha dan dana yang cukup besar. Faktor utama untuk menilai kualitas pembelajaran dan kelulusan siswa dari suatu lembaga pendidikan, sering didasarkan pada hasil belajar siswa yang tertera pada nilai tes hasil belajar. Faktor-faktor yang mempengaruhi indeks ranking siswa diantaranya yaitu, ketekunan belajar siswa, minat belajar siswa, prestasi belajar siswa, belajar mandiri siswa, cara guru merencanakan PBM, cara guru melaksanakan PBM, invensi guru, lingkungan sekolah, cara orang tua mendidik siswa, relasi antar anggota keluarga, pendidikan orang tua, penghasilan orang tua, lamanya belajar siswa, les tambahan siwa, frekuensi tugas siswa, belajar kelompok siswa. Dari faktor-faktor tersebut kita dapat mengetahui faktor utama dalam penentuan indeks ranking siswa dengan menggunakan metode analisis diskriminan.
untuk melihat perbedaan antar kelompok tersebut. Analisis diskriminan dapat digunakan untuk menganalisis faktor-faktor yang menentukan indeks ranking siswa berdasarkan perilaku belajar siswa, karena analisis diskriminan dapat memisahkan faktor-faktor yang menentukan tingkat indeks ranking siswa.
Berdasarkan uraian diatas, maka penulis tertarik untuk melakukan penelitian lebih lanjut dan menuangkannya di dalam penulisan skripsi yang berjudul “ Faktor-Faktor yang Mempengaruhi Ranking Siswa Dengan
Menggunakan Analisis Diskriminan (Studi kasus di SMP Negeri 10 Medan)”.
1.2 Perumusan Masalah
Yang menjadi rumusan masalah dalam penelitian ini yaitu, faktor – faktor apa saja yang mempengaruhi ranking siswa berdasarkan perilaku belajar siswa dan diperolehnya data yang mendukung untuk menganalisis faktor-faktor yang menentukan ranking siswa sehingga perlu diteliti.
1.3 Batasan Masalah
Agar penelitian ini tepat sasaran, penulis menetapkan pembatasan masalah:
1. Penelitian ini difokuskan terhadap nilai ranking siswa secara umum atau ranking yang dihitung dari seluruh siswa kelas tiga.
2. Faktor-faktor yang mempengaruhi indeks ranking siswa dalam penelitian ini antara lain : Ketekunan belajar siswa, minat belajar siswa, prestasi belajar siswa, belajar mandiri siswa, cara guru merencanakan PBM, cara guru melaksanakan PBM, invensi guru, lingkungan sekolah, cara orang tua mendidik siswa, relasi antar anggota keluarga, pendidikan orang tua, penghasilan orang tua, lamanya belajar siswa, les tambahan siwa, frekuensi tugas siswa, belajar kelompok siswa.
3. Dari beberapa faktor tersebut diperoleh variabel independen dalam penelitian ini antara lain : Motivasi belajar, kreativitas guru dalam PBM, lingkungan keluarga, dan cara belajar.