ANALISIS DISKRIMINAN FAKTOR-FAKTOR YANG MEMPENGARUHI INDEKS RANKING SISWA BERDASARKAN CARA BELAJAR SISWA
(STUDI KASUS SMA VAN DUYNHOVEN SARIBUDOLOK)
SKRIPSI
LESTARI FRIMADONA RUMAHORBO
100823005
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : ANALISIS DISKRIMINAN FAKTOR-FAKTOR
YANG MEMPENGARUHI INDEKS RANKING SISWA BERDASARKAN CARA BELAJAR SISWA
(Studi Kasus Sma Van Duynhoven Saribudolok)
Kategori : SKRIPSI
Nama : LESTARI FRIMADONA RUMAHORBO
Nomor Induk Mahasiswa : 100823005
Program Studi : SARJANA (S1) MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PERNGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan Di Medan, Juli 2012
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs.Pengarapen Bangun, M.Si Drs. Henry Rani Sitepu, M.Si Nip. 195608151985031005 Nip. 195303031983031002
Diketahui / Disetujui Oleh
Departemen Matematika Fmipa USU Ketua,
PERNYATAAN
ANALISIS DISKRIMINAN FAKTOR-FAKTOR YANG MEMPENGARUHI INDEKS RANKING SISWA BERDASARKAN CARA BELAJAR SISWA
(STUDI KASUS SMA VAN DUYNHOVEN SARIBUDOLOK)
SKRIPSI
Saya Mengakui Bahwa Skripsi Ini Adalah Hasil Kerja Saya Sendiri, Kecuali Beberapa Kutipan Dan Ringkasan Yang Masing-Masing Disebutkan Sumbernya,
Medan, Juli 2012
PENGHARGAAN
Dengan segala kerendahan hati penulis mengucapkan Puji dan Syukur kehadirat Tuhan Yang Maha Kuasa dan Bunda Maria karena atas rahmat dan karunia-Nya memberikan pengetahuan, pengalaman, dan kesempatan kepada penulis dapat menyelesaikan Skripsi ini dengan baik tepat waktu.
Abstrak
Analisis Diskriminan adalah salah satu tehnik statistik yang bisa digunakan pada hubungan dependensi (hubungan antarvariabel dimana sudah dapat dibedakan mana variabel respon dan mana variabel penjelas). Dalam Analisis Diskriminan dibutuhkan asumsi data harus berdistribusi normal multivariate. Penggunaan Analisis Diskriminan dalam penelitian ini bertujuan untuk mengetahui variabel-variabel yang menentukan indeks ranking siswa di SMA Van Duynhoven Saribudolok. Data yang digunakan dalam penelitian ini diperoleh dari SMA Van Duynhoven Saribudolok. Dengan menggunakan Analisis Diskriminan diperoleh hasil penelitian yang menunjukkan bahwa ada 4 (empat) variabel yang berpengaruh terhadap indeks ranking siswa di SMA Van Dunyhohen Saribudolok diantaranya X1 (nilai tugas), X2 (waktu belajar di
sekolah), X3 (waktu belajar di rumah), X4 (nilai rata-rata ujian). Dari keempat faktor
tersebut yang sangat dominan mempengaruhi indeks ranking siswa di SMA Van Duynhoven Saribudolok adalah X4 (nilai rata-rata ujian). Dan model yang dihasilkan
Abstract
Discriminant analysis is one of statistical technique that can be used on the dependency relationship (intervariable relationship which can be distinguished where the response variable and where the explanatory variables). Discriminant analysis of the assumptions required in the data must be multivariate normal distribution. Use of discriminant analysis in this study aims to determine the variables that determine students index ranking at SMA Van Duynhoven Saribudolok. Used data in this study obtained from SMA Van Duynhoven Saribudolok. By using discriminant analysis of the research project shost that there are 4 (four) variables influencing the students index ranking SMA Van Duynhoven Saribudolok including X1 (value of homework),
X2 (at time study in the school), X3 (at time study in the home), X4 ( Value rate of
examination). The four most dominant factors affecting students index ranking at SMA Van Duynhoven Saribudolok is X4 (value rate of examination). And the model
Daftar Isi
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak vi
Abstract vii
Daftar Isi viii
Daftar Tabel x
Bab 1 Pendahuluan 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 2
1.3 Pembatasan Masalah 3
1.4 Tinjauan Penelitian 3
1.5 Tujuan Penelitian 5
1.6 Kontribusi Penelitian 5
1.7 Metodologi Penelitian 6
Bab 2 Landasan Teori 8
2.1 Variabel 8
2.2 Data 9
2.3 Belajar 10
2.3.1 Pengertian Belajar 10
2.3.2 Prinsip Belajar 11
2.3.3 Faktor-Faktor Yang Mempengaruhi Belajar 12
2.4 Analisis Diskriminan 14
2.4.1 Tujuan Analisis Diskriminan 15
2.4.2 Proses Dasar Analisis Diskriminan 15
2.4.3 Asumsi Dalam Analisis Diskriminan 16
2.4.5 Fungsi Analisis Diskriminan 19
2.4.6 Algoritma Dan Model Matematis 25
2.4.7 Pengujian Hipotesis 30
Bab 3 Pembahasan 32
3.1 Pengumpulan Data 32
3.1.1 Sumber Data 32
3.1.2 Populasi 32
3.2 Analisis Data 33
3.3 Interpretasi Output 38
3.3.1 Nilai Eigen 40
3.3.2 Uji Signifikansi 41
3.3.3 Standartdized Canonical Discriminant Function Coefisient 41 3.3.4 Koefisien Fungsi Diskriminan Kanonik 42
3.3.5 Fungsi Grup Terpusat 43
3.3.6 Classification Statistik 43
3.3.7 Ketepatan Klasifikasi Fungsi Diskriminan 44
Bab 4 Kesimpulan Dan Saran 46
4.1 Kesimpulan 45
4.2 Saran 47
Daftar Pustaka 48
Daftar Tabel
Halaman
Tabel 2.1 Matriks Pengamatan 20
Tabel 2.2 Matriks Data Pengamatan Dari Grup I 21
Tabel 2.3 Matriks Data Pengamatan Dari Grup II 22 Tabel 3.1 Jumlah Siswa Kelas III Sma Van Duynhoven Saribudolok 33
Tabel 3.2 Uji Kesamaan Rata-Rata 34
Tabel 3.3 Hasil Output Uji Kesamaan Matriks Covarians 34
Tabel 3.4 Hasil Uji Box’s M 35
Tabel 3.5 Grup Statistic 38
Tabel 3.6 Variabels Entered / Removed 39
Tabel 3.7 Variabels In The Analysis 40
Tabel 3.8 Eigen Values 41
Tabel 3.9 Wilks’lambda 41
Tabel 3.10 Structure Matrix 42
Tabel 3.11 Koefisien Fungsi Diskriminan Kanonik 42
Tabel 3.12 Function At Grup Centroids 43
Tabel 3.13 Peluang Utama Untuk Grup 44
Abstrak
Analisis Diskriminan adalah salah satu tehnik statistik yang bisa digunakan pada hubungan dependensi (hubungan antarvariabel dimana sudah dapat dibedakan mana variabel respon dan mana variabel penjelas). Dalam Analisis Diskriminan dibutuhkan asumsi data harus berdistribusi normal multivariate. Penggunaan Analisis Diskriminan dalam penelitian ini bertujuan untuk mengetahui variabel-variabel yang menentukan indeks ranking siswa di SMA Van Duynhoven Saribudolok. Data yang digunakan dalam penelitian ini diperoleh dari SMA Van Duynhoven Saribudolok. Dengan menggunakan Analisis Diskriminan diperoleh hasil penelitian yang menunjukkan bahwa ada 4 (empat) variabel yang berpengaruh terhadap indeks ranking siswa di SMA Van Dunyhohen Saribudolok diantaranya X1 (nilai tugas), X2 (waktu belajar di
sekolah), X3 (waktu belajar di rumah), X4 (nilai rata-rata ujian). Dari keempat faktor
tersebut yang sangat dominan mempengaruhi indeks ranking siswa di SMA Van Duynhoven Saribudolok adalah X4 (nilai rata-rata ujian). Dan model yang dihasilkan
Abstract
Discriminant analysis is one of statistical technique that can be used on the dependency relationship (intervariable relationship which can be distinguished where the response variable and where the explanatory variables). Discriminant analysis of the assumptions required in the data must be multivariate normal distribution. Use of discriminant analysis in this study aims to determine the variables that determine students index ranking at SMA Van Duynhoven Saribudolok. Used data in this study obtained from SMA Van Duynhoven Saribudolok. By using discriminant analysis of the research project shost that there are 4 (four) variables influencing the students index ranking SMA Van Duynhoven Saribudolok including X1 (value of homework),
X2 (at time study in the school), X3 (at time study in the home), X4 ( Value rate of
examination). The four most dominant factors affecting students index ranking at SMA Van Duynhoven Saribudolok is X4 (value rate of examination). And the model
BAB I
PENDAHULUAN
1.1Latar Belakang
Dalam upaya meningkatkan Sumber Daya Manusia (SDM) yang bermutu, bidang pendidikan memegang peranan penting. Dengan pendidikan diharapkan kemampuan mutu pendidikan dan martabat manusia Indonesia dapat ditingkatkan. Upaya meningkatkan SDM dilakukan melalui jalur pendidikan dasar, pendidikan menengah, dan pendidikan tinggi. Perkembangan ilmu pengetahuan dan teknologi menuntut peningkatan mutu pendidikan. Peningkatan mutu pendidikan dapat dilakukan dengan melakukan perbaikan, perubahan dan pembaharuan terhadap faktor-faktor yang mempengaruhi keberhasilan pendidikan. Salah satu parameter yang digunakan untuk mengukur tingkat keberhasilan pendidikan adalah prestasi belajar siswa. Prestasi belajar dipengaruhi oleh dua faktor yaitu faktor intern dan faktor ekstern. Faktor intern yaitu faktor yang berasal dari dalam diri manusia yang terdiri dari: faktor biologis (karena sakit, karena kurang sehat, karena cacat tubuh) dan faktor psikologis (intelegensi, bakat, minat, motivasi, dan faktor kesehatan mental). Faktor ekstern yaitu faktor yang berasal dari luar diri manusia yang terdiri dari lingkungan keluarga, lingkungan sekolah dan lingkungan masyarakat dan media massa. Prestasi belajar adalah hasil suatu penilaian dibidang pengetahuan, keterampilan dan sikap sebagai hasil belajar yang dinyatakan dalam bentuk nilai.
kualitas pembelajaran dan kelulusan siswa dari suatu lembaga pendidikan, sering didasarkan pada hasil belajar siswa yang tertera pada nilai tes hasil belajar. Adapun faktor-faktor yang mempengaruhi indeks ranking siswa diantaranya yaitu lamanya belajar siswa, les tambahan siswa, nilai rata-rata siswa, frekuensi tugas siswa, lingkungan sekolah, pendidikan orang tua, penghasilan orang tua dan lain-lain. Dari faktor-faktor tersebut dapat kita ketahui faktor apa saja yang menjadi faktor utama dalam penentuan indeks ranking siswa dengan menggunakan metode analisis diskriminan.
Analisis diskriminan adalah salah satu teknik statistik yang bisa digunakan pada hubungan dependensi (hubungan antar faktor dimana sudah bisa dibedakan mana variabel tak bebas dan mana variabel bebas ). Lebih spesifik lagi, analisis diskriminan digunakan pada kasus dimana variabel tak bebas berupa data kualitatif dan variabel bebas berupa data kuantitatif. Fungsi diskriminan ini dibentuk dengan memaksimumkan jarak antar kelompok, sehingga memiliki kemampuan untuk membedakan antar kelompok. Dalam penelitian ini menggunakan analisis diskriminan karena tujuan dalam penelitian ini adalah untuk melihat perbedaan antar kelompok beserta faktor-faktor apa saja yang paling membedakan antar kelompok tersebut. Analisis diskriminan dapat digunakan untuk menganalisis faktor-faktor yang menentukan tingkat indeks ranking siswa berdasarkan perilaku belajar siswa karena analisis diskriminan dapat memisahkan faktor-faktor yang menentukan tingkat indeks ranking siswa. Berdasarkan penjelasan tersebut penulis memilih judul “ Analisis Diskriminan faktor yang mempengaruhi indeks ranking siswa berdasarkan perilaku belajar siswa.”
1.2Perumusan Masalah
1.3Pembatasan Masalah
Agar penelitian ini tepat sasaran, penulisan menetapkan pembatasan permasalahan :
1. Penelitian ini menggunakan analisis diskriminan untuk mengetahui faktor-faktor yang mempengaruhi indeks ranking siswa di SMA Van Duynhoven Saribudolok. Penelitian ini dilakukan di kelas III SMA Van Duynhoven Saribudolok tahun ajaran 2011/2012.
2. Data yang digunakan adalah nilai rata – rata siswa semester I sampai dengan semester V SMA Van Duynhoven Saribudolok dan hasil kuesioner dari responden yakni siswa – siswi SMA Van Duynhoven Saribudolok.
1.4Tinjauan Pustaka
Analisis diskriminan adalah teknik multivariat termasuk pada Dependence Method, dengan ciri adanya variabel tak bebas dan bebas. Dengan demikian, ada variabel yang hasilnya tergantung pada data variabel bebas. Ciri khusus analisis diskriminan adalah data variabel tak bebas harus berupa data kategori, sedangkan data untuk variabel bebas justru berupa data rasio. Dengan demikian, kegunaan utama dari analisis diskriminan ada dua yaitu, pertama adalah kemampuan memprediksi terjadinya variabel tak bebas dengan masukan data variabel bebas. Kedua adalah kemampuan memilih mana variabel bebas yang secara nyata mempengaruhi variabel tak bebas dan mana yang tidak, (S. Santoso, 2010).
Analisis diskriminan mirip dengan regresi linear berganda (multivariabel regression). Perbedaannya, analisis diskriminan dipakai jika faktor tak bebasnya
Analisis diskriminan merupakan salah satu teknik menganalisis dalam analisis multivariat. Analisis diskriminan merupakan teknik menganalisis data, kalau variabel tak bebas (disebut criterion ) merupakan kategori (non-metrik, nominal atau ordinal, bersifat kualitatif) sedangkan variabel bebas merupakan rasio, bersifat metrik (interval atau rasio, bersifat kuantitatif). Teknik analisis diskriminan dua kelompok atau kategori, kalau variabel tak bebas Y dikelompokkan menjadi dua, diperlukan satu fungsi diskriminan. Jika variabel tak bebas dikelompokkan menjadi lebih dua kelompok disebut analisis diskriminan berganda, diperlukan fungsi diskriminan sebanyak (k-1), kalau memang ada k kategori.
Model analisis diskriminan berkenaan dengan kombinasi linear yang bentuknya sebagai berikut:
= + + + + …+ + …+
Dengan:
Di = nilai (skor) diskriminan dari responden (objek) ke-i.
i = 1, 2, …, n. D merupakan variabel tak bebas. Xij = variabel (atribut) ke-j dari responden ke-i
bj = koefisien atau timbangan diskriminan dari variabel atau atribut ke j.
bk = koefisien atau timbangan diskriminan dari variabel atau atribut ke k
Xi = variabel bebas atau prediktor ke j dari responden ke i, juga disebut atribut,
seperti disebutkan diatas.
Xik = variabel (atribut) ke-k dari responden ke-i.
Koefisien atau timbangan (weigh) fungsi diskriminan bj perkirakan sedemikian
kelompok A, B dan C, nilai fungsi diskriminan kelompok A sangat berbeda dengan kelompok B dan sangat berbeda dengan kelompok C. Ini terjadi kalau rasio sum of squares antar kelompok dengan sum of squares dalam kelompok untuk nilai/skor fungsi diskriminan maksimum atau rasio varian antar kelompok dengan varian dalam kelompok sebesar mungkin. Objek dalam kelompok homogen atau relative homogen, sedangkan antar kelompok sangat heterogen. Setiap kombinasi linear prediktor lainnya akan memberikan nilai rasio yang lebih kecil, ( Supranto, 2004).
1.5Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah untuk mencari diskriminan (perbedaan) atau indeks ranking siswa antara siswa yang satu dengan yang lain berdasarkan perilaku belajar siswa selama belajar di sekolah.
1.6Kontribusi Penelitian
1.7Metodologi Penelitian
Penelitian ini dilakukan dengan beberapa langkah yaitu: 1. Pengumpulan Data
Data yang digunakan dalam penelitian ini adalah data primer dan data sekunder. Data primer bersumber dari hasil wawancara terhadap responden dengan menggunakan angket (kuesioner) yang diberikan kepada responden. Sedangkan data sekunder diperoleh dari hasil penilaian belajar siswa-siswi kelas III SMA Van Duynhoven Saribudolok. Populasi dalam penelitian ini adalah seluruh siswa-siswi kelas III SMA Van Duynhoven Saribudolok. Dan populasi telah diketahui homogen dan diasumsikan bahwa populasi berdistribusi normal.
2. Pengolahan Data
Metode analisis data yang digunakan adalah teknik analisis diskriminan dengan bantuan SPSS dengan tahapan sebagai berikut:
1. Memisahkan faktor ke dalam faktor dependen dan independen.
2. Analysis Case Processing Summary, tabel yang menyatakan bahwa responden (jumlah kasus atau baris SPSS) semuanya valid (sah) untuk diproses, dapat mengetahui data yang hilang (missing).
3. Group Statistics, tabel yang menunjukkan jumlah responden yang mempunyai pengaruh terhadap indeks ranking siswa.
4. Test of Equality Group Means, tabel yang menunjukkan apakah terdapat perbedaan yang signifikan untuk dua grup diskriminan berdasarkan Uji F. 5. Variable Entered/Removed, tabel yang menyajikan tujuh faktor yang dapat
dimasukkan (entered) dalam persamaan diskriminan.
6. Variable in The Analysis, tabel yang berisi rangkaian proses tahap sebelumnya, mengenai pemilihan faktor satu persatu yang dimasukkan ke dalam model.
8. Eigenvalues, interpretasi dari pengelompokan faktor ke dalam satu atau lebih faktor yang dianalisis.
9. Wilk’s Lambda, mengindikasi perbedaan yang signifikan (nyata) antara kelima grup dalam k model diskriminan berdasarkan angka Chi-Square. 10.Standardized Canonical Discriminant Function Coefficient, menentukan
faktor mana yang akan masuk ke faktor mana, dasar pemasukan faktor dilihat pada besar korelasi kanonikal, dengan korelasi terbesar masuk ke faktor yang bersangkutan.
11.Structure Matrix, menunjukkan faktor yang paling membedakan perilaku terhadap indeks ranking siswa.
12.Functions Of Group Centroid, tabel ini mengelompokkan ke lima grup ke dalam fungsi 1 dan fungsi 2.
13.Casewise Statistics, tabel yang berisi rincian tiap kasus, penempatannya dalam model diskriminan serta perbandingan apakah penempatan (predicted) telah sesuai dengan kenyataan.
14.Classification Result, menunjukkan angka ketepatan prediksi dari model diskriminan. Pada umumnya ketepatan diatas 50 % di anggap memadai atau valid.
BAB II
LANDASAN TEORI
2.1 Variabel
Variabel adalah konsep yang mempunyai bermacam-macam nilai. Dengan demikian, variabel adalah merupakan objek yang berbentuk apa saja yang ditentukan oleh peneliti dengan tujuan untuk memperoleh informasi agar bisa ditarik suatu kesimpulan. Secara teori, definisi variabel penelitian adalah merupakan suatu objek, atau sifat, atau atribut atau nilai dari orang, atau kegiatan yang mempunyai bermacam-macam variasi antara satu dengan lainnya yang ditetapkan oleh peneliti dengan tujuan untuk dipelajari dan ditarik kesimpulan, (http://id.shvoong.com/writing-and-speaking/2120715-definisi-variabel/).
Menurut hubungan antara suatu variabel dengan variabel lainnya, variabel terbagi atas beberapa yaitu:
1. Variabel Dependen
Variabel dependen dalam bahasa Indonesia sering disebut sebagai peubah tak bebas, variabel output, kriteria, atau konsekuen. Variabel ini juga sering disebut sebagai variabel terikat. Variabel terikat atau peubah tak bebas ini merupakan variabel yang dipengaruhi atau yang menjadi akibat, karena adanya variabel sebab atau peubah bebas.
2. Variabel Independen
Variabel independen atau variabel bebas, atau peubah bebas sering juga disebut dengan variabel stimulus atau predictor, atau variabel antecedent. Jika diterjemahkan dalam bahasa Indonesia, variabel independen disebut juga sebagai peubah bebas. Peubah bebas ini adalah merupakan peubah yang mempengaruhi atau yang menjadi sebab terjadinya perubahan terhadap peubah tak bebas. Atau yang menyebabkan terjadinya variasi bagi peubah tak bebas (variabel dependen).
2.2 Data
Data adalah sesuatu yang belum mempunyai arti bagi penerimanya dan masih memerlukan adanya suatu pengolahan. Data bisa berwujud suatu keadaan, gambar, suara, huruf, angka, matematika, bahasa ataupun simbol-simbol lainnya yang bisa kita gunakan sebagai bahan untuk melihat lingkungan, obyek, kejadian ataupun suatu konsep. Jenis data berdasarkan cara memperolehnya dapat dibagi atas dua bagian, yaitu:
1. Data Primer
2. Data Sekunder
Data sekunder adalah data yang di dapat secara tidak langsung dari objek penelitian. Peneliti mendapatkan data yang sudah jadi yang dikumpulkan oleh pihak lain dengan berbagai cara atau metode baik secara komersial maupun non komersial.
2.3 Belajar
2.3.1 Pengertian Belajar
Belajar adalah key term, ‘istilah kunci’ yang vital dalam setiap usaha pendidikan, sehingga tanpa belajar yang sesungguhnya tak pernah ada pendidikan. Sebagai suatu proses, belajar selalu mendapat tempat yang luas dalam berbagai disiplin ilmu yang berkaitan dengan upaya pendidikan, misalnya psikologi pendidikan dan psikologi belajar. Karena demikian pentingnya arti belajar, maka bagian terbesar upaya riset dan eksperimen psikologi belajar pun diarahkan pada tercapainya pemahaman yang lebih luas dan mendalam mengenai proses perubahan manusia itu, (Muhibbin Syah, hal 59).
Pendapat tentang pengertian belajar ada bermacam-macam. Pendapat tersebut lahir berdasarkan sudut pandang yang berbeda-beda. Menurut Slameto (2003:2) belajar adalah suatu proses usaha yang dilakukan seseorang untuk memperoleh sesuatu perubahan tingkah laku yang baru secara keseluruhan sebagai hasil pengalamannya sendiri dalam interaksi dengan lingkungannya.
didapatkan itu bukan perubahan fisik, tetapi perubahan jiwa dengan sebab masuknya kesan-kesan yang baru. Perubahan sebagai hasil dari proses belajar adalah perubahan yang mempengaruhi tingkah laku seseorang.
Belajar adalah kegiatan yang berproses dan merupakan unsur yang sangat fundamental dalam penyelenggaraan setiap jenis dan jenjang pendidikan. Ini berarti bahwa berhasil atau gagalnya pencapaian tujuan pendidikan itu amat bergantung pada proses belajar yang dialami siswa baik ketika ia berada di sekolah maupun di lingkungan rumah atau keluarganya, (Muhibbin Syah, hal 63).
2.3.2 Prinsip – Prinsip Belajar
Proses belajar adalah suatu hal yang kompleks, tetapi dapat juga dianalisa dan diperinci dalam bentuk prinsip-prinsip atau asas-asas belajar. Hal ini perlu kita ketahui agar kita memiliki pedoman dan teknik belajar yang baik. Prinsip-prinsip itu adalah:
1. Belajar harus bertujuan dan terarah. Tujuannya akan menuntutnya dalam belajar untuk mencapai harapan-harapan.
2. Belajar memerlukan bimbingan, baik dari guru maupun buku pelajaran itu sendiri.
3. Belajar memerlukan pemahaman atas hal-hal yang dipelajari sehingga diperoleh pengertian-pengertian.
4. Belajar memerlukan latihan dan ulangan agar apa-apa yang telah dipelajari dapat dikuasainya.
5. Belajar adalah suatu proses aktif dimana terjadi saling pengaruh secara dinamis antara murid dengan lingkungannya.
7. Belajar dikatakan berhasil apabila telah sanggup menerapkan ke dalam bidang praktek sehari-hari.
(Zainal Aqib 2002, hal 44-45)
2.3.3 Faktor – Faktor Yang Mempengaruhi Belajar
Menurut Slameto (2003:54) faktor-faktor yang mempengaruhi belajar siswa dapat digolongkan kedalam dua golongan yaitu faktor intern yang bersumber pada diri siswa dan faktor ekstern yang bersumber dari luar diri siswa. Faktor intern terdiri dari motivasi, perhatian, senang terhadap suatu materi, kemampuan dalam mengolah materi yang diberikan. Sedangkan faktor esktern terdiri dari lingkungan keluarga, lingkungan rumah dan lingkungan sekolah.
Faktor-faktor yang mempengaruhi belajar siswa terhadap pelajaran sehingga siswa dapat meningkatkan mutu belajarnya adalah:
1. Metode pelajaran yang memuaskan dan menyenangkan
Metode pembelajaran yang memuaskan dan menyenangkan mengandung arti bahwa metode yang dibawakan oleh guru dapat menyenangkan siswa dan dapat menarik perhatian siswa sehingga siswa dapat menangkap pelajaran yang diberikan oleh guru dengan mudah. Metode yang baik dan menyenangkan merupakan faktor yang cukup penting bagi pelajaran siswa. Diharapkan siswa dapat belajar lebih giat dan tidak mudah bosan.
2. Keprihatinan dan motivasi dari orang-orang sekitar yang baik
senang dan giat belajar sehingga itu akan berdampak dan berpengaruh terhadap siswa lain.
3. Fasilitas sekolah yang nyaman
Fasilitas sekolah yang nyaman mengandung arti bahwa sekolah tersebut hendaknya mempunyai peralatan termasuk alat peraga semua bidang studi dan tentunya juga memiliki ventilasi udara yang baik, kondisi kelas yang nyaman dan jauh dari keributan.
4. Keadaan ekonomi yang cukup
Keadaan ekonomi yang cukup mengandung arti bahwa suatu keluarga sudah bisa mencukupi kebutuhan pokok, sekunder dan biaya sekolah siswa.
5. Hubungan keluarga yang harmonis
Hubungan keluarga yang harmonis mengandung arti bahwa hubungan antara tiap personel dalam keluarga tersebut tidak sedang mengalami persengketaan, dendam antara satu dengan yang lainnya.
6. Kesehatan jasmani
Siswa hendaknya memenuhi sarapan pagi sebelum berangkat sekolah. Karena dengan demikian berpengaruh terhadap daya tahan tubuh saat siswa nanti belajar di sekolah.
7. Kemampuan siswa yang baik
2.4 Analisis Diskriminan
Analisis Diskriminan merupakan suatu analisis multivariat yang digunakan untuk mengelompokkan suatu individu atau objek ke dalam suatu kelompok yang telah di tentukan sebelumnya berdasarkan variabel-variabel tertentu. Analisis diskriminan dapat digunakan jika variabel dependen terdiri dari dua kelompok atau lebih kelompok. Pengelompokan pada analisis bersifat apriori, artinya seorang peneliti, sudah mengetahui sebelumnya individu atau objek mana saja yang masuk ke dalam kelompok 1, 2 dan 3.
Analisis diskriminan adalah salah satu teknik analisa statistika dependensi yang memiliki kegunaan untuk mengklasifikasikan objek beberapa kelompok. Pengelompokan dengan analisis diskriminan ini terjadi karena ada pengaruh satu atau lebih variabel lain yang merupakan variabel independen. Kombinasi linier dari variabel-variabel ini akan membentuk suatu fungsi diskriminan, (Tatham et. Al., 1998).
Analisis diskriminan adalah teknik multivariat yang termasuk dependence method, yakni adanya variabel dependen dan variabel independen. Dengan demikian
Sama seperti regresi berganda, dalam analisis diskriminan variabel dependen hanya satu, sedangkan variabel independennya banyak (multiple). Analisis diskriminan merupakan teknik yang akurat untuk memprediksi seseorang termasuk dalam kategori apa, dengan catatan data-data yang dilibatkan terjamin akurasinya.
2.4.1 Tujuan Analisis Diskriminan
Adapun tujuan analisis diskriminan secara umum adalah:
1. Ingin mengetahui apakah ada perbedaan yang jelas antar grup pada variabel dependen.
2. Jika ada perbedaan, variabel independen manakah pada fungsi diskriminan yang membuat perbedaan tersebut.
3. Membuat fungsi atau model diskriminan, yang pada dasarnya mirip dengan persamaan regresi.
4. Melakukan klasifikasi terhadap objek ( dalam terminology SPSS disebut baris), apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya) termasuk pada grup 2, atau lainnya.
2.4.2 Proses Dasar Analisis Diskriminan
Adapun proses dasar dari analisis diskriminan adalah:
1. Memisah variabel-variabel menjadi variabel dependen dan variabel independen
a. Simultaneous Estimation, dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses analisis diskriminan.
b. Step-Wise Estimation, dimana variabel dimasukkan satu persatu kedalam model diskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model, dan ada kemungkinan satu atau lebih variabel independen yang ‘dibuang’ dari model.
3. Menguji signifikansi dari fungsi diskriminan yang telah terbentuk menggunakan Wilk’s Lambda, Pillai, F test lainnya.
4. Menguji ketepatan klasifikasi dari fungsi diskriminan, termasuk mengetahui ketepatan klasifikasi secara individual dengan Casewise Diagnostics.
5. Melakukan interpretasi terhadap fungsi diskriminan tersebut. 6. Melakukan uji validitas fungsi diskriminan.
2.4.3 Asumsi Dalam Analisis Diskriminan
Adapun berikut ini asumsi yang harus dipenuhi agar model diskriminan dapat digunakan:
1. Multivariat Normality, atau variabel independen seharusnya berdistribusi
bersama-sama (multivariat) variabel-variabel tersebut juga bisa dianggap memenuhi asumsi normalitas. Adapun kriteria pengujiannya adalah:
a. Angka signifikansi (Sig) > 0,05, maka data tersebut berdistribusi normal.
b. Angka signifikansi (Sig) < 0,05, maka data tidak berdistribusi normal.
2. Matriks kovarians dari semua variabel independen seharusnya sama.
3. Tidak ada korelasi antara dua variabel independen.
4. Tidak adanya data yang sangat ekstrim pada variabel independen.
Jika sebuah variabel mempunyai sebaran data yang tidak normal, maka perlakuan yang di mungkinkan agar menjadi normal, (Santoso, 2010):
1. Menambah jumlah data. Seperti pada kasus, bisa dicari 20 atau 30 atau sejumlah data baru untuk menambah ke 75 data berat badan konsumen yang sudah ada. Kemudian dengan jumlah data yang baru, dilakukan pengujian sekali lagi.
2. Menghilangkan data yang di anggap penyebab tidak normalnya data. Seperti pada variabel berat, jika dua data yang ekstrim dibuang, yakni berat 100 dan 120, kemudian diulang proses pengujian, mungkin data bisa menjadi normal, ulangi pengurangan data yang dianggap penyebab ketidaknormalan data. Namun demikian, pengurangan data harus dipertimbangkan, apakah tidak mengaburkan tujuan penelitian karena hilangnya data-data yang seharusnya ada.
4. Data diterima apa adanya, memang dianggap tidak normal dan tidak perlu dilakukan berbagai treatment. Untuk itu, alat analisis yang dipilih harus diperhatikan, seperti untuk multivariat mungkin faktor analisis tidak begitu mementingkan asumsi kenormalan. Atau pada kasus statistik univariat, bisa dilakukan alat analisis nonparametrik, (Santoso, 2010).
2.4.4 Model Analisis Diskriminan
Model dasar analisis diskriminan mirip regresi berganda. Perbedaannya adalah kalau variabel dependen regresi berganda dilambangkan dengan Y, maka dalam analisis diskriminan dilambangkan dengan D. Model analisis diskriminan adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai variabel independen, yaitu :
= + + + + …+ + …+
Dengan:
Di = nilai (skor) diskriminan dari responden (objek) ke-i.
i = 1, 2, …, n. D merupakan variabel tak bebas. Xij = variabel (atribut) ke-j dari responden ke-i
bj = koefisien atau timbangan diskriminan dari variabel atau atribut ke j.
bk = koefisien atau timbangan diskriminan dari variabel atau atribut ke k
Xi = variabel bebas atau prediktor ke j dari responden ke i, juga disebut atribut,
seperti disebutkan diatas.
Yang diestimasi adalah koefisien ‘b’, sehingga nilai ‘D’ setiap grup sedapat mungkin berbeda. Ini terjadi pada saat rasio jumlah kuadrat antargrup (between group sum of squares) terhadap jumlah kuadrat dalam grup (within grup sum of square) untuk skor
diskriminan mencapai maksimum. Berdasarkan nilai D itulah keanggotaan seseorang diprediksi.
2.4.5 Fungsi Diskriminan
Fungsi Diskriminan merupakan fungsi atau kombinasi linear peubah-peubah asal yang akan menghasilkan cara terbaik dalam pemisahan kelompok-kelompok. Fungsi ini akan memberikan nilai-nilai yang sedekat mungkin dalam kelompok dan sejauh mungkin antar kelompok (Dillon dalam Solikhan, 2003).
Dengan kata lain Analisis Diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Suatu fungsi diskriminan layak untuk dibentuk bila terdapat perbedaan nilai rataan di antara kelompok-kolompok yang ada. Oleh karena itu sebelum fungsi diskriminan perlu dilakukan pengujian terhadap perbedaan vektor nilai rataan dari kelompok-kelompok tersebut.
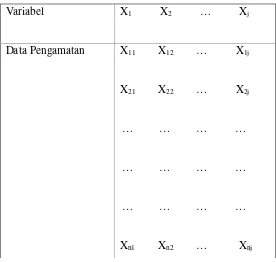
Pada data pengamatan ke-i yang berukuran n (i = 1, 2, 3, …, n) yang terdiri atas j buah variabel yaitu X1, X2, X3, …, Xj. Data pengamatan tersebut dapat disajikan
Tabel 2.1 Matriks Pengamatan
Variabel X1 X2 … Xj
Data Pengamatan X11 X12 … X1j
X21 X22 … X2j
… … … …
… … … …
… … … …
Xn1 Xn2 … Xnj
Untuk Variabel Xj yang dihitung adalah variansnya, diberi lambang Sij, dengan rumus:
= ∑ – ∑
( )
Semuanya ada j buah varians, yaitu S11, S22, …, Sij yang masing-masing merupakan varians untuk variabel X1, X2, …, Xj. Untuk variabel X1 dan X2 dimana i ≠ j terdapat
kovarians, diberi lambang Sij yang dapat dihitung dengan rumus berikut:
= ∑ – (∑ ) ∑
( )
= ⎝ ⎜ ⎜ ⎛ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋮⋯ ⋮ ⋯ ⋯ ⋯ ⋮ ⋯ ⎠ ⎟ ⎟ ⎞
Misalkan ada dua grup yang memiliki variabel masing-masing j buah yaitu X111, X121,
…, X1jk dalam grup I dan X211, X222, …, X2jk dalam grup II. Perhatikan bahwa Xijk
menyatakan grup ke-I, dengan i = grup I dan grup II, variabel ke-j dan kelompok ke-k. Variabel dalam setiap grup dapat pula dituliskan dalam bentuk vektor kolom sebagai berikut: = ⎝ ⎜ ⎜ ⎛ ⋯⋯ ⋯ ⎠ ⎟ ⎟ ⎞ = ⎝ ⎜ ⎜ ⎛ ⋯⋯ ⋯ ⎠ ⎟ ⎟ ⎞
X1jk = menyatakan grup – 1, variabel X ke - j dan kelompok ke - k
X2jk = menyatakan grup – 2, variabel X ke - j dan kelompok ke - k
Dari setiap grup berukuran n1 dari grup ke-1 dan berukuran n2 dari grup ke-2. Data
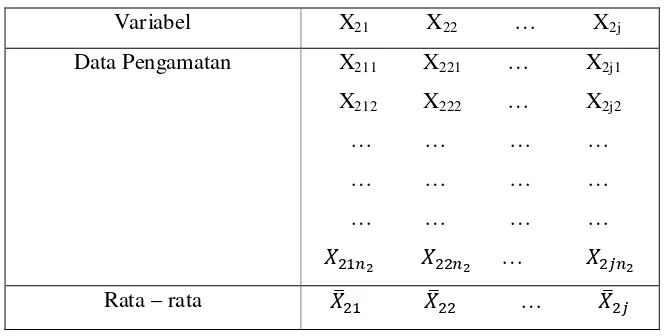
[image:32.612.196.330.79.160.2]pengamatan akan berbentuk matriks yang bentuknya seperti di bawah ini:
Tabel 2.2 Matriks Data Pengamatan dari Grup I
Variabel X11 X12 … X1j
Data Pengamatan X111 X121 … X1j1
X112 X222 … X2j2
… … … … … … … … … … … …
…
Tabel 2.3 Matriks Data Pengamatan dari Grup II
Variabel X21 X22 … X2j
Data Pengamatan X211 X221 … X2j1
X212 X222 … X2j2
… … … … … … … … … … … …
… Rata – rata …
Hasil pengamatan ini menghasilkan rata-rata untuk tiap variabel yang dalam bentuk vektor bisa ditulis:
=
⎝ ⎜ ⎛ ⋯⋯
⋯ ⎠ ⎟ ⎞
dan =
⎝ ⎜ ⎛ ⋯⋯
⋯ ⎠ ⎟ ⎞
Dengan:
= grup ke – 1, variabel X ke-j yang berukuran n1
= grup ke - 2, variabel X ke-j yang berukuran n2
= rata-rata variabel ke-j dalam grup ke-1
= rata-rata variabel ke-j dalam grup ke-2
Dari masing masing rata-rata dari grup I dan rata-rata dari grup II, selanjutnya akan dihitung varians dan kovariansnya tersebut dalam matriks S1 dan S2, masing-masing
= ⎝ ⎜ ⎜ ⎛ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋮⋯ ⋮ ⋯ ⋯ ⋯ ⋮ ⋯ ⎠ ⎟ ⎟ ⎞
dan =
⎝ ⎜ ⎜ ⎛ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋮⋯ ⋮ ⋯ ⋯ ⋯ ⋮ ⋯ ⎠ ⎟ ⎟ ⎞ Dengan:
S1 = matriks varians kovarians dari grup ke-1
S2 = matriks varians kovarians dari grup ke-2
Meskipun dalam S1 dan S2 digunakan Sij yang sama namun jelas besarnya berlainan
antara Sij dalam S1 dan Sij dalam S2, kedua datanya juga berlainan yaitu S1 diambil
dari grup I dan S2 diambil dari grup II. Kedua buah matriks varians-kovarians ini bisa
dihitung matriks varians-kovarians gabungan, diberi lambang S dengan rumus:
S = ( ) ( )
Matriks varians-kovarians gabungan ini mempunyai invers, yaitu .
Dengan adanya vektor rata-rata dan dan juga matriks varians-kovarians gabungan S bersama dengan persyaratan bahwa data variabel independen seharusnya berdistribusi normal multivariat disingkat multinormal dan matriks varian-kovarians kedua relatif sama maka rumus fungsi diskriminan untuk ini adalah:
Y = ( − )
X adalah vektor pengamatan yaitu X =
⎝ ⎜ ⎛⋯⋯ ⋯ ⎠ ⎟ ⎞
Aturan I
Jika Y > ( − ) ( + ) klasifikasi objek dengan data pengamatan X
Dimasukkan ke dalam grup I
Jika Y ≤ ( − ) ( + ) suatu objek diklasifikasi ke dalam grup II
Aturan II
Fungsi ini akan memberikan nilai-nilai yang sedekat mungkin dalam kelompok dan sejauh mungkin antar kelompok (Dillon dalam Solikhan, 2003). Fungsi diskriminan untuk hal ini adalah menggunakan statistik W (Wuld Anderson, 1998):
W = ( − ) − ( − ) ( + )
Dengan:
X : Vektor pengamatan
: vektor rata-rata variabel independen
: invers matriks varians kovarian dalam kelompok gabungan
Yang akan menghasilkan model atau fungsi analisis diskriminan berkenaan dengan kombinasi linear sebagai berikut:
= + + + + …+ + …+ Dengan:
Di = nilai (skor) diskriminan dari responden (objek) ke-i.
i = 1, 2, …, n. D merupakan variabel tak bebas. Xij = variabel (atribut) ke-j dari responden ke-i
bj = koefisien atau timbangan diskriminan dari variabel atau atribut ke j.
bk = koefisien atau timbangan diskriminan dari variabel atau atribut ke k
Xi = variabel bebas atau prediktor ke j dari responden ke i, juga disebut atribut,
seperti disebutkan diatas.
2.4.6 Algoritma dan Model Matematis
Secara ringkas, langkah-langkah dalam analisis diskriminan adalah sebagai berikut:
1. Pengecekan adanya kemungkinan hubungan linier antara variabel penjelas. Maka dilakukan dengan bantuan matriks korelasi (pembentukan matriks korelasi sudah difasilitasi pada analisis diskriminan). Pada output SPSS, matriks korelasi bisa dilihat pada Pooled Within-Groups Matrices.
2. Uji vektor rata-rata kedua kelompok H0 : µ1 = µ2
H1 : µ1≠ µ2
Angka signifikan:
H0 : Jika Sig > 0,05 berarti tidak ada perbedaan antar grup
H1 : Jika Sig < 0,05 berarti ada perbedaan antar grup
Diharapkan dalam uji ini adalah hipotesis nol ditolak, sehingga diperoleh informasi awal bahwa variabel yang sedang diteliti memang membedakan kedua kelompok. Pada SPSS, uji ini dilakukan secara univariate (yang diuji bukan berupa vektor), dengan bantuan tabel Test of Equality of Group Means.
3. Dilanjutkan pemeriksaan asumsi homoskedastisitas dengan uji Box’s M. Diharapkan dalam uji ini hipotesis nol tidak ditolak (H0 : ∑1 = ∑2 = ∑3 = ∑4 = ∑5). Hipotesis:
H0 : Matriks kovarians grup adalah sama
H1 : Matriks kovarians grup adalah berbeda secara nyata
Keputusan dengan dasar signifikansi (lihat angka signifikan) H0 : Jika Sig > 0,05 berarti H0 diterima
Sama tidaknya grup kovarian matriks juga bisa dilihat dari tabel output Log Determinant. Jika dalam pengujian ini H0 ditolak maka proses selanjutnya
seharusnya tidak bisa dilakukan.
4. Pembentukan model diskriminan Kriteria Fungsi Linier Fisher
a. Pembentukan fungsi linier (teoritis)
Fisher mengelompokkan suatu observasi berdasarkan nilai skor yang
dihitung dari suatu fungsi linier Y = λ'X dimana λ menyatakan vektor yang
berisi koefisien-koefisien variabel penjelas yang membentuk persamaan linier terhadap variabel respon,
λ' = [λ1, λ2, …, λp]
X =
Xk menyatakan matriks data pada kelompok ke-k
Xk = … …
… …
⋱
…
⋯
i = 1, 2, …, n
j = 1, 2, …, p
k = 1 dan 2
Xijk menyatakan observasi ke-i variabel ke-j pada kelompok ke-k.
Dibawah asumsi Xk ~ N (µk, ∑k) maka :
µ = = µµ dan ∑k = E (Xk - µk) (Xk - µk)’ ;
µk = µ
. .
∙
µkadalah vektor rata-rata tiap variabel X pada kelompok ke-k. ∑ = ⎣ ⎢ ⎢ ⎢ ⎡ 0 0 0 0 0 0 0 ∙ ∙ ∙ ∙ ∙ 0 0 ∙ ∙ 0 ∙ ∙ ∙ ∙ 0 ∙ ∙ ⎦ ⎥ ⎥ ⎥ ⎤
Σj1j2 =
=
≠
b. Pembentukan Fungsi Linier (dengan bantuan SPSS)
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model dapat dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient bagian Unstandardized diaktifkan.
c. Menghitung Discriminant Score
Setelah dibentuk fungsi liniernya, maka dapat dihitung skor diskriminan untuk tiap observasi dengan memasukkan nilai-nilai variabel penjelasnya.
d. Menghitung Cutting Score
Untuk memprediksi responden mana masuk golongan mana, kita dapat menggunakan Optimum Cutting Score. Memang dari computer informasi ini sudah diperoleh. Sedangkan cara mengerjakan secara manual Cutting score (m) dapat dihitung dengan rumus sebagai berikut dengan ketentuan
untuk dua grup yang mempunyai ukuran yang sama cutting score dinyatakan dengan rumus, (Simamora, 2005).
= Dengan :
Zce = cutting score untuk grup yang sama ukuran
ZA = centroid grup A
Apabila dua grup berbeda ukuran, rumus cutting score yang digunakan adalah:
= Dengan :
ZCU = Cutting score untuk grup tak sama ukuran
NA = Jumlah anggota grup A
NB = Jumlah anggota grup B
ZA = Centroid grup A
ZB = Centroid grup B
Kemudian nilai-nilai discriminant score tiap observasi akan dibandingkan dengan cutting score, sehingga dapat diklasifikasikan suatu observasi akan termasuk ke dalam kelompok yang mana. Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota kelompok kode 1 jika: Y = (µ1 - µ2)’ ∑ -1 x ≥ m, selain itu dimasukkan dalam kelompok 2
[image:39.612.180.504.111.259.2](kode nol) perhitungan m dilakukan secara manual, karena SPSS tidak mengeluarkan output m. Namun, dapat dihitung nilai m dengan bantuan tabel Function at Group Centroids dari output SPSS.
e. Perhitungan Hit Ratio setelah semua observasi diprediksi keanggotaannya, dapat dihitung Hit Ratio, yaitu rasio antara observasi yang tepat pengklasifikasiannya dengan total seluruh observasi. Misalkan ada sebanyak n observasi, akan dibentuk fungsi linier dengan observasi sebanyak n-1. Observasi yang tidak disertakan dalam pembentukan fungsi linier ini akan diprediksi keanggotaannya dengan fungsi yang sudah dibentuk tadi. Proses ini akan diulang dengan kombinasi observasi yang berbeda-beda, sehinggga fungsi linier yang dibentuk ada sebanyak n. Inilah yang disebut dengan metode Leave One Out.
f. Kriteria Posterior probability
berasal dari suatu kelompok. Nilai peluang ini disebut Posterior probability dan bisa ditampilkan pada sheet SPSS dengan mengaktifkan
option probabilities of group membership pada bagian Save di kotak dialog
utama.
( | = ( )
∑ ( )
Dengan :
Pk adalah prior probability kelompok ke-k dan fk(x) =
( ) / |∑| / exp− ( − µ ) ∑ ( − µ ) ; = 0.01
Suatu observasi dengan karakteristik x akan diklasifikasikan sebagai anggota kelompok 0 jika p ( k = 0|x) > p (k = 1|x). Nilai-nilai posterior probability inilah yang mengisi kolom di 1_1 dan kolom di 1_2 pada sheet SPSS.
g. Akurasi statistik, dapat diuji secara statistik apakah klasifikasi yang dilakukan (dengan menggunakan fungsi diskriminan) akurat atau tidak. Uji statistik tersebut adalah press-Q statistik. Ukuran sederhana ini membandingkan jumlah kasus yang diklasifikasi secara tepat dengan ukuran sampel dan jumlah grup. Nilai yang diperoleh dari perhitungan kemudian dibandingkan dengan nilai kritis (critical value) yang diambil dari tabel Chi-Square dan tingkat keyakinan sesuai yang diinginkan. Statistik Q ditulis dengan rumus :
Press-Q = [ ( ) ]
( )
Dengan:
N = ukuran total sampel
2.4.7 Pengujian Hipotesis
Intepretasi hasil analisis diskriminan tidak berguna jika fungsinya tidak signifikan. Hipotesis yang diuji adalah H0 yang menyatakan bahwa rata-rata semua variabel
dalam semua grup adalah sama. Dalam SPSS, uji dilakukan dengan menggunakan
Wilks’λ. Jika dilakukan pengujian sekaligus beberapa fungsi sebagaimana dilakukan
pada analisis diskriminan, stttistik Wilks’λ adalah hasil λ univariat untuk setiap fungsi.
Kemudian, tingkat signifikasi dietimasi berdasarkan chi-square yang telah ditransformasi secara statistik. Setelah analisis diketahui, kemudian dilihat apakah
Wilks’λ berasosiasi dengan fungsi diskriminan. Selanjutnya, angka ini ditransformasi
menjadi chi-square dengan derajat kebebasan (df) yang akan digunakan dalam pengambilan kesimpulan dengan uji kriteria hipotesis berikut:
Jika F hitung > F tabel maka H0 ditolak dan H1 diterima
Jika F hitung ≤ F tabel maka H0 diterima dan H1 ditolak
Selanjutnya dengan menggunakan nilai F, dapat diambil keputusan untuk menerima atau menolak H0. Jika H0 diterima, akan memberikan kesimpulan bahwa
tidak ada perbedaan pada faktor yang mempengaruhi indeks ranking siswa. Sebaliknya jika H0 ditolak maka terdapat perbedaan faktor yang mempengaruhi indeks ranking siswa, dengan nilai signifikan < α, H0 ditolak. Sehingga proses analisis
BAB III
PEMBAHASAN
3.1 Pengumpulan Data
3.1.1 Sumber Data
Dalam penelitian ini data yang digunakan adalah data primer dan data sekunder. Data primer bersumber dari hasil wawancara terstruktur terhadap responden dengan menggunakan kuesioner. Responden dalam penelitian ini adalah siswa siswi kelas III SMA Sw Cr Van Duynhoven Saribudolok. Sedangkan data sekunder berupa laporan hasil belajar mulai dari semester I sampai semester V.
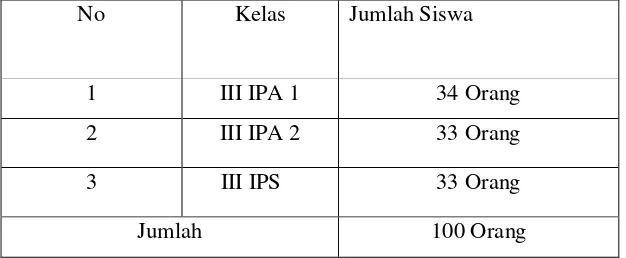
3.1.2 Populasi
Tabel 3.1 Jumlah Siswa Kelas III SMA Van Duynhoven Saribudolok
No Kelas Jumlah Siswa
1 III IPA 1 34 Orang
2 III IPA 2 33 Orang
3 III IPS 33 Orang
Jumlah 100 Orang
3.2 Analisis Data
Analisis diskriminan dimulai dengan hal-hal yang ringan. Pertama, pemilihan variabel dependen dan independen, dimana variabel dependen harus merupakan variabel kategorik sedangkan variabel independen merupakan variabel numerik. Kemudian melakukan analisis univariat untuk mengetahui kenormalan data. Klasifikasi normal ketika ∑1 = ∑2 = ∑ anggap bahwa kepadatan bersama dari = [X1, X2, …, Xp] untuk populasi π1 dan π2 diberikan oleh : f1 (X) =
( ) / |∑| / exp − −µ ∑ −
µ ) untuk i = 1, 2. Anggap juga bahwa parameter-parameter populasi µ1, µ2 dan ∑
diketahui. Hal ini dilihat dari uji Kolmogorov Smirnov. Jika p value Kolmogorov Smirnov > 0,05 maka data berdistribusi normal. Karena mempunyai nilai p Kolmogorov Smirnov < 0,05. Oleh sebab itu dilakukan usaha untuk menormalkan distribusi data dengan proses transformasi data.
Tabel 3.2 Uji Kesamaan Rata-rata
Wilks' Lambda F df1 df2 Sig.
X1 .955 1.107 4 95 .358
X2 .938 1.565 4 95 .190
X3 .987 .314 4 95 .868
[image:44.612.126.337.283.422.2]X4 .896 2.758 4 95 .032
Tabel 3.3 Hasil Output Uji Kesamaan Matriks Covarians
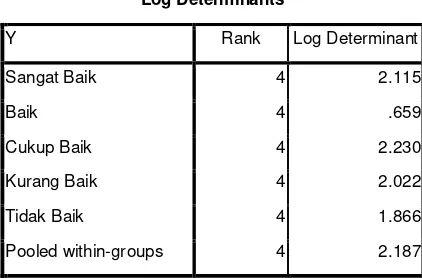
Log Determinants
Y Rank Log Determinant
Sangat Baik 4 2.115
Baik 4 .659
Cukup Baik 4 2.230
Kurang Baik 4 2.022
Tidak Baik 4 1.866
Pooled within-groups 4 2.187
Nilai rank dan logaritma natural determinan di peroleh dari
grup matriks kovarians
Nilai log determinan yang besar menunjukkan semakin tinggi perbedaan antara grup covariance matrices dimana kolom Rank menunjukkan jumlah variabel independen, yaitu 4 buah variabel independen.
Tabel 3.4 Hasil Uji Box’s M
Test Results
Box's M 38.853
F Approx. .881
df1 40
df2 1.991E4
Sig. .683
Pengujian hipotesis nol kesamaan
[image:44.612.125.256.559.675.2]Dan pada bagian ini juga Analisis Diskriminan akan membagi responden menjadi 5 grup, yaitu grup ‘sangat baik’, ‘baik’, ‘cukup baik’, ‘kurang baik’ dan ‘tidak baik’ untuk setiap faktor yang ada. Tabel 3.2 menguji perbedaan antar grup untuk setiap faktor bebas yang ada. Dengan angka Wilks’Lambda yang berkisar 0 sampai 1. Jika angka mendekati 0, maka data tiap grup cenderung berbeda, sedangkan jika angka mendekati 1 data tiap grup cenderung sama. Dari tabel 3.2 terlihat angka Wilk’s Lambda berkisar antara 0,896 sampai 0,987 (mendekati 1). Dari kolom signifikan bisa dilihat bahwa faktor X1, X2 dan X3 yang cenderung tidak berbeda.
Berdasarkan pada angka F test, jika signifikan > 0,05 berarti tidak ada perbedaan antar grup; jika signifikan < 0,05 berarti ada perbedaan antar grup. Faktor indeks ranking X4
angka signifikan adalah 0,032 < 0,05.
Dari hasil Uji kesamaan matriks covarians terlihat bahwa nilai p pada Box’S M > 0,05 yaitu 0,683 > 0,05 yang berarti grup covariance matrices adalah sama. Dengan demikian data tersebut sudah memenuhi asumsi analisis diskriminan. Sama atau tidaknya grup covariance matrices juga bisa dilihat dari tabel output log determinant. Terlihat angka log determinant untuk kategori sangat baik (2,115), baik
(0,659), cukup baik (2,230), kurang baik (2,022), tidak baik (1,866).
Setelah diketahui bahwa data berdistribusi normal dan matriks kovarians dari semua faktor independen sama (equal) dan tidak ada masalah kolinearitas pada faktor independen maka dapat dilakukan analisis diskriminan. Sebelum melakukan analisis diskriminan. Variabel dependen diperoleh dari jumlah rata-rata nilai siswa mulai dari semester I hingga semester V. Hasil rata-rata nilai siswa tersebut akan diurutkan mulai dari urutan terbesar hingga urutan terkecil, yang akan diperoleh ranking siswa tertinggi hingga ranking siswa terendah. Variabel dependen dibagi menjadi 5 grup dari keseluruhan jumlah sampel, yaitu:
Grup I (X1) dengan indeks ranking ‘sangat baik’ yaitu urutan ranking 1 hingga 20.
Grup II (X2) dengan indeks ranking ‘baik’ yaitu urutan ranking 21 hingga 40,
Grup III (X3) dengan indeks ranking ‘cukup baik’ yaitu urutan ranking 41 hingga 60,
dan Grup V (X5) dengan indeks ranking ‘tidak baik’ yaitu urutan ranking 81 hingga
100.
Sedangkan variabel independen pada penelitian ini adalah yaitu: X1 = nilai tugas
X2 = waktu belajar di sekolah
X3 = waktu belajar di rumah
X4 = nilai hasil ujian
Grup I n1 = 20 siswa yang indeks ranking sangat baik, grup II n2 = 20 siswa yang
indeks ranking baik, grup III n3 = 20 siswa yang indeks ranking cukup baik, grup IV
n4 = 20 siswa yang indeks ranking kurang baik, grup V n5 = 20 siswa yang indeks
ranking tidak baik. Kemudian, dianggap memiliki n1 observasi dari faktor acak
multivariate X' = [X1, X2, …, Xp] dari π1 dan n2pengukuran quantitas ini dari π2,
dengan n1 + n2 + n3 + n4 + n5 – 5 ≥ p. Kemudian matriks data respektif sebagai
berikut: ( ) = ⎣ ⎢ ⎢ ⎢ ⎡ ⋮ ⋮ ⎦ ⎥ ⎥ ⎥ ⎤ ( ) = ⎣ ⎢ ⎢ ⎢ ⎡ ⋮ ⋮ ⎦ ⎥ ⎥ ⎥ ⎤
Xij menyatakan nilai siswa yang mempunyai indeks ranking sangat baik, untuk i = 1,
2, 3, 4; dan j = 1, 2, …, 20.
Xij menyatakan nilai siswa yang mempunyai indeks ranking baik, untuk i = 1, 2, 3, 4; dan j = 1, 2, …, 20.
= ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ ⋮ ⋮ ( ) ⋮ ⋮ ( ) ⋮ ⋮ ( ) ⋮ ⋮ ( )⎦ ⎥ ⎥ ⎥ ⎥ ⎤
Sama halnya dengan Xij untuk indeks ranking siswa ‘cukup baik’, ‘kurang baik’,
dan’tidak baik’. Sehingga:
=
⎣ ⎢ ⎢ ⎢
⎡ 1912 56 4,32,3 21
17 4
⋮
17,8 3⋮
2 1
⋮
2,3 4⋮⎦⎥
⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎢
⎡ 1919 34 2,31,3 44
17 4,5 ⋮ 17 ⋮ 4,5 2 1 ⋮
1,7 4⋮⎦⎥
⎥ ⎥ ⎤
( ) = ∑ ( ) = ∑ − ̅ − ̅ ′
Adapun langkah-langkah dalam melakukan analisis diskriminan dengan SPSS adalah:
1. Klik Analyse 2. Pilih Classify 3. Pilih Diskriminan
4. Masukkan faktor dependen ke dalam kotak gruping variabel dan faktor-faktor independen yang memenuhi syarat kedalam kotak ‘independent(s)’
5. Pada define range, isi nilai minimum dan maksimum faktor dependen
6. Pada statistiks pilih Descriptive : Means and Function Coefficients : Fishers’s dan Unstandardized; pada matrices pilih grups correlation dan within-groups covariance.
7. Pada bagian tengah kotak dialog utama, pilih Use Stepwise method, maka secara otomatis icon Method akan aktif.
8. Pada Method pilih Mahalanibis Distance, merupakan metode yang digunakan untuk menganalisis kasus pada analisa diskriminan, dimana metode ini juga dapat mengidentifikasi multivariate outlier. Mahalanibis Distance adalah jarak antara kasus dengan centroid pada setiap kelompok faktor dependen. Setiap kasus mempunyai satu jarak Mahalanibis untuk setiap kelompok dan akan diklasifikasikan ke dalam kelompok dimana jarak tersebut paling kecil.
9. Pada Criteria pilih Use Probability of F, tetapi jangan mengubah isi yang sudah ada. Disini lolos tidaknya sebuah faktor akan di uji dengan uji F, dengan batasan signifikansi 5 % (0,05).
10.Pada bagian tengah kotak dialog utama, klik icon Classify
3.3 Interpretasi Output
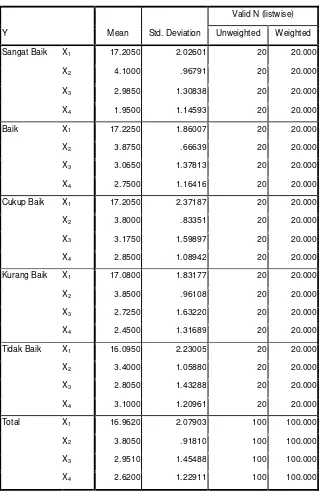
Tabel 3.5 Grup Statistik
Group Statistiks
Y Mean Std. Deviation
Valid N (listwise)
Unweighted Weighted
Sangat Baik X1 17.2050 2.02601 20 20.000
X2 4.1000 .96791 20 20.000
X3 2.9850 1.30838 20 20.000
X4 1.9500 1.14593 20 20.000
Baik X1 17.2250 1.86007 20 20.000
X2 3.8750 .66639 20 20.000
X3 3.0650 1.37813 20 20.000
X4 2.7500 1.16416 20 20.000
Cukup Baik X1 17.2050 2.37187 20 20.000
X2 3.8000 .83351 20 20.000
X3 3.1750 1.59897 20 20.000
X4 2.8500 1.08942 20 20.000
Kurang Baik X1 17.0800 1.83177 20 20.000
X2 3.8500 .96108 20 20.000
X3 2.7250 1.63220 20 20.000
X4 2.4500 1.31689 20 20.000
Tidak Baik X1 16.0950 2.23005 20 20.000
X2 3.4000 1.05880 20 20.000
X3 2.8050 1.43288 20 20.000
X4 3.1000 1.20961 20 20.000
Total X1 16.9620 2.07903 100 100.000
X2 3.8050 .91810 100 100.000
X3 2.9510 1.45488 100 100.000
Tabel Grup statatistik pada dasarnya berisi data statistik (deskriptif) yang utama, yakni rata-rata dan standart deviasi dari kelima grup. Dari tabel 3.6 grup statistik terlihat ada 20 siswa ranking sangat bagus, 20 siswa ranking baik, 20 siswa ranking cukup baik, 20 siswa ranking kurang baik, 20 siswa ranking tidak baik, sedangkan total adalah jumlah seluruh siswa yaitu 100 siswa.
Dapat diketahui penilaian siswa terhadap faktor yang telah ditentukan. Penilaian ini berdasarkan perbandingan mean (rata-rata) tiap variabel untuk semua grup. Semakin besar koefisien, semakin responden mempunyai penilaian yang positif (bagus) terhadap faktor. Pada faktor nilai tugas X1 nilai mean untuk grup sangat baik,
baik, cukup baik lebih tinggi dari nilai mean untuk grup kurang baik dan tidak baik. Hal ini berarti siswa yang belajar tekun disekolah mempunyai kemungkinan besar untuk mencapai indeks ranking yang tinggi.
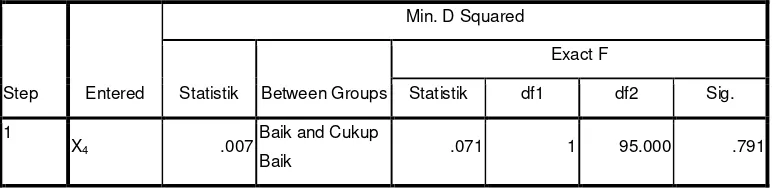
[image:50.612.127.515.567.661.2]Tabel variabel Entered dari analisis 1 (Stepwise Statistik) memperlihatkan faktor mana saja yang masuk ke dalam fungsi diskriminan, dimana nilai p < 0,05 karena menggunakan metode Stepwise Discriminan Analysis, dapat dilihat langkah-langkah pemilihan faktor yang masuk ke dalam fungsi diskriminan seperti pada tabel 3.6 variabel dalam analisis.
Tabel 3.6 Variabels Entered/Removeda,b,c,d
Step Entered
Min. D Squared
Statistik Between Groups
Exact F
Statistik df1 df2 Sig.
1
X4 .007
Baik and Cukup
Baik .071 1 95.000 .791
Pada setiap langkah variabel yang memaksimumkan jarak mahalanobis antara dua grup tertutup dimasukkan.
Tabel 3.6 Variabels Entered/Removeda,b,c,d
Step Entered
Min. D Squared
Statistik Between Groups
Exact F
Statistik df1 df2 Sig.
1
X4 .007
Baik and Cukup
Baik .071 1 95.000 .791
Pada setiap langkah variabel yang memaksimumkan jarak mahalanobis antara dua grup tertutup dimasukkan.
a. Banyaknya langkah maksimum adalah 8.
b. Nilai signifikan maksimum F adalah 0,05.
c. Nilai minimum signifikan F adalah 0,1.
d. Toleransi tingkat F atau VIN tidak cukup untuk perhitungan selanjtnya.
Tabel 3.7 Variabels in the Analysis
Step Tolerance
Sig. of F to
Remove
1 X4 1.000 .032
Pada tahap 1 faktor X4 (nilai ujian) masuk ke dalam fungsi diskriminan karena
faktor ini mempunyai nilai p < 0,05. Kebalikan dari tabel 3.6 dan tabel 3.7 variabel not in the analysis memperlihatkan proses pengeluaran faktor secara bertahap dari
faktor yang nilai p < 0,05 paling kecil, sehingga semua faktor yang mempunyai nilai p < 0.05 dikeluarkan semua. Faktor yang tersisa pada tahap akhir adalah faktor yang tidak masuk dalam fungsi diskriminan karena nilai p < 0,05.
3.3.1 Nilai Eigen
[image:51.612.126.319.385.439.2]Tabel 3.8 Eigenvalues
Function Eigenvalue % of Variance Cumulative % Canonical Correlation
1 .116a 100.0 100.0 .323
a. Fungsi diskriminan kanonik pertama yang digunakan dalam analisis
Korelasi kanonik mengukur keeratan hubungan antara discriminant score dengan grup (dalam hal ini karna ada lima tipe, maka ada 5 grup). Angka 0,323 menunjukkan keeratan yang cukup tinggi dengan ukuran skala asosiasi antara 0 sampai 1.
3.3.2 Uji Signifikansi
Tingkat signifikansi diestimasi berdasarkan Chi-Square yang telah ditransformasi secara statistik. Pada hasil analisis terlihat bahwa Wilks’Lambda berasosiasi sebesar 0,896 dengan fungsi diskriminan. Angka ini kemudian ditransformasi menjadi chi-square dengan derajat kebebasan (df) sebesar 1. Nilai Chi-Square adalah dengan nilai 10,546. Kesimpulannya, cukup bukti untuk menolak H0 dengan tingkat kesalahan 0,032. Biasanya, batas signifikansi pengujian adalah α =
0,05. Jika nilai signifikansi sama atau dibawah 0,05 maka dapat menolak H0.
Tabel 3.9 Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
[image:52.612.146.485.559.599.2]3.3.3 Standardized Canonical Discriminant Function Coefficient
Secara relatif, prediktor yang memiliki Standardized Coefficient yang lebih besar menyumbangkan kekuatan diskriminan (diskriminan power) yang lebih besar terhadap fungsi dibandingkan prediktor yang memiliki Standardized Coefficient lebih kecil.
[image:53.612.129.357.307.435.2]Dapat juga dilihat dalam struktur matriks yang juga disebut canonical loading dan discriminan loading.
Tabel 3.10 Structure Matrix
Function
1
X4 1.000
X3a -.178
X2a -.142
X1a -.065
Tabel struktur matriks menjelaskan korelasi antara faktor independen dengan fungsi diskriminan dengan fungsi diskriminan yang terbentuk. Terlihat faktor X4 yang
paling erat hubungannya dengan fungsi diskriminan, diikuti oleh faktor X3, X2, dan X1
hanya disini faktor X3, X2 dan X1 tidak dimasukkan dalam model diskriminan (karena
3.3.4 Koefisien Fungsi Diskriminan Kanonik
Tabel 3.11 Koefisien Fungsi Diskriminan Kanonik
Function
1
X4 .842
(Constant) -2.206
Unstandardized coefficients
Dengan menggunakan Koefisien Fungsi Diskriminan Kanonik maka dapat dibentuk fungsi diskriminan, yaitu:
D = -2,206 + 0,842 X4
Kegunaan fungsi ini untuk mengetahui sebuah case (dalam kasus ini adalah seorang siswa) masuk pada kelompok yang satu ataukah tergolong pada kelompok lainnya.
3.3.5 Fungsi pada Grup Terpusat
Fungsi pada grup terpusat memperlihatkan nilai rata-rata tiap kelompok. Oleh karena ada 5 tipe siswa, maka disebut Five Group Discriminat, dimana grup yang satu mempunyai centroid (grup means) negative (-0,564 dan -0,143) dan grup yang lainnya centroid positif (0,109, 0,194 dan 0,404).
Tabel 3.12 Functions at Group Centroids
Y
Function
1
Sangat Baik -.564
Baik .109
Cukup Baik .194
Kurang Baik -.143
[image:54.612.128.401.545.680.2]3.3.6 Classication Statistiks
[image:55.612.127.476.213.377.2]Pada tabel 3.14 Peluang utama untuk grup memperlihatkan komposisi responden pada fungsi diskriminan.
Tabel 3.13 Peluang Utama Untuk Grup
Y Prior
Cases Used in Analysis
Unweighted Weighted
Sangat Baik .200 20 20.000
Baik .200 20 20.000
Cukup Baik .200 20 20.000
Kurang Baik .200 20 20.000
Tidak Baik .200 20 20.000
Total 1.000 100 100.000
3.3.7 Menguji ketepatan klasifikasi fungsi diskriminan.
Menguji ketepatan klasifikasi fungsi diskriminan untuk mengetahui ketepatan klasifikasi fungsi diskriminan dilihat dari hasil klasifikasi (Classification Result) dari output terlihat bahwa ketepatan prediksi dari model adalah 31,0 %.
Tabel 3.14 Classification Resultsb,c
Y
Predicted Group Membership
Total Sangat
Baik Baik
Cukup
Baik
Kurang
Baik
Tidak
Baik
Original Count Sangat Baik 16 0 0 0 4 20
Baik 8 0 0 0 12 20
Cukup Baik 7 0 0 0 13 20
Kurang Baik 9 0 0 0 11 20
Tidak Baik 5 0 0 0 15 20
% Sangat Baik 80.0 .0 .0 .0 20.0 100.0
Baik 40.0 .0 .0 .0 60.0 100.0
Cukup Baik 35.0 .0 .0 .0 65.0 100.0
Kurang Baik 45.0 .0 .0 .0 55.0 100.0
Tidak Baik 25.0 .0 .0 .0 75.0 100.0
Cross-validateda Count Sangat Baik 16 0 0 0 4 20
Baik 8 0 0 0 12 20
Cukup Baik 7 0 0 0 13 20
Kurang Baik 9 0 0 0 11 20
Tidak Baik 5 0 0 0 15 20
% Sangat Baik 80.0 .0 .0 .0 20.0 100.0
Baik 40.0 .0 .0 .0 60.0 100.0
Cukup Baik 35.0 .0 .0 .0 65.0 100.0
Kurang Baik 45.0 .0 .0 .0 55.0 100.0
Tisdak Baik 25.0 .0 .0 .0 75.0 100.0
a. Validasi silang dilakukan hanya untuk kasus tersebut dalam analisis. Dalam validasi silang setiap kasus diklasifikasikan
melalui fungsi-fungsi yang diturunkan dari semua kasus lain yang dibandingkan dengan kasus tersebut.
b. 31.0% dari grup yang tepat terklasifikasi dengan baik
BAB IV
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil penelitian di SMA Van Duynhoven Saribudolok, maka diperoleh kesimpulan sebagai berikut:
1. Faktor-faktor yang mempengaruhi indeks ranking siswa di SMA Van Duynhoven Saribudolok adalah nilai tugas sebesar -0,065 artinya hubungan antara nilai tugas dengan indeks ranking secara langsung sangat lemah, waktu belajar di sekolah dan waktu belajar di rumah masingmasing 0,142 dan -0,178 artinya hubungan waktu belajar di sekolah dan waktu belajar di rumah secara langsung sangat lemah. Nilai rata-rata ujian sebesar 1,000, artinya hubungan antara nilai ujian terhadap indeks ranking secara langsung sangat kuat.
2. Ada perbedaan yang signifikan pada kelima grup tersebut. Hal ini dibuktikan pada analisis Wilks’Lambda . Karena terlihat bahwa Wilks’Lambda berasosiasi sebesar 0,896 dengan fungsi diskriminan. Angka ini kemudian ditransformasi menjadi chi-square adalah dengan nilai 10,546. Berarti cukup bukti untuk menolak H0 dengan tingkat kesalahan 0,323. Dimana: 10,546 >
0,05 H0 ditolak dan H1 diterima.
4.2Saran
1. Pihak sekolah diharapkan untuk memperhatikan nilai-nilai hasil belajar siswa terutama nilai pada saat ujian dan meningkatkan peran sertanya dengan memberikan metode dan pendekatan belajar yang tepat sehingga dapat mencapai indeks ranking yang tinggi.
DAFTAR PUSTAKA
Aqib, Zainal. 2000. Guru dan Profesionalisme. Jakarta: Pustaka Belajar
Djamarah, Syaiful, Bahri. 2002. Psikologi Belajar: PT Rinelka Cipta
PKSDM-DIKTI Pediknas Jur. Statistika Fak MM dan IPA Institut Pertanian Bogor Bogor
Riduwan. 2004. Statistika untuk Lembaga dan Instansi Pemerintah / Swasta. Bandung: Alfabeta Bandung
Santoso, Singgih 2010. Statistik Multivariat Konsep dan Aplikasi dengan SPSS. Jakarta: PT Elex Media Komputindo
Howard Anton 1987. Aljabar Linier Elemnter. Ediisi Kelima. Jakarta: Pernerbit Erlangga
Simamora, B. 2005. Analisis Multivariat Pemasaran. Jakarta: PT Gramedia Pustaka Utama
Slameto. 2003. Belajar dan Faktor-Faktor yang mempengaruhiI. Jakarta: PT Rineka Cipta
Sudjana. 2002. Metoda Statistika. Bandung: Penerbit Transito
Supranto, J. 2004. Analisis Multivariat Arti dan Interpretasi. Jilid 3. Bandung: Rineka Cipta
Syah, Muhibbin. 1999. Psikologi Belajar: PT Rajagrafindo Persada
masbied.files.wordpress.com/2011/05/modul-matematika-analisis-diskriminan.pdf
file.upi.edu/direktori/FPIPS/lainnya/MEITRI_hening/modul/modul_diskrimina n.pdf
http:id.shvoong.com/writing-and-speaking/2120715-defenisi-variabel/