APLIKASI ANALISIS DISKRIMINAN DALAM PENENTUAN
FAKTOR-FAKTOR YANG MEMPENGARUHI KELULUSAN
SISWA SMPN 1 GUNUNG MERIAH KABUPATEN
ACEH SINGKIL
SKRIPSI
ASTRIA PUJI ASTUTI
060803053
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
2010
APLIKASI ANALISIS DISKRIMINAN DALAM PENENTUAN
FAKTOR-FAKTOR YANG MEMPENGARUHI KELULUSAN
SISWA SMPN 1 GUNUNG MERIAH KABUPATEN
ACEH SINGKIL
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
ASTRIA PUJI ASTUTI
060803053
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
2010
PERSETUJUAN
Judul : APLIKASI ANALISIS DISKRIMINAN DALAM
PENENTUAN FAKTOR-FAKTOR YANG
MEMPENGARUHI KELULUSAN SISWA SMPN 1 GUNUNG MERIAH KABUPATEN ACEH
SINGKIL
Kategori : SKRIPSI
Nama : ASTRIA PUJI ASTUTI
Nomor Induk Mahasiswa : 060803053
Program Studi : SARJANA (SI) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, November 2010
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Suwarno Ariswoyo, M.Si. Dr. Sutarman, M.Sc
NIP. 195003211980031001 NIP. 196310261991031001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU
Ketua,
Dr. Saib Suwilo, M.Sc.
NIP: 194601091988031004
PERNYATAAN
APLIKASI ANALISIS DISKRIMINAN DALAM PENENTUAN
FAKTOR-FAKTOR YANG MEMPENGARUHI KELULUSAN
SISWA SMPN 1 GUNUNG MERIAH KABUPATEN
ACEH SINGKIL
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Desember2010
Astria Puji Astuti
060803053
Puji dan syukur penulis panjatkan ke hadirat Allah SWT Yang Maha Esa dan Kuasa atas limpahan rahmat dan karunia-Nya sehingga skripsi ini dapat diselesaikan.
Skripsi ini merupakan salah satu syarat yang harus dipenuhi dan diselesaikan oleh seluruh mahasiswa Fakultas FMIPA Departemen Matematika. Pada skripsi ini penulis mengambil judul skripsi tentang Aplikasi Analisis Diskriminan dalam Penentuan Faktor-faktor yang Mempengaruhi Kelulusan Siswa SMPN 1 Gunung Meriah Kabupaten Aceh Singkil.
Dalam penyusunan skripsi ini banyak pihak yang membantu, sehingga dengan segala rasa hormat penulis mengucapkan terima kasih kepada:
1.
Bapak Dr. Sutarman, M.Sc. selaku Dekan FMIPA USU.2.
Bapak Dr. Saib Suwilo M.Sc dan Bapak Drs. Henry Rani Sitepu, M.si selaku ketua dan sekretaris Departemen Matematika FMIPA USU.3. Dr. Sutarman, M.Sc. selaku dosen dan pembimbing I yang berkenan dan rela mengorbankan waktu, tenaga dan pikiran guna memberikan petunjuk dan bimbingannya dalam penulisan skripsi ini.
4. Drs. Suwarno Ariswoyo, M.Si. selaku dosen dan pembimbing II yang juga berkenan dan rela mengorbankan waktu, tenaga dan pikiran guna memberikan petunjuk dan bimbingannya dalam penulisan skripsi ini.
5. Bapak Prof . Dr. Herman Mawengkang dan Drs. H. Haluddin Panjaitan selaku komisi penguji atas masukan dan saran yang telah diberikan demi perbaikan skripsi ini.
6.
Ibu Dra. Ester Sorta M. Nababan, M.Sc selaku Penasehat Akademik.7. Teristimewa kepada Ayahanda Asmuddin dan Ibunda tercinta Sutia, yang telah memberikan kasih sayang semangat dan doa yang tiada pernah berhenti buat saya, serta adik-adikku tersayang Dwi Rizky Septriadi dan Tiastri Marshanda Ridha dan juga saudara-saudaraku tercinta yang telah memberikan perhatian dan dorongan serta bantuan kepada penulis sehingga penulis bisa menyelesaikan pendidikan S-1 di Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara. 8. Sahabatku Mahater, Linda, Zuanda, Aghni, Fikoh, Rina, Agung, Afrida wati,
Annisa, Edy, Azwar, Yudha, Iqbal, Daniel, Ali, Novi, yessy, Andri dan masih banyak lagi yang tak tersebutkan namanya yang telah banyak membantu penulis dengan memberikan semangat dan doa dalam menyelesaikan tulisan ini.
9. Buat sahabat hatiku Khairul Hadi,SP yang selalu memberikan semangat dan motivasi kepada penulis dalam menyelesaikan tulisan ini.
10.Buat senior-seniorku kholizha, Rini, Amin, Radi, Toni, Dika, Santri dan masih banyak lagi yang tak tersebutkan namanya yang telah banyak membantu penulis dengan memberikan semangat dan doa dalam menyelesaikan tulisan ini.
11.Buat junior-juniorku Risky, Nelly, Kessy, Memel, Zulham, Dian, Warsini dan masih banyak lagi yang tak tersebutkan namanya yang telah banyak membantu penulis dengan memberikan semangat dan doa dalam menyelesaikan tulisan ini.
Penulis juga menyadari masih banyak kekurangan dalam skripsi ini, baik dalam teori maupun penulisannya. Oleh karena itu, penulis mengharapkan saran dari pembaca demi perbaikan bagi penulis, semoga segala kebaikan dalam bentuk bantuan yang telah diberikan mendapat balasan dari Allah SWT.
Akhirnya penulis berharap agar kiranya tulisan ini bermanfaat bagi para pembaca.
Medan, Desember 2010 Penulis
Astria Puji Astuti
ABSTRAK
Analisis diskriminan adalah salah satu teknik statistik yang bisa digunakan pada hubungan dependensi (hubungan antarvariabel dimana sudah dapat dibedakan mana variabel respon dan mana variabel penjelas ). Dalam Analisis Diskriminan dibutuhkan asumsi data harus berdistribusi normal multivariate. Penggunaan Analisis Diskriminan dalam penelitian ini bertujuan untuk menentukan variabel-variabel yang menentukan kelulusan siswa di SMPN 1 Gunung Meriah. Data yang digunakan dalam penelitian ini diperoleh dari SMPN 1 Gunung Meriah Kabupaten Aceh Singkil. Kemudian pengujian klasifikasinya dengan menggunakan uji Press’s Q. Dengan menggunakan analisis diskriminan diperoleh hasil penelitian yang menunjukkan bahwa ada 4 (empat) variabel yang berpengaruh terhadap kelulusan siswa SMPN 1 Gunung Meriah diantaranya X1 (nilai UNAS SD), X2 (nilai UAS SD), X4 (nilai Tryout) dan X5 (nilai UAS SMP). Dari keempat faktor tersebut yang sangat dominan mempengaruhi kelulusan siswa di SMPN 1 Gunung Meriah adalah X4 (nilai Tryout). Dan model yang dihasilkan dengan menggunakan Analisis Diskriminan mempunyai tingkat accuracy
klasifikasi sebesar 78,6%.
ABSTRACT
Discriminant analysis is one of statistical technique that can be used on the dependency relationship (intervariable relationship which can be distinguished where the response variable and where the explanatory variables). Discriminant analysis of the assumptions required in the data must be multivariate normal distribution. Use of Discriminant Analysis in this study aims to determine the variables that determine students' graduation at SMPN 1 Gunung Meriah. Used data in this study obtained from SMPN 1 Gunung Meriah Aceh Singkil. Then classification test using Press's Q test. By using discriminant analysis of the research project shows that there are 4 (four) variables influencing the students' graduation SMPN 1 Gunung Meriah including X1 (value UNAS SD), X2 (UAS value SD), X4 (the tryout) and X5 (UAS value SMP). The four most dominant factors affecting students' graduation at SMPN 1 Gunung Meriah is X4 (the tryout). And the model generated by using Discriminant Analysis has a classification accuracy rate of 78.6%.
DAFTAR ISI
Halaman
Persetujuan i
Pernyataan ii
Penghargaan iii
Abstrak v
Abstract vi
Daftar Isi vii
Daftar Tabel ix
Daftar Lampiran x
Bab 1 PENDAHULUAN 1
1.1Latar Belakang 1
1.2Perumusan Masalah 3
1.3Pembatasan Masalah 3
1.4Tinjauan Pustaka 3
1.5Tujuan Penelitian 6
1.6Kontribusi Penelitian 6
1.7Metodologi Penelitian 7
Bab 2 LANDASAN TEORI 9
2.1 Variabel 9
2.2 Data 10
2.2.1 Data ditinjau dari Aspek Sifatnya 10
2.2.2 Data ditinjau dari Aspek Waktu 10
2.3 Analisis Korelasi 11
2.3.1 Macam-macam Analisis Korelasi 12
2.4 Analisis Regresi 15
2.5 Regresi Linier Ganda 17
2.6 Analisis Diskriminan 18
2.6.1 Hal-hal Pokok Tentang Analisis Diskriminan 19
2.6.2 Klasifikasi dengan Dua Populasi Multivariat Normal 21
2.6.3 Format Data Dasar dan Program Komputer yang digunakan 25
2.6.4 Algoritma Pokok Analisis dan Model Matematis 25
2.7 Pengujian Hipotesis 31
Bab 3 METODE PENELITIAN 33
3.1 Pengumpulan Data 33
3.1.1 Sumber Data 33
3.1.2 Populasi 33
3.2 Analisis Data 34
3.2.1 Interpretasi Output 46
3.2.2 Akurasi Statistik 52
Bab 4 KESIMPULAN DAN SARAN 55
4.1 Kesimpulan 55
4.2 Saran 56
DAFTAR PUSTAKA 57
LAMPIRAN 59
DAFTAR TABEL
Halaman
Tabel 2.1 Tabel Format Data untuk Analisis Diskriminan 25
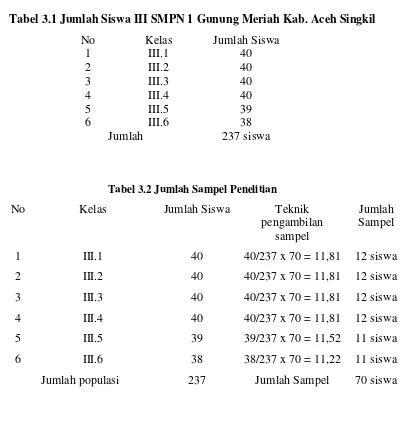
Tabel 3.1 Jumlah kelas III SMPN 1 Gunung Meriah Kab. Aceh Singkil 34
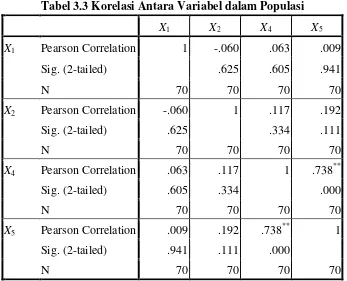
Tabel 3.2 Jumlah Sampel Penelitian 34
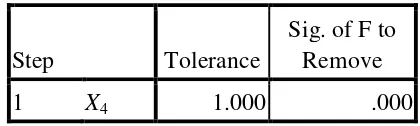
Tabel 3.3 Korelasi antara Variabel dalam Populasi 36
Tabel 3.4 Interpretasi Koefisien Korelasi 36
Tabel 3.5 Uji Kesamaan Rata-rata 39
Tabel 3.6 Hasil Output Uji Kesamaan Matriks Covarians 39
Tabel 3.7 Hasil Uji Box’s M 39
Tabel 3.8 Grup StatistiK 46
Tabel 3.9 Variables Entered/ 47
Tabel 3.10 Variabel dalam Analisis 47
Tabel 3.11 Variabel yang Tidak Masuk dalam Analisis 48
Tabel 3.12 Nilai Eigen 48
Tabel 3.13 Wilk’s Lambda 49
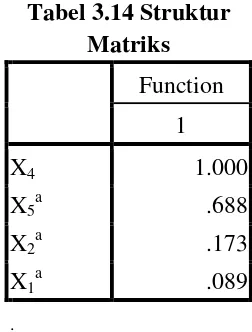
Tabel 3.14 Struktur Matriks 49
Tabel 3.15 Koefisien Fungsi Diskriminan Kanonik 50
Tabel 3.16 Fungsi pada Grup Terpusat 50
Tabel 3.17 Peluang Utama untuk Grup 51
Tabel 3.18 Hasil Klasifikasi 52
DAFTAR LAMPIRAN
Halaman
Lampiran A : Data variabel siswa 59
Lampiran B : Data Nilai UNAS SD 61
Lampiran C : Data Nilai UAS SD 63
Lampiran D : Data Nilai Raport Siswa 65
Lampiran E : Data Nilai Tryout SMP 67
Lampiran F : Data Nilai UAS SMP 69
Lampiran G : Hasil Outpot SPSS 71
Lampiran H : Angket Penelitian 85
Lampiran I : Tabel Distribusi F untuk = 0,05 87
Lampiran J : Tabel Distribusi Student’s (t) 88
ABSTRAK
Analisis diskriminan adalah salah satu teknik statistik yang bisa digunakan pada hubungan dependensi (hubungan antarvariabel dimana sudah dapat dibedakan mana variabel respon dan mana variabel penjelas ). Dalam Analisis Diskriminan dibutuhkan asumsi data harus berdistribusi normal multivariate. Penggunaan Analisis Diskriminan dalam penelitian ini bertujuan untuk menentukan variabel-variabel yang menentukan kelulusan siswa di SMPN 1 Gunung Meriah. Data yang digunakan dalam penelitian ini diperoleh dari SMPN 1 Gunung Meriah Kabupaten Aceh Singkil. Kemudian pengujian klasifikasinya dengan menggunakan uji Press’s Q. Dengan menggunakan analisis diskriminan diperoleh hasil penelitian yang menunjukkan bahwa ada 4 (empat) variabel yang berpengaruh terhadap kelulusan siswa SMPN 1 Gunung Meriah diantaranya X1 (nilai UNAS SD), X2 (nilai UAS SD), X4 (nilai Tryout) dan X5 (nilai UAS SMP). Dari keempat faktor tersebut yang sangat dominan mempengaruhi kelulusan siswa di SMPN 1 Gunung Meriah adalah X4 (nilai Tryout). Dan model yang dihasilkan dengan menggunakan Analisis Diskriminan mempunyai tingkat accuracy
klasifikasi sebesar 78,6%.
ABSTRACT
Discriminant analysis is one of statistical technique that can be used on the dependency relationship (intervariable relationship which can be distinguished where the response variable and where the explanatory variables). Discriminant analysis of the assumptions required in the data must be multivariate normal distribution. Use of Discriminant Analysis in this study aims to determine the variables that determine students' graduation at SMPN 1 Gunung Meriah. Used data in this study obtained from SMPN 1 Gunung Meriah Aceh Singkil. Then classification test using Press's Q test. By using discriminant analysis of the research project shows that there are 4 (four) variables influencing the students' graduation SMPN 1 Gunung Meriah including X1 (value UNAS SD), X2 (UAS value SD), X4 (the tryout) and X5 (UAS value SMP). The four most dominant factors affecting students' graduation at SMPN 1 Gunung Meriah is X4 (the tryout). And the model generated by using Discriminant Analysis has a classification accuracy rate of 78.6%.
Bab 1
PENDAHULUAN
1.1 Latar Belakang
Dalam upaya meningkatkan Sumber Daya Manusia (SDM) yang bermutu, bidang
pendidikan memegang peranan penting. Dengan pendidikan diharapkan kemampuan
mutu pendidikan dan martabat manusia Indonesia dapat ditingkatkan. Upaya
meningkatkan SDM dilakukan melalui jalur pendidikan dasar, pendidikan menengah,
dan pendidikan tinggi. Perkembangan ilmu pengetahuan dan teknologi menuntut
peningkatan mutu pendidikan. Peningkatan mutu pendidikan dapat dilakukan dengan
melakukan perbaikan, perubahan dan pembaharuan terhadap faktor-faktor yang
mempengaruhi keberhasilan pendidikan. Salah satu parameter yang digunakan untuk
mengukur tingkat keberhasilan pendidikan adalah prestasi belajar siswa. Prestasi
belajar dipengaruhi oleh dua faktor yaitu faktor intern dan faktor eksteren. Faktor
intern yaitu faktor yang berasal dari dalam manusia yang terdiri dari: faktor biologis
(karena sakit, karena kurang sehat, karena cacat tubuh) dan faktor psikologis
(intelegensi, bakat, minat, motivasi, dan faktor kesehatan mental). Faktor ekstern yaitu
faktor yang berasal dari luar diri manusia yang terdiri dari lingkungan keluarga,
lingkungan sekolah dan lingkungan masyarakat dan media massa. Prestasi belajar
adalah hasil suatu penilaian dibidang pengetahuan, keterampilan dan sikap sebagai
hasil belajar yang dinyatakan dalam bentuk nilai.
Untuk mengevaluasi prestasi belajar pemerintah melaksanakan ujian nasional,
yang merupakan kegiatan pengukuran dan penilaian kompetensi peserta didik secara
nasional pada jenjang pendidikan. Pendidikan merupakan investasi jangka panjang
yang memerlukan usaha dan dana yang cukup besar. Hal ini diakui oleh semua orang
atau suatu bangsa demi kelangsungan masa depan. Demikian halnya dengan Indonesia
menaruh harapan besar terhadap pendidikan dalam perkembangan masa depan bangsa
dibentuk. Faktor utama untuk menilai kualitas pembelajaran dan kelulusan siswa dari
suatu lembaga pendidikan, sering didasarkan pada hasil belajar siswa yang tertera
pada nilai tes hasil belajar. Adapun faktor-faktor yang mempengaruhi kelulusan siswa
diantaranya yaitu nilai UNAS SD, nilai UAS SD, nilai rapor, nilai tryout, nilai UAS SMP, lingkungan sekolah, pendidikan orang tua, penghasilan orang tua dan lain-lain.
Dari faktor-faktor tersebut dapat kita ketahui faktor apa saja yang menjadi faktor
utama dalam penentuan kelulusan siswa dengan menggunakan metode analisis
diskriminan.
Analisis diskriminan adalah salah satu teknik statistik yang bisa digunakan
pada hubungan dependensi (hubungan antar faktor dimana sudah bisa dibedakan mana
faktor respon dan mana faktor penjelas). Lebih spesifik lagi, analisis diskriminan
digunakan pada kasus dimana faktor respon berupa data kualitatif dan faktor penjelas
berupa data kuantitatif. Analisis diskriminan bertujuan untuk mengklasifikasikan
suatu individu atau observasi ke dalam kelompok yang saling bebas (mutually exclusive/disjoint) dan menyeluruh (exhaustive) berdasarkan sejumlah faktor penjelas. Fungsi diskriminan ini dibentuk dengan memaksimumkan jarak antar kelompok,
sehingga memiliki kemampuan untuk membedakan antar kelompok. Selain analisis
diskriminan, analisis regresi logistik juga dapat digunakan untuk mengklasifikasikan
suatu individu atau observasi kedalam kelompok yang saling bebas dan menyeluruh
berdasarkan sejumlah faktor penjelas. Dalam penelitian ini menggunakan analisis
diskriminan karena tujuan dalam penelitian ini adalah untuk melihat perbedaan antar
kelompok beserta faktor-faktor apa saja yang paling membedakan antar kelompok
tersebut, meskipun analisis regresi logistik juga dapat digunakan dalam hal ini, tetapi
analisis diskriminan lebih sesuai untuk digunakan. Sedangkan jika tujuan analisis
lebih bertujuan untuk melihat probabilitas suatu subjek diklasifikasikan ke kelompok
tertentu sebaiknya menggunakan analisis regresi logistik. Analisis diskriminan dapat
digunakan untuk menganalisis faktor-faktor yang mempengaruhi kelulusan siswa
karena analisis diskriminan dapat memisahkan faktor lulus dengan faktor tidak lulus
sehingga dapat dikatakan faktor-faktor tersebut mempengaruhi kelulusan siswa.
1.2 PERUMUSAN MASALAH
Berdasarkan uraian diatas, penulis merumuskan masalah sebagai berikut:
1. Faktor-faktor apa saja yang mempengaruhi kelulusan siswa SMPN 1 Gunung
Meriah Kabupaten Aceh Singkil tahun ajaran 2009/2010.
2. Bagaimana mengklasifikasikan nilai kelulusan siswa SMPN 1 Gunung Meriah
Kabupaten Aceh Singkil tahun ajaran 2009/2010 sesuai dengan faktor-faktor
yang mempengaruhinya.
1.3 PEMBATASAN MASALAH
Penelitian ini dibatasi dalam beberapa hal, yaitu:
1. Penelitian ini hanya dilakukan di kelas 3 SMPN 1 Gunung Meriah
Kabupaten Aceh Singkil tahun ajaran 2009/2010.
2. Hanya untuk mengkategorikan faktor-faktor yang mempengaruhi kelulusan
siswa kelas 3 SMPN 1 Gunung Meriah Kabupaten Aceh Singkil tahun
ajaran 2009/2010 dengan menggunakan Analisis Diskriminan.
1.4 TINJAUAN PUSTAKA
Suryatmojo (2006), melakukan penelitian terhadap perilaku PNS Administrasi UNS
berbelanja di toko KPRI UNS Surakarta dengan Analisis Diskriminan dan didapatkan
hasil bahwa terdapat perbedaan perilaku belanja yang signifikan antara perilaku PNS
Administrasi UNS yang sering berbelanja dengan yang jarang berbelanja ditoko KPRI
UNS Surakarta.
Pengklasifikasian adalah salah satu analisis statistika yang diperlukan jika ada beberapa kelompok kemudian ingin diketahui apakah kelompok-kelompok tersebut
memang berbeda secara statistika. Kelompok-kelompok ini terjadi karena ada
pengaruh satu atau lebih faktor lain yang merupakan faktor independen. Kombinasi
linier dari faktor-faktor ini akan membentuk suatu fungsi diskriminan (Tatham et.al,
1998).
Ada dua asumsi utama yang harus dipenuhi pada analisis diskriminan ini, yaitu:
1. Sejumlah p faktor penjelas harus berdistribusi normal.
2. Matriks varians-covarians faktor penjelas berukuran pada kedua
kelompok harus sama.
Analisis diskriminan mirip dengan regresi linear berganda (multivariabel regression). Perbedaannya, analisis diskriminan dipakai kalau faktor dependennya kategoris (maksudnya kalau menggunakan sklala ordinal ataupun skala nominal) dan
faktor independennya menggunakan skala metrik (interval dan rasio). Sedangkan
dalam regresi independen, bisa metrik maupun nonmetrik. Model analisis diskriminan
adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai
variabel independen, Simamora (2005).
Model analisis diskriminan berkenaan dengan kombinasi linear yang
bentuknya sebagia berikut :
Di =b0 +b1Xi1+b2Xi2 +b3Xi3 + +bjXij + +bkXik
Dengan :
Di = nilai (skor) diskriminan dari responden (objek) ke-i.
Dimana i = 1, 2, . . . , n. D merupakan variabel tak bebas.
ij
X = faktor (atribut) ke-j dari responden ke-i
j
b = koefisien atau timbangan diskriminan dari faktor atau atribut ke-j
ij
X = faktor bebas/prediktor ke-j dari responden ke-i, juga disebut atribut,
seperti disebutkan diatas.
Koefisien atau timbangan (weigh) fungsi diskriminan bj diperkirakan sedemikian rupa sehingga kelompok (katagori) mempunyai nilai fungsi diskriminan (skor) yang sangat
yang satu (A) sangat berbeda dengan kelompok ke dua (B). kalau ada tiga kelompok
A, B, dan C. Nilai fungsi diskriminan kelompok A sanngat berbeda dengan kelompok
B dan sangat berbeda dengan kelompok C. Ini terjadi kalau rasio sum of squares
antara kelompok dengan sum of squares dalam kelompok untuk nilai/skor fungsi diskriminan maksimum atau rasio varian antar-kelompok dengan varian dalam
kelompok sebesar mungkin (maksimum). Objek dalam kelompok homogen atau
relatif homogen, sedangkan antar-kelompok sangat heterogen. Setiap kombinasi linear
prediktor lainnya akan memberikan nilai rasio yang lebih kecil, Supranto (2004).
Menurut Maholtra (1999), analisis diskriminan terdiri dari lima tahap, yaitu :
1. Merumuskan masalah, tahap ini mencakup jawaban atas pertanyaan kenapa
analisis diskriminan dilakukan (latar belakang masalah) dan apa tujuan analisis
diskriminan, termasuk variabel-variabel apa yang dilibatkan.
2. Mengestimasi fungsi diskriminan, estimasi dapat dilakukan setelah sampel
analisis diperoleh. Ada dua pendekatan umum yang diperoleh. Pertama, metode
langsung (direct method), yaitu suatu cara mengestimasi fungsi diskriminan dengan melibatkan faktor-faktor prediktor sekaligus. Setiap faktor di masukkan
tanpa memperhatikan kekuatan diskriminan masing-masing faktor. Metode ini
baik kalau faktor-faktor prediktor dapat di terima secara teoritis. Kedua,
stepwise method dalam metode ini faktor prediktor di masukkan secara bertahap, tergantung pada kemampuannya melakukan diskriminan grup. Metode
ini cocok kalau peneliti ingin memilih sejumlah faktor prediktor untuk
membentuk fungsi diskriminan.
3. Memastikan signifikansi determinan.
4. Interpretasi output.
5. Uji signifikansi, tak ada gunanya mengintepretasi hasil analisis diskriminan
kalau fungsinya tidak signifikan.
Suranto dan Riza (2005), melakukan penentuan strategi pemasaran
berdasarkan perilaku konsumen dengan metode diskriminan, di dapat hasil bahwa
model diskriminan yang ada ternyata valid dan dapat digunakan, karena mempunyai
tingkat ketepatan prediksi dari model adalah 60,7%, yaitu lebih besar dari 50% dan
sehingga terdapat perbedaan perilaku yang nyata antara konsumen yang sering
berbelanja dengan mereka yang jarang berbelanja di PT. Gudang Rabat Alfa
Retailindo. Untuk model diskriminan dengan tiga kelompok, pembagian faktor bebas
tidak seperti kasus dua kelompok, yakni ‘langsung’ faktor A ke kelompok 1, faktor B
ke kelompok 2 dan seterusnya. Pada kasus tiga kelompok, seluruh faktor bebas
dilakukan proses reduksi faktor dahulu, yakni menjadi satu atau beberapa faktor.
Setelah itu, setiap kelompok (sering, cukup dan jarang) akan ditentukan lebih
cenderung masuk ke faktor yang mana. Jadi dasar pembagian adalah faktor dan bukan
faktor bebas yang semula.
1.5 TUJUAN PENELITIAN
Adapun yang menjadi tujuan penelitian ini adalah :
1. Untuk mendiskriminan (mengelompokkan) faktor-faktor yang mempengaruhi
kelulusan siswa SMPN 1 Gunung Meriah Kabupaten Aceh Singkil tahun ajaran
2009/2010.
2. Untuk mengetahui faktor-faktor apa saja yang lebih dominan mempengaruhi
kelulusan siswa SMPN 1 Gunung Meriah Kabupaten Aceh Singkil tahun ajaran
2009/2010.
1.6 KONTRIBUSI PENELITIAN
Dapat memberikan manfaat bagi pembaca untuk lebih mengetahui dan memahami
tentang analisis diskriminan. Selain itu tulisan ini diharapkan dapat di manfaatkan
oleh sekolah sebagai bahan acuan dan pendukung untuk mengetahui faktor-faktor
yang mempengaruhi kelulusan siswa.
1.7 METODOLOGI PENELITIAN
Penelitian ini di lakukan dengan beberapa langkah yaitu:
1. Pengumpulan Data
Data yang digunakan dalam penelitian ini adalah data primer dan data skunder.
Data primer bersumber dari hasil wawancara terhadap responden dengan
menggunakan angket (kuesioner) yang diberikan kepada responden. Sedangkan
data skunder diperoleh dari hasil penilaian belajar siswa/i kelas III SMPN 1
Gunung Meriah Kabupaten Aceh Singkil Tahun Ajaran 2009/2010. Populasi
dalam penelitian ini adalah seluruh siswa/i kelas III SMPN 1 Gunung Meriah
Kabupaten Aceh Singkil. Dan populasi telah diketahui homogen dan diasumsikan
bahwa populasi berdistribusi normal.
2. Pengolahan Data
Metode analisis data yang digunakan adalah teknik analisis diskriminan dengan
bantuan SPSS dengan tahapan sebagai berikut:
1. Memisahkan faktor ke dalam faktor dependent dan faktor independent.
2. Analysis Case Processing Summary, tabel yang menyatakan bahwa responden (jumlah kasus atau baris SPSS) semuanya valid (sah) untuk di
proses, dapatmengetahui data yang hilang(missing).
3. Group Statistics, tabel yang menunjukkan jumlah responden yang mempunyai pengaruh terhadap kelulusan siswa yaitu lulus atau tidak lulus.
4. Test of Equality Group Means, tabel yang menunjukkan apakah terdapat perbedaan yang signifikan untuk dua grupdiskriminan dengan berdasarkan
uji F.
5. Variable Entered/Removed, tabel yang menyajikan dari tujuh faktor yang dapat dimasukkan (entered) dalam persamaan diskriminan.
6. Variable in The Analysis, tabel yang berisi rangkaian proses tahap sebelumnya, mengenai pemilihan faktor satu persatu yang dimasukkan ke
dalam model.
7. Variable Not in The Analysis, tabel ini berisi ‘kebalikan’ dari tabel sebelumnya, yang memuat faktor yang akan dikeluarkan satu per-satu dari
model.
8. Eigenvalues, interpretasi dari pengelompokkan faktor ke dalam satu atau lebih faktor yang dianalis.
9. Wilk’s Lambda, mengindikasi perbedaan yang signifikan (nyata) antara kedua grup dalam k model diskriminan berdasarkan angka Chi-Square. 10. Standardized Canonical Discriminant Function Coefficient, menentukan
faktor mana yang akan masuk ke faktor mana, dasar pemasukan faktor
dilihat pada besar korelasi kanonikal, dengan korelasi terbesar masuk ke
faktor yangbersangkutan.
11. Structure Matrix, menunjukkan faktor yang paling membedakan perilaku terhadap kelulusan siswa.
12. Functions At Group Centroid, tabel ini mengelompokkan ke dua grup dalam fungsi 1ataufungsi 2.
13. Casewise Statistics, tabel yang berisi rincian tiap kasus, penempatannya dalam model diskriminan serta perbandingan apakah penempatan
(predicted) telah sesuai dengan kenyataan.
14.Classification Result, menunjukkan angka ketepatan prediksi dari model diskriminan. Pada umumnya ketepatan di atas 50% di anggap memadai
atau valid.
d) Menarik kesimpulan, yaitu menyimpulkan hasil dari SPSS 17
Bab 2
LANDASAN TEORI
2.1 Variabel
Variabel adalah suatu sebutan yang dapat diberi nilai angka (kuantitatif) atau nilai
mutu (kualitatif). Variabel merupakan pengelompokan secara logis dari dua atau lebih
atribut dari objek yang diteliti. Misalnya: tidak sekolah, tidak tamat SD, tidak tamat
SMP. Maka variabelnya adalah tingkat pendidikan dari objek penelitian itu. Variabel
tingkat pendidikan merangkum semua atribut tadi.
Variabel merupakan suatu istilah yang berasal dari kata vary dan able yang berarti “berubah” dan “dapat”. Jadi kata variabel berarti dapat berubah. Oleh sebab itu
setiap variabel dapat diberi nilai dan nilai itu berubah-ubah. Nilai itu berupa nilai
kuntitatif maupun kualitatif. Dilihat dari segi nilainya, variabel dibedakan menjadi
dua, yaitu variabel diskrit dan variabel kontinu. Variabel diskrit nilai kuantitatifnya
selalu berupa bilangan bulat. Variabel kontinu nilai kuantitatifnya bisa berupa
pecahan. (http://rakim-ypk.blogspot.com).
Variabel penelitian pada dasarnya adalah segala sesuatu yang berbentuk apa
saja yang ditetapkan oleh peneliti untuk dipelajari sehingga diperoleh informasi
tentang hal tersebut, kemudian ditarik kesimpulannya, (Sugiyono, 2007).
Menurut hubungan antara suatu variabel dengan variabel lainnya, variabel
terbagi atas beberapa yaitu :
a. Variabel independent (independent variable) atau variabel bebas yaitu variabel yang menjadi sebab terjadinya (terpengaruhnya) variabel
dependent (variabel tak bebas).
b. Variabel dependent (dependent variable) atau variabel tak bebas yaitu variabel yang nilainya dipengaruhi oleh variabel independent.
c. Variabel moderator yaitu variabel yang memperkuat atau memperlemah
hubungan antara suatu variabel dependent dengan independent.
d. Variabel intervening, seperti variabel moderator, tetapi nilainya tidak dapat
diukur, seperti kecewa, gembira, sakit hati, dsb.
e. Variabel kontrol, yaitu variabel yang dapat dikendalikan oleh peneliti.
2.2 DATA
Data merupakan kumpulan fakta atau angka atau segala sesuatu yang dapat dipercaya
kebenarannya sehingga dapat digunakan sebagai dasar penarikan kesimpulan. Data
dapat dikelompokkan dalam beberapa golongan antara lain berdasarkan aspek sifat,
dimensi waktu, cara memperoleh dan pengukurannya, muhidin (2009).
2.2.1 Data ditinjau dari Aspek sifat angka
Ditinjau dari aspek sifat angka, data digolongkan menjadi dua, yaitu:
1. Data diskrit, yaitu data yang satuannya merupakan bilangan bulat dan tidak
berbentuk pecahan. Contohnya data mengenai jumlah pada sebuah PTN di
Kota Bandung.
2. Data kontinu adalah data yang satuannya merupakan bilangan pecahan.
Contohnya data mengenai rata-rata berat badan mahasiswa pada sebuah PTN
di Kota Bandung.
2.2.2 Data ditinjau dari Aspek waktu
Ditinjau dari aspek waktu, data digolongkan menjadi dua yaitu:
1. Data time series, yaitu data yang dikumpulkan pada waktu tertentu yang dapat menggambarkan keadaan/karakteristik objek pada saat penelitian dilakukan,
contoh: data jumlah mahasiswa PTN di Indonesia tahun 2006.
2. Data cross section adalah data yang dikumpulkan dari waktu ke waktu yang dapat digambarkan tentang perkembangan suatu kejadian atau kegiatan
tertentu, contoh: data perkembangan jumlah mahasiswa sebuah PTN di
Indonesia selama 5 tahun terakhir.
2.3 Analisis Korelasi
Analisis korelasi adalah metode yang digunakan untuk mengukur kekuatan atau
derajat hubungan antara dua variabel atau lebih. Perhitungan derajat keeratan
didasarkan pada persamaan regresi. Dalam ilmu statistika, istilah korelasi diberi
pengertian sebagai hubungan linier antara dua variabel atau lebih. Hubungan antara
dua variabel dikenal dengan istilah bivariate correlation, sedangkan hubungan antar lebih dari dua variabel disebut multivariate correlation. Contoh bivariate correlation: hubungan antara motivasi kerja dengan kerja. Sedangkan contoh multivariate correlation: hubungan antara motivasi kerja dan disiplin kerja dengan kinerja, Mann (2004). Tujuan dilakukan analisis korelasi antara lain adalah:
1. Untuk mencari bukti terdapat tidaknya hubungan (korelasi) antarvariabel
2. Bila sudah ada hubungan, untuk melihat tingkat keeratan hubungan
antarvariabel
3. Dan untuk memperoleh kejelassan dan kepastian apakah hubungan tersebut
berari (meyakinkan/siignifikan) atau tidak berarti.
Tinggi-rendah, kuat-lemah atau besar-kecilnya suatu korelasi dapat diketahui
dengan melihat besar kecilnya suatu angka (koefisien) yang disebut angka indeks
korelasi atau coefficient of correlation, yang disimbolkan dengan atau r. Koefisien korelasi untuk data populasi disimbolkan dengan , sedangkan korelasi untuk data
sampel disimbolkan dengan r. Angka korelasi berkisar antara 0 sampai dengan ± 1,00. Perhatikan tanda plus minus (±) pada angka indeks korelasi. Tanda plus minus pada
angka indeks korelasi ini fungsinya hanya untuk menunjukkan arah korelasi jadi
bukan sebagai tanda aljabar. Apabila angka indeks korelasi bertanda plus (+) maka
korelasi tersebut positif dan arah korelasi satu arah, sedangkan apabila angka indeks
berlawanan arah; serta apabila angka indeks korelasi sama dengan 0, maka hal ini
menunjukkan tidak ada korelasi. Dengan demikian, arah korelasi dapat dibedakan
menjadi dua, yaitu yang bersifat satu arah dan yang sifatnya berlawanan arah, Mann
(2009).
2.3.1 Macam-macam Analisis Korelasi
1. Korelasi untuk skala pengukuran ordinal
Apabila kita kita punya dua buah variabel X dan Y yang kedua-duanya memiliki tingkat pengukuran ordinal maka koefisien korelasii yang dapat dipergunakan
adalah koefisien korelasi Spearman atau Spearman’s coefficient of (Rank)
correlation dan koefisien korelasi Kendal atau Kendall’s coefficient of (Rank)
correlation.
a. Spearman’scoefficient of (Rank) correlation
Angka indek korelasi Spearman dapat dihitung dengan menggunakan rumus
berikut:
(Siegel and Castellan 1988)
dimana:
= koefisien korelasi rank spearman
n = banyaknya ukuran sampel
= jumlah koadrat dari selisih rank variabel x dengan rank
variabel y
Penggunaan rumus untuk mencari koefisien korelasi Spearman diatas, berlaku
bila kurang dari 20% skor-skor pada sebuah kelompok peringkatnya sama. Bila
lebih dari 20%, maka rumus koreksian harus digunakan (Siegel and Castellan,
1988). Rumus koreksian tersebut adalah:
! "#
dimana:
$%$&'()
(
*%*&'()
( $%$&'()
(
*%*&'()
(
d = Selisih dari rank variabel x dengan rank variabel y
t = Banyak anggota kembar pada suatu perkembaran
selain rumus koreksian dari Spearman, ada rumus lain yang dapat digunakan bila
terdapat data kembar, yaitu rumusnya adalah (Conover, 1999):
( ) ( )
( )
− +( )
− + + − = = = n i i n i i n i i i n n Y R n n X R n n Y R X R 1 2 2 1 2 2 1 2 2 1 2 1 2 1 . dimana:= Koefisien korelasi rank spearman
( ) ( )
xi R yiR . = Jumlah dari hasil kali rank variabel x denngan rank variabel y
( )
2i x
R = Jumlah dari rank kuadrat variabel x
( )
2i y R
= Jumlah dari rank kuadrat variabel y
( )
xiR = Rank variabel x
( )
yiR = Rank variabel y
n = Banyaknya ukuran sampel
b. Kendall’s Coefficient of (Rank) Correlation
Rumus lain yang dapat digunakan untuk menghitung koefisien korelasi dengan dua
buah variabel x dan y, yang kedua-duanya memiliki tingkat pengukuran ordinal adalah koefisien korelasi dari kendall atau Kendall’s Coefficient of (Rank) Correlation.
Dengan demikian rumus koefisien korelasi kendall ini, sama dengan spearman, yaitu
digunakan untuk jenis data peringkat (ordinal). Bedanya koefisien kendall
memperhitung posisi wajar peringkat yang satu terhadap yang lainnya dari
peringkat di kelompok keduanya. Rumus yang digunakan untuk koefisien korelasi
dari kendall adalah (Conover, 1998):
2 / ) 1 ( −
− =
n n
N
Nc d
τ
dimana:
c
N = Jumlah pasangan yang sesuai dari pengamatan
d
N = Jumlah pasangan yang tidak sesuai dari pengamatan
n = Banyaknya pengamatan
2. Korelasi untuk skala pengukuran Interval
Koefisien korelasi untuk dua buah variabel x dan y yang kedua-duanya memiliki tingkat pengukuran interval, dapat dihitung dengan menggunakan korelasi product moment atau product moment Coefficient (pearson’s Coefficien of Correlation) yang dikembangkan oleh Karl Pearson. Perbedaan dengan korelasi Spearman
adalah, pada korelasi Spearman yang dikorelasikan adalah data peringkatnya
(rangking), sementara pada korelasi product moment data observasinya yang
dikorelasikan, (Conover, 1999). Koefisien korelasi product moment dapat
diperoleh dengan rumus:
(
) (
)
(
)
[
−]
[
−(
)
]
⋅ −
=
2 2
2 2
Y Y
N X X
N
Y X
XY N rxy
2.3.2 Korelasi Parsial dan Ganda
Korelasi parsial (Partial Correlation) adalah suatu nilai yang memberikan kuatnya hubungan dua atau lebih variabel X dengan variabel Y, yang salah satu bagian variabel bebasnya dianggap konstan atau dibuat tetap. Koefisien korelasi parsial dirumuskan
sebagai berikut (Conover, 1999):
• Hubungan antara variabel bebas-X1 dengan variabel tak bebas-y, apabila variabel-X2 tetap.
( )
(
2)(
1 2)
2 1 2 12 , 2 2
1 1 . x x y x x x y x y x y x x r r r r r r − − − =
• Hubungan antara variabel bebas-X2 dengan variabel tak bebas-Y, apabila variabel bebas-X1tetap.
( )
(
1)(
1 2)
2 1 1 2 21 2 2
1 1 . x x y x x x y x y x y x x r r r r r r − − − =
• Hubungan antara variabel bebas-X1 dengan variabel tak bebas-X2, apabila variabel tak bebas-Y tetap.
( )
(
xy)(
x y)
y x y x x x x x y r r r r r r 2 1 2 1 2 1 2
1 2 2
1 1 . − − − =
• Korelasi ganda (Multiple Correlation) adalah suatu nilai yang memberikan kuatnya hubungan dua atau lebih variabel bebas X secara bersama-sama dengan variabel tak bebas- Y. koefisien korelasi ganda dirumuskan sebagai berikut: 2 1 2 1 2 1 2 1 2 1 2 2 2 1 . . . 2 x x x x y x y x y x y x y x x r r r r r r R − − + =
(Kapur and Saxena, 2007)
2.4 Analisis Regresi
Analisis regresi adalah teknik statistika yang berguna untuk memeriksa dan
memodelkan hubungan diantara variabel-variabel. Secara umum ada dua macam
hubungan antara dua variabel atau lebih, yaitu bentuk hubungan dan keeratan
hubungan. Untuk keeratan hubungan dapat diketahui dengan analisis korelasi.
Analisis regresi dipergunakan untuk menelaah hubungan antara dua variabel atau
lebih, terutama untuk menelusuri pola hubungan yang modelnya belum diketahui
denngan sempurna, atau untuk mengetahui bagaimana variasi dari beberapa variabel
independen mempengaruhi variabel dependen dalam suatu fenomena yang kompleks.
Jika X1, X2, …, Xi adalah variabel-variabel independen dan Y adalah variabel dependen, maka terdapat hubungan fungsional antara X dan Y, dimana variasi dari X
akan diiringi pula oleh variasi dari Y. Secara matematika hubungan diatas dapat dijabarkan sebagai berikut:
(
x x x e)
f
Y = 1, 2, , i,
dimana:
Y = variabel dependen
x = variabel independen
e = variabel residu (disturbance term)
Berkaitan dengan analisis regresi ini, setidaknya ada 4 yang dilakukan dalam analisis
regresi ini diantaranya: mengadakan estimasi terhadap parameter berdasarkan data
empiris, menguji berapa besar variasi variabel dependen dapat diterangkan oleh
variasi variabel independen, menguji apakah estimasi parameter tersebut signifikan
atau tidak dan melihat apakah tanda dan magnitud dari estimasi parameter cocok
dengan teori (Nazir, 1983).
Regresi sederhana bertujuan untuk mempelajari hubungan antara dua variabel.
Model regresi sederhana adalah + = a + bx dimana, + adalah variabel tak bebas (terikat), x adalah variabel bebas, a adalah penduga bagi intersap ( ), b adalah penduga bagi koefisien regresi ( ), dan , adalah parameter yang nilainya tidak
diketahui sehingga diduga menggunakan statistic sampel, (Triola, 2005). Rumus yang
dapat digunakan untuk mencari a dan b adalah:
X b Y N
x b y
a= − = −
(
)
(
)
− −
= 2
2 .
X X
N
Y X XY
N b
dimana:
i
X = Rata-rata skor variabel X
i
Y = Rata-rata skor variabel Y
2.5 Regresi Linier Ganda
Dalam regresi linier ganda variabel terikat y bergantung pada dua atau lebih varibel bebas. Mungkin terdiri dari beberapa variabel bebas, misalnya: X1,X2, ,Xn
Hubungan seperti ini dapat dicari dengan menggunakan analisis regresi berganda
dengan bentuk umum sebagai berikut :
Yi = 0 + 1X1 + 2X2 + …+ nXn + i
dengan :
Yi = Variabel terikat (Variabel respon) 0 , 1, 2, … , n = Parameter regresi
X1 X2, …, Xn = Variabel bebas
1 = Kesalahan/galat
Estimasi parameter-parameter menggunakan metode kuadrat terkecil, misalnya:
,-I= Nilai penafsir (ramalan) Y
./0 = Penaksir .0
./1 = Penaksir .(
1
./n = penaksir ./n
Dengan prosedur metode kuadrat terkecil menghasilkan :
,-I = ./0 + ./1X1 + ./2X2 + … + ./nXn + i
Untuk menentukan koefisien-koefisien variabel ./0,./1,./2, …, ./n diperlukan n buah pasangan data (X1,X2, ,Xn,YI) yang diperoleh dari pengamatan (Johnson and
Bhattacharyya, 1987).
2.6 Analisis Diskriminan
Analisis diskriminan mirip regresi linier berganda (multivariable regression). Perbedaannya, analisis diskriminan dipakai kalau variabel dependennya kategori
(maksudnya kalau menggunakan skala ordinal ataupun nominal) dan variabel
independennya menggunakan skala metrik (interval dan rasio). Sedangkan dalam
regresi berganda variabel dependentnya harus metrik, dan jika variabelnya
independen, bisa metrik maupun nonmetrik. Sama seperti regresi berganda, dalam
analisis diskriminan variabel independen hanya satu, sedangkan variabel independen
banyak (multiple). Misalnya, variabel dependen adalah pilihan merek mobil: Kijang, Kuda, dan Panther. Variabel independen adalah rating setiap merek pada sejumlah
atribut yang memakai skala 1 sampai 7, (Simamora, 2005).
Analisis diskriminan adalah metode statistik untuk mengelompokkan atau
mengklasifikasi sejumlah obyek ke dalam beberapa kelompok, berdasarkan beberapa
variabel, sedemikian hingga setiap obyek yang menjadi anggota lebih dari pada satu
kelompok. Pada prinsipnya analisis diskriminan bertujuan untuk mengelompokkan
setiap obyek ke dalam dua atau lebih kelompok berdasarkan pada kriteria sejumlah
variabel bebas. Pengelompokkan ini bersifat mutually exclusive, dalam artian jika obyek A sudah masuk kelompok 1, maka ia tidak mungkin juga dapat menjadi
anggota kelompok 2. Analisis kemudian dapat dikembangkan pada ‘variabel mana
saja yang membuat kelompok 1 berbeda dengan kelompok 2, berapa persen yang
masuk ke kelompok 1, berapa persen yang masuk ke kelompok 2. Oleh karena ada
sejumlah variabel independen, maka akan terdapat satu variabel dependen
(tergantung), ciri analisis diskriminan adalah jenis data dari variabel dependent bertipe
nominal (kategori), seperti kode 0 dan 1, atau kode 1, 2 dan 3 serta kombinasi lainnya
(Overall and Klett, 1972).
2.6.1 Hal-hal Pokok Tentang Analisis Diskriminan
Bentuk multivariat dari analisis diskriminan adalah dependen sehingga variabel
dependen adalah variabel yang menjadi dasar analisis diskriminan. Variabel dependen
bisa berupa kode grup 1 atau grup 2 atau lainnya, (Santoso, 2010).
Tujuan diskriminan secara umum adalah:
1. Ingin mengetahui apakah ada perbedaan yang jelas antar-grup pada variabel
dependen? Atau bisa dikatakan apakah ada perbedaan antara anggota Grup 1
dengan anggota Grup 2?
2. Jika ada perbedaan, variabel independen manakah pada fungsi diskriminan yang
membuat perbedaan tersebut?
3. Membuat fungsi atau model diskriminan, yang pada dasarnya mirip dengan
persamaan regresi.
4. Melakukan klasifikasi terhadap objek (dalam terminology SPSS disebut baris),
apakah suatu objek (bisa nama orang, nama tumbuhan, benda atau lainnya)
termasuk pada grup 2, atau lainnya.
Proses dasar dari analisis diskriminan ialah:
• Memisah variabel-variabel menjadi Variabel Dependen dan Variabel Independen.
• Menentukan metode untuk membuat Fungsi Diskriminan. Pada prinsipnya ada dua
metode dasar untuk itu, yakni :
1. Simultaneous Estimation, dimana semua variabel dimasukkan secara bersama-sama kemudian dilakukan proses analisis diskriminan.
2. Step-Wise Estimation, dimana variabel dimasukkan satu persatu kedalam model diskriminan. Pada proses ini, tentu ada variabel yang tetap ada pada model, dan
ada kemungkinan satu atau lebih variabel independen yang ‘dibuang’ dari
model.
• Menguji signifikansi dari fungsi diskriminan yang telah terbentuk, menggunakan
Wilk’s lambda, pilai, F test dan lainnya.
• Menguji ketepatan klasifikasi dari fungsi diskriminan, termasuk mengetahui
ketepatan klasifikasi secara individual dengan Casewise Diagnostics.
• Melakukan interpretasi terhadap fungsi diskriminan tersebut.
• Melakukan uji validitas fungsi diskriminan.
Berikut ini beberapa asumsi yang harus dipenuhi agar model diskriminan dapat
digunakan:
1. Multivariate Normality, atau variabel independen seharusnya berdistribusi normal, hal ini akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan.
Regresi logistic (Logistic Regression ) bisa dijadikan alternative metode jika memang data tidak berdistribusi normal. Tujuan uji normal adalah ingin
mengetahui apakah distribusi data dengan bentuk lonceng (bell shaped). Data yang ‘baik’ adalah data yang mempunyai pola seperti distribusi normal, yakni distribusi
data tersebut tidak menceng ke kiri atau menceng ke kanan. Uji normalitas pada
multivariat sebenarnya sangat kompleks, karena harus dilakukan pada seluruh
variabel secara bersama-sama. Namun, uji ini bisa juga dilakukan pada setiap
variabel dengan logika bahwa jika secara individual masing-masing variabel
memenuhi asumsi normalitas, maka secara bersama-sama (multivariat)
variabel-variabel tersebut juga bisa dianggap memenuhi asumsi normalitas. Adapun criteria
pengujiannya adalah:
• Angka signifikansi (Sig) > 0,05, maka data tersebut berdistribusi normal.
• Angka signifikansi (Sig) < 0,05, maka data tidak berdistribusi normal.
Jika sebuah variabel mempunyai sebaran data yang tidak normal, maka perlakuan
yang dimungkinkan agar menjadi normal, (Santoso, 2010):
Menambah jumlah data. Seperti pada kasus, bisa dicari 20 atau 30 atau
sejumlah data baru untuk menambah ke-75 data berat badan konsumen
yang sudah ada. Kemudian dengan jumlah data yang baru, dilakukan
pengujian sekali lagi.
Menghilangkan data yang dianggap penyebab tidak normalnya data. Seperti
pada variabel berat, jika dua data yang outlier dibuang, yakni berat 100 dan 120, kemudian diulang proses pengujian, mungkuin data bisa menjadi
normal. Jika belum normal, ulangi pengurangan data yang dianggap
penyebab ketidaknormalan data. Namun demikian, pengurangan data harus
dipertimbangkan apakah tidak mengaburkan tujuan penelitian karena
hilangnya data-data yang seharusnya ada.
Dilakukan transformasi data, misal mengubah data ke logaritma atau
kebentuk natural (ln) atau bentuk lainnya, kemudian dilakukan pengujian
ulang.
Data diterima apa adanya, memang dianggap tidak normal dan tidak perlu
dilakukan berbagai treatment. Untuk itu, alat analisis yang dipilih harus diperhatikan, seperti untuk multivariate mungkin faktor analisis tidak begitu
mementingkan asumsi kenormalan. Atau pada kasus statistik univariat, bisa
dilakukan alat analisis nonparametrik, (Santoso, 2010).
2.6.2 Klasifikasi dengan Dua Populasi Multivariat Normal
Dalam buku Johnson and Wichern (2007), dijelaskan bahwa fungsi diskriminan
pertama kali diperkenalkan oleh Ronald A. Fisher (1936) dengan menggunakan
beberapa kombinasi linier dari pengamatan yang cukup mewakili populasi. Menurut
Fisher, untuk mencari kombinasi linier dari p variabel bebas tersebut dapat dilakukan dengan pemilihan koefisien-koefisiennya yang menghasilkan hasil bagi maksimum
antara matrik peragam antar kelompok (between-group) dan matrik peragam dalam
kelompok (within-group).
Adapun asumsi-asumsi yang harus dipenuhi sebelum melakukan analisis
diskriminan, antara lain yaitu:
• Variabel independen berdistribusi normal multivariat (multivariates normal distribution)
• Varians dalam setiap kelompok adalah sama (equal variances)
Prosedur–prosedur klasifikasi yang didasarkan pada populasi normal lebih
unggul dalam statistik karena tidak rumit dan tingkat efisiensi yang tinggi yang
melibatkan banyak model variasi populasi. Sekarang asumsikan bahwa f1(x)dan f2(x)
kepadatan multivariat normal, pertama dengan vektor rata-rata 1 dan matriks
kovarian 1dan yang kedua dengan vector rata-rata 2 dan matriks kovarian 2.
Klasifikasi populasi normal ketika 1= 2= anggap bahwa kepadatan bersama dari X’ = [X1, ,X2, . . , .XP]untuk populasi 1 dan 2 diberikan oleh:
fi(x) = (
3 4 &5 6 67 & 5
exp8 ( 9 : ; '( 9 : < untuk i = 1,2 (2.1)
Anggap juga bahwa parameter-parameter populasi 1, 2, dan diketahui. Kemudian,
setelah cancelasi dari istilah "= >5 ? ?( 5 daerah Expected Cost of
Misclassification (ECM) minimum pada region R1 dan R2 yang meminimalisir ECM didefenisikan oleh nilai x untuk ketidaksamaan yang berlaku sebagai berikut:
R1 = @@7 9 & 9 A B
C D(E
C D E(F B>>7&F
R2 = @@7 9 & 9 G B
C D(E
C D E(F B>>7&F
menjadi :
(
−)
(
−)
+(
−)
(
−)
≥− 1 ' −1 1 2 ' −1 2
1
2 1 2
1 exp
: x x x x
R BC D(E
C D E(F B
>7
>&F
(
−)
(
−)
+(
−)
(
−)
<− 1 ' −1 1 2 ' −1 2
2
2 1 2
1 exp
: x x x x
R BC D(E
C D E(F B
>7
>&F (2.2)
Diberikan daerah R1 dan R2, sehingga dapat membentuk aturan klasifikasi yang diberikan pada hasil berikut:
Anggap populasi 1 dan 2 dideskripsikan oleh idensitas multivariate normal dengan
bentuk pada persamaan (2.1). Kemudian aturan alokasi yang meminimalisir ECM
sebagai berikut :
Alokasikan x0 ke 1 jika
:( : ; '(90 ( :( : ; '( :( : A L 8BC D(EC D E( F B>>&7F< (2.3)
Dengan cara lain alokasikan x0 ke 2.
Bukti: karena quantitas pada persamaan (2.2) tidak negatif untuk semua x, maka dapat
( 9 :
( ; '( 9 :( ( 9 : ; '( 9 :
= :( : ; '(9 ( :( : ; '( :( : (2.4) dan akibatnya
R1 :
(
)
(
)
(
1 2)
1 ' 2 1 1 ' 2
1 − − − +
− −
2 1
x A L 8BC D(E
C D E(F B >&
>7F<
R2 :
(
)
(
)
(
1 2)
1 ' 2 1 1 ' 2
1 − − − +
− −
2 1
x G L 8BC D(E
C D E(F B >&
>7F< (2.5)
Pada kebanyakan situasi, quantitas populasi 1, 2, dan tidak diketahui, sehingga
aturan (2.3) harus dimodifikasi. Wald dan Anderson menyarankan mengganti parameter-parameter populasi dengan sampel mereka.
Kemudian, anggap kita memiliki n1 observasi dari variabel acak multivariat X’ = [X1,
X2, …, Xp] dari 1 dan n2 pengukuran quantitas ini dari 2, dengan n1+ n2– 2 p.
Kemudian matriks data respektif sebagai berikut:
( ) = × ' ' ' x x x
X
1 1 1 12 11 1 n p n ; ( ) = × ' ' ' x x xX
2 2 1 22 21 2 n p n (2.6)Dari data matriks tersebut, vektor sampel rata-rata dan matriks kovarians adalah:
( ×) = = 1 1 1 1 1 1 1 n j j p n x
X
; ( )(
)(
)
= × − − − = 1 1 1 ' 1 1 1 1 1 1 1 n j j j p p n x x x xS
( ×) = = 2 1 2 2 1 1 2 n j j p n xX
; ( )(
)(
)
= × − − − = 2 2 1 ' 2 2 2 2 1 1 2 n j j j p p n x x x xS
(2.7)Karena diasumsikan bahwa populasi memiliki matriks kovarian yang sama , sampel
matriks kovarian S1 dan S2 dikombinasikan untuk diturunkan menjadi perkiraan objektif tunggal dari . Secara umum, berat rata-rata
(
) (
)
1(
) (
)
22 S S S − + − − + − + − − = 1 1 1 1 1 1 2 1 2 1 1 n n n n n n
pooled (2.8)
Adalah suatu estimasi unbias dari jika matriks data X1 dan X2 memuat sampel-sampel acak dari populasi 1 dan 2 berturut-turut. Substitusikan 9M1 untuk 1, 9M2 untuk
2, dan Spooled untuk pada persamaan (2.3) menjadi “sampel” aturan klasifikasi. Estimasi aturan Expected Cost of Misclassification (ECM) minimum untuk dua populasi normal:
Alokasikan x0 ke 1 jika
(9M1-9M2)NO>PPQRS '( 90 ((9M1- 9M2)NO>PPQRS '( (9M1 + 9M2) A L 8BC D(EC D E(F B>>&
7F< (2.9)
Alokasikan x0 ke 2, jika pada (2.9), BC D(EC D E(F B>>&
7F = 1
Kemudian ln (1) = 0, dan estimasi aturan ECM minimum untuk 2 populasi normal ditotalkan untuk membandingkan variabel scalar:
T = (9M1-9M2)NO>PPQRS '( 9 UTN9
Dievaluasi pada 0, dengan jumlah :
VT = ( (9M1-9M2)NO>PPQRS '( (9M1 + 9M2)
= ( W( W
dimana :
W(= (9M1-9M2)NO>PPQRS '( 9M( UTN9M( dan
W = (9M1-9M2)NO>PPQRS '( 9M UTN9M
Oleh karena itu, estimasi aturan ECM minimum untuk dua populasi normal sama dengan membentuk dua populasi univariat untuk nilai y dengan mengambil suatu kombinasi linier yang sesuai dari observasi-observasi populasi 1 dan 2 dan kemudian menandai suatu observasi baru x0 ke 1 atau 2, bergantung pada apakah T = UTN9M0
jatuh kekanan atau kekiri titik tengah VT antara dua rata-rata univariat W(dan W .
Sekali estimasi parameter disisipkan pada kuantitas populasi tak diketahui yang
bersesuaian, tidak ada jaminan bahwa aturan hasil akan meminimalisir biaya
ekspektasi kesalahan klasifikasi pada klasifikassi yang umum. Hal ini karena aturan
f1(x) dan f2(x) diketahui secara lengkap. Persamaan (2.9) adalah satu estimasi
sederhana dari aturan optimal. Akan tetapi, kelihatannya beralasan untuk
mengekspektasi bahwa hal tersebut harusnya ada dengan baik jika ukuran sampel
besar. Sebagai hasilnya, jika data muncul menjadi multivariat normal, statistik
klasifikasi bergeser kekiri dari pertidaksamaan di (2.9) dapat dihitung untuk setiap
observasi baru x0. Observasi-observasi ini diklasifikasikan dengan membandingkan
nilai-nilai statistik dengan nilai-nilai dari ln X%Y D E" ZY D"E ) Z ( [.
2.6.3 Format Data Dasar dan Program Komputer yang Digunakan
Data dasar yang digunakan otomatis adalah data yang kontinu (karena adanya asumsi
kenormalan) untuk variabel penjelas (Xj) dan data kategorik/kualitatif/nonmetrik untuk
[image:39.612.142.507.427.495.2]variabel respon (Y).
Tabel 2.1 Tabel Format Data untuk Analisis Diskriminan
X1 X2 . . . Xp Y
… … … …
… … … …
Beberapa software yang bisa digunakan adalah SPSS, SAS, dan Minitab.
2.6.4 Algoritma dan Model Matematis
Secara ringkas, langkah-langkah dalam analisis diskriminan adalah sebagai berikut :
1) Pengecekan adanya kemungkinan hubungan linier antara variabel penjelas. Untuk
point ini, dilakukan dengan bantuan matriks korelasi (pembentukan matriks
korelasi sudah difasilitasi pada analisis diskriminan). Pada output SPSS, matriks
korelasi bisa dilihat pada pooled Within-Groups Matrices.
2) Uji vektor rata-rata kedua kelompok
2 1 :
2 1 :
≠ =
1 0 H H
Angka signifikan :
Jika Sig. > 0,05 berarti tidak ada perbedaan antar-grup
Jika Sig. < 0,05 berarti ada perbedaan antar-grup
Diharapkan dalam uji ini adalah hipotesis nol ditolak, sehingga kita mempunyai informasi awal bahwa variabel yang sedang diteliti memang membedakan kedua kelompok. Pada SPSS, uji ini dilakukan secara univariate (jadi yang diuji bukan berupa vektor), dengan bantuan table Tests of Equality of Group Means.
3) Dilanjutkan pemeriksaan asumsi homoskedastisitas dengan uji Box’s M. Diharapkan dalam uji ini hipotesis nol tidak ditolak (H0: 1 = 2). Hipotesis:
H0: matriks kovarians grupadalah sama
H1: matriks kovarians grup adalah berbeda secara nyata
Keputusan dengan dasar signifikansi (lihat angka signifikan)
Jika Sig. > 0,05 berarti H0 diterima Jika Sig. < 0,05 berarti H0 ditolak
Sama tidaknya grup kovarians matriks juga bisa dilihat dari tabel output Log Determinant. Jika dalam pengujian ini H0 ditolak maka proses lanjutan seharusnya
tidak bisa dilakukan.
4) Pembentukan model diskriminan
Kriteria Fungsi Linier Fisher
a. Pembentukan fungsi Linier (teoritis)
Fisher mengelompokkan suatu observasi berdasarkan nilai skor yang dihitung
dari suatu fungsi linier Y = 'X dimana ' menyatakan vektor yang berisi koefisien-koefisien variabel penjelas yang membentuk persamaan linier
' = [ 1, 2, …, p]
X = 8 (<
Xk menyatakan matriks data pada kelompok ke-k
Xk= .
2 1 2 21 21 1 12 11 npk k n k n pk k k pk k k x x x x x x x x x
i = 1, 2, …, n j = 1, 2,…, p k = 1 dan 2
xijkk menyatakan observasi ke-i variabel ke-j pada kelompok ke-k.
Dibawah asumsi Xk\N
(
µk, k)
maka] ^__`a(
a bc 8] <]( dan k _ ad ]d ad ]d N ;
1= 2=
]d =
pk pk µ µ . . . ;
]d adalah vekor rata-rata tiap variabel X pada kelompok ke-k.
e pp p p σ σ σ σ σ σ 0 0 0 0 0 . . . 0 0 0 . . . . 0 0 . . . 0 . . . . 2 22 1 12 11
j1j2=
{
mnfg hg i fg hgjkL lfg hg i fg hgjkL l g gjhLg l( l( !g l g gjhLgl( o l
Fisher mentransformasikan observasi-observasi x yang multivariate menjadi observasi y yang univariate. Dari persamaan Y = ’X diperoleh:
]dp E(Yk) = E( ’X) = ’ k ;
qr = var( ’X) = ’
]dpadalah rata-rata Y yang diperoleh dari X yang termasuk dalam kelompok ke-k.
qr = adalah varians Y dan diasumsikan sama untuk kedua kelompok.
Kombinasi linier yang menarik menurut Fisher adalah yang dapat
memaksimumkan rasio antara jarak kuadrat rata-rata Y yang diperoleh dari X
kelompok 1 dan 2 dengan varians Y, atau dirumuskan sebagai berikut:
](r ] r
qr s
; ]( ] ]( ] ;s
s; s
Jika ]( ] ) = maka persamaan diatas menjadi %tuv)
&
tu t karena adalah
matriks definit positif maka menurut teori pertidaksamaan Cauchy-Schwartz,
rasio %tuv)
&
tu t dapat dimaksimumkan jika s
; Y '( = Y '( ]( ] dengan
memilih c = 1, menghasilkan kombinasi linier yang disebut kombinasi linier
Fisher sebagai berikut :
(
)
XX
Y= ' = 1 − 2 ' −1
b. Pembentukan Fungsi Linier (dengan bantuan SPSS)
Pada output SPSS, koefisien untuk tiap variabel yang masuk dalam model
dapat dilihat pada tabel Canonical Discriminant Function Coefficient. Tabel ini akan dihasilkan pada output apabila pilihan Function Coefficient bagian
Unstandardized diaktifkan.
c. Menghitung discriminant score
Setelah dibentuk fungsi liniernya, maka dapat dihitung skor diskriminan
untuk tiap observasi dengan memasukkan nilai-nilai variabel penjelasnya.
d. Menghitung Cutting Score
Untuk memprediksi responden mana masuk golongan mana, kita dapat
menggunakan optimum cutting score. Memang dari computer informasi ini sudah diperoleh. Sedangkan cara mengerjakan secara manual Cutting Score
(m) dapat dihitung dengan rumus sebagai berikut dengan ketentuan untuk dua
grup yang mempunyai ukuran yang sama cutting score dinyatakan dengan rumus, (Simamora, 2005):
Zce= wxywz
dengan :
Zce = cutting score untuk grup yang sama ukuran
ZA = centroid grup A
ZB = Centroid grup B
Apabila dua grup berbeda ukuran, rumus cutting score yang digunakan adalah :
ZCU = $x$wzy$zwx
xy$z
dengan :
ZCU = Cutting score untuk grup tak sama ukuran
NA = Jumlah anggota grup A
NB = Jumlah anggota grup B
ZA = Centroid grup A
ZB = Centroid grup B
Kemudian nilai-nilai discriminant score tiap obsservasi akan dibandingkan dengan cutting score, sehingga dapat diklasifikasikan suatu obsevasi akan termasuk kedalam kelompok yang mana. Suatu observasi dengan
karakteristik x akan diklasifikasikan sebagai anggota kelompok kode 1 jika
(
)
x ,nol) perhitungan m dilakukan secara manual, karena SPSS tidak
mengeluarkan output m. Namun, dapat di hitung nilai m dengan bantuan
tabel Function at Group Centroids dari output SPSS.
e. Perhitungan Hit Ratio setelah semua observasi diprediksi keanggotaannya, dapat dihitung hit ratio, yaitu rasio antara observasi yang tepat pengklasifikasiannya dengan total seluruh observasi. Misalkan ada sebanyak
n observasi, akan dibentuk fungsi linier dengan observasi sebanyak n-1. Observasi yang tidak disertakan dalam pembentukan fungsi linier ini akan
diprediksi keanggotaannya dengan fungsi yang sudah dibentuk tadi. Proses
ini akan diulang dengan kombinasi observasi yang berbeda-beda, sehingga
fungsi linier yang dibentuk ada sebanyak n. Inilah yang disebut dengan
metode Leave One Out.
f. Kriteria posterior probability
Aturan pengklasifikasian yang ekivalen dengan model linier Fisher adalah
berdasarkan nilai peluang suatu observasi dengan karakteristik tertentu (x)
berasal dari suatu kelompok. Nilai peluang ini disebut posterior probability
dan bisa ditampilkan pada sheet SPSS dengan mengaktifkan option
probabilities of group membership pada bagian Save di kotak dialog utama.
p DmE
( )
( )
kk k
k k
x f p
x f p
,
dimana :
pk adalah prior prob