KEMENTERIAN PENDIDIKAN DAN KEBUDAYAAN UNIVERSITAS SUMATERA UTARA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
DEPARTEMEN MATEMATIKA
Jl. Bioteknologi No.1 Kampus USU, Telp. (061) 8211050, Fax (061) 8214290
Medan 20155
SURAT KETERANGAN
Hasil Uji Implementasi Sistem Tugas Akhir
Yang bertanda tangan dibawah ini menerangkan bahwa Mahasiswa Tugas Akhir Program Studi D3 Statistika:
Nama Mahasiswa : Elvan Rifiyanto Pane
Nomor Induk Mahasiswa : 122407118
Judul Tugas Akhir : Faktor – faktor yang mempengaruhi tingkat kejahatan Di Kabupaten Tapanuli Selatan
Telah melaksanakan test program Tugas Akhir Mahasiswa tersebut di atas pada tanggal :
Dengan Hasil : Sukses/Gagal
Demikian diterangkan untuk digunakan melengkapi syarat pendaftaran Ujian Meja Hijau Tugas Akhir Mahasiswa bersangkutan di Departemen Matematika FMIPA USU Medan.
Medan, Juli 2015 Dosen Pembimbing
KEMENTERIAN PENDIDIKAN DAN KEBUDAYAAN
Nama Mahasiswa : ELVAN RIFIYANTO PANE
KARTU BIMBINGAN TUGAS AKHIR MAHASISWA
Nomor Induk Mahasiswa : 122407118
Judul Tugas Akhir : Faktor – faktor Yang Mempengaruhi Tingkat Kejahatan Di Kabupaten Tapanuli Selatan
Dosen Pembimbing : Prof. Dr. Saib Suwilo, M.Sc
Disetujui oleh
Program Studi D3 Statistika FMIPA USU
Ketua, Pembimbing,
Dr. Faigiziduhu Bu’ulölö, M.Si
DAFTAR PUSTAKA
Algifari. 2000. Analisa Regresi Teori, Kasus dan Solusi, Edisi 2. Yogyakarta: BPFE. Atmasasmita, R. 1997. Kriminologi. Bandung: Mandar Maju.
Badan Pusat Statistik. Sumatera Utara Dalam Angka 2014. BPS. Medan. Sudjana. 1996. Teknik Analisi Regresis regresi dan Korelasi Bagi Para Peneliti.
Bandung: Tarsito.
Sudjana. 2005. Metode Statistika. Bandung: Tarsito.
Sugiyono. 2011. Statistik untuk Penelitian, Edisi 19. Bandung: Alfabeta. Suharjo, Bambang. Analisis Regresi Terapan dengan SPSS. Edisi 1.
Surabaya: Graha Ilmu.
BAB 3
PENGOLAHAN DATA
3.1 Pengumpulan Data
Data yang diambil dari Badan Pusat Statistika adalah data Jumlah penduduk, Jumlah Penduduk Miskin, Jumlah pengeluaran dan konsumsi penduduk, dan data yang diperoleh dari POLRES TAPSEL yaitu Jumlah tindak kejahatan yang terjadi di kabupaten Tapanuli Selatan pada tahun 2006 – 2013. Adapun datanya adalah sebagai berikut:
Tabel 3.1 Data tindak kejahatan, jumlah penduduk, jumlah penduduk miskin, jumlah industri, jumlah pengeuaran dan konsumsi penduduk tahun 2006 – 2013.
di mana:
Y = Jumlah Kejahatan X1 = Jumlah Penduduk X2 = Jumlah Penduduk Miskin
X3 = Jumlah Pengeluaran dan Konsumsi Penduduk
3.2 Pengolahan Data
Untuk membahas dan memecahkan masalah mengenai pengaruh jumlah kejahatan di tapanuli selatan, akan digunakan data yang telah dikumpulkan sebelumnya. Yaitu tentang Jumlah penduduk, Jumlah penduduk miskin, dan Jumlah pengeluaran dan konsumsi penduduk di tapanuli Selatan. Proses pengolahan dan penganalisisan data dilakukan dengan menggunakan program spss, yaitu salah satu program statistik yang mampu mengolah data dengan cepat namun hasilnya dapat mewakili dalam pengambilan keputusan yang relatif baik karena mendekati keadaan sebenarnya.
3.3 Persamaan Regresi Linier Berganda
Regression
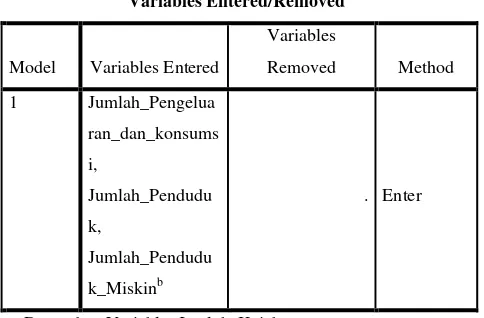
Variables Entered/Removeda
Model Variables Entered
Variables
Removed Method
1 Jumlah_Pengelua
ran_dan_konsums
i,
Jumlah_Pendudu
k,
Jumlah_Pendudu
k_Miskinb
. Enter
a. Dependent Variable: Jumlah_Kejahatan
b. All requested variables entered.
Tabel 3.2 Metode Kotak Dialog Regresi Linier
Model Summaryb
a. Predictors: (Constant), Jumlah_Pengeluaran_dan_Konsumsi, Jumlah_Penduduk, Jumlah_Penduduk_Miskin
b. Dependent Variable: Jumlah_Kejahatan
Tabel 3.3 Metode Hasil Penjumlahan
Tabel di atas menunjukkan bahwa nilai R Square sebesar 0,916 yang jika
dihitung secara manual diperoleh dari hasil satu dikurangi dari jumlah kuadrat regresi dibagi jumlah kuadrat total dari variabel Y.
Nilai Adjusted R Square sebagai nilai yang disarankan dapat diketahui besarnya adalah 0,853 yang artinya variabel Jumlah Pengeluaran dan konsumsi penduduk (X1), Jumlah Penduduk (X2), jumlah penduduk miskin (X3),
memiliki pengaruh sebesar 85,3% terhadap jumlah kejahatan (Y) dan sisanya dipengaruhi oleh variabel lain seperti, Ekonomi, pendapatan per KK, dan Konsumsi akan bahan pokok.
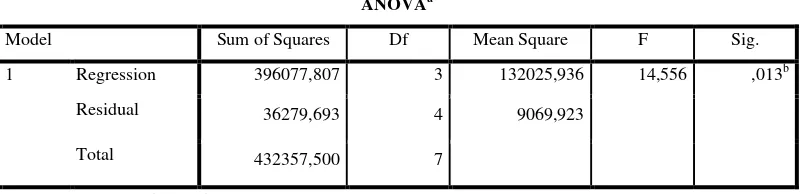
ANOVAa
Model Sum of Squares Df Mean Square F Sig.
1 Regression 396077,807 3 132025,936 14,556 ,013b
Residual 36279,693 4 9069,923
Total 432357,500 7
a. Dependent Variable: Jumlah_Kejahatan
b. Predictors: (Constant), Jumlah_Pengeluaran_dan_Konsumsi, Jumlah_Penduduk,
Tabel 3.4 Output ANOVA 1 Arah
Analisa variansi di atas digunakan untuk uji hipotesis beberapa rata-rata. Dari tabel dapat diketahui: Derajat kebebesannya (degree of freedom) = 3, residual = 4 Nilai Fhit = 14,556 dengan signifikan sebesar 0,013 atau 0,13%, yang berarti
signifikan kurang dari 5%, sehingga hipotesis ditolak. Itu artinya rata-rata Jumlah Pengeluaran dan konsumsi penduduk (X1), Jumlah Penduduk (X2), jumlah
penduduk miskin (X3), cukup signifikan. Dengan akta lain terdapat perbedaan
antara Jumlah Pengeluaran dan konsumsi penduduk (X1), Jumlah Penduduk (X2),
Jumlah Penduduk Miskin (X3).
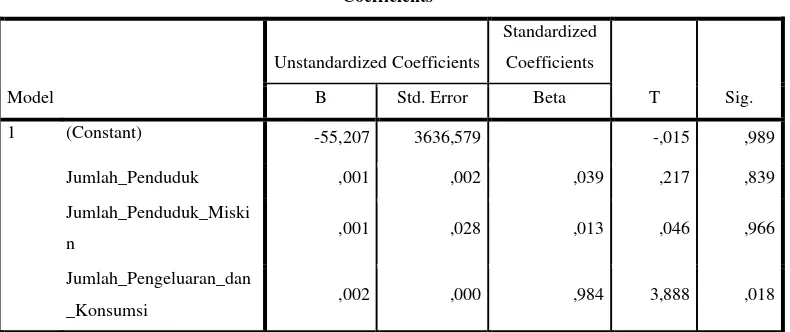
Coefficientsa
a. Dependent Variable: Jumlah_Kejahatan
Tabel 3.5 Nilai-nilai Koefisien
Pada Tabel 3.5 diatas tepatnya pada kolom signifikan ditunjukkan bahwa variabel Jumlah kejahatan yang mempengaruhi Jumlah penduduk miskin berada dibawah 0,05. Pada Tabel 3.5 diatas dapat juga diketahui nilai-nilai:
B0 =-55,207
B1 = 0,01
B2 = 0,01
B3 = 0,02
Sehingga diperoleh persamaan regresinya:
Ŷ = b0 + b1X1 +b2X2 + b3X3
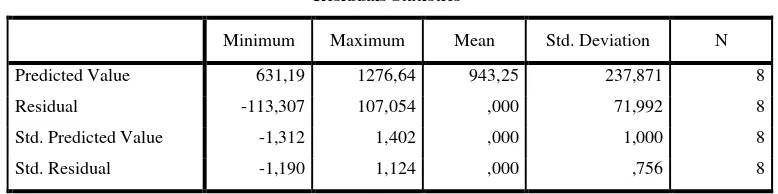
Residuals Statisticsa
a. Dependent Variable: Jumlah_Kejahatan
Tabel 3.6 Nilai-Nilai Residu
3.4 Uji Keberartian
Pada uji ini, hipotesis yang digunakan adalah: H0 = koefisien regresi tidak signifikan
Hn = koefisien regresi signifikan
Uji Keberartian ini dilakukan untuk masing-masing koefisien regresi berikut ini: 1. Konstanta
a tabel 3.5 tepatnya pada kolom unstandardized coefficents, nilai konstanta adalah sebesar -55,207 nilai Thit = -0,15 dengan dk = 8-4 dan α = 0,05 : nilai t(0,05.4) = 2,776, sehingga
Thit < Ttab. Artinya, H0 diterima yang berarti bahwa konstanta tidak
memiliki pengaruh nyata terhadap model regresi. 2. Jumlah penduduk (X1)
a tabel 3.5 yaitu pada kolom unstandardized coefficents, nilai X1 adalah sebesar 0,01. Nilai Thit = 0,217
dengan dk = 8 - 4 dan α = 0,05 : nilai t(0,05.4) = 2,776, sehingga Thit < Ttob.
Artinya, H0 diterima yang berarti bahwa jumlah penduduk (X1) tidak
memiliki pengaruh nyata terhadap model regresi. 3. Jumlah penduduk miskin (X2)
a tabel 3.5 yaitu pada kolom unstandardized coefficents, nilai X2 adalah sebesar 0,01. Nilai Thit = 0,46
dengan dk = 8 - 4 dan α = 0,05 : nilai t(0,05.4) = 2,776, sehingga Thit < Ttob.
Artinya, H0 ditolak yang berarti bahwa jumlah penduduk miskin (X2)
a tabel 3.5 yaitu pada kolom unstandardized coefficents, nilai X3 adalah sebesar 0,02. Nilai Thit = 3,888
dengan dk = 8-4 dan α = 0,05 : nilai t(0,05.4) = 2,776, sehingga Thit >Ttob.
Artinya, H0 ditolak yang berarti bahwa jumlah Pengeluaran dan konsumsi
penduduk (X3) memiliki pengaruh nyata terhadap model regresi.
3.5 Uji Liniaritas Garis regresi
Uji liniaritas Garis regresi dimaksudkan untuk mengambil keputusan dalam memilih model regresi yang akan dipergunakan. Uji ini adalah syarat yang perlu karna akan memperoleh garis regresi yang akan digunakan dalam menganlisis data.
Uji liniaritas Garis regresi, Hipotesisnya adalah : H0 = Koefisien regresi tidak signifikan
Hu = Koefisien regresi signifikan
Berdasarkan hasil pengolahan data atau (output) yang telah diperoleh, maka liniaritas regresi ditentukan dengan melihat tabel 3.4. Kriteria yang akan digunakan adalah apabila nilai sig ≥ 0,005 maka H 0 diterima, artinya
persamaanya garis regresi tidak linier. Jika sebaliknya, maka H0 Ditolak yang
artinya persamaan artinya adalah persamaan garis regresi linier.. Dari Tabel 3.4 diketahui nilai sig ,013,Artinya kurang dari 0,005. Dengan demikian H0 ditolak
dan persamaanya adalah persamaan regresi linier.
3.6 Uji Normalitas Menggunakan Regresi Linier
Dalam teori model linier, hanya variabel tak bebaslah yang mempunyai uji normalitasnya, sedangkan variabel-variabel diasumsikan bukan merupakan fungsi distribusi sehingga tidak perlu diuji normalitasnya.
Charts
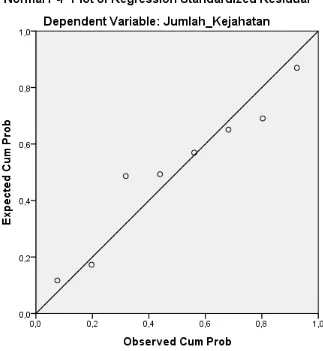
Gambar 3.2 Output berupa Normal P-P Of Regression Standardized Residul
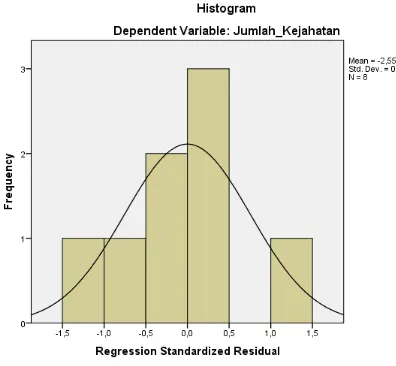
Dari hasil tabel 3.2, dapat dilihat bahwa data menyebar disekitar data diagonal dan mengikuti arah garis histograf dan menjadi pola distribusi normal sehingga dapat dipastikan bahwa modal regresi tersebut memenuhi asumsi normalitas.
3.7 Analisis Korelasi
Analisis korelasi digunakan untuk meneliti hubungan antara dua buah variabel yang analisis. Berikut adalah koefisien-koefisien korelasi yang di hasilkan dengan program spss
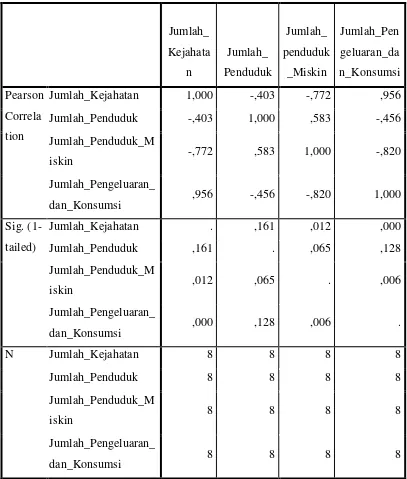
Tabel 3.7 Nilai –Nilai Korelasi
Koefisien Korelasi memiliki nilai paling kecil -1 dan paling besar +1 (-1 ≤ r ≤ 1). Pada tabel 3.7 telah ditunjukkan bahwa koefisien korelasi antar jumlah penduduk (X1) dengan jumlah kejahatan (Y) = -0,403. Itu artinya korelasi tinggi sehingga
semakin tinggi jumlah Penduduk maka jumlah kejahatan (Y) semakin tinggi. Koefisien korelasi antara jumlah penduduk miskin (X2) dengan jumlah
berbanding terbalik sehingga, jumlah penduduk miskin memiliki pengaruh yang kuat.
Koefisien korelasi antara Jumlah Pengeluaran dan konsumsi penduduk (X3) dengan jumlah kejahatan (Y) = 0,956. Artinya, korelasi yang kuat dan
BAB 4
IMPLEMENTASI SISTEM
4.1 Pengertian Implementasi
Implementasi sistem adalah prosedur yang dilakukan untuk menyelesaikan desain sistem yang ada dalam desain yang telah disetuji, menginstal dan memulai sistem baru atau sistem yang diperbaiki. Tahapan implementasi sistem adalah tahapan penerapan hasil desain tertulis kedalam programming. Dalam pengolahan data pada Tugas Akhir ini penulis menggunakan perangkat lunak (softwere) sebagai implementasi sistem yaitu IBM SPSS statistics 22 for windows dalam masalah memperoleh perhitungan.
4.2 SPSS dalam Statistika
SPSS (Statistical package for the social sciences) merupakan salah satu paket program komputer yang digunakan dalam mengolah data statistik. SPSS merupakan software yang paling populer, dan banyak yang digunakan sebagai alat bantu dalam berbagai riset. SPSS pertama kali diperkenalkan oleh tiga mahasiswa Standford University pada tahun 1968. SPSS sebelumnya dirancang untuk pengolahan data statistik pada ilmu-ilmu sosial, sehingga SPSS merupakan singkatan dari Statistical Package for the Social Sciences. Namun, dalam perkembangan selanjutnya penggunaan SPSS diperluas untuk berbagai jenis user, sehingga SPSS yang sebelumnya disingkat dari Statistical Package for the Social Sciences berubah menjadi Statistical Product and Service Solutions. Penggunaan SPSS dimaksudkan untuk melakukan analisis dengan praktis, cepat dan akurat.
4.3 Cara Kerja SPSS
1. Input
a komputer, input berupa data yang akan diolah dengan komputer. Proses inputting dapat melalui keyboard, touch screen, atau hardisk. Pada statistik, input berupa data yang telah dikumpulkan, diedit, dan ditabulasi dan kemudian dianalisis. Pada SPSS input berupa data yang telah ditabulasi pada data editor bagian view data, sedangkan proses accoading dan pendefinisian variabel pada view variabel.
2. Process
a komputer proses berupa eksekusi program komputer menjalankan perintah-perintah sesuai dengan apa yang telah diprogramkan. Pada statistik proses berupa analisis perhitungan, baik secara deskriptip maupun inferensi, baik statistik parametrik maupun statistik nonparametrik. Pada SPSS proses berupa eksekusi program SPSS untuk menganalisis input yang ada di data editor sesuai dengan perintah dari operator.
3. Output
a komputer, output berupa hasil pengolahan yang telah diproses dengan program komputer yang sesuai. Bentuk output komputer bias dalam bentuk cetakan, tampilan, gambar, damn suara. Pada statistik output berupa hasil analisis, baik dalam bentuk penyajian data maupun dalam bentuk grafik atau tabel serta kesimpulan yang diperoleh dari hasil analisis. Pada SPSS, bentuk output disajikan dalam bentuk output navigator.
4.4 Langkah-Langkah Pengolahan Data dengan SPSS
Adapun langkah-langkah pengolahan data dengan menggunakan program SPSS, yaitu :
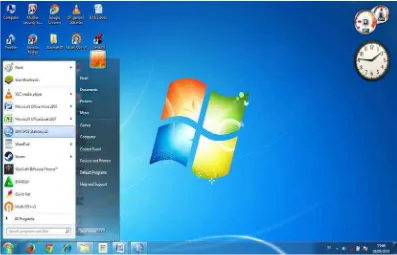
1. Aktifkan program SPSS pada window dengan perintah:
Gambar 4.1 Tampilan Saat Memulai Membuka IBM SPSS 22
2. Cara memasukkan Data
Langkah-langkah dalam pengentrian data dengan menggunakan SPSS yaitu: buka lembar kerja baru dari menu file, pilih new, lalu klik data. Pada pemasukan data view isilah kolom dengan ketentuan data yang akan diolah. Cara mengentri datanya adalah sebagai berikut:
1. Input Variabel Y (Tingkat Kejahatan)
a. Name
Letakkan pointer pada kolom name, double klik pada kolom tersebut dan ketik Y.
b. Type
Karena Y berupa angka, maka klik kotak kecil pada kanan sel tersebut yaitu pilih numeric.
c. Width
Untuk keseragaman pada SPSS, ketik 8.
d. Decimals
e. Label
Label adalah keterangan untuk nama variabel yang bersangkutan. Maka untuk Y ketik Tingkat Kejahatan.
2. Input variabel X1 (Jumlah Penduduk)
a. Name
Letakkan pointer pada kolom name, double klik pada kolom tersebut dan ketik X1.
b. Type
Karena X1 berupa angka, maka klik kotak kecil pada kanan sel
tersebut yaitu pilih numeric. c. Width
Untuk keseragaman pada SPSS, ketik 8.
d. Decimals
Berhubung datanya tidak berkoma, maka ketik 0 e. Label
Label adalah keterangan untuk nama variabel yang bersangkutan. Maka untuk X1 ketik Jumlah Penduduk.
3. Input Variabel X2 (Jumlah Penduduk Miskin)
a. Name
Letakkan pointer pada kolom name, double klik pada kolom tersebut dan ketik X2.
b. Type
Karena X2 berupa angka, maka klik kotak kecil pada kanan sel
tersebut yaitu pilih numeric. c. Width
Untuk keseragaman pada SPSS, ketik 8.
d. Decimals
Berhubung datanya tidak berkoma, maka ketik 0 e. Label
keterangan untuk nama variabel yang bersangkutan. Maka untuk X2
4. Input variabel X3(Jumlah Pengeluaran dan konsumsi)
a. Name
Letakkan pointer pada kolom name, double klik pada kolom tersebut dan ketik X3.
b. Type
Karena X3 berupa angka, maka klik kotak kecil pada kanan sel
tersebut yaitu pilih numeric. c. Width
Untuk keseragaman pada SPSS, ketik 8.
d. Decimals
Berhubung datanya tidak berkoma, maka ketik 0 e. Label
Label adalah keterangan untuk nama variabel yang bersangkutan. Maka untuk X3 ketik Jumlah pengeluaran dan konsumsi
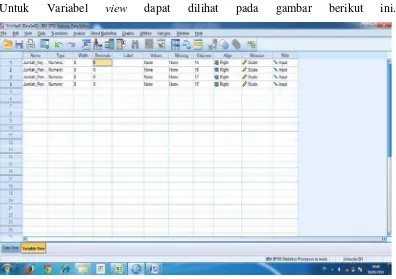
Untuk Variabel view dapat dilihat pada gambar berikut ini.
Gambar 4.2 Tampilan Pada pengertian Data di Variabel View
Gambar 4.3 Tampilan saat di Data View
3. Analisis regresi dengan SPSS
Langkah-langkah untuk mencari analisis regresi linier berganda dengan menggunakan SPSS adalah sebagai berikut:
Gambar 4.4 Tampilan saat membuka Persamaan Regresi
2. Langkah selanjutnya adalah masukan Y ke kolom dependent, dan variabel X1,X2,X3, dan X4 ke kolom independent. Maka tampilannya adalah sebagai
berikut:
3. Langkah selanjutnya pada kolom statictic dengan mengklik tab statisctik dan member tanda ceklist pada kotak estimate, model fit, descruptivees, part and partial correlations, kemudian pada residuals berikan ceklist pada casewise diagnostics seta all cases, kemudian klik continue akan tampil seperti berikut:
Gambar 4.6 Tampilan Pada Pengentrian Linier Regression Statictics
Gambar 4.7 Tampilan Pada Pengertian Linier Regression Plot
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan hasil pengolahan data, maka dapat diambil beberapa kesimpulan sebagai berikut:
1. Persamaan regresi linier berganda yang diperoleh adalah Ŷ = -55,207 + 0,001X1 + 0,001 X2 + 0,002 X3. Atau jumlah penduduk = -55,207 + 0,001
jumlah penduduk + 0,001 Jumlah Penduduk Miskin 0,002 Jumlah Pengeluaran dan Konsumsi.
2. Pada tabel 3,5 variabel jumlah kejahatan yang mempengaruhi jumlah penduduk miskin, karena angka signifikannya berada dibawah 0,05 yaitu 0,018. Sedangkan variabel jumlah penduduk dan jumlah pengeluaran dan konsumsi berada diatas 0,05 yaitu masing-masing adalah 0,839 dan 0,966. a. Nilai Adjusted R Square sebesar 0,853. Artinya, variabel bebas jumlah
penduduk (X1), jumlah penduduk miskin (X2), jumlah pengeluaran dan
konsumsi (X3), memiliki pengaruh sebesar 85,3% terhadap jumlah
kejahatan (Y) dan sisanya dipengaruhi oleh variabel lain seperti misalnya pendapatan penduduk dan barang pengganti.
b. Pada tabel ANOVA dijelaskan bahwa nilai Fhitung yang didapat seperti
14,556 dengan tingkat signifikani sebesar 0,013 atau 0,13% yang berarti signifikansi. Sehingga H0 diterima yang artinya, bahwa persamaannya
adalah persamaan garis regresi linear.
5.2Saran
1. Dalam menganalisa soal regresi linier berganda khususnya, selain dikerjakan perhitungan dengan komputer, sebaiknya dikerjakan juga melakukan perhitungan secara manual, agar model dapat lebih diteliti.
2. Bagi pihak Kabupaten Tapanuli Selatan diharapkan untuk lebih
BAB 2
LANDASAN TEORI
2.1 Pengertian Regresi
Dalam ilmu statistika teknik yang umum digunakan untuk menganalisa hubungan
anatara dua variabel atau lebih adalah analisa regresi linier. Regresi pertama digunakan
sebagai konsep statistik pada tahun 1877 oleh Sir Francis Galton. Dia telah melakukan
studi tentang kecenderungan tinggi badan anak. Hasil studi tersebut merupakan suatu
kesimpulan bahwa kecenderungan tinggi badan anak yang lahir terhadap orang tuanya
adalah menurun mengarah pada tinggi badan rata-rata penduduk. Istilah regresi dapat
digunakan sebagai alat untukmembuat perkiraan nilai suatu variabel tersebut. (Alfigari,
2000.analisis regresi teori.kasus dan solusi, Edisi Kedua, Yogyakarta : BPFE halaman 1
dan 2). Pada dasar dalam suatu persamaan regresi terdapat dua macam
variabel, yaitu variabel bebas (independent variable) yang dinyatakan dengan simbol X
dan variabel terikat (dependent variable) yang biasanya dinyatakan dengan simbol Y.
Variabel terikat adalah variabel yang dipengaruhi atau yang nilainya bergantung dari
nilai variabel lain. Variabel bebas adalah variabel yang memberikan pengaruh. Bila
variabel bebas diketahui maka variabel terikatnya dapat diprediksi besarnya. Prinsip
dasar yang harus dipenuhi dalam membangun suatu persamaan regresi adalah bahwa
2.2 Analisis regresi linier
Analisis regresi merupakan teknik yang digunakan dalam persamaan matematika yang
menyatakan hubungan fungsional antara variabel-variabel. Analisi regresi linier atau
regresi garis lurus digunakan untuk:
Menentukan hubungan fungsional antar variabel dependent dengan independent.
Hubungan fungsional ini dapat disebut sebagai persamaan garis regresi yang berbentuk
linier
Meramalkan atau menduga nilai dari satu variabel dengan hubungannya dengan
variabel yang lain yang diketahui persamaan garis regresi. Variabel yang lain diketahui
melalui persamaan garis regresinya. Analisis regresi terdiri dari dua bentuk, yaitu Analisis
Regresi Linier Sederhana dan Analisis Regresi Linier Berganda.
Analisis regresi linier sederhana adalah bentuk
regresi dengan model yang bertujuan untuk mempelajari hubungan antara dua variabel,
yakni variabel terikat dan variabel bebas. Sedangkan analisis regresi regresi berganda
adalah bentuk regresi dengan model yang memiliki hubungan antara satu variabel
terikat dengan dua atau lebih variabel bebas. Variabel bebas adalah variabel yang
nilainya tergantung dengan variabel lainnya, sedangkan variabel terikat adalah variabel
yang nilainya tergantung dari variabel lainnya.
Analisis regresi digunakan untuk mengetahui hubungan anatara dua variabel
atau lebih, terutama untuk menelusuri pola hubungan yang modelnya belum dikertahui
dengan baik, atau untuk mengetahui bagaimana variasi dari beberapa variabel bebas
mempengaruhi variabel terikat dalam suatu fenomena yang komplek. Jika X1,X2, ... , Xk
adalah variabel-variabel bebas dan Y adalah variabel terikat, maka terdapat hubungan
antara fungsional antara X dan Y dimana variasi dari X akan diiringi pula oleh variasi dari
2.2.1 Analisis Regresi Linier Sederhana
Analisis regresi linier sederhana terdiri dari satu variabel bebas dan satu variabel terikat.
Dengan kata lain variabel yang dianalisis terdiri dari satu variabel prediktor dan satu
variabel kriterium. Model regresi linier sederhananya adalah:
Ŷ= a + bX
di mana:
Y = Variabel terikat (dependent variable)
X = Variabel bebas (independent variable)
a =Konstanta (Intercept)
b = Kemiringan (slope)
Penggunaan regresi linier sederhana didasarkanpada asumsi, diantaranya sebagai
berikut:
1. Model regresi harus linier dalam parameter.
2. Variabel bebas tidak berkolerasi dengan disturbance term(eror).
3. Nilai disturbance term sebesar 0 atau dengan simbol sebagai e.
4. Varian untuk masing-masing error term (kelahan) konstan
5. Tidak terjadi autokorelasi
6. Model regresi dispesifikasikan secara benar. Ridak terdapat bias spesifikasi dalam
model yang digunakan dalam analisis empiris.
�
=
(∑�1)(∑ ��²)−(∑��)(∑����) �∑��2− (∑��)²
(2.1)
Jika koefisien b terlebih dahulu dihitung, maka koefisien a dapat dihitung dengan rumus:
�
=
�(∑����)− (∑��)(∑��) �∑��2− (∑��)²
(2.2)
Dengan Y dan X masing-masing rata-rata untuk variabel-variabel X dan Y.
2.2.2 Analisis Regresi Linier berganda
Regresi linier ganda (Multiple Regression) berguna untuk mencari pengaruh atau untuk
meramalkan dua variabel prediktor atau lebih terhadap variabel kriteriumnya. Suatu
persamaan regresi linier yang memiliki lebih dari satu variabel bebas X dan satu variabel
terikat Y akan membentuk suatu persamaan regresi yang baru, disebut persamaan
regresi linier berganda (multiple regression). Model persamaan regresi linier berganda
hampir sama dengan model regresi linier sederhana, letak perbedaannya hanya pada
jumlah variabel bebasnya.
Secara umum model regresi linier berganda adalah sebagai berikut:
Ŷ = b0 + b1X1 + b2X2 + b3X3 + ... + bkXk + Ɛ
di mana:
Ŷ = Variabel terikat (dependent variable)
b0 = Konstanta regresi
bk = Koefisien regresi variabel bebas Xk
Ɛ = Pengamatan variabel eror
Untuk memudahkan pengolahan data, maka data-data dapat dimasukkan ke
dalam tabel. Bentuk umum dari tabel untuk variabel penduga yang lebih dari satu adalah
seperti bentuk tabel di bawah ini:
TABEL 2.1 BENTUK UMUM TABEL DATA REGRESI LINIER BERGANDA
Dalam penelitian ini digunakan enam variabel yang terdiri dari satu variabel
terikat (Y) dan lima variabel bebas (X). Maka persamaan regresi bergandanya adalah Ŷ =
bo + b1X1i + b2X2i + b3X3i
2.3 Uji Keberartian Regresi
Sebelum persamaan regresi yang diperoleh digunakan untuk membuat kesimpulan,
terlebih dahulu diperiksa setidaknya mengenai kelinieran dan keberartiannya.
Pemeriksaan ini ditempuh melalui pengujian hipotesis. Uji keberartian dilakukan untuk
meyakinkan diri apakah regresi yang didapat berdasarkan penelitian ada artinya bila
dipakai untuk membuat kesimpulan mengenai hubungan sejumlah peubah yang sedang
dipelajari.
Untuk itu diperlukan dua macam jumlah kuadrat (JK) yaitu jumlah kuadrat untuk
regresi yang ditulis JKres. Maka secara umum jumlah kuadrat-kuadrat tersebut dapat
dihitung dengan rumus:
(2.3)
Dengan derajat kebebasan dk = k
Jk
reg =∑
(Y
1 –Ŷ
I)
2
Dengan derajat kebebasan dk = (n – k – 1) untuk sampel ukuran n.
Fhitung =
�����/ �
�����(�−�−1) (2.4)
Dimana statistik F yang menyebar mengikuti distribusi F dengan derajat kebebasan
pembilang V1 = K dan penyebut V2 = n – k – 1
2.3.1 Pengujian Hipotesis
Pengujian hipotesis merupakan salah satu yang akan dibuktikan dalam penelitian. Jika
terdapat deviasi antara sampel yang ditentukan dengan jumlah populasi maka tidak
tertutup kemungkinan untuk terjadinya kesalahan dalam mengambil keputusan antara
menolak atau menerima suatu hipotesis. Pengujian hipotesis
dapat didasarkan dengan menggunakan dua hal, yaitu : tingkat signifikan atau
probabilitas (α) dan tingkat kepercayaan atau confidence interval. Didasarkan tingkat signifikansi pada umumnya orang menggunakan 0,05. Kisaran tingkat signifikansi mulai
dari 0,01 sampai dengan 0,1. Yang dimaksud dengan tingkat signifikan adalah
probabilitas melakukan kesalahan tipe 1, yaitu kesalahan menolak hipotesis ketika
hipotesis tersebut benar. Tingkat kepercayaan pada umumnya ialah sebesar 95%, yang
dimaksud dengan tngkat kepercayaan ialah tingkat dimana sebesar 95% nilai sampel
akan mewakili nilai populasi dimana sampel berasal. Dalam malakukan uji hipotesis
terdapat dua hipotesis, yaitu: H0 (hipotesis 0) dan Ha (hipotesis alternatif). H0 bertujuan
untuk memberikan usulan dugaan kemungkinan tidak adanya perbedaan antara
perkiraan penelitian dengan keadaan yang sesungguhnya yang akan diteliti. Ha bertujuan
memberikan usulan dugaan adanya perbedaan perkiraan dengan keadaan
susungguhnya yang akan diteliti.
Pembentukan suatu hipotesis memerlukan teori-teori maupun hasil penelitian
terlebih dahulu sebagai pendukung pernyataan hipotesis yang diusulkan. Dalam
membentuk hipotesis ada beberapa hal yang dipertimbangkan, yaitu :
2. Daerah penerimaan dan penolakan serta teknik arah pengujian (one tailed atau two
tailed).
3. Penentuan nilai hitung statistik.
4. Menarik kesimpulan apakah menerima atau menolak hipotesis yang diusulkan
dalam uji keberartian regresi
Langkah-langkah yang dibutuhkan untuk pengujian hipotesis ini antara lain.
1. H0 : ᵝ0 = ᵝ1 = ... = ᵝk = 0
k terdapat hubungan fungsional yang signifikan antara variabel bebas dengan variabel terikat.
Minimal satu parameter koefisien regresi ᵝk yang ≠ 0
Terdapat hubungan fungsional yang signifikan antara variabel bebas dengan
variabel terikat.
2. Pilih taraf nyata α yang diiginkan.
3. Hitung statistik Fhitung dengan menggunakan persamaan.
4. Nilai Ftabel menggunakan daftar table F dengan taraf signifikan α yaitu Ttabel = F(1-α)(K),(n
-k-1).
5. Kriteria pengujian : jika Fhitung ≥ Ftabel, maka H0 ditolak dan Ha diterima. Sebaliknya jika
Fhitung < Ftabel, maka H0 diterima dan Ha ditolak.
2.4 Koefisien Determinasi
Koefisien determinasi yang dinyatakan dengan R2 untuk pengujian regresi linier
berganda yang mencakup lebih dari dua variabel adalah untuk mengetahui proporsi
keragaman total dalam variabel tak bebas (Y) yang dapat dijelaskan atau diterangkan
oleh variabel-variabel bebas (X) yang ada di dalam model persamaan regresi linier
berganda secara bersama-sama. Maka R2 akan ditentukan dengan rumus, yaitu :
R2=�����
∑�12
di mana:
JKreg = Jumlah kuadrat regresi
Harga R2 diperoleh sesuai dengan variansi yang dijelaskan masing – masing
variabel yang tinggal dalam regresi tersebut . Hal ini mengakibatkan variansi yang
dijelaskan penduga yang disebabkan oleh variabel yang berpengaruh saja ataupun
dengan kata lain hanya yang bersifat nyata.
2.5 Uji Koefisien Regresi Linier Berganda
Untuk mengetahui bagaimana keberartian setiap variabel bebas dalam regresi, perlu
diadakan pengujian tersendiri mengenai koefisien-koefisien regresi. Model persamaan
regresi linier berganda:
Ŷ = b0 + b1X1 + b2X2 + b3X3 + ... + bkXk + Ɛ
Perumusan Hipotesa:
H0 :ᵝi = 0 dimana i = 1,2, . . . , k
Ha : ᵝi≠ 0 dimana i = 1.2. . . . , k
Untuk menguji hipotesis ini digunakan kekeliruan baku taksiran ��2,1,2,...,K, dan dii =
elemen matriks (X’X)-1 dari baris i kolom i yang terletak pada diagonal utama. Dengan
Sb1 = �(��2,1,2,...,k)dii (2.6)
Selanjutnya hitung statistik:
Ti =
b1
��1
(2.7)
Kriteria Pengujian :
Jika thitung ≥ ttabel, maka H0 ditolak dan Haditerima
Jika thitung < ttabel, maka H0 diterima dan Ha ditolak
Dengan derajat kebebasan dk = (n-k-1) dan ttabel = ttabel = t(n-k-1;α)
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Salah satu faktor pendukung terciptanya kesejahteraan masyarakat adalah rendahnya
tingkat kejahatan/ kriminalitas yang terjadi ditengah tengah kehidupan masyarakat.
Tingkat rendahnya kejahatan yang terjadi sangat tergantung pada seberapa banyak
pelaku kejahatan/ pelanggaran dapat diselesaikan secara hukum.
Kriminalitas atau tindak kejahatan adalah tingkah laku yang melanggar hukum
dan norma-norma sosial, sehingga masyarakat menentangnya. Dalam banyak kasus
kejahatan terjadi karena beberapa faktor. Faktor penyebab kejahatan antara lain faktor
Jumlah Penduduk, Jumlah Penduduk Miskin yang terdiri dari faktor-faktor ekonomi
(Jumlah Pendapatan dan Pengeluaran Konsumsi Penduduk), faktor-faktor mental
(agama, bacaan, harian-harian, film), dan faktor-faktor pribadi (umur, ras dan
nasionalitas, alkohol, perang).
Kondisi Kejahatan Kabupaten Tapanuli Selatan tahun 2006 sebanyak 628 kasus,
tahun 2007 sebanyak 692 kasus, tahun 2008 sebanyak 752 kasus, tahun 2009 sebanyak
890 kasus, tahun 2010 sebanyak 988 kasus, tahun 2011 sebanyak 1051 kasus, tahun
2012 sebanyak 1270 kasus, tahun 2013 sebanyak 1275 kasus. Berdasarkan kondisi
tersebut Kabupaten Tapanuli Selatan mengalami naik turunnya tindak kejahatan (Polres
Tapsel, 2014)
L.M Cristone (1791-1848) mengatakan bahwa ada hubungan antara industri
dengan pertambahan kemiskinan yang mengakibatkan naiknya kejahatan. Kemiskinan
merupakan penyebab dari revolusi dan kriminalitas (Aristoteles).
Kemiskinan diartikan sebagai suatu keadaan dimana seseorang tidak sanggup
memelihara dirinya sendiri sesuai dengan taraf kehidupan kelompok dan juga tidak
mampu memanfaatkan tenaga mental maupun fisiknya dalam kelompok.
Masalah penganguran dinilai menjadi faktor utama pemicu terjadinya tindak
kejahatan di Kabupaten Tapanuli Selatan. Sulitnya mencari penghasilan, tuntutan perut
Berbagai penyimpangan yang mereka lakukan adalah buah dari sendi kehidupan
masyarakat pengangguran yang tiada pilihan.
Aparat keamanan yang punya tugas memberikan rasa aman kepada masyarakat
seakan tidak mampu berbuat banyak. Ini karena jumlah pelaku kejahatan kendati
ditangkap terus bertambah, bahkan modusnya makin berani dan menggila. kenyataan di
lapangan selalu menunjukkan, rata-rata pelaku kejahatan adalah para pengangguran
yang terdesak kebutuhan ekonomi, khususnya pelaku kejahatan kelas teri.
sesungguhnya tingkat pengangguran yang sangat akrab dengan kemiskinan itu tidak
pantas dibiarkan berlarut-larut, sebab bakal memicu berbagai kerawanan.
Dengan melihat realita dan memiliki harapan atau mimpi bangsa ini untuk
menjadi negara yang makmur dan sejahtera maka penulis ingin mengusulkan judul
"Faktor-Faktor Yang Mempengaruhi Tingkat Kejahatan Di Kabupaten Tapanuli
Selatan''.
1.2 Rumusan Masalah
Kehidupan yang aman, nyaman dan tentram tentunya merupakan suatu hal yang sangat
diinginkan oleh setiap manusia. Sebagai usaha untuk meningkatkan keamanan di
Kabupaten Tapanuli Selatan diperlukan adanya pengkajian data yang dapat
menggambarkan faktor apa yang paling mempengaruhi terjadinya tindakan kejahatan
dengan cara mengolah dan menganalisa data yang diperoleh.
1.3 Batasan Masalah
Untuk mempermudah pembahasan dan pemecahan masalah, maka perlu dibuat suatu
pembatasan masalah agar sesuai dengan tujuan dan tepat sasaran, yaitu :
2. Pemecahan masalahnya dibatasi pada jumlah kejahatan, persentase tingkat
pengangguran, jumlah industri, jumlah penduduk dan jumlah penduduk miskin
dengan menggunakan data pada tahun 2006 sampai dengan tahun 2013.
1.4 Tujuan Penelitian
Ada pun tujuan dilakukan penelitian ini adalah:
1. Untuk menentukan persamaan linier berganda dari faktor penduga terjadinya
tingkat kejahatan.
2. Untuk mengetahui seberapa besar faktor-faktor tersebut mempengaruhi tindak
kejahatan.
3. Untuk mengetahui faktor yang paling berpengaruh terhadap tingginya tingkat
kejahatan.
1.5 Manfaat Penelitian
Ada pun metode-metode yang dilakukan dalam pengumpulan data faktor yang
mempengaruhi tingkat tindak kejahatan di Kabupaten Tapanuli Selatan Diantaranya
adalah :
1. Metode Penelitian Kepustakaan (Studi Literatur)
Penelitian yang dilakukan dengan mengamati data yang tersedia, data tersebut
diperoleh dengan membaca buku-buku serta bahan-bahan yang bersifat teoritis yang
berasal dari perpustakaan dimana data itu diperoleh.
2. Metode Pengumpulan Data
Pengumpulan data bersumber dari data sekunder yang diperoleh dari Badan Pusat
Statistik (BPS) Provinsi Sumatera Utara dan dari Kepolisian Negara Tapanuli Selatan.
angka-angka dengan tujuan untuk mendapatkan gambaran yang jelas tentang
sekumpulan data tersebut
3. Metode Pengolahan Data
Data dianalisa menggunakan metode regresi linier berganda untuk melihat
persamaan regresi liniernya dan untuk mengetahui hubungan setiap variabel digunakan
analisi korelasi.
Langkah-langkah yang dilakukan dalam pengolahan data adalah:
1. Mengelompokkan data menjadi variabel bebas (X) dan variabel terikat
(Y).
2. Menentukan hubungan antara variabel bebas (X) dengan variabel terikat (Y)
sehingga didapat regresi Y atas X1, X2, ... , Xk
3. Uji Regresi Linier berganda untuk mengetahui besarnya pengaruh variable
bebas X secara bersama-sama terhadap variabel terikat Y.
4. Uji korelasi untuk mengetahui seberapa besar pengaruh hubungan
variabel-variabel bebas tersebut terhadap variabel-variabel terikat.
1.6 Metode Penelitian
Ada pun metode-metode yang dilakukan dalam pengumpulan data faktor yang
mempengaruhi tingkat tindak kejahatan di Tapanuli Selatan diantaranya adalah:
1. Metode Penelitian Kepusatakaan (Studi literature)
Penelitian yang dilakukan dengan mengamati data yang telah tersedia, data
tersebut diperoleh dengan membaca buku-buku serta bahan-bahan yang bersifat
teoritis yang berasal dari perpustakaan dimana data itu diperoleh.
2. Metode Pengumpulan Data
Pengumpulan data bersumber dari data sekunder yang diperoleh dari Bada Pusat
Statistik (BPS) Provinsi Sumatera Utara Dan Dari Polres Tapanuli Selatan. Data yang
angka-angka dengan tujuan untuk mendapatkan gambaran yang jelas tentang sekumpulan
data tersebut.
3. Metode Pengolahan Data
Data dianalisa menggunakan metode regresi linier berganda untuk variable
digunakan analisis korelasi.
Langkah-langkah yang dilakukan dalam pengolahan data adalah:
1. Mengelompokkan data menjadi variable bebas (X) dan variable terikat (Y).
2. Menentukan hubungan antara variable bebas (X) dengan variable terikat (Y)
sehingga didapat regresi Y atas X1,X2, … ,Xk.
3. Uji Regresi Linier Berganda untuk mengetahui besarnya pengaruh variable bebas
X secara bersama-sama terhadap variable terikat Y.
4. Uji Korelasi untuk mengetahui seberapa besar pengaruh hubungan
variable-variabel bebas tersebut terhadap terikat.
1.7 Tinjauan Pustaka
Analisi regresi merupakan suatu metode yang digunakan untuk menganalisis hubungan
antara variabel, hubungan tersebut dapat dikorespondensikan dalam bentuk persamaan
yang menghubungkan variabel terikat/ defendent dengan satu atau lebih variabel
bebas/ independent, maka pada regresi berganda digunakan lebih dari satu variabel
bebas/ independent.
Dengan semakin banyaknya variabel bebas berarti semakin tinggi pula
kemampuan regresi yang dibuat untuk menerangkan variabel terikat, atau peran
faktor-faktor lain diluar variabel bebas yang digunakan, yang dicerminkan oleh error semakin
kecil. Studi yang menyangkut masalah ini dikenal dengan analisis regresi berganda.
Persamaan Regresi Linier Berganda:
di mana:
Y : Variabel tak bebas/ variabel terikat
X1, X2, ... Xk : Variabel Bebas
∑ : Kesalahan
b0 : Konstanta
b0, b1, b2, ... , bk : Koefisien variabel bebas
Maka variabel-variabel penelitian dapat dimasukkan kedalam persamaan dengan::
Y = Tingkat Kejahatan
X1 = Jumlah Penduduk
X2 = Jumlah Penduduk Miskin
X3 = Jumlah pengeluaran dan konsumsi Penduduk
Nilai koefisien korelasi
Nilai koefisien korelasi merupakan nilai yang digunakan untuk mengukur kekuatan
(keeratan) suatu hubungan antar variable. Koefisien korelasi biasanya disimbolkan
FAKTOR – FAKTOR YANG MEMPENGARUHI TINGKAT KEJAHATAN DI KABUPATEN TAPANULI SELATAN
TUGAS AKHIR
ELVAN RIFIYANTO PANE 122407118
PROGRAM STUDI D3 STATISTIKA DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
FAKTOR – FAKTOR YANG MEMPENGARUHI TINGKAT KEJAHATAN DI KABUPATEN TAPANULI SELATAN
TUGAS AKHIR
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh Ahli Madya
ELVAN RIFIYANTO PANE 122407118
PROGRAM STUDI D3 STATISTIKA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul :FAKTOR – FAKTOR YANG MEMPENGARUHI
TINGKAT KEJATAHATAN DI KABUPATEN TAPANULI SELATAN TAHUN
2006-2013
Kategori :TUGAS AKHIR
Nama :ELVAN RIFIYANTO PANE
Nomor Induk Mahasiswa :122407118
Program Studi :DIPLOMA (DIII) STATISTIKA
Departemen :MATEMATIKA
Fakultas :MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Juli 2015
Diketahui oleh:
Pembimbing, Ketua Program Studi D3 Statistika
FMIPA USU
Dr. Faigiziduhu Bu’ulӧlӧ, M.Si.
NIP. 19531218 198003 1 003 NIP. 19640109 198803 1 004
PERNYATAAN
FAKTOR – FAKTOR YANG MEMPENGARUHI TINGKAT KEJAHATAN DI TAPANULI SELATAN
TUGAS AKHIR
Saya mengakui bahwa tugas akhir ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2015
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala kasih karunia dan penyertaanNya penulis dapat menyelesaikan penyusunan tugas akhir ini dengan judul Faktor – faktor yang Mempengaruhi Tingkat Kejahatan Di Kabupaten Tapanuli Selatan.
Pada kesempatan ini, dalam penulis mendapatkan banyak bantuan dari barbagai pihak. Terimakasih Penulis sampaikan kepada bapak Prof. Dr. Saib Suwilo, M.Sc selaku pembimbing dan bapak Dr. Faigiziduhu Bu’ulölö, M.Si. dan Bapak Dr. Suwarno Ariswoyo, M.Si selaku Ketua dan selaku Sekertaris Program Studi D3 Statistika FMIPA USU yang telah meluangkan waktunya selama penyusunan tugas akhir ini. Terimakasih kepada Bapak Prof. Dr. Tulus, M.Si dan Ibu Dr. Mardiningsih, M.Si selaku Ketua dan Sekertaris Departemen Matematika FMIPA USU, Bapak Dr. Sutarman, M.Sc selaku Dekan FMIPA USU, seluruh Dosen Program Studi D3 Statistika FMIPA USU, pegawai FMIPA USU. Akhirnya tidak terlupakan kepada orang tua saya Bapak Panyahatan Pane dan Ibu Rita Berlian Batubara dan keluarga yang selalu memberikan dukungan kepada saya baik itu berupa dukungan moril maupun dukungan materil, teman-teman seperjuangan yang selalu memberikan motivasi baik berupa sharing pendapat dan hal-hal lainnya dalam rangka pembuatan tugas akhir ini. Penulis berharap Tuhan Yang Maha Esa membalasnya.
Medan, Juli 2015
Penulis,
BAB 4 IMPLEMENTASI SISTIM 26
4.1 Pengertian Implementasi 26
4.2 Hasil Implementasi 26
4.3 Cara Kerja SPSS 26
4.4 Langkah-Langkah Pengolahan Data dengan SPSS 27
BAB 5 KESIMPULAN DAN SARAN 35
5.1 Kesimpulan 35
5.2 Saran 36
DAFTAR TABEL
Halaman
Tabel 3.1 Data Tindak Kejahatan, Jumlah Penduduk, Jumlah 15
Penduduk Miskin Jumlah Industri, Jumlah Pengeluaran dan Konsumsi Penduduk Tahun 2006 – 2014. Tabel 3.2 Metode Kota Dialog Regresi Linier 17
Tabel 3.3 Metode Hasil Penjumlahan 18
Tabel 3.4 Output ANOVA 1 Arah 18
Tabel 3.5 Nilai-nilai Koefisien 19
Tabel 3.6 Nilai Residual 20
DAFTAR GAMBAR
Halaman
Gambar 3.1 Output Berupa Histogram 22
Gambar 3.2 Output berupa Normal P-P Of regression 23
Standardized Residul
Gambar 4.1 Tampilan Saat Memulai Membuka IBM SPSS 22 28