SISTEM TEMU KEMBALI NAMA ILMIAH DENGAN
MENGGUNAKAN ALGORITME FONETIK
WAHYU DIAS HARSOWIYONO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Sistem Temu Kembali Nama Ilmiah dengan Menggunakan Algoritme Fonetik adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
WAHYU DIAS HARSOWIYONO. Sistem Temu Kembali Nama Ilmiah dengan Menggunakan Algoritme Fonetik. Dibimbing oleh JULIO ADISANTOSO.
Penelitian ini melakukan temu kembali dokumen berdasarkan pencarian dengan menggunakan nama ilmiah sebagai kata kuncinya. Pendekatan yang dilakukan menggunakan algoritme fonetik, yaitu Soundex, Phonix, dan Metaphone. Tujuan dari penelitian ini adalah untuk mempelajari ketiga algoritme fonetik yang dikombinasikan dengan teknik similaritas kata (exact matching, biner (N-Grams), dan levenshtein distance), sehingga diharapkan dapat menangani permasalahan pencarian kata dengan menggunakan dua suku kata. Dokumen yang digunakan dalam penelitian ini sebanyak 100 dokumen uji yang telah diberi tanda (tag). Kata yang sudah diberi tanda akan dikonversi ke dalam kode tertentu sesuai dengan algoritme fonetik, yang nantinya akan dihitung similaritasnya dengan kata input yang sudah dikonversikan juga. Pencarian nama ilmiah dengan dikombinasikan teknik similaritas berhasil mengatasi masalah, baik itu salah pada saat pengetikan atau salah dalam pengejaan kata karena kemiripan ucapan dan juga dalam menangani pencarian dengan menggunakan dua suku kata. Hal ini ditunjukkan berdasarkan persentase average precision (AVP) dari hasil pencarian yaitu sebesar 77.8% (Soundex), 88% (Phonix), dan 97.5% (Metaphone). Kata kunci: fonetik, Metaphone, Phonix, similaritas, Soundex
ABSTRACT
WAHYU DIAS HARSOWIYONO. Retrieval System of Scientific Names using Phonetics Algorithm. Supervised by JULIO ADISANTOSO.
This research did document retrieval by its scientific name as the search keywords. The approach was taken by using the phonetics algorithm, Soundex, Phonix, and Metaphone. The purpose of this research is to apply the three algorithms phonetic similarity with combined technique, in terms of using exact matching, binary (N-Grams), and levensthein distance. So that expected to overcome the issue by using the search word two syllables. Documents used in this research were 100 documents that have been tagged. The word that has been tagged will be converted into specific code in accordance with phonetic algorithms, which will be calculated similarity with the input word. Search scientific name combined with similarity techniques succeed to solve the problem, whether it’s wrong typing or spelling words wrong as well as similarities in handling the search by using two syllables. This is indicated by the percentage of average precision (AVP) from the search result is equal to 77.8% (Soundex), 88% (Phonix), and 97.5% (Metaphone).
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
SISTEM TEMU KEMBALI NAMA ILMIAH DENGAN
MENGGUNAKAN ALGORITME FONETIK
WAHYU DIAS HARSOWIYONO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Sistem Temu Kembali Nama Ilmiah dengan Menggunakan Algoritme Fonetik
Nama : Wahyu Dias Harsowiyono NIM : G64104006
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Agustus 2012 ini ialah temu kembali informasi, dengan judul Sistem Temu Kembali Nama Ilmiah dengan Menggunakan Algoritme Fonetik.
Terima kasih penulis ucapkan kepada Bapak Ir Julio Adisantoso, MKom selaku pembimbing yang telah banyak memberi saran dan masukan selama penelitian ini dilakukan. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, seluruh keluarga, serta teman-teman atas segala doa, kasih sayang, dan dorongannya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE PENELITIAN 2
Pemrosesan Offline 3
Pemrosesan Online 6
Similaritas 6
Evaluasi 8
Lingkungan Pengembangan Sistem 9
HASIL DAN PEMBAHASAN 9
Pengumpulan Dokumen 9
Tagging Nama ilmiah 10
Query Input 10
Indexing 11
Similaritas 15
Pengujian dan Evaluasi Sistem 18
SIMPULAN DAN SARAN 20
Simpulan 20
Saran 21
DAFTAR PUSTAKA 21
DAFTAR
TABEL1 Tabel pengodean konsonan algoritme Soundex (Primasari 1997) 4
2 Contoh penghitungan Soundex 5
3 Tabel pengodean konsonan algoritme Phonix (Primasari 1997) 5
4 Contoh penghitungan Levenshtein 7
5 Kumpulan query uji 11
6 Tabel perbandingan kecepatan proses Soundex, Phonix, dan
Metaphone 12
7 Contoh hasil penghitungan similaritas dengan N-Grams 16 8 Contoh hasil penghitungan similaritas dengan Levenshtein distance 17 9 Contoh hasil penghitungan kombinasi linear terhadap beberapa query 18
DAFTAR GAMBAR
1 Alur pemrosesan offline dan online. 3
2 Contoh format dokumen uji 3
3 Contoh dokumen sebelum diberi tag 10
4 Contoh dokumen setelah diberi tag 10
5 Grafik perbandingan kecepatan rata-rata proses 14 6 Grafik perbandingan akurasi untuk ketiga algoritme fonetik 19 7 Grafik recall precision query uji dengan AVP 20
DAFTAR LAMPIRAN
1 Tabel aturan Metaphone (Syaroni dan Munir 2004) 22 2 Nilai recall-precision untuk query uji yang salah pada sistem temu
kembali nama ilmiah 23
PENDAHULUAN
Latar Belakang
Nama merupakan identitas yang digunakan untuk mengenali suatu objek tertentu. Begitu pula dengan nama latin dari suatu tumbuhan yang merupakan cara penamaan yang dipakai universal untuk membedakan suatu spesies dengan spesies lainnya. Satu spesies yang sama bisa memiliki banyak nama untuk daerah yang berbeda dan bahkan dalam daerah yang sama suatu spesies bisa memiliki nama yang berbeda-beda.
Dalam sistem temu kembali informasi, sering terjadi kesalahan pencarian nama karena nama tidak diketahui secara lengkap atau terjadi kesalahan pengetikan nama. Banyak algoritme dalam temu kembali informasi untuk pencarian nama, tetapi algoritme yang sesuai untuk diterapkan dalam permasalahan pencarian nama latin belum diketahui.
Ada beberapa metode pencarian nama berbasis fonetik, antara lain algoritme Soundex, Phonix, dan Metaphone. Algoritme Soundex adalah metode yang dikenal dengan membandingkan kata dengan memperhatikan kesamaan ucapan/fonetik (Pfeifer et al. 1996). Teknik yang diambil adalah mengubah atau mengodekan huruf konsonan dan menghilangkan huruf vokal, sedangkan huruf selain huruf pertama dari kata akan dikodekan ke dalam kode tertentu sehingga kode Soundex bernilai sama untuk kata bila diucapkan terdengar mirip.
Algoritme Phonix merupakan algoritme yang sama seperti Soundex, tetapi algoritme Phonix lebih rumit karena banyak perlakuan yang berbeda terhadap jenis konsonan tertentu. Algoritme Metaphone dikembangkan pertama kali oleh Philips (1990) dengan tujuan mencari kata-kata yang memiliki persamaan bunyi seperti algoritme Soundex dan Phonix. Dari algoritme yang dijelaskan sebelumnya muncul permasalahan jika nama terdiri atas dua suku kata.
Penelitian sebelumnya pernah dilakukan oleh Primasari (1997) yang membandingkan metode Soundex dan Phonix. Permasalahan yang terjadi adalah ketidakmampuan dalam mendeteksi penambahan suatu konsonan pada suatu kata. Contohnya kata AKHMAD mempunyai kode Soundex A253, sedangkan kata AHMAD mempunya kode Soundex A53. Kedua kata ini mempunyai pengucapan yang sama tetapi memiliki kode Soundex yang berbeda sehingga tidak dianggap sebagai kata yang mirip. Di samping itu, Primasari (1997) tidak menjelaskan kemampuan sistem jika diberikan dua buah suku kata dalam pencarian.
Syaroni dan Munir (2004) melakukan perbandingan antara Soundex dan Metaphone dan menyimpulkan bahwa kedua algoritme tersebut dapat mengenali dengan baik kata yang dicari, tetapi jika diberikan dua buah suku kata dalam pencarian, hasil pencarian tidak sesuai dengan yang diinginkan.
2
Perumusan Masalah
Bertitik tolak dari latar belakang di atas maka rumusan masalah dalam penelitian ini sebagai berikut:
1 Apakah algoritme fonetik bisa diterapkan pada pencarian nama latin atau nama ilmiah?
2 Dapatkah sistem menangani pencarian nama latin atau nama ilmiah dengan kesalahan pada pengetikan query input?
3 Dapatkah sistem menangani pencarian dengan menggunakan dua suku kata?
Tujuan Penelitian
Penelitian ini bertujuan mempelajari ketiga algoritme fonetik (Soundex, Phonix, dan Metaphone) yang dikombinasikan dengan teknik similaritas kata (exact matching, biner (N-Grams), dan Levenshtein distance) dalam mesin pencari nama ilmiah dari tumbuhan. Penelitian ini diharapkan dapat menangani permasalahan pencarian kata dengan menggunakan dua suku kata.
Manfaat Penelitian
Manfaat dari penelitian ini adalah membantu pengguna dalam melakukan pencarian nama latin atau nama ilmiah dari tumbuhan dengan menggunakan satu atau dua suku kata. Walaupun ketika melakukan pencarian terjadi kesalahan dalam memasukkan kata, sistem masih dapat menampilkan dokumen yang memiliki kedekatan dari kata masukan.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini adalah:
1 Dokumen uji yang digunakan mengandung sedikitnya satu nama ilmiah dari tumbuhan.
2 Query input yang dimasukkan berupa nama ilmiah dari tumbuhan yang terdiri atas satu atau dua suku kata.
METODE PENELITIAN
3
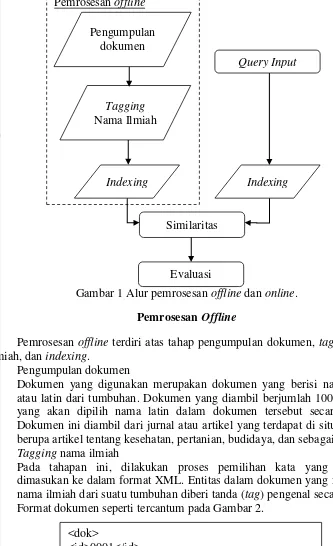
Gambar 1 Alur pemrosesan offline dan online.
Pemrosesan Offline
Pemrosesan offline terdiri atas tahap pengumpulan dokumen, tagging nama ilmiah, dan indexing.
1 Pengumpulan dokumen
Dokumen yang digunakan merupakan dokumen yang berisi nama ilmiah atau latin dari tumbuhan. Dokumen yang diambil berjumlah 100 dokumen, yang akan dipilih nama latin dalam dokumen tersebut secara manual. Dokumen ini diambil dari jurnal atau artikel yang terdapat di situs Internet, berupa artikel tentang kesehatan, pertanian, budidaya, dan sebagainya. 2 Tagging nama ilmiah
Pada tahapan ini, dilakukan proses pemilihan kata yang kemudian dimasukan ke dalam format XML. Entitas dalam dokumen yang merupakan nama ilmiah dari suatu tumbuhan diberi tanda (tag) pengenal secara manual. Format dokumen seperti tercantum pada Gambar 2.
Gambar 2 Contoh format dokumen uji <dok>
<id>0001</id>
<subject>Klasifikasi Kelapa Sawit</subject> <deskripsi>
Pohon Kelapa Sawit dengan nama latin <latin>Elaeis guineensis</latin> terdiri daripada dua spesies <latin>Arecaceae </latin>
</deskripsi> </dok>
Pemrosesan offline Pengumpulan
dokumen
Tagging Nama Ilmiah
Query Input
Similaritas
Evaluasi
4
Dokumen memiliki tag sebagai berikut:
<DOK></DOK>, mewakili keseluruhan dokumen dan melingkupi tag-tag lain yang lebih spesifik.
<ID></ID>, menunjukkan identitas dari suatu dokumen.
<SUBJECT></SUBJECT>, menunjukkan judul dari suatu dokumen.
<LATIN></LATIN>, menunjukkan nama latin atau nama ilmiah dari tanaman.
<DESKRIPSI></DESKRIPSI>, meliputi deskripsi tanaman dan kegunaannya.
3 Indexing
Pada tahapan ini dilakukan pengodean terhadap nama latin yang sudah diberi tanda sebelumnya ke setiap kelas fonetik yang akan digunakan. Ketiga algoritme fonetik akan melakukan konversi nama ilmiah ke dalam kode-kode tertentu sesuai dengan susunan huruf pada nama ilmiah (Tabel 1, 3, dan 4).
Algoritme Soundex dan Phonix melakukan penghitungan kode fonetik untuk setiap nama yang diberikan. Nama-nama yang berbagi dengan kode yang sama diasumsikan mirip (Pfeifer et al. 1996). Algoritme Soundex adalah sebagai berikut:
1 Buang semua huruf hidup atau vokal, konsonan H, W, Y, dan dalam urutan yang sama.
2 Untuk huruf pertama tidak dibuang dan dibiarkan apa adanya.
3 Buatlah kode Soundex dengan menggunakan acuan Tabel 1 yang kemudian akan digabungkan dengan huruf pertama.
4 Panjang maksimum kode Soundex dibatasi sampai empat karakter.
Fonetik Soundex dibatasi untuk kumpulan konsonan yang berbunyi mirip ke dalam kelas-kelas yang berbeda. Pengelompokan huruf tersebut berdasarkan kemiripan pengucapan atau bunyi dari setiap hurufnya dapat dilihat pada Tabel 1.
Tabel 1 Tabel pengodean konsonan algoritme Soundex (Primasari 1997)
5 Contoh kasus pada pengodean nama latin dari pohon jati, yaitu Tectona grandis. Jika dilihat dari aturan yang ada, huruf pertama dari nama latin dibiarkan dan huruf selanjutnya dikodekan sesuai aturan tabel yang ada.
Tabel 2 Contoh penghitungan Soundex
Nama latin Kode Keterangan
T T Dibiarkan karena huruf pertama E - Dihilangkan karena huruf vokal
C 2 Kelompok 2
T 3 Kelompok 3
O - Dihilangkan karena huruf vokal
N 5 Kelompok 5
A - Dihilangkan karena huruf vokal atau karena jumlah karakter sudah 4
Jadi, kode Soundex untuk nama latin Tectona adalah T235. Untuk huruf terakhir sebenarnya tidak perlu diperhatikan lagi karena sudah mencapai maksimum kode dari aturan Soundex.
Tabel 3 Tabel pengodean konsonan algoritme Phonix (Primasari 1997)
Alfabet Kode
A, I, U, E, O, H, W, Y (dihilangkan)
B, P 1
C, G, J, K, Q 2
D, T 3
L 4
M, N 5
R 6
F, V 7
S, X, Z 8
Algoritme Phonix lebih rumit daripada Soundex, karena pada Phonix dilakukan aturan yang lebih banyak dan khusus untuk huruf tertentu dan terjadi aturan penggantian huruf yang rumit. Pengelompokan huruf pada algoritme Phonix dapat dilihat pada Tabel 3. Prinsip dasar cara kerja Phonix menurut Primasari (1997) adalah sebagai berikut:
1 Jika huruf pertama adalah huruf hidup atau konsonan Y, ganti huruf pertama tersebut dengan huruf V.
6
3 Buang semua huruf hidup, konsonan H, W, dan Y, dan semua huruf sama yang berurutan.
4 Buat kode Phonix dari kata tersebut tanpa bunyi akhir dengan mengganti semua huruf yang tersisa dengan nilai numerik seperti Tabel 2, kecuali huruf pertama. Panjang maksimum kode Phonix dibatasi sampai delapan karakter. Menurut penelitian yang dilakukan oleh Syaroni dan Munir (2004), langkah-langkah dalam melakukan pengodean huruf alfabet adalah:
1 Menghilangkan semua karakter di luar alfabet.
2 Alfabet yang digunakan hanya 16 suara konsonan yaitu: B, F, H, J, K, L, M, N, P, R, S, T, W, X, Y, (kosong) O adalah simbol untuk suara yang dihasilkan oleh “th”.
3 Menghilangkan semua huruf vokal A, I, U, E, O.
4 Mengelompokkan huruf-huruf yang bersifat variabel, yaitu: C, G, P, S, T.
5 Melakukan konversi kata menjadi Metaphone
dengan melakukan pengecekan setiap huruf yang sesuai dengan aturan bahasa tertentu.
Aturan pengelompokan huruf konsonan dari algoritme Metaphone secara lengkap berdasarkan penelitian Syaroni dan Munir (2004) dapat dilihat pada Lampiran 1.
Pemrosesan Online
Pemrosesan online terdiri atas query input, indexing, penghitungan similaritas, dan evaluasi hasil percobaan. Tahapan-tahapan ini dilakukan pada saat sistem berjalan, pada query input dimasukan berupa nama ilmiah yang ingin dicari, baik itu satu atau dua suku kata. Indexing pada proses online dan offline menggunakan algoritme yang sama, bedanya indexing pada proses online ini dilakukan ketika sistem sedang berjalan dan dilakukan secara otomatis, sedangkan indexing pada proses offline dilakukan secara manual.
Similaritas
Pada tahapan ini dilakukan proses penghitungan terhadap kedekatan antara query input yang sudah dilakukan konversi ke dalam kode fonetik dan data yang terdapat dalam korpus. Pada penelitian ini digunakan tiga metode dalam penghitungan kedekatan dua buah kode fonetik tersebut, yaitu exact string matching, biner, dan Levenshtein distance.
1 Exact string matching
Exact string matching merupakan pencocokan string secara tepat antara query input dengan data yang berada di dalam korpus, baik itu berupa jumlah karakter maupun dari urutan karakternya.
2 Biner (N-Grams)
7 Teknik N-Grams memiliki beberapa tipe penghitungan berdasarkan jumlah ‘N’ yang digunakan antara lain Bigram, Trigram, Quadgram, dan seterusnya. Jika dua buah string dibandingkan dengan memperhatikan pada n-grams-nya, himpunan n-grams akan dihitung untuk kedua string. Kemudian kedua himpunan ini dibandingkan dan semakin banyak n-grams yang sama muncul pada kedua himpunan, maka kedua string tersebut semakin mirip (Primasari 1997).
Untuk mendapatkan nilai kedekatan dari N-Grams, digunakan rumus Dice coefficient (Holmes dan McCabe 2002). Penghitungan ini dimaksudkan untuk medapatkan nilai kedekatan dari dua buah string yang dibandingkan. Rumus dari Dice coefficient adalah sebagai berikut:
(1)
Nilai δ adalah nilai kesamaan, adalah jumlah irisan antara dua nama, α adalah jumlah kode pada nama pertama, dan β adalah jumlah kode pada nama kedua. Dice coefficient digunakan untuk menghitung nilai kesamaan antara dua masukan query.
3 Levenshtein distance
Jarak Levenshtein digunakan untuk mengukur jarak nilai antara dua buah string. Setiap huruf dalam query input akan diukur atau dibandingkan dengan data dalam korpus dengan menggunakan fungsi:
(2)
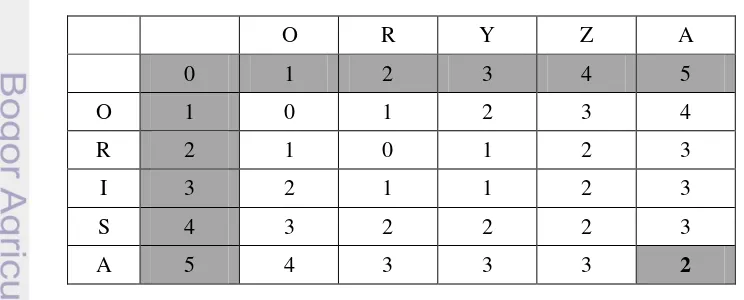
Levenshtein distance merupakan jumlah minimal yang dibutuhkan untuk mengubah suatu string ke string yang lain. Operasi-operasi tersebut adalah penyisipan, penghapusan, dan penggantian (substitusi) karakter yang dibutuhkan. Tabel 4 menampilkan contoh penghitungan jarak Levenshtein untuk string “ORYZA” dengan “ORISA”.
Tabel 4 Contoh penghitungan Levenshtein
O R Y Z A
0 1 2 3 4 5
O 1 0 1 2 3 4
R 2 1 0 1 2 3
I 3 2 1 1 2 3
S 4 3 2 2 2 3
A 5 4 3 3 3 2
8
adalah ukuran kesamaan suku kata kedua, maka ukuran kesamaan kedua suku kata adalah:
δ a - b (3) dengan adalah konstanta pembobot (0 sampai dengan 1), dalam penelitian ini digunakan sebesar 0.5, yang artinya memberikan bobot yang sama kepada kedua suku kata. Jadi, kedua suku kata tersebut memiliki informasi yang sama pentingnya.
Evaluasi
Evaluasi yang dilakukan untuk mengukur relevansi atau efektifitas dari hasil temu-kembali, yaitu menggunakan metode recall dan precision. Recall adalah rasio jumlah dokumen yang dapat ditemu-kembalikan oleh sebuah proses pencarian di sistem IR dengan total jumlah dokumen dalam kumpulan dokumen yang relevan (Manning 2008).
all
Jumlah dokumen rele an hasil temu kembaliJumlah seluruh dokumen yang rele an (4) Precision adalah rasio jumlah dokumen relevan yang ditemukan dengan total jumlah dokumen yang ditemukan dalam IR. Precision menunjukkan kualitas himpunan jawaban, tetapi tidak memandang total jumlah dokumen yang relevan dalam kumpulan dokumen (Manning et al. 2008).
Jumlah dokumen rele an hasil temu kembaliJumlah dokumen seluruh hasil temu kembali (5) Sebuah sistem yang baik akan menghasilkan tingkat recall dan precision yang tinggi. Namun, nilai recall dan precision biasanya bertolak belakang sehingga, ketika precision-nya menaik maka nilai recall menurun, dan sebaliknya (Primasari 1997).
Menurut Baeza-Yates dan Ribeiro-Neto (1999), algoritme temu kembali yang dievaluasi menggunakan beberapa query berbeda, akan menghasilkan nilai R-P yang berbeda untuk masing-masing query. Average Precision (AVP) diperlukan untuk menghitung rata-rata tingkat precision pada 11 tingkat recall, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0.
( ) ∑
(6)
9
Lingkungan Pengembangan Sistem
Penelitian ini menggunakan perangkat lunak dan perangkat keras dengan spesifikasi sebagai berikut:
Perangkat Lunak:
Sistem operasi Microsoft Windows 7
Microsoft Visual Studio 2010
Web Browser (melalui Localhost): Google Chrome
Perangkat Keras:
Intel Pentium Core i5 @2.5 Ghz
RAM kapasitas 4096 MB
Harddisk dengan kapasitas sisa 300 GB
Monitor resolusi 1366 x 768 pixel
Mouse dan keyboard
HASIL DAN PEMBAHASAN
Dalam pembuatan sistem ini, sebagian source code (kode sumber) didapatkan dari sebuah situs bernama blackbeltcoder yang sudah menyediakan secara gratis. Barisan kode yang diambil adalah untuk membentuk class phonetics (Soundex, Phonix, Metaphone). Kelemahan dari class ini adalah tidak dapat menerima masukan dengan jumlah suku kata lebih dari satu sehingga perlu pengubahan dalam class tersebut agar dapat menerima input dua suku kata atau lebih.
Sama seperti lainnya, class Levenshtein distance juga didapatkan dari situs blackbeltcoder, sementara class N-Grams didapatkan dari situs codeproject. Pada kedua class ini dilakukan pengubahan kode yaitu pada saat melakukan kalkulasi kedekatan antar katanya.
Pengumpulan Dokumen
Dokumen yang digunakan berisi nama ilmiah atau nama latin dari tumbuhan. Dokumen yang berhasil dikumpulkan berjumlah 100 dokumen dengan format XML. Data ini diambil dari jurnal atau artikel yang terdapat di situs internet, berupa artikel tentang kesehatan, pertanian, budidaya, dan sebagainya. Contoh dokumen yang diambil dari jurnal atau artikel dapat dilihat pada Gambar 3.
10
Gambar 3 Contoh dokumen sebelum diberi tag
Gambar 4 Contoh dokumen setelah diberi tag
Tagging Nama ilmiah
Pada tahap ini dilakukan pemilihan kata kunci (tag) yaitu nama latin dari tumbuhan yang terdapat dalam suatu dokumen yang sudah dikumpulkan. Proses tagging untuk id, judul, deskripsi, dan nama latin dalam sebuah dokumen dilakukan secara manual, sehingga memakan waktu yang cukup lama. Contoh dokumen yang sudah dilakukan pengolahan tagging nama dapat dilihat pada Gambar 4.
Query Input
Query yang digunakan dalam penelitian ini berupa nama ilmiah yang akan dijadikan sebagai masukan ke dalam sistem. Query ini diubah ke dalam bentuk kode phonetics sesuai dengan algoritme yang digunakan. Setelah itu akan dilakukan penghitungan similaritas terhadap koleksi dokumen yang di dalamnya terdapat nama-nama ilmiah.
Dikenal Kokoh dan Tahan Api
Pohon jati dengan nama ilmiah Tectona grandis dapat dikatakan sebagai salah satu pohon yang paling peka terhadap perubahan cuaca. Hal ini terbukti dengan pengguguran daun saat kemarau untuk mengurangi penguapan melalui daun sehingga persediaan air tidak cepat habis. Jati cocok tumbuh di area tanah agak basa yang memiliki pH 6-8, mengandung kapur yang cukup banyak, mengandung fosfor, dan tidak terlalu tergenang air.
<dok>
<id>0001</id>
<subject>Dikenal Kokoh dan Tahan Api </subject> <deskripsi>
Pohon jati dengan nama ilmiah <latin>Tectona grandis</latin> dapat dikatakan sebagai salah satu pohon yang paling peka terhadap perubahan cuaca. Hal ini terbukti dengan pengguguran daun saat kemarau untuk mengurangi penguapan melalui daun sehingga persediaan air tidak cepat habis. Jati cocok tumbuh di area tanah agak basa yang memiliki pH 6-8, mengandung kapur yang cukup banyak, mengandung fosfor, dan tidak terlalu tergenang air. </deskripsi>
11 Pengujian sistem dilakukan menggunakan query uji yang terdiri atas 20 query yang terdiri atas 10 query benar dan 10 query salah. Kumpulan query uji ini digunakan sebagai query input dalam pengujian sistem. Kumpulan query uji dapat dilihat pada Tabel 5.
Pembentukan query dengan penulisan yang salah berdasarkan empat kategori, yaitu insertion (penambahan), omission (penghapusan), subsitution (penggantian), dan transposition (penukaran tempat).
Indexing
Seperti yang dijelaskan sebelumnya bahwa pada tahap ini dilakukan pengubahan nama ilmiah yang sudah diberi tanda menjadi kode tertentu sesuai dengan algoritme yang digunakan.
1 Algoritme Soundex
Algoritme Soundex merupakan algoritme phonetics yang cukup sederhana jika dibandingkan dengan kedua algoritme lainnya. Prinsip dari algoritme ini adalah mengubah huruf ke dalam kode tertentu sesuai dengan aturan Soundex (Tabel 1). Contoh tahapan pengubahan algoritme Soundex dapat dilihat pada Tabel 2.
12
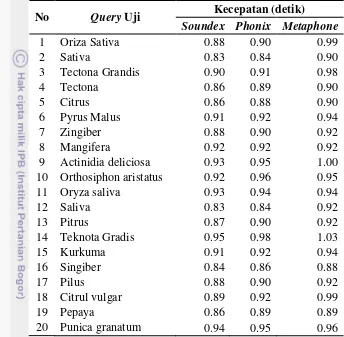
proses yang tercepat karena dari sekumpulan query uji ini kecepatan proses rata-ratanya mencapai 0.88 detik, dapat dilihat pada tabel perbandingan Tabel 6. Tabel 6 Tabel perbandingan kecepatan proses Soundex, Phonix, dan Metaphone
No Query Uji Kecepatan (detik)
Hal ini terjadi karena kesederhanaan dari algoritme Soundex yang hanya melakukan pengelompokan menjadi enam kelompok dan membentuk empat karakter hasil pengodean, tetapi di samping itu algoritme Soundex merupakan algoritme dengan kinerja yang terburuk jika dibandingkan dengan algoritme yang lain (Gambar 6). Hal tersebut disebabkan algoritme Soundex memperhatikan huruf di awal kata, jika pada huruf awal dari suatu query sudah salah, walaupun huruf setelah huruf awal itu benar, maka kemungkinan akan dilihat sebagai dua query yang berbeda. Hal itulah yang menyebabkan nilai precision rendah. Salah satu contohnya adalah Pitrus yang merupakan contoh query uji yang terdapat kesalahan di awal kata dalam hal ini adalah karakter ‘P’.
13 karakter awal kata saja yang berbeda. Hal ini dapat dilihat dari hasil recall-precision algoritme Soundex yang lebih kecil dibanding algoritme yang lain.
Kelebihan dari algoritme Soundex selain dari sisi kecepatan adalah kesederhanaan dalam pembentukan kode fonetik yang hanya berjumlah maksimal empat karakter sehingga tidak terlalu memperhatikan huruf pada akhir kata jika sudah membentuk empat karakter kode Soundex. Jadi, jika huruf-huruf awal dari suatu kata benar dan tepat walaupun huruf terakhir terdapat kesalahan, maka query tersebut akan dilihat sebagai dua query yang sama, karena algoritme Soundex hanya mengambil pengodean sampai berjumlah empat karakter. Sebagai contohnya adalah query uji Orthosiphon aristatus, nama latin dari tumbuhan kumis kucing. Jika dilakukan pencarian menggunakan keseluruhan kata, maka bisa didapatkan dokumen yang sesuai dengan yang diinginkan. Namun, jika yang digunakan hanya bagian awal kata, misalnya ‘O th ’, belum tentu semua algoritme fonetik dapat mengenalinya. Lain hal dengan Soundex, karena kesederhanaanya, yang mampu mengenali potongan query tersebut sehingga bisa mengembalikan dokumen yang relevan sesuai dengan yang diinginkan.
2 Algoritme Phonix
Algoritme Phonix sama seperti algoritme Soundex, yaitu dengan membagi ke dalam beberapa kelompok tertentu yang sudah ditentukan sebelumnya (lihat Tabel 3). Perbedaan Phonix dengan Soundex adalah jumlah kelompok pembaginya. Pada algoritme Phonix kelompok yang dibentuk menjadi delapan dan maksimal kode yang dibentuk juga delapan karakter, jika dilihat pada Tabel 1 (Soundex) dan Tabel 3 (Phonix) terjadi perbedaan pada pembentukan kelompok 7 yang beranggotakan huruf F dan V, dan kelompok 8 yang beranggotakan huruf S, X, dan Z. Pada Tabel 1 (Soundex), kelompok 7 pada Tabel 3 merupakan bagian dari kelompok 1, sedangkan kelompok 8 pada Tabel 3 merupakan bagian dari kelompok 2 pada Tabel 1.
Dari tambahan aturan pada algoritme Phonix, hasil pengujian dengan menggunakan query uji berhasil meningkatkan nilai precision pada pengujian query dengan kesalahan penulisan yang dilakukan pada algoritme Soundex dapat dilihat pada Gambar 6 dalam bentuk grafik perbandingan. Hal ini dikarenakan pada algoritme Phonix dilakukan penambahan pengelompokan konsonan menjadi delapan kelompok dan juga ditambahkannya aturan untuk huruf di awal dan di akhir kata. Dari pengubahan yang terdapat di algoritme Phonix terbukti efektif untuk meningkatkan hasil pencarian dilihat dari nilai precision yang dihasilkan. Hasil penghitungan recall precision dapat dilihat pada Lampiran 2.
14
query ini, dapat dipastikan bahwa sistem dengan algoritme fonetik akan dapat mengembalikan hasil pencarian dokumen dengan tepat karena tidak terdapat kesalahan di manapun pada query.
Namun, jika query ‘O za’ diubah menjadi ‘E za’ dan dilakukan pencarian kembali, maka belum tentu hasil pencarian akan sesuai dengan yang diinginkan. Beda hal dengan menggunakan algoritme Phonix, sesuai dengan aturan tambahan yang sudah dijelaskan sebelumnya, maka huruf di awal kata jika merupakan huruf vokal maka akan diubah menjadi huruf ‘V’. Oleh karena itu, kata ‘Eriza’ dan kata ‘Oriza’ pada korpus akan diubah menjadi ‘Vriza’ sehingga kedua kata tersebut akan bernilai sama dan ketika dilakukan pencarian kembali, dapat menghasilkan nilai recall-precision yang baik.
Penambahan aturan ini juga mengakibatkan terdapat ada satu query uji yang memiliki kecepatan prosesnya paling lama jika dibandingkan algoritme lainnya, yaitu query uji “Orthosiphon aristatus” yang mencapai 0.96 detik pada proses pencariannya. Hal ini sama seperti kasus di atas yang dikarenakan penambahan aturan khusus untuk di awal kata dan di akhir kata. Jika aturan tersebut dihilangkan, maka kecepatan prosesnya menjadi lebih cepat dari sebelumnya walau tidak secara signifikan, yaitu menjadi 0.95 detik.
Gambar 5 Grafik perbandingan kecepatan rata-rata proses 3 Algoritme Metaphone
Algoritme Metaphone sama seperti kedua algoritme sebelumnya, yaitu membagi huruf tertentu ke dalam beberapa kelompok. Yang menjadikan algoritme ini lebih kompleks terdapat pada pembagian kelompok konsonan yang lebih banyak yaitu 16 suara konsonan (Lampiran 1) karena, pada algoritme Metaphone, pemberian kode fonetik memperhatikan juga interaksi antara konsonan dan vokal dalam kata serta kelompok konsonan, bukan hanya sebuah konsonan seperti pada algoritme Soundex dan Phonix.
15 serangkaian pengujian yang dilakukan menggunakan query uji pada Tabel 5, algoritme Metaphone dapat menggembalikan hampir semua dokumen yang relevan dari setiap query uji yang dilakukan.
Hasil penelitian menunjukkan bahwa terdapat kesamaan pada algoritme Metaphone dan algoritme Phonix yaitu jika diberikan query uji yang hanya sebagian dari query tersebut dan dilakukan pencarian, belum tentu hasil yang dikembalikan sesuai dengan yang diinginkan. Hal ini dikarenakan ketika dilakukan pengodean, panjang kode karakter query uji dengan data berbeda sehingga ketika dihitung kedekatan antara keduanya bisa berbeda. Salah satu contoh query-nya adalah Orthosiphon aristatus. Karena query ini cukup panjang, pembentukan kode karakter pada Phonix dan Metaphone juga akan menjadi panjang. Maka, ketika diberikan query hanya sebagian dari yang sebenarnya misalnya menjadi ‘Orthos’, algoritme Phonix dan Metaphone tidak bisa menggembalikan dokumen relevan sesuai dengan yang diinginkan.
Similaritas
Setelah dilakukan penghitungan indexing (pengubahan kode fonetik) terhadap algoritme yang digunakan, tahap selanjutnya adalah melakukan penghitungan similaritas, maksudnya adalah proses penghitungan terhadap kedekatan antara query input yang sudah dilakukan konversi ke dalam kode algoritme fonetik dengan data yang terdapat dalam korpus yang sudah dikonversikan. Pada penelitian ini digunakan tiga metode similaritas, yaitu exact string matching, biner, dan Levenshtein distance. Jadi, setiap metode similaritas ini akan dilakukan penghitungan dengan algoritme fonetik yang digunakan.
1 Exact string matching
Algoritme ini hanya memberikan nilai dua jenis saja, yang pertama bernilai 1 jika query input dengan data sama (exact) dengan kata lain memiliki kedekatan yang tinggi. Kedua adalah bernilai 0, yaitu jika query input dengan data berbeda, dengan kata lain memiliki kedekatan yang rendah.
Nilai yang dihasilkan hanya terdiri atas dua nilai yaitu 1 dan 0. Dari setiap pengujian yang dilakukan kemungkinan mendapatkan nilai 1 sangatlah kecil, kecuali kata yang dicari dengan kata dalam dokumen itu sama. Hal itu dikarenakan pada algoritme ini hanya menilai kesamaan kata yang dicari, jika sama maka akan bernilai 1 dan jika berbeda maka akan bernilai 0.
2 Biner (N-Grams)
N-16
Grams ini sangat membantu dalam mengoreksi kesalahan dalam pengetikan tersebut.
N-Grams melakukan penghitungan dengan memecah kata, baik untuk query input ataupun untuk data dalam korpus. Pembagian ini memecah kata menjadi himpunan urutan huruf-huruf dalam suatu kata sebanyak ‘N’ yang ingin digunakan. Jumlah ‘N’ yang digunakan dalam penelitian ini adalah Bigram atau dua huruf.
Contoh bentuk N-Grams :
Query input: Teknota (Soundex: T253) Himpunan A: _t – t2 – 25 – 53 – 3_
Data: Tectona (Soundex: T235) Himpunan B: _t – t2 – 23 – 35 – 5_
Jadi kata yang sudah dipecah menjadi himpunan urutan disamakan dengan data pada korpus. Diberikan nilai 1 jika sama dengan himpunan dan 0 jika tidak ada yang sama. Setelah itu dilakukan tahapan penghitungan menggunakan rumus Dice Coefisient (Holmes dan McCabe 2002) pada persamaan 1.
Tabel 7 Contoh hasil penghitungan similaritas dengan N-Grams
Query korpus Query uji Similaritas
Oriza Sativa: (O62 S31) (N-Grams)
Brassica oleracea: (B62 O462) O62 S31 0.25
Carica papaya: (C62 P1) O62 S31 0.40
Citrus sp: (C362 S1) O62 S31 0.50
Cupressaceae: (C162) O62 S31 0.15
Oriza Sativa: (O62 S31) O62 S31 1.00
Orthosiphon aristatus: (O632 A632) O62 S31 0.12
Orthosiphon Spicatus: (O632 S123) O62 S31 0.44
Pyrus malus: (P62 M42) O62 S31 0.25
Santalum album: (S534 A15) O62 S31 0.25
Sonchus Arvensis: (S52 A615) O62 S31 0
Nilai yang dihasilkan pada metode ini sangat bervariasi karena range pada metode ini dari nilai 0 sampai dengan 1. Nilai tertinggi pada pengujian yang dilakukan adalah 1, tetapi pada pengujian dengan menggunakan query uji yang salah pengetikan nilai tertinggi rata-ratanya menjadi 0.85, sedangkan nilai terendah yang diambil pada pengujian ini adalah 0.1 bukan bernilai 0, karena jika bernilai 0 maka dokumen tersebut tidak relevan sama sekali sehingga tidak ditampilkan. Jadi, jika melihat hasil penghitungan similaritas pada Tabel 7 dengan menggunakan N-Grams, query “Sonchus Arvensis” tidak akan dikembalikan karena tidak menunjukkan dokumen yang relevan.
3 Levenshtein distance
17 standardisasi nilai, yaitu bahwa nilai terbesar dari penghitungan similaritas ialah 1 dan terkecil ialah 0 sehingga nilai yang didapatkan dari penghitungan awal Levensthein dibagi dengan panjang kata dari salah satu query input atau dengan data, panjang kata yang dipilih merupakan panjang kata yang paling panjang, kemudian dikurangi dengan nilai 1. Hal ini dilakukan untuk menyeragamkan rentang nilai yang didapatkan dari algoritme lainnya.
Tabel 8 Contoh hasil penghitungan similaritas dengan Levenshtein distance
Query korpus Query uji Levenshtein
Oriza Sativa: (O62 S31)
Brassica oleracea: (B62 O462) O62 S31 0.38
Carica papaya: (C62 P1) O62 S31 0.57
Citrus sp: (C362 S1) O62 S31 0.57
Cupressaceae: (C162) O62 S31 0.14
Oriza Sativa: (O62 S31) O62 S31 1.00
Orthosiphon aristatus: (O632 A632) O62 S31 0.56
Orthosiphon Spicatus: (O632 S123) O62 S31 0.56
Pyrus malus: (P62 M42) O62 S31 0.43
Santalum album: (S534 A15) O62 S31 0.13
Sonchus Arvensis: (S52 A615) O62 S31 0.38
Dari serangkainya pengujian yang dilakukan seperti pada contoh Tabel 8, nilai yang dihasilkan oleh Levenshtein distance berkisar dari nilai 0 sampai dengan 1. Sama seperti pada algoritme N-Grams, pada pengujian dengan Levenshtein distance menghasilkan nilai tertinggi adalah 1, tetapi pada pengujian dengan menggunakan query uji yang salah pengetikan nilai tertinggi rata-ratanya menjadi 0.8, sedangkan nilai terendah dari pengujian ini adalah 0.1. Perbedaan yang terjadi antara Levenshtein distance dan N-Grams terdapat pada query “Sonchus Arvensis”, nilai penghitungan N-Grams untuk query tersebut mendapatkan 0, sedangkan pada Levenshtein distance mendapatkan nilai 0.38. Hal ini dikarenakan, pada N-Grams tujuan penghitungannya adalah untuk mencari kedekatan dua buah kata, sedangkan Levenshtein distance melihat jarak dan perbedaan antara dua buah kata.
Nilai similaritas dari hasil penghitungan menggunakan teknik similaritas yang digunakan dalam penelitian ini berkisar dari nilai 0 sampai dengan nilai 1. Nilai 0 merupakan nilai dengan similaritas yang kecil, dan nilai 1 merupakan nilai dengan similaritasyang besar.
18
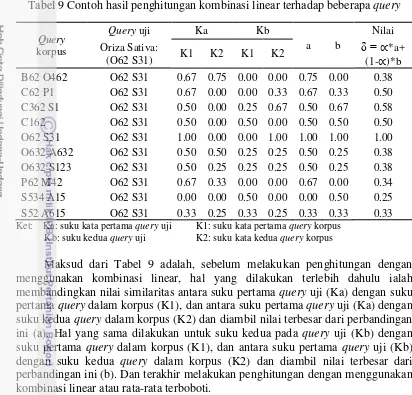
Tabel 9 Contoh hasil penghitungan kombinasi linear terhadap beberapa query
Query
Maksud dari Tabel 9 adalah, sebelum melakukan penghitungan dengan menggunakan kombinasi linear, hal yang dilakukan terlebih dahulu ialah membandingkan nilai similaritas antara suku pertama query uji (Ka) dengan suku pertama query dalam korpus (K1), dan antara suku pertama query uji (Ka) dengan suku kedua query dalam korpus (K2) dan diambil nilai terbesar dari perbandingan ini (a). Hal yang sama dilakukan untuk suku kedua pada query uji (Kb) dengan suku pertama query dalam korpus (K1), dan antara suku pertama query uji (Kb) dengan suku kedua query dalam korpus (K2) dan diambil nilai terbesar dari perbandingan ini (b). Dan terakhir melakukan penghitungan dengan menggunakan kombinasi linear atau rata-rata terboboti.
Jika melihat hasil penghitungan kombinasi linear pada Tabel 9, maka nilai 1 dengan query korpus dengan kode fonetik “O62 S3 ” memiliki tingkat similaritas yang besar terhadap query ujinya. Selain dari pada itu, kode fonetik “C362 S ” merupakan query yang paling mendekati setelah query sebelumnya. Hal itu dikarenakan jika dilihat strukturnya, maka kode inilah yang setidaknya mendekati query yang diuji. Kode fonetik “S534 A 5“ merupakan query dengan similaritas yang paling rendah yaitu dengan nilai 0.25 sehingga query ini akan ditampilkan paling bawah.
Pengujian dan Evaluasi Sistem
Proses evaluasi yang dilakukan terhadap sistem temu kembali ini menggunakan dua metode, yaitu recall dan precision. Pada penelitian ini juga menggunakan batas nilai similaritas tidak sama dengan 0 sebagai nilai batas dokumen yang relevan, yang nantinya akan ditampilkan dalam sistem ini sebagai hasil pencarian dari query input.
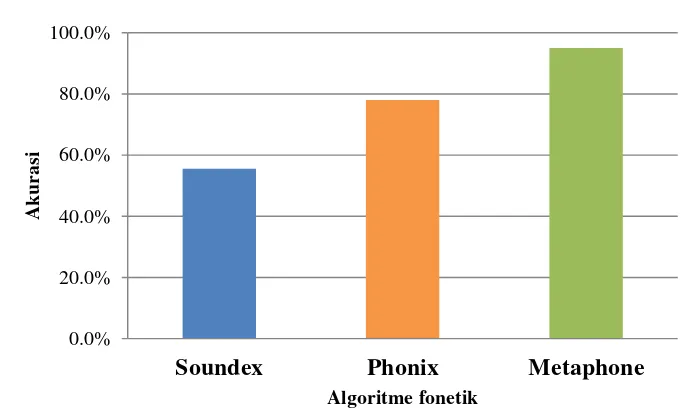
19 Pengujian pertama menggunakan 10 query yang terdapat kesalahan pada pengetikan query input. Query uji ini merupakan contoh kesalahan pengetikan dari kata misalnya query uji “Kurkurma” yang seharusnya adalah “Cu uma”, kesalahannya terjadi penggantian (substitution antara huruf ‘C’ dengan huruf ‘K’. Dengan menggunakan query uji pada Tabel 5, sistem masih dapat mengembalikan dokumen yang relevan dan sesuai dengan yang dimaksudkan oleh query uji. Akurasi dari setiap algoritme fonetik pada pengujian dengan menggunakan query uji yang salah masing-masing sebesar 55.5% (Soundex), 78% (Phonix), dan 95% (Metaphone). Perbandingan hasil persentase pengujian dengan query uji yang salah dalam bentuk grafik dapat dilihat pada Gambar 6.
Gambar 6 Grafik perbandingan akurasi untuk ketiga algoritme fonetik Pengujian selanjutnya menggunakan 10 query uji tanpa ada kesalahan pengetikan. Dengan menggunakan query uji ini sistem dapat mengenali dengan sangat baik dan mencapai persentase 100% untuk setiap algoritme fonetik yang digunakan. Dapat disimpulkan bahwa sistem temu kembali informasi ini mampu mengembalikan dokumen dengan tingkat keakuratan yang baik untuk setiap query uji yang diberikan.
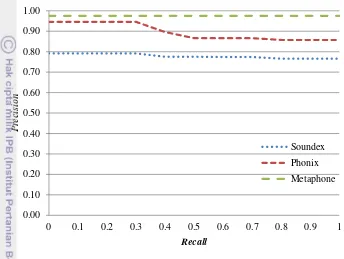
Hal ini dibuktikan dengan melihat hasil dokumen yang dikembalikan dan dari grafik recall-precision, serta jika dilihat pada average precision (AVP) dari setiap algoritme fonetik, yaitu 77.8% (Soundex), 88% (Phonix), dan 97.5% (Metaphone). Selain itu, jika melihat hasil persentase dari setiap algoritme fonetik pada penelitian ini, maka Metaphone merupakan algoritme yang paling baik menangani pencarian kata dengan menggunakan nama latin sebagai query pencariannya walaupun dengan penulisan yang salah.
Gambar 7 merupakan grafik perbandingan algoritme Soundex, Phonix, dan Metaphone dengan melihat average precision (AVP) dari setiap algoritme. Dari grafik tersebut dapat dilihat bahwa Soundex merupakan algoritme dengan recall precision yang terrendah, tetapi lebih konsisten (tidak turun terlalu jauh) dibandingkan dengan algoritme Phonix. Hal ini dikarenakan untuk Soundex memiliki kelebihan dalam kesederhanaan dalam pembuatan kode fonetik sehingga lebih general dalam mengenali query pencarian, sedangkan Phonix memiliki
20
kelebihan dalam mengenali query yang lebih spesifik dan memiliki aturan khusus yang mana menjadinya kekurangan juga kelebihan dari algoritme Phonix sendiri. Selain itu, di antara yang lain, maka algoritme Metaphone merupakan algoritme dengan dengan recall precision tertinggi juga yang paling konsisten (tidak turun) di antara algoritme yang lain.
Gambar 7 Grafik recall precision query uji dengan AVP
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa, penerapan algoritme fonetik dapat dilakukan pada permasalahan nama ilmiah atau nama latin, baik terdiri atas satu atau dua suku kata dan pencarian temu kembali informasi dengan menggunakan algoritme fonetik sangat membantu dalam kegiatan pencarian kata, walaupun kata yang digunakan salah. Permasalahan dalam pencarian kata bisa terjadi pada saat pengetikan, salah dalam pengejaan kata karena kemiripan ucapan, atau dalam menangani pencarian dengan menggunakan dua suku kata.
Pada penelitian ini, walaupun terjadi kesalahan-kesalahan tersebut, sistem masih dapat menampilkan hasil berdasarkan kemiripan kata masukan itu. Hal ini dikarenakan sistem ini mengombinasikan algoritme fonetik dengan teknik similaritas sehingga memaksimalkan kemiripan suatu kata terhadap kata yang lain. Hal tersebut ditunjukan berdasarkan persentase average precision (AVP) dari hasil pencarian yaitu sebesar 77.8% (Soundex), 80.8% (Phonix), dan 97.5% (Metaphone). Selain itu, jika melihat hasil persentase dari setiap algoritme fonetik yang diperoleh, maka Metaphone merupakan algoritme yang paling baik
21 menangani pencarian kata dengan menggunakan nama latin sebagai query pencariannya walaupun dengan penulisan yang salah.
Saran
Beberapa hal yang perlu dikembangkan lebih lanjut dalam penelitian ini adalah:
1 Menggunakan korpus atau dokumen uji yang lebih banyak dan beragam. 2 Menampilkan hasil dengan memperhitungkan nilai pembobotan menggunakan
TF-IDF, sehingga dapat dilihat dokumen yang paling banyak menggandung kata tersebut.
DAFTAR PUSTAKA
Baeza-Yates R, Riberio-Neto B. 1999. Modern Information Retrieval. New York (US): Addison Wesley.
Herawan Y. 2011. Ekstraksi ciri dokumen tumbuhan obat menggunakan chi-kuadrat dengan klasifikasi naive bayes [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Holmes D, McCabe C. 2002. Improving precision and recall for Soundex retrieval. Di dalam: Grossman D, Frieder O, editor. International Conference on Information Technology: Coding and Computing; 2002 Apr 8-10; Las Vegas (US): hlm 22-26.
Manning CD, Raghavan P, Schutze H. 2008. Introduction to Information Retrieval. Cambridge (GB): Cambridge University Press.
Pfeifer U, Poersch T, Fuhr N. 1996. Retrieve effective of proper name search methods. Information Processing & Management 32(6):667-679.
Philips L. 1990. Hanging on Metaphone. Computer Language 7(12).
Primasari D. 1997. Pencarian nama menggunakan metode kesamaan fonetik [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor, Institut Pertanian Bogor.
Sarno R, Anistyasari Y, Fitri R. 2012. Semantic Search Pencarian Berdasarkan Konten. Yogyakarta (ID): Penerbit Andi.
22
Lampiran 1 Tabel aturan Metaphone (Syaroni dan Munir 2004)
Awal Akhir Keterangan
Jika dalam ‘-GE’,’GI’,’GY’dan tidak dalam ‘GG’
H
dihapus
H
Jika sesudah vokal dan tidak diikuti vokal
23
Lampiran 2 Nilai recall-precision untuk query uji yang salah pada sistem temu kembali nama ilmiah
Keterangan:
S = Soundex
P = Phonix
24
Lampiran 3 Hasil pengubahan query uji menjadi kode fonetik
No Query Uji Fonetik
Soundex Phonix Metaphone
1 Oriza Sativa O62 S31 V68 S37 ORS STF
2 Sativa S31 S37 STF
3 Tectona Grandis T235 G653 T235 G6538 TKTN KRNTS
4 Tectona T235 T235 TKTN
5 Citrus C362 C368 STRS
6 Pyrus Malus P62 M42 P68 M48 PRS MLS
7 Zingiber Z521 Z5216 SNJBR
8 Mangifera M521 M5276 MNJFR
9 Actinidia deliciosa A235 D42 V2353 D428 AKTNTT TLSS 10 Orthosiphon aristatus O632 A623 V63815 V6838 OR0SFN ARSTTS
11 Oryza saliva O62 S41 V68 S47 ORS SLF
12 Saliva S41 S47 SLF
13 Pitrus P362 P368 PTRS
14 Teknota Gradis T253 G632 T253 G638 TKNT KRTS
15 Kurkuma K625 K625 KRKM
16 Singiber S521 S5216 SNJBR
17 Pilus P42 P48 PLS
18 Citrul vulgar C364 V26 C364 V26 STRL FLKR
19 Pepaya P1 P1 PPY
25
RIWAYAT HIDUP
Penulis Lahir di Bekasi Provinsi Jawa Barat, pada tanggal 21 Juni 1989 dari pasangan Tukijo dan Marwiyah. Penulis merupakan anak kedua dari dua bersaudara.
Penulis memulai pendidikan dari sekolah dasar yang ditempuh di Sekolah Dasar Negeri Jatimekar VII Bekasi pada tahun 1995 dan lulus pada tahun 2001. Setelah itu melanjutkan pendidikan ke SLTPN 81 Lubang Buaya Jakarta Timur dan lulus pada tahun 2004. Kemudian penulis pun melanjutkan jenjang pendidikan selanjutnya di SMA Negeri 48 Pinang Ranti Jakarta Timur dan lulus pada tahun 2007.