KLASIFIKASI KEMUNCULAN TITIK PANAS PADA LAHAN
GAMBUT DI SUMATERA DAN KALIMANTAN
MENGGUNAKAN ALGORITME
RANDOM FOREST
RESA RUKMIGAYATRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Prediksi Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan Algoritme Random Forestadalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
RESA RUKMIGAYATRI. Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan Algoritme Random Forest. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Pengelolaan lahan gambut dengan menanam jenis tanaman yang tidak sesuai dengan karakteristik lahan gambut serta kebakaran menyebabkan lahan gambut mengalami degradasi. Titik panas merupakan suatu indikator kebakaran hutan dan lahan,meskipun tidak semua titik panas mengindikasikan kebakaran. Kemungkinan kemunculan titik panas dapat diprediksi berdasarkan karakteristik lahan gambut. Penelitian ini mengembangkan model klasifikasi dari kemunculan titik panas pada lahan gambut di Sumatera dan Kalimantan pada periode 2001 sampai 2014 menggunakan algoritme Random Forest. Algoritme ini merupakan pengembangan dari Classification and Regression Tree (CART). Penerapan algoritme Random Forest pada dataset menghasilkan akurasi rata-rata model klasifikasi tahun 2001 untuk dataset Sumatera sebesar 87.40% dan 72.50% untuk dataset Kalimantan. Model klasifikasi terbaik diterapkan pada data baru tahun 2015. Hasil klasifikasi menunjukkan bahwa 60.80% data titik panas di Sumatera diklasifikasikan benar dan 39.13% data titik panas di Kalimantan diklasifikasikan benar.
Kata kunci: klasifikasi model prediksi, random forest, titik panas
ABSTRACT
RESARUKMIGAYATRI. Classification of Hotspot Occurences on Peatland in Sumatera and Kalimantan using Random Forest Algorithm. Supervised by IMAS SUKAESIH SITANGGANG.
Peatland mismanagement by planting inappropriate plant and the peatland fire cause peatland degradation. A hotspot is an indicator of forest and land fire. However, not every hotspot actually indicates a fire. The possibility of hotspot occurrences can be predicted based on the characteristics of the peatland. This research developed a classification model of hotspot occurrences on Sumatera and Kalimantan peatlands within 2001 to 2014 period using Random Forest algorithm. The Random Forest algorithm is an improvement of Classification and Regression Tree (CART). The implementation of the Random Forest algorithm on the dataset resulted in average classification accuracy of 87.40% for Sumatera and 72.50% for Kalimantan using 2001 data. The best classification model also tested using a new data from 2015. The results show that 60.80% and 39.13% of hotspots in Sumatera and Kalimantan, respectively, are correctly classified.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI KEMUNCULAN TITIK PANAS PADA LAHAN
GAMBUT DI SUMATERA DAN KALIMANTAN
MENGGUNAKAN ALGORITME
RANDOM FOREST
RESA RUKMIGAYATRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji :
1 Husnul Khotimah, SKomp, MKom
Judul Skripsi : Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di
Sumatera dan Kalimantan Menggunakan Algortime Random Forest Nama : Resa Rukmigayatri
NIM : G64134011
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhana wa ta'ala.Shalawat serta salam semoga senantiasa dilimpahkan kepada Nabi Muhammad, keluarganya, sahabatnya, dan kepada kita yang selau berusaha menggapai ridha Allah.
Alhamdulillah atas bimbingan dan petunjuk dari Allah Subhana wa ta'ala serta bimbingan dari semua pihak, penyusunan tugas akhir yang berjudul “Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan Algoritme Random Forest” dapat diselesaikan. Tugas akhir ini tidak mungkin dapat diselesaikan tanpa adanya bantuan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih dan penghargaan yang setinggi-tingginya kepada:
Papa (Sabari Maryono), Mama (Aida Refni), adik-adikku Niken Safitri dan Wahyu Agung Wicaksono, serta keluarga yang selalu mendoakan, memberi nasihat, kasih sayang, semangat, dan dukungan sehingga penelitian ini bisa diselelsaikan.
Ibu Dr Imas Sukaesih Sitanggang, SSi, MKom selaku pembimbing yang telah memberi saran, masukan dan ide-ide dalam penelitian ini.
IbuHusnul Khotimah, SKomp, MKom dan Bapak Muhammad Asyhar Agmalaro, SSi, MKom sebagai penguji.
Pihak Wetlands International yang telah memberikan izin untuk menggunakan data lahan gambut Sumatera dan Kalimantan.
Teman seperjuangan Elin, Fitri, dan Dhita yang telah memberikan semangat dan masukan.
Departemen Ilmu Komputer IPB, staf dan dosen yang telah banyak membantu selama masa perkuliahan hingga penelitian.
Semoga penelitian ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL x
DAFTAR GAMBAR x
DAFTAR LAMPIRAN x
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Data Penelitian 2
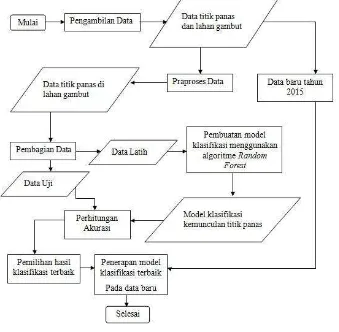
Tahapan Penelitian 4
Pengumpulan Data 4
Praproses Data 5
Pembagian Data 6
Pembuatan Model Klasifikasi Menggunakan Algoritme Random Forest 6
Perhitungan Akurasi 8
Penerapan Model Klasifikasi pada Data Baru 8
Peralatan Penelitian 8
HASIL DAN PEMBAHASAN 8
Praproses Data 8
Pembagian Data 12
Pembuatan model klasifikasi menggunakan algoritme Random Forest 12
Perhitungan Akurasi 14
Penerapan pada Model Data Baru 14
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 16
DAFTAR PUSTAKA 16
DAFTAR TABEL
1 Atribut dari titik panas 3
2 Luas lahan gambut berdasarkan tipe gambut di Sumatera 5 3 Luas lahan gambut berdasarkan tipe gambut di Kalimantan 5 4 Akurasi rata-rata model klasifikasi untuk dataset tahun 2001 sampai
2014 13
5 Model klasifikasi terbaik pada datast Sumatera tahun 2001 13 6 Model klasifikasi terbaik pada dataset Kalimantan tahun 2001 14 7 Confusion matrix untuk klasifikasi pada data Sumatera tahun 2015 15 8 Confusion matrix untuk klasifikasi pada data Kalimantan tahun
2015 15
DAFTAR GAMBAR
1 Lahan gambut di Sumatera 3
2 Lahan gambut di Kalimantan 4
3 Tahapan penelitian 6
4 Arsitektur umum Random Forest (Verikas et al. 2011) 7 5 Zona sistem koordinat di Indonesia (Oswald dan Astrini 2012) 9
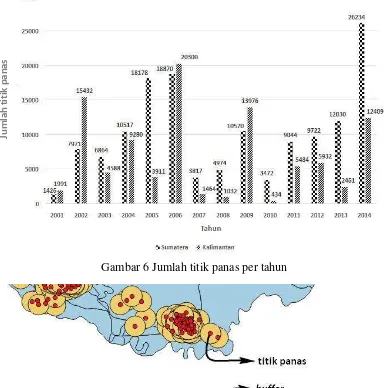
6 Jumlah titik panas per tahun 10
7 Hasil buffer titik panas 10
8 Hasil pembangkitan random point (non titik panas) disekitar titik
panas 11
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Indonesia merupakan negara yang mempunyai lahan gambut seluas 32.656.106 Ha (Suwanto et al. 2010). Penyebaran lahan gambut tersebut meliputi pulau Sumatera, Kalimantan, Sulawesi, Papua, dan Jawa. Gambut adalah material organik yang terbentuk dari sisa-sisa tumbuhan yang telah mengalami dekomposisi dan terakumulasi di daerah rawa atau genangan air (Suwanto et al. 2010). Kemampuan gambut dalam menyerap air relatif tinggi, oleh karena itu lahan gambut alaminya tidak mudah terbakar. Namun, keseimbangan ekologis dapat terganggu dengan adanya konversi lahan atau pembuatan kanal. Pada musim kemarau, kondisi lahan gambut akan sangat kering sampai kedalaman tertentu dan hal ini yang menyebabkan lahan mudah terbakar. Terbakarnya lahan gambut mengakibatkan kerugian besar, seperti kebakaran lahan gambut yang terjadi di Riau pada bulan Maret tahun 2014.
Menurut Adinugroho et al. (2005) kebakaran lahan dapat diketahui melalui suatu indikator yaitu titik panas. Dengan indikator titik panas kebakaran hutan dapat diprediksi dan hal ini dapat membantu pencegahan terjadinya kebakaran. Salah satu teknik data mining yang dapat dilakukan untuk memprediksi kemunculan titik panas klasifikasi.
Penelitian mengenai model klasifikasi untuk titik panas yang dilakukan oleh Sitanggang dan Ismail (2011) menggunakan algoritme Decision Tree dengan hasil akurasi sebesar 63.17%. Pada penelitian Fernando dan Sitanggang (2014), pemodelan klasifikasi data spasial kemunculan titik panas dilakukan dengan menggunakan algoritme ID3. Penelitian tersebut membuat model klasifikasi dan memprediksi kemunculan titik panas di Provinsi Riau pada tahun 2005. Penelitian berikutnya yang pernah dilakukan oleh Nurpratami dan Sitanggang (2015) menggunakan algoritme pohon keputusan untuk memprediksi kejadian titik panas pada Kabupaten Bengkalis, Provinsi Riau. Penelitian tersebut menghasilkan model dengan rata-rata akurasi sebesar 89.04% untuk data latih dan 52.05% untuk data uji. Model klasifikasi dari ketiga penelitian tersebut baru diimplementasikan dalam bentuk single tree.
Pada penelitian ini dibangun model klasifikasi kemunculan titik panas pada lahan gambut di Sumatera dan Kalimantan menggunakan algoritme Random Forest. Algoritme Random Forest merupakan salah satu metode klasifikasi yang merupakan pengembangan dari Classification and Regression Tree (CART), yaitu dengan menerapkan metode bootstrap aggregating bagging dan random feature selection (Breiman 2001).
Perumusan Masalah
2
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menerapkan algoritme Random Forest pada data titik panas di lahan gambut di Sumatera dan Kalimantan.
2 Evaluasi akurasi model klasifikasi untuk prediksi kemunculan titik panas di lahan gambut di pulau Sumatera dan Kalimantan.
Manfaat Penelitian
Manfaat dari penelitian ini adalah bahwa model klasifikasi yang dihasilkan dapat digunakan untuk mendapatkan karakteristik lahan gambut di lokasi titik panas terjadi. Informasi ini berguna bagi pihak terkait untuk pencegahan kebakaran hutan.
Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini adalah:
1 Pembentukan model klasifikasi menggunakan algoritme Random Forest pada data titik panas dan lahan gambut wilayah Sumatera dan Kalimantan.
2 Karakteristik lahan gambut yang dianalisis adalah tipe lahan gambut (legend), ketebalan gambut, dan tutupan lahan (landuse).
3 Implementasi klasifikasi model yang digunakan yaitu package randomForest yang tersedia di R.
METODE
Data Penelitian
Data yang digunakan pada penelitian ini adalah data lahan gambut pulau Sumatera dan Kalimantan dari tahun 1990-2002 yang didapatkan dari Wetlands International–Indonesia Programme (WI-IP) dalam format shp. Sementara itu, data titik panas dari tahun 2001-2015 diperoleh dari Fire Information for Resource Management System (FIRMS) MODIS NASA dalam format csv. Data titik panas terdiri dari 12 atribut dan tipe dari masing-masing atribut dapat dilihat pada Tabel 1. Sementara itu, peta lahan gambut di Sumatera dan Kalimantan dapat dilihat pada Gambar 1 dan Gambar 2. Pemilihan atribut dari titik panas dan lahan gambut berdasarkan penelitian yang dilakukan oleh Sitanggang et al. (2012) serta berdasarkan ketersediaan data yang diperoleh dari WI-IP dan FIRMS.
3 Tabel 1 Atribut dari titik panas
No Atribut Tipe
1 Latitude Numerik
2 Longitude Numerik
3 Brigthness Numerik
4 Scan Numerik
5 Track Numerik
6 Acq_date Date
7 Acq_time Character varying (5) 8 Satelite Character varying (1)
9 Confidence Integer
10 Version Character varying (3)
11 Bright_T31 Numerik
12 FRP Numerik
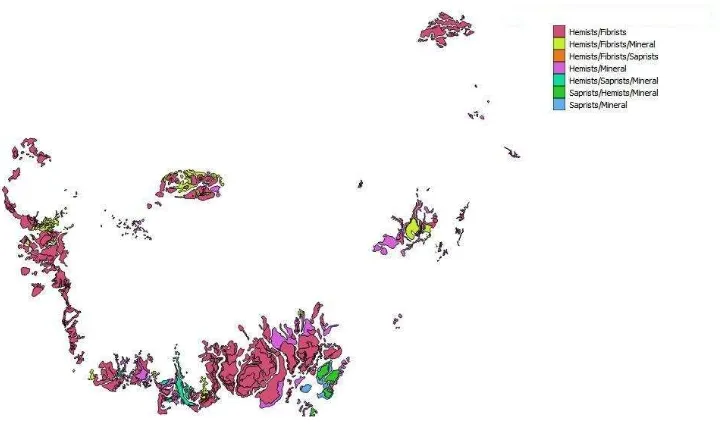
Gambar 1 Lahan gambut di Sumatera
4
Gambar 2 Lahan gambut di Kalimantan
Tipe gambut saprists adalah gambut yang tingkat pelapukannya sudah lanjut (matang), berupa serat kasar kurang dari 1/4 bagian, dan air perasan berwarna hitam. Tiga jenis lahan gambut yang berada di Sumatera dan Kalimantan dapat dilihat pada Gambar 1 dan Gambar 2. Pada Gambar 1 terdapat keterangan Fibrists/Saprists (60/40), sedang. Maksud dari keterangan tersebut adalah Fibrists dan Saprists adalah tipe lahan gambut, 60/40 merepresentasikan kombinasi dari Fibrists sebesar 60% dan Saprists sebesar 40%, kemudian "sedang" menunjukkan ketebalan dari lahan gambut tersebut. Ketebalan dari lahan gambut dibagi menjadi 5 yaitu sangat dangkal (D0), dangkal (D1), sedang (D2), dalam (D3), dan sangat dalam (D4). D0 merupakan kedalaman lahan gambut < 50 cm. D1 kedalaman lahan gambut antara 10-50 cm, kedalaman lahan gambut D2 100-200 cm, D3 sedalam 200-400cm, dan kedalaman lahan gambut D4 > 400 cm. Pada Tabel 2 dan Tabel 3 dapat dilihat luas area (Ha) dari setiap tipe lahan gambut dari pulau Sumatera dan Kalimantan. Tipe lahan gambut yang berada di Sumatera berjumlah 28 dan tipe lahan gambut di Kalimantan berjumlah 7.
Tahapan Penelitian
Tahapan-tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 3.
Pengumpulan Data
5 Tabel 2 Luas lahan gambut berdasarkan tipe gambut di Sumatera
No Tipe Gambut Luas (Ha)
1 Hemists/Saprists (60/40), sedang 1.490.145.52
2 Saprists/min (50/50), dangkal 16.859.44
3 Saprists/Hemists (60/40), sedang 18.698.39
4 Saprists/min (30/70), sedang 9.911.10
5 Saprists/min (90/10), sedang 178.408.66
6 Hemists (100), dalam 2.200.51
7 Hemists/Saprists (60/40), dalam 639.263.34
8 Hemists (100), sedang 86.697.37
9 Saprists/min (50/50), dalam 7.748.19
10 Hemists/min (90/10), sangat dalam 30.179.83 11 Hemists/Saprists (60/40), sedang 211.082.31
12 Hemists/min (30/70), dangkal 308.112.73
13 Hemists/Saprists (60/40), sangat dalam 957.561.63 14 Saprists/Hemists (60/40), dalam 553.762.97 15 Saprists/Hemists (60/40), sedang 236.659.27
16 Hemists/min (90/10), dangkal 7.950.21
17 Hemists/Saprists (60/40), dangkal 49.355.05
18 Hemists/min (70/30), sedang 91.797.22
19 Saprists/min (30/70), dalam 12.671.89
20 Hemists/min (90/10), sedang 0.63
21 Hemists/min (50/50), dangkal 2.218.86
22 Saprists/min (50/50), sedang 118.152.46
23 Hemists/min (90/10), sedang 578.525.94
24 Fibrists/Saprists (60/40), sedang 10.721.84 25 Saprists/Hemists (60/40), sangat dalam 1.181.264.70
26 Hemists/min (30/70), sedang 308.958.76
27 Saprists (100), sedang 87.885.62
28 Saprists (100), dalam 35.182.65
Tabel 3 Luas lahan gambut berdasarkan tipe gambut di Kalimantan
No Tipe Gambut Luas (Ha)
6
dilakukan penambahan variabel class dan digunakan saat pembuatan model klasifikasi.
Gambar 3 Tahapan penelitian
Pembagian Data
Pembagian data pada tahapan penelitian dibagi menjadi data latih dan data uji. Metode yang digunakan dalam pembagian data adalah K-fold cross validation dengan nilai K=10, sehingga 10% dari data akan dijadikan sebagai data uji. Menurut Fu (1994) K-fold cross validation merupakan metode yang membagi himpunan contoh secara acak menjadi K himpunan bagian.
Pembuatan Model Klasifikasi Menggunakan Algoritme Random Forest
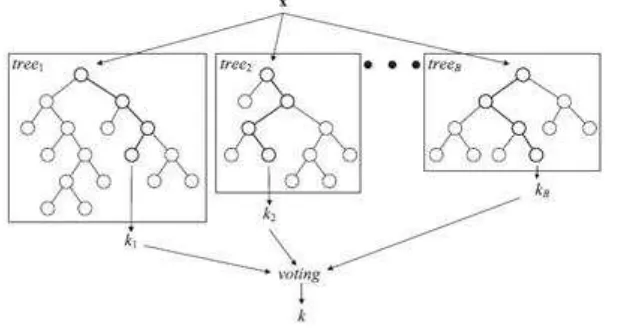
7 tree dan vote terbanyak yang menjadi pemenang. Arsitektur umum dari RF dapat dilihat pada Gambar 4.
Gambar 4 Arsitektur umum Random Forest (Verikas et al. 2011)
Berikut ini adalah prosedur atau algoritme untuk membangun Random Forest pada gugus data yang terdiri dari n amatan dan p peubah penjelas (Breiman 2001; Breiman dan Cutler 2003):
1 Lakukan penarikan contoh acak berukuran n dengan pemulihan pada gugus data. Langkah ini dinamakan dengan bootstrap (bag).
2 Dengan menggunakan contoh bootstrap, pohon dibangun sampai mencapai ukuran maksimum yaitu tanpa pemangkasan (pruning). Pembangunan pohon dilakukan dengan menerapkan random feature selection yaitu m peubah penjelas dipilih secara acak dengan m << p, selanjutnya pemilah terbaik dipilih berdasarkan m peubah penjelas.
Langkah 1 dan 2 diulangi sebanyak k kali untuk membuat sebuah forest yang terdiri dari k pohon. Contoh dataset sederhana dapat dilihat pada Lampiran 1.
Tahapan pembuatan model klasifikasi menggunakan algoritme Random Forest dilakukan setelah membuat pemodelan data latih menggunakan package randomForest di R. Pembentukan tree pada algoritme Random Forest dilakukan dengan cara melakukan training pada sampel. Variabel yang digunakan untuk split diambil secara acak dan klasifikasi dijalankan setelah semua tree terbentuk. Penentuan klasifikasi pada Random Forest ini diambil berdasarkan vote dari masing-masing tree dan vote terbanyak yang menjadi pemenang.
Pada pembentukan Random Forest menggunkan nilai Gini Index untuk menentukan split yang akan dijadikan root. Berikut ini adalah rumus-rumus untuk mencari nilai Gini Index (Yin 2013):
Gini S =1- ∑ ��2
k
i=1
dengan pi adalah probabilitas dari S milik class i. Setelah menghitung nilai Gini (S),
langkah berikutnya adalah menghitung nilai Gini Gain, menggunakan persamaan berikut:
Gini Gain S = Gini (S) – Gini (A,S)= Gini (S) -∑||SSi| Gini (| Si n
i=1
8
Perhitungan Akurasi
Perhitungan akurasi dilakukan setelah proses klasifikasi selesai dilakukan. Perhitungan ini berfungsi menunjukkan tingkat kebenaran pengkalisifikasian data terhadap data yang sebenarnya. Perhitungan akurasi dilakukan dengan menggunakan rumus sebagai berikut:
Akurasi = ∑data uji yang benar diklasifikasikan
∑data uji ×100% (3)
Setelah menghitung nilai akurasi dari setiap tahun maka dilakukan penghitungan nilai precision atau nilai presisi. Rumus untuk menghitung nilai presisi (Han et al. 2012) sebagai berikut:
Akurasi= tp +tpfp ×100% (4) dengan tp adalah jumlah true positive dan fp adalah jumlah false negative. True positive merupakan jumlah titik panas yang sama antara data latih (predictive) dengan data uji (reference).
Penerapan Model Klasifikasi pada Data Baru
Penerapan model pada data baru tahun 2015 dilakukan setelah mendapatkan dataset dengan akurasi tertinggi pada dataset tahun 2001 sampai 2014 dari masing-masing pulau. Model klasifikasi terbaik dataset tersebut yang akan digunakan untuk memprediksi data baru tahun 2015.
Peralatan Penelitian
Perangkat lunak yang digunakan dalam penelitian ini adalah: • Sistem operasi Windows 7 Ultimate
• Bahasa pemrograman R
• Antarmuka bahasa pemrogramanR Studio
• Quantum GIS versi 2.6.1 untuk pengolahan data spasial • Microsoft Excel 2007 untuk pengolahan data
• PostgreSql versi 1.20 sistem manajemen basis data
Perangkat keras yang digunakan dalam penelitian ini adalah komputer personal dengan spesifikasi:
• Prosesor Intel Core i5-2430MCPU @ 2.40 GHz • Memory 4 GB
• System type 64-bit operating system • VGANVDIA GeForce GT540M
HASIL DAN PEMBAHASAN
Praproses Data
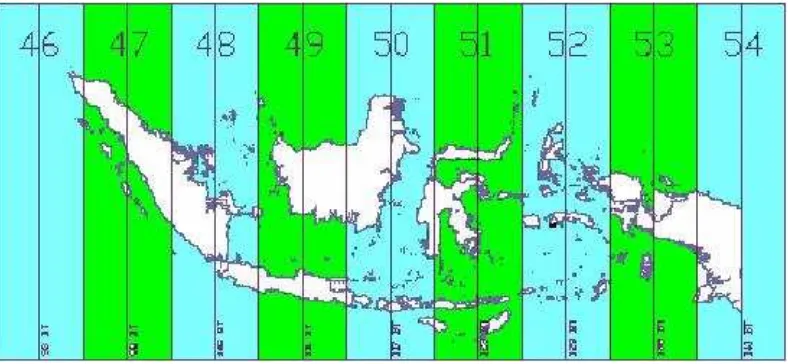
9 lahan gambut. Oleh karena itu, coordinate reference system (crs) atau sistem referensi koordinat kedua data tersebut harus sesuai yaitu ESPG: 32647-WGS 84/UTM Zone 47N untuk Sumatera dan ESPG: 32647-WGS 84/UTM Zone 49N untuk Kalimantan. Operasi spasial antara kedua data tidak dapat dilakukan jika crs tidak sama. Bumi dibagi menjadi beberapa zona yaitu antara 01 sampai dengan 60 dengan satuan meter. Sistem koordinat di Indonesia paling cocok menggunakan crs WGS84/EPSG: 4326. Pembagian zona di Indonesia dapat dilihat pada Gambar 5. Pada sistem koordinat bumi dibagi menjadi dua bagian yaitu di atas khatulistiwa sebagai bagian utara disimbolkan dengan N serta dibagian selatan disimbolkan dengan S.
10
Gambar 6 Jumlah titik panas per tahun
Gambar 7 Hasil buffer titik panas
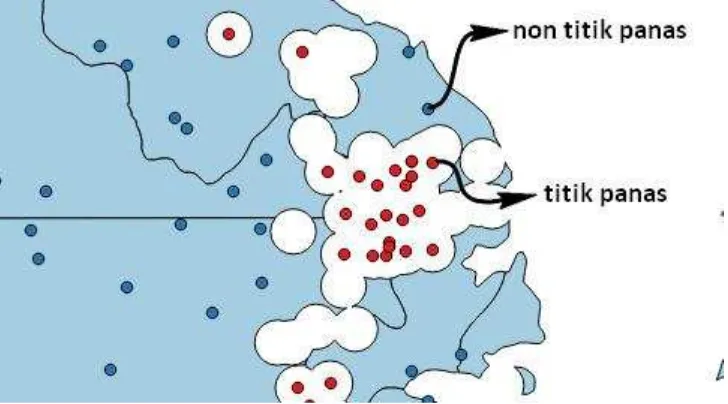
Titik panas berada di bagian tengah buffer, hasil buffer titik panas yang bertumpuk satu sama lain dilebur menggunakan operasi dissolve yang tersedia pada QGIS. Hasil dissolve digunakan untuk memotong lahan gambut menggunakan operasi difference pada QGIS. Data non titik panas didapatkan dengan membuat random point, jumlah titik disesuaikan dengan titik panas per tahun dengan nilai confidence > 70. Hasil pembangkitan random point (non titik panas) di sekitar titik panas dapat dilihat pada Gambar 8.
Ju
m
la
h
ti
ti
k p
a
na
11
Gambar 8 Hasil pembangkitan random point (non titik panas) disekitar titik panas
Praproses selanjutnya dilakukan import data lahan gambut, data titik panas, non titik panas ke PostgreSql. Query untuk menambahkan class T dan F pada dataset sebagai berikut:
update titikpanassumatera2_2001_rep set class=’T’;
update false_alarm_2001_rep set class=’F’;
Tabel target dibuat dengan query sebagai berikut: CREATE TABLE target2001_1 AS SELECT
gid,the_geom,longitude,latitude,confidence,class FROM titikpanassumatera2_2001_rep
Proses selanjutnya yaitu menggabungkan data non titik panas ke dalam tabel target. Penggabungan data dilakukan dengan menggunakan query sebagai berikut:
INSERT INTO target2001_1 (gid,the_geom,class) SELECT gid,the_geom,class
FROM false_alarm_2001_rep;
Perbandingan jumlah titik panas (T) dan non titik panas (F) pada lahan gambut adalah seimbang. Langkah selanjutnya adalah mengganti nama atribut gid pada target2001_1 menjadi gid2, kemudian menambahkan gid auto number dengan cara sebagai berikut:
ALTER TABLE target2001_1 ADD COLUMN gid BIGSERIAL PRIMARY KEY;
Hal ini dilakukan agar gid asli dari data target tidak berubah. Tahapan selanjutnya adalah pembuatan dataset yang diambil dari tabel target dan tabel lahan gambut. Query yang digunakan sebagai berikut:
CREATE TABLE dataset1 AS
SELECT t.gid,t.gid2,t.the_geom,t.confidence,g.legend, g.landuse,g.ketebalan
12
WHERE ST_Within(t.the_geom, g.the_geom) ORDER BY t.gid;
Dataset1 terdiri dari 7 variabel yaitu gid, gid2, the_geom, confidence, legend, landuse, dan ketebalan. Variabel legend menunjukkan tipe dari lahan gambut. Dataset yang akan diolah untuk klasifikasi terdiri dari 4 variabel yaitu class, legend, landuse, dan ketebalan. Query untuk membuat dataset yang digunakan untuk tahapan klasifikasi menggunakan algoritme Random Forest tersebut sebagai berikut:
CREATE TABLE dataset3 AS
SELECT t.class,g.legend,g.landuse,g.ketebalan FROM target2001_1 as t,gambutsumatera1_out as g WHERE ST_Within(t.the_geom, g.the_geom);
Pembagian Data
Pembagian data latih dan data uji pada dataset menggunakan 10-fold cross validation. Data yang digunakan merupakan dataset yang sudah tidak mengandung missing value. Dataset dibagi menjadi 10 bagian (fold). Pembentukan model klasifikasi dilakukan menggunakan data latih. Sementara itu, hasil akurasi model klasifikasi diperoleh dari data uji.
Pembuatan model klasifikasi menggunakan algoritme Random Forest
Jumlah tree yang akan dibangun pada algoritme Random Forest sebanyak 100. Sementara itu, pembagian untuk setiap node sebanyak 3, berdasarkan jumlah variabel penjelas. Berikut ini adalah pernyataan yang digunakan untuk membangun model menggunakan algoritme Random Forest:
>tmp.predict.rf1 <- predict(rf1, newdata = testData1, type = "class")
>conf.mat1 <- table(testData1$CLASS, tmp.predict.rf1, dnn = c("Prediction", "Reference"))
>accuracy.percent.test1<-
100*sum(diag(conf.mat1))/sum(conf.mat1)
13
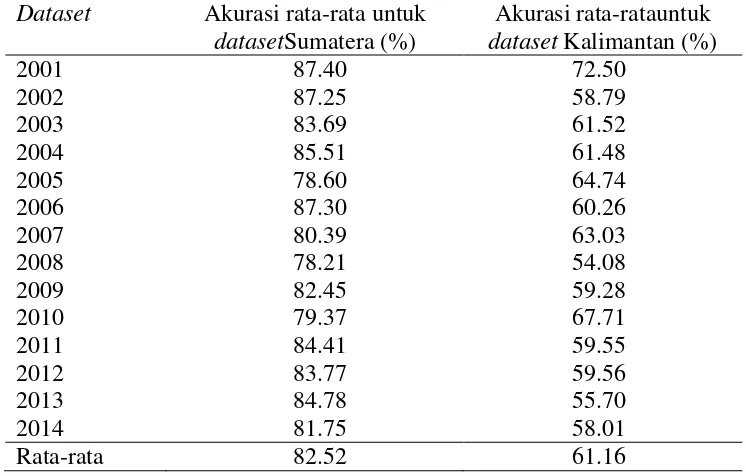
Tabel 4 Akurasi rata-rata model klasifikasi untuk dataset tahun 2001 sampai 2014
Pada Tabel 4 nilai akurasi rata-rata model klasifikasi dataset tertinggi untuk Sumatera adalah 87.40% dan untuk Kalimantan adalah 72.50% di tahun yang sama yaitu tahun 2001. Pemodelan menggunakan algoritme Random Forest yang dijalankan di R ini tidak menghasilkan model berupa tree dan vote yang terpilih. Algoritme ini menghasilkan confusion matrix dari data latih dan data uji. Confusion matrix untuk model klasifikasi terbaik pada dataset tahun 2001 di Sumatera dan Kalimantan diberikan pada Tabel 5 dan Tabel 6.
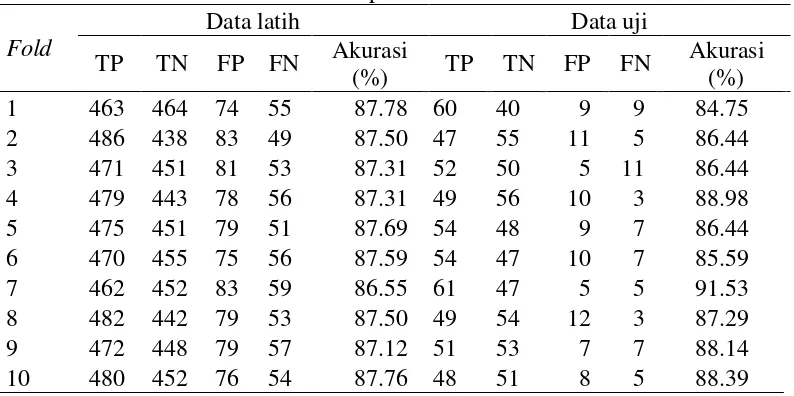
Tabel 5 Model klasifikasi terbaik pada datast Sumatera tahun 2001 Fold
14
Negative), FP (False Positive), dan FN (False Negative). TP adalah jumlah titik panas diprediksi benar sebagai titik panas. TN adalah jumlah data bukan titik panas yang diprediksi benar sebagai bukan titik panas. FP adalah jumlah data bukan titik panas diprediksi benar sebagai bukan titik panas. Sementara itu, FN adalah jumlah data titik panas yang diprediksi salah sebagai bukan titik panas. Berdasarkan Tabel 6 akurasi model klasifikasi tertinggi adalah pada fold ke-4. Akurasi dihitung dari data uji untuk dataset Sumatera dan Kalimantan. Akurasi model klasifikasi dataset pulau Sumatera dan Kalimantan dari tahun 2001 sampai dengan 2014 dapat dilihat pada halaman Lampiran 2 sampai Lampiran 29.
Tabel 6 Model klasifikasi terbaik pada dataset Kalimantan tahun 2001 Fold
Proses klasifikasi dan pembuatan model telah dilakukan pada tahapan sebelumnya. Selanjutnya perhitungan akurasi yang telah dilakukan (pada Tabel 5 dan 6) dapat menunjukkan tingkat kebenaran pengklasifikasian data. Akurasi rata-rata dari data uji Sumatera didapatkan sebesar 87.40% dan akurasi rata-rata-rata-rata untuk Kalimantan sebesar 72.50%.
Penerapan pada Model Data Baru
15 mendapatkan nilai akurasi. Akurasi model pada data baru Sumatera tahun 2015 adalah 60.80%. Confusion matrix hasil klasifikasi pada dataset Sumatera tahun 2015 dapat dilihat pada Tabel 7. Akurasi model pada data baru Kalimantan tahun 2015 adalah 39.13%. Confusion matrix hasil klasifikasi pada dataset Kalimantan dapat tahun 2015 dilihat pada Tabel 8.
Tabel 7 Confusion matrix untuk klasifikasi pada data dengan classtrue (merupakan titik panas) diklasifikasikan benar sebanyak 210 titik panas. Sebaliknya terdapat 96 data dengan class bukan titik panas (false) diklasifikasi salah ke class titik panas (true). Tabel 8 menunjukkan bahwa terdapat 8 titik dengan class bukan titik panas (false) diklasifikasi salah ke class titik panas (true). Sementara itu, data titik panas (true) yang diklasifikasikan benar sebanyak 3 titik panas. Selain informasi dari tabel confusion matrix juga dapat dihitung nilai presisi (precision). Nilai presisi ini untuk melihat titik panas yang benar diklasifikasi berdasarkan class true. Nilai presisi pada data baru tahun 2015 di Sumatera adalah 68.63%. Nilai presisi data baru tahun 2015 di Sumatera tersebut menunjukkan keakuratan model klasifikasi. Sementara itu, untuk data baru tahun 2015 di Kalimantan, presisi atau keakuratan hasil klasifikasi untuk kemunculan titik panas adalah 27.27%.
SIMPULAN DAN SARAN
Simpulan
16
data baru Kalimantan hanya berhasil mengklasifikasikan class true (merupakan titik panas) sebanyak 3 titik dari 11 titik.
Saran
Saran yang dapat diberikan untuk penelitian selanjutnya yaitu pengembangan sistem berbasis web untuk memvisualisasikan hasil klasifikasi titik panas dalam bentuk peta.
DAFTAR PUSTAKA
Adinugroho WC, Suryadiputra INN, Saharjo BH, dan Siboro L.2005. Panduan Pengendalian Kebakaran Hutan dan Lahan Gambut. Proyek Climate Changes, Forest and Peatlands in Indonesia. Bogor (ID): Wetlands International-Indonesia Programme dan Wildlife Habitat Canada.
Breiman L. 2001. Random Forests. Machine Learning. 45: 11–13.
Breiman L dan A Cutler. 2003. Manual–setting up, using, and understanding Random Forests V4.0. [Internet]. [Diunduh tanggal 06/06/2015]. Tersedia pada: https://www.stat.berkeley.edu/forests_V3.1.pdf.
Fernando V, Sitanggang IS. 2014. Klasifikasi data spasial untuk kemunculan hotspot di provinsi Riau menggunakan algoritme ID3. Di dalam: Integrasi Sains MIPA untuk mengatasi Masalah Pangan, Energi, Kesehatan, Reklamasi, dan Lingkungan; 09-11 Mei 2014. Bogor, Indonesia. Bogor (ID): SEMIRATA, hlm 428-436. ISBN: 978-602-70491-0-9.
Fu L. 1994. Neural Network in Computers Intelligence. Singapura (SG): McGraw-Hill.
Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques 3rd ed. Massachusetts (US): Morgan Kaufmann Publishers.
Nurpratami ID, Sitanggang IS. 2015. Classification rules for hotspot occurences using spatial entropy-based decision tree algorithm. Di dalam: The 1st International Symposium on LAPAN-IPB Satellite for Food Security and Environmental Monitoring. Bogor, Indonesia. Bogor (ID): Procedia Environmental Sciences, hlm 120-126. DOI: 10.1016/j.proenv.2015.03.016. Oswald P, Astrini R. 2012. Tutorial Quantum GIS Tingkat Dasar Versi 1.8.0 Lisboa.
Mataram (ID): GIZ Decentralization as Contribution to Good Governance (DeCGG).
Sitanggang IS, Ismail MH. 2011. Classification model for hotspot occurences using a decision tree method. Di dalam: Geomatics, Natural Hazard and Risk, hlm 111-121. DOI: 10.1080/19475705.2011.565807.
Sitanggang IS, Yaakob R, Mustapha N, Ainuddin AN. 2012. Application of classification algorithms in data mining for hotspots occurrence prediction in Riau province Indonesia. JATIT. 43(2): 214-221. ISSN: 1992-8645.
17 Verikas A, Gelzinis A, Becausekiene M. 2011. Mining data with random forest: a survey and result of new tests. Pattern Recognition. 44(2): 330-349. DOI: 10.1016/j.patcog.2010.08.011.
18
Lampiran 1 Contoh dataset sederhana untuk wilayah Kalimantan
No Ketebalan Tipe Class
Diketahui dataset Kalimantan pada Lampiran 29: n = 10 baris
p=3 kolom m=2, m << p
1 Memilih contoh acak dari 10 baris dataset 2 Membangun sebuah “random” tree
a. Pilih m (2) atribut dari seluruh (3) atribut
b. Contoh: Ketebalan, Tipe: dari 2 atribut tersebut dihitung nilai Gini Index-nya. Nilai yang paling tinggi dijadikan node (split).
19 Lanjutan
Gini ketebalan= - =1–[ 49 + 19 ]
Gini ketebalan= - =49= .
Gini ketebalan= - =1–[ P T| - + P F| - ]
Gini ketebalan= - =1–[ 12 + 12 ]
Gini ketebalan= - =12= .
Gini ketebalan= - =1–[ P T| - + P F| - ]
Gini ketebalan= - =1–[ + ]
Gini ketebalan= - = - =
Gini ketebalan= - =1–[ P T| - + P F| - ]
Gini ketebalan= - =1–[ 12 + 12 ]
Gini ketebalan= - =12= .
Gini ketebalan= - =1–[ P T| - + P F| - ]
Gini ketebalan= - =1–[ 22 + ]
Gini ketebalan= - = - =
GiniGain ketebalan = Gini (class) –∑ P ketebalan * Gini ketebalan
n
i=1
GiniGain ketebalan = . - [103 ×49+102 ×21+101 × +102 ×12+102 × ]
GiniGain ketebalan = .
Gini index tipe: Tipe:
P(Hemists/min) = 103, T=3; F=0 P(Hemists/fib) = 107, T=3; F=4
Gini tipe=Hemists/min =1–[ P T|Hemists/min + P F|Hemists/min ]
Gini tipe=Hemists/min =1–[ 33 + ]
Gini tipe=Hemists/min =0
Gini tipe=Hemists/fib =1–[ P T|Hemists/min + P F|Hemists/min ]
Gini tipe=Hemists/min =1–[ 37 + 47 ]
Gini tipe=Hemists/fib =2449= .
GiniGain tipe = . - [103 × +107 ×2449]
20 Lanjutan
Pilih nilai GiniGain yang paling tinggi nilainya, maka yang menjadi root untuk tree pertama adalah Ketebalan.
Berikutnya ambil baris yang ada 50-100:
No Ketebalan Tipe Class
1 50-100 Hemists/min T
2 50-100 Hemists/min T
3 50-100 Hemists/fib F
Gini index (class) P(T) = 23
P(F) = 13
Gini class =1–[ 23 + 13 ]
Gini class =1–59= .
Gini index tipe:
P(Hemists/min) = 23, T=2; F=0 P(Hemists/fib) = 13, T=0; F=1
Gini tipe=Hemists/min =1–[ P T|Hemists/min + P F|Hemists/min ]
Gini tipe=Hemists/min =1–[ 22 + ]
Gini tipe=Hemists/min =0
Gini tipe=Hemists/fib =1–[ P T|Hemists/min + P F|Hemists/min ]
Gini tipe=Hemists/min =1–[ + ]
Gini tipe=Hemists/fib =
GiniGain tipe = . - [23× +13× ]
21 Lanjutan
No Ketebalan Tipe Class
7 400-800 Hemists/fib F
8 400-800 Hemists/min T
Gini index (class) P(T) = 12
P(F) = 12
Gini class =1–[ 12 + 12 ]
Gini class =1–12= .
Gini index tipe:
P(Hemists/min) = 12, T=1; F=0 P(Hemists/fib) = 12, T=0; F=1
Gini tipe=Hemists/min =1–[ P T|Hemists/min + P F|Hemists/min ]
Gini tipe=Hemists/min =1–[ + ]
Gini tipe=Hemists/min =0
Gini tipe=Hemists/fib =1–[ P T|Hemists/min + P F|Hemists/min ]
Gini tipe=Hemists/min =1–[ + ]
Gini tipe=Hemists/fib =
GiniGain tipe = . - [12× +12× ]
22 Lanjutan Tree 1
Selanjutnya lakukan hal yang sama untuk membangun tree yang lainnya sebanyak k, dalam contoh ini k=3.
Tree yang ke-2 root-nya masih sama yaitu ketebalan (50-100 dan 200-400). Ambil baris yang ada 200-400:
No Ketebalan Tipe Class
6 200-400 Hemists/fib F
Tree 2
Tree yang ke-3 root-nya masih sama yaitu ketebalan (800-1200 dan 20-100). Ambil baris yang ada 80-1200:
No Ketebalan Tipe Class
9 800-1200 Hemists/fib T
23 Lanjutan
Tree 3
Kombinasi tree yang terbentuk dapat menghasilkan ukuran dan bentuk yang berbeda-beda karena setiap pembentukan tree dilakukan penarikan contoh secara acak. Setelah tree-tree terbentuk dilakukan prediksi class terhadap 2 data uji seperti pada tabel di bawah ini.
No Ketebalan Tipe Class
1 500-1200 Hemists/min ?
2 400-800 Hemists/fib ?
Data uji no 1 dan 2 akan dicari class-nya, maka telusuri tree-tree yang telah dibuat. Data uji no 1
Tree 1: T Tree 2: T Tree 3: T
Majority vote untuk data uji 1 adalah T (true)
Data uji no 2 Tree 1: F
24
Lampiran 2 Akurasi model untuk dataset pulau Sumatera tahun 2001 Fold
Lampiran 3 Akurasi model untuk dataset pulau Sumatera tahun 2002 Fold Lampiran 4 Akurasi model untuk dataset pulau Sumatera tahun 2003
25 Lampiran 5 Akurasi model untuk dataset pulau Sumatera tahun 2004
Fold Lampiran 6 Akurasi model untuk dataset pulau Sumatera tahun 2005
Fold Lampiran 7 Akurasi model untuk dataset pulau Sumatera tahun 2006
26
Lampiran 8 Akurasi model untuk dataset pulau Sumatera tahun 2007 Fold Lampiran 9 Akurasi model untuk dataset pulau Sumatera tahun 2008
Fold Lampiran 10 Akurasi model untuk dataset pulau Sumatera tahun 2009
27 Lampiran 11 Akurasi model untuk dataset pulau Sumatera tahun 2010
Fold Lampiran 12 Akurasi model untuk dataset pulau Sumatera tahun 2011
Fold Lampiran 13 Akurasi model untuk dataset pulau Sumatera tahun 2012
28
Lampiran 14 Akurasi model untuk dataset pulau Sumatera tahun 2013 Fold Lampiran 15 Akurasi model untuk dataset pulau Sumatera tahun 2014
Fold Lampiran 16 Akurasi model untuk dataset pulau Kalimantan tahun 2001
29 Lampiran 17 Akurasi model untuk dataset pulau Kalimantan tahun 2002
Fold Lampiran 18 Akurasi model untuk dataset pulau Kalimantan tahun 2003
Fold Lampiran 19 Akurasi model untuk dataset pulau Kalimantan tahun 2004
30
Lampiran 20 Akurasi model untuk dataset pulau Kalimantan tahun 2005 Fold Lampiran 21 Akurasi model untuk dataset pulau Kalimantan tahun 2006
Fold Lampiran 22 Akurasi model untuk dataset pulau Kalimantan tahun 2007
31 Lampiran 23 Akurasi model untuk dataset pulau Kalimantan tahun 2008
Fold Lampiran 24 Akurasi model untuk dataset pulau Kalimantan tahun 2009
Fold Lampiran 25 Akurasi model untuk dataset pulau Kalimantan tahun 2010
32
Lampiran 26 Akurasi model untuk dataset pulau Kalimantan tahun 2011 Fold Lampiran 27 Akurasi model untuk dataset pulau Kalimantan tahun 2012
Fold Lampiran 28 Akurasi model untuk dataset pulau Kalimantan tahun 2013
33 Lampiran 29 Akurasi model untuk dataset pulau Kalimantan tahun 2014
Fold
Data latih Data uji
TP TN FP FN Akurasi
(%) TP TN FP FN
34