SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
BAMBANG IMAM HERMAWAN
10110511
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
Segala puji dan syukur penulis panjatkan kehadirat Allah SWT, atas segala rahmat dan hidayah–Nya sehingga penulis dapat menyelesaikan tugas akhir ini dengan mengambil judul “ANALISIS PERFORMANSI ALGORITMA
WINNOWING DAN ALGORITMA MANBER UNTUK DETEKSI
KESAMAAN DOKUMEN TEKS BERBAHASA INDONESIA”. Adapun tujuan
dari penyusunan tugas akhir ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan jenjang studi stara satu (S1) di Program Studi Teknik Informatika, Universitas Komputer Indonesia.
Dengan selesainya penyusunan tugas akhir ini, penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Kedua orang tua, terima kasih atas doa dan dukungan yang tidak pernah ada hentinya, baik secara moril dan materil.
2. Ibu Nelly Indriani W, S.Si., M.T. selaku dosen pembimbing yang telah banyak meluangkan waktu untuk membimbing serta mengarahkan dalam proses penyusunan tugas akhir.
3. Bapak Alif Finandhita S.Kom selaku dosen wali IF12 Angkatan 2010.
4. Ibu Ednawati Rainarli, S.Si., M.Si. selaku dosen reviewer yang telah memberikan inspirasi dan membimbing dengan sangat teliti dalam proses penyusunan tugas akhir.
5. Teman-teman mahasiswa seperjuangan dari semester awal hingga akhir yaitu Amir Ibrahim Hasan, Muhammad Iqbal, Septiyan Hendiyana, Gustiar Prasetyo Hadi dan Muhammad Septiana yang selalu berbagi pemikiran akan penyusunan tugas akhir.
6. Teman-teman yang telah mendukung proses seminar
7. Seluruh Panitia Skripsi yang telah bekerja keras mengatur jalannya proses dengan sangat baik
8. Penyedia tempat untuk bertukar informasi yaitu Haditya Dwi Perkasa, Eko Harianto, Giri Muria Shaleh , Fatahudin Azis, Arief Firmansyah, Aidil Pratama Putra dan Taufik Mardan Dwi Putra
Penulis menyadari tugas akhir ini masih jauh dari kata sempurna dengan segala kekurangan yang dimiliki. Untuk itu penulis mengharapkan adanya kritik dan saran yang bersifat membangun dari semua pihak demi kesempurnaan tugas akhir ini.
Akhir kata, semoga tugas akhir ini dapat bermanfaat.
Bandung, Februari 2015
v
2.4 Tokenizing ... 13
2.5 Algoritma Winnowing ... 14
2.6 Algoritma Manber ... 16
2.7 Rolling Hash ... 17
2.8 Jaccard’s Similarity Coefficient ... 18
2.9.1 Kompleksitas Waktu dan Ruang ... 20
2.9.1.1 Kompleksitas Waktu ... 20
2.9.2 Aturan Algoritma ... 22
2.10 Pengertian ASCII ... 23
2.10.1 Tabel Karakter ASCII ... 23
2.11 Data Flow Diagram (DFD) ... 24
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 27
3.1 Analisis Masalah ... 27
3.2 Analisis Input dan Output ... 28
3.2.1 Analisis Input dan Output Algoritma Winnowing ... 28
3.2.1.1 Analisis Input ... 28
3.2.1.2 Analisis Output ... 28
3.2.2 Analisis Input dan Output Algoritma Manber ... 28
3.2.2.1 Analisis Input ... 27
3.2.2.2 Analisis Output ... 29
3.3 Analisis Algoritma ... 29
vi
3.4 Analisis Kebutuhan Perangkat Lunak ... 43
3.4.1 Analisis Kebutuhan Non-Fungsional ... 43
3.4.1.1 Analisis Perangkat Keras ... 43
3.4.1.2 Analisis Perangkat Lunak ... 44
3.4.1.3 Analisis Perangkat Pikir ... 44
3.4.2 Analisis Kebutuhan Fungsional ... 44
3.4.2.1 Diagram Konteks ... 45
3.4.2.2 Data Flow Diagram ... 45
3.4.2.2.1 Data Flow Diagram Level 1 ... 45
3.4.2.2.2 Data Flow Diagram Level 2 Pendeteksian Algoritma Winnowing ... 46
3.4.2.2.3 Data Flow Diagram Level 2 Pendeteksian Algoritma Manber ... 47
3.4.2.2.4 Data Flow Diagram Level 2 Proses Cek Histori ... 48
3.4.2.3 Spesifikasi Proses ... 48
3.4.2.3.1 Spesifikasi Proses Input Teks ... 48
3.4.2.3.2 Spesifikasi Proses Preprocessig ... 49
3.4.2.3.3 Spesifikasi Proses Hitung Kemiripan ... 50
3.4.2.3.4 Spesifikasi Proses Download Dokumen ... 51
3.4.2.3.5 Spesifikasi Proses Lihat Upload Dokumen ... 51
3.4.2.3.6 Spesifikasi Proses Lihat Histori Perhitungan Dokumen ... 52
3.4.3 Kamus Data... 52
3.4.4 Perancangan Sistem ... 54
vii
3.4.4.2.3 Perancangan Antar Muka T03 ... 56
3.4.4.2.4 Perancangan Antar Muka T04 ... 57
3.4.4.2.5 Perancangan Antar Muka T05 ... 59
3.4.4.2.6 Perancangan Antar Muka T06 ... 59
3.4.4.3 Jaringan Semantik ... 60
3.4.4.4 Perancangan Basis Data ... 60
3.4.4.4.1 Tabel tb_dokumen ... 61
3.4.4.4.2 Tabel histori ... 61
3.4.4.4.3 Tabel Stopword ... 62
3.4.4.5 Perancangan Prosedural ... 62
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 65
4.1 Implementasi ... 65
4.1.1 Implementasi Perangkat Keras ... 65
4.1.2 Implementasi Perangkat Lunak ... 65
4.1.3 Implementasi Database ... 66
4.1.4 Implementasi Antarmuka ... 67
4.2 Pengujian Metode ... 68
4.2.1 Pengujian Metode Winnowing ... 69
4.2.1.1 Pengujian Jumlah Gram ... 69
4.2.1.2 Pengujian Jumlah Window ... 71
viii
4.2.2.3 Pengujian Basis Bilangan Prima ... 81
4.3 Kesimpulan Pengujian ... 81
BAB 5 KESIMPULAN ... 85
5.1 Kesimpulan ... 85
5.2 Saran ... 85
87
DAFTAR PUSTAKA
[1] Lako, Andreas, "Plagiarisme Akademik1," Jawa Pos Radar Semarang, Juni 2012.
[2] Kurniawati, Ana; Wicaksana, Wayan Simri, "PERBANDINGAN PENDEKATAN DETEKSI PLAGIARISM DOKUMEN DALAM BAHASA INGGRIS," Seminar Ilmiah Nasional Komputer dan Sistem Intelijen, Agustus 2008.
[3] Stein, S; Eissen, Zu Meyer;, "Near Similarity Search and Plagiarism Analys," Annual Conference of the German Classification Society (GfKl), pp. 430-437, 2006.
[4] Kharisman, Obed; Susanto, Budi; Suwarno, Sri, "IMPLEMENTASI ALGORITMA WINNOWING UNTUK MENDETEKSI KEMIRIPAN DOKUMEN TEKS," INFORMATIKA, vol. 9, April 2013.
[5] Permana, Budi, "Algoritma Pemrograman Dalam Bahasa Pascal," 2003-2007, pp. 1-32, 2007.
[6] Munir, Rinaldy, Algoritma dan Pemrograman, Edisi Pertama ed. Bandung, Indonesia: CV INFORMATIKA, 1998.
[7] Harlian, Milkha, "Machine Learnig Text Categorization," University Of Texas At Austin, 2006.
[8] Priantara, Wayan Surya; Purwitasari, Diana; Yuhana, Umi Laili, "IMPLEMENTASI DETEKSI PENJIPLAKAN DENGAN ALGORITMA WINNOWING PADA DOKUMEN TERKELOMPOK," 2011, Juli 2011.
[9] Manber, Udi, "Finding Similar Files in a Large File System," Department of Computer Science, 1994.
88
[11] Munir, Rinaldy, MATEMATIKA DISKRIT, 3rd ed. Bandung, Indonesia: Informatika Bandung, 2009.
[12] Suarga , Algoritma dan Pemrograman, Edisi II ed., Sigit Suyantoro, Ed. Yogyakarta, Indonesia: CV ANDI, 2012.
[13] theasciicode. [Online]. www.theasciicode.com.ar
[14] Sutanta, Edhy;, Algoritma : Teknik Penyelesaian Permasalahan Untuk Komputasi, Cetakan Pertama ed., F Wiwiek Nurwiyati, Ed. Yogyakarta, Indonesia: Graha Ilmu, 2004.
[15] Purwanto, Eko Budi, Perancangan dan Analisis Algoritma, Edisi Pertama ed. Yogyakarta, Indonesia: Graha Ilmu, 2008.
1
1.1Latar Belakang Masalah
Perkembangan teknologi informasi saat ini membuat dokumen yang tadinya bersifat fisik kini telah banyak dibuat dalam bentuk digital sehingga dapat dengan mudah dilakukan penyalinan digital yang dapat menimbulkan plagiarisme. Plagiarisme merupakan tindakan menjiplak, mencuri atau mengambil ide, hasil karya atau tulisan orang lain, baik seluruh, sebagian besar maupun sebagian kecil, untuk jadi ide atau karya tulisan sendiri tanpa menyebutkan nama penulis dan sumber aslinya [1]. Dalam mendeteksi plagiarisme dokumen digital terdapat beberapa metode yang dapat digunakan untuk mengukur tingkat similaritas sebuah dokumen yaitu metode perbandingan teks lengkap, metode kesamaan kata kunci dan metode fingerprinting [2,3].
Dalam penelitian ini akan dilakukan analisis pengukuran similaritas antar dokumen menggunakan metode fingerprinting. Metode fingerprinting adalah metode yang menelusuri karakter satu persatu pada deret karakter. Prinsip kerja dari metode dokumen fingerprinting ini adalah dengan menggunakan teknik hashing. Teknik hashing adalah sebuah fungsi yang mengkonversi setiap string menjadi bilangan. Bilangan-bilangan tersebut menghasilkan nilai-nilai fingerprints sebagai acuan dalam perhitungan kesamaan dokumen. Kelebihan dari metode fingerprinting adalah waktu proses lebih cepat dibandingkan dari metode perbandingan teks lengkap dan metode kesamaan kata kunci [2]. Pengujian similaritas dokumen fingerprinting memiliki tahapan pencarian nilai hashing dari setiap kata, pengambilan nilai fingerprints dan pembobotan persentasi kemiripan.
fingerprinting yaitu Algoritma Winnowing dan Algoritma Manber yang dapat diterapkan untuk mendeteksi similaritas pada dokumen teks. Analisis performansi dilakukan dengan tujuan mendapatkan informasi dari kedua algoritma yaitu berupa informasi kecepatan, ketepatan, dan jumlah langkah dari Algoritma Winnowing dan Algoritma Manber dalam penerapannya pada sebuah sistem.
Dari sedikitnya penelitian dalam lingkup analisis performansi kedua algoritma ini maka menjadi dasar penelitian ini. Terdapat penelitian sebelumnya mengenai perbandingan pendekatan kedua algoritma ini yang berjudul “Perbandingan Pendekatan Deteksi Plagiarisme Dokumen Dalam Bahasa Inggris” oleh Ana Kurniawati dan I Wayan Simri Wicaksana dalam jurnalnya yang menganalisis perbandingan dan penerapannya pada dokumen berbahasa inggris. Berdasarkan hasil penelitian tersebut, disimpulkan bahwa algoritma winnowing lebih baik dari algoritma manber karena memberikan jaminan terdeteksinya dokumen sama [2]. Penerapan penelitian tersebut dilakukan pada sistem yang memproses teks berbahasa inggris. Berdasarkan hal tersebut maka akan dilakukan analisis yang nantinya akan diterapkan pada dokumen berbahasa Indonesia.
Penelitian lainnya dari kedua algoritma yaitu berjudul “Implementasi Algoritma
Winnwoing untuk Mendeteksi Kemiripan Pada Dokumen Teks” [4], hanya berfokus
1.2Rumusan Masalah
Berdasarkan latar belakang masalah yang diuraikan, maka dapat diidentifikasi masalah dalam penelitian ini yaitu:
1. Bagaimana mendeteksi kesamaan antar dokumen teks sebagai dugaan plagiarisme menggunakan metode fingerprinting.
2. Bagaimana performansi Algoritma Winnowing dan Algoritma Manber dalam mendeteksi similaritas dokumen.
3. Bagaimana pengaruh jumlah parameter input terhadap persentasi kemiripan dokumen yang dibandingkan.
1.3Maksud dan Tujuan 1.3.1 Maksud
Maksud dari penelitian ini adalah untuk menganalisis Algoritma Winnowing dan Algoritma Manber dalam mendeteksi kesamaan dokumen teks berbahasa Indonesia
1.3.2 Tujuan
Sedangkan tujuan yang akan dicapai yaitu mendapatkan informasi dari Algoritma Winnowing dan Algoritma Manber berupa informasi perbandingan kecepatan, ketepatan, keefektifan langkah dan pengaruh jumlah parameter input dalam proses mendeteksi kesamaan dokumen.
1.4Batasan Masalah
Batasan masalah dari penelitian ini yaitu:
1. Metode yang digunakan adalah metode fingerprinting.
2. Penerapan algoritma pada sistem memproses dokumen berbahasa Indonesia. 3. Penerapan algoritma pada sistem tidak membedakan arti atau sinonim dari
4. Penerapan algoritma menggunakan metode Jaccard’s Similarity Coefficient sebagai perhitungan kesamaan.
5. Parameter yang akan diukur adalah kecepatan, ketepatan dan jumlah langkah dari kedua algoritma.
6. Sistem tidak melihat acuan referensi yang digunakan dokumen. 7. Dokumen yang akan dideteksi berextensi .txt
8. Jumlah gram dibatasi 2 sampai 10
1.5Metodologi Penelitian
Metodologi penelitian yang dimaksud adalah segala hal yang berhubungan dengan metode-metode yang digunakan dalam melakukan penelitian ini dengan cara melakukan pendekatan terhadap metode-metode yang telah ada. Dalam penelitian ini menggunakan metode-metode yang diuraikan di bawah ini.
1.5.1 Metode Penelitian
Metode penelitian yang dipakai adalah metode penelitian deskriptif. Dalam metode penelitian ini digunakan teknik-teknik analisis, klasifikasi masalah, studi literatur terhadap masalah-masalah yang berhubungan dengan skripsi yang disusun, dan teknik test terhadap objek penelitian yang telah ada..
Dengan metode deskriptif, data yang telah dikumpulkan mula-mula disusun, dijelaskan, dianalisis, dan kemudian diimplementasikan dalam sebuah perangkat lunak.
1.5.2 Tahap Pengumpulan Data
1.5.3 Tahap Pengembangan Perangkat Lunak
Teknik analisis data dalam pembuatan perangkat lunak menggunakan paradigma perangkat lunak secara prototyping, yang meliputi beberapa proses diantaranya:
1. Pengumpulan kebutuhan
Pendefinisian format seluruh perangkat lunak, mengidentifikasikan semua kebutuhan, dan garis besar sistem yang akan dibuat.
2. Membangun prototyping
Membangun prototyping dengan membuat perancangan sementara yang berfokus pada penyajian kepada pengguna (misalnya dengan membuat input dan format output)
3. Evaluasi protoptyping
Evaluasi ini dilakukan oleh pengguna apakah prototyping yang sudah dibangun sudah sesuai dengan keinginann pengguna. Jika sudah sesuai maka langkah 4 akan diambil. Jika tidak prototyping direvisi dengan mengulangi langkah 1, 2 , dan 3. dites dahulu sebelum digunakan. Pengujian ini dilakukan dengan metode pengujian Black Box yaitu pengujian luar sistem.
6. Evaluasi Sistem
7. Menggunakan sistem
Perangkat lunak yang telah diuji dan diterima pengguna siap untuk digunakan .
1.6Sistematika Penulisan
Penyusunan skripsi ini dibagi ke dalam beberapa bab secara sistematis sesuai dengan pokok-pokok permasalahan yang dibahas. Adapun sistematika penulisan secara umum adalah sebagai berikut:
BAB I . PENDAHULUAN
Bab ini menjelaskan secara singkat mengenai latar belakang masalah, identifikasi masalah, maksud dan tujuan, metodologi penelitian, batasan masalah, serta sistematika penulisan.
BAB II . LANDASAN TEORI
Pada bab ini berisi tentang analisis kebutuhan dalam membangun aplikasi ini yang sesuai dengan metode pembangunan perangkat lunak yang digunakan. Selain itu terdapat juga teori-teori yang berkaitan dengan penelitian yang dijalankan.
BAB III . ANALISIS DAN PERANCANGAN SISTEM
Bab ini menerangkan analisis yang dilakukan terhadap cara kerja aplikasi yang dibuat. Bab ini juga membahas mengenai lingkungan bahasa pemrograman yang digunakan dan perancangandalam tahapan-tahapan yang sistematis.
BAB IV . IMPLEMENTASI SISTEM
Pada bab ini berisi tentang analisis kebutuhan dalam membangun aplikasi ini yang sesuai dengan metode pembangunan perangkat lunak yang digunakan. Selain itu terdapat juga perancangan antarmuka dan pengujian untuk aplikasi yang akan dibangun sesuai dengan hasil analisis.
BAB V . KESIMPULAN DAN SARAN
7
BAB 2
TINJAUAN PUSTAKA
2.1Plagiarisme
2.1.1 Pengertian Plagiarisme
Plagiarisme merupakan tindakan menjiplak, mencuri atau mengambil ide, hasil karya atau tulisan orang lain, baik seluruh, sebagian besar maupun sebagian kecil, untuk jadi ide atau karya tulisan sendiri tanpa menyebutkan nama penulis dan sumber aslinya[1].
2.1.2 Jenis Plagiarisme
Berdasarkan sejumlah pola atau modus operansi tersebut, paling sedikit ada empat jenis plagiarisme[1].
a. Plagiarisme total yaitu tindakan plagiasi yang dilakukan seorang penulis dengan cara menjiplak atau mencuri hasil karya orang lain seluruhnya dan mengklaim sebagai karyanya sendiri.
b. Plagiarisme parsial yaitu tindakan plagiasi yang dilakukan sesorang penulis dengan cara cara menjiplak sebagian hasil karya orang lain untuk menjadi hasil karyanya sendiri. Biasanya, dalam plagiasi jenis ini seorang penulis mengambil pernyataan, landasan teori, sampel, metode analisis, pembahasan dan atau kesimpulan tertentu dari hasil karya orang lain menjadi karyanya tanpa menyebutkan sumber aslinya.
c. Auto-plagiasi (self-plagiarisme) yaitu plagiasi yang dilakukan seorang penulis terhadap karyanya sendiri, baik sebagian maupun seluruhnya. Misalnya, ketika menulis suatu artikel ilmiah seorang penulis meng-copy paste bagian-bagian tertentu dari hasil karyanya dalam suatu buku yang sudah diterbitkan tanpa menyebut sumbernya
Indonesia. Kemudian, penulis menjadikan hasil terjemahan tersebut sebagai hasil karyanya tanpa menyebut sumbernya. Modus operandinya hampir mirip dengan jenis plagiasi total dan plagiasi parsial. Asumsinya, para pembaca tidak akan tahu bahwa artikel tersebut adalah hasil terjemahan karena berbeda bahasa.
2.2Metode Pendeteksian Kesamaan Dokumen
Metode pendeteksian kesamaan dokumen dibagi menjadi tiga bagian yaitu metode perbandingan teks lengkap, metode dokumen fingerprinting, dan metode kesamaan kata kunci [3]. Metode pendeteksi plagiarism dapat dilihat pada Gambar 2.1.
Gambar 2.1 Metode Pendeteksi Plagiarisme
Penjelasan dari masing-masing metode dan algoritma pendeteksi kesamaan dokumen sesuai Gambar 2.1 yaitu:
Metode perbandingan teks lengkap tidak dapat diterapkan untuk kumpulan dokumen yang tidak terdapat pada dokumen lokal. Algoritma yang digunakan pada metode ini adalah algoritma Brute-Force, algoritma edit distance, algoritma Boyer Moore dan algoritma lavenshtein distance.
2. Dokumen Fingerprinting. Dokumen fingerprinting merupakan metode yang digunakan untuk mendeteksi keakuratan salinan antar dokumen, baik semua teks yang terdapat di dalam dokumen atau hanya sebagian teks saja. Prinsip kerja dari metode dokumen fingerprinting ini adalah dengan menggunakan teknik hashing. Teknik hashing adalah sebuah fungsi yang mengkonversi setiap string menjadi bilangan. Misalnya Rabin-Karp, Winnowing dan Manber.
3. Kesamaan Kata Kunci. Prinsip dari metode ini adalah mengekstrak kata kunci dari dokumen dan kemudian dibandingkan dengan kata kunci pada dokumen yang lain. Pendekatan yang digunakan pada metode ini adalah teknik dot.
2.3Algoritma
Algoritma adalah suatu perintah yang berisi langkah-langkah untuk menyelesaikan masalah [5]. Algoritma berasal dari nama tokoh ilmuan islam pada masa itu yaitu Abu Ja‟far Muhammad Ibu Musa Al Khawārizmi yang hidup sekitar abad ke-9. Dengan karya bukunya yang terkenal yaitu Al Jabar Wal Muqabala yang berarti “Buku Pemugaran dan Pengurangan”.
Pada awalnya kata algoritma adalah istilah yang merujuk kepada aturan-aturan aritmetis untuk menyelesaikan persoalan dengan menggunakan bilangan numerik arab (sebenarnya dari India, sepertitertulis pada judul di atas). Pada abad ke-18, istilah ini berkembang menjadi algoritma, yang mencakup semua prosedur atau urutan langkah yang jelas dan diperlukan untuk menyelesaikan suatu permasalahan. Berikut adalah contoh bagaimana algoritma dapat menyelesaikan masalah :
A dan gelas yang berwarna biru adalah gelas B. Jika isi gelas A ingin kita pindahkah ke dalam gelas B dan isi gelas B berpindah ke gelas A agar tidak merubah warna masing-masing gelas tentukan cara bagaimana mana gelas tersebut dapat berpindah tempat tanpa merubah isi dalam gelas tersebut.
Penyelesaiannya :
1. tambahkan gelas kosong yang diasumsikan sebagai gelas C.
2. Pindahkan isi gelas A ke dalam gelas kosong C sehingga sekarang gelas A kosong dan isi gelas C adalah air berwarna merah.
3. Setelah itu pindahkan isi gelas B ke dalam gelas A sehingga isi gelas B kosong dan berpindah ke gelas A.
4. Pindahkan isi gelas C yang berisi air berwarna merah kedalam gelas B yang sudah kosong karena isinya sudah berpindah ke dalam gelas A.
5. Hasil akhirnya adalah A berisi air berwarna biru dan B berisi air berwarna merah.
2.3.1 Dasar Algoritma
Dasar algoritma terdiri dari beberapa tahapan. Tahapan-tahapan ini merupakan tindakan yang sering digunakan seperti sequence, pemilihan dan perulangan.
2.3.1.1Sequence
Algoritma merupakan runtunan satu atau lebih instruksi, yang berarti bahwa : a. Tiap instruksi di kerjakan satu persatu;
b. Tiap instruksi dilaksanakan tepat sekali; tidak ada instruksi yang di ulang;
c. Urutan instruksi yang dilaksanakan pemroses sama dengan urutan instruksi sebagaimana yang tertulis didalam teks algoritmanya
d. Akhir dari instruksi terakhir adalah akhir algoritma.
Langkah 1
Langkah 2
Tuangkan isi gelas B ke dalam gelas A
Langkah 3
Tuangkan isi gelas C ke dalam gelas B
2.3.1.2Pemilihan
Adakalanya sebuah program dihadapkan pada suatu kondisi dimana kondisi tersebut menentukan alur program yang akan kita buat.
Contoh 1
Jika keran air kita tutup maka Air tidak akan keluar
Pernyataan diatas dapat kita tulis dalam pernyataan kondisional sebagai berikut : If kondisithen Aksi
Jika kita tulis :
If keran air di tutup then Air tidak akan keluar If keran air di buka then Air akan keluar
Dalam bahasa Indonesia If berarti jika dan then berarti maka dimana setiap kondisi bisa menghasilkan nilai benar atau salah.
2.3.1.3Perulangan
Jika di banding dengan manusia kelebihan komputer adalah tidak mengenal kata lelah jika mengerjakan pekerjaan yang sama secara berulang kali. Contoh algoritma yang kurang cerdas untuk menuliskan kata sebanyak 100 x sebagai berikut:
Program menulis_kata;
{Tidak ada} Algoritma
Tulis „Saya akan belajar yang rajin‟; Tulis „Saya akan belajar yang rajin‟; Tulis „Saya akan belajaryang rajin‟; Tulis „Saya akan belajar yang rajin‟; Tulis „Saya akan belajar yang rajin‟; ………..
Alangkah baiknya jika pengulangan tersebut dibuat secara otomatis yaitu dengan menggunakan algoritma perulangan sebagai berikut :
Program menulis_kata;
{Menuliskan kata sebanyak 100 kali}
Deklarasi
Algoritma
For i dari 1 sampai 100
Tulis ‘Saya akan belajar yang rajin’; End for
Algoritma diatas akan mengulangi kata „Saya akan belajar yang rajin‟ sampai 100 kali, apabila perulangan sudah terpenuhi maka perulangan pun akan berhenti.
2.3.2 Stuktur Algoritma
Berikut ini merupakan salah satu struktur algoritma yang dipakai sebagai patokan yaitu:
a. Bagian kepala (Header)
b. Bagian Deklarasi (Definisi Variable)
Pada bagian ini memuat definisi nama variable, nama tetapan, nama procedure, nama fungsi, dan tipe data yang digunakan oleh algoritma
c. Bagian Deskripsi (Rincian Langkah)
Pada bagian ini memuat langkah-langkah penyelesaian masalah termasuk beberapa perintah seperti baca data, tampil data, perulangan yang mengubah data input menjadi output [6]
2.4Tokenizing
Tahap tokenizing / parsing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya. Karakter selain huruf dihilangkan dan dianggap delimiter. Tokenizing biasanya digunakan pada tahap preprocessing sehingga kata-kata pada sebuah dokumen dibagi menjadi beberapa kata sesuai dengan delimeter pembagi kata yang telah ditentukan. Tokenizing sangat berguna ketika sebuah program pengolah teks memerlukan data sebuah kata yang tersusun dan terbagi menjadi array. Proses tokenizing dapat dilihat pada Gambar 2.3 [7] :
2.5Algoritma Winnowing
Algoritma winnowing merupakan algoritma dokumen fingerprinting yang digunakan untuk mendeteksi salinan dokumen dengan menggunakan teknik hashing [4]. Input dari algoritma ini adalah dokumen teks yang diproses sehingga menghasilkan output berupa kumpulan nilai-nilai hash, nilai hash merupakan nilai numerik yang terbentuk dari perhitungan ASCII tiap karakter . Kumpulan-kumpulan nilai hash tersebut selanjutnya disebut fingerprint. Fingerprint inilah yang digunakan dalam deteksi penjiplakan [8].
Langkah awal dalam penerapan algoritma Winnowing adalah membuang karakter-karakter dari isi dokumen yang tidak relevan misal tanda baca spasi dan simbol lain sehingga yang terbaca hanya karakter string. Sebagai contoh:
Deteksi plagiarisme
deteksiplagiarisme
Langkah kedua, isi dokumen yang telah dilakukan pembersihan selanjutnya dilakukan pembentukan rangkaian gram, dimana k =5.
deteksiplagiarisme
detek ksipl lagia arism eteks sipla agiar risme teksi iplag giari
Langkah ketiga dari rangkaian gram yang telah terbentuk dibentuk nilai hash dengan nilai ASCII tiap karakter. Perhitungan nilai hash menggunakan metode Rolling Hash dan menghasilkan nilai hash dari setiap gram sebagai berikut:
12281, 12658, 13536, 12532, 13161, 13579, 12895, 13275, 12706, 11988, 12498, 12580, 12334, 13532
Setelah mendapatkan nilai hash langkah selanjutnya adalah pembagian nilai hash menurut window dengan besar window w = 4
{12281, 12658, 13536, 12532} {12658, 13536, 12532, 13161} {13536, 12532, 13161, 13579} {12532, 13161, 13579, 12895} {13161, 13579, 12895, 13275} {13579, 12895, 13275, 12706} {12895, 13275, 12706, 11988} {13275, 12706, 11988, 12498} {12706, 11988, 12498, 12580} {11988, 12498, 12580, 12334} {12498, 12580, 12334, 13532}
Langkah ke lima adalah memeilih nilai hash terkecil dari setiap window untuk dijadikan nilai fingerprints dari dokumen tersebut:
12281, 12532, 12895, 12706, 11988, 12334
Implementasi algoritma winnowing yang efisien sebaiknya menyimpan posisi fingerprints yang telah didapatkan (Elbegbayan, 2005), dimana posisi dimulai dari 0 dari nilai hash pada gram yang terbentuk sebelumnya [fingerprints, posisi].
2.6Algoritma Manber
Algoritma Manber melakukan pemilihan nilai fingerprints yang telah diperoleh dari proses hashing dengan memilih nilai fingerprints yang memenuhi kriteria 0 mod p [9] Contoh tahapan Algoritma Manber dapat dilihat sebagai berikut:
Langkah awal dalam penerapan algoritma manber adalah membuang karakter-karakter dari isi dokumen yang tidak relevan misal tanda baca spasi dan simbol lain. Sebagai contoh:
Deteksi plagiarisme
deteksiplagiarisme
Langkah kedua isi dokumen yang telah dilakukan pembersihan selanjutnya dilakkukan pembentukan rangkaian gram, dimana k =5.
deteksiplagiarisme
detek ksipl lagia arism eteks sipla agiar risme teksi iplag giari
eksip plagi iaris
12281, 12658, 13536, 12532, 13161, 13579, 12895, 13275, 12706, 11988, 12498, 12580, 12334, 13532
Setelah mendapatkan nilai hash langkah selanjutnya adalah pemilihan nilai hash menurut ukuran 0 mod p, p=4 maka diperoleh nilai fingerprints:
13536, 13161, 13275, 11988, 12498
2.7Rolling Hash
Rolling hash adalah suatu cara menyimpan dan mengambil target elemen tanpa searching, yaitu dengan cara menghitung lokasi target. Fungsi hash dengan basis disebut dengan Rolling Hash. Pada awalnya metode Rolling Hash digunakan pada Algoritma Rabin Karp dimana metode ini digunakan untuk membandingan nilai hashing dari semua k-gram kedalam sebuah string yang panjang [10]. Persamaannya adalah sebagai berikut :
�( 1.. �+1) = 1∗
�−1+
2∗ �−2+⋯+ �−1∗ + � (2.1)
Keterangan: H: nilai hash
c : nilai ascii karakter b : basis (bilangan prima) k : banyak karakter
Diambil nilai ascii dari setiap karakter dari kata “sepeda” didapatkan nilai ascii sebagai berikut:
s=115, e=101, p=112, e=101, d=100, a=97
Dari rumus Rolling Hash pertama didapatkan hasil sebagai berikut: 155*35 + 101*34 +112*33+ 101*32 + 100*3 + 97=40456 115*243 + 101* 81 + 112*27 + 101*9 + 100*3 + 97 = 40456 27945 + 8181 + 3024 + 909 + 300 + 97 = 40456
Rolling hash memiliki dua rumus untuk menghitung nilai hash karakter berikutnya yaitu H(c2...ck+1) dapat dilakukan dengan cara:
�
2.. �+1 = � 1.. �)− 1∗ �−1 ∗ + (�+1)
(2.2)
Dengan begitu tidak perlu melakukan iterasi dari indeks pertama sampai terakhir untuk menghitung nilai hash untuk gram ke-2 sampai terakhir.
Contoh Penggunaan: - Kata: “sepedaitubagus”
- Diambil nilai ascii dari setiap karakter dari kata “sepeda” dan dilakukan perhitungan menggunakan rumus Rolling Hash pertama didapatkan nilai hash 40456
- Karena setiap kata yang bergeser memiliki huruf yang pernah dihitung sebelumnya yaitu “sepeda” dan bergeser menjadi “epedai” digunakanlah rumus Rolling Hash kedua dan menghasilan nilai sebagai berikut:
H=((40456-(115*243))*3+105) = 37638
2.8Jaccard’s Similarity Coefficient
, = | | sama dari dokumen 1 dan 2, | | dalah jumlah seluruh fingerprint dari dokumen 1 dan 2. Sebagai contoh a={1,2,4} dan b={1,2,4,7,8} maka | | = {1,2,4} dan | | = {1,2,4,7,8} sehingga, D(a,b) = 3/5 * 100 = 60
2.9Teori Analisis Algoritma
Algoritma yang baik adalah algoritma yang mangkus. Kemangkusan algoritma diukur dari berapa jumlah waktu dan ruang(space) memori yang dibutuhkan untuk menjalankannya. Algoritma yang mangkus ialah algoritma yang meminimumkan kebutuhan waktu dan ruang [11] Kebutuhan waktu dan ruang suatu algoritma bergantung pada ukuran masukan yang secara khas adalah jumlah data yang diproses. Ukuran masukan itu disimbolkan dengan n. Misalkan bila mengurutkan 1000 buah data maka n=1000.
Analisis waktu sebuah algoritma bergantung pada mesin komputer yang digunakan. Perbedaan kecepatan sebuah komputer atau mesin compiler dalam memproses sebuah eksekusi program mengakibatkan perbedaan hasil waktu proses. Misalkan terdapat sebuah komputer yang mampu menjalankan program dengan masukan berukuran n dalam waktu − × � detik. Maka dapat dihitung bahwa untuk,
Jika kita mengganti mesin baru yang dapat memproses 100 kali lebih cepat dari mesin pertama menjadi −�, maka proses yang dapat dilakukan lebih banyak karena waktu proses semakin cepat menjadi menjadi −�× � detik.
2.9.1 Kompleksitas Waktu dan Ruang
Secara teoritis model abstrak pengukuran waktu atau ruang harus independen dari pertimbangan mesin compiler apapun. Model abstrak seperti itu dapat dipakai untuk membandingkan algoritma yang berbeda. Kompleksitas waktu diekspresikan sebagai jumlah tahapan komputasi yang dibutuhkan untuk menjalankan algoritma sebagai fungsi dari ukuran masukan n [11]. kompleksitas ruang diekspresikan sebagai jumlah memori yang digunakan oleh struktur data yang terdapat di dalam algoritma sebagai fungsi dari ukuran masukan n. dengan menggunakan besaran kompleksitas waktu/ruang algoritma, dapat ditentukan laju peningkatan waktu/ruang yang diperlukan algoritma dengan meningkatnya ukuran masukan n. Umumnya Algoritma mempunyai parameter utama yang paling menentukan waktu proses. Parameter ini berkaitan dengan jumlah data yang diproses algoritma tersebut. Parameter ini dapat berupa pangkat suatu persamaan polinom atau jumlah record yang akan diurutkan atau dicari. Kompleksitas algoritma menyatakan kelajuan perkembangan waktu proses dibandingkan dengan kelajuan perkembangan data yang diproses . Salah satu notasi kompleksitas algoritma adalah Big-Oh. Definisi dari Big-O Adalah fungsi yang lebih berkaitan dengan kelajuan proses daripada kelajuan pertambahan data yang dirumuskan dengan T(n) = O( f(n) ). Jika ada konstan c dan no sedemikian rupa sehingga T(n) ≤ c. f(n) untuk n ≥ no. Secara sederhana dikatakan bahwa O( f(n) ) dapat dianggap sebagai nilai maksimum dari c.f(n).
2.9.1.1Kompleksitas Waktu
memiliki proses pengisian nilai dan penjumlahan sesuai dengan pseudocode sebagai berikut:
a. Operasi Pengisian Nilai
Jumlah ← 0, jumlah eksekusi 1 kali
k ← 1, jumlah eksekusi 1 kali
jumlah ← jumlah + ��, jumlah eksekusi n kali k ← k+1, jumlah eksekusi n kali r ← jumlah/n jumlah eksekusi 1 kali
Jumlah seluruh operasi pengisian nilai adalah:
t1 = 1 + 1 + n + n + 1 = 3 + 2n
b. Operasi Penjumlahan
Jumlah + ��, jumlah eksekusi n kali
k + 1, jumlah eksekusi n kali
jumlah seluruh operasi penjumlahan adalah:
t2 = n + n = 2n
Dari kedua proses pengisian nilai dan penjumlahan pada algoritma tersebut dapat dihitung jumlah kompleksitas waktu berdasarkan jumlah operasi yang telah dilakukan yaitu:
2.9.2 Aturan Algoritma
Aturan algoritma digunakan untuk mengklasifikasikan sebuah algoritma termasuk pada jenis algoritma seperti apa keterhubungan algoritma tersebut pada T(n) [11].
a. Perulangan (For Loop)
Algoritma yang termasuk pada jenis ini memiliki waktu eksekusi maksimum sebanyak waktu eksekusi statement yang ada didalam loop dikalikan banyaknya iterasi. Contoh:
For(a=0;a<n;a++) {
m=a+b; n=c+d; }
Waktu eksekusi yaitu 2 x n sehinggal T(n) = O(n). Algoritma yang memiliki 1 kali perulangan termasuk pada klasifikasi O(n).
b. Perulangan Bersarang (Nested For Loop )
Algoritma yang termasuk pada jenis ini yaitu algoritma yang memiliki perulangan bersarang. Waktu eksekusi total sebuah statement yaitu waktu eksekusi statement dikalikan hasil kali dari banyaknya iterasi semua loop yang ada didalamnya. Contoh:
for(int i=0;i<n;i++)
for(int j=0;j<m;j++)
a[i,j]=0;
c. Statement Yang Berurutan (Consecutive Statement)
Untuk statement yang berurutan, waktu eksekusinya adalah jumlah dari masing-masing statement. Contoh:
for(int k=0;k<10;k++)
x[k]=0;
for(int i=0;i<n;i++)
for(int j=0;j<m;j++)
a[i,j]=0;
Jadi T(n)=T1(n)+T2(n)+T3(n) = O(� )
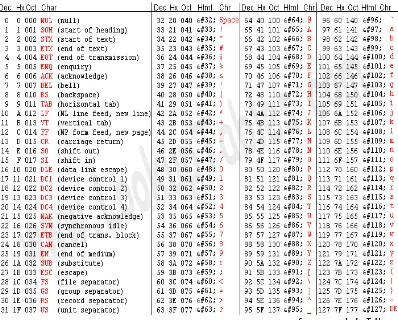
2.10 Pengertian ASCII
Kode Standar Amerika untuk Pertukaran Informasi atau ASCII (American Standard Code for Information Interchange) merupakan suatu standar internasional dalam kode huruf dan simbol seperti Hex dan Unicode tetapi ASCII lebih bersifat universal, contohnya 124 adalah untuk karakter "|". Ia selalu digunakan oleh komputer dan alat komunikasi lain untuk menunjukkan teks. Kode ASCII sebenarnya memiliki komposisi bilangan biner sebanyak 8 bit. Dimulai dari 0000 0000 hingga 1111 1111. Total kombinasi yang dihasilkan sebanyak 256, dimulai dari kode 0 hingga 255 dalam sistem bilangan Desimal
2.10.1 Tabel Karakter ASCII
Gambar 2.3 Table ascii
2.11 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) merupakan diagram yang mengunakan notasi-notasi atau simbol-simbol untuk mengambarkan sistem jaringan kerja antar fungsi-fungsi yang berhubungan satu sama lain dengan aliran dan penyimpanan data (Jogiyanto, 2005).
memudahkan pemakai (user) yang kurang menguasai bidang komputer untuk mengerti sistem yang akan dikerjakan.
DFD terdiri dari diagram konteks (context diagram) dan diagram rinci (level diagram). Diagram konteks adalah diagram yang terdiri dari suatu proses dan menggambarkan ruang lingkup suatu sistem. Diagram konteks merupakan level tertinggi dari DFD yang menggambarkan seluruh input ke sistem atau output dari sistem. Sistem dibatasi oleh boundary (dapat digambarkan dengan garis putus). Dalam diagram konteks biasanya hanya ada satu proses. Tidak boleh ada store dalam diagram konteks. Diagram rinci adalah diagram yang menguraikan proses apa yang ada dalam diagram level di atasnya.
Adapun yang digunakan dalam DFD adalah: 1. Entitas Eksternal (External Entity)
Entitas Eksternal (entity) di lingkungan luar sistem yang dapat berupa orang, organisasi atau sistem lainnya yang berada di lingkungan luarnya yang akan memberikan input atau menerima output dari sistem. Suatu kesatuan luar dapat disimbolkan dengan suatu notasi persegi panjang.
Gambar 2.4 Entitas 2. Aliran data
Gambar 2.5 Aliran Data 3. Proses
Suatu proses adalah kegiatan atau kerja yang dilakukan oleh orang, mesin atau komputer dari hasil suatu aliran data yang masuk ke dalam proses untuk dihasilkan aliran data yang akan keluar dari proses. Suatu proses dapat disimbolkan dengan notasi lingkaran.
Gambar 2.6 Proses
4. Penyimpan Data (Data Store)
Penyimpan data (data store) merupakan penyimpan data yang dapat berupa: a. Suatu file atau basis data di sistem komputer.
b. Suatu arsip atau catatan manual. c. Suatu tabel acuan manual. d. Suatu agenda atau buku.
Simpanan data di DFD dapat disimbolkan dengan sepasang garis horizontal paralel yang ujungnya tidak ditutup.
27 3.1Analisis Masalah
Beberapa algoritma yang termasuk dalam metode fingerprinting yaitu Algoritma Rabin Karp, Algoritma Winnowing dan Algoritma Manber. Dalam penelitian ini akan dilakukan analisis performansi dari dua buah algoritma yang termasuk dalam metode fingerprinting yaitu Algoritma Winnowing dan Algoritma Manber yang dapat diterapkan untuk mendeteksi similaritas pada dokumen teks. Analisis performansi dilakukan dengan tujuan mendapatkan informasi dari kedua algoritma yaitu berupa informasi kecepatan, ketepatan, dan jumlah langkah dari Algoritma Winnowing dan Algoritma Manber dalam penerapannya pada sebuah sistem.
Dari sedikitnya penelitian dalam lingkup analisis performansi kedua algoritma ini maka menjadi dasar penelitian ini. Terdapat penelitian sebelumnya mengenai
perbandingan pendekatan kedua algoritma ini yang berjudul “Perbandingan
Pendekatan Deteksi Plagiarisme Dokumen Dalam Bahasa Inggris” oleh Ana Kurniawati dan I Wayan Simri Wicaksana dalam jurnalnya yang menganalisis perbandingan dan penerapannya pada dokumen berbahasa inggris. Berdasarkan hasil penelitian tersebut, disimpulkan bahwa algoritma winnowing lebih baik dari algoritma manber karena memberikan jaminan terdeteksinya dokumen sama [2]. Penerapan penelitian tersebut dilakukan pada sistem yang memproses teks berbahasa inggris. Berdasarkan hal tersebut maka akan dilakukan analisis yang nantinya akan diterapkan pada dokumen berbahasa Indonesia.
mendapatkan akurasi yang lebih tepat dalam mendeteksi similaritas dari dokumen yang dibandingkan. Parameter yang perlu diuji yaitu jumlah gram, jumlah window, basis bilangan prima yang di gunakan dan proses pemilihan nilai hash yang berpengaruh pada persentasi kemiripan dari dokumen yang dibandingkan.
3.2Analisis Input dan Output
Analisis Input dan Output sistem menjelaskan tentang bagaimana sistem menerima inputan dan menghasilkan output dari proses yang telah dilakukan. Berikut ini merupakan analisis input dan output dari sistem yang akan dibuat.
3.2.1 Analisis Input dan Output Algoritma Winnowing
Algoritma Winnowing memiliki input dan output data sebagai berikut.
3.2.1.1Analisis Input
Pada penerapan Algoritma Winnowing dalam sebuah sistem membutuhkan beberapa inputan meliputi:
1. Dokumen Teks berektensi .txt 2. Jumlah Karakter Minimal 100 Huruf
3. Jumlah Gram = 5 , diambil berdasarkan jumlah penelitian sebelumnya [4]. 4. Jumlah Window = 4, diambil berdasarkan jumlah penelitian sebelumnya [4].
3.2.1.2Analisis Output
Output yang dihasilkan dari sistem berupa:
1. Persentasi Kemiripan dari dokumen yang dibandingkan 2. Informasi Waktu Proses
3.2.2 Analisis Input dan Output Algoritma Manber
3.2.2.1Analisis Input
Pada penerapan Algoritma Manber dalam sebuah sistem membutuhkan beberapa inputan meliputi:
1. Dokumen Teks berektensi .txt 2. Jumlah Karakter Minimal 100 Huruf
3. Jumlah Gram = 5, diambil berdasarkan jumlah penelitian sebelumnya [2]. 4. Jumlah Ukuran P = 4, diambil berdasarkan jumlah penelitian sebelumnya [2].
3.2.2.2Analisis Output
Output yang dihasilkan dari sistem berupa:
1. Persentasi Kemiripan dari dokumen yang dibandingkan 2. Informasi Waktu Proses
3.3Analisis Algoritma
Analisis algoritma yaitu tahapan analisis algoritma apa saja yang akan dianalisis dalam penelitian ini yaitu :
1. Analisis Algoritma Winnowing 2. Analisis Algoritma Manber
3.3.1 Analisis Algoritma Winnowing
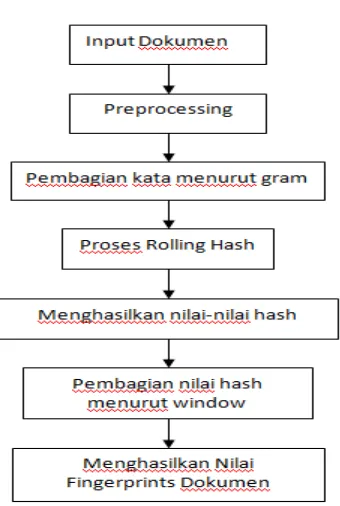
Gambar 3.1 Langkah Algoritma Winnowing
Gambar 3.1 menjelaskan tahapan dari Algoritma Winnowing sampai pada proses menghasilkan nilai hash. Tahapan tersebut dilakukan pada dokumen pertama, setelah itu dilakukan tahapan yang sama untuk dokumen kedua sehingga menghasilkan dua nilai-nilai fingerprints dari kedua dokumen. Setelah itu proses dilanjutkan dengan perhitungan persentasi kemiripan dari kedua dokumen berdasarkan nilai fingerprints yang telah diperoleh. Persentasi kemiripan dihitung menggunakan metode jaccard similarity coefficient.
Input dari proses document fingerprinting adalah file teks. Kemudian output-nya berupa sekumpulan nilai hash yang disebut fingerprint. Fingerprint inilah yang akan dijadikan dasar pembanding antara file-file teks yang telah dimasukkan .
karakter-karakter yang berupa huruf yang akan diproses lebih lanjut . Berikut merupakan contoh dari alur proses Algoritma Winnowing:
1. Langkah 1:
Contoh kalimat : Hari Minggu sangat cerah!!!!.
Langkah awal pada Algoritma Winnowing yaitu melakukan lowercase pada setiap karakter dan membuang karakter-karakter yang tidak dibutuhkan seperti spasi dan symbol, sehingga teks menjadi bersih dari symbol-simbol selain huruf [a-z]. maka kalimat diatas akan menjadi
hariminggusangatcerah
2. Langkah 2:
Langkah berikutnya yaitu pembagian kata menurut gram yang diinputkan oleh pengguna. Sebagai contoh nilai gram=5. Maka teks akan terbagi menjadi :
harim mingg gusan ngatc cerah arimi inggu usang gatce
rimin nggus sanga atcer iming ggusa angat tcera
3. Langkah 3:
Langkah berikutnya setelah dibagi menurut gram yaitu dilakukan proses Rolling Hash untuk menghasilkan nilai hash dari setiap gram yang dibentuk. Proses Rolling Hash menggunakan persamaan (2.1) dan persamaan (2.2).
Contoh kata “harim”
h=104, a=97, r=114, i=105, m=109 (nilai ascii karakter) 104*34 + 97*33 + 114*32 + 105*3 + 109
8424 + 2619 + 1026 + 315 + 109 = 12493
Dengan menggunakan rumus tersebut maka dapat dihasilkan nilai-nilai hash dari proses pembentukan gram sebelumnya
12493, 12312, 13475, 12826, 13066, 12828, 13084, 12619, 12938, 13888, 13330, 12161, 13011, 12404, 12297, 13417, 12167
4. Langkah 4:
Setelah mendapatkan nilai hash dari proses Rolling Hash maka langkah berikutnya adalah membagi nilai-nilai hash tersebut menurut window, nilai window dinputkan oleh pengguna sebagai contoh nilai window = 4. Pemilihan window hampir sama seperti pembentukan gram. Maka akan didapatkan window sebagai berikut:
{ 12493 12312 13475 12826 }, { 12312 13475 12826 13066 } { 13475 12826 13066 12828 }, { 12826 13066 12828 13084 } { 13066 12828 13084 12619 }, { 12828 13084 12619 12938 } { 13084 12619 12938 13888 }, { 12619 12938 13888 13330 } { 12938 13888 13330 12161 }, { 13888 13330 12161 13011 } { 13330 12161 13011 12404 }, { 12161 13011 12404 12297 } { 13011 12404 12297 13417 }, { 12404 12297 13417 12167 }
5. Langkah 5:
{ 12493 12312 13475 12826 }, { 12312 13475 12826 13066 } { 13475 12826 13066 12828 }, { 12826 13066 12828 13084 } { 13066 12828 13084 12619 }, { 12828 13084 12619 12938 } { 13084 12619 12938 13888 }, { 12619 12938 13888 13330 } { 12938 13888 13330 12161 }, { 13888 13330 12161 13011 } { 13330 12161 13011 12404 }, { 12161 13011 12404 12297 } { 13011 12404 12297 13417 }, { 12404 12297 13417 12167 }
Dari hasil pemilihan nilai terkecil dari setiap window maka didapatkan nilai fingerprints yaitu
12312, 12826, 12619, 12161, 12297,12167
Setelah itu dilakukan penambahan posisi dari fingerprints menjadi:
[12312, 1], [12826, 3], [12619, 8], [12161, 12], [12297, 15], [12167, 17]
6. Langkah 6:
Langkah berikutnya yaitu perhitungan persentasi kemiripan menggunakan jaccard’s similarity coefficient dengan rumus (2.3)
Sebagai contoh untuk mengetahui persentasi kesamaan dari dua dokumen sebagai berikut:
a. Dokumen A berisi kalimat : Hari minggu sangat cerah !!! b. Dokumen B berisi kalimat : Hari minggu mendung
Menggunakan proses Rolling hash dan pemilihan window didapat hasil fingerprints Dokumen A : 12312, 12826, 12619, 12161, 12297,12167
Dokumen B menghasilkan nilai hash dengan dilakukan proses yang sama seperti proses Dokumen A sehingga didapatkan hasil fingerprints 12312, 12826, 12605, 12512 . Berdasarkan rumus jaccard similarity coefficient maka dapat dilakukan perhitungan berikut ini berdasarkan hasil dari fingerprints Dokumen A dan B:
| | = 12312, 12826
| | = 12312, 12826, 12619, 12161, 12297,12167, 12605, 12512 , = (2/8)*100 = 25%
Jadi total persentasi kemiripan dari Dokumen A dan B yaitu sebesar 25%
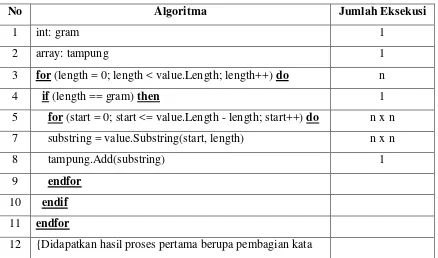
3.3.1.1Analisis Kompleksitas Algoritma Winnowing
Perhitungan kompleksitas waktu asimptotik Algoritma Winnowing dapat dihitung dengan menelusuri setiap langkah algoritma winnowing pada pseudocode pada tabel 3.1
Table 3.1 Pseudocode Winnowing
No Algoritma Jumlah Eksekusi
1 int: gram 1
menurut gram yang diinputkan}
13 {Proses selanjutnya perhitungan nilai hash}
14 array: tampungnilaihash 1
15 for (k = 0; k < tampung.Count; k++) do n
26 tampungnilaihash.Add(jumlah) 1
27 endfor
28 {Mendapatkan hasil hashing dari setiap gram}
29 {tahap selanjutnya pembagian window dari hasil hashing}
30 array : tampungwindow 1
36 window1 = tampungnilaihash[bts2] n
38 if (min < max) then 1
39 max = min 1
40 endif
41 tampungwindow.Add(window1) 1
42 endfor
43 tampungfingerprints.Add(max) 1
44 endfor
Algoritma Winnowing terdiri dari banyak perulangan for atau lebih dikenal sebagai nested for loop. Perhitungan jumlah T(n) pada nested for loop memiliki dua aturan, yaitu :
1. Dianalisis dari loop terdalam kemudian keluar.
2. Waktu eksekusi total sebuah statement adalah waktu eksekusi statement tersebut dikalikan hasil kali dari banyaknya iterasi semua loop yang ada di luarnya.
Dari perhitungan pada tabel 3.1 didapatkan hasil kompleksitas waktu T(n) = 5�2+ 7n + 18 dan termasuk pada kelompok algoritma kuadratik sesuai dengan aturan nested for loop dengan kompleksitas waktu asimptotik yaitu T(n) = �2.
Perhitungan waktu yang dibutuhkan sesuai kerja mesin yaitu jika misalkan mesin dapat memproses 1 kali eksekusi membutuhkan waktu 10−6 detik, maka untuk memasukan data jika T(n) = 1000, maka T(n) = (n-1) menjadi T(1000) = (1000 – 1) x 10−6 = 0,000999 detik untuk n=1000.
Tabel 3.2 Pertumbuhan n terhadap T(n) Winnowing
n T(n) = 5�2 + 7n + 18 �2
10 750 100
100 52.500 10.000
1000 5.025.000 1.000.000
Dari tabel 3.2 dapat dikatakan bahwa T(n) tumbuh sama seperti �2 ketika n bertambah.
3.3.2 Analisis Algoritma Manber
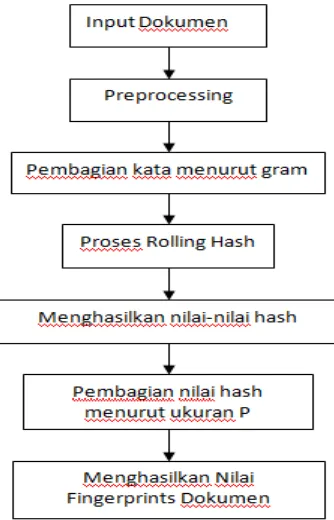
Tahapan pada Algoritma Manber hampir sama dengan Algoritma Winnowing yang membedakan adalah proses pemilihan fingerprints dari hasil perhitungan Rolling Hash. Contoh tahapan Algoritma Manber dapat dilihat pada gambar 3.2.
Gambar 3.2 Tahapan Algoritma Manber
yang telah diperoleh. Persentasi kemiripan dihitung menggunakan metode jaccard similarity coefficient. Berikut ini merupakan contoh dari tahapan Algoritma Manber:
1. Langkah 1:
Contoh kalimat : Hari Minggu sangat cerah!!!!.
Langkah awal pada Algoritma Winnowing yaitu melakukan lowercase pada setiap karakter dan membuang karakter-karakter yang tidak dibutuhkan seperti spasi dan symbol, sehingga teks hanya menjadi bersih dari symbol-simbol selain huruf [a-z]. maka kalimat diatas akan menjadi
hariminggusangatcerah
2. Langkah 2:
Langkah berikutnya yaitu pembagian kata menurut gram yang diinputkan oleh pengguna. Sebagai contoh nilai gram=5. Maka teks akan terbagi menjadi :
harim mingg gusan ngatc cerah arimi inggu usang gatce
rimin nggus sanga atcer iming ggusa angat tcera
3. Langkah 3:
Langkah berikutnya setelah dibagi menurut gram yaitu dilakukan proses Rolling Hash untuk menghasilkan nilai hash dari setiap gram yang dibentuk. Proses Rolling Hash menggunakan persamaan (2.1) dan persamaan (2.2).
Contoh kata “harim”
104*34 + 97*33 + 114*32 + 105*3 + 109 8424 + 2619 + 1026 + 315 + 109 = 12493
Dengan menggunakan rumus tersebut maka dapat dihasilkan nilai-nilai hash dari proses pembentukan gram sebelumnya
12493, 12312, 13475, 12826, 13066, 12828, 13084, 12619, 12938, 13888, 13330, 12161, 13011, 12404, 12297, 13417, 12167
4. Langkah 4:
Langkah berikutnya pemilihan nilai hash yang memenuhi kriteria H mod P=0, ukuran P merupakan inputan pengguna. Sebagai contoh nilai P=5 sehingga dari hasil nilai hash sebelumnya dapat diambil nilai fingerprints yang memenuhi kriteria H mod P=0 yaitu:
13475, 13330 5. Langkah 5:
Langkah berikutnya yaitu perhitungan persentasi kemiripan menggunakan jaccard’s similarity coefficient dengan rumus:
, =| |
| | × 100
Sebagai contoh untuk mengetahui persentasi kesamaan dari dua dokumen sebagai berikut:
Dokumen A berisi kalimat : Hari minggu sangat cerah !!! Dokumen B berisi kalimat : Hari minggu mendung
Dokumen A : 13475, 13330 Dokumen B : 13475,12605
Dokumen B menghasilkan nilai hash dengan dilakukan proses yang sama seperti proses Dokumen A sehingga didapatkan hasil fingerprints 12312, 12826, 12605, 12512 . Berdasarkan rumus jaccard similarity coefficient sebelumnya maka dapat dilakukan perhitungan berikut ini berdasarkan hasil dari fingerprints Dokumen A dan B:
| | = 13475
| | = 13475,13330,12605 , = (1/3)*100 = 33,33%
Jadi total persentasi kemiripan dari Dokumen A dan B yaitu sebesar 33,33%
3.3.2.1Analisis Kompleksitas Manber
Perhitungan kompleksitas waktu asimptotik Algoritma Manber dapat dihitung dengan menelusuri setiap langkah algoritma winnowing pada pseudocode metode ini.
Tabel 3.3 Pseudocode Manber
No Algoritma Jumlah Eksekusi
1 int: gram 1
2 array: tampung 1
3 for (length = 0; length < value.Length; length++) do n
4 if (length == gram) then 1
5 for (start = 0; start <= value.Length - length; start++) do n x n 7 substring = value.Substring(start, length) n x n
8 tampung.Add(substring) 1
11 endfor
12 {Didapatkan hasil proses pertama berupa pembagian kata menurut gram yang diinputkan}
13 {Proses selanjutnya perhitungan nilai hash}
14 array: tampungnilaihash 1
15 for (k = 0; k < tampung.Count; k++) do n
26 tampungnilaihash.Add(jumlah) 1
27 endfor
28 {Mendapatkan hasil hashing dari setiap gram} 29 {tahap selanjutnya pemilihan nilai fingerprints}
30 array: tampungfingerprints 1
31 for (n = 0; n < tampungnilaihash.Count; n++) do n
32 mod = tampungnilaihash[n] % window n
33 if(mod == 0) 1
34 tampungfingerprints.Add(tampungnilaihash[n]) n 35 endif
Pseudocode Manber terdiri dari banyak perulangan for atau lebih dikenal sebagai nested for loop. Perhitungan jumlah T(n) pada nested for loop memiliki dua aturan, yaitu :
1. Dianalisis dari loop terdalam kemudian keluar.
2. Waktu eksekusi total sebuah statement adalah waktu eksekusi statement tersebut dikalikan hasil kali dari banyaknya iterasi semua loop yang ada di luarnya
Dari perhitungan pada tabel didapatkan hasil kompleksitas waktu T(n) = 4�2+ 7n + 13 dan termasuk pada kelompok algoritma kuadratik sesuai dengan aturan nested for loop dengan kompleksitas waktu asimptotik yaitu T(n) = �2.
Perhitungan waktu yang dibutuhkan sesuai kerja mesin yaitu jika misalkan mesin dapat memproses 1 kali eksekusi membutuhkan waktu 10−6 detik, maka untuk memasukan data jika T(n) = 1000, maka T(n) = (n-1) menjadi T(1000) = (1000 – 1) x 10−6 = 0,000999 detik untuk n=1000.
Tabel 3.4 Pertumbuhan n terhadap T(n) Manber
n T(n) = 4�2 + 7n + 13 �2
10 600 100
100 42.000 10.000
1000 4.020.000 1.000.000
10.000 400.200.000 100.000.000
3.4Analisis Kebutuhan Perangkat Lunak
Analisis kebutuhan perangkat lunak dilakukan bertujuan untuk mensimulasikan kedua algoritma kedalam sebuah perangkat lunak. Analisis kebutuhan perangkat lunak terbagi menjadi dua bagian yaitu:
1. Analisis Kebutuhan Non-Fungsional 2. Analisis Kebutuhan Fungsional
3.4.1 Analisis Kebutuhan Non-Fungsional
Analisis kebutuhan non fungsional adalah langkah dimana seorang pembangun perangkat lunak (software developer) menganalisis sumber daya yang akan digunakan dan menggunakan perangkat lunak yang dibangun. Perangkat keras dan perangkat lunak yang dimiliki harus sesuai dengan kebutuhan sehingga dapat ditentukan kompabilitas aplikasi yang dibangun terhadap sumber daya yang ada.
Analisis kebutuhan non fungsional yang dilakukan dibagi dalam tiga tahap, yaitu:
1. Analisis perangkat keras (hardware). 2. Analisis perangkat lunak (software). 3. Analisis pengguna (user)
3.4.1.1Analisis Perangkat Keras
Spesifikasi perangkat keras minimum yang butuhkan untuk menjalankan sistem Deteksi similaritas dokumen dapat dilihat pada tabel 3.5.
Tabel 3.5 Spesifikasi Perangkat Keras
No Perangkat Keras Spesifikasi
1 Prosesor Kecepatan Minimal 1.8 GHz
2 Monitor Monitor 14.1‟‟
3.4.1.2Analisis Perangkat Lunak
Komponen perangkat lunak pendukung yang dibutuhkan untuk menjalankan sistem Deteksi Similaritas Dokumen ini, dapat dilihat pada table 3.6
Tabel 3.6 Spesifikasi Perangkat Lunak
No Perangkat Lunak
1 Sistem operasi Windows XP/ 7 2 Visual Studio 2010
3 Notepad++ 4 Wampserver
5 Mysql
3.4.1.3Analisis Perangkat Pikir
Analisis kebutuhan perangkat pikir merupakan uraian mengenai siapa saja yang akan menggunakan sistem dan terlibat dalam pengolahan data beserta karakteristiknya sehingga dapat diketahui tingkat pengalaman dan pemahaman pengguna terhadap sistem. Adapun karakteristik dari pengguna adalah sebagai berikut:
1. Pengguna dapat membaca tulisan.
2. Pengguna minimal mampu menggunakan keyboard dan mouse sebagai untuk berinteraksi dengan sistem.
3. Pengguna sudah terbiasa menggunakan komputer.
3.4.2 Analisis Kebutuhan Fungsional
3.4.2.1Diagram Konteks
Diagram konteks adalah diagram yang menggambarkan input , process dan output secara umum yang terjadi pada sistem perangkat lunak yang akan di bangun . Berikut Diagram konteks dari Sistem Deteksi Kesamaan Dokumen:
PENGGUNA Sistem Deteksi
Kesamaan Dokumen Input dokumen
Input Jumlah Gram Input Jumlah Window
Info Persentasi Kemiripan Info Total Waktu Proses Info Penggunaan Memory
Gambar 3.3 Diagram Konteks
3.4.2.2Data Flow Diagram
Data Flow Diagram merupakan suatu media yang digunakan untuk menggambarkan aliran data yang mengalir pada suatu sistem informasi. Dalam Data Flow Diagram (DFD) terdiri dari entitas luar, aliran data, proses, dan penyimpanan data.
3.4.2.2.1 Data Flow Diagram Level 1
2
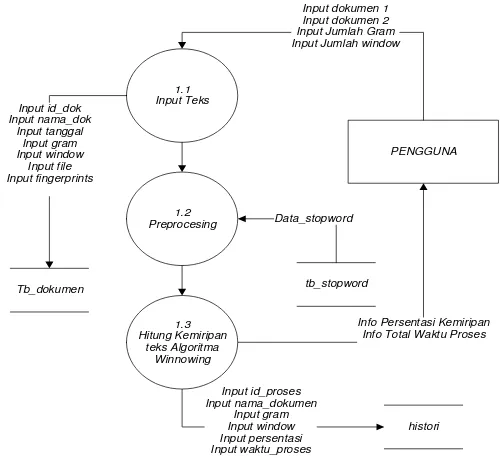
3.4.2.2.2 Data Flow Diagram Level 2 Pendeteksian Algoritma Winnowing Berikut ini adalah Data Flow Diagram ( DFD) Level 2 proses pendeteksian algoritma winnowing dari Sistem Deteksi Kesamaan Dokumen ditunjukan pada gambar 3.5.
Ket : tb_dokumen dan histori merupakan tabel yang terdapat dalam database
data_dokumen
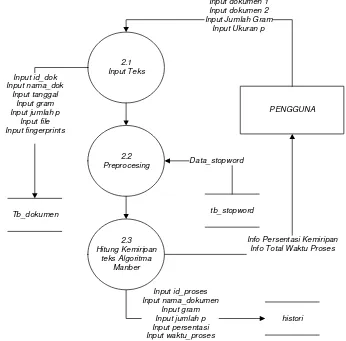
3.4.2.2.3 Data Flow Diagram Level 2 Pendeteksian Algoritma Manber
Berikut ini adalah Data Flow Diagram ( DFD) Level 2 proses pendeteksian algoritma manber dari Sistem Deteksi Kesamaan Dokumen ditunjukan pada gambar 3.6.
Gambar 3.6 DFD Level 2 Proses Pendeteksian Manber
Ket : tb_dokumen dan histori merupakan tabel yang terdapat dalam database
3.4.2.2.4 Data Flow Diagram Level 2 Proses Cek Histori
Berikut ini adalah Data Flow Diagram ( DFD) Level 2 proses cek histori dari Sistem Deteksi Kesamaan Dokumen ditunjukan pada gambar 3.7.
PENGGUNA
Gambar 3.7 DFD Level 2 Proses Cek Histori
Ket : tb_dokumen dan histori merupakan tabel yang terdapat dalam database
data_dokumen
3.4.2.3 Spesifikasi Proses
Spesifikasi proses merupakan deskripsi dari setiap elemen proses yang terdapat dalam program, yang meliputi nama proses, input, output dan keterangan dari proses. Berikut ini spesifikasi proses dari Sistem Deteksi Kesamaan Dokumen ditunjukan pada tabel berikut ini
3.4.2.3.1 Spesifikasi Proses Input Teks
Spesifikasi Proses pada proses 1.1 Input Teks dapat dilihat pada table 3.7. Tabel 3.7 Spesifikasi Proses Input Teks
1 No Proses 1.1
Nama Input Teks
Source Pengguna
Input Input Dokumen 1, Input Dokumen 2, Input Jumlah Gram, Input Jumlah Window Output Info Persentasi Kemiripan
Info Total Waktu Proses
Logika Proses 1. Pengguna Melakukan input dokumen teks atau input manual teks pada form yang disediakan sistem
2. Pengguna melakukan input jumlah gram dan window
3. Sistem menampung inputan dan menyimpan info ke tabel tb_dokumen dalam database data_dokumen
3.4.2.3.2 Spesifikasi Proses Preprocessig
Spesifikasi Proses pada proses 1.2 Preprocessing dapat dilihat pada tabel 3.8 berikut:
Tabel 3.8 Spesifikasi Proses Preprocessing No Proses Keterangan
1 No Proses 1.2
Nama Preprocessing
Source 1.1 Input Teks Input Teks 1 , Teks 2
Output String yang sudah dilakukan proses penghapusan kata stopword dalam dokumen
2. Sistem menghapus kata-kata stopword yang bersumber dari database tabel tb_stopword
3. Sistem memberikan output berupa string yang bebas dari kata-kata stopword
3.4.2.3.3 Spesifikasi Proses Hitung Kemiripan
Spesifikasi Proses pada proses 1.3 Hitung Kemiripan Teks Algoritma Winnowing dapat dilihat pada table 3.9.
Tabel 3.9 Spesifikasi Proses Hitung Kemiripan
No Proses Keterangan
1 No Proses 1.3
Nama Hitung Kemiripan Teks Algoritma Winnowing Source 1.1 Input Teks
Input Dokumen 1, Dokumen 2, Jumlah Gram, Jumlah Window Output Info Persentasi Kemiripan
Info Total Waktu Proses Info Penggunaan Memory
Logika Proses 1. Pengguna Menginput dokumen teks atau input manual teks pada form yang disediakan sistem 2. Sistem menampung inputan dan menyimpan
info ke database dokumen
3. Sistem menghitung kemiripan dokumen menggunakan algoritma winnowing
3.4.2.3.4 Spesifikasi Proses Download Dokumen
Spesifikasi Proses pada proses 1.2 Hitung Kemiripan Teks Algoritma Winnowing dapat dilihat pada table 3.10.
Tabel 3.10 Spesifikasi Proses Download Dokumen No Proses Keterangan
1 No Proses 3.1
Nama Download Dokumen
Source 3.2 Lihat Upload Dokumen, tb_dokumen
Input -
Output Isi File
Logika Proses 1. Pengguna memilih link download pada tabel dokumen
2. Sistem menampilkan file yang bersumber dari tb_dokumen dalam database data_dokumen
3.4.2.3.5 Spesifikasi Proses Lihat Upload Dokumen
Spesifikasi Proses pada proses 3.2 Lihat Upload Dokumen dapat dilihat pada table 3.11.
Tabel 3.11 Spesifikasi Proses Lihat Upload Dokumen No Proses Keterangan
1 No Proses 3.2
Nama Lihat Upload Dokumen
Source tb_dokumen
Input -
2. Sistem menampilkan data dokumen yang pernah diupload yangbbersumber dari tb_dokumen dalam database data_dokumen
3.4.2.3.6 Spesifikasi Proses Lihat Histori Perhitungan Dokumen
Spesifikasi Proses pada proses 3.3 Lihat Histori Perhitungan Dokumen dapat dilihat pada table 3.11.
Tabel 3.11 Spesifikasi Proses Lihat Histori Perhitungan Dokumen
No Proses Keterangan
1 No Proses 3.3
Nama Lihat Histori Perhitungan Dokumen Source Tabel histori
Input -
Output Info Dokumen yang pernah dilakukan perhitungan Logika Proses 1. Pengguna memilih menu histori
2. Sistem menampilkan data dokumen yang pernah dilakukan perhitungan yang bersumber dari tabel histori dalam database data_dokumen
3.4.3 Kamus Data
Tabel 3.12 Tabel Kamus Data
No Kamus Keterangan
1 Nama Aliran Data Data Input Teks Digunakan Pada Proses 1.1, Proses 2.1
Deskripsi Berisi data input yang dilakukan pengguna Struktur Data nama_dok+ +gram+window
nama_dok
Digunakan Pada Proses 1.1, Proses 2.1, Proses 3.1, Proses 3.2 Deskripsi Berisi data hasil input pengguna sebelum diolah Struktur Data Id_dok+nama_dok+gram+window+tanggal+file+
3 Nama Aliran Data Data Hasil Perhitungan
Digunakan Pada Proses 1.3, Proses 2.3, Proses 3.3 Deskripsi Berisi data hasil perhitungan sistem
id_proses nama_dokumen gram
window algoritma persentasi waktu_proses
[0-9] [a-z] [0-9] [0-9]
[Algoritma Winnowing|Algoritma Manber] [0-9|%]
[0-9]
3.4.4 Perancangan Sistem
Pada tahap ini digambarkan rancangan sistem yang akan dibangun sebelum dilakukan pengkodean ke dalam suatu bahasa pemrograman.
3.4.4.1Perancangan Struktur Menu
Perancangan struktur menu dilakukan sebagai panduan pengguna dalam memilih menu dan fungsi yang tersedia di halaman tampilan. Struktur menu pengguna dapat dilihat pada gambar 3.8.
3.4.4.2Perancangan Antar Muka
Perancangan antar muka Sistem Deteksi Similaritas Dokumen dilakukan agar membantu dalam proses implementasi antar muka sistem dari hasil analisis yang telah dilakukan.
3.4.4.2.1 Perancangan Antar Muka T01
Antar muka halaman pertama yaitu berisi menu-menu pilihan yang dapat dilihat pada gambar 3.9.
Gambar 3.9 Antar Muka Menu Utama 3.4.4.2.2 Perancangan Antar Muka T02
Gambar 3.10 Antar Muka Winnowing
3.4.4.2.3 Perancangan Antar Muka T03
Gambar 3.11 Antar Muka Manber
3.4.4.2.4 Perancangan Antar Muka T04
Gambar 3.12 Antar Muka Histori Tab 1
Tampilan berikutnya yaitu tampilan TO4 tab 2 yaitu berisi tentang dokumen apa saja yang pernah di unggah pengguna. Tampilan TO4 tab 2 dapat dilihat pada gambar 3.13.
3.4.4.2.5 Perancangan Antar Muka T05
Antar muka T05 merupakan antar muka yang menampilkan menu tentang yang berisi tentang teks tujuan dibuatnya aplikasi dan deskripsi aplikasi. Antar muka TO5 dapat dilihat pada gambar 3.14.
Gambar 3.14 Antar Muka Tentang Aplikasi 3.4.4.2.6 Perancangan Antar Muka T06
Gambar 3.15 Antar Muka Bantuan 3.4.4.3Jaringan Semantik
Jaringan semantik menggambarkan keterkaitan antar halaman yang dibangun. Jaringan semantik sistem dapat dilihat pada gambar 3.16.
3.4.4.4Perancangan Basis Data
Perancangan basis data merupakan perancangan database yang meliputi struktur data dari suatu tabel dalam database. Tabel di bawah ini merupakan tabel beserta field dan data type yang digunakan dalam database dengan menggunakan MYSQL Database
3.4.4.4.1 Tabel tb_dokumen
Tabel tb_dokumen merupakan tabel untuk menampung data dokumen yang di upload oleh pengguna. Dapat dilihat pada tabel 3.13.
Tabel 3.13 Tabel tb_dokumen
Atribut Type Keterangan
Id_dok Int(10) Primary key dari tabel
nama_dok Varchar(30) Nama dari dokumen yang di upload tanggal DateTime Tanggal ketika pengguna upload
gram Int(10) Jumlah gram yang diinputkan window Int(10) Jumlah window yang diinputkan
file Varbinary(50000) Berisi file yang di upload pengguna fingerprints Varchar(10000) Nilai fingerprints dari proses
perhitungan dari dokumen yang diupload
3.4.4.4.2 Tabel histori
Tabel histori merupakan tabel untuk menampung data dokumen yang di upload oleh pengguna. Tabel histori dapat dilihat pada tabel 3.14.
Tabel 3.14 Tabel Histori